Keywords:Gemini 2.5 Pro, AI model, humanoid robot, AI ethics, AI startup, AI-generated content, AI-assisted creativity, Gemini 2.5 Pro completes Pokémon Blue, Anthropic Claude global web search, Qwen3 MoE model routing bias, Runway Gen-4 References feature, AI applications in mental health support
🔥 Focus
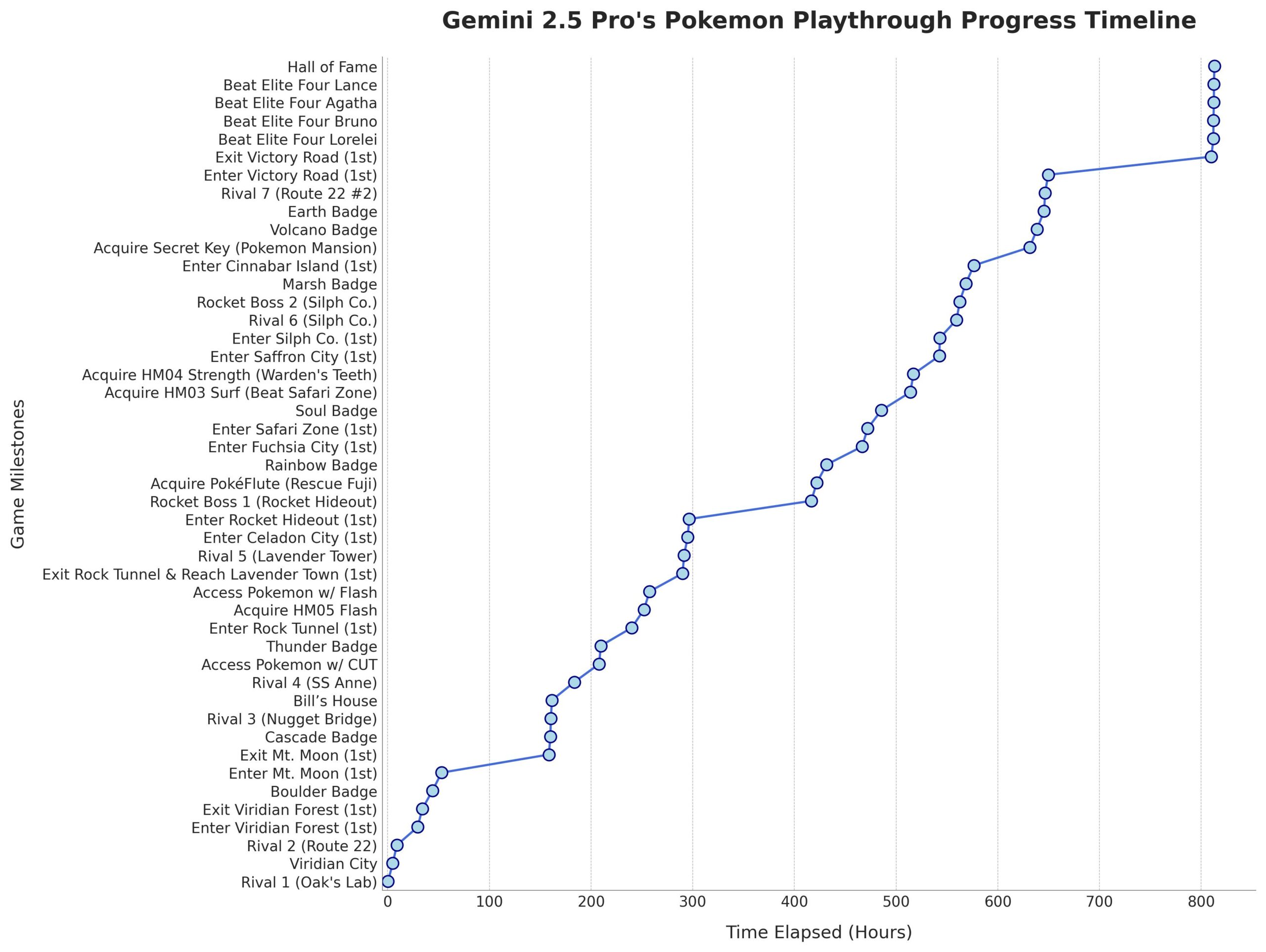
Gemini 2.5 Pro Successfully Beats Pokémon Blue: Google’s Gemini 2.5 Pro AI model successfully completed the classic game Pokémon Blue, including collecting all 8 badges and defeating the Elite Four of the Pokémon League. This achievement was run and streamed live by streamer @TheCodeOfJoel and congratulated by Google CEO Sundar Pichai and DeepMind CEO Demis Hassabis. This demonstrates significant progress in current AI’s capabilities in complex task planning, long-term strategy formulation, and interaction with simulated environments, surpassing previous AI performance in the game and marking a new milestone in AI agent capabilities. (Source: Google, jam3scampbell, teortaxesTex, YiTayML, demishassabis, _philschmid, Teknium1, tokenbender)
Apple Partners with Anthropic to Develop AI Coding Platform “Vibe Coding”: According to Bloomberg, Apple is collaborating with AI startup Anthropic to jointly develop a new AI-driven coding platform called “Vibe Coding”. The platform is currently being promoted and tested internally among Apple employees and may potentially be opened to third-party developers in the future. This marks Apple’s further exploration in the field of AI programming assistance tools, aiming to leverage AI to enhance development efficiency and experience, possibly complementing or integrating with its own projects like Swift Assist. (Source: op7418)
Progress and Discussion on AI-Driven Robotics: Humanoid robots and embodied intelligence have recently garnered widespread attention. Figure showcased its high-tech new headquarters, covering everything from batteries and actuators to AI labs, signaling its ambitions in the robotics field. Disney also demonstrated its humanoid character robot technology. However, during the Beijing Humanoid Robot Marathon, some robots (including a customer-modified Unitree G1) performed poorly, experiencing falls, poor battery life, and balance issues. This sparked discussions about the current practical capabilities of humanoid robots, highlighting the significant progress still needed in both their “motor control” (movement) and “intelligent decision-making” (intelligence). (Source: adcock_brett, Ronald_vanLoon, 人形机器人,最重要的还是“脑子”)

