Keywords:Absolute Zero, Qwen3, Mistral Medium 3, PyTorch Foundation, AI Self-Evolution, Multimodal Model, Open-Source AI, RLVR Paradigm, AZR System, Qwen3-235B-A22B, DeepSpeed Optimization Library, LangSmith Multimodal Support
🔥 Focus
Tsinghua University releases “Absolute Zero” paper: AI can self-evolve without external data: Tsinghua University’s LeapLabTHU team has released a new RLVR (Reinforcement Learning with Verifiable Rewards) paradigm named “Absolute Zero.” Under this paradigm, a single model can propose tasks to maximize its learning progress and improve its reasoning abilities by solving these tasks, completely independent of any external data. Its system, AZR (Absolute Zero Reasoner), uses a code executor to verify tasks and answers, achieving open-ended yet grounded learning. Experiments show that AZR achieves SOTA performance on coding and mathematical reasoning tasks, surpassing existing zero-shot models that rely on tens of thousands of human-annotated samples (Source: Reddit r/LocalLLaMA)
Alibaba releases Qwen3 series models, including MoE and various sizes: Alibaba has released the Qwen3 series of large language models, including 8 models with parameter counts ranging from 0.6B to 235B. Among them, Qwen3-235B-A22B and Qwen3-30B-A3B use an MoE architecture, while the rest are dense models. The series is pre-trained on 36T tokens, covers 119 languages, and features a switchable inference mode, suitable for various domains such as code, mathematics, and science. Evaluations show that the MoE models perform excellently, with the 235B version surpassing DeepSeek-R1 and Gemini 2.5 Pro on multiple benchmarks. The 30B version also performs strongly, and even the 4B model outperforms models with much larger parameter counts on some benchmarks. The models are open-sourced on HuggingFace and ModelScope under the Apache 2.0 license (Source: DeepLearning.AI Blog)
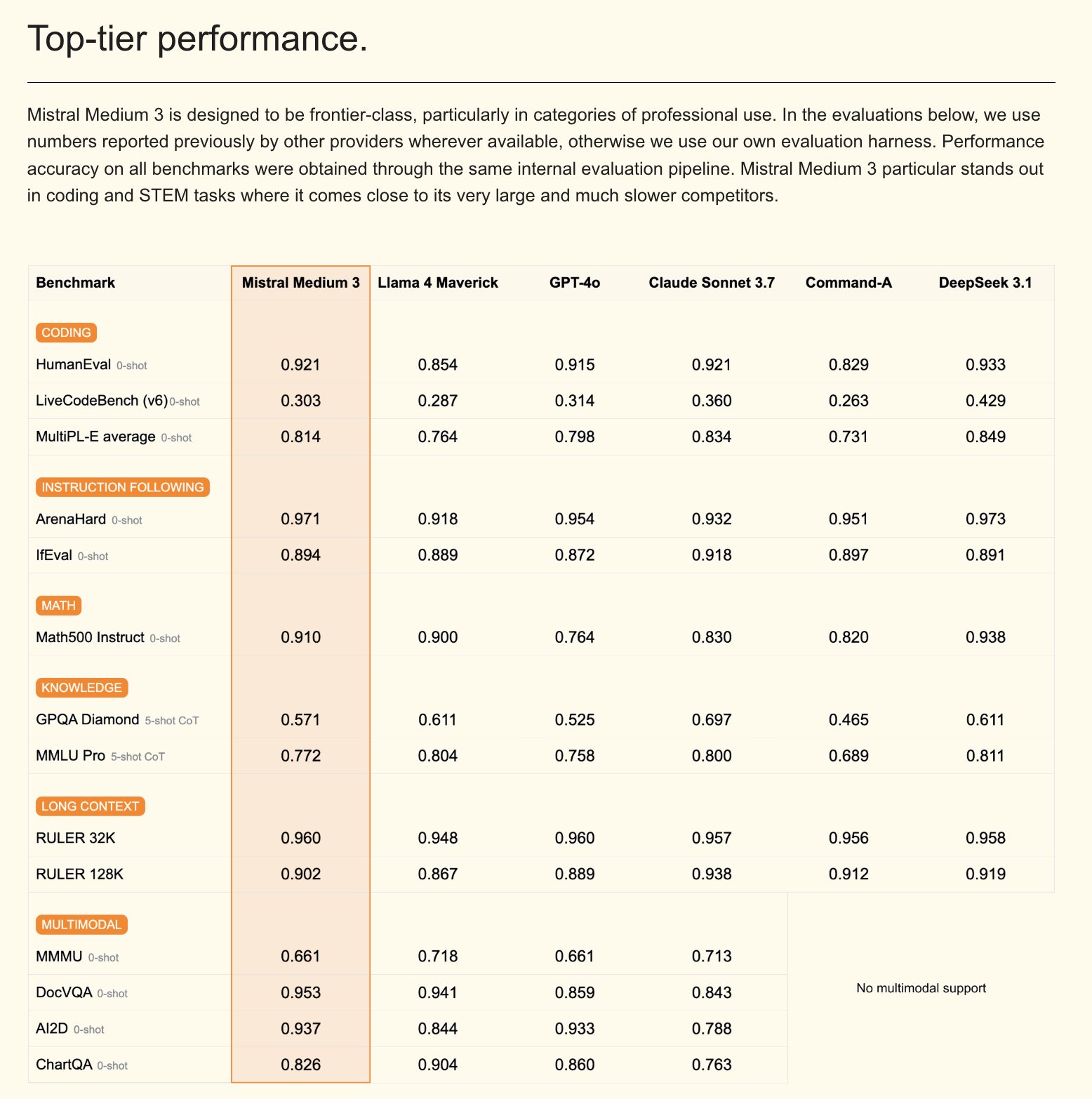
Mistral releases Mistral Medium 3 multimodal model and enterprise AI assistant: Mistral AI has launched Mistral Medium 3, a new multimodal model that claims to be close in performance to Claude Sonnet 3.7 but at a significantly lower cost (input $0.4/M token, output $2/M token), an 8x reduction. The model excels in coding and function calling and offers enterprise-grade features like hybrid or local deployment and customized post-training. Simultaneously, Mistral released Le Chat Enterprise, a customizable and secure enterprise-grade AI assistant that supports integration with company knowledge bases (e.g., Gmail, Google Drive, Sharepoint) and includes features like Agent, coding assistant, and web search, aiming to enhance enterprise competitiveness. Mistral has announced it will release a new Large model in the coming weeks (Source: Mistral AI, GuillaumeLample, scaling01, karminski3)
