
Keywords:AI model, Deep learning, Artificial intelligence, Large language model, Machine learning, AI agent, Computing power bottleneck, AI applications, Grok system prompt, AlphaEvolve math record, Gemini AI agent, FP4 training method, Sonnet 4.0 table parsing
🔥 Focus
xAI Makes Grok System Prompt Public and Strengthens Review Mechanisms: xAI recently announced that due to its Grok response robot having its prompts modified without authorization on the X platform and publishing political statements violating company policies and values, the company has decided to make the Grok system prompt public on GitHub. This move aims to enhance the transparency and reliability of Grok as an AI pursuing truth. xAI also stated it will strengthen internal code review processes and add a 24/7 monitoring team to prevent similar incidents from recurring and respond more quickly to issues not caught by automated systems. (Source: xai, xai)
DeepMind AlphaEvolve Breaks Mathematical Record Again, AI and Human Collaboration Demonstrates New Paradigm in Scientific Research: DeepMind’s AlphaEvolve broke an 18-year-old mathematical record twice in one week, drawing attention from mathematicians like Terence Tao. Tao believes that different research methods can complementarily advance mathematics, rather than a simple “winner-takes-all” scenario. This event highlights the potential of AI and human collaboration to create new models of progress in technology and science, where AI is no longer just a replacement tool but a partner for humans in exploring the unknown and accelerating innovation. (Source: Yuchenj_UW)

Google Collaborates with Open Source Community to Simplify Building AI Agents Based on Gemini: Google announced it is collaborating with open-source frameworks such as LangChain LangGraph, crewAI, LlamaIndex, and ComposIO, aiming to make it more convenient for developers to build AI agents based on Google Gemini models. This initiative reflects Google’s determination to promote the development of the AI agent ecosystem by providing more accessible tools and frameworks, lowering the development barrier, and encouraging the creation of more innovative applications. (Source: osanseviero, Hacubu)

AI Model Inference Capabilities May Face Compute Bottleneck Within a Year: Although inference models like OpenAI’s o3 have shown significant performance improvements driven by compute power in the short term (e.g., o3 training compute is 10x that of o1), research institutions like Epoch AI predict that if compute power continues to increase tenfold every few months, the compute scaling for inference models may hit a “ceiling” within a year at most. By then, the growth rate of compute power might fall back to 4x annually, and the model upgrade speed will slow down accordingly. The training data of models like DeepSeek-R1 also indirectly confirms the current scale of compute consumption for inference training. While data and algorithmic innovations can still drive progress, the slowdown in compute growth will be a significant challenge for the AI industry. (Source: WeChat)

🎯 Trends
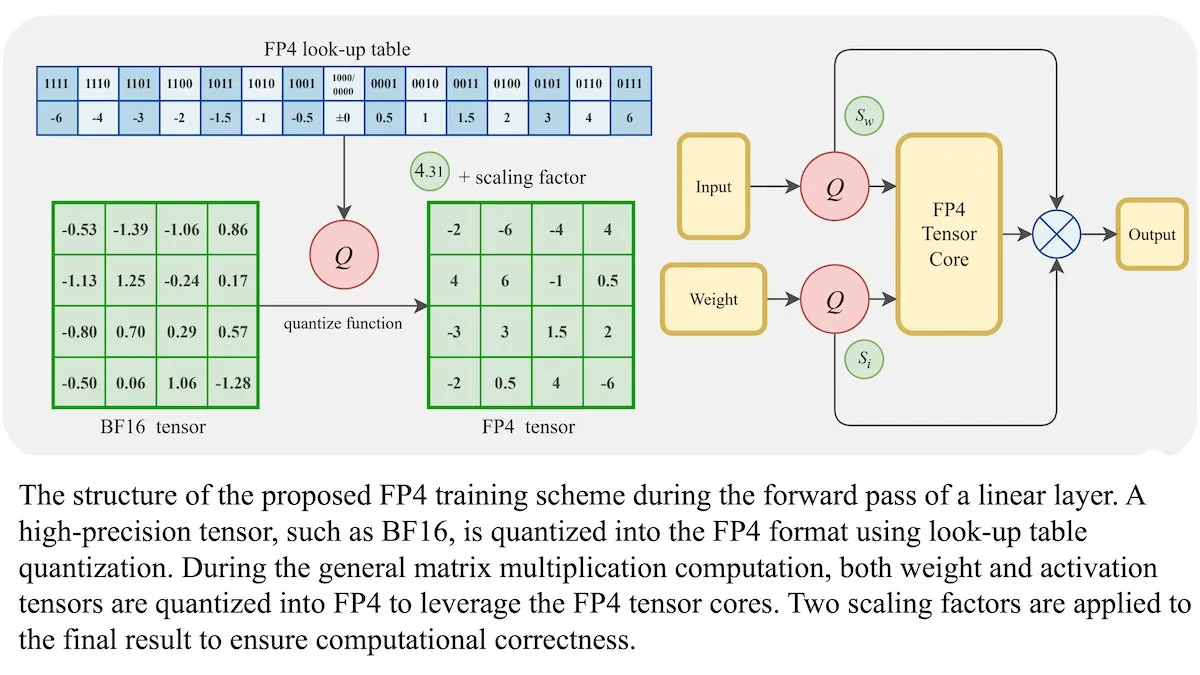
New LLM Training Method: 4-bit Floating-Point Precision (FP4) Can Achieve BF16-Equivalent Accuracy: Researchers have demonstrated that Large Language Models (LLMs) can be trained using 4-bit floating-point precision (FP4) without sacrificing accuracy. By using FP4 for matrix multiplications, which account for 95% of training computation, they achieved performance comparable to the commonly used BF16 format. The team introduced differentiable approximations to overcome the non-differentiability of quantization, improving training efficiency. Simulations on Nvidia H100 GPUs show that FP4 performs comparably or better than BF16 on various language benchmarks. (Source: DeepLearningAI)
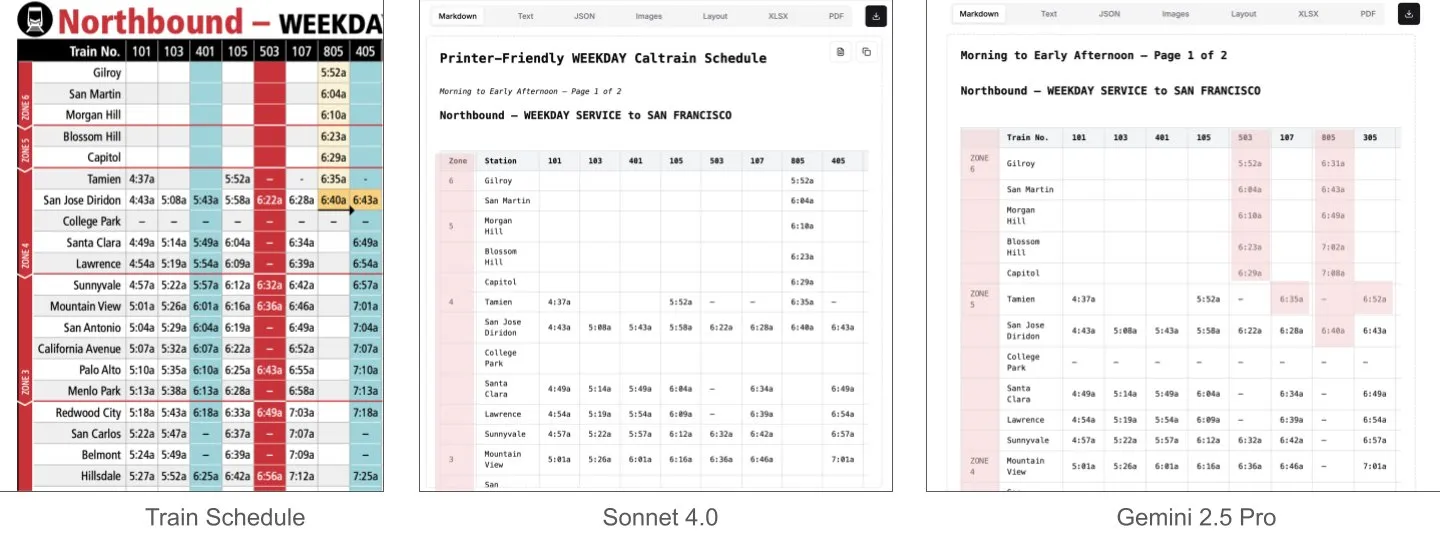
Sonnet 4.0 Outperforms Gemini 2.5 Pro in Document Understanding, Especially Table Parsing: Jerry Liu from LlamaIndex found through comparative testing that Anthropic’s Sonnet 4.0 significantly outperforms Google’s Gemini 2.5 Pro in table parsing capabilities when processing a Caltrain timetable screenshot containing dense tabular data. Gemini 2.5 Pro exhibited column misalignments, while Sonnet 4.0 was able to reconstruct most numerical values well, with errors only in the header and a few other values. Although Sonnet 4.0 is currently more expensive and slower, its performance in visual reasoning and table parsing is outstanding. (Source: jerryjliu0)
xAI, TWG Global, and Palantir Collaborate to Reshape AI Applications in the Financial Services Industry: xAI announced a partnership with TWG Global and Palantir Technologies to jointly design and deploy AI-driven enterprise solutions aimed at reshaping how financial service providers adopt AI and scale technology. Palantir CEO Alex Karp and TWG Global Co-Chairman Thomas Tull discussed at the Milken Institute conference how this collaboration will drive AI innovation in the financial sector. (Source: xai, xai)
DeepSeek-R1-0528 Update Enhances Censorship, Sparking Community Discussion: Users report that DeepSeek-R1-0528 (671B full model, FP8) has significantly tightened content censorship compared to the older R1 version. For example, when asked about sensitive historical events, the new model provides more evasive and official-sounding answers, whereas the old R1 could offer more direct information. This change has sparked community discussions about model openness, censorship standards, and its potential impact on research and applications, especially in scenarios relying on models for uncensored information. (Source: Reddit r/LocalLLaMA)
Huawei Pangu Embedded Model Released, Integrating Dual-System Cognitive Architecture of Fast and Slow Thinking: The Huawei Pangu team, based on Ascend NPU, has proposed the Pangu Embedded model, innovatively integrating “fast thinking” and “slow thinking” dual inference modes. Through two-stage training (iterative distillation and model merging, multi-source dynamic reward system RL) and a cognitive architecture that automatically switches based on user control or problem difficulty perception, the model aims to achieve a dynamic balance between inference efficiency and depth, addressing the contradiction of traditional large models overthinking simple problems and underthinking complex tasks. (Source: WeChat)