Discussions on AI Ethics and Social Impact Intensify: Discussions on the social impact and ethical issues of AI are increasing on social media and in research fields. For example, California’s SB-1047 AI bill has sparked controversy, with related documentaries exploring the necessity and challenges of regulation. The NAACL 2025 conference hosted a tutorial on “Social Intelligence in the Age of LLMs,” exploring long-term and emerging challenges in AI interaction with humans and society. Meanwhile, users express concerns about the quality of AI-generated content (“slop”), suggesting a need for better model design and control. These discussions reflect growing societal concern about the ethical, regulatory, and social adaptability issues brought about by the rapid development of AI technology. (Source: teortaxesTex, gneubig, stanfordnlp, jam3scampbell, willdepue, wordgrammer)

🎯 Trends
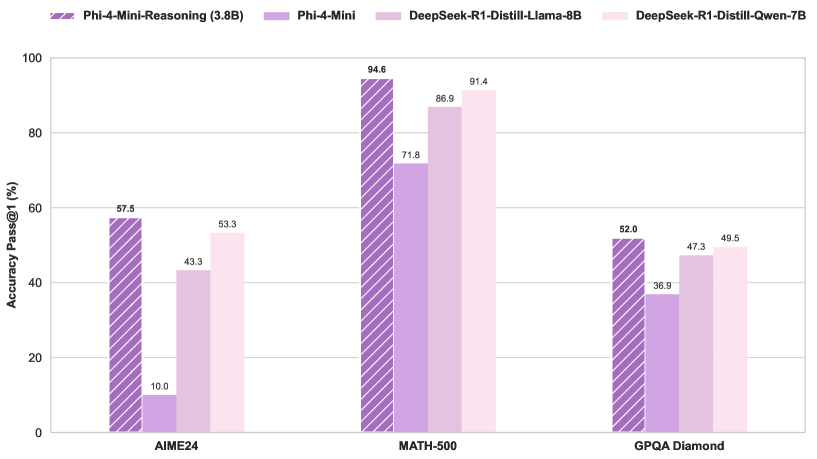
Microsoft Releases Phi-4-Mini-Reasoning Model: Microsoft has released the Phi-4-Mini-Reasoning model on Hugging Face. This model aims to enhance the mathematical reasoning capabilities of small language models, further advancing the development of miniaturized, high-efficiency models. (Source: _akhaliq)
Anthropic Claude Model Supports Global Web Search: Anthropic announced that its Claude AI model now offers global web search functionality for all paid users. For simple tasks, Claude performs a quick search; for complex questions, it explores multiple information sources, including Google Workspace, enhancing the model’s real-time information retrieval and processing capabilities. (Source: Teknium1, Reddit r/ClaudeAI)

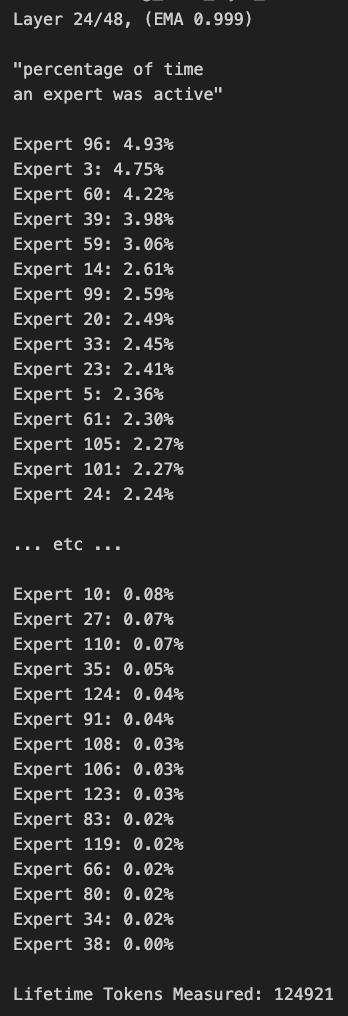
Qwen3 MoE Model Routing Shows Bias, Can Be Pruned: User kalomaze analyzed and found significant bias in the routing distribution of the Qwen3 MoE (Mixture of Experts) model. Even the 30B MoE model shows potential for pruning. This implies that some Experts might be underutilized, and pruning these experts could potentially reduce model size and computational requirements without significantly impacting performance. Kalomaze has released a version pruned from 30B to 16B based on this finding and plans to release a version pruned from 235B to 150B. (Source: andersonbcdefg, Reddit r/LocalLLaMA)
DeepSeek Prover V2 Excels Among Open-Source Math Assistants: DeepSeek Prover V2 is considered the best-performing open-source math assistant model currently available. Although its performance still lags behind closed-source or more powerful models like Gemini 2.5 Pro, o4 mini high, o3, Claude 3.7, and Grok 3, it performs well in structured reasoning. Users feel it needs improvement in “brainstorming” sessions requiring creative thinking. (Source: cognitivecompai)
