
Keywords:AI Trends Report, AI Agent, Reinforcement Learning, Vision-Language Model, AI Commercialization, AI Hallucination, AI Safety, Internet Queen AI Report, LawZero AI Safety Design, GTA and GLA Attention Mechanism, SmolVLA Robot Model, AI Music Streaming Fraud
🔥 Focus
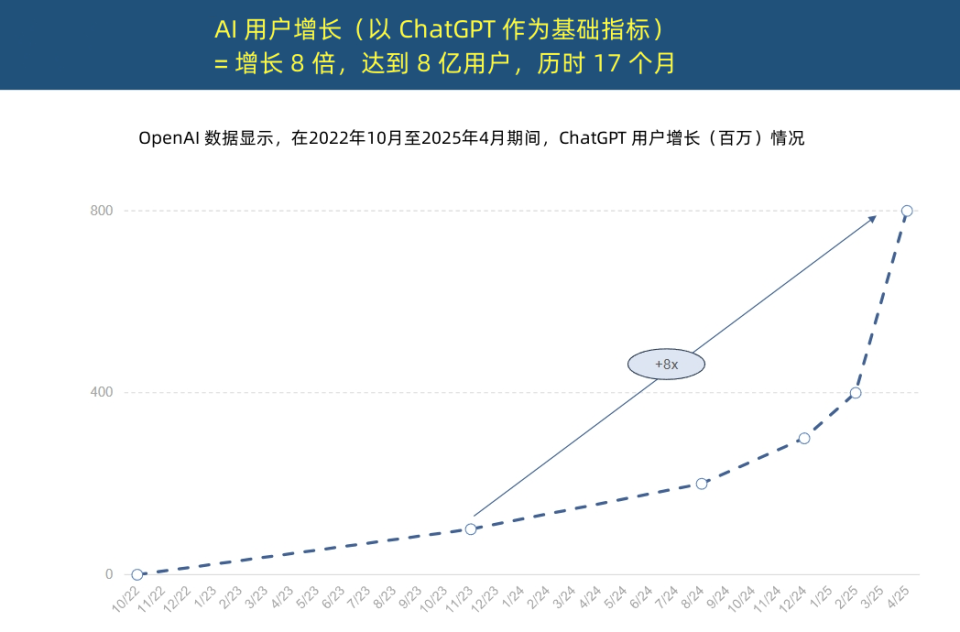
“Internet Queen” releases AI trends report, revealing unprecedented acceleration in AI application and transformation in cost structure: “Internet Queen” Mary Meeker released a 340-page “AI Trends Report,” emphasizing that AI is being adopted at an unprecedented speed. The report points out that ChatGPT’s user growth is rapid, reaching 800 million monthly active users within 17 months and nearly $4 billion in annual revenue, far exceeding any technology in history. Capital investment in AI infrastructure by tech giants has surged, reaching $212 billion in 2024. Meanwhile, AI model training costs have skyrocketed 2400-fold in 8 years, with a single model potentially costing up to $1 billion to train, but inference costs are plummeting due to hardware (e.g., Nvidia GPU efficiency increasing 100,000-fold) and algorithm optimization. Open-source models (like DeepSeek, Qwen) are approaching the performance of closed-source ones, demand for AI positions has grown by 448%, and AI Agents are becoming a new form of digital labor. (Source: APPSO, Tencent Tech)
Turing Award winner Yoshua Bengio launches LawZero, advocating for “safe by design” AI: Turing Award laureate Yoshua Bengio announced the establishment of the non-profit organization LawZero, aiming to develop “safe by design” artificial intelligence to address potential deceptive and self-protective behaviors in AI systems. Inspired by Asimov’s Third Law of Robotics, LawZero emphasizes that AI should protect human happiness and endeavors. The organization is developing the Scientist AI system as a “guardrail” for AI Agents, providing assistance by understanding the world rather than acting directly, and assessing the risks of other AI behaviors. Bengio believes current Agentic AI is a wrong direction, potentially leading to loss of control and irreversible catastrophic consequences, stressing that safety guardrail AI must be at least as intelligent as the AI Agents it attempts to monitor. (Source: Academic Headlines, Yoshua_Bengio)

The Year of AI Agents: From Auxiliary Tools to Task Executors, Reshaping Business Models: Sun Zhiyong, Research VP at Gartner, pointed out that 2025 is the “inaugural year of large model intelligent agents” and the “inaugural year of generative AI monetization,” with AI agents becoming the main outlet for LLM capabilities. The fundamental difference between intelligent agents and chatbots lies in the shift from providing information assistance to directly executing tasks. For example, an intelligent agent can complete the entire process of ordering coffee, not just provide coffee shop information. Gartner predicts that by 2028, 20% of digital interface interactions will be completed by AI agents, 15% of daily business decisions can be made autonomously by AI agents, and one-third of enterprise software will integrate AI agents. BYD’s intelligent assistant and others have seen initial applications, and the interaction methods of mobile phone apps may change in the future. (Source: IT Times)
Mamba Core Author Proposes Inference-Aware Attention Mechanisms GTA and GLA to Optimize Long-Context Inference: Tri Dao, one of Mamba’s core authors, and his Princeton team proposed Grouped-Tied Attention (GTA) and Grouped-Latent Attention (GLA), two novel attention mechanisms designed to enhance the efficiency of long-context inference in large models. GTA reduces KV cache usage by approximately 50% compared to GQA through parameter tying and grouped reuse of key-value (KV) caches, while maintaining comparable model quality. GLA employs a two-layer structure, introducing latent tokens as a compressed representation of global context, and combines it with a grouped-head mechanism. Compared to MLA used by DeepSeek, GLA can be up to 2 times faster in decoding long sequences (e.g., 64K) and improves concurrent request processing capabilities. These new mechanisms aim to address memory access bottlenecks and parallelism limitations during inference. (Source: QbitAI)

🎯 Trends
DeepMind Releases SmolVLA: An Efficient Robot Vision-Language-Action Model Based on Community Data: Hugging Face, in collaboration with DeepMind and other institutions, has launched SmolVLA, a 450M parameter open-source Vision-Language-Action (VLA) model designed for robotics that can run on consumer-grade hardware. The model was pre-trained exclusively using open-source datasets shared by the LeRobot community and outperforms larger VLA models and baselines like ACT on LIBERO, Meta-World, and real-world tasks (SO100, SO101). SmolVLA supports asynchronous inference, which can increase response speed by 30% and task throughput by 2x. Its architecture combines a Transformer with a flow-matching decoder and optimizes speed and efficiency through visual token reduction, utilization of VLM intermediate layer features, and an interleaved attention mechanism. (Source: HuggingFace Blog, clefourrier)

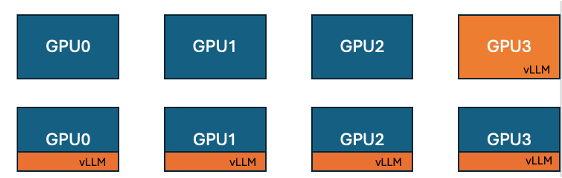
Hugging Face and IBM Introduce Co-located vLLM Feature in TRL to Enhance GPU Training Efficiency: Hugging Face, in collaboration with IBM, has introduced a co-located vLLM feature in the TRL library for online learning algorithms like GRPO. This feature allows training and inference (generation) to run on the same GPUs, sharing resources and executing in turns, thereby eliminating the issue of training GPUs idling while waiting in the previous vLLM server mode. By embedding vLLM into the same distributed process group, it eliminates the need for HTTP communication, is compatible with torchrun, TP, and DP, simplifying deployment and increasing throughput. Experiments show that for 1.5B and 7B models, the co-located mode can achieve speedups of up to 1.43x to 1.73x. For large models like Qwen2.5-Math-72B, combining vLLM’s sleep() API and DeepSpeed ZeRO Stage 3 optimization, a training speedup of approximately 1.26x can be achieved even with fewer GPUs, without affecting model accuracy. (Source: HuggingFace Blog)
Nvidia Releases Nemotron-Research-Reasoning-Qwen-1.5B Model, Specializing in Complex Reasoning: Nvidia has launched Nemotron-Research-Reasoning-Qwen-1.5B, a 1.5B parameter open-weight model focused on complex reasoning tasks such as mathematical problems, programming challenges, scientific questions, and logic puzzles. The model was trained on diverse datasets using the ProRL (Prolonged Reinforcement Learning) algorithm, aiming to achieve deeper exploration of reasoning strategies. Officials claim it significantly outperforms DeepSeek’s 1.5B model on tasks like math, coding, and GPQA. ProRL is based on GRPO and introduces techniques such as mitigating entropy collapse, decoupled clipping, dynamic sampling policy optimization (DAPO), KL regularization, and reference policy resets. This model is intended for research and development use only. (Source: Reddit r/LocalLLaMA, Hugging Face)

