
Keywords:Gemini model, Mistral AI, NVIDIA NeMo, LTX-Video, Safari browser, RTX 5060, AI Agent, reinforcement learning fine-tuning, native image generation with Gemini, Mistral Medium 3 programming performance, modular NeMo framework 2.0, DiT real-time video generation, AI-driven search transformation
🔥 Focus
Google Gemini’s native image generation feature upgraded, improving visual quality and text rendering accuracy: Google announced a significant update to its Gemini model’s native image generation feature, with the new version “gemini-2.0-flash-preview-image-generation” now live on Google AI Studio and Vertex AI. This upgrade significantly improves the visual quality of images and the accuracy of text rendering, and reduces latency. The new feature supports image element fusion, real-time editing (such as adding objects, modifying local content), and, in conjunction with Gemini 2.0 Flash, enables AI to autonomously conceive and generate images. Users can try it for free in Google AI Studio, and API calls are priced at $0.039 per image. Despite significant progress, some users believe its overall performance is still slightly inferior to GPT-4o. (Source: QbitAI)

Mistral AI releases Mistral Medium 3, focusing on programming and multimodality, with significantly reduced costs: French AI startup Mistral AI has launched its latest multimodal model, Mistral Medium 3. The model excels in programming and STEM tasks, reportedly achieving or surpassing 90% of Claude Sonnet 3.7’s performance on various benchmarks at only 1/8th the cost ($0.4/million tokens for input, $2/million tokens for output). Mistral Medium 3 offers enterprise-grade capabilities such as hybrid deployment, customized post-training, and integration with enterprise tools. It is now available on Mistral La Plateforme and Amazon Sagemaker, with plans to roll out on more cloud platforms. Simultaneously, Mistral AI has also launched Le Chat Enterprise, a chatbot service for businesses. (Source: QbitAI)

NVIDIA NeMo Framework 2.0 released, enhancing modularity and usability, supporting Hugging Face models and Blackwell GPUs: NVIDIA NeMo framework has been updated to version 2.0. Key improvements include replacing YAML with Python configurations for increased flexibility, simplifying experimentation and customization through PyTorch Lightning’s modular abstractions, and enabling seamless scaling of large-scale experiments with the NeMo-Run tool. The new version adds support for pre-training and fine-tuning Hugging Face AutoModelForCausalLM models and has initial support for NVIDIA Blackwell B200 GPUs. Additionally, the NeMo framework integrates support for the NVIDIA Cosmos world foundation model platform to accelerate the development of world models for physical AI systems, including the video processing library NeMo Curator and the Cosmos tokenizer. (Source: GitHub Trending)

Lightricks releases LTX-Video: A real-time DiT video generation model: Lightricks has open-sourced LTX-Video, claiming it to be the first real-time video generation model based on Diffusion Transformer (DiT). The model can generate high-quality videos at 1216×704 resolution at 30FPS, supporting various functions such as text-to-image, image-to-video, keyframe animation, video outpainting, and video-to-video conversion. The latest version, 13B v0.9.7, improves prompt adherence and physical understanding, and introduces a multi-scale video pipeline for fast, high-quality rendering. The model is available on Hugging Face with ComfyUI and Diffusers integrations. (Source: GitHub Trending)

Apple considers major Safari browser overhaul, potentially shifting to AI-driven search, Google partnership under scrutiny: Apple’s Senior Vice President Eddy Cue, testifying in the U.S. Department of Justice’s antitrust case against Google, revealed that Apple is actively considering a revamp of its Safari browser, with a focus on AI-driven search engines. He noted that Safari search volume has declined for the first time, partly due to users turning to AI tools like OpenAI and Perplexity AI. Apple has held discussions with Perplexity AI and may introduce more AI search options into Safari. This move could impact Apple’s approximately $20 billion annual default search engine agreement with Google and affect both companies’ stock prices. Apple has already integrated ChatGPT into Siri and plans to add Google Gemini. (Source: 36Kr)

🎯 Trends
NVIDIA RTX 5060 desktop graphics card to be released on May 20th, priced at 2499 RMB in China: NVIDIA announced that the RTX 5060 desktop graphics card will go on sale on May 20th Beijing time, with a domestic price of 2499 RMB. The card features the Blackwell RTX architecture, 3840 CUDA cores, 8GB GDDR7 memory, and a total power of 145W. Officially, in games supporting DLSS 4 multi-frame generation technology, its performance is twice that of the RTX 4060, aiming to allow users to run games at over 100 FPS. Reviews and sales will commence on the same day. (Source: QbitAI)

Google Gemini API introduces implicit caching feature, saving up to 75% on costs: Google announced the launch of an implicit caching feature for its Gemini API. When a user’s request hits the cache, the cost of using the Gemini 2.5 model can be automatically reduced by 75%. Simultaneously, the minimum number of tokens required to trigger the cache has been lowered: to 1K tokens for Gemini 2.5 Flash and 2K tokens for Gemini 2.5 Pro. This feature aims to reduce costs for developers using the Gemini API without needing to explicitly create a cache. (Source: matvelloso, demishassabis, algo_diver, jeremyphoward)
Meta FAIR appoints Rob Fergus as new head, focusing on Advanced General Intelligence (AGI): Meta announced that Rob Fergus will take over leadership of its Fundamental AI Research (FAIR) team. Yann LeCun stated that FAIR will refocus on advanced machine intelligence, commonly referred to as human-level AI or AGI. This news has received widespread attention and congratulations from the AI research community. (Source: ylecun, Ar_Douillard, soumithchintala, aaron_defazio, sainingxie)
OpenAI introduces Reinforcement Learning Fine-tuning (RFT) for o4-mini model: OpenAI announced that its o4-mini model now supports Reinforcement Learning Fine-tuning (RFT). This technology, in development since last December, utilizes chain-of-thought reasoning and task-specific scoring to improve model performance, especially in complex domains. A model fine-tuned by Ambience using RFT achieved 27% higher accuracy in ICD-10 coding than expert clinical coders. Harvey has also trained models with RFT to improve citation accuracy in legal tasks. Meanwhile, OpenAI’s fastest and smallest model, 4.1-nano, is also now open for fine-tuning. (Source: stevenheidel, aidan_mclau, andrwpng, teortaxesTex, OpenAIDevs, OpenAIDevs)
Tsinghua University proposes Absolute Zero Reasoner: AI self-generates training data for superior reasoning: A team from Tsinghua University has developed an AI model called Absolute Zero Reasoner, which can entirely generate training tasks through self-play and learn from them without any external data. In fields like mathematics and coding, its performance has surpassed models trained on expert-curated data. This achievement may alleviate the data bottleneck issue in AI development and open new paths towards AGI. (Source: corbtt)

