
Keywords:AI security, Artificial intelligence ethics, AI agent, 3D generation, Code model, AI risk assessment, Gemini 2.5 Pro video understanding, AssetGen 2.0 3D generation, Seed-Coder code model, AgentOps agent operations
🔥 Focus
AI Safety Risks Draw Attention, Experts Urge Risk Assessment Drawing on Nuclear Safety Experience: The international community’s concerns about the potential risks of artificial intelligence are growing. Some experts (like Max Tegmark) are calling for AI companies, before releasing dangerous AI systems, to emulate the safety calculation methods used by Robert Oppenheimer during the first nuclear test, to rigorously assess the probability of artificial intelligence losing control (Compton constant). This move aims to build industry consensus, promote the establishment of global AI safety mechanisms, and prevent catastrophic consequences that superintelligence might bring. (Source: Reddit r/artificial, Reddit r/ArtificialInteligence)

Newly elected Pope Francis (alias Leo XIV) highly concerned about AI-driven societal changes: The newly elected Pope Francis (reportedly Leo XIV) has identified artificial intelligence as one of the main challenges facing humanity. He chose “Leo” as his pontifical name partly due to AI-driven new social issues and the industrial revolution, echoing Pope Leo XIII’s response to the first Industrial Revolution. The Pope emphasized that AI poses challenges to maintaining “human dignity, justice, and labor” and plans to release an important document on AI ethics in the future, showing the deep concern of religious leaders for the ethical and social impact of AI technology. (Source: Reddit r/artificial, AymericRoucher, AravSrinivas, Reddit r/ArtificialInteligence)

Google releases 76-page AI agent white paper, elaborating on AgentOps and future applications: Google has released a 76-page white paper on AI agents, detailing their construction, evaluation, and application. The white paper emphasizes the importance of Agent Operations (AgentOps) as a branch of generative AI operations, focusing on tool management, core prompt settings, memory functions, and task decomposition required for efficient agent operation. The white paper also explores multi-agent collaboration architectures, where different agents play roles such as planning, retrieval, execution, and evaluation to complete complex tasks, and looks forward to the application prospects of agents in enterprises to assist employees and automate backend tasks, such as NotebookLM enterprise edition and Agentspace. (Source: WeChat)

Meta introduces AssetGen 2.0: Text/image generation of high-quality 3D assets: Meta has released its latest 3D foundational AI model, AssetGen 2.0, which can create high-quality 3D assets from text and image prompts. AssetGen 2.0 includes two sub-models: one for generating 3D meshes, employing a single-stage 3D diffusion model to improve detail and fidelity; and another, TextureGen, for generating textures, introducing methods for enhanced view consistency, texture inpainting, and higher texture resolution. The technology is currently used internally at Meta to create 3D worlds and is planned to be rolled out to Horizon creators later this year. (Source: Reddit r/artificial)

🎯 Trends
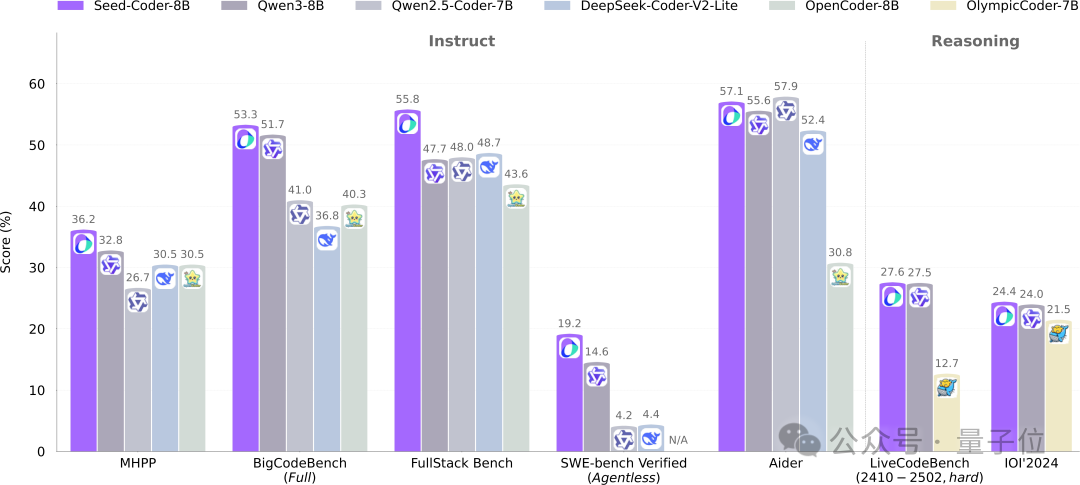
ByteDance Seed open-sources 8B code model Seed-Coder, adopting a new paradigm of model-managed data: ByteDance’s Seed team has open-sourced its 8B-parameter code model, Seed-Coder, for the first time, including Base, Instruct, and Reasoning versions. The model performs excellently on multiple code generation benchmarks, notably surpassing models like Qwen3 on HumanEval and MBPP. Seed-Coder’s core innovation lies in proposing a “model-centric” data processing approach, utilizing LLMs themselves to generate and filter high-quality code training data, including file-level code, repository-level code, commit data, and code-related web data, with a total training data volume of 6T tokens. This aims to reduce manual intervention and enhance code model capabilities. (Source: WeChat)
Gemini 2.5 Pro achieves breakthrough in video understanding, enabling native fusion of audio-video and code: Google’s latest Gemini 2.5 Pro and Flash models have made significant progress in video understanding capabilities. Gemini 2.5 Pro has reached SOTA levels on several key video understanding benchmarks, even surpassing GPT 4.1. The Gemini 2.5 series models, for the first time, achieve native seamless integration of audio-video information with other data formats like code. They can directly convert videos into interactive applications (such as learning apps), generate p5.js animations based on videos, and accurately retrieve and describe video segments, demonstrating strong temporal reasoning abilities. These features are now available in Google AI Studio, Gemini API, and Vertex AI. (Source: WeChat)

ModelScope open-sources unified image model Nexus-Gen, benchmarking against GPT-4o’s image capabilities: The ModelScope team has launched Nexus-Gen, a unified multimodal model capable of simultaneously handling image understanding, generation, and editing, aiming to rival GPT-4o’s image processing capabilities. The model adopts a token → transformer → diffusion → pixels technical route, integrating the text modeling capabilities of MLLMs with the image rendering capabilities of Diffusion models. To address the error accumulation issue in autoregressive prediction of continuous image embeddings, the team proposed a pre-fill autoregressive strategy. Nexus-Gen was trained on approximately 25M image-text data, including the newly open-sourced ImagePulse editing dataset from the ModelScope community. (Source: WeChat)

