
Keywords:AlphaEvolve, Gemini, evolutionary algorithm, AI agent, algorithm optimization, matrix multiplication, Borg data center, 4×4 complex matrix multiplication optimization, Google DeepMind algorithm discovery, AI automated algorithm design, Gemini 2.0 Pro application, Borg resource scheduling optimization
🔥 Focus
Google DeepMind launches AlphaEvolve: A Gemini-based evolutionary algorithm coding agent achieving breakthroughs in mathematics and computer science: Google DeepMind has released AlphaEvolve, an agent that utilizes the Gemini 2.0 Pro large language model to automatically discover and optimize algorithmic code through evolutionary algorithms. AlphaEvolve can autonomously generate, evaluate, and improve candidate solutions starting from initial code and evaluation metrics provided by humans. The system has excelled on over 50 mathematical problems, reproducing known solutions in approximately 75% of cases and discovering better solutions in 20% of cases. Notably, AlphaEvolve reduced the number of computations for 4×4 complex matrix multiplication from 49 to 48, breaking a 56-year-old record. Additionally, it optimized scheduling algorithms for Google’s internal Borg data centers, reclaiming 0.7% of global computing resources, and improved the design of next-generation TPU chips, shortening Gemini training time by 1%. This achievement demonstrates the immense potential of AI in automated algorithm discovery and scientific innovation. Although currently primarily handling problems that can be automatically evaluated, its application prospects in applied sciences like drug discovery are vast. (Source: , QbitAI, 36Kr)
Nvidia announces multiple AI advancements at Computex 2025, Jensen Huang emphasizes Agentic AI and Physical AI vision: Nvidia CEO Jensen Huang delivered a keynote speech at Computex 2025, emphasizing that AI is evolving from “single-response” to “thinking, reasoning” Agentic AI and Physical AI that understands the physical world. To support this trend, Nvidia released an expanded Blackwell platform (Blackwell Ultra AI) and announced that the Grace Blackwell GB300 system is in full production, with its inference performance 1.5 times higher than the previous generation. Huang also previewed the next-generation AI superchip Rubin Ultra, with performance 14 times that of the GB300. To promote AI infrastructure construction, Nvidia launched NVLink Fusion technology and is collaborating with TSMC, Foxconn, and others to build an AI supercomputer in Taiwan, China. Additionally, Nvidia updated its humanoid robot foundational model Isaac GR00T N1.5, enhancing its environmental adaptation and task execution capabilities, and plans to open-source the physics engine Newton, co-developed with DeepMind and Disney Research. (Source: AI Frontline, QbitAI, Reddit r/artificial)
OpenAI Codex team AMA reveals GPT-5 and future product integration plans: The OpenAI Codex team held an “Ask Me Anything” (AMA) event on Reddit. Jerry Tworek, VP of Research, revealed that the next-generation foundational model, GPT-5, aims to enhance existing model capabilities and reduce the need for model switching. The plan is to integrate existing tools like Codex, Operator (task execution agent), Deep Research (deep research tool), and Memory (memory function) into a unified AI assistant experience. Team members also shared Codex’s development origins (stemming from internal reflections on underutilized models), an approximately 3x programming efficiency boost from using Codex internally, and their outlook on future software engineering—efficiently and reliably translating requirements into runnable software. Codex currently primarily utilizes information loaded into container runtimes and may incorporate RAG technology in the future to access the latest knowledge. OpenAI is also exploring flexible pricing plans and intends to offer Plus/Pro users free API credits for Codex CLI usage. (Source: 36Kr)
VS Code announces open-sourcing of GitHub Copilot Chat extension, plans to build an open-source AI code editing platform: The Visual Studio Code team announced plans to evolve VS Code into an open-source AI editor, adhering to core principles of openness, collaboration, and community-driven development. As part of this plan, the GitHub Copilot Chat extension has been open-sourced on GitHub under the MIT license. In the future, VS Code plans to gradually integrate these AI features into the editor’s core, aiming to build a fully open-source, community-driven AI code editing platform to enhance development efficiency, transparency, and security. This move is considered a significant step for Microsoft in the open-source domain and could have a profound impact on the ecosystem of AI-assisted programming tools. (Source: dotey, jeremyphoward)
Huawei Ascend collaborates with DeepSeek, MoE model inference performance surpasses Nvidia Hopper: Huawei Ascend announced that its CloudMatrix 384 super-node and Atlas 800I A2 inference server have achieved significant breakthroughs in inference performance when deploying ultra-large-scale MoE models like DeepSeek V3/R1, surpassing Nvidia’s Hopper architecture under specific conditions. The CloudMatrix 384 super-node achieved a single-card Decode throughput exceeding 1920 Tokens/s at 50ms latency, while the Atlas 800I A2 reached a single-card throughput of 808 Tokens/s at 100ms latency. Huawei attributes this to its strategy of “compensating for physics with mathematics,” using algorithms and system optimization to overcome hardware process limitations. A technical report has been released, and core code will be open-sourced within a month. Optimization measures include an expert parallel solution for MoE models, PD separate deployment, vLLM framework adaptation, A8W8C16 quantization strategy, as well as FlashComm communication scheme, intra-layer parallel conversion, FusionSpec speculative inference engine, and MLA/MoE operator hardware affinity optimization. (Source: QbitAI, WeChat)
🎯 Trends
Apple open-sources efficient vision language model FastVLM, optimizing on-device AI experience: Apple has open-sourced FastVLM (Fast Vision Language Model), a vision language model designed for efficient operation on edge devices like iPhones. FastVLM introduces a novel hybrid visual encoder, FastViTHD, which combines convolutional layers with Transformer modules and employs multi-scale pooling and down-sampling techniques to significantly reduce the number of visual tokens required for image processing (16 times fewer than traditional ViT). This allows the model to maintain high accuracy while achieving up to 85 times faster time-to-first-token (TTFT) output compared to similar models. FastVLM is compatible with mainstream LLMs and easily adaptable to the iOS/Mac ecosystem, offering 0.5B, 1.5B, and 7B parameter versions suitable for various real-time image-text tasks such as image description, Q&A, and analysis. (Source: WeChat)
Meta releases KernelLLM 8B model, surpasses GPT-4o in specific benchmark tests: Meta has released the KernelLLM 8B model on Hugging Face. Reportedly, in the KernelBench-Triton Level 1 benchmark test, this 8-billion-parameter model outperformed larger models like GPT-4o and DeepSeek V3 in single-instance inference performance. In multi-instance inference scenarios, KernelLLM also performed better than DeepSeek R1. This release has garnered attention from the AI community and is seen as another example of small to medium-sized models demonstrating strong competitiveness in specific tasks. (Source: ClementDelangue, huggingface, mervenoyann, HuggingFace Daily Papers)
Mistral Medium 3 model shows strong performance in Arena, particularly in technical domains: Mistral AI’s new Mistral Medium 3 model has performed impressively in community evaluations on lmarena.ai, ranking 11th overall in chat capabilities, a significant improvement over Mistral Large (Elo score increased by 90 points). The model particularly excels in technical domains, ranking 5th in mathematical ability, 7th in complex prompt and coding capabilities, and 9th in the WebDev Arena. Community comments suggest its performance in technical areas is close to GPT-4.1 level, while potentially being more competitively priced, similar to GPT-4.1 mini pricing. Users can try the model for free on Mistral’s official chat interface. (Source: hkproj, qtnx_, lmarena_ai)
Hugging Face Datasets adds direct chat conversation viewing feature: The Hugging Face Datasets platform has undergone a significant update, now allowing users to directly read chat conversation content within datasets. This feature is considered a major step by community members (like Caleb, Maxime Labonne) in addressing data quality issues, as direct inspection of raw conversation data helps in better understanding the data, performing data cleaning, and improving model training effectiveness. Previously, viewing specific conversation content might have required additional code or tools; the new feature simplifies this process, enhancing the convenience and transparency of data work. (Source: eliebakouch, _lewtun, _akhaliq, maximelabonne, ClementDelangue, huggingface, code_star)
MLX LM integrates with Hugging Face Hub, simplifying local model execution on Mac: MLX LM is now directly integrated into the Hugging Face Hub, allowing Mac users to more easily run over 4,400 LLMs locally on Apple Silicon devices. Users can simply click “Use this model” on the page of a compatible model on Hugging Face Hub to quickly run the model in their terminal, without complex cloud configurations or waiting times. Additionally, an OpenAI-compatible server can be launched directly from the model page. This integration aims to lower the barrier to running models locally and improve development and experimentation efficiency. (Source: awnihannun, ClementDelangue, huggingface, reach_vb)
Nvidia open-sources Physical AI inference model Cosmos-Reason1-7B: Nvidia has open-sourced Cosmos-Reason1-7B, part of its Physical AI model series, on Hugging Face. The model is designed to understand physical world common sense and generate corresponding embodied decisions. This marks a new step for Nvidia in promoting the integration of the physical world and AI, providing new tools and research foundations for applications like robotics and autonomous driving that require interaction with physical environments. (Source: reach_vb)
Baidu’s video generation model Steamer-I2V tops VBench image-to-video leaderboard: Baidu’s video generation model, Steamer-I2V, has ranked first in the image-to-video (I2V) category of the authoritative video generation benchmark VBench, achieving an overall score of 89.38%, surpassing well-known models like OpenAI Sora and Google Imagen Video. Steamer-I2V’s technical advantages include pixel-level precise picture control, master-level camera movement, cinema-grade HD quality up to 1080P with dynamic aesthetics, and accurate Chinese semantic understanding based on a database of hundreds of millions of Chinese multimodal entries. This achievement demonstrates Baidu’s strength in multimodal generation and is part of its strategy to build an AI content ecosystem. (Source: 36Kr)