Meta and NVIDIA collaborate to enhance Faiss GPU vector search performance with cuVS: Meta and NVIDIA announced a collaboration to integrate NVIDIA’s cuVS (CUDA Vector Search) into Meta’s open-source similarity search library Faiss v1.10, significantly boosting vector search performance on GPUs. This integration improves IVF index build times by up to 4.7x and search latency by up to 8.1x. For graph indexes, CUDA ANN Graph (CAGRA) build times are 12.3x faster than CPU HNSW, with search latency reduced by 4.7x. (Source: AIatMeta)
Google AI Studio and Firebase Studio integrate Gemini 2.5 Pro: Google announced that it has integrated the Gemini 2.5 Pro model into Gemini Code Assist (Personal) and Firebase Studio. This will provide developers with more convenience and powerful features when using top-tier coding models on these platforms, aiming to enhance coding efficiency and experience. (Source: algo_diver)
Microsoft Copilot introduces Pages feature, supporting inline editing and text highlighting: Microsoft Copilot has added a “Pages” feature, allowing users to inline edit AI-generated responses directly within the Copilot interface. Users can highlight text and request specific modifications. This feature aims to help users more quickly and intelligently transform questions and research into usable documents, improving work efficiency. (Source: yusuf_i_mehdi)
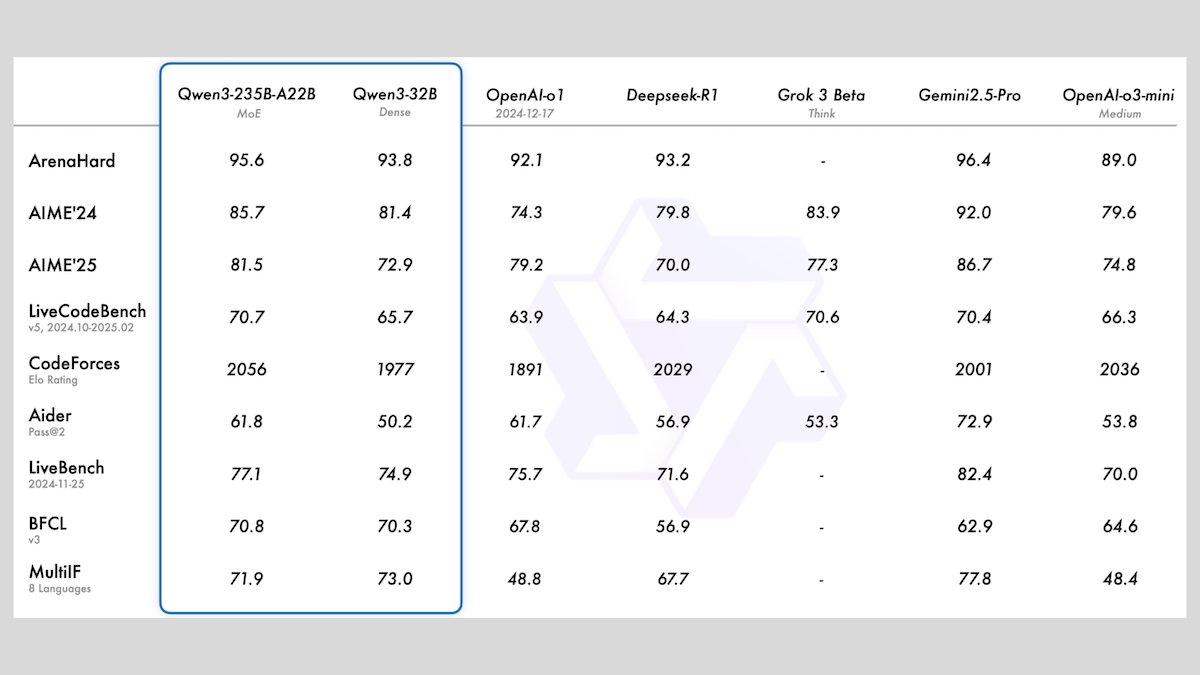
Alibaba launches Qwen3 series models, including 8 open-source large language models: Alibaba has released the Qwen3 series, comprising 8 open-source large language models, including 2 Mixture-of-Experts (MoE) models and 6 dense models with parameter ranges from 0.6B to 32B. All models support optional inference modes and multilingual capabilities across 119 languages. Qwen3-235B-A22B and Qwen3-30B-A3B demonstrate excellent performance in reasoning, coding, and function calling tasks, comparable to top models like OpenAI’s, with Qwen3-30B-A3B gaining particular attention for its strong performance and local run capabilities. (Source: DeepLearningAI)
Meta introduces Meta Locate 3D model for precise object localization in 3D environments: Meta AI has released Meta Locate 3D, a model designed for accurately locating objects in 3D environments. This model aims to help robots better understand their surroundings and interact more naturally with humans. Meta has made the model, dataset, research paper, and a demo available for public use and experimentation. (Source: AIatMeta)
Google releases new report detailing AI use in combating online scams: Google has published a new report on how it utilizes artificial intelligence technology to combat online scams across its Search engine, Chrome browser, and Android system. The report details Google’s decade-long efforts and latest advancements in using AI to protect users from online fraud, emphasizing AI’s critical role in identifying and blocking fraudulent activities. (Source: Google)
Cohere launches Embed 4 embedding model, strengthening AI search and retrieval capabilities: Cohere has released its latest embedding model, Embed 4, designed to revolutionize how enterprises access and utilize data. As Cohere’s most powerful embedding model to date, Embed 4 focuses on enhancing the accuracy and efficiency of AI search and retrieval, helping organizations unlock hidden value from their data. (Source: cohere)