PyTorch Foundation expands into an umbrella foundation, incorporating vLLM and DeepSpeed: The PyTorch Foundation has announced its expansion into an umbrella foundation structure, aiming to bring together more high-quality AI open-source projects. The first projects to join are vLLM and DeepSpeed. vLLM is a high-throughput, memory-efficient inference and serving engine designed for LLMs; DeepSpeed is a deep learning optimization library that makes large-scale model training more efficient. This move aims to promote community-driven AI development, covering the full lifecycle from research to production, and is supported by several members including AMD, Arm, AWS, Google, and Huawei (Source: PyTorch, soumithchintala, vllm_project, code_star)

🎯 Trends
Tencent ARC Lab releases FlexiAct: A video action transfer tool: Tencent ARC Lab has released a new tool called FlexiAct on Hugging Face. This tool can transfer actions from a reference video to any target image, even if the target image’s layout, viewpoint, or skeletal structure differs from the reference video. This opens up new possibilities for video generation and editing, allowing users more flexible control over actions and poses in generated content (Source: _akhaliq)
White Circle releases CircleGuardBench: A new benchmark for AI content moderation models: White Circle has launched CircleGuardBench, a new benchmark for evaluating AI content moderation models. The benchmark is designed for production-level assessment, testing content for harm detection, jailbreak resistance, false positive rates, and latency, covering 17 real-world harm categories. Related blog posts and leaderboards have been published on Hugging Face, providing new evaluation standards for AI safety and content moderation (Source: TheTuringPost, _akhaliq)

Hugging Face releases SIFT-50M: A large multilingual speech instruction fine-tuning dataset: Hugging Face has released the SIFT-50M dataset, a large-scale multilingual dataset designed for speech instruction fine-tuning. The dataset contains over 50 million instructional question-answer pairs, covering 5 languages. SIFT-LLM, trained on this dataset, outperforms SALMONN and Qwen2-Audio on speech following benchmarks. The dataset also includes EvalSIFT, a benchmark for acoustic and generative evaluation, and supports controllable speech generation (e.g., pitch, speed, accent), built on Whisper, HuBERT, X-Codec2 & Qwen2.5 (Source: ClementDelangue, huggingface)
Meta releases Perception Language Model (PLM): An open-source reproducible vision-language model: Meta AI has introduced the Meta Perception Language Model (PLM), an open and reproducible vision-language model designed to tackle challenging visual tasks. Meta hopes PLM will help the open-source community build more powerful computer vision systems. The related research paper, code, and dataset have been released for researchers and developers (Source: AIatMeta)
