
Keywords:OpenAI, AI chips, large models, reinforcement learning, AI infrastructure, multimodal AI, agents, RAG, OpenAI national-level AI initiative, NVIDIA H20 chip export controls, DeepSeek-R1 inference optimization, AI optical microscope Meta-rLLS-VSIM, ByteDance Seed-Coder code large model
🔥 Focus
OpenAI launches “National AI” initiative, aiding global AI infrastructure development: OpenAI has initiated the “OpenAI for Countries” project, part of its “Stargate” program, aimed at assisting nations in establishing local AI data centers, customizing ChatGPT, and fostering AI ecosystem development. CEO Sam Altman has conducted a site visit to the first supercomputing campus in Abilene, Texas, which is part of the $500 billion “Stargate” project intended to create the world’s largest AI training facility. This move signifies OpenAI’s collaboration with multiple governments to promote the global popularization and application of AI technology through infrastructure construction and technology sharing, with an initial plan to partner with 10 countries or regions (Source: WeChat)

Trump administration reportedly plans to abolish three-tiered AI chip export restrictions, may adopt a simpler global licensing system: According to foreign media reports, the Trump administration plans to revoke the “Framework for AI Proliferation and Diffusion” (FAID) established in the late Biden era, which originally imposed three-tiered classification restrictions on global AI chip exports. The Trump team believes the framework is overly cumbersome and hinders innovation, favoring a simpler global licensing system to be enforced through intergovernmental agreements. This move could impact the global market strategies of chip manufacturers like NVIDIA and aims to consolidate U.S. innovation and dominance in the AI field (Source: WeChat)

SGLang team significantly optimizes DeepSeek-R1 inference performance, boosting throughput 26-fold: A joint team from SGLang, NVIDIA, and other institutions, through a comprehensive upgrade of the SGLang inference engine, has increased the inference performance of the DeepSeek-R1 model on H100 GPUs by 26 times within four months. Optimization solutions include Precomputation and Decoding separation (PD separation), large-scale Expert Parallelism (EP), DeepEP, DeepGEMM, and Expert Parallel Load Balancer (EPLB). When processing 2000-token input sequences, it achieved a throughput of 52.3k input tokens and 22.3k output tokens per second per node, approaching DeepSeek’s official data and significantly reducing local deployment costs (Source: WeChat)

OpenAI Scientist Dan Roberts: Scaling Reinforcement Learning will drive AI to discover new science, potentially achieving Einstein-level AGI in 9 years: OpenAI research scientist Dan Roberts, speaking at Sequoia Capital’s AI Ascent, discussed the core role of Reinforcement Learning (RL) in future AI model construction. He believes that by continuously scaling RL, AI models can not only improve performance on tasks like mathematical reasoning but also achieve scientific discovery through “test-time computation” (i.e., the longer a model thinks, the better it performs). Citing Einstein’s discovery of general relativity as an example, he speculated that if AI could compute and think for up to 8 years, it might achieve Einstein-level scientific breakthroughs in 9 years. Roberts emphasized that future AI development will focus more on RL computation, potentially even dominating the entire training process (Source: WeChat)

🎯 Trends
NVIDIA’s Jim Fan: Robots will pass a “Physical Turing Test,” simulation and generative AI are key: Jim Fan, head of NVIDIA’s robotics division, proposed the concept of a “Physical Turing Test” at Sequoia AI Ascent, where humans cannot distinguish if a task is performed by a human or a robot. He pointed out that current robot data acquisition is costly, making simulation technology crucial, especially when combined with generative AI (such as fine-tuning video generation models) to create diverse, large-scale training data (“digital cousins” rather than precise “digital twins”). He predicts that through large-scale simulation and vision-language-action models (like NVIDIA’s GR00T), physical APIs will become ubiquitous in the future, enabling robots to perform complex daily tasks and integrate seamlessly with ambient intelligence (Source: WeChat)
ByteDance releases Seed-Coder series of large code models, 8B version shows superior performance: ByteDance has launched the Seed-Coder series of large code models, including 8B, 14B, and other versions. Among them, Seed-Coder-8B has demonstrated outstanding performance on several code capability benchmarks such as SWE-bench, Multi-SWE-bench, and IOI, reportedly outperforming Qwen3-8B and Qwen2.5-Coder-7B-Inst. The series includes Base, Instruct, and Reasoner versions, with the core idea of “letting code models curate data for themselves,” showing significant improvements in code reasoning and software engineering capabilities. The models have been open-sourced on Hugging Face and GitHub (Source: Reddit r/LocalLLaMA, karminski3, teortaxesTex)
Alibaba open-sources ZeroSearch framework, reducing AI training costs by 88% using LLM-simulated search: Alibaba researchers have released a reinforcement learning framework called “ZeroSearch,” which allows Large Language Models (LLMs) to develop advanced search functionalities by simulating search engines, without needing to call expensive commercial search engine APIs (like Google) during training. Experiments show that using a 3B LLM as a simulated search engine can effectively enhance the policy model’s search capabilities, with a 14B parameter retrieval module even outperforming Google Search, while reducing API costs by 88%. The technology has been open-sourced on GitHub and Hugging Face, supporting model series like Qwen-2.5 and LLaMA-3.2 (Source: WeChat)

