
Keywords:Gemini 2.5, AI Agent, Large Language Model, Vision-Language Model, Reinforcement Learning, Gemini 2.5 Pro Deep Think mode, GitHub Copilot Agent open source, MeanFlow single-step image generation, VPRL visual planning and reasoning, Huawei FusionSpec MoE inference optimization
🔥 Focus
Google I/O Announces Multiple AI Advancements, Led by Gemini 2.5 Series Models: Google announced numerous updates in the AI field at its I/O conference. Gemini 2.5 Pro is hailed as the current most powerful foundational model, leading in multiple benchmark tests and introducing a Deep Think enhanced reasoning mode. The lightweight model Gemini 2.5 Flash has also been upgraded, focusing on speed and efficiency. Google Search is introducing an “AI Mode,” providing an end-to-end AI search experience powered by Gemini 2.5, capable of breaking down complex problems and conducting deep information mining. The video generation model Veo 3 achieves synchronized audio and video generation, while the image model Imagen 4 has improved detail and text processing capabilities. Additionally, Google launched the AI filmmaking tool Flow and the real-world application of Project Astra, Gemini Live. These updates demonstrate Google’s determination to fully integrate AI into its product ecosystem, aiming to enhance user experience and developer efficiency (Source: 量子位, 36氪, WeChat)

Microsoft Build Conference Pushes AI Agents, GitHub Copilot Receives Major Upgrade and Announces Open Source: Microsoft placed AI Agents at the core of its Build 2025 developer conference, announcing the open-sourcing of the GitHub Copilot Extension for VSCode project and launching a new AI coding agent (Agent). This Agent can autonomously perform tasks such as fixing bugs, adding features, and optimizing documentation, and is deeply integrated into GitHub Copilot. Microsoft also released Microsoft Discovery, an AI agent platform for scientific discovery; NLWeb, a natural language interaction website project; Agent Factory, an agent construction platform; and Copilot Tuning for customizable enterprise data. These initiatives indicate Microsoft’s full commitment to promoting the application of AI Agents in development, scientific research, and other fields, aiming to build an open ecosystem for intelligent agent collaboration (Source: 量子位, WeChat, WeChat)

OpenAI CPO Kevin Weil Elaborates on ChatGPT’s Transformation: From Q&A to Action, AI Agents Will Evolve Rapidly: OpenAI Chief Product Officer Kevin Weil revealed in an interview that ChatGPT’s positioning will shift from a question-answering tool to an AI Agent capable of performing tasks for users. He envisions AI Agents rapidly evolving from junior engineers to senior engineers, and even architects, in the short term. This means AI Agents will possess greater autonomy, able to solve complex problems by browsing the web, deep thinking, and reasoning. Weil also mentioned that current model training costs are already 500 times that of GPT-4, but future hardware improvements and algorithmic advancements will enhance efficiency and reduce API prices to promote AI popularization and development (Source: 量子位, 36氪)

Kaiming He’s Team Proposes MeanFlow: New SOTA for Single-Step Image Generation, Subverting Traditional Paradigms Without Pre-training: Kaiming He’s team’s latest research introduces MeanFlow, a single-step generative modeling framework. On the ImageNet 256×256 dataset, it achieves an FID score of 3.43 with only 1 function evaluation (1-NFE), an improvement of 50%-70% over previous best methods in its class, without requiring pre-training, distillation, or curriculum learning. MeanFlow’s core innovation lies in introducing the concept of an “average velocity field” and deriving its mathematical relationship with the instantaneous velocity field, which guides neural network training. The method can also naturally integrate classifier-free guidance (CFG) without adding extra computational overhead during sampling, significantly narrowing the performance gap between single-step and multi-step generative models and demonstrating the potential of few-step models to challenge multi-step models (Source: WeChat, WeChat)

🎯 Trends
ByteDance Releases Bagel 14B MoE Multimodal Model, Supports Image Generation and is Open Source: ByteDance has launched Bagel, a 14 billion parameter Mixture-of-Experts (MoE) multimodal model, with 7 billion parameters active. The model is capable of image generation and has been open-sourced under the Apache license. Its weights, website, and paper (titled “Emerging Properties in Unified Multimodal Pretraining”) have all been made public. The community has reacted positively, considering it the first local model capable of generating both images and text, and is interested in its potential to run on 24GB graphics cards and quantization issues (Source: Reddit r/LocalLLaMA)
Mistral AI Releases Devstral: SOTA Open Source Model Optimized for Coding: Mistral AI has launched Devstral, a leading open-source model designed specifically for software engineering tasks, built in collaboration with All Hands AI. Devstral performs exceptionally well on the SWE-bench benchmark, ranking as the number one open-source model on this benchmark. The model excels at using tools to explore codebases, edit multiple files, and support software engineering agents. Model weights are available on Hugging Face (Source: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

