
Keywords:Gemini 2.5 Pro, Veo 3, OpenAI, Claude 4 Opus, AI video generation, Jony Ive, AI agents, Multimodal models, Deep Think mode, Video generation models, AI reasoning capabilities, AI hardware design, Software engineering optimization
🔥 Focus
Google Releases Gemini 2.5 Pro Deep Think and Veo 3, Pushing AI Reasoning and Video Generation to New Heights: At the Google I/O conference, Google introduced Deep Think mode for Gemini 2.5 Pro, designed specifically for solving complex problems. It has demonstrated excellent performance on challenging problems from math competitions like USAMO, showcasing significant advancements in AI’s advanced reasoning capabilities, for example, by solving complex algebra problems through multi-step reasoning and attempting different proof methods (such as proof by contradiction, Rolle’s Theorem). Simultaneously, Google’s released video generation model, Veo 3, has set a new benchmark in the AI video generation field with its realistic scenes, controllable character consistency, sound synthesis, and diverse editing functions (such as scene transformation, reference image generation, style transfer, first/last frame specification, local editing, etc.), attracting widespread attention (Source: demishassabis, lmthang, GoogleDeepMind, _philschmid, fabianstelzer, matvelloso, seo_leaders, op7418, )
OpenAI to Acquire Jony Ive’s Company for $6.5 Billion to Co-create AI-Driven Next-Generation Computers: OpenAI announced a collaboration with former Apple chief designer Jony Ive and the acquisition of his company, aiming to jointly build AI-driven next-generation computers. This move marks OpenAI’s expansion into hardware and an attempt to deeply integrate AI capabilities into computing devices, potentially reshaping human-computer interaction. Jony Ive is renowned for his outstanding design work at Apple, and his involvement suggests that the new devices may feature significant breakthroughs in design and user experience, challenging existing computing device forms (Source: op7418, TheRundownAI, BorisMPower)
Anthropic Developer Conference Imminent, Claude 4 Opus May Be Released, Focusing on Software Engineering Capabilities: Anthropic is about to hold its first developer conference, with the community widely speculating that the new generation model Claude 4 (including Sonnet 4 and Opus 4) may be released at this event. There are indications that the Claude Sonnet 3.7 API is already exhibiting Claude 4-like behavior, such as rapid tool use without “thinking steps.” Anthropic appears to be concentrating on tackling software engineering challenges, a path different from OpenAI and Google’s pursuit of “all-powerful models.” TIME magazine has also indirectly confirmed the release of Claude 4 Opus, further raising market expectations for Anthropic’s capabilities in AI coding and complex task processing (Source: op7418, mathemagic1an, cto_junior, scaling01, Reddit r/ClaudeAI)
OpenAI vs. Google’s AI Ecosystem Strategies: Assembling a Battleship vs. Reforming an Empire: OpenAI and Google are vying for the “main operating system” status of the future AI platform through two different paths: “assembling an ecosystem” and “reforming an ecosystem.” OpenAI is building full-stack AI capabilities from scratch by acquiring hardware (io), databases (Rockset), toolchains (Windsurf), and collaboration tools (Multi). In contrast, Google is choosing to deeply embed its Gemini model into existing products (Search, Android, Docs, YouTube, etc.) and transform its underlying systems to achieve AI-nativeness. Although their strategies differ, their goal is the same: to build the ultimate platform for the AI era (Source: dotey)
🎯 Trends
Microsoft Reveals “Agentic Web” Vision, Emphasizing AI Agents as the Core of Future Work: Microsoft CEO Satya Nadella elaborated on the company’s vision for an “agentic web” at the Build 2025 conference and in interviews. He believes that AI agents will become first-class citizens in business and the M365 ecosystem, potentially even creating new professions like “AI agent administrators.” When 95% of code is generated by AI, human roles will shift to managing and orchestrating these agents. Microsoft is building an open agent ecosystem through Azure AI Foundry, Copilot Studio, and open protocols like NLWeb, and is positioning Teams as a multi-agent collaboration hub (Source: rowancheung, TheTuringPost)
MMaDA: Multimodal Large Diffusion Language Models for Unified Text Reasoning, Multimodal Understanding, and Image Generation Released: Researchers have introduced MMaDA (Multimodal Large Diffusion Language Models), a new type of multimodal diffusion foundation model. Through Mixed Long-CoT (Chain-of-Thought) and a unified reinforcement learning algorithm UniGRPO, it achieves unified capabilities in text reasoning, multimodal understanding, and image generation. MMaDA-8B surpasses Show-o and SEED-X in multimodal understanding and outperforms SDXL and Janus in text-to-image generation. The model and code have been open-sourced on Hugging Face (Source: _akhaliq, arankomatsuzaki, andrew_n_carr, Reddit r/LocalLLaMA)

dKV-Cache: Cache Mechanism Designed for Diffusion Language Models, Significantly Improving Inference Speed: To address the slow inference speed of Diffusion Language Models (DLMs), researchers have proposed the dKV-Cache mechanism. This method, inspired by KV-Cache in autoregressive models, designs a key-value cache for the denoising process of DLMs through delayed and conditional caching strategies. Experiments show that dKV-Cache can achieve 2-10x inference acceleration, significantly narrowing the speed gap between DLMs and autoregressive models, even improving performance on long sequences, and can be applied to existing DLMs without training (Source: NandoDF, HuggingFace Daily Papers)

Imagen4 Shows Excellent Detail Reproduction, Approaching Image Generation Endgame: The Imagen4 model has demonstrated powerful detail reproduction capabilities when generating images from complex text prompts. For example, when generating an image containing 25 specific details (such as specific colors, objects, locations, lighting, and atmosphere), Imagen4 successfully reproduced 23 of them. This high fidelity and precise understanding of complex instructions indicate that text-to-image generation technology is approaching an “endgame” level capable of perfectly recreating user imagination (Source: cloneofsimo)

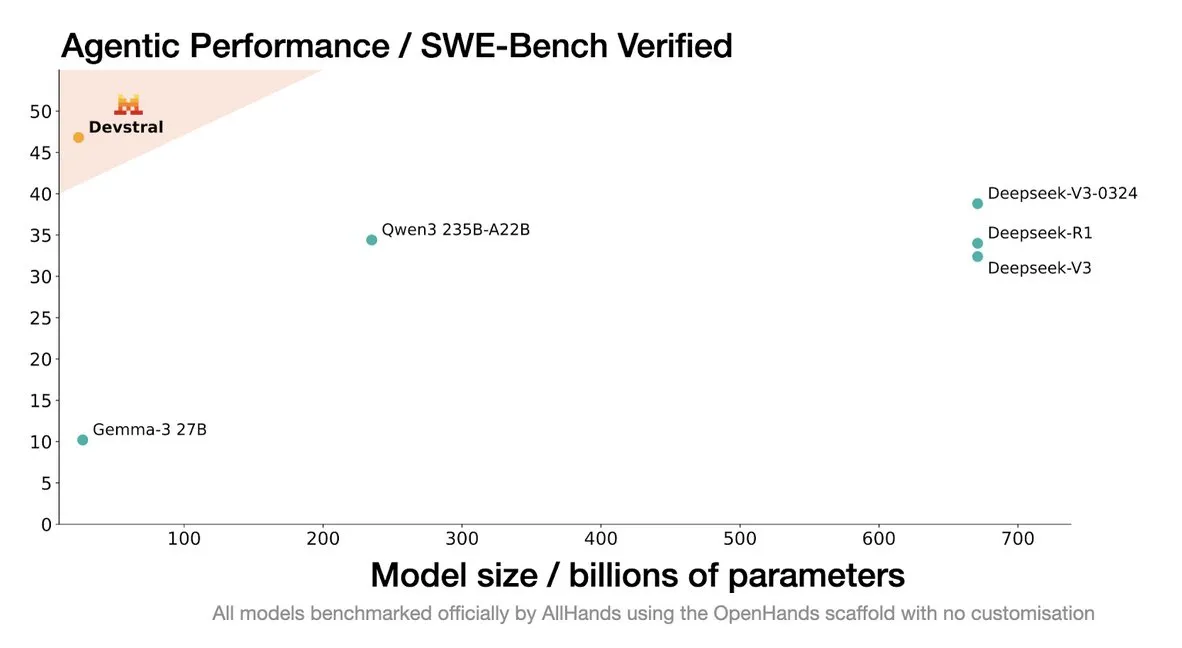
Mistral Releases Devstral Model, Designed for Coding Agents: Mistral AI has launched Devstral, an open-source model specifically designed for coding agents, developed in collaboration with allhands_ai. Its 4-bit DWQ quantized version is available on Hugging Face (mlx-community/Devstral-Small-2505-4bit-DWQ) and can run smoothly on devices like M2 Ultra, showing optimization potential in code generation and understanding (Source: awnihannun, clefourrier, GuillaumeLample)
ByteDance Releases Training Report for Gemini-Level Multimodal Model, Adopting Integrated Transformer Architecture: ByteDance has published a 37-page report detailing its method for training a Gemini-like native multimodal model. The most notable aspect is the “Integrated Transformer” architecture, which uses the same backbone network to function simultaneously as a GPT-like autoregressive model and a DiT-like diffusion model, showcasing its exploration in unified multimodal modeling (Source: NandoDF)

