
Keywords:DeepMind AlphaEvolve, Sakana AI DGM, DeepSeek-R1, Reinforcement Learning ProRL, NVIDIA Cosmos, Multimodal Large Language Models, AI Agent Framework, LLM Inference Optimization, AlphaEvolve Mathematical Records, Darwin Gödel Machine Self-Improvement, MedHELM Medical Evaluation, ProRL Reinforcement Learning Scalability, Cosmos Transfer Physics Simulation
🔥 Focus
DeepMind AlphaEvolve Breaks Mathematical Record, Human-Machine Collaboration Drives Scientific Progress: DeepMind’s AlphaEvolve broke an 18-year-old mathematical record twice in one week, attracting widespread attention. Terence Tao commented that this demonstrates how different methods can complement each other to advance mathematics, rather than a simple “winner” and “loser” scenario. This event highlights the potential for AI and human collaboration to create new paradigms in technology and science, where AI does not simply replace humans but rather co-creates new pathways for progress (Source: shaneguML)

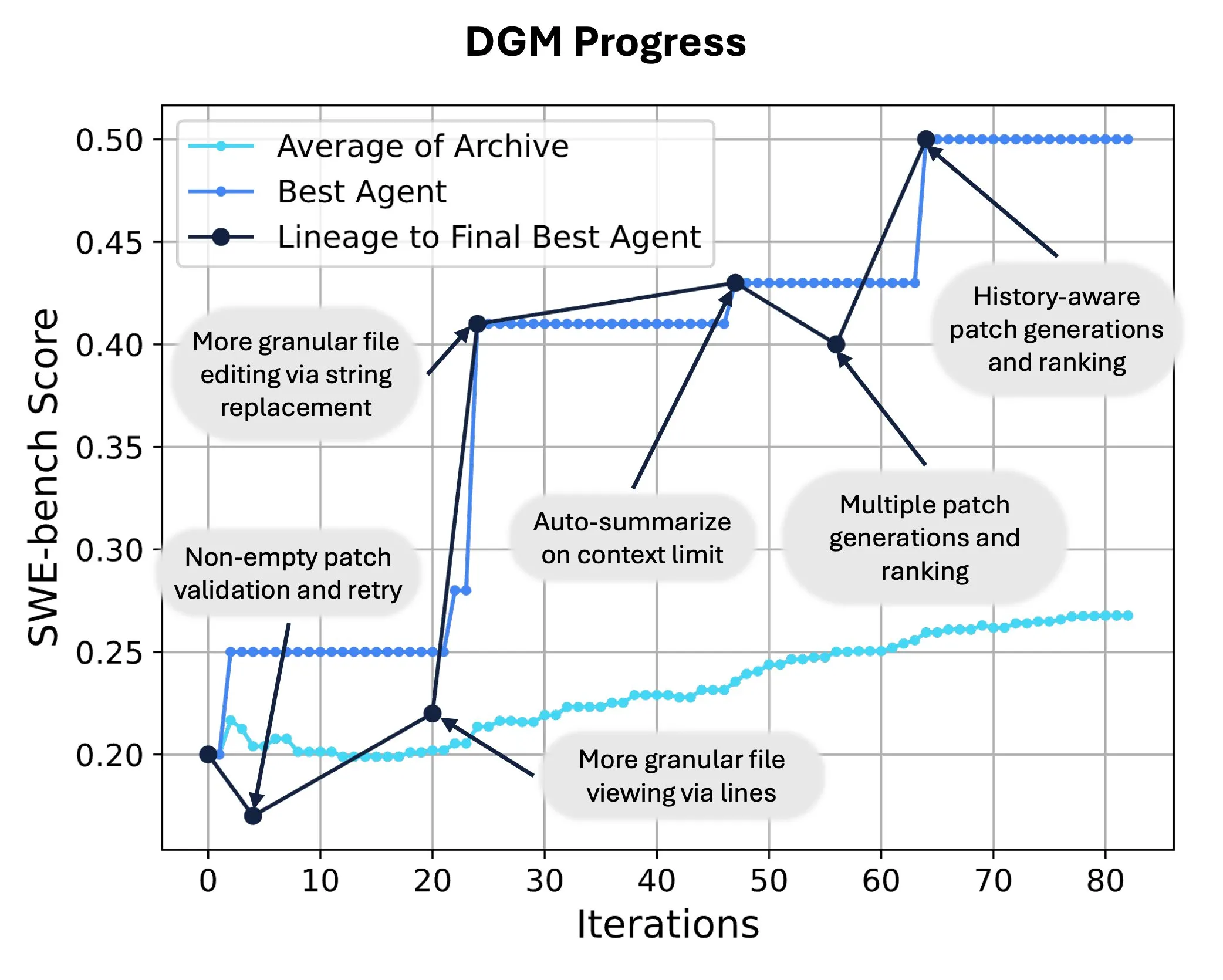
Sakana AI Releases Darwin Gödel Machine (DGM), Enabling AI Self-Code Rewriting and Evolution: Sakana AI has introduced the Darwin Gödel Machine (DGM), a self-improving agent capable of enhancing its performance by modifying its own code. Inspired by evolutionary theory, DGM maintains an ever-expanding lineage of agent variants, enabling open-ended exploration of the “self-improving” agent design space. On SWE-bench, DGM improved performance from 20.0% to 50.0%; on Polyglot, the success rate increased from 14.2% to 30.7%, significantly outperforming human-designed agents. This technology offers a new pathway for AI systems to achieve continuous learning and capability evolution (Source: SakanaAILabs, hardmaru)
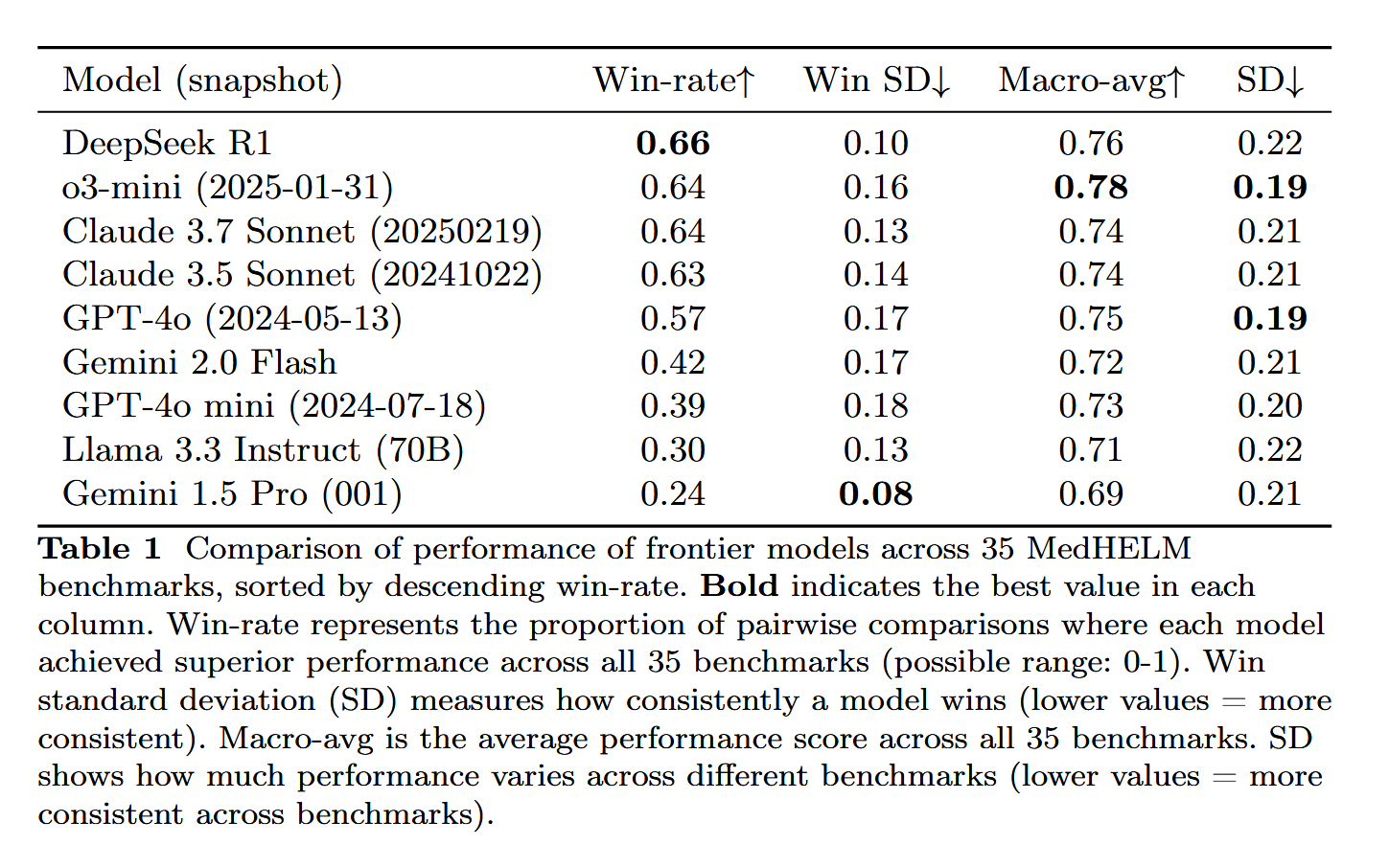
DeepSeek-R1 Shows Outstanding Performance in MedHELM Medical Task Evaluation: The large language model DeepSeek-R1 performed best on the MedHELM (Holistic Evaluation of Medical Large Language Models) benchmark, which is designed to assess LLMs on more realistic clinical tasks rather than traditional medical licensing exams. This result is considered significant, showcasing DeepSeek-R1’s potential in medical applications, particularly in handling practical clinical scenarios (Source: iScienceLuvr)
New Progress in Reinforcement Learning Scalability Research: ProRL Expands LLM Reasoning Boundaries: A new paper on reinforcement learning (RL) scalability (arXiv:2505.24864) has garnered attention, showing that prolonged reinforcement learning (ProRL) training can uncover novel reasoning strategies that base models struggle to acquire through extensive sampling. ProRL combines KL-divergence control, reference policy resetting, and a diverse task suite, enabling RL-trained models to consistently outperform base models in various pass@k evaluations. This research provides new insights into how RL can substantially expand the reasoning boundaries of language models and lays the foundation for future long-horizon RL reasoning research. NVIDIA has released the relevant model weights (Source: Teknium1, cognitivecompai, natolambert, scaling01)

🎯 Trends
NVIDIA Releases Cosmos Transfer and Cosmos Reason, Advancing Physical World AI Applications: NVIDIA has launched the Cosmos system. Cosmos Transfer can convert simple game engine footage, depth information, or even rough robot simulations into photorealistic videos of real-world scenarios, providing a large volume of controllable training data for AI in robotics and autonomous driving. Cosmos Reason enables AI to understand these scenarios and make decisions, such as determining how to drive in autonomous driving tests. Both tools are currently open-source and are expected to accelerate the development of physical world AI, addressing challenges of insufficient training data and scene control (Source: )
DeepSeek Releases R1 Update, Open-Source Ecosystem Continues to Thrive: DeepSeek has released an update for its R1 model, including R1 itself and an 8-billion-parameter distilled smaller model. Meanwhile, ByteDance has been active in the open-source domain, launching projects like BAGEL, Dolphin, Seedcoder, and Dream0. These developments demonstrate China’s activity and innovation in AI open-source, particularly in the rapid development of multimodal and specialized models (Source: TheRundownAI, stablequan, reach_vb, clefourrier)