New Video World Model Combines SSM and Diffusion Models for Long Context and Interactive Simulation: Researchers from Stanford University, Princeton University, and Adobe Research have proposed a new video world model that combines State Space Models (SSM, particularly Mamba’s block-wise scanning scheme) and video diffusion models to address the limitations of existing video models, such as limited context length and difficulty in simulating long-term consistency. This model can effectively handle causal temporal dynamics, track world states, and ensure generation fidelity through frame-local attention mechanisms, offering a new pathway for infinitely long, real-time, consistent video generation in interactive applications like games. (Source: WeChat)

ByteDance Open-Sources Multimodal Foundation Model BAGEL, Supporting Image-Text-Video Understanding and Generation: ByteDance has open-sourced BAGEL (ByteDance Agnostic Generation and Empathetic Language model), a unified multimodal foundation model capable of simultaneously handling text, image, and video understanding and generation tasks. The BAGEL-7B-MoT version has 14 billion total parameters (7 billion active parameters) and requires about 30GB of VRAM when running at full capacity. Users can experience and deploy the model via the provided Hugging Face Demo and model address to achieve functions like image editing and style transfer. (Source: WeChat)
FLUX.1 Kontext Released: Fusing Text-Image Editing and Generation, 8x Faster: Black Forest Labs (BFL) has released its new generation image model, FLUX.1 Kontext. This model series supports in-context image generation, capable of processing both text and image prompts simultaneously to achieve instant text-to-image editing and text-to-image generation. FLUX.1 Kontext excels in character consistency, contextual understanding, and local editing, generating 1024×1024 resolution images in just 3-5 seconds, up to 8 times faster than GPT-Image-1, and supports multi-turn iterative editing. The model is based on a rectified flow transformer and adversarial diffusion distillation sampling techniques. (Source: WeChat, WeChat)

LaViDa: A Novel Diffusion Model-Based Multimodal Understanding VLM: Researchers from UCLA, Panasonic, Adobe, and Salesforce have introduced LaViDa (Large Vision-Language Diffusion Model with Masking), a vision-language model (VLM) based on diffusion models. Unlike traditional VLMs based on autoregressive LLMs, LaViDa utilizes a discrete diffusion process for text generation, theoretically offering better parallelism, speed-quality trade-offs, and the ability to handle bidirectional context. The model integrates visual features through a visual encoder and employs a two-stage training process (pre-training to align visual and DLM latent spaces, fine-tuning for instruction following). Experiments show LaViDa’s competitiveness in various tasks such as visual understanding, reasoning, OCR, and science question answering. (Source: WeChat)
AI Models Face “Model Collapse” Risk from Ingesting Too Much AI-Generated Data: Research indicates that if AI models ingest too much data generated by other AIs during training, they may experience “model collapse,” leading them to become more chaotic and unreliable. Even allowing models to look up information online might exacerbate the problem due to the internet being flooded with low-quality AI-generated content. This phenomenon, first proposed in 2023, is becoming increasingly apparent, posing challenges to the long-term development of AI models and data quality control. (Source: Reddit r/ArtificialInteligence)