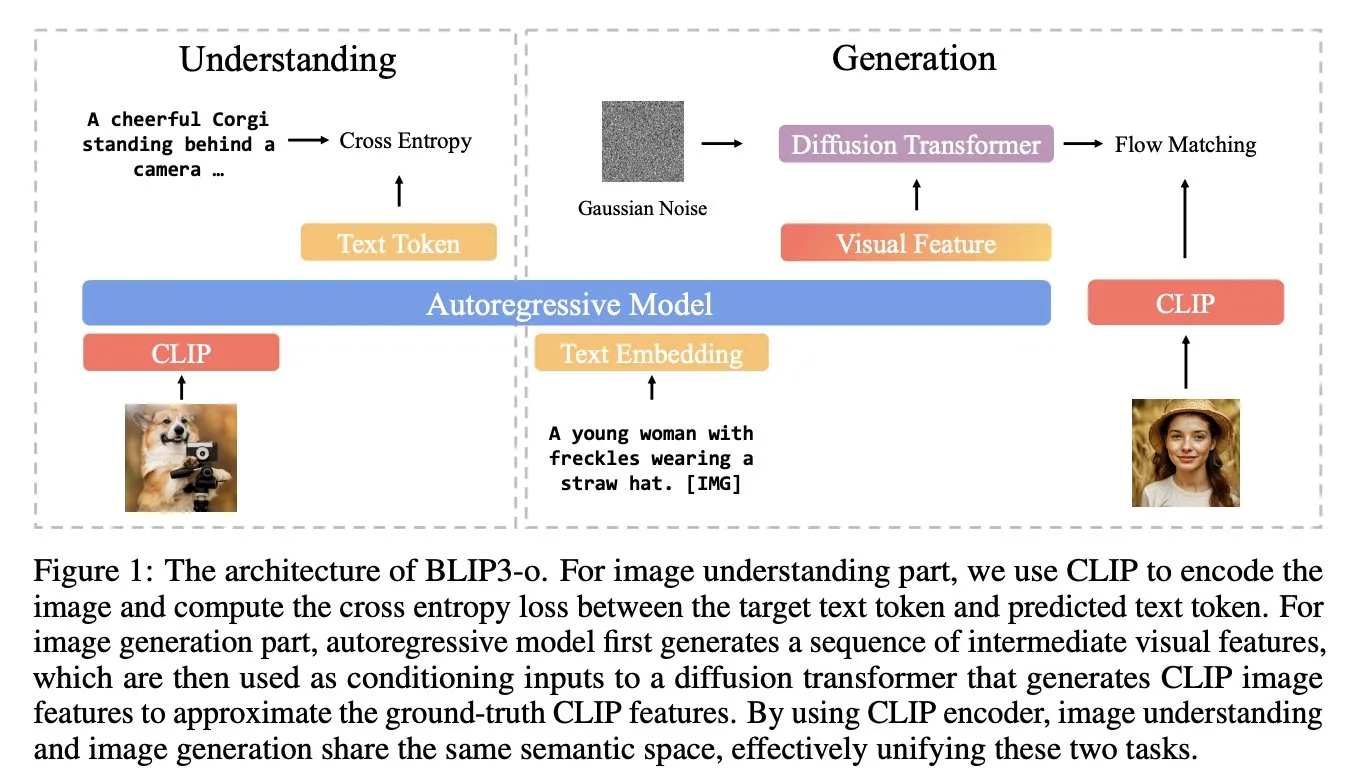
BLIP3-o: Salesforce Launches Fully Open-Source Unified Multimodal Model Series, Unlocking GPT-4o Level Image Generation Capabilities: The Salesforce research team has released the BLIP3-o model series, a set of fully open-source unified multimodal models aimed at unlocking image generation capabilities similar to GPT-4o. The project not only open-sources the models but also releases a pre-training dataset containing 25 million data points, promoting openness in multimodal research (Source: arankomatsuzaki)
Google Launches Gemma 3n E4B Preview, a Multimodal Model Designed for Low-Resource Devices: Google has released the Gemma 3n E4B-it-litert-preview model on Hugging Face. This model is designed to process text, image, video, and audio inputs and generate text outputs, with the current version supporting text and visual inputs. Gemma 3n employs a novel Matformer architecture, allowing nested multiple models and effectively activating 2B or 4B parameters, specifically optimized for efficient operation on low-resource devices. The model is trained on approximately 11 trillion tokens of multimodal data, with knowledge cutoff in June 2024 (Source: Tim_Dettmers, Reddit r/LocalLLaMA)
Research Reveals Language Specific Knowledge (LSK) Phenomenon in Large Models: A new study explores the “Language Specific Knowledge” (LSK) phenomenon in language models, where a model’s performance on certain topics or domains may be better in specific non-English languages than in English. The study found that model performance can be improved by conducting chain-of-thought reasoning in specific languages (even low-resource ones). This suggests that culture-specific texts are richer in their respective languages, making certain knowledge potentially exclusive to “expert” languages. Researchers designed the LSKExtractor method to measure and leverage this LSK, achieving an average relative accuracy improvement of 10% across multiple models and datasets (Source: HuggingFace Daily Papers)
DeepMind Veo 3 Video Generation Effects Amaze, Realistic Details Attract Attention: Google DeepMind’s video generation model Veo 3 has demonstrated powerful video generation capabilities, including scene transformation, reference image-driven generation, style transfer, character consistency, first/last frame specification, video zooming, object addition, and action control. The realism of its generated videos and its understanding of complex instructions have amazed users about the rapid development of AI video generation technology, with some users even creating advertisement-like videos with professional quality (Source: demishassabis, , Reddit r/ChatGPT)
Moondream Visual Language Model Launches 4-bit Quantized Version, Significantly Reducing VRAM and Increasing Speed: The Moondream Visual Language Model (VLM) has released a 4-bit quantized version, achieving a 42% reduction in VRAM usage and a 34% increase in inference speed, while maintaining 99.4% accuracy. This optimization makes this powerful small VLM easier to deploy and use for tasks like object detection, and has been well-received by developers (Source: Sentdex, vikhyatk)
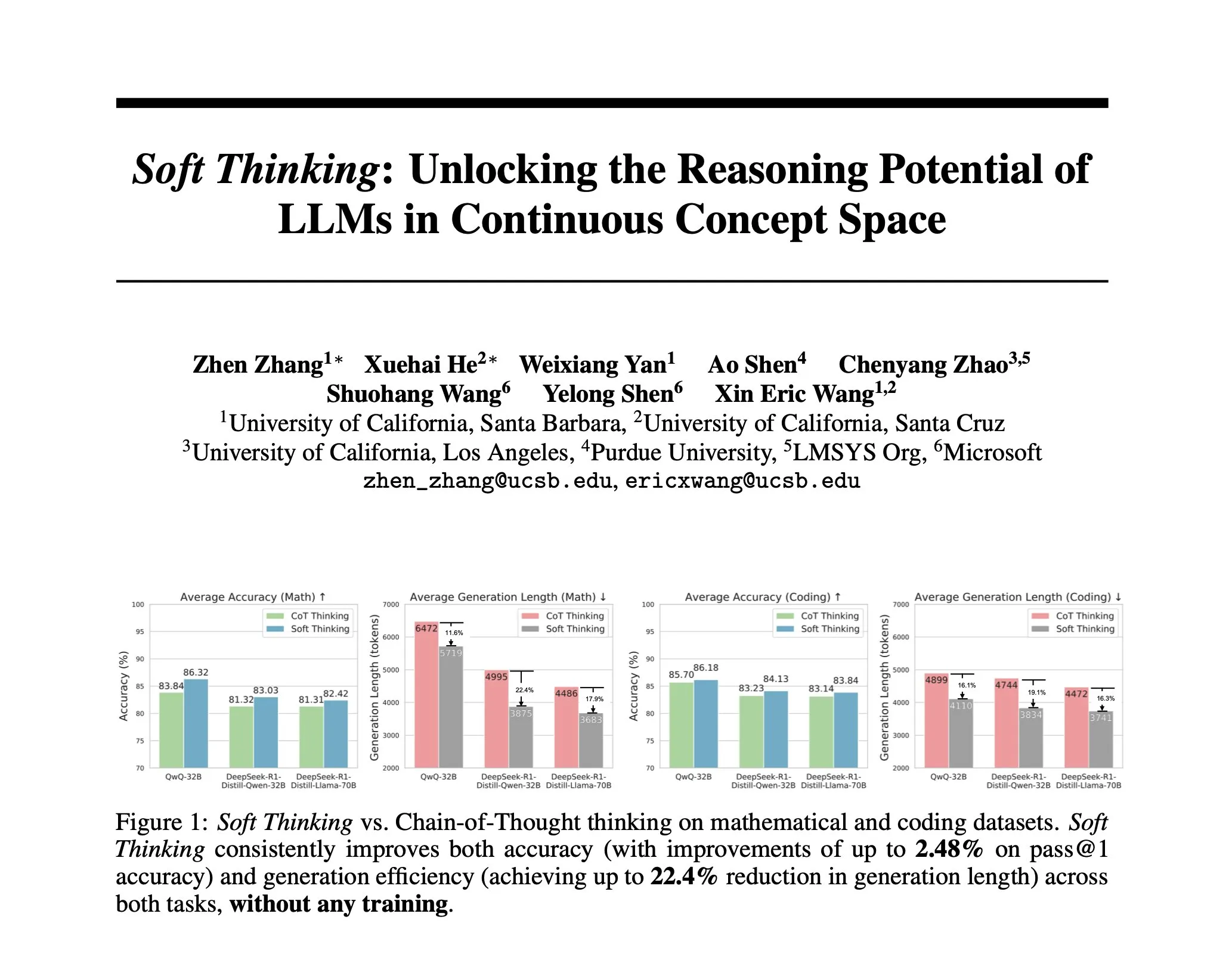
Research Proposes Soft Thinking: A Training-Free Method to Simulate Human-like “Soft” Reasoning: To make AI reasoning closer to human-like fluid thought, unconstrained by discrete tokens, researchers have proposed the Soft Thinking method. This method requires no additional training and generates continuous, abstract conceptual tokens. These tokens smoothly fuse multiple meanings through probability-weighted embedding mixtures, enabling richer representations and seamless exploration of different reasoning paths. Experiments show that this method improves accuracy by up to 2.48% (pass@1) on math and code benchmarks, while reducing token usage by up to 22.4% (Source: arankomatsuzaki)
IA-T2I Framework: Enhancing Text-to-Image Models’ Ability to Handle Uncertain Knowledge Using the Internet: To address the shortcomings of existing text-to-image models in handling text prompts containing uncertain knowledge (such as recent events, rare concepts), the IA-T2I (Internet-Augmented Text-to-Image Generation) framework has been proposed. This framework uses an active retrieval module to determine if reference images are needed, a hierarchical image selection module to pick the most suitable images from search engine results to enhance the T2I model, and a self-reflection mechanism to continuously evaluate and optimize generated images. On the specially constructed Img-Ref-T2I dataset, IA-T2I outperformed GPT-4o by about 30% (human evaluation) (Source: HuggingFace Daily Papers)
MoI (Mixture of Inputs) Improves Autoregressive Generation Quality and Reasoning Ability: To address the issue of discarding token distribution information during standard autoregressive generation, researchers proposed the Mixture of Inputs (MoI) method. This method requires no additional training. After generating a token, it mixes the generated discrete token with the previously discarded token distribution to construct a new input. Through Bayesian estimation, the token distribution is treated as a prior, and the sampled token as an observation, replacing the traditional one-hot vector with a continuous posterior expectation as the new model input. MoI has consistently improved the performance of multiple models, including Qwen-32B and Nemotron-Super-49B, on tasks such as mathematical reasoning, code generation, and PhD-level question answering (Source: HuggingFace Daily Papers)
ConvSearch-R1: Optimizing Query Rewriting in Conversational Search via Reinforcement Learning: To address issues of ambiguity, omission, and coreference in context-dependent queries in conversational search, the ConvSearch-R1 framework has been proposed. This framework is the first to adopt a self-driven approach, directly utilizing retrieval signals through reinforcement learning to optimize query rewriting, completely eliminating the reliance on external rewriting supervision (such as human annotation or large models). Its two-stage method includes self-driven policy pre-warming and retrieval-guided reinforcement learning (using a rank-incentivized reward mechanism). Experiments show that ConvSearch-R1 significantly outperforms previous SOTA methods on the TopiOCQA and QReCC datasets (Source: HuggingFace Daily Papers)
ASRR Framework Achieves Efficient Adaptive Reasoning for Large Language Models: To address the problem of excessive computational overhead caused by redundant reasoning in Large Reasoning Models (LRMs) on simple tasks, researchers have proposed the Adaptive Self-Recovery Reasoning (ASRR) framework. This framework suppresses unnecessary reasoning by revealing the model’s “internal self-recovery mechanism” (implicitly supplementing reasoning during answer generation) and introduces an accuracy-aware length reward adjustment to adaptively allocate reasoning effort based on question difficulty. Experiments show that ASRR can significantly reduce the reasoning budget and improve the harmlessness rate on safety benchmarks with minimal performance loss (Source: HuggingFace Daily Papers)