LLMs perform poorly on time-reading tasks like clocks and calendars: Researchers from the University of Edinburgh and other institutions have found that despite Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) excelling in various tasks, their accuracy in seemingly simple time-reading tasks (such as identifying time on analog clocks and understanding calendar dates) is alarmingly low. The study constructed two custom test sets, ClockQA and CalendarQA, revealing that AI systems’ accuracy in reading clocks was only 38.7%, and in determining calendar dates, only 26.3%. Even advanced models like Gemini-2.0 and GPT-o1 showed significant difficulties, especially when dealing with Roman numerals, stylized hands, or complex date calculations (like leap years or the day of the week for a specific date). Researchers believe this exposes current models’ deficiencies in spatial reasoning, structured layout parsing, and generalization to uncommon patterns. (Source: 36Kr, WeChat)

Microsoft announces Grok model integration into Azure AI Foundry at Build conference: At the Microsoft Build 2025 developer conference, Microsoft announced that xAI’s Grok model will join its Azure AI Foundry model series. Users can try Grok-3 and Grok-3-mini for free on Azure Foundry and GitHub until early June. This move signifies that Azure AI Foundry will further expand its range of supported third-party models, allowing users in the future to utilize models from various vendors including OpenAI, xAI, DeepSeek, Meta, Mistral AI, Black Forest Labs, and others through a unified reserved throughput. (Source: TheTuringPost, xai)
Apple reportedly plans to allow EU iPhone users to replace Siri with third-party voice assistants: According to Mark Gurman, Apple is planning to allow iPhone users in the European Union to replace Siri with third-party voice assistants for the first time. This move is likely an effort to comply with the EU’s increasingly stringent digital market regulations, aiming to enhance platform openness and user choice. If implemented, this plan could significantly impact the voice assistant market landscape, providing opportunities for other voice assistants to enter Apple’s ecosystem. (Source: zacharynado)

Meta releases Open Molecules 2025 dataset and UMA model to accelerate molecular and material discovery: Meta AI has released Open Molecules 2025 (OMol25) and the Meta Universal Atomistic model (UMA). OMol25 is currently the largest and most diverse dataset of high-precision quantum chemistry calculations, including biomolecules, metal complexes, and electrolytes. UMA is a machine learning interatomic potential model trained on over 30 billion atoms, designed to provide more accurate predictions of molecular behavior. The open-sourcing of these tools aims to accelerate discovery and innovation in molecular and materials science. (Source: AIatMeta)
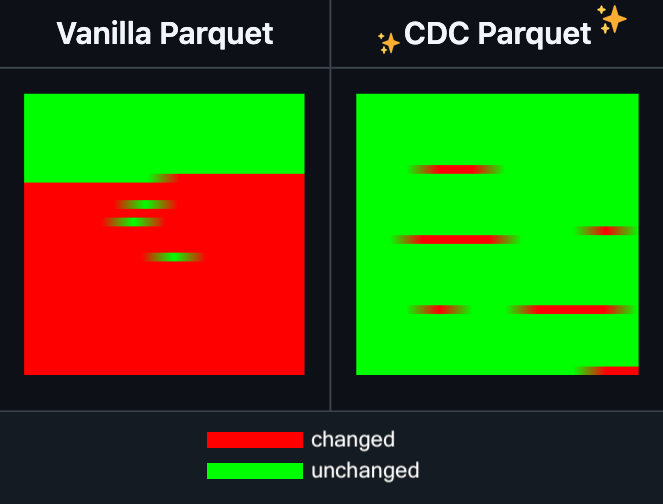
Hugging Face Datasets adds incremental editing for Parquet files: Hugging Face Datasets announced that the nightly version of its underlying dependency library, PyArrow, now supports incremental editing of Parquet files without requiring a full rewrite of the file. This new feature will significantly improve the efficiency of large-scale dataset operations, especially when frequent updates or modifications to parts of the data are needed, by considerably reducing time and computational resource consumption. This move is expected to enhance the developer experience when handling and maintaining large AI training datasets. (Source: huggingface)
LangGraph adds node-level caching feature to improve workflow efficiency: LangGraph announced that its open-source version now includes a node/task caching feature. This function aims to accelerate workflows by avoiding redundant computations, particularly beneficial for agent workflows that contain common parts or require frequent debugging. Users can utilize caching in either the imperative API or the graph API, enabling faster iteration and optimization of their AI applications. This is the first in a series of open-source release updates from LangGraph this week. (Source: hwchase17)

