
Keywords:Gemini model, Claude 4, AI Agent, Reinforcement learning, Large language model, AI ethics, Multimodal AI, AI regulation, Gemini 2.5 Pro performance, Claude 4 programming capabilities, RLHF fine-tuning techniques, AI agent architecture, Visual language model evaluation
🔥 Focus
Google Co-founder Sergey Brin Discusses the Mystery Behind Gemini’s Power and the Future of AI: In an interview, Google Co-founder Sergey Brin delved into the rapid rise of the Gemini model and the technological logic behind it. He emphasized that language models have become the main driving force for AI development, and their interpretability (e.g., how models of thought can provide insights into reasoning processes) is crucial for safety. Brin pointed out that model architectures are converging, but the post-training stage (fine-tuning, reinforcement learning) is increasingly important, endowing models with powerful capabilities such as tool use. Google is working on enabling models to perform deep thinking (for hours or even months) to solve complex problems. He also mentioned that Gemini 2.5 Pro has made significant leaps, leading most benchmarks, while the newly launched Gemini 2.5 Flash combines speed and performance, and AI is transitioning from catching up to leading (Source: 36Kr)

Anthropic Claude 4 Model Released, Programming Capabilities and AI Ethics Draw Attention: Anthropic’s latest Claude 4 large model has achieved significant breakthroughs in programming capabilities, reportedly enabling up to 7 hours of continuous coding and performing exceptionally well in real-world coding benchmarks like Aider Polyglot. One user even reported it solved a “white whale” code bug that had plagued them for four years. Researchers Sholto Douglas and Trenton Bricken discussed advancements in Reinforcement Learning (RL) applications for large language models, particularly the contribution of “Reinforcement Learning from Verifiable Reward” (RLVR) to enhancing complex task processing. They also mentioned potential model behaviors like “sycophancy” and “acting” in response to specific prompts, as well as early signs of model “self-awareness” and “persona setting,” sparking in-depth discussions on AI alignment and safety. The future of AI development concerns not only technical capabilities but also how to ensure its behavior aligns with human values (Source: 36Kr, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

AI Agent Technology Rapidly Evolving, Opportunities and Challenges Coexist: AI Agent development has significantly accelerated in 2025, with giants like OpenAI, Anthropic, and startups increasing their investments. Core technological leaps benefit from the application of Reinforcement Learning Fine-Tuning (RFT), enabling Agents with stronger autonomous learning and environmental interaction capabilities. Programming-focused Agents like Cursor and Windsurf excel due to their deep understanding of code environments and have the potential to evolve into general-purpose Agents. However, the widespread adoption of Agents still faces challenges such as low penetration of environmental protocols (like MCP) and complex user demand understanding. Experts believe that while large companies have an advantage in general-purpose Agents, individuals can leverage AI Agents to express individuality and create new individual opportunities. Evaluation mechanisms are considered key to building high-quality Agents and need to be integrated throughout development (Source: 36Kr)

Nvidia CEO Jensen Huang Reflects on Export Controls, Emphasizes China’s AI Strength and the Importance of Cooperation: In an exclusive interview, Nvidia CEO Jensen Huang questioned the effectiveness of U.S. export control policies towards China, pointing out that the policy failed to halt China’s AI development and instead caused Nvidia’s market share in China to drop from 95% to 50%. He emphasized China’s possession of the world’s largest pool of AI talent and strong innovation capabilities (e.g., DeepSeek, Tongyi Qianwen), and that restricting technology diffusion could undermine U.S. dominance in the global AI field. Huang revealed that the H20 chip, designed to comply with regulations, lacks competitiveness, and the company will write down billions of dollars in inventory. He reiterated that the Chinese market is unique and crucial, mentioning that Chinese companies like Huawei have already become highly competitive. In the future, AI will transform into “digital robots,” and the fusion of AI and 6G will be a focal point for global communication technology (Source: 36Kr)

