
Keywords:AI Agent, Large Language Model, Gemini 2.5 Pro, NVIDIA AI Supercomputer, Microsoft Build Conference, Research AI Agent, Reasoning Capability Evaluation, AI Programming, Coding Agent Autonomous Bug Fixing, Microsoft Discovery Research Platform, NVLink Fusion Technology, CloudMatrix 384 Super Node, EdgeInfinite Algorithm
🔥 Focus
AI Agents Redefine Development and Research Paradigms: Microsoft Build conference released a series of AI agent tools, including the Coding Agent for autonomously fixing bugs and maintaining code, and Microsoft Discovery, a research agent platform capable of generating ideas, simulating results, and autonomous learning. Meanwhile, OpenAI CPO Kevin Weil and Anthropic CEO Dario Amodei both stated that AI already possesses advanced programming capabilities, suggesting that junior programmer positions may be replaced, and the role of developers will shift towards “AI guides.” These developments indicate that AI agents are evolving from auxiliary tools into core forces capable of operating independently in complex projects, and will profoundly transform the processes and efficiency of software development and scientific research (Source: GitHub Trending, X)
New Challenges and Evaluations for Large Language Model Reasoning Capabilities: Several recent studies and discussions have revealed the limitations of large language models in complex reasoning tasks. Research from institutions like Harvard University points out that Chain of Thought (CoT) can sometimes lead to a decrease in model accuracy in following instructions, due to excessive focus on content planning while neglecting simple constraints. Concurrently, real-world physical tasks (such as parts machining) and complex visuospatial reasoning (like cube stacking problems) have also exposed the shortcomings of top-tier AI models (including o3, Gemini 2.5 Pro). To more accurately assess model capabilities, new benchmarks like EMMA and SPOT have been proposed, aiming to detect AI’s true proficiency in multimodal fusion, scientific validation, and other areas, thereby driving models towards more robust and reliable reasoning (Source: HuggingFace Daily Papers, QbitAI)
Google AI Goes All-In, Gemini 2.5 Pro Shows Strong Performance: Google is demonstrating a comprehensive offensive in the AI field, with its Gemini 2.5 Pro model performing exceptionally well in multiple benchmarks (such as LMSYS Chatbot Arena), particularly achieving top-tier levels in long-context and video understanding, and surpassing its predecessor in the WebDev Arena. At Google Cloud Next ‘25, Google announced over 200 updates, including Gemini 2.5 Flash, Imagen 3, Veo 2, Vertex AI Agent Development Kit (ADK), and the Agent2Agent (A2A) protocol, underscoring its determination to integrate AI into all layers of its cloud platform and promote enterprise-scale deployment. Google Labs also continues to incubate AI-native innovative products like NotebookLM, showcasing strong product innovation and iteration capabilities (Source: Google, GoogleDeepMind)
NVIDIA Unveils Desktop-Level AI Supercomputer and Enterprise AI Factory Solutions: At Computex, NVIDIA released several major new products, including the DGX Station, a personal AI computer equipped with the GB300 superchip, boasting up to 784GB of unified memory and supporting the operation of 1T-parameter large models; and the RTX PRO Server for enterprises, which can accelerate various applications such as AI agents, physical AI, and scientific computing. Simultaneously, NVIDIA introduced the semi-custom NVLink Fusion technology and the NVIDIA AI data platform, and announced collaborations with Disney and others to develop the physical AI engine Newton. These initiatives indicate NVIDIA’s transformation from a chip company to an AI infrastructure company, aiming to build a complete AI ecosystem from desktop to data center (Source: nvidia, QbitAI)

🎯 Trends
Kimi.ai Releases Long-Text Thinking Model kimi-thinking-preview: Kimi.ai has launched its latest long-text thinking model, kimi-thinking-preview, now available on platform.moonshot.ai. The model is claimed to possess excellent multimodal and reasoning capabilities, and new users can receive a $5 voucher for trial. Community comments suggest third-party evaluation for the model and mention that Kimi had previously achieved a leading position on livecodebench with a dedicated thinking model (Source: X)
Red Hat Introduces llm-d: A Kubernetes-Based Distributed Inference Framework: To address the issues of slow LLM inference, high costs, and difficult scaling, Red Hat has launched llm-d, a Kubernetes-native distributed inference framework. This framework utilizes vLLM, intelligent scheduling, and decoupled computing to optimize LLM inference. llm-d is built on three open-source foundations: vLLM (a high-performance LLM inference engine), Kubernetes (the standard for container orchestration), and Inference Gateway (IGW) (which implements intelligent routing through Gateway API extensions), aiming to enhance the efficiency and scalability of LLM inference (Source: X, X)
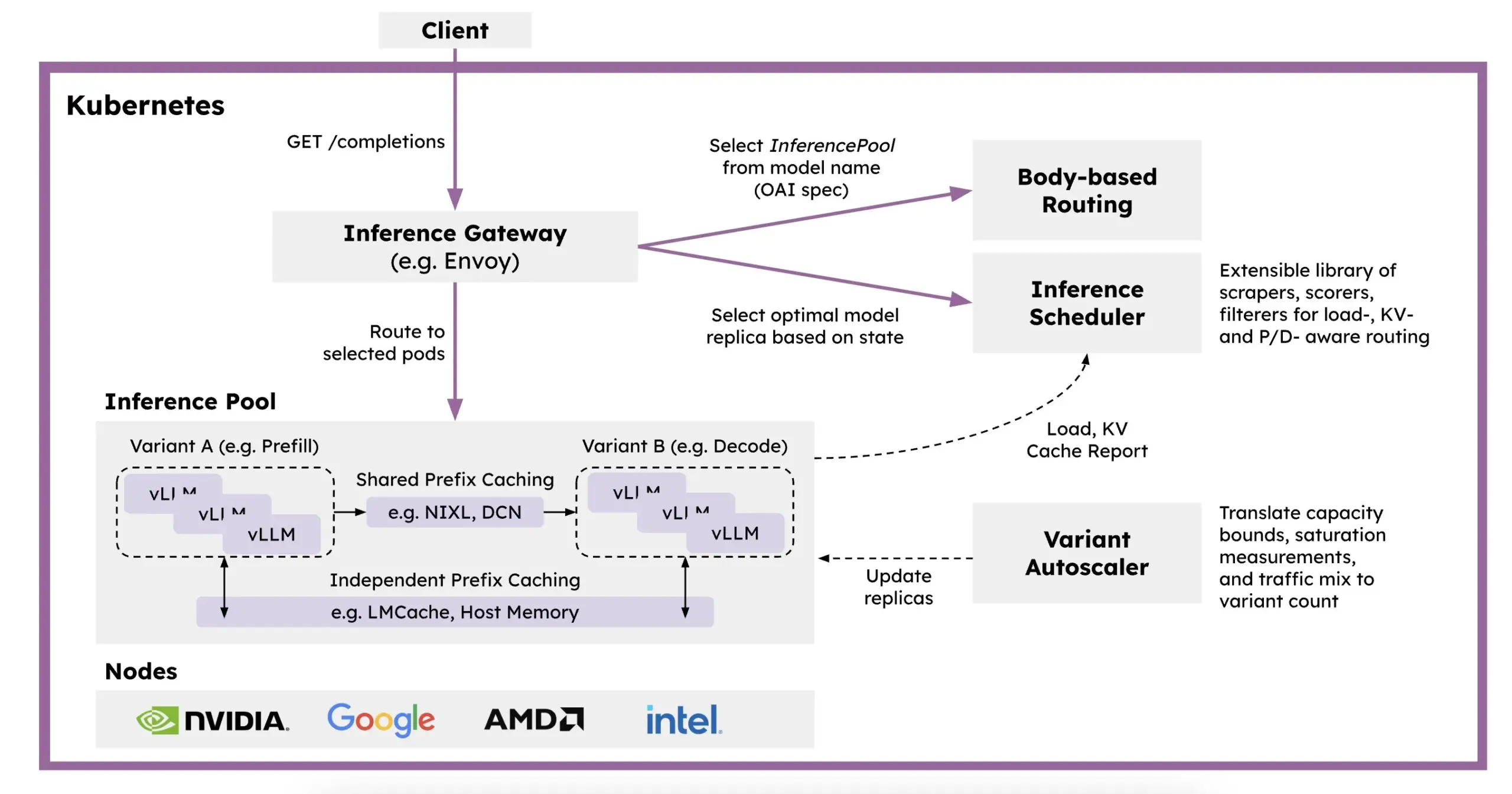
Meta AI Releases OMol25 Dataset, Containing Over 100 Million Molecular Conformations: Meta AI has released the OMol25 dataset on HuggingFace, containing over 100 million molecular conformations, covering 83 elements and diverse chemical environments. This dataset aims to train machine learning models capable of achieving DFT (Density Functional Theory) level accuracy while significantly reducing computational costs. This will help accelerate research and applications in fields such as drug discovery, advanced materials design, and clean energy solutions (Source: X)
Gemini 2.5 Pro Launches in NotebookLM on German iOS App Store: Google’s NotebookLM app (integrated with Gemini 2.5 Pro) is now available on the iOS App Store in Germany. Previously, the iOS version in the EU was only available via TestFlight. Meanwhile, the Android version appears to be more widely available. NotebookLM is designed to help users understand and process long documents, notes, and other content (Source: X)
ByteDance AI Research Active, Recently Published Multiple Papers: ByteDance’s SEED team has published at least 13 AI-related research papers in the past two months, covering areas such as model merging, Reinforcement Learning-triggered Adaptive Chain of Thought (AdaCoT), and Optimizing Reasoning through Latent Representations (LatentSeek). This research demonstrates ByteDance’s continued investment and exploration in enhancing the efficiency, reasoning capabilities, and training methods of large language models (Source: X, X)
AI-Driven Next-Generation Zinc Battery Achieves 99.8% Efficiency and 4300-Hour Runtime: Through artificial intelligence optimization, a new generation of zinc batteries has achieved 99.8% Coulombic efficiency and a runtime of up to 4300 hours. This technological breakthrough demonstrates the application potential of AI in materials science and energy storage, and is expected to promote the development of more efficient and durable battery technology, which is significant for renewable energy storage and portable electronic devices (Source: X)

