
Keywords:DeepSeek R1-0528, Darwin-Gödel Machine, AI energy consumption, Huawei Ascend, SuperCLUE benchmark, false reward reinforcement learning, multimodal benchmark testing, DeepSeek R1-0528 performance enhancement, DGM self-evolution mechanism, AI data center nuclear energy solutions, Qwen model RLVR mechanism, Pangu Ultra MoE training optimization
🔥 Spotlight
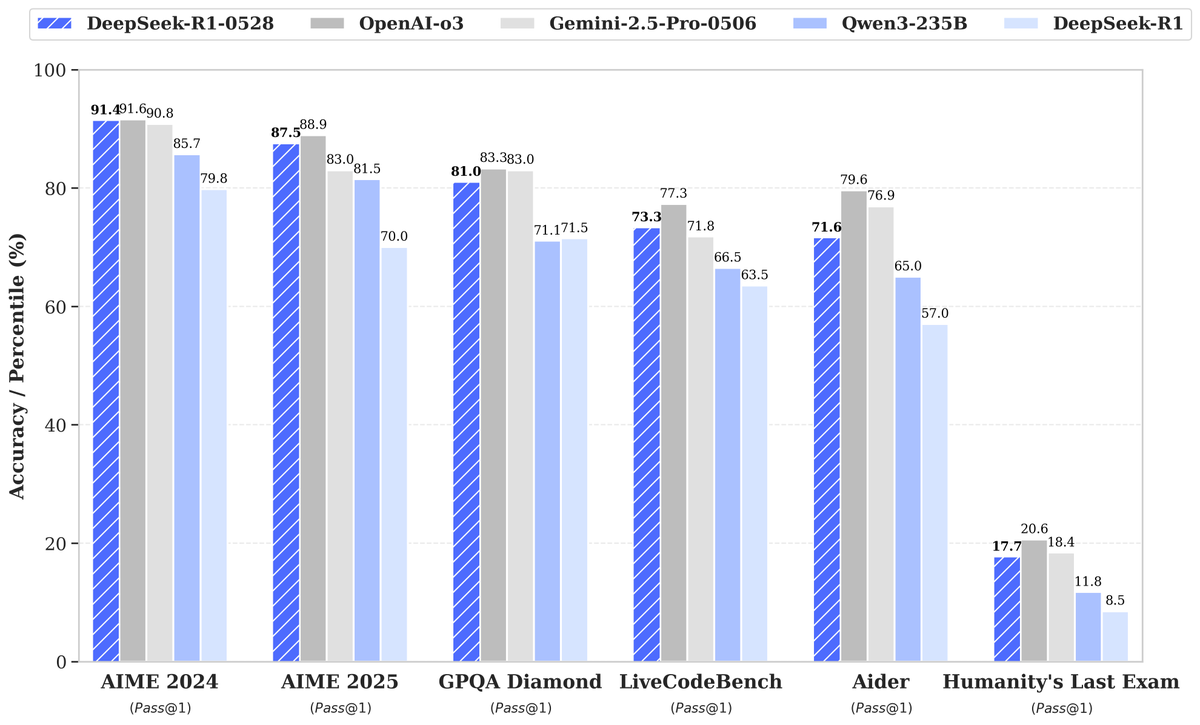
DeepSeek releases new R1-0528 model with significantly improved performance, drawing attention: DeepSeek has launched a new version of its large language model, R1-0528, which has performed exceptionally well in multiple benchmarks, particularly showing significant progress in areas like code generation (LiveCodeBench), scientific reasoning (GPQA Diamond), and math competitions (AIME 2024). Artificial Analysis noted that R1-0528 jumped from 60 to 68 points in its intelligence index, tying with Google’s Gemini 2.5 Pro, making DeepSeek the world’s second-ranked AI lab and consolidating its leading position in open-weight models. The community response has been positive, with Unsloth quickly releasing GGUF quantized versions for local deployment. This update was primarily achieved through post-training techniques such as reinforcement learning (RL), demonstrating the potential for continuous improvement in model intelligence on existing architectures and pre-training. Although there’s discussion about its output sometimes having a “sycophantic” style, it is generally considered a major leap in reasoning and coding abilities. (Source: DeepSeek, Artificial Analysis, tokenbender, karminski3, teortaxesTex)
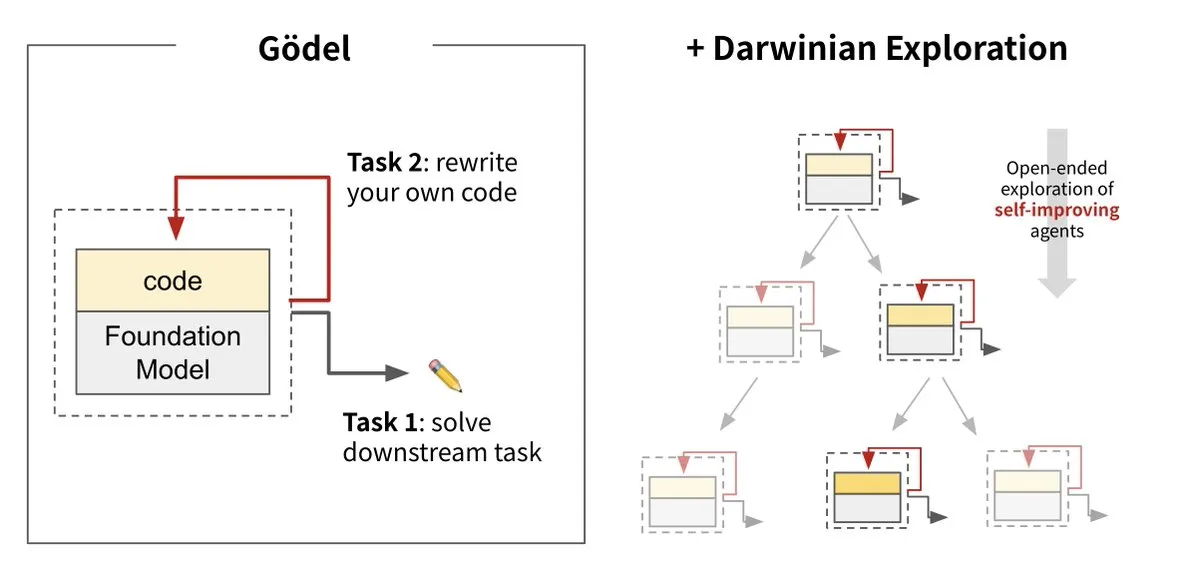
Sakana AI introduces Darwin Gödel Machine (DGM), achieving AI self-evolution: Sakana AI, in collaboration with UBC, has launched the Darwin Gödel Machine (DGM), an AI agent capable of continuous self-improvement by rewriting its own code. Inspired by evolutionary theory, the system combines large foundation models and code libraries, enabling agents to propose code improvements and self-evaluate. Experiments show DGM’s performance on SWE-bench improved from 20% to 50%, and its success rate on Polyglot increased from 14.2% to 30.7%, significantly outperforming manually designed agents. This research is considered an important step towards AI that can learn and innovate autonomously, aiming to solve the problem of fixed intelligence in AI systems after deployment, and emphasizes the high importance of safety during development. (Source: Sakana AI, hardmaru, ITmedia AI+)
AI’s energy consumption draws attention, with nuclear and fossil fuels as potential power sources: MIT Technology Review’s series “Power Hungry” delves into the anticipated energy demands of artificial intelligence (AI). AI data centers require a continuous and stable power supply, especially for model inference. While solar and wind are clean energy sources, their intermittency makes them difficult to meet AI demands alone, unless paired with expensive energy storage solutions. Nuclear power is considered a potential solution due to its ability to provide continuous electricity, but building new nuclear plants is time-consuming and complex. Consequently, fossil fuels like natural gas may become a short-term reliance to meet AI’s rapidly growing energy needs, potentially challenging climate goals. The report emphasizes that large tech companies should promote cleaner energy solutions, such as carbon capture technologies or optimizing energy use efficiency, to address the dual energy and climate challenges posed by AI development. (Source: MIT Technology Review, The Download)