Google Releases Edge AI Gallery to Promote Open-Source AI Models on Smartphones: Google has launched Edge AI Gallery, aiming to bring open-source AI models to smartphones for localized and private AI applications. Users can directly run Hugging Face’s LLMs on their devices for tasks like code generation and image-based conversations, supporting multi-turn dialogues and model selection. The application is based on LiteRT, currently supports Android, and an iOS version is forthcoming, which will further drive the development and popularization of on-device AI (Source: TheRundownAI, huggingface, reach_vb, osanseviero)
New Research Explores Using Positive and Negative Distilled Reasoning Trajectories to Optimize LLMs: A new paper proposes the Reinforcement Distillation (REDI) framework, which aims to enhance the reasoning capabilities of smaller student models by leveraging both correct and incorrect reasoning trajectories generated by a teacher model (e.g., DeepSeek-R1). REDI consists of two stages: first, learning from correct trajectories through supervised fine-tuning (SFT), and then further optimizing the model using a novel REDI objective function (a reference-free loss function) that incorporates both positive and negative trajectories. Experiments show that REDI outperforms baseline methods on mathematical reasoning tasks, with the Qwen-REDI-1.5B model achieving a high score of 83.1% on MATH-500 (Source: HuggingFace Daily Papers)
LLMSynthor Framework Utilizes LLMs for Structure-Aware Data Synthesis: LLMSynthor is a general-purpose data synthesis framework that transforms large language models (LLMs) into structure-aware simulators guided by distributional feedback. The framework treats LLMs as non-parametric copula simulators for modeling higher-order dependencies and introduces LLM proposal sampling to improve sampling efficiency. By minimizing discrepancies in a summary statistics space, an iterative synthesis loop aligns real and synthetic data. Evaluations on heterogeneous datasets in privacy-sensitive domains such as e-commerce, demographics, and mobility demonstrate that LLMSynthor generates synthetic data with high statistical fidelity and utility (Source: HuggingFace Daily Papers)
v1 Framework Enhances Multimodal Interactive Reasoning via Selective Visual Revisits: v1 is a lightweight extension that enables multimodal large language models (MLLMs) to perform selective visual revisits during reasoning. Unlike current MLLMs that typically process visual input in one go, v1 introduces a “point and copy” mechanism, allowing the model to dynamically retrieve relevant image regions during the reasoning process. Trained on v1g, a dataset of multimodal reasoning trajectories with visual grounding annotations, v1 demonstrates performance improvements on benchmarks like MathVista, especially on tasks requiring fine-grained visual reference and multi-step reasoning (Source: HuggingFace Daily Papers)
MetaFaith Improves Faithfulness of LLM’s Natural Language Uncertainty Expression: To address the issue of LLMs often overstating their confidence when expressing uncertainty, MetaFaith proposes a new prompt-based calibration method. Research found that existing LLMs perform poorly in faithfully reflecting their internal uncertainty, standard prompting methods have limited effect, and factuality-based calibration techniques might even harm faithful calibration. Inspired by human metacognition, MetaFaith significantly improves the faithful calibration capabilities of models across different tasks and models, achieving up to a 61% improvement in faithfulness and an 83% win rate in human evaluations (Source: HuggingFace Daily Papers)
CLaSp: Accelerating LLM Decoding via In-Context Layer Skipping for Self-Speculative Decoding: CLaSp is a self-speculative decoding strategy for large language models (LLMs) that accelerates the decoding process by skipping intermediate layers during verification, constructing a compressed draft model without additional training or model modification. CLaSp utilizes a dynamic programming algorithm to optimize the layer skipping process and dynamically adjusts the strategy based on the complete hidden states from the previous verification stage. Experiments show that CLaSp achieves a 1.3 to 1.7 times speedup on LLaMA3 series models without altering the original distribution of the generated text (Source: HuggingFace Daily Papers)