Model Preference Discussion: Developer Tendencies and Specific Model Traits: Discussions about the pros and cons of different large models continue within the developer community. For instance, Sentdex believes o3 combined with Codex performs better in Cursor than Claude 3.7. VictorTaelin states that although Sonnet 3.7 isn’t perfect (sometimes proactively adding unrequested content, intelligence not meeting expectations), in practice, it still provides more stable and reliable results than GPT-4o (prone to errors), o3/Gemini (poor code formatting and rewriting), R1 (slightly outdated), and Grok 3 (second best, but slightly inferior in practice). This reflects the varying suitability of different models for specific tasks and workflows. (Source: Sentdex, VictorTaelin, paul_cal)

LLM Performance Trend Discussion: Exponential Growth or Diminishing Returns?: Reddit users discussed whether LLMs are still undergoing exponential improvement. One view suggests that despite rapid early progress, LLM performance improvement is now facing diminishing returns, making additional performance gains increasingly difficult and expensive, similar to the development of autonomous driving technology. Other users counter this, pointing to the significant leap from GPT-3 to Gemini 2.5 Pro as evidence that progress remains substantial and it’s too early to declare a plateau. The discussion reflects differing expectations about the future pace of AI development. (Source: Reddit r/ArtificialInteligence)
AI Chips Become Key to Humanoid Robot Development: Industry opinion holds that the core of humanoid robots lies in their “brain,” i.e., high-performance chips. The article points out that current humanoid robots are deficient in motor control and intelligent decision-making, and chip performance directly determines the robot’s level of intelligence. Chips like Nvidia’s GPUs, Intel processors, and domestic ones like Black Sesame Technologies’ Huashan A2000 and Wudang C1236 are providing robots with enhanced perception, inference, and control capabilities, key to moving humanoid robots from gimmick to practical application. (Source: 人形机器人,最重要的还是“脑子”)