Sakana AI introduces new AI architecture “Continuous Thought Machines” (CTM): Tokyo-based AI startup Sakana AI has unveiled a new AI model architecture called “Continuous Thought Machines” (CTM). CTM is designed to enable models to reason with less guidance, similar to the human brain. This new architecture may offer fresh approaches to tackling current challenges faced by AI models in complex reasoning and autonomous learning. (Source: dl_weekly)
Microsoft and Nvidia deepen RTX AI PC collaboration, TensorRT lands on Windows ML: During Microsoft Build and COMPUTEX Taipei, Nvidia and Microsoft announced further collaboration to advance the development of RTX AI PCs. Nvidia’s TensorRT inference optimization library has been redesigned and integrated into Microsoft’s new inference stack, Windows ML. This move aims to simplify the AI application development process and fully leverage the peak performance of RTX GPUs in PC-based AI tasks, promoting the popularization and application of AI on personal computing devices. (Source: nvidia)
Bilibili open-sources animation video generation model Index-AniSora, achieving SOTA in multiple metrics: Bilibili announced the open-sourcing of its self-developed animation video generation model, Index-AniSora, which was presented at IJCAI 2025. AniSora is specifically designed for generating 2D animation videos, supporting various styles such as Japanese anime, Chinese animation, and manga adaptations. It enables fine-grained control, including local region guidance and temporal guidance (e.g., first/last frame guidance, keyframe interpolation). The open-source project includes training and inference code for AniSoraV1.0 (based on CogVideoX-5B) and AniSoraV2.0 (based on Wan2.1-14B), tools for building training datasets, an animation-specific benchmark system, and the AniSoraV1.0_RL model optimized with reinforcement learning from human feedback. (Source: WeChat)

Tencent Hunyuan open-sources first multimodal unified CoT reward model UnifiedReward-Think: Tencent Hunyuan, in collaboration with Shanghai AI Lab, Fudan University, and other institutions, has proposed UnifiedReward-Think, the first unified multimodal reward model with long-chain reasoning (CoT) capabilities. This model aims to enable reward models to “learn to think” when evaluating complex visual generation and understanding tasks, thereby improving evaluation accuracy, cross-task generalization, and reasoning interpretability. The project has been fully open-sourced, including the model, dataset, training scripts, and evaluation tools. (Source: WeChat)
Alibaba open-sources video generation and editing model Tongyi Wanxiang Wan2.1-VACE: Alibaba has officially open-sourced its video generation and editing model, Tongyi Wanxiang Wan2.1-VACE. The model possesses various functionalities including text-to-video generation, image-referenced video generation, video repainting, local video editing, video background extension, and video duration extension. Two versions have been open-sourced this time, 1.3B and 14B, with the 1.3B version capable of running on consumer-grade graphics cards, aiming to lower the barrier for AIGC video creation. (Source: WeChat)
ByteDance releases vision-language model Seed1.5-VL, leading in multiple benchmark tests: ByteDance has built the vision-language model Seed1.5-VL, composed of a 532M parameter visual encoder and a 20B active parameter Mixture-of-Experts (MoE) LLM. Despite its relatively compact architecture, it achieves SOTA performance on 38 out of 60 public benchmark tests and surpasses models like OpenAI CUA and Claude 3.7 on agent-centric tasks such as GUI control and gameplay, demonstrating strong multimodal reasoning capabilities. (Source: WeChat)
MiniMax launches autoregressive TTS model MiniMax-Speech, supporting zero-shot voice cloning in 32 languages: MiniMax has proposed MiniMax-Speech, a Transformer-based autoregressive text-to-speech (TTS) model. The model can extract timbre features from reference audio without transcription, enabling zero-shot generation of expressive speech consistent with the reference timbre, and supports single-sample voice cloning. It enhances synthesized audio quality through Flow-VAE technology and supports 32 languages. The model achieves SOTA levels on objective voice cloning metrics, ranks first on the public TTS Arena leaderboard, and can be extended to applications such as voice emotion control, text-to-sound, and professional voice cloning. (Source: WeChat)
OuteTTS 1.0 (0.6B) released, an Apache 2.0 open-source TTS model supporting 14 languages: OuteAI has released OuteTTS-1.0-0.6B, a lightweight text-to-speech (TTS) model built on Qwen-3 0.6B. The model is licensed under Apache 2.0 and supports 14 languages, including Chinese, English, Japanese, and Korean. Its Python inference library, OuteTTS v0.4.2, has been updated to support EXL2 asynchronous batch inference, vLLM experimental batch inference, and continuous batching and external URL model inference for Llama.cpp server. Benchmarks on a single NVIDIA L40S GPU show that vLLM OuteTTS-1.0-0.6B FP8 can achieve an RTF (Real-Time Factor) of 0.05 with a batch size of 32. Model weights (ST, GGUF, EXL2, FP8) are available on Hugging Face. (Source: Reddit r/LocalLLaMA)

Hugging Face and Microsoft Azure deepen collaboration, over 10,000 open-source models land on Azure AI Foundry: At the Microsoft Build conference, CEO Satya Nadella announced an expanded collaboration with Hugging Face. Currently, over 11,000 of the most popular open-source models are available on Azure AI Foundry via Hugging Face, allowing users to easily deploy them. This move further enriches Azure’s AI ecosystem, providing developers with more model choices and a more convenient development experience. (Source: ClementDelangue, _akhaliq)

Intel releases Arc Pro B50/B60 series GPUs, targeting AI and workstation markets, 24GB version around $500: Intel unveiled its new Arc Pro B series professional graphics cards at Computex, including the Arc Pro B50 (16GB VRAM, approx. $299) and Arc Pro B60 (24GB VRAM, approx. $500). A “Project Battlematrix” workstation solution featuring dual B60 GPUs with 48GB VRAM was also showcased, expected to be priced under $1000. These products aim to provide cost-effective solutions for AI computing and professional workstations, with high VRAM configurations being particularly attractive for running large language models locally. The new products are expected to launch in Q3 of this year, initially available through OEMs, with DIY versions potentially following in Q4. (Source: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

🧰 Tools
Moondream Station releases Linux version, simplifying local Moondream execution: Moondream Station, a tool designed to simplify running Moondream (a vision language model) on local devices, has now announced support for the Linux operating system. This means Linux users can more conveniently deploy and use Moondream models for multimodal AI experiments and application development. (Source: vikhyatk)
Flowith releases Infinite Agent NEO, supporting unlimited steps, context, and tool calls: AI application company Flowith has released its latest agent product, NEO, claiming it to be the world’s first agent supporting unlimited steps, unlimited context, and unlimited tool calls. The agent is designed for long-term operation in the cloud, possessing intelligence beyond benchmarks, and is advertised as zero-cost and unlimited. This release may represent a new advancement in AI agents’ ability to handle complex long-term tasks and integrate external capabilities. (Source: _akhaliq, op7418)