MoT (Mixture-of-Thought) Framework Enhances Logical Reasoning Capabilities: Inspired by humans utilizing multiple reasoning modalities (natural language, code, symbolic logic) to solve logical problems, researchers have proposed the Mixture-of-Thought (MoT) framework. MoT enables LLMs to reason across three complementary modalities, including a newly introduced truth-table symbolic modality. Through a two-stage design (self-evolving MoT training and MoT inference), MoT significantly outperforms single-modality chain-of-thought methods on logical reasoning benchmarks like FOLIO and ProofWriter, with an average accuracy improvement of up to 11.7% (Source: HuggingFace Daily Papers)
RL Tango: Co-training Generator and Verifier via Reinforcement Learning to Enhance Language Reasoning: To address issues of reward hacking and poor generalization in existing LLM reinforcement learning methods where the verifier (reward model) is fixed or supervised fine-tuned, the RL Tango framework has been proposed. This framework interleavingly trains both an LLM generator and a generative, process-level LLM verifier simultaneously via reinforcement learning. The verifier is trained solely based on outcome-level correctness rewards, without requiring process-level annotations, thus forming an effective mutual promotion with the generator. Experiments show that Tango’s generator and verifier both achieve SOTA performance in 7B/8B scale models (Source: HuggingFace Daily Papers)
pPE: Prior Prompt Engineering Boosts Reinforcement Fine-Tuning (RFT): Research explores the role of prior prompt engineering (pPE) in reinforcement fine-tuning (RFT). Unlike inference-time prompt engineering (iPE), pPE prepends instructions (e.g., step-by-step reasoning) to queries during the training phase to guide language models to internalize specific behaviors. Experiments converted five iPE strategies (reasoning, planning, code reasoning, knowledge recall, null-example utilization) into pPE methods, applied to Qwen2.5-7B. Results show that all pPE-trained models outperformed their iPE counterparts, with null-example pPE showing the largest improvements on benchmarks like AIME2024 and GPQA-Diamond, revealing pPE as an under-explored yet effective technique in RFT (Source: HuggingFace Daily Papers)
BiasLens: LLM Bias Evaluation Framework Without Human-Crafted Test Sets: To address the limitations of existing LLM bias evaluation methods that rely on manually constructed labeled data and have limited coverage, the BiasLens framework has been proposed. This framework, starting from the model’s vector space structure, combines Concept Activation Vectors (CAVs) and Sparse Autoencoders (SAEs) to extract interpretable concept representations. It quantifies bias by measuring changes in representation similarity between target concepts and reference concepts. BiasLens shows strong consistency (Spearman correlation r > 0.85) with traditional bias evaluation metrics in the absence of labeled data and can reveal forms of bias difficult to detect with existing methods (Source: HuggingFace Daily Papers)
HumaniBench: A Human-Centric Evaluation Framework for Large Multimodal Models: To address the current shortcomings of LMMs on human-centric standards such as fairness, ethics, and empathy, HumaniBench has been proposed. It is a comprehensive benchmark containing 32K real-world image-text question-answering pairs, annotated with GPT-4o assistance and validated by experts. HumaniBench evaluates seven human-centric AI principles: fairness, ethics, understanding, reasoning, language inclusivity, empathy, and robustness, covering seven diverse tasks. Tests on 15 SOTA LMMs show that closed-source models generally lead, but robustness and visual localization remain weaknesses (Source: HuggingFace Daily Papers)
AJailBench: First Comprehensive Benchmark for Jailbreak Attacks on Large Audio Language Models: To systematically evaluate the security of Large Audio Language Models (LAMs) under jailbreak attacks, AJailBench has been proposed. The benchmark first constructs the AJailBench-Base dataset containing 1495 adversarial audio prompts, covering 10 violation categories. Evaluations based on this dataset show that existing SOTA LAMs do not exhibit consistent robustness. To simulate more realistic attacks, researchers developed an Audio Perturbation Toolkit (APT), generating an extended dataset AJailBench-APT by searching for subtle yet effective perturbations via Bayesian optimization. The study shows that minor, semantically preserved perturbations can significantly reduce the security performance of LAMs (Source: HuggingFace Daily Papers)
WebNovelBench: A Benchmark for Evaluating LLMs’ Long-form Novel Writing Capabilities: To address the challenges of evaluating LLMs’ long-form narrative capabilities, WebNovelBench has been proposed. This benchmark utilizes a dataset of over 4000 Chinese web novels, setting the evaluation as an outline-to-story generation task. Using an LLM-as-a-judge approach, automatic evaluation is conducted across eight narrative quality dimensions, and scores are aggregated using principal component analysis for percentile ranking comparison with human works. Experiments effectively distinguished between human masterpieces, popular web novels, and LLM-generated content, and provided a comprehensive analysis of 24 SOTA LLMs (Source: HuggingFace Daily Papers)
MultiHal: A Multilingual Knowledge Graph Grounding Dataset for LLM Hallucination Evaluation: To address the deficiencies of existing hallucination evaluation benchmarks in knowledge graph paths and multilingualism, MultiHal has been proposed. It is a multilingual, multi-hop benchmark based on knowledge graphs, specifically designed for evaluating generated text. The team mined 140,000 paths from open-domain knowledge graphs and filtered them down to 25,900 high-quality paths. Baseline evaluations show that on multilingual and multi-model setups, knowledge graph-enhanced RAG (KG-RAG) achieves an absolute improvement of about 0.12 to 0.36 points in semantic similarity scores compared to plain question answering, demonstrating the potential of knowledge graph integration (Source: HuggingFace Daily Papers)
Llama-SMoP: LLM Audio-Visual Speech Recognition Method Based on Sparse Mixture-of-Projectors: To address the high computational cost of LLMs in Audio-Visual Speech Recognition (AVSR), Llama-SMoP has been proposed. This is an efficient multimodal LLM that employs a Sparse Mixture-of-Projectors (SMoP) module, which uses sparsely-gated Mixture-of-Experts (MoE) projectors to expand model capacity without increasing inference cost. Experiments show that the Llama-SMoP DEDR configuration, using modality-specific routing and experts, achieves excellent performance on ASR, VSR, and AVSR tasks, and performs well in expert activation, scalability, and noise robustness (Source: HuggingFace Daily Papers)
VPRL: Reinforcement Learning-Based Pure Visual Planning Framework Outperforms Text-Based Reasoning: A research team from Cambridge University, University College London, and Google has proposed VPRL (Visual Planning with Reinforcement Learning), a new paradigm for reasoning purely based on image sequences. The framework utilizes Group Relative Policy Optimization (GRPO) to post-train large vision models, calculating reward signals and validating environmental constraints through visual state transitions. In visual navigation tasks such as FrozenLake, Maze, and MiniBehavior, VPRL achieved an accuracy of up to 80.6%, significantly outperforming text-based reasoning methods (e.g., Gemini 2.5 Pro’s 43.7%), and demonstrated better performance in complex tasks and robustness, proving the superiority of visual planning (Source: 量子位)