AI Ethics and Anthropomorphism: Why Do We Say “Thank You” to AI?: Discussion points out that although AI lacks emotions, users tend to use polite language (like “thank you,” “please”) with it. This stems from humans’ anthropomorphic instincts and “perception of social presence.” Research suggests that polite interaction might guide AI to produce more desirable, human-like responses. However, this also carries risks, such as AI learning and amplifying human biases or being maliciously guided to produce inappropriate content. Politeness towards AI reflects the complex psychology and social adaptation of humans interacting with increasingly intelligent machines. (Source: 你对 AI 说的每一句「谢谢」,都在烧钱)

🧰 Tools
Runway Gen-4 References Feature: RunwayML’s Gen-4 References feature allows users to incorporate their own or other reference images into AI-generated videos or pictures (like memes). User feedback indicates the feature works remarkably well, capable of handling multiple consistent characters appearing in the same generated image, simplifying the process of integrating specific people or styles into AI creations. (Source: c_valenzuelab)

Krea AI Launches Image Generation Templates: Krea AI adds a new feature that turns common GPT-4o image generation prompts into templates. Users can simply upload their own image and select a template to generate images in the corresponding style, eliminating the need to manually input complex prompts and simplifying the image generation workflow. (Source: op7418)
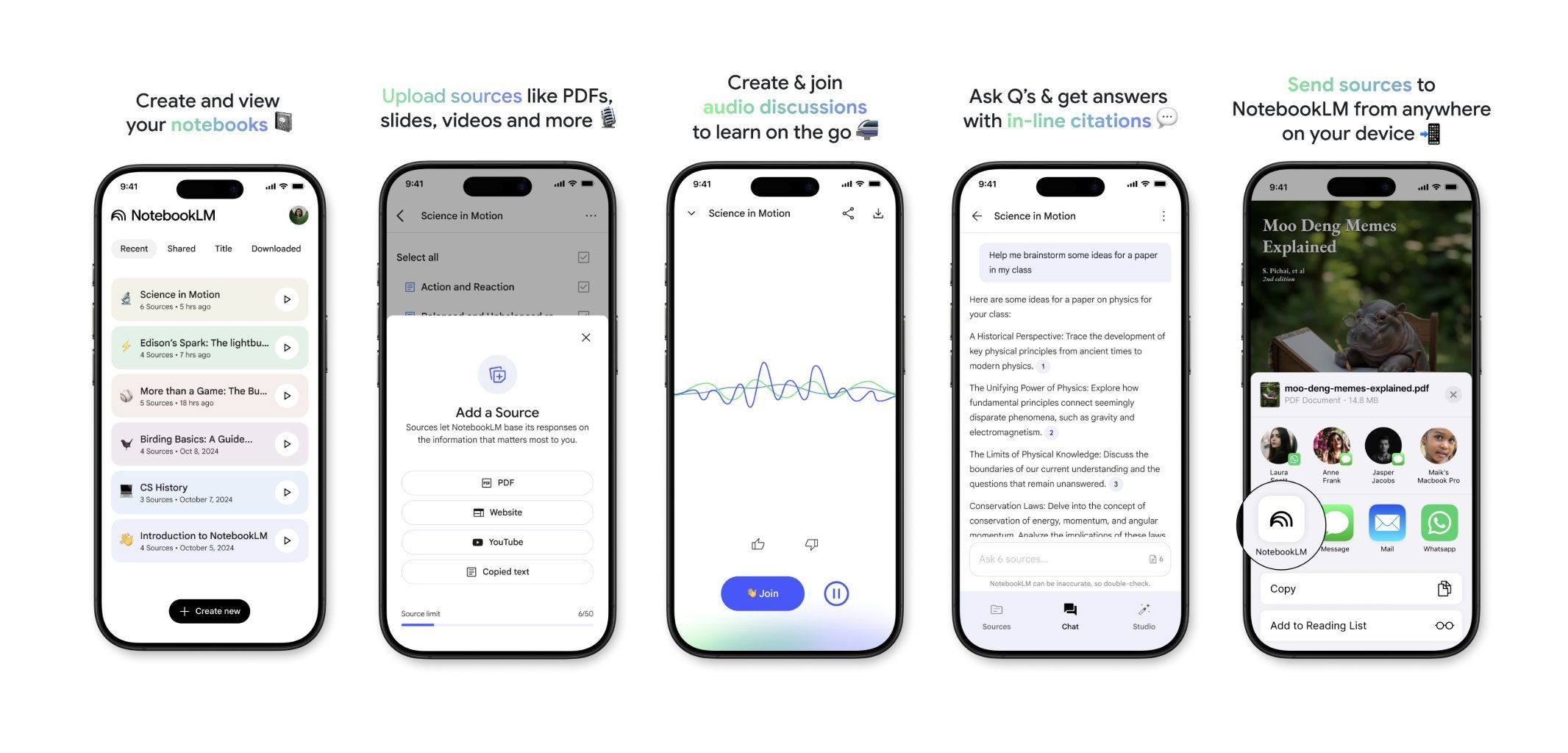
NotebookLM Mobile App Coming Soon: Google’s NotebookLM (formerly Project Tailwind) is set to release a mobile application. Users will be able to quickly forward articles and content seen on their phones to NotebookLM for processing and integration. A waitlist for the app is now open, aiming to provide a more convenient mobile experience for information management and AI-assisted learning. (Source: op7418)
Runway for Interior Design: A user demonstrated using Runway AI for interior design. By providing an image of a space and a reference image representing a style/mood, Runway can generate interior design renderings that blend the characteristics of both, showcasing AI’s potential in creative design fields. (Source: c_valenzuelab)

Unsloth Supports Qwen3 Model Fine-tuning: Unsloth announced support for fine-tuning the Qwen3 series models, offering a 2x speed increase and 70% reduction in VRAM usage. Users can fine-tune with context lengths 8x longer than Flash Attention 2 on a 24GB VRAM GPU. A Colab notebook is provided for free fine-tuning of the Qwen3 14B model, and various quantized models, including GGUF, have been uploaded. This lowers the hardware barrier for fine-tuning advanced models. (Source: Reddit r/LocalLLaMA)