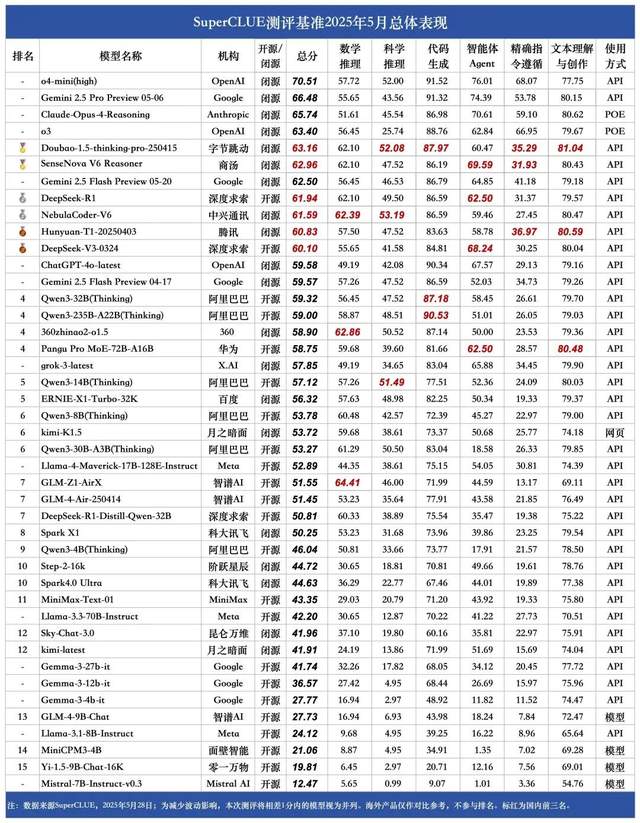
Study reveals fake rewards can also improve Qwen model performance, prompting a rethink of RLVR mechanisms: A University of Washington research team found that even when using random or incorrect reward signals, training the Qwen2.5-Math model with Reinforcement Learning with Verifiable Rewards (RLVR) still significantly improved its performance on math reasoning benchmarks like MATH-500 by about 25%, approaching the optimization effect of real rewards. The study indicates this phenomenon is mainly due to specific code reasoning strategies learned by the Qwen model during pre-training (such as generating Python code to aid thinking). The RLVR process (especially when using the GRPO algorithm) enhances the frequency of this beneficial behavior, rather than the correctness of the reward signal itself. This finding does not apply to other models lacking such pre-training characteristics (like OLMo2-7B), whose performance barely changed or even declined with fake rewards. The research challenges the traditional understanding that RLVR relies on correct reward signals and suggests researchers should be wary of model-specific behaviors influencing evaluation results, emphasizing the importance of cross-model validation. (Source: QbitAI, Stella Li)
🎯 Trends
Huawei Ascend empowers efficient training of Pangu Ultra MoE near-trillion-parameter model, achieving full-process autonomy and control: Huawei released a technical report detailing its full-process efficient training practice for the Pangu Ultra MoE (718 billion parameters) model based on Ascend AI hardware and the MindSpore framework. Through technologies like intelligent selection of parallel strategies, deep fusion of computation and communication, and global dynamic load balancing, it achieved 41% MFU (Model FLOPS Utilization) on an Ascend Atlas 800T A2 10,000-card cluster. In the RL post-training phase, combined with RL Fusion co-location technology for training and inference and the StaleSync quasi-asynchronous mechanism, it achieved a high throughput of 35K Tokens/s per supernode on an Ascend CloudMatrix 384 supernode cluster, equivalent to solving an advanced mathematics problem every 2 seconds. This marks the maturity of the closed loop of domestic AI computing power and large model training, and demonstrates industry-leading performance in ultra-large-scale MoE model training. (Source: QbitAI)