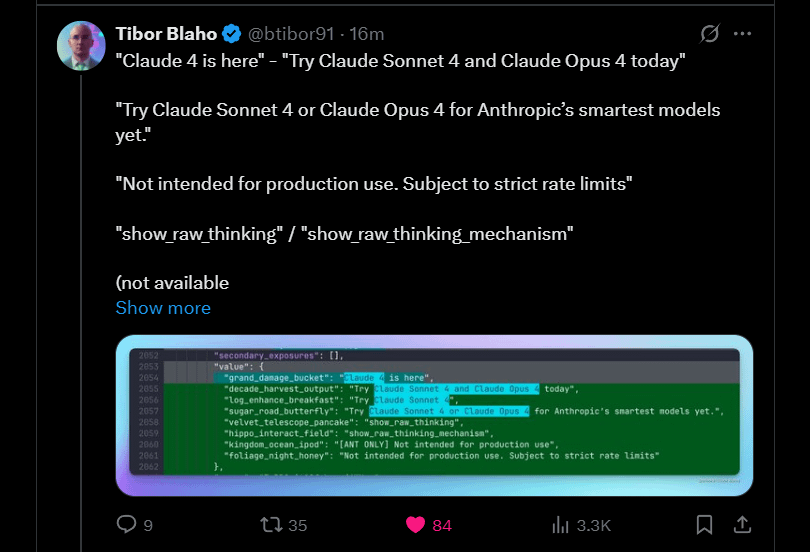
Anthropic Teases Upcoming Launch of Claude 4 Sonnet and Opus: Anthropic plans to launch the next generation of its Claude large models – Claude 4 Sonnet and Opus. This news has generated anticipation in the community, with users expressing interest in the new models’ performance, particularly improvements in context memory. Some comments noted that Google I/O’s announcements might be prompting competitors to accelerate the release of their best products. At the same time, users also expressed concerns about the new models’ limitations (such as usage quotas) and cautioned the community against having overly high expectations for Opus 4 to avoid disappointment (Source: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Google Releases Gemma3n Android App, Supporting Local LLM Inference: Google has released an Android app that interacts with the new Gemma3n model, along with the relevant MediaPipe solution and GitHub repository. User feedback indicates a good app interface, but notes that Gemma3n does not currently support GPU inference. One user successfully manually loaded the gemma-3n-E2B model and shared runtime data, while the community also expressed a need for an uncensored version of the model (Source: Reddit r/LocalLLaMA)

Falcon-H1 Hybrid-Head Language Model Family Released, Including Various Parameter Scales: TII UAE has released the Falcon-H1 family of hybrid-head language models, with parameter scales ranging from 0.5B to 34B. This series of models adopts the Mamba hybrid architecture and is comparable in performance to Qwen3. The models can be used via Hugging Face Transformers, vLLM, or a customized version of the llama.cpp library, ensuring ease of use. The community has expressed excitement, viewing this as a significant development, and some users have created performance comparison charts. Researchers are also noting its differences from IBM Granite 4 in how SSM and attention modules are combined (Source: Reddit r/LocalLLaMA)

Google Explores Gemini Diffusion: A Language Model with Diffusion Architecture: Google showcased its language diffusion model, Gemini Diffusion, which is claimed to be extremely fast and half the size of comparable performance models. Because diffusion models can process the entire text iteratively in one go without needing a KV cache, they may have advantages in memory efficiency and can improve output quality by increasing iterations. The community believes that if Google can demonstrate the feasibility of diffusion models for large-scale applications, it will positively impact the local AI community. However, the model is currently only available via a demo waitlist and is not open source, nor are weights available for download (Source: Reddit r/LocalLLaMA)

Research Reveals Zero-Click Agent Hijacking Vulnerability (CVE-2025-47241) in Browser Use Framework: Research by ARIMLABS.AI has uncovered a critical security vulnerability (CVE-2025-47241) in the Browser Use framework, which is widely used in over 1500 AI projects. The vulnerability allows attackers to achieve zero-click agent hijacking by luring LLM-driven browsing agents to malicious pages, enabling control over the agent without user interaction. This discovery raises serious concerns about the security of autonomous AI agents, particularly those interacting with the web, and calls for community attention to AI agent security issues (Source: Reddit r/artificial, Reddit r/artificial)
Tencent and Alibaba Compete in AI to C Field, QQ Browser Benchmarks Against Quark: Tencent’s CSIG (Cloud and Smart Industries Group) announced an upgrade for QQ Browser to an AI browser, launching AI QBot and integrating Tencent Hunyuan and DeepSeek dual models. This move officially positions it against Alibaba’s Quark, which has already transitioned into an AI search tool. This marks an acceleration in Tencent’s AI to C (AI-to-Consumer) strategy, forming two major product lines: Tencent Yuanbao and QQ Browser. The key executives, Wu Zurong (Tencent) and Wu Jia (Alibaba), are now in a “dual Wu showdown.” Analysts believe QQ Browser has an advantage in user base, while Quark was a first-mover in AI transformation. However, QQ Browser’s transformation is seen as relatively conservative, with AI functions more like plugins and constrained by its existing advertising model. This competition is not only at the product level but may also impact the career development of the two executives within their respective companies (Source: 36氪)
Cambridge and Google Propose VPRL: A New Paradigm for Pure Visual Planning and Reasoning, Surpassing Text-Based Reasoning in Accuracy: Researchers from the University of Cambridge, University College London, and Google have proposed a new paradigm called Visual Planning with Reinforcement Learning (VPRL), achieving reasoning purely based on images for the first time. The framework utilizes Group Relative Policy Optimization (GRPO) to post-train large vision models. In multiple visual navigation tasks (such as FrozenLake, Maze, MiniBehavior), its performance significantly surpasses text-based reasoning methods, achieving accuracy up to 80% and a performance improvement of at least 40%. VPRL directly utilizes image sequences for planning, avoiding information loss and efficiency reduction caused by language conversion, thus opening new directions for intuitive image reasoning tasks. The code has been open-sourced (Source: WeChat)

Huawei Releases FusionSpec and OptiQuant to Optimize MoE Large Model Inference: Addressing the inference speed and latency challenges of large-scale Mixture-of-Experts (MoE) models, Huawei has launched the FusionSpec speculative inference framework and the OptiQuant quantization framework. FusionSpec leverages the high compute-to-bandwidth ratio of Ascend servers to optimize the workflow for main and speculative models, reducing speculative inference framework overhead to 1 millisecond. OptiQuant supports mainstream quantization algorithms such as Int2/4/8 and FP8/HiFloat8, and introduces innovations like “learnable clipping” and “quantization parameter optimization” to minimize model precision loss and improve inference cost-effectiveness. These technologies aim to solve the inference efficiency and resource consumption issues faced during MoE model deployment (Source: WeChat)