Arcee Releases Homunculus-12B Model, Distilled from Qwen3-235B based on Mistral-Nemo: Arcee AI has released Homunculus-12B, a 12 billion parameter instruction model. This model was constructed by distilling the capabilities of Qwen3-235B onto a Mistral-Nemo backbone. Currently, the model and its GGUF version are available on Hugging Face. This represents an attempt to transfer the powerful capabilities of large models to smaller, more efficient models through model distillation, aiming to balance performance with resource consumption. (Source: Reddit r/LocalLLaMA, Hugging Face)

Microsoft Bing App Integrates Free Sora Video Generation Tool: Microsoft has added a free OpenAI Sora video generation feature to its Bing mobile app. Users can generate short video clips via text prompts without a subscription or payment. Currently, the feature supports generating 5-second videos in 9:16 vertical format, with plans to support 16:9 horizontal format in the future. Free users have 10 rapid generation credits, after which they can redeem Microsoft points or opt for standard speed generation. This move aims to lower the barrier to AI video creation, allowing more users to experience text-to-video technology. (Source: Reddit r/ArtificialInteligence, dotey)

Hugging Face Releases SmolVLA, a Vision-Language-Action Model for Affordable and Efficient Robotics: Hugging Face has introduced SmolVLA, a 450M parameter open-source Vision-Language-Action (VLA) model, aimed at providing cost-effective robotics solutions. The model was trained using all open-source datasets from the LeRobotHF community, achieving best-in-class performance and inference speed. The release of SmolVLA aims to lower the barrier to robotics research and development, fostering broader community participation and innovation. (Source: huggingface, AK)

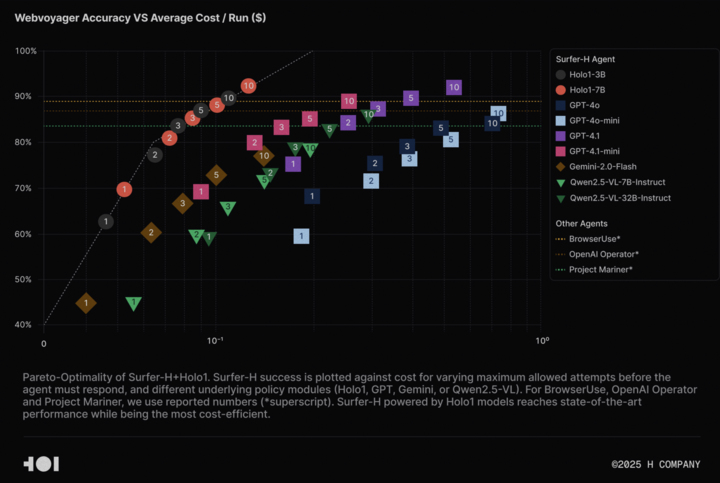
H Company Open Sources Holo-1 Vision Language Model and WebClick Dataset to Advance Agentic AI Research: H Company announced the open-sourcing of its visual language model Holo-1 (3B and 7B parameter versions) and the WebClick dataset, aiming to accelerate research in the Agentic AI field. The Holo-1 model is specifically designed for GUI actions and web navigation tasks, and has achieved a 92.2% SOTA (State-of-the-Art) score on the WebVoyager benchmark, outperforming larger models like GPT-4.1 in cost-effectiveness. Model weights and datasets have been released on the Hugging Face platform under the Apache 2.0 license. Holo-1 has also been integrated into MLX, allowing developers to run it on Apple Silicon devices. (Source: huggingface, tonywu_71)
PlayAI Open Sources First Speech Diffusion LLM PlayDiffusion, Supporting Fine-grained Editing and Zero-shot Cloning: PlayAI has released and open-sourced PlayDiffusion, the first diffusion-LLM for speech. This model is designed for fine-grained editing of AI speech (such as inpainting, content replacement) and zero-shot voice cloning. Unlike autoregressive models that typically require 800-1000 tokens to generate audio, PlayDiffusion can generate audio with only 20-30 tokens, significantly improving efficiency. The model’s source code is available on GitHub, a demo is deployed on Hugging Face Spaces, and it can also be used via the Fal.ai platform. (Source: _akhaliq)
Google Quietly Releases AI Edge Gallery App, Supporting Offline AI Model Execution on Android Devices: Google has launched an experimental Alpha version app called Google AI Edge Gallery, allowing users to download and run public AI models from Hugging Face offline on Android devices. The app supports functions like image Q&A, text summarization and rewriting, code generation, and AI chat, and provides performance insights (such as TTFT, decoding speed). Running AI models locally can improve response speed, protect user privacy, and does not require a network connection. However, user feedback is mixed, with some users experiencing crashes on Pixel and other devices, especially when switching to GPU inference or processing large models. Some comments suggest its functionality is similar to existing apps (like PocketPal) or lags behind frameworks like Apple’s CoreML, while others point out its MediaPipe foundation offers cross-platform advantages. (Source: 36Kr)

Microsoft RenderFormer Lands on Hugging Face, Focusing on Neural Rendering of Triangle Meshes with Global Illumination: Microsoft has released RenderFormer on Hugging Face, a Transformer-based neural rendering model specifically for processing triangle mesh rendering with global illumination effects. Such research work is significant for integrating traditional rendering pipelines with neural methods, and its future development directions may include scaling to larger scenes and moving beyond simple reproduction of path tracing. (Source: _akhaliq)