Google announces Google I/O conference to be held on May 20th: Google has officially announced that its annual developer conference, Google I/O, will be held on May 20th, and registration is now open. The event will feature keynotes, new product launches, and technology announcements, with AI expected to be a core theme. (Source: Google)
NVIDIA Parakeet model sets new audio transcription record: 60 minutes of audio transcribed in 1 second: NVIDIA’s Parakeet model has achieved a breakthrough in audio transcription, capable of transcribing up to 60 minutes of audio in just 1 second, ranking at the top of relevant Hugging Face leaderboards. This achievement showcases NVIDIA’s leadership in speech recognition technology and provides developers with efficient audio processing tools. (Source: huggingface)

🧰 Tools
LlamaParse adds GPT 4.1 and Gemini 2.5 Pro support, enhancing document parsing capabilities: LlamaParse has recently undergone a series of feature updates, including the introduction of new parsing models GPT 4.1 and Gemini 2.5 Pro to improve accuracy. Additionally, the new version adds automatic orientation and skew detection for perfectly aligned parsing, provides confidence scores to assess parsing quality, and allows users to customize error tolerance and how failed pages are handled. LlamaParse offers a free tier of 10,000 pages per month. (Source: jerryjliu0)

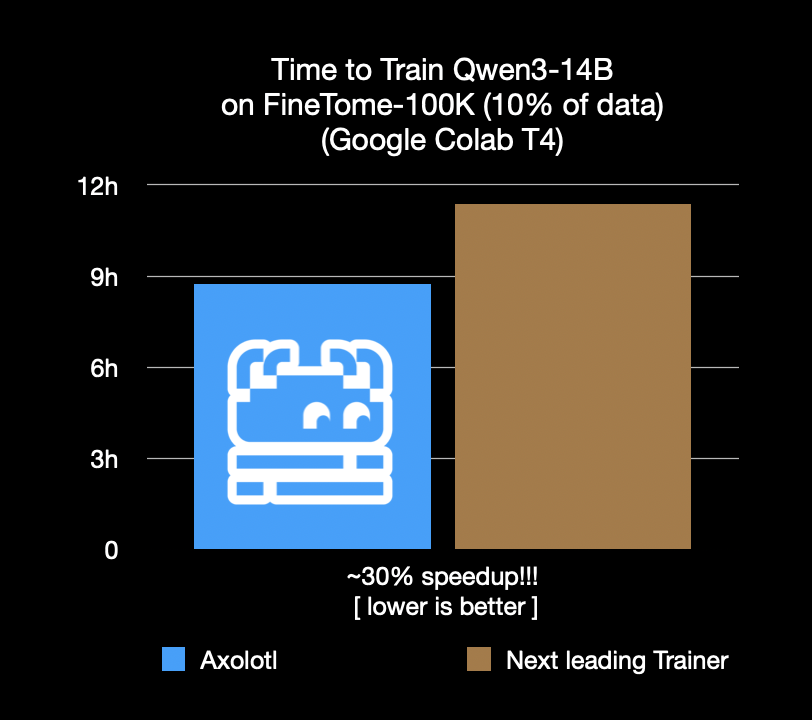
Axolotl fine-tuning framework speeds up by 30%, saving costs and time: The Axolotl fine-tuning framework announced that it is 30% faster than the next best framework on real-world workloads like FineTome-100k. For medium to large machine learning teams, this translates to thousands of dollars in cost savings per month. The framework’s optimizations aim to help users fine-tune models more efficiently and economically. (Source: Teknium1, winglian, maximelabonne)
Runway launches animated pilot “Mars & Siv: No Vacancy,” showcasing Gen-4 model capabilities: Runway’s AI studio has launched an animated pilot episode, “Mars & Siv: No Vacancy,” created by Jeremy Higgins and Britton Korbel. The work demonstrates the application of Runway’s Gen-4 model across various stages of the animation production pipeline, from concept to final product, highlighting AI’s potential in creative content generation. (Source: c_valenzuelab, c_valenzuelab)
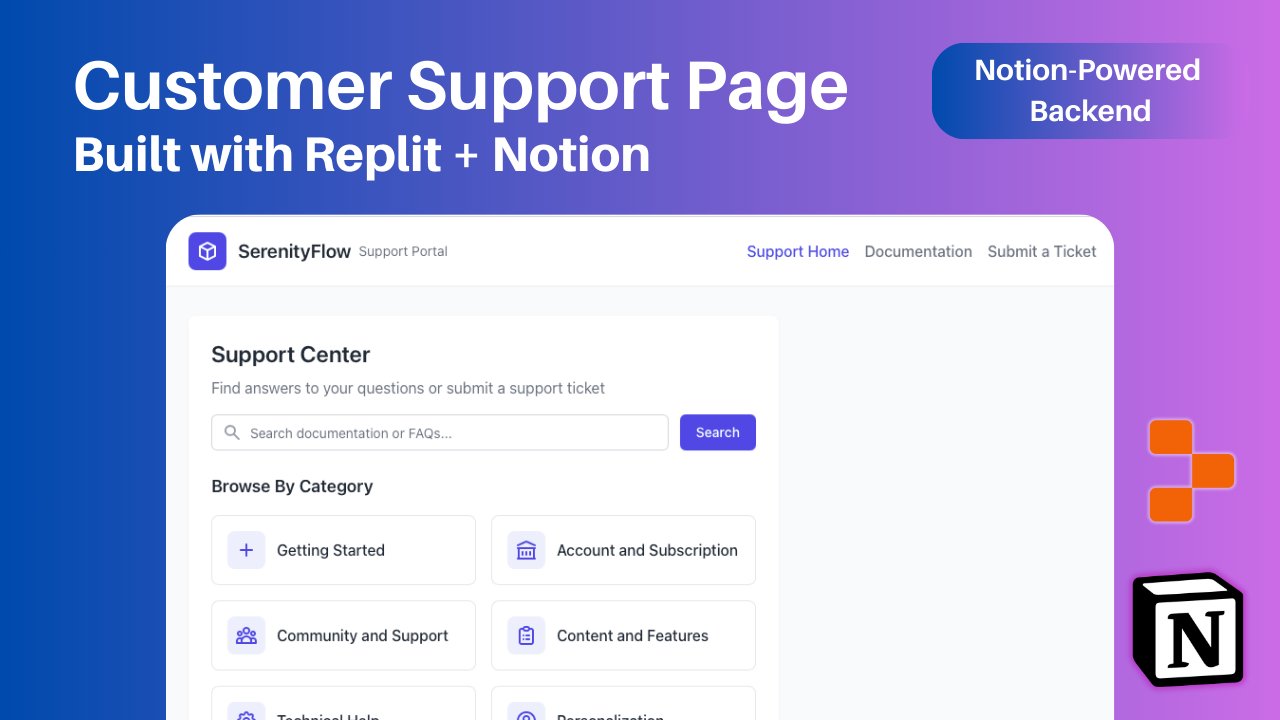
