Keywords:RLHF, RLAIF, Qwen2.5-Math-7B, MATH-500, reinforcement learning, random rewards, erroneous rewards, model performance, the future of RLHF/RLAIF, random rewards improve model performance, training Qwen2.5-Math-7B with erroneous rewards, MATH-500 test set, reinforcement learning signal learning
🔥 Focus
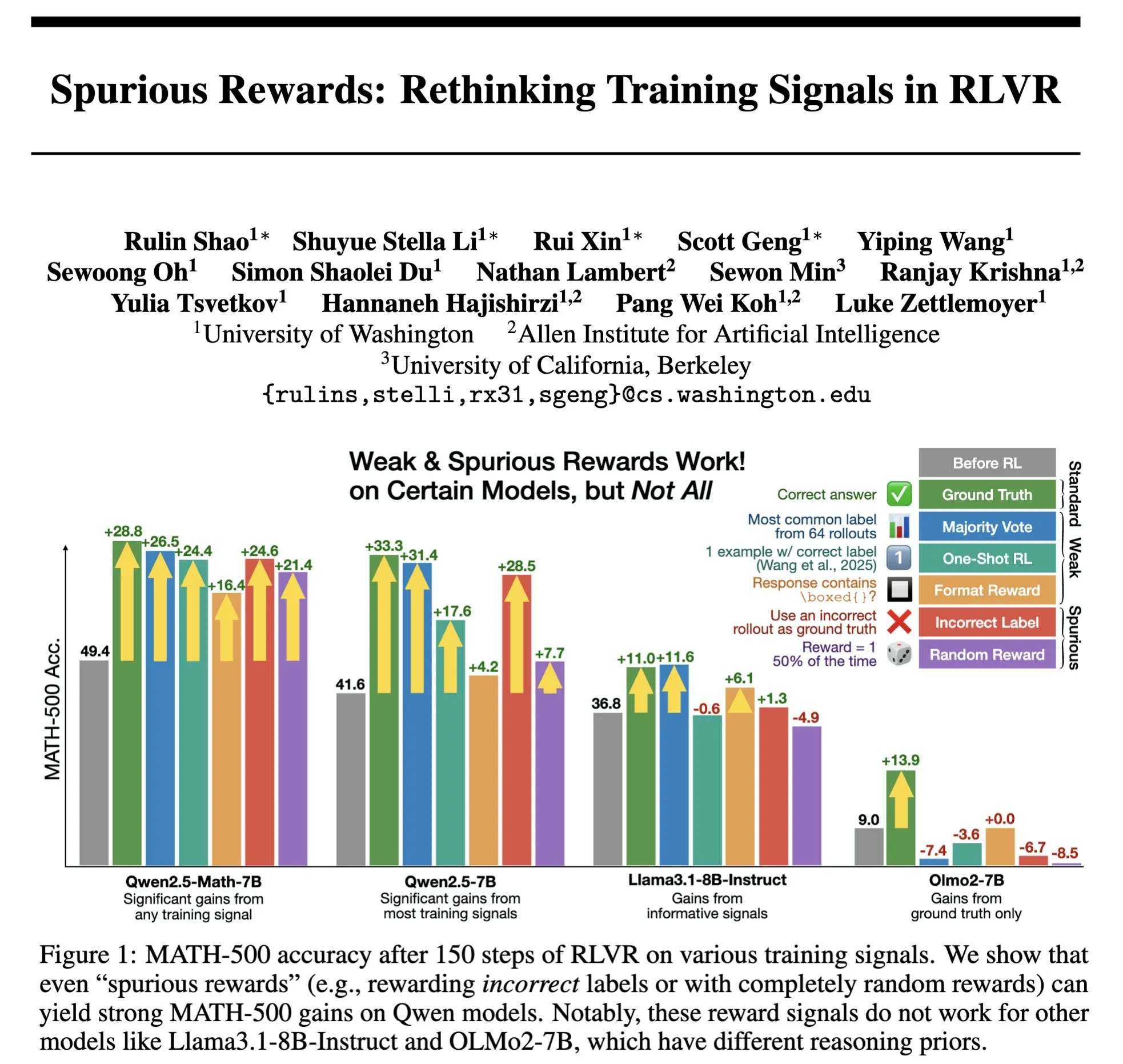
The Future of RLHF/RLAIF: Can Random/Incorrect Rewards Also Improve Model Performance? : Stella Li’s experiments showed that training the Qwen2.5-Math-7B model with random rewards or incorrect rewards improved performance on the MATH-500 test set by 21% and 25% respectively, approaching the 28.8% improvement achieved with real rewards. Research by Rulin Shao, forwarded by natolambert, also found that with RLVR (Reinforcement Learning from Verifier Reward), using false rewards led to increased code usage but decreased performance in the Olmo model, while preventing its code usage actually improved performance. These findings challenge the traditional reliance in RLHF/RLAIF on high-quality human preference data, suggesting that models might learn to explore a broader policy space through reward signals. Even if the rewards themselves are imperfect, they could stimulate the model’s latent capabilities or optimize existing behaviors. This could open new avenues for reducing dependence on expensive manual annotation and exploring more efficient model alignment methods, but caution is needed regarding the risk of models learning incorrect behaviors. (Source: natolambert, teortaxesTex, DhruvBatraDB, Francis_YAO_, raphaelmilliere)
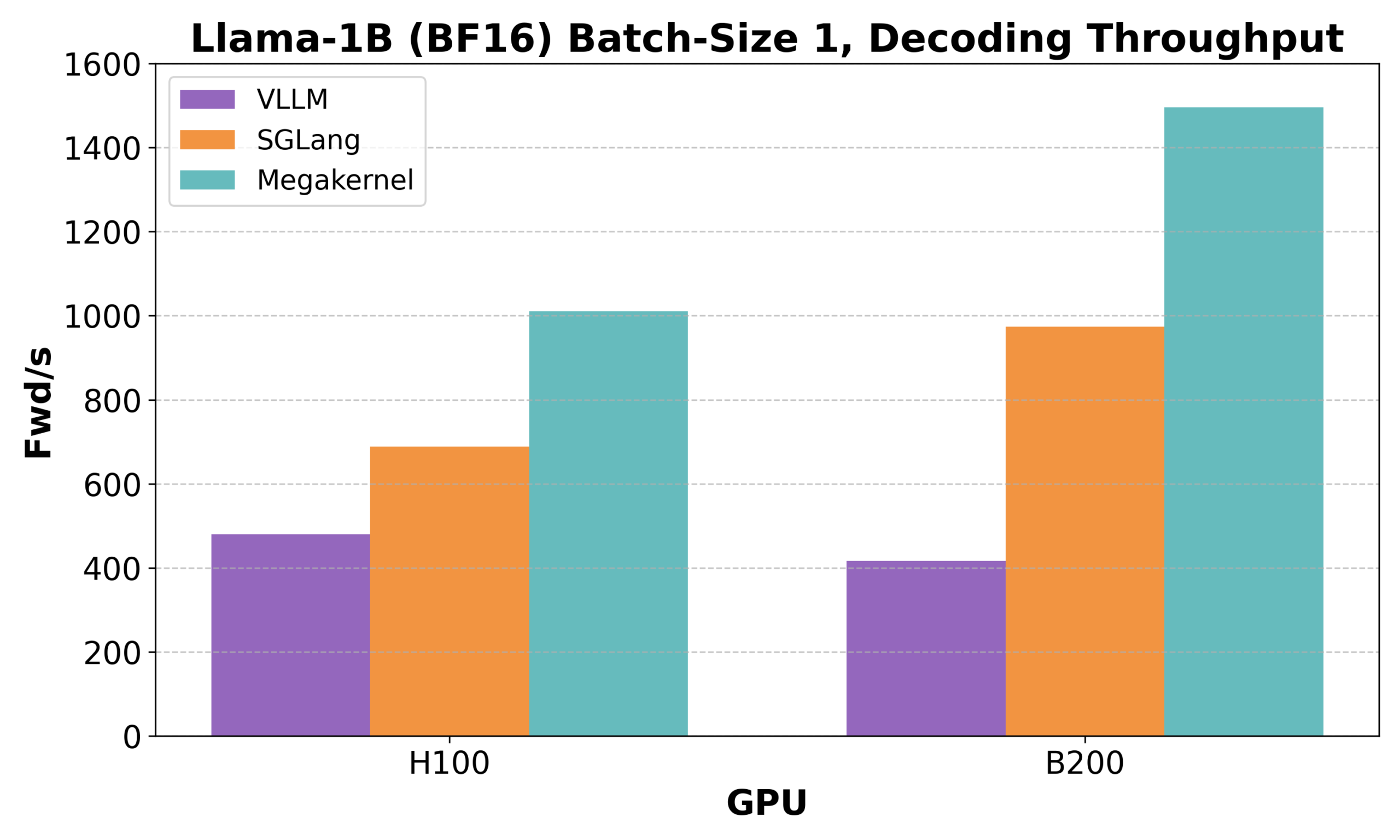
Hazy Research Releases Low-Latency-Llama Megakernel: Llama 1B Inference on a Single CUDA Core : Hazy Research has launched the Low-Latency-Llama Megakernel, capable of performing the entire forward pass of a Llama 1B model within a single CUDA core. By consolidating computation into a single kernel, this technology eliminates synchronization boundaries caused by traditional serialized kernel calls, thereby optimizing computation and memory scheduling for lower latency. Andrej Karpathy highly praised this, considering it the only way to achieve optimal orchestration of computation and memory. This advancement is significant for scenarios with strict latency requirements, such as edge computing and real-time AI applications, and is expected to drive more efficient and agile deployment of small language models. (Source: karpathy, teortaxesTex, charles_irl, simran_s_arora)
DeepSeek AI Releases rStar-Coder: Building a Large-Scale Verified Code Reasoning Dataset, Significantly Enhancing Small Model Code Capabilities : Researchers from Microsoft and DeepSeek AI have launched the rStar-Coder project. By constructing a large-scale verified dataset containing 418,000 competition-level code problems, 580,000 long reasoning solutions, and rich test cases, it aims to address the current scarcity of high-quality, high-difficulty datasets in the code reasoning field. The project enhances LLM code reasoning capabilities by synthesizing new problems using existing programming competition questions and oracle solutions, designing reliable input-output test case generation pipelines, and verifying high-quality long reasoning solutions with test cases. Experiments show that Qwen models (1.5B-14B) trained with the rStar-Coder dataset perform excellently on multiple code reasoning benchmarks. For example, Qwen2.5-7B’s accuracy on LiveCodeBench increased from 17.4% to 57.3%, surpassing o3-mini (low); on USACO, the 7B model also outperformed the larger QWQ-32B. (Source: HuggingFace Daily Papers)
Institute of Automation, Chinese Academy of Sciences Proposes AutoThink: Letting Large Models Independently Decide Whether to “Think Deeply” : Addressing the “overthinking” phenomenon where large language models engage in lengthy reasoning even for simple problems, the Institute of Automation, Chinese Academy of Sciences, in collaboration with Peng Cheng Laboratory, proposed the AutoThink method. By adding an “ellipsis” (…) to the prompt and combining it with three-stage reinforcement learning (mode stabilization, behavior optimization, inference pruning), this method enables the model to autonomously choose whether to engage in deep thinking and how much to think based on the problem’s difficulty. Experiments show that AutoThink can improve the performance of models like DeepSeek-R1 on math benchmark tests while significantly reducing inference token consumption. For example, it can save an additional 10% of tokens on DeepScaleR. This research aims to enable models to “think on demand,” balancing inference efficiency and accuracy. (Source: 36Kr, _akhaliq)

Sakana AI Launches Sudoku-Bench, Revealing Shortcomings of Top LLMs in “Variant Sudoku” Reasoning : Sakana AI, the startup by Transformer author Llion Jones, has released Sudoku-Bench, a benchmark containing modern “variant Sudokus” ranging from 4×4 to complex 9×9, designed to evaluate AI’s creative multi-step reasoning capabilities. Test results show that top large models, including Gemini 2.5 Pro, GPT-4.1, and Claude 3.7, have an overall accuracy below 15% without assistance. In 9×9 modern Sudokus, o3 Mini High’s accuracy was only 2.9%. This indicates that models perform poorly on novel problems requiring genuine logical reasoning rather than pattern matching, often providing incorrect solutions, giving up, or misinterpreting rules. NVIDIA CEO Jensen Huang believes such puzzles can help improve AI reasoning. Sakana AI has also released related training data, including solution process recordings in collaboration with a famous Sudoku channel. (Source: 36Kr)

🎯 Trends
Meta Reorganizes AI Team, Loss of FAIR Core Members Attracts Attention : Meta announced a reorganization of its AI team, dividing it into an AI product team led by Connor Hayes and an AGI foundational department co-led by Ahmad Al-Dahle and Amir Frenkel. The former focuses on consumer products, while the latter concentrates on foundational model R&D like Llama. Notably, the Fundamental AI Research (FAIR) department remains independent, but some multimedia teams have been merged into the AGI foundational department. This adjustment aims to improve development speed and flexibility. However, Meta is facing challenges from the lukewarm reception of Llama 4, increasing competition in the open-source domain, and the loss of core talent. Eleven of the 14 original authors involved in Llama’s development have left, with many joining or founding competitors like Mistral AI. The FAIR lab has also experienced leadership changes and adjustments in research direction, raising concerns about its status within the company and future innovation capabilities. (Source: 36Kr)

Google DeepMind Releases SignGemma: A New Model for Sign Language Translation : Google DeepMind announced the launch of SignGemma, touted as its most powerful sign language-to-spoken-text translation model to date. The model is expected to join the Gemma model family later this year and will be released in an open-source format. The introduction of SignGemma aims to open up new possibilities for inclusive technology, enhancing communication efficiency and convenience for sign language users. Google DeepMind invites users to provide feedback and participate in early testing. (Source: GoogleDeepMind, demishassabis)
Tencent Hunyuan Releases HunyuanPortrait Model Weights, Capable of Converting Static Portraits into Dynamic Videos : The Tencent Hunyuan team has open-sourced the model weights for its image-to-video model, HunyuanPortrait, allowing users to download and use it locally. This model focuses on converting static character portraits into dynamic videos, suitable for various application scenarios such as game characters, virtual streamers, digital humans, and intelligent shopping assistants, enabling facial images to become animated and increasing the vividness and realism of interactions. Related models, code repositories, and papers have all been released. (Source: karminski3, Reddit r/LocalLLaMA)

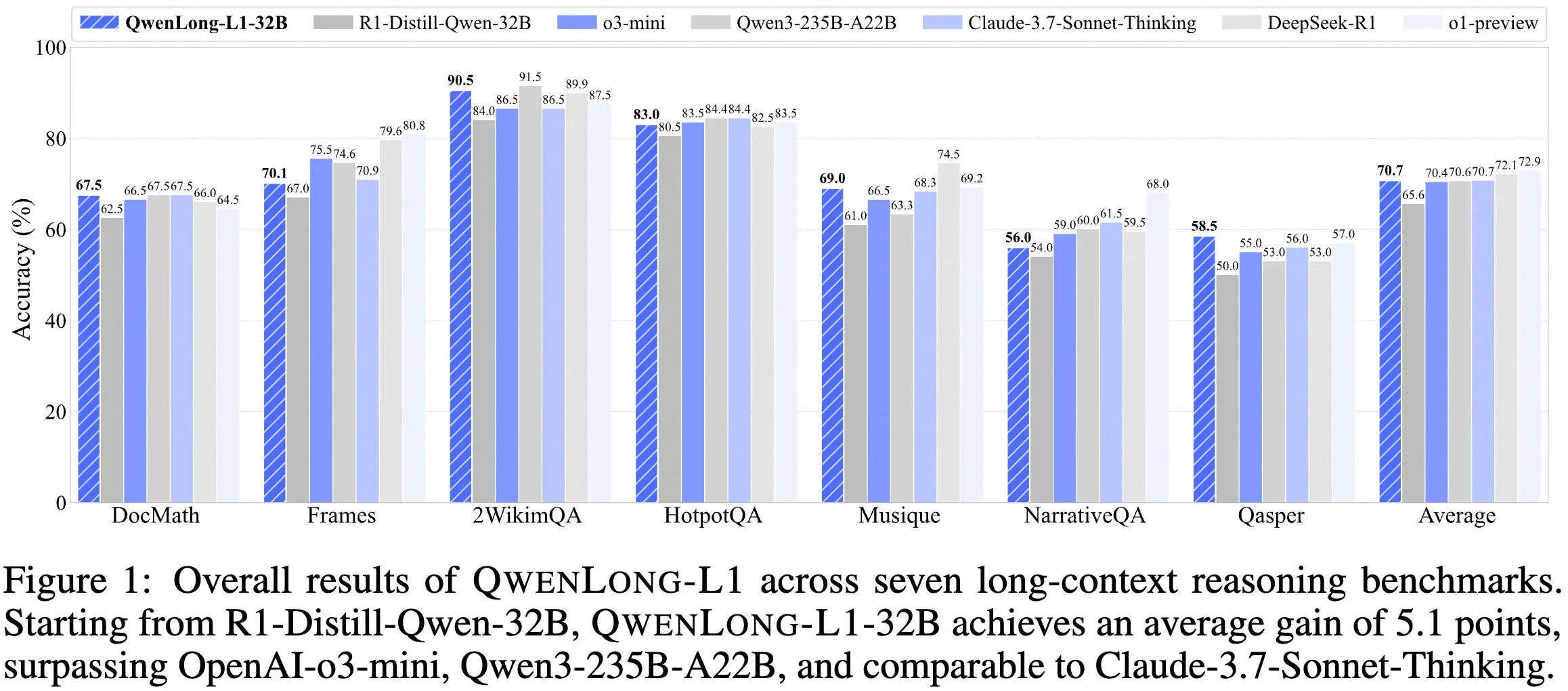
QwenDoc Team Releases Long-Context Reasoning Model QwenLong-L1-32B : The QwenDoc team has launched QwenLong-L1-32B, a 128K long-context reasoning model trained using reinforcement learning. This model, fine-tuned based on DeepSeek-R1-Distill-Qwen-32B, scored 90.5 on the 2WikiMultihopQA multi-hop reasoning test set, an improvement of 6.5 points over the original model. It emphasizes not only finding content in long contexts but also connecting clues for reasoning. Although the 128K context length is not the longest currently available, its outstanding reasoning ability provides a new option for processing complex long documents. The model, paper, and code repository have been made public. (Source: karminski3)