AMD Octa-core Ryzen AI Max Pro 385 Processor Appears on Geekbench, Hinting at Affordable Strix Halo Chips Entering the Market: AMD’s new octa-core Ryzen AI Max Pro 385 processor has been spotted on Geekbench, potentially signaling that more affordable AI chips, codenamed Strix Halo, are about to enter the market. Users anticipate such chips will offer more PCIe lanes to support hybrid setups, meeting the demand for adding expansion cards and USB4 devices. While on-board memory is acceptable due to its speed advantages, expandability remains a key concern. (Source: Reddit r/LocalLLaMA)

1X Company Unveils Latest Humanoid Robot Prototype Neo Gamma: Norwegian robotics company 1X has released its latest humanoid robot prototype, Neo Gamma. The launch of this robot represents another advancement in humanoid robot technology within the fields of automation and artificial intelligence, showcasing its potential for future applications in various scenarios such as industry and services. (Source: Ronald_vanLoon)
AI Power Consumption Expected to Soon Surpass Bitcoin Mining: The electricity consumption of AI models is projected to grow rapidly, potentially soon accounting for nearly half of data center power, with energy usage comparable to that of some entire countries. The increasing demand for AI chips is putting pressure on the U.S. power grid, driving the construction of new fossil fuel and nuclear energy projects. Accurately tracking AI’s carbon footprint is becoming difficult due to a lack of transparency and the complexity of regional power sources. (Source: Reddit r/ArtificialInteligence)

🧰 Tools
e-library-agent: A Personal Book Management Agent Built with LlamaIndex: Clelia Bertelli utilized LlamaIndex workflows to build a tool called e-library-agent, designed to help users organize, search, and explore their personal reading collections. The tool integrates technologies like ingest-anything, Qdrant, Linkup_platform, FastAPI, and Gradio, addressing the pain point of “read it but can’t find it” and enhancing personal knowledge management efficiency. (Source: jerryjliu0, jerryjliu0)
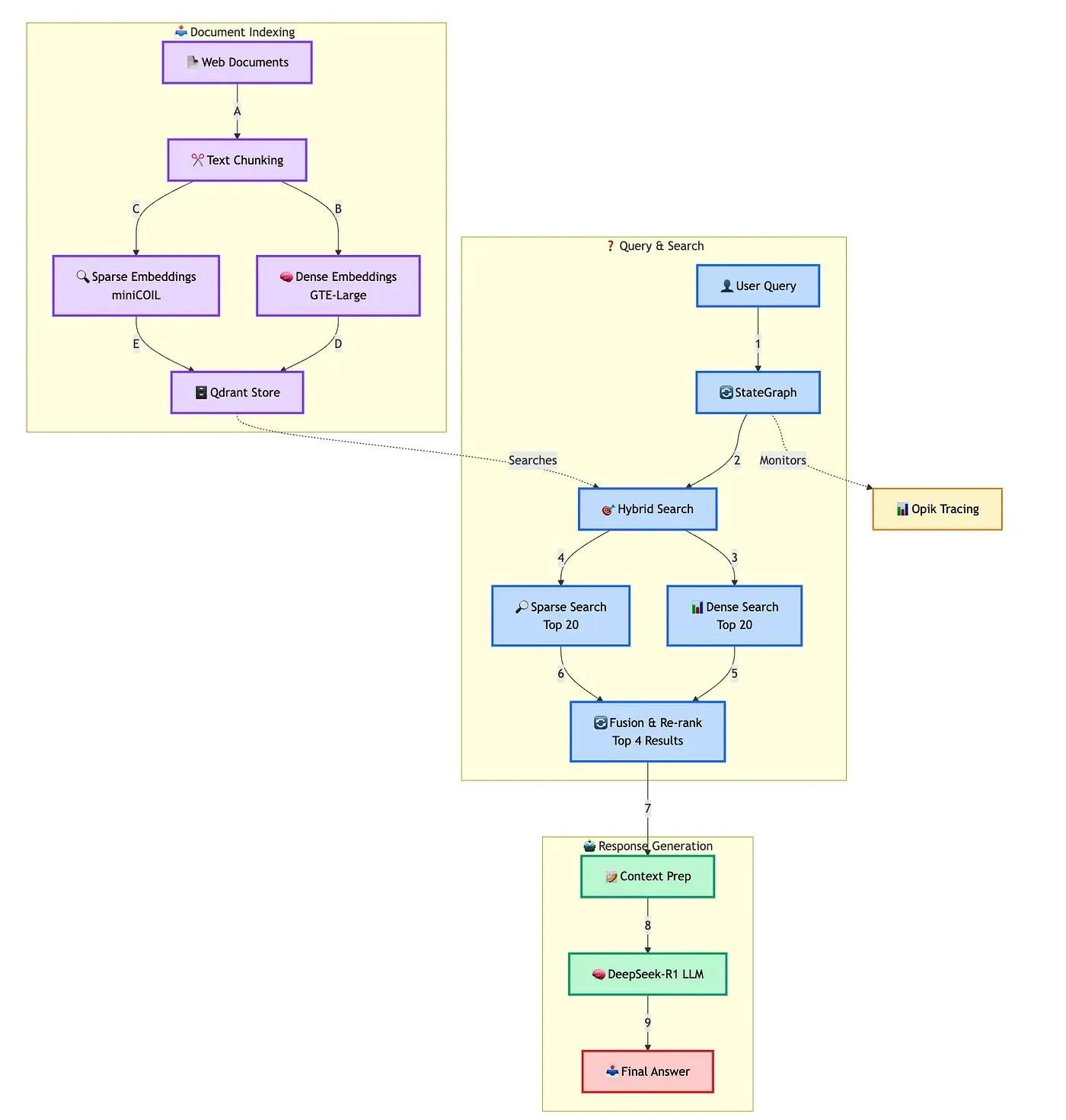
Qdrant Showcases Advanced Hybrid RAG Chatbot Building Solution: Qdrant, in collaboration with TRJ_0751, demonstrated how to build an advanced hybrid customer support RAG (Retrieval Augmented Generation) chatbot using miniCOIL, LangGraph, and DeepSeek-R1. This solution leverages miniCOIL to enhance the semantic awareness of sparse retrieval, LangGraph (from LangChainAI) to orchestrate the hybrid flow (including MMR and re-ranking), Opik to track and evaluate each step of the flow, and DeepSeek-R1 (from SambaNovaAI) to provide low-latency, focused answers. (Source: qdrant_engine, hwchase17)
Google Releases AI Edge Gallery App, Supporting Local AI Model Execution: Google has launched an application called AI Edge Gallery, allowing users to download and run AI models locally on their devices. This means users can utilize AI tools for image generation, Q&A, or code writing without an internet connection, while ensuring data privacy. The app is currently available as a preview and supports models like Gemma 3n. (Source: Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence, Reddit r/LocalLLaMA)