Replit adds Notion integration, allowing Notion content to serve as application backend: Replit announced a new integration partnership with Notion, enabling developers to use Notion as the backend for their applications. Users can connect Notion databases to Replit projects to display FAQs, power document-based custom AI chatbots, and log support tickets back into Notion. This move aims to combine Notion’s backend organizational capabilities with Replit’s flexible frontend creation abilities. (Source: amasad, amasad, pirroh)
Langchain-huggingface v0.2 released, supporting HF Inference Providers: Langchain-huggingface has released v0.2, which adds support for Hugging Face Inference Providers. This update will make it more convenient to use inference services provided by Hugging Face within the LangChain ecosystem. (Source: LangChainAI, huggingface, ClementDelangue, hwchase17, Hacubu)
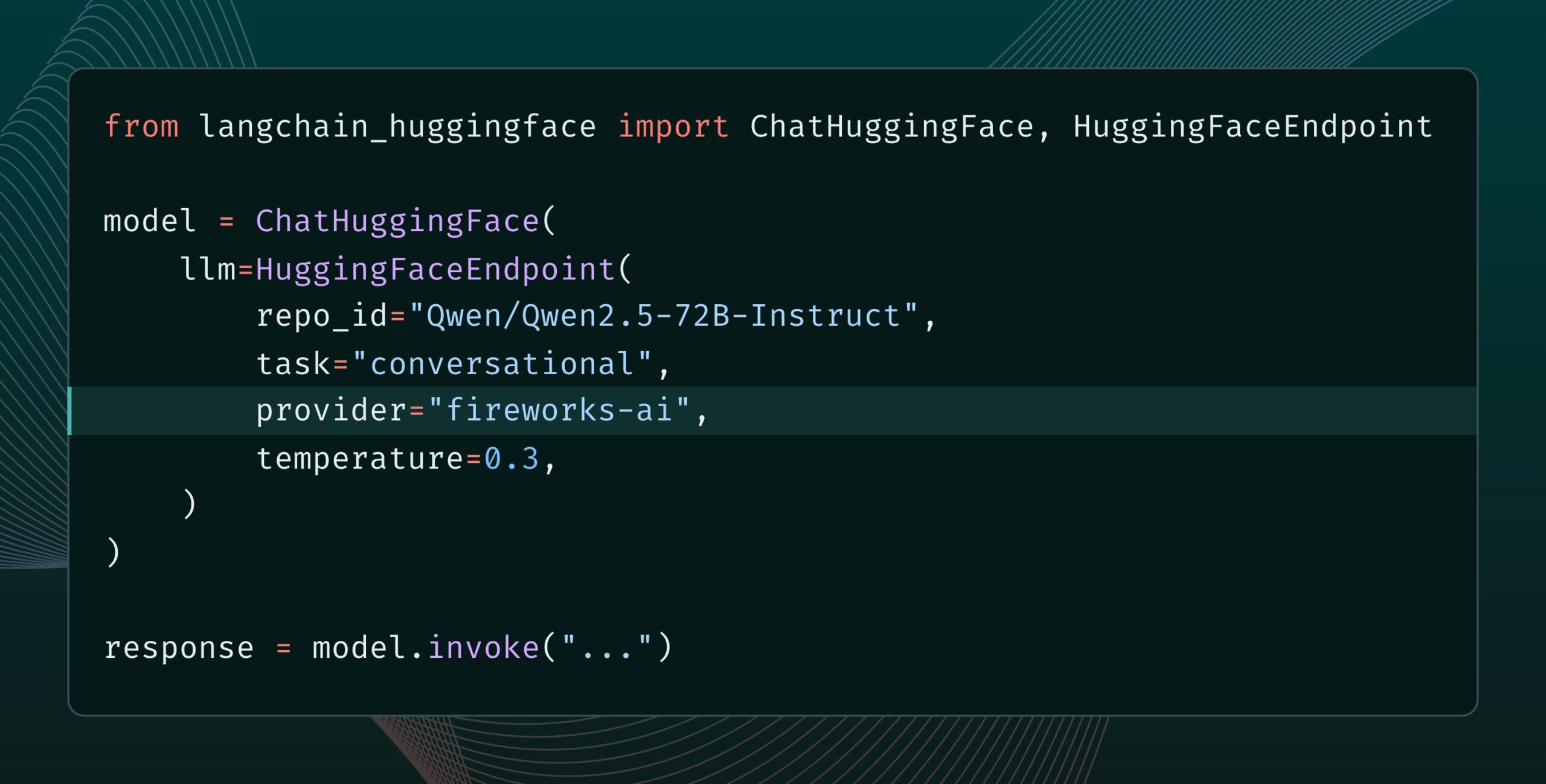
smolagents 1.15 released, adding streaming outputs feature: AI agent framework smolagents has released version 1.15, introducing streaming outputs. Users can enable this by setting stream_outputs=True when initializing CodeAgent, which will make all interactions feel smoother. (Source: huggingface, AymericRoucher, ClementDelangue)
Better-Qwen3 project: Enabling Qwen3 models to automatically switch thinking modes: A GitHub project named Better-Qwen3 is gaining attention. It aims to enable Qwen3 models to automatically control whether to activate “thinking mode” based on the complexity of user queries. For simple questions, the model will answer directly; for complex ones, it will automatically enter thinking mode to provide more in-depth answers. Project address: http://github.com/AaronFeng753/Better-Qwen3 (Source: karminski3, Reddit r/LocalLLaMA)
MLX-Audio: TTS/STT/STS library based on Apple MLX framework: MLX-Audio is a Text-to-Speech (TTS), Speech-to-Text (STT), and Speech-to-Speech (STS) library specifically built for Apple Silicon, based on Apple’s MLX framework, aiming to provide efficient speech processing capabilities. The library supports multiple languages, voice customization, speed control, and offers an interactive web interface and REST API. (Source: GitHub Trending)
Runway References model supports image outpainting feature: Runway’s References model now supports image outpainting. Users can simply place an image in References, select the desired output format, leave the prompt empty, and click generate to extend the original image. This feature further enhances Runway’s capabilities in image editing and creation. (Source: c_valenzuelab)