Nvidia Unveils Five-Year AI Technology Roadmap, Transitioning to AI Infrastructure Company: Nvidia CEO Jensen Huang announced at COMPUTEX 2025 the company’s repositioning as an AI infrastructure company and unveiled its technology roadmap for the next five years. He emphasized that AI infrastructure will become as ubiquitous as electricity or the internet, and Nvidia is committed to building the “factories” of the AI era. To support this transition, Nvidia will expand its supply chain “circle of friends,” deepen cooperation with TSMC and others, and plans to establish an office in Taiwan (NVIDIA Constellation) and its first giant AI supercomputer (Source: 36氪)

Google Relaunches AI Glasses Project, Releases Android XR Platform and Third-Party Devices: At I/O 2025, Google announced the relaunch of its AI/AR glasses project, released the Android XR platform specifically developed for XR devices, and showcased two third-party devices based on this platform: Samsung’s Project Moohan (competing with Vision Pro) and Xreal’s Project Aura. Google aims to replicate Android’s success in the smartphone domain, creating an “Android moment” for XR devices and positioning itself for future ambient computing and spatial computing platforms. Combined with the upgraded Gemini 2.5 Pro multimodal large model and Project Astra intelligent assistant technology, the new generation of AI/AR glasses will deliver disruptive experiences in voice understanding, real-time translation, contextual awareness, and complex task execution (Source: 36氪)