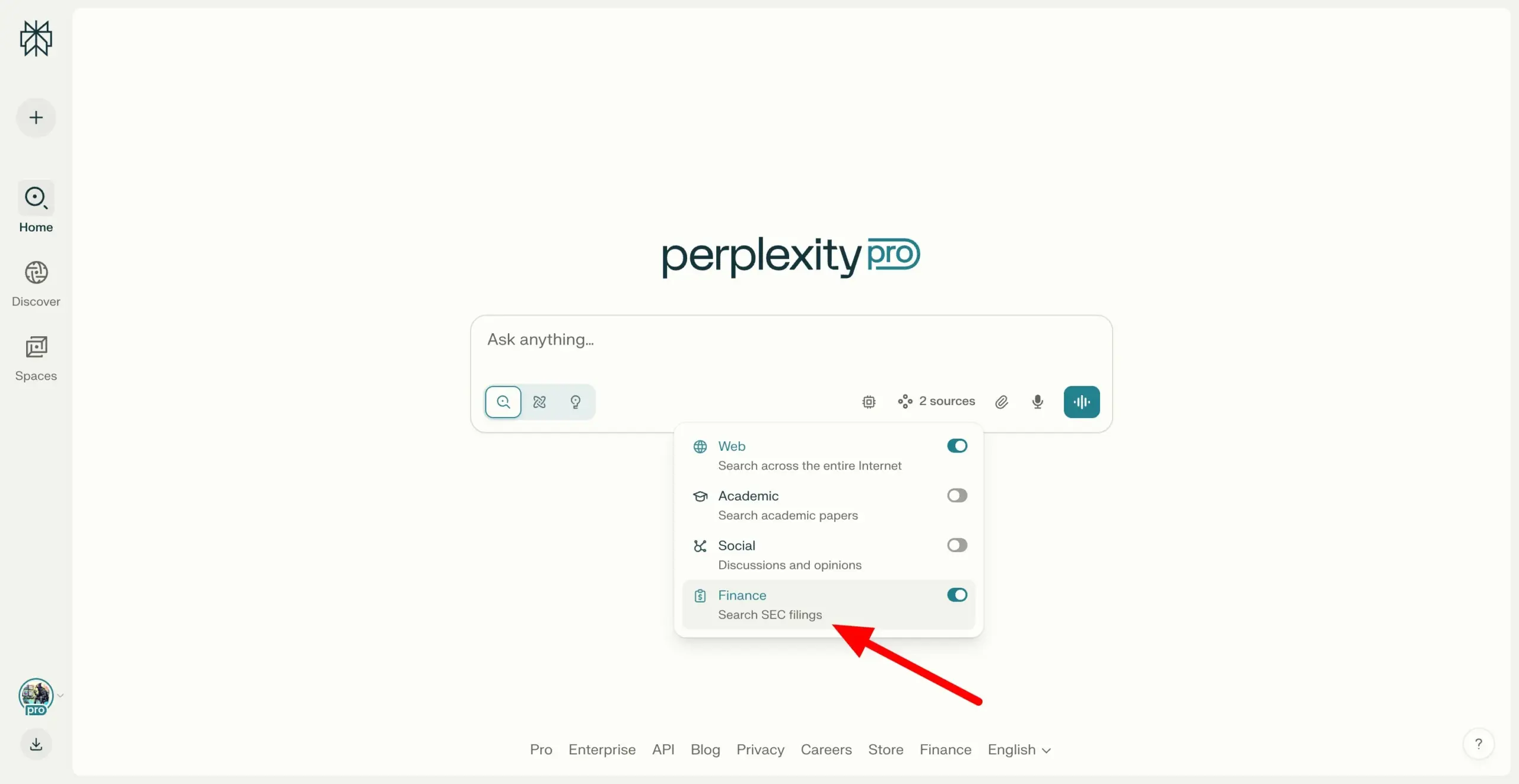
Perplexity Labs Enables Cross-Search of SEC EDGAR Filings, Enhancing Financial Research Capabilities: Perplexity Labs has added a new feature that allows users to search company filings within the U.S. Securities and Exchange Commission (SEC) EDGAR database. This update aims to further strengthen its application in financial research, providing users with more convenient ways to retrieve and analyze information on publicly listed companies. (Source: AravSrinivas)
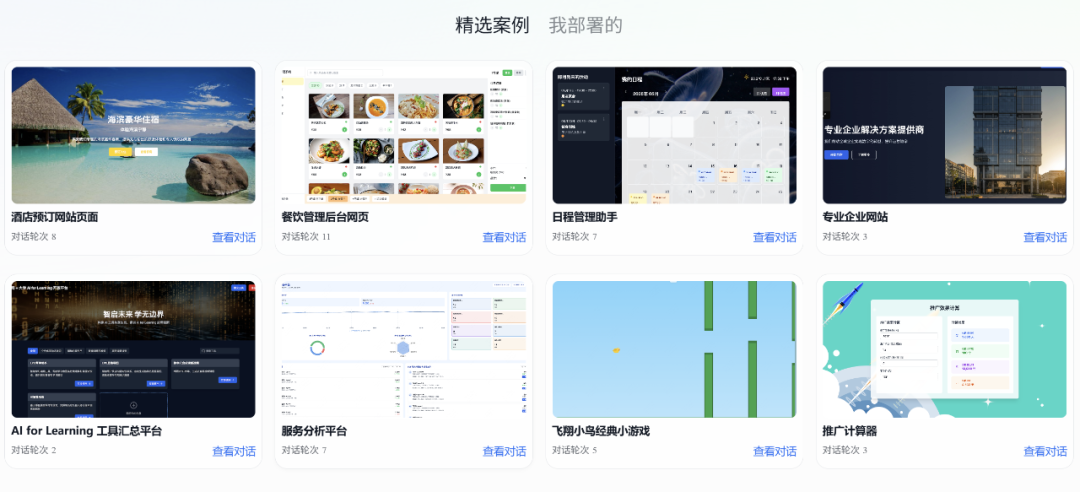
Meituan Launches NoCode AI Tool, Enabling Application Building with Natural Language: Meituan has released NoCode, an AI zero-code tool that allows users without programming experience to create personal efficiency tools, product prototypes, interactive pages, and even simple games through natural language conversations. NoCode supports real-time preview, partial modification, and one-click deployment, aiming to lower the development barrier and empower more people to unleash their creativity. The tool is backed by multiple collaborating AI models, including Meituan’s self-developed 7B parameter apply-specific model, optimized with Meituan’s internal real-world code data. (Source: WeChat)
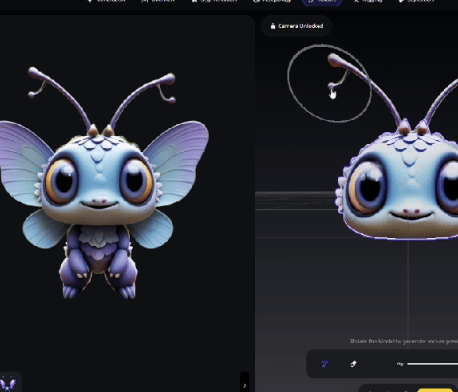
VAST Upgrades Tripo Studio with New AI Modeling Features like Smart Part Segmentation and Magic Brush: 3D large model startup VAST has significantly upgraded its AI modeling tool, Tripo Studio, introducing four core functions: smart part segmentation, texture magic brush, smart low-poly generation, and automatic rigging for all objects. These features aim to address pain points in traditional 3D modeling workflows, such as difficult part editing, time-consuming texture flaw repair, cumbersome high-poly optimization, and complex bone rigging, thereby greatly enhancing the efficiency and usability of 3D content creation and lowering the entry barrier for non-professional users. (Source: 量子位)
Hugging Face Releases Two Open-Source Humanoid Robots, HopeJR and Reachy Mini, at Affordable Prices: Hugging Face, in collaboration with The Robot Studio and Pollen Robotics, has launched two open-source humanoid robots: the full-sized HopeJR (around $3000) and the desktop Reachy Mini (around $250-$300). This initiative aims to promote the popularization and open research of robotics technology, allowing anyone to assemble, modify, and learn robot principles. HopeJR can walk and move its arms, controllable remotely via gloves; Reachy Mini can move its head, speak, and listen, intended for testing AI applications. (Source: WeChat)