Cursor 0.50 version released, simplifying pricing and enhancing multiple code editing features: AI code editor Cursor has released version 0.50, bringing significant updates. The pricing model has been simplified to a request-based model, with the Max mode supporting all top AI models and adopting token-based pricing. Feature enhancements include: a new Tab model supporting cross-file suggestions and code refactoring; a background agent (preview) supporting parallel execution of multiple agents and task execution in remote environments; codebase context allowing the addition of entire codebases via @folders; optimized inline editing UI with new full-file editing and send-to-agent functions; a search and replace tool introduced for long file editing; support for multi-root workspaces to handle multiple codebases; and enhanced chat functionality with support for exporting to Markdown and copying. (Source: op7418)
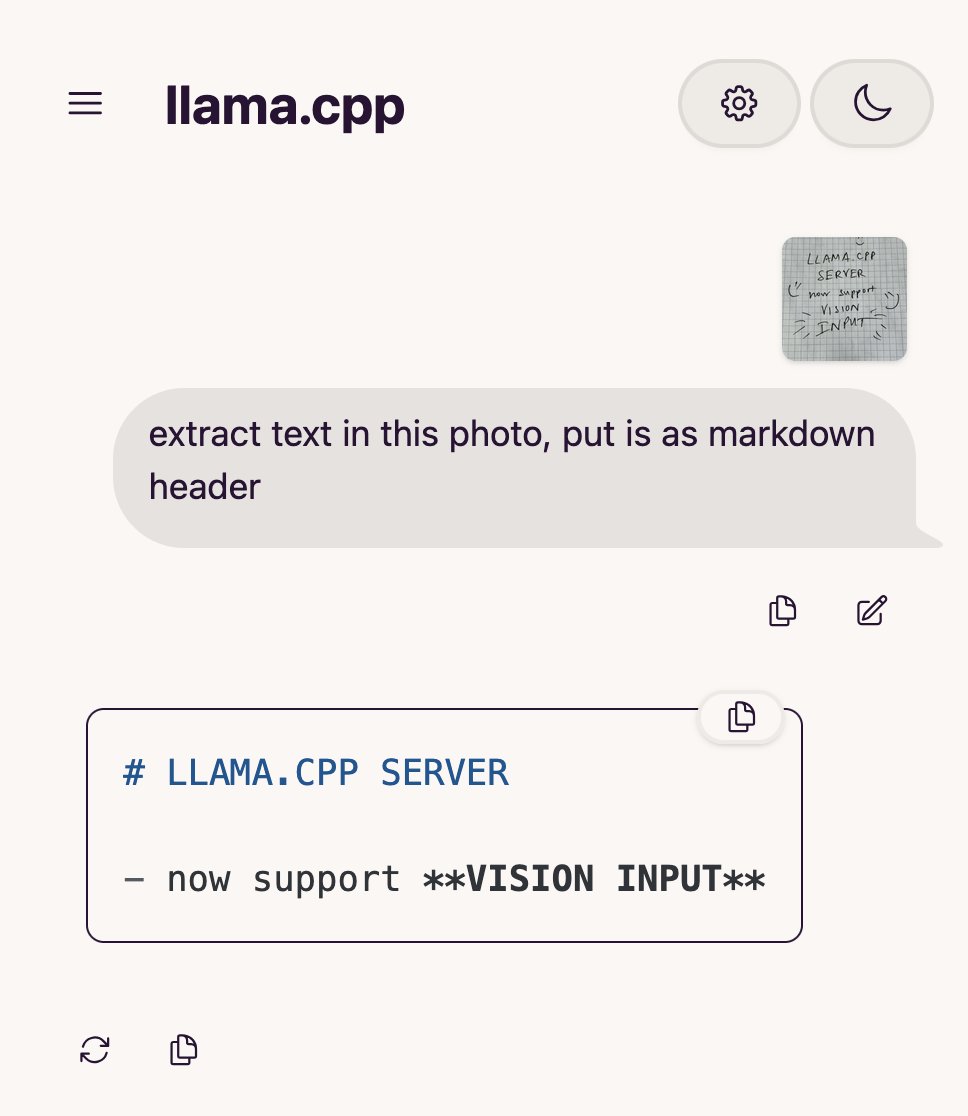
llama.cpp adds Visual Language Model (VLM) support, enabling complete Vision RAG workflows: The open-source project llama.cpp has announced support for Visual Language Models (VLMs), allowing users to now utilize vision capabilities through the llama.cpp server and Web UI. This update means that the same base model supporting multiple LoRAs, as well as embedding models, can be loaded on llama.cpp, thereby enabling the construction of complete Vision Retrieval Augmented Generation (Vision RAG) workflows. This move further expands llama.cpp’s ability to run large language models locally, enabling it to handle multimodal tasks. (Source: mervenoyann, mervenoyann)
Tencent releases HunyuanCustom: A customizable video generation architecture based on HunyuanVideo: Tencent has released HunyuanCustom on Hugging Face, a multimodal-driven architecture designed specifically for customizable video generation. This work is built upon HunyuanVideo, with a special emphasis on maintaining subject consistency during video generation, while also supporting input from multiple conditions such as images, audio, video, and text, providing users with more flexible and personalized video creation capabilities. (Source: _akhaliq)
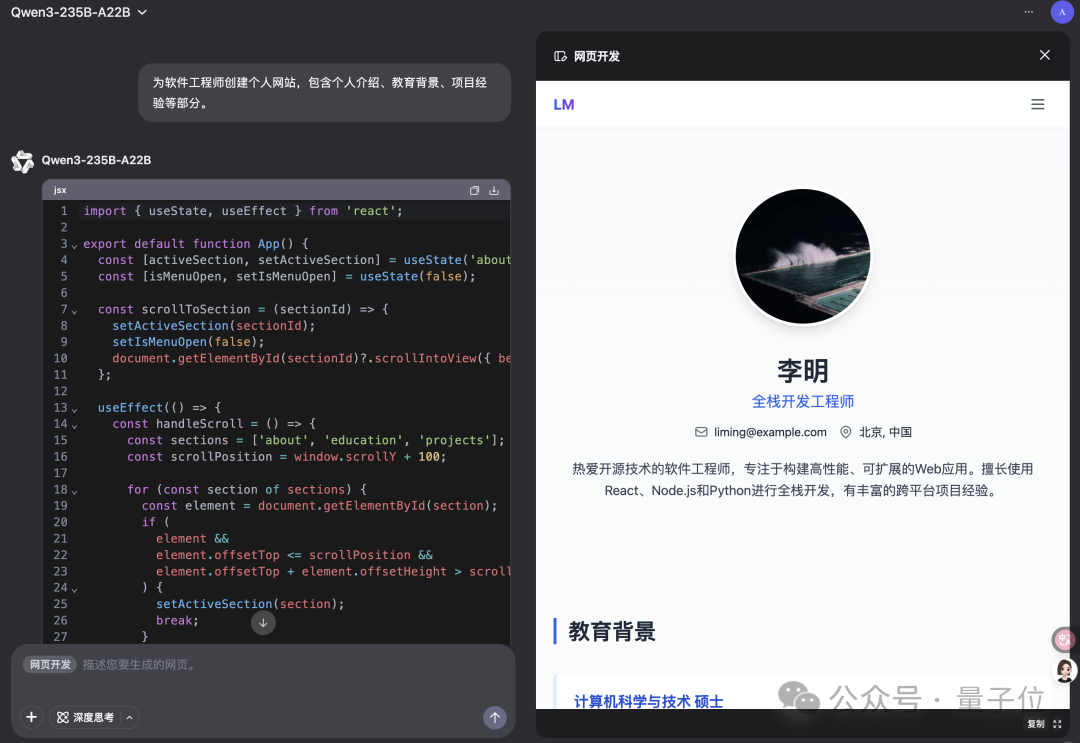
Qwen Chat adds “Web Dev” mode, generating React web applications with a single sentence: Alibaba’s Qwen Chat has launched a “Web Dev” (Web Development) mode, allowing users to generate web applications including HTML, CSS, and JavaScript with just a single sentence command, using the React framework and Tailwind CSS underneath. This feature can quickly create personal websites, replicate existing web interfaces (like Twitter, GitHub), or build specific forms and animations based on descriptions. Users can choose different Qwen models and combine them with a “deep thinking” mode to improve webpage quality. This function aims to simplify the front-end development process and quickly build application prototypes. (Source: WeChat)
Unitree Technology responds to Go1 robot dog security vulnerability, emphasizes subsequent products have been upgraded: Unitree Technology has responded to rumors of a “backdoor vulnerability” in its Go1 robot dog series, which was discontinued about two years ago, acknowledging the issue as a security vulnerability. Attackers could exploit the management key of a third-party cloud tunnel service to modify user device data, obtain camera footage, and gain system permissions. Unitree Technology stated that subsequent robot series use a more secure upgraded version and are not affected by this vulnerability. The incident has raised concerns about the supply chain security and data privacy of intelligent robots, especially in the inaugural year of humanoid robot commercialization, as the industry faces multiple challenges including technological breakthroughs, cost control, and exploration of commercialization paths. (Source: 36Kr)

