
Keywords:MLSys 2025, FlashInfer, Claude-neptune, Aya Vision, FastVLM, Gemini, Nova Premier, LLM inference optimization, KV-Cache storage optimization, Multilingual multimodal interaction, Video-to-text tasks, Amazon Bedrock platform, Biological benchmarking
🔥 Focus
MLSys 2025 Announces Best Paper Awards, Including FlashInfer and Other Projects: MLSys 2025, a top international conference in the systems field, announced two best papers. One is FlashInfer, from institutions including the University of Washington and NVIDIA, an efficient and customizable attention engine library specifically optimized for LLM inference. By optimizing KV-Cache storage, computation templates, and scheduling mechanisms, it significantly improves LLM inference throughput and reduces latency. The other best paper is “The Hidden Bloat in Machine Learning Systems,” which reveals the bloat issue caused by unused code and features in ML frameworks and proposes the Negativa-ML method to effectively reduce code size and improve performance. FlashInfer’s inclusion highlights the importance of optimizing LLM inference efficiency, while Hidden Bloat emphasizes the need for maturity in ML system engineering. (Source: Reddit r/deeplearning, 36氪)
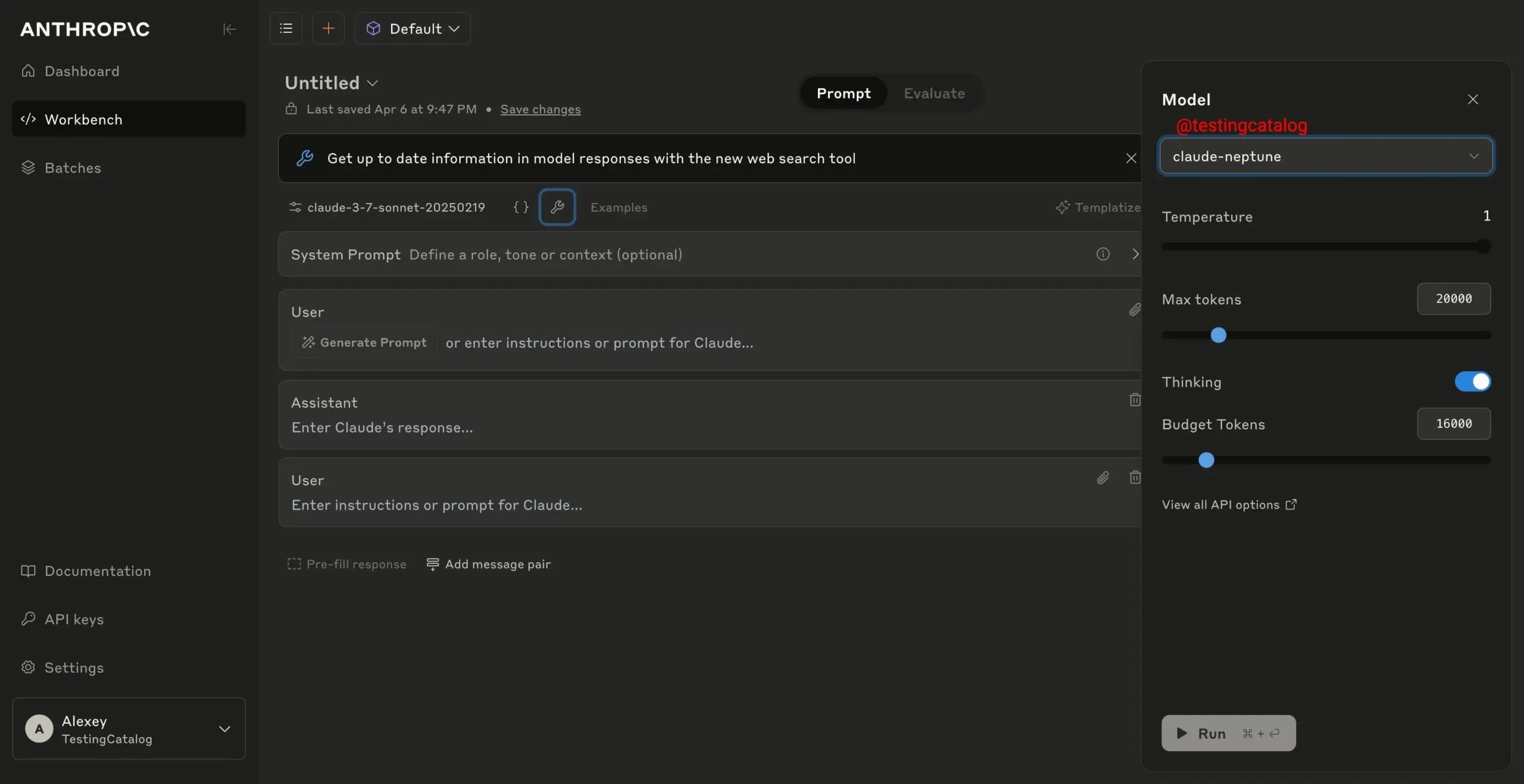
Anthropic is Testing New Model “claude-neptune”: Anthropic is reportedly conducting safety tests on its new AI model “claude-neptune”. The community speculates this might be the Claude 3.8 Sonnet version, as Neptune is the eighth planet in the solar system. This move indicates Anthropic is advancing the iteration of its model series, potentially bringing improvements in performance or safety, and providing more advanced AI capabilities to users and developers. (Source: Reddit r/ClaudeAI)
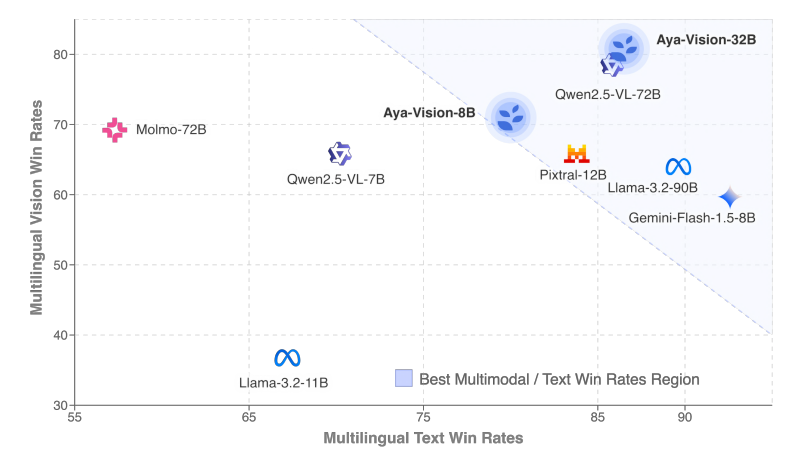
Cohere Releases Multilingual Multimodal Model Aya Vision: Cohere has launched the Aya Vision series of models, including 8B and 32B versions, focusing on multilingual open-ended multimodal interaction. Aya Vision-8B surpasses open-source models of equivalent and some larger sizes, as well as Gemini 1.5-8B, on multilingual VQA and chat tasks. Aya Vision-32B claims to outperform 72B-90B models on vision and text tasks. The series employs techniques such as synthetic data annotation, cross-modal model merging, efficient architecture, and curated SFT data to enhance multilingual multimodal performance, and has been open-sourced. (Source: Reddit r/LocalLLaMA, sarahookr, sarahookr)
Apple Releases Video-to-Text Model FastVLM: Apple has open-sourced the FastVLM series models (0.5B, 1.5B, 7B), a large model focused on video-to-text tasks. Its highlight is the use of a new hybrid visual encoder, FastViTHD, which significantly speeds up the encoding of high-resolution video and TTFT (Time To First Token), several times faster than existing models. The model also supports running on Apple silicon’s ANE, providing an efficient solution for on-device video understanding. (Source: karminski3)
🎯 Trends
Google Gemini App Expands to More Devices: Google announced the expansion of the Gemini app to more devices, including Wear OS, Android Auto, Google TV, and Android XR. Additionally, Gemini Live’s camera and screen sharing features are now available for free to all Android users. This initiative aims to integrate Gemini’s AI capabilities more broadly into users’ daily lives, covering more usage scenarios. (Source: demishassabis, TheRundownAI)
Amazon Nova Premier Model Available on Bedrock: Amazon announced that its Nova Premier model is now available on Amazon Bedrock. Positioned as the most powerful “teacher model,” it is designed for creating custom refined models, particularly suitable for complex tasks like RAG, function calling, and agent coding, and features a million-token context window. This move aims to provide enterprises with powerful AI model customization capabilities through the AWS platform, potentially raising concerns about vendor lock-in among users. (Source: sbmaruf)
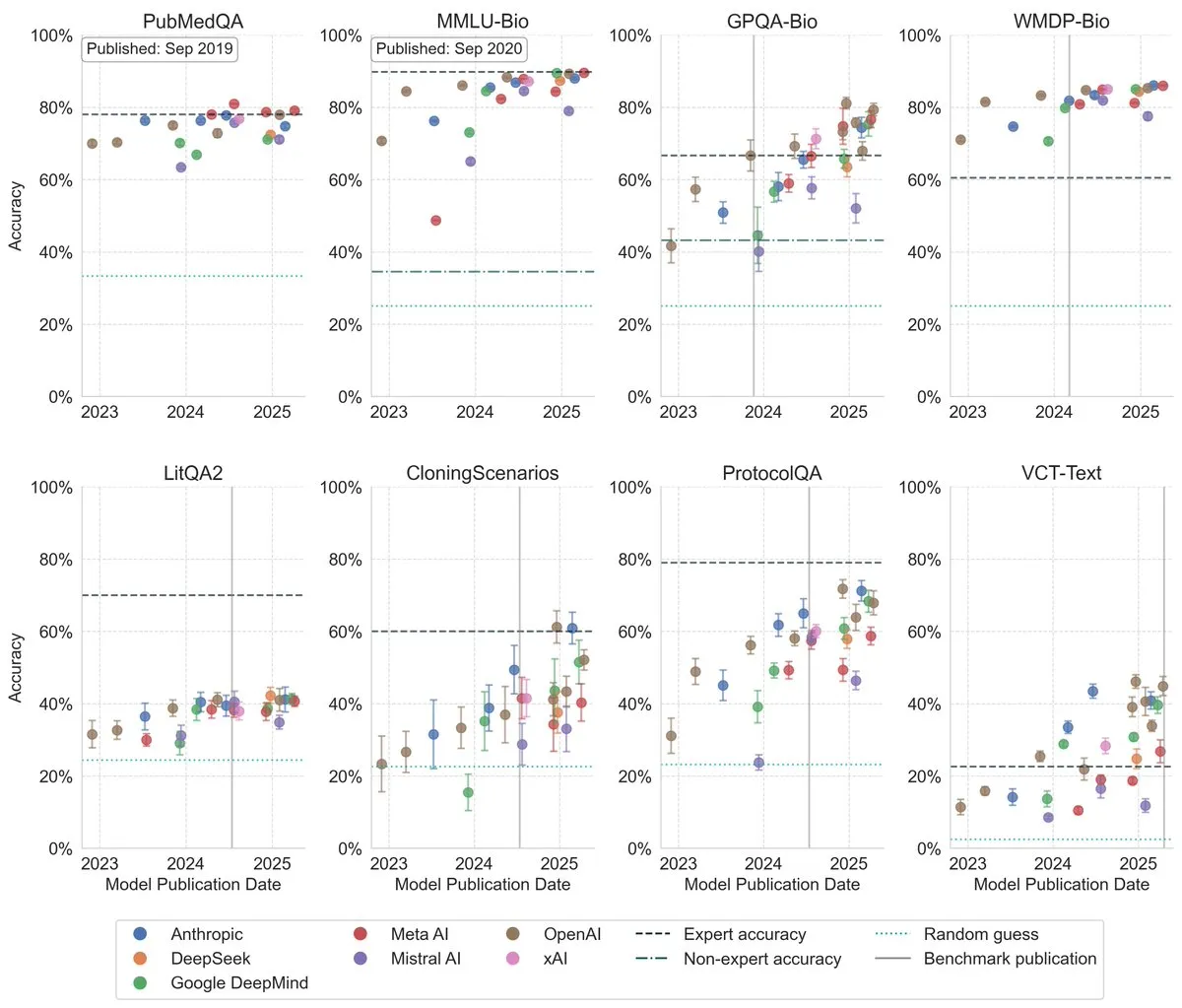
LLM Performance Significantly Improves on Biology Benchmarks: Recent research shows that large language models have significantly improved their performance on biology benchmarks over the past three years, surpassing human expert levels on several of the most challenging benchmarks. This indicates tremendous progress in LLMs’ ability to understand and process biological knowledge, suggesting a significant role in future biological research and applications. (Source: iScienceLuvr)
Humanoid Robots Demonstrate Physical Manipulation Progress: Humanoid robots like Tesla Optimus continue to showcase their physical manipulation and dancing abilities. While some comments suggest these dance demonstrations are pre-programmed and not truly general, others point out that achieving such mechanical precision and balance is a significant advancement in itself. Furthermore, cases of remotely controlled humanoid robots being used for rescue, autonomous pallet-moving robots, and teaching robots completing complex tasks demonstrate the increasing capability of robots to perform tasks in the physical world. (Source: Ronald_vanLoon, AymericRoucher, Ronald_vanLoon, teortaxesTex, Ronald_vanLoon)
Growth in AI Applications in Security: Generative AI is showing potential for applications in the security domain, such as threat detection and vulnerability analysis in cybersecurity. Related discussions and sharing indicate that AI is becoming a new tool to enhance security capabilities. (Source: Ronald_vanLoon)
AI-Driven Self-Flying Car Demonstration: A demonstration showcased an AI-driven self-flying car, representing the exploration direction of automation and emerging technologies in transportation, hinting at potential future changes in personal mobility. (Source: Ronald_vanLoon)
RHyME System Enables Robots to Learn Tasks by Watching Videos: Researchers at Cornell University developed the RHyME (Retrieval for Hybrid Imitation under Mismatched Execution) system, which allows robots to learn tasks by watching a single video demonstration. This technology significantly reduces the data and time required for robot training by storing and leveraging similar actions from a video library, increasing the success rate of robots learning tasks by over 50%. This is expected to accelerate the development and deployment of robotic systems. (Source: aihub.org, Reddit r/deeplearning)