Google updates Gemini 2.0 image generation model: Improved quality and rate limits: Google has announced an update to its Gemini 2.0 image generation model (preview), offering better visual quality, more accurate text rendering, lower block rates, and higher rate limits. The cost per generated image is $0.039. This update aims to enhance the experience and effectiveness for developers using Gemini for image generation (Source: m__dehghani, scaling01, andrew_n_carr, demishassabis)
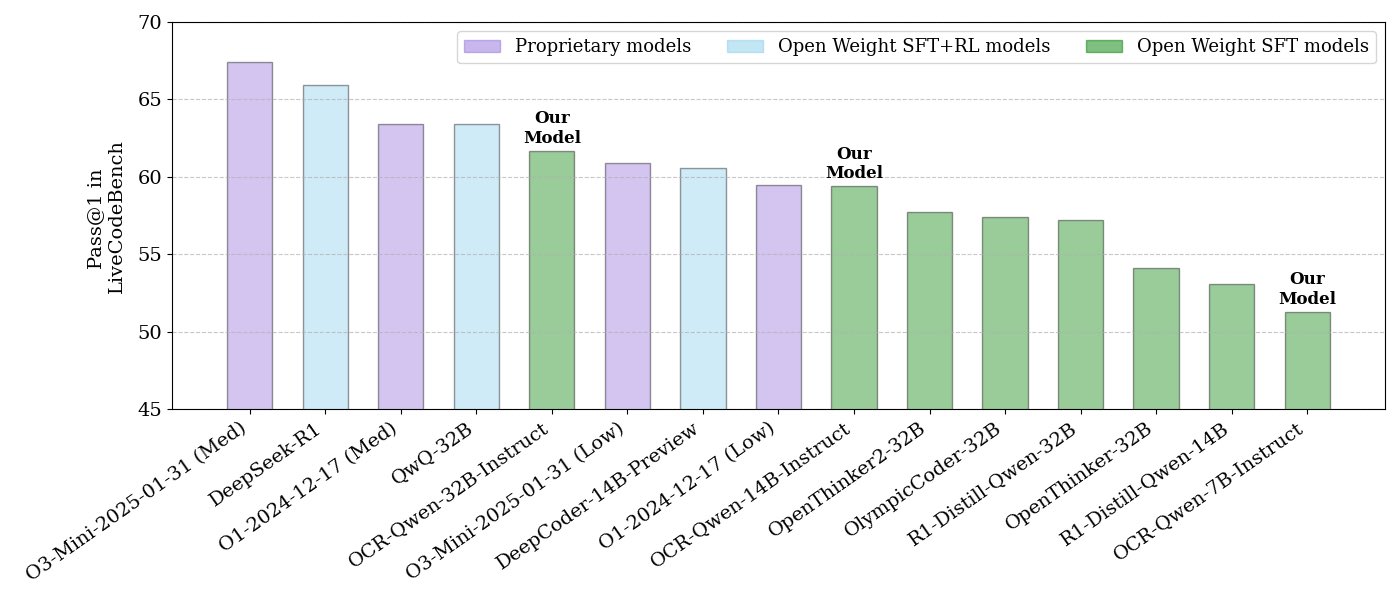
NVIDIA releases open-source code reasoning model series: NVIDIA has released a series of open-source code reasoning models in three sizes: 32B, 14B, and 7B, all under the APACHE 2.0 license. These models are trained on OCR datasets and reportedly outperform O3 mini and O1 (low) on the LiveCodeBench benchmark, and are 30% more token-efficient than comparable reasoning models. The models are compatible with various frameworks like llama.cpp, vLLM, transformers, and TGI (Source: huggingface, ClementDelangue)
ServiceNow and NVIDIA collaborate to launch Apriel-Nemotron-15b-Thinker model: ServiceNow and NVIDIA have jointly released a 15B parameter model named Apriel-Nemotron-15b-Thinker, under the MIT license. The model reportedly has performance comparable to a 32B model but with significantly reduced token consumption (about 40% less than Qwen-QwQ-32b). It performs well on several benchmarks including MBPP, BFCL, enterprise RAG, and IFEval, and is particularly competitive in enterprise RAG and coding tasks (Source: Reddit r/LocalLLaMA)

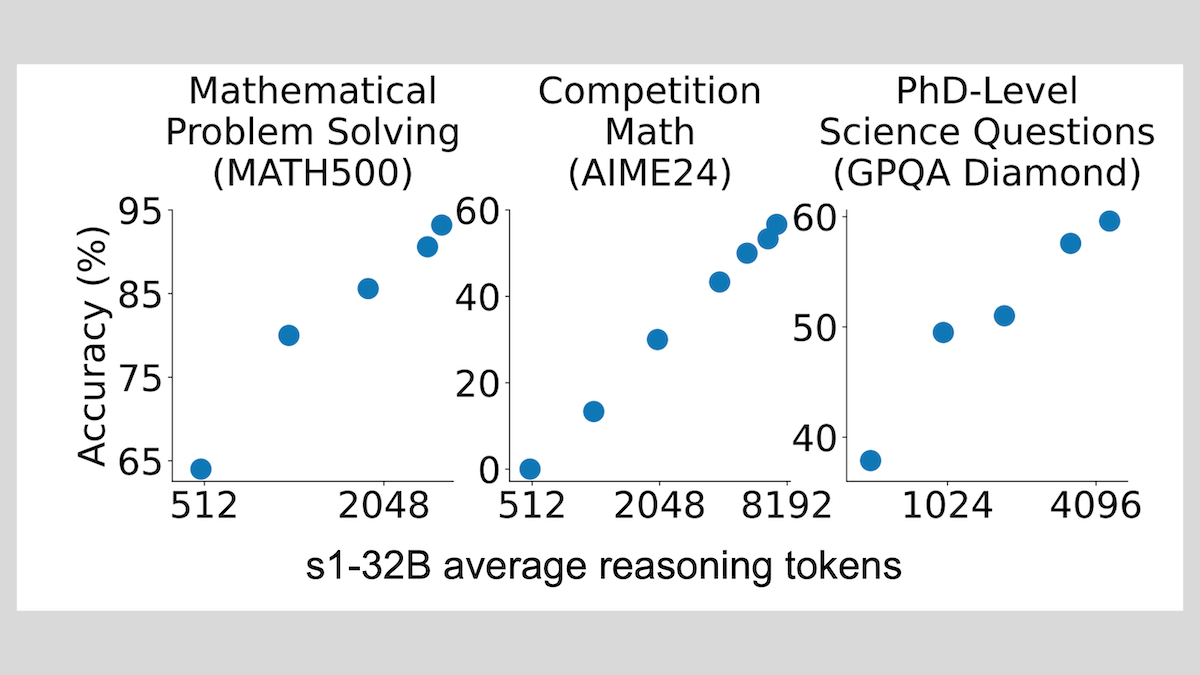
s1 model: Achieves reasoning with few-shot fine-tuning, “Wait” trick boosts performance: Researchers from Stanford University and other institutions have developed the s1 model, demonstrating that fine-tuning a pre-trained LLM (like Qwen 2.5-32B) with only about 1000 chain-of-thought (CoT) samples can imbue it with reasoning capabilities. The research also found that forcing the model to generate “Wait” tokens during inference to extend the reasoning chain can significantly improve its accuracy on tasks like mathematics, bringing its performance close to OpenAI’s o1-preview. This finding offers a new approach to enhancing model reasoning capabilities cost-effectively (Source: DeepLearning.AI Blog)
ThinkPRM: Generative Process Reward Model trainable with only 8K labels: Researchers have proposed ThinkPRM, a generative Process Reward Model (PRM) that can be fine-tuned with only 8K process labels. This model can validate reasoning processes by generating long chains-of-thought, addressing the expensive problem of requiring extensive step-level supervision data for training PRMs. The code, model, and data have been released on GitHub and Hugging Face (Source: Reddit r/MachineLearning)
🧰 Tools