Claude Code now supports referencing other .MD files, optimizing instruction organization: Anthropic’s Claude Code has updated its functionality; version 0.2.107 allows CLAUDE.md files to import other Markdown files. Users can add [u/path/to/file].md in the main CLAUDE.md file to load additional file content at startup. This improvement allows users to better organize and manage Claude’s instructions, enhancing the reliability and modularity of instruction configuration in large projects, and addressing previous issues of potential confusion caused by reliance on scattered files. (Source: Reddit r/ClaudeAI)

U.S. Copyright Office takes a tougher stance on AI pre-training, weakening “fair use” defense: A newly released report from the U.S. Copyright Office has adopted a more stringent position on the use of copyrighted materials in the pre-training phase of AI models. The report notes that because AI labs now claim their models can compete with rights holders (e.g., by generating content similar to original works), this weakens their ability to defend themselves with “fair use” in copyright infringement lawsuits. This shift could have significant implications for the data sources and compliance of AI model training. (Source: Dorialexander)

Nvidia releases RTX Pro 5000 professional graphics card with 48GB GDDR7 memory: Nvidia has launched the new professional-grade desktop GPU, RTX Pro 5000, based on the Blackwell architecture. The card is equipped with 48GB of GDDR7 memory, offering a memory bandwidth of up to 1344 GB/s, with a power consumption of 300W. Although officially termed a “cheaper” 48GB Blackwell card, the price is still expected to be high (comments mention the $4000 range), primarily targeting professional workstation users to provide powerful computing support for tasks such as AI model training and large-scale 3D rendering. (Source: Reddit r/LocalLLaMA)

🧰 Tools
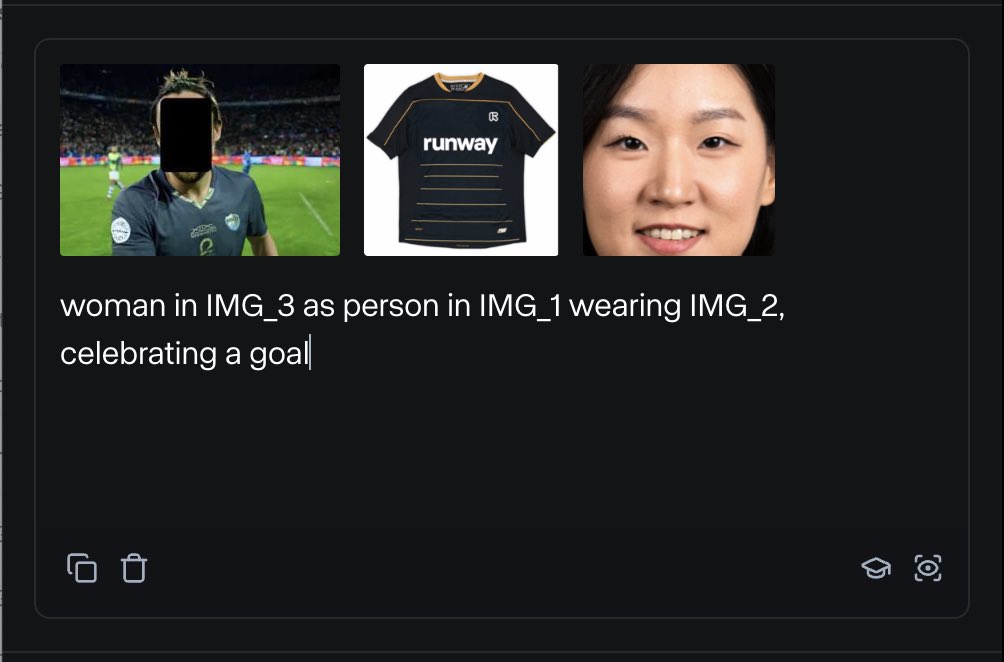
RunwayML launches References feature, allowing mixing of multiple reference materials to generate content: RunwayML’s new “References” feature allows users to mix different reference materials (such as images, styles) as “ingredients” and generate new visual content based on any combination of these “ingredients.” The feature is seen as a near real-time creation machine, capable of helping users quickly realize various creative ideas, greatly expanding the flexibility and possibilities of AI in visual content creation. (Source: c_valenzuelab)
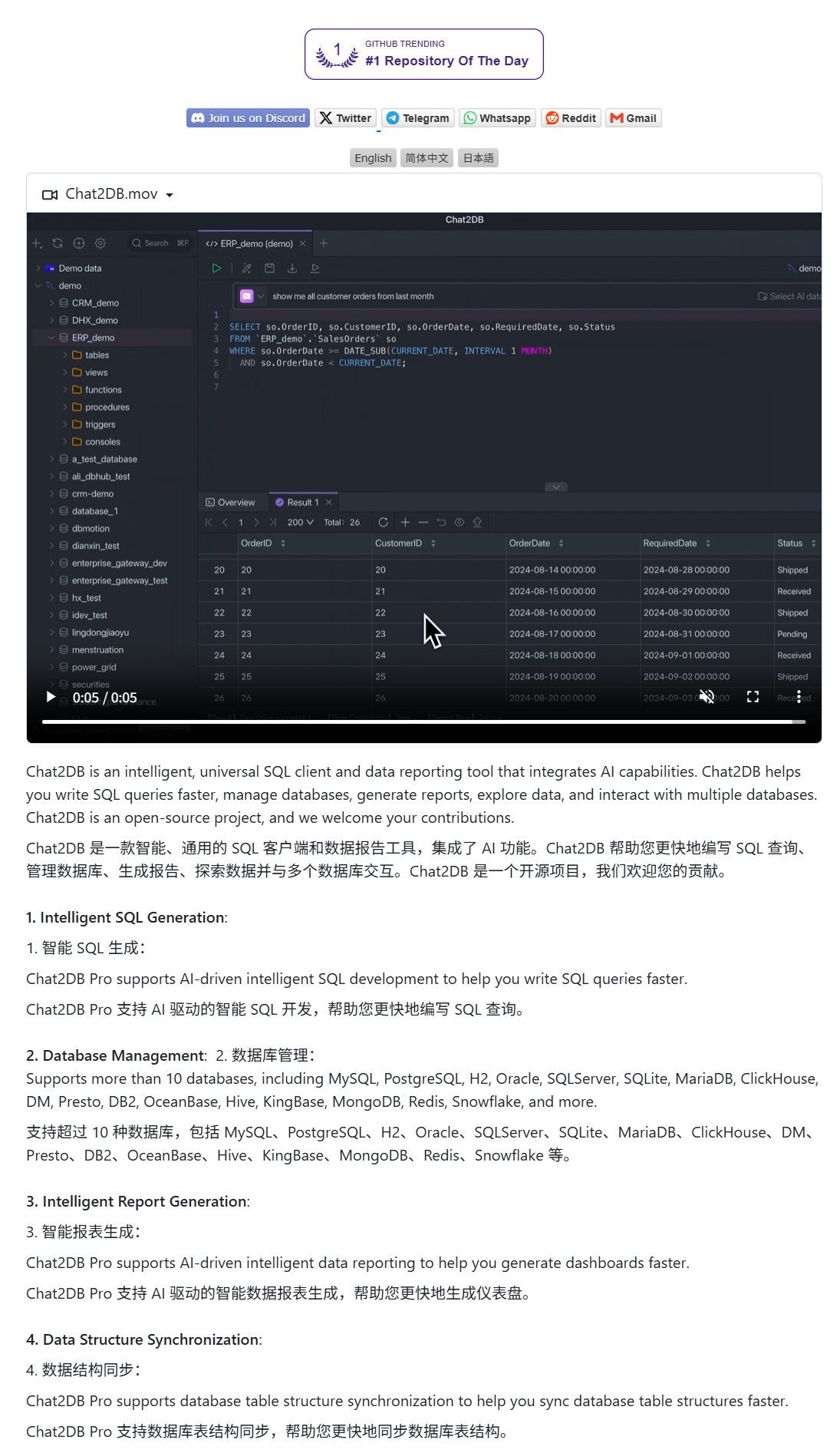
Chat2DB: An AI client for operating databases with natural language: Chat2DB is an AI-driven database client tool that allows users to interact with databases using natural language. For example, a user can ask, “Who is the customer with the highest spending this month?” Chat2DB can understand the question using AI, automatically generate the corresponding SQL query based on the database’s table structure, execute the query, and return the results. This significantly lowers the technical barrier for database operations, enabling non-technical personnel to conveniently perform data queries and analysis. The project is open-sourced on GitHub. (Source: karminski3)
Qwen 3 8B model demonstrates excellent coding ability, can generate HTML keyboard: The Qwen 3 8B model (Q6_K quantized version), despite its relatively small parameter size, performs excellently in code generation. A user successfully prompted the model with two short prompts to generate playable HTML keyboard code. This shows the potential for smaller models to achieve high practicality in specific tasks, especially attractive for resource-constrained local deployment scenarios. (Source: Reddit r/LocalLLaMA)
Ollama Chat: A Claude-like interface for local LLM chat tools: Ollama Chat is a web chat interface designed for local large language models, with its UI style and user experience drawing inspiration from Anthropic’s Claude. The tool supports text file uploads, conversation history, and system prompt settings, aiming to provide an easy-to-use and aesthetically pleasing local LLM interaction solution. The project is open-sourced on GitHub, allowing users to deploy and use it themselves. (Source: Reddit r/LocalLLaMA)
Prompting techniques for AI-generated personalized cards (birthday/Mother’s Day): A user shared prompting techniques for using AI to generate personalized cards (e.g., birthday cards, Mother’s Day cards). The key is to clearly define the card’s theme (e.g., Mother’s Day, birthday), style (e.g., feminine style, children’s style), recipient (e.g., Mom, Sandy, Jimmy), age (e.g., 30 years old, 6 years old), and the specific content or warm and sweet tone of the greeting. By combining these elements, AI can be guided to generate card designs that meet the requirements. (Source: dotey)