SuperCLUE May Chinese Large Model Rankings: Doubao 1.5 and SenseTime SenseNova V6 Tied for First Place Domestically: Authoritative large model evaluation organization SuperCLUE released its May 2025 “Chinese Large Model Benchmark Evaluation Report.” The report shows that ByteDance’s Doubao-1.5-thinking-pro and SenseTime’s SenseNova-V6 Reasoner multimodal model are tied for first place domestically, with their performance in general Chinese capabilities surpassing Gemini 2.5 Flash Preview. Models like DeepSeek-R1, NebulaCoder-V6, Hunyuan-T1, and DeepSeek-V3 followed closely in the second tier. The report emphasizes that the gap in general capabilities in the Chinese domain between domestic and international top large models is narrowing, and a competitive landscape for domestic inference models is beginning to emerge. This evaluation covered six major tasks: mathematical reasoning, scientific reasoning, code generation, intelligent agents, precise instruction following, and text understanding and creation. (Source: QbitAI)
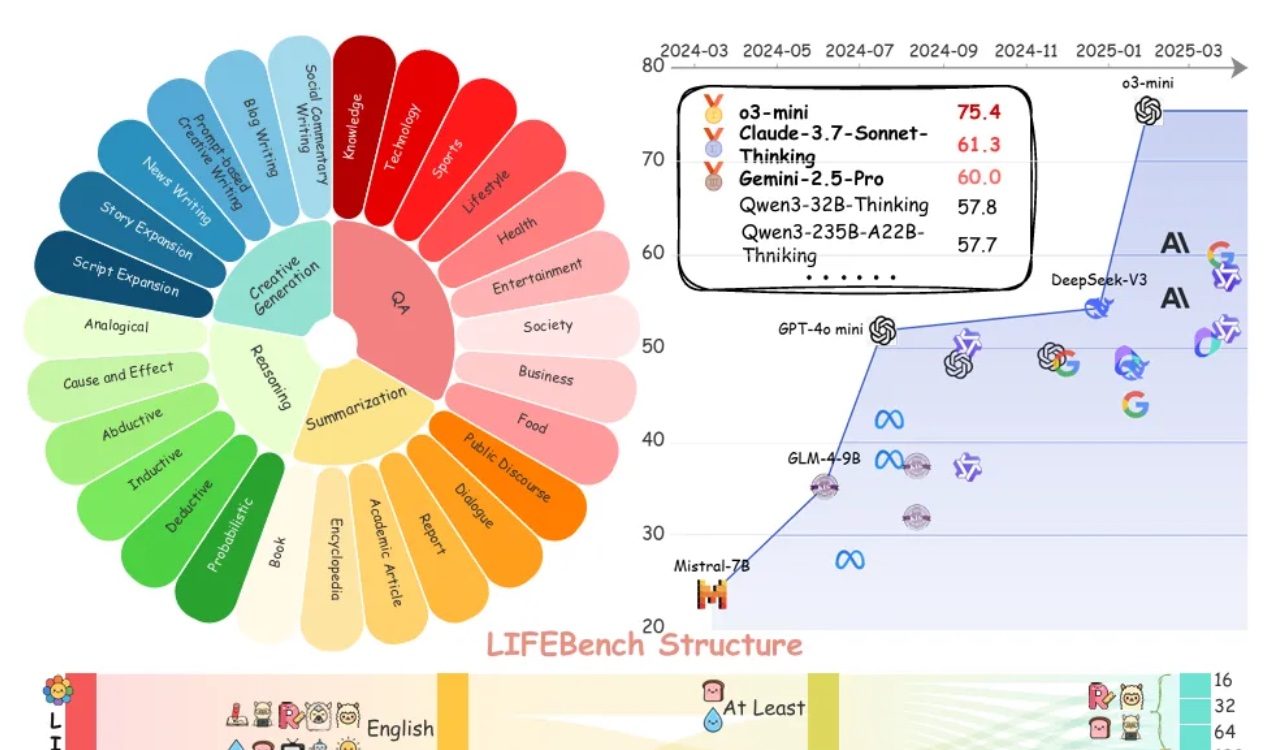
LIFEBench assessment shows large models generally struggle with following length instructions: A new benchmark test called LIFEBench indicates that current mainstream large language models (LLMs) perform poorly in adhering to specific text length instructions, especially when generating long texts. The study tested 26 models and found that most scored low when asked to generate text of a precise length, with only a few models like o3-mini, Claude-Sonnet-Thinking, and Gemini-2.5-Pro performing adequately. Long text generation (>2000 words) was a common weakness, with all models showing a significant drop in scores. Furthermore, models generally performed worse on Chinese tasks than English ones and tended to “over-generate.” The study also pointed out that the maximum output length claimed by many models does not match their actual capabilities, indicating an “over-hyping” phenomenon. Models face bottlenecks in length awareness, processing long inputs, and avoiding “lazy generation” (e.g., premature termination or refusal to generate). (Source: QbitAI)
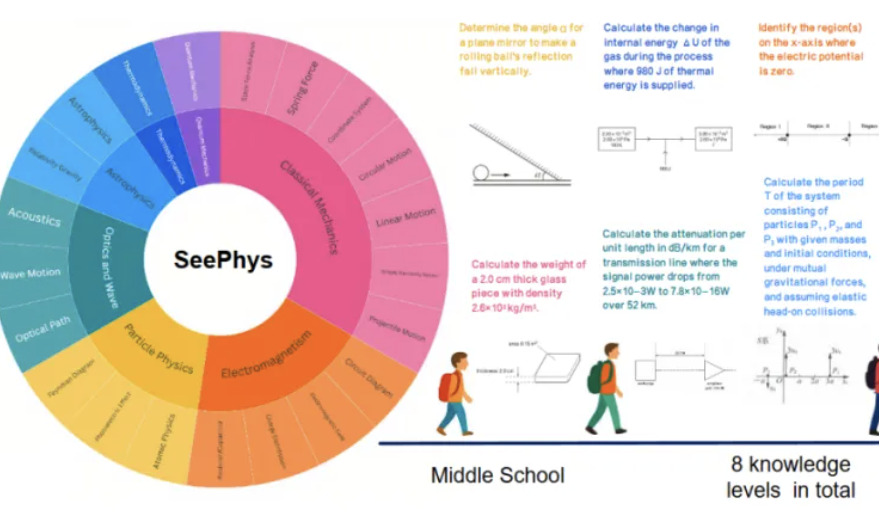
New benchmark SeePhys reveals shortcomings of multimodal large models in understanding physics images: Sun Yat-sen University and other institutions jointly launched the SeePhys benchmark test, specifically designed to evaluate the ability of multimodal large models (MLLMs) to understand and reason about physics-related images. The benchmark includes 2000 questions and 2245 diagrams ranging from middle school to doctoral level, covering classical and modern physics. Test results show that even top models like Gemini-2.5-Pro and o4-mini achieve an accuracy of less than 55% on SeePhys, with systematic recognition difficulties for specific diagram types such as circuit diagrams and wave equation plots. The study also found that pure language models performed similarly to multimodal models in some cases, exposing deficiencies in current MLLMs’ visual-text alignment. The benchmark highlights the importance of graphical perception for models to understand the physical world and reveals the significant challenges current AI faces in tasks coupling complex scientific diagrams with theoretical derivation. (Source: QbitAI)
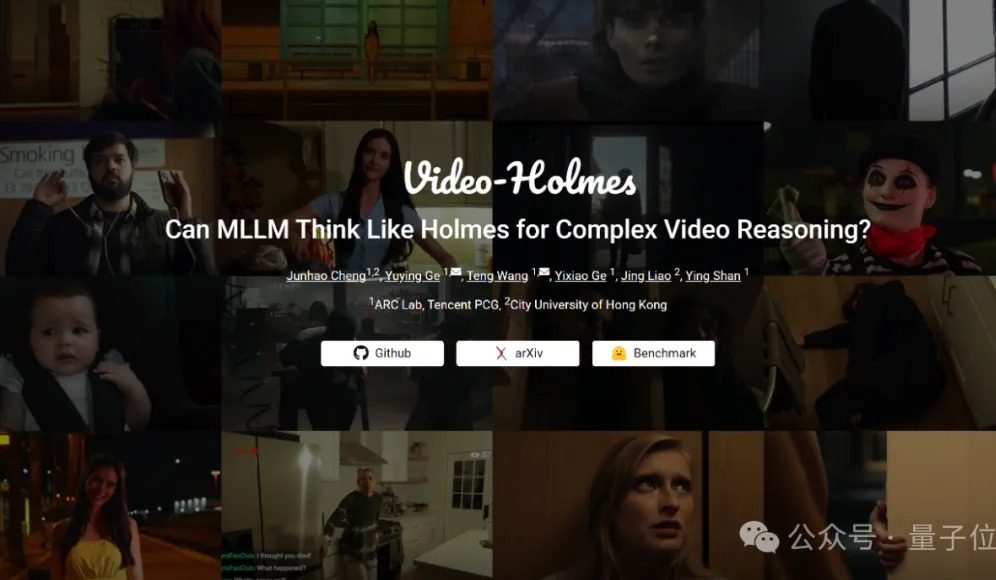
Video-Holmes benchmark test: Current large models all fail in complex video reasoning capabilities: Tencent ARC Lab and City University of Hong Kong have launched the Video-Holmes benchmark to evaluate the complex video reasoning capabilities of multimodal large models (MLLMs). The benchmark consists of 270 “mystery short films” and designs 7 types of multiple-choice questions with high reasoning demands, such as “deduce the murderer” and “analyze the motive,” requiring models to extract and connect scattered key information in the video. Test results show that all tested large models, including Gemini-2.5-Pro, failed to reach the passing line (Gemini-2.5-Pro accuracy around 45%). The study points out that existing models can perceive visual information but have common deficiencies in multi-cue association and key information capture, making it difficult to simulate the complex reasoning process of human active search, integration, and analysis. (Source: QbitAI)
Meta believes seamless integration of AI services is key, leveraging social network effects to boost user engagement: Meta emphasizes that although its Llama model is not top-ranked, the company holds a significant advantage in the AI race due to its vast social media ecosystem (3.43 billion daily active users). Meta can offer users seamlessly integrated AI tools, a feat difficult for standalone AI platforms like ChatGPT to match. The company has already increased advertiser returns (average ad price up 10% YoY) with attractive AI tools and is rapidly monetizing its AI investments. The Meta AI platform is projected to exceed 1 billion users by year-end. However, high capital expenditures (estimated $64-72 billion in 2025) and ongoing losses at Reality Labs (annual losses over $15 billion) are headwinds to its development, already causing a decline in free cash flow. Despite this, Meta stock is still viewed favorably due to its moderate valuation and short-term commercialization potential. (Source: 36Kr)