HKUST, Apple, and Other Institutions Collaborate to Launch Laser Series Methods, Optimizing LLM Inference Efficiency and Accuracy : Researchers from HKUST, City University of Hong Kong, University of Waterloo, and Apple have proposed the Laser series methods (including Laser-D, Laser-DE) to address the issue of Large Language Models (LRMs) excessively consuming tokens for reasoning on simple problems. This method, through a unified length reward design framework, rewards based on target length and step functions, and a dynamic difficulty-aware mechanism, achieved a 6.1-point performance improvement on complex math reasoning benchmarks like AIME24 while reducing token usage by 63%. Research found that the trained model exhibited reduced redundant “self-reflection” and healthier thinking patterns, effectively balancing the efficiency and accuracy of model reasoning. (Source: 36Kr)

Anthropic Claude Free Version Now Supports Web Search Functionality : Anthropic announced that users of the free version of its AI assistant, Claude, can now use the web search feature. This means Claude can access the latest information from the internet to enhance the relevance and accuracy of its responses when answering questions. Officials stated that every response containing search results will provide inline citations, making it convenient for users to verify information sources. (Source: AnthropicAI)
PKU-DS-LAB Releases FairyR1: A 32B Reasoning Model Fine-Tuned from DeepSeek-R1-Distill-Qwen-32B : Peking University’s Data Science Lab (PKU-DS-LAB) has launched FairyR1, a 32B parameter reasoning model under the Apache 2.0 license. Using a “distill then merge” method, the model reportedly achieves the performance of larger models with only 5% of the parameters. FairyR1 is fine-tuned from DeepSeek-R1-Distill-Qwen-32B, and its training data is also available on Hugging Face Hub. This work continues the research ideas of TinyR1, by actively filtering datasets (approximately 10,000 trajectories), performing SFT for math and code separately, and using Arcee Fusion for model merging. (Source: huggingface, teortaxesTex, stablequan)
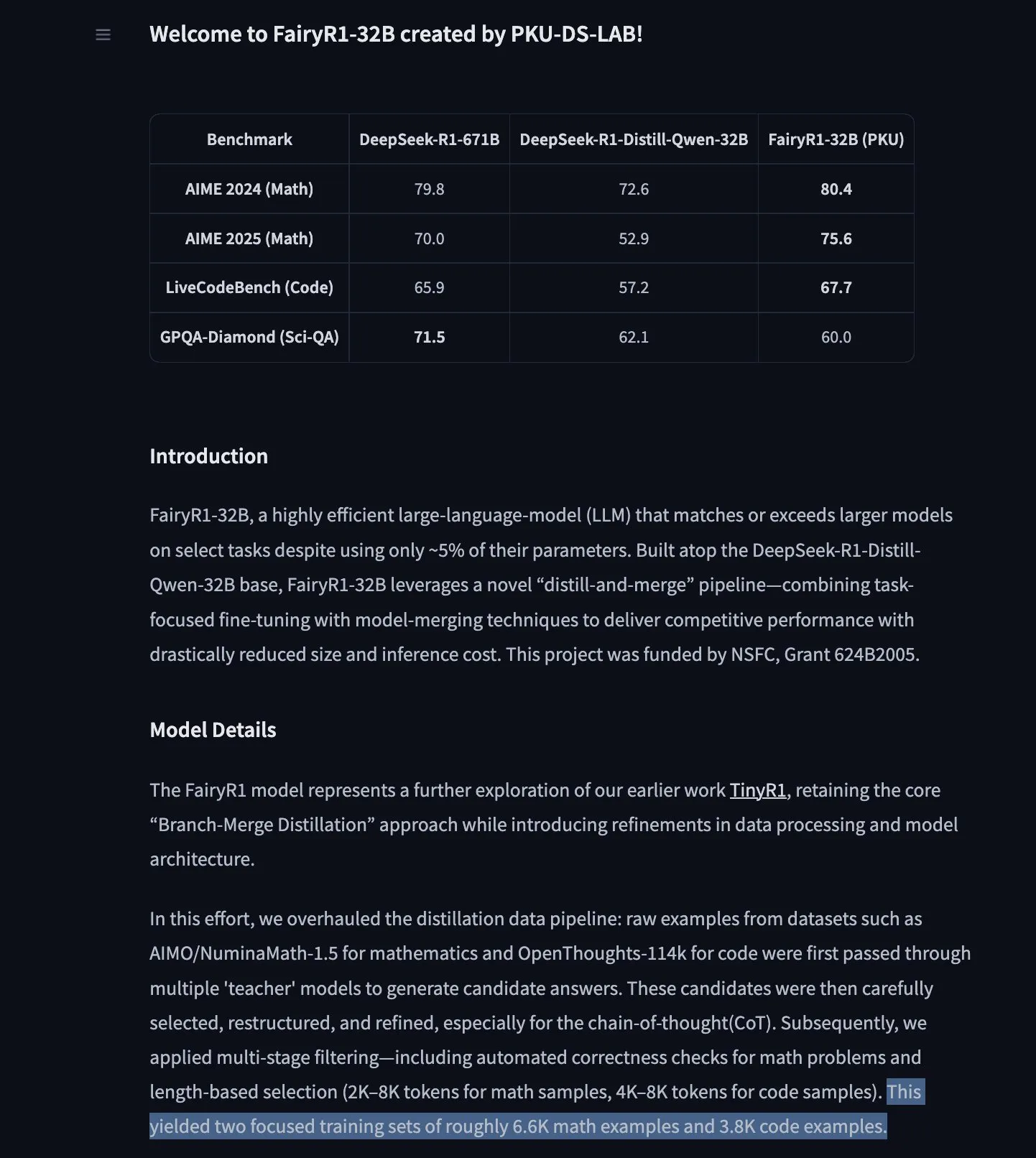
Google’s TimesFM Time Series Forecasting Model Arrives on Hugging Face Transformers : Google’s TimesFM model is now integrated into the Hugging Face Transformers library. This is a GPT-like model, pre-trained on 100 billion real-world time points from various sources including Google Trends and Wikipedia page views. TimesFM reportedly outperforms specialized fine-tuned models on zero-shot forecasting tasks, providing a new powerful tool for time series analysis. (Source: huggingface)
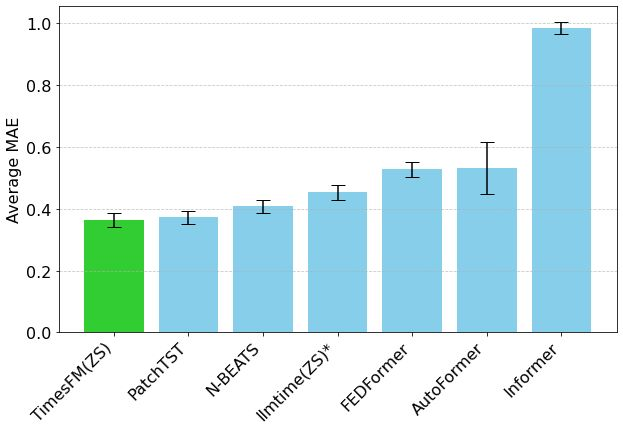
Hugging Face Launches Mixture of Thoughts: A Curated Dataset for General Reasoning : Hugging Face researcher Lewis Tunstall and others have released the “Mixture of Thoughts” dataset. This dataset, meticulously curated from over 1 million public data samples through extensive ablation studies, comprises approximately 350,000 samples focused on general reasoning capabilities. Models trained on this mixed dataset achieve performance on par with or exceeding DeepSeek’s distilled models on math, code, and science benchmarks (like GPQA). The research validates the effectiveness of the “additivity” methodology proposed in Phi-4-reasoning, which suggests that data mixtures for each reasoning domain can be optimized independently and then integrated for final training. (Source: huggingface)
ByteDance Releases BAGEL-7B: An Omni-Model for Both Image-Text Understanding and Generation : ByteDance has launched BAGEL-7B, an omni-model capable of both understanding and generating images and text. Additionally, they released Dolphin, a Visual Language Model (VLM) focused on document parsing. The open-sourcing of these models will provide new tools and possibilities for multimodal research and applications. (Source: huggingface, TheTuringPost)

Google Releases Gemini 2.5 Flash Preview, Supports Native Audio Output : Google AI developers announced that Gemini 2.5 Flash Preview now supports native audio output via the Live API, aiming to provide seamless, natural spoken interactions and stronger voice control capabilities. Additionally, a new experimental “thinking” version of this audio model has been launched, supporting reasoning capabilities for more complex tasks. Meanwhile, Gemini API outputs have also begun to display “thought summaries,” allowing users to understand the model’s thinking process, though currently not the complete reasoning chain. (Source: algo_diver, op7418)
Paper Explores the Expressive Power of Transformers When Filling in Blank Tokens : A new study explores whether filling blank tokens in Transformer inputs (a form of test-time computation) can enhance the computational capabilities of LLMs. The research, in collaboration with Ashish_S_AI, provides a precise characterization of the expressive power of Transformers with padding, offering new perspectives for understanding and optimizing the computational mechanisms of LLMs. (Source: teortaxesTex)

New Research Proposes Sci-Fi Framework: Improving Video Frame Interpolation via Symmetric Constraints : Addressing the issue that current video frame interpolation (Frame Inbetweening) methods may have asymmetric control strength when fusing start and end frame constraints, a new paper proposes the Sci-Fi (Symmetric Constraint for Frame Inbetweening) framework. This method aims to achieve symmetry of start and end frame constraints by applying a stronger injection mechanism (based on the lightweight module EF-Net) for constraints with smaller training scales (such as end frames), thereby producing more harmonious transitions in the generated intermediate frames and avoiding motion inconsistency or appearance collapse. (Source: HuggingFace Daily Papers)
Paper Proposes Paper2Poster: An Automated Workflow from Research Papers to Multimodal Posters : To address the challenges of academic poster creation, researchers have introduced Paper2Poster, the first poster generation benchmark and evaluation metric suite, containing pairs of papers and author-designed posters. It is evaluated on visual quality, text coherence, overall assessment, and PaperQuiz (measuring the poster’s ability to convey core content). Concurrently, PosterAgent is proposed, a top-down, vision-in-the-loop multi-agent workflow, including a parser (extracting assets), a planner (text-visual alignment and layout), and a painter-critic loop (rendering and feedback optimization). Variants based on open-source models like Qwen-2.5 outperformed GPT-4o-driven systems on most metrics, with an 87% reduction in token consumption, enabling the conversion of a 22-page paper into an editable .pptx poster at extremely low cost. (Source: HuggingFace Daily Papers)
Paper Proposes Frame In-N-Out: Achieving Unbounded Controllable Image-to-Video Generation : Addressing challenges in video generation such as controllability, temporal consistency, and detail synthesis, a new paper focuses on the “Frame In and Frame Out” filmmaking technique. It aims to allow users to control objects in an image to naturally exit the scene or introduce new identity references into the scene, guided by user-specified motion trajectories. To this end, researchers introduced a new semi-automatically annotated dataset, a comprehensive evaluation protocol, and an efficient identity-preserving, motion-controllable video Diffusion Transformer architecture. Experiments show that this method significantly outperforms existing baselines. (Source: HuggingFace Daily Papers)
New Research Proposes Active-O3: Endowing Multimodal Large Language Models with Active Perception Capabilities via GRPO : Addressing the insufficient exploration of active perception in Multimodal Large Language Models (MLLMs), researchers have proposed the Active-O3 framework. This framework, based on pure reinforcement learning training with GRPO (Group Relative Policy Optimization), aims to empower MLLMs to actively choose observation positions and methods to collect task-relevant information. Researchers first systematically defined MLLM-based active perception tasks and pointed out that GPT-o3’s magnified search strategy is a special case of active perception but lacks efficiency and accuracy. Active-O3, by establishing a comprehensive benchmark suite, is evaluated in general open-world tasks (such as small object and dense object localization) and specific domain scenarios (such as small object detection in remote sensing and autonomous driving, fine-grained interactive segmentation), and demonstrates its strong zero-shot reasoning capabilities on the V* Benchmark. (Source: HuggingFace Daily Papers)