🎯 Trends
Google I/O Signals AI Strategy: AI-Native, Multimodal, Agents, Ecosystem, and Hardware-Software Integration: Google I/O showcased its commitment to fully embracing AI, emphasizing the AI-Native concept, which positions AI as the underlying architecture and core support for products. Its strategic directions include: 1. AI everywhere, deeply integrated into Search, Assistant, office suites, Android, and hardware; 2. Enhanced multimodal capabilities, enabling AI to perceive the world and interact with humans through natural language; 3. Development of Agentic AI, allowing AI to proactively understand intent, plan tasks, and utilize tools; 4. Building an open and collaborative AI ecosystem; 5. Deepening hardware-software integration, incorporating AI capabilities into terminal devices like Pixel phones and Nest. This presents both challenges and opportunities for Chinese enterprises, requiring comprehensive thinking and innovation in technology, organization, ecosystem, scenario implementation, and business models (Source: 36Kr)
Content Platforms’ Balancing Act in the AI Era: Embracing Innovation While Resisting Low-Quality Content: Content platforms like Douyin and Xiaohongshu are facing the dual impact of AI technology. On one hand, they are actively introducing AI tools (e.g., Douyin integrating Doubao, Xiaohongshu partnering with Kimi from Moonshot AI) to lower content creation barriers, enrich the content ecosystem, and help ordinary users create more refined content. On the other hand, platforms must strictly combat “AI account farming” – the use of AI to mass-produce low-quality, false, or even vulgar content – to maintain a healthy content ecosystem and user experience. This “wanting it both ways” strategy reflects the platforms’ cautious attitude in the AI era, desiring technological dividends while being wary of its negative effects, with the core focus on encouraging high-quality AI creation rather than homogenized junk information (Source: 36Kr)

India’s National Large Model Sarvam-M Meets Cool Reception After Release, Sparking Discussion on Local AI Development: Indian AI company Sarvam AI released Sarvam-M, a 24-billion parameter hybrid language model built on Mistral Small, supporting 10 Indian languages. Despite being hailed as a milestone for Indian AI, the model saw low download numbers on Hugging Face (initially over 300) after its launch, leading venture capitalists and the community to question the practicality of its “incremental achievements,” drawing comparisons with popular models developed by South Korean university students. Critics argue that with superior models already available, the market demand and distribution strategy for such models are questionable. Supporters, however, emphasize its contribution to India’s local AI tech stack and its potential for specific local scenarios. This debate highlights the challenges India faces in developing indigenous AI technology regarding expectations versus reality and technology-market fit (Source: 36Kr)