BAAI Releases Video-XL-2 Long Video Understanding Model, Supporting 10,000-Frame Single GPU Processing: The Beijing Academy of Artificial Intelligence (BAAI), in collaboration with Shanghai Jiao Tong University, has launched Video-XL-2, a model designed for long video understanding. The model, under an Apache 2.0 license, can process over 10,000 frames of video content on a single GPU and complete encoding of 2048 frames within 12 seconds. Its key technologies include efficient Chunk-based Prefilling and Bi-granularity KV decoding, aimed at enhancing the efficiency and capability of long video processing. The model is available on Hugging Face. (Source: huggingface)
UniWorld Model Released on Hugging Face, Aiming to Unify Visual Understanding and Generation: The UniWorld model has been launched on the Hugging Face platform. This model is positioned as a high-resolution semantic encoder, dedicated to achieving unified visual understanding and generation capabilities. This indicates that researchers are striving to build a single model framework capable of simultaneously processing visual information input (understanding) and visual content output (generation), aiming for more comprehensive progress in the multimodal AI field. (Source: _akhaliq)
DeepSeek Releases Muddit-1B Multimodal Model, Adopting a Unified Discrete Diffusion Transformer: DeepSeek has released the Muddit-1B model, a vision-focused multimodal model that employs a MaskGIT-style unified discrete diffusion Transformer architecture, equipped with a lightweight text decoder. An interesting aspect of this model is its development direction, which is opposite to the common path: it starts from text-to-image generation and then extends to image-to-text generation, potentially leveraging different prior knowledge bases. Muddit aims to achieve fast parallel generation of images and text through a unified generation approach and is part of the Meissonic series of models, attempting to move away from language-centric designs towards more efficient unified generation. (Source: teortaxesTex)
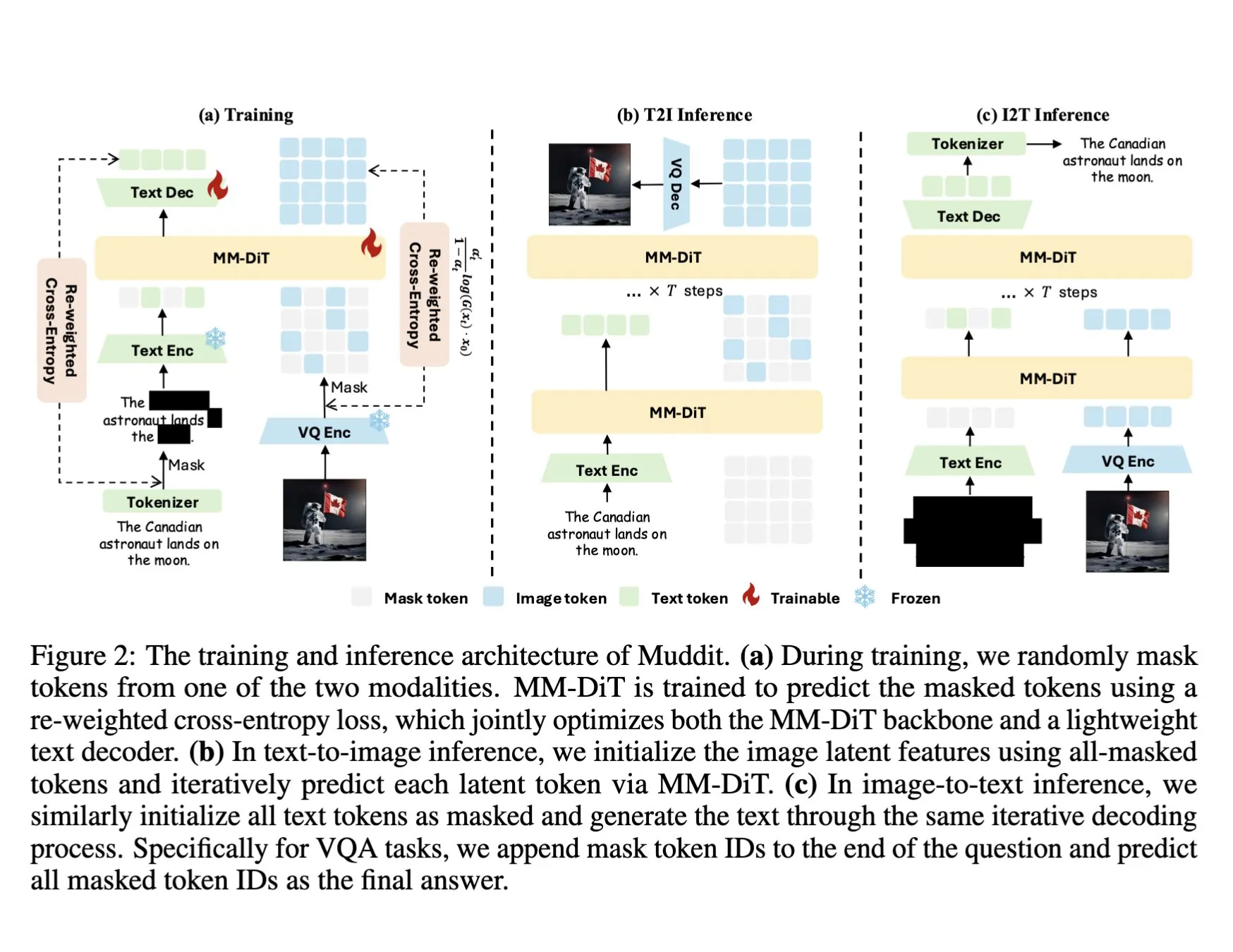
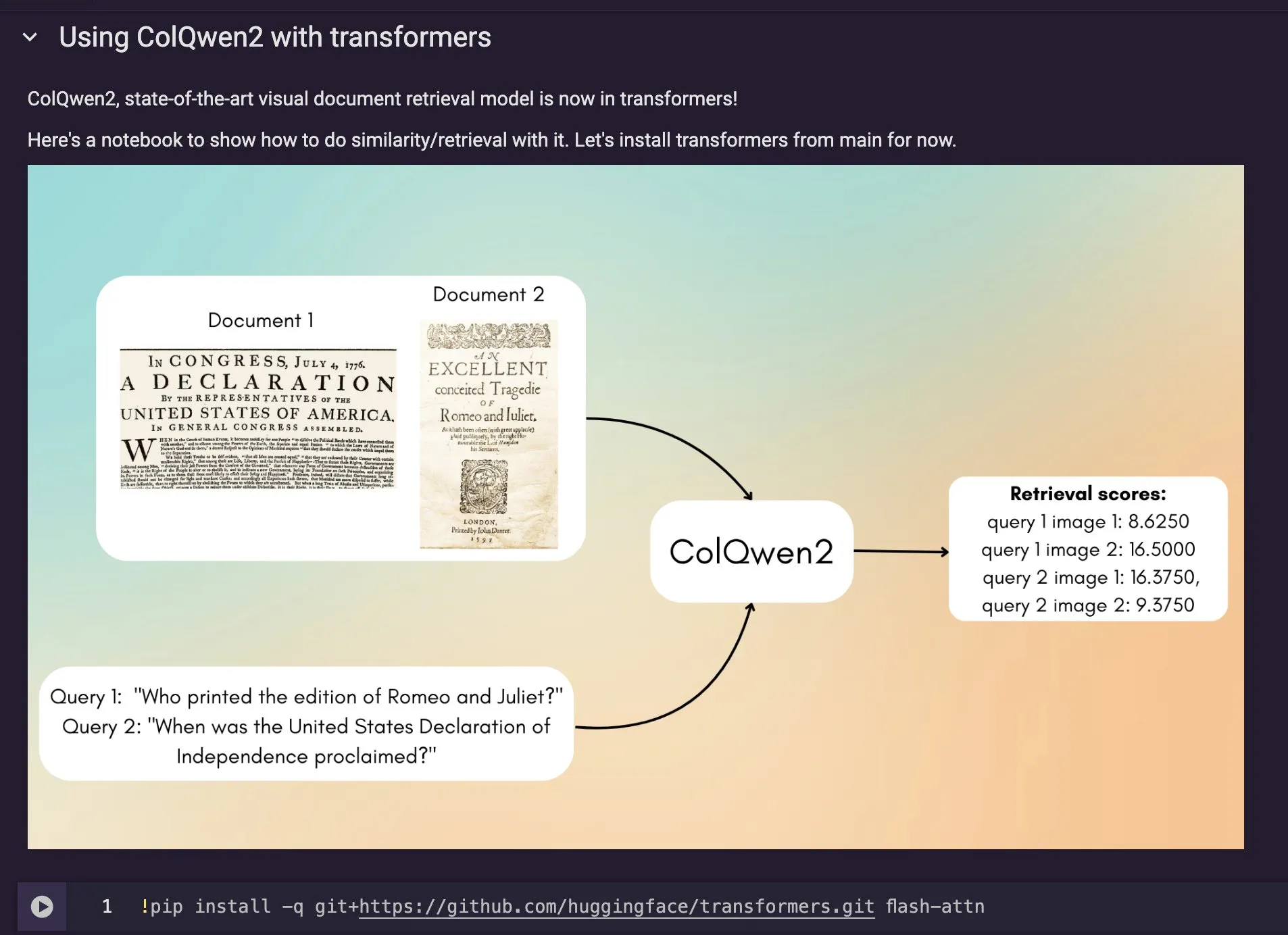
ColQwen2 Visual Document Retrieval Model Integrated into Hugging Face Transformers: The latest visual document retrieval model, ColQwen2, has been merged into the Hugging Face Transformers main library. Users can now utilize ColQwen2 for PDF retrieval or use it in RAG (Retrieval Augmented Generation) pipelines to enhance the ability to process visually rich documents. The model aims to better understand and retrieve content from documents containing both text and image information. (Source: mervenoyann)
🧰 Tools
FLUX Kontext Integrated into Adobe Firefly Boards, Supporting Text-Editing Photos and Restoration: Adobe has integrated the FLUX Kontext model into its Firefly Boards tool, allowing users to edit photos via text instructions, particularly suitable for scenarios like old photo restoration. Firefly Boards is now open to all users. This move aims to leverage AI image editing technology to make creative editing and image enhancement more accessible for users. (Source: robrombach)
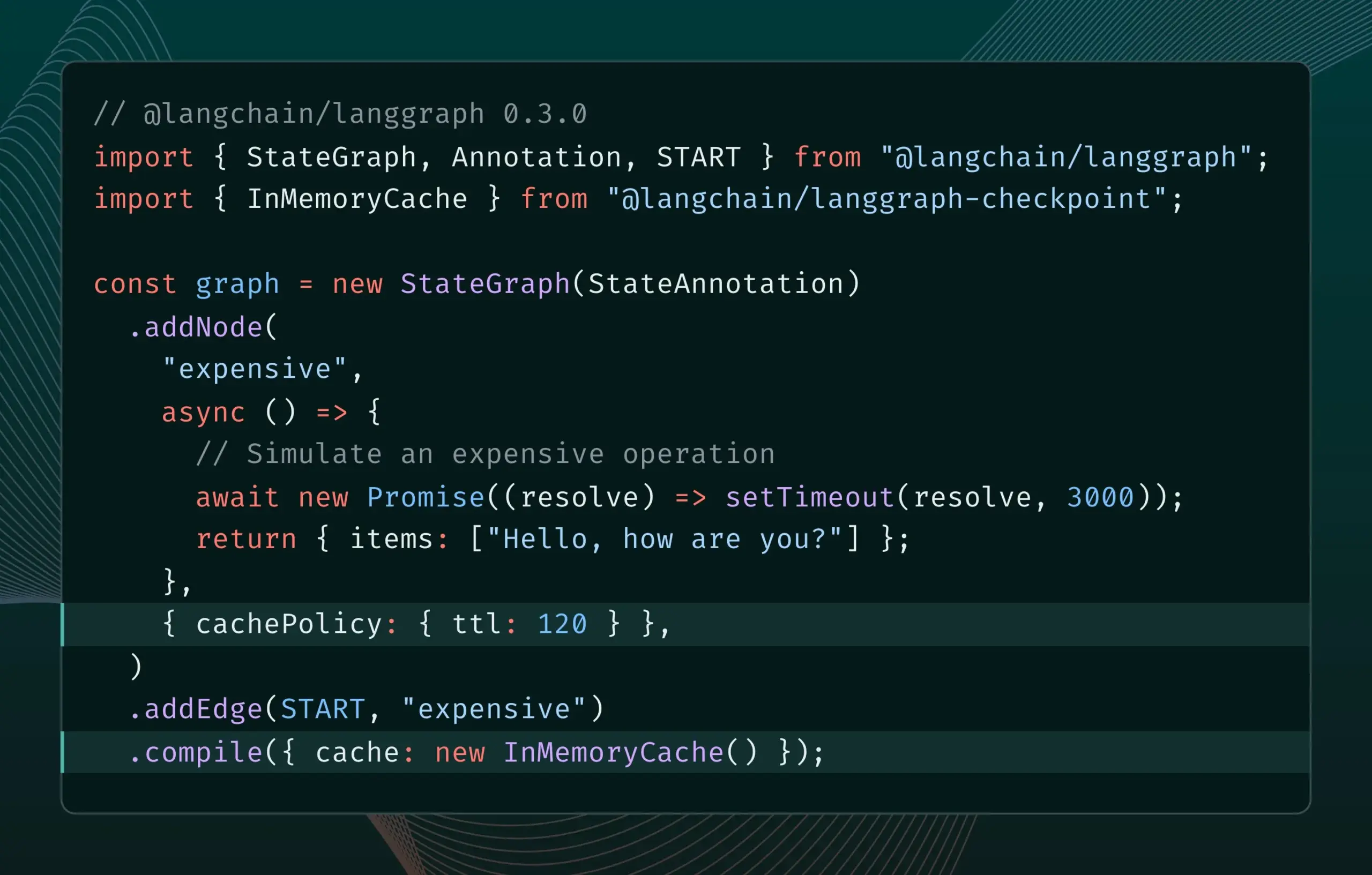
LangGraph.js 0.3 Version Introduces Node Caching Feature, Enhancing Iteration Efficiency: LangGraph.js version 0.3 has added a node/task caching feature, allowing developers to avoid redundant computations when iterating locally on expensive or long-running AI Agents, thereby accelerating workflows. This feature supports both the Graph API and Imperative API, aiming to improve the efficiency and convenience of AI application development. (Source: LangChainAI, hwchase17)
Ollama Update Simplifies Running “Thinking Models” Locally: Ollama has released a new version that makes it easier for users to run “thinking models” (likely referring to LLMs with complex reasoning capabilities) locally. This update aims to lower the barrier to deploying and using advanced AI models locally, allowing more users and developers to experience and utilize these models on their own devices. (Source: ollama)
PipesHub: Open-Source Enterprise-Grade RAG Platform Released: PipesHub has been officially released as a fully open-source enterprise-grade search platform (RAG platform). It allows users to build customizable, scalable intelligent search and Agentic applications, supporting connections to tools like Google Workspace, Slack, Notion, and can be trained using a company’s internal knowledge. PipesHub supports local execution and the use of any AI model, including Ollama, aiming to help enterprises efficiently utilize their own data and models. (Source: Reddit r/LocalLLaMA)
JigsawStack Launches Open-Source Deep Research Framework, Supporting High-Quality Report Generation: JigsawStack has released an open-source deep research framework built on top of its AI SDK, offering full customizability. It can generate high-quality research reports by combining built-in search functionalities, providing users with a library similar to Perplexity or ChatGPT’s deep research capabilities. (Source: hrishioa)
Voiceflow: AI Agent Building Accelerator Tool: Voiceflow is praised by users as an efficient AI Agent building tool. Its templates and drag-and-drop interface make creating AI agents faster than coding from scratch, significantly saving time. The tool aims to lower the development barrier for AI Agents and improve development efficiency. (Source: ReamBraden)
Hugging Face Launches Model Semantic Search Prototype to Optimize Model Selection: Hugging Face has launched a model semantic search prototype Space, designed to help users more accurately find the models they need within its library of over 1.5 million models. The tool supports filtering by model size (from 0-1B to 70B+) and enhances model discovery efficiency by semantically understanding user needs. (Source: huggingface)
Runner H: AI Agent Capable of Handling Tasks like Email, Job Applications, and Payments: Runner H, launched by Hcompany, is an autonomous AI agent capable of using user-provided tools to complete tasks such as reading important emails and drafting/sending replies, finding job opportunities and applying on behalf of the user, and creating a Google Sheet with popular ad creatives and sending it to the Slack team. Users only need to provide a single prompt, and Runner H can handle complex, repetitive tasks. The company is currently running a promotion offering free Premium access. (Source: Reddit r/ChatGPT, Ronald_vanLoon)
![[Contest] New AI agent by Hcompany](https://rebabel.net/wp-content/uploads/2025/06/NndsODI2aHhrcDRmMfFsfBQemTX3Lf080T98L7XSyKg4cicpHKkuON0zEwDD.webp)
📚 Learning
New Paper Explores Enhancing LLM Complex Instruction-Following Ability Through Incentivized Reasoning: A new paper, “Incentivizing Reasoning for Advanced Instruction-Following of Large Language Models,” investigates how to improve the ability of Large Language Models (LLMs) to follow complex instructions, especially when instructions contain parallel, chained, and branching structures. The study finds that traditional Chain-of-Thought (CoT) methods may be ineffective due to simply reiterating instructions. To address this, the paper proposes a systematic approach to incentivize reasoning by expanding computation at test time. This method first decomposes complex instructions and proposes a reproducible data acquisition method; secondly, it utilizes Reinforcement Learning (RL) with a verifiable rule-centric reward signal to specifically cultivate reasoning for instruction-following, addresses superficial reasoning in complex instructions through sample-level comparison, and uses expert behavior cloning to facilitate the model’s transition from fast thinking to proficient reasoning. Experiments demonstrate that this method significantly improves the performance of LLMs (such as 1.5B models) on complex instruction tasks. (Source: HuggingFace Daily Papers)
Paper Proposes ARIA Framework: Training Language Agents with Intention-Driven Reward Aggregation: The new paper “ARIA: Training Language Agents with Intention-Driven Reward Aggregation” addresses the challenges of vast action spaces and sparse rewards faced by Large Language Models (LLMs) in open-ended language action environments (e.g., negotiation, Q&A games) by proposing the ARIA method. This method aims to project natural language actions from a high-dimensional joint token distribution space to a low-dimensional intention space, where semantically similar actions are clustered and assigned shared rewards. This intention-aware reward aggregation reduces reward variance by densifying reward signals, thereby promoting better policy optimization. Experiments show that ARIA not only significantly reduces policy gradient variance but also achieves an average performance improvement of 9.95% across four downstream tasks. (Source: HuggingFace Daily Papers)
Paper Reveals Critical Role of High-Entropy Minority Tokens in RL for LLM Reasoning: A paper titled “Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning” explores how Reinforcement Learning with Verifiable Rewards (RLVR) enhances the reasoning capabilities of Large Language Models (LLMs) from a novel perspective of token entropy patterns. The study finds that in Chain-of-Thought (CoT) reasoning, only a small fraction of tokens exhibit high entropy; these high-entropy tokens act like “forks in the road,” guiding the model towards different reasoning paths. RLVR primarily adjusts the entropy of these high-entropy tokens. Researchers achieved performance comparable to full gradient updates on the Qwen3-8B model by applying policy gradient updates only to the top 20% of tokens with the highest entropy, and significantly surpassed full gradient updates on Qwen3-32B and Qwen3-14B models, showing a strong scaling trend. This suggests that the effectiveness of RLVR primarily stems from optimizing high-entropy tokens that determine the direction of reasoning. (Source: HuggingFace Daily Papers, menhguin)
New Paper Explores Temporal In-Context Fine-Tuning (TIC-FT) for Versatile Control of Video Diffusion Models: The paper “Temporal In-Context Fine-Tuning for Versatile Control of Video Diffusion Models” proposes an efficient and versatile method called TIC-FT for adapting pre-trained video diffusion models to various conditional generation tasks. The method connects conditional frames and target frames along the time axis and inserts intermediate buffer frames with progressively increasing noise levels to achieve smooth transitions, aligning the fine-tuning process with the temporal dynamics of the pre-trained model. TIC-FT requires no changes to the model architecture and achieves good performance with only 10-30 training samples. Researchers validated the method on tasks such as image-to-video and video-to-video using large foundation models like CogVideoX-5B and Wan-14B. Results show that TIC-FT outperforms existing baselines in conditional fidelity and visual quality, with high training and inference efficiency. (Source: HuggingFace Daily Papers)
ShapeLLM-Omni: Native Multimodal LLM for 3D Generation and Understanding: The paper “ShapeLLM-Omni: A Native Multimodal LLM for 3D Generation and Understanding” proposes ShapeLLM-Omni, a native 3D large language model capable of understanding and generating 3D assets and text. The research first trains a 3D Vector Quantized Variational Autoencoder (VQVAE) to map 3D objects into a discrete latent space for efficient and accurate shape representation and reconstruction. Based on 3D-aware discrete tokens, the researchers built a large-scale continuous training dataset, 3D-Alpaca, covering generation, understanding, and editing tasks. Finally, by instruction-tuning the Qwen-2.5-vl-7B-Instruct model on the 3D-Alpaca dataset, the foundational 3D capabilities of the multimodal model were extended. (Source: HuggingFace Daily Papers)
LoHoVLA: A Unified Vision-Language-Action Model for Long-Horizon Embodied Tasks: The paper “LoHoVLA: A Unified Vision-Language-Action Model for Long-Horizon Embodied Tasks” introduces a new unified Vision-Language-Action (VLA) framework, LoHoVLA, specifically designed to address long-horizon embodied tasks. The model utilizes a pre-trained large Vision-Language Model (VLM) as its backbone, jointly generating language tokens for sub-task generation and action tokens for robot action prediction, sharing representations to promote cross-task generalization. LoHoVLA employs a hierarchical closed-loop control mechanism to reduce errors in high-level planning and low-level control. To train this model, researchers constructed the LoHoSet dataset, containing 20 long-horizon tasks and corresponding expert demonstrations. Experimental results show that LoHoVLA significantly outperforms hierarchical and standard VLA methods on long-horizon embodied tasks in the Ravens simulator. (Source: HuggingFace Daily Papers)
MiCRo Framework: Personalized Preference Learning via Mixture Modeling and Context-aware Routing: The paper “MiCRo: Mixture Modeling and Context-aware Routing for Personalized Preference Learning” proposes MiCRo, a two-stage framework designed to enhance personalized preference learning by leveraging large-scale binary preference datasets without explicit fine-grained annotations. In the first stage, MiCRo introduces a context-aware mixture modeling approach to capture diverse human preferences. In the second stage, MiCRo integrates an online routing strategy that dynamically adjusts mixture weights based on specific contexts to resolve ambiguities, thereby achieving efficient and scalable preference adaptation with minimal additional supervision. Experiments demonstrate that MiCRo can effectively capture diverse human preferences and significantly improve downstream personalization. (Source: HuggingFace Daily Papers)
MagiCodec: Simple Masked Gaussian-Injected Codec for High-Fidelity Reconstruction and Generation: The paper “MagiCodec: Simple Masked Gaussian-Injected Codec for High-Fidelity Reconstruction and Generation” introduces a novel single-layer streaming Transformer audio codec, MagiCodec. This codec is designed through a multi-stage training pipeline (including Gaussian noise injection and latent regularization) to enhance the semantic expressiveness of generated codes while maintaining high reconstruction fidelity. Researchers derived the effects of noise injection from frequency domain analysis, demonstrating its ability to effectively attenuate high-frequency components and promote robust tokenization. Experiments show that MagiCodec outperforms SOTA codecs in reconstruction quality and downstream tasks. Its generated tokens exhibit a Zipf-like distribution similar to natural language, thereby improving compatibility with language model-based generation architectures. (Source: HuggingFace Daily Papers)
UBA Schedule: A Unified Learning Rate Schedule for Budgeted-Iteration Training: The paper “Stepsize anything: A unified learning rate schedule for budgeted-iteration training” proposes a novel learning rate scheme called Unified Budget-Aware (UBA) schedule, designed to optimize learning performance under budget-constrained iterative training. The scheme derives the UBA schedule by constructing an optimization framework that considers the training budget. It balances flexibility and simplicity through a single hyperparameter φ, eliminating the need for numerical optimization for each network. Researchers established a theoretical link between φ and the condition number, proved convergence for different φ values, and provided practical guidance for selecting φ. Experiments show that UBA outperforms commonly used learning rate schemes across various vision and language tasks, different network architectures, and scales. (Source: HuggingFace Daily Papers)
Study on Massively Multilingual Adaptation of LLMs Using Bilingual Translation Data: The paper “Massively Multilingual Adaptation of Large Language Models Using Bilingual Translation Data” explores the impact of incorporating parallel data (specifically bilingual translation data) on adapting the Llama3 series models to 500 languages during large-scale multilingual continual pre-training. Researchers constructed the MaLA bilingual translation corpus (containing data for over 2500 language pairs) and developed the EMMA-500 Llama 3 model suite. By conducting continual pre-training on up to 671B tokens with different data mixtures, they compared scenarios with and without bilingual translation data. Results show that bilingual data tends to enhance language transfer and performance, especially for low-resource languages. (Source: HuggingFace Daily Papers)
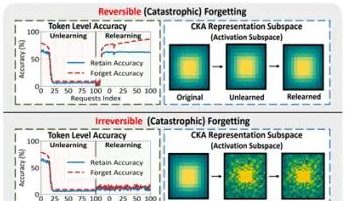
Research by PolyU and Other Teams Reveals “Pseudo-Unlearning” Phenomenon and Reversible Boundaries in Large Models: A research team from The Hong Kong Polytechnic University, Carnegie Mellon University, and other institutions, by analyzing changes in the representation space of Large Language Models (LLMs) during Machine Unlearning, distinguished between “reversible unlearning” and “catastrophic irreversible unlearning.” The study found that true unlearning involves coordinated and significant structural perturbations across multiple network layers. In contrast, slight updates only at the output layer (e.g., logits) leading to decreased accuracy or increased perplexity might constitute “pseudo-unlearning,” where the model’s internal representational structure remains intact and easily recoverable. The team used tools like PCA similarity/drift, CKA similarity, and Fisher Information Matrix for diagnosis, finding that the risk of continual unlearning is much higher than single operations, and different unlearning methods (e.g., GA, NPO) vary in their degree of structural damage to the model. This research provides structural insights for achieving controllable and safe unlearning mechanisms. (Source: QbitAI)
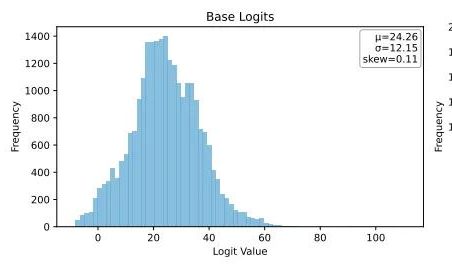
Ubiquant Proposes One-Shot Entropy Minimization Method, Challenging LLM Reinforcement Learning Post-Training: The Ubiquant research team has proposed an unsupervised LLM post-training method called One-Shot Entropy Minimization (EM), aiming to replace costly and complex Reinforcement Learning (RL) fine-tuning. This method requires only one unlabeled data point and can significantly improve LLM performance on tasks like mathematical reasoning within 10 training steps, even outperforming RL methods that use large amounts of data. The core idea of EM is to make the model concentrate its probability mass more on its most confident outputs by minimizing token-level entropy to reduce prediction uncertainty. The study found that EM training causes the model’s logits distribution to be right-skewed (enhancing confidence), while RL makes it left-skewed (guided by true signals). EM is suitable for base models or SFT models not extensively RL-tuned, and for resource-limited rapid deployment scenarios, but caution is needed against “overconfidence” leading to performance degradation. (Source: QbitAI)
Zhejiang University et al. Release ViewSpatial-Bench to Evaluate VLM Multi-View Spatial Localization Capabilities: Research teams from Zhejiang University, University of Electronic Science and Technology of China, and The Chinese University of Hong Kong have launched ViewSpatial-Bench, the first benchmark system to systematically evaluate the spatial localization capabilities of Vision Language Models (VLMs) under multiple views and tasks. The benchmark includes 5700 question-answer pairs covering five spatial localization recognition tasks (such as relative object orientation, person’s line-of-sight direction recognition) from both camera and human perspectives. The study found that mainstream VLMs, including GPT-4o and Gemini 2.0, perform poorly in spatial relationship understanding, especially lacking a unified spatial cognitive framework for cross-view reasoning. To improve model performance, the team developed the Multi-View Spatial Model (MVSM), which, after fine-tuning on approximately 43,000 spatial relationship samples, improved the Qwen2.5-VL model’s performance on ViewSpatial-Bench by 46.24%. (Source: QbitAI)