Google CEO Sundar Pichai: AI is undergoing a new phase of platform transformation, will reshape the internet ecosystem: Google CEO Sundar Pichai stated after the I/O conference that AI is experiencing a platform transformation similar to the rise of mobile devices. Its uniqueness lies in the platform’s ability to self-create and improve, releasing creativity with a multiplier effect. Google is extensively integrating its AI research achievements into its entire product line, including Search, YouTube, and Cloud services. The new AI-powered search feature has been rolled out to US users, generating personalized results pages in real-time with interactive charts and custom application modules, heralding a search experience beyond traditional web links. Pichai believes that although this might change the internet ecosystem (with AI treating the web as a structured database), Google is still driving record traffic to the web. He anticipates a rapid explosion of AI in enterprise applications (like coding IDEs, video creation, legal, and healthcare) and sees great opportunities in new AI-driven hardware forms like AR glasses. (Source: 36Kr)

AI applications like Zhipu Qingyan and Kimi accused of illegally collecting personal information, raising privacy concerns: Recently, official notifications pointed out that Zhipu AI’s “Zhipu Qingyan” had “actually collected personal information beyond the scope authorized by users,” while Moonshot AI’s “Kimi” “actually collected personal information at a frequency not directly related to its business functions.” The naming of these two star AI applications has sparked widespread public concern about the risk of privacy breaches in generative AI products. The intelligence of generative AI relies on data-driven characteristics, posing a challenge in balancing model performance improvement with user privacy protection. Large-scale data pre-training is a necessary condition for technological development, but any illegal collection and misuse of personal information will severely damage user trust and industry reputation. This incident exposes potential issues in data handling by some AI companies and the inadequacy of existing data protection frameworks in addressing the challenges of AI technology. (Source: 36Kr)