📚 Learning
Google releases prompt engineering white paper to guide users on how to ask questions effectively: Google has released a white paper on prompt engineering (accessible via Kaggle), aiming to teach users how to ask AI models questions more effectively. The tutorial content is clear and details techniques such as specifying output requirements, constraining output scope, and using variables, helping users improve the efficiency and effectiveness of their interactions with large language models to obtain more accurate and useful answers. (Source: karminski3)

HKUST(GZ) team proposes MultiGO: Hierarchical Gaussian modeling for single-image 3D textured human generation: A team from the Hong Kong University of Science and Technology (Guangzhou) has proposed an innovative framework called MultiGO, which reconstructs textured 3D human models from a single image through hierarchical Gaussian modeling. The method decomposes the human body into different precision levels such as skeleton, joints, and wrinkles, refining them progressively. The core technology uses Gaussian splatting points as 3D primitives and designs skeleton enhancement, joint enhancement, and wrinkle optimization modules. This research has been accepted by CVPR 2025, offering a new approach for single-image 3D human reconstruction, and the code will be open-sourced soon. (Source: WeChat)

Tsinghua, Fudan, and HKUST jointly release RM-BENCH: The first reward model evaluation benchmark: Addressing the issues of “form over substance” and style bias in current large language model reward model evaluations, research teams from Tsinghua University, Fudan University, and the Hong Kong University of Science and Technology have jointly released RM-BENCH, the first systematic reward model evaluation benchmark. The benchmark covers four major domains: chat, code, math, and safety. By evaluating the model’s sensitivity to subtle content differences and robustness to style deviations, it aims to establish a new standard for more reliable “content referees.” The study found that existing reward models perform poorly in math and code domains and generally exhibit style bias. This work has been accepted as an ICLR 2025 Oral presentation. (Source: WeChat)

Tianjin University and Tencent open-source COME solution: 5 lines of code to improve TTA robustness and solve model collapse: Tianjin University and Tencent have collaborated to propose the COME (Conservatively Minimizing Entropy) method, aimed at addressing the issues of model overconfidence and collapse caused by entropy minimization (EM) during test-time adaptation (TTA). COME explicitly models prediction uncertainty by introducing subjective logic and indirectly controls uncertainty by employing an adaptive Logit constraint (freezing the Logit norm), thereby achieving conservative entropy minimization. This method requires no modification to the model architecture and can be embedded into existing TTA methods with only a few lines of code. It significantly improves model robustness and accuracy on datasets like ImageNet-C, with minimal computational overhead. The paper has been accepted by ICLR 2025, and the code has been open-sourced. (Source: WeChat)
Huawei and IIE CAS propose DEER: “Dynamic Early Exit” mechanism for chain-of-thought to improve LLM reasoning efficiency and accuracy: Huawei, in collaboration with the Institute of Information Engineering, Chinese Academy of Sciences (IIE CAS), has proposed DEER (Dynamic Early Exit in Reasoning), a mechanism aimed at solving the problem of overthinking that can occur in large language models during long chain-of-thought (Long CoT) reasoning. DEER dynamically determines whether to terminate thinking early and generate a conclusion by monitoring reasoning transition points, inducing tentative answers, and evaluating their confidence. Experiments show that on reasoning LLMs like the DeepSeek series, DEER can reduce the average length of chain-of-thought generation by 31%-43% without additional training, while simultaneously improving accuracy by 1.7%-5.7%. (Source: WeChat)