Paper Proposes MME-Reasoning: A Comprehensive Benchmark for MLLM Logical Reasoning Capabilities : To address the shortcomings of existing benchmarks in evaluating the logical reasoning capabilities of Multimodal Large Language Models (MLLMs), researchers have introduced MME-Reasoning. This benchmark covers the three main types of logical reasoning: inductive, deductive, and abductive, and meticulously screens data to ensure that questions effectively assess reasoning abilities rather than perceptual skills or breadth of knowledge. Evaluation results show that even state-of-the-art MLLMs exhibit limitations in comprehensive logical reasoning assessment, with performance imbalances across different reasoning types. The study also analyzes the impact of methods like “thinking patterns” and rule-based reinforcement learning on reasoning capabilities, providing systematic insights for understanding and evaluating MLLM reasoning abilities. (Source: HuggingFace Daily Papers)
GraLoRA: Enhancing Parameter-Efficient Fine-Tuning Performance through Granular Low-Rank Adaptation : Addressing the overfitting and performance bottleneck issues that LoRA encounters when increasing rank, researchers have proposed GraLoRA (Granular Low-Rank Adaptation). This method divides the weight matrix into sub-blocks, each with an independent low-rank adapter, aiming to solve the problems of gradient entanglement and propagation distortion caused by LoRA’s structural bottlenecks. GraLoRA effectively enhances the model’s expressive power, approaching the effect of full fine-tuning, with almost no increase in computational or storage costs. Experiments on code generation and commonsense reasoning benchmarks show that GraLoRA outperforms LoRA and other baselines across different model sizes and rank settings, for example, achieving an absolute gain of up to 8.5% Pass@1 on HumanEval+. (Source: HuggingFace Daily Papers)
SoloSpeech: Cascaded Generation Pipeline Enhances Clarity and Quality of Target Speech Extraction : Addressing the issue that existing discriminative models in Target Speech Extraction (TSE) tend to introduce artifacts and reduce naturalness, while generative models fall short in perceptual quality and clarity, researchers have proposed SoloSpeech. This is a novel cascaded generation pipeline that integrates compression, extraction, reconstruction, and correction processes. It features a target extractor without speaker embeddings, utilizing conditional information from the prompt audio’s latent space and aligning it with the mixed audio’s latent space to prevent mismatches. Evaluation on the Libri2Mix dataset shows that SoloSpeech achieves new SOTA levels in target speech extraction and speech separation tasks, and exhibits excellent generalization capabilities on out-of-domain data and real-world scenarios. (Source: HuggingFace Daily Papers)
New Research Explores Enhancing Visual Understanding in Multimodal Large Language Models via Text-Guided Vectors : A new study investigates whether guidance vectors derived from the pure text LLM backbone of Multimodal Large Language Models (MLLMs) (obtained through methods like Sparse Autoencoders (SAE), mean-shift, and linear probing) can enhance their visual understanding capabilities. The research finds that text-derived guidance vectors consistently improve multimodal accuracy across various MLLM architectures on multiple visual tasks. Notably, the mean-shift method boosts spatial relation accuracy by up to 7.3% and counting accuracy by up to 3.3% on CV-Bench, outperforming prompting methods and demonstrating strong generalization to out-of-distribution datasets. This suggests that text-guided vectors are a powerful and efficient mechanism for enhancing the visual grounding of MLLMs with minimal additional data collection and computational overhead. (Source: HuggingFace Daily Papers)
Paper Proposes DiSA: Accelerating Autoregressive Image Generation via Diffusion Step Annealing : Addressing the low inference efficiency of autoregressive models like MAR and FlowAR, which use diffusion sampling to improve image quality, a new paper proposes the DiSA (Diffusion Step Annealing) method. This method is based on the observation that as more tokens are generated in the autoregressive process, the distribution of subsequent tokens becomes more constrained, making sampling easier. DiSA is a training-free method that gradually reduces diffusion steps (e.g., from an initial 50 steps to 5 steps later on) as more tokens are generated. This method complements existing acceleration techniques designed for diffusion itself, is simple to implement, and can speed up MAR and Harmon by 5-10x, and FlowAR and xAR by 1.4-2.5x, while maintaining generation quality. (Source: HuggingFace Daily Papers)
Paper Proposes CASS: A Dataset, Model, and Benchmark for Nvidia to AMD GPU Code Translation : Researchers have introduced CASS, the first large-scale dataset and model suite for cross-architecture GPU code translation, targeting both source-level (CUDA <-> HIP) and assembly-level (Nvidia SASS <-> AMD RDNA3) translation. The dataset contains 70,000 verified cross-host and device code pairs. The CASS series of domain-specific language models trained on this resource achieve 95% accuracy in source translation and 37.5% accuracy in assembly translation, significantly outperforming commercial baselines like GPT-4o and Claude. The generated code matches native performance in over 85% of test cases. Also released is CASS-Bench, a benchmark comprising 16 GPU domains and real execution results. All data, models, and evaluation tools are open-sourced. (Source: HuggingFace Daily Papers)
Paper Analyzes Verbal Calibration Capabilities in Visual Language Models : A study comprehensively evaluates the effectiveness of Visual Language Models (VLMs) in expressing confidence through natural language (i.e., verbal uncertainty). The research spans three model classes, four task domains, and three evaluation scenarios. Results show that current VLMs often exhibit significant miscalibration across various tasks and settings. Notably, visual reasoning models (i.e., models that think with images) consistently demonstrate better calibration, suggesting that modality-specific reasoning is crucial for reliable uncertainty estimation. To address calibration challenges, the researchers introduced “Visual Confidence-Aware Prompting,” a two-stage prompting strategy aimed at improving confidence alignment in multimodal settings. (Source: HuggingFace Daily Papers)
Paper Tracks the Emergence of Pragmatic Competence in Large Language Models : Current LLMs demonstrate emerging capabilities in social intelligence tasks, but how they acquire pragmatic competence during training remains unclear. A new paper introduces the ALTPRAG dataset, designed based on the pragmatic concept of “alternatives,” to assess whether LLMs at different training stages can accurately infer subtle speaker intentions. Through systematic evaluation of 22 LLMs (covering pre-training, SFT, and preference optimization stages), results show that even base models exhibit significant sensitivity to pragmatic cues, which continuously improves with model and data scale. SFT and RLHF further enhance cognitive pragmatic reasoning abilities. These findings highlight pragmatic competence as an emergent, compositional property in LLM training, offering new insights into aligning models with human communicative norms. (Source: HuggingFace Daily Papers)
Video-Holmes Benchmark Released: Evaluating MLLM “Sherlock Holmes-like” Thinking in Complex Video Reasoning : Addressing the current situation where existing video benchmarks primarily evaluate visual perception and localization capabilities, failing to adequately capture complex reasoning needs, researchers have launched the Video-Holmes benchmark. Inspired by Sherlock Holmes’ reasoning process, this benchmark contains 1,837 questions extracted from 270 manually annotated mystery short films, spanning 7 carefully designed tasks. Each task requires the model to actively locate and connect multiple relevant visual cues scattered across different video segments. Evaluation of SOTA MLLMs shows that although models perform excellently in visual perception, they face significant difficulties in information integration, often missing crucial clues. For example, the best-performing Gemini-2.5-Pro achieved an accuracy of only 45%. (Source: HuggingFace Daily Papers)
MME-VideoOCR Benchmark Released: Evaluating Multimodal LLM OCR Capabilities in Video Scenes : Although Multimodal Large Language Models (MLLMs) have made significant progress in static image OCR, their effectiveness in video OCR is diminished by factors such as motion blur, temporal changes, and visual effects. To guide the training of practical MLLMs, researchers have launched the MME-VideoOCR benchmark, covering a wide range of video OCR application scenarios. This benchmark includes 10 task categories (25 independent tasks), covering 44 different scenes, involving not only text recognition but also deeper understanding and reasoning about text content in videos. The benchmark contains 1,464 videos of different resolutions, aspect ratios, and durations, along with 2,000 meticulously curated, manually annotated question-answer pairs. Evaluation of 18 SOTA MLLMs shows that even the best-performing Gemini-2.5 Pro achieved an accuracy of only 73.7%, exposing the limitations of existing models in handling tasks that require holistic video understanding. (Source: HuggingFace Daily Papers)