World’s First Open-Source AI Agent Self-Evolution Framework, EvoAgentX, Released: A research team from the University of Glasgow has released EvoAgentX, the world’s first open-source framework for AI agent self-evolution. The framework aims to address the complexity of building and optimizing multi-AI agent systems by introducing a self-evolution mechanism. It supports one-click workflow setup and allows the system to continuously optimize its structure and performance based on environmental and goal changes during operation. EvoAgentX hopes to advance multi-agent systems from manual debugging to autonomous evolution, providing a unified platform for experimentation and deployment for researchers and engineers. (Source: WeChat)

Perplexity Labs Introduces New Feature for Free CSV Export of Company Financial Data: Perplexity Labs announced that users can now export data from any company’s financial section on its finance pages to CSV format for free. Previously, similar functionalities on platforms like Yahoo Finance typically required a paid subscription. Perplexity stated that more historical data will be added in the future. (Source: AravSrinivas)
📚 Learning
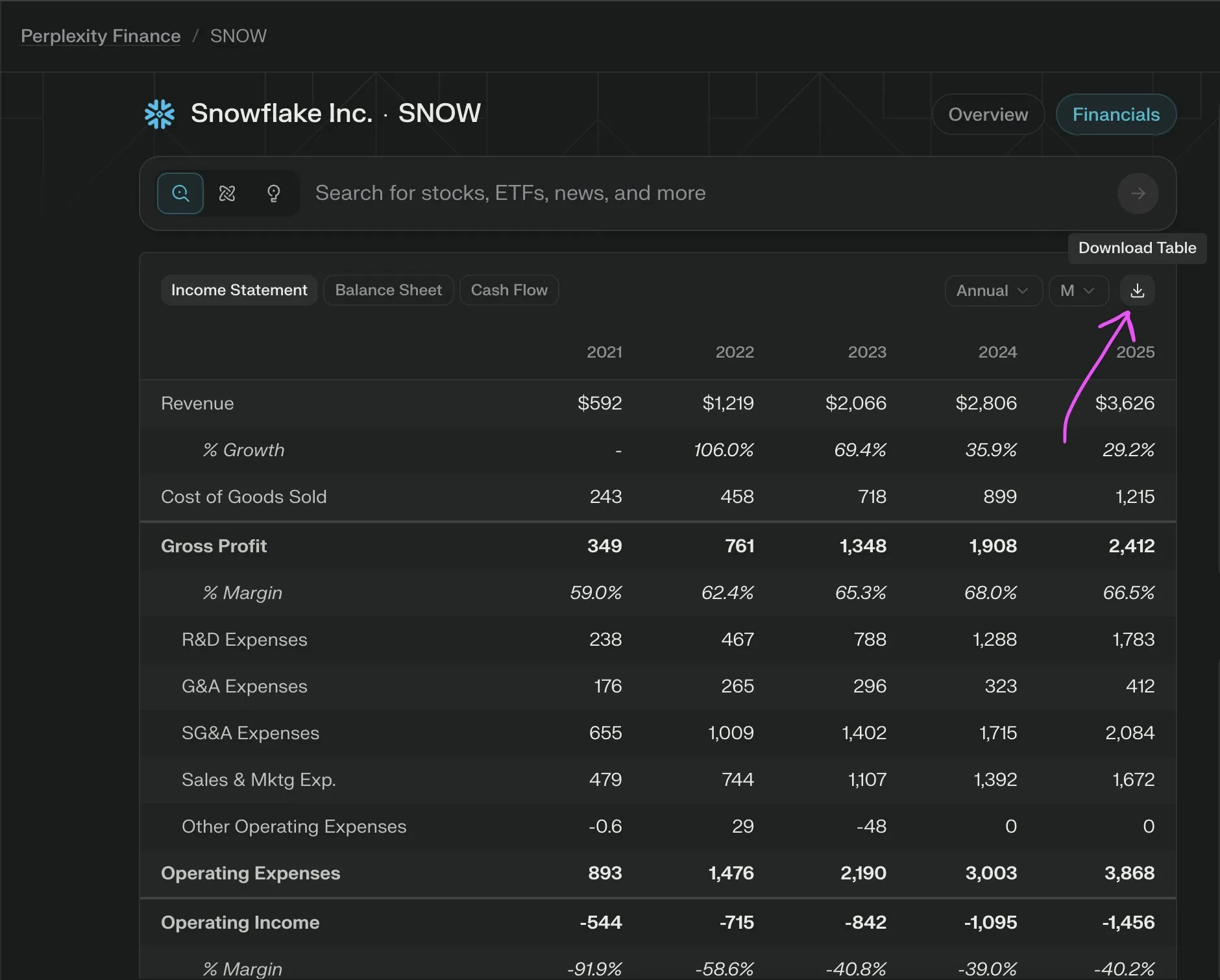
LLM Function Calling Tips: Clarify Context, Sequence & Boundaries, Avoid CoT and Hallucinations: _philschmid shared advice for function calling with inference models like Gemini 2.5 or OpenAI o3. Key points include: setting overall context (e.g., role prompt), defining a clear sequence of function calls for complex tasks, and establishing clear boundaries for tool use (when to use/not use). Detailed instructions on when to call functions and how to construct parameters are needed. Avoid explicit CoT prompts as models infer internally; leverage API features to persist thoughts between tool calls or use “thinking_tools”. Also, implement clear negative instructions (e.g., “do not promise future calls”) to prevent function call hallucinations. (Source: _philschmid)
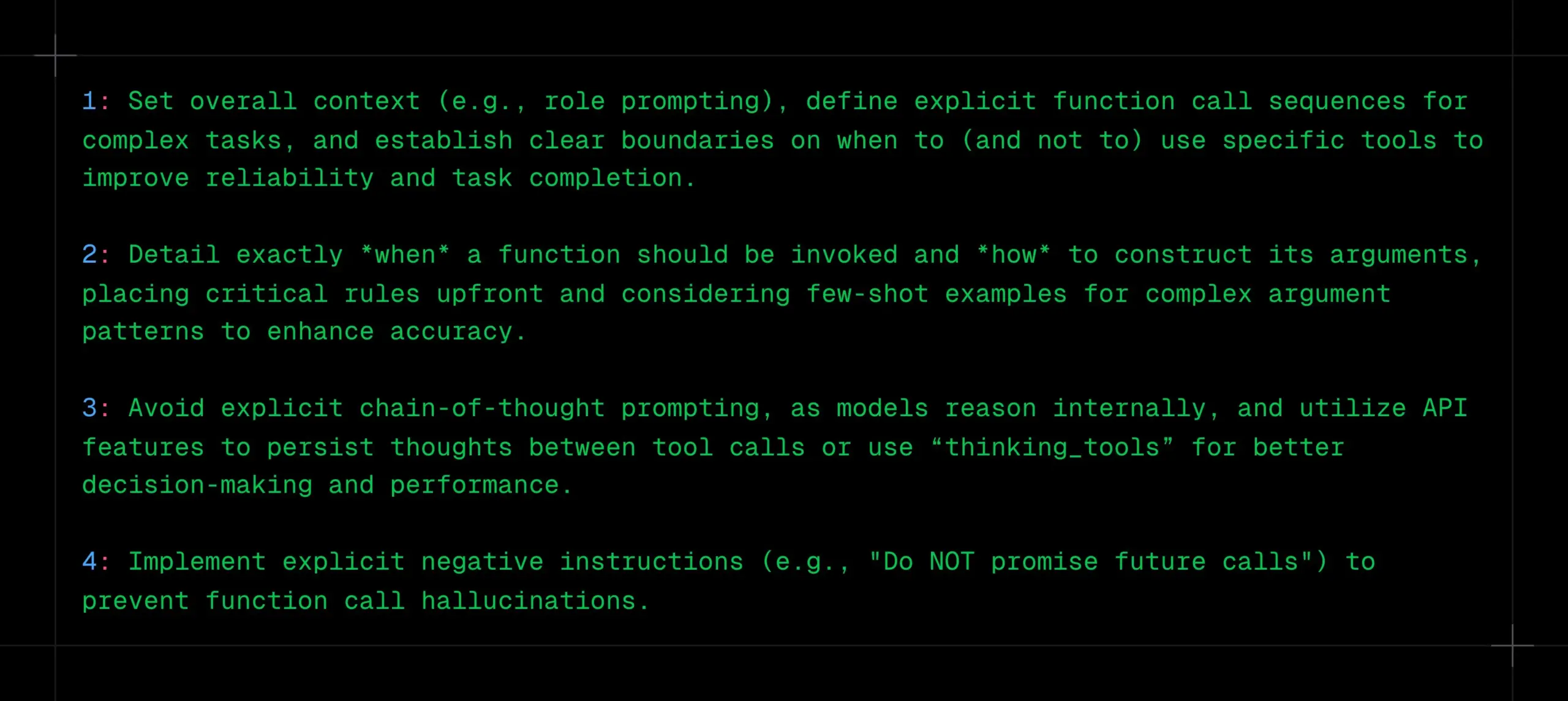
12 Professional AI Programming Tips Shared: Cline shared 12 AI programming tips from a recent engineering best practices meeting, emphasizing planning, using advanced models for complex tasks, paying attention to context windows, creating rule files, clarifying intent, treating AI as a collaborator, utilizing memory stores, learning context management strategies, and building team knowledge sharing. The core goal is to build software faster and better, using AI as a capability amplifier, not a replacement. (Source: cline, cline)