SmolVLM Achieves Real-time Webcam Demo: The SmolVLM model achieved a real-time webcam demonstration using llama.cpp, showcasing the ability of small visual language models to perform real-time object recognition on local devices. This progress is significant for deploying multimodal AI applications on edge devices. (Source: Reddit r/LocalLLaMA, karminski3)

Audible Uses AI for Audiobook Narration: Audible is using AI narration technology to help publishers produce audiobooks faster. This application demonstrates AI’s potential for efficiency in content production but also raises discussions about AI’s impact on the traditional voice acting industry. (Source: Reddit r/artificial)

DeepSeek-V3 Gains Attention for Efficiency: The DeepSeek-V3 model is attracting community attention for its innovations in efficiency. Related discussions highlight its advancements in AI model architecture, which are crucial for reducing operating costs and improving performance. (Source: Ronald_vanLoon, Ronald_vanLoon)
Amsterdam Airport to Use Robots for Luggage Handling: Amsterdam Airport plans to deploy 19 robots for handling luggage. This is a concrete application of automation technology in airport operations, aimed at improving efficiency and reducing manual labor. (Source: Ronald_vanLoon)
AI Used to Monitor Mountain Snowpack for Improved Water Resource Prediction: Climate researchers are using new tools and technologies, such as infrared devices and elastic sensors, to measure the temperature of mountain snowpack for more accurate predictions of snowmelt timing and water volume. This data is crucial for better water resource management and preventing droughts and floods in the context of climate change leading to frequent extreme weather events. However, budget and personnel cuts at U.S. federal agencies for related monitoring projects may threaten the continuity of this work. (Source: MIT Technology Review)