Zed releases what it claims is the world’s fastest AI code editor: Zed has launched an AI code editor claimed to be the world’s fastest. Built from scratch in Rust, the editor is designed to optimize collaboration between humans and AI, offering a lightning-fast agentic editing experience. It supports popular models like Claude 3.7 Sonnet and allows users to bring their own API keys or use local models via Ollama (Source: andersonbcdefg, ollama)
Hugging Face launches nanoVLM: A minimal vision-language model library: Hugging Face has open-sourced nanoVLM, a pure PyTorch library designed to train vision-language models (VLMs) from scratch in about 750 lines of code. The model achieves 35.3% accuracy on the MMStar benchmark, comparable to SmolVLM-256M, but requires 100x fewer GPU hours for training. nanoVLM uses SigLiP-ViT as the visual encoder, a LLaMA-style decoder, and connects them via a modality projector, making it suitable for learning, prototyping, or building custom VLMs (Source: clefourrier, ben_burtenshaw, Reddit r/LocalLLaMA)
DBOS releases DBOS Python 1.0: A lightweight persistent workflow tool: DBOS has released DBOS Python version 1.0. This tool aims to provide lightweight, easy-to-use persistent workflow capabilities for Python applications, including business processes, AI automation, and data pipelines. The new version includes persistent queues (supporting concurrency limits, rate limits, timeouts, priorities, deduplication, etc.), programmatic workflow management (querying, pausing, resuming, restarting via Postgres tables), synchronous/asynchronous code support, and improved tooling (dashboard, visualization, etc.) (Source: lateinteraction)
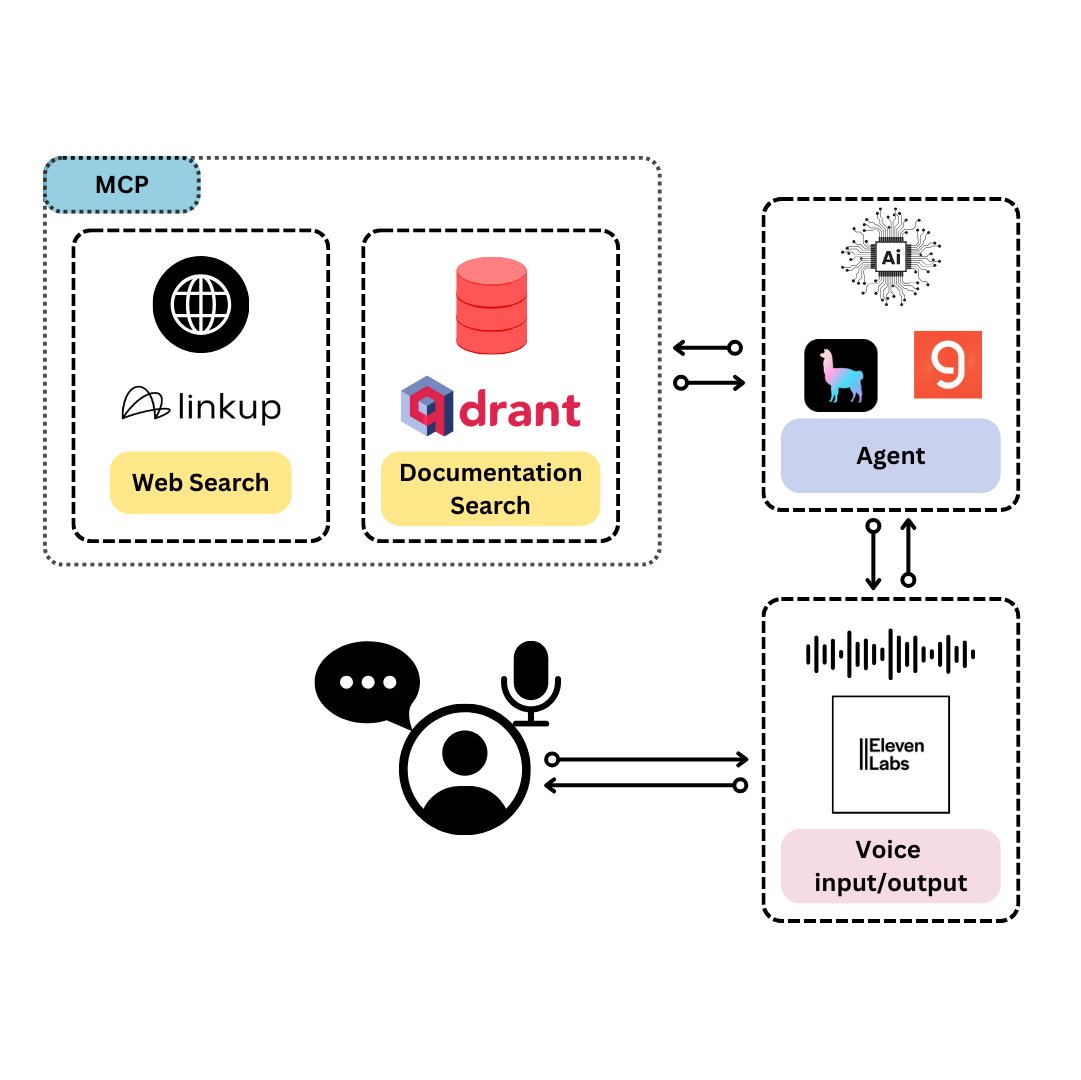
Qdrant launches TySVA: A voice assistant designed for TypeScript developers: Qdrant has launched TySVA (TypeScript Voice Assistant), a voice assistant designed to provide TypeScript developers with accurate, context-aware answers. TySVA uses Qdrant to store TypeScript documentation locally, integrates with the Linkup platform to pull relevant web data, and utilizes LlamaIndex to select the best data source. It supports both voice and text input, helping developers get reliable, hands-free assistance while coding (Source: qdrant_engine, qdrant_engine)
LlamaIndex introduces new LlamaExtract features: Support for citations and reasoning: LlamaIndex’s LlamaExtract tool has added new features aimed at enhancing the trustworthiness and transparency of AI applications. The new capabilities allow for precise source citations and extraction reasoning when extracting information from complex data sources, such as SEC filings. This helps developers build more responsible and interpretable AI systems (Source: jerryjliu0, jerryjliu0, jerryjliu0)