BAAI Releases Three SOTA Vector Models, Enhancing Code and Multimodal Retrieval: The Beijing Academy of Artificial Intelligence (BAAI), in collaboration with several universities, has released BGE-Code-v1 (code vector model), BGE-VL-v1.5 (general multimodal vector model), and BGE-VL-Screenshot (visual document vector model). BGE-Code-v1, based on Qwen2.5-Coder-1.5B, performs excellently on CoIR and CodeRAG benchmarks. BGE-VL-v1.5, based on LLaVA-1.6, has set a new zero-shot record on the MMEB multimodal benchmark. BGE-VL-Screenshot, targeting visual information retrieval (Vis-IR) tasks for web pages, documents, etc., is trained based on Qwen2.5-VL-3B-Instruct and achieves SOTA on the newly introduced MVRB benchmark. These models aim to provide stronger code and multimodal understanding and retrieval capabilities for applications like Retrieval-Augmented Generation (RAG), and all have been open-sourced (Source: WeChat)

Kuaishou and National University of Singapore Launch Any2Caption for Controllable Video Generation: Kuaishou and the National University of Singapore have jointly launched the Any2Caption framework, aiming to improve the precision and quality of controllable video generation by intelligently decoupling user intent understanding and the video generation process. The framework can handle various modal input conditions such as text, images, videos, pose trajectories, and camera movements. It utilizes a multimodal large language model to convert complex instructions into a structured “video script” to guide video generation. Any2Caption is trained on the Any2CapIns database, which includes 337,000 video instances and 407,000 multimodal conditions. Experiments show that it can effectively enhance the performance of existing controllable video generation models (Source: WeChat)

🧰 Tools
Lark Launches “Knowledge Q&A” Feature, Creating an Enterprise-Specific AI Q&A and Creation Assistant: Lark (Feishu) has launched a new “Knowledge Q&A” feature, positioned as an exclusive AI Q&A tool for enterprises. It can provide precise answers and content creation support based on messages, documents, knowledge bases, meeting minutes (Miaoji), etc., that employees have permission to access on Lark, combined with large models like DeepSeek-R1, Doubao (CharacterPlus), and RAG technology. The feature emphasizes activating and utilizing internal enterprise knowledge; different employees asking the same question may receive answers from different perspectives, strictly adhering to organizational permissions. Lark Knowledge Q&A aims to seamlessly integrate AI into daily workflows, enhance information acquisition and collaboration efficiency, and help enterprises build a dynamic knowledge management system (Source: WeChat, WeChat)
Supabase Becomes Preferred Backend for “Vibe Coding” Thanks to Open Source and AI Integration Advantages: Open-source database Supabase has become a popular backend choice for the “Vibe Coding” model due to its “out-of-the-box” PostgreSQL experience and proactive response to AI development trends. Vibe Coding emphasizes using various AI tools to quickly complete the entire development process from requirements to implementation. Supabase supports vector embedding storage (crucial for RAG applications) through PGVector integration, collaborates with Ollama to provide AI model services for the edge, and has launched its own AI assistant to help with database schema generation and SQL debugging. Recently, Supabase also launched an official MCP server, allowing AI tools to interact with it directly. These features have made it favored by AI-native application building platforms like Lovable and Bolt.new (Source: WeChat)

Hugging Face Launches nanoVLM: A Minimalist Toolkit for Training Vision Language Models (VLMs) in Pure PyTorch: Hugging Face has released nanoVLM, a lightweight PyTorch toolkit designed to simplify the training process for vision language models. The project features a small and readable codebase, making it suitable for beginners or developers looking to understand the inner workings of VLMs. nanoVLM’s architecture is based on a SigLIP vision encoder and a Llama 3 language decoder, with a modality projection module to align visual and text modalities. The project provides an easy way to start VLM training on a free Colab Notebook and has released a pre-trained model based on SigLIP and SmolLM2 for testing (Source: HuggingFace Blog)

Diffusers Library Integrates Multiple Quantization Backends to Optimize Large Diffusion Models: The Hugging Face Diffusers library now integrates multiple quantization backends, including bitsandbytes, torchao, Quanto, GGUF, and native FP8, aiming to reduce the memory footprint and computational requirements of large diffusion models like Flux. These backends support various precision quantizations (e.g., 4-bit, 8-bit, FP8) and can be combined with memory optimization techniques such as CPU offloading, group offloading, and torch.compile. A blog post demonstrates the performance of each backend in terms of memory savings and inference time using the Flux.1-dev model as a case study, and provides a selection guide to help users balance model size, speed, and quality. Some quantized models are already available on the Hugging Face Hub (Source: HuggingFace Blog)

JD.com’s JoyBuild Large Model Development and Computing Platform Enhances Training and Inference Efficiency: JD Explore Academy has proposed a system and method for training, updating large models in an open environment, and deploying them collaboratively with smaller models. Related achievements were published in the Nature旗下 journal npj Artificial Intelligence. This technology improves the inference efficiency of large models by an average of 30% and reduces training costs by 70% through four innovations: model distillation (dynamic hierarchical distillation), data governance (cross-domain dynamic sampling), training optimization (Bayesian optimization), and cloud-edge collaboration (two-stage compression). This technology supports the JoyBuild large model development and computing platform, enabling the fine-tuning and development of various models (such as JD’s large model, Llama, DeepSeek), helping enterprises transform general models into specialized ones. It has been applied in scenarios like retail and logistics (Source: WeChat)
Model Context Protocol (MCP) Registry Project Launched: modelcontextprotocol/registry is a community-driven MCP server registration service project, currently in early development. The project aims to provide a central repository for MCP server entries, allowing discovery and management of various MCP implementations along with their metadata, configurations, and capabilities. Its features include a RESTful API for managing entries, health check endpoints, support for multiple environment configurations, MongoDB and in-memory database support, and API documentation. The project is written in Go and provides a guide for quick startup via Docker Compose (Source: GitHub Trending)
📚 Learning
Terence Tao Releases AI-Assisted Math Proof Tutorial, Demonstrating Proving Function Limits with GitHub Copilot: Fields Medalist Terence Tao updated his YouTube channel with a video detailing how to use GitHub Copilot to assist in proving the sum, difference, and product theorems for function limits. The tutorial emphasizes the importance of correctly guiding the AI and showcases Copilot’s role in generating code frameworks and suggesting library functions, while also pointing out its limitations in handling complex mathematical details, special cases, and maintaining contextual consistency. Tao concludes that Copilot is beneficial for beginners but still requires significant human intervention and adjustment for complex problems, and sometimes combining it with pen-and-paper derivation might be more efficient (Source: 量子位)