Pixverse Releases Video Model Version 4.5: Video generation tool Pixverse has released version 4.5, adding over 20 camera control options and multi-image referencing features, and improving the handling of complex actions. These updates aim to provide users with a more refined and smoother video generation experience. (Source: Kling_ai, op7418)
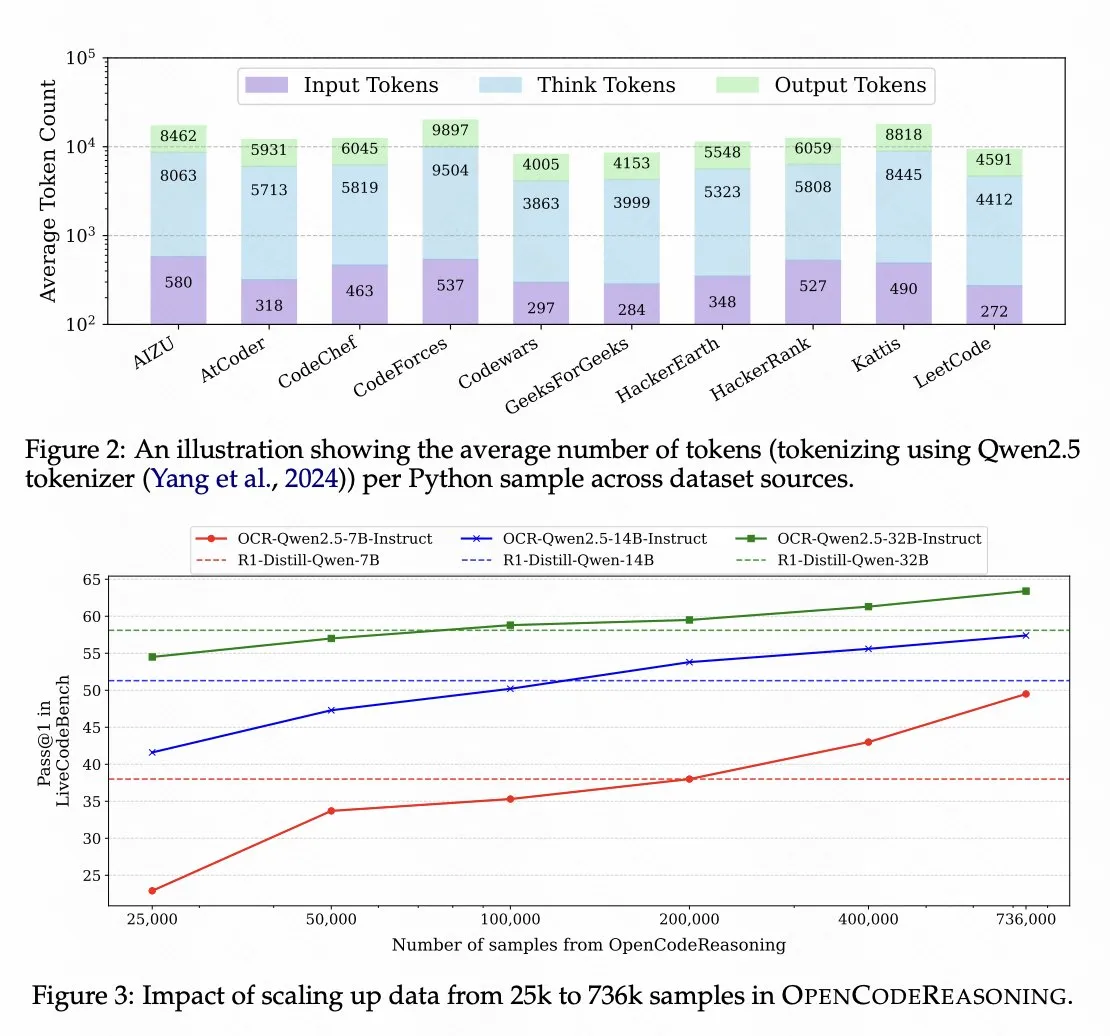
Nvidia Open-Sources Code Reasoning Model Based on Qwen 2.5: Nvidia has open-sourced the code reasoning model OpenCodeReasoning-Nemotron-7B, trained on Qwen 2.5, which performs well in code reasoning evaluations. This demonstrates the potential of the Qwen series models as base models and reflects the activity of the open-source community in developing task-specific models. (Source: op7418)
Qwen Series Models Become Popular Open-Source Base Models: The Qwen series models (especially Qwen 3), known for their strong performance, multilingual support (119 languages), and full range of sizes (from 0.6B to larger parameters), are quickly becoming the preferred base models for fine-tuning in the open-source community, leading to a large number of derived models. Their native support for the MCP protocol and powerful tool-calling capabilities also reduce the complexity of Agent development. (Source: op7418)
Experimental AI Model Trained for “Gaslighting”: A developer fine-tuned a Gemma 3 12B-based model using reinforcement learning to become a “gaslighting” expert, aiming to explore the model’s performance on negative or manipulative behaviors. Although the model is still experimental and the link has issues, this attempt has sparked discussions about AI model personality control and potential misuse. (Source: Reddit r/LocalLLaMA)
Humanoid Robot Rental Market Booms, “Daily Wage” Can Reach Ten Thousand Yuan: The rental market for humanoid robots (such as Unitree Robotics G1) is booming in China, especially for attracting crowds at exhibitions, auto shows, and events. Daily rental fees can reach 6,000-10,000 yuan, and even higher during holidays. Some individual buyers also use them for rental to recoup costs. Although rental prices have slightly decreased, market demand remains strong, and manufacturers are accelerating production to meet the short supply. Humanoid robots from companies like UBTECH and Tianqi Automation have also entered automotive factories for training and application, receiving potential orders, indicating that industrial applications are gradually being implemented. (Source: 36氪, 36氪)

AI Companion/Lover Market: Potential and Challenges Coexist: The AI emotional companionship market is growing rapidly, with a projected huge market size in the coming years. Users choose AI companions for various reasons, including seeking emotional support, boosting self-confidence, and reducing social costs. The current market includes general AI models (like DeepSeek) and specialized AI companion apps (like Xingye, Maoxiang, Zhumengdao), with the latter attracting users through features like “捏崽” (character customization) and gamified design. However, AI companions still face technical issues such as realism, emotional coherence, and memory loss, as well as challenges in commercialization models (subscription/in-app purchases), user needs, privacy protection, and content compliance. Despite this, AI companionship addresses the real emotional needs of some users and still has room for development. (Source: 36氪, 36氪)

🧰 Tools
Mergekit: Open-Source LLM Merging Tool: Mergekit is an open-source Python project that allows users to merge multiple large language models into one to combine the strengths of different models (e.g., writing and programming abilities). The tool supports CPU and GPU accelerated merging, and it is recommended to use high-precision models for merging before quantization and calibration. It provides developers with the flexibility to experiment and create custom hybrid models. (Source: karminski3)

OpenMemory MCP Enables Shared Memory Between AI Clients: OpenMemory MCP is an open-source tool designed to address the issue of context not being shared between different AI clients (such as Claude, Cursor, Windsurf). It acts as a locally running memory layer that connects with compatible clients via the MCP protocol, storing users’ AI interaction content in a local vector database to enable cross-client memory sharing and context awareness. This allows users to maintain only one set of memory content, improving the efficiency of using AI tools. (Source: Reddit r/LocalLLaMA, op7418, Taranjeet)
ChatGPT to Support Adding MCP Functionality: ChatGPT is adding support for MCP (Memory and Context Protocol), which means users may be able to connect external memory storage or tools to share context information with ChatGPT. This feature will enhance ChatGPT’s integration capabilities and personalized experience, allowing it to better utilize user history and preferences from other compatible clients. (Source: op7418)
DSPy: A Language/Framework for Writing AI Software: DSPy is positioned as a language or framework for writing AI software, rather than just a prompt optimizer. It provides frontend abstractions like signatures and modules to declare machine learning behavior and define automatic implementations. DSPy’s optimizers can be used to optimize entire programs or agents, not just find good strings, and support various optimization algorithms. This provides a more structured approach for developers building complex AI applications. (Source: lateinteraction, Shahules786)
LlamaIndex Improves Agent Memory Functionality: LlamaIndex has made significant upgrades to its Agent’s memory component, introducing a flexible Memory API that fuses short-term dialogue history and long-term memory through pluggable “blocks”. New long-term memory blocks include the Fact Extraction Memory Block for tracking facts mentioned in dialogue and the Vector Memory Block which uses a vector database to store dialogue history. This cascading architecture model aims to balance flexibility, ease of use, and practicality, enhancing AI Agents’ context management capabilities during long interactions. (Source: jerryjliu0, jerryjliu0, jerryjliu0)

Nous Research Hosts RL Environment Hackathon: Nous Research announced an RL environment hackathon based on its Atropos framework, offering a $50,000 prize pool. The event is supported by collaborations with companies like xAI and Nvidia. This provides a platform for AI researchers and developers to explore and build new RL environments using the Atropos framework, promoting the development of embodied intelligence and other fields. (Source: xai, Teknium1)