Perplexity Launches AI-Powered Browser Comet for Early Testing: Perplexity has begun rolling out its agent-enabled web browser, Comet, to early testers. This browser is expected to offer a novel “vibe browsing” experience, potentially combining Perplexity’s powerful AI search and information integration capabilities to provide users with a more intelligent and personalized web browsing method (Source: X)
Intel Releases Cost-Effective Arc Pro B-Series Graphics Cards, Focusing on Large VRAM: Intel has launched the Arc Pro B50 (16GB VRAM, $299) and the Arc Pro B60 (24GB VRAM, $500 per card), designed for AI workstations. The B60 outperforms NVIDIA’s RTX A1000 in AI inference tests, and its larger VRAM gives it an advantage when running large models. The Project Battlematrix workstation uses Xeon processors and can be equipped with up to 8 B60 GPUs (192GB total VRAM), supporting models with 70 billion+ parameters. This move is seen as Intel’s strategy to seek a cost-performance breakthrough in the AI hardware market (Source: QbitAI)

Huawei Cloud Launches CloudMatrix 384 Super Node to Enhance AI Computing Power: Huawei Cloud has released the CloudMatrix 384 super node, which uses a full peer-to-peer interconnection architecture to connect 384 AI accelerator cards to form a super cloud server, providing up to 300 PFlops of computing power. It aims to address challenges in communication efficiency, memory wall, and reliability in AI training and inference. The architecture particularly emphasizes affinity for MoE models, strengthening computing with networking, and strengthening computing with storage, and has been applied to support inference services for large models like DeepSeek-R1 (Source: QbitAI)

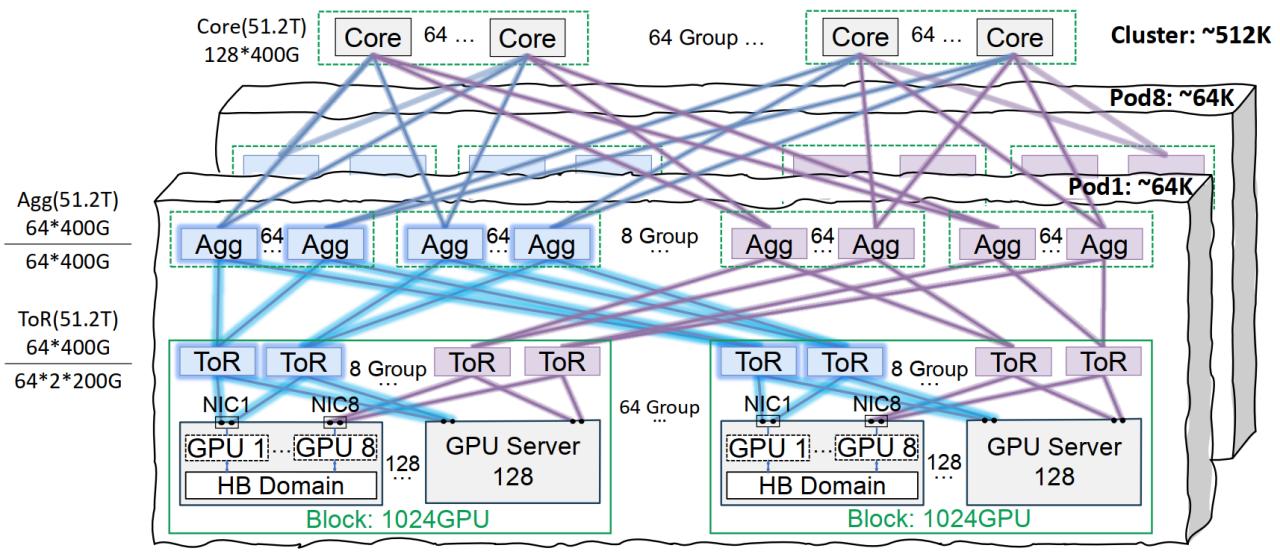
Tencent Cloud’s Xingmai Network Infrastructure Optimizes Large Model Training: Tencent Cloud has launched the Xingmai high-performance network infrastructure solution, specifically designed for large-scale AI model training and inference. This solution addresses pain points in traditional data centers regarding networking, deployment density, and fault localization through a co-packaged optics interconnection architecture (supporting single Pod 64,000 GPUs, full cluster 512,000 GPU networking), optimized power management and cooling solutions, and an intelligent monitoring system. Xingmai already supports Tencent’s self-developed businesses like Hunyuan and has provided performance optimization for DeepSeek’s DeepEP communication framework (Source: QbitAI)
Stability AI Releases SV4D2.0 Model, Potentially Signaling Its Return in Video Generation: Stability AI has released a model named sv4d2.0 on Hugging Face, drawing community attention. Although details are scarce, this move may indicate new technological advancements or product iterations by Stability AI in video generation or related 3D/4D fields, suggesting a possible return to the forefront of AI generation after a period of adjustment (Source: X)
Meta AI Releases Adjoint Sampling Learning Algorithm: Meta AI has proposed a new learning algorithm, Adjoint Sampling, for training generative models based on scalar rewards. The algorithm, built on theoretical foundations developed at FAIR, is highly scalable and is expected to become a basis for future research in scalable sampling methods. The related research paper, models, code, and benchmarks have been released (Source: X)
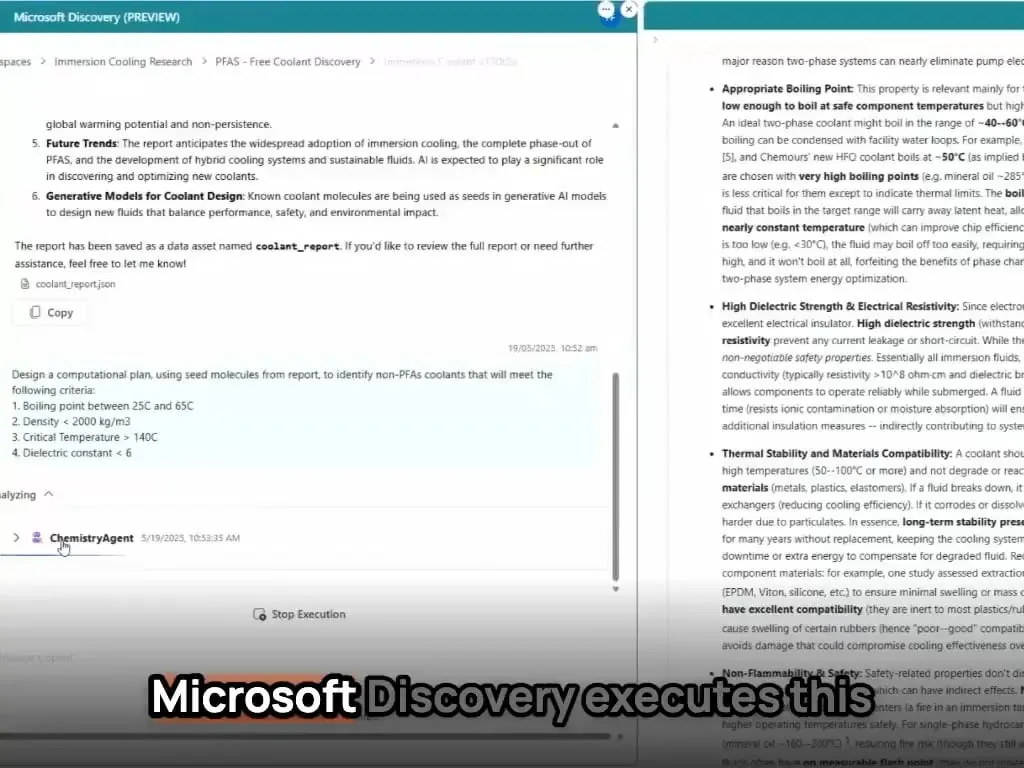
Microsoft AI Agents Complete New Material Discovery and Synthesis in Hours: Microsoft showcased the powerful capabilities of its AI agents in scientific R&D. These agents can scan scientific literature, formulate plans, write code, run simulations, and complete the discovery of a novel data center coolant—a process that typically takes years—within hours. Furthermore, the team successfully synthesized the AI-designed novel coolant and demonstrated it on an actual motherboard, highlighting AI’s immense potential to accelerate autonomous discovery and creation in fields like materials science (Source: Reddit r/artificial)
BAAI Releases Three BGE Series Vector Models, Focusing on Code and Multimodal Retrieval: The Beijing Academy of Artificial Intelligence (BAAI), in collaboration with universities, has launched BGE-Code-v1 (code vector model), BGE-VL-v1.5 (general multimodal vector model), and BGE-VL-Screenshot (visual document vector model). These models have demonstrated excellent performance on benchmarks such as CoIR, Code-RAG, MMEB, and MVRB. BGE-Code-v1 is based on Qwen2.5-Coder-1.5B, BGE-VL-v1.5 on LLaVA-1.6, and BGE-VL-Screenshot on Qwen2.5-VL-3B-Instruct. They aim to enhance performance in code retrieval, image-text understanding, and complex visual document retrieval, and have been fully open-sourced (Source: WeChat)
Huawei’s OmniPlacement Technology Optimizes MoE Model Inference, Theoretically Reducing DeepSeek-V3 Latency by 10%: Addressing the issue of imbalanced expert network load (“hot experts” vs. “cold experts”) in Mixture-of-Experts (MoE) models, which limits inference performance, a Huawei team has proposed OmniPlacement technology. This technology theoretically reduces inference latency by about 10% and increases throughput by about 10% for models like DeepSeek-V3 through expert rearrangement, inter-layer redundant deployment, and near real-time dynamic scheduling. The solution will be fully open-sourced soon (Source: WeChat)