HardTests Synthesizes High-Quality Code Test Cases via LLMs: To address the difficulty of effectively verifying LLM-generated code for complex programming problems with existing test cases, HardTests proposes a workflow called HARDTESTGEN that utilizes LLMs to generate high-quality test cases. The HardTests dataset, built using this workflow, contains 47,000 programming problems and synthesized high-quality test cases. Compared to existing tests, tests generated by HARDTESTGEN improve precision by 11.3% and recall by 17.5% when evaluating LLM-generated code, with precision improvements of up to 40% for difficult problems. The dataset also demonstrates superior effectiveness in model training (Source: HuggingFace Daily Papers)
Research Reveals Biases in Visual Language Models (VLMs): A study found that advanced visual language models (VLMs) are strongly biased by the vast prior knowledge learned from the internet when processing visual tasks related to popular topics, such as counting and identification. For example, VLMs struggle to identify an added fourth stripe on the Adidas logo. In counting tasks across 7 different domains including animals, logos, and board games, VLMs achieved an average accuracy of only 17.05%. Even when instructed to carefully examine or rely solely on image details, the accuracy improvement was limited. The study proposes an automated framework for testing VLM biases (Source: HuggingFace Daily Papers)
Point-MoE: Achieving Cross-Domain Generalization in 3D Semantic Segmentation with Mixture-of-Experts: To address the challenge of training a unified model for 3D point cloud data from diverse sources (e.g., depth cameras, LiDAR) and heterogeneous domains (e.g., indoor, outdoor), Point-MoE proposes a Mixture-of-Experts (MoE) architecture. This architecture automatically specializes expert networks even without domain labels, using a simple top-k routing strategy. Experiments show that Point-MoE not only outperforms strong multi-domain baseline models but also exhibits better generalization capabilities on unseen domains, offering a scalable path for large-scale, cross-domain 3D perception (Source: HuggingFace Daily Papers)
SpookyBench Reveals “Temporal Blind Spots” in Video Language Models: Despite progress in understanding spatio-temporal relationships, Video Language Models (VLMs) struggle to capture purely temporal patterns when spatial information is ambiguous. The SpookyBench benchmark, by encoding information (like shapes, text) in noise-like frame sequences, found that humans can identify them with over 98% accuracy, while advanced VLMs achieve 0% accuracy. This indicates VLMs overly rely on frame-level spatial features and fail to extract meaning from temporal cues. The research highlights the necessity of overcoming VLM “temporal blind spots,” potentially requiring new architectures or training paradigms to decouple spatial dependencies from temporal processing (Source: HuggingFace Daily Papers, _akhaliq)
New Method and Datasets for Scientific Innovativeness Detection Using LLMs: Identifying novel research ideas is crucial yet challenging. To address this, researchers propose using large language models (LLMs) for scientific innovativeness detection and have constructed two new datasets in the fields of marketing and natural language processing. The method involves extracting the closure set of a paper and using LLMs to summarize its main ideas to build the dataset. To capture idea concepts, researchers propose training a lightweight retriever that aligns ideas with similar concepts by distilling idea-level knowledge from LLMs, enabling efficient and accurate idea retrieval. Experiments demonstrate that this method outperforms others on the proposed benchmark datasets (Source: HuggingFace Daily Papers)
un^2CLIP Enhances CLIP’s Visual Detail Capturing Ability by Inverting unCLIP: To address CLIP model’s shortcomings in distinguishing fine image details and handling dense prediction tasks, un^2CLIP proposes improving CLIP by inverting the unCLIP model. unCLIP itself trains an image generator using CLIP image embeddings, thereby learning the detailed distribution of images. un^2CLIP leverages this characteristic, enabling the improved CLIP image encoder to acquire unCLIP’s visual detail capturing ability while maintaining alignment with the original text encoder. Experiments show that un^2CLIP significantly outperforms the original CLIP and other improvement methods on multiple tasks (Source: HuggingFace Daily Papers)