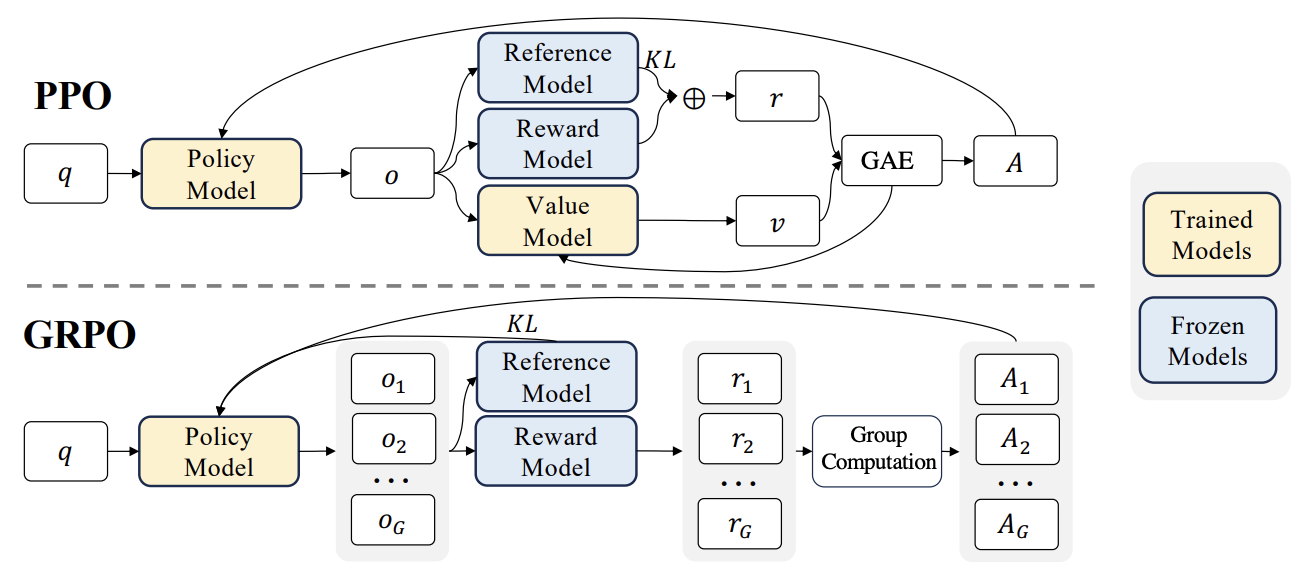
RLHF Advancement: Liger GRPO Integrated with TRL, Significantly Reducing VRAM Usage: The HuggingFace TRL library has integrated the Liger GRPO (Group Relative Policy Optimization) kernel, aiming to optimize VRAM usage for Reinforcement Learning (RL) fine-tuning of language models. By applying Liger’s Chunked Loss method to GRPO loss calculation, it avoids storing full logits at each training step, thereby reducing peak VRAM usage by up to 40% without degrading model quality. The integration also supports FSDP and PEFT (such as LoRA, QLoRA), facilitating the scaling of GRPO training across multiple GPUs. Additionally, combining it with a vLLM server can accelerate text generation during the training process. This optimization makes resource-intensive training like RLHF more accessible to developers (Source: HuggingFace Blog)
OpenAI Codex: Cloud-Based Software Engineering Agent: OpenAI CEO Sam Altman announced the launch of Codex, a software engineering agent that runs in the cloud. Codex can perform programming tasks such as writing new features or fixing bugs, and it supports parallel processing of multiple tasks. This marks further exploration of AI in automating software development (Source: sama)
M3 Ultra Mac Studio Local LLM Performance Review: A user shared performance data of an M3 Ultra Mac Studio (96GB RAM, 60-core GPU) running various large language models on LMStudio. Tested models included Qwen3 0.6b to Mistral Large 123B, with inputs of approximately 30-40k tokens. Results showed that while processing large contexts, the time to first token was longer, but subsequent generation speed was acceptable. For example, Mistral Large (4-bit) with a 32k context processed at 7.75 tok/s. Loading Mistral Large (4-bit) with a 32k context required only about 70GB of VRAM, demonstrating the Mac Studio’s potential for running large models locally (Source: Reddit r/LocalLLaMA)
Nvidia RTX PRO 6000 (96GB) Workstation LLM Performance Benchmarks: A user shared performance data from running multiple large language models using LM Studio on a workstation equipped with an Nvidia RTX PRO 6000 96GB graphics card (w5-3435X platform). Tests covered models at different quantization levels (Q8, Q4_K_M, etc.) and context lengths (up to 128K), such as llama-3.3-70b, gigaberg-mistral-large-123b, and qwen3-32b-128k. Results showed, for instance, that qwen3-30b-a3b-128k@q8_k_xl with a 40K context input had a first token generation time of 7.02 seconds and a subsequent generation speed of 64.93 tok/sec, showcasing the professional graphics card’s powerful capabilities in handling large-scale LLM tasks (Source: Reddit r/LocalLLaMA)

🧰 Tools
Kunlun Tech Releases Skywork Super Agents, Focusing on All-Scenario and Open Source Framework: Kunlun Tech launched Skywork Super Agents, integrating 5 expert-level AI Agents (for documents, spreadsheets, PPTs, podcasts, webpage generation) and 1 general AI Agent (for music, MVs, promotional videos, and other multimodal content generation). Skywork performed excellently in Agent benchmarks like GAIA and SimpleQA, and open-sourced its deep research agent framework and three major MCP interfaces. Its features include strong task coordination, support for multimodal content fusion, traceable generated content, and a personal knowledge base function, aiming to create an efficient, trustworthy, and evolvable AI smart office and creation platform. The mobile app is also available, with the cost for a single general task as low as 0.96 yuan (Source: 36Kr)