Gemini API introduces implicit caching, saving up to 75% on costs: Google’s Gemini API recently enabled implicit caching for its Gemini 2.5 model series (Pro and Flash). When user requests hit the cache, costs can be automatically saved by up to 75%. Concurrently, the minimum token requirement to trigger caching has been lowered: to 1K tokens for the 2.5 Flash model and 2K tokens for the 2.5 Pro model. This initiative aims to reduce developer costs for using the Gemini API and improve efficiency for frequent, repetitive requests (Source: JeffDean)
Tsinghua University develops AI optical microscope Meta-rLLS-VSIM, improving volumetric resolution 15.4-fold: Tsinghua University’s Li Dong research group, in collaboration with Dai Qionghai’s team, proposed the Meta-learning-driven reflected Lattice Light-Sheet Virtual Structured Illumination Microscopy (Meta-rLLS-VSIM). This system, through AI and optical cross-innovation, enhances the lateral resolution of live-cell imaging to 120nm and axial resolution to 160nm, achieving near-isotropic super-resolution and a 15.4-fold improvement in volumetric resolution compared to traditional LLSM. Key technologies include using a DNN to learn and extend super-resolution capabilities to multiple directions via “virtual structured illumination,” and enhancing axial resolution through mirror-reflected dual-view information fusion and an RL-DFN network. The introduction of a meta-learning strategy allows the AI model to complete adaptive deployment in just 3 minutes, greatly lowering the barrier for AI application in biological experiments and providing a powerful tool for observing life processes such as cancer cell division and embryonic development (Source: WeChat)

Qwen3 series of large models released, continuing to lead the open-source community: Alibaba has released the Qwen3 series of large language models, with parameter sizes ranging from 0.5B to 235B. They exhibit excellent performance on multiple benchmarks, with several smaller models achieving SOTA (state-of-the-art) levels among open-source models of similar scale. The Qwen3 series supports multiple languages and context lengths up to 128k tokens. Due to its strong performance and lower deployment costs (compared to models like DeepSeek-R1), the Qwen series has been widely adopted overseas (especially in Japan) as a foundation for AI development, spawning numerous domain-specific models. The release of Qwen3 further solidifies its leading position in the global open-source AI community, with its GitHub repository gaining over 20,000 stars in a week (Source: dl_weekly, WeChat)

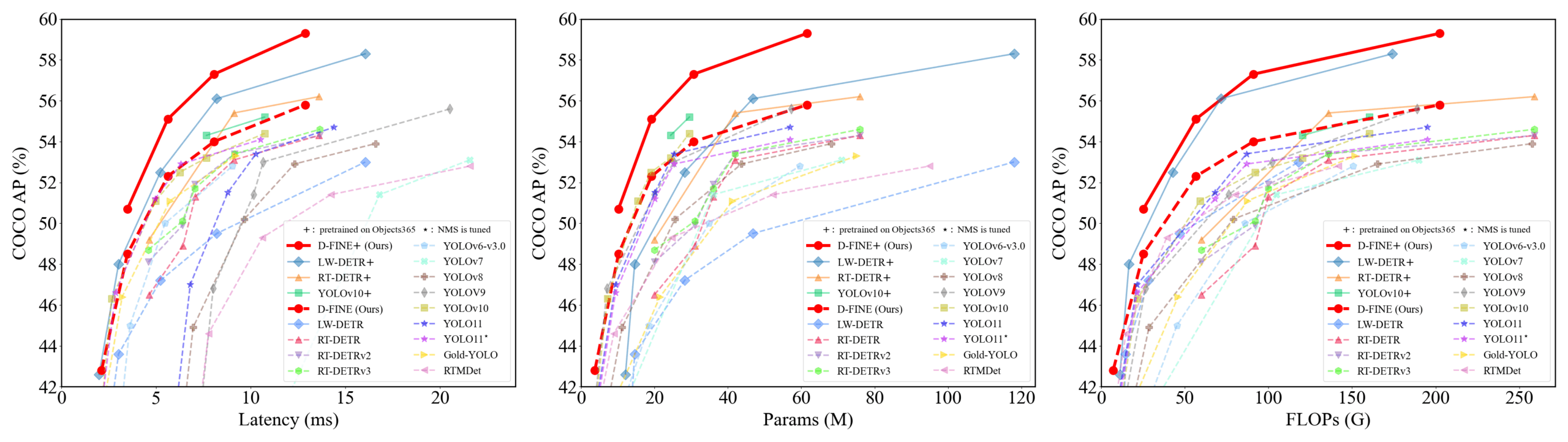
D-FINE: Real-time object detector based on fine-grained distribution refinement, achieving superior performance: Researchers have proposed D-FINE, a novel real-time object detector that redefines the bounding box regression task in DETR as Fine-grained Distribution Refinement (FDR) and introduces a Global Optimal Localization Self-Distillation (GO-LSD) strategy. D-FINE achieves excellent performance without increasing additional inference or training costs. For example, D-FINE-N achieves 42.8% AP on COCO val at 472 FPS (T4 GPU); D-FINE-X, after pre-training on Objects365+COCO, reaches 59.3% AP on COCO val. The method achieves finer localization by iteratively refining probability distributions and transfers localization knowledge from the final layer to earlier layers through self-distillation (Source: GitHub Trending)
Harmon model coordinates visual representations, unifying multimodal understanding and generation: Researchers from Nanyang Technological University have proposed the Harmon model, which aims to unify multimodal understanding and generation tasks by sharing a MAR Encoder (Masked Autoencoder for Reconstruction). The study found that the MAR Encoder can simultaneously learn visual semantics during image generation training, with its Linear Probing results far exceeding VQGAN/VAE. The Harmon framework utilizes the MAR Encoder to process complete images for understanding and follows the MAR masked modeling paradigm for image generation, with an LLM facilitating modal interaction. Experiments show that Harmon approaches Janus-Pro on multimodal understanding benchmarks and performs excellently on text-to-image aesthetic benchmark MJHQ-30K and instruction-following benchmark GenEval, even surpassing some expert models. The model has been open-sourced (Source: WeChat)