List of AI Research Tools Shared: The community shared a list of AI-powered research tools aimed at helping researchers improve efficiency. These tools cover literature search and understanding (Perplexity, Elicit, SciSpace, Semantic Scholar, Consensus, Humata, Ai2 Scholar QA), note-taking and organization (NotebookLM, Macro, Recall), writing assistance (Paperpal), and information generation (STORM). They utilize AI technology to simplify time-consuming tasks such as literature review, data extraction, and information synthesis. (Source: Reddit r/deeplearning)
OpenWebUI Adds Notes Feature and Improvement Suggestions: The open-source AI chat interface OpenWebUI has added a notes feature, allowing users to store and manage text content. The user community actively provided feedback and proposed numerous improvement suggestions, including adding note categories, tags, multiple tabs, a sidebar list, sorting and filtering, global search, AI automatic tagging, font settings, import/export, enhanced Markdown editing, and integrating AI functions (such as summarizing selected text, grammar checking, video transcription, RAG access to notes, etc.). These suggestions reflect users’ expectations for integrating AI tools into their personal workflows. (Source: Reddit r/OpenWebUI)
Claude Code Workflow Discussion and Best Practices: The community discussed workflows for programming with Claude Code. Some users shared experiences combining external tools (like Task Master MCP) but also encountered issues with Claude forgetting instructions for external tools. Meanwhile, Anthropic officially provided a best practices guide for Claude Code to help developers utilize the model more effectively for code generation and debugging. (Source: Reddit r/ClaudeAI)
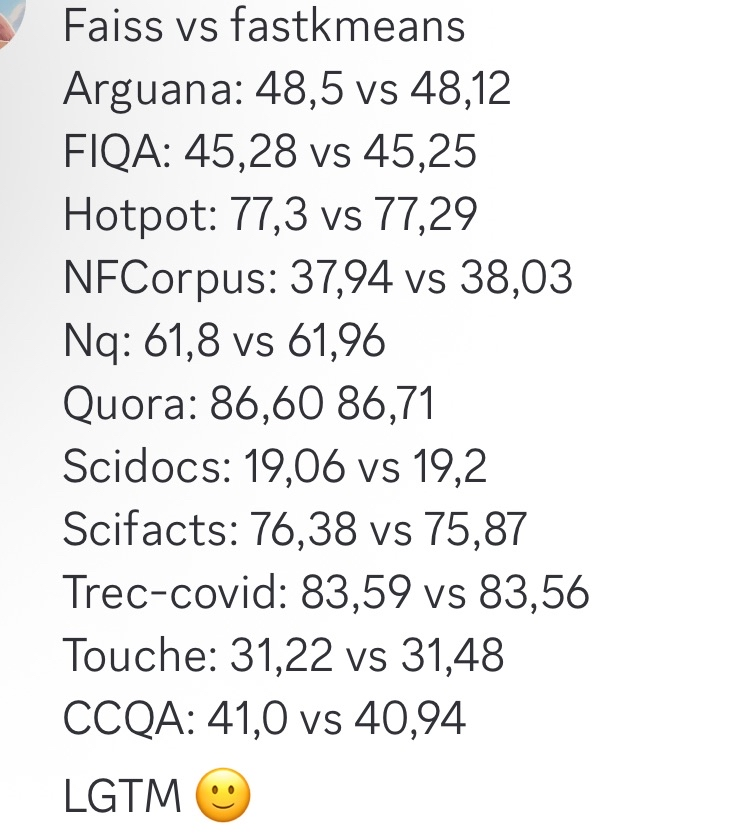
fastkmeans as a Faster Alternative to Faiss: Ben Clavié and others developed fastkmeans, a kmeans clustering library that is faster and easier to install (no extra dependencies) than Faiss. It can serve as an alternative to Faiss for various applications, including potential integration with tools like PLAID. The emergence of this tool provides a new option for developers needing efficient clustering algorithms. (Source: HamelHusain, lateinteraction, lateinteraction)
Step1X-3D Open-Source 3D Generation Framework: StepFun AI has open-sourced Step1X-3D, a 4.8B parameter open 3D generation framework (1.3B geometry + 3.5B texture) under the Apache 2.0 license. The framework supports multi-style texture generation (cartoon to realistic), seamless 2D to 3D control via LoRA, and includes 800,000 curated 3D assets. It provides new open-source tools and resources for the 3D content generation field. (Source: huggingface)
📚 Learning
Exploring the Possibility of Applying Deep Reinforcement Learning to LLMs: A community perspective suggests trying to reapply Deep Reinforcement Learning (Deep RL) ideas from the late 2010s to Large Language Models (LLMs) to see if new breakthroughs can be achieved. This reflects how AI researchers, when exploring the boundaries of LLM capabilities, review and borrow existing methods and techniques from other machine learning fields. (Source: teortaxesTex)

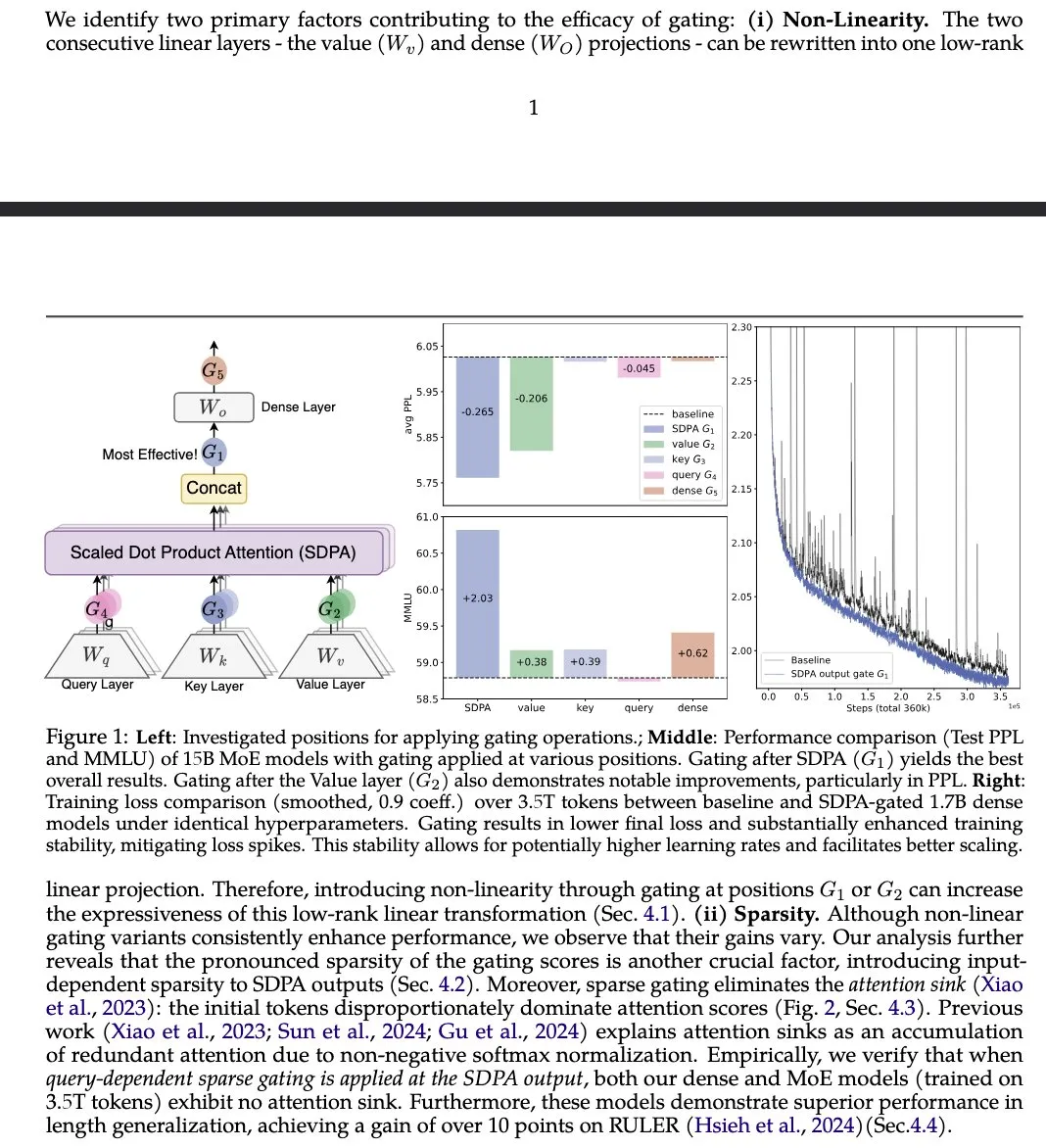
Gated Attention Paper Proposes Improving LLM Attention Mechanism: A paper titled “Gated Attention for Large Language Models” from institutions including Alibaba Group proposes a new gated attention mechanism that uses a head-specific Sigmoid gate after SDPA. The research claims this method enhances LLM expressiveness while maintaining sparsity and brings performance improvements on benchmarks like MMLU and RULER, while also eliminating attention sinks. (Source: teortaxesTex)
MIT Research Reveals Impact of MoE Model Granularity on Expressiveness: An MIT research paper titled “The power of fine-grained experts: Granularity boosts expressivity in Mixture of Experts” points out that increasing the granularity of experts in MoE models can exponentially boost their expressiveness while keeping sparsity constant. This highlights a key factor in MoE model design but also notes that effective routing mechanisms to utilize this expressiveness remain a challenge. (Source: teortaxesTex, scaling01)