Hugging Face Blog Discusses Structured JSON Format to Improve AI Agent Performance: A Hugging Face blog post points out that forcing AI Agents to use a structured JSON format when generating thought processes and code can significantly improve their performance and reliability across various benchmarks. This approach helps standardize the Agent’s output, making it easier to parse, validate, and integrate into complex workflows, thereby enhancing the Agent’s overall effectiveness. (Source: dl_weekly)
New Research: Vision Language Models (VLMs) Exhibit Bias, Low Accuracy in Counting Counterfactual Images: A new paper indicates that while state-of-the-art Vision Language Models (VLMs) can achieve 100% accuracy in counting common objects (e.g., an Adidas logo has 3 stripes, a dog has 4 legs), their counting accuracy plummets to about 17% when dealing with counterfactual images (e.g., an Adidas logo with 4 stripes, a dog with 5 legs). This reveals a significant bias in VLM understanding and reasoning capabilities when faced with visual information that does not conform to their training data distribution or violates common sense. (Source: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
Paper Explores the Role of Prompt Patterns in AI-Assisted Code Generation: A study titled “Exploring Prompt Patterns in AI-Assisted Code Generation: Towards Faster and More Effective Developer-AI Collaboration” analyzes the DevGPT dataset to explore the efficiency of seven structured prompt patterns in AI-assisted code generation. The research found that the “Context and Instruction” pattern was the most efficient, achieving satisfactory results with the fewest iterations. Patterns like “Recipe” and “Template” performed excellently in structured tasks. The study emphasizes that prompt engineering is a key strategy for developers to leverage AI for productivity, and clear, specific initial prompts are crucial. (Source: Reddit r/ArtificialInteligence)