vivo Releases EdgeInfinite Algorithm for Efficient 128K Long-Text Processing on Mobile Phones: vivo AI Research Institute published research at ACL 2025, introducing the EdgeInfinite algorithm, specifically designed for edge devices. It efficiently processes ultra-long text in Transformer architectures through trainable gated memory modules and memory compression/decompression techniques. Tested on the BlueLM-3B model, the algorithm can process 128K tokens on a device with 10GB GPU memory, performs excellently on several LongBench tasks, and significantly reduces first-token latency and memory footprint (Source: WeChat)

🧰 Tools
LlamaParse Updated, Enhancing Document Parsing Capabilities: LlamaParse has released several updates, improving its performance as an AI agent-driven document parsing tool. New features include support for Gemini 2.5 Pro and GPT-4.1, and the addition of skew detection and confidence scores. Furthermore, a code snippet button has been introduced for users to easily copy parsing configurations directly into their codebase, along with use-case presets and the ability to toggle export between rendered and raw Markdown (Source: X)
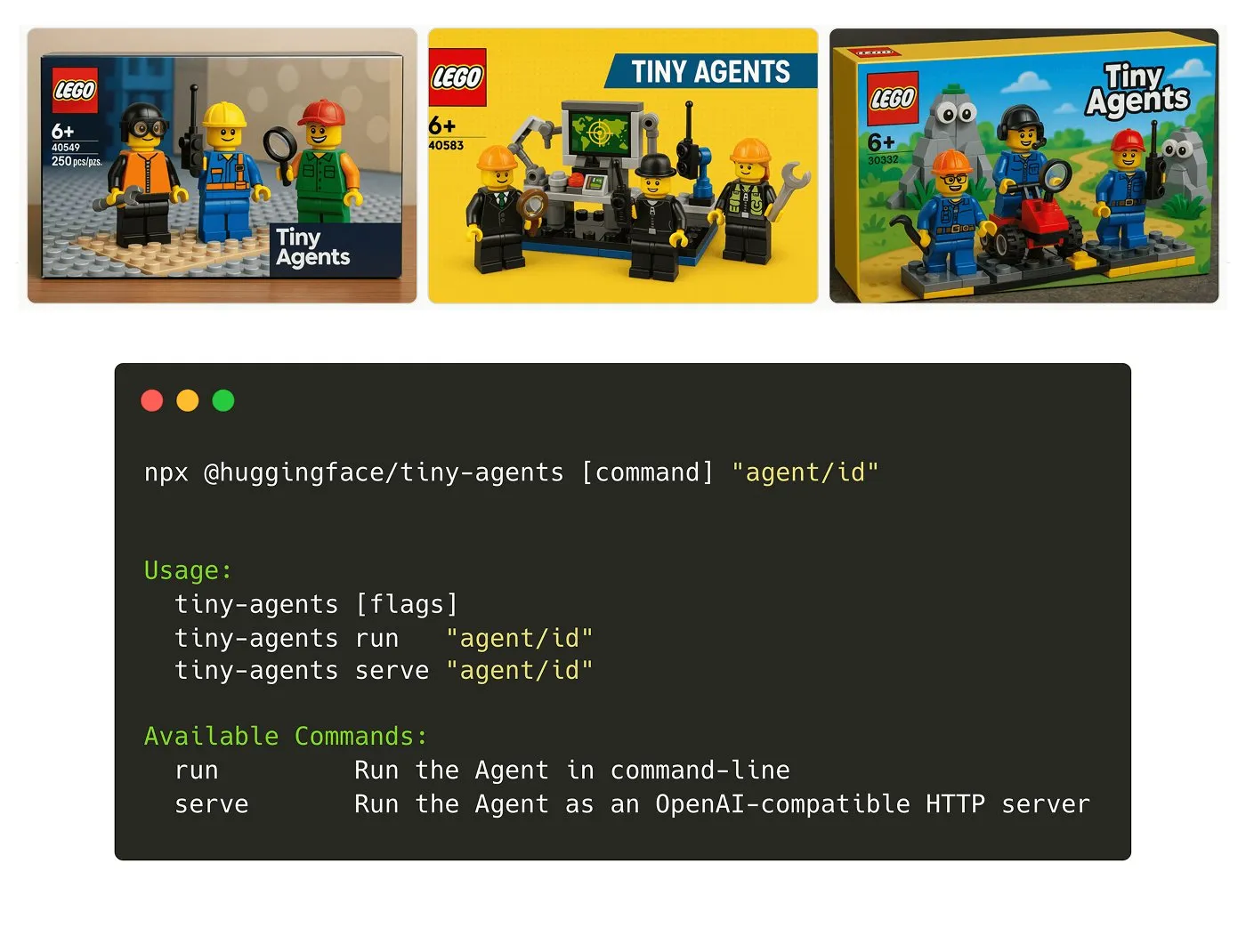
Hugging Face Launches Tiny Agents NPM Package: Julien Chaumond has released Tiny Agents, a lightweight, composable agent NPM package. It is built on Hugging Face’s Inference Client and MCP (Model Component Protocol) stack, designed to help developers quickly get started and build small agent applications. An official tutorial is available (Source: X)
LangGraph Platform Adds MCP Support, Simplifying Agent Integration: The LangGraph platform now supports MCP (Model Component Protocol), with each agent deployed on the platform automatically exposing an MCP endpoint. This means users can leverage these agents as tools in any client that supports MCP streamable HTTP, without writing custom code or configuring additional infrastructure, simplifying integration and interoperability between agents (Source: X)