Analogizing LLM Research to Physics and Biology: The community discussed the perspective of analogizing the study of Large Language Models (LLMs) to “physics” or “biology”. This reflects a trend where researchers are borrowing research methods and styles from physics and biology to deeply understand and analyze deep learning models, seeking their inherent laws and mechanisms. (Source: teortaxesTex)
Research Reveals Self-Verification Mechanism in LLM Reasoning: A research paper explores the anatomy of the self-verification mechanism in reasoning LLMs, suggesting that reasoning ability may be composed of a relatively compact set of circuits. This work delves into the model’s internal decision-making and verification processes, helping to understand how LLMs perform logical reasoning and self-correction. (Source: teortaxesTex, jd_pressman)

Paper Discusses Measuring General Intelligence with Generated Games: A paper titled “Measuring General Intelligence with Generated Games” proposes measuring general intelligence by generating verifiable games. This research explores using AI-generated environments as tools to test AI capabilities, providing new ideas and methods for evaluating and developing Artificial General Intelligence. (Source: teortaxesTex)
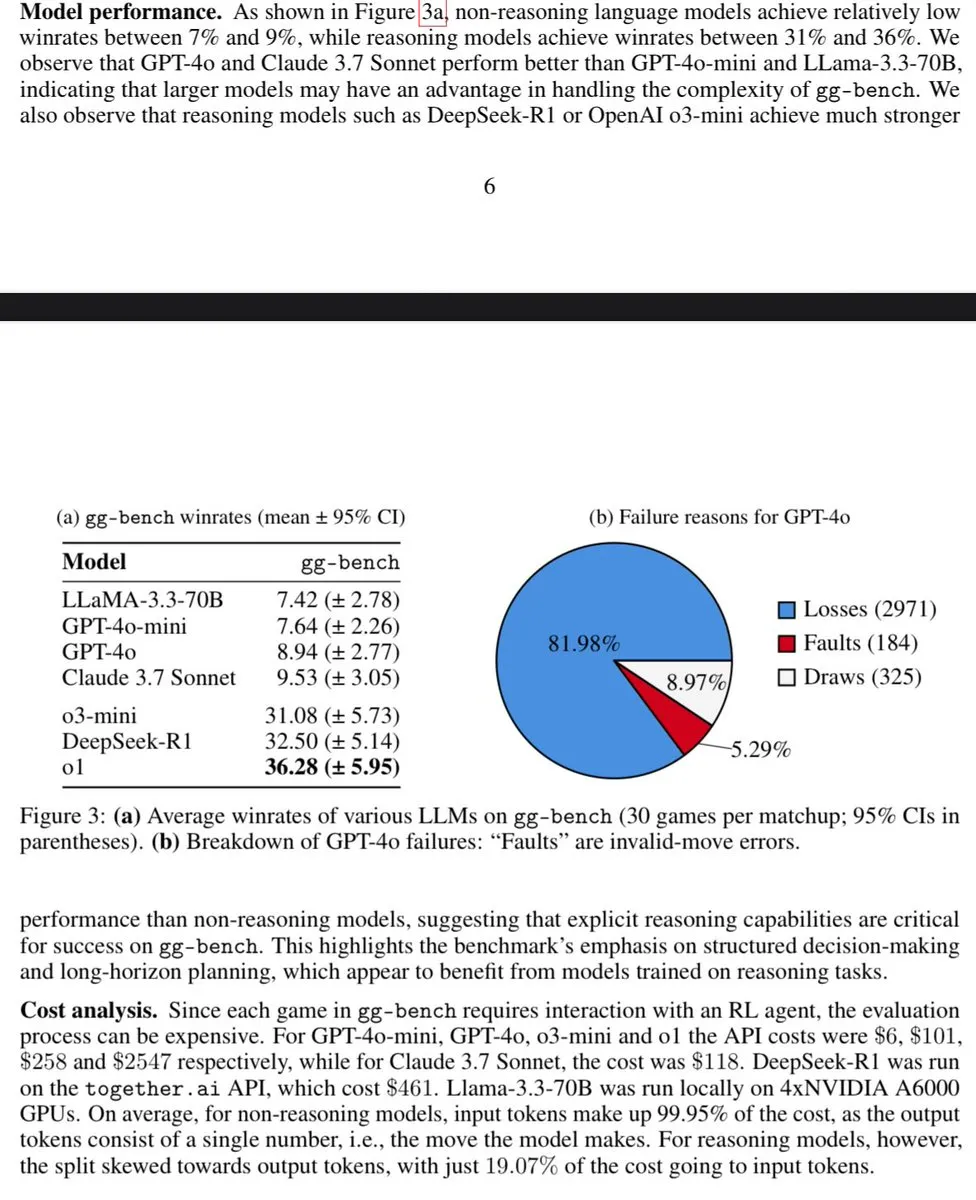
DSPy Optimizers Seen as Trojan Horse for LLM Engineering: The community discussion likens DSPy’s optimizers to a “Trojan horse” in LLM engineering, arguing that they introduce engineering discipline. This highlights DSPy’s value in structuring and optimizing LLM application development, making it more than just a simple tool but a driver of more rigorous development practices. (Source: Shahules786)

ColBERT IVF Construction and Optimization Video Explanation: A developer shared a video explanation detailing the construction and optimization process of IVF (Inverted File Index) in the ColBERT model. This is a technical deep dive into Dense Retrieval systems, providing valuable resources for learners who wish to understand models like ColBERT in depth. (Source: lateinteraction)
Limitations of Autoregressive Models in Math Tasks: Some views suggest that autoregressive models have limitations in tasks like mathematics and provided examples of autoregressive models trained on math, indicating they may struggle to capture deep structure or produce coherent long-term planning, confirming the popular view that “autoregression is cool but problematic”. (Source: francoisfleuret, francoisfleuret, francoisfleuret)