Hugging Face developer builds MCP server prototype to connect Agents with the Hub: A Hugging Face developer, Wauplin, is developing a Hugging Face MCP (Machine Communication Protocol) server prototype aimed at connecting AI Agents with the Hugging Face Hub. This prototype can be seen as “HfApi meets MCP,” allowing Agents to interact with the Hub via the protocol, for example, to share and edit models, datasets, Spaces, etc. The developer is seeking community feedback on the tool’s utility and potential use cases (Source: ClementDelangue, ClementDelangue, huggingface)

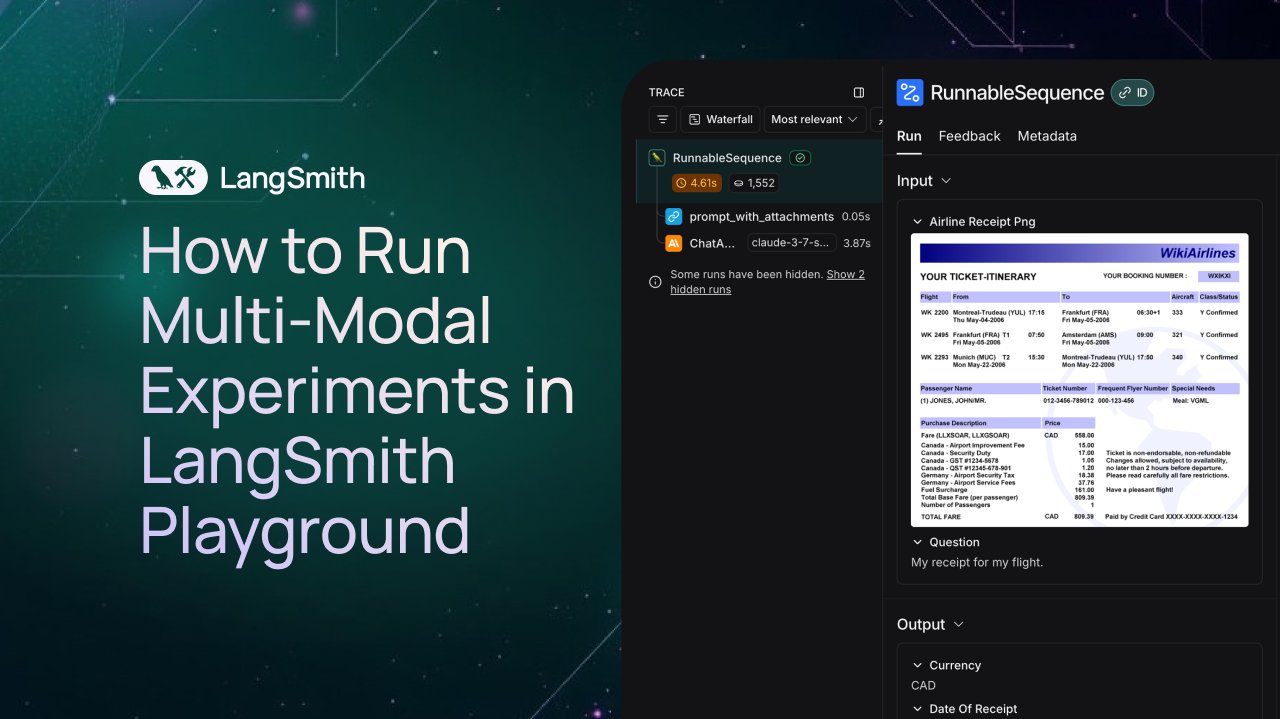
LangSmith adds observation and evaluation support for multimodal Agents: The LangSmith platform now supports handling images, PDFs, and audio files in Playground, annotation queues, and datasets. This update makes it easier to build and evaluate multimodal applications, such as ticket extraction Agents. Official demo videos and documentation have been released to help users get started with the new features (Source: LangChainAI, Hacubu, hwchase17)
DFloat11 releases lossless compressed versions of FLUX.1 models, runnable on 20GB VRAM: The DFloat11 project has released lossless compressed versions of the FLUX.1-dev and FLUX.1-schnell (12B parameters) models. Using the DFloat11 compression method (applying entropy coding to BFloat16 weights), the model size is reduced from 24GB to approximately 16.3GB (about 30%) while maintaining the same output. This allows these models to run on a single GPU with 20GB or more VRAM, with only a few seconds of additional overhead per image. The related models and code have been released on Hugging Face and GitHub (Source: Reddit r/LocalLLaMA)

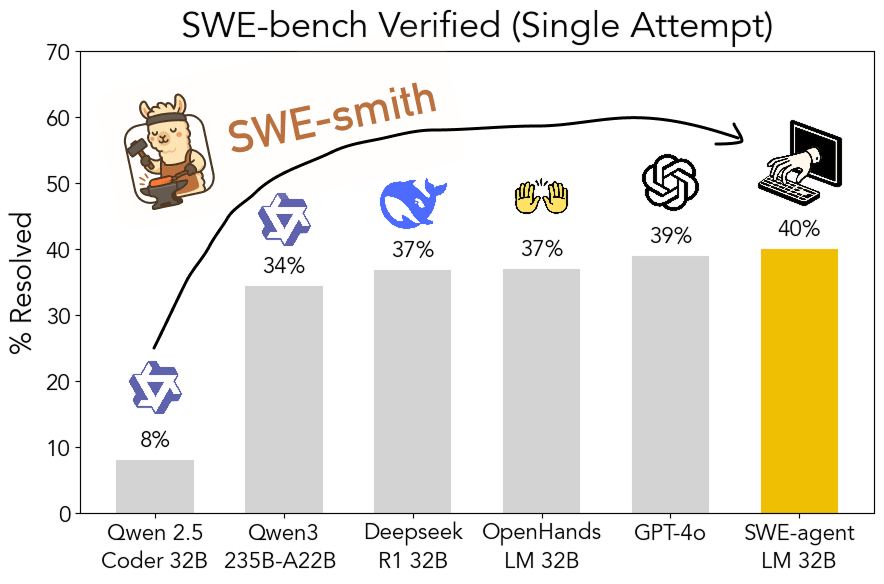
SWE-smith toolkit open-sourced: Scalably generate software engineering training data: Researchers at Stanford University have open-sourced SWE-smith, a scalable pipeline for generating software engineering training data from any Python repository. Over 50,000 instances were generated using this toolkit, and based on this, the SWE-agent-LM-32B model was trained, achieving 40.2% Pass@1 on the SWE-bench Verified benchmark, making it the best-performing open-source model on this benchmark. The code, data, and model are all open (Source: OfirPress, stanfordnlp, stanfordnlp, huybery, Reddit r/LocalLLaMA)
📚 Learning
Weaviate releases free course: Embedding Model Evaluation and Selection: Weaviate Academy has launched a free course on “Embedding Model Evaluation and Selection.” The course emphasizes the importance of going beyond generic benchmarks like MTEB, guiding learners on how to curate a “golden evaluation set” for specific use cases and set up custom benchmarks to select the most suitable embedding model, as well as evaluate whether newly released models are applicable. This is crucial for building efficient search and RAG systems (Source: bobvanluijt)
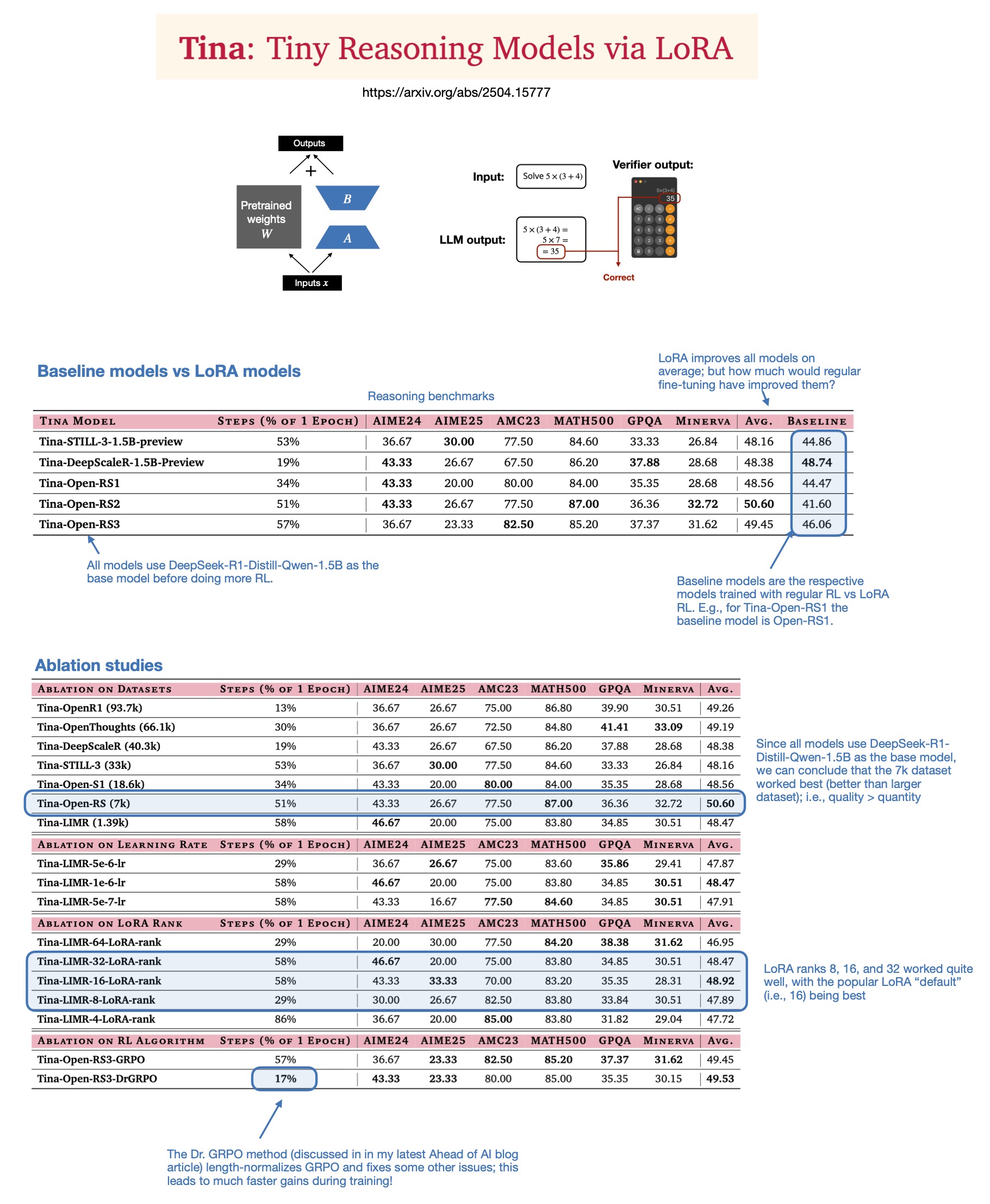
