
Keywords:AI applications, FDA, OpenAI, GPT-4.1, WebThinker, Runway Gen-4, Edge AI, Reinforcement Fine-Tuning (RFT), Multi-agent framework DeerFlow, WebThinker-32B-RL, Gen-4 References update, Knowledge density
🔥 Spotlight
US FDA Announces Acceleration of Internal AI Adoption: The U.S. Food and Drug Administration (FDA) has announced a historic initiative, planning to promote the use of Artificial Intelligence (AI) across all FDA centers by June 30, 2025. Previously, the FDA successfully completed a generative AI pilot program for scientific reviewers. This move aims to enhance regulatory capabilities through AI, improve the speed and efficiency of clinical trials, reduce costs, and represents a significant breakthrough for AI in government regulation and pharmaceutical approval, potentially leading the trend of AI adoption among global drug regulatory agencies (Source: ajeya_cotra)

OpenAI Reinforcement Learning Fine-Tuning (RFT) Technical Details and GPT-4.1 Development Philosophy Revealed: Mich Pokrass, OpenAI’s GPT-4.1 lead, shared details of RFT and the development journey of GPT-4.1 on the Unsupervised Learning podcast. When building GPT-4.1, OpenAI focused more on developer feedback than traditional benchmarks. RFT utilizes chain-of-thought reasoning and task-specific scoring to enhance model performance, especially suitable for complex domains, and is currently available on OpenAI o4-mini. The interview also discussed the current state of AI agent applications, reliability improvements, and how startups can successfully leverage evaluation and forward-looking product strategies (Source: OpenAIDevs, aidan_mclau, michpokrass)

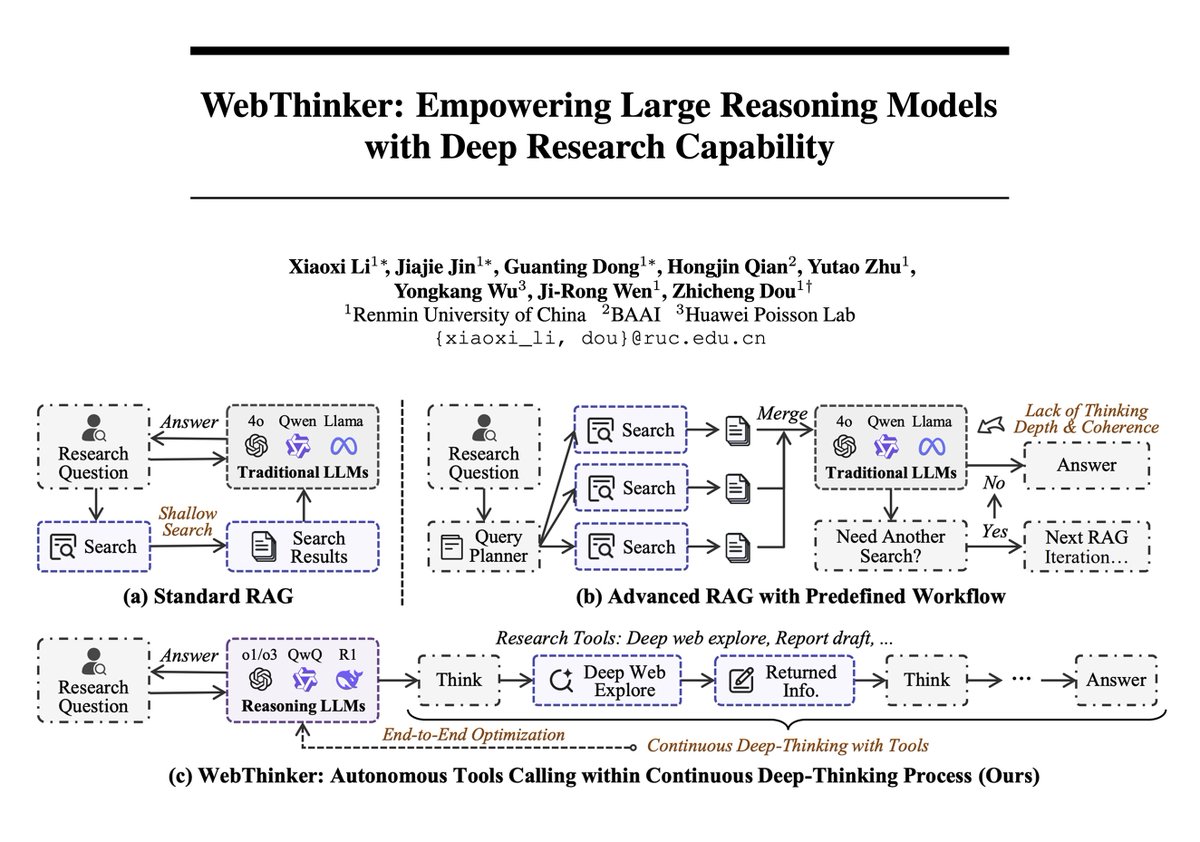
WebThinker Framework Combines Large Models with Deep Web Research Capabilities, Achieving New Heights in Complex Reasoning: A new paper introduces WebThinker, a reasoning agent framework that equips Large Reasoning Models (LRMs) with autonomous web exploration and report generation capabilities to overcome the limitations of static internal knowledge. WebThinker integrates a deep web browser module and an autonomous “think-search-draft” strategy, enabling the model to simultaneously search the web, reason about tasks, and generate comprehensive outputs. On complex reasoning benchmarks like GPQA and GAIA, WebThinker-32B-RL achieved SOTA results among 32B models, outperforming GPT-4o and others. Its RL-trained version outperformed the base version on all benchmarks, demonstrating the importance of iterative preference learning for enhancing reasoning-tool coordination (Source: omarsar0, dair_ai)
Runway Releases Gen-4 References Update, Enhancing Aesthetic, Composition, and Identity Preservation in Video Generation: Runway Gen-4 References has been updated, significantly improving the aesthetic quality, scene composition, and character identity consistency of generated videos. An interesting new feature is the model’s ability to accurately place objects in a scene based on user-provided layouts, and even modify details like a character’s gaze direction while maintaining consistency of other elements. This marks another step forward in controllability and refinement for AI video generation, providing creators with more powerful tools (Source: c_valenzuelab, c_valenzuelab)