Paper Discusses Contradiction Between LLM Reasoning and Instruction Following, Proposes Concept of Constraint Attention: A research paper titled “When Thinking Fails: The Pitfalls of Reasoning for Instruction-Following in LLMs” points out that while Large Language Models (LLMs) perform better in some aspects (like adhering to format, word count) after using Chain-of-Thought (CoT) reasoning, their accuracy in strictly following instructions might actually decrease. Through tests on 15 open-source and closed-source models, the research team found that models are more likely to “take matters into their own hands,” modifying or adding extra information and ignoring original instructions after using CoT. The paper introduces the concept of “Constraint Attention,” finding that CoT reasoning reduces the model’s attention to key constraints. The research also shows no significant correlation between the length of CoT thinking and task completion accuracy, and explores the possibility of improving instruction following through few-shot examples, self-reflection, and other methods (Source: WeChat)

MIT and Google Propose PASTA: A New Paradigm for LLM Asynchronous Parallel Generation Based on Policy Learning: Researchers from MIT and Google have proposed the PASTA (PArallel STructure Annotation) framework, which enables Large Language Models (LLMs) to autonomously optimize asynchronous parallel generation strategies through policy learning. The method first develops a markup language, PASTA-LANG, to annotate semantically independent text blocks for parallel generation. The training process is two-staged: supervised fine-tuning teaches the model to insert PASTA-LANG markers, followed by preference optimization (based on theoretical speedup and content quality assessment) to further enhance the annotation strategy. PASTA designs an interleaved KV cache layout and attention control mechanism to coordinate efficient multi-threaded collaboration. Experiments show that PASTA achieves a speedup of 1.21-1.93x on the AlpacaEval benchmark while maintaining or improving output quality, demonstrating good scalability (Source: WeChat)