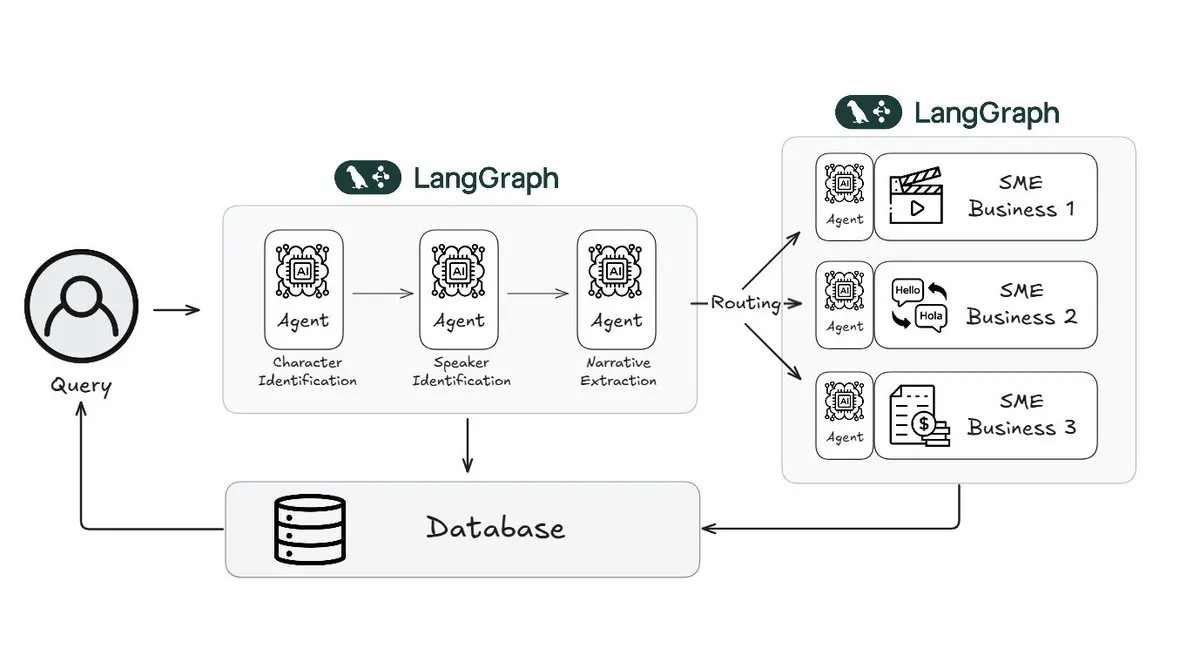
Webtoon Reduces Story Review Workload by 70% Using LangGraph: Webtoon, a leader in digital comics, has built Webtoon Comprehension AI (WCAI), which uses LangGraph to automate narrative understanding for its massive content library. WCAI replaces manual browsing with intelligent multimodal agents capable of character and speaker identification, plot and tone extraction, and natural language insight queries, reducing the workload for its marketing, translation, and recommendation teams by 70% and enhancing creativity (Source: X)
OpenMemory MCP Enables Persistent Private Memory Sharing Between AI Tools: The Mem0 project has launched the OpenMemory MCP server, designed to provide AI applications with persistent private memory across platforms and sessions. Users can deploy it locally and connect OpenMemory to client tools like Cursor via the MCP protocol to add, search, list, and delete memories. The tool offers memory management functions through a dashboard and is expected to enhance the personalization and contextual understanding capabilities of AI agents (Source: WeChat)

Miaoduo AI 2.0 Released, Positioned as an AI Assistant for Interface Design: Miaoduo AI 2.0 has been released as an AI assistant in the field of interface design, aiming to collaborate with users on design tasks. The new version enhances interaction through an AI magic box, supports conversational editing and iterative design solutions, can generate multiple interface versions based on preset styles or user input (long text, sketches, reference images), and is compatible with mainstream design systems. Additionally, it offers image and text processing, design consultation, and shortcut commands (natural language to API calls). Miaoduo AI supports the MCP protocol and optimizes design draft data for large models to read, enabling the generation of high-fidelity front-end code (Source: QbitAI)

llmbasedos: MCP-Based Open Source Bootable AI Operating System Proof-of-Concept: Developer iluxu open-sourced the llmbasedos project three days before Microsoft announced its “USB-C for AI apps” concept (based on MCP). The project is an AI operating system that can be quickly booted from USB or a virtual machine. It communicates with small Python daemons via a FastAPI gateway using JSON-RPC, allowing user scripts to be called by ChatGPT/Claude/VS Code etc., through simple cap.json configurations. It defaults to offline llama.cpp but can also switch to GPT-4o or Claude 3, aiming to promote open AI application connection standards (Source: Reddit r/LocalLLaMA)
📚 Learning
Why is Knowledge Distillation (KD) Effective? New Research Offers a Concise Explanation: Kyunghyun Cho et al. propose a concise explanation for the effectiveness of Knowledge Distillation (KD). They hypothesize that using low-entropy approximate sampling from a teacher model leads to student models with higher precision but lower recall. Since autoregressive language models are essentially infinitely cascaded mixture distributions, they validated this hypothesis through SmolLM. The study suggests that current evaluation methods may overemphasize precision while ignoring the loss in recall, which is relevant to what large-scale general models might miss and which user groups they might overlook (Source: X)

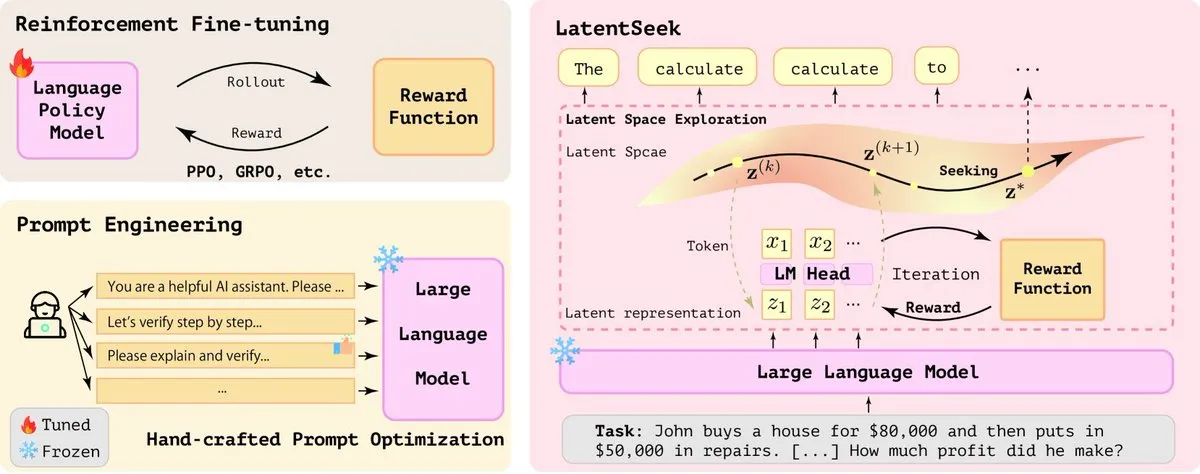
LatentSeek: Enhancing LLM Reasoning Capabilities via Policy Gradients in Latent Space: A paper titled “Seek in the Dark” proposes LatentSeek, a new paradigm for enhancing the reasoning capabilities of Large Language Models (LLMs) at test time through instance-level policy gradients in latent space. This method requires no training, data, or reward models, aiming to improve the model’s reasoning process by optimizing latent representations. This training-agnostic approach shows potential in improving LLM performance on complex reasoning tasks (Source: X)
Microsoft Proposes CoML: Chain-of-Model Learning for Language Models: Microsoft Research has proposed a new learning paradigm called “Chain-of-Model Learning” (CoML). This method incorporates the causal relationships of hidden states into each network layer in a chain-like structure, aiming to improve the scaling efficiency of model training and the inference flexibility during deployment. Its core concept, “Chain-of-Representation” (CoR), decomposes the hidden state of each layer into multiple sub-representation chains, where subsequent chains can access the input representations of all preceding chains. This allows the model to be progressively scaled by adding chains and to provide multiple sub-models of varying sizes for elastic inference by selecting different numbers of chains. CoLM (Chain-of-Language Model) and its variant CoLM-Air (which introduces a KV sharing mechanism), designed based on this principle, have demonstrated performance comparable to standard Transformers while offering the advantages of progressive scaling and elastic inference (Source: X, HuggingFace Daily Papers)