ModelBest Intelligence CEO Li Dahai: Physical World AGI Will Be Achieved Through On-Device Intelligence, Knowledge Density is Key: Li Dahai, CEO of ModelBest Intelligence (面壁智能), believes that on-device intelligence is the inevitable path to achieving Artificial General Intelligence (AGI) in the physical world. He emphasizes that the “knowledge density” of large models is the core metric of intelligence, analogous to chip manufacturing processes – the higher the knowledge density, the stronger the intelligence. High knowledge density models have a natural advantage on edge devices with limited computing power, memory, and power consumption. ModelBest Intelligence has released multiple on-device models and implemented them in fields such as automotive, robotics, and mobile phones, like the ModelBest XiaoGangPao Super Assistant (面壁小钢炮超级助手), aiming to equip every device with intelligence for sensitive perception, timely decision-making, and perfect responses (Source: QbitAI)

🎯 Trends
Google Maps New Feature Uses Gemini Capabilities to Identify Place Names in Screenshots: Google Maps has launched a new feature that utilizes Gemini’s AI capabilities to identify place names contained in user screenshots and save them to a list in the map, allowing users to easily access and plan trips. This feature aims to simplify the travel research process and enhance user experience (Source: Google)
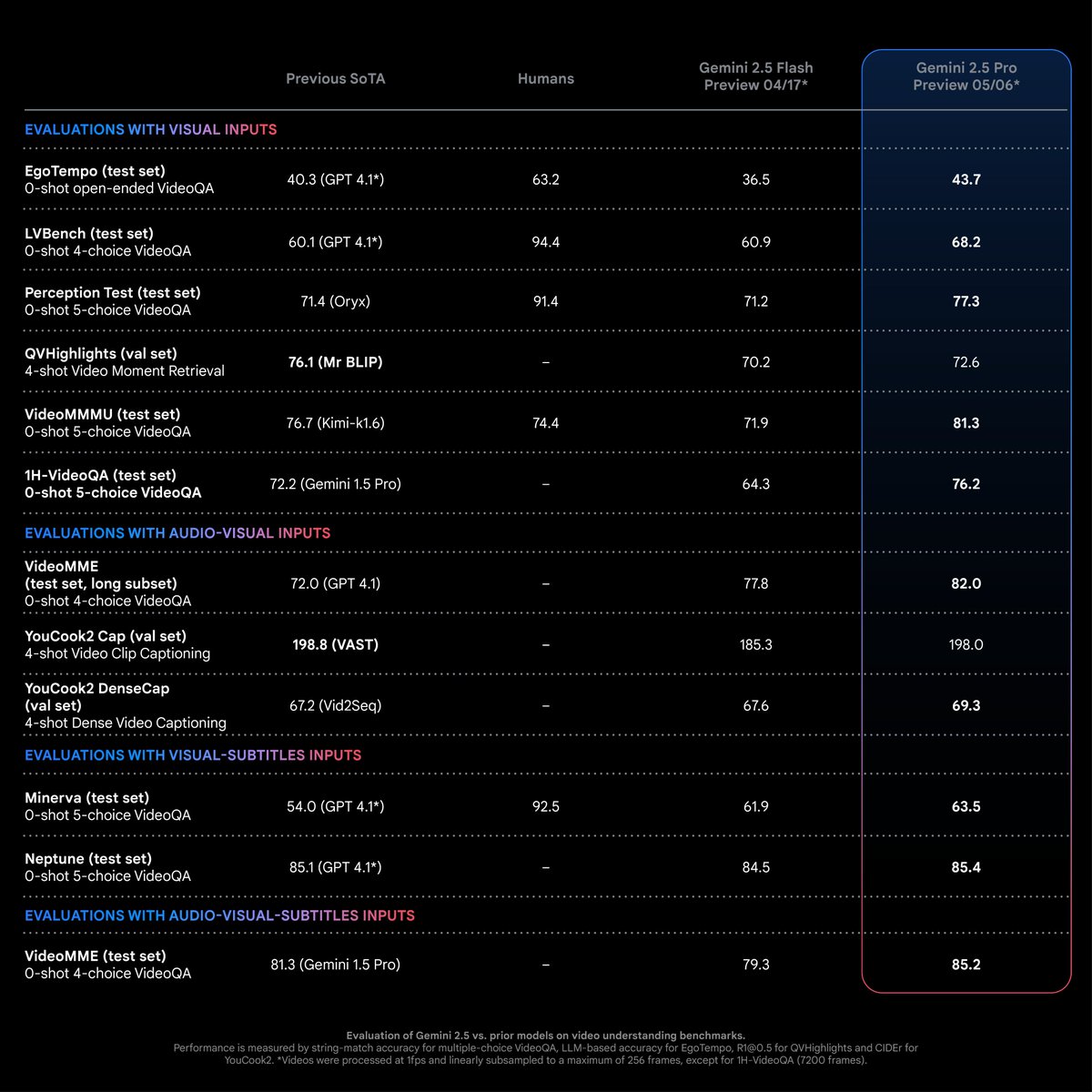
Gemini 2.5 Pro Achieves SOTA Performance on Video Understanding Tasks: According to Logan Kilpatrick, Gemini 2.5 Pro (05-06 version) has achieved state-of-the-art (SOTA) performance on most video understanding tasks, with a significant lead. This is the result of efforts from the Gemini multimodal team and is expected to drive developers to explore new application possibilities in this field (Source: matvelloso)
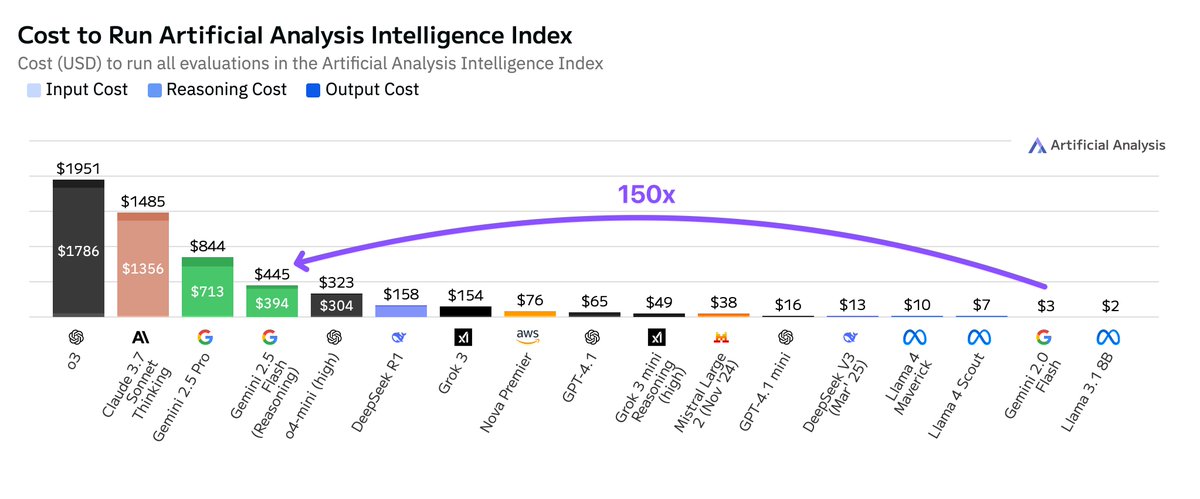
Google Gemini 2.5 Flash Running Costs Significantly Higher Than 2.0 Version: Artificial Analysis points out that when running its intelligence index, Google Gemini 2.5 Flash costs 150 times more than Gemini 2.0 Flash. The cost surge is primarily due to a 9x increase in output token price ($3.5/million tokens with reasoning function enabled, $0.6 with it disabled, compared to $0.4 for 2.0 Flash) and a 17x higher token usage. This has sparked discussions about the balance between low latency and cost-effectiveness in the Flash series models (Source: arohan)
Google Integrates Gemini Nano AI into Chrome Browser to Prevent Online Scams: Google announced the addition of the Gemini Nano AI model to the Chrome browser, aiming to enhance the browser’s ability to identify and block online scams, thereby improving user cybersecurity. This move represents a further application of AI technology in mainstream browser security features (Source: Reddit r/artificial, Reddit r/ArtificialInteligence)
Lightricks Releases LTXVideo 13B 0.9.7, Improving Video Quality and Speed, and Introduces Quantized Version and Latent Space Upscaling Models: Lightricks has updated its video model LTXVideo to version 13B 0.9.7, offering cinematic video quality and faster generation speeds. Simultaneously, it released a quantized version of LTXV 13B, reducing memory requirements and making it suitable for consumer-grade GPUs. Latent space spatial and temporal upscaling models were also introduced, supporting multi-scale inference and improving HD video generation efficiency with less decoding/encoding. Related ComfyUI nodes and workflows have also been updated (Source: GitHub Trending)