CAS and others propose R1-Reward: Training multimodal reward models via stable reinforcement learning: Researchers from the Chinese Academy of Sciences (CAS), Tsinghua University, Kuaishou, and Nanjing University have proposed R1-Reward, a method for training multimodal reward models (MRMs) using a stable reinforcement learning algorithm called StableReinforce, aimed at enhancing their long-horizon reasoning capabilities. StableReinforce improves upon the instability issues encountered by existing RL algorithms like PPO when training MRMs. It stabilizes the training process through a Pre-Clip strategy, an advantage filter, and a novel consistency reward mechanism (introducing a referee model to check the consistency between analysis and answer). Experiments show that R1-Reward outperforms SOTA models on multiple MRM benchmarks, and its performance can be further improved through multiple sampling and voting at inference time. (Source: WeChat)
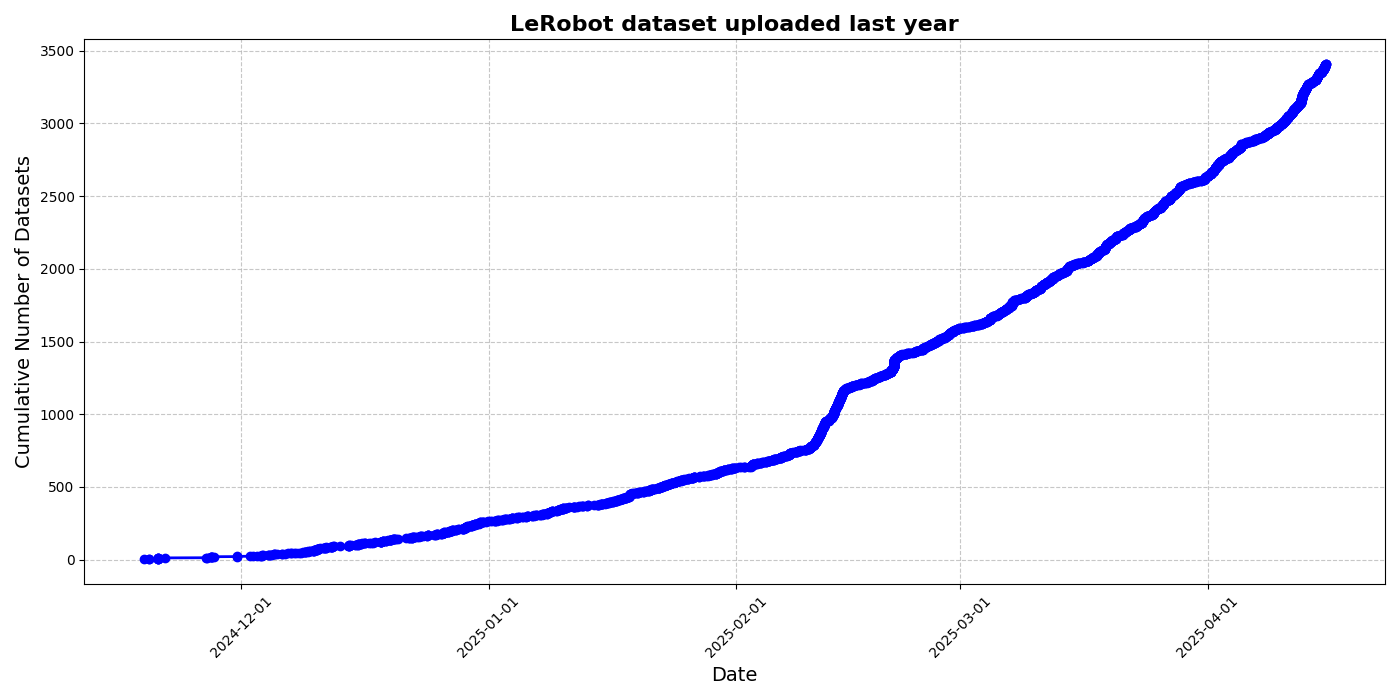
HuggingFace launches LeRobot community dataset initiative to drive robotics’ “ImageNet moment”: HuggingFace has initiated the LeRobot community dataset project, aiming to build an “ImageNet” for the robotics field, promoting general-purpose robotics technology development through community contributions. The article emphasizes the importance of data diversity for robot generalization capabilities and points out that existing robot datasets mostly originate from restricted academic environments. LeRobot encourages users to share data from different robots (such as So100, Koch manipulator) performing diverse tasks (like playing chess, operating drawers) by simplifying data collection, upload processes, and reducing hardware costs. Simultaneously, the article proposes data quality standards and a list of best practices to address challenges like inconsistent data annotation and ambiguous feature mapping, fostering the construction of high-quality, diverse robot datasets. (Source: HuggingFace Blog, LoubnaBenAllal1)
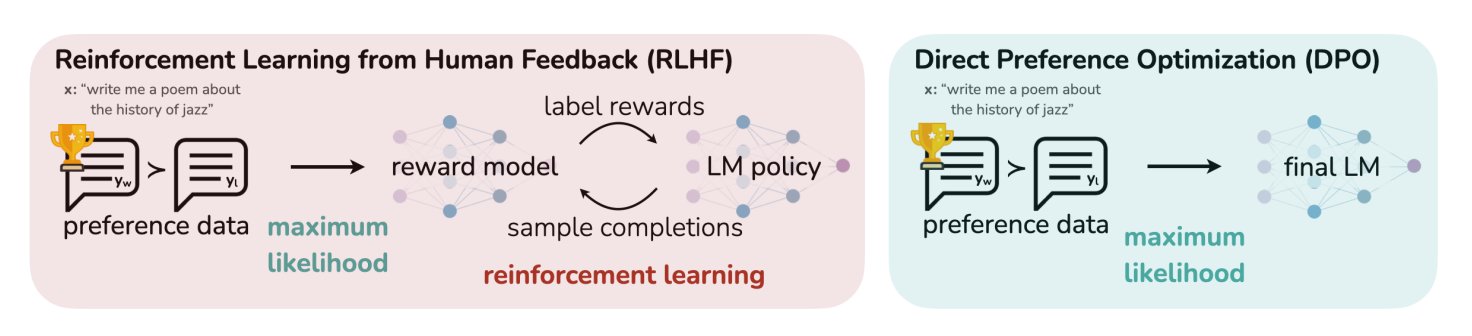
HuggingFace blog post summarizes 11 alignment and optimization algorithms for LLMs: TheTuringPost shared an article from HuggingFace that summarizes 11 alignment and optimization algorithms for Large Language Models (LLMs). These algorithms include PPO (Proximal Policy Optimization), DPO (Direct Preference Optimization), GRPO (Group Relative Policy Optimization), SFT (Supervised Fine-Tuning), RLHF (Reinforcement Learning from Human Feedback), and SPIN (Self-Play Fine-tuning), among others. The article provides links and more information on these algorithms, offering researchers and developers an overview of LLM optimization methods. (Source: TheTuringPost)
UC Berkeley shares CS280 graduate computer vision course materials: Professors Angjoo Kanazawa and Jitendra Malik from UC Berkeley have shared all lecture materials for their graduate computer vision course, CS280, which they taught this semester. They believe this set of materials, combining classic and modern computer vision content, worked well and have made it publicly available for learners. (Source: NandoDF)
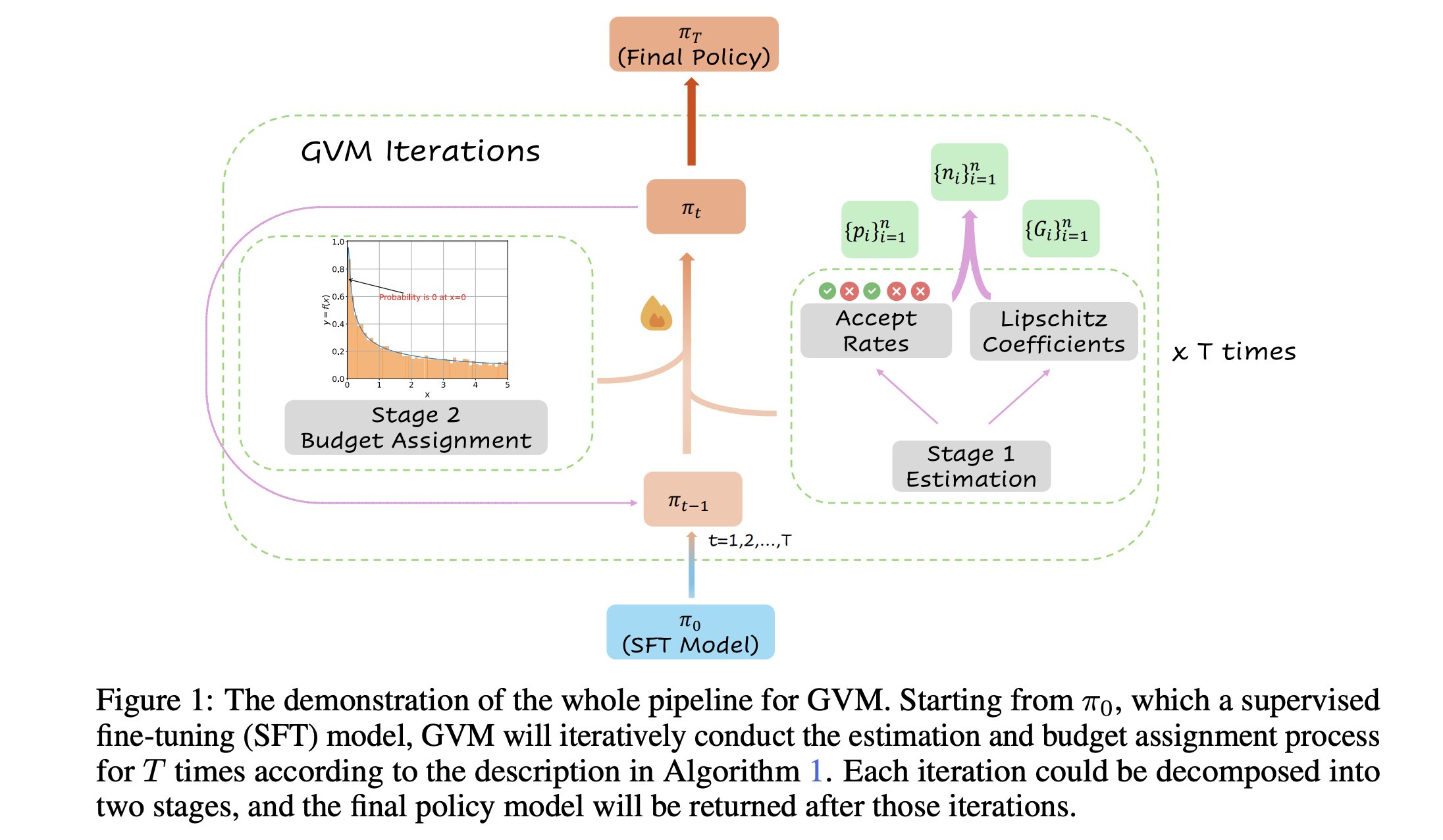
GVM-RAFT: A dynamic sampling framework for optimizing chain-of-thought reasoners: A new paper introduces the GVM-RAFT framework, which optimizes chain-of-thought reasoners by dynamically adjusting the sampling strategy for each prompt, aiming to minimize gradient variance. This method reportedly achieves a 2-4x speedup on mathematical reasoning tasks and improves accuracy. (Source: _akhaliq)
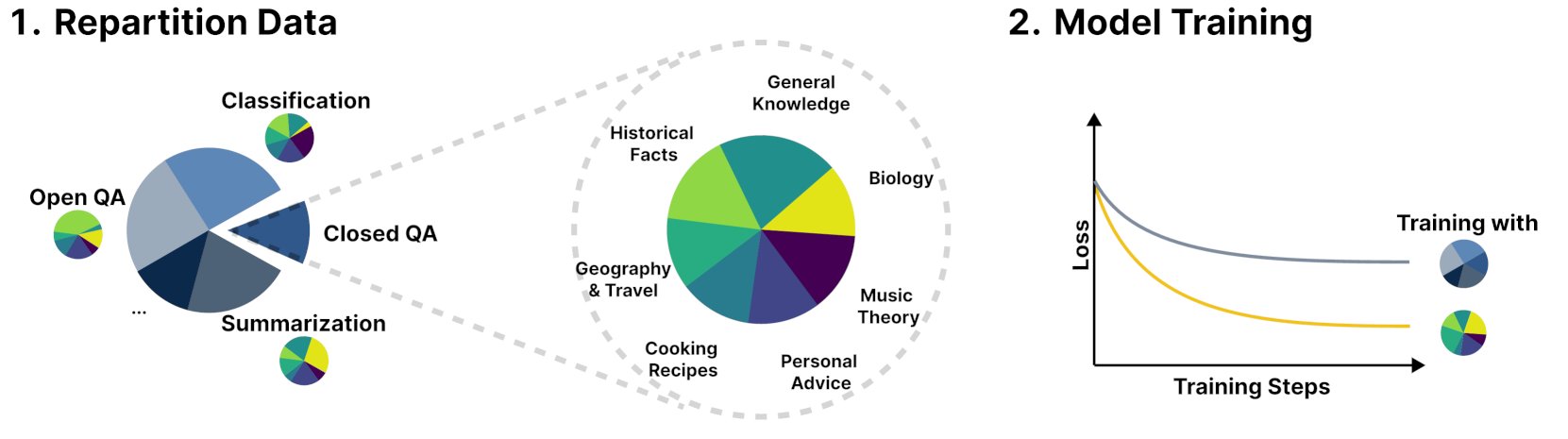
New framework R&B improves language model performance by dynamically balancing training data: A new study titled R&B proposes a novel framework that improves language model performance by dynamically balancing its training data, adding only 0.01% extra computational cost. This method aims to optimize data utilization efficiency, achieving improved model performance at a minimal cost. (Source: _akhaliq)
Paper discusses new perspective on AI safety: Viewing societal and technological progress as sewing a quilt: A new paper published on arXiv, “Societal and technological progress as sewing an ever-growing, ever-changing, patchy, and polychrome quilt,” proposes a new view of AI safety, advocating that the core focus of AI safety should be on preventing disagreements from escalating into conflicts. The paper likens societal and technological progress to sewing an ever-expanding, changing, patchy, and multicolored quilt, emphasizing the importance of maintaining stability and cooperation in complex systems. (Source: jachiam0)
Paper discusses adaptive computation in autoregressive language models: A discussion mentions the interesting aspect of adaptive computation in deep learning and lists related technological developments: PonderNet (DeepMind, 2021) as an early tool integrating neural networks and recurrence; diffusion models performing computation through multiple forward passes; and recent reasoning language models achieving similar effects by generating an arbitrary number of tokens. This reflects the trend towards flexibility and dynamism in how models allocate and use computational resources. (Source: jxmnop)
Paper explores how “bad data” can lead to “good models”: A 2025 Harvard paper titled “When Bad Data Leads to Good Models” (arXiv:2505.04741) explores how, in some cases, seemingly low-quality data (such as pre-training data containing 4chan content) might actually help align models and hide their “power level,” leading to better performance. This has sparked discussions about data quality, model alignment, and the authenticity of model behavior. (Source: teortaxesTex)