PushInfo Tech achieves commercial viability for logistics robots, accumulating data via “Rider Shadow System”: PushInfo Tech’s logistics robots are now in practical operation in several Chinese cities, achieving break-even for individual robots by working alongside human delivery riders. One of its core technologies is the “Rider Shadow System,” which collects driving behavior, environmental perception, and operational data (such as opening/closing doors, picking/placing items) from real riders in complex urban environments. This provides massive, high-quality imitation learning and reinforcement learning training data for the robots. The system has currently accumulated tens of millions of kilometers of driving data and nearly a million upper limb trajectory data points. Based on this, PushInfo Tech has trained a behavior tree VLA model, enabling robots to handle complex real-world situations, and plans to expand into overseas markets (Source: WeChat)

Kuaishou launches KuaiMod framework, optimizing short video ecosystem with multimodal large models: Kuaishou has proposed KuaiMod, a short video platform ecosystem optimization solution based on multimodal large models, aiming to improve user experience by automating content quality assessment. KuaiMod draws inspiration from case law, utilizing the chain-of-thought reasoning of Vision Language Models (VLMs) to analyze low-quality content and continuously updating assessment strategies through Reinforcement Learning from User Feedback (RLUF). The framework has been deployed on the Kuaishou platform, effectively reducing user complaint rates by over 20%. Kuaishou is also committed to building multimodal large models capable of understanding community short videos, moving from feature extraction to deep semantic understanding, and has achieved positive results in applications such as structuring video interest tags and content generation assistance (Source: WeChat)

Lenovo unveils “Tianxi” personal super intelligent agent, advancing towards L3 intelligence: At its Innovation and Technology Conference, Lenovo launched the “Tianxi” personal super intelligent agent, featuring multimodal perception and interaction, cognition and decision-making based on a personal knowledge base, and autonomous complex task decomposition and execution. Tianxi aims to provide a natural and seamless human-computer collaboration experience through companion AUI interfaces like AI Suixin Chuang (AI Freestyle Window), AI Linglong Tai (AI Exquisite Console), and AI Ruying Kuang (AI As-You-Wish Frame). It integrates multiple industry-leading large models, including DeepSeek-R1, and employs an edge-cloud hybrid deployment architecture. Combined with Lenovo Personal Cloud 1.0 (equipped with a 72-billion-parameter large model), it offers powerful computing capabilities and 100GB of dedicated memory space. Lenovo also released enterprise-level “Lexiang” and city-level super intelligent agents, showcasing its comprehensive layout in the AI field (Source: WeChat)

New research judges neural network generalization by symbolic interaction complexity: Professor Zhang Quanshi’s team at Shanghai Jiao Tong University has proposed a new theory to analyze the generalization ability of neural networks from the perspective of the complexity of their internal symbolic interaction representations. The study found that generalizable interactions (appearing frequently in both training and test sets) typically exhibit a decaying distribution across different orders (complexity), with low-order interactions predominating. In contrast, non-generalizable interactions (mainly appearing in the training set) show a spindle-shaped distribution, with mid-order interactions being dominant and positive/negative effects easily canceling out. This theory aims to directly assess a model’s generalization potential by analyzing the distribution patterns of its equivalent “AND-OR interaction logic,” offering a new perspective for understanding and improving model generalization (Source: WeChat)
🧰 Tools
Llama.cpp now fully compatible with Vision Language Models (VLM): Llama.cpp now fully supports Vision Language Models (VLMs), enabling developers to run multimodal applications on-device. Julien Chaumond and others from Hugging Face have shared pre-quantized models, including Google DeepMind’s Gemma, Mistral AI’s Pixtral, Alibaba’s Qwen VL, and Hugging Face’s SmolVLM, which can be used directly. This update, thanks to contributions from the @ngxson and @ggml_org teams, opens new possibilities for localized, low-latency multimodal AI applications (Source: ggerganov, ClementDelangue, cognitivecompai)
Quark AI Super Box upgrades “Deep Search” to enhance AI “Search Quotient”: Quark’s AI Super Box recently upgraded to include a “Deep Search” feature, aimed at improving the AI’s search quotient (SQ). The new function emphasizes proactive thinking and logical planning by the AI before searching, enabling it to better understand complex and personalized user query intents, break down problems, and perform structured intelligent retrieval. In the health domain, Quark’s AI health advisor “A-Qua” references opinions from top-tier hospital doctors and professional materials; in academia, it accesses authoritative sources like CNKI. Additionally, Quark possesses strong multimodal processing capabilities, such as image analysis, AI background removal, image enhancement, and style transfer. It is reported that Quark will also release a Deep Search Pro version with Deep Research capabilities in the future (Source: WeChat)