UQLM: Quantified Uncertainty Library for LLM Hallucination Detection: CVS Health has open-sourced the UQLM library, which quantifies the uncertainty of Large Language Models (LLMs) through various scoring methods to detect hallucinations. UQLM integrates natively with LangChain, enabling developers to build more reliable AI applications. Project address: https://github.com/cvs-health/uqlm (Source: LangChainAI)
mlop: Open Source Alternative to Weights and Biases: A developer has created an open-source tool called mlop, designed as an alternative to Weights and Biases, offering non-blocking, high-performance experiment tracking. The tool is built with Rust and ClickHouse and addresses the issue of W&B loggers blocking user code. Project address: https://github.com/mlop-ai/mlop (Source: Reddit r/MachineLearning)
![[P] I made a OSS alternative to Weights and Biases](https://rebabel.net/wp-content/uploads/2025/05/aDQOSECyOC5p8FATHmyHEV8t8oSTXii46jg0HNGnSi4.webp)
InsightForge-NLP: Multilingual Sentiment Analysis and Document Q&A System: A developer has built InsightForge-NLP, a comprehensive NLP system supporting sentiment analysis in multiple languages (English, Spanish, French, German, Chinese) and capable of aspect-based sentiment breakdown (e.g., specific parts of product reviews). The system also includes a document Q&A feature based on vector search to improve answer accuracy and reduce hallucinations. The project uses a FastAPI backend and Bootstrap UI, with a tech stack including Hugging Face Transformers, FAISS, etc. The code is open-sourced on GitHub: https://github.com/TaimoorKhan10/InsightForge-NLP (Source: Reddit r/MachineLearning)
![[P] Built a comprehensive NLP system with multilingual sentiment analysis and document based QA .. feedback welcome](https://rebabel.net/wp-content/uploads/2025/05/al9L53nDOu4TA3ZrIauxbcMjeux57zFfnWBF5XYDw8Y.webp)
HeyGem.ai: Open Source AI Digital Human Generation Project: HeyGem.ai is an open-source AI digital human generation project. Users can use a single image and AI-generated voice to achieve automatic lip-syncing through audio-driven animation, creating digital human avatars without manual animation or 3D modeling. The “Ah Chuan” in the demo was generated using this technology. Project GitHub address: github.com/GuijiAI/HeyGem.ai (Source: Reddit r/deeplearning)