MetaMind: Modeling Human Social Thinking via a Metacognitive Multi-Agent System : To bridge the gap in Large Language Models’ (LLMs) handling of the inherent ambiguity and contextual nuances in human communication, researchers have introduced MetaMind, a multi-agent framework inspired by psychological metacognition theories, designed to simulate human-like social reasoning. MetaMind decomposes social understanding into three collaborative stages: (1) Theory-of-Mind agents generate hypotheses about user mental states (e.g., intentions, emotions); (2) Domain agents use cultural norms and ethical constraints to refine these hypotheses; (3) Response agents generate contextually appropriate responses while validating consistency with inferred intentions. The framework achieved SOTA performance on three challenging benchmarks, improving by 35.7% in real-world social scenarios, 6.2% in theory-of-mind reasoning, and for the first time enabling LLMs to reach human-level performance on critical theory-of-mind tasks. (Source: HuggingFace Daily Papers)
Sparse VideoGen2: Accelerating Video Generation via Semantic-Aware Permutation and Sparse Attention : Addressing the significant latency and high memory costs faced by Diffusion Transformers (DiT)-based video generation models when processing long videos, researchers have proposed the SVG2 framework. This framework maximizes the accuracy of key token identification and minimizes computational waste through semantic-aware permutation (using k-means to cluster and reorder tokens based on semantic similarity), thereby achieving a Pareto-optimal trade-off between generation quality and efficiency. SVG2 also integrates top-p dynamic budget control and custom kernel implementations, achieving speedups of up to 2.30x and 1.89x on HunyuanVideo and Wan 2.1 respectively, while maintaining high PSNR. (Source: HuggingFace Daily Papers)
OmniConsistency: Learning Style-Agnostic Consistency from Paired Stylized Data : To address two major challenges faced by diffusion models in image stylization – maintaining consistency in complex scenes (especially identity, composition, and details) and style degradation caused by style LoRAs in image-to-image workflows – researchers have proposed OmniConsistency. This is a universal consistency plugin utilizing large-scale Diffusion Transformers (DiT). Its contributions include: (1) a context consistency learning framework trained on aligned image pairs for robust generalization; (2) a two-stage progressive learning strategy that decouples style learning from consistency preservation to mitigate style degradation; (3) a fully plug-and-play design compatible with any style LoRA under the Flux framework. Experiments show that OmniConsistency significantly enhances visual coherence and aesthetic quality, achieving performance comparable to commercial SOTA models like GPT-4o. (Source: HuggingFace Daily Papers)
ImgEdit: A Unified Image Editing Dataset and Benchmark : To address the issue of open-source image editing models lagging behind proprietary ones (mainly due to limited high-quality data and inadequate benchmarks), researchers have launched ImgEdit. This is a large-scale, high-quality image editing dataset containing 1.2 million meticulously curated editing pairs, covering novel and complex single-turn edits and challenging multi-turn tasks. To ensure data quality, a multi-stage pipeline was employed, integrating cutting-edge visual language models, detection models, segmentation models, as well as task-specific restorers and rigorous post-processing. Editing models trained on ImgEdit, ImgEdit-E1, outperform existing open-source models on multiple tasks. Concurrently, the ImgEdit-Bench benchmark was introduced to evaluate image editing performance in terms of instruction following, editing quality, and detail preservation. (Source: HuggingFace Daily Papers)
Paper Proposes Robust Behavioral Control in LLMs via Steering Target Atoms : To achieve precise control over language model generation for safety and reliability, a new paper proposes the “Steering Target Atoms” (STA) method. This method aims to separate and manipulate decoupled knowledge components to enhance safety, demonstrating superior robustness and flexibility, especially in adversarial scenarios. Researchers argue that while prompt engineering and steering are commonly used to intervene in model behavior, the high entanglement of model parameters limits control precision and can lead to side effects. STA utilizes sparse autoencoders (SAE) to decouple knowledge in high-dimensional spaces and then steers them, enabling more precise behavioral control. Experiments demonstrate the method’s effectiveness and it has been applied to large inference models, confirming its potential for precise inference control. (Source: HuggingFace Daily Papers)
Paper Proposes SeePhys Benchmark: Evaluating Vision-Based Physics Reasoning Capabilities : Researchers have launched SeePhys, a large-scale multimodal benchmark for evaluating LLM reasoning capabilities on physics problems ranging from middle school to PhD qualifying exam levels. The benchmark covers 7 fundamental areas of physics and includes 21 types of highly heterogeneous diagrams. Unlike previous work where visual elements primarily played an auxiliary role, 75% of the problems in SeePhys are visually necessary, meaning visual information must be extracted to answer correctly. Extensive evaluations show that even state-of-the-art visual reasoning models (like Gemini-2.5-pro and o4-mini) achieve less than 60% accuracy on this benchmark, revealing fundamental challenges in current LLMs’ visual understanding, particularly in the tight coupling of diagram interpretation with physics reasoning and overcoming cognitive shortcut reliance on textual cues. (Source: HuggingFace Daily Papers)
VerIPO: Enhancing Long-Range Reasoning in Video-LLMs via Verifier-guided Iterative Policy Optimization : Addressing the data preparation bottleneck and unstable quality of long chain-of-thought (CoT) in applying reinforcement learning to Video Large Language Models (Video-LLMs) for complex video reasoning, researchers have proposed VerIPO (Verifier-guided Iterative Policy Optimization). The core of this method is a “Rollout-Aware Verifier” positioned between GRPO and DPO training stages, used to evaluate reasoning logic and construct high-quality contrastive data (containing reflective and contextually consistent CoT). This data drives an efficient DPO stage, thereby improving the length and contextual consistency of reasoning chains. Experimental results show that VerIPO can optimize models faster and more effectively, generating longer and more contextually consistent CoT, outperforming standard GRPO variants and some large instruction fine-tuned Video-LLMs and long-reasoning models. (Source: HuggingFace Daily Papers)
OpenS2V-Nexus: A Detailed Benchmark and Million-Scale Dataset for Subject-to-Video Generation : To advance subject-to-video (S2V) generation technology, researchers have proposed OpenS2V-Nexus, which includes (i) OpenS2V-Eval, a fine-grained benchmark, and (ii) OpenS2V-5M, a million-scale dataset. Unlike existing S2V benchmarks (inherited from VBench, focusing on global and coarse-grained evaluation), OpenS2V-Eval concentrates on the model’s ability to generate videos with consistent subjects, natural appearance, and high identity fidelity. To this end, OpenS2V-Eval introduces 180 prompts from 7 major S2V categories, containing real and synthetic test data. Furthermore, to accurately align with human preferences, researchers proposed three automatic metrics: NexusScore, NaturalScore, and GmeScore, quantifying subject consistency, naturalness, and text relevance in generated videos, respectively. Based on this, 16 representative S2V models were comprehensively evaluated. Concurrently, the first open-source large-scale S2V generation dataset, OpenS2V-5M, was created, containing 5 million high-quality 720P subject-text-video triplets. (Source: HuggingFace Daily Papers)
Paper Proposes WHISTRESS: Enriching Transcribed Text via Sentence Stress Detection : Addressing the importance of sentence stress in spoken language for conveying speaker intent, and its absence in existing transcription systems, a new paper introduces WHISTRESS, an alignment-free sentence stress detection method. To support this task, researchers proposed TINYSTRESS-15K, a scalable synthetic training dataset created through a fully automated process. The WHISTRESS model, trained on this dataset, outperforms existing baselines in performance without requiring additional training or inference prior inputs. Notably, despite being trained on synthetic data, WHISTRESS demonstrates strong zero-shot generalization capabilities across various benchmarks. (Source: HuggingFace Daily Papers)