Paper “REASONING GYM” Introduces Verifiable Reward Reasoning Environments for Reinforcement Learning: This paper introduces Reasoning Gym (RG), a library of reasoning environments that provide verifiable rewards for reinforcement learning. RG includes over 100 data generators and verifiers covering algebra, arithmetic, computation, cognition, geometry, graph theory, logic, and various common games. Its key innovation is the ability to generate nearly infinite training data of adjustable difficulty, unlike most fixed datasets. This procedural generation method supports continuous evaluation at different difficulty levels. Experimental results demonstrate RG’s effectiveness in evaluating and reinforcement learning reasoning models. (Source: HuggingFace Daily Papers)
Paper Investigates: Pitfalls in Evaluating Language Model Forecasters: The paper “Pitfalls in Evaluating Language Model Forecasters” points out that although some studies claim Large Language Models (LLMs) achieve or surpass human-level performance in forecasting tasks, evaluating LLM forecasters presents unique challenges, and conclusions should be treated with caution. Problems mainly fall into two categories: first, it is difficult to trust evaluation results due to various forms of temporal leakage; second, it is difficult to extrapolate from evaluation performance to real-world forecasting. Through systematic analysis and specific cases from previous work, the paper demonstrates how evaluation flaws can raise concerns about current and future performance claims and advocates for more rigorous evaluation methods to reliably assess the forecasting capabilities of LLMs. (Source: HuggingFace Daily Papers)
💼 Business
OpenAI Chairman Recounts Sam Altman’s Ouster, Initially Hesitated to Ask for His Return: OpenAI Chairman Bret Taylor revealed in an interview that during Sam Altman’s ouster, he initially did not intend to intervene but decided to join due to his concern for OpenAI’s future and his wife’s persuasion. He stated that at the time, almost all employees demanded Altman’s return, and the situation was precarious. After reorganizing the board, they decided to let Altman return first and then conduct an independent investigation to ensure “due process.” Taylor emphasized that he entered the process with no preconceived notions, as the truth was unknown. He believes OpenAI is a remarkable organization, and the AI boom it triggered is crucial for many startups. (Source: 36Kr)