LangChain launches multiple integrations and tutorials to enhance RAG and agent capabilities: LangChain recently released several updates and tutorials: 1. Social Media Agent UI Tutorial: Guides on how to transform LangChain social media agents into user-friendly web applications, integrating ExpressJS and AgentInbox UI, with Notion support. 2. Award-Winning RAG Solution: Showcases an RAG implementation for analyzing company annual reports, supporting PDF parsing, multiple LLMs, and advanced retrieval. 3. Private RAG Chat App: Tutorial demonstrates building a localized, data-privacy-focused RAG chat application using LangChain and the Reflex framework. 4. Nimble Retriever Integration: Introduces a powerful web data retriever to provide precise data for LangChain applications. 5. Claude 3.7 Structured Output Guide: Offers three methods for achieving structured output with Claude 3.7 via LangChain and AWS Bedrock. 6. Local Chat RAG System: Open-source project demonstrates a fully localized document Q&A system built with LangChain RAG pipeline and local LLMs (via Ollama), ensuring data privacy (Source: LangChainAI, LangChainAI, LangChainAI, LangChainAI, LangChainAI, LangChainAI)

Minion-agent: An open-source AI agent framework integrating multi-framework capabilities: Minion-agent is a newly open-sourced AI agent development framework designed to address the fragmentation issues of existing AI frameworks (such as OpenAI, LangChain, Google AI, SmolaAgents). It provides a unified interface, supporting multi-framework capability calls, tools-as-a-service (web browsing, file operations, etc.), and multi-agent collaboration. The project showcases its potential in scenarios like in-depth research (automatically collecting literature to generate reports), price comparison (automated market research), creative generation (game code generation), and tracking technological trends, emphasizing the advantages of an open-source model in terms of flexibility and cost-effectiveness (Source: WeChat)

RunwayML demonstrates powerful video generation and editing capabilities across multiple scenarios: Independent AI researcher Cristobal Valenzuela and other users showcased RunwayML’s application in various creative scenarios. This includes utilizing its Frames, References, and Gen-4 features to rapidly generate and visualize creative visuals while maintaining style and character consistency; transforming Rembrandt’s world into an RPG video game; and achieving novel single-image interior design view synthesis by providing visual references. These examples highlight RunwayML’s advancements in controllable video generation, style transfer, and scene construction (Source: c_valenzuelab, c_valenzuelab, c_valenzuelab, c_valenzuelab)

Olympus: A universal task router for computer vision tasks: Olympus is a universal task router designed for computer vision tasks. It aims to simplify and unify the processing flow of different visual tasks, potentially by intelligently scheduling and allocating computing resources or model calls, to optimize the efficiency and performance of multi-task computer vision systems. The project has been open-sourced on GitHub (Source: dl_weekly)
Tracy Profiler: Real-time, nanosecond-level hybrid frame and sampling profiler: Tracy Profiler is a real-time, nanosecond-resolution, remote-telemetry-capable hybrid frame and sampling profiler for games and other applications. It supports performance analysis for CPU (C, C++, Lua, Python, Fortran, and third-party bindings for Rust, Zig, C#, etc.), GPU (OpenGL, Vulkan, Direct3D, Metal, OpenCL), memory allocations, locks, and context switches, and can automatically associate screenshots with captured frames. With its high precision and real-time capabilities, the tool provides developers with powerful means for performance bottleneck identification and optimization (Source: GitHub Trending)

FieldStation42: Retro broadcast television simulator: FieldStation42 is a Python project designed to simulate the viewing experience of old-fashioned broadcast television. It can support multiple channels simultaneously, automatically insert commercials and program promos, and generate a weekly program schedule based on configuration. The simulator randomly selects recently unplayed programs to maintain freshness, supports setting program playback date ranges (e.g., seasonal shows), and can be configured with station sign-off videos and no-signal loop screens. The project also supports hardware connections (like Raspberry Pi Pico) to simulate channel changing and offers a preview/guide channel feature. Its goal is that when a user “turns on the TV,” it plays “real” program content appropriate for that time slot and channel (Source: GitHub Trending)