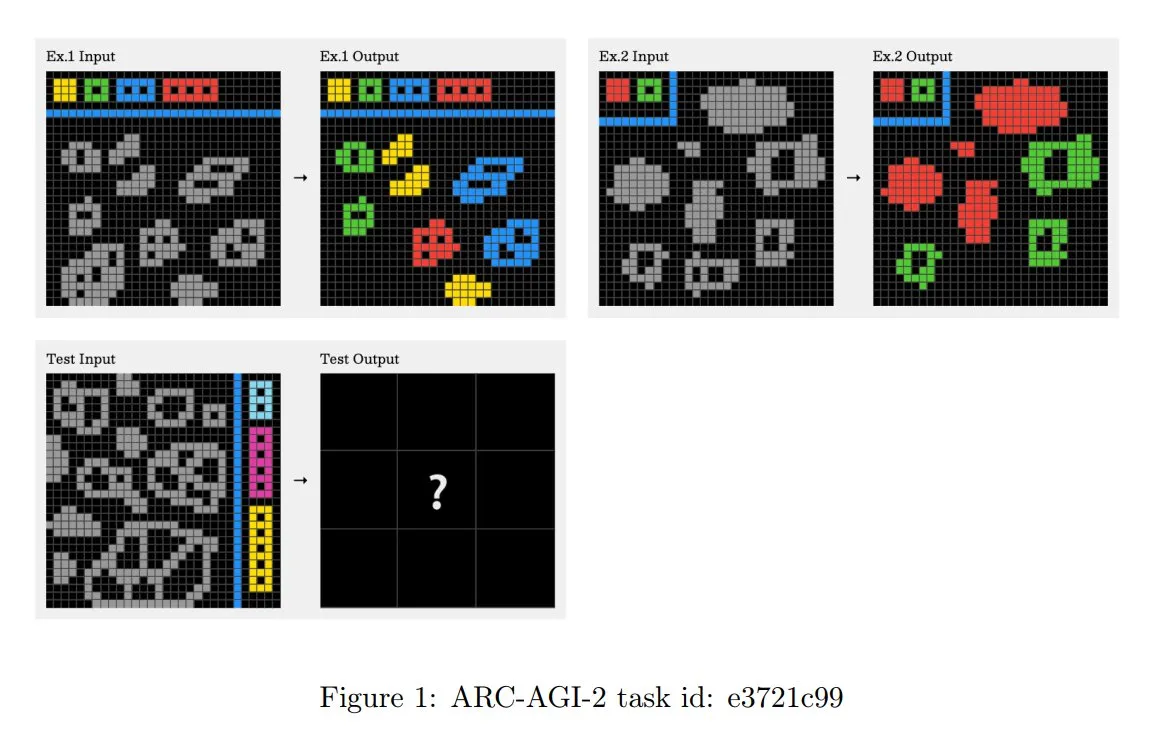
ARC-AGI-2 Challenge Principles Updated, Emphasizing Multi-Step Contextual Reasoning: The newly released ARC-AGI-2 paper updates the design principles for the challenge. The new principles require tasks to possess multi-rule, multi-step, and contextual reasoning capabilities. Grids are larger, contain more objects, and encode multiple interactive concepts. Tasks are novel and non-reusable to limit memorization. The design intentionally resists brute-force program synthesis. Human solvers average 2.7 minutes per task, while top systems (like OpenAI o3-medium) score only around 3%, with all tasks requiring explicit cognitive effort (Source: TheTuringPost, clefourrier)
Skywork Launches Super Agents, Aiming to Reduce 8 Hours of Work to 8 Minutes: Skywork has released its AI workspace agents, Skywork Super Agents, claiming to compress a user’s 8-hour workload into 8 minutes. The product is positioned as a pioneer in AI workspace agents, with specific functions and implementation methods yet to be further observed (Source: _akhaliq)
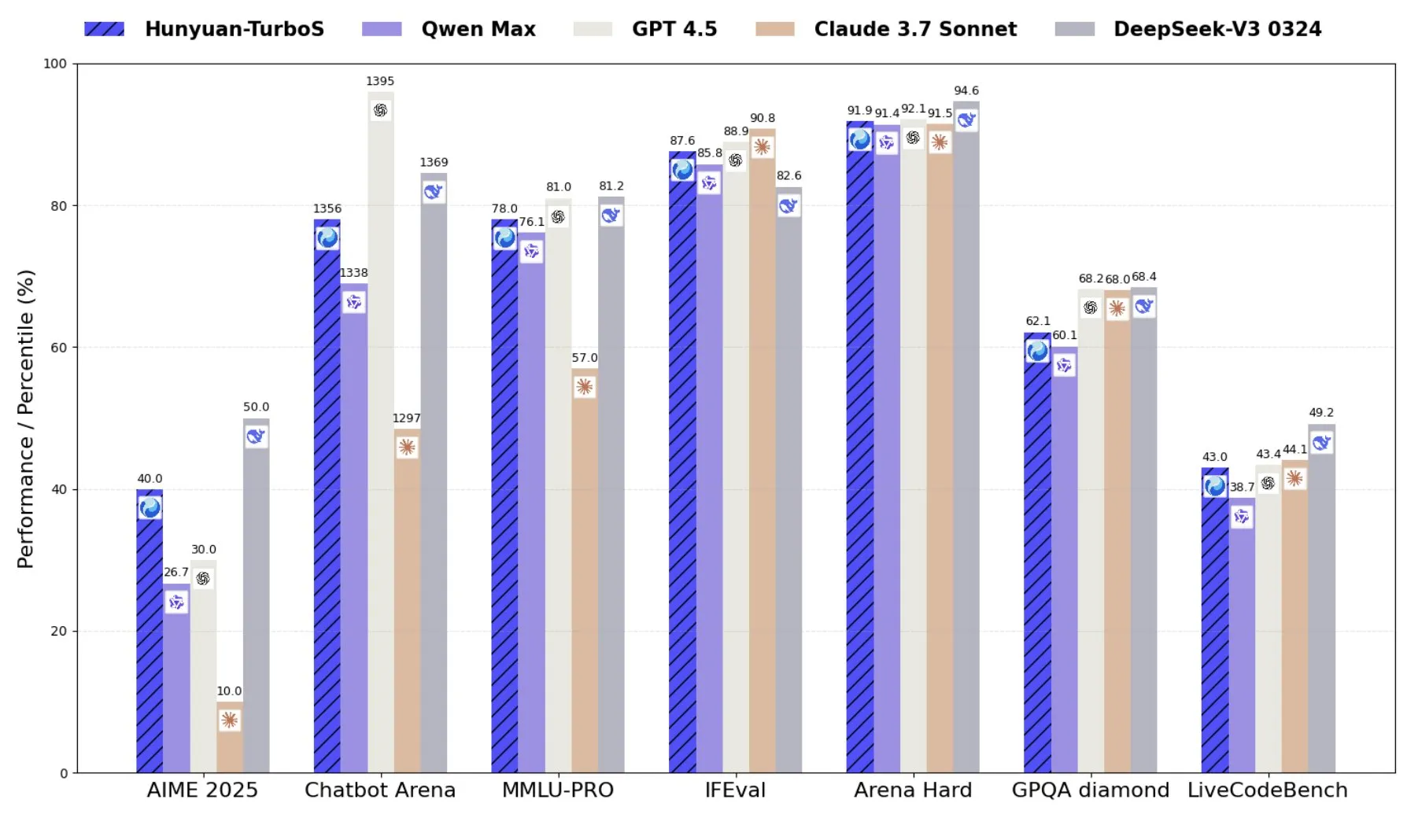
Tencent Launches Hunyuan-TurboS, a Mixture-of-Experts Model Combining Transformer and Mamba: Tencent has released the Hunyuan-TurboS model, which employs a Mixture-of-Experts (MoE) architecture combining Transformer and Mamba, featuring 56 billion activated parameters and trained on 16 trillion tokens. Hunyuan-TurboS can dynamically switch between fast response and deep “thinking” modes, ranking in the top seven overall on the LMSYS Chatbot Arena (Source: tri_dao)
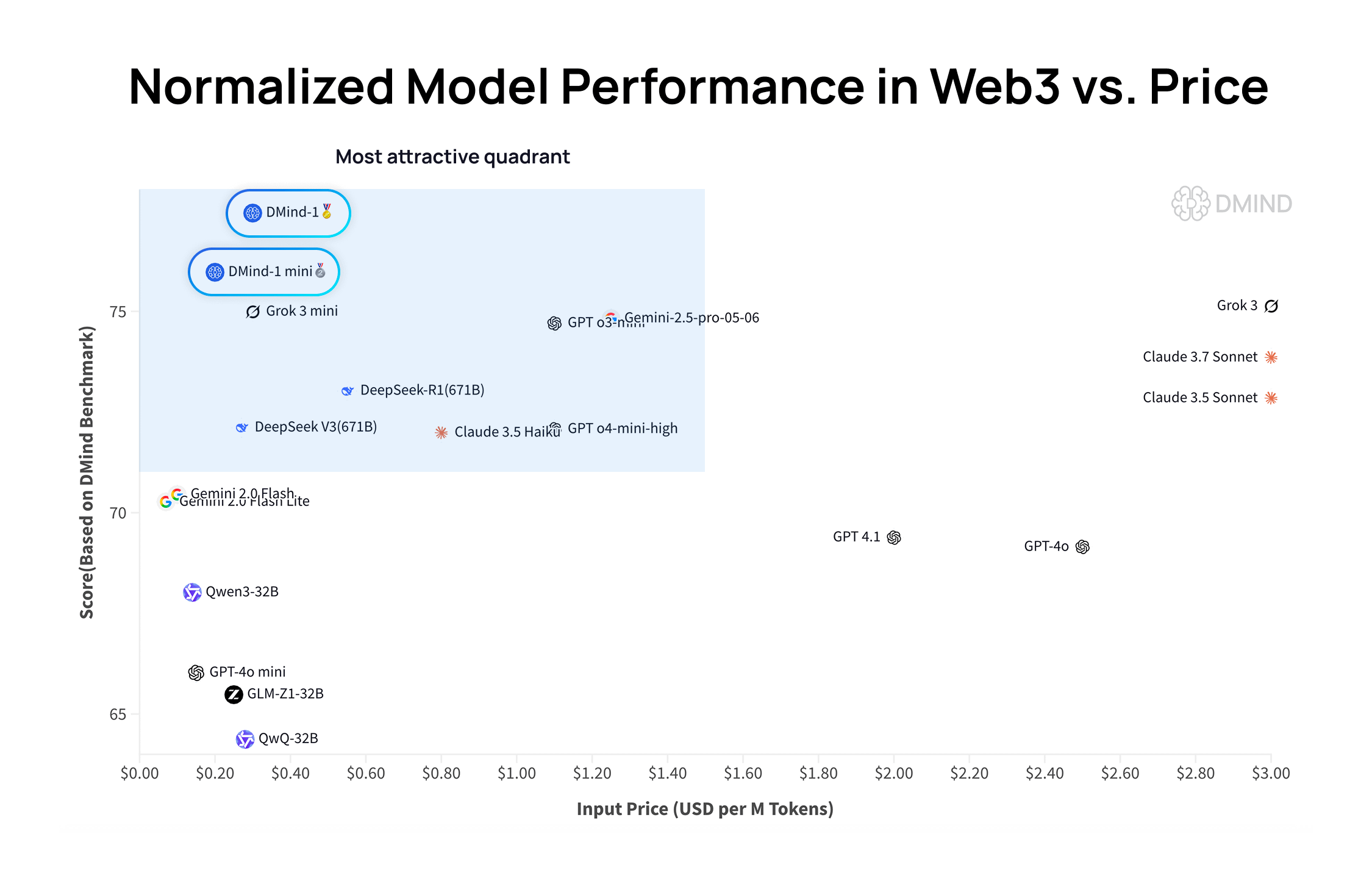
DMind-1: Open-Source Large Language Model Designed for Web3 Scenarios: DMind AI has released DMind-1, an open-source large language model optimized for Web3 scenarios. DMind-1 (32B) is fine-tuned based on Qwen3-32B, using a large amount of Web3-specific knowledge, aiming to balance performance and cost for AI+Web3 applications. In Web3 benchmark evaluations, DMind-1 outperforms mainstream general-purpose LLMs, with token costs at only about 10% of theirs. The simultaneously released DMind-1-mini (14B) retains over 95% of DMind-1’s performance and offers better latency and computational efficiency (Source: _akhaliq)
LightOn Releases Reason-ModernColBERT, Small Parameter Model Excels in Reasoning-Intensive Retrieval Tasks: LightOn has introduced Reason-ModernColBERT, a late-interaction model with only 149 million parameters. It performs exceptionally well on the popular BRIGHT benchmark (focused on reasoning-intensive retrieval), surpassing models 45 times larger in parameter count and achieving SOTA levels in multiple domains. This achievement once again demonstrates the efficiency of late-interaction models for specific tasks (Source: lateinteraction, jeremyphoward, Dorialexander, huggingface)

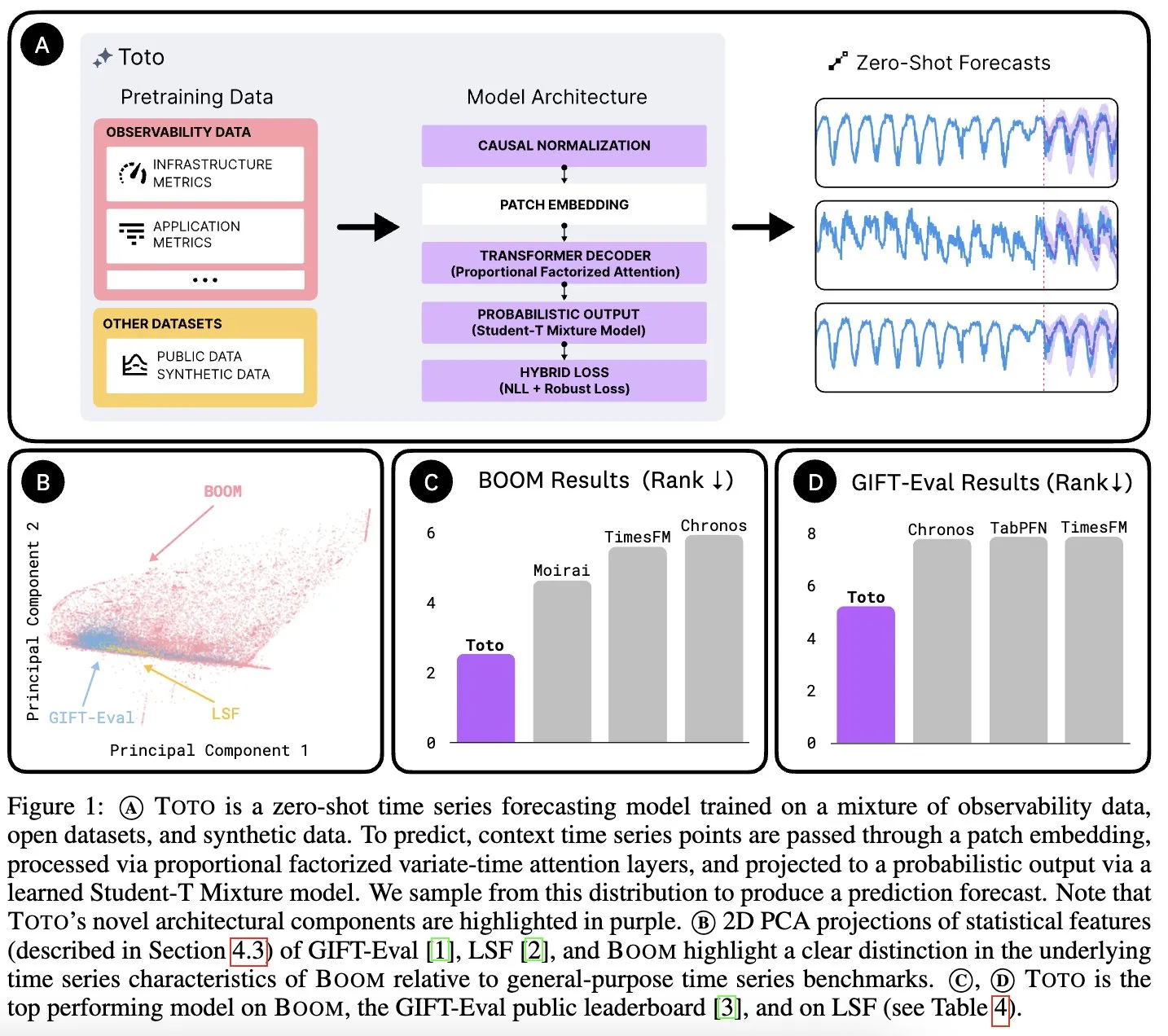
Datadog AI Research Releases Time Series Foundation Model Toto and Observability Metrics Benchmark BOOM: Datadog AI Research has launched Toto, a new time series foundation model that significantly leads existing SOTA models in relevant benchmarks. Also released is BOOM, currently the largest observability metrics benchmark. Both are open-sourced under the Apache 2.0 license, aiming to promote research and application in time series analysis and observability (Source: jefrankle, ClementDelangue)
TII Releases Falcon-H1 Series of Hybrid Transformer-SSM Models: The Technology Innovation Institute (TII) of the UAE has released the Falcon-H1 series of models, a group of hybrid architecture language models combining Transformer attention mechanisms with Mamba2 State Space Model (SSM) heads. The series ranges from 0.5B to 34B parameters, supports context lengths up to 256K, and performs better than or comparably to top Transformer models like Qwen3-32B and Llama4-Scout on multiple benchmarks, especially showcasing advantages in multilingual capabilities (natively supporting 18 languages) and efficiency. The models have been integrated into vLLM, Hugging Face Transformers, and llama.cpp (Source: Reddit r/LocalLLaMA)