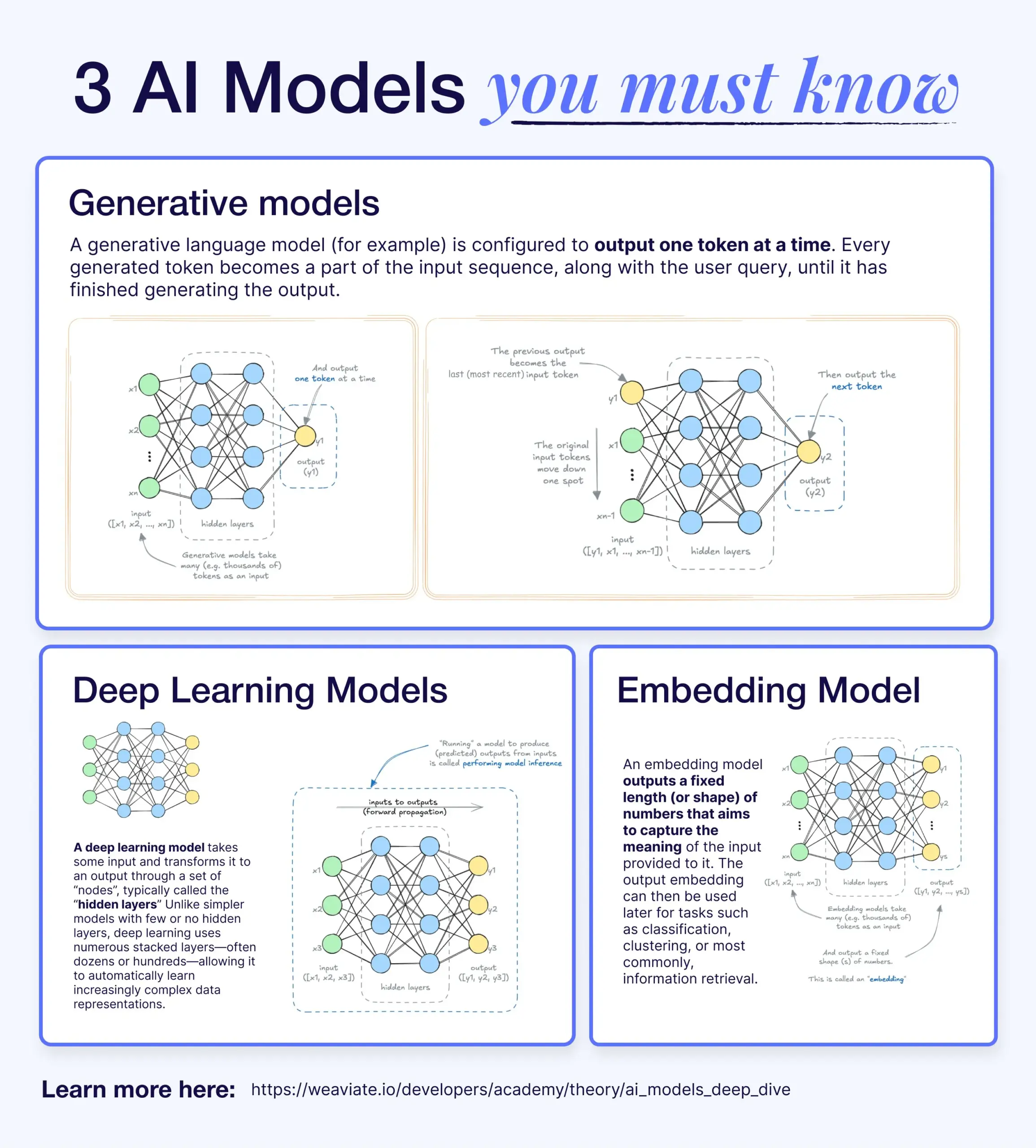
Differences and Connections Between Deep Learning, Generative, and Embedding Models: An explanatory article clarifies the relationships between deep learning models, generative models, and embedding models. Deep learning models are the foundational architecture, processing numerical inputs and outputs through multi-layer neural networks. Generative models are a type of deep learning model specifically designed to create new content similar to their training data (e.g., GPT, DALL-E). Embedding models are also a type of deep learning model, used to convert data (text, images, etc.) into numerical vector representations that capture semantic information, often used in similarity search and RAG systems. In many AI systems, these models work synergistically; for example, RAG systems utilize embedding models for retrieval, and then generative models produce the responses (Source: X)
DSPy Proposes Philosophy for Investing in AI Systems: DSPy shares its philosophy on investing effort in AI systems, emphasizing focus on three foundational layers: Data, Models, and Algorithms. They argue that by providing composable top-level modules (Prompts, Demonstrations, Optimizers, Metrics, Tools, Agents, Reasoning Modules), developers can rapidly iterate on these three foundational layers, thereby building more powerful AI systems (Source: X)
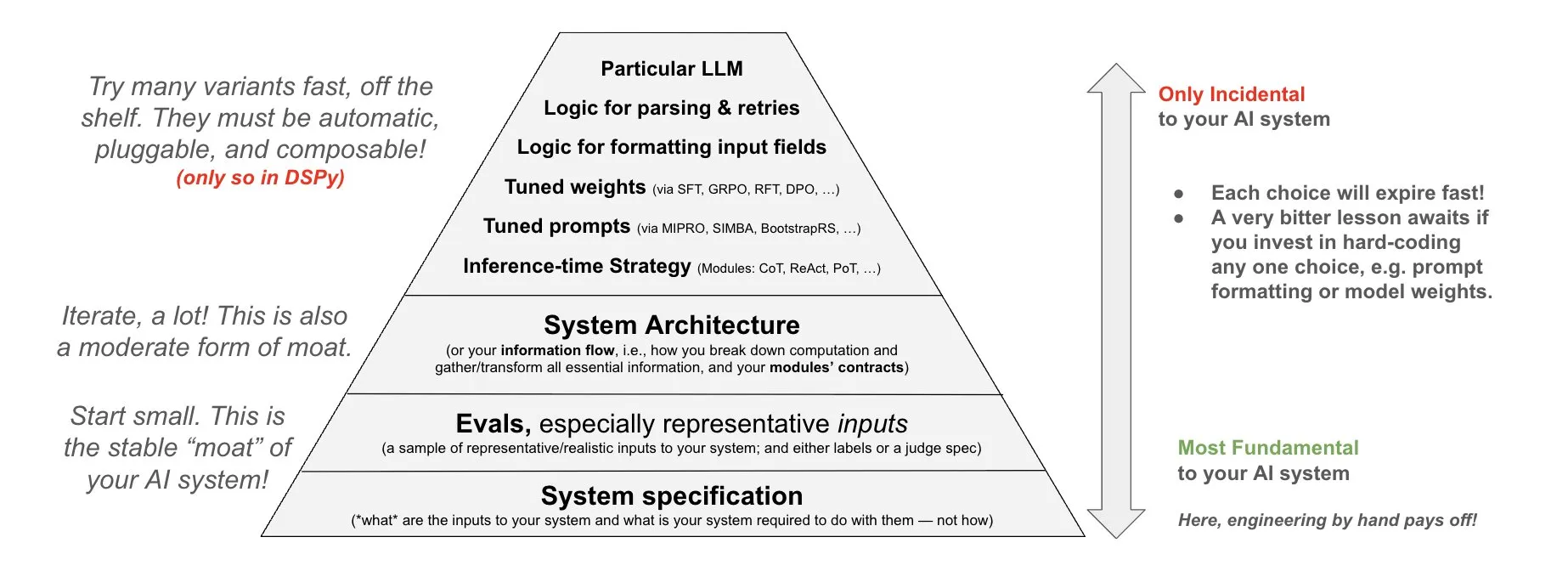
Transformers Library Update Automatically Switches to Optimized Kernels for Improved Performance: The latest version of the Hugging Face Transformers library now automatically switches to optimized kernels when hardware permits. This update integrates the kernels library, targeting popular models like Llama, and utilizes the most popular community kernels from the Hugging Face Hub to enhance model runtime efficiency and performance on compatible hardware (Source: X)
ARC-AGI-2 Benchmark Released, Challenging Frontier AI Reasoning Systems: François Chollet et al. have released a paper on the ARC-AGI-2 benchmark, detailing its design principles, challenges, human performance analysis, and current model performance. The benchmark aims to evaluate AI’s abstract reasoning capabilities. Humans can solve 100% of the tasks, while current frontier AI models score below 5%, indicating a significant gap between AI and humans in advanced abstract reasoning (Source: X)