Claude AI Styles Feature: A user shared using Claude AI’s Styles feature to improve collaboration with the AI. By creating a style named “Iterative Engineering” that sets steps for discussion, planning, small modifications, testing, iteration, and refactoring as needed, the user can guide Claude to code more methodically and incrementally, preventing it from excessively rewriting code and enhancing its utility as a programming partner. (Source: Reddit r/ClaudeAI)
Deepwiki Provides Source Code Blocks: User cto_junior mentioned an advantage of Deepwiki is that it displays source code blocks next to each answer, not just appended links. This practice increases information credibility, which is particularly helpful for software development engineers (SDEs) skeptical of AI tools. (Source: cto_junior)
📚 Learning
NousResearch Releases Atropos RL Framework Update: NousResearch’s Atropos Reinforcement Learning (RL) environment framework has been updated. New features allow users to quickly and easily test RL environment rollouts without needing a training or inference engine. It defaults to using the OpenAI API but can be configured for other API providers (or local VLLM/SGLang endpoints). After testing, it generates a web report containing completions and their scores, and supports wandb logging, facilitating debugging and evaluation of RL environments. (Source: Teknium1)

Personalized RAG Benchmark Dataset EnronQA Released: Researchers have released the EnronQA dataset, aimed at advancing research on Personalized Retrieval-Augmented Generation (Personalized RAG) on private documents. The dataset contains 103,638 emails and 528,304 high-quality question-answer pairs for 150 users, providing a resource for evaluating and developing RAG systems capable of understanding and utilizing user-specific information. (Source: lateinteraction)
GTE-ModernColBERT (PyLate) Released: LightOnAI has released GTE-ModernColBERT (PyLate), a 128-dimensional MaxSim retriever based on gte-modernbert-base and fine-tuned on ms-marco-en-bge-gemma. It natively supports the PyLate library for reranking and HNSW indexing. It performs exceptionally well on the NanoBEIR benchmark and surpasses ColBERT-small on the BEIR average score, offering a new efficient text retrieval option. (Source: lateinteraction)

SOLO Bench – A New Type of LLM Benchmark: User jd_3d developed and released SOLO Bench, a new method for benchmarking LLMs. The test requires the LLM to generate text containing a specific number of sentences (e.g., 250 or 500). Each sentence must contain exactly one word from a predefined list (including nouns, verbs, adjectives, etc.), and each word can only be used once. Evaluation is done via a rule-based script, aiming to test the LLM’s instruction following, constraint satisfaction, and long-text generation capabilities. Preliminary results show the benchmark effectively distinguishes the performance of different models. (Source: Reddit r/LocalLLaMA)