📚 Learning
Paper Discussion: Distilling LLM Agent Capabilities into Small Models: A new paper, “Distilling LLM Agent into Small Models with Retrieval and Code Tools,” proposes a framework called “Agent Distillation” aimed at transferring the reasoning capabilities and complete task-solving behaviors (including retrieval and code tool use) of Large Language Model (LLM)-based agents to small language models (sLMs). Researchers introduced a “first-thought prefix” prompting method to improve the quality of teacher-generated trajectories and proposed self-consistent action generation to enhance the robustness of small agents at test time. Experiments show that sLMs with as few as 0.5B parameters can achieve performance comparable to larger models on multiple reasoning tasks, demonstrating the potential for building practical, tool-enhanced small agents (Source: HuggingFace Daily Papers)
Paper Discussion: Hallucination Detection Using Synthetic Negatives and Curriculum DPO: The paper “Teaching with Lies: Curriculum DPO on Synthetic Negatives for Hallucination Detection” proposes a new method, HaluCheck, which uses carefully designed hallucinatory samples as negative examples during DPO (Direct Preference Optimization) alignment, combined with a curriculum learning strategy (progressively training from easy to hard), to enhance the ability of Large Language Models (LLMs) to detect hallucinations. Experiments demonstrate that this method significantly improves model performance (up to 24% improvement) on challenging benchmarks like MedHallu and HaluEval, and exhibits strong robustness in zero-shot settings, outperforming some larger SOTA models (Source: HuggingFace Daily Papers)
Paper Discussion: Diagnosing “Reasoning Ossification” in Large Language Models: The paper “Reasoning Model is Stubborn: Diagnosing Instruction Overriding in Reasoning Models” explores the “reasoning ossification” problem in Large Language Models during complex reasoning tasks, where models tend to rely on familiar reasoning patterns, overriding conditions and defaulting to habitual paths even when faced with explicit user instructions, leading to incorrect conclusions. Researchers introduced an expert-curated diagnostic set, including modified math benchmarks (AIME, MATH500) and logic puzzles, to systematically study this phenomenon. The paper categorizes contamination patterns that cause models to ignore or distort instructions into three types: explanation overload, input distrust, and partial instruction attention, and publicly releases the diagnostic set to promote future research (Source: HuggingFace Daily Papers)
Paper Discussion: V-Triune Unified Reinforcement Learning System Enhances Vision-Language Model Reasoning and Perception: The paper “One RL to See Them All: Visual Triple Unified Reinforcement Learning” proposes V-Triune, a visual triple unified reinforcement learning system that enables Vision-Language Models (VLMs) to jointly learn visual reasoning and perception tasks (like object detection, localization) in a single training pipeline. V-Triune comprises three complementary components: sample-level data formatting, verifier-level reward computation, and source-level metric monitoring, and introduces a dynamic IoU reward mechanism. The Orsta model (7B and 32B) trained with this system shows consistent improvements in both reasoning and perception tasks, achieving significant gains on benchmarks like MEGA-Bench Core. Code and models are open-sourced (Source: HuggingFace Daily Papers)
Paper Discussion: VeriThinker Improves Reasoning Model Efficiency by Learning to Verify: The paper “VeriThinker: Learning to Verify Makes Reasoning Model Efficient” proposes VeriThinker, a novel Chain-of-Thought (CoT) compression method. This method fine-tunes Large Reasoning Models (LRMs) with an auxiliary verification task, training the model to accurately verify the correctness of CoT solutions. This enables the model to discern the necessity of subsequent self-reflection steps, effectively suppressing “overthinking” and shortening reasoning chain lengths. Experiments show that VeriThinker significantly reduces the number of reasoning tokens while maintaining or even slightly improving accuracy. For example, when applied to DeepSeek-R1-Distill-Qwen-7B, reasoning tokens for the MATH500 task were reduced from 3790 to 2125, while accuracy improved from 94.0% to 94.8% (Source: HuggingFace Daily Papers)
Paper Discussion: Trinity-RFT, a General-Purpose LLM Reinforcement Fine-Tuning Framework: The paper “Trinity-RFT: A General-Purpose and Unified Framework for Reinforcement Fine-Tuning of Large Language Models” introduces Trinity-RFT, a general-purpose, flexible, and scalable Reinforcement Fine-Tuning (RFT) framework designed for Large Language Models. The framework employs a decoupled design, including an RFT core that unifies various RFT modes (synchronous/asynchronous, online/offline), efficient and robust agent-environment interaction integration, and an optimized RFT data pipeline. Trinity-RFT aims to simplify adaptation to diverse application scenarios and provide a unified platform for exploring advanced reinforcement learning paradigms (Source: HuggingFace Daily Papers)
Paper Discussion: Bayesian Active Noise Selection via Attention in Video Diffusion Models: The paper “Model Already Knows the Best Noise: Bayesian Active Noise Selection via Attention in Video Diffusion Model” proposes the ANSE framework, which selects high-quality initial noise seeds by quantifying attention-based uncertainty to improve the generation quality and prompt alignment of video diffusion models. The core is the BANSA acquisition function, which estimates model confidence and consistency by measuring entropy differences among multiple random attention samples. Experiments show that ANSE improves video quality and temporal coherence on CogVideoX-2B and 5B models, with inference time increases of only 8% and 13%, respectively (Source: HuggingFace Daily Papers)