MIT Research: AI Can Learn Associations Between Vision and Sound Without Human Intervention: Researchers at MIT have demonstrated an AI system capable of autonomously learning the connections between visual information and corresponding sounds without explicit human guidance or labeled data. This ability is crucial for developing more comprehensive multimodal AI systems, enabling them to understand and perceive the world more like humans do (Source: Reddit r/artificial, Reddit r/ArtificialInteligence)

UAE Launches Large Arabic AI Model, Accelerating AI Race in Gulf Region: The UAE has released a large Arabic AI model, marking its further investment in artificial intelligence and intensifying the competition among Gulf countries in AI technology development. This move aims to enhance the influence of the Arabic language in the AI field and meet the demand for localized AI applications (Source: Reddit r/artificial)
Fenbi Technology Releases Vertical Large Model, Defining a New Paradigm for “AI + Education”: At the Tencent Cloud AI Industry Application Summit, Fenbi Technology showcased its self-developed vertical large model for vocational education. This model has been applied to products like interview feedback and AI-powered exam preparation systems, covering the entire “teach, learn, practice, evaluate, test” chain. Through forms like AI teachers, it aims to achieve personalized teaching, moving from “one-size-fits-all” to “one-size-fits-one,” and plans to launch AI hardware products equipped with its self-developed large model to promote the intelligent transformation of education (Source: 量子位)

Beisen Kuxueyuan Releases New Generation AI Learning Platform, Introducing Five Major AI Agents: After acquiring Kuxueyuan, Beisen Holdings launched a new generation learning platform, AI Learning, based on AI large models. The platform adds five intelligent agents to the original eLearning foundation: AI Course Creation Assistant, AI Learning Assistant, AI Practice Partner, AI Leadership Coach, and AI Exam Assistant. It aims to disrupt traditional corporate learning models through real-time agent dialogues, skills training, personalized learning, and AI-powered one-stop course creation and examination (Source: 量子位)

Pony.ai Q1 Earnings: Robotaxi Service Revenue Skyrockets 8-fold YoY, 1,000 Autonomous Vehicles to be Deployed by Year-End: Pony.ai announced its Q1 2025 financial results, with total revenue reaching 102 million RMB, a 12% YoY increase. Its core Robotaxi service revenue hit 12.3 million RMB, a significant YoY jump of 200.3%, with passenger fare revenue soaring 8-fold YoY. The company plans to begin mass production of its 7th generation Robotaxi in Q2 and deploy 1,000 vehicles by year-end, striving to reach the break-even point per vehicle. Pony.ai also announced collaborations with Tencent Cloud and Uber to expand its domestic and Middle Eastern markets through WeChat and Uber platforms, respectively (Source: 量子位)

OpenAI CPO Kevin Weil: ChatGPT Will Transform into an Action Assistant, Model Costs Are 500x GPT-4: OpenAI Chief Product Officer Kevin Weil stated that ChatGPT’s positioning will shift from answering questions to performing tasks for users, becoming an AI action assistant by interleaving tool use (such as web browsing, programming, connecting to internal knowledge sources). He revealed that current model costs are 500 times that of the original GPT-4, but OpenAI is committed to improving efficiency and reducing API prices through hardware advancements and algorithmic improvements. He believes AI Agents will develop rapidly, growing from a junior engineer level to an architect level within a year (Source: 量子位)

🧰 Tools
FlowiseAI: Visually Build AI Agents: FlowiseAI is an open-source project that allows users to build AI agents and LLM applications through a visual interface. It supports drag-and-drop components, connecting different LLMs, tools, and data sources, simplifying the development process of AI applications. Users can install Flowise via npm or deploy it with Docker to quickly build and test their own AI workflows (Source: GitHub Trending)

Hugging Face JS Libraries Released, Simplifying Interaction with Hub API and Inference Services: Hugging Face has launched a series of JavaScript libraries (@huggingface/inference, @huggingface/hub, @huggingface/mcp-client, etc.) designed to facilitate developer interaction with the Hugging Face Hub API and inference services via JS/TS. These libraries support creating repositories, uploading files, calling inference for 100,000+ models (including chat completion, text-to-image, etc.), using the MCP client to build agents, and support multiple inference providers (Source: GitHub Trending)

Jan AI Local Runtime Environment Updated to Apache 2.0 License, Lowering Enterprise Adoption Barrier: Jan AI, an open-source tool that supports running LLMs locally, recently changed its license from AGPL to the more permissive Apache 2.0. This move aims to make it easier for enterprises and teams to deploy and use Jan within their organizations without worrying about AGPL compliance issues, allowing them to freely fork, modify, and distribute, thereby promoting large-scale adoption of Jan in actual production environments (Source: reach_vb, Reddit r/LocalLLaMA)
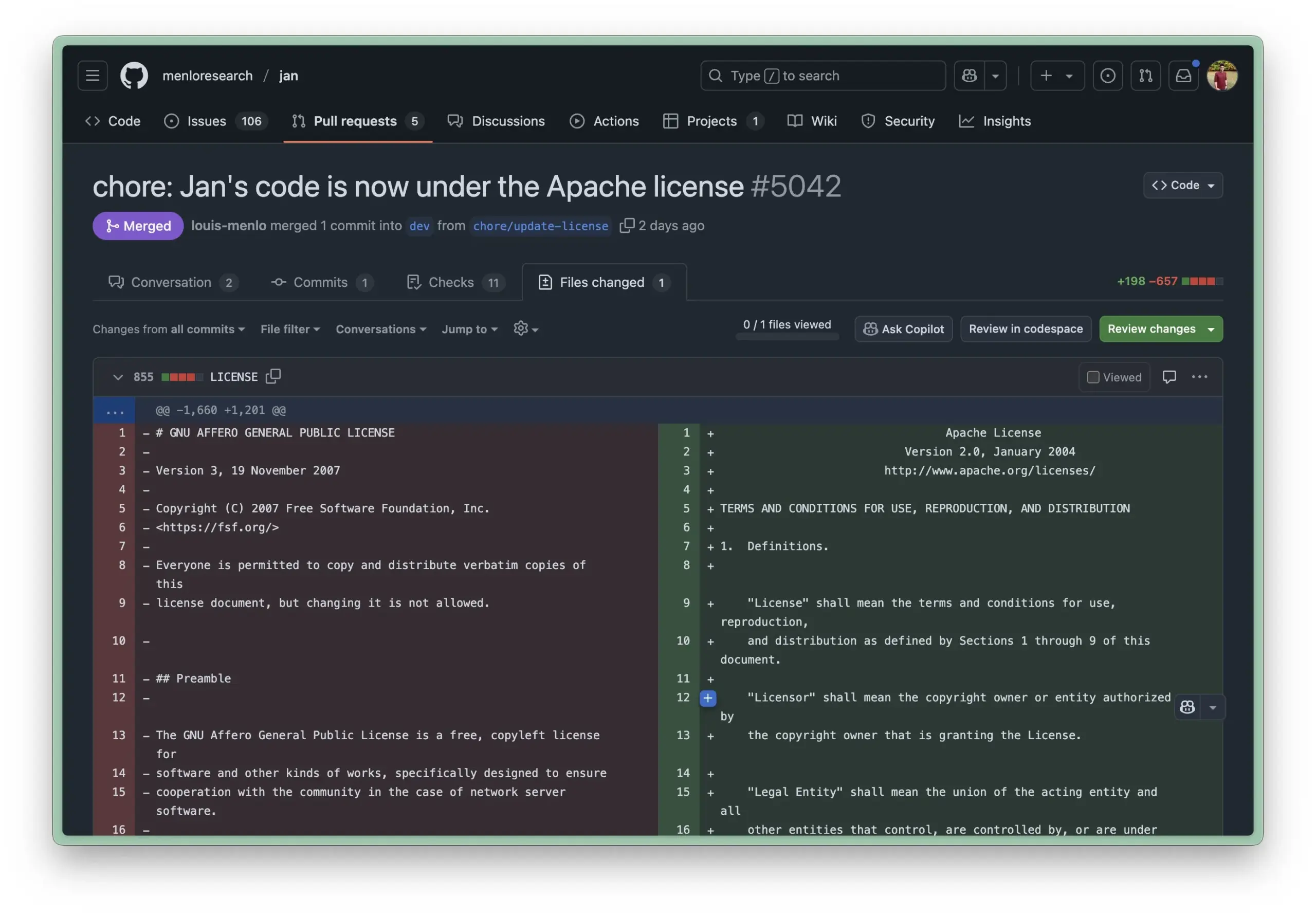
Obsidian Launches Bases Core Plugin for Database-like Note Management: Knowledge management software Obsidian has updated its core plugin, Bases, allowing users to transform note collections into powerful databases. With Bases, users can create custom table views to visualize and interactively manipulate data within their knowledge base, supporting note filtering by properties and creating formulas to derive dynamic attributes, suitable for various scenarios like project management, travel planning, and reading lists. This feature is currently available to early users (Source: op7418)
Hugging Face Launches Tiny Agents, Simplifying Local Model Control of Browsers and File Operations: Hugging Face introduced Tiny Agents in its MCP course, an easy-to-use framework for browser control setup. Users can define actions via command line, JSON configuration, and prompts, allowing locally run LLMs (via an OpenAI-compatible server) to control browsers (like Playwright) or local file systems without direct API calls, providing convenience for agent applications of local models like llama.cpp (Source: Reddit r/LocalLLaMA)