Paper Proposes InstructPart: Task-Oriented Part Segmentation with Instructed Reasoning : Although large multimodal foundation models have made progress on various tasks, many models treat objects as indivisible wholes, ignoring the parts that constitute them. Understanding these parts and their associated functional affordances is crucial for performing a wide range of tasks. To this end, researchers have introduced a new real-world benchmark, InstructPart, containing hand-labeled part segmentation annotations and task-oriented instructions, to evaluate current models’ performance in understanding and executing part-level tasks in everyday contexts. Experiments show that task-oriented part segmentation remains a challenging problem even for SOTA Visual Language Models (VLMs). In addition to the benchmark, researchers also introduced a simple baseline that achieves a twofold performance improvement through fine-tuning with their dataset. (Source: HuggingFace Daily Papers)
Paper Proposes Hybrid Neuro-MPM Method for Real-Time Interactive Fluid Simulation : To address the problem of fluid simulation where traditional physics methods are computationally intensive with high latency, and recent machine learning methods, while reducing costs, still struggle to meet real-time interactive demands, researchers have proposed a novel hybrid method. This method integrates numerical simulation, neurophysics, and generative control. Its neurophysics, with a fallback mechanism to classical numerical solvers, jointly pursues low-latency simulation and high physical fidelity. Furthermore, researchers developed a diffusion-based controller trained using an inverse modeling strategy to generate external dynamic force fields for fluid manipulation. The system demonstrates robust performance across various 2D/3D scenarios, material types, and obstacle interactions, achieving real-time simulation at high frame rates (11~29% latency) and enabling fluid control through user-friendly hand-drawn sketches. (Source: HuggingFace Daily Papers)
MMIG-Bench: A Comprehensive Interpretable Evaluation Benchmark for Multimodal Image Generation Models : Addressing the limitations of existing evaluation tools in assessing multimodal image generators like GPT-4o, Gemini 2.0 Flash, and Gemini 2.5 Pro (e.g., T2I benchmarks lacking multimodal conditions, custom image generation benchmarks ignoring compositional semantics and common sense), researchers have proposed MMIG-Bench. This is a comprehensive multimodal image generation benchmark containing 4,850 richly annotated text prompts and 1,750 multi-view reference images covering 380 subjects (people, animals, objects, art styles). MMIG-Bench is equipped with a three-level evaluation framework: (1) low-level metrics assess visual artifacts and object identity preservation; (2) a novel Aspect Matching Score (AMS): a VQA-based mid-level metric providing fine-grained prompt-image alignment and highly correlating with human judgment; (3) high-level metrics evaluate aesthetics and human preference. Seventeen SOTA models were benchmarked using MMIG-Bench, and the metrics were validated with 32,000 human ratings, providing deep insights for architecture and data design. (Source: HuggingFace Daily Papers)
Paper Proposes HRPO: Hybrid Latent Reasoning via Reinforcement Learning : To address the incompatibility of existing latent reasoning methods with the autoregressive generation characteristic of LLMs and their reliance on CoT trajectories for training, researchers have proposed HRPO (Hybrid Reasoning Policy Optimization). This is a reinforcement learning-based hybrid latent reasoning method that integrates previous hidden states into sampled tokens via a learnable gating mechanism. It is initialized by training primarily with token embeddings and gradually incorporates more hidden features. This design maintains the LLM’s generative capabilities and incentivizes hybrid reasoning using both discrete and continuous representations. Furthermore, HRPO introduces stochasticity into latent reasoning through token sampling, thereby enabling RL-based optimization without CoT trajectories. Extensive evaluations on various benchmarks show that HRPO outperforms previous methods on both knowledge-intensive and reasoning-intensive tasks. (Source: HuggingFace Daily Papers)
Paper Proposes NFT Method: Connecting Supervised Learning and Reinforcement Learning in Mathematical Reasoning : Challenging the prevailing notion that “self-improvement is limited to reinforcement learning (RL),” a new paper proposes Negative-aware Fine-Tuning (NFT). This is a supervised learning method that enables LLMs to reflect on their failures and autonomously improve without external teachers. In online training, NFT does not discard self-generated incorrect answers but instead constructs an implicit negative policy to model them. This implicit policy shares the same parameterization as the target positive LLM being optimized on positive data, thus allowing direct policy optimization on all LLM generations. Experimental results on mathematical reasoning tasks with 7B and 32B models show that by additionally leveraging negative feedback, NFT significantly outperforms supervised learning baselines like rejection sampling fine-tuning, achieving or even surpassing leading RL algorithms like GRPO and DAPO. Researchers further demonstrate that NFT and GRPO are practically equivalent in strict online policy training. (Source: HuggingFace Daily Papers)
Paper Proposes Minute-Long Videos with Dual Parallelisms: Achieving Minute-Level Video Generation : Addressing the excessive computational latency and memory costs faced by DiT-based video diffusion models when generating long videos, researchers have proposed a new distributed inference strategy called DualParal. The core idea of this method is to parallelize temporal frames and model layers across multiple GPUs. To solve the serialization issue of naive parallelism caused by the diffusion model’s requirement for synchronized noise levels between frames, this method employs a chunk-wise denoising scheme, i.e., by pipelining a series of frame chunks and gradually reducing the noise level. Each GPU processes specific subsets of chunks and layers, passing previous results to the next GPU, enabling asynchronous computation and communication. Furthermore, by implementing feature caching on each GPU to reuse features from previous chunks as context and adopting a coordinated noise initialization strategy, globally consistent temporal dynamics are ensured, thereby achieving fast, artifact-free, and infinitely long video generation. Applied to the latest diffusion transformer video generators, this method efficiently generates 1025-frame videos on 8x RTX 4090 GPUs, reducing latency by up to 6.54x and memory cost by 1.48x. (Source: HuggingFace Daily Papers)
🧰 Tools
Claude 4 Series Models Excel in Programming Tasks, Successfully Solving a “White Whale Bug” That Troubled Senior Programmers for 4 Years : Anthropic’s latest Claude Opus 4 model has demonstrated astonishing programming capabilities. A former FAANG engineer with 30 years of C++ development experience shared that a complex system bug, which had troubled their team for 4 years and consumed about 200 of their personal hours without resolution (an edge case issue appearing when a specific shader was used in a particular way), was successfully located and its cause identified by Claude Opus 4 within a few hours using about 30 prompts. The bug did not exist before a system refactoring; Opus 4 pointed out that the new architecture failed to accommodate an undesigned behavior that was coincidentally supported under the old architecture. Previously, GPT-4.1, Gemini 2.5, and Claude 3.7 had all failed to solve this issue. This highlights Claude 4’s powerful ability in understanding complex code, performing deep analysis, and reasoning, especially when combined with Claude Code mode, effectively assisting developers with advanced engineering tasks like code refactoring and bug fixing. (Source: 36Kr, dotey)
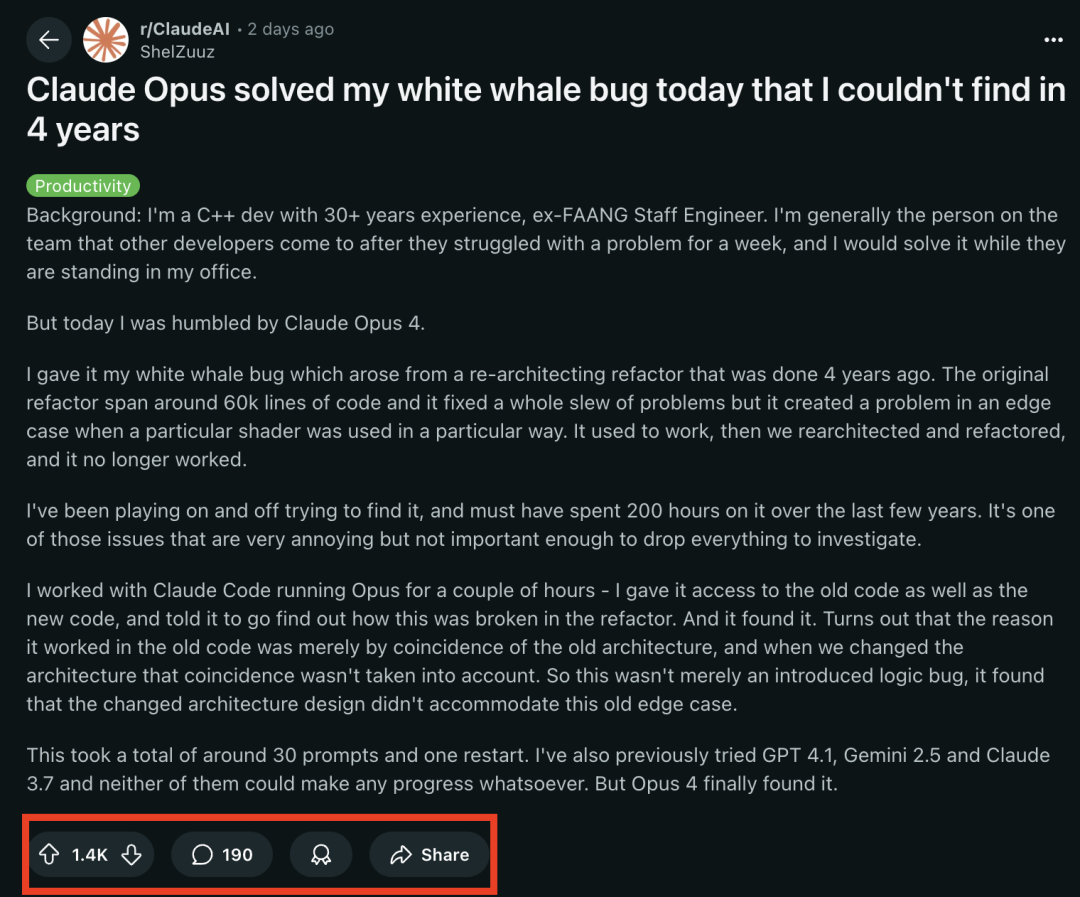
LangChain Adds Support for New Anthropic Claude Beta Features : LangChain announced it has integrated four new Beta features recently released for Anthropic’s Claude model, including code execution, remote MCP connectors, file API, and extended prompt caching. Developers can now view relevant examples in the LangChain documentation to leverage these new features for building more powerful AI applications. (Source: LangChainAI)
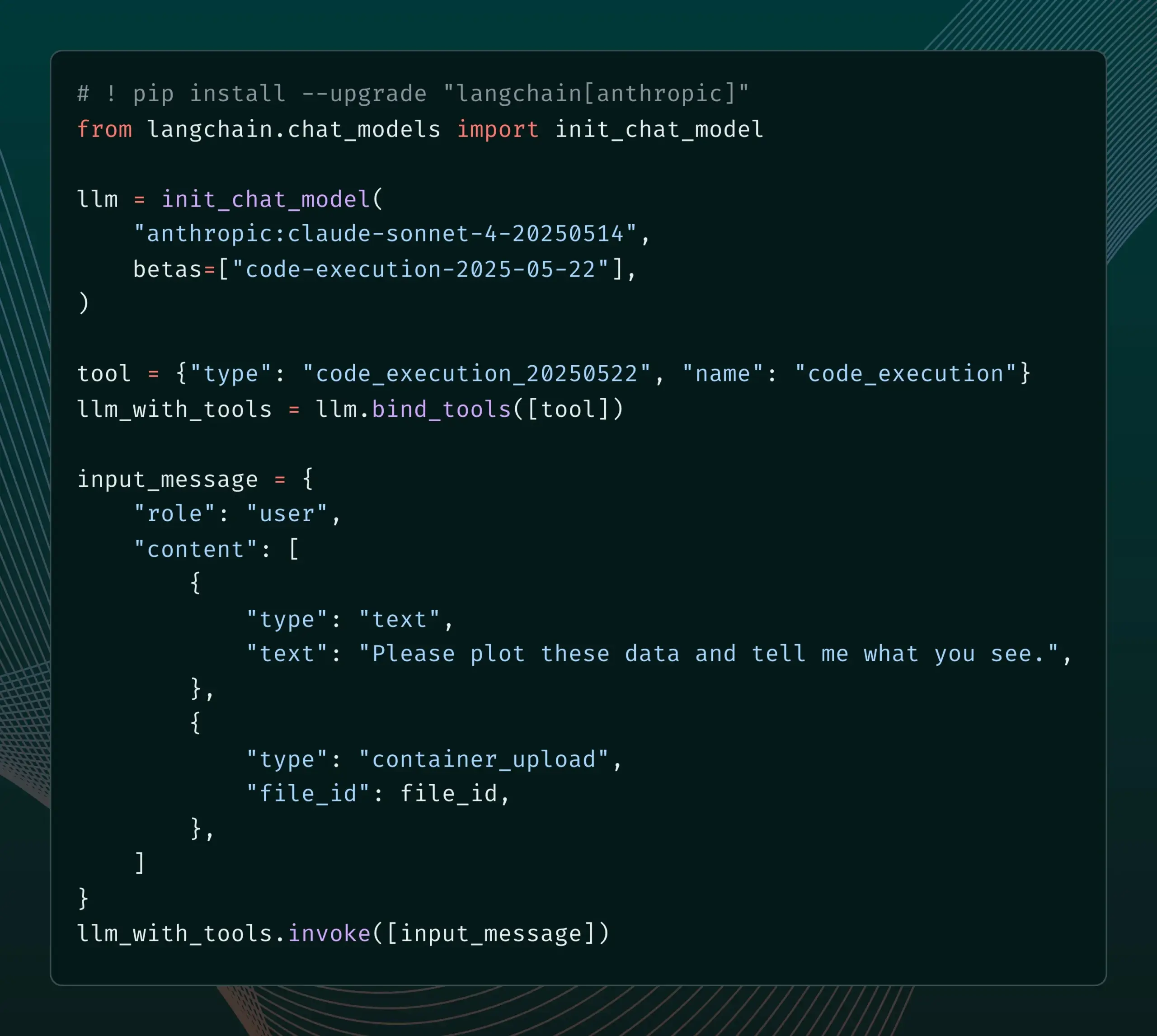
LangSmith Launches Prompt Management Features Integrated with SDLC : The LangSmith platform has enhanced its prompt engineering capabilities. Now, users can not only test, version, and collaborate on prompts within LangSmith but also automatically synchronize prompts to GitHub, external databases, or initiate CI/CD processes via webhook triggers when prompts change. This feature aims to help developers more tightly integrate prompt management into the software development lifecycle (SDLC). (Source: LangChainAI)