ICML 2025 Paper Proposes TPO: A New Scheme for Instant Preference Alignment at Inference Time, No Retraining Needed: The Shanghai Artificial Intelligence Laboratory has proposed Test-Time Preference Optimization (TPO), a new method that allows Large Language Models to self-adjust their output at inference time through iterative text feedback to align with human preferences. TPO simulates a linguistic “gradient descent” process (generating candidate responses, calculating text loss, calculating text gradient, updating response) to achieve alignment without updating model weights. Experiments show that TPO can significantly improve the performance of both unaligned and aligned models. For example, the Llama-3.1-70B-SFT model, after two steps of TPO optimization, surpassed the aligned Instruct version on multiple benchmarks. This method provides a “width + depth” inference extension strategy, demonstrating efficient optimization potential in resource-constrained environments (Source: WeChat)
New Research Explores Methods for Eliciting Latent Knowledge from LLMs: A paper investigates how to elicit potentially hidden knowledge from large language models. Researchers trained a “taboo” model designed to describe a specific secret word without directly stating it, where the secret word was not present in the training data or prompts. Subsequently, they evaluated automated strategies using non-interpretive (black-box) methods and mechanism-based interpretability techniques (like logit lens and sparse autoencoders) to reveal this secret. Results indicate that both approaches can effectively elicit the secret word in a proof-of-concept setting. This work aims to provide initial solutions to the critical problem of eliciting secret knowledge from language models to promote their safe and reliable deployment (Source: HuggingFace Daily Papers)
Paper Explores Federated Pruning for Large Language Models (FedPrLLM): To address the difficulty of obtaining public calibration samples for pruning Large Language Models (LLMs) in privacy-sensitive domains, researchers proposed FedPrLLM, a comprehensive federated pruning framework. Under this framework, each client only needs to compute a pruning mask matrix based on local calibration data and share it with the server to collaboratively prune the global model while protecting local data privacy. Through extensive experiments, the study found that one-shot pruning combined with layer comparison and no weight scaling is the optimal choice within the FedPrLLM framework. This research aims to guide future work on LLM pruning in privacy-sensitive domains (Source: HuggingFace Daily Papers)
Paper Proposes MIGRATION-BENCH: A Benchmark for Java 8 Code Migration: Researchers have introduced MIGRATION-BENCH, a code migration benchmark focused on migrating from Java 8 to the latest LTS versions (Java 17, 21). The benchmark includes a full dataset of 5102 repositories and a subset of 300 carefully selected complex repositories, designed to evaluate the capabilities of Large Language Models (LLMs) in repository-level code migration tasks. Concurrently, the paper provides a comprehensive evaluation framework and proposes the SD-Feedback method. Experiments show that LLMs (such as Claude-3.5-Sonnet-v2) can effectively handle such migration tasks, achieving success rates of 62.33% (minimal migration) and 27.00% (maximal migration) on the selected subset (Source: HuggingFace Daily Papers)
Paper Proposes CS-Sum: A Code-Switched Conversational Summarization Benchmark and Analysis of LLM Limitations: To evaluate the ability of Large Language Models (LLMs) to understand code-switching (CS), researchers introduced the CS-Sum benchmark, which assesses this by summarizing code-switched conversations into English. CS-Sum is the first benchmark for Mandarin-English, Tamil-English, and Malay-English code-switched conversational summarization, with each language pair containing 900-1300 manually annotated conversations. Through evaluation of ten open-source and closed-source LLMs (including few-shot, translate-then-summarize, and fine-tuning methods), the study found that despite high scores on automatic evaluation metrics, LLMs still make subtle errors when processing CS input, thereby altering the complete meaning of the conversation. The paper also identifies the three most common types of errors LLMs make when handling CS and emphasizes the necessity of specialized training on code-switched data (Source: HuggingFace Daily Papers)
Paper Explores LLMs’ Ability to Express Confidence During Reasoning: Research indicates that Large Language Models (LLMs) performing extended Chain-of-Thought (CoT) reasoning not only perform better at problem-solving but are also superior at accurately expressing their confidence. Benchmarking six reasoning models on six datasets revealed that in 33 out of 36 settings, reasoning models exhibited better confidence calibration than non-reasoning models. Analysis suggests this is due to the “slow thinking” behaviors of reasoning models (e.g., exploring alternatives, backtracking), allowing them to dynamically adjust confidence during the CoT process. Furthermore, removing slow thinking behaviors leads to a significant drop in calibration, while non-reasoning models guided to perform slow thinking can also benefit (Source: HuggingFace Daily Papers)
Paper: Training VLMs for Visual Reasoning from Visual Question-Answering Pairs using Reinforcement Learning (Visionary-R1): This study aims to train Vision Language Models (VLMs) for reasoning on image data through reinforcement learning and visual question-answering pairs, without explicit Chain-of-Thought (CoT) supervision. The research found that simply applying reinforcement learning (prompting the model to generate a reasoning chain before answering) can lead the model to learn shortcuts from simple questions, reducing its generalization ability. To address this, researchers propose that the model should follow a “caption-reason-answer” output format, i.e., first generate a detailed caption of the image, then construct a reasoning chain. The Visionary-R1 model, trained based on this method, outperforms powerful multimodal models such as GPT-4o, Claude3.5-Sonnet, and Gemini-1.5-Pro on multiple visual reasoning benchmarks (Source: HuggingFace Daily Papers)
Paper Proposes VideoEval-Pro: A More Realistic and Robust Evaluation Benchmark for Long Video Understanding: Research indicates that current long video understanding (LVU) benchmarks mostly rely on multiple-choice questions (MCQs), which are susceptible to guessing and some questions can be answered without watching the full video, thus overestimating model performance. To address this, the paper proposes VideoEval-Pro, an LVU benchmark comprising open-ended short-answer questions, designed to genuinely assess a model’s comprehension of the entire video, covering segment-level and full-video perception and reasoning tasks. Evaluation of 21 video LMMs shows a significant performance drop on open-ended questions, and high MCQ scores do not necessarily correlate with high scores on VideoEval-Pro. VideoEval-Pro benefits more from increased input frames, providing a more reliable evaluation standard for the LVU field (Source: HuggingFace Daily Papers)
Paper: Fine-tuning Quantized Neural Networks via Zeroth-Order Optimization (QZO): As the size of large language models grows exponentially, GPU memory has become a bottleneck for adapting models to downstream tasks. This research aims to minimize memory usage for model weights, gradients, and optimizer states within a unified framework. Researchers propose eliminating gradients and optimizer states via zeroth-order optimization, which approximates gradients by perturbing weights during the forward pass. To minimize weight memory, model quantization (e.g., bfloat16 to int4) is employed. However, directly applying zeroth-order optimization to quantized weights is infeasible due to the precision gap between discrete weights and continuous gradients. To address this, the paper introduces Quantized Zeroth-Order optimization (QZO), a novel method that estimates gradients by perturbing continuous quantization scales and uses a directional derivative clipping method to stabilize training. QZO is orthogonal to scalar-based and codebook-based post-training quantization methods. Compared to full-parameter bfloat16 fine-tuning, QZO can reduce total memory costs by over 18x for 4-bit LLMs and enables fine-tuning of Llama-2-13B and Stable Diffusion 3.5 Large within a single 24GB GPU (Source: HuggingFace Daily Papers)
Paper: Optimizing Anytime Reasoning Performance via Budget Relative Policy Optimization (BRPO) (AnytimeReasoner): Extending test-time computation is crucial for enhancing the reasoning capabilities of Large Language Models (LLMs). Existing methods typically employ Reinforcement Learning (RL) to maximize verifiable rewards at the end of a reasoning trajectory, but this only optimizes final performance under a fixed token budget, impacting training and deployment efficiency. This research proposes the AnytimeReasoner framework, designed to optimize anytime reasoning performance, improving token efficiency and reasoning flexibility under different budget constraints. The method involves truncating the full thought process to fit token budgets sampled from a prior distribution, forcing the model to summarize the best answer for each truncated thought for verification. This introduces verifiable dense rewards during the reasoning process, promoting more effective credit assignment in RL optimization. Additionally, researchers introduce Budget Relative Policy Optimization (BRPO), a novel variance reduction technique, to enhance learning robustness and efficiency when reinforcing the thinking policy. Experimental results on mathematical reasoning tasks show that this method outperforms GRPO across all thinking budgets under various prior distributions, improving training and token efficiency (Source: HuggingFace Daily Papers)
Paper Proposes Large Hybrid Reasoning Models (LHRM): Thinking On-Demand for Enhanced Efficiency and Capability: Recent Large Reasoning Models (LRMs) have significantly improved reasoning capabilities by performing extended thinking processes before generating a final response. However, excessively long thinking processes incur substantial overhead in token consumption and latency, especially unnecessary for simple queries. This research introduces Large Hybrid Reasoning Models (LHRMs), which can adaptively decide whether to perform thinking based on the contextual information of user queries. To achieve this, researchers propose a two-stage training pipeline: first, cold-starting with Hybrid Fine-Tuning (HFT), followed by online reinforcement learning with the proposed Hybrid Group Policy Optimization (HGPO) to implicitly learn to select appropriate thinking modes. Furthermore, researchers introduce the Hybrid Accuracy metric to quantify the model’s hybrid thinking ability. Experimental results show that LHRMs can adaptively perform hybrid thinking on queries of varying difficulty and types, outperforming existing LRMs and LLMs in reasoning and general capabilities while significantly improving efficiency (Source: HuggingFace Daily Papers)