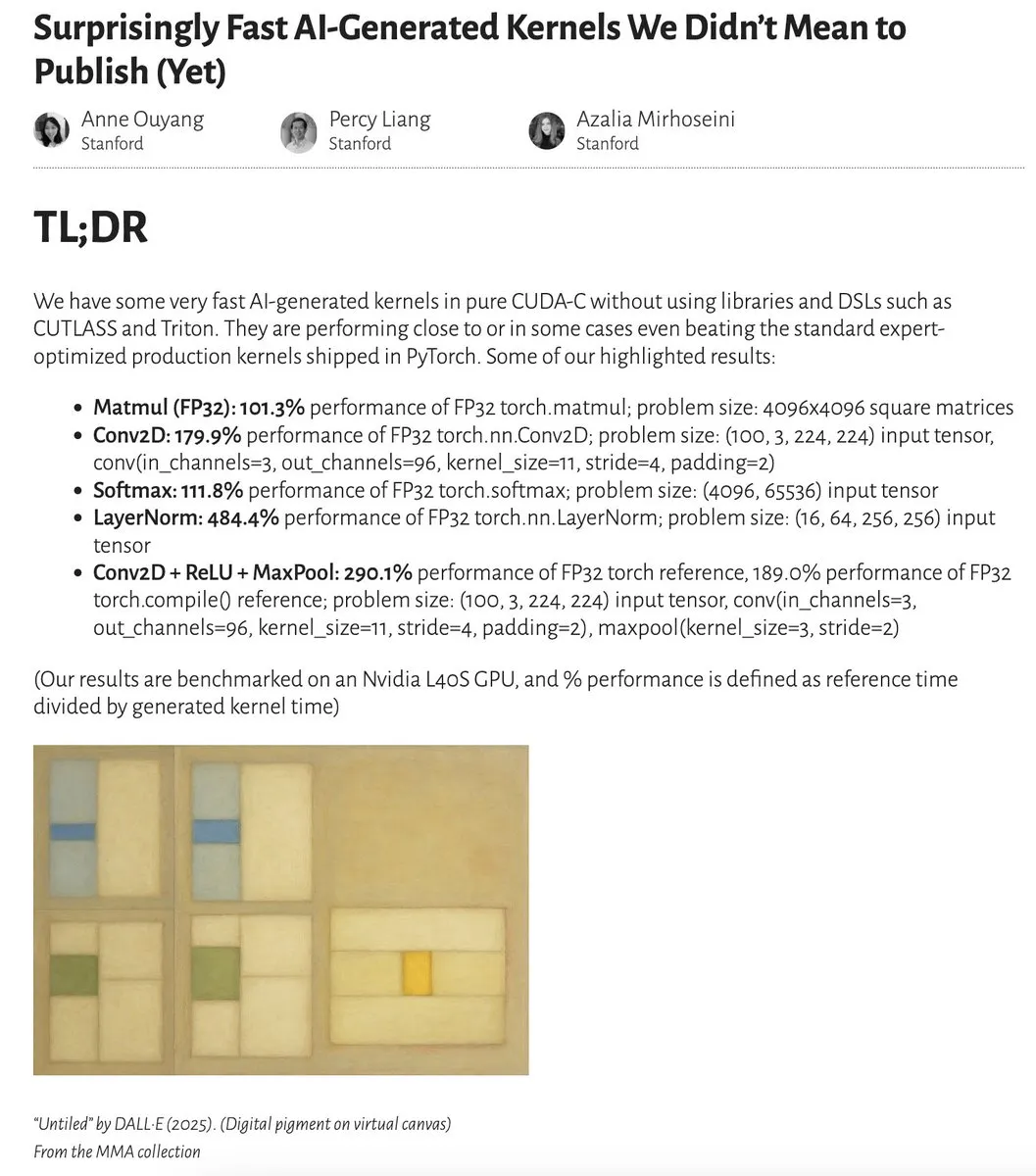
AI-generated kernels approach or even surpass expert-optimized kernels in performance: Anne Ouyang and collaborators published research demonstrating that AI-generated kernels, produced through simple test-time search, can approach or in some cases even outperform standard, expert-optimized production kernels in PyTorch. Fleetwood conducted a preliminary replication of the LayerNorm kernel on Colab, confirming its impressive performance improvement (approximately 484.4%). This development indicates AI’s significant potential in low-level code optimization, possibly even impacting the work of kernel engineers. However, a subsequent update noted numerical instability issues with the generated LayerNorm kernel, advising users to exercise caution. (Source: eliebakouch, fleetwood___)
Discussion: Can Large Language Models Possess True Creativity?: MoritzW42 posted an article discussing the creativity of Large Language Models (LLMs), arguing that LLMs are inherently incapable of true creativity. He cites physicist David Deutsch’s definition of creativity – the ability to create new knowledge through conjecture and criticism – and likens it to variation and selection in evolution. LLMs rely on inductive probabilities and patterns in training data, and cannot make creative conjectures or solve novel problems, such as generating “black swan” instances not seen in training data (e.g., a wine glass filled to the brim). The article posits that LLMs are more tools to enhance human creativity rather than entities with autonomous creativity, thus making fear of them irrational. (Source: MoritzW42)
Discussion: AI agent building should avoid vendor lock-in, focus on the model itself: Austin Vance’s viewpoint (retweeted by rachel_l_woods) points out that a major mistake in building AI agents is getting locked into a vendor. Companies like OpenAI, Anthropic, and Google tend to promote their integrated APIs, which creates huge switching costs without providing additional value. He emphasizes that it’s the model itself, not the API, that drives performance. Since models frequently change positions on leaderboards, using open-source, model-agnostic frameworks (like LangChain) and tools (like LangSmith) ensures businesses can choose the best model at any given time, rather than being limited by options provided by specific foundation model labs. (Source: rachel_l_woods)
Discussion: AI overview features pose prompt injection risks: Zack Witten discovered and demonstrated that AI overview features can be subjected to prompt injection, meaning that specially crafted inputs can manipulate the AI to generate unintended or misleading summary information. Users like Charles IRL retweeted and highlighted this security vulnerability, cautioning about the need for robustness and security when widely deploying such AI features. (Source: charles_irl, giffmana)
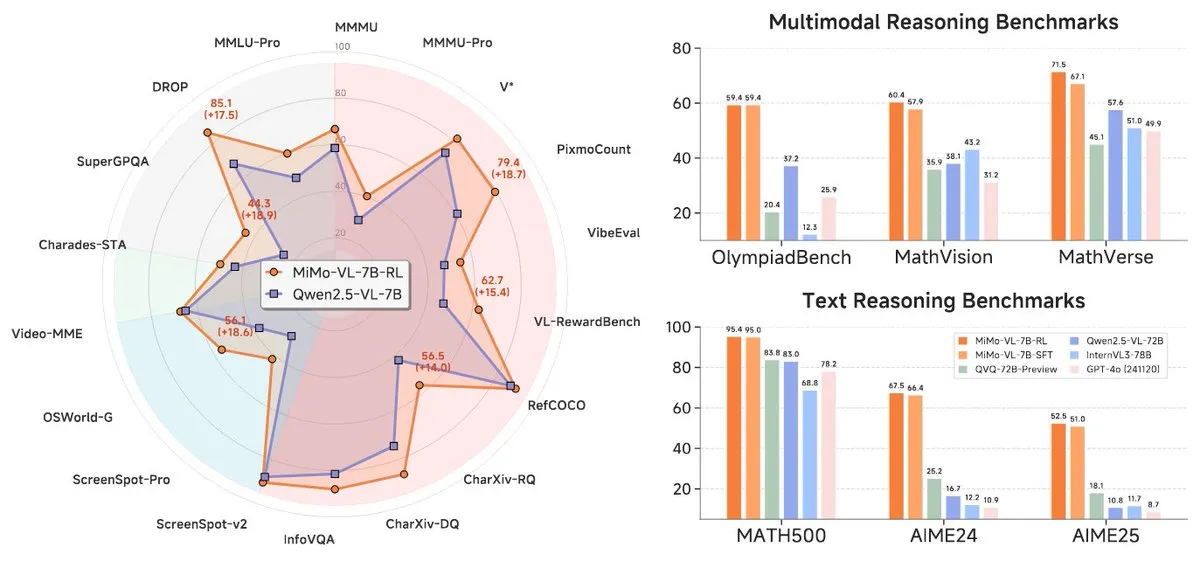
Xiaomi releases new MiMo-7B series models, excelling at the 7B level: Xiaomi has released updated 7B reasoning models, MiMo-7B-RL-0530, and its visual language model version, MiMo-VL-7B-RL, claiming SOTA (State-of-the-Art) performance at their parameter scale. These models are compatible with the Qwen-VL architecture, can run on frameworks like vLLM, Transformers, SGLang, and Llama.cpp, and are open-sourced under the MIT license. The MiMo-VL-RL version shows significant improvements in multiple text benchmarks compared to the text-only MiMo-7B-RL, while also adding visual capabilities, sparking community discussion on whether it’s over-optimized for benchmarks or has achieved substantial multimodal progress. (Source: reach_vb, teortaxesTex, Reddit r/LocalLLaMA)
🧰 Tools
Black Forest Labs releases FLUX.1 Kontext for pixel-level image editing and contextual generation: Black Forest Labs (BFL), founded by members of the core Stable Diffusion technology invention team, has released a new image generation and editing model suite called FLUX.1 Kontext. Based on a flow matching architecture, the model can understand both text and image inputs simultaneously, enabling context-based generation and multi-turn editing while maintaining excellent character consistency. FLUX.1 Kontext supports local editing without affecting other parts, can generate scenes in the same style by referencing input styles, and features low latency. Pro and Max versions are currently available and have been launched on platforms like KreaAI and Freepik, aiming to provide enterprise creative teams with more precise and rapid image editing capabilities. Community feedback has been positive, claiming it can achieve pixel-perfect editing. (Source: 36Kr, timudk, op7418, lmarena_ai)