Docker2exe: Convert Docker images into executable files: Docker2exe is a tool that can convert Docker images into standalone executable files, making them easy for users to share and run. It supports an embed mode, which directly packages the Docker image’s tarball into the executable. When run on a target device, if the corresponding Docker image is not present locally, it will automatically load the embedded image or pull it from the network. (Source: GitHub Trending)
Smoothie Qwen: Smoothing Qwen model token probabilities to balance multilingual generation: Smoothie Qwen is a lightweight adjustment tool that aims to enhance the balance of Qwen models in multilingual generation by smoothing token probabilities. It reduces unintended bias towards specific languages (like Chinese) while maintaining core performance. The tool utilizes Unicode ranges to identify tokens, performs N-gram analysis, and adjusts token weights in the lm_head. Pre-adjusted models are available on Hugging Face. (Source: Reddit r/LocalLLaMA)

ComfyGPT: Self-Optimizing Multi-Agent System for Comprehensive ComfyUI Workflow Generation: A paper titled “ComfyGPT: A Self-Optimizing Multi-Agent System for Comprehensive ComfyUI Workflow Generation” has been submitted to arXiv, introducing a system called ComfyGPT. This system utilizes a self-optimizing multi-agent approach to comprehensively generate ComfyUI workflows, simplifying the construction of complex image generation processes. (Source: Reddit r/LocalLLaMA)
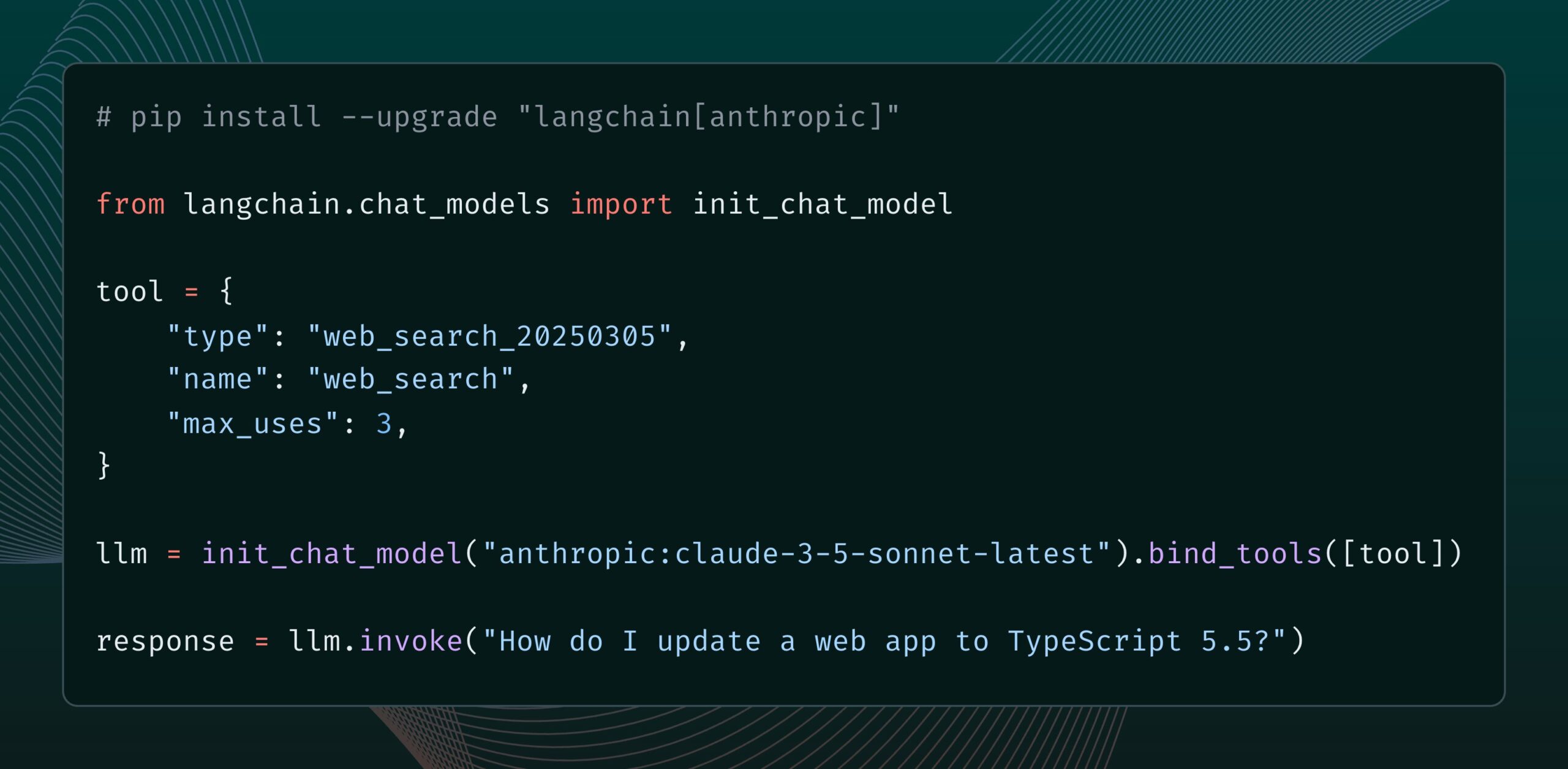
Anthropic Claude model adds web search tool: Anthropic has released a new web search tool for its Claude model. This tool allows Claude to perform web searches while generating responses and use the search results as a basis, providing answers with citations. This feature has been integrated into the langchain-anthropic library, enhancing Claude’s ability to access and utilize real-time information. (Source: LangChainAI, hwchase17)
Glass Health launches Workspace feature, utilizing AI to assist in clinical diagnosis and treatment planning: Glass Health has released its new Workspace feature, which allows clinicians to use AI to more effectively complete complex diagnostic reasoning, treatment planning, and documentation workflows. This initiative aims to improve the efficiency and quality of medical work through AI technology. (Source: GlassHealthHQ)
OpenWebUI adds AI-enhanced notes and meeting recording features: The latest version of OpenWebUI includes an AI-enhanced notes feature. Users can create notes, attach meeting or voice audio, and have AI instantly enhance, summarize, or optimize the notes using audio transcription. Additionally, it supports meeting audio recording and import functions, making it convenient for users to review and extract important discussion information. (Source: Reddit r/OpenWebUI)