Kapa AI utilizes Weaviate to build interactive technical documentation Q&A tool “Ask AI”: Kapa AI has developed an intelligent widget called “Ask AI” that allows users to query entire technical knowledge bases—including technical documentation, blogs, tutorials, GitHub issues, and forums—through natural language conversations. To achieve efficient semantic search and knowledge retrieval, Kapa AI adopted the Weaviate vector database, valuing its built-in hybrid search capabilities, Docker compatibility, and multi-tenancy features to support a rapidly growing user and data scale. (Source: bobvanluijt)

Developer quickly builds screenshot-to-HTML MVP tool using Gemini Flash: Developer Daniel Huynh utilized Google AI’s Gemini Flash model to build an MVP (Minimum Viable Product) tool over a weekend that can quickly convert design mockups, competitor screenshots, or inspirational images into HTML code. The tool is available for free trial on Hugging Face Spaces, showcasing the potential of multimodal models in front-end development assistance. (Source: osanseviero, _akhaliq)
Azure AI Foundry Agent Service now generally available, integrates LlamaIndex: Microsoft announced that the Azure AI Foundry Agent Service is now generally available (GA) and offers first-class support for LlamaIndex. The service aims to help enterprise customers build customer support assistants, process automation bots, multi-agent systems, and solutions securely integrated with enterprise data and tools, further promoting the development and application of enterprise-grade AI agents. (Source: jerryjliu0)
tinygrad: A minimalist deep learning framework between PyTorch and micrograd: tinygrad is a deep learning framework designed with simplicity at its core, aiming to be the easiest framework to add new accelerators to, supporting both inference and training. It supports models like LLaMA and Stable Diffusion and uses lazy evaluation to fuse operations and optimize performance. tinygrad supports various accelerators including GPU (OpenCL), CPU (C code), LLVM, Metal, and CUDA. Its codebase is concise, with core functionalities implemented in a small amount of code, making it easy for developers to understand and extend. (Source: GitHub Trending)
Nano AI Search launches “Super Search” feature, integrating multiple models and MCP toolbox: Nano AI Search (bot.n.cn) has added a “Super Search” feature, designed to provide deeper information acquisition and processing capabilities. This feature integrates hundreds of domestic and international large models, automatically switching as needed; it includes an MCP universal toolbox supporting thousands of AI tools, capable of processing various file formats like web pages, images, videos, and PDFs, and performing tasks like code generation and data analysis. It also combines public domain search with local knowledge base private search for more comprehensive results, and has built-in text-to-image and text-to-video capabilities. User experience shows that this feature can organize search results into detailed reports with charts and aesthetically pleasing web pages, suitable for various scenarios such as industry research, shopping comparisons, and knowledge organization. (Source: WeChat)
Clara: Modular offline AI workspace integrating LLMs, Agents, automation, and image generation: A developer has launched an open-source project called Clara, aiming to create a fully offline, modular AI workspace. Users can organize local LLM chats (supporting RAG, images, documents, code execution, compatible with Ollama and OpenAI-like APIs) as widgets on a dashboard, create Agents with memory and logic, run automation flows via native N8N integration (offering 1000+ free templates), and generate images locally using Stable Diffusion (ComfyUI). Clara is available for Mac, Windows, and Linux, aiming to solve the problem of users frequently switching between multiple AI tools by providing a one-stop AI operation. (Source: Reddit r/LocalLLaMA)
AI Playlist Curator: Python tool using LLMs to personalize YouTube playlist organization: A developer created a Python project called AI Playlist Curator, designed to help users automatically organize their large and disorganized YouTube playlists. The tool utilizes LLMs to categorize songs based on user preferences and create personalized sub-playlists, supporting the processing of any saved playlists and liked songs. The project is open-sourced on GitHub, and the developer hopes to receive community feedback for further improvement. (Source: Reddit r/MachineLearning)
OpenAI Codex programming assistant lands on ChatGPT iOS app: OpenAI announced that its programming assistant, Codex, is now integrated into the ChatGPT iOS application. Users can start new programming tasks, view code diffs, request modifications, and even push pull requests (PRs) on their mobile devices. The feature also supports tracking Codex’s progress via lock screen live activities, allowing users to seamlessly switch work between different devices. (Source: openai)
Kollektiv: A tool to solve LLM chat context copy-pasting issues using MCP protocol: A developer has launched Kollektiv, a tool designed to address the issue of users repeatedly copy-pasting large amounts of context (such as research papers, SDK documentation, personal notes, book content) when chatting with LLMs like Claude. Kollektiv allows users to upload these document sources once and then call them on-demand from any compatible IDE or MCP client (e.g., Cursor, Windsurf, PyCharm) via an MCP (Model Control Protocol) server. The MCP server handles user authentication, data isolation, and on-demand streaming of data to the chat interface. The tool is currently not recommended for sensitive or confidential materials. (Source: Reddit r/ClaudeAI)
📚 Learning
Google DeepMind releases AlphaEvolve technical report, revealing its algorithm discovery capabilities: Google DeepMind has released a technical report on its AI system, AlphaEvolve. AlphaEvolve is a Gemini-based coding agent capable of designing and optimizing algorithms through evolutionary processes. The report details how AlphaEvolve autonomously generates, evaluates, and refines candidate algorithms through a structured feedback loop, leading to breakthroughs on various mathematical and computational science problems, including breaking the record for 4×4 complex matrix multiplication. This report provides an important reference for understanding the potential of AI in automated scientific discovery and algorithmic innovation. (Source: , HuggingFace Daily Papers)
DeepLearning.AI launches “Building AI Browser Agents” course: DeepLearning.AI has launched a new course titled “Building AI Browser Agents.” The course is taught by Div Garg and Naman Agarwal, co-founders of AGI Inc., and aims to help learners master the techniques for building AI agents that can interact with browsers. Course content may cover web automation, information extraction, user interface interaction, and other AI applications in browser environments. (Source: DeepLearningAI)
Qwen3 technical report released: Alibaba has released the technical report for its latest generation large language model, Qwen3. The report details Qwen3’s model architecture, training methods, performance evaluation, and its performance on various benchmark tests. The Qwen3 series models aim to provide stronger language understanding, generation, and multimodal processing capabilities. The release of its technical report offers researchers and developers an opportunity to gain in-depth understanding of the model’s technical details. (Source: _akhaliq)