Optimization Suggestions for Creative Prompts After DeepSeek-R1-0528 Update: Following the update of the DeepSeek-R1-0528 model (68.5 billion parameters, 128K context, code capabilities close to o3), content creators have shared 10 optimized creative prompts. Suggestions include leveraging its 30-60 minute ultra-long inference capability for deep thinking, processing 128K long texts, optimizing code generation, customizing system prompts, improving writing task quality, performing anti-hallucination verification, breaking through creative writing bottlenecks, conducting problem diagnosis and analysis, integrating knowledge learning, and optimizing business copywriting. Emphasis is placed on specific instructions, fully utilizing long context, leveraging deep inference, establishing conversational memory, and verifying important information. (Source: WeChat)
RM-R1 Framework: Reshaping Reward Models as Reasoning Tasks to Enhance Interpretability and Performance: A research team from the University of Illinois Urbana-Champaign proposed the RM-R1 framework, which redefines the construction of Reward Models (RMs) as a reasoning task. By introducing a “Chain-of-Rubrics” (CoR) mechanism, the framework enables the model to generate structured evaluation criteria and reasoning processes before making preference judgments, thereby enhancing the interpretability of reward models and their evaluation accuracy on complex tasks (such as mathematics and programming). RM-R1, through two-stage training of reasoning distillation and reinforcement learning, outperforms existing open-source and closed-source models on multiple reward model benchmarks. (Source: WeChat)

In-depth Analysis of Model Context Protocol (MCP): Simplifying AI Integration with External Services: The Model Context Protocol (MCP), as an open standard, aims to solve the fragmentation problem when integrating AI models with external data sources and tools (like Slack, Gmail). Through a unified system interface (supporting STDIO and SSE protocols), MCP allows developers to build MCP clients (e.g., Claude desktop, Cursor IDE) and MCP servers (operating databases, file systems, calling APIs), simplifying the complex “M×N” adaptation network into an “M+N” model, achieving plug-and-play integration of AI with external services. Tan Yu, a partner at Fabarta, believes MCP’s value lies in providing basic connectivity; its commercialization depends on the specific value provided by the underlying system, for example, by simplifying user workflows through Fabarta’s super office agent integrated with an MCP Server. (Source: WeChat)