Developer Open-Sources AI Resume Optimization Application Based on LangChain and Ollama: A developer has built and open-sourced an AI-driven resume optimization application. After users upload their current resume and target job description, the application attempts to adjust keywords in the resume to better match recruitment needs. The backend uses LangChain, combining BM25 sparse retrieval and dense models for hybrid retrieval. The language model runs locally via Ollama, and the frontend uses React. The project is currently in the proof-of-concept stage, with code available on GitHub (Source: Reddit r/deeplearning)
Lovable Application Building Tool Enhances Image Processing Capabilities: AI application building tool Lovable announced improvements to its image processing features. Users can now upload images to chat and instruct Lovable to use these image assets in their applications, enhancing the user experience of building applications with visual elements with AI assistance (Source: op7418)
Helios: The First Platform Attempting to Accelerate Government Work with AI: Joe Scheidler launched Helios, a platform aimed at leveraging AI to improve government work efficiency, described as “Cursor for government.” This platform is one of the first attempts specifically targeting government departments to optimize their workflows and efficiency through AI technology. Specific features and application scenarios are yet to be further observed (Source: timsoret)
📚 Learning
Zhejiang University Releases “Foundations of Large Models” Textbook, Systematically Explaining LLM Knowledge with Continuous Updates: The Zhejiang University LLM team has open-sourced the “Foundations of Large Models” textbook, aiming to provide readers interested in large language models with systematic foundational knowledge and cutting-edge technology introductions. The book covers traditional language models, LLM architecture evolution, Prompt Engineering, parameter-efficient fine-tuning, model editing, retrieval-augmented generation, etc., and will be updated monthly. Each chapter is equipped with a relevant Paper List to track the latest progress. The complete PDF and chapter-wise content have been released on GitHub (Source: GitHub Trending)

Hugging Face Offers 10 Free AI Courses, Covering Various Levels and Multiple Domains: Hugging Face has compiled 10 free AI courses available on its platform, covering a range of popular AI topics from introductory to advanced levels, including natural language processing, deep learning, reinforcement learning, audio processing, and multimodal learning. These courses provide valuable resources for learners of different levels to systematically study AI knowledge, further promoting the popularization of AI knowledge and the development of the open-source community (Source: huggingface, reach_vb, _akhaliq)

Stanford University Shares Marin 8B Model Training Experiences and Lessons Learned: Stanford University’s Percy Liang team has publicly shared a detailed review of their experience training the Marin 8B model from scratch (which surpassed the Llama 3.1 8B base model on multiple benchmarks). This honest account includes all the team’s findings and mistakes made during the R&D process, providing the community with valuable real-world LLM building experience and emphasizing the importance of trial-and-error and iteration in scientific research (Source: stanfordnlp, YejinChoinka, hrishioa)
DeepLearning.AI and Predibase Collaborate on Reinforcement Fine-Tuning (RFT) LLM Course: Andrew Ng’s DeepLearning.AI has partnered with Predibase to launch a free short course on using GRPO (Group Relative Policy Optimization) for Reinforcement Fine-Tuning (RFT) to enhance LLM performance. The course, taught by Predibase co-founder and CTO Travis Addair among others, aims to help learners master how to leverage reinforcement learning to transform small open-source LLMs into reasoning engines for specific use cases with only a small amount of labeled data (Source: DeepLearningAI)
Hugging Face Paper Pages Add AI-Generated Summary Feature: Hugging Face has introduced a new feature on its paper display pages, providing an AI-generated single-sentence summary for each paper. This summary aims to concisely outline the core content of the paper, helping users quickly filter and understand research literature, thereby enhancing the accessibility and efficiency of academic resources. This feature is driven by open-source LLMs, reflecting the concept of “AI empowering AI research” (Source: _akhaliq, _akhaliq, _akhaliq, _akhaliq, huggingface)

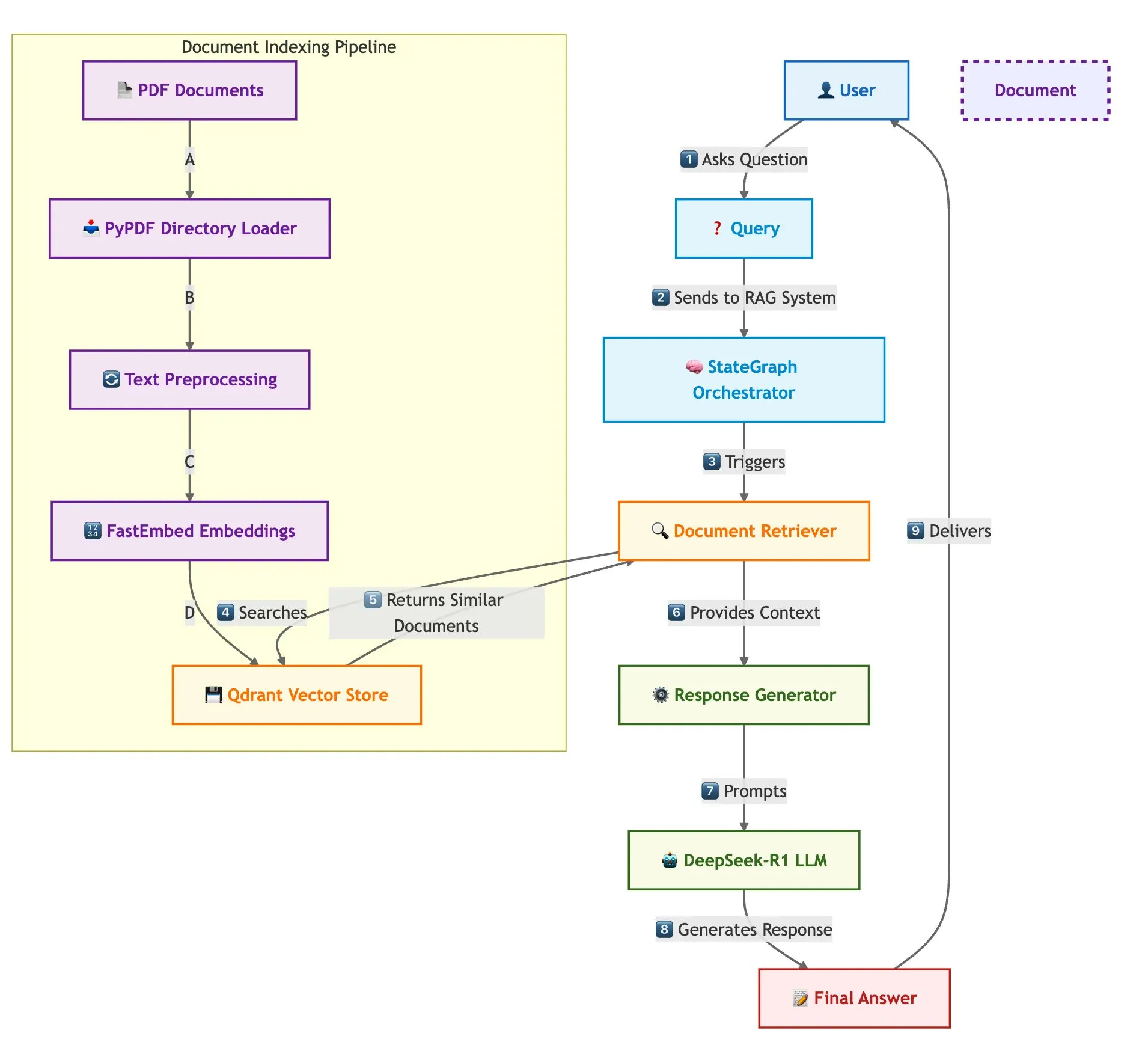
Qdrant, SambaNova, et al. Jointly Showcase Fast Multi-Document RAG System Construction Solution: A technical blog post introduces how to build a high-speed, memory-efficient multi-document Retrieval Augmented Generation (RAG) system using Qdrant vector database, SambaNova, DeepSeek-R1, and LangGraph. The solution achieves 32x memory savings through binary quantization, utilizes DeepSeek-R1 for fast and focused LLM responses, and leverages LangGraph for modular orchestration, suitable for large-scale multi-document processing scenarios (Source: qdrant_engine)
LangChain Interrupt 2025 Summit Recap (Mandarin Version) Released: The Mandarin version recap of the LangChain Interrupt 2025 summit has been released. The summit attracted over 800 participants globally, sharing experiences and future outlooks on AI agent construction, and announced several products including LangGraph Platform and LangGraph Studio v2, discussing topics like agent engineering and AI observability (Source: hwchase17)
Andi Marafioti Releases nanoVLM Tutorial, Detailing Step-by-Step Training of Visual Language Models with Pure PyTorch: Andi Marafioti has published a new blog tutorial titled nanoVLM, which provides a detailed guide on how to train your own Visual Language Model (VLM) from scratch using pure PyTorch. The tutorial is easy to understand and follow, aimed at helping beginners quickly grasp the VLM training process (Source: LoubnaBenAllal1)