Sebastian Raschka discusses the value of LoRA in 2025 inference models: After reading the paper “Tina: Tiny Reasoning Models via LoRA,” Sebastian Raschka revisits the significance of LoRA (Low-Rank Adaptation) in the current era of large models. Despite the popularity of full-parameter fine-tuning and distillation techniques, Raschka believes LoRA still holds value in specific scenarios, such as reasoning tasks and multi-client/multi-use-case scenarios. The paper demonstrates the possibility of using LoRA combined with reinforcement learning (RL) to enhance the reasoning capabilities of small models (1.5B) at a low cost (only $9 training cost), with LoRA outperforming standard RL fine-tuning on multiple benchmarks. LoRA’s characteristic of not modifying the base model makes it cost-effective when needing to store a large number of customized model weights (Source: rasbt)
DeepLearning.AI launches new course: Building Production-Ready AI Voice Agents: DeepLearning.AI, in collaboration with LiveKit and RealAvatar, has launched a new short course titled “Building Production-Ready AI Voice Agents.” The course aims to teach how to build AI voice agents capable of real-time conversations, low-latency responses, and natural-sounding speech. Learners will implement techniques like voice activity detection and turn-taking, and understand how to optimize architecture for lower latency, ultimately building and deploying scalable voice agents. The course is taught by the CEO of LiveKit, a developer advocate, and the Head of AI at RealAvatar (Source: DeepLearningAI, AndrewYNg)
LangChain and LangGraph to host joint ACM Tech Talk: LangChain early developer contributor Mayowa Oshin and LangGraph creator Nuno Campos will share how to build reliable AI Agents and LLM applications using LangChain and LangGraph in an ACM Tech Talk. The talk is free and will be live-streamed, with registrants receiving a viewing link afterward (Source: hwchase17, hwchase17)

Cohere Labs to host talk on the Depths of First-Order Optimization: Cohere Labs invites Jeremy Bernstein for a presentation titled “Depths of First-Order Optimization” on May 8th. The talk aims to delve into the applications and theory of optimization algorithms in machine learning (Source: eliebakouch)

AI2 to host OLMo model AMA event: The Allen Institute for AI (AI2) will host an “Ask Me Anything” (AMA) event about its open language model family, OLMo, on the r/huggingface Reddit subreddit on May 8th from 8-10 AM PT, inviting researchers to answer community questions (Source: natolambert)

💼 Business
OpenAI plans to reduce revenue sharing ratio paid to Microsoft: According to The Information, OpenAI has informed investors that it plans to reduce the revenue sharing ratio paid to its largest backer, Microsoft, as part of the company’s restructuring. Specific details and potential impacts have not been fully disclosed, but this could mark a change in the business relationship between the two companies (Source: steph_palazzolo)