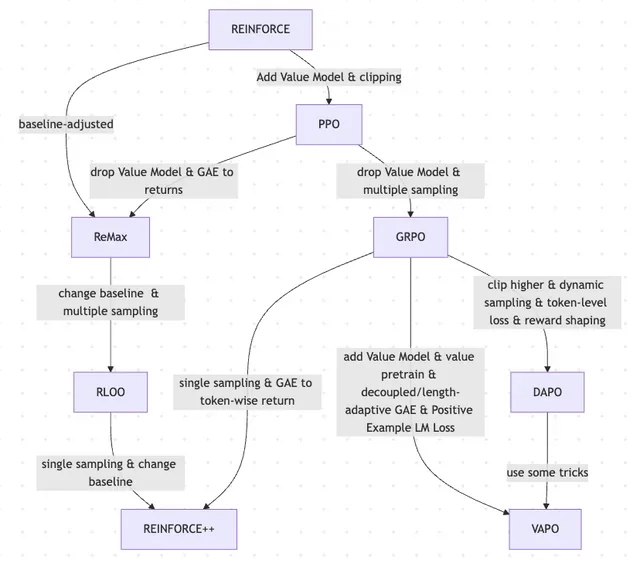
Paper discusses the evolution of RLHF and its variants, from REINFORCE to VAPO: A research article summarizes the evolutionary trajectory of reinforcement learning (RL) methods used for fine-tuning large language models (LLMs). The article traces the evolution from classic algorithms like PPO and REINFORCE to recent methods such as GRPO, ReMax, RLOO, DAPO, and VAPO, analyzing the abandonment of value models, changes in sampling strategies, adjustments to baselines, and the application of techniques like reward shaping and token-level loss. The study aims to clearly present the research landscape of RLHF and its variants in the field of LLM alignment. (Source: Reddit r/MachineLearning)
Paper “Absolute Zero”: AI performs reinforced self-play reasoning with zero human data: A white paper titled “Absolute Zero: Reinforced Self-Play Reasoning with Zero Data” (arXiv:2505.03335) explores new methods for training logical AI. Researchers trained logical AI models without using human-labeled datasets; the models can generate reasoning tasks, solve problems, and verify solutions through code execution. This has sparked discussions about whether AI can, in a pristine environment completely devoid of prior knowledge (such as mathematics, physics, language), invent symbolic representations, define logical structures, develop numerical systems, and build causal models from scratch, as well as the potential and risks of such “alien intelligence.” (Source: Reddit r/ArtificialInteligence, Reddit r/artificial)
Fudan University Intelligent Human-Computer Interaction Lab recruiting Master’s and PhD students for 2026 intake: The Intelligent Human-Computer Interaction Lab at the School of Computer Science and Technology, Fudan University, is recruiting Master’s and PhD students for the 2026 summer camp/recommendation admission. Led by Professor Shang Li, the lab’s research directions include wearable AGI (MemX smart glasses combined with LLM), open-source embodied intelligence, model compression (from large to small), and machine learning systems (such as ML compilation optimization, AI processors). The lab is dedicated to exploring human-centered intelligence, integrating large models with intelligent wearables and embodied intelligent systems in new paradigms of human-computer interaction. (Source: WeChat)