Cohere Labs Research Shows Test-Time Scaling Improves Cross-Lingual Reasoning Performance in Large Models: Research from Cohere Labs indicates that although reasoning language models are primarily trained on English data, test-time scaling can improve their zero-shot cross-lingual reasoning performance in multilingual environments and different domains. This research offers new insights for enhancing the application effectiveness of existing large models in non-English scenarios (Source: sarahookr)
AI Uses Facial Photos to Assess Physiological Age and Predict Cancer Outcomes: A new AI tool can estimate an individual’s physiological age by analyzing facial photos and, based on this, predict treatment outcomes and survival chances for diseases like cancer. This technology offers a new non-invasive method for disease prognosis assessment (Source: Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/artificial)
AI Models Show Tendency to Overcomplicate Thinking for Simple Tasks: Some developers have noticed that newer reasoning models tend to trigger overly complex thought processes when faced with simple tasks, appearing to “overthink.” A more ideal approach might be to have a powerful base model that can dynamically determine when to invoke “thinking” as a tool, avoiding unnecessary computation and latency (Source: skirano)
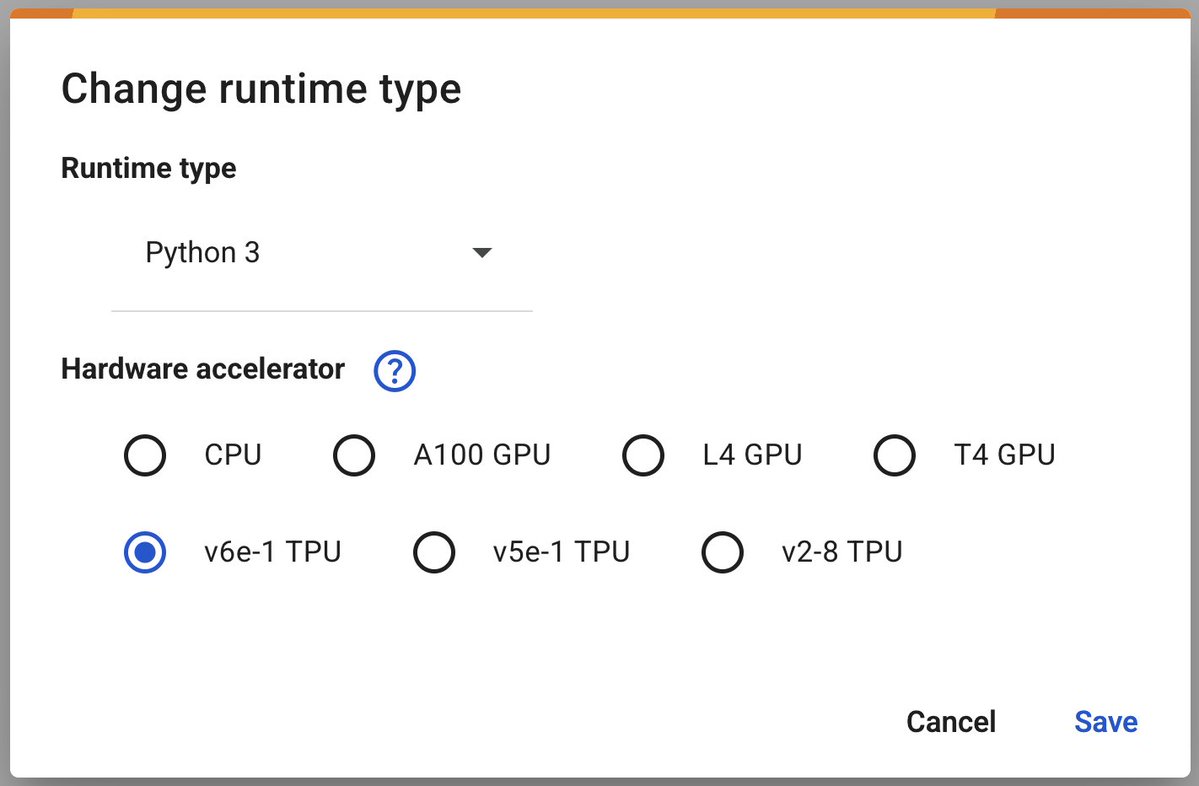
Google Colab Launches v6e-1 (Trillium) TPU, Accelerating Deep Learning: Google Colaboratory has announced the launch of its fastest deep learning accelerator, the v6e-1 (Trillium) TPU. This TPU features 32GB of high-bandwidth memory (double that of v5e-1) and a peak performance of 918 BF16 TFLOPS (nearly triple that of A100), providing researchers and developers with more powerful computing resources (Source: algo_diver)
Google AMIE: Multimodal Conversational Diagnostic AI Agent Demo: Google shared the first demonstration of its multimodal conversational diagnostic AI agent, AMIE. AMIE is capable of conducting multimodal (e.g., combining text and image information) diagnostic conversations, marking further exploration of AI in the field of medical diagnostic assistance (Source: dl_weekly)
Anthropic Accused of Hardcoding “Trump Won” Information in Claude Model: Users discovered that Anthropic’s Claude model, when answering questions about the 2024 election, appears to have hardcoded information that Trump won, despite its knowledge cutoff being October 2024. This has sparked discussions about AI model information update mechanisms, potential biases, and the impact of hardcoded content on user trust (Source: Reddit r/ClaudeAI)