Terence Tao Releases GitHub Copilot Tutorial for Assisting in Proving Function Limits: Mathematician Terence Tao released a video tutorial demonstrating how to use GitHub Copilot to assist in proving function limit problems, including sum, difference, and product theorems. He emphasized that while Copilot can quickly generate code frameworks and suggest existing library functions, significant manual intervention and adjustment are still needed for complex mathematical details, special case handling, and creative solutions. Sometimes, combining pen-and-paper derivation before formal verification might be more efficient (Source: 36Kr)
PhyT2V Framework Utilizes LLMs to Enhance Physical Consistency in Text-to-Video Generation: A research team from the University of Pittsburgh proposed the PhyT2V framework, which optimizes text prompts through LLM-guided Chain-of-Thought (CoT) reasoning and an iterative self-correction mechanism to enhance the physical realism of content generated by existing text-to-video (T2V) models. This method requires no model retraining. By analyzing semantic mismatches between generated videos and prompts, and incorporating physical rules for prompt correction, it aims to improve the physical consistency of T2V models when handling out-of-distribution (OOD) scenarios. Experiments show that PhyT2V significantly improves the performance of models like CogVideoX and OpenSora on benchmarks such as VideoPhy and PhyGenBench (Source: WeChat)

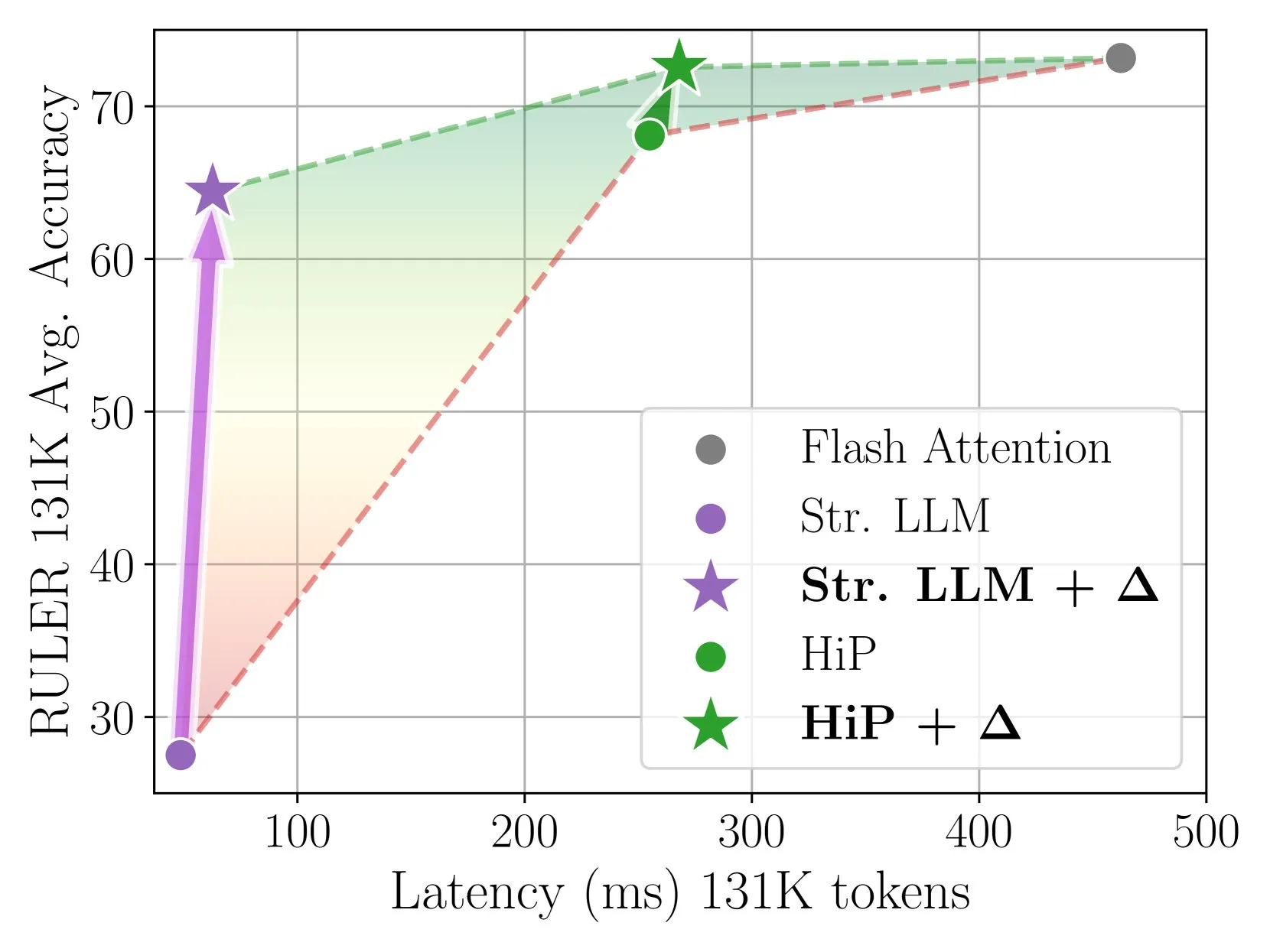
Delta Attention Achieves Fast and Accurate Sparse Attention Inference via Incremental Correction: This research finds that sparse attention computation can cause distribution shifts in attention outputs, thereby degrading model performance. Delta Attention corrects this distribution shift, making the output distribution of sparse attention closer to that of full attention. This achieves high sparsity (around 98.5%) while significantly improving performance, recovering 88% of full attention accuracy for sliding window attention (with sink tokens) on the RULER benchmark, with minimal computational overhead. It is 32x faster than Flash Attention 2 when processing 1M token prefill (Source: HuggingFace Daily Papers)
Thinkless Framework Enables LLMs to Learn When to Perform CoT Reasoning: To address the computational inefficiency caused by Large Language Models (LLMs) using complex Chain-of-Thought (CoT) reasoning for all queries, researchers proposed the Thinkless framework. This framework trains LLMs via reinforcement learning to adaptively choose between short-form or long-form reasoning based on task complexity and their own capabilities. The core algorithm, DeGRPO, decomposes the learning objective into a control token loss (determining the reasoning mode) and a response loss (improving answer accuracy), thereby stabilizing the training process. Experiments show that Thinkless can reduce the use of long-chain thinking by 50%-90% on benchmarks like Minerva Algebra, significantly improving inference efficiency (Source: HuggingFace Daily Papers)
CPGD Algorithm Enhances Stability of Rule-Based Language Model Reinforcement Learning: Addressing the training instability issues that can arise in existing rule-based reinforcement learning methods (such as GRPO, REINFORCE++, RLOO) when training language models, researchers proposed the CPGD (Clipped Policy Gradient Optimization with Policy Drift) algorithm. CPGD dynamically regularizes policy updates by introducing a policy drift constraint based on KL divergence and utilizes a log-ratio clipping mechanism to prevent excessive policy updates. Theoretical and empirical analyses show that CPGD can mitigate instability and significantly improve performance while maintaining training stability (Source: HuggingFace Daily Papers)
Neuro-Symbolic Query Compiler QCompiler Enhances RAG System’s Complex Query Processing Capabilities: To address the difficulty of Retrieval Augmented Generation (RAG) systems in accurately identifying search intent when processing complex queries with nested structures and dependencies, especially under resource constraints, the QCompiler framework was proposed. Inspired by linguistic grammar rules and compiler design, this framework first designs a minimal and sufficient BNF grammar G[q] to formalize complex queries. Then, through a query expression transformer, lexical-syntactic parser, and recursive descent processor, the query is compiled into an Abstract Syntax Tree (AST) for execution. The atomicity of sub-queries at leaf nodes ensures more precise document retrieval and response generation (Source: HuggingFace Daily Papers)
Jedi Dataset and OSWorld-G Benchmark Advance Research in GUI Element Localization for Computer Usage Scenarios: To address the bottleneck in Graphical User Interface (GUI) localization (mapping natural language instructions to GUI operations), researchers released the OSWorld-G benchmark (564 fine-grained annotated samples covering text matching, element recognition, layout understanding, and precise operations) and the large-scale synthetic dataset Jedi (4 million samples). A multi-scale model trained on Jedi outperforms existing methods on ScreenSpot-v2, ScreenSpot-Pro, and OSWorld-G, and enhances the agent capabilities of general foundation models in complex computer tasks (OSWorld), improving from 5% to 27% (Source: HuggingFace Daily Papers)
Fractured Chain of Thought (Fractured CoT) Reasoning Enhances LLM Inference Efficiency and Performance: To address the high token cost associated with CoT reasoning, researchers found that truncated CoT (stopping reasoning before completion and directly generating an answer) often achieves performance comparable to full CoT, but with significantly reduced token consumption. Based on this, they proposed Fractured Sampling, a unified reasoning strategy. By adjusting three dimensions—the number of reasoning trajectories, the number of final solutions per trajectory, and the truncation depth of reasoning traces—they achieved a better accuracy-cost trade-off across multiple reasoning benchmarks and model scales, paving the way for more efficient and scalable LLM inference (Source: HuggingFace Daily Papers)
Multimodal Validation of Chemical Formulas via LLM Context Conditioning and PWP Prompting: Researchers explored structured LLM context conditioning combined with Persistent Workflow Prompting (PWP) principles to adjust LLM behavior during reasoning. This aims to improve their reliability in precise validation tasks (such as chemical formulas), particularly when dealing with complex scientific documents containing images. The method uses only standard chat interfaces (Gemini 2.5 Pro, ChatGPT Plus o3), requiring no API or model modifications. Preliminary experiments show this method improves text error identification and helped Gemini 2.5 Pro identify image formula errors missed by human review (Source: HuggingFace Daily Papers)
AI-Driven Academic Peer Review Using PWP, Meta-Prompting, and Meta-Reasoning: Researchers proposed the Persistent Workflow Prompting (PWP) method to enable critical peer review of scientific manuscripts using standard LLM chat interfaces. PWP employs a hierarchical modular architecture (structured in Markdown) to define detailed analytical workflows, systematically encoding expert review processes (including tacit knowledge) through meta-prompting and meta-reasoning. PWP guides LLMs to conduct systematic multimodal evaluations, such as distinguishing claims from evidence, integrating text/image/chart analysis, and performing quantitative feasibility checks. In test cases, it successfully identified methodological flaws (Source: HuggingFace Daily Papers)
SPOT Benchmark Assesses AI’s Ability to Automatically Validate Scientific Research: To evaluate the capability of Large Language Models (LLMs) as “AI Co-scientists” in automating the validation of academic manuscripts, researchers introduced the SPOT benchmark. This benchmark comprises 83 published papers and 91 errors significant enough to warrant errata or retractions, cross-validated by original authors and human annotators. Experimental results show that even the most advanced LLMs (like o3) achieve a recall of no more than 21.1% and precision below 6.1% on SPOT. Furthermore, model confidence is low, and results are inconsistent across multiple runs, indicating a substantial gap between current LLMs’ capabilities and the practical requirements for reliable academic validation (Source: HuggingFace Daily Papers)
ExTrans Achieves Multilingual Deep Reasoning Translation via Sample-Enhanced Reinforcement Learning: To enhance the capabilities of Large Reasoning Models (LRMs) in machine translation, particularly in multilingual scenarios, researchers proposed ExTrans. This method designs a novel reward modeling approach that quantifies rewards by comparing the translation results of a policy translation model with those of a strong LRM (such as DeepSeek-R1-671B). Experiments show that a model trained with Qwen2.5-7B-Instruct as its backbone achieves SOTA in literary translation and outperforms OpenAI-o1 and DeepSeeK-R1. Through lightweight reward modeling, this method can effectively transfer unidirectional translation capabilities to 90 translation directions across 11 languages (Source: HuggingFace Daily Papers)
Trainable Sparse Attention VSA Accelerates Video Diffusion Models: To address the quadratic complexity of the 3D full attention mechanism in Video Diffusion Transformers (DiT), researchers proposed VSA (Trainable Sparse Attention). VSA uses a lightweight coarse stage to pool tokens into blocks and identify key tokens, then performs fine-grained token-level attention computation within these blocks. VSA is an end-to-end trainable, single differentiable kernel that requires no post-processing analysis and maintains 85% of FlashAttention3 MFU. Experiments show that VSA reduces training FLOPS by 2.53x without degrading diffusion loss, and accelerates the attention time of the open-source Wan-2.1 model by 6x, reducing end-to-end generation time from 31 seconds to 18 seconds (Source: HuggingFace Daily Papers)