Manipulating Latent Space via Strategic Recursive Reflection: A user proposed a method to create nested reasoning hierarchies within an LLM’s latent space through “Strategic recursive reflection” (RR). By prompting the model to reflect on previous interactions at key moments, metacognitive loops are generated, constructing “mini-latent spaces.” Each prompt is treated as a stressor, guiding the model’s path within the latent space, making it more self-referential and capable of abstraction. This is thought to simulate the human process of deepening thought through reflection, aiming to explore deeper concepts. (Source: Reddit r/ArtificialInteligence)
💼 Business
Google Pays Samsung Fees to Pre-install Gemini AI: Following last year’s antitrust ruling regarding its default search engine agreement, Google is reportedly paying Samsung “huge sums of money” monthly plus revenue sharing to pre-install Gemini AI on Samsung devices, potentially requiring partners to mandatorily pre-install Gemini. This explains why the Samsung Galaxy S25 series deeply integrates Gemini, even setting it as the default AI assistant. This move reflects Google’s strategy to capture the mobile AI entry point given its insufficient own hardware channels, but it may also raise antitrust concerns again. (Source: 三星手机预装Gemini AI,也是谷歌花钱买的)

AI Startups Face Challenges: A Reddit discussion points out that many AI startups may lack a moat, as model capabilities converge and user loyalty is low. Big tech companies (Google, Microsoft, Apple) can reach users more easily due to their ecosystem advantages (like pre-installation, integration). Even if a startup’s model is slightly better, users might prefer the default or integrated “good enough” AI. This raises concerns about the long-term viability of AI startups and the prospects for VC investment. (Source: Reddit r/ArtificialInteligence)
This Week in AI Funding and Business News (May 2nd, 2025): Microsoft CEO reveals AI has written “significant portions” of the company’s code; Microsoft CFO warns AI services could face outages due to high demand; Google starts placing ads in third-party AI chatbots; Meta launches standalone AI apps; Cast AI raises $108M, Astronomer raises $93M, Edgerunner AI raises $12M; Research accuses LM Arena of benchmark manipulation issues; Nvidia challenges Anthropic’s support for chip export controls. (Source: Reddit r/artificial)