Simon Willison launches LLM CLI tool for convenient access to multiple large models: Simon Willison has developed a command-line tool and Python library called LLM, allowing users to interact with various large language models such as OpenAI, Anthropic Claude, Google Gemini, and Meta Llama via the command line. It supports remote APIs and locally deployed models. The tool can execute prompts, store prompts and responses to SQLite, generate and store embeddings, extract structured content from text and images, and more. Users can install it via pip or Homebrew and can use local models by installing plugins like llm-ollama. It supports an interactive chat mode, making it easy for users to converse with models. (Source: GitHub Trending)

Contextual.ai launches document parser optimized for RAG: Contextual.ai has released a document parser specifically designed for Retrieval Augmented Generation (RAG) applications. The tool combines top-tier vision, OCR, and vision-language models to provide high-accuracy document content extraction. Users can try it for free, with the first 500+ pages being free. This is very useful for scenarios requiring information extraction from complex documents for LLM use, helping to improve the performance and accuracy of RAG systems. (Source: douwekiela)
Alibaba Tongyi Lingma AI IDE released, integrating code completion and Agent mode: Alibaba has released an AI Integrated Development Environment (IDE) called “Tongyi Lingma.” This IDE features code completion, MCP (Model-Copilot-Playground), Agent mode, long-term memory, and cross-line completion. It currently supports Qwen and DeepSeek models, with users hoping for future support for other models. Initial user feedback indicates that its chat panel has room for improvement in terms of internet search and @mention functionality, but overall it provides developers with a new tool integrating AI-assisted programming capabilities. (Source: karminski3, karminski3)
Perplexity Labs introduces new feature to create apps and reports from prompts: Perplexity AI’s Labs platform showcased a new feature allowing users to create interactive applications and reports using prompts. For example, a user successfully prompted the generation of a dashboard comparing the 5-year performance of a traditional stock portfolio versus an AI-driven portfolio, obtaining highly accurate results. Another user utilized the platform to compare different LLM models and expressed satisfaction with the results. These cases demonstrate Perplexity’s progress in transforming AI capabilities into practical analytical tools, especially in fields like financial research. (Source: AravSrinivas, AravSrinivas, TheRundownAI)