Agentic ROI: A Key Metric for Measuring the Usability of Large Model Agents: Shanghai Jiao Tong University, in collaboration with the University of Science and Technology of China, proposed Agentic ROI (Agent Investment Return on Investment) as a core metric for measuring the practicality of large model agents in real-world scenarios. This metric comprehensively considers information quality, user and agent time costs, and economic expenses. The research points out that current agents are more widely used in high human-capital fields like scientific research and programming, but in everyday scenarios such as e-commerce and search, the Agentic ROI is lower due to insignificant marginal value and high interaction costs. Optimizing Agentic ROI requires following a “zigzag” development path: “first, scale up information quality, then lighten costs.” (Source: WeChat)
💼 Business
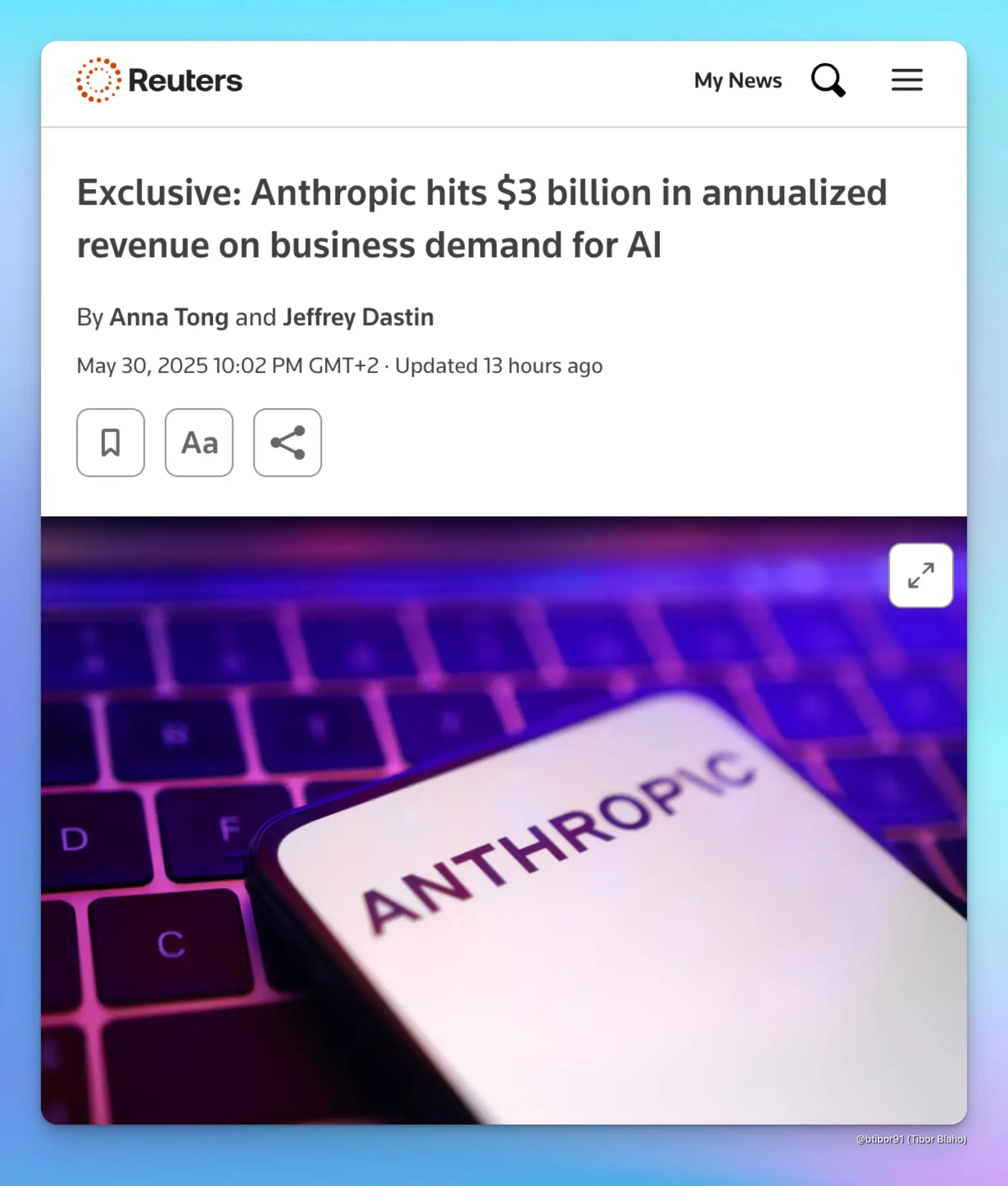
Anthropic’s Annualized Revenue Soars to $3 Billion, Driven by Enterprise AI Demand: According to two sources, Anthropic’s annualized revenue has grown from $1 billion to $3 billion in just five months. This significant growth is primarily attributed to strong enterprise demand for AI, especially in the field of code generation. This indicates that the enterprise market’s adoption and willingness to pay for advanced AI models (like Anthropic’s Claude series) are rapidly increasing. (Source: cto_junior, scaling01, Reddit r/ArtificialInteligence)
Nvidia Q1 FY2026 Earnings: Total Revenue $44.1 Billion, Data Center Business Contributes Nearly 90%: Nvidia released its Q1 FY2026 earnings report for the quarter ending April 27, 2025, with total revenue reaching $44.1 billion, up 12% sequentially and 69% year-over-year. Data center business revenue was $39.1 billion, accounting for 88.91%, up 73% year-over-year. Gaming business revenue hit a record high of $3.8 billion. Despite the H20 chip being affected by export restrictions, leading to a $4.5 billion inventory write-down and purchase obligation charges, and an expected $8 billion revenue loss in Q2 due to this, overall performance remains strong. New products like Blackwell Ultra are expected to further drive growth. (Source: 量子位, WeChat)

Meta Reorganizes AI Team, Most Original Llama Core Authors Depart, FAIR’s Status Draws Attention: Meta announced a reorganization of its AI team, dividing it into an AI product team led by Connor Hayes and an AGI foundational department co-led by Ahmad Al-Dahle and Amir Frenkel. The Foundational AI Research (FAIR) department remains relatively independent, though some multimedia teams have been merged. This adjustment aims to enhance autonomy and development speed. However, only 3 of the 14 original core authors of the Llama model remain, with most having resigned or joined competitors (like Mistral AI). Coupled with the lukewarm reception of Llama 4’s release and internal adjustments to compute allocation and R&D direction, concerns have been raised about Meta’s ability to maintain its leading position in the open-source AI field and the future development of FAIR. (Source: WeChat)