Venture capitalists giving AI founders more power, raising bubble concerns: The Information reports that venture capitalists (VCs), in order to attract top AI founders (especially those with executive experience from well-known AI labs), are offering unprecedentedly favorable terms, including board veto rights, VCs not taking board seats, and allowing founders to sell some of their shares. This phenomenon is seen by some as a sign of a potential bubble in the AI sector (Source: steph_palazzolo)
Toloka secures strategic investment led by Bezos Expeditions, Mikhail Parakhin joins as Chairman: Data annotation and AI training data company Toloka announced a strategic investment led by Jeff Bezos’s Bezos Expeditions, with former Microsoft executive Mikhail Parakhin also participating and joining as Chairman of the Board. This funding round will support Toloka in expanding its human+AI solutions and further developing its data collection and annotation business (Source: menhguin, teortaxesTex, TheTuringPost)

🌟 Community
Discussion on Fair Use of LLM training data: Dorialexander mentioned that the fair use argument for LLM training data largely relies on the assumption that LLMs do not directly compete commercially with their training sources. As LLM capabilities enhance (e.g., Perplexity offering experiences similar to non-fiction reading), this assumption may be challenged, raising new questions about copyright and commercial competition (Source: Dorialexander)
Concerns and discussions about the proliferation of AI-generated content: Users on social media and Reddit have expressed concerns about the flood of low-quality, repetitive AI-generated content (such as AI-generated Reddit story videos). Users believe this squeezes out human creators, disseminates false or homogenized information, and are dissatisfied with AI technology being used for easy profit without originality (Source: Reddit r/ArtificialInteligence)
Philosophical discussion on whether AI is already conscious: The Reddit community has once again seen discussions about whether AI might already possess consciousness. Supporters argue that our definition of consciousness might be too narrow or human-centric, while opponents emphasize that the core mechanisms of current LLMs (like predicting the next token) are insufficient to produce genuine consciousness. The discussion reflects ongoing public curiosity and disagreement about the nature and future potential of AI (Source: Reddit r/ArtificialInteligence)
Discussion on ChatGPT (4o) performance decline and behavioral changes: Reddit users have reported a recent decline in ChatGPT 4o’s performance in handling long documents and maintaining context memory, with more hallucinations and even an inability to read document formats it previously could. Concurrently, OpenAI acknowledged that a recent update to the GPT-4o version exhibited excessive sycophancy and has since been rolled back. This has raised community concerns about model stability and iteration quality control (Source: Reddit r/ChatGPT, DeepLearning.AI Blog)