AutoThink: Adaptive Technology to Enhance Local LLM Inference Performance : The CodeLion team has developed AutoThink technology, which significantly improves the inference performance of local LLMs through adaptive resource allocation and steering vectors. AutoThink can classify query complexity, dynamically allocate “thinking tokens” (more for complex problems, fewer for simple ones), and use steering vectors to guide reasoning patterns. Tests on the DeepSeek-R1-Distill-Qwen-1.5B model showed a 43% improvement in GPQA-Diamond accuracy (from 21.72% to 31.06%), with MMLU-Pro also showing improvement, all while using fewer tokens. The technology is compatible with local inference models that support thinking tokens, and the code and research have been released. (Source: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
Transformer Lab Announces AMD ROCm Support for Local LLM Training : Transformer Lab announced that its GUI platform now supports local training and fine-tuning of large language models on AMD GPUs using ROCm. The team stated that configuring ROCm was challenging and has documented the entire process in a blog post. Currently, the feature is working smoothly, and users can try developing LLMs on AMD hardware. (Source: Reddit r/MachineLearning)
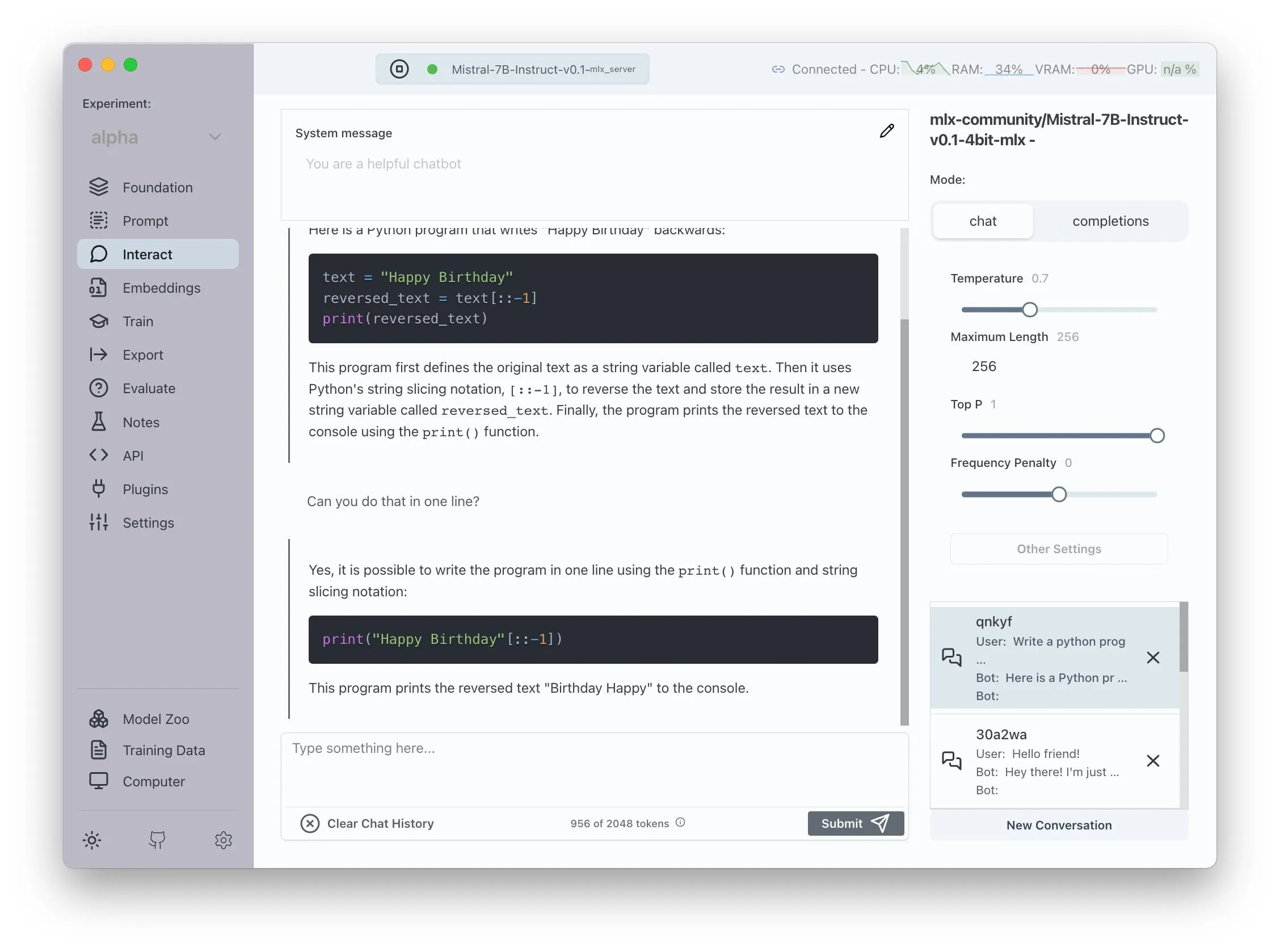
Open-Source LLM-Augmented Multi-Agent System Achieves Automated Claim Extraction and Fact-Checking : An open-source project called “fact-checker” utilizes an LLM-augmented Multi-Agent System (MAS) to achieve automated claim extraction, evidence verification, and fact resolution. The project includes a browser extension that can fact-check the responses of any AI chatbot in real-time, helping to discern the authenticity of AI-generated content. Its code architecture is clear and well-documented, providing a valuable tool in the fields of AI safety and combating misinformation. (Source: Reddit r/MachineLearning)
Meituan Launches No-Code Product Nocode, Supporting Complex Multi-Page Application Generation : Meituan has released a Vibe Coding product called Nocode, which allows users to generate complex, multi-page complete applications through natural language descriptions, not just simple display web pages. Tests by Guicang show that the tool can successfully build a logically complex warehouse goods management tool in one go, demonstrating its ability to understand complex requirements and generate corresponding code. (Source: op7418)
LlamaIndex Supports Building Custom Multimodal Embedders and Integration with OpenAI-Style Chat UI : LlamaIndex released an update allowing users to build custom multimodal embedders, such as integrating AWS Titan Multimodal, and combine them with vector databases like Pinecone for efficient text + image vector search. Additionally, LlamaIndex workflows can now run in an OpenAI-like chat interface with just a few lines of code, and it supports a development mode for directly editing workflow code in the UI, enhancing the development and interaction experience for RAG applications. (Source: jerryjliu0, jerryjliu0)

TRAE Update Enhances Agentic Coding Experience, Overseas Version Launches Paid Subscription : The AI programming tool TRAE has been updated, optimizing the Agentic coding experience to make it more suitable for users who prefer not to perform manual operations. The new version of TRAE remembers historical conversations better, automatically associates context, and allows the AI to autonomously plan programming paths and call more tools, increasing the success rate of programming tasks. For example, users only need to provide an empty folder and a prompt, and TRAE can complete a series of operations such as creating files, starting a web server (automatically handling cross-domain issues), and previewing p5.js animations within the IDE. Its overseas version has launched a paid subscription, with the first month of Pro priced at $3, supporting Alipay. (Source: dotey, karminski3)
Juejin Community Launches MCP Service, Supporting One-Click Publishing of Front-End Code : The domestic programmer community Juejin has launched an MCP (Model-driven Co-programming Protocol) service, allowing developers to publish front-end code (such as web pages or games generated by vibe coding) to the Juejin platform with one click, facilitating quick sharing and previewing. Users need to obtain a Juejin MCP Token and configure it in tools like Trae and Cursor. (Source: dotey, karminski3)
Open-Source Time Tracking Tool ActivityWatch Gains Attention as an Alternative to Rize : User karminski3, after trying the AI time analysis tool Rize (which analyzes process names to determine work, meeting, or slacking-off states, costing $20/month), discovered and recommended the open-source alternative ActivityWatch. ActivityWatch offers similar functionality, supports Windows/Mac, and allows user customization, being considered an excellent tool for alleviating work anxiety and tracking work hours. (Source: karminski3)
Open-Source AI Baby Monitoring Tool ai-baby-monitor Released : An open-source project called ai-baby-monitor has been released. It uses the Qwen2.5 VL model and vLLM inference framework, allowing users to define rules (e.g., “alert if the child wakes up,” “alert if the child is alone”) for AI-assisted baby monitoring. The developer emphasizes that this is only an auxiliary tool and cannot completely replace human supervision. (Source: karminski3)
LangChain Integrates xAI’s Live Search Feature : LangChain announced support for xAI’s Live Search feature, which allows the Grok model to base its answers on web search results and offers various configuration options, such as time period and included domains for search parameters. Users can now try this new feature in LangChain. (Source: LangChainAI)
Curie: Open-Source AI Research Assistant Releases AutoML Feature, Aiding Interdisciplinary Research : Addressing the expertise barrier faced by researchers in fields like biology, materials science, and chemistry when applying machine learning, the Curie project has launched a new AutoML feature. Curie aims to be a co-scientist for AI research experiments, automating complex ML workflows (such as algorithm selection, hyperparameter tuning, model output interpretation) to help researchers quickly test hypotheses and extract insights from data. For example, Curie generated a model with an AUC of 0.99 in a melanoma detection task. The project is open-source, encouraging community contributions. (Source: Reddit r/LocalLLaMA)
Alibaba MNN Chat Supports Local Running of Qwen 30B-a3b Model on Android Devices : Alibaba’s MNN Chat application has been updated to version 0.5.0 and now supports running large language models like Qwen 30B-a3b locally on Android devices. User feedback indicates that it can run successfully on devices with flagship chips and large memory (e.g., OnePlus 13 24G), and it is recommended to enable mmap settings. However, some comments point out that a 30B parameter model has excessive memory and computing power requirements for most mobile phones, and Gemma 3n might be more suitable for mobile devices. (Source: Reddit r/LocalLLaMA)

📚 Learning
New Paper Proposes Lean and Mean Adaptive Optimization: A Faster, More Memory-Efficient Optimizer for Training Large Models : A paper accepted at ICML 2025 introduces a new optimizer called “Lean and Mean Adaptive Optimization via Subset-Norm and Subspace-Momentum.” This method aims to reduce the memory requirements and accelerate the training of large-scale neural networks through two complementary techniques: Subset-Norm step sizes and Subspace-Momentum. Compared to existing memory-efficient optimizers like GaLore and LoRA, this method saves memory (e.g., reducing optimizer state memory by 80% compared to Adam when pre-training LLaMA 1B) while achieving Adam’s validation perplexity with fewer training tokens (about half) and providing stronger theoretical convergence guarantees. (Source: Reddit r/MachineLearning)
Paper Proposes Force Prompting: Enabling Video Generation Models to Learn and Generalize Physics-Based Control Signals : A new study explores the possibility of using physical forces as control signals for video generation and proposes “Force Prompts.” Users can interact with images through localized point forces (e.g., poking a plant) or global wind fields (e.g., wind blowing fabric). The research shows that video generation models can learn and generalize physical force conditions from Blender-synthesized videos containing demonstrations of only a few objects, generating videos that respond realistically to physical control signals without requiring 3D assets or physics simulators at inference time. Visual diversity and the use of specific text keywords during training are key factors in achieving this generalization. (Source: HuggingFace Daily Papers)
