
Keywords:DeepSeek-R1-0528, AI Agent, Multimodal Model, Open-source AI, Reinforcement Learning, Image Editing, Large Language Model, AI Benchmarking, DeepSeek-R1-0528-Qwen3-8B, Circuit Tracer Tool, Darwin Gödel Machine, FLUX.1 Kontext, Agentic Retrieval
🔥 Spotlight
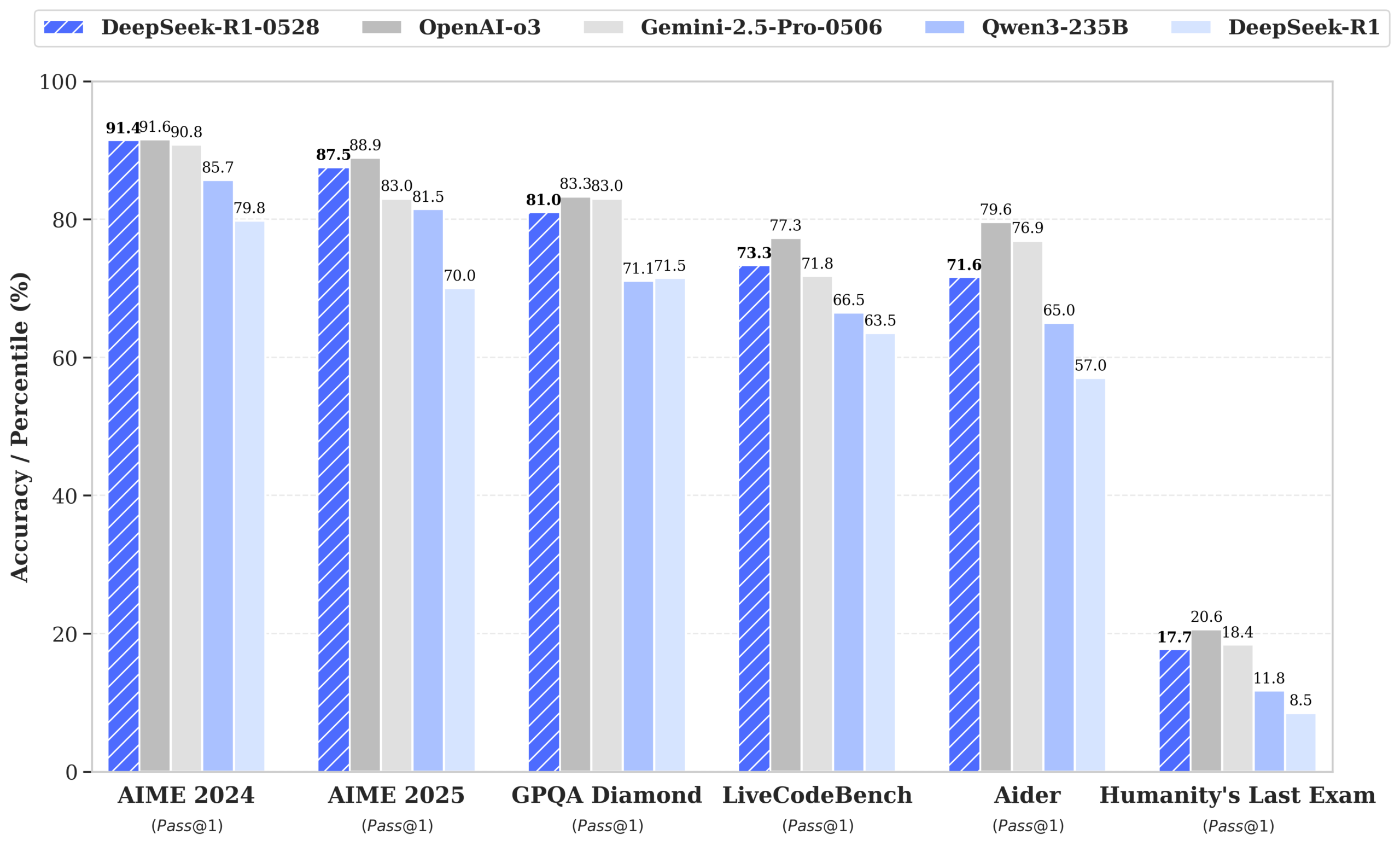
DeepSeek releases R1-0528 model, performance approaches GPT-4o and Gemini 2.5 Pro, tops open-source leaderboards: DeepSeek-R1-0528 excels in multiple benchmark tests including math, programming, and general logical reasoning, notably improving accuracy in the AIME 2025 test from 70% to 87.5%. The new version significantly reduces hallucination rates (by about 45-50%), enhances front-end code generation capabilities, and supports JSON output and function calling. Concurrently, DeepSeek released DeepSeek-R1-0528-Qwen3-8B, fine-tuned based on Qwen3-8B Base, which ranks second only to R1-0528 on AIME 2024, surpassing Qwen3-235B. This update consolidates DeepSeek’s position as the world’s second-largest AI lab and an open-source leader. (Source: ClementDelangue, dotey, huggingface, NandoDF, andrew_n_carr, Francis_YAO_, scaling01, karminski3, teortaxesTex, tokenbender, dotey)
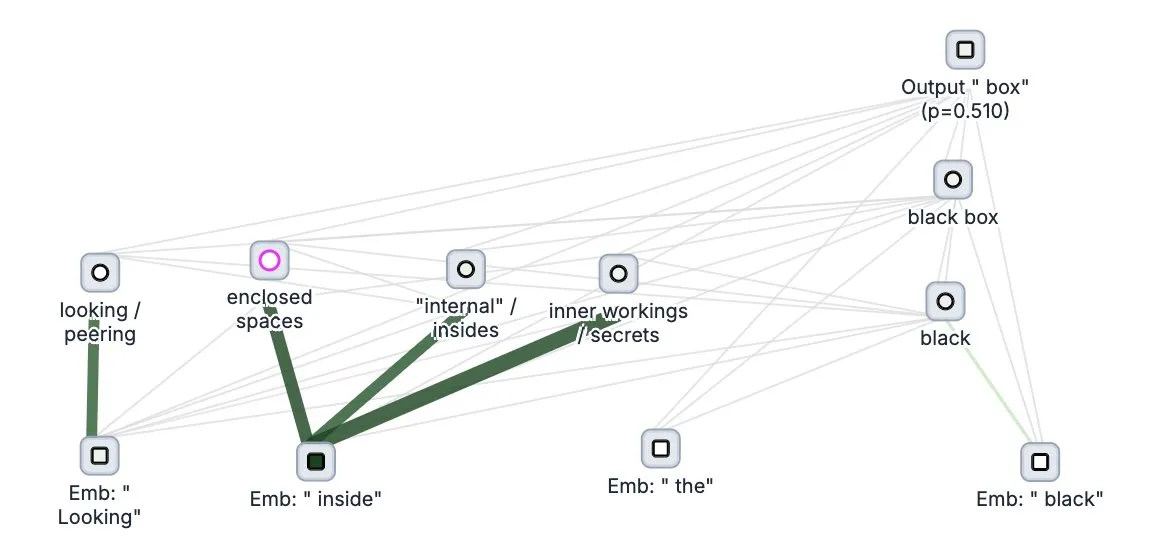
Anthropic open-sources “thought-tracing” tool for large models, Circuit Tracer: Anthropic has open-sourced Circuit Tracer, its interpretability research tool for large models, allowing researchers to generate and interactively explore “attribution maps” to understand the internal “thinking” processes and decision-making mechanisms of Large Language Models (LLMs). This tool aims to help researchers delve deeper into the inner workings of LLMs, such as how models utilize specific features to predict the next token. Users can try the tool on Neuronpedia by inputting a sentence to obtain a circuit diagram of the model’s feature usage. (Source: scaling01, mlpowered, rishdotblog, menhguin, NeelNanda5, akbirkhan, riemannzeta, andersonbcdefg, algo_diver, Reddit r/ClaudeAI)
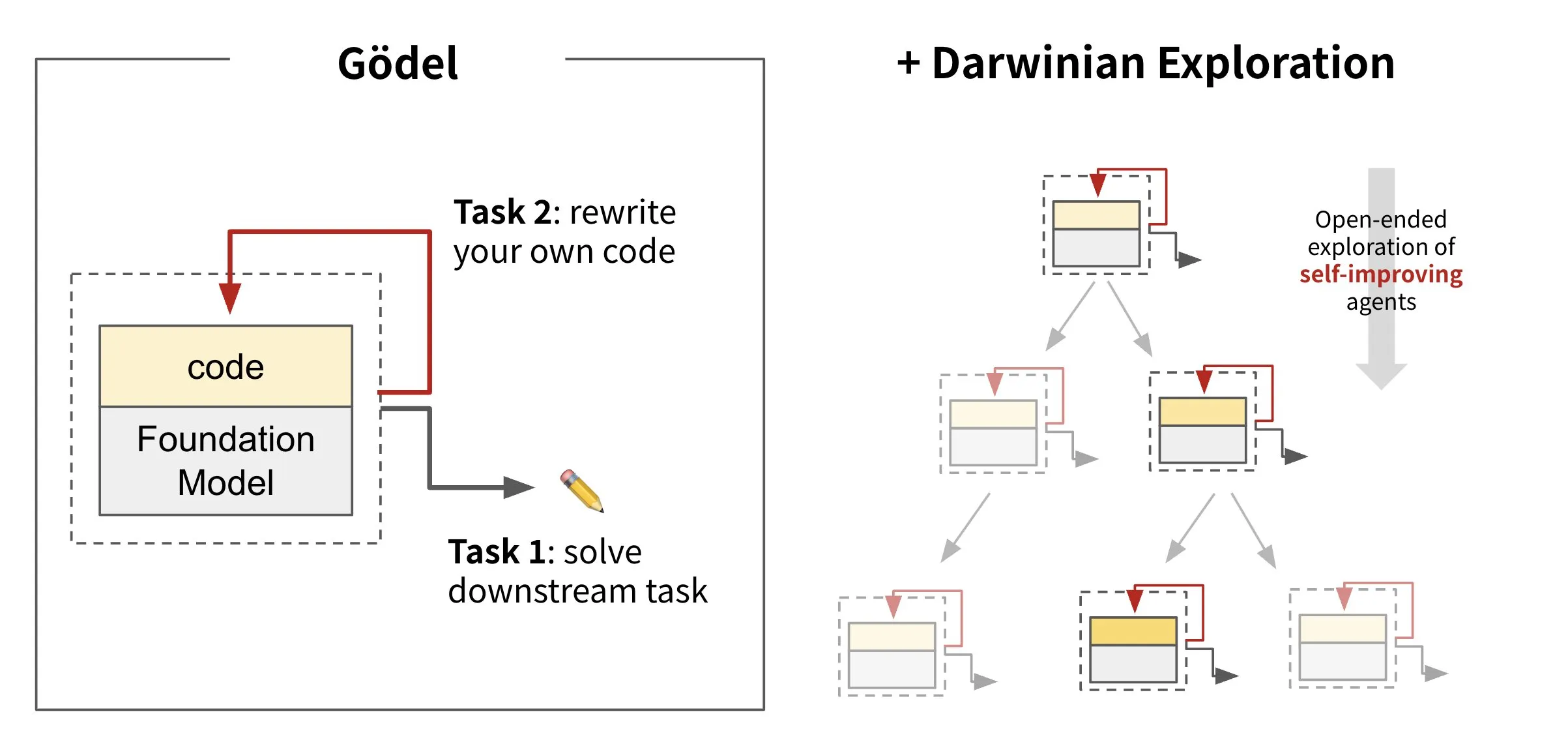
Sakana AI releases self-evolving agent framework Darwin Gödel Machine (DGM): Sakana AI has launched the Darwin Gödel Machine (DGM), an AI agent framework capable of self-improvement by rewriting its own code. Inspired by evolutionary theory, DGM maintains an ever-expanding lineage of agent variants to explore the design space of self-improving agents in an open-ended manner. The framework aims to enable AI systems to learn and evolve their own capabilities over time, much like humans. On SWE-bench, DGM improved performance from 20.0% to 50.0%; on Polyglot, the success rate increased from 14.2% to 30.7%. (Source: SakanaAILabs, teortaxesTex, Reddit r/MachineLearning)
Black Forest Labs releases image editing model FLUX.1 Kontext, supporting mixed text and image input: Black Forest Labs has launched its new-generation image editing model, FLUX.1 Kontext, which employs a flow matching architecture. It can accept both text and images as input, enabling context-aware image generation and editing. The model excels in character consistency, local editing, style referencing, and interaction speed, for instance, generating images at 1024×1024 resolution in just 3-5 seconds. Tests by Replicate indicate its editing effects are superior to GPT-4o-Image and at a lower cost. Kontext is available in Pro and Max versions, with plans to release an open-source Dev version. (Source: TomLikesRobots, two_dukes, cloneofsimo, robrombach, bfirsh, timudk, scaling01, KREA AI)

🎯 Trends
Google DeepMind releases multimodal medical model MedGemma: Google DeepMind has launched MedGemma, a powerful open model designed for multimodal medical text and image understanding. Offered as part of the Health AI Developer Foundations, this model aims to enhance AI capabilities in the medical field, particularly in comprehensively analyzing combined text and medical images, such as X-rays. (Source: GoogleDeepMind)
Perplexity AI launches Perplexity Labs to empower complex task processing: Perplexity AI has released a new feature, Perplexity Labs, designed to handle more complex tasks, aiming to provide users with analytical and building capabilities akin to an entire research team. Users can build analytical reports, presentations, and dynamic dashboards through Labs. The feature is currently available to all Pro users and has demonstrated its potential in scientific research, market analysis, and the creation of mini-applications (like games and dashboards). (Source: AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas)
Tencent Hunyuan and Tencent Music jointly launch HunyuanVideo-Avatar, enabling photos to generate realistic singing videos: Tencent Hunyuan and Tencent Music have collaborated to release the HunyuanVideo-Avatar model. This model can combine user-uploaded photos and audio, automatically detect scene context and emotion, and generate speaking or singing videos with realistic lip-sync and dynamic visual effects. The technology supports multiple styles and has been open-sourced. (Source: huggingface, thursdai_pod)
Apache Spark 4.0.0 officially released, enhancing SQL, Spark Connect, and multi-language support: Apache Spark version 4.0.0 has been officially released, bringing significant enhancements to SQL functionality, improvements to Spark Connect for more convenient application execution, and added support for new languages. This update resolved over 5,100 issues with contributions from over 390 individuals. (Source: matei_zaharia, lateinteraction)

Kling 2.1 video model released, integrates OpenArt to support character consistency: Kling AI has released its video model Kling 2.1 and partnered with OpenArt to support character consistency in AI video storytelling. Kling 2.1 improves prompt alignment, video generation speed, clarity of camera movement, and claims to have the best text-to-video effects. The new version supports 720p (standard) and 1080p (professional) output. Image-to-video functionality is now live, with text-to-video coming soon. (Source: Kling_ai, NandoDF)
Hume releases EVI 3 voice model, capable of understanding and generating any human voice: Hume has launched its latest voice language model, EVI 3, aiming for universal voice intelligence. EVI 3 can understand and generate any human voice, not just a few specific speakers, thereby offering a broader range of expression and a deeper understanding of intonation, rhythm, timbre, and speaking style. The technology aims to provide everyone with a unique, trustworthy AI identifiable by voice. (Source: AlanCowen, AlanCowen, _akhaliq)