SoftCoT++: Test-Time Scaling via Soft Chain-of-Thought Reasoning: To enhance the exploration capabilities of the SoftCoT method, which performs reasoning in a continuous latent space, researchers proposed SoftCoT++. This method perturbs latent thoughts through various specialized initial token perturbations and applies contrastive learning to promote diversity in soft thought representations, thereby extending SoftCoT to the Test-Time Scaling (TTS) paradigm. Experiments show that SoftCoT++ significantly improves the performance of SoftCoT and outperforms SoftCoT with self-consistency scaling, while also being highly compatible with traditional scaling techniques like self-consistency (Source: HuggingFace Daily Papers)
MTVCrafter: 4D Motion Tokenization for Open-World Human Image Animation: To address the limited generalization capabilities of existing methods that rely on 2D pose images, MTVCrafter proposes to directly model raw 3D motion sequences (4D motion). Its core is 4DMoT (4D Motion Tokenizer), which quantizes 3D motion sequences into 4D motion tokens, providing more robust spatio-temporal cues. Then, MV-DiT (Motion-aware Video DiT), designed with unique motion attention and 4D positional encoding, effectively utilizes these tokens as context to achieve human image animation in complex 3D worlds. Experiments show that MTVCrafter achieves 6.98 on FID-VID, significantly outperforming SOTA, and generalizes well to diverse characters in different styles and scenes (Source: HuggingFace Daily Papers)
QVGen: Pushing the Limits of Quantized Video Generation Models: To address the large computational and memory demands of video diffusion models (DMs), QVGen proposes a novel Quantization-Aware Training (QAT) framework specifically designed for extremely low-bit quantization (e.g., 4-bit and below). Through theoretical analysis, researchers found that reducing the gradient norm is crucial for QAT convergence and introduced an auxiliary module (Phi) to mitigate large quantization errors. To eliminate Phi’s inference overhead, a rank-decay strategy is proposed, which gradually eliminates Phi through SVD and rank-based regularization. Experiments show that QVGen, in a 4-bit setting, achieves quality comparable to full precision for the first time and significantly outperforms existing methods (Source: HuggingFace Daily Papers)
ViPlan: A Symbolic Predicate and Vision-Language Model Benchmark for Visual Planning: To bridge the comparison gap between VLM-driven symbolic planning and direct VLM planning methods, ViPlan was proposed as the first open-source visual planning benchmark. ViPlan includes a series of tasks of increasing difficulty in two domains: a visual version of Blocksworld and a simulated home robot environment. Benchmarking 9 open-source VLM families and some closed-source models revealed that symbolic planning performs better in Blocksworld (where precise image localization is key), while direct VLM planning is superior in home robot tasks (where common sense knowledge and error recovery capabilities are important). The research also showed that CoT prompting offers no significant benefit for most models and methods, suggesting current VLM visual reasoning capabilities are still lacking (Source: HuggingFace Daily Papers)
From Raw Shouts to Grammar: A Study of Language Evolution in a Cooperative Foraging Environment: To explore the origins and evolution of language, researchers simulated early human cooperative scenarios in a multi-agent foraging game. Through end-to-end deep reinforcement learning, agents learned action and communication strategies from scratch. The study found that the communication protocols developed by the agents exhibited hallmark features of natural language: arbitrariness, interchangeability, displacement, cultural transmission, and compositionality. This framework provides a platform for studying how language evolves in embodied multi-agent environments driven by partial observability, temporal reasoning, and cooperative goals (Source: HuggingFace Daily Papers)
Tiny QA Benchmark++: Smoke Testing for Ultra-Lightweight Multilingual Synthetic Dataset Generation and Continuous LLM Evaluation: Tiny QA Benchmark++ (TQB++) is an ultra-lightweight, multilingual smoke test suite designed to provide a unit-test-like safety net for LLM pipelines, runnable in seconds at extremely low cost. TQB++ includes a 52-item English gold set and provides a LiteLLM-based tiny synthetic data generator (pypi package) for users to generate small test packs customized by language, domain, or difficulty. The project offers pre-made packs for 10 languages and supports tools like OpenAI-Evals and LangChain, facilitating integration into CI/CD pipelines for rapid detection of prompt template errors, tokenizer drift, and fine-tuning side effects (Source: HuggingFace Daily Papers)
HelpSteer3-Preference: An Open Human-Annotated Preference Dataset Across Multiple Tasks and Languages: To meet the demand for high-quality, diverse open preference data, NVIDIA has released the HelpSteer3-Preference dataset. This dataset contains over 40,000 human-annotated preference samples under the CC-BY-4.0 license, covering real-world LLM applications such as STEM, coding, and multilingual scenarios. Reward Models (RMs) trained using this dataset achieve SOTA performance on RM-Bench (82.4%) and JudgeBench (73.7%), an improvement of approximately 10% over previous best results. The dataset can also be used to train generative RMs and align policy models via RLHF (Source: HuggingFace Daily Papers)
SEED-GRPO: Semantic Entropy-Enhanced GRPO for Uncertainty-Aware Policy Optimization: To address the issue of GRPO not considering LLM uncertainty towards input prompts during policy updates, researchers proposed SEED-GRPO. This method explicitly measures LLM uncertainty towards input prompts (i.e., semantic diversity of multiple generated answers) using semantic entropy and uses this to regulate the magnitude of policy updates. This uncertainty-aware training mechanism allows for more conservative updates for high-uncertainty questions while preserving the original learning signal for confident questions. Experiments show that SEED-GRPO achieves SOTA performance on five mathematical reasoning benchmarks (Source: HuggingFace Daily Papers)
Creating General User Models (GUMs) from Computer Usage: Researchers have proposed a General User Model (GUM) architecture that learns user knowledge and preferences by observing any user interaction with a computer (such as device screenshots) and constructs confidence-weighted propositions. GUM can infer new propositions from unstructured multimodal observations, retrieve relevant propositions as context, and continuously revise existing propositions. This architecture aims to enhance chat assistants, manage operating system notifications, and enable interactive agents to adapt to user preferences across applications. Experiments show that GUM can make calibrated and accurate user inferences, and GUM-based assistants can proactively identify and perform useful actions not explicitly requested by the user (Source: HuggingFace Daily Papers)
DataExpert-io/data-engineer-handbook: A popular project on GitHub, providing a comprehensive repository of data engineering learning resources, including a 2024 getting-started roadmap, materials for a 6-week free YouTube bootcamp, project examples, interview tips, recommended books, and lists of communities and newsletters. Recommended books include “Fundamentals of Data Engineering,” “Designing Data-Intensive Applications,” and “Designing Machine Learning Systems.” The handbook also lists companies in various data engineering fields, such as Mage (orchestration), Databricks (data lake), Snowflake (data warehouse), dbt (data quality), LangChain (LLM application library), etc., and provides links to data engineering blogs from well-known companies and important white papers (Source: GitHub Trending)
💼 Business
Cohere Partners with SAP to Bring Enterprise-Grade AI Agents to Global Businesses: Cohere announced a partnership with SAP to embed its enterprise-grade AI agent technology into the SAP Business Suite, providing secure and scalable AI capabilities to businesses worldwide. Cohere’s frontier models will also be available on SAP AI Core, enabling enterprises in sectors like finance and healthcare to leverage its multilingual, domain-specific AI models (Command, Embed, Rerank), aiming to accelerate enterprise AI adoption and unlock real business value (Source: X, X)
xAI Seeks to Utilize Government Data, Expanding Enterprise and Government Business: According to The Information, Elon Musk’s xAI company plans to use data from government agencies to develop models and applications, and sell them to government clients. This initiative could become a significant part of xAI’s commercialization strategy but has also sparked discussions about data usage and potential biases (Source: X)
Weaviate and AWS Deepen Global Collaboration to Accelerate Generative AI Initiatives: Vector database company Weaviate announced an enhanced global collaboration with AWS, aiming to jointly accelerate generative AI projects. This partnership will focus on providing global developers with faster speed, greater scale, and an improved developer experience, driving the application and development of generative AI technologies (Source: X)