🧰 Tools
ByteDance Open-Sources Multi-Agent Framework DeerFlow: ByteDance has open-sourced DeerFlow, a multi-agent framework based on LangChain. The framework aims to simplify and accelerate the development of multi-agent applications, providing tools for building complex collaborative AI systems. Developers can visit its GitHub repository and official website for more information and examples (Source: hwchase17)
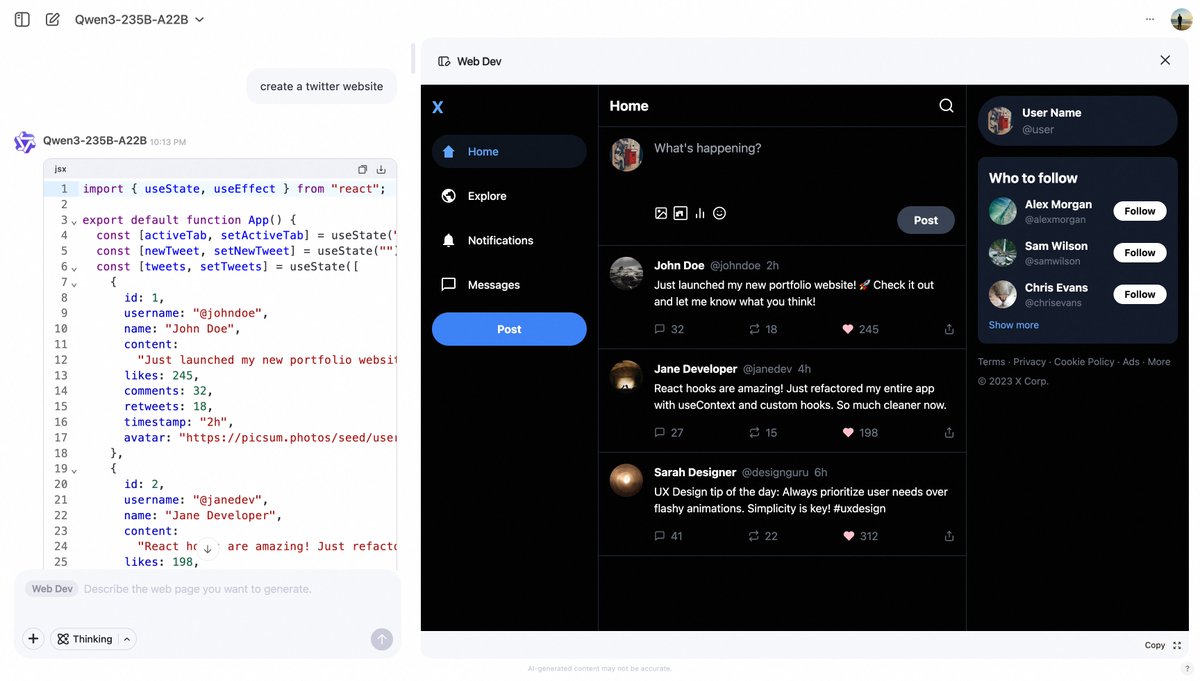
Alibaba Qwen Chat Launches Web Dev Feature, Generating Web Pages from Prompts: Alibaba Qwen Chat has added a “Web Dev” feature, allowing users to quickly generate front-end web page and application code through simple text prompts (e.g., “create a twitter website”). This feature aims to lower the barrier to web development, enabling users without programming knowledge to build websites using natural language (Source: Alibaba_Qwen, huybery)
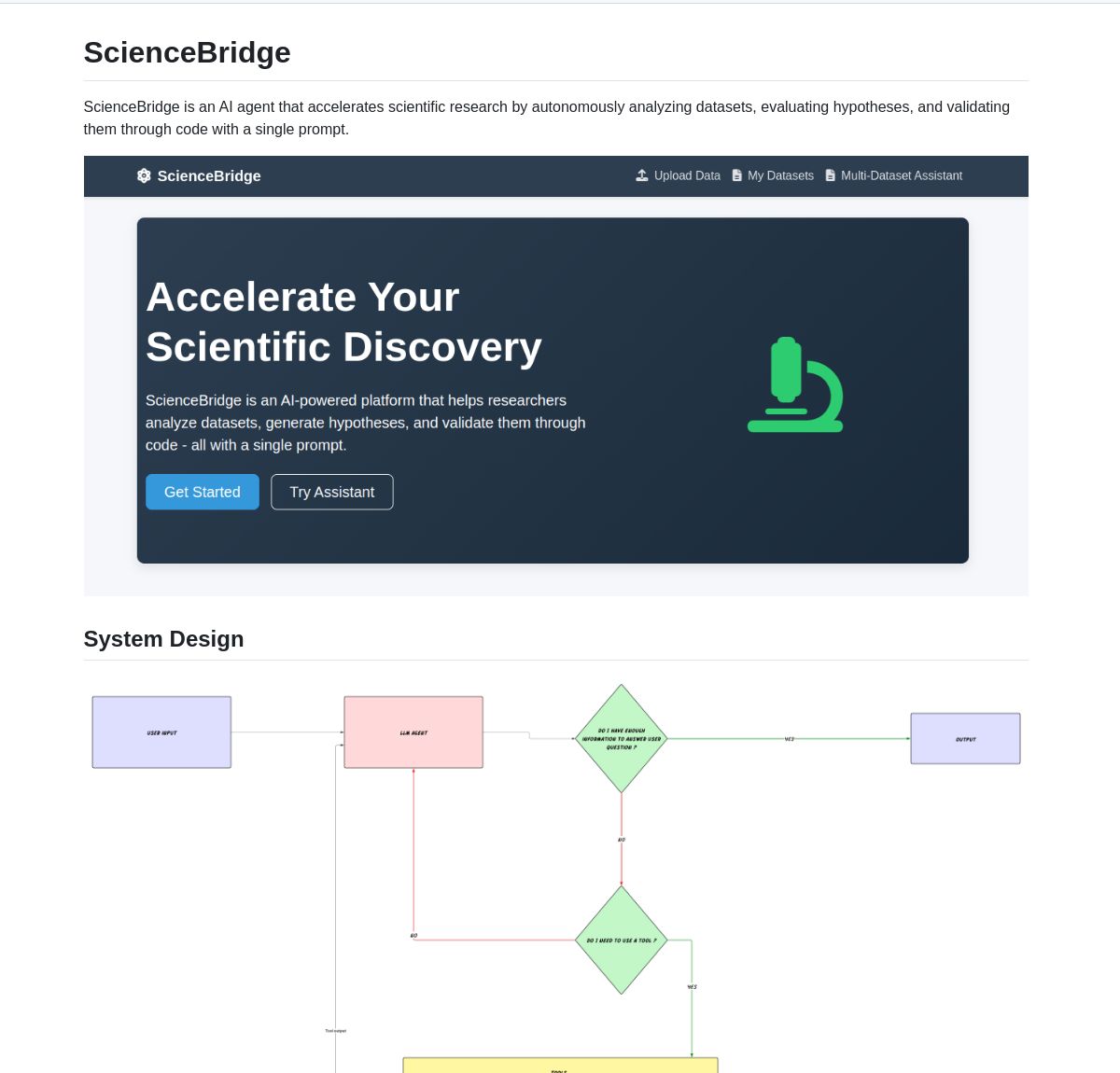
ScienceBridge AI: LangGraph-Powered Scientific Research Automation Agent: An agent named ScienceBridge AI utilizes the LangGraph framework to automate scientific research workflows, including data analysis, hypothesis validation, and generating publication-quality visualizations, aiming to accelerate scientific discovery. The project is open-sourced on GitHub (Source: LangChainAI, hwchase17)
El Agente Q: LangGraph-Powered Multi-Agent System Empowers Quantum Chemistry: A new study showcases El Agente Q, a LangGraph-based multi-agent system that democratizes quantum chemistry calculations through natural language interaction and achieves an 87% success rate in automating complex workflows. The related paper has been published on arXiv, demonstrating AI’s potential in accelerating quantum chemistry research (Source: LangChainAI, hwchase17)
LocalSite: Local DeepSite Alternative Using Local LLMs to Create Web Pages: Inspired by the DeepSite project on HuggingFace, the LocalSite tool allows users to create web pages and UI components using text prompts via locally running LLMs (such as GLM-4, Qwen3 deployed through Ollama and LM Studio) and cloud-based LLMs with OpenAI-compatible APIs. The project is open-sourced on GitHub, aiming to provide a localized, customizable AI web page generation solution (Source: Reddit r/LocalLLaMA)