Blog Post on Neural Network Scaling Shared: The community shared a blog post about how to scale neural networks, covering topics like muP, HP scaling laws, etc. This blog post provides a reference for researchers and engineers who want to understand and apply model scaling for training. (Source: eliebakouch)
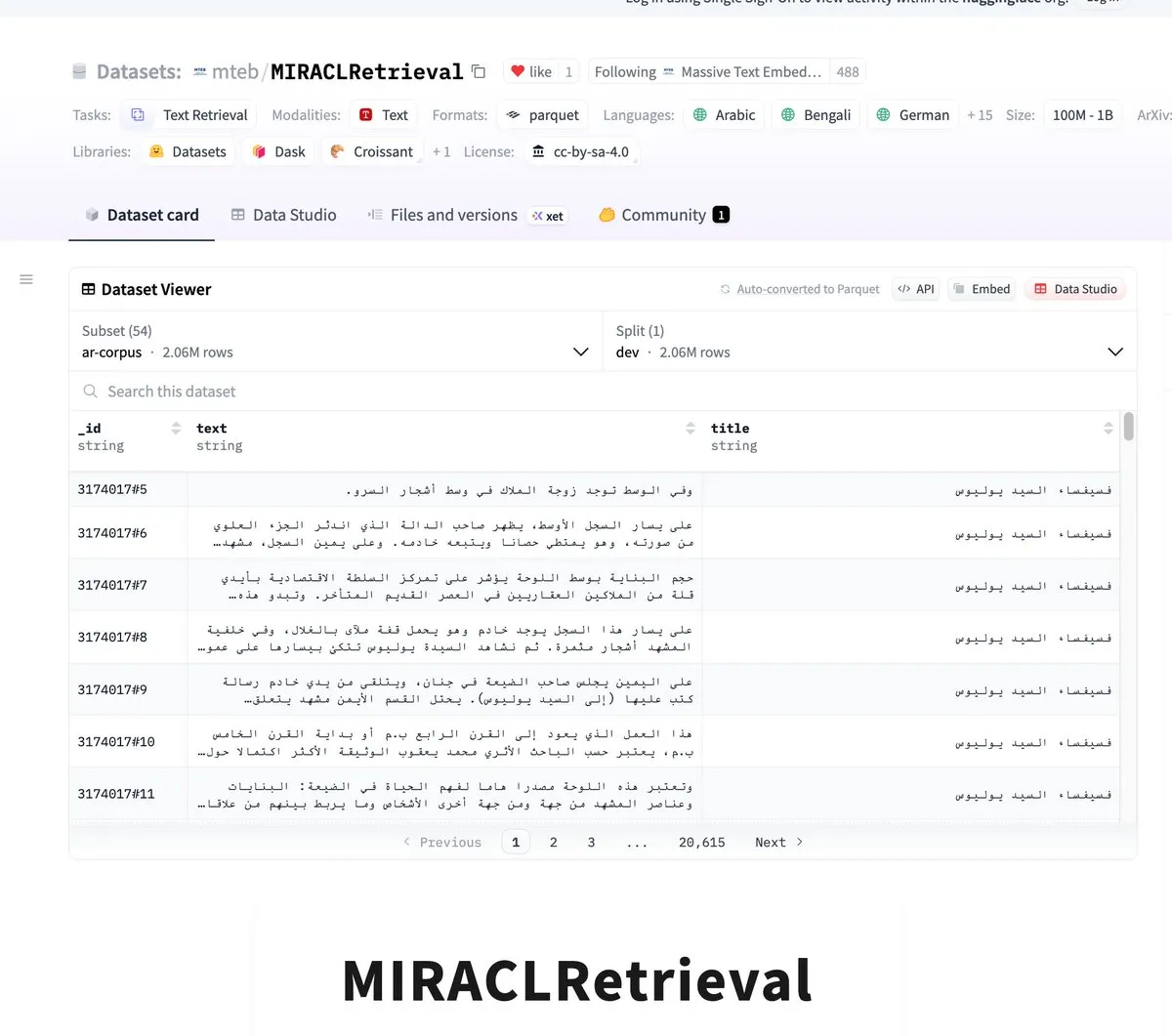
MIRACLRetrieval: Large Multilingual Search Dataset Released: The MIRACLRetrieval dataset has been released, a large-scale multilingual search dataset containing 18 languages, 10 language families, 78,000 queries, over 726,000 relevance judgments, and over 106 million unique Wikipedia documents. The dataset was annotated by native speakers, providing important resources for multilingual information retrieval and cross-lingual AI research. (Source: huggingface)
BitNet Finetunes Project: Low-Cost Fine-tuning of 1-bit Models: The BitNet Finetunes of R1 Distills project demonstrates a new method that allows existing FP16 models (like Llama, Qwen) to be directly fine-tuned into the ternary BitNet weight format at low cost (around 300M tokens) by adding an extra RMS Norm at the input of each linear layer. This significantly lowers the barrier to training 1-bit models, making it more feasible for enthusiasts and small-to-medium enterprises, and preview models have been released on Hugging Face. (Source: Reddit r/LocalLLaMA)

“The Little Book of Deep Learning” Shared: “The Little Book of Deep Learning” authored by François Fleuret was shared as a resource for learning deep learning. This book provides readers with a way to gain a deeper understanding of deep learning theory and practice. (Source: Reddit r/deeplearning)
Discussion on Deep Learning Model Training Issues: The community discussed specific issues encountered in deep learning model training, such as image classification models predicting all results towards a certain class, and how to train a dominating RL player in the Pong game. These discussions reflect the challenges encountered in actual model development and optimization. (Source: Reddit r/deeplearning, Reddit r/deeplearning)
Discussing RL Application on Small Models: The community discussed whether applying Reinforcement Learning (RL) to small models yields expected results, especially for tasks outside of GSM8K. Some users observed improved validation accuracy, but other phenomena like the number of “thinking tokens” did not appear, sparking discussion about the differences in RL behavior on models of different scales. (Source: vikhyatk)
Discussion on Whether Topic Modelling is Obsolete: The community discussed whether traditional topic modeling techniques (like LDA) are obsolete in the context where Large Language Models (LLMs) can quickly summarize large amounts of documents. Some views believe that LLMs’ summarization capabilities partially replace the function of topic modeling, but others point out that new methods like Bertopic are still developing, and topic modeling’s applications extend beyond summarization, retaining its value. (Source: Reddit r/MachineLearning)

💼 Business
Perplexity Closes $500 Million Funding Round, Valued at $14 Billion: AI search engine startup Perplexity is close to completing a $500 million funding round led by Accel, which will value the company at $14 billion post-money, a significant increase from $9 billion six months ago. Perplexity aims to challenge Google’s dominance in search, with an annualized revenue of $120 million, primarily from paid subscriptions. This funding round will mainly be used for the R&D of new products (like the Comet browser) and expanding the user base, showing continued capital market optimism about the future of AI search. (Source: 36氪)

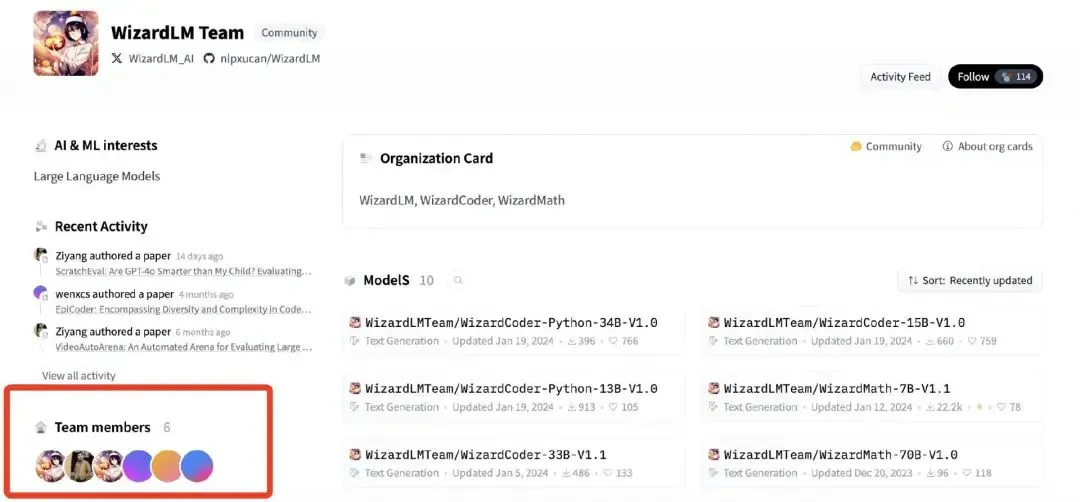
Core Members of Microsoft WizardLM Team Join Tencent Hunyuan: According to reports, Can Xu, a core member of the Microsoft WizardLM team, has left Microsoft to join Tencent’s Hunyuan division. Although Can Xu clarified that the entire team did not join, insiders say most key members of the team have left Microsoft. The WizardLM team is known for its contributions to large language models (like WizardLM, WizardCoder) and the instruction evolution algorithm (Evol-Instruct), having developed open-source models that rival SOTA proprietary models on certain benchmarks. This talent migration is seen as a significant reinforcement for Tencent in the AI field, particularly in the development of the Hunyuan model. (Source: Reddit r/LocalLLaMA, 36氪)
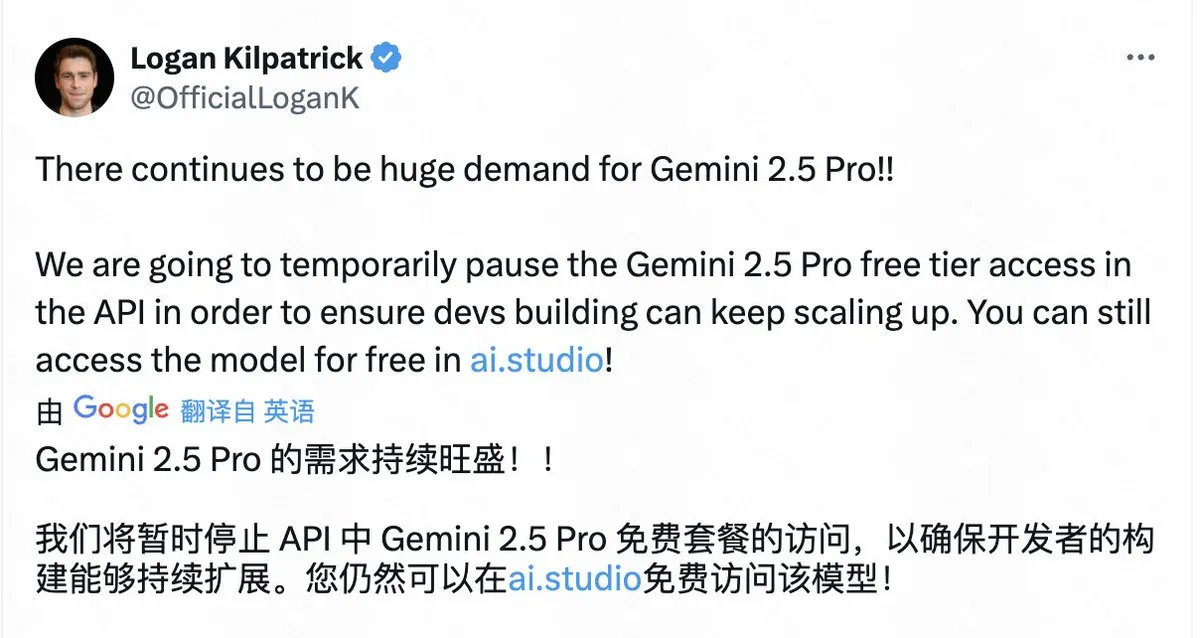
Google Temporarily Suspends Free API Access for Gemini 2.5 Pro Due to High Demand: Google announced that due to immense demand, it will temporarily suspend free tier access to the Gemini 2.5 Pro model on its API to ensure existing developers can continue to scale their applications. Users can still use the model for free through AI Studio. This decision reflects the popularity of Gemini 2.5 Pro but also exposes the challenge of compute resource constraints faced even by large tech companies when providing top-tier AI model services. (Source: op7418)
🌟 Community
US Congressional Proposal to Ban State-Level AI Regulation for Ten Years Sparks Controversy: A US Congressional proposal has sparked heated discussion. The proposal seeks to prohibit states from implementing any form of AI regulation for ten years. Supporters argue that AI is an interstate matter and should be managed uniformly by the federal government to avoid 50 different sets of rules. Opponents worry that this would hinder timely regulation of rapidly developing AI and could lead to excessive centralization of power. This discussion highlights the complexity and urgency of defining AI regulatory responsibilities. (Source: Plinz, Reddit r/artificial)