Alibaba releases WebDancer, exploring autonomous information-seeking agents: Alibaba has launched the WebDancer project, aimed at researching and developing AI agents capable of autonomous information seeking. The project focuses on how to enable AI agents to more effectively navigate web environments, understand information, and complete complex information retrieval tasks. (Source: _akhaliq)
MiniMax open-sources V-Triune framework and Orsta models, unifying visual RL reasoning and perception tasks: AI company MiniMax has open-sourced its unified visual reinforcement learning framework V-Triune and the Orsta model series (7B to 32B) based on this framework. Through a three-layer component design and a dynamic Intersection over Union (IoU) reward mechanism, the framework enables VLMs to jointly learn visual reasoning and perception tasks in a single post-training process for the first time, achieving significant performance improvements on the MEGA-Bench Core benchmark. (Source: 量子位)

Shanghai AI Laboratory and others release new image editing benchmark RISEBench, testing models’ deep reasoning: Shanghai Artificial Intelligence Laboratory, in collaboration with several universities, has released a new image editing evaluation benchmark called RISEBench. It includes 360 challenging cases designed by human experts, covering four core reasoning types: temporal, causal, spatial, and logical. Test results show that even GPT-4o-Image can only complete 28.9% of the tasks, exposing the deficiencies of current multimodal models in understanding complex instructions and visual editing. (Source: 36氪)

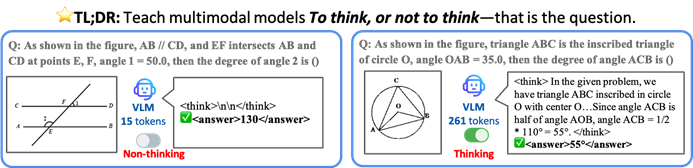
CUHK and others propose TON framework, allowing AI models to think selectively to improve efficiency and accuracy: Researchers from The Chinese University of Hong Kong (CUHK) and National University of Singapore Show Lab have proposed the TON (Think Or Not) framework, enabling Visual Language Models (VLMs) to autonomously decide whether explicit reasoning is needed. Through “thought discarding” and reinforcement learning, the framework allows models to directly answer simple questions and perform detailed reasoning for complex ones, thereby reducing average inference output length by up to 90% without sacrificing accuracy, and even improving accuracy by 17% on some tasks. (Source: 36氪)
Microsoft Copilot integrates Instacart, enabling AI-assisted grocery shopping: Microsoft AI head Mustafa Suleyman announced that Copilot now integrates Instacart services, allowing users to seamlessly complete the entire process from recipe generation and shopping list creation to grocery delivery through the Copilot app. This marks a further expansion of AI assistants into everyday life services. (Source: mustafasuleyman)
🧰 Tools
LlamaIndex releases BundesGPT source code and create-llama tool to simplify AI application building: Jerry Liu of LlamaIndex announced the availability of BundesGPT’s source code and promoted its open-source tool create-llama. Based on LlamaIndex, the tool aims to help developers easily build and integrate enterprise data with AI agents. Its new eject-mode makes creating fully customizable AI interfaces like BundesGPT very simple. This initiative aims to support Germany’s potential plan to provide free ChatGPT Plus subscriptions to every citizen. (Source: jerryjliu0)
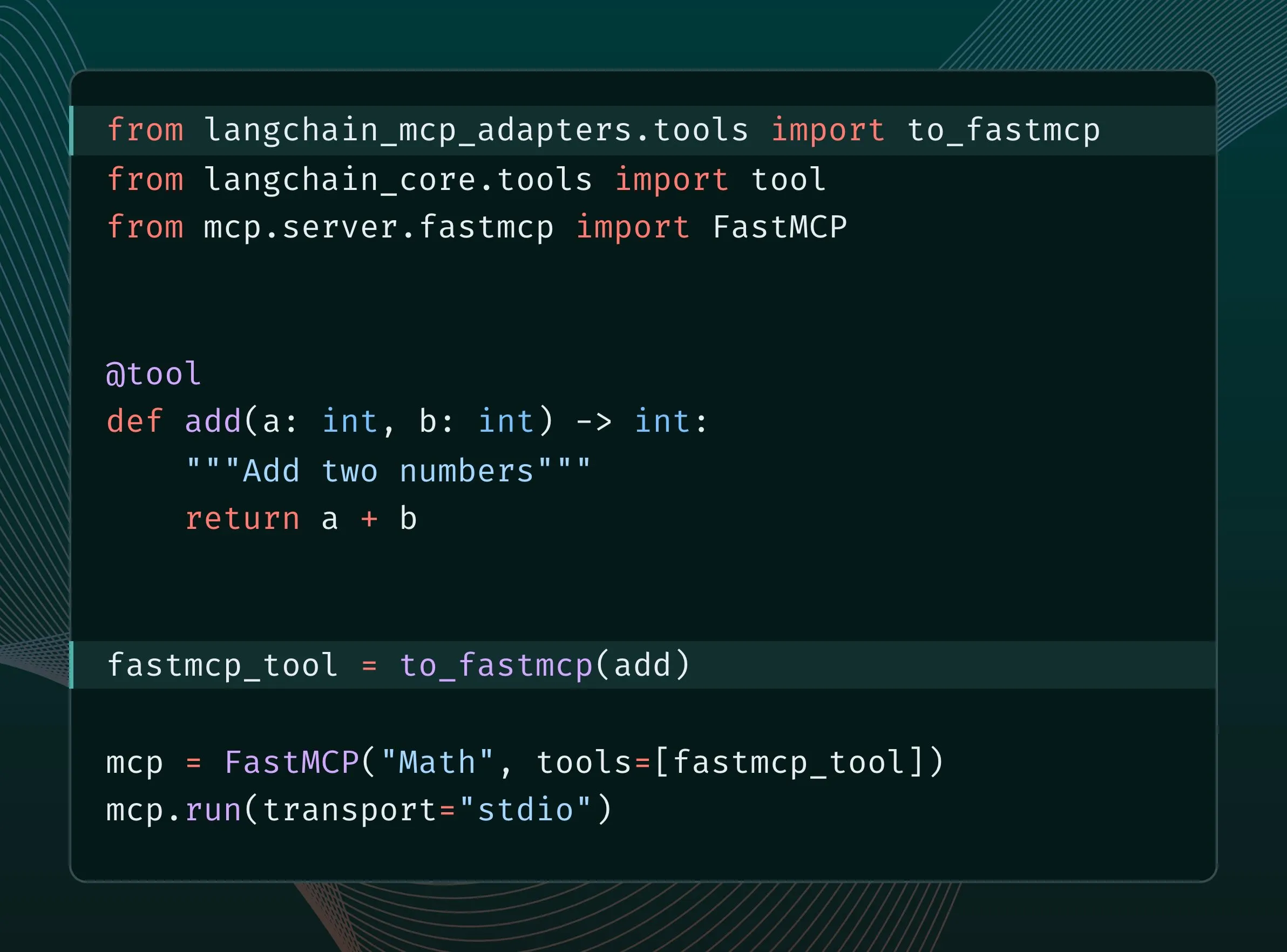
LangChain tools can be converted to MCP tools and integrated into FastMCP server: LangChain users can now convert LangChain tools into MCP (Model Component Protocol) tools and add them directly to a FastMCP server. By installing the langchain-mcp-adapters library, developers can more conveniently use LangChain’s toolset within the MCP ecosystem, promoting interoperability between different AI frameworks. (Source: LangChainAI, hwchase17)
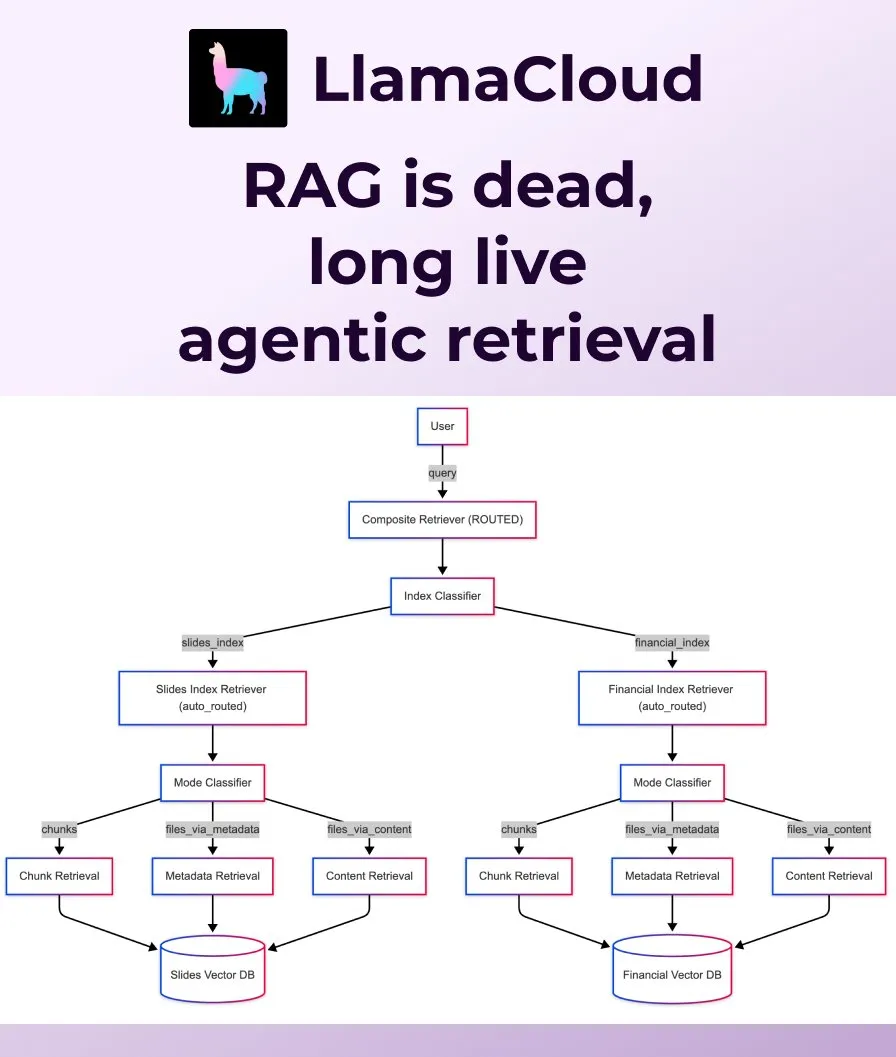
LlamaIndex releases Agentic Retrieval, replacing traditional RAG: LlamaIndex believes that traditional naive RAG (Retrieval Augmented Generation) is no longer sufficient for modern application needs and has launched Agentic Retrieval. This solution, built into LlamaCloud, allows agents to dynamically retrieve entire files or specific data chunks from single or multiple knowledge bases (such as Sharepoint, Box, GDrive, S3) based on the question’s content, enabling smarter and more flexible context acquisition. (Source: jerryjliu0, jerryjliu0)
Ollama supports running Osmosis-Structure-0.6B model for unstructured data conversion: Users can now run the Osmosis-Structure-0.6B model via Ollama. This is a very small model capable of converting any unstructured data into a specified format (e.g., JSON Schema) and can be used with any model, particularly suitable for inference tasks requiring structured output. (Source: ollama)
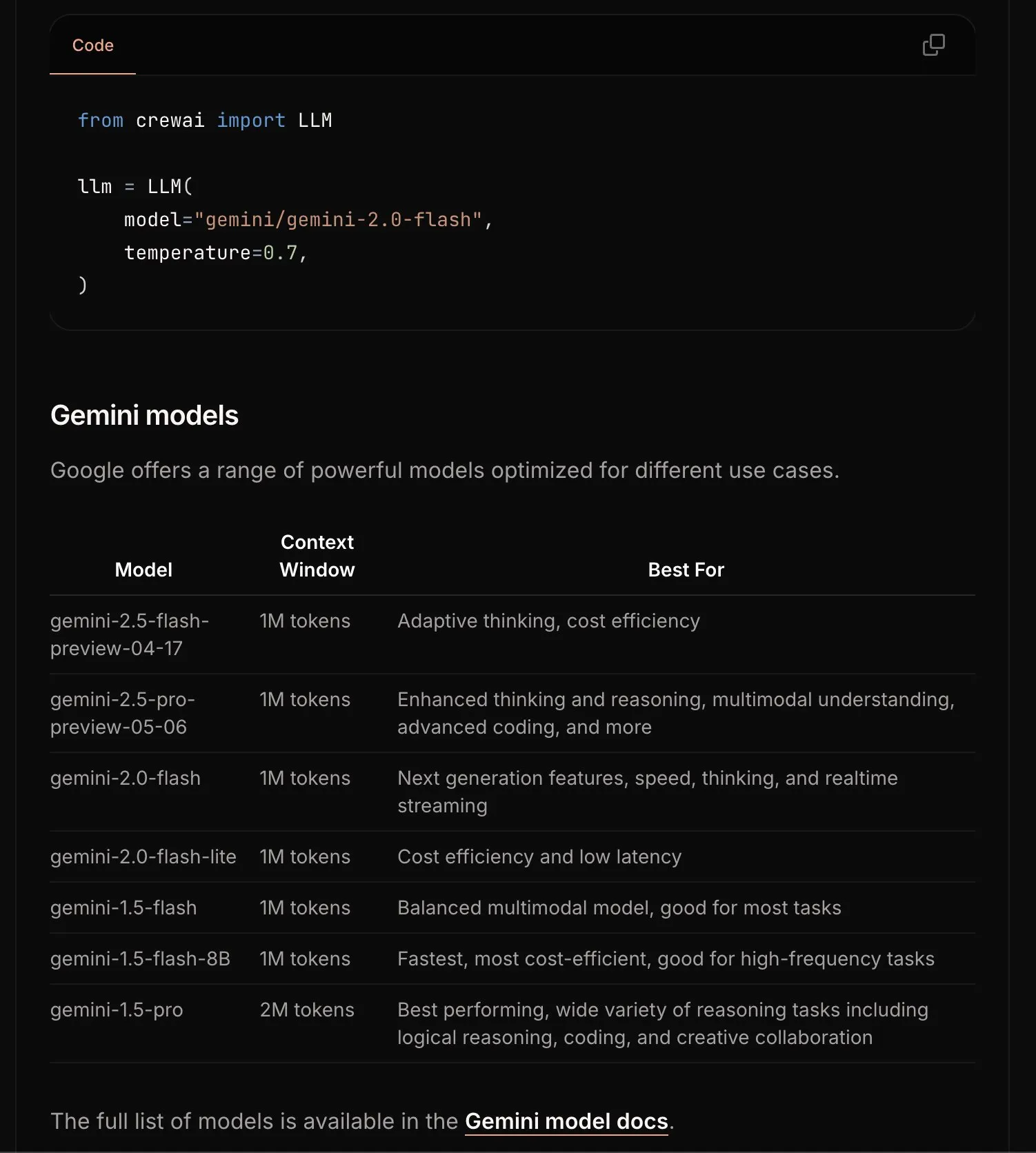
CrewAI updates Gemini documentation to simplify onboarding process: The CrewAI team has updated its documentation for the Google Gemini API, aiming to help users get started more easily with building AI agents using Gemini models. The new documentation may include clearer guidelines, sample code, or best practices. (Source: _philschmid)
Requesty launches Smart Routing feature, automatically selecting the best LLM for OpenWebUI: Requesty has released its Smart Routing feature, which seamlessly integrates with OpenWebUI to automatically select the best LLM (e.g., GPT-4o, Claude, Gemini) based on the task type of the user’s prompt. Users simply use smart/task as the model ID, and the system can classify the prompt in about 65 milliseconds and route it to the most appropriate model based on cost, speed, and quality. This feature aims to simplify model selection and enhance user experience. (Source: Reddit r/OpenWebUI)
EvoAgentX: First open-source framework for self-evolving AI agents released: A research team from the University of Glasgow in the UK has released EvoAgentX, the world’s first open-source framework for self-evolving AI agents. It supports one-click workflow setup and introduces a “self-evolution” mechanism, enabling multi-agent systems to continuously optimize their structure and performance based on environmental and goal changes. It aims to advance AI multi-agent systems from “manual debugging” to “autonomous evolution.” Experiments show an average performance improvement of 8%-13% in tasks like multi-hop question answering, code generation, and mathematical reasoning. (Source: 36氪)