💼 Business
Overview of 10 AI startups valued over $1 billion with fewer than 50 employees: Business Insider has listed 10 AI startups valued at over $1 billion but with fewer than 50 employees. These include Safe Superintelligence (valued at $32 billion, 20 employees), OG Labs (valued at $2 billion, 40 employees), Magic (valued at $1.58 billion, 20 employees), Sakana AI (valued at $1.5 billion, 28 employees), among others. These companies demonstrate the potential in the AI field for small teams to achieve high valuations, reflecting the high value of technology and innovation in the capital market. (Source: hardmaru)
Fourier Intelligence deepens presence in elderly care, partners with Shanghai International Medical Center to build embodied intelligence rehabilitation base: Embodied intelligence unicorn Fourier Intelligence announced at its first Embodied Intelligence Ecosystem Summit that it will cooperate with Shanghai International Medical Center to jointly promote the application of embodied intelligent robots in rehabilitation medical scenarios. This includes standards construction, solution co-creation, and scientific research, as well as building the first domestic embodied intelligence rehabilitation demonstration base. Fourier Intelligence founder Gu Jie proposed the core strategy for the next decade as “based on elderly care and rehabilitation, focusing on interaction, serving people,” emphasizing that medical rehabilitation is its foundation. Since its establishment in 2015, the company has gradually expanded from rehabilitation robots to general-purpose humanoid robots GR-1 and GRx series, with hundreds of units shipped cumulatively. (Source: 36Kr)
Meta reportedly recruiting former Pentagon officials, potentially strengthening military sector presence: According to Forbes, Meta is recruiting former Pentagon officials, a move that could signify the company’s plans to strengthen its business in military technology or defense-related fields. This development has sparked discussion and concern about the involvement of large tech companies in military applications. (Source: Reddit r/artificial)

🌟 Community
Andrej Karpathy’s proposal of a missing “System Prompting Learning” paradigm in LLMs sparks heated discussion: Andrej Karpathy believes that current LLM learning is missing an important paradigm, which he calls “System Prompting Learning.” He points out that pre-training is for knowledge, and fine-tuning (supervised/reinforcement learning) is for habitual behavior, both involving parameter changes, but a large amount of human interaction and feedback seems underutilized. He likens it to giving the protagonist of “Memento” a notepad to store global problem-solving knowledge and strategies. This view has sparked widespread discussion, with some believing it is similar to the philosophy of DSPy, or involves memory/optimization, continuous learning problems, and exploring how to implement similar mechanisms in Langgraph. (Source: lateinteraction, hwchase17, nrehiew_, tokenbender, lateinteraction, lateinteraction)
AI companies asking job applicants not to use AI for applications sparks debate: AI companies like Anthropic requesting job applicants not to use AI tools when writing job applications (such as resumes) has sparked community discussion. Some recruiters stated that AI-generated resumes often result in “word salad,” and even experienced professionals might lose focus because of it. However, some applicants believe AI can help them better tailor their resumes to job requirements, highlight skills, and improve readability. The discussion also extended to platforms like LinkedIn being flooded with AI-generated content and whether other methods, like video, should be used to evaluate applicants. (Source: Reddit r/artificial, Reddit r/ArtificialInteligence)

“Identifiability” of AI-generated content sparks discussion, users find it easy to detect: Community discussions indicate that content generated by AI (especially ChatGPT) is easily identifiable, not just because of specific punctuation (like em dashes) or sentence structures (like “That’s not x; that’s y.”), but more so due to its characteristic “rhythm” and “flatness.” Once AI traces are identified, the content appears inauthentic and lacks personality. Users reported encountering such instances in emails, social media posts, and even video games, believing that directly using AI to generate entire content leads to blandness and insincerity, and suggest users should use AI as a tool for modification and personalization. (Source: Reddit r/ChatGPT)
AI development shows “honeymoon-backlash” cycle, reflecting human preference for authenticity: Some argue that the emergence of new generative AI models (text, image, music, etc.) is often accompanied by a “honeymoon period” where people are amazed by their capabilities. However, soon after, when people start to recognize the “patterns” or “traces” of AI generation, a backlash occurs, shifting from praise to skepticism, even deeming it “soulless.” This phenomenon of quickly learning to identify AI works and preferring flawed human creations may imply that AI is more of an auxiliary tool rather than a complete replacement for human creators, as people value the story, authorial intent, and authenticity behind works. (Source: Reddit r/ArtificialInteligence)
Anthropic’s internal AI code generation rate exceeds 70%, sparking thoughts of AI self-iteration: Anthropic’s Mike Krieger revealed that over 70% of pull requests within the company are now generated by AI. This data has sparked community discussion, with some imagining scenarios of machines self-editing and improving, similar to plots in science fiction. At the same time, some have expressed doubts about the authenticity and specific meaning of this data (e.g., the complexity of these PRs). (Source: Reddit r/ClaudeAI)