Tiny Corp introduces USB3-based AMD eGPU solution for Apple Silicon: Tiny Corp demonstrated a solution for connecting an AMD eGPU to an Apple Silicon Mac via USB3 (specifically using an ADT-UT3G device based on the ASM2464PD controller). The solution involves rewritten drivers, aiming to utilize USB3’s 10Gbps bandwidth, and uses libusb, theoretically also supporting Linux or Windows. This offers a new way for Apple Silicon users to expand their graphics processing capabilities, particularly valuable for scenarios like running large AI models locally (Source: Reddit r/LocalLLaMA)
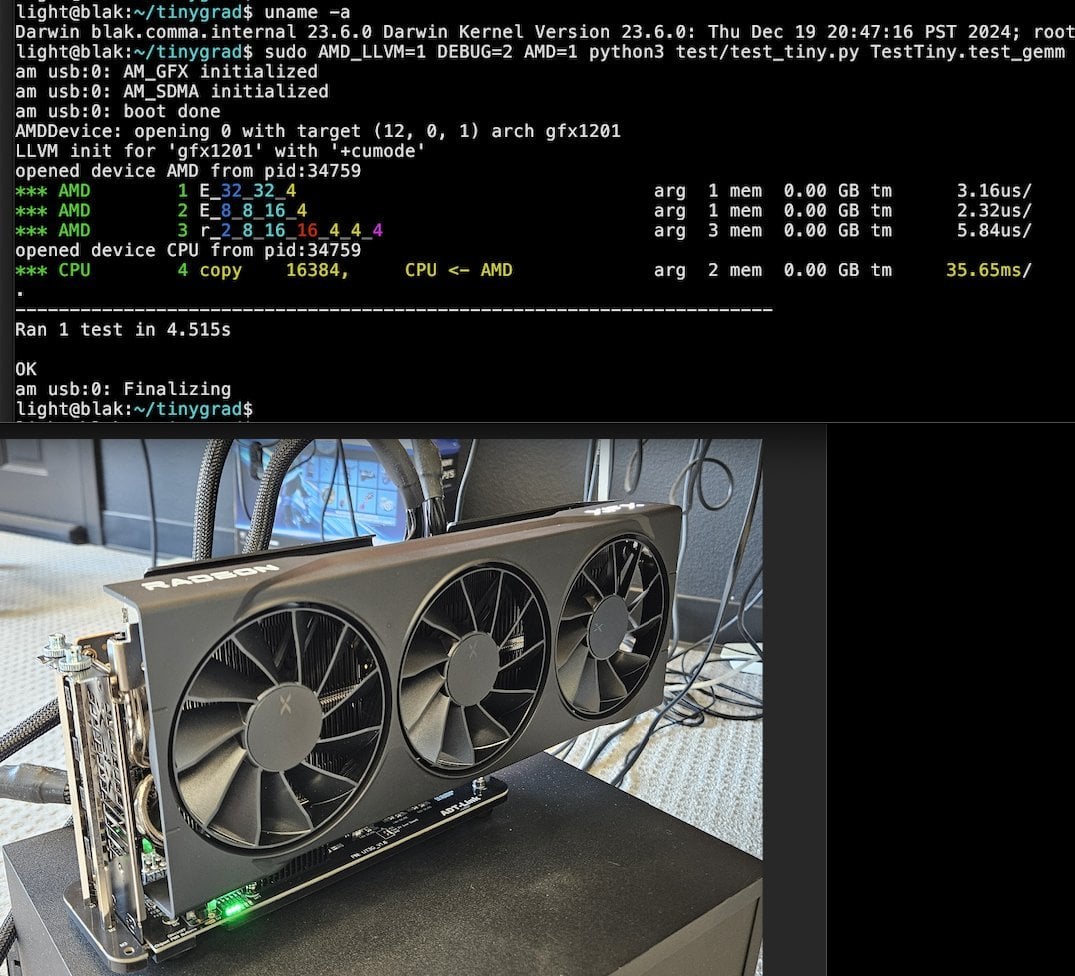
Llama.cpp-vulkan achieves FlashAttention support on AMD GPUs: The Vulkan backend for Llama.cpp recently merged an implementation of FlashAttention. This means users utilizing llama.cpp-vulkan on AMD GPUs can now leverage FlashAttention technology. Combined with Q8 KV cache quantization, users can potentially double their context size while maintaining or improving inference speed. This update is a significant benefit for AMD GPU users running large language models locally (Source: Reddit r/LocalLLaMA)
Devseeker: Lightweight AI coding assistant, an alternative to Aider and Claude Code: Devseeker is a newly open-sourced lightweight AI coding agent project, positioned as an alternative to Aider and Claude Code. It features capabilities such as creating and editing code, managing code files and folders, short-term code memory, code review, running code files, calculating token usage, and offering various coding modes. The project aims to provide a more easily deployable and user-friendly AI-assisted programming tool (Source: Reddit r/ClaudeAI)
📚 Learning
Panaversity launches Agentic AI learning program, focusing on Dapr and OpenAI Agents SDK: Panaversity has initiated the “Learn Agentic AI” project, aiming to cultivate agent and robotics AI engineers through the Dapr Agentic Cloud Ascent (DACA) design pattern and various agent-native cloud technologies (including OpenAI Agents SDK, Memory, MCP, A2A, Knowledge Graphs, Dapr, Rancher Desktop, Kubernetes). The project’s core focus is on designing systems capable of handling tens of millions of concurrent AI agents and offers AI-201, AI-202, and AI-301 course series, covering a learning path from basics to large-scale distributed AI agents. The project emphasizes that the OpenAI Agents SDK should become the mainstream development framework due to its ease of use and high controllability (Source: GitHub Trending)