📚 Learning
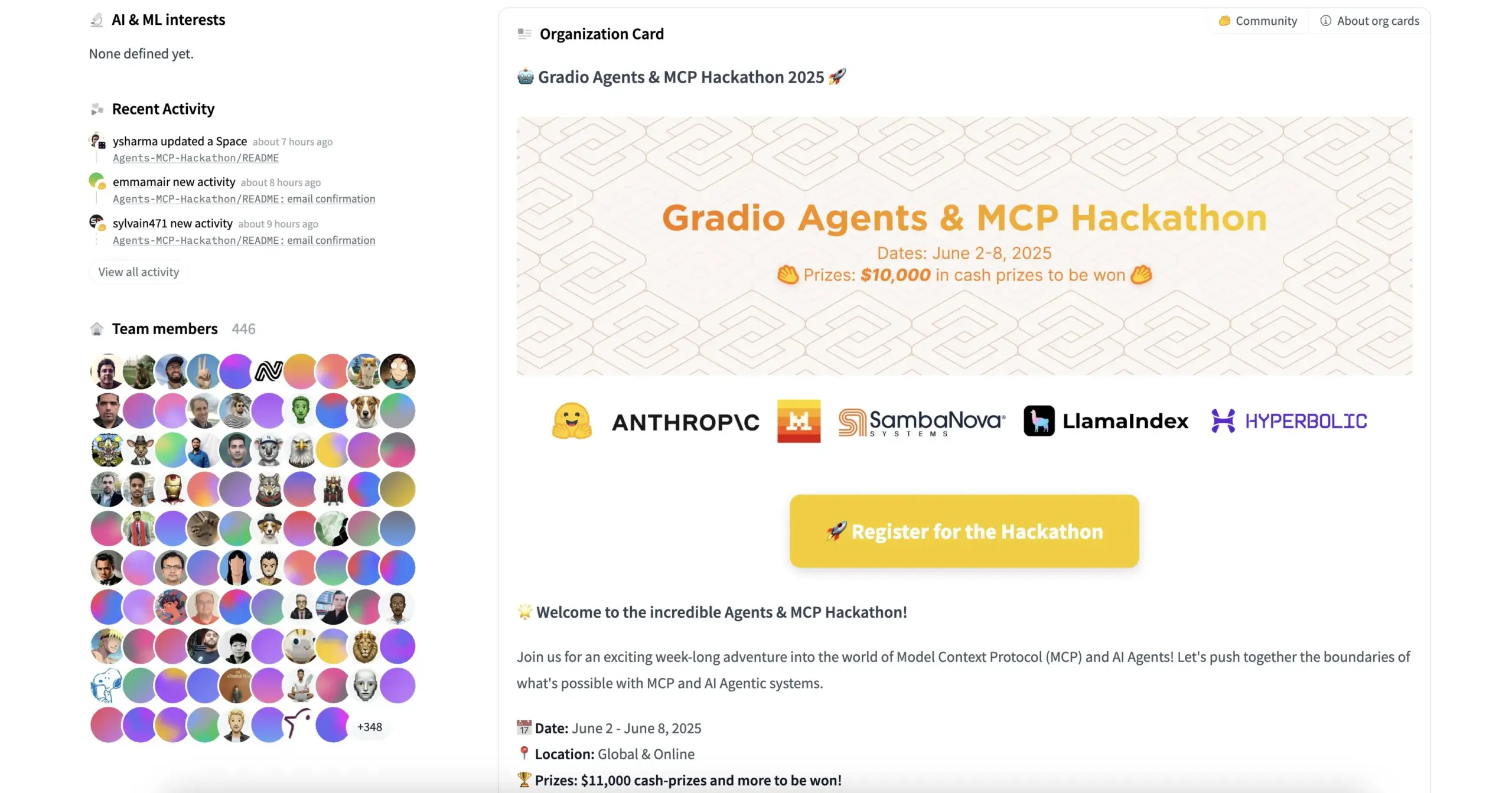
HuggingFace, Gradio, and others co-host Agents & MCP Hackathon with generous prizes and API credits: HuggingFace, Gradio, Anthropic, SambaNovaAI, MistralAI, LlamaIndex, and other organizations will co-host the Gradio Agents & MCP Hackathon (June 2-8). The event offers a total of $11,000 in prizes and free API credits from Hyperbolic, Anthropic, Mistral, and SambaNova for early registrants. Modal Labs has also pledged $250 worth of GPU credits for all participants, totaling over $300,000. (Source: huggingface, _akhaliq, ben_burtenshaw, charles_irl)
LangChain shares JPMorgan Chase’s practice of using multi-agent systems for investment research: David Odomirok and Zheng Xue from JPMorgan Chase shared how they built a multi-agent AI system called “Ask David.” The system aims to automate the investment research process for thousands of financial products, showcasing the potential of multi-agent architecture in complex financial analysis. (Source: LangChainAI, hwchase17)
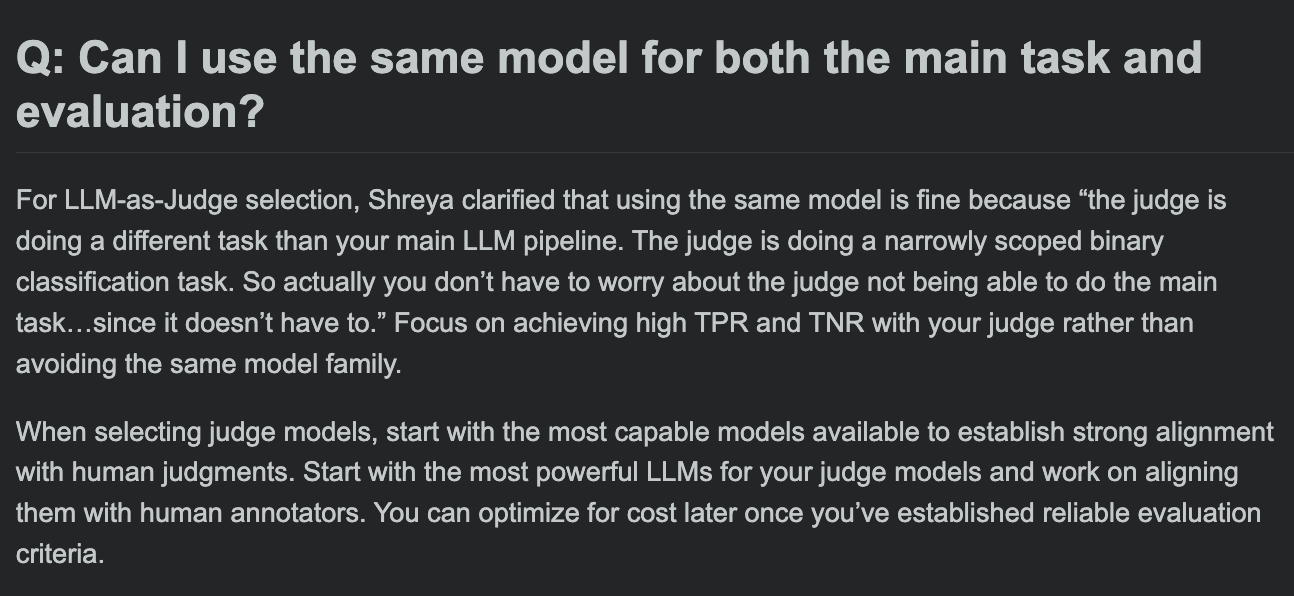
Hamel Husain shares LLM evaluation course FAQ, discusses whether evaluation model and main task model can be the same: In the Q&A session of his LLM evaluation course, Hamel Husain discussed a common question: whether the same model can be used for main task processing and task evaluation. This discussion helps developers understand potential biases and best practices in model evaluation. (Source: HamelHusain, HamelHusain)
The Rundown AI launches personalized AI education platform: The Rundown AI announced the launch of the world’s first personalized AI education platform, offering customized training, use cases, and live workshops tailored to different industries, skill levels, and daily workflows. Platform content includes industry-specific AI certificate courses in 16 tech verticals, over 300 real-world AI use cases, expert workshops, and discounts on AI tools. (Source: TheRundownAI, rowancheung)
Common Crawl releases March-May 2025 host and domain-level web graphs: Common Crawl has published its latest host and domain-level web graph data, covering March, April, and May 2025. This data is highly valuable for researching web structure, training language models, and conducting large-scale web analysis. (Source: CommonCrawl)
Bill Chambers initiates “20 Days of DSPyOSS” learning campaign: To help the community better understand the features and usage of DSPyOSS, Bill Chambers has launched a 20-day DSPyOSS learning campaign. Each day, a DSPy code snippet and its explanation will be posted, aiming to help users master the framework from beginner to advanced levels. (Source: lateinteraction)
DeepLearning.AI releases The Batch weekly, Andrew Ng discusses risks of cutting research funding: In the latest issue of The Batch weekly, Andrew Ng discusses the potential risks of cutting research funding to national competitiveness and security. The weekly also covers Claude 4 model’s performance on coding benchmarks, AI announcements from Google I/O, DeepSeek’s low-cost training methods, and the possibility of GPT-4o being trained on copyrighted books. (Source: DeepLearningAI)
Google DeepMind offers UK university students free access to Gemini 2.5 Pro and NotebookLM: Google DeepMind announced that it is providing UK university students with free access to its most advanced models, including Gemini 2.5 Pro and NotebookLM, for 15 months. This initiative aims to support students in their studies, including research, writing, and exam preparation, and provides 2TB of free storage. (Source: demishassabis)
AI Paper Explained: Prot2Token: A Unified Framework for Protein Modeling via Next-Token Prediction: The paper “Prot2Token: A Unified Framework for Protein Modeling via Next-Token Prediction” introduces Prot2Token, a unified protein modeling framework that converts various prediction tasks, from protein sequence properties and residue features to protein-protein interactions, into a standard next-token prediction format. The framework employs an autoregressive decoder, utilizing embeddings from pre-trained protein encoders and learnable task tokens for multi-task learning, aiming to improve efficiency and accelerate biological discovery. (Source: HuggingFace Daily Papers)
AI Paper Explained: Hard Negative Mining for Domain-Specific Retrieval in Enterprise Systems: The paper “Hard Negative Mining for Domain-Specific Retrieval in Enterprise Systems” proposes a scalable hard negative mining framework for enterprise-specific domain data. The method dynamically selects semantically challenging but contextually irrelevant documents to enhance the performance of deployed reranking models. Experiments on an enterprise corpus in the cloud services domain show MRR@3 and MRR@10 improvements of 15% and 19%, respectively. (Source: HuggingFace Daily Papers)
AI Paper Explained: FS-DAG: Few Shot Domain Adapting Graph Networks for Visually Rich Document Understanding: The paper “FS-DAG: Few Shot Domain Adapting Graph Networks for Visually Rich Document Understanding” proposes the FS-DAG model architecture for visually rich document understanding in few-shot scenarios. The model utilizes domain-specific and language/vision-specific backbone networks within a modular framework to adapt to different document types with minimal data, showing faster convergence and better performance than SOTA methods in information extraction tasks. (Source: HuggingFace Daily Papers)
AI Paper Explained: FastTD3: Simple, Fast, and Capable Reinforcement Learning for Humanoid Control: The paper “FastTD3: Simple, Fast, and Capable Reinforcement Learning for Humanoid Control” introduces a reinforcement learning algorithm called FastTD3. It significantly accelerates the training speed of humanoid robots in popular suites like HumanoidBench, IsaacLab, and MuJoCo Playground through parallel simulation, large batch updates, distributed critics, and carefully tuned hyperparameters. (Source: HuggingFace Daily Papers, pabbeel, cloneofsimo, jachiam0)
AI Paper Explained: HLIP: Towards Scalable Language-Image Pre-training for 3D Medical Imaging: The paper “Towards Scalable Language-Image Pre-training for 3D Medical Imaging” introduces HLIP (Hierarchical attention for Language-Image Pre-training), a scalable pre-training framework for 3D medical imaging. HLIP employs a lightweight hierarchical attention mechanism, enabling direct training on uncurated clinical datasets and achieving SOTA performance on multiple benchmarks. (Source: HuggingFace Daily Papers)