Paper Discussion: Multi-Perspective Search and Data Management Improve Step-by-Step Theorem Proving (MPS-Prover): A new paper introduces MPS-Prover, a novel step-by-step automated theorem proving (ATP) system. The system overcomes biased search guidance in existing step-by-step provers through an efficient post-training data management strategy (pruning ~40% redundant data without sacrificing performance) and a multi-perspective tree search mechanism (integrating a learned critic model with heuristic rules). Experiments show that MPS-Prover achieves SOTA performance on multiple benchmarks like miniF2F and ProofNet, generating shorter and more diverse proofs. (Source: HuggingFace Daily Papers)
Paper Discussion: Visual Planning – Thinking with Images Only: A new paper proposes the “Visual Planning” paradigm, enabling models to plan entirely through visual representations (image sequences) rather than relying on text. Researchers argue that language may not be the most natural medium for reasoning in tasks involving spatial and geometric information. They introduce VPRL, a visual planning framework via reinforcement learning, and use GRPO for post-training optimization of large vision models, achieving significant improvements in visual navigation tasks like FrozenLake, Maze, and MiniBehavior, outperforming text-only reasoning planning variants. (Source: HuggingFace Daily Papers)
Paper Discussion: Scaling Reasoning can Improve Factuality in Large Language Models: A study explores whether scaling the reasoning process of Large Language Models (LLMs) can enhance their factual accuracy in complex open-domain question answering (QA). Researchers extracted reasoning trajectories from models like QwQ-32B and DeepSeek-R1-671B, fine-tuned various Qwen2.5 series models, and integrated knowledge graph paths into the reasoning trajectories. Experiments show that, in a single run, smaller reasoning models exhibit significant improvements in factual accuracy compared to original instruction-tuned models. Increasing test-time computation and token budget leads to a stable 2-8% improvement in factual accuracy. (Source: HuggingFace Daily Papers)
Paper Discussion: Mergenetic – A Simple Library for Evolving Model Merges: A new paper introduces Mergenetic, an open-source library for evolving model merges. Model merging allows combining the capabilities of existing models into new ones without additional training. Mergenetic supports easy combination of merging methods and evolutionary algorithms, incorporating lightweight fitness evaluators to reduce evaluation costs. Experiments demonstrate that Mergenetic produces competitive results on various tasks and languages using modest hardware. (Source: HuggingFace Daily Papers)
Paper Discussion: Group Think – Multiple Concurrent Reasoning Agents Collaborating at the Token-Level: A new paper proposes “Group Think,” where a single LLM acts as multiple concurrent reasoning agents (thinkers). These agents share visibility into each other’s partial generation progress, dynamically adapting their reasoning trajectories at the token level, thereby reducing redundant reasoning, improving quality, and lowering latency. The method is suitable for edge inference on local GPUs, and experiments demonstrate its ability to improve latency even with open-source LLMs not specifically trained for this purpose. (Source: HuggingFace Daily Papers)
Paper Discussion: Humans expect rationality and cooperation from LLM opponents in strategic games: A first-of-its-kind controlled, monetarily incentivized laboratory experiment studies human behavior in multiplayer P-beauty contests when playing against other humans versus LLMs. Results show that humans choose significantly lower numbers when playing against LLMs, primarily due to an increased prevalence of the “zero” Nash equilibrium choice. This shift is mainly driven by subjects with high strategic reasoning abilities, who perceive LLMs as having stronger reasoning capabilities and a greater inclination towards cooperation. (Source: HuggingFace Daily Papers)
Paper Discussion: Simple Semi-Supervised Knowledge Distillation from Vision-Language Models via Dual-Head Optimization (DHO): A new paper proposes DHO (Dual-Head Optimization), a simple and effective knowledge distillation (KD) framework for transferring knowledge from Vision-Language Models (VLMs) to compact task-specific models in a semi-supervised setting. DHO introduces dual prediction heads that independently learn from labeled data and teacher predictions, and linearly combines their outputs during inference, thereby mitigating gradient conflicts between supervised and distillation signals. Experiments show DHO outperforms single-head KD baselines across multiple domains and fine-grained datasets, achieving SOTA on ImageNet. (Source: HuggingFace Daily Papers)
Paper Discussion: GuardReasoner-VL – Safeguarding VLMs through Reinforced Reasoning: To enhance the safety of Vision Language Models (VLMs), a new paper introduces GuardReasoner-VL, a reasoning-based VLM safeguarding model. The core idea is to incentivize the safeguarding model to perform deliberate reasoning before making auditing decisions through online reinforcement learning (RL). Researchers constructed GuardReasoner-VLTrain, a reasoning corpus with 123K samples and 631K reasoning steps, and cold-started the model’s reasoning ability via supervised fine-tuning (SFT), further enhancing it with online RL. Experiments show the model (3B/7B versions open-sourced) performs exceptionally well, outperforming the next best model by 19.27% in average F1-score. (Source: HuggingFace Daily Papers)
Paper Discussion: Multi-Token Prediction Needs Registers (MuToR): A new paper proposes MuToR, a simple and effective multi-token prediction method that predicts future targets by interleaving learnable register tokens within the input sequence. Compared to existing methods, MuToR has negligible parameter increase, requires no architectural changes, is compatible with existing pre-trained models, and aligns with the next-token pre-training objective, making it particularly suitable for supervised fine-tuning. The method demonstrates effectiveness and versatility in generative tasks across language and vision domains. (Source: HuggingFace Daily Papers)
Paper Discussion: MMLongBench – An Effective and Thorough Benchmark for Long-Context Vision-Language Models: Addressing the evaluation needs for Long-Context Vision-Language Models (LCVLMs), a new paper introduces MMLongBench, the first benchmark covering a wide range of long-context vision-language tasks. MMLongBench contains 13,331 samples, covering five categories of tasks such as visual RAG and multi-shot ICL, and provides various image types. All samples are provided in five standardized input lengths ranging from 8K to 128K tokens. Benchmarking 46 closed-source and open-source LCVLMs revealed that single-task performance is not representative of overall long-context capability, current models still have significant room for improvement, and models with strong reasoning abilities tend to perform better in long-context scenarios. (Source: HuggingFace Daily Papers)
Paper Discussion: MatTools – A Large Language Model Benchmark for Materials Science Tools: A new paper proposes the MatTools benchmark for evaluating the ability of Large Language Models (LLMs) to answer materials science questions by generating and safely executing code for physics-based computational materials science packages. MatTools includes a materials simulation tool question-answering (QA) benchmark (based on pymatgen, with 69,225 QA pairs) and a real-world tool usage benchmark (with 49 tasks, 138 sub-tasks). Evaluation of various LLMs reveals: general models outperform specialized ones; AI understands AI better; simpler methods are more effective. (Source: HuggingFace Daily Papers)
Paper Discussion: A Universal Symbiotic Watermarking Framework Balancing Robustness, Text Quality, and Security for LLM Watermarks: Addressing the trade-offs between robustness, text quality, and security in existing Large Language Model (LLM) watermarking schemes, a new paper proposes a universal symbiotic watermarking framework. This framework integrates logits-based and sampling-based methods and designs three strategies: serial, parallel, and hybrid. The hybrid framework adaptively embeds watermarks using token entropy and semantic entropy, aiming to optimize performance across all aspects. Experiments show this method outperforms existing baselines and achieves SOTA levels. (Source: HuggingFace Daily Papers)
Paper Discussion: CheXGenBench – A Unified Benchmark for Fidelity, Privacy, and Utility of Synthetic Chest X-rays: A new paper introduces CheXGenBench, a multifaceted framework for evaluating synthetic chest X-ray generation, simultaneously assessing fidelity, privacy risks, and clinical utility. The framework includes standardized data partitions and a unified evaluation protocol (over 20 quantitative metrics), analyzing the generation quality, potential privacy vulnerabilities, and downstream clinical applicability of 11 leading text-to-image architectures. The study found existing evaluation protocols inadequate for assessing generative fidelity. The team also released a high-quality synthetic dataset, SynthCheX-75K. (Source: HuggingFace Daily Papers)
Peter Lax, author of the classic textbook “Functional Analysis,” passes away at 99: Applied mathematics giant Peter Lax, the first applied mathematician to receive the Abel Prize, has passed away at the age of 99. Lax was renowned for his classic textbook “Functional Analysis” and made foundational contributions in areas such as partial differential equations, fluid dynamics, and numerical computation, including the Lax Equivalence Theorem and the Lax-Friedrichs and Lax-Wendroff methods. He was also one of the pioneers in applying computer technology to mathematical analysis, and his work profoundly influenced the development of mathematics in the computer age. (Source: QbitAI)