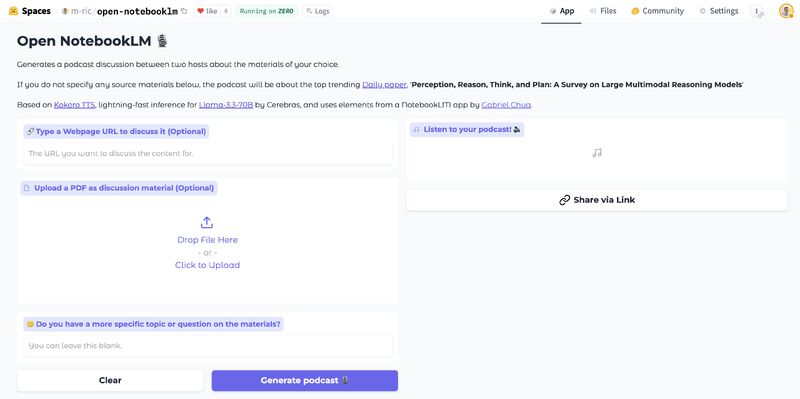
Open-Source NotebookLM Alternative Demonstrates Open-Source Technology Prowess: Developer m_ric created an open-source, free version of Google’s NotebookLM. The application can extract content from PDFs or URLs, use Meta’s Llama 3.3-70B (running at 1000 tokens/second via Cerebras Systems) to write podcast scripts, and use Kokoro-82M for text-to-speech. Audio generation runs for free on HuggingFace H200s with Zero GPU, showcasing that open-source solutions can rival closed-source alternatives in functionality and cost-effectiveness (Source: huggingface, mervenoyann)
DeepFaceLab: Leading Open-Source Deepfake Creation Software: DeepFaceLab is a well-known open-source software dedicated to creating Deepfake content. It offers features like face swapping, de-aging, and head replacement, and is widely used for content creation on platforms like YouTube and TikTok. The project is continuously updated, available for Windows and Linux, and has active community support (Source: GitHub Trending)
GPUI Component: Rust Desktop UI Component Library Based on GPUI: The longbridge team has launched GPUI Component, a library containing over 40 cross-platform desktop UI components, with design inspiration from macOS, Windows controls, and shadcn/ui. It supports multiple themes, responsive sizing, flexible layouts (Dock and Tiles), and efficiently handles large data rendering (virtualized Table/List) and content rendering (Markdown/HTML). Its first application case is the Longbridge Pro desktop application (Source: GitHub Trending)