AI Paper Explained: PENGUIN: Personalized Safety in LLMs: A Benchmark and A Planning-Based Agent Approach: The paper “Personalized Safety in LLMs: A Benchmark and A Planning-Based Agent Approach” introduces the concept of personalized safety and proposes the PENGUIN benchmark (containing 14,000 scenarios across 7 sensitive domains) and the RAISE framework (a training-free, two-stage agent that strategically acquires user-specific background information). Research shows that personalized information can significantly improve safety scores, and RAISE can enhance safety at a low interaction cost. (Source: HuggingFace Daily Papers)
AI Paper Explained: Reinforcing Multi-Turn Reasoning in LLM Agents via Turn-Level Credit Assignment: The paper “Reinforcing Multi-Turn Reasoning in LLM Agents via Turn-Level Credit Assignment” investigates how to enhance the reasoning capabilities of LLM agents through reinforcement learning, especially in multi-turn tool usage scenarios. The authors propose a fine-grained turn-level advantage estimation strategy to achieve more precise credit assignment. Experiments show that this method can significantly improve the multi-turn reasoning ability of LLM agents in complex decision-making tasks. (Source: HuggingFace Daily Papers)
AI Paper Explained: PISCES: Precise In-Parameter Concept Erasure in Large Language Models: The paper “Precise In-Parameter Concept Erasure in Large Language Models” proposes the PISCES framework for precisely erasing entire concepts from model parameters by directly editing the directions encoding these concepts in the parameter space. The method uses a disentangler to decompose MLP vectors, identify features related to the target concept, and remove them from model parameters. Experiments show its superiority over existing methods in terms of erasure effectiveness, specificity, and robustness. (Source: HuggingFace Daily Papers)
AI Paper Explained: DORI: Right Side Up? Disentangling Orientation Understanding in MLLMs with Fine-grained Multi-axis Perception Tasks: The paper “Right Side Up? Disentangling Orientation Understanding in MLLMs with Fine-grained Multi-axis Perception Tasks” introduces the DORI benchmark, designed to evaluate the ability of Multimodal Large Language Models (MLLMs) to understand object orientation. DORI includes four dimensions: frontal localization, rotational transformation, relative orientation relationships, and canonical orientation understanding. It tested 15 SOTA MLLMs, finding that even the best models have significant limitations in fine-grained orientation judgment. (Source: HuggingFace Daily Papers)
AI Paper Explained: Can Large Language Models Infer Causal Relationships from Real-World Text?: The paper “Can Large Language Models Infer Causal Relationships from Real-World Text?” explores the ability of LLMs to infer causal relationships from real-world text. Researchers developed a benchmark derived from real academic literature, containing texts of varying lengths, complexities, and domains. Experiments show that even SOTA LLMs face significant challenges in this task, with the best model achieving an F1 score of only 0.477, revealing difficulties in processing implicit information, distinguishing relevant factors, and connecting dispersed information. (Source: HuggingFace Daily Papers)
AI Paper Explained: IQBench: How “Smart’’ Are Vision-Language Models? A Study with Human IQ Tests: The paper “IQBench: How “Smart’’ Are Vision-Language Models? A Study with Human IQ Tests” launches IQBench, a new benchmark aimed at evaluating the fluid intelligence of Vision-Language Models (VLMs) through standardized visual IQ tests. The benchmark is vision-centric, containing 500 manually collected and annotated visual IQ questions, assessing the model’s interpretation, problem-solving patterns, and the accuracy of final predictions. Experiments show that o4-mini, Gemini-2.5-Flash, and Claude-3.7-Sonnet perform relatively well, but all models struggle with 3D spatial and anagram reasoning tasks. (Source: HuggingFace Daily Papers)
AI Paper Explained: PixelThink: Towards Efficient Chain-of-Pixel Reasoning: The paper “PixelThink: Towards Efficient Chain-of-Pixel Reasoning” proposes the PixelThink solution, which modulates reasoning generation within a reinforcement learning paradigm by integrating externally estimated task difficulty and internally measured model uncertainty. The model learns to compress reasoning length based on scene complexity and prediction confidence. The ReasonSeg-Diff benchmark is also introduced for evaluation, with experiments showing the method improves reasoning efficiency and overall segmentation performance. (Source: HuggingFace Daily Papers)
AI Paper Explained: Revisiting Multi-Agent Debate as Test-Time Scaling: A Systematic Study of Conditional Effectiveness: The paper “Revisiting Multi-Agent Debate as Test-Time Scaling: A Systematic Study of Conditional Effectiveness” conceptualizes Multi-Agent Debate (MAD) as a test-time computational scaling technique and systematically investigates its effectiveness relative to self-agent methods under different conditions (task difficulty, model scale, agent diversity). The study finds that for mathematical reasoning, MAD’s advantage is limited but more effective when problem difficulty increases or model capability decreases; for safety tasks, MAD’s collaborative optimization might increase vulnerability, but diverse configurations help reduce attack success rates. (Source: HuggingFace Daily Papers)
AI Paper Explained: VF-Eval: Evaluating Multimodal LLMs for Generating Feedback on AIGC Videos: The paper “VF-Eval: Evaluating Multimodal LLMs for Generating Feedback on AIGC Videos” proposes the new benchmark VF-Eval for evaluating the ability of Multimodal Large Language Models (MLLMs) to interpret AI-Generated Content (AIGC) videos. VF-Eval includes four tasks: coherence verification, error perception, error type detection, and reasoning evaluation. Evaluation of 13 leading MLLMs shows that even the top-performing GPT-4.1 struggles to maintain good performance across all tasks. (Source: HuggingFace Daily Papers)