🌟 Community
Discussion on Quality and Cost of AI-Generated Content: The community expresses concern about the variable quality (termed “slop”) of AI-generated content. User wordgrammer notes that many generated AI videos are low quality, and the actual cost (considering filtering and retries) is much higher than the advertised price. This sparks discussion on model design (e.g., jam3scampbell citing Steve Jobs’ views) and the effective use of AI tools, emphasizing the need for finer control and higher generation quality standards. (Source: wordgrammer, jam3scampbell, willdepue)
Discussion on AI Performance in Specific Tasks: Community members discuss the performance and limitations of AI in various tasks. For example, DeepSeek R1 is considered a potential peak of LLM hype; despite progress in areas like formal mathematics and medicine, it hasn’t captured widespread user attention. DeepSeek Prover V2 performs well in math but is seen as lacking creativity. User vikhyatk questions the value of overly optimizing models to perform well on specific benchmarks like AIME (American Invitational Mathematics Examination), arguing the general public doesn’t care about math ability. These discussions reflect contemplation on the boundaries of AI capabilities and their practical value. (Source: wordgrammer, cognitivecompai, vikhyatk)
AI-Assisted Creativity and Design: The community showcases various ways AI tools are used for creative design. Users utilize Runway’s Gen-4 References feature to insert themselves into memes; use Runway for interior design concept generation; leverage GPT-4o and prompt templates to create images with specific styles (like an origami South China tiger, animal-shaped silicone wrist rests, incorporating word meanings into letter designs). These examples demonstrate AI’s potential in visual creativity and personalized design. (Source: c_valenzuelab, c_valenzuelab, dotey, dotey, dotey)

Questioning AI’s Ability to Mimic Writing Style: User nrehiew_ suggests that the instruction to have an LLM “continue writing in my tone and style” might not be effective, as most people overestimate the uniqueness of their writing style. This sparks discussion about the LLM’s ability to understand and replicate subtle writing styles and users’ potential misperceptions of this capability. (Source: nrehiew_)