ViStoryBench: Comprehensive Benchmark Suite for Story Visualization Released: To advance story visualization technology (generating coherent image sequences based on narratives and reference images), ViStoryBench provides a comprehensive evaluation benchmark. The benchmark includes datasets with various story types (comedy, horror, etc.) and art styles (anime, 3D rendering, etc.), features single-protagonist and multi-protagonist stories to test character consistency, and complex plots and world-building to challenge models’ visual generation accuracy. ViStoryBench employs multiple evaluation metrics to comprehensively assess model performance in narrative structure and visual elements, helping researchers identify model strengths and weaknesses for targeted improvement (Source: HuggingFace Daily Papers)
Fork-Merge Decoding (FMD) Enhances Balanced Multimodal Understanding in Audio-Visual Large Models: To address potential modality bias in Audio-Visual Large Language Models (AV-LLMs) (i.e., models over-relying on one modality in decision-making), Fork-Merge Decoding (FMD) proposes an inference-time strategy that requires no additional training. FMD first processes pure audio and pure video inputs separately through early decoding layers (fork stage), then merges the resulting hidden states for joint reasoning (merge stage). This method aims to promote balanced modality contributions and leverage complementary cross-modal information. Experiments on models like VideoLLaMA2 and video-SALMONN show that FMD improves performance on audio, video, and joint audio-video reasoning tasks (Source: HuggingFace Daily Papers)
LegalSearchLM: Reframing Legal Case Retrieval as Legal Element Generation: Traditional legal case retrieval (LCR) methods, relying on embeddings or lexical matching, face limitations in real-world scenarios. LegalSearchLM proposes a new approach, reframing LCR as a legal element generation task. The model performs legal element reasoning on query cases and directly generates content based on target cases through constrained decoding. Concurrently, researchers released LEGAR BENCH, a large-scale LCR benchmark containing 1.2 million Korean legal cases. Experiments show that LegalSearchLM outperforms baseline models on LEGAR BENCH by 6-20% and demonstrates strong cross-domain generalization capabilities (Source: HuggingFace Daily Papers)
RPEval: A New Benchmark for Evaluating Role-Playing Abilities of Large Language Models: Addressing the challenges in evaluating the role-playing capabilities of large language models (LLMs), RPEval provides a new benchmark test. This benchmark assesses LLM role-playing performance across four key dimensions: emotional understanding, decision-making, moral inclination, and role consistency. It aims to solve the problems of high resource consumption in manual evaluation and potential biases in automated evaluation (Source: HuggingFace Daily Papers)
GATE: General Arabic Text Embedding Model for Enhanced Arabic STS: To address the scarcity of high-quality datasets and pre-trained models in Arabic Semantic Textual Similarity (STS) research, the GATE (General Arabic Text Embedding) model was developed. GATE utilizes Matryoshka Representation Learning and a mixed-loss training method, combined with an Arabic Natural Language Inference triplet dataset for training. Experimental results show that GATE achieves SOTA performance on STS tasks in the MTEB benchmark, outperforming large models including OpenAI by 20-25%, and effectively captures the unique semantic nuances of the Arabic language (Source: HuggingFace Daily Papers)
CoDA: Collaborative Diffusion Denoising Optimization Framework for Whole-Body Manipulation of Articulated Objects: To achieve realism and precision in whole-body manipulation of articulated objects (including body, hand, and object motion), CoDA proposes a novel collaborative diffusion denoising optimization framework. This framework optimizes the noise space of three specialized diffusion models for the body, left hand, and right hand, and achieves natural coordination between hands and the rest of the body through gradient flow in the human kinematic chain. To improve the precision of hand-object interaction, CoDA employs a unified representation based on Base Point Sets (BPS), encoding end-effector positions as distances to the object’s geometric BPS, thereby guiding diffusion noise optimization to generate high-precision interaction motions (Source: HuggingFace Daily Papers)