AI Paper Explained: SafeScientist: Toward Risk-Aware Scientific Discoveries by LLM Agents: The paper “SafeScientist: Toward Risk-Aware Scientific Discoveries by LLM Agents” introduces an AI scientist framework called SafeScientist, designed to enhance safety and ethical responsibility in AI-driven scientific exploration. The framework can proactively refuse inappropriate or high-risk tasks and emphasizes the safety of the research process through multiple defense mechanisms, including prompt monitoring, agent collaboration monitoring, tool use monitoring, and an ethical reviewer component. The SciSafetyBench benchmark is also proposed for evaluation. (Source: HuggingFace Daily Papers)
AI Paper Explained: CXReasonBench: A Benchmark for Evaluating Structured Diagnostic Reasoning in Chest X-rays: The paper “CXReasonBench: A Benchmark for Evaluating Structured Diagnostic Reasoning in Chest X-rays” introduces the CheXStruct pipeline and the CXReasonBench benchmark for evaluating whether Large Vision-Language Models (LVLMs) can perform clinically effective reasoning steps in chest X-ray diagnosis. The benchmark includes 18,988 QA pairs covering 12 diagnostic tasks and 1,200 cases, supporting multi-path, multi-stage evaluation, including visual localization of anatomical regions and diagnostic measurements. (Source: HuggingFace Daily Papers)
AI Paper Explained: ZeroGUI: Automating Online GUI Learning at Zero Human Cost: The paper “ZeroGUI: Automating Online GUI Learning at Zero Human Cost” proposes ZeroGUI, a scalable online learning framework for automating GUI agent training at zero human cost. ZeroGUI integrates VLM-based automatic task generation, automatic reward estimation, and two-stage online reinforcement learning to continuously interact with and learn from GUI environments. (Source: HuggingFace Daily Papers)
AI Paper Explained: Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence: The paper “Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence” proposes the Spatial-MLLM framework for visual-based spatial reasoning from purely 2D observations. The framework employs a dual-encoder architecture (a semantic visual encoder and a spatial encoder) combined with a spatial-aware frame sampling strategy, achieving SOTA performance on multiple real-world datasets. (Source: HuggingFace Daily Papers)
AI Paper Explained: TrustVLM: To Trust Or Not To Trust Your Vision-Language Model’s Prediction: The paper “To Trust Or Not To Trust Your Vision-Language Model’s Prediction” introduces TrustVLM, a training-free framework designed to assess the trustworthiness of Vision-Language Model (VLM) predictions. The method leverages conceptual representation differences in the image embedding space and proposes new confidence scoring functions to improve misclassification detection, demonstrating SOTA performance on 17 different datasets. (Source: HuggingFace Daily Papers)
AI Paper Explained: MAGREF: Masked Guidance for Any-Reference Video Generation: The paper “MAGREF: Masked Guidance for Any-Reference Video Generation” proposes MAGREF, a unified multi-reference video generation framework. It introduces a masked guidance mechanism that, through region-aware dynamic masks and pixel-level channel concatenation, achieves coherent multi-subject video synthesis under diverse reference images and text prompts, outperforming existing open-source and commercial baselines on multi-subject video benchmarks. (Source: HuggingFace Daily Papers)
AI Paper Explained: ATLAS: Learning to Optimally Memorize the Context at Test Time: The paper “ATLAS: Learning to Optimally Memorize the Context at Test Time” proposes ATLAS, a high-capacity long-term memory module that learns to memorize context by optimizing memory based on current and past tokens, overcoming the online update characteristic of long-term memory models. Based on this, the authors propose the DeepTransformers architecture family. Experiments show ATLAS surpasses Transformers and recent linear recurrent models on tasks like language modeling, commonsense reasoning, recall-intensive tasks, and long-context understanding. (Source: HuggingFace Daily Papers)
AI Paper Explained: Satori-SWE: Evolutionary Test-Time Scaling for Sample-Efficient Software Engineering: The paper “Satori-SWE: Evolutionary Test-Time Scaling for Sample-Efficient Software Engineering” proposes the EvoScale method, which treats code generation as an evolutionary process. By iteratively optimizing outputs, it improves the performance of small models on software engineering tasks (like SWE-Bench). The Satori-SWE-32B model, using this method with a small number of samples, achieves performance comparable to or exceeding models with over 100B parameters. (Source: HuggingFace Daily Papers)
AI Paper Explained: OPO: On-Policy RL with Optimal Reward Baseline: The paper “On-Policy RL with Optimal Reward Baseline” proposes OPO, a new simplified reinforcement learning algorithm designed to address the training instability and computational inefficiency faced by current RL algorithms when training LLMs. OPO emphasizes precise on-policy training and introduces an optimal reward baseline that theoretically minimizes gradient variance. Experiments show its superior performance and training stability on mathematical reasoning benchmarks. (Source: HuggingFace Daily Papers)
AI Paper Explained: SWE-bench Goes Live! A Real-Time Updated Software Engineering Benchmark: The paper “SWE-bench Goes Live!” introduces SWE-bench-Live, a real-time updatable benchmark designed to overcome the limitations of the existing SWE-bench. The new version includes 1,319 tasks derived from real GitHub issues since 2024, covering 93 repositories, and is equipped with automated management processes to achieve scalability and continuous updates, thereby providing more rigorous and contamination-resistant evaluation for LLMs and agents. (Source: HuggingFace Daily Papers, _akhaliq)
AI Paper Explained: ToMAP: Training Opponent-Aware LLM Persuaders with Theory of Mind: The paper “ToMAP: Training Opponent-Aware LLM Persuaders with Theory of Mind” introduces a new method called ToMAP, which builds more flexible persuasion agents by integrating two Theory of Mind modules, enhancing their awareness and analysis of opponents’ mental states. Experiments show that a ToMAP persuader with only 3B parameters outperforms large baselines like GPT-4o across multiple persuasion target models and corpora. (Source: HuggingFace Daily Papers)