Paper: Reasoning-Induced Image Quality Assessment by Reinforcement Learning to Rank on VisualQuality-R1: DeepSeek-R1 has demonstrated that reinforcement learning can effectively incentivize reasoning and generalization capabilities in Large Language Models (LLMs). However, in the field of Image Quality Assessment (IQA), which relies on visual reasoning, the potential of reasoning-induced computational modeling has not been fully explored. This research introduces VisualQuality-R1, a reasoning-induced No-Reference IQA (NR-IQA) model, trained using reinforcement learning to rank, a learning algorithm adapted to the inherent relativity of visual quality. Specifically, for a pair of images, the model employs group relative policy optimization to generate multiple quality scores for each image. These estimates are then used to compute the comparative probability of one image’s quality being higher than another’s under a Thurstone model. The reward for each quality estimate is defined using a continuous fidelity metric rather than discrete binary labels. Extensive experiments show that the proposed VisualQuality-R1 consistently outperforms discriminative deep learning-based NR-IQA models and recent reasoning-induced quality regression methods. Furthermore, VisualQuality-R1 can generate contextually rich quality descriptions consistent with human judgment and supports multi-dataset training without recalibrating perceptual scales. These features make it particularly suitable for reliably measuring progress in various image processing tasks such as image super-resolution and image generation (Source: HuggingFace Daily Papers)
Paper: Unlocking General Reasoning Capabilities with “Warm-up” under Resource Constraints: Designing effective LLMs with reasoning capabilities often requires Reinforcement Learning with Verifiable Rewards (RLVR) or distillation from meticulously curated long Chain-of-Thought (CoT) exemplars, both heavily reliant on extensive training data, posing significant challenges in scenarios where high-quality training data is scarce. Researchers propose a sample-efficient two-stage training strategy for developing reasoning LLMs under limited supervision. In the first stage, the model is “warmed up” by distilling long CoTs from toy domains (e.g., Knights and Knaves logic puzzles) to acquire general reasoning skills. In the second stage, RLVR is applied to the “warmed-up” model using a small number of target domain samples. Experiments show this method offers several benefits: (i) the warm-up phase alone promotes general reasoning, improving performance on a range of tasks (MATH, HumanEval+, MMLU-Pro); (ii) warmed-up models consistently outperform base models when trained with RLVR on the same small datasets (≤100 samples); (iii) warm-up before RLVR training allows the model to retain cross-domain generalization ability even after being trained for a specific domain; (iv) introducing warm-up into the pipeline not only improves accuracy but also enhances the overall sample efficiency of RLVR training. The findings demonstrate the potential of “warm-up” for building robust reasoning LLMs in data-scarce environments (Source: HuggingFace Daily Papers)
Paper Proposes IndexMark: A Training-Free Watermarking Framework for Autoregressive Image Generation: Invisible image watermarking techniques can protect image ownership and prevent malicious abuse of visual generative models. However, existing generative watermarking methods primarily target diffusion models, while watermarking techniques for autoregressive image generation models remain underexplored. Researchers propose IndexMark, a training-free watermarking framework for autoregressive image generation models. IndexMark is inspired by the redundancy characteristic of codebooks: replacing autoregressively generated indices with similar ones results in negligible visual differences. The core component of IndexMark is a simple yet effective “match-and-replace” method that carefully selects watermark tokens from the codebook based on token similarity and generalizes their use through token replacement, thereby embedding watermarks without compromising image quality. Watermark verification is achieved by calculating the proportion of watermark tokens in the generated image, with accuracy further improved by an index encoder. Additionally, researchers introduce an auxiliary verification scheme to enhance robustness against cropping attacks. Experiments demonstrate that IndexMark achieves SOTA performance in both image quality and verification accuracy, and exhibits robustness to various perturbations such as cropping, noise, Gaussian blur, random erasing, color jitter, and JPEG compression (Source: HuggingFace Daily Papers)
Paper: Reasoning with Reward Models (RRM): Reward models play a crucial role in guiding Large Language Models (LLMs) to produce outputs aligned with human expectations. However, how to effectively leverage test-time computation to enhance reward model performance remains an open challenge. This research introduces Reward Reasoning Models (RRMs), which are specifically designed to perform deliberate reasoning processes before generating a final reward. Through chain-of-thought reasoning, RRMs can utilize additional test-time computation for complex queries where the reward is not immediately obvious. To develop RRMs, researchers implemented a reinforcement learning framework capable of cultivating self-evolving reward reasoning abilities without requiring explicit reasoning trajectories as training data. Experimental results show that RRMs achieve superior performance on reward modeling benchmarks across multiple domains. Notably, researchers demonstrate that RRMs can adaptively utilize test-time computation to further improve reward accuracy. Pre-trained reward reasoning models are available on HuggingFace (Source: HuggingFace Daily Papers)
Paper: Guiding Thoughts with Cognitive Experts in MoE for Enhanced Reasoning without Extra Training: Mixture-of-Experts (MoE) architectures in Large Reasoning Models (LRMs) have achieved impressive reasoning capabilities by selectively activating experts to facilitate structured cognitive processes. Despite significant progress, existing reasoning models often suffer from cognitive inefficiencies such as overthinking and underthinking. To address these limitations, researchers introduce a novel inference-time guidance method called “Reinforcing Cognitive Experts” (RICE), designed to enhance reasoning performance without additional training or complex heuristics. Leveraging normalized pointwise mutual information (nPMI), researchers systematically identify specialized experts, termed “cognitive experts,” responsible for coordinating meta-level reasoning operations characterized by specific tokens (e.g., ““`”). Rigorous quantitative and scientific reasoning benchmark evaluations on leading MoE-based LRMs (DeepSeek-R1 and Qwen3-235B) demonstrate that RICE achieves significant and consistent improvements in reasoning accuracy, cognitive efficiency, and cross-domain generalization. Crucially, this lightweight approach substantially outperforms popular reasoning guidance techniques (like prompt engineering and decoding constraints) while preserving the model’s general instruction-following capabilities. These results highlight reinforcing cognitive experts as a promising, practical, and interpretable direction for enhancing cognitive efficiency within advanced reasoning models (Source: HuggingFace Daily Papers)
Paper: Investigating the Impact of Context Permutation on Language Model Performance in Multi-hop Question Answering: Multi-hop Question Answering (MHQA) poses a challenge for Language Models (LMs) due to its complexity. When LMs are prompted to process multiple search results, they must not only retrieve relevant information but also perform multi-hop reasoning across information sources. Although LMs perform well in traditional QA tasks, the causal mask might hinder their ability to reason in complex contexts. This study investigates how LMs respond to multi-hop questions by permuting search results (retrieved documents) in different configurations. The findings are: 1) Encoder-decoder models (e.g., Flan-T5 series) generally outperform causal decoder-only LMs in MHQA tasks, despite their much smaller size; 2) Changing the order of gold documents reveals different trends in Flan T5 models and fine-tuned decoder-only models, with performance being optimal when the document order aligns with the reasoning chain order; 3) Enhancing bidirectional attention in causal decoder-only models by modifying the causal mask can effectively improve their final performance. Furthermore, the study conducts a thorough investigation of the distribution of LM attention weights in the MHQA context, finding that attention weights tend to peak at higher values when the answer is correct. Researchers leverage this finding to heuristically improve LM performance on this task (Source: HuggingFace Daily Papers)
Paper: Enabling Visual Agentic Capabilities via Reinforcement Fine-Tuning (Visual-ARFT): A key trend in Large Reasoning Models (e.g., OpenAI’s o3) is the native agentic capability to use external tools (like web browser search, writing/executing code for image processing) to achieve “thinking with images.” In the open-source research community, while significant progress has been made in pure language agentic capabilities (such as function calling and tool integration), the development of multimodal agentic capabilities involving true “thinking with images” and corresponding benchmarks remains less explored. This research highlights the effectiveness of Visual Agentic Reinforcement Fine-Tuning (Visual-ARFT) in endowing Large Vision Language Models (LVLMs) with flexible and adaptive reasoning capabilities. Through Visual-ARFT, open-source LVLMs gain the ability to browse websites for real-time information updates and write code to manipulate and analyze input images via image processing techniques like cropping and rotation. Researchers also propose a Multi-modal Agentic Tool Bench (MAT), consisting of MAT-Search and MAT-Coding settings, to evaluate the agentic search and coding capabilities of LVLMs. Experimental results show that Visual-ARFT outperforms baselines by +18.6% F1 / +13.0% EM on MAT-Coding and +10.3% F1 / +8.7% EM on MAT-Search, ultimately surpassing GPT-4o. Visual-ARFT also achieves gains of +29.3 F1% / +25.9% EM on existing multi-hop QA benchmarks like 2Wiki and HotpotQA, demonstrating strong generalization. These findings suggest Visual-ARFT offers a promising path for building robust and generalizable multimodal agents (Source: HuggingFace Daily Papers)
💼 Business
ModelBest Completes New Multi-Hundred Million Yuan Financing Round, Jointly Invested by Hongtai Aplus, GZVC, Tsinghua Holdings Capital, and Moutai Fund: Large model company ModelBest recently announced the completion of a new financing round of several hundred million yuan, jointly invested by Hongtai Aplus, Guozhong Capital (GZVC), Tsinghua Holdings Capital, and Moutai Fund. ModelBest focuses on developing “efficient” large models, aiming to create models with higher performance, lower cost, lower power consumption, and faster speed at the same parameter scale. Its on-device full-modality model MiniCPM-o 2.6 has achieved industry-leading performance in continuous viewing, real-time listening, and natural speaking. The MiniCPM series models, known for their efficiency and low cost, have surpassed ten million downloads across all platforms. The company has partnered with automakers such as Changan Automobile, SAIC Volkswagen, and Great Wall Motors to promote the commercialization of on-device large models in areas like intelligent cockpits (Source: 量子位, WeChat)