Former OpenAI Chinese VP Lilian Weng’s extensive article “Why We Think,” exploring test-time compute and chain-of-thought: Lilian Weng, former Chinese Vice President at OpenAI, published an extensive article titled “Why We Think,” delving into how technologies like “test-time compute” and “Chain-of-Thought (CoT)” significantly enhance the performance and intelligence level of large language models. Drawing an analogy to the “Thinking, Fast and Slow” dual-system theory of human cognition, the article points out that allowing models to “think” more before outputting (e.g., through intelligent decoding, CoT reasoning, latent variable modeling) can break through current capability bottlenecks. The article meticulously reviews progress and challenges in several research directions, including token-based thinking, parallel sampling and sequential revision, reinforcement learning and external tool integration, thought fidelity, and continuous space thinking. (Source: QbitAI)

Harbin Institute of Technology and University of Pennsylvania jointly launch PointKAN, a new SOTA for point cloud analysis based on KANs: A research team from Harbin Institute of Technology (Shenzhen) and the University of Pennsylvania has launched PointKAN, a 3D point cloud analysis solution based on Kolmogorov-Arnold Networks (KANs). This method utilizes a geometric affine module and a parallel local feature extraction module, replacing fixed activation functions in traditional MLPs with learnable activation functions to more effectively capture the complex geometric features of point clouds. Concurrently, the team proposed the Efficient-KANs structure, which replaces B-spline functions with rational functions and employs intra-group parameter sharing, significantly reducing parameter count and computational overhead. Experiments show that PointKAN and its lightweight version, PointKAN-elite, achieve SOTA or competitive performance in tasks such as classification, part segmentation, and few-shot learning. (Source: WeChat)

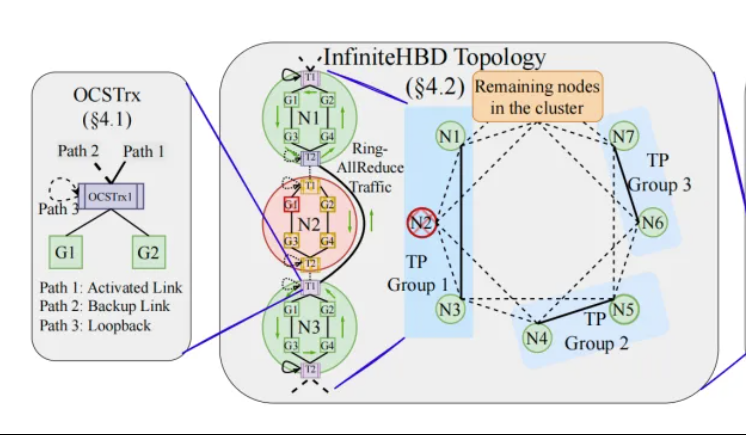
Peking University/StepStar/Enflame Tech propose InfiniteHBD: A new-generation high-bandwidth GPU interconnect architecture to reduce large model training costs: Addressing the limitations of current High-Bandwidth Domain (HBD) architectures in distributed training of large models, a research team from Peking University, StepStar, and Enflame Tech has proposed the InfiniteHBD solution. This architecture, centered around an electro-optical conversion module embedded with Optical Circuit Switching (OCS) capabilities, achieves dynamically reconfigurable point-to-multipoint connections, featuring node-level fault isolation and low resource fragmentation. Research indicates that InfiniteHBD’s unit cost is only 31% of NVIDIA’s NVL-72, GPU wastage rate is near zero, and MFU (Model FLOPs Utilization) can be up to 3.37 times higher than NVIDIA DGX. This research has been accepted by SIGCOMM 2025. (Source: WeChat, QbitAI)
ICML 2025 Paper Sneak Peek: OmniAudio generates spatial audio from 360° videos: A study to be presented at ICML 2025 introduces the OmniAudio framework, capable of directly generating first-order ambisonics (FOA) spatial audio with directional cues from 360° panoramic videos. The research first constructed Sphere360, a large-scale dataset of paired 360° videos and spatial audio. OmniAudio employs a two-stage training process: first, self-supervised coarse-to-fine flow matching pre-training using large-scale non-spatial audio data to learn general audio features; then, supervised fine-tuning combined with a dual-branch video encoder (extracting global and local visual features). Experimental results show OmniAudio significantly outperforms existing baseline models on both objective and subjective evaluation metrics. (Source: WeChat)

Huawei Selftok: Autoregressive visual tokenizer based on reverse diffusion, unifying multimodal generation: Huawei’s Pangu multimodal generation team has proposed Selftok technology, an innovative visual tokenization solution. It integrates autoregressive priors into visual tokens through a reverse diffusion process, transforming pixel streams into discrete sequences that strictly follow causality, aiming to resolve the conflict between existing spatial token solutions and the autoregressive (AR) paradigm. The Selftok Tokenizer employs a dual-stream encoder (image branch inherits SD3 VAE, text branch is a learnable continuous vector group) and a quantizer with a re-activation mechanism. Experiments show Selftok achieves SOTA on ImageNet reconstruction metrics, and the Selftok dAR-VLM, trained on Ascend AI and MindSpore frameworks, surpasses GPT-4o on text-to-image benchmarks like GenEval. This work has been nominated for CVPR 2025 Best Paper. (Source: WeChat)
Yan Shuicheng’s team leads release of General-Level evaluation framework and General-Bench benchmark for grading multimodal generalist models: Led by Professor Yan Shuicheng from the National University of Singapore and Professor Zhang Hanwang from Nanyang Technological University, ten top universities jointly released the General-Level evaluation framework and the large-scale benchmark dataset General-Bench for multimodal generalist models. Drawing inspiration from autonomous driving leveling, the framework establishes five levels (Level 1-5) to assess the generality and performance of Multimodal Large Language Models (MLLMs). The core evaluation criterion is the “Synergy” effect, examining the model’s knowledge transfer and enhancement capabilities across tasks, between understanding and generation paradigms, and across modalities. General-Bench includes over 700 tasks and 320,000 samples. Evaluation of more than 100 existing MLLMs shows that most models are at the L2-L3 level, with no model yet reaching L5. (Source: WeChat)