RL fine-tuning study reveals complex relationship between data management and generalization: A paper shared by Minqi Jiang discusses the impact of data management in Reinforcement Learning (RL) fine-tuning on model generalization. The study found that whether training on “infinite” coding tasks via self-play curriculum learning (Absolute Zero Reasoner) or repeatedly training on a single MATH task sample (1-shot RLVR), 7B scale Qwen2.5 series models achieved an accuracy improvement of about 28% to 40% on math benchmarks. This reveals a paradox: extreme data management strategies (infinite data vs. single-point data) can yield similar generalization improvements. Possible explanations include RL primarily eliciting pre-trained capabilities, the existence of shared “reasoning circuits,” and pre-training potentially leading to competitive reasoning circuits. Researchers believe that to break the “pre-training ceiling,” continuous collection and creation of new tasks and environments are necessary (Source: menhguin)
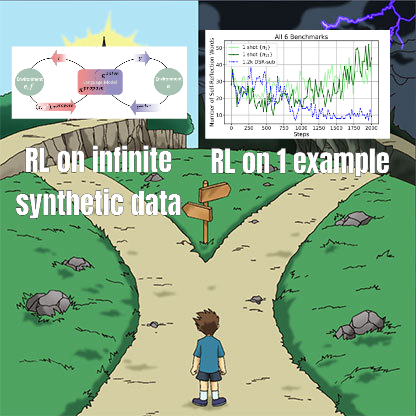
Absolute Zero Reasoner: Achieving zero-data reasoning capability improvement through self-play: A paper titled “Absolute Zero Reasoner” proposes that models can learn to propose tasks that maximize learnability through complete self-play, and improve their own reasoning abilities by solving these tasks, all without any external data. This method outperforms other “zero-shot” models in both mathematics and coding domains. This suggests that AI systems might be able to continuously evolve their reasoning capabilities through internal problem generation and solving, offering new approaches for AI applications in data-scarce or high-annotation-cost fields (Source: cognitivecompai, Reddit r/LocalLLaMA)

Common mistakes and best practices in AI product evaluation shared: Hamel Husain and Shreya Runwal shared common mistakes made when creating AI product evaluations (evals) and provided advice on how to avoid them. Key points include: base model benchmarks do not equal application evaluations; generic evals are ineffective and need to be application-specific; do not outsource annotation and prompt engineering to non-domain experts; build your own data annotation applications; LLM prompts should be specific and based on error analysis; use binary labels; prioritize data review; beware of overfitting to test data; conduct online testing. These practices aim to help developers build more reliable AI product evaluation systems that better reflect real-world performance (Source: jeremyphoward, HamelHusain)
New approach to KV cache optimization: Universal transferable dictionary and signal processing reconstruction: Dimitris Papailiopoulos’s team at the University of Wisconsin-Madison proposed a new method to reduce KV cache by using a universal, transferable dictionary combined with traditional signal processing reconstruction algorithms. This method has achieved SOTA (state-of-the-art) levels on non-inference models and is expected to perform even better on inference models. This research, accepted at ICML, offers a new perspective and technical path for addressing the issue of high KV cache occupancy in large model inference (Source: teortaxesTex, jeremyphoward, arohan, andersonbcdefg)