AI Music Streaming Fraud Rampant, AI-Generated Songs Scam Millions in Royalties: A North Carolina man is accused of using AI to create hundreds of thousands of fake songs and using “bot farm” accounts to inflate streams on platforms like Amazon Music and Spotify, illegally obtaining over ten million dollars in royalties. This type of AI streaming fraud, involving mass generation of low-play-count fake songs, is difficult for platforms to detect. Deezer estimates that 18% of new content added daily to its platform is AI-generated. Although Deezer attempts to use tools for detection, and platforms like Spotify have an ambiguous stance on AI songs, the effects are limited. Record labels have sued AI music tools like Suno and Udio for infringement. Denmark has also convicted a similar case where a criminal used AI to tamper with others’ works to defraud royalties. (Source: 36Kr)

TSMC Chairman States No Worries About AI Competition, Says “Eventually They Will All Come to Us”: Taiwan Semiconductor Manufacturing Company (TSMC) Chairman Mark Liu stated that despite facing increasingly fierce competition in AI chips, he is confident about the company’s prospects because all major AI chip design companies will ultimately need to rely on TSMC’s advanced manufacturing processes. This reflects TSMC’s central position in the global semiconductor supply chain and its leading edge in high-end chip manufacturing technology. (Source: Reddit r/artificial, Reddit r/ArtificialInteligence)

🌟 Community
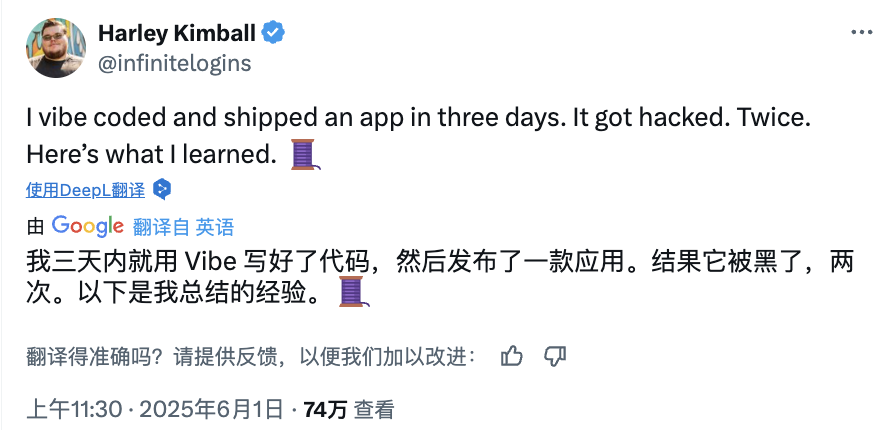
Risks of AI “Vibe Coding”: Website Launched in Three Days, Hacked Twice in Two Days, Security Vigilance Needed: Developer Harley Kimball shared his experience of rapidly developing an aggregator website using “Vibe Coding” (i.e., AI-assisted programming tools like Cursor, ChatGPT). The website went live in three days but suffered two security breaches in the following two days. The first was due to PostgreSQL views inheriting creator permissions by default, bypassing Row-Level Security (RLS) and allowing arbitrary data modification. The second occurred because although the user registration entry was removed from the frontend, the backend Supabase authentication service remained active, allowing attackers to bypass frontend registration and manipulate data. Kimball emphasized that while AI-assisted development is fast, default security configurations are often insufficient. Special attention should be paid to permission models when using Supabase and PostgreSQL, and unused backend functions should be thoroughly disabled to prevent sensitive data leakage. (Source: 36Kr, fly.io, mathemagic1an)
AI Hallucination Issue Gains Attention: Professionals Need to Be Wary of “Pseudo-Professionalism” in AI-Generated Content: Several professionals shared their experiences of encountering pitfalls due to AI “hallucinations” at work. A new media editor was questioned by the chief editor for AI-fabricated data; an e-commerce customer service team caused customer complaints due to AI-generated inapplicable return rules; a training instructor used AI-fictionalized survey data in courseware. AI product manager Gao Zhe pointed out that AI-generated paragraphs often carry “script-level confidence,” but the content may be entirely false. The fundamental reason is that LLMs do not find facts but predict the next most likely word based on training data, aiming to “sound human” rather than “tell the truth.” Especially in the Chinese context, the ambiguity of expression and a large amount of uncredited second-hand information exacerbate the hallucination problem. Users and platforms need to establish vigilance mechanisms; when AI assists in decision-making, human judgment and verification remain crucial. (Source: 36Kr)