📚 Learning
United Nations releases 200-page report on AI and global human development: The United Nations Development Programme (UNDP) has released a 200-page report examining artificial intelligence from the perspective of global human development. The report explores AI’s impact on Sustainable Development Goals, inequality, governance, and the future of work, among other areas, and offers policy recommendations. The report has gained attention for its distinct viewpoints. (Source: random_walker)
The Turing Post publishes in-depth analysis of Agent2Agent (A2A) protocol: Given the community’s strong interest in communication protocols between AI Agents, The Turing Post has released its in-depth analysis of Google’s A2A protocol for free on Hugging Face. The article explores the importance of the A2A protocol (aimed at breaking down AI Agent silos to enable collaboration), potential applications (such as specialized Agent team collaboration, cross-enterprise workflows, standardization of human-computer collaboration, searchable Agent directories), as well as its working principles and how to get started. (Source: TheTuringPost, TheTuringPost, TheTuringPost, dl_weekly)

Prompt engineer shares: How to easily write effective prompt templates: Prompt engineer dotey shared a three-step method for creating efficient prompt templates: 1. Collect prompts of the same style but different themes; 2. Identify commonalities and differences (AI can assist); 3. Test and optimize repeatedly. He emphasized that good templates are like functions in programming, generating different results with minor variable changes. He also shared an instruction template for quickly generating new prompts using AI and pointed out that not all styles are suitable for templating; themes with complex details still require personalized optimization. (Source: dotey)

DeepMind researcher John Jumper’s team is hiring to expand LLM-based scientific discovery: Google DeepMind researcher John Jumper announced that his team is hiring for multiple positions to expand their work on scientific discovery based on Large Language Models (LLMs). The open positions include Research Scientists (RS) and Research Engineers (RE), aiming to advance the future of natural language science AI. (Source: demishassabis, NandoDF)
Ragas blog shares two years of experience in improving AI applications: Shahules786 published an article on the Ragas blog, summarizing lessons learned from two years of close collaboration with AI teams, delivering evaluation cycles, and improving LLM systems. The article aims to provide practical guidance and insights for practitioners building and optimizing AI applications. (Source: Shahules786)