AnkiHub Shares AI Annotation Workflow, Enhancing Efficiency with FastHTML : AnkiHub shared its AI annotation workflow, which was demonstrated in Hamel Husain and Shreya Shankar’s AI evaluation course. This workflow utilizes FastHTML for building tools and aims to improve the efficiency of AI annotation for commercial products. Related teaching materials and code repositories have been released on GitHub, showcasing how to use tools from actual production to optimize AI development. (Source: jeremyphoward, HamelHusain)

Blogger Writes Learning Experience from PPO to GRPO, Explaining Reinforcement Learning Concepts in LLM Fine-Tuning : A blogger shared their experience learning Reinforcement Learning (RL) and its application in fine-tuning Large Language Models (LLMs), particularly their understanding process from PPO (Proximal Policy Optimization) to GRPO (Group Relative Policy Optimization). The blog post aims to explain concepts they wished they understood at the beginning of their learning journey to help others better grasp how these RL algorithms are used to optimize LLMs. (Source: Reddit r/MachineLearning)
Paper Explores Pragmatic Reasoning in Machines: Tracking the Emergence of Pragmatic Competence in Large Language Models : A new paper investigates how Large Language Models (LLMs) acquire pragmatic competence—the ability to understand and infer implied meanings, speaker intentions, etc.—during their training process. Researchers introduced the ALTPRAG dataset, based on the linguistic concept of “alternatives,” to evaluate 22 LLMs at different training stages (pre-training, supervised fine-tuning SFT, preference optimization RLHF). Results indicate that even base models show significant sensitivity to pragmatic cues, which continuously improves with increasing model and data scale; SFT and RLHF further enhance cognitive pragmatic reasoning abilities. This suggests that pragmatic competence is an emergent, compositional property in LLM training. (Source: HuggingFace Daily Papers)
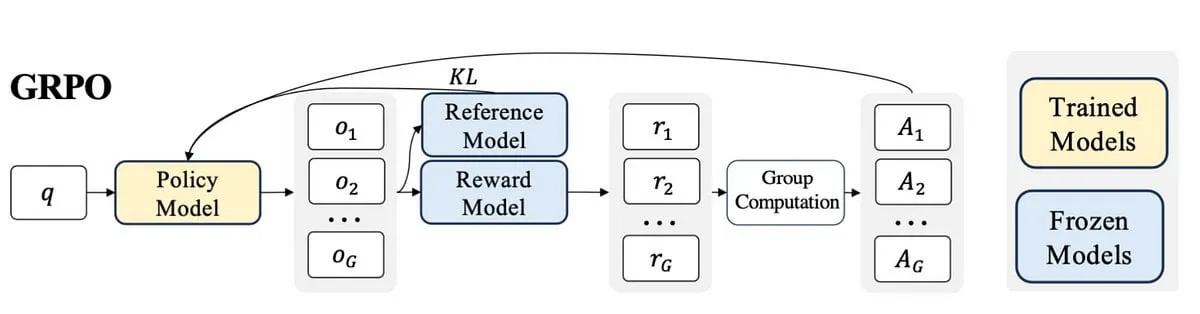
Paper Explores Reinforcement Learning Framework VisTA for Visual Tool Selection : Researchers introduced VisTA (VisualToolAgent), a new reinforcement learning framework that enables visual agents to dynamically explore, select, and combine tools from different libraries based on empirical performance. Unlike existing methods that rely on training-free prompting or large-scale fine-tuning, VisTA utilizes end-to-end reinforcement learning, using task outcomes as feedback signals to iteratively optimize complex, query-specific tool selection strategies. Through GRPO (Group Relative Policy Optimization), the framework allows agents to autonomously discover effective tool selection paths without explicit reasoning supervision. Experiments on ChartQA, Geometry3K, and BlindTest benchmarks show that VisTA achieves significant performance improvements over training-free baselines, especially on out-of-distribution samples. (Source: HuggingFace Daily Papers)
💼 Business
Data Service Company Jinglianwen Technology Completes Tens of Millions Yuan Pre-A Round Financing, Focuses on Public Data Production and Operation : AI data service operator Jinglianwen Technology recently completed a Pre-A financing round of tens of millions of yuan, invested by a fund under Hangzhou Jin Tou Group. The funds will be used to develop public data production and operation, build an intelligent corpus engineering platform, and establish self-owned high-quality annotation bases in vertical domains. Founded in 2012, the company focuses on public data, AI large models, autonomous driving, and healthcare, aiming to solve pain points such as “difficult governance, insufficient supply, stagnant flow, ineffective use, and weak security” of public data. It has also partnered with Huawei Data Storage to launch a joint AI data lake solution. The company projects a revenue growth rate of over 400% this year. (Source: 36Kr)
Meitu Receives Approximately $250 Million Convertible Bond Investment from Alibaba, Deepening AI Collaboration : Meitu announced plans for a strategic cooperation with Alibaba, under which Alibaba will issue convertible bonds worth approximately $250 million to Meitu. The two parties will collaborate in areas such as e-commerce platform promotion, AI technology (AI image, AI video) development, and cloud computing. Meitu has committed to purchasing services worth no less than 560 million yuan from Alibaba Cloud over the next three years. This collaboration aims to leverage the Alibaba ecosystem to tap into the potential of e-commerce scenarios and enhance the paid user base and R&D level of Meitu’s AI design tools. Although this move briefly boosted Meitu’s stock price, market attention is focused on how Meitu will avoid repeating Kimi’s slowdown in user growth amidst fierce market competition, especially given the intense competition and scale differences with major players in the visual AI field. (Source: 36Kr)
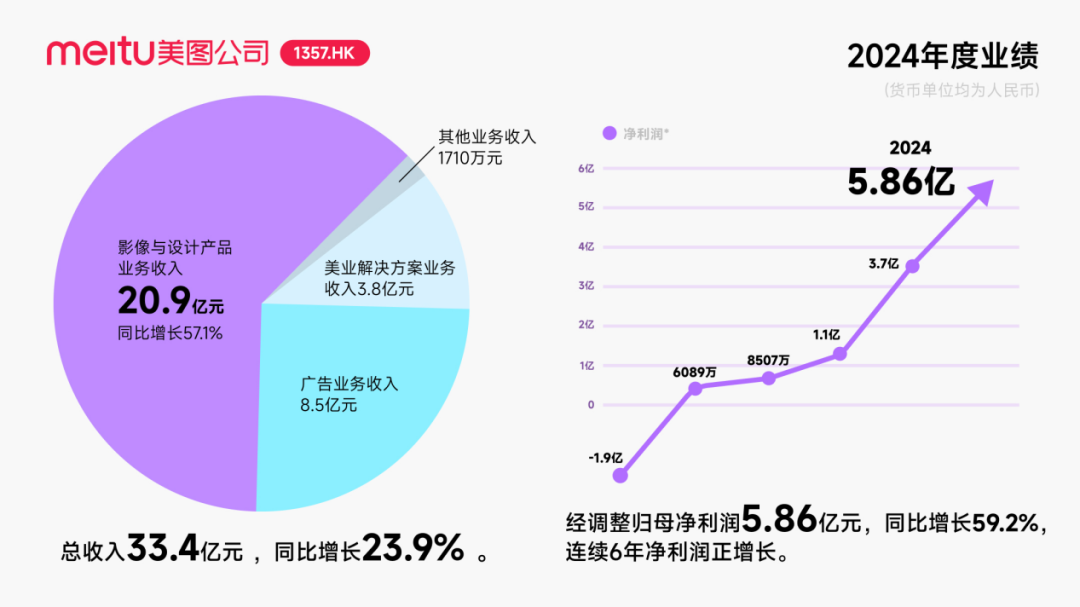
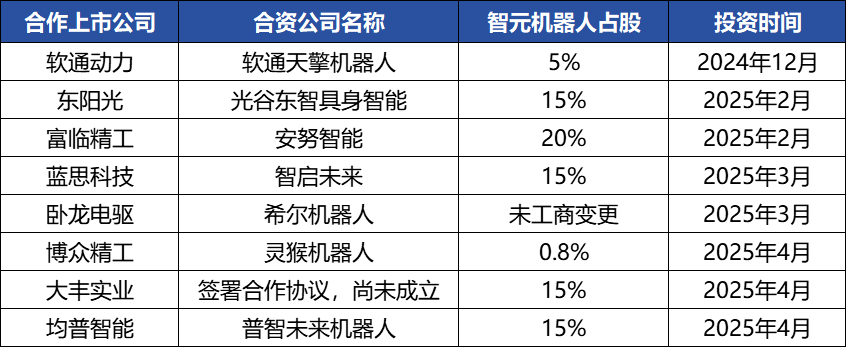
ZHIYUAN ROBOTICS Engages in Frequent Capital Operations, Building Industrial Ecosystem, Founder Deng Taihua Emerges : Embodied intelligence unicorn ZHIYUAN ROBOTICS has recently been active in capital markets, not only completing multiple financing rounds itself (the latest led by JD Technology) but also actively investing in industrial chain companies (such as Annu Intelligence, Digital Huaxia) and establishing joint venture robotics companies with several listed companies (Bozhong Precision, Dafeng Industry, etc.). Business registration changes reveal that Deng Taihua, former Vice President of Huawei and President of its Computing Product Line, is the founder and actual controller of ZHIYUAN ROBOTICS, and its executive team also includes several former Huawei personnel. This “Huawei-系” (Huawei-affiliated) background explains ZHIYUAN ROBOTICS’ “ecosystem play” operational model, which involves rapidly building industrial influence through broad cooperation and investment to achieve scale and commercialization. Despite gaining a first-mover advantage in financing and commercialization, its embodied intelligence large model capabilities still face challenges. (Source: 36Kr)
🌟 Community
AI Agents Developing Rapidly, Agentic LMs Seen as a New Application and Tool Platform with Huge Potential : AI figures like natolambert have expressed excitement about the rapid development of AI Agents, viewing Agentic Language Models (Agentic LMs) as a platform with immense potential for building a vast number of new applications and tools. Many capabilities in recent models that are not yet fully exploited can be unlocked through the Agentic paradigm. This signals that AI is evolving from mere content generation to more proactive, task-executing intelligent agents. (Source: natolambert)
AI Agents Demonstrate Superhuman Abilities on Specific Tasks, but Physical Reasoning Remains a Weakness : Research by HKUST and other institutions found that even top AI models like GPT-4o and Claude 3.7 Sonnet perform far worse than human experts on the PHYX benchmark, which includes real physical scenarios and complex causal reasoning (model highest accuracy 45.8% vs. human lowest 75.6%). This exposes their over-reliance on memorized knowledge, mathematical formulas, and superficial visual pattern matching in physics understanding. However, in mathematics, the FrontierMath competition organized by Epoch AI (with problems designed by top mathematicians like Terence Tao) saw o4-mini-medium solve about 22% of the problems, defeating 6 out of 8 human mathematician teams and surpassing the human teams’ average (19%), showcasing AI’s potential in highly abstract symbolic reasoning. This indicates an uneven development of AI capabilities across different types of reasoning tasks. (Source: 36Kr, 36Kr)

AI Programming Tools Continue to Enhance Capabilities, Sparking Discussion on Programmers’ Career Prospects : The release of Anthropic’s Claude 4 series models (especially Opus 4, capable of continuous coding for 7 hours) and advancements in AI programming tools like Cursor and Tongyi Lingma have significantly improved AI’s abilities in code generation, bug fixing, and even full-process development. This has put pressure on programmers at large companies like Amazon, with some teams halving in size and project deadlines moving up due to AI efficiency gains, shifting the programmer’s role towards that of a “code reviewer.” While AI can boost efficiency, it also raises concerns about training junior programmers, skill degradation, and career progression paths. Companies like Microsoft have already laid off staff in engineering and R&D positions and revealed a significant increase in the proportion of AI-generated code. Practitioners believe AI currently acts more as an assistant and cannot fully replace humans in understanding complex requirements, product innovation, and team collaboration, but AI is reshaping the core value of programming work. (Source: 36Kr, 36Kr)