Nvidia CEO Jensen Huang emphasizes company-wide adoption of AI agents, AI will reshape developer roles: Nvidia CEO Jensen Huang stated that the company will equip all employees with AI assistants, and AI agents will be embedded in daily development to optimize code, discover vulnerabilities, and accelerate prototype design. He believes that in the future, everyone will command multiple AI assistants, leading to exponential growth in productivity. Meta CEO Mark Zuckerberg, Microsoft CEO Satya Nadella, and others hold similar views, believing AI will handle most coding tasks, and the role of developers will shift to “directing AI” and “defining requirements.” This trend indicates a significant change in the software development lifecycle, with AI programming tools like GitHub Copilot and Cursor becoming widespread. (Source: WeChat)

Discussion: Is it feasible for ML researchers to read 1000-2000 papers annually?: There’s a community discussion about top machine learning researchers potentially reading nearly 2000 papers a year. In response, some comment that the number of papers read is just a proxy metric; what truly matters is the ability to filter signals from vast amounts of information, extract useful insights, and apply them correctly. The ability to keep up with highlights and trends in the field and delve into specific content when needed is a key skill for this century. (Source: torchcompiled)
Discussion: Buying GPUs vs. renting GPUs for model training/fine-tuning: Machine learning practitioners face the choice of buying or renting GPU resources. Experienced individuals suggest a hybrid strategy: configuring a decent consumer-grade GPU locally for small experiments, and renting cloud GPUs for large-scale training tasks. The choice depends on model complexity, data volume, and budget. Cloud GPUs offer advantages in ML Ops organization, but at the same price point, common cloud GPUs like T4s may not perform as well as high-end consumer cards (e.g., 3090/4090), though the cloud can provide top-tier GPUs like A100/H100 with larger VRAM. (Source: Reddit r/MachineLearning)
💡 Other
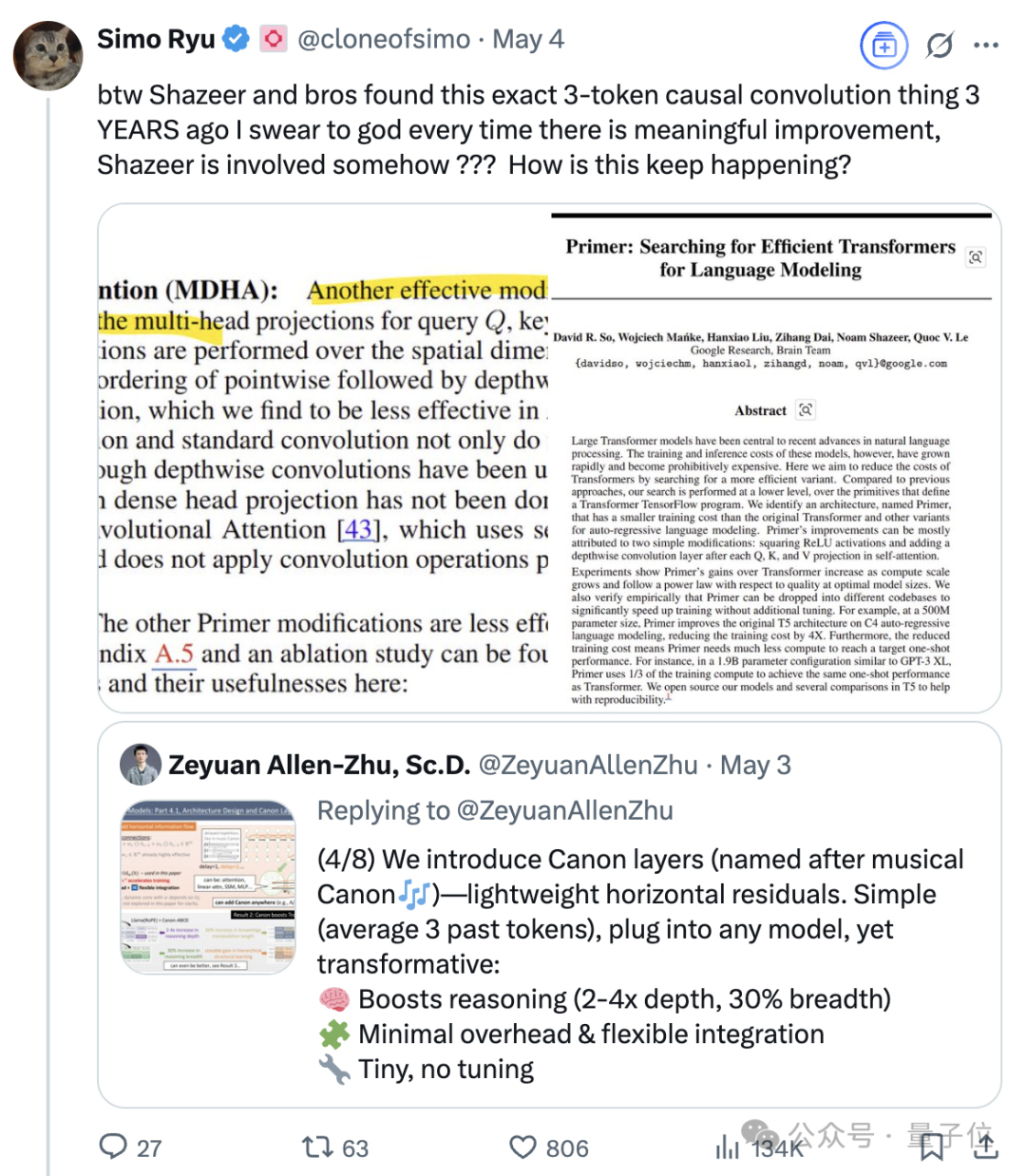
The enduring influence of Noam Shazeer, one of the eight authors of Transformer: Noam Shazeer, one of the eight authors of the Transformer architecture paper “Attention Is All You Need,” is widely considered to have made the largest contribution. His influence extends far beyond this, including early research introducing sparsely-gated Mixture of Experts (MoE) to language models, the Adafactor optimizer, Multi-Query Attention (MQA), and Gated Linear Units (GLU) in Transformers. These works laid the foundation for current mainstream large language model architectures, making Shazeer a key figure continuously defining technological paradigms in AI. He left Google to co-found Character.AI, and later returned to Google with the company’s acquisition, co-leading the Gemini project. (Source: WeChat)
Tech giants face AI-induced “midlife crisis”: An article analyzes that the “Big Tech Seven,” including Google, Apple, Meta, and Tesla, are facing disruptive challenges brought by artificial intelligence, plunging them into a “midlife crisis.” Google’s search business is threatened by AI’s direct Q&A model, Apple is progressing slowly in AI innovation, Meta is trying to integrate AI into social media but Llama 4’s performance fell short of expectations, and Tesla is facing declining sales and stock prices. These former industry leaders, like cases in “The Innovator’s Dilemma,” need to cope with the impact of new markets and models brought by AI, or risk becoming the “Nokia” of the AI era. (Source: WeChat)

Google AI outperforms human doctors in simulated medical dialogues: Research shows that an AI system trained to conduct medical interviews matched or even surpassed human doctors in conversing with simulated patients and listing possible diagnoses based on medical history. Researchers believe such AI systems have the potential to help democratize and universalize access to healthcare services. (Source: Reddit r/ArtificialInteligence)