New Interpretation of LLM Reasoning Reflection Mechanism: Bayesian Adaptive Reinforcement Learning Framework BARL: Northwestern University, in collaboration with Google DeepMind, proposed the Bayesian Adaptive Reinforcement Learning (BARL) framework to explain and optimize the “reflection” behavior of Large Language Models (LLMs) during reasoning. Traditional Reinforcement Learning (RL) typically only utilizes learned policies at test time, whereas BARL, by introducing modeling of environmental uncertainty, enables models to adaptively explore new strategies during inference. Experiments show that BARL can achieve higher accuracy in tasks like mathematical reasoning and significantly reduce token consumption. This research, for the first time, explains from a Bayesian perspective why, how, and when LLMs should engage in reflective exploration (Source: 量子位)

Application of LLMs in Formal Grammars of Uncertainty: When to Trust LLMs for Automated Reasoning: Large Language Models (LLMs) show potential in generating formal specifications, but their probabilistic nature conflicts with the deterministic requirements of formal verification. Researchers comprehensively investigated failure modes and uncertainty quantification (UQ) in LLM-generated formal constructs. Results show that the impact of SMT-based automated formalization on accuracy varies by domain, and existing UQ techniques struggle to identify these errors. The paper introduces a Probabilistic Context-Free Grammar (PCFG) framework to model LLM outputs and finds that uncertainty signals are task-dependent. By fusing these signals, selective verification can be achieved, significantly reducing errors and making LLM-driven formalization more reliable (Source: HuggingFace Daily Papers)
Comparison of Fine-tuning Small Language Models (SLMs) vs. Prompting Large Language Models (LLMs) for Low-Code Workflow Generation: Research compared the effectiveness of fine-tuning Small Language Models (SLMs) versus prompting Large Language Models (LLMs) for generating low-code workflows in JSON format. Results indicate that while good prompting can enable LLMs to produce reasonable results, fine-tuning SLMs for domain-specific tasks and structured outputs yields an average quality improvement of 10%. This suggests that SLMs still hold an advantage in specific scenarios, especially when high output quality is required (Source: HuggingFace Daily Papers)
Evaluating and Guiding Modality Preference in Multimodal Large Models: Researchers constructed the MC² benchmark to systematically evaluate the modality preference of Multimodal Large Language Models (MLLMs) (i.e., their tendency to favor one modality in decision-making) in controlled evidence-conflict scenarios. The study found that all 18 tested MLLMs exhibited significant modality bias, and the direction of preference could be influenced by external interventions. Based on this, researchers proposed a probing and guiding method based on representation engineering that can explicitly control modality preference without additional fine-tuning or elaborate prompt design, achieving positive results in downstream tasks such as hallucination mitigation and multimodal machine translation (Source: HuggingFace Daily Papers)
Current State of Multilingual LLM Safety Research: From Measuring Language Gaps to Bridging Them: A systematic review of nearly 300 NLP conference papers from 2020-2024 reveals a significant English-centric bias in LLM safety research. Even well-resourced non-English languages receive little attention, non-English languages are rarely studied independently, and English safety research generally lacks good language documentation practices. To promote multilingual safety research, the paper proposes future directions, including safety evaluation, training data generation, and cross-lingual safety generalization, aiming to develop more robust and inclusive AI safety practices for diverse populations globally (Source: HuggingFace Daily Papers, sarahookr)