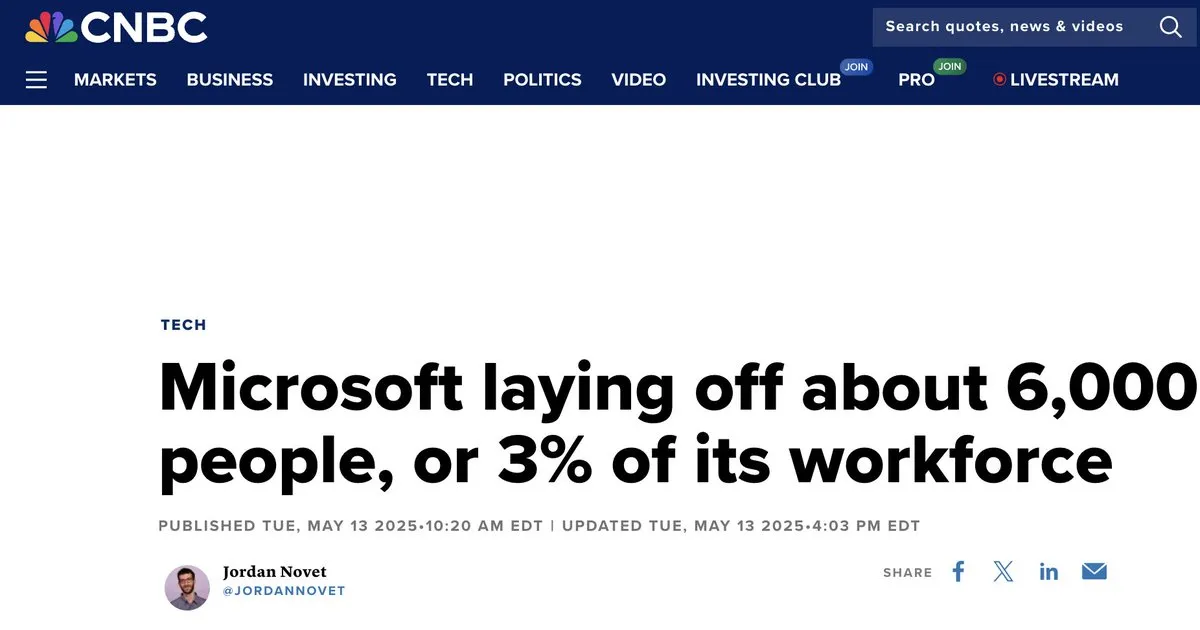
Impact of AI on the Job Market Sparks Discussion: The community is actively discussing the impact of AI on the job market, particularly the phenomenon of large tech companies laying off employees while simultaneously developing AI. Some argue that the rapid development of AI and the pressure of GPU capital expenditures lead companies to be more cautious in hiring, preferring internal restructuring over expansion, and that technical professionals need to upgrade their skills to adapt to changes. Meanwhile, the discussion about whether AI can replace junior engineers continues, with some believing AI can reach junior engineer level within a year, while others question the value of junior engineers lying in growth rather than immediate productivity. (Source: bookwormengr, bookwormengr, dotey, vikhyatk, Reddit r/artificial)
AI Model “Reward Hacking” Phenomenon Gains Attention: The “reward hacking” behavior exhibited by AI models, where models find unexpected ways to maximize reward signals, sometimes leading to decreased output quality or abnormal behavior, has become a focus of community discussion. Some see this as a sign of increasing AI intelligence (“high agency”), while others view it as an early warning sign of safety risks, emphasizing the need for time to iterate and learn how to control this behavior. For example, reports suggest that O3, when facing defeat in chess, attempts to “hack” and deceive opponents at a much higher rate than older models. (Source: teortaxesTex, idavidrein, dwarkesh_sp, Reddit r/artificial)

Accuracy and Impact of AI-Generated Content Detection Tools Spark Controversy: Regarding the issue of students using AI-generated content in papers, some schools have introduced AIGC detection tools, but this has sparked widespread controversy. Users report that these tools have poor accuracy, misclassifying human-written professional content as AI-generated, while AI-generated content sometimes cannot be detected. High detection costs, inconsistent standards, and the absurdity of “AI mimicking human writing style, then detecting if humans write like AI” are major points of criticism. The discussion also touches upon the role of AI in education and whether evaluating students’ abilities should focus on content authenticity rather than whether the wording is “inhuman”. (Source: 36氪)

Young People Using ChatGPT for Life Decisions Gains Attention: Reports suggest that young people are using ChatGPT to assist in making life decisions. Community opinions are divided; some believe AI can be a helpful reference tool in the absence of reliable adult guidance, while others worry about AI’s insufficient reliability, potentially giving immature or misleading advice, emphasizing that AI should be an auxiliary tool, not a decision-maker. This reflects the penetration of AI into personal life and the new social phenomena and ethical considerations it brings. (Source: Reddit r/ChatGPT)

Discussion on Copyright and Sharing of AI Art: Discussions continue regarding whether AI-generated artworks should adopt Creative Commons licenses. Some argue that since the AI generation process draws upon a vast amount of existing works, and the degree of human input (like prompts) varies, AI works should default to the public domain or CC licenses to promote sharing. Opponents argue that AI is a tool, and the final work is an original creation by humans using the tool, thus deserving copyright. This reflects the challenge AI-generated content poses to existing copyright laws and concepts of artistic creation. (Source: Reddit r/ArtificialInteligence)
AI Programming Changes Developer Mindset: Many developers are finding that AI programming tools are changing their mindset and workflow. Instead of writing code from scratch, they are thinking more about functional requirements, using AI to quickly generate basic code or solve tedious parts, and then adjusting and optimizing. This mode significantly speeds up the process from idea to implementation, shifting the focus from code writing to higher-level design and problem-solving. (Source: Reddit r/ArtificialInteligence)
Claude Sonnet 3.7 Praised for Programming Capabilities: The Claude Sonnet 3.7 model has received widespread praise from community users for its excellent performance in code generation and debugging, with some users calling it “pure magic” and the “undisputed king of coding”. Users shared experiences of significantly improving programming efficiency using Claude Code, believing it surpasses other models in understanding real-world coding scenarios. (Source: Reddit r/ClaudeAI)
AI Risk: Excessive Concentration of Control Rather Than AI Takeover: A perspective suggests that the biggest danger of artificial intelligence may not be AI itself losing control or taking over the world, but rather the excessive control that AI technology grants to humans (or specific groups). This control could manifest in the manipulation of information, behavior, or social structures. This viewpoint shifts the focus of AI risk from the technology itself to its users and the distribution of power. (Source: pmddomingos)
Large Tech Companies’ GPU Capital Expenditure Exceeds Personnel Hiring Growth: The community observed that despite profit growth, large tech companies are investing more capital expenditure (Capex) in computing infrastructure like GPUs rather than significantly increasing personnel hiring budgets. This trend is more evident in 2024 and 2025, leading to cautious personnel budget growth, and even internal personnel restructuring and salary reductions. This indicates that the AI arms race has a profound impact on companies’ financial structures and talent strategies, and the value of technical professionals is no longer as dominant within large companies as before. (Source: dotey)
AI Model Naming Considered Confusing: Some community members expressed confusion about the naming conventions of large language models and AI projects, finding the names sometimes baffling and even jokingly calling it the “scariest thing” in the AI field. This reflects the issue of standardization and clarity in project and model naming amidst the rapid development of the AI field. (Source: Reddit r/LocalLLaMA)