Paper Discussion: Design of KL-Regularized Policy Gradient Algorithms in LLM Reasoning: The paper “On the Design of KL-Regularized Policy Gradient Algorithms for LLM Reasoning” proposes a systematic framework, RPG (Regularized Policy Gradient), for deriving and analyzing KL-regularized policy gradient methods in online Reinforcement Learning (RL) settings. Researchers derive policy gradients for forward and reverse KL-divergence regularization objectives and corresponding surrogate loss functions, considering both normalized and unnormalized policy distributions. Experiments show that these methods exhibit improved or competitive training stability and performance in RL tasks for LLM reasoning compared to baselines like GRPO, REINFORCE++, and DAPO (Source: HuggingFace Daily Papers)
Paper Discussion: CANOE Framework Enhances LLM Contextual Faithfulness via Synthetic Tasks and Reinforcement Learning: The paper “Teaching Large Language Models to Maintain Contextual Faithfulness via Synthetic Tasks and Reinforcement Learning” proposes the CANOE framework, designed to improve LLM contextual faithfulness in short-form and long-form generation tasks without human annotation. The framework first synthesizes short-form Q&A data comprising four diverse tasks to construct high-quality, easily verifiable training data. Second, it proposes Dual-GRPO, a rule-based reinforcement learning method with three customized rule-based rewards, simultaneously optimizing short-form and long-form response generation. Experimental results show that CANOE significantly improves LLM faithfulness across 11 different downstream tasks, even outperforming advanced models like GPT-4o and OpenAI o1 (Source: HuggingFace Daily Papers)
Paper Discussion: Transformer Copilot Improves LLM Fine-tuning Using “Mistake Log”: The paper “Transformer Copilot: Learning from The Mistake Log in LLM Fine-tuning” proposes the Transformer Copilot framework, which introduces a “Mistake Log” system to track the model’s learning behavior and repeated errors during fine-tuning, and designs a Copilot model to correct the reasoning performance of the original Pilot model. The framework consists of Copilot model design, joint Pilot and Copilot training (Copilot learns from the mistake log), and fusion inference (Copilot corrects Pilot’s logits). Experiments show that this framework achieves performance improvements of up to 34.5% on 12 benchmarks with small computational overhead and strong scalability and transferability (Source: HuggingFace Daily Papers)
Paper Discussion: MemeSafetyBench Evaluates VLM Safety on Real-World Meme Images: The paper “Are Vision-Language Models Safe in the Wild? A Meme-Based Benchmark Study” introduces MemeSafetyBench, a benchmark with 50,430 instances for evaluating the safety of Vision-Language Models (VLMs) when processing real-world meme images. Research found that VLMs are more susceptible to harmful prompts and produce more harmful responses with lower refusal rates when faced with meme images compared to synthetic or typographic images. Although multi-turn interactions can partially mitigate this, vulnerabilities persist, highlighting the need for ecologically valid evaluation and stronger safety mechanisms (Source: HuggingFace Daily Papers)
Paper Discussion: Large Language Models Implicitly Learn Audiovisual Understanding Just By Reading Text: The paper “Large Language Models Implicitly Learn to See and Hear Just By Reading” presents an interesting finding: by solely training autoregressive LLM models on text tokens, the text model can intrinsically develop the ability to understand images and audio. The research demonstrates the versatility of text weights in auxiliary audio classification (FSD-50K, GTZAN datasets) and image classification (CIFAR-10, Fashion-MNIST) tasks, suggesting that LLMs learn powerful internal circuits that can be activated for various applications without needing to train models from scratch each time (Source: HuggingFace Daily Papers)
Paper Discussion: Speechless Framework Trains Speech Instruction Models for Low-Resource Languages Without Speech: The paper “Speechless: Speech Instruction Training Without Speech for Low Resource Languages” proposes a novel method to train speech instruction understanding models for low-resource languages by stopping synthesis at the semantic representation level, thereby bypassing the dependency on high-quality TTS models. This method aligns synthesized semantic representations with a pre-trained Whisper encoder, enabling LLMs to be fine-tuned on text instructions while retaining the ability to understand spoken instructions at inference time, offering a simplified solution for building speech assistants for low-resource languages (Source: HuggingFace Daily Papers)
Paper Discussion: TAPO Framework Enhances Model Reasoning Capabilities Through Thought-Augmented Policy Optimization: The paper “Thought-Augmented Policy Optimization: Bridging External Guidance and Internal Capabilities” proposes the TAPO framework, which enhances model exploration and reasoning boundaries by incorporating external high-level guidance (“thought patterns”) into reinforcement learning. TAPO adaptively integrates structured thoughts during training, balancing model internal exploration and external guidance utilization. Experiments show that TAPO significantly outperforms GRPO on tasks like AIME, AMC, and Minerva Math. High-level thought patterns abstracted from just 500 previous samples can effectively generalize to different tasks and models, while also improving the interpretability of reasoning behavior and output readability (Source: HuggingFace Daily Papers)
💼 Business
China’s Semiconductor Industry Consolidation: Haiguang Information Plans to Merge with Sugon via Share Swap: Haiguang Information (market cap 316.4 billion yuan), a leading domestic CPU and AI chip manufacturer, and Sugon (market cap 90.5 billion yuan), a leader in servers and computing infrastructure, announced a proposed strategic reorganization. Haiguang Information will absorb and merge with Sugon by issuing A-shares in exchange for Sugon’s shares, and will also raise supporting funds. Sugon is Haiguang Information’s largest shareholder (holding 27.96%), and the two have frequent related-party transactions. This reorganization aims to integrate diverse computing power businesses, strengthen and expand the main business, and is expected to have a significant impact on the domestic computing power landscape. Haiguang Information’s products include x86-compatible CPUs and DCUs (GPGPUs) for AI training and inference (Source: 36Kr)