Kyunghyun Cho discusses teaching methods for graduate machine learning courses in the LLM era: NYU Professor Kyunghyun Cho shared his thoughts and experiments on teaching content for first-year graduate machine learning courses in the current era of LLMs and large-scale computation. He proposed teaching all content that accepts SGD (Stochastic Gradient Descent) and is non-LLM, and guiding students to read classic papers. (Source: ylecun, sainingxie)

Intelligent Document Processing (IDP) leaderboard launched, unifying evaluation of VLM document understanding capabilities: A new Intelligent Document Processing (IDP) leaderboard has gone live, aiming to provide a unified benchmark for various document understanding tasks such as OCR, KIE, VQA, and table extraction. The leaderboard covers 6 core IDP tasks, 16 datasets, and 9229 documents. Preliminary results show Gemini 2.5 Flash leading overall, but all models perform poorly on long document understanding, and table extraction remains a bottleneck. The latest version of GPT-4o even showed a performance decrease. (Source: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
LangGraph introduces Cron Jobs feature, supporting scheduled triggering of AI agents: LangChain’s LangGraph platform has added a Cron Jobs feature, allowing users to set up scheduled tasks to automatically trigger the execution of AI agents. This functionality enables AI agents to perform tasks according to a predefined schedule, suitable for scenarios requiring periodic processing or monitoring. (Source: hwchase17)
💼 Business
AI software debugging tool Lightrun secures $70 million Series B funding, led by Accel and Insight Partners: AI software observability and debugging tool developer Lightrun announced the completion of a $70 million Series B funding round, led by Accel and Insight Partners, with participation from Citigroup and others, bringing its total funding to $110 million. Its core product, Runtime Autonomous AI Debugger, can pinpoint problematic code within the IDE and provide repair suggestions, aiming to reduce debugging time from hours to minutes. The company’s revenue grew 4.5 times in 2024, with clients including Fortune 500 companies like Citigroup and Microsoft. (Source: 36Kr)

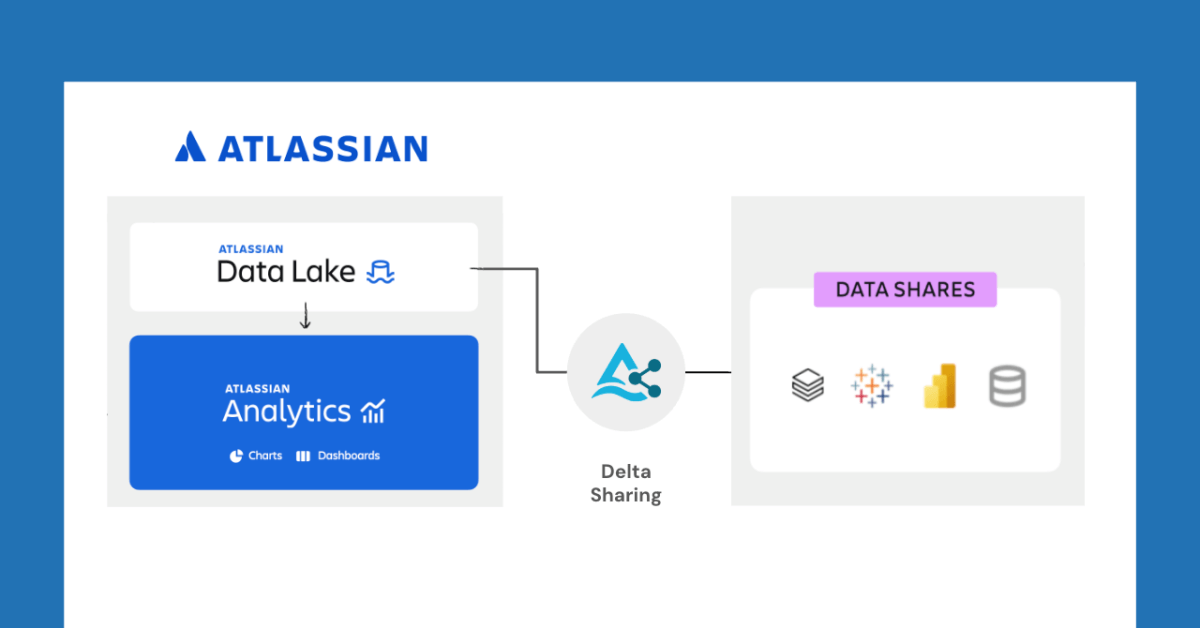
Databricks and Atlassian collaborate to unlock new data sharing capabilities via Delta Sharing: Databricks announced a collaboration with Atlassian to bring new data sharing capabilities to Atlassian Analytics. Through the open protocol of Delta Sharing, Atlassian customers can securely access and analyze their data in the Atlassian Data Lake using tools of their choice. This feature supports use cases such as BI integration, custom data workflows, and cross-team collaboration. (Source: matei_zaharia)
Fastino raises $17.5M for Task-specific Language Models (TLMs): Startup Fastino announced $17.5 million in funding (totaling $25 million pre-seed) led by Khosla Ventures to develop its innovative Task-specific Language Models (TLMs). Fastino claims its TLMs are small, task-specific architectures trainable on low-end gaming GPUs, offering high cost-effectiveness. TLMs achieve task specialization at architectural, pre-training, and post-training levels, eliminating parameter redundancy and architectural inefficiencies. They aim to improve accuracy on specific tasks and can be embedded in latency and cost-sensitive applications. (Source: Reddit r/MachineLearning)