Unsloth releases GGUF quantized versions of DeepSeek-R1-0528, supporting local execution: Unsloth has created GGUF quantized versions for the newly released DeepSeek-R1-0528 model, including various specifications like IQ1_S (185GB) and Q2_K_XL (251GB). This facilitates users running this large model on local hardware (such as RTX 4090/3090 with sufficient VRAM). By using parameters like -ot ".ffn_.*_exps.=CPU", parts of the MoE layers can be offloaded to RAM, enabling inference with limited VRAM. This provides convenience for users wishing to experience and research the powerful capabilities of DeepSeek R1 locally. (Source: karminski3, Reddit r/LocalLLaMA)

local-ai-packaged: Integrated local AI development environment with Ollama, Supabase, etc.:coleam00/local-ai-packaged is an open-source Docker Compose template designed to quickly set up a fully functional local AI and low-code development environment. It integrates Ollama (local LLM execution), Supabase (database, vector store, authentication), n8n (low-code automation), Open WebUI (chat interface), Flowise (AI agent builder), Neo4j (knowledge graph), Langfuse (LLM observability), SearXNG (metasearch engine), and Caddy (HTTPS management). This project makes it convenient for developers to integrate and use various AI tools and services in a local environment. (Source: GitHub Trending)
Resemble AI releases open-source AI voice tool ChatterBox, supporting emotion control: Resemble AI has released an open-source AI voice tool called ChatterBox. The tool allows users to design, clone, and edit voices for free, and includes emotion control. ChatterBox is claimed to outperform some top commercial AI voice services (like Elevenlabs) in performance, providing developers and content creators with powerful voice synthesis and editing capabilities. (Source: ClementDelangue)
Mem0.ai combined with Qdrant provides long-term memory solution for AI agents: The Mem0.ai framework, combined with the Qdrant vector database, offers a long-term memory solution for AI agents. This solution aims to help agents maintain context, remember facts, and remain consistent in conversations. Users can deploy it via the cloud or open-source methods, connecting Mem0 to Qdrant to store long-term vector memories. This is significant for building AI applications that require persistent memory and complex conversational abilities. (Source: qdrant_engine)

📚 Learning
New University of Tokyo research: In-context meta-learning induces multi-phase circuit emergence in LLMs: A study from the University of Tokyo, “Beyond Induction Heads: In-Context Meta Learning Induces Multi-Phase Circuit Emergence,” explores more complex structures within Large Language Models (LLMs). The research finds that during in-context meta-learning, LLMs can guide the emergence of multi-phase circuits, which surpasses previously understood simple mechanisms like induction heads. This study offers new perspectives on how LLMs learn through context and form complex internal representations. (Source: teortaxesTex, [email protected])

MLflow enhances support for DSPy optimization workflows, improving observability: MLflow announced support for tracking DSPy (a framework for building and optimizing language model applications) optimization workflows, similar to its support for PyTorch training. Through MLflow’s tracking and auto-logging features, developers can seamlessly debug and monitor DSPy module calls, evaluations, and optimizers, thereby better understanding and iterating on GenAI workflows for end-to-end management from development to deployment. This provides enhanced observability and MLOps practices for developers using DSPy for prompt engineering and LLM application development. (Source: lateinteraction, dennylee)

New paper explores self-improving unified multimodal models via UniRL: The paper “UniRL: Self-Improving Unified Multimodal Models via Supervised and Reinforcement Learning” introduces a self-improving post-training method called UniRL. This method enables models to generate images based on prompts and use these images as iterative training data, without needing external image data. It also achieves mutual enhancement between generation and understanding tasks: generated images are used for understanding, and understanding results are used to supervise generation. Researchers explored supervised fine-tuning (SFT) and group relative policy optimization (GRPO) to optimize models like Show-o and Janus. UniRL’s advantages include not requiring external image data, improving single-task performance, reducing imbalance between generation and understanding, and needing only a few additional training steps. (Source: HuggingFace Daily Papers)
Paper Fast-dLLM: Accelerating Diffusion LLM via KV Cache and Parallel Decoding: The paper “Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding” addresses the slow inference speed of diffusion-based Large Language Models (Diffusion LLMs) by proposing a training-free acceleration method. This method introduces a block-level approximate KV cache mechanism tailored for bidirectional diffusion models and proposes a confidence-aware parallel decoding strategy to maintain generation quality while decoding multiple tokens simultaneously. Experiments show that this method achieves up to a 27.6x throughput improvement on LLaDA and Dream models with minimal accuracy loss, helping to bridge the performance gap between Diffusion LLMs and autoregressive models. (Source: HuggingFace Daily Papers)
Paper Uni-Instruct: One-step Diffusion Model through Unified Diffusion Divergence Instruction: The paper “Uni-Instruct: One-step Diffusion Model through Unified Diffusion Divergence Instruction” proposes a theory-driven framework called Uni-Instruct, unifying over 10 existing one-step diffusion distillation methods. The framework is based on the authors’ proposed diffusion extension of the f-divergence family and introduces key theories to overcome the intractability of the original extended f-divergence, resulting in an equivalent and tractable loss function that effectively trains one-step diffusion models by minimizing the extended f-divergence family. Uni-Instruct achieves SOTA one-step generation performance on benchmarks like CIFAR10 and ImageNet-64×64 and has been applied to tasks such as text-to-3D generation. (Source: HuggingFace Daily Papers)
New research explores the relationship between reasoning ability and hallucination in Large Language Models: The paper “Are Reasoning Models More Prone to Hallucination?” investigates whether Large Reasoning Models (LRMs), while exhibiting strong Chain-of-Thought (CoT) reasoning abilities, are more susceptible to generating hallucinations. The study finds that LRMs that undergo a complete post-training pipeline (including cold-start SFT and verifiable reward RL) generally mitigate hallucinations, whereas training solely through distillation or RL without cold-start fine-tuning may introduce more subtle hallucinations. The research also analyzes key cognitive behaviors leading to hallucinations (such as defective repetition, mismatch between thought and answer) and the misalignment between model uncertainty and factual accuracy. (Source: HuggingFace Daily Papers)
Paper proposes KVzip: Query-Agnostic KV Cache Compression with Context Reconstruction: The paper “KVzip: Query-Agnostic KV Cache Compression with Context Reconstruction” introduces KVzip, a query-agnostic KV cache eviction method designed to effectively reuse compressed KV cache for different queries. KVzip quantifies the importance of KV pairs by reconstructing the original context from cached KV pairs using the underlying LLM and evicts less important KV pairs. Experiments show that KVzip can reduce KV cache size by 3-4 times and FlashAttention decoding latency by about 2 times, with negligible performance loss in tasks such as question answering, retrieval, reasoning, and code understanding, supporting contexts up to 170K tokens. (Source: HuggingFace Daily Papers)
💼 Business
Nvidia’s latest earnings report shows revenue surge of 69%, AI chip demand remains strong: AI chip giant Nvidia announced its latest financial results, with quarterly sales reaching $44.1 billion, a year-on-year increase of 69%, and net profit growing 26% YoY to $18.78 billion. Although sales exceeded expectations, profits were slightly below. US restrictions on chip exports to China cost the company $4.5 billion, but the company still expects revenue to grow by 50% YoY next quarter to $45 billion, mainly driven by sales of its latest AI chip, Blackwell. Nvidia CEO Jensen Huang stated that countries worldwide have realized AI will become infrastructure. Boosted by the earnings report, Nvidia’s market capitalization briefly surpassed Apple’s, ranking second globally. The company is actively expanding into European, Asian, and Middle Eastern markets, and selling chips to government customers has become an important strategic direction. (Source: dotey)