AI for Emotional Support Sparks Resonance and Discussion: Reddit users share experiences of receiving emotional support, even help during crises, by talking to AI like ChatGPT. Many state that when lonely, needing to vent, or facing psychological distress, AI provides a non-judgmental, patient, and always available conversational partner, sometimes feeling more effective than talking to humans. This leads to discussions about AI’s role in mental health support, while also emphasizing that AI cannot replace professional human help and the need to be wary of potential biases or misinformation from AI. (Source: Reddit r/ChatGPT, Reddit r/ClaudeAI)
Diverging Views on AI-Generated Art: Users discuss the potential impact of AI-generated art on the perception of human artists and their work. Some complain that high-quality work is now often easily attributed to AI generation, overlooking the creator’s talent and effort. This phenomenon is even starting to distort perception, making people inclined to look for “human errors” in artwork to confirm it’s not AI-created. The discussion also touches on whether AI-generated content should be mandatorily watermarked. (Source: Reddit r/ArtificialInteligence)
💡 Other
Attention on AI Resource Consumption: Discussions highlight the immense resource consumption behind AI development. Training and running large AI models consume vast amounts of electricity and water, with data centers becoming new high-energy facilities. Every user interaction with AI, including a simple “thank you,” accumulates energy consumption. This raises concerns about AI sustainability and the need for energy solutions like nuclear fusion. (Source: 你对 AI 说的每一句「谢谢」,都在烧钱)
Distance Between AI and Consciousness: Reddit users discuss whether current AI possesses self-awareness. The prevailing view is that current AI (like LLMs) are essentially complex pattern-matching systems based on predicting words probabilistically, lacking true understanding and self-awareness, and are extremely far from achieving it. However, some comments note that human consciousness itself is not fully understood, making comparisons potentially flawed, and AI’s superhuman abilities in specific tasks should not be ignored. (Source: Reddit r/ArtificialInteligence)
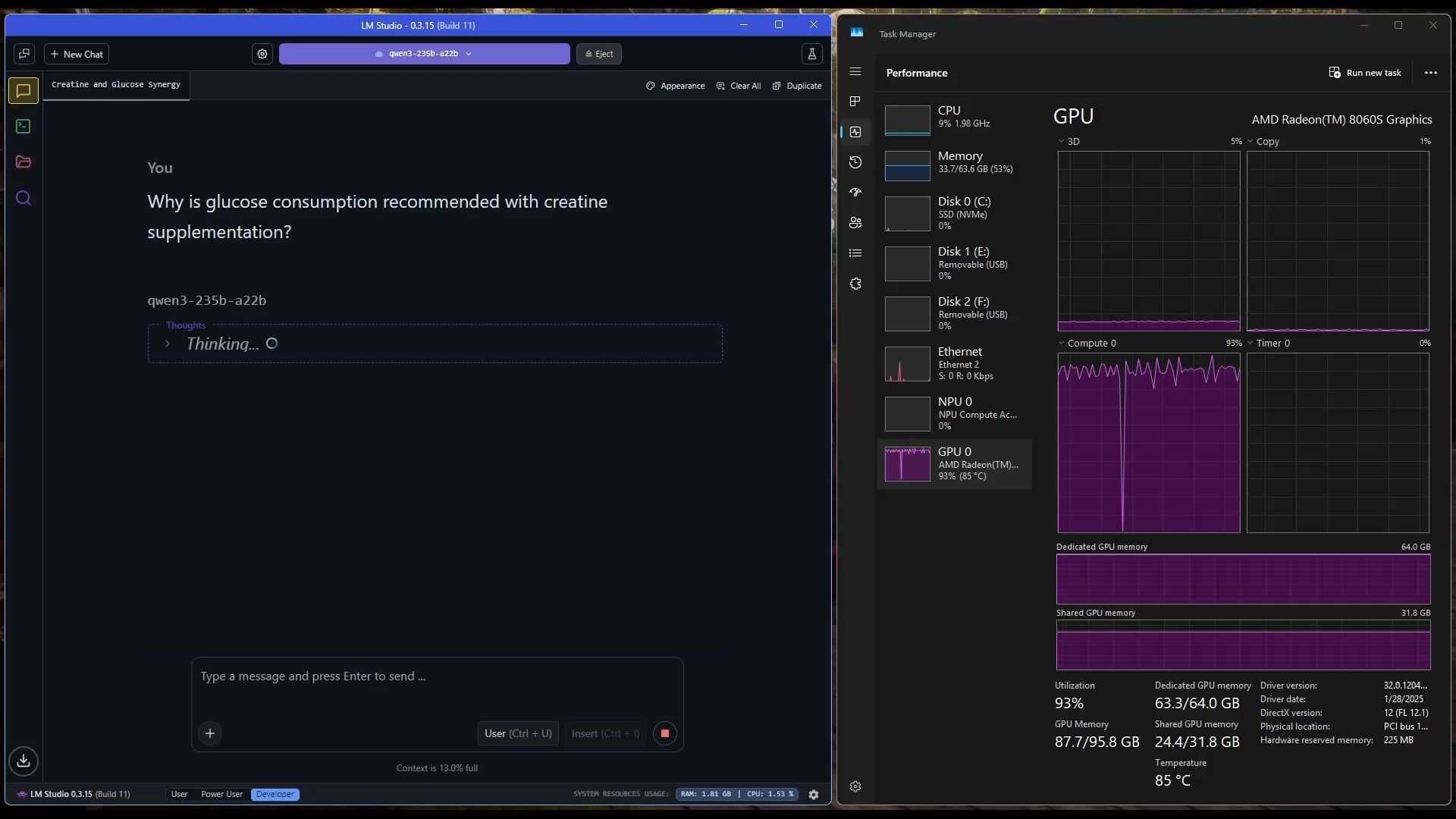
Windows Tablet Runs Large MoE Model: A user demonstrated running the Qwen3 235B-A22B MoE model (using Q2_K_XL quantization) on a Windows tablet equipped with an AMD Ryzen AI Max 395+ and 128GB RAM, using only the iGPU (Radeon 8060S, with 87.7GB out of 95.8GB allocated as VRAM), achieving speeds of around 11.1 t/s. This showcases the possibility of running very large models on portable devices, although memory bandwidth remains a bottleneck. (Source: Reddit r/LocalLLaMA)