🌟 Community
AI-assisted job application tools raise cheating concerns, prompting companies to strengthen countermeasures: Recently, the use of AI tools to assist with online interviews and written tests has increased. These “AI interview artifacts” can customize answers based on a user’s resume, helping applicants gain an advantage in their job search. Such software is easily accessible, even offering tiered paid packages and remote guidance. This trend can be traced back to the emergence of early AI cheating tools like “Interview Coder.” Companies have begun to implement countermeasures, such as paying attention to abnormal behavior during interviews, considering the introduction of screen detection, or resuming offline interviews. Lawyers point out that using AI to cheat violates the principle of good faith, may lead to termination of employment contracts, and carries privacy leakage risks. (Source: 36Kr)

LangChain CEO Harrison Chase proposes “Ambient Agents” and “Agent Inbox” concepts: LangChain CEO Harrison Chase shared his views on the future development of AI agents at the Sequoia AI Ascent event, proposing the concepts of “Ambient Agents” and “Agent Inbox.” Ambient Agents refer to AI systems that can run continuously in the background, responding to events rather than direct human commands, while an Agent Inbox is a new human-computer interaction interface for managing and supervising the activities of these agents. (Source: hwchase17, hwchase17, hwchase17)

Jim Fan proposes “Physical Turing Test” as new North Star for AI: NVIDIA scientist Jim Fan, at the Sequoia AI Ascent event, proposed the concept of a “Physical Turing Test” as the next “North Star” for the AI field. The test envisions a scenario: after a Sunday hackathon, your home is a mess. You return on Monday evening to find the living room spotless and a candlelight dinner prepared, and you cannot tell if it was done by a human or a machine. He believes this is the goal for general-purpose robotics and shared first principles for solving this problem, including data strategy and scaling laws. (Source: DrJimFan, killerstorm)
AI model evaluation faces a crisis, EvalEval alliance calls for improvements: Addressing the shortcomings in current AI model evaluation methods, such as benchmark saturation and lack of scientific rigor, the EvalEval alliance was mentioned. It aims to unite those concerned about the state of evaluation to collaboratively improve evaluation reporting, address saturation issues, enhance scientific rigor in evaluation, and improve infrastructure. Related discussions suggest a greater focus on the validity of evaluations. (Source: ClementDelangue)

Reddit discussion: Observations and experiences in building LLM workflows: A developer shared on Reddit a summary of experiences from building complex LLM workflows over the past year. Key points include: decomposing tasks into minimal steps and chaining prompts is superior to single complex prompts; using XML tags to structure prompts works better; LLMs need to be explicitly told their role is solely semantic parsing and transformation, not to introduce their own knowledge; use traditional NLP libraries like NLTK to validate LLM output; fine-tuned BERT-like classifiers often outperform LLMs on small tasks; LLMs are unreliable as arbiters or for confidence scoring, especially without clear scoring criteria; in agentic loops, setting conditions for LLMs to exit the loop is challenging; performance typically degrades when input context window exceeds 4K tokens; 32B models are sufficient for structured tasks; structured CoT is better than unstructured; self-written CoT is better than relying on reasoning models; the long-term goal is to fine-tune all components and pay attention to building balanced fine-tuning datasets. (Source: Reddit r/LocalLLaMA)
Reddit users discuss Claude Sonnet 3.7 system prompt settings: Users in the Reddit r/ClaudeAI community reported instability in the Claude Sonnet 3.7 model regarding instruction following, code fixing, and context memory, and solicited effective system prompts. Some users shared prompts mimicking Sonnet 3.5 behavior, as well as detailed instructions emphasizing efficient, practical solutions and adherence to core computer science principles (like DRY, KISS, SRP). Other users suggested improving effectiveness by having Claude rewrite and optimize the system prompt itself, or by using concise, clear single-line instructions. (Source: Reddit r/ClaudeAI)
Discussion on the number of epochs required for LLM fine-tuning: On Reddit r/MachineLearning, a user questioned the Deepseek R1 paper’s fine-tuning of the Deepseek-V3-Base model (approx. 800k samples) with only 2 epochs, exploring metrics beyond the loss function that determine the number of fine-tuning epochs, such as evaluation data performance and data quality. (Source: Reddit r/MachineLearning)
💡 Other
François Chollet: Building solid mental models is a prerequisite for solving difficult problems: AI thinker François Chollet emphasizes that establishing clear, self-consistent mental models is a prerequisite for creatively solving difficult problems (rather than relying on luck), which is different from the ability to quickly solve simple problems. He believes elegance is a combination of expressiveness and conciseness, closely related to compression. (Source: fchollet, teortaxesTex, fchollet, pmddomingos)

Replit CEO Amjad Masad: AI Agents will be the new wave in programming: Replit’s CEO and co-founder Amjad Masad stated in an interview with The Turing Post that he has always believed AI Agents will lead the next wave in programming. He shared his shift in thinking from teaching programming to building agents that can program themselves. He mentioned that software agents are already producing results in real businesses, such as helping a real estate company optimize its lead distribution algorithm, increasing conversion rates by 10%. He believes future billion-dollar startups might be built by AI-augmented solo founders and discussed the conditions needed to achieve this vision, the current state and future of programming, the evolution of Replit’s vision, and the importance of AGI and open source. (Source: TheTuringPost, TheTuringPost)
LazyVim: A Neovim setup for “lazy” people: LazyVim is a Neovim configuration based on lazy.nvim, designed to make it easy for users to customize and extend their Neovim environment. It provides a pre-configured, feature-rich IDE-like experience while maintaining a high degree of flexibility, allowing users to adjust it according to their needs. (Source: GitHub Trending)