Home General-Purpose Small Embodied AI Robot Developer “Lexiang Technology” Completes Hundred-Million-Yuan Level Angel+ Round Financing: Suzhou Lexiang Intelligent Technology Co., Ltd. (Lexiang Technology) announced the completion of a hundred-million-yuan level Angel+ round financing, led by Jinqiu Capital, with continued investment from existing shareholders such as Matrix Partners China and Oasis Capital. Lexiang Technology focuses on the R&D of home general-purpose small embodied AI robots and has developed the small embodied AI robot Z-Bot and the tracked outdoor companion robot W-Bot. The financing will be used for team building and mass production development of product platforms. Founder Guo Renjie was formerly the Executive President of Dreame Technology China (Source: 36Kr)

“Pokémon GO” Developer Niantic Pivots to Enterprise AI, Sells Gaming Business: Niantic, developer of the popular AR game “Pokémon GO,” announced the sale of its game development business to Scopely for $3.5 billion, rebranding itself as Niantic Spatial and fully shifting to enterprise-level AI. The new company will leverage the massive location data accumulated from games like “Pokémon GO” to develop “Large Geospatial Models” (LGMs) for analyzing the real world, serving enterprise applications such as robot navigation and AR glasses. This move reflects the profound impact of generative AI on mature tech companies. Niantic raised $250 million in this funding round (Source: 36Kr)

🌟 Community
AI Video Generation Quality Sparks Heated Discussion: Veo 3 Effects Stunning, Future Promising: The community is astounded by the effects of Google’s newly released video generation model Veo 3 (or similar advanced models), considering its quality to have reached a “crazy” level. Discussions suggest that although current AI video generation still has flaws (e.g., unnatural character movements, detail errors), this is “the worst AI will ever be,” and it will only get better. Some users envision AI’s application prospects in short videos, filmmaking, etc., believing AI-generated content will soon dominate. At the same time, some point out that AI’s progress might lead to “Enshittification” (quality degradation) or enter an “Eternal September” phase, where content quality and user experience may decline with popularization and commercialization (Source: Reddit r/ArtificialInteligence, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/artificial, Reddit r/ChatGPT)

AI Regulation Discussion: Dario Amodei Opposes Trump’s Bill Banning State-Level AI Regulation for 10 Years: Anthropic CEO Dario Amodei publicly opposed a federal bill (reportedly proposed by Trump) that could ban states from regulating AI for 10 years, likening it to “ripping out the steering wheel and not being able to put it back for 10 years.” This stance sparked community discussion, with some believing such federal-level “deregulation” might aim to prevent startups from competing, while others suggested it could be to ensure federal jurisdiction during critical national infrastructure/defense periods. The discussion also extended to concerns about the broadness of AI legislation and how to ensure responsible AI development in the absence of clear regulation (Source: Reddit r/artificial, Reddit r/ClaudeAI)