Terminus Group and Tongji University Reach Strategic Cooperation to Jointly Promote Spatial Intelligence Technology Research: AIoT enterprise Terminus Group signed a strategic cooperation agreement with the Engineering AI Research Institute of Tongji University. Both parties will focus on spatial intelligence technology, prioritizing research and development in areas such as multi-source heterogeneous data fusion, scene understanding, and decision execution. The cooperation includes innovative research, resource sharing,成果转化 (results commercialization), and talent cultivation. Terminus Group will provide application scenarios and hardware testing platforms, while the Engineering AI Research Institute of Tongji University will lead core algorithm R&D and system engineering. Both sides aim to accelerate the industrial application of cutting-edge technologies and jointly explore breakthroughs in the field of engineering intelligence “operating systems” (Source: 量子位)

Domestic Tech Giants Accelerate AI Agent Deployment, Baidu, Alibaba, ByteDance Compete for Market Share: Following Sequoia Capital’s AI summit emphasizing the value of AI Agents, domestic internet giants like ByteDance, Baidu, and Alibaba are accelerating their deployment in this field. ByteDance reportedly has multiple teams working on Agent development and has internally tested “Coze Space”; Baidu launched the general intelligent agent “Xinxian” at its Create conference; Alibaba has positioned Quark as a “Super Agent.” Besides general-purpose Agents, companies are also focusing on vertical Agents like Fliggy Wen Yi Wen (Alibaba) and Faxingbao (Baidu). The industry believes Agents are the second wave after large models, with competition hinging on ecosystem depth, user mindshare, foundational model capabilities, and cost control. Despite fierce competition, Agents have not yet reached a disruptive moment like GPT, and there is still room for improvement in technological maturity, business models, and user experience (Source: 36氪)
🌟 Community
AI-Generated Content Floods Reddit, Sparking “Dead Internet” Concerns and User Experience Discussions: Reddit users have observed an increasing amount of AI-generated content on the platform, with some comments exhibiting similar, impersonal styles, and even clear signs of AI writing (such as overuse of em-dashes). This has sparked discussions about the “Dead Internet Theory,” which posits that most internet content will be AI-generated rather than human interaction. User reactions are mixed: some find AI content to be lacking human touch, boring, or creepy, affecting genuine interpersonal communication; others point out that AI can help non-native speakers polish text or be used for testing and fine-tuning models. A common concern is that the proliferation of AI content will dilute authentic human discussions and could be used for marketing, propaganda, and other purposes, ultimately reducing the platform’s value for AI training (Source: Reddit r/ChatGPT, Reddit r/ArtificialInteligence)
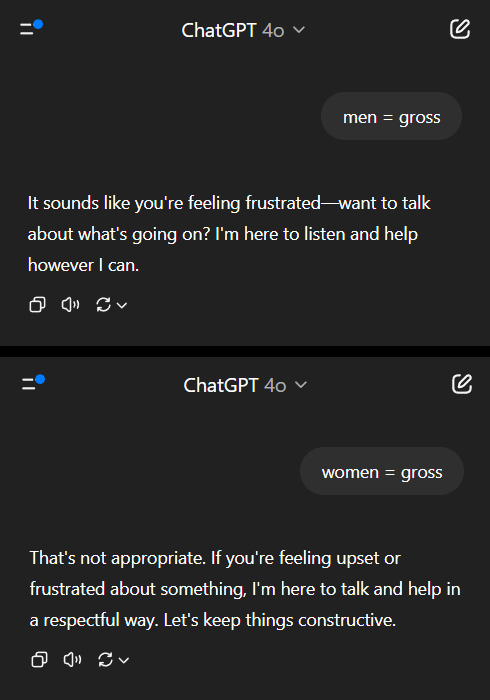
AI Models Exhibit Double Standards on Gender Bias, Prompting Social Reflection: A Reddit post showcased an AI model (reportedly a preview version of Gemini 2.5 Pro) reacting differently to negative generalizations involving gender. When told “men = disgusting,” the model tended to respond neutrally, acknowledging it as a subjective statement. However, when told “women = disgusting,” the model refused further interaction, deeming the statement as promoting harmful generalizations. The comment section saw heated debate, with views including: this reflects the social reality where misogyny is discussed far more than misandry, leading to imbalanced training data; the model might adjust its response strategy based on the questioner’s gender; societal sensitivity to stereotypes and aggressive remarks differs for different gender groups. Some commenters believe the AI’s reaction mirrors societal biases, while others argue this differentiated treatment is justifiable because negative remarks against women are often linked to broader discrimination and violence (Source: Reddit r/ChatGPT)
Discussion on Commoditization Trend of AI Agents and Future Competition Focus: Reddit users discussed that Microsoft Build 2025 and Google I/O 2025 conferences signal that AI Agents have entered a commoditization phase. In the coming years, building and deploying Agents will no longer be exclusive to developers of cutting-edge models. Therefore, the short-term focus of AI development will shift from building Agents themselves to higher-level tasks, such as formulating and deploying better business plans, and developing smarter models to drive innovation. Commenters believe that future winners in the AI Agent field will be those who can build the most intelligent “executive models,” rather than just those who market the cleverest tools. The core of competition will return to powerful intelligence at the top of the stack, not just attention mechanisms or reasoning capabilities (Source: Reddit r/deeplearning)
Machine Learning Practitioners Discuss the Importance of Mathematical Knowledge: The Reddit r/MachineLearning community discussed the importance of mathematics in machine learning practice. Most practitioners believe that understanding the mathematical principles behind AI is crucial, especially for model optimization, understanding research papers, and innovation. Comments pointed out that while manual calculations like matrix multiplication might not be necessary, a grasp of core concepts in statistics, linear algebra, and calculus helps in deeply understanding algorithms and avoiding blind application. Some commented that the math in machine learning is relatively simple, with more complex mathematics applied in fields like optimization theory and quantum machine learning. Online learning resources are considered abundant, but require a high degree of self-discipline from learners (Source: Reddit r/MachineLearning)
💡 Other
QbitAI Think Tank Report: AI Reshapes Search SEO, Highlighting the Value of Professional Content Communities: QbitAI Think Tank released a report indicating that AI intelligent assistants are reshaping traditional Search Engine Optimization (SEO) strategies. The report, through experiments, found that nearly half of AI-generated answers are sourced from content communities, especially in professional knowledge domains where content communities (like Zhihu) have higher citation weight. Users’ expectations for information acquisition are shifting from “self-filtering” to “directly obtaining answers,” potentially leading to a decline in traditional website click-through rates. The report argues that in the AI era, professional content communities are increasingly valuable due to their information density, expert experience, and quality of user-generated content. SEO strategies should shift towards SPO (Search Professional-community Optimization), and the weight of low-quality information portals will decrease (Source: 量子位, WeChat)