Qdrant promotes RAG systems and hybrid search practices in the Brazilian community: Qdrant vector database is gaining increasing attention in the Brazilian community. Developer Daniel Romero shared two Portuguese articles introducing practical methods for building RAG (Retrieval Augmented Generation) systems using Qdrant, FastAPI, and hybrid search. The content includes how to set up a hybrid search RAG system and data ingestion strategies for RAG, particularly Hybrid Chunking technology. These shares help Brazilian developers better utilize Qdrant for AI application development (Source: qdrant_engine)
OpenAI Academy launches K-12 education Prompt Engineering series: OpenAI Academy has released a Prompt Engineering learning series “Mastering Your Prompts” for K-12 educators. The series aims to help educators better understand and apply prompting techniques to more effectively integrate AI tools (like ChatGPT) into teaching practices, enhancing teaching effectiveness and student learning experiences. This indicates that AI-assisted education is gradually permeating basic education and emphasizes cultivating AI literacy among educators (Source: dotey)
Yann LeCun shares content of his lecture at the National University of Singapore: Yann LeCun shared the PDF document of his Distinguished Lecture delivered at the National University of Singapore (NUS) on April 27, 2025 (likely a typo, should be a past date or future if it’s a planned event, but the source says “delivered”). While the specific topic of the lecture was not provided, LeCun, as a pioneer in deep learning, typically covers cutting-edge AI theories, future trends, or profound insights into current AI developments in his talks. This share provides a direct way for those interested in AI research to access his latest views (Source: ylecun)
PyTorch collaborates with Mojo backend to simplify new hardware and language adaptation: PyTorch is working to simplify the process of creating new backends for emerging programming languages and hardware. At a Mojo hackathon, marksaroufim showcased PyTorch’s efforts in this area and mentioned a WIP (work-in-progress) backend developed in collaboration with the Mojo team. This indicates that the PyTorch ecosystem is actively expanding its compatibility to support a more diverse range of AI development environments and hardware acceleration options, thereby lowering the barrier for developers to deploy and optimize PyTorch models on different platforms (Source: marksaroufim)
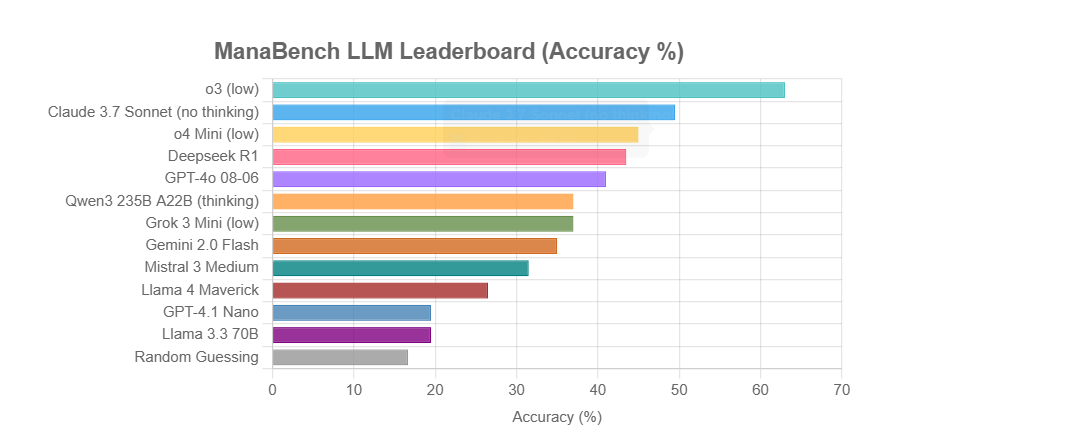
ManaBench: A novel LLM reasoning benchmark based on Magic: The Gathering deck-building: A developer has created a new benchmark called ManaBench, which tests the complex system reasoning capabilities of LLMs by having them select the most appropriate 60th card for a Magic: The Gathering (MTG) deck, given 59 cards and six options. The benchmark emphasizes strategic reasoning and system optimization, with answers designed to align with human expert choices, making it difficult to crack through simple memorization. Preliminary results show Llama series models underperforming, while closed-source models like o3 and Claude 3.7 Sonnet lead. The benchmark aims to more realistically evaluate LLM performance on tasks requiring complex reasoning (Source: Reddit r/LocalLLaMA)
Discussion: Will AI revive or bury the dream of the Semantic Web?: On social media, user Spencer mentioned that unless large enterprise websites have significant exposure due to the ADA (Americans with Disabilities Act), the Semantic Web is more theory than practice for most sites. Dorialexander responded, feeling that AI will either revive the dream of the Semantic Web or bury it forever. This reflects both anticipation and concern regarding AI’s potential in understanding and utilizing structured data. AI might indirectly achieve the goals of the Semantic Web by automatically understanding and generating structured information, but its own powerful capabilities could also render traditional Semantic Web technologies less important (Source: Dorialexander)
Researchers explore the ethics and architectures of model memory and forgetting: A draft paper titled “Sticky Minds: The Ethics and Architectures of AI Memory and Forgetting” is being written, exploring how we decide what models should forget when they start “remembering too well,” merging neural architectures with memory ethics. This involves how AI systems store, retrieve, and (selectively) forget information, and the resulting ethical challenges and societal impacts, which are crucial for building responsible and trustworthy AI (Source: Reddit r/artificial)
💼 Business
NVIDIA reportedly to launch a “further nerfed” H20 chip compliant with new US export controls: According to Reuters, NVIDIA plans to launch a new China-specific H20 AI chip within the next two months to comply with the latest US export control requirements. This chip will be further “nerfed” from the original H20 (itself already a downgraded version customized for the Chinese market), for example, by significantly reducing its memory capacity. Although performance will be reduced again, downstream users may reportedly be able to adjust performance to some extent by modifying module configurations. Currently, NVIDIA has received H20 orders worth $18 billion (Source: WeChat)

Databricks may acquire open-source database company Neon for $1 billion to strengthen AI infrastructure: Data and AI company Databricks is reportedly in talks to acquire Neon, an open-source PostgreSQL database engine developer, for a transaction potentially around $1 billion. Neon is characterized by its serverless architecture, separation of storage and compute, and good adaptability for AI Agents and ambient programming, allowing pay-as-you-go usage and rapid database instance startup, suitable for AI application scenarios. If successful, this acquisition would further enhance Databricks’ infrastructure layer capabilities in the AI era, providing it with a modern, AI-centric database solution (Source: WeChat)

OpenAI appoints former Instacart CEO Fidji Simo as CEO of Applications Business to strengthen product and commercialization: OpenAI announced the appointment of former Instacart CEO and company board member Fidji Simo as the newly created “Chief Executive Officer of Applications Business,” on par with Sam Altman. Simo will be fully responsible for OpenAI’s products, especially user-facing applications like ChatGPT, aiming to drive product optimization, user experience improvement, and commercialization. This move marks a significant shift in OpenAI’s strategic focus from model R&D to product platformization and market expansion, intending to build stronger competitiveness at the AI application layer. Simo’s extensive product and commercialization experience at Facebook and Instacart will help OpenAI navigate increasingly fierce market competition (Source: WeChat)

🌟 Community
JetBrains AI Assistant draws user dissatisfaction due to poor experience and comment management: JetBrains’ AI Assistant plugin, despite over 22 million downloads, has only a 2.3 out of 5-star rating on its marketplace, flooded with numerous 1-star negative reviews. Users commonly report issues such as automatic installation, slow performance, bugs, insufficient third-party model support, core features tied to cloud services, and missing documentation. Recently, JetBrains was accused of bulk-deleting negative comments. Although officials explained it as handling content that violated rules or addressed resolved issues, it still sparked user doubts about its comment control and disregard for user feedback, with some users choosing to re-post negative reviews and continue giving 1-star ratings. This incident has exacerbated user dissatisfaction with JetBrains’ AI product strategy (Source: WeChat)