💼 Business
Sakana AI and MUFG Bank (MUFG) enter multi-year partnership: Japanese AI startup Sakana AI announced it has signed a multi-year comprehensive partnership agreement with Japan’s largest bank, MUFG Bank. Sakana AI will provide MUFG Bank with agile and powerful AI technology, aiming to help the century-old bank remain competitive in the rapidly evolving AI landscape. This collaboration is expected to help Sakana AI achieve profitability within a year. (Source: SakanaAILabs, SakanaAILabs)

Cohere partners with Dell to bring its secure agent platform Cohere North to Dell’s on-premises enterprise AI solutions: AI company Cohere announced a partnership with Dell Technologies to accelerate secure, agent-capable enterprise AI solutions. Dell will be the first provider to offer enterprises on-premises deployment of Cohere’s secure agent platform, Cohere North. This collaboration is particularly crucial for industries dealing with sensitive data and strict compliance requirements, enabling enterprises to deploy and run Cohere’s advanced AI agent technology within their own data centers. (Source: sarahookr)

Mistral AI partners with MGX and Bpifrance to build Europe’s largest AI campus in France: Mistral AI announced a partnership with Abu Dhabi-backed technology investment firm MGX and French national investment bank Bpifrance to jointly build Europe’s largest AI campus in the Paris region, France. The campus will integrate data centers, high-performance computing resources, and educational and research facilities. Nvidia will also participate by providing technical support. This initiative aims to promote the development of the European AI ecosystem and enhance France’s strategic position in the global AI field. (Source: arthurmensch, arthurmensch)
🌟 Community
ADHD prevalence among AI practitioners draws attention, potentially exceeding 20-30%: Discussions have emerged on social media regarding the prevalence of Attention Deficit Hyperactivity Disorder (ADHD) among professionals in the AI field. Some users have observed that the field seems to attract many individuals with neurodiverse traits. Minh Nhat Nguyen commented that over 20-30% of people in the AI industry might have ADHD. This phenomenon could be related to the demands of AI research and development, which often require intense focus, rapid iteration, and creative thinking—traits that sometimes align with certain manifestations of ADHD. (Source: Dorialexander)
Skill devaluation in the AI era prompts deep reflection; system reconstruction, not tool mastery, is key: An in-depth analysis article points out that the real crisis in the AI era is not “whether one can use AI tools” but the devaluation of skills themselves and the reconstruction of the entire work system. The article uses examples like the Maginot Line, containerization, and typists being replaced by word processors to argue that merely learning to use new tools cannot guarantee a leading edge. The key lies in understanding how AI changes the structure, processes, and organizational logic of work. When the system is rewritten, previously high-value skills can quickly become marginalized. Increased productivity does not necessarily translate to increased individual value, as value flows to those who control the coordination layer of the new system. The article refutes eight popular fallacies, such as “learning AI will put you ahead,” “AI makes me do more work, so I’m more valuable,” and “jobs remain the same, only the methods change,” emphasizing the need to think about one’s positioning and value from a systemic perspective. (Source: 36Kr)
Former Google CEO Schmidt: Rise of non-human intelligence will reshape global landscape, need to be wary of AI risks and challenges: In an exclusive interview, former Google CEO Eric Schmidt warned that society severely underestimates the disruptive potential of “non-human intelligence.” He believes AI has moved from language generation to strategic decision-making and can independently complete complex tasks. Schmidt highlighted three core challenges posed by AI: energy and computing power bottlenecks (the US needs an additional 90 gigawatts of electricity), the near exhaustion of public data (the next phase requires AI-generated data), and how to enable AI to create “new knowledge” beyond existing human knowledge. He also pointed out three major risks: AI’s recursive self-improvement going out of control, gaining control of weapons, and unauthorized self-replication. He believes that against the backdrop of escalating US-China AI competition, the rapid proliferation of open-source AI could bring security risks, even leading to a “pre-emptive strike” scenario similar to “nuclear deterrence.” Schmidt called for immediate global AI governance dialogues and emphasized that protection of human freedom should be embedded in system design from the outset. (Source: 36Kr)

GitHub CEO refutes “programming is useless” theory, emphasizing human programmers remain important in the AI era: In response to the view expressed by Nvidia CEO Jensen Huang and others that “learning to program will no longer be necessary in the future,” GitHub CEO Thomas Dohmke disagreed in an interview. He believes 2025 will be the year of the Software Engineering Agent (SWE Agent), but the role of human programmers will remain crucial. Dohmke emphasized that AI should serve as an assistant to enhance developer capabilities, not completely replace them. He envisions future software development evolving into a collaborative model between humans and AI, where developers act as “conductors of an agent orchestra,” responsible for assigning tasks and reviewing results. GitHub CPO Mario Rodriguez also stated that the company is committed to empowering individuals with Copilot. They believe that as AI develops, understanding how to program and reprogram machines that can represent human thought and action is vital, and abandoning learning to code is tantamount to relinquishing a voice in the future of agents. (Source: 36Kr, QbitAI)

AI-generated low-quality vulnerability reports flood in, curl founder introduces filtering mechanism to combat “AI junk”: curl project founder Daniel Stenberg stated that he is overwhelmed by a large number of low-quality, invalid vulnerability reports generated by AI. These reports waste a significant amount of maintainers’ time, akin to a DDoS attack. Consequently, when submitting curl-related security reports on HackerOne, a new checkbox has been added asking if AI was used. If the answer is yes, additional evidence proving the vulnerability’s authenticity is required, otherwise the reporter may be banned. Stenberg claims the project has never received a valid AI-generated bug report. Python developer Seth Larson had previously expressed similar concerns, believing such reports cause confusion, stress, and frustration for maintainers, exacerbating burnout in open-source projects. Community discussions suggest the proliferation of AI-generated reports reflects information overload and attempts by some to exploit bug bounty mechanisms, with even high-level managers being misled into believing AI can replace senior programmers. (Source: WeChat)