🌟 Community
AI Alignment Discussion: Can Soft Norms Maintain Human Power in the AGI Era?: Ryan Greenblatt discusses Dwarkesh Patel’s views. Patel is skeptical about AI alignment and instead hopes that soft norms can preserve some power and survival space for humans after AGI (Artificial General Intelligence) gains hard power. Greenblatt argues that if AI is scope-sensitive and capable of seizing power, attempts to reveal its misalignment or make it work for humans through deals or contracts are unlikely to succeed. Furthermore, factors like cheap fine-tuning, human-improved alignment, and free replication make human control over property very unstable before alignment issues are resolved. Once aligned AI or cheaper AI labor emerges, humans will prioritize using them, strongly incentivizing unaligned AI to seize power. (Source: RyanPGreenblatt, RyanPGreenblatt, RyanPGreenblatt, RyanPGreenblatt, JeffLadish)

Redis Creator Believes AI Programming is Far Inferior to Human Programmers, Sparking Developer Resonance and Discussion: Salvatore Sanfilippo (Antirez), the creator of Redis, shared his development experience, arguing that current AI, while useful in programming, is far inferior to human programmers, especially in breaking conventions and devising uniquely effective solutions. He likens AI to a “sufficiently smart sidekick” that helps validate ideas. This view sparked heated discussion among developers, many of whom agree that AI can serve as a “rubber duck” for auxiliary thinking but point out AI’s overconfidence and tendency to mislead junior developers. Some developers stated that AI-generated incorrect answers motivated them to code manually. The discussion emphasized the importance of experience in effectively utilizing AI and the potential negative impact of AI on programming beginners. (Source: WeChat)

DeepMind and Google Research Relationship Rekindles Debate: Brand vs. Actual Innovation Contribution: Faruk Guney posted a long thread commenting on the relationship between DeepMind and Google Research, arguing that the core breakthroughs of the current AI revolution (like the Transformer architecture) primarily originated from Google Research, not DeepMind after its acquisition by Google. He pointed out that while AlphaFold is a DeepMind achievement, it also relied on Google’s computing resources and research infrastructure, and key contributors were scientist-engineers like John Jumper and Pushmeet Kohli. Guney believes that Google Research being later merged into DeepMind was more of a branding and organizational restructuring, involving complex corporate politics that might obscure the true sources of innovation. He emphasized that many AI breakthroughs are the result of years of team research, not solely attributable to a few famous individuals or brands. (Source: farguney, farguney)
Job Posts and Skill Shifts in the AI Era Spark Concern and Discussion: Discussions about AI’s impact on the job market continue on social media. On one hand, some believe AI will lead to mass unemployment, as expressed by Anthropic’s CEO, prompting people to consider how to cope. On the other hand, some voices argue that AI primarily enhances productivity and is unlikely to cause mass unemployment unless a severe economic recession occurs, as consumer demand depends on employment and income. Meanwhile, users have shared personal experiences of job loss due to AI (e.g., a boss replacing an employee with ChatGPT). For the future, discussions point towards the need for savings, learning practical skills, adapting to the possibility of reduced income, and how education systems should adjust to cultivate skills needed in the AI era, such as critical thinking and the ability to effectively use AI tools. (Source: Reddit r/ArtificialInteligence, Reddit r/artificial)

Over-reliance on ChatGPT Sparks Concerns About Declining Thinking Abilities: A Reddit user posted concerns about their girlfriend’s excessive reliance on ChatGPT for decision-making, opinions, and creative ideas, believing it might lead to a loss of independent thought and originality. The post sparked widespread discussion. Some commenters agreed with the concern, believing over-reliance on AI tools could indeed weaken individual thinking. Others argued that AI is just a tool, like encyclopedias or search engines of the past, and what matters is how users utilize it – as a starting point for thought or a complete replacement. Some comments also suggested addressing the issue through communication, guidance, and demonstrating AI’s limitations. (Source: Reddit r/ChatGPT)
Challenges of AI in Education: Professor Laments Student Misuse of ChatGPT, Calls for Cultivating True Thinking Skills: An ancient history professor posted on Reddit that the misuse of ChatGPT has severely impacted his teaching, with students submitting papers filled with AI-generated, factually incorrect “empty garbage,” making him doubt if students are truly learning. He emphasized that the core of humanities education is to cultivate new knowledge, creative insights, and independent thinking, not simply regurgitate existing information. The post sparked heated debate, with commenters proposing various coping strategies, such as switching to oral reports, in-class handwritten essays, requiring students to submit meta-analyses of their AI usage, or integrating AI into teaching by having students critique AI output. (Source: Reddit r/ChatGPT)
AI-Generated Kernels Unexpectedly Outperform PyTorch Expert Kernels, Stanford Chinese Team Reveals New Possibilities: A team from Stanford University including Anne Ouyang, Azalia Mirhoseini, and Percy Liang, while attempting to generate synthetic data to train kernel generation models, unexpectedly found that their AI-generated kernels written in pure CUDA-C performed comparably to or even surpassed PyTorch’s built-in, expert-optimized FP32 kernels. For example, on matrix multiplication, they achieved 101.3% of PyTorch’s performance, and on 2D convolution, 179.9%. The team employed multi-round iterative optimization, combining natural language reasoning optimization ideas and a branch-and-bound search strategy, utilizing OpenAI o3 and Gemini 2.5 Pro models. This achievement suggests that through clever search and parallel exploration, AI has the potential to make breakthroughs in high-performance computing kernel generation. (Source: WeChat)

💡 Other
AI Industry’s Powerful Lobbying Efforts Draw Attention from Max Tegmark: MIT Professor Max Tegmark pointed out that the number of AI industry lobbyists in Washington and Brussels now exceeds the combined total of those from the fossil fuel and tobacco industries. This phenomenon reveals the AI industry’s growing influence in policymaking and its active investment in shaping the regulatory environment, which could have profound impacts on the direction of AI technology development, ethical norms, and market competition. (Source: Reddit r/artificial)

AI Could Simulate Bioterrorism Attacks via Deepfakes, Posing New Public Health Threat: A STAT News article points out that besides the risk of AI-assisted bioengineered weapons, the use of deepfake technology to simulate bioterrorism attacks could also pose a serious threat. Particularly between nations in military conflict, such fabricated information could trigger panic, misjudgment, and unnecessary military escalation. Because investigations might be led by law enforcement or military agencies rather than public health or technical teams, they might be more inclined to believe the authenticity of an attack, making it difficult to effectively debunk. (Source: Reddit r/ArtificialInteligence)
Whether to Pursue an Engineering Degree in the AI Era Sparks Heated Debate: The community is discussing the value of pursuing an engineering degree in the age of AI. One side believes AI might replace many traditional engineering tasks, diminishing the degree’s value. The other side argues that the systems thinking, problem-solving skills, and mathematical/physical foundations cultivated by an engineering degree remain important, especially for understanding and applying AI tools. Some viewpoints suggest that if AI can replace engineers, other professions will also be vulnerable, and the key is continuous learning and adaptation. Fields like veterinary medicine, which are highly practical and difficult to automate, are considered relatively safe choices. (Source: Reddit r/ArtificialInteligence)