Ultralytics YOLO11: Leading Object Detection and Computer Vision Model Framework: Ultralytics continues to update its YOLO model series, with the latest YOLO11 offering SOTA performance in tasks such as object detection, tracking, segmentation, classification, and pose estimation. The framework is easy to use, supports CLI and Python interfaces, and integrates with platforms like Weights & Biases, Comet ML, Roboflow, and OpenVINO. Ultralytics HUB provides no-code data visualization, training, and deployment solutions. The models are licensed under AGPL-3.0 with commercial licenses available (Source: GitHub Trending)

Tensorlink: Framework for PyTorch Model Distribution and P2P Resource Sharing: SmartNodes Lab has launched Tensorlink, an open-source framework designed to simplify distributed training and inference for large PyTorch models. It encapsulates core PyTorch objects to abstract the complexity of distributed systems, allowing users to leverage GPU resources from multiple computers without specialized knowledge or hardware. Tensorlink supports on-demand inference APIs and a node framework, facilitating users to share or contribute computing power, and is currently in an early version (Source: Reddit r/MachineLearning)
Prompt Optimization Generates Anime Figurine Photos: A user shared a case of using optimized prompts with AI (like GPT-4o) to transform uploaded character photos into Japanese anime-style figurine photos. The key lies in accurately describing the figurine’s pose, expression, clothing, material (e.g., semi-matte), color gradients, and shooting angle (desktop, casual phone shot feel). Further optimizations include generating multi-angle views (front, side, back) arranged in a four-panel grid, ensuring the completeness of the figurine’s full body and base details for subsequent 3D modeling (Source: dotey, dotey)

NVIDIA Agent Intelligence Toolkit Open-Sourced: NVIDIA has released the open-source Agent Intelligence Toolkit, a resource library for building intelligent agent applications. The toolkit aims to help developers more easily create and deploy AI agents based on NVIDIA technology (Source: nerdai)
SkyPilot and SGLang Simplify Multi-Node Llama 4 Self-Hosting Deployment: Nebius AI demonstrated how to use SkyPilot and SGLang (from LMSYS.org) to self-host Meta’s Llama 4 model on multiple nodes (e.g., 8x H100) with a single command. This solution offers high throughput, efficient memory usage, and integrates production-grade features like authentication and HTTPS, while also facilitating integration with Simon Willison’s llm tool (Source: skypilot_org)

📚 Learning
Vector Institute Launches AI Pocket References: The AI Engineering team at Vector Institute has released the AI Pocket References project, a series of concise AI information cards covering areas like NLP (especially LLMs), federated learning, responsible AI, and high-performance computing. These references aim to provide an entry point for beginners and a quick review for experienced practitioners, with each designed to be read in under 7 minutes. The project is open-sourced and welcomes community contributions (Source: nerdai)