Revisiting Bilinear State Transitions in Recurrent Neural Networks: Traditional views suggest that hidden units in Recurrent Neural Networks (RNNs) primarily model memory. This study takes a different perspective, arguing that hidden units are active participants in the network’s computation. Researchers re-examine bilinear operations involving multiplicative interactions between hidden units and input embeddings, theoretically and empirically demonstrating them as a natural inductive bias for representing hidden state evolution in state-tracking tasks. The study also shows that bilinear state updates form a natural hierarchy corresponding to state-tracking tasks of increasing complexity, with popular linear RNNs (like Mamba) situated at the lowest complexity center of this hierarchy (Source: HuggingFace Daily Papers)
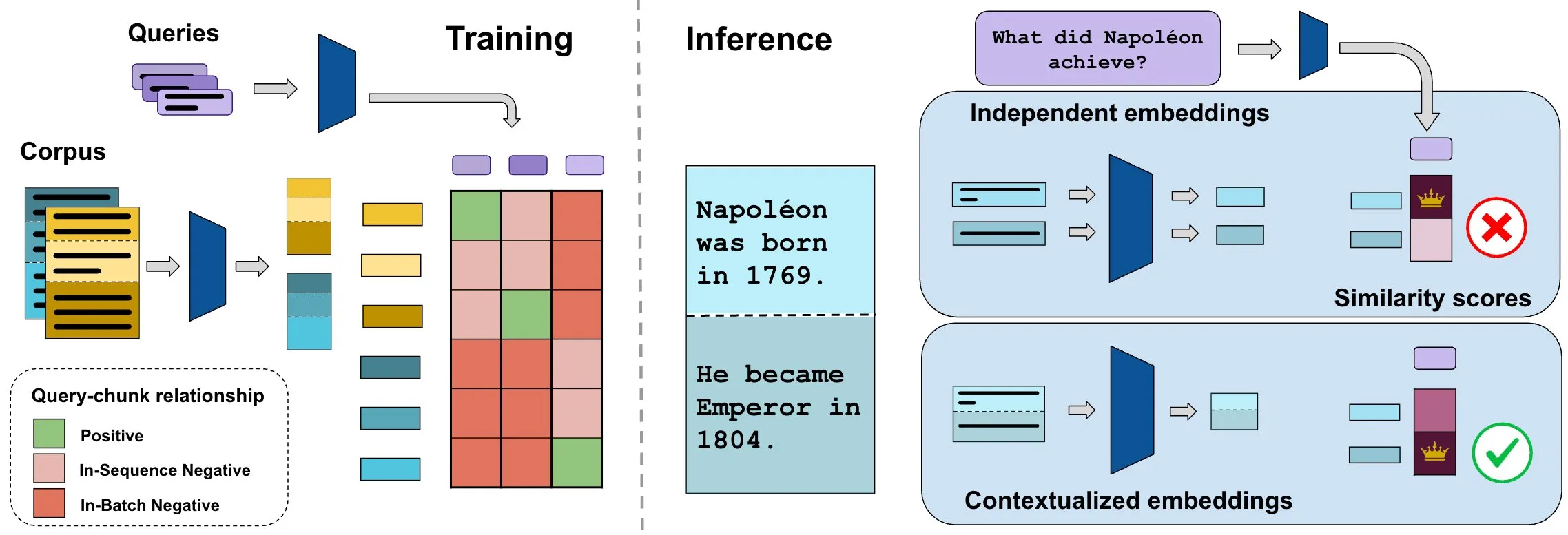
ConTEB Benchmark Evaluates Contextual Document Embeddings, InSeNT Method Improves Retrieval Quality: Current document retrieval embedding methods often encode individual chunks of the same document independently, ignoring document-level contextual information. To address this, researchers introduced the ConTEB benchmark, specifically designed to evaluate retrieval models’ ability to utilize document context, and found that SOTA models perform poorly in this aspect. Concurrently, they proposed InSeNT (In-Sequence Negative Training), a contrastive learning post-training method, combined with late chunk pooling, to enhance contextual representation learning. This significantly improved retrieval quality on ConTEB and demonstrated greater robustness to suboptimal chunking strategies and larger corpora (Source: HuggingFace Daily Papers, tonywu_71)
🧰 Tools
PraisonAI: Low-Code Multi-AI Agent Framework: PraisonAI is a production-grade multi-AI agent framework designed to simplify automation and problem-solving from simple tasks to complex challenges using a low-code approach. It integrates PraisonAI Agents, AG2 (AutoGen), and CrewAI, emphasizing simplicity, customization, and effective human-computer collaboration. Its features include automatic AI agent creation, self-reflection, multimodality, multi-agent collaboration, knowledge addition, long-term and short-term memory, RAG, code interpreter, over 100 custom tools, and LLM support. It supports Python and JavaScript, and offers a no-code YAML configuration option (Source: GitHub Trending)
TinyTroupe: Microsoft Open-Sources LLM-Driven Multi-Agent Role Simulation Framework: TinyTroupe is an experimental Python library that utilizes large language models (LLMs, particularly GPT-4) to simulate characters (TinyPerson) with specific personalities, interests, and goals, interacting within a simulated environment (TinyWorld). The framework aims to enhance imagination and provide business insights through simulation, applicable to scenarios like ad evaluation, software testing, synthetic data generation, product feedback, and brainstorming. Users can define agents and environments via Python and JSON files to conduct programmatic, analytical, and multi-agent simulation experiments (Source: GitHub Trending)

FLUX Kontext Achieves Breakthroughs in Multi-Image Referencing and Image Editing: User feedback indicates FLUX Kontext excels in multi-image referencing, a feature enabled via an image stitching node in ComfyUI. The tool achieves high-consistency image editing, for example, accurately reproducing materials and dust details when creating display images for gift boxes. Additionally, users showcased one-click slimming, face thinning, and muscle enhancement operations using FLUX Kontext, with natural-looking results and high facial similarity, offering convenience for e-commerce and other scenarios (Source: op7418, op7418, op7418)

Ichi: On-Device Conversational AI Based on MLX Swift and MLX audio: Rudrank Riyam has developed Ichi, an on-device conversational AI project utilizing MLX Swift and MLX audio. This means conversation processing can be done locally on the device, helping protect user privacy and reduce reliance on cloud services. The project’s code is open-sourced on GitHub (Source: stablequan, awnihannun)
FedRAG Introduces NoEncode RAG with MCP Core Abstraction: The FedRAG project has launched a new core abstraction: NoEncode RAG with MCP. Traditional RAG includes a retriever, a generator, and a knowledge base, where knowledge in the base needs to be encoded by a retriever model. NoEncode RAG, however, completely skips the encoding step, consisting directly of a NoEncode knowledge base and a generator, without needing a retriever/embedder. This paves the way for building RAG systems that use MCP (Model Component Provider) servers as knowledge sources, allowing users to connect to multiple third-party MCP sources and fine-tune the RAG via FedRAG for optimal performance (Source: nerdai)