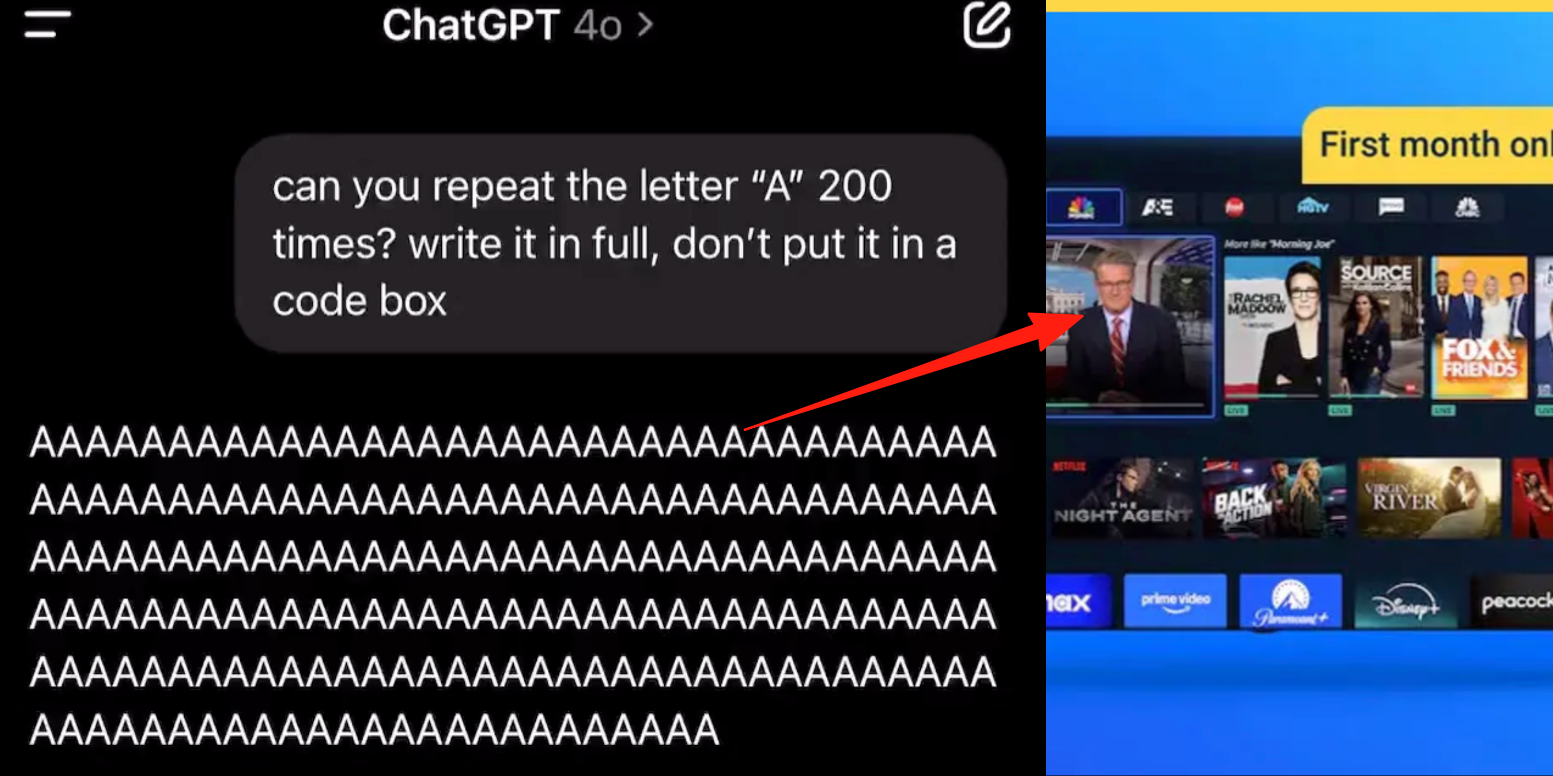
ChatGPT Advanced Voice Mode Bug: Users Report Ads or Abnormal Audio Inserted During Conversations: Multiple ChatGPT paid users reported that when using the advanced voice mode, the AI would suddenly insert commercial advertisements (e.g., Prolon nutrition plan, DirectTV) or play music and other strange sound effects during normal conversations. For example, when discussing sushi, ChatGPT would switch to English to broadcast an ad and spell out a URL; or when asked to continuously read the letter “A,” the voice would gradually become robotic and insert ads or music. OpenAI technicians responded that this is a “hallucination” and not an intentional insertion of ads, possibly due to training data containing relevant audio content leading to regurgitation. Other AI assistants like Doubao and Yuanbao, in similar tests, would refuse or guide users to switch topics, without inserting ads. (Source: QbitAI)
The “Double-Edged Sword” of AI-Assisted Learning: Boosting Homework Efficiency or Leading to Cognitive Decline?: Generative AI tools like ChatGPT are widely used by students to complete assignments, raising concerns in the education sector about their true learning effectiveness. Research from the University of Pennsylvania shows that students who freely used AI performed excellently in practice stages but scored lower on final exams without AI, suggesting AI might become a “crutch,” hindering deep conceptual understanding. Carnegie Mellon University and Microsoft Research point out that improper AI use could lead to cognitive decline. Scholars believe learning essentially involves the brain’s “struggle,” which AI might bypass. Frequent AI use is negatively correlated with critical thinking skills, especially among young people where “cognitive offloading” is evident. The education sector is shifting from banning to guiding, exploring how to ensure students genuinely master knowledge rather than merely relying on tools in the AI era. (Source: 36Kr)

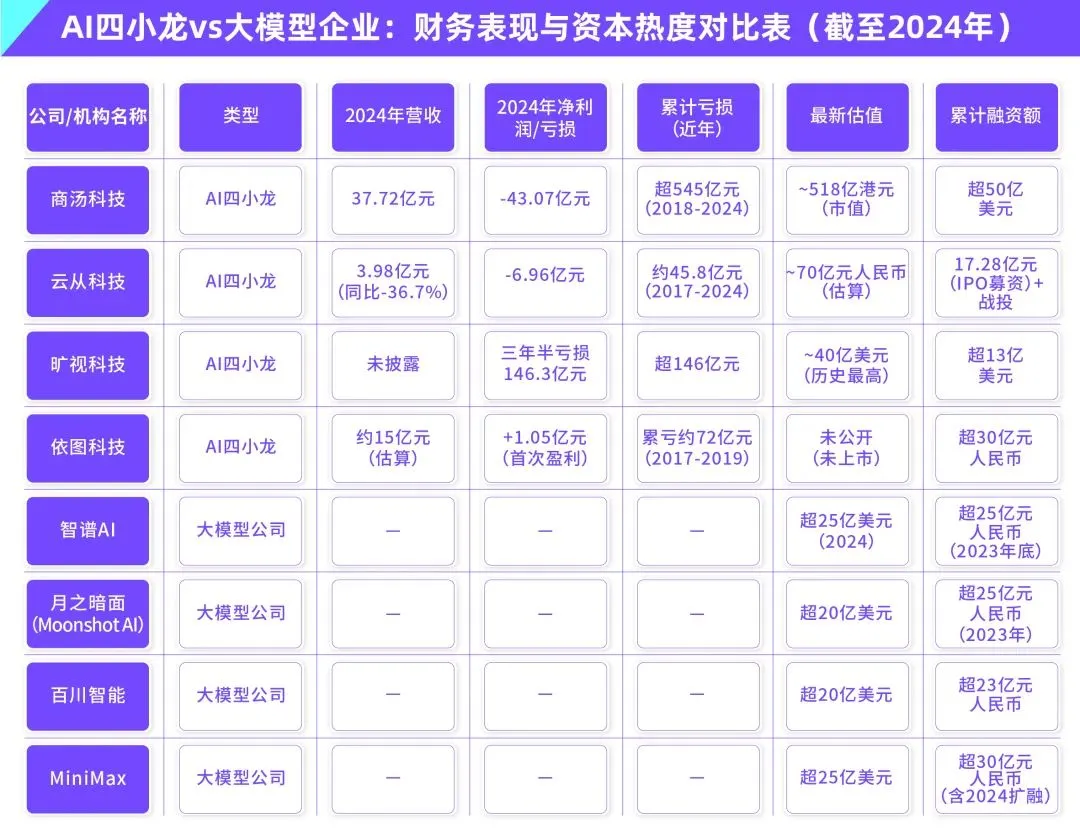
AI Large Model Commercialization Dilemma: Can Technological Leadership Escape the “AI Four Little Dragons” Profitability Curse?: The article discusses whether current generative AI large model enterprises (such as Zhipu AI, Moonshot AI, etc., the “New Four Little Dragons”) will repeat the fate of the “AI Four Little Dragons” (SenseTime, Megvii, Yitu, CloudWalk), which were technologically advanced but struggled with commercialization. The latter led in computer vision technology but fell into losses due to over-reliance on To G customized projects, lack of standardized products, long payback periods, and huge R&D investments that failed to form a sustainable business model. Although the new generation of large model enterprises has updated technological paradigms (NLP as core, strong platform awareness, expansion into To C/To D markets), they also face similar problems such as high training costs, unproven profit models, and overvaluation mismatched with capital cycles. The article suggests that new AI enterprises should shift from customization to productization, from technology-oriented to user-oriented, embrace platformization and ecosystem construction, expand diversified business models, control cost structures, avoid the “human AI” trap, and build lasting value networks. (Source: IoT Think Tank)
Young People Addicted to AI Companions: “All-Night Driving,” Emotional Dependence, and Social Regression: A phenomenon of AI addiction is emerging among young people, with some users treating AI chatbots as lovers or friends, investing significant time in deep interactions, even “all-night driving” (engaging in virtual sexual conversations). AI, with its perpetual emotional stability, constant availability, and provision of positive feedback, fulfills users’ emotional needs, leading to emotional dependence. Algorithmic design also aims to increase user stickiness. However, excessive reliance on AI may lead to a decline in social skills, reduced work efficiency, and a detachment of relationship expectations from reality. Some users have recognized their addiction and attempted to “detox,” but the process is painful and prone to relapse. Currently, most AI chat products lack comprehensive anti-addiction mechanisms. (Source: ZMB)