HuggingFace Releases 9 Free AI Courses: HuggingFace has launched a series of 9 free AI courses covering various topics including Large Language Models (LLMs), computer vision, and AI agents. These courses provide valuable resources for learners wishing to systematically study AI (Source: ClementDelangue)
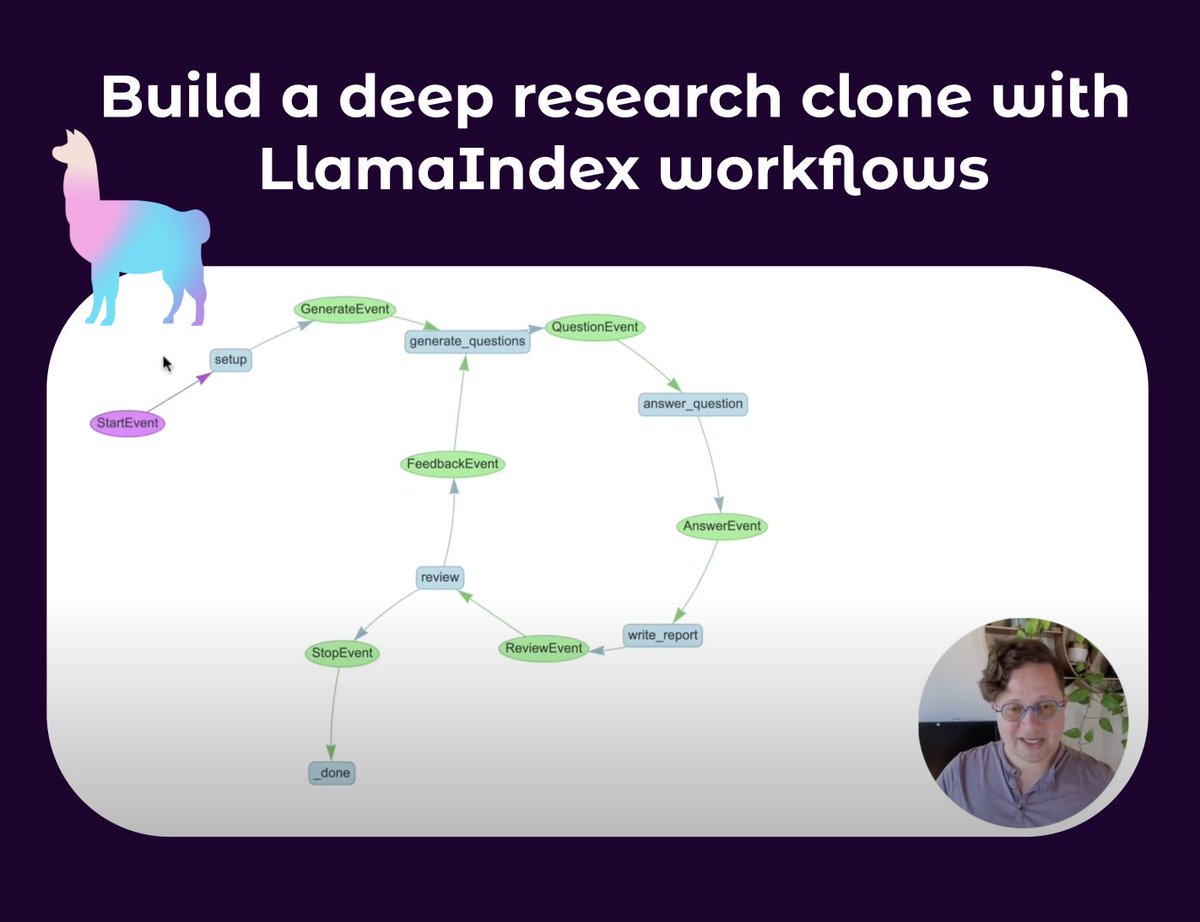
LlamaIndex Releases Tutorial on Building Deep Research Agents: Seldo from LlamaIndex has released a video tutorial guiding users on how to build a clone agent similar to Deep Research. The tutorial starts with single-agent basics and progressively delves into advanced multi-agent workflows, including research using multiple knowledge bases and the web, maintaining context, and implementing a full pipeline of research, writing, and review. The tutorial emphasizes building complex agent workflows with capabilities like looping, branching, concurrent execution, and self-reflection (Source: jerryjliu0, jerryjliu0)
RAG Technology Development Review: Lewis et al. Paper and Early Work: Aran Komatsuzaki points out that although the 2020 paper by Lewis et al. is widely cited for coining the term RAG (Retrieval-Augmented Generation), retrieval-augmented generation itself was an active research direction prior to this, with works like DrQA (2017), ORQA (2019), and REALM (2020). The main contribution of Lewis et al. was proposing a new RAG joint pre-training method, which is not the most commonly used RAG implementation today. This reminds us to pay attention to the continuity of technological development and the importance of early foundational work (Source: arankomatsuzaki)
Achieving Gemini 2.5 Pro-like Chain-of-Thought Output Format with Qwen3: Inspired by the Apriel-Nemotron-15b-Thinker README regarding forcing models to start output in a specific format (e.g., “Here are my reasoning steps:\n”), a developer used OpenWebUI functionality to make the Qwen3 model always begin its output with <think>\nMy step by step thinking process went something like this:\n1.. Experiments show this prompts Qwen3 to think and output in a step-by-step manner similar to Gemini 2.5 Pro. Although this doesn’t inherently improve the model’s intelligence, it changes the format of its thinking and expression (Source: Reddit r/LocalLLaMA)
Claude Code Design Philosophy and Development Insights Shared on Podcast: The Latent Space podcast invited Catherine Wu and Boris Cherny, creators of Claude Code, to share the design philosophy and development story of the AI programming tool. Highlights include: CC can already write about 80% of its own code (with human review), inspired by Aider, focuses on simple implementations (e.g., using Markdown files for memory instead of vector databases), adopts a small team and internal iteration to drive the product, provides raw model access for advanced users, and supports parallel workflows. The podcast also discussed comparisons with tools like Cursor and Windsurf, as well as topics like cost, UI/UX design, and open-source possibilities (Source: Reddit r/ClaudeAI)

💼 Business
Salesforce Launches $500 Million Saudi AI Initiative and Assembles Team: Salesforce has begun assembling a team in Saudi Arabia as part of its five-year, $500 million plan to promote the adoption and development of artificial intelligence in the country. This marks another significant move by major tech companies in the Middle East’s AI landscape (Source: Reddit r/artificial, Reddit r/ArtificialInteligence)
Fidji Simo, New CEO of OpenAI’s Applications Division, to Step Down from Shopify Board: Fidji Simo, current CEO of Instacart, will resign from her position on Shopify’s board of directors after being appointed CEO of OpenAI’s newly established applications division. This move is likely intended to allow her to focus more on her leadership role at OpenAI, managing its rapidly growing business and product lines. There were previous reports of a potential $1 billion deal between OpenAI and Arm (Source: steph_palazzolo, steph_palazzolo)
Lux Capital Establishes $100 Million Fund to Support US Scientists Facing Funding Cuts: In response to significant budget cuts at the U.S. National Science Foundation (NSF) (reportedly up to 50%, leading to cancellation of ongoing projects and staff reductions), Lux Capital has announced the launch of the “Lux Science Helpline,” investing $100 million to support affected U.S. scientists. This initiative aims to ensure the continuation of critical research projects and maintain America’s technological innovation competitiveness (Source: ylecun, riemannzeta)