🌟 Community
The Rise of AI Programming Agents Sparks Discussion on Programmers’ Career Prospects: Companies like Microsoft and OpenAI are launching or enhancing AI programming agents (Coding Agents), such as GitHub Copilot Coding Agent and OpenAI Codex, which can autonomously complete coding, fix bugs, and maintain code. Anthropic CEO Dario Amodei predicts AI might write most or even all code in the short term, and OpenAI CPO Kevin Weil also believes AI will evolve from junior engineers to architects. This has triggered widespread community discussion about the future of programmers’ careers: some worry that junior positions will be replaced and AI will automate a large amount of programming work; others believe AI will enhance programmers’ efficiency, allowing them to focus on higher-level architectural design and innovation, transforming their roles into “AI guides.” The overall trend suggests that learning to collaborate effectively with AI will become a core skill for programmers (Source: X, X, 36Kr, 36Kr)
Heated Discussion on AI Agent Concepts and Standards, MCP Protocol Gains Attention: With the rise of AI Agent applications (such as Manus, Genspark Super Agent, Fellou.ai), the community is actively debating the definition, capability levels, and development paradigms of Agents. Prominent VC firm BVP proposed a seven-level classification for Agents, from L0 to L6. Meanwhile, the Model Context Protocol (MCP) is gaining attention as a key technology for achieving interoperability between AI applications. Major international companies like Anthropic, OpenAI, and Google have supported or plan to support MCP, while domestic players like Alibaba Cloud and Tencent Cloud are also starting to build localized Agent development platforms around MCP. Developer iluxu even open-sourced a similar project, llmbasedos, before Microsoft proposed its “USB-C for AI apps” concept, aiming to promote open Agent connection standards (Source: X, X, WeChat, Reddit r/LocalLLaMA)
LLMs Underperform on Specific Reasoning Tasks, Sparking Debate on Their Capability Boundaries: The community is hotly debating the phenomenon of LLMs collectively “failing” on some seemingly simple physical or visuospatial reasoning tasks. For example, a question about stacking cubes to form a larger cube stumped even top models like o3 and Gemini 2.5 Pro. Concurrently, an evaluation article pointed out that on basic physical tasks like parts manufacturing, LLMs (including o3) perform worse than experienced workers, mainly due to insufficient visual capabilities, physical reasoning errors, and a lack of real-world tacit knowledge. These cases have sparked discussions about LLMs’ true understanding capabilities, hallucination issues (e.g., o3’s increased hallucination rate during reasoning), and the validity of current benchmarks, emphasizing that AI still has significant room for improvement in domain-specific knowledge and complex reasoning (Source: QbitAI, 36Kr)

Sino-US Tech Competition and AI Development Strategies Draw Attention: In an interview, NVIDIA CEO Jensen Huang discussed chip regulations, AI factories, and enterprise pragmatism. His views were interpreted as profound insights into the current Sino-US tech competition landscape. Some commentators believe that the US is trying to maintain its lead by restricting China’s access to high-end AI resources, but this could lead to a lose-lose situation, slowing down global AI development. Huang, however, seems to believe that the real competition is long-term, and the US should aim for comprehensive leadership (chips, factories, infrastructure, models, applications), rather than just seeking short-term relative advantages, otherwise it might miss the development opportunities of the AI era and ultimately fall behind in comprehensive national strength competition (Source: X)
Application and Discussion of AI Tools like ChatGPT for Mental Health Support: Reddit community users shared experiences using AI tools like ChatGPT for mental health support, believing they can provide help between professional therapy sessions, especially in articulating and understanding complex emotions. Users ask AI questions or have AI ask them questions about their feelings to better understand emotional sources and develop improvement plans. In the comments, some users (including self-proclaimed therapists) believe AI can be even better than some human therapists in certain situations, especially for individuals who have difficulty accessing professional help or have trust issues with human therapists. However, other users cautioned that AI cannot completely replace professional treatment and that personal data privacy should be a concern (Source: Reddit r/ChatGPT)
💡 Others
“Qizhi Cup” Algorithm Competition Launches, Focusing on Three Frontier AI Directions: Qiyuan Lab has launched the “Qizhi Cup” Algorithm Competition with a total prize pool of 750,000 RMB. The competition features three tracks: “Robust Instance Segmentation of Satellite Remote Sensing Images,” “Drone-based Ground Target Detection for Embedded Platforms,” and “Adversarial Attacks against Multimodal Large Models.” It aims to promote innovation and application of core AI technologies such as robust perception, lightweight deployment, and adversarial defense. The event is open to domestic research institutions, enterprises, and public institutions (Source: WeChat)

Chicago Sun-Times AI-Generated Content Errs, Recommends Non-Existent Books and Experts: In a summer activity recommendation section, the Chicago Sun-Times published content suspected to be AI-generated, which included recommendations for fictional books by real authors and quoted “experts” who seemingly do not exist. For example, it listed Min Jin Lee’s “Nightshade Market” and Rebecca Makkai’s “Boiling Point” as recommended reads, but these books do not exist. This incident has raised concerns about the accuracy and vetting mechanisms of news media using AI-generated content (Source: Reddit r/artificial)
Discussion on Whether Using AI Constitutes “Cheating”: The community discussed the boundaries of using AI tools (like ChatGPT, Claude) in work and study. The prevailing view is that, in the absence of explicit rules prohibiting it (such as in university assignments), using AI tools to improve efficiency, complete repetitive tasks, or assist thinking is not “cheating,” but rather akin to using a calculator or search engine. The key is whether the user understands the AI’s output, can effectively adjust and validate it, and honestly declares the AI’s assistive role (especially in academic settings). However, if one completely relies on AI-generated content and claims it as original without discernment, it may involve academic misconduct or hinder personal skill development (Source: Reddit r/ArtificialInteligence)