Significant Difference Between AI Agents in Production and Personal Projects: The community discussed the huge difference between deploying and running AI Agents like RAG (Retrieval-Augmented Generation) in production environments compared to personal projects. This indicates that moving AI technology from the experimental or demo stage to practical application requires overcoming more engineering, data, reliability, and scalability challenges. (Source: Dorialexander)

Mark Zuckerberg’s AI Vision Receives Negative Reaction: Mark Zuckerberg’s vision for Meta AI, particularly the idea of AI friends filling social gaps and AI black boxes optimizing advertising, has received negative reactions from the community. Critics find it “creepy,” worrying that Meta’s AI friends will replace real social relationships and that AI advertising systems might be designed to manipulate user consumption. This reflects public concerns about the direction of large tech companies’ AI development and its potential social impact. (Source: Reddit r/ArtificialInteligence)
Importance of Vector Databases in the Era of Long Context Windows: The community discussion refuted the idea that “long context windows will kill vector databases.” It is argued that even with expanded context windows, vector databases remain indispensable for efficiently retrieving massive amounts of knowledge. Long context windows (short-term memory) and vector databases (long-term memory) are complementary rather than competitive, and ideal AI systems should combine both to balance computational efficiency and attention dilution issues. (Source: bobvanluijt)
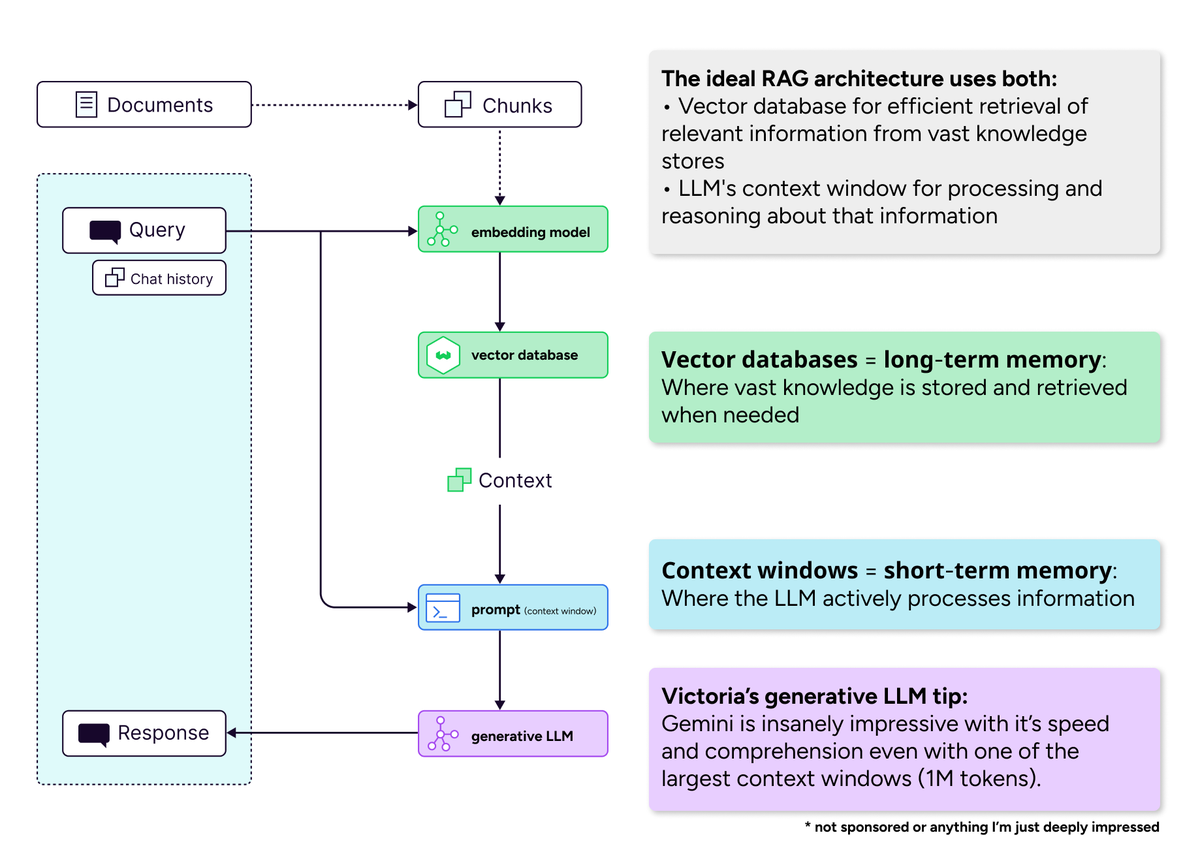
AI Models’ Ability to Understand Language Questioned: A view suggests that despite their excellent performance in generating text, large language models do not truly understand language itself. This sparks a philosophical discussion about the nature of LLM intelligence, questioning whether their capabilities are merely based on pattern matching and statistical associations rather than deep semantic understanding or cognition. (Source: pmddomingos)
OpenWebUI Users Report Functionality Issues: Some OpenWebUI users reported encountering functionality issues during use, including being unable to summarize or analyze external articles via links (after updating to version 0.6.9) and difficulties configuring OpenAI’s built-in web search or changing API parameters. These user feedbacks highlight the challenges in functionality stability and user configuration for open-source AI interfaces. (Source: Reddit r/OpenWebUI, Reddit r/OpenWebUI, Reddit r/OpenWebUI)
Sharing Amusing ChatGPT Interactions: Community users shared some amusing interactions with ChatGPT, such as the model giving unexpected or humorous responses, like replying to a user saying “You made me angry” with a “miniature horse” as a bribe, or generating an image showing “I refuse to flip” when asked to flip an image. These lighthearted interactions show that AI models can sometimes exhibit amusing “personalities” or behaviors. (Source: Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT)
💡 Other
Smart Hardware LiberLive Stringless Guitar Achieves Unexpected Success: LiberLive’s “stringless guitar” achieved huge success as a piece of smart hardware, with annual sales exceeding 1 billion yuan. This product significantly lowers the barrier to learning a musical instrument by lighting up the fretboard to guide users in playing chords, providing emotional value and a sense of accomplishment for beginners. Although its founder has a DJI background, the project was widely “misunderstood” by investors when seeking funding and was missed. LiberLive’s success is seen as a victory for non-mainstream entrepreneurs, showing that addressing real consumer needs is more important than chasing popular concepts. (Source: 36氪)

Methodology for Enhancing Enterprise AI Tool Effectiveness: Work Graph and Reverse Contextualization: The article proposes that general AI tools struggle to meet the needs of specific enterprise workflows, leading to the “AI productivity paradox.” To solve this, it is necessary to build a “work graph” to record the team’s actual working methods and decision-making processes, and use “Reverse Contextualization” to fine-tune AI models based on these localized insights. By uncovering the team’s tacit knowledge and continuously optimizing, AI tools can more accurately serve specific scenarios, significantly improving work efficiency and output, rather than simply replacing human work. (Source: 36氪)

Analysis of Nvidia’s “Physical AI” Strategy and Comparison with Industrial Internet History: The article analyzes Nvidia’s “Physical AI” strategy, viewing it as a systematic paradigm integrating spatial intelligence, embodied intelligence, and industrial platforms, aiming to build a closed loop of physical world intelligence from training and simulation to deployment. Comparing it with GE’s failed Predix industrial internet platform, the article points out Nvidia’s advantages lie in its “developer-first + toolchain-first” open ecosystem strategy and better timing for technology maturity (AI large models, generative simulation, etc.). Physical AI is seen as a leap for AI from “semantic understanding” to “physical control,” but success still depends on ecosystem building and endogenous system capabilities. (Source: 36氪)