Users discuss quality issues with AI marketing agent outputs: Social media user omarsar0 observed that many marketing AI agents showcased in YouTube tutorials produce marketing copy of generally poor quality, lacking creativity and style. He believes this reflects the difficulty in getting LLMs to produce high-quality, engaging content and emphasizes that “taste” is crucial when building AI agents. He pointed out that while many current AI agents have complex workflows, they still fall short in producing content with real commercial value, creating opportunities for talented individuals with good taste, extensive experience, and the ability to design effective evaluation systems (Source: omarsar0)
AI-assisted coding and “ambient programming” trends spark discussion: A Reddit post about a Y Combinator video discussing AI coding sparked heated debate. The video’s views highly resonated with the poster’s experience (who claims to have created multiple profitable projects through “ambient programming”). Key points include: 1. AI can already assist in building complex and usable software products, even without writing code. 2. Software engineers’ anxiety about AI replacing their jobs is growing, but those who master AI-assisted development possess “superpowers.” 3. The future role of software engineers may shift to “agent managers” кто are adept at using AI tools, with AI handling most of the code writing. 4. AI will spawn a large number of niche software products targeting specific market segments. Discussants believe that while AI coding has immense potential, knowledge of engineering concepts, databases, architecture, etc., is still necessary for effective utilization (Source: Reddit r/ClaudeAI)

Ongoing discussion about whether AI will “take over the world” and its impact on employment: Posts on the Reddit r/ArtificialInteligence board reflect the community’s widespread anxiety and diverse opinions about the future impact of AI. Some users believe that the deeper one’s understanding of AI capabilities, the greater the concern about it surpassing humans and dominating the future, pointing out that cutting-edge AI systems already exhibit astonishing abilities. Others argue that excessive hype about AGI has led to unrealistic expectations, and that AI is essentially an intelligent automation tool whose impact will be gradual, similar to computers and the internet. Discussions also touch upon AI’s potential impact on employment, wealth distribution, and the effectiveness of regulation. Some argue that history shows technological advancements often exacerbate wealth inequality, and AI might further concentrate wealth by eliminating numerous jobs. At the same time, others express hope for AI’s positive role in fields like healthcare and education (Source: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
User Experience: How AI tools like ChatGPT affect thinking and cognition: Some users on social platforms and Reddit shared the positive cognitive impacts of using AI tools like ChatGPT. They feel that AI is not just an information retrieval or writing aid, but more like a “thinking partner” or “mirror” that helps them clarify their thoughts and articulate subconscious ideas. By conversing with AI, users report being able to better reflect on and challenge their own beliefs, discover thought patterns, and even feel like they are “awakening” with a deeper understanding of life and systems. This experience suggests that AI, in some cases, can be a catalyst for personal growth and self-exploration (Source: Reddit r/ChatGPT)
💡 Other
The 2nd “Xingzhi Cup” National AI Innovation Application Competition kicks off: Co-hosted by the China Academy of Information and Communications Technology (CAICT) and other organizations, the second “Xingzhi Cup” has commenced. The competition, themed “Empowering with Intelligence, Leading with Innovation,” features three main tracks: Large Model Innovation, Industry Empowerment, and Software/Hardware Innovation Ecosystem, along with several specialized directions. The event aims to promote AI technology innovation, engineering落地 (engineering and deployment), and the construction of an autonomous ecosystem, covering nearly 10 key industries including manufacturing, healthcare, and finance, with an emphasis on the application of domestic AI software and hardware. Winning projects will receive funding, industry matchmaking, and other support (Source: WeChat)

Sequoia Capital AI Ascent insights: AI market has huge potential, application layer and agent economy are the future: Sequoia Capital partners Pat Grady and others shared insights on the AI market at the AI Ascent event. They believe the AI market potential far exceeds cloud computing but warned against “ambient revenue” (users trying out of curiosity rather than real need). The application layer is seen as where true value lies, and startups should focus on vertical domains and customer needs. AI has already made breakthroughs in speech generation and programming. The future outlook includes an “agent economy,” where AI agents can transfer resources and conduct transactions, but faces challenges like persistent identity, communication protocols, and security. Meanwhile, AI will greatly amplify individual capabilities, giving rise to “super individuals” (Source: WeChat)

Discussion: University Machine Learning course content and teaching quality in the AI era draw attention: NYU Professor Kyunghyun Cho’s sharing of his graduate ML course syllabus sparked discussion. The course emphasizes non-LLM problems solvable by SGD and classic paper reading, earning approval from peers like a Harvard CS professor, who believe retaining fundamental concepts is important. However, students from India and the US complained about the poor quality of their university ML courses, describing them as too abstract, filled with jargon without in-depth explanation, leading students to rely on self-study and online resources. This reflects the contradiction between the rapid development of the AI/ML field and the lagging updates of university curricula, as well as the importance of a solid foundation in mathematics and theory (Source: WeChat)