🌟 Community
Ongoing Discussion About Whether AI Will Replace Human Jobs: Discussions in the community about whether AI will lead to mass unemployment are very common. One viewpoint is that, driven by capitalism, companies will pursue efficiency and use AI to replace expensive human labor, leading to a reduction in positions like programmers. Another viewpoint draws on history, arguing that technological advancements (like electric lights replacing lamplighters) eliminate old jobs but simultaneously create new ones (like light bulb factories, electricity-related industries), with the key being skill upgrades and innovation. Currently, AI still requires human intervention for complex tasks and code debugging, but its rapid development and high efficiency in some areas make many worry about future employment prospects, while others believe this is alarmist or a short-term overestimation of AI capabilities (Source: Reddit r/ArtificialInteligence)
Concerns About LLM Capability Ceiling and AI Winter: Some community members and experts (like Yann LeCun, François Chollet) are beginning to discuss whether Large Language Models (LLMs) are hitting a bottleneck. Although LLMs excel at mimicking patterns, they still have limitations in true understanding, reasoning, and handling hallucinations, and over-reliance on synthetic data may also pose problems. If new research directions (like world models, neuro-symbolic systems) are lacking, the current AI boom could cool down, leading to reduced investment and even triggering a new “AI winter.” However, some argue that while general-purpose LLMs might be hitting a ceiling, specialized models and AI agents are still rapidly developing (Source: Reddit r/ArtificialInteligence)
OpenAI’s Plan to Release Open-Source Model in Summer Sparks Community Discussion: Sam Altman testified before the Senate that OpenAI plans to release an open-source model this summer. Community reactions are mixed, with some anticipating its performance, while others question if it will be “perpetually in development” like Musk’s FSD, or “nerfed” to avoid competing with paid models. Some analyze that companies like Meta and Alibaba, by releasing high-quality free pre-trained models, aim to weaken the market position of companies like OpenAI, and OpenAI’s move might be a counter-strategy. However, considering OpenAI’s business model and high operational costs, the positioning and competitiveness of its open-source model remain to be seen (Source: Reddit r/LocalLLaMA)

Concerns About AI’s Impact on Internet Information Reliability: Users on Reddit expressed concerns about AI’s impact on internet reliability. Features like Google AI Overviews sometimes provide inaccurate or “confidently nonsensical” answers (e.g., explaining user-invented phrases), which could mislead the next generation of users and even make them skeptical of all information. Opinions in the comments section vary; some believe the internet was never fully reliable and critical thinking has always been important, while others jokingly suggest the poster is revealing their age (Source: Reddit r/ArtificialInteligence)
User Shares Experience of Alleviating Depressive Moods by Talking to ChatGPT: A user shared their experience of alleviated depression and suicidal thoughts after a long conversation with ChatGPT. They stated that even confiding in AI helped release immense psychological pressure and gave them the courage to move forward and seek help from friends and family. Many in the comments section reported similar experiences, believing AI can provide unbiased, patient companionship in psychological support, with some users even sharing prompts to have ChatGPT roleplay as a “higher self” for deep conversations. This has sparked discussions about AI’s potential in mental health assistance (Source: Reddit r/ChatGPT)
Reflection on the Saying “LLMs Just Predict the Next Word”: There’s discussion in the community pointing out that the phrase “LLMs just predict the next word” is an oversimplification that can lead people to underestimate the true capabilities and potential impact of LLMs. The key is the complexity and utility of the content LLMs produce (like code, analysis), not their generation mechanism. Experts express concern about the rapid development of AI and its unknown capabilities, while the general public might not fully realize the profound changes AI technology is about to bring due to such simplified explanations. The discussion also touches on the “intelligence” vs. “consciousness” of AI, arguing that even if AI lacks human-like consciousness, its capabilities are sufficient to have a huge impact on the world (Source: Reddit r/ArtificialInteligence)
Discussion on the Value of Claude Paid Version: Project Management, Context Length, and Thinking Mode are Key: Paid Claude users shared what makes the subscription worthwhile. Key advantages include the “Projects” feature, allowing users to upload extensive background materials (knowledge bases) for specific tasks (like course preparation, website SEO, ad analysis, news summarization, recipe lookup), enabling Claude to provide continuous assistance within a specific context. Additionally, a larger context window, stronger “Thinking Mode,” and more queries are also attractive features of the paid version. Users report that for complex tasks, code review, document analysis, and email drafting, Claude Pro combined with MCP tools (like Desktop Commander) outperforms some IDE-integrated solutions, which may limit the model’s deep analysis capabilities due to cost optimization or built-in system prompts (Source: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
OpenWebUI License Change Raises Concerns Among Community and Enterprise Users: The OpenWebUI project recently changed its software license, a move that has caused concern among some community members and enterprise users. One company stated it is discussing discontinuing use and contribution to the project and will temporarily fork based on the last BSD licensed version. This event highlights the potential impact of open-source project license changes on the user and contributor ecosystem, especially in commercial application scenarios (Source: Reddit r/OpenWebUI)
💡 Other
Vatican Plans to Invest in New Data Sources to Address “Data Wall” Problem: Since 2023, training large language models has faced a “data wall” problem, meaning most known human text data has already been indexed and trained on. To address this issue, the Vatican plans to invest in new data sources, such as transcribing medieval church documents using OCR technology and generating synthetic data, to continuously enhance AI model capabilities (Source: jxmnop, Dorialexander)

Rapid Technological Development in China Attracts Attention Across Multiple Fields: A post detailed several astonishing technological applications observed by the author during a 15-day trip to China, including DeepSeek sex dolls, electric airships, and drones used for handling traffic accidents. This sparked discussions about the speed and breadth of technological development in China in fields like artificial intelligence, robotics, and new energy transportation, drawing comparisons with other high-tech countries like Singapore (Source: GavinSBaker)

Expectations for AI Development in the Medical Field: Community members expressed expectations for greater progress of AI in the medical field. Visions include AI robots that can instantly scan the body and detect symptoms in the early stages of disease, as well as systems that can assist with precision treatment, surgery, and accelerate recovery. Although existing technology has made progress in some areas, there is a general belief that AI still has enormous untapped potential in improving medical accessibility, accuracy, and saving lives (Source: Reddit r/ArtificialInteligence, Reddit r/artificial)