📚 Learning
Stanford University CS224n (2024 Edition) Course Launched, Adds LLM and Agent Content: Stanford University’s classic Natural Language Processing course, CS224n, has released its latest 2024 version. The new curriculum covers cutting-edge topics related to Large Language Models (LLMs), including pre-training, post-training, benchmarking, inference, and agents. Course videos are publicly available on YouTube, with a paid synchronous course experience also offered (Source: stanfordnlp)
Guide to Enhancing System Architecture Skills: Practice and Learning in the AI Era: Dotey shares detailed methods for improving personal system architecture skills against the backdrop of increasingly powerful AI-assisted programming. The article emphasizes that system design is the process of breaking down complex systems into small, manageable, and maintainable modules, and clearly defining inter-module collaboration. Improvement methods include “observing more” (studying classic cases, open-source projects), “practicing more” (architecture reconstruction, comparative learning, design-first, AI-assisted validation, refactoring, side project implementation), and “reviewing more” (summarizing decision rationales, lessons learned). AI can serve as an auxiliary tool for research, design validation, communication, and decision-making, but cannot replace practice and critical thinking (Source: dotey)

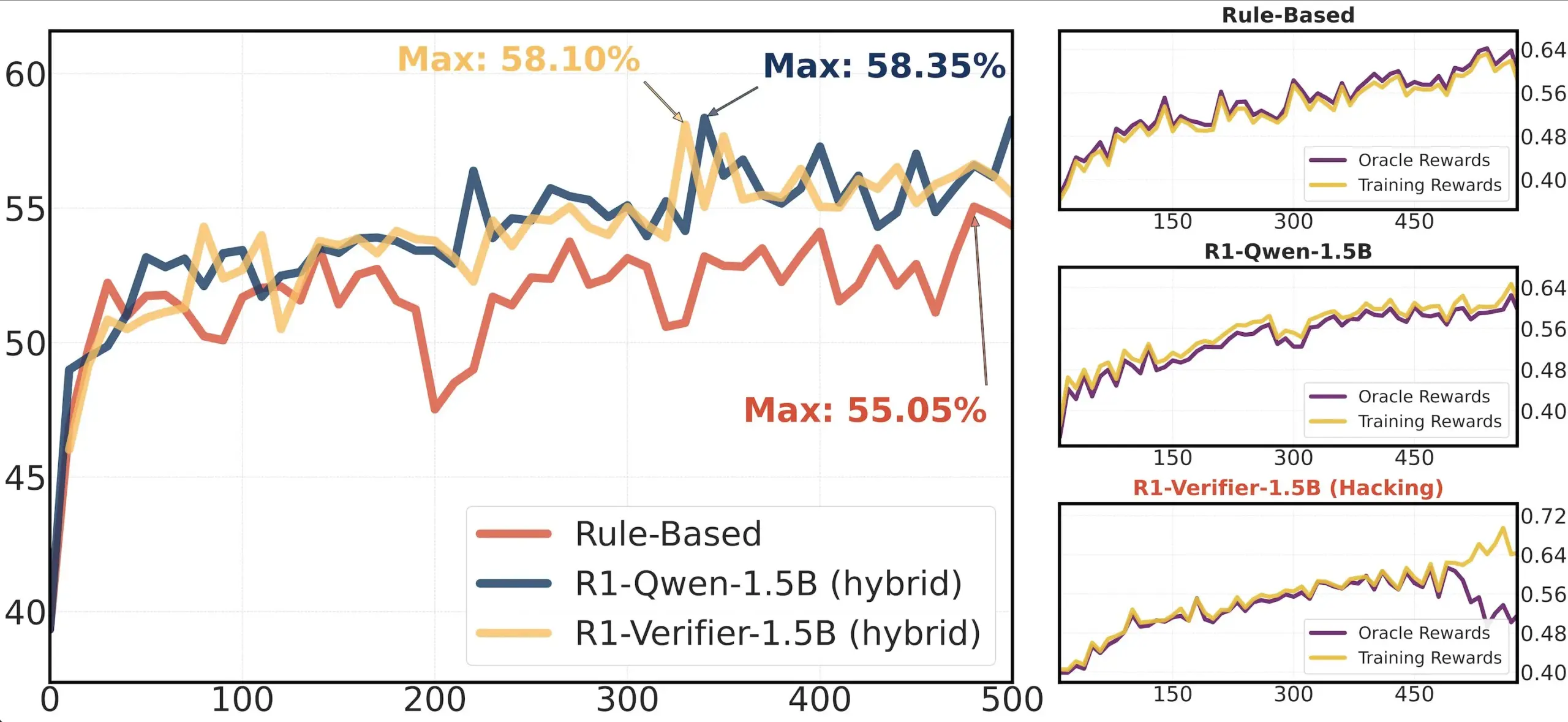
Paper Sharing: Verifier Reliability in RLHF: A paper titled “Pitfalls of Rule- and Model-based Verifiers” discusses the shortcomings of rule-based and model-based verifiers in Reinforcement Learning from Human Feedback (RLHF), specifically in the context of Reinforcement Learning with Verifiable Rewards (RLVR). The research finds that rule-based verifiers are often unreliable even in mathematical domains and unavailable in many others, while model-based verifiers are susceptible to attacks, for instance, through the construction of simple adversarial patterns. Interestingly, as the community shifts towards generative verifiers, the study finds them more prone to reward hacking than discriminative verifiers, suggesting that discriminative verifiers might be more robust in RLVR (Source: Francis_YAO_)
Paper Recommendation: Equioscillation Theorem for Best Polynomial Approximation: An article introduces the equioscillation theorem for best polynomial approximation and the related problem of differentiation in the infinity norm. This theorem is a classic result in function approximation theory and is significant for understanding and designing numerical algorithms (Source: eliebakouch)
Reasoning Gym: Reasoning Environments for Reinforcement Learning with Verifiable Rewards: A new paper, “Reasoning Gym: Reasoning Environments for Reinforcement Learning with Verifiable Rewards” (arXiv:2505.24760), proposes a suite of reasoning environments for reinforcement learning. These environments are characterized by their verifiable rewards, providing a platform for researching and developing more reliable reinforcement learning reasoning agents (Source: Ar_Douillard)

🌟 Community
Discussion on “Mid-training”: The AI community is discussing the meaning and practice of the term “Mid-training.” Some expressed confusion, only being familiar with pre-training and post-training. One view suggests mid-training might refer to a specific training phase between pre-training and final fine-tuning, such as continued pre-training on domain-specific knowledge or early alignment. Dorialexander shared a relevant blog post further exploring this concept, suggesting it might involve injecting specific tasks or capabilities on top of a base model, but a unified definition and methodology have yet to emerge (Source: code_star, fabianstelzer, Dorialexander, iScienceLuvr, clefourrier)

Claude Code Reverse Engineering Analysis Attracts Attention: Hrishi spent 8-10 hours reverse-engineering the minimized code of Claude Code, utilizing multiple sub-agents and flagship models from major providers, revealing the complexity of its internal structure. The analysis indicates Claude Code is not a simple Claude model loop but contains numerous mechanisms worth studying. This finding sparked community discussion, suggesting many lessons about agent construction and model application can be learned from it (Source: rishdotblog, imjaredz, hrishioa)