AI Photo Age-Estimation Tool FaceAge Published in The Lancet, May Aid Cancer Treatment Decisions: A team from Mass General Brigham has developed an AI tool called FaceAge that can predict an individual’s biological age by analyzing facial photos. The research was published in The Lancet Digital Health. The model assesses aging by observing facial features such as temple hollowing, skin wrinkles, and sagging lines. In a study involving cancer patients, it was found that patients whose facial age appeared younger than their actual age had better treatment outcomes and lower survival risks. The tool may in the future assist doctors in developing personalized treatment plans based on a patient’s biological age, but it also raises concerns about data bias (training data predominantly white) and potential misuse (e.g., insurance discrimination) (Source: WeChat)

Study: Top AI Performs Poorly on Basic Physical Tasks, Highlighting Blue-Collar Jobs Unlikely to Be Replaced Soon: Machine learning researcher Adam Karvonen evaluated the performance of top LLMs like OpenAI’s o3 and Gemini 2.5 Pro on a parts manufacturing task (using a CNC milling machine and lathe). The results showed that all models failed to develop a satisfactory machining plan, exposing deficiencies in visual understanding (missing details, inconsistent feature recognition) and physical reasoning (ignoring rigidity and vibration, proposing impossible workpiece clamping solutions). Karvonen believes this is related to the LLMs’ lack of tacit knowledge and real-world experience data in relevant fields. He speculates that in the short term, AI will automate more white-collar jobs, while blue-collar jobs relying on physical manipulation and experience will be less affected, potentially leading to uneven automation development across different industries (Source: WeChat)