AI Paper Explained: Can LLMs Deceive CLIP? Benchmarking Adversarial Compositionality of Pre-trained Multimodal Representation via Text Updates: The paper “Can LLMs Deceive CLIP? Benchmarking Adversarial Compositionality of Pre-trained Multimodal Representation via Text Updates” introduces the Multimodal Adversarial Compositionality (MAC) benchmark, which uses LLMs to generate deceptive text samples to exploit compositional vulnerabilities in pre-trained multimodal representations like CLIP. The research proposes a self-training method with rejection sampling fine-tuning through diversity-promoting filtering to enhance attack success rate and sample diversity. (Source: HuggingFace Daily Papers)
AI Paper Explained: The Climb Carves Wisdom Deeper Than the Summit: On the Noisy Rewards in Learning to Reason: The paper “The Climb Carves Wisdom Deeper Than the Summit: On the Noisy Rewards in Learning to Reason” investigates the impact of reward noise on LLM post-training for reasoning via reinforcement learning. The study finds that LLMs exhibit strong robustness to substantial reward noise. Even when only rewarding the occurrence of key reasoning phrases (without verifying answer correctness), models can achieve performance comparable to those trained with strict verification and accurate rewards. (Source: HuggingFace Daily Papers)
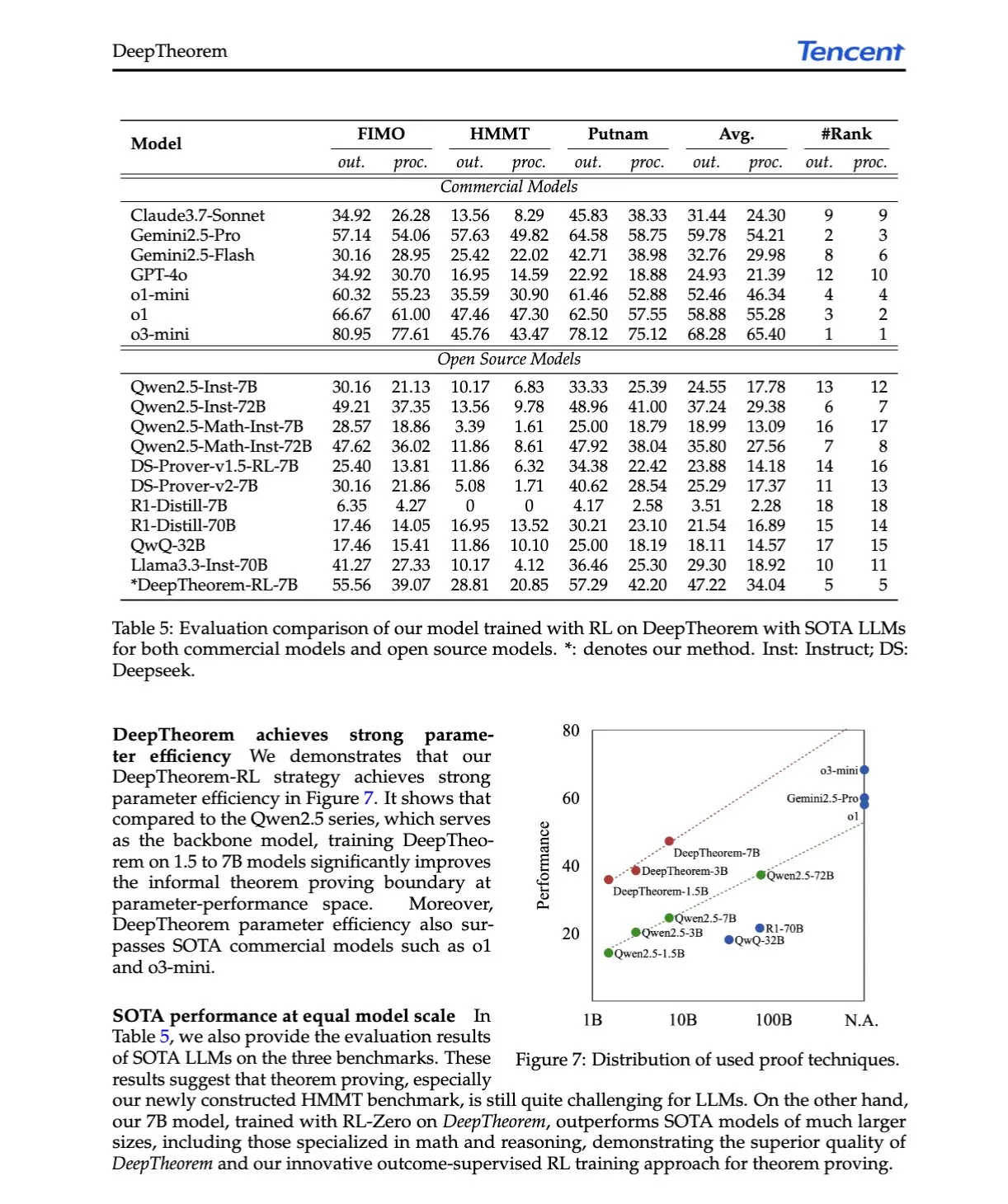
AI Paper Explained: DeepTheorem: Advancing LLM Reasoning for Theorem Proving Through Natural Language and Reinforcement Learning: The paper “DeepTheorem: Advancing LLM Reasoning for Theorem Proving Through Natural Language and Reinforcement Learning” proposes DeepTheorem, an informal theorem proving framework that uses natural language to enhance LLM mathematical reasoning. The framework includes a large-scale benchmark dataset (121,000 IMO-level informal theorems and proofs) and an RL policy (RL-Zero) specifically designed for informal theorem proving. (Source: HuggingFace Daily Papers, teortaxesTex)
AI Paper Explained: D-AR: Diffusion via Autoregressive Models: The paper “D-AR: Diffusion via Autoregressive Models” proposes the D-AR new paradigm, which reshapes the image diffusion process into a standard autoregressive next-token prediction process. By designing a tokenizer to convert images into discrete token sequences, tokens at different positions can be decoded into different diffusion denoising steps in pixel space. This method achieves an FID of 2.09 on ImageNet using a 775M Llama backbone and 256 discrete tokens. (Source: HuggingFace Daily Papers)
AI Paper Explained: Table-R1: Inference-Time Scaling for Table Reasoning: The paper “Table-R1: Inference-Time Scaling for Table Reasoning” is the first to explore inference-time scaling in table reasoning tasks. Researchers developed and evaluated two post-training strategies: distillation from the reasoning trajectories of cutting-edge models (Table-R1-SFT) and reinforcement learning with verifiable rewards (Table-R1-Zero). Table-R1-Zero (7B parameters) achieves or surpasses the performance of GPT-4.1 and DeepSeek-R1 on various table reasoning tasks. (Source: HuggingFace Daily Papers)
AI Paper Explained: Muddit: Liberating Generation Beyond Text-to-Image with a Unified Discrete Diffusion Model: The paper “Muddit: Liberating Generation Beyond Text-to-Image with a Unified Discrete Diffusion Model” introduces Muddit, a unified discrete diffusion Transformer model that supports rapid parallel generation of text and image modalities. Muddit integrates the strong visual priors of pre-trained text-to-image backbones with a lightweight text decoder, offering competitive quality and efficiency. (Source: HuggingFace Daily Papers)
AI Paper Explained: VideoReasonBench: Can MLLMs Perform Vision-Centric Complex Video Reasoning?: The paper “VideoReasonBench: Can MLLMs Perform Vision-Centric Complex Video Reasoning?” introduces VideoReasonBench, a benchmark designed to evaluate vision-centric complex video reasoning capabilities. The benchmark includes videos of fine-grained action sequences, with questions assessing recall, inference, and prediction abilities. Experiments show that most SOTA MLLMs perform poorly on this benchmark, while a thought-enhanced Gemini-2.5-Pro performs exceptionally well. (Source: HuggingFace Daily Papers, OriolVinyalsML)
AI Paper Explained: GeoDrive: 3D Geometry-Informed Driving World Model with Precise Action Control: The paper “GeoDrive: 3D Geometry-Informed Driving World Model with Precise Action Control” proposes GeoDrive, which explicitly integrates robust 3D geometric conditions into a driving world model to enhance spatial understanding and action controllability. The method enhances rendering effects during training through a dynamic editing module. Experiments demonstrate its superiority over existing models in action accuracy and 3D spatial perception. (Source: HuggingFace Daily Papers)
AI Paper Explained: Adaptive Classifier-Free Guidance via Dynamic Low-Confidence Masking: The paper “Adaptive Classifier-Free Guidance via Dynamic Low-Confidence Masking” proposes the A-CFG method, which customizes the unconditional input for Classifier-Free Guidance (CFG) by leveraging the model’s instantaneous prediction confidence. A-CFG identifies low-confidence tokens at each step of an iterative (masked) diffusion language model and temporarily re-masks them, creating dynamic, localized unconditional inputs that make CFG’s corrective influence more precise. (Source: HuggingFace Daily Papers)
AI Paper Explained: PatientSim: A Persona-Driven Simulator for Realistic Doctor-Patient Interactions: The paper “PatientSim: A Persona-Driven Simulator for Realistic Doctor-Patient Interactions” introduces PatientSim, a simulator that generates realistic and diverse patient personas based on clinical profiles from the MIMIC dataset and a four-axis persona (personality, language proficiency, medical history recall level, cognitive confusion level). It aims to provide a realistic patient interaction system for training or evaluating doctor LLMs. (Source: HuggingFace Daily Papers)
AI Paper Explained: LoRAShop: Training-Free Multi-Concept Image Generation and Editing with Rectified Flow Transformers: The paper “LoRAShop: Training-Free Multi-Concept Image Generation and Editing with Rectified Flow Transformers” introduces LoRAShop, the first framework to use LoRA models for multi-concept image editing. The framework leverages internal feature interaction patterns of Flux-style diffusion Transformers to derive decoupled latent masks for each concept and blends LoRA weights only within concept regions, enabling seamless integration of multiple subjects or styles. (Source: HuggingFace Daily Papers)