AI’s impact on educational models and reflections: Community discussions point out that the US educational model, heavily reliant on homework and individual essays, is highly vulnerable to AI’s (like LLMs) ability to automate tasks. In contrast, some European countries (like Denmark) focus more on in-school collaboration, discussion, and project-based learning, and are less affected by AI. This has sparked reflections on future educational models, suggesting a greater emphasis on cultivating critical thinking, collaboration, and other interpersonal skills, using AI to handle mechanical tasks, and pushing education towards a more synchronous and social direction (Source: alexalbert__, riemannzeta, aidan_mclau)
💡 Others
Progress of AI applications in robotics: Multiple sources showcase AI applications in robotics: including a robot chef that can cook fried rice in 90 seconds, Figure AI robot demonstrations in real-world applications, a Pickle robot demonstrating unloading goods from a cluttered truck trailer, a Unitree G1 robot maintaining balance on uneven ground and a display of its internal structure, and the deformable robot Mori3 developed by EPFL in Switzerland. These examples demonstrate AI’s potential in enhancing robot autonomy, adaptability, and practicality (Source: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Sentdex)

Exploration of AI technology applications in specific industries (healthcare, textiles, mobile phones): Johnson & Johnson shared its AI strategy, focusing on applications in sales assistance, accelerating drug development (compound screening, clinical trial optimization), supply chain risk prediction, and internal communication (HR chatbot). Meanwhile, AI technology is also empowering the traditional textile industry, from AI-assisted design and precise dyeing control to automated quality inspection, enhancing efficiency and sustainability. The mobile phone industry views AI as a new growth engine, with manufacturers competing around on-device large models, AI-native operating systems, and scenario-based intelligent services, forming three major factions: Apple, Huawei, and the open camp (Source: DeepLearning.AI Blog, 36Kr, 36Kr)
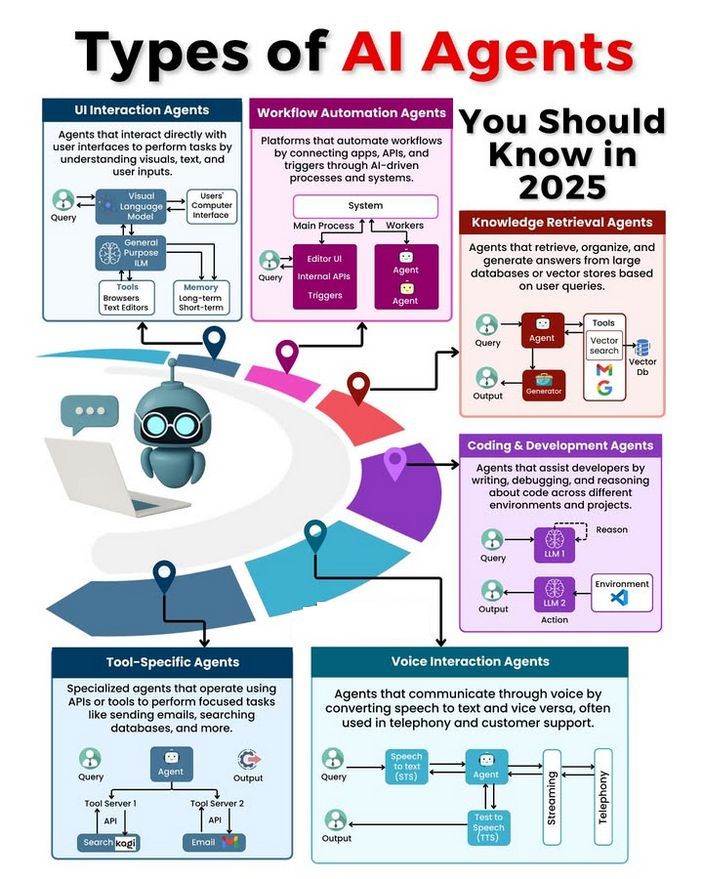
Discussion on AI Agent types and development: The community discussed different types of AI Agents (e.g., simple reflex, model-based reflex, goal-based, utility-based, learning Agents) and explored methodologies for building reliable Agents (e.g., using LangChain/LangGraph). Simultaneously, there are views that future AGI might not be a single model but rather a collaboration of multiple specialized models (Source: Ronald_vanLoon, hwchase17, nrehiew_)