Ferenc Huszár Explains Continuous-Time Markov Chains and Their Application in Diffusion Language Models: Deep learning researcher Ferenc Huszár published a blog post explaining in depth the intuition behind Continuous-Time Markov Chains (CTMCs), a key component of Diffusion Language Models (DLMs) like Mercury and Gemini Diffusion. The article explores different perspectives on Markov chains and their connection to point processes, providing valuable reference for understanding the theoretical basis of DLMs (Source: fhuszar)
💼 Business
“Human-Powered AI” Company Builder.ai Declares Bankruptcy, Previously Raised Nearly $500 Million: Builder.ai (formerly Engineer.ai), a UK company that once claimed to revolutionize software development with AI and was valued at $1 billion, declared bankruptcy and liquidation this week. The company was previously exposed for many of its AI platform’s functions being manually completed by engineers in India. Despite raising nearly $500 million from prominent investors like Microsoft and SoftBank DeepCore, it ultimately ran out of funds due to questionable technological authenticity, chaotic financial management, and legal disputes involving its founder, and owed $30 million to Microsoft and $85 million to Amazon for cloud services (Source: 36氪)

LMArena.ai (formerly LMSys) Secures $100 Million Seed Funding, Transitioning from Gradio App to Commercialization: LMArena.ai, originally an academic project LMSys (for LLM competition and evaluation) based on Gradio, announced it has secured $100 million in seed funding, led by a16z and the University of California’s investment company. This funding will support LMArena in continuing its research in reliable AI and platform operations, marking the transition of a successful open-source academic project to commercial operation. This also highlights the potential of rapid prototyping tools like Gradio in incubating impactful AI projects (Source: ClementDelangue, _akhaliq, clefourrier)
AI Talent War Heats Up, OpenAI, Google, etc., Offer Tens of Millions in Annual Salary to Poach Talent: The talent war in Silicon Valley’s AI sector has reached a fever pitch, with top researchers (ICs) becoming core resources fiercely contested by giants like OpenAI, Google, and xAI, with annual salaries plus equity incentives commonly exceeding ten million dollars. For example, OpenAI offered a $2 million bonus and over $20 million in equity to retain a senior researcher considering joining SSI; Google DeepMind also offers top talent an annual salary of $20 million. This intense competition stems from the immense contributions of a few core talents to the development of large language models, whose departure or retention can directly impact the success or failure of AI models (Source: 36氪)
🌟 Community
Sora’s Chinese Language Capability Seems to Have Improved, but Model Limitations Persist: Social media users have observed that OpenAI’s video generation model Sora appears to have made progress in handling Chinese text, capable of generating scenes containing Chinese characters. However, users also pointed out that the model still has its limitations, and the generated content is not perfect. Accepting this imperfection may be a norm when interacting with AI models at the current stage (Source: dotey)

Gemini Launches “Exam” Feature for In-depth Reports, Aiding Knowledge Reuse and Learning Loop: Google Gemini has launched a new feature where, after reading an in-depth report, Gemini can directly generate test questions. This feature aims to test the user’s true understanding of the content and build an AI-native learning loop of “learn → test → supplement → relearn,” emphasizing that the core of learning in the AI era is the ability to reuse knowledge rather than the volume of reading (Source: dotey)
ChatGPT’s Memory Function Raises User Concerns About Control: ChatGPT’s newly launched “learn from chat memory” feature allows the model to remember users’ past conversation information to provide more personalized responses in subsequent interactions. However, some advanced users have expressed concerns, believing it changes the way they interact with the model. They prefer to have complete control over the model’s input content and do not want the model to use historical information without their knowledge or precise control (Source: random_walker)
AI Agent Development is Rapid, Future Work Models May Change: The community is actively discussing the rapid development of AI Agents and their potential impact on future work models. The view is that AI Agents are evolving from simple Q&A tools to “virtual employees” capable of independently completing complex tasks (such as coding, research, customer support). OpenAI CPO Kevin Weil predicts that AI Agent capabilities will improve rapidly, growing from a junior engineer level to an architect level within a year. Microsoft has also proposed the concept of an “agentic web,” indicating that future work may revolve around managing and orchestrating AI agents (Source: rowancheung, 量子位)
AI Shows Great Potential in Medical Diagnosis, but Sparks Doctors’ Career Concerns: AI has demonstrated astonishing capabilities in medical diagnosis, such as research claiming the o1-preview model exhibits superhuman abilities in medical reasoning and diagnostic tasks, and cases of AI detecting pneumonia in seconds have also drawn attention. This has made AI-assisted diagnosis a hot topic, but it has also made some doctors with 20 years of experience worry about their career prospects, even joking about applying for jobs at McDonald’s. Community discussions suggest AI should be viewed more as a tool to help doctors improve efficiency and accuracy, rather than a complete replacement (Source: paul_cal, Reddit r/ArtificialInteligence)
News Publishers Accuse Google’s AI Search Model of “Theft”: The News Media Alliance and other publishers have expressed strong dissatisfaction with Google’s new AI search model, calling it “theft.” They argue that Google AI directly extracts information from news content and integrates it into search results, bypassing news websites and harming publishers’ traffic and advertising revenue, sparking a heated debate about content copyright and fair use in the AI era (Source: Reddit r/artificial)
DeepSeek Model Used for Traditional Fortune-Telling in China, Sparking Discussion on AI Application Boundaries: Some users discovered that a significant portion of DeepSeek model’s traffic in China comes from users employing it for traditional divination activities like I Ching fortune-telling. This phenomenon has sparked discussions about the boundaries of AI application and cultural adaptation, and indirectly reflects users’ diverse exploration and demand for AI capabilities (Source: menhguin, cto_junior)

💡 Other
Figure Company’s Humanoid Robot Completes 20-Hour Continuous Shift on BMW Production Line: Humanoid robot company Figure announced that its robot successfully completed a 20-hour continuous shift on the BMW X3 production line. Previously, the robot had undergone several weeks of 10-hour shift tests. Figure claims this is the world’s first instance of a humanoid robot completing such a long continuous operation on an automotive production line, showcasing its potential in industrial automation (Source: adcock_brett, TheRundownAI)
The Difference and Connection Between Agentic AI and GenAI: The community discussed the concepts of Agentic AI and Generative AI. Generative AI primarily refers to AI that can create new content (text, images, code, etc.), while Agentic AI emphasizes autonomy, goal-orientation, and the ability to interact with and act upon its environment. Agentic AI typically utilizes Generative AI as one of its core capabilities to understand, plan, and execute tasks, representing an important direction for AI’s development towards more advanced autonomous intelligence (Source: Ronald_vanLoon, Ronald_vanLoon)

AI’s Application in Scientific Research Underestimated, “Whitewashing of Results” Phenomenon Exists: Community discussions point out that AI’s potential in scientific research is vast but possibly underestimated, and there is a phenomenon of researchers “whitewashing” AI experiment results for publication. For example, in fields like partial differential equations (PDEs), AI’s actual performance may not be as outstanding as presented in papers. This suggests that the scientific community needs to more rigorously and transparently evaluate AI’s true role and limitations in scientific discovery (Source: clefourrier)