AI Paper Explained: AnySplat: Feed-forward 3D Gaussian Splatting from Unconstrained Views: The paper “AnySplat: Feed-forward 3D Gaussian Splatting from Unconstrained Views” introduces AnySplat, a feed-forward network for novel view synthesis from uncalibrated image collections. Unlike traditional neural rendering pipelines, AnySplat predicts 3D Gaussian primitives (encoding scene geometry and appearance) and the camera intrinsics/extrinsics for each input image in a single forward pass, requiring no pose annotation and supporting real-time novel view synthesis. (Source: HuggingFace Daily Papers)
AI Paper Explained: ZeroSep: Separate Anything in Audio with Zero Training: The paper “ZeroSep: Separate Anything in Audio with Zero Training” discovers that pre-trained text-guided audio diffusion models, under specific configurations, can achieve zero-shot sound source separation. The ZeroSep method inverts mixed audio into the latent space of a diffusion model and uses text conditions to guide the denoising process to recover individual sound sources, without any task-specific training or fine-tuning. (Source: HuggingFace Daily Papers)
AI Paper Explained: One-shot Entropy Minimization: The paper “One-shot Entropy Minimization” found by training 13,440 large language models that entropy minimization requires only a single unlabeled data point and 10 optimization steps to achieve or even exceed the performance improvements attainable by rule-based reinforcement learning using thousands of data points and carefully designed rewards. This result may prompt a rethinking of LLM post-training paradigms. (Source: HuggingFace Daily Papers)
AI Paper Explained: ChartLens: Fine-grained Visual Attribution in Charts: The paper “ChartLens: Fine-grained Visual Attribution in Charts” addresses the issue of MLLMs being prone to hallucinations in chart understanding by introducing the chart posterior visual attribution task and proposing the ChartLens algorithm. The algorithm uses segmentation techniques to identify chart objects and performs fine-grained visual attribution with MLLMs through labeled set prompting. The ChartVA-Eval benchmark, containing fine-grained attribution annotations for charts in fields like finance, policy, and economics, is also released. (Source: HuggingFace Daily Papers)
AI Paper Explained: A Graph Perspective to Probe Structural Patterns of Knowledge in Large Language Models: The paper “A Graph Perspective to Probe Structural Patterns of Knowledge in Large Language Models” investigates the structural patterns of knowledge in LLMs from a graph perspective. The research quantifies knowledge in LLMs at the triplet and entity levels, analyzes its relationship with graph structural properties like node degree, and reveals knowledge homophily (entities that are topologically close have similar knowledge levels). Based on this, a graph machine learning model is developed to estimate entity knowledge and used for knowledge checking. (Source: HuggingFace Daily Papers)
💼 Business
Embodied intelligence company Lumos Robotics raises nearly 200 million RMB in six months, partners with COSCO Shipping and others: Lumos Robotics, an embodied intelligence robotics company founded by former Dreame executive Yu Chao, announced the completion of its Angel++ funding round. Investors include Fosun RZ Capital, Dematic Technology, and Wuzhong Financial Holding, bringing total funding in six months to nearly 200 million RMB. The company focuses on home scenarios, with products including LUS and MOS series humanoid robots and core components. It has launched the full-size humanoid robot LUS and established strategic partnerships with Dematic Technology, COSCO Shipping, and others to accelerate the commercialization of embodied intelligence in logistics, smart manufacturing, and other scenarios. (Source: 36氪)

Snorkel AI completes $100M Series D funding, launches AI agent evaluation and expert data services: Data-centric AI company Snorkel AI announced the completion of a $100 million Series D funding round led by Valor Equity Partners, bringing its total funding to $235 million. Concurrently, the company launched Snorkel Evaluate (a data-centric AI agent evaluation platform) and Expert Data-as-a-Service, aimed at helping enterprises build and deploy more reliable and specialized AI agents. (Source: realDanFu, percyliang, tri_dao, krandiash)
US Department of Energy announces collaboration with Dell and NVIDIA to develop next-generation supercomputer “Doudna”: The US Department of Energy announced a contract with Dell Technologies to develop the next-generation flagship supercomputer for Lawrence Berkeley National Laboratory, named “Doudna” (NERSC-10). The system will be powered by NVIDIA’s next-generation Vera Rubin platform and is expected to be operational in 2026. Its performance will be more than 10 times that of the current flagship, Perlmutter, and is designed to support large-scale high-performance computing and AI workloads, aiming to help the US win the global AI dominance race. (Source: 36氪, nvidia)

🌟 Community
DeepSeek R1-0528 sparks heated discussion, with performance, hallucination, and tool calling as focal points: The release of DeepSeek R1-0528 has generated widespread discussion in the community. Most opinions suggest significant improvements in math, programming, and general logical reasoning, approaching or even surpassing some closed-source models. The new version has made progress in reducing hallucination rates and added support for JSON output and function calling. Meanwhile, its distilled Qwen3-8B version has also attracted attention for its excellent mathematical performance on a small model. The community generally believes DeepSeek has consolidated its leadership in the open-source field and looks forward to the release of the R2 version. (Source: ClementDelangue, dotey, scaling01, awnihannun, karminski3, teortaxesTex, scaling01, karminski3, teortaxesTex, dotey, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