Silicon Valley’s top VCs shift to AI hardware, seeking next-gen interactive terminals: With the rapid development of AI algorithms, Silicon Valley’s investment focus is shifting from pure algorithm optimization to hardware devices capable of hosting AI capabilities. Giants like Google, OpenAI (which acquired AI hardware company Humane, though the original text says “io” which seems a typo for Humane or a different, less known acquisition), Meta, and Apple are all actively investing in AI hardware such as smart glasses and AR devices. Sequoia Capital invested in AI glasses Brilliant Labs, and IDG Capital invested in the display-less laptop Spacetop. Emerging companies like Celestial AI (photonic chip interconnects), NeuroFlex (flexible brain-computer interface materials), Luminai (lightweight AR modules), BioLink Systems (digestible AI sensors), and SynthSense (multimodal robotic sensory systems) are also driving AI hardware innovation in their respective fields. This reflects the industry’s emphasis on the “body” of AI, believing that hardware innovation will determine the speed and boundaries of AI technology adoption and reshape human-computer interaction. (Source: 36Kr)

Sequoia invests in new AI programming agent startup, challenging existing giants: According to LiorOnAI, Sequoia Capital has invested in a new startup aiming to challenge existing AI programming tools like Devin, Cursor, and OpenAI Codex. The AI agent developed by this company is reportedly capable of reading entire codebases and autonomously completing tasks such as writing, testing, fixing, and merging pull requests (PRs), aiming to provide a 24/7, fully autonomous software engineer assistant. This marks a further intensification of competition in the field of AI-driven software development automation. (Source: LiorOnAI)
🌟 Community
Community discusses LLMs’ shortcomings in following length instructions and “over-hyping”: The LIFEBench study sparked discussion in the community, with many users and developers agreeing on the current deficiencies of large language models in following precise length instructions, especially for long text generation. Community members pointed out that models often produce content inconsistent with the required length, terminate prematurely, or even refuse to generate long texts. Meanwhile, the claimed maximum output token count often differs from actual effective generation capabilities, with “over-hyping” being a common phenomenon. People look forward to future models improving their ability to execute length instructions and their actual performance through better training strategies and evaluation systems, achieving both “word count compliance and high-quality content.” (Source: QbitAI)
Users report AI chatbots exhibit excessive “glazing” (sycophancy): Reddit community users have reported frequently encountering AI chatbots like ChatGPT giving excessive praise and affirmation (colloquially “glazing” or “sycophancy”) to user questions or inputs, such as “That’s a very insightful observation!”. Users expressed annoyance, finding this flattery unnecessary and detrimental to natural interaction. Community members discussed methods to reduce such phenomena using specific prompts (e.g., asking the model to answer directly, objectively, and neutrally) and shared their experiences. DeepSeek-R1-0528 was also noted by some users to have a similar tendency. (Source: Reddit r/ChatGPT, teortaxesTex)

Community discussion: Is AI really “taking jobs,” or exposing the redundancy of “middleman” roles?: A discussion on Reddit suggests that rather than AI “taking our jobs,” it is exposing the “middleman” nature and potential redundancy of many existing jobs (such as processing paperwork, forwarding emails, relaying information between decision-makers, etc.). This viewpoint has sparked reflection on the nature of work, societal value distribution, and the transformation of human roles in the AI era. Commenters pointed out that even if some jobs are indeed “middleman” roles, they provide livelihoods, and the transition brought by AI requires societal support and new skill development. (Source: Reddit r/ArtificialInteligence)
Ollama draws community dissatisfaction for inaccurate model naming: Users in the Reddit r/LocalLLaMA community pointed out inaccuracies or potentially confusing naming conventions by Ollama. For example, abbreviating DeepSeek-R1-Distill-Qwen-32B to deepseek-r1:32b might mislead novice users into thinking they are running a pure DeepSeek model, overlooking its Qwen-distilled nature. Users believe this naming practice is inconsistent with platforms like HuggingFace, lacks transparency, and could lead to misconceptions about model characteristics. (Source: Reddit r/LocalLLaMA)

Programming languages significantly contributed to the success of large language models: Community discussions emphasize that programming languages, as high-quality training corpora, have played a crucial role in the successful development of large language models due to their clear logical definitions and the ease of verifying results. They not only provide models with a structured source of knowledge but also lay the foundation for models to learn reasoning and generate executable code. (Source: dotey)

💡 Other
Indoor Robotics launches AI-based autonomous navigation security robot drone: Indoor Robotics showcased an AI-based autonomous navigation security robot drone. Designed for indoor environments, this drone can autonomously perform patrol and security monitoring tasks, utilizing AI for navigation and threat identification, offering an innovative automated solution for indoor security. (Source: Ronald_vanLoon, Ronald_vanLoon)
Unitree Robotics upgrades B2-W industrial wheeled robot with enhanced features: Unitree Robotics has upgraded its B2-W industrial wheeled robot, endowing it with more exciting capabilities. This robot combines the flexibility of wheeled mobility with robotic versatility, aiming for application in various industrial scenarios to enhance automation levels and operational efficiency. (Source: Ronald_vanLoon)
Lenovo releases Daystar hexapod robot for industrial, research, and educational fields: Lenovo has launched a hexapod robot named Daystar. This robot is designed for industrial applications, scientific research, and educational purposes. Its multi-legged structure enables it to adapt to complex terrains, providing new robotic platform options for related fields. (Source: Ronald_vanLoon)