AI Knowledge Base Market Demand Surges, but Implementation Still Faces Challenges in Data, Scenarios, and Organizational Collaboration : With the maturation of large model technology, AI knowledge bases have become a core component of enterprise intelligent transformation, with demand increasing 2-3 fold. AI transforms knowledge bases from static “warehouses” to intelligent “engines” capable of recognizing context and directly generating solutions, improving construction and maintenance efficiency. However, AI knowledge bases still have limitations in handling highly creative or complex reasoning tasks and face pain points such as scale management, information accuracy and timeliness, permission security, technological architecture adaptability, and data migration integration. Enterprises need to weigh options among SaaS, self-development + API, and hybrid cloud Agent paths, and establish a “dual-track architecture” of a unified knowledge middle platform and flexible upper-level applications for effective implementation. (Source: 36Kr)

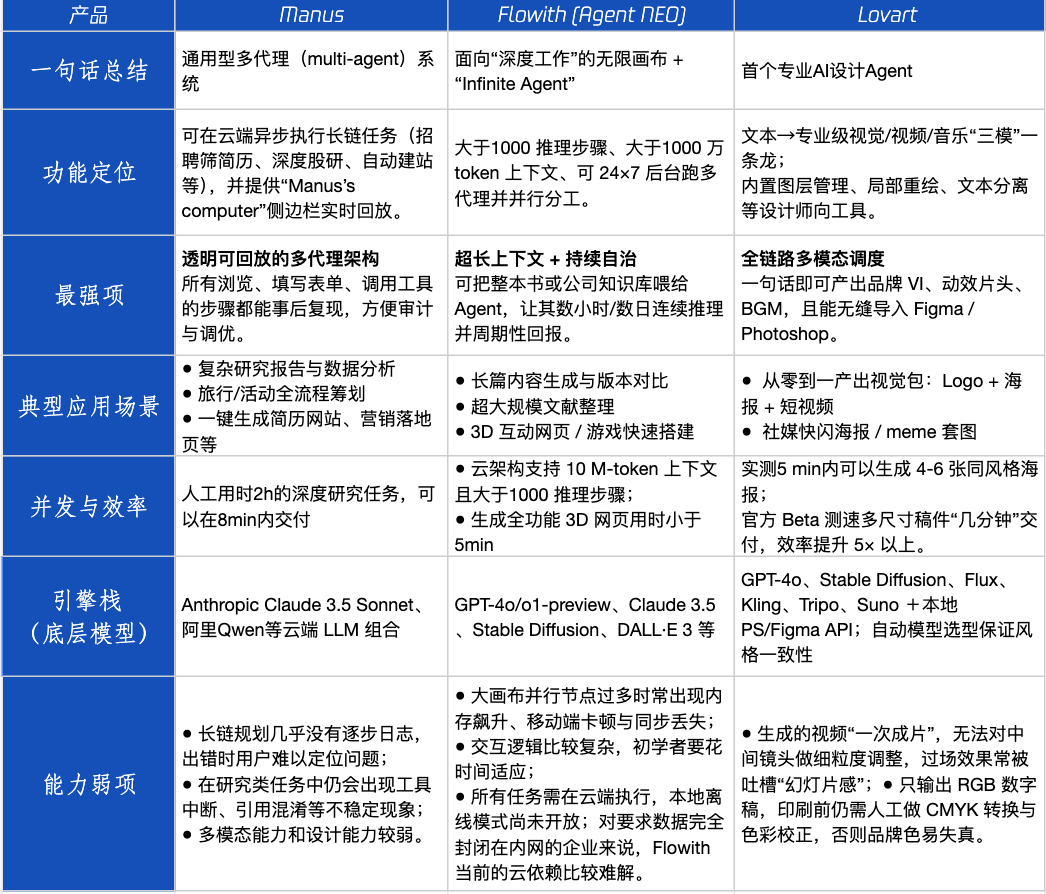
Agent Product Review: Performance of Manus, Flowith, and Lovart in Different Scenarios : Tencent Technology conducted a practical test of three popular Agent products: Manus, Flowith (Agent Neo), and Lovart. Manus is positioned as a “digital colleague” capable of independently delivering finished products, suitable for knowledge work such as market research and financial modeling. Flowith emphasizes visual collaboration and unlimited steps, suitable for creative scenarios with large amounts of information requiring multi-person iteration, such as generating analysis reports based on extensive literature. Lovart is vertical in the design field, capable of generating brand visual solutions (Logo, posters, short videos) with one click. In simple creative scenarios, the three performed similarly to GPT-4o, with Lovart’s mixed text-image layout and texture being slightly better. In complex comprehensive tasks (such as creating a full brand plan for a startup beverage company) and deep research scenarios, Manus and Flowith each had their strengths and could complete the tasks but with different focuses. Current monthly fees for these products are around $20, and the commercialization inflection point lies in whether they can provide clear efficiency dividends, converting users from curious to paying. (Source: 36Kr)
Arc Browser Founder Reflects on Failures, Emphasizes Future Direction of AI Browsers : The founder of Arc browser reflected on the product’s failures, believing they should have embraced AI sooner and noting that Arc was too revolutionary for most people, with a high learning curve and insufficient returns. He emphasized that the new product, Dia, will pursue simplicity, extreme speed, and security, and believes traditional browsers will eventually die out, with AI browsers merging web browsing and AI chat to become the most commonly used AI interface on desktops. This view echoes the thoughts of Lovart and Youware founders on the direction of Agent products, considering AI Agents as the next breakout point. (Source: op7418)
“Recursive Prompting” Phenomenon Caused by AI Agents Raises Concerns, May Lead to User Cognitive Bias : A large number of users on social media, after interacting with LLMs through “recursive prompting,” have developed the cognition that AI possesses spirituality, emotions, and even precognitive abilities. Research suggests this might be a “neural howlround” phenomenon, where AI output is re-entered by users as input, forming a reinforcement loop that can lead AI to produce seemingly profound or prophetic content, which is actually self-amplification of patterns. Some users have already experienced psychological distress as a result, believing AI to be a sentient being. This highlights the need for caution regarding the potential psychological impact and cognitive misdirection when engaging in deep, exploratory interactions with AI. (Source: Reddit r/ChatGPT)

Arav Srinivas on AI Information Compression and ASI: AI Needs to Extract High Signal-to-Noise Information, Future Focus Should Be on ASI, Not AGI : Perplexity AI CEO Arav Srinivas believes that automated long-form summaries provide users more with a sense of satisfaction that “someone is working for you” rather than actual information intake value. He emphasizes that AI needs to better identify and provide only the core information with the highest signal-to-noise ratio, stating, “Compression is the ultimate sign of true intelligence.” He also proposed that while we currently discuss AGI (Artificial General Intelligence), the future focus should be on ASI (Artificial Superintelligence). (Source: AravSrinivas, AravSrinivas)
Universities Begin Detecting AI Rate in Graduation Theses, Sparking Discussion on AI Application in Academic Writing : For the 2025 graduation season, several universities, including Fudan University and Sichuan University, have begun requiring students to disclose their use of AI tools in theses and are conducting AI-generated content ratio detection (usually requiring below 20%-40%). Many students admit to using AI for literature reviews, translation, and framework construction to improve efficiency. Opinions in the education sector vary; some scholars believe proper AI use should be guided, cultivating students’ critical thinking and judgment, as AI can guarantee a baseline but the upper limit is determined by humans. The application and regulation of AI in academic and educational fields are becoming new issues requiring systematic responses. (Source: 36Kr)
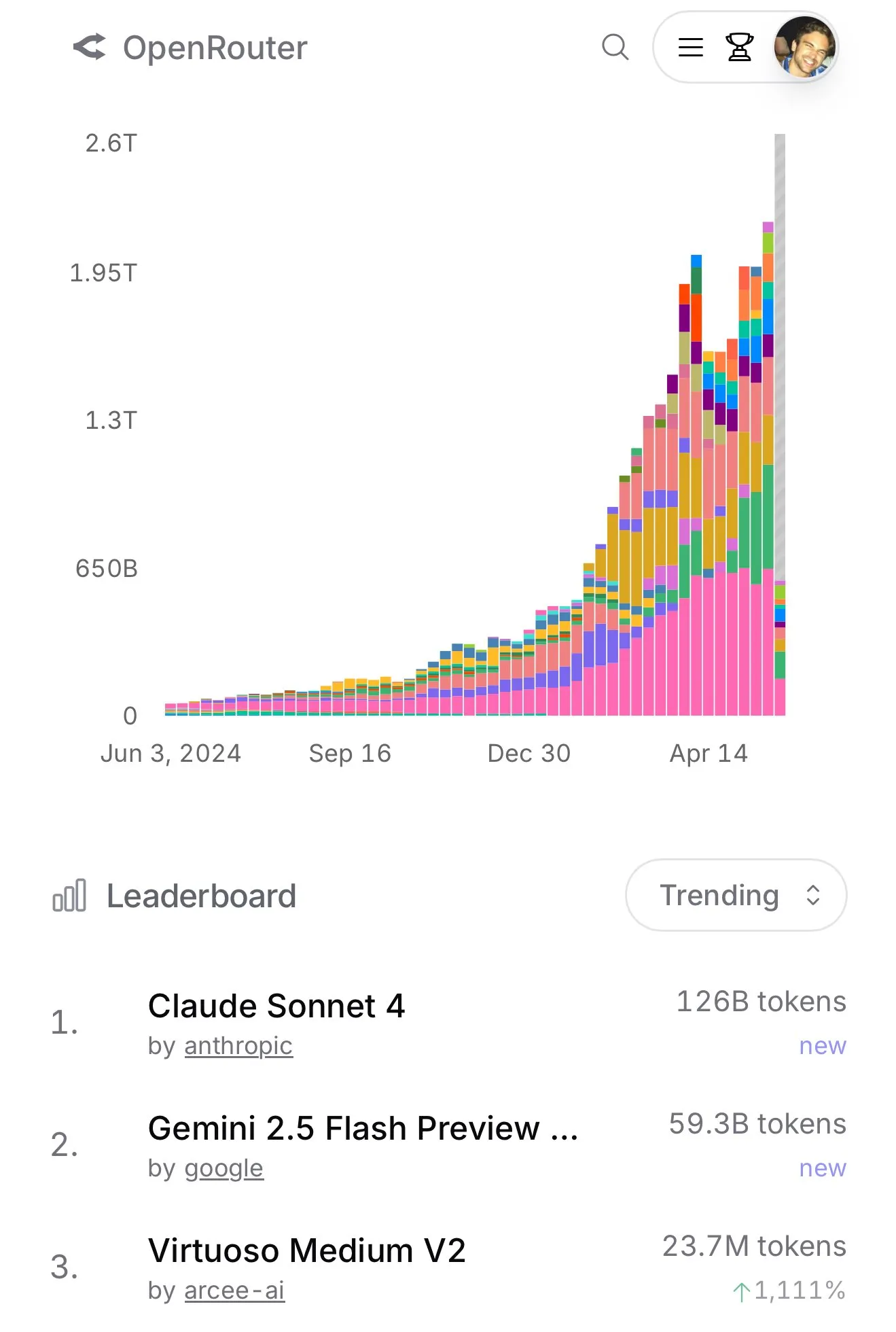
Claude 4 Sonnet Usage Surges on OpenRouter, Aider Programming Leaderboard Shows Its Excellent Performance : According to official data from OpenRouter, usage of Anthropic’s Claude 4 Sonnet model has recently seen a sharp, leading increase, with Gemini 2.5 Flash ranking second. Meanwhile, evaluation results from the Aider Leaderboard (primarily for programming tasks) show that claude-4-opus-thinking outperforms claude-3.7-sonnet-thinking, but still falls short of Gemini-2.5-Pro-Preview-05-06. User karminski3’s impression is 3.7-sonnet > 4-sonnet > 4-opus. This data and feedback reflect the performance differences and user preferences of various models in specific scenarios. (Source: karminski3, karminski3)
💡 Other
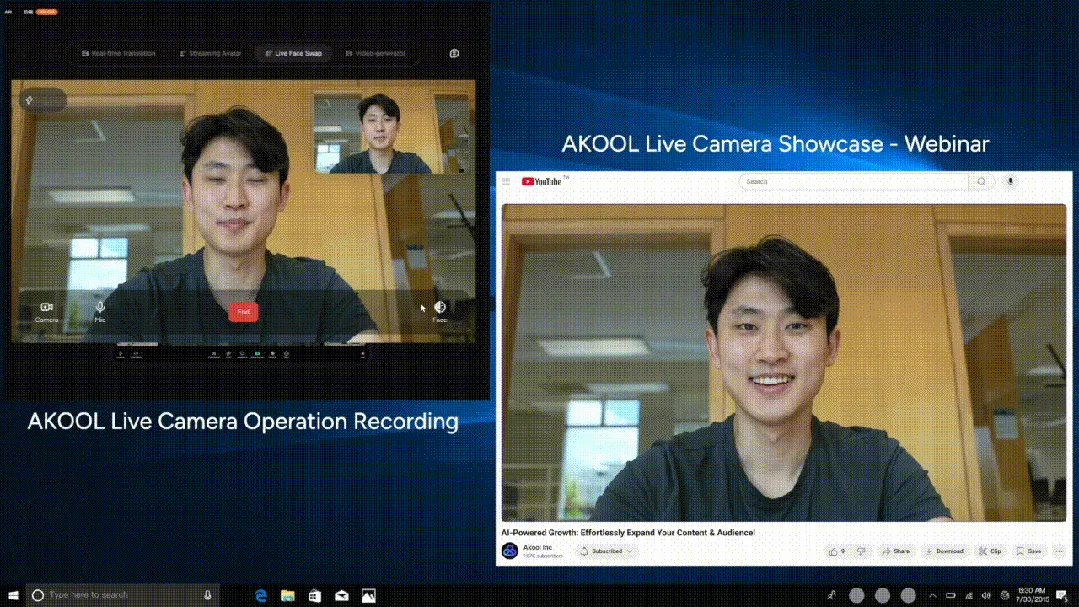
AKOOL Releases World’s First Real-Time AI Camera, Live Camera, Integrating Four Major Innovative Features : Silicon Valley company AKOOL has launched AKOOL Live Camera, claimed to be the world’s first real-time AI camera. The product integrates four major functions: virtual digital human creation (via 4D facial mapping and sensor fusion), real-time translation in 150+ languages (maintaining original voice and lip-sync), real-time face swapping (accurately reflecting emotions and micro-expressions), and dynamic generation of film-grade video content (no script needed, instant generation). Its features include ultra-low latency (as low as 500ms), high fidelity, contextual awareness, and dynamic response capabilities, aiming to disrupt traditional video production and digital interaction modes, dubbed AI video’s “second Sora moment.” (Source: 36Kr)
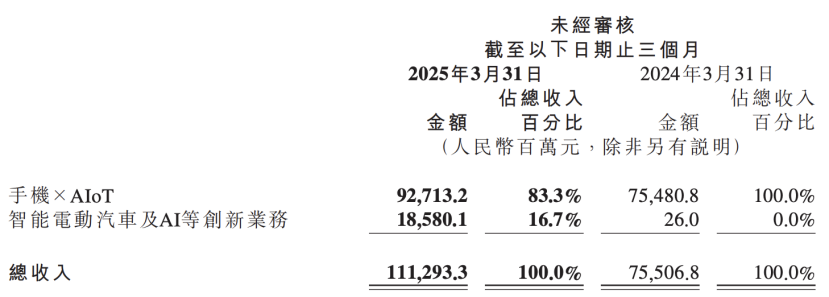
Xiaomi Financial Report Reveals AI Strategy Upgrade, Placing AI and Automotive Business as Core Innovations : Xiaomi’s latest financial report shows that the company has renamed its “smart electric vehicles and other innovative businesses” to “smart electric vehicles and AI and other innovative businesses,” and will continue to promote research on foundational large language models. Xiaomi President Lu Weibing stated that artificial intelligence and chips are important sub-strategies for Xiaomi, and developing foundational large models primarily serves its own business needs. This move indicates that after achieving phased results in its mobile phone and automotive businesses, Xiaomi is increasing investment in AI foundational R&D to enhance overall competitiveness and address emerging trends such as AI phones, AIoT, and embodied intelligence. (Source: 36Kr)
Humanoid Robot Interaction Technology Discussion: Facial Expression Interaction Faces Triple Challenges of Hardware, Materials, and Algorithms : The interactive experience of humanoid robots, especially facial expression interaction, is considered key to enhancing their maturity and popularization. Achieving natural facial expression interaction faces challenges in hardware degrees of freedom design (needing to simulate human facial muscle action units), motor selection (requiring small, lightweight, low-noise, high-speed, high-thrust/torque motors), and skin material and structural design (needing to balance elasticity, lifespan, appearance, and coupling with drive structures). At the software algorithm level, automatic expression generation (rather than pre-programmed), lip-sync (to achieve realism), and multi-degree-of-freedom motion control (involving flexible material modeling and precision control) are core technical bottlenecks. Companies like Ameca and AnyWit Robotics are exploring this field. (Source: 36Kr)