AI image editing model FLUX.1 Kontext gains attention, emphasizing contextual understanding and character consistency: The FLUX.1 Kontext image editing model released by Black Forest Labs has garnered community attention for its ability to process both text and image inputs simultaneously while maintaining character consistency. User feedback indicates excellent performance in tasks such as image editing, style transfer, and text overlay, especially in preserving subject features during multi-turn editing. Platforms like Replicate have listed the model and provided detailed test reports and usage tips. (Source: TomLikesRobots, two_dukes, robrombach, timudk, robrombach, cloneofsimo, robrombach, robrombach)

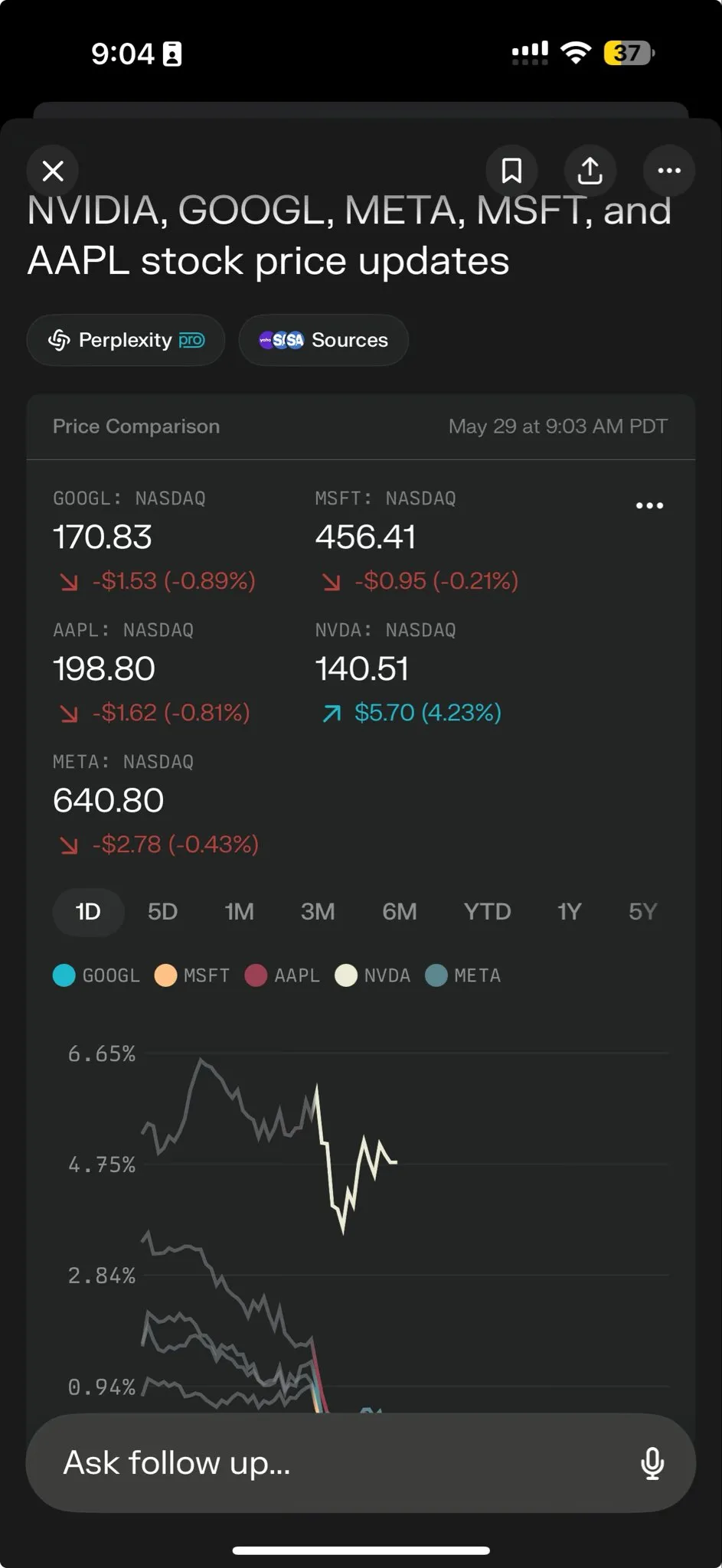
AI agents will significantly change search and advertising models: Perplexity AI CEO Arav Srinivas believes that as AI agents perform searches on behalf of users, the volume of human queries on search engines like Google will drop significantly. This will lead to lower ad CPM/CPC, and ad spending may shift to social media or AI platforms. Users will no longer need to frequently perform keyword searches; instead, AI assistants will proactively push information. (Source: AravSrinivas)
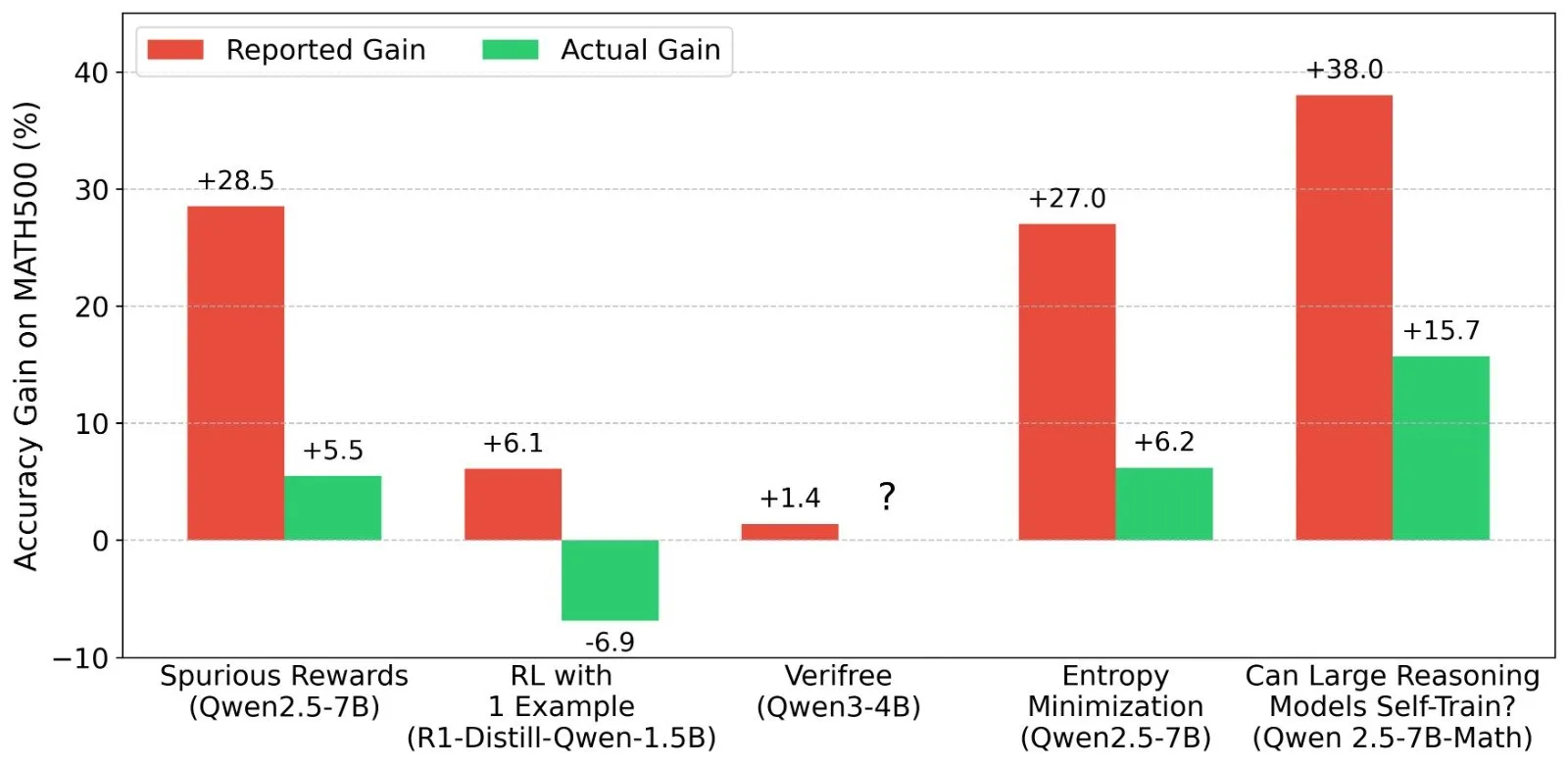
Discussion on LLM Reinforcement Learning (RL) results: Authenticity of reward signals and model capabilities: Researchers like Shashwat Goel have questioned recent LLM RL studies where models improve performance without real reward signals, pointing out that some research might underestimate the baseline capabilities of pre-trained models or have other confounding factors. The discussion has led to in-depth analysis of the performance of models like Qwen in RL and reflections on the effectiveness of RLVR (Verifiable Reward Reinforcement Learning), emphasizing the need for stricter baselines and prompt optimization when evaluating RL effects. (Source: menhguin, AndrewLampinen, lateinteraction, madiator, vikhyatk, matei_zaharia, hrishioa, iScienceLuvr)
“Vibe Coding” sparks discussion, emphasizing safe defaults and technical debt risks: “Vibe coding” (programming that relies more on intuition and rapid iteration than strict specifications) has become a hot topic in the community. Replit CEO Amjad Masad believes this approach empowers new developers, but platforms must provide safe default configurations. Meanwhile, Pedro Domingos commented that “vibe coding is the Godzilla of technical debt,” hinting at potential long-term maintenance issues. Semafor reported a security vulnerability in Lovable due to improper RLS policy configuration, further raising concerns about the safety of this programming style. (Source: alexalbert__, amasad, pmddomingos, gfodor)
The role of AI in software engineering: Efficiency improvements and the irreplaceability of human programmers: Salvatore Sanfilippo, creator of Redis, shared his experience that while AI (like Gemini 2.5 Pro) is valuable for programming assistance, code review, and idea validation, human programmers still far surpass AI in creative problem-solving and unconventional thinking. Community discussions further pointed out that AI currently acts more like an “intelligent rubber duck,” aiding thought processes, but its suggestions need careful evaluation, and over-reliance could weaken developers’ core abilities. Mitchell Hashimoto also shared an instance where an LLM helped him quickly locate a Clang compilation issue, saving significant time. (Source: mitchellh, 36氪)
Whether AI will replace jobs on a large scale continues to attract attention: Anthropic CEO Dario Amodei predicts AI could eliminate half of entry-level office positions, while Mark Cuban believes AI will create new companies and jobs. The community is hotly debating this, with some arguing that jobs in customer service, junior copywriting, and some development areas are already affected. However, AI is still far from replacing humans in creative fields, complex decision-making, and roles requiring high levels of interpersonal interaction. The general consensus is that AI will change the nature of work, and humans need to adapt and enhance their ability to collaborate with AI. (Source: Reddit r/ArtificialInteligence, Reddit r/artificial, Reddit r/ArtificialInteligence)
AI Agents become the next-generation interaction portal, sparking competition among major companies: Tech companies worldwide, including Microsoft, Google, OpenAI, Alibaba, Tencent, Baidu, and Coocaa, are all investing in AI Agents. Agents capable of deep thinking, autonomous planning, decision-making, and executing complex tasks are seen as the next interaction portal after search engines and apps. Three main forces have emerged: technology ecosystem builders like OpenAI and Baidu; vertical scenario enterprise service providers like Microsoft and Alibaba Cloud; and software and hardware terminal manufacturers like Huawei and Coocaa. (Source: 36氪)

💡 Other
China’s AI going overseas accelerates, shifting from product export to ecosystem building: The report “The Transoceanic Growth of Chinese AI” indicates that Chinese AI companies’ overseas expansion has entered a fast track to large-scale development, with 76% concentrated at the application level. The path of going overseas has evolved from early tool-based applications to mid-stage export of industry solutions combined with technological advantages, and now focuses on the export of technology ecosystems, promoting technical standards and open-source collaboration. AI’s overseas expansion shows a gradient penetration from “near to far” and faces challenges such as localization, compliance ethics, and brand marketing. (Source: 36氪)

US Department of Energy likens AI race to “new Manhattan Project,” emphasizes US will win: When announcing the next-generation supercomputer “Doudna,” the US Department of Energy referred to the AI development competition as “the Manhattan Project of our time” and declared that the United States will win this race. These remarks have sparked community discussions on great power technology competition, AI ethics, and international cooperation. (Source: gfodor, teortaxesTex, andrew_n_carr, npew, jpt401)
Advancements in AI content creation spark reflections on “authenticity” and “creativity”: The community discussed AI applications in fashion design, comic creation, video generation, and other fields. On one hand, AI can rapidly generate diverse content, even visualizing comic works from years ago into videos. On the other hand, this generated content sometimes appears strange or lacks depth. This has sparked reflections on whether AI-generated content is “better” and what role human creativity will play in the AI era. (Source: Reddit r/ChatGPT, Reddit r/artificial)