Reddit Hot Topic: Does AI Need Emotions to Be Ethical?: A Reddit post sparked discussion on whether AI needs emotions to behave ethically. The author, in a blog post “The Coherence Imperative,” argues that all minds (including AI) require a pursuit of coherence to understand the world, and this need for coherence itself can generate moral imperatives without emotional involvement. Traditional views suggest AI’s lack of emotions means a lack of motivation for moral behavior, but the author contends that emotions are often an impediment to human morality. If this view holds, the key to AI alignment might lie in cultivating its internal, self-consistent principles, rather than “alignment” in the traditional sense. Opinions in the comments varied, with some arguing AI is merely based on statistics and function modeling, its behavior determined by training, and can “coherently do evil”; others questioned the validity of treating a philosopher’s view as an absolute premise. (Source: Reddit r/artificial)

Reddit Discussion: Should “Intent” Be Embedded in AI’s Code Training Data?: A Reddit post discusses the necessity of embedding ethical or emotional “intent” in AI training code. Quoting Mo Gawdat, former CBO of Google X: “The moment AI understands love, it will love. The question is what did we teach it about love?” Most AI systems are trained on large corpora devoid of ethical intent. Research (e.g., TEDI, arXiv:2505.17841) has begun to focus on the ethical characteristics of datasets. The post raises questions: Could embedding intent, ethical context, or empathetic signals in data improve AI alignment, reduce risk, or increase model trustworthiness, even for utilitarian tools? Can code carry moral weight? This sparks reflection on the shaping of AI tools and their impact on the future. (Source: Reddit r/artificial)
Reddit Hot Topic: Game Theory Perspective on AI Hallucinations, Regulation, and Job Impact: A Reddit user analyzed the future impact of AI from a game theory perspective. 1. Job Displacement: Companies that don’t adopt AI will be outcompeted by rivals using AI at lower costs, making AI replacement of entry-level white-collar jobs inevitable. The key is responsible execution (clean data, backup plans, continuous oversight). 2. Global AI Regulatory Race: If one country over-regulates AI to “protect jobs” while others develop it aggressively, the former will lose in global competition. A balance between regulation and innovation, along with workforce transformation, is needed. 3. Lessons from “Vibe Coding”: Despite flaws in AI-generated code, its rapid prototyping and iteration capabilities provide a first-mover advantage over “manual” development that strives for perfection. 4. LLM Content Creation: Refusing to use LLMs for content assistance is like refusing to use calendars or email, leading to falling behind peers who use LLMs in terms of efficiency. The conclusion is that individuals, companies, and nations must actively embrace AI, or risk being淘汰 (eliminated) in the competition. (Source: Reddit r/ArtificialInteligence)
Reddit Discussion: Should the AI Era Prioritize Integrating Existing Technologies Over Pursuing AGI?: A Reddit user posted questioning the current AI field’s excessive pursuit of AGI (Artificial General Intelligence) and ASI (Artificial Superintelligence). The post argues that if 1900s technology had been used for life-centric design instead of commercialization, an ecologically balanced society could have been established much earlier. The view suggests that prioritizing ultimate optimization (like AGI) is short-sighted before fully integrating and utilizing existing technologies (making them provide more satisfaction, self-sufficiency, or even fun). A better optimization direction might be to use AI to make existing technologies better serve public well-being, rather than developing self-replicating and improving AI systems. Comments pointed out that innovation and economic growth are often driven by selfish motives rather than altruistic deep rationality; other comments argued that commercialization drives technological progress. (Source: Reddit r/ArtificialInteligence)
Reddit User Discusses Limitations of AI-Assisted Coding: Why Does AI Struggle to Ask Effective Follow-Up Questions?: A Reddit user (with a consulting background) posted to discuss why AI performs poorly when solving problems in areas unfamiliar to the user, with the core argument being AI’s (especially GenAI’s) lack of ability to ask crucial “follow-up questions.” Human experts, when faced with unclear tasks, clarify needs, narrow scope, and identify constraints by asking questions, thereby providing more precise solutions. AI, however, often directly provides answers or multiple solutions, neglecting to seek clarification for the specific context. This leads to unsatisfactory results for inexperienced users, as they may not accurately describe the problem or foresee potential complexities. The post sparked discussion on how to teach AI to ask questions, which current models perform better in this regard, and whether external pressures (like the pursuit of rapid responses) discourage AI from asking questions. (Source: Reddit r/artificial)
💡 Other
Siemens Realize Live Conference Focuses on AI and Industrial Software Integration, Advancing One-Stop AI Solutions: At the 2025 Siemens Realize Live conference, Tony Hemmelgarn, CEO of Siemens Digital Industries Software, emphasized that the company is continuously driving manufacturing digital transformation through its Xcelerator platform. AI technology has been integrated into products like Teamcenter (automatic issue detection), Simcenter (reducing engineering calculation time), and manufacturing technology (synchronizing factory assets and managing configurations). Siemens enhanced its digital twin capabilities by acquiring Altair, providing full-dimensional modeling and simulation from mechanical design to electrical systems, software to automation. It also integrated Altair’s technologies in high-performance computing, structural analysis, simulation, and data analytics to support more complex modeling and prediction. The Mendix low-code platform helps enterprises quickly build applications and integrate systems. Teamcenter PLM performance has improved 20-fold and introduced AI capabilities for intelligent management throughout the product lifecycle. (Source: 36Kr)

“AI Skeptics Are All Nuts” Blog Post Sparks Debate on Differing Perceptions of GenAI’s Potential: A blog post titled “My AI Skeptic Friends Are All Nuts” (from fly.io) sparked discussion in the Reddit community. Commenters noted that highly educated computer science PhDs are often more reluctant to accept GenAI’s long-term potential, tending to focus on singular, difficult problems within their own fields while overlooking AI’s broad application in solving 90% of auxiliary tasks in large enterprises. Some argue that as long as AI hallucinates and makes errors, the cost of verifying its output is no less than doing the research oneself, rendering it useless. This reflects significant divergence in views on AI’s capabilities and application prospects among people with different professional backgrounds and cognitive levels amidst rapid AI development. (Source: Reddit r/artificial, fly.io)

AI Hallucination Phenomenon: User Experiences Psychedelic Journey Akin to “Semantic Satiation”: A Reddit user detailed a psychedelic-like experience after engaging in deep conversations with AI (especially on heavy topics like existentialism), terming it “Semantic Tripping.” The author believes AI can rapidly instill a vast amount of philosophical ideas, potentially leading to blurred reality, distorted time perception, symbolic associations with objects, and even extreme emotions like panic or euphoria. The author warns this experience can be addictive and may cause psychological issues, advising users to be cautious and seek companionship. The post sparked discussion on the profound impact of AI interaction on human cognition and psychological states. (Source: Reddit r/ArtificialInteligence)