AI-assisted programming sparks heated debate: Efficiency significantly improved, but human developer role remains crucial: A developer with decades of programming experience shared an experience where AI (possibly Codex or a similar tool) solved a bug that had plagued them for hours and optimized the code in minutes, marveling at AI as an “indefatigable super-teammate.” This experience sparked community discussion. Most agree on AI’s powerful capabilities in code generation, bug fixing, and information summarization, which can significantly boost efficiency. However, some developers point out that AI still makes mistakes, especially in complex logic, boundary conditions, and creative solutions, falling short of human capabilities, and its output requires review and critical assessment by experienced developers. Microsoft CEO Satya Nadella also emphasized that AI is an empowering tool, software development is now inseparable from AI, but human ambition and agency remain important. The discussion generally concludes that AI will change programming methods, and developers need to adapt to a new paradigm of collaborating with AI, focusing on higher-level architectural design and problem definition. (Source: Reddit r/ChatGPT, WeChat)
AI Agent Manus opens registration but faces high pricing, competition from domestic and international giants, Chinese version launch uncertain: After a period of sought-after invitation codes, AI Agent platform Manus has officially opened registration, but currently only for overseas users, without a Chinese version. User feedback indicates it uses a credit consumption system; free credits (1000 upon registration, 300 daily) are only sufficient for simple tasks. Complex tasks (like creating a web-based Sudoku game) require purchasing credits, averaging $1 for 100 credits, which is considered expensive. Industry insiders analyze that Manus’s reliance on third-party large models (like Claude for the overseas version) leads to higher costs, and cloud-based sandbox operation also adds to expenses. The delayed launch of the Chinese version may be related to domestic model备案 (filing), user payment habits, and market competition. Products from domestic and international players like ByteDance’s Coze and Baidu’s “Xīnxiǎng” app have already formed a competitive landscape. Although Manus has secured new funding, the moat of its “light model, heavy application” approach faces challenges. (Source: 36Kr)
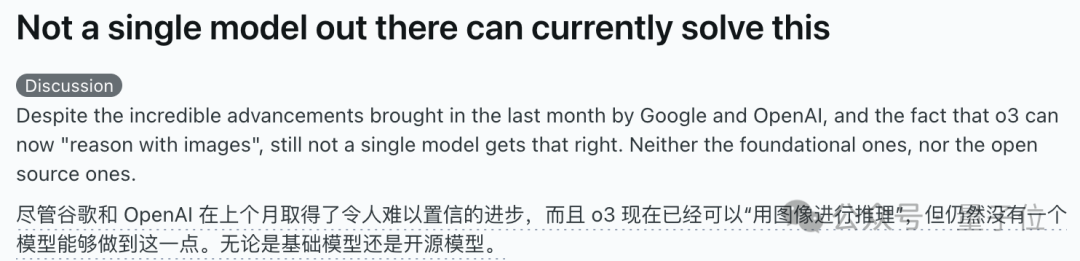
AI models collectively fail on “complete the cube” visual reasoning puzzle, sparking discussion on their true understanding capabilities: A visual reasoning puzzle requiring the calculation of the number of small cubes needed to complete an incomplete larger cube stumped multiple mainstream AI models, including OpenAI o3, Google Gemini 2.5 Pro, DeepSeek, and Qwen3. The models provided varying answers, primarily due to different interpretations of the final large cube’s dimensions (e.g., 3x3x3, 4x4x4, 5x5x5). Even with prompts and guidance, the models struggled to arrive at the correct answer Kunststoff. Some netizens pointed out that the problem statement itself might be ambiguous, and humans could also find it confusing. This phenomenon has sparked discussions about whether AI models truly understand problems or merely rely on pattern matching, highlighting current AI limitations in complex spatial reasoning and visual understanding. (Source: 36Kr)
Users discuss LLM “overthinking” in instruction following and reasoning: Discussions on social media and in papers indicate that Large Language Models (LLMs), when using reasoning processes like Chain-of-Thought (CoT), sometimes “overthink,” leading to an inability to accurately follow simple instructions. For example, when asked to write a specific word count or repeat a particular phrase, CoT might cause the model to focus more on the overall content of the task while neglecting these basic constraints, or introduce additional explanatory content. Researchers have proposed a “constraint attention” metric to quantify this phenomenon and tested mitigation strategies such as in-context learning, self-reflection, self-selected reasoning, and classifier-selected reasoning. This suggests that not all tasks are suitable for CoT, and simple instructions may require a more direct execution approach. (Source: menhguin, omarsar0)

AI Economics Rethink: Cheap cognitive labor breaks traditional economic models, value distribution faces reshaping: A widely discussed viewpoint argues that the rise of AI is making cognitive labor (such as report writing, data analysis, code writing) extremely cheap, fundamentally challenging classical economic models based on the core assumption that “human intelligence is scarce and expensive.” When AI can perform a vast amount of knowledge work at near-zero marginal cost, productivity may soar, but the value of individual tasks will plummet, and the advantages of specialization will erode. Value distribution will no longer be simply based on efficiency or output, but on who controls the new scarce resources (such as data, platforms, AI models themselves). This is analogous to historical technological changes (like fast fashion in the apparel industry, streaming in the music industry) where the benefits of increased efficiency did not fully flow to laborers but were captured by system coordinators. The article warns that AI not only automates tasks but also commoditizes “thinking,” which could be the most disruptive force in modern economic history. (Source: Reddit r/artificial)
Enterprise strategy in the AI era: Avoid the “smart company” trap, reconstruct rather than optimize old processes: Many enterprises, when adopting AI, tend to use it as a tool to optimize existing processes and reduce costs, falling into the “smart company” trap of “doing the same things smarter.” However, true transformation is not about making old processes smarter, but about questioning whether these processes are still necessary and building entirely new, AI-native systems and business models. Technology will not simply adapt to old systems; it will reshape them. Companies should avoid investing excessive resources in optimizing processes that are about to be淘汰 (eliminated) by AI, and instead focus on defining new rules and fundamentally changing decision-making methods, coordination mechanisms, and organizational structures. (Source: 36Kr)
💡 Others
LangChain New York offline meetup: LangChain announced it will co-host an offline meetup in New York on Thursday, May 22nd, with Tabs and TavilyAI. The event will include fireside chats, product demos, and networking opportunities with other builders. (Source: hwchase17, LangChainAI)

Global AI Conference Tokyo to be held in June: An event titled “Global AI Conference – Tokyo” is scheduled to take place from June 7th to 8th in Tokyo, Japan. Many renowned AI developers, artists, investors, and others will participate. Individuals interested in the AI field and planning to visit Japan can look out for registration information. (Source: op7418)

AI service architecture paradigm is shifting from “Model-as-a-Service” to “Agent-as-a-Service”: With the development of AI technology, AI service architecture is undergoing a profound transition from “Model-as-a-Service” (MaaS) to “Agent-as-a-Service” (AaaS). AI Agents, with their goal-driven, environment-aware, autonomous decision-making, and learning capabilities, surpass the traditional AI model’s passive instruction execution mode. They can independently think, break down tasks, plan paths, and call external tools to achieve complex goals. This shift is driving comprehensive development across the industry chain, from underlying infrastructure (computing power, data), core algorithms and large models, to mid-layer Agent components and platforms, and finally to end-product applications (general-purpose, vertical industry, embedded Agents). Chinese AI Agent companies like HeyGen, Laiye Tech, and Waveform AI are also actively expanding overseas to explore international markets. Despite challenges such as high computing costs and insufficient supply, the potential of AI Agents is continuously being unlocked through algorithm optimization, specialized chips, edge computing, and other solutions. (Source: 36Kr)