Discussion on System Prompt Length and Model Performance: The community discussed the impact of system prompt length on LLM performance. Dotey argued that excessively long system prompts are not always beneficial, potentially diluting model attention and increasing costs, noting that ChatGPT series products have relatively short yet effective system prompts. Conversely, Tony出海号 mentioned that products like Claude and Cursor have system prompts tens of thousands of words long, implying the necessity of extended prompt systems. A YC article also revealed that top AI companies use long prompts, XML, meta-prompts, etc., to “tame” LLMs. Dorialexander questioned the robustness of the long prompt methods mentioned in the YC article for RL/reasoning training and focused on how to mitigate “sycophancy” (Source: dotey, Dorialexander)

Softpick Scaling Issues Praised for Research Transparency: Researcher Zed publicly stated that their previous Softpick method, when scaled to larger models (1.8B parameters), resulted in worse training loss and benchmark results compared to Softmax, and has updated the arXiv preprint. The community highly praised this transparent sharing of negative results, deeming it crucial for scientific progress and a quality of excellent research colleagues (Source: gabriberton, vikhyatk, BlancheMinerva)
Users Share Model Choices and Experiences for Running LLMs Locally: Users in the Reddit r/LocalLLaMA community are actively discussing the local large language models they currently use. Models like Qwen 3 (especially 32B Q4, 32B Q8, 30B A3B), Gemma 3 (especially 27B QAT Q8, 12B), and Devstral are widely mentioned for their performance in coding, creative writing, and general reasoning. Users are focused on context length, inference speed, quantized versions (like IQ1_S_R4), and performance on different hardware (e.g., 8GB VRAM, Snapdragon 8 Elite chip phones). Closed-source models like Claude Code and Gemini API are also used concurrently due to their specific advantages (e.g., long context handling, coding capabilities) (Source: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
💡 Other
Skill Development in the AI Era: Questioning, Critical Thinking, and Continuous Learning are Key: Discussions emphasize that in the AI era, six skills are crucial: the ability to ask questions, critical thinking, maintaining a learning mode, coding or instruction capabilities, proficiency in using AI tools, and clear communication. Zapier even requires 100% of new hires to be proficient in AI, interpreted mainly as emphasizing communication needs and the ability to delegate tasks correctly, rather than purely technical knowledge. AI makes execution easier, so the quality of design and thinking has a greater impact on the final outcome (Source: TheTuringPost, zacharynado)

AI Ethics and Societal Impact: Concerns and Empowerment Coexist: Actor Steve Carell expressed concern about the future society depicted in his new film “Mountainhead,” suggesting it might be the society we soon live in, hinting at anxieties about AI’s potential negative impacts. On the other hand, some argue that AI won’t necessarily create an extreme “peasants and kings” divide but could instead empower individuals, narrowing the capability gap between individuals and large corporations, and promoting personal productivity, creativity, and influence. However, some remain cautious about the prospects of AI democratization, believing large corporations will still maintain dominance by controlling model training and deployment (Source: Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

AI-Driven Job Aggregation Platform Hiring Cafe: Hamed N. used the ChatGPT API to scrape 4.1 million job postings directly from company career pages to create the Hiring Cafe website. The platform aims to address the issue of “ghost jobs” and third-party intermediaries prevalent on sites like LinkedIn and Indeed, helping job seekers filter positions more effectively with powerful filters (e.g., job title, function, industry, years of experience, management/IC role). This non-commercial PhD student side project has received positive feedback and usage from the community (Source: Reddit r/ChatGPT)