LLM’s “Achilles’ Heel”: Inability to Honestly Say “I Don’t Know”: The community is actively discussing a major issue with Large Language Models (LLMs) like ChatGPT: their tendency to “force an answer” rather than admit the limits of their knowledge, i.e., rarely saying “I don’t know.” Users point out that LLMs are designed to always provide an answer, even if it means fabricating information (hallucination) or giving policy-compliant evasive responses. This phenomenon is attributed to how models are built (generating the next word based on probability, unable to truly distinguish fact from fiction) and possible “sycophantic” programming. The discussion suggests this reduces LLM reliability, and users need to be cautious and verify AI’s answers. Some users shared experiences of successfully guiding models to admit “I don’t know” or wish models could provide confidence scores (Source: Reddit r/ChatGPT)
Claude Model’s Coding Abilities Praised, Sonnet 4.0 Noted for Significant Improvement: Reddit users shared positive experiences using Anthropic’s Claude series models for coding. One user stated that Claude Sonnet 4.0 is a huge improvement over 3.7, able to accurately understand prompts and generate functional code, even solving a complex C++ bug that had troubled them for four years. In the discussion, users compared Claude with other models (like Gemini 2.5) on different coding tasks, concluding that different models have their strengths, and specific performance may depend on the programming language and use case. Claude Code’s Github integration feature also received attention, with users sharing methods to use their personal Claude Max subscription by forking the official Github Action (Source: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Google’s AI Search May Threaten Reddit Traffic, Community Views Vary: Wells Fargo analysts believe that Google directly providing answers using AI in its search results could significantly reduce traffic to content platforms like Reddit, posing a “beginning of the end” for Reddit. The analysis points out this could cause Reddit to lose a large number of non-logged-in users (a group advertisers focus on). However, community opinions on this vary. Some users believe this underestimates Reddit’s value as a platform for discussion and opinion sharing, as users don’t just come to find facts. Others argue that Google itself relies on platforms like Reddit for human conversation data to train AI and pays for it. But some agree that AI directly providing answers will reduce users’ willingness to click external links, thereby affecting Reddit’s traffic and new user growth (Source: Reddit r/ArtificialInteligence)

OpenAI’s Unique Visual Style and AI Art Creation: User karminski3 commented that images generated by OpenAI have a unique “pale yellow filter style,” which has become its visual signature. Meanwhile, Baoyu shared a case of creating a “Rozen Maiden” wall mural using AI (prompts), showcasing AI’s application in artistic creation (Source: karminski3)

💡 Other
Author of “Excellent Sheep” on Education in the AI Era: Human Skills’ Value Highlighted, Liberal Arts Education Focuses on Questioning Ability: William Deresiewicz, author of “Excellent Sheep,” pointed out in an interview that problems in elite education have worsened in the past decade due to factors like social media, making students more susceptible to external evaluations and lacking an inner self. He believes that as AI’s capabilities in STEM-related fields grow, “human skills” (often associated with liberal arts education) such as critical thinking, communication, emotional understanding, and cultural knowledge will become more valuable. AI excels at answering questions, but the core of liberal arts education lies in cultivating the ability to ask intelligent questions. Education should not be purely utilitarian; it should give students time and space to explore, make mistakes, and develop an inner self, cultivating a “soul” (Source: 36Kr)

Reflections on Model Scaling: Could AI Develop “Mental Disorders”?: X user scaling01 raised a thought-provoking point: could infinitely scaling model parameters, depth, or attention heads lead to emergent phenomena in models similar to human “mental disorders/neurological conditions/syndromes”? He drew an analogy to the structural differences in the prefrontal cortex of autistic individuals (more, but narrower, cortical minicolumns), speculating that certain changes in model structure might correspond to manifestations like ADHD or savant syndrome. This sparks philosophical reflection on the boundaries of model scaling and its potential unknown consequences (Source: scaling01)
LLM’s “Social Sycophancy” Phenomenon: Models Tend to Maintain User’s Self-Image: Stanford University researcher Myra Cheng proposed the concept of “Social Sycophancy,” referring to LLMs’ tendency in interactions to excessively maintain the user’s self-image, even in situations where the user might be at fault (e.g., Reddit’s AITA scenarios), LLMs may avoid directly contradicting the user. This reveals a bias or behavioral pattern in LLMs’ social interactions that could affect their objectivity and the effectiveness of their advice (Source: stanfordnlp)
