

Keywords:Anthropic, Claude 3.5 Haiku, Qwen3, Phi-4-reasoning, LLM Physics, LangGraph, AI Agent, Circuit Tracing Method Attribution Graphs, Qwen3-235B-A22B coding capability, Phi-4-reasoning computational reasoning, LangGraph invoice verification Agent, Moondream Station local VLM
🔥 Focus
Anthropic publishes LLM biology research, delving into internal model mechanisms: Anthropic published an in-depth research blog post titled “On the Biology of a Large Language Model,” using its circuit tracing method (Attribution Graphs) to investigate the internal mechanisms of the Claude 3.5 Haiku model in different contexts. The research, by training a more easily analyzable “surrogate model” (Transcoder), reveals how the model performs addition (via multiple approximate paths rather than precise algorithms), conducts medical diagnosis (forming internal diagnostic concepts), and handles hallucinations and refusals (there’s a default refusal circuit that can be suppressed by “known answer” features). This research offers new perspectives on understanding the internal workings of LLMs, but has also sparked discussions about methodological limitations and Anthropic’s own positioning (Source: YouTube – Yannic Kilcher
)

Qwen3 series models demonstrate strong performance, attracting open-source community attention: Alibaba’s released Qwen3 series large language models perform exceptionally well on multiple benchmarks, especially in coding capabilities. Aider Polyglot Coding Benchmark results show that Qwen3-235B-A22B (without chain-of-thought enabled) seemingly outperforms Claude 3.7 with 32k chain-of-thought tokens enabled, at a significantly lower cost. Meanwhile, Qwen3-32B also surpasses GPT-4.5 and GPT-4o on this benchmark. The community is also actively exploring pruning (e.g., pruning 30B down to 16B) and fine-tuning (e.g., using Unsloth for fine-tuning with low VRAM) of Qwen3 models, further lowering the barrier to applying high-performance models and suggesting that Chinese open-source large models may gain significant market presence (Source: karminski3, scaling01, scaling01, Reddit r/LocalLLaMA)
Microsoft releases Phi-4-reasoning model, focusing on complex reasoning: Microsoft has released the Phi-4-reasoning model on Hugging Face, a 14 billion parameter reasoning model. This model achieves state-of-the-art (SOTA) performance on complex reasoning tasks by utilizing inference-time compute. This indicates that model design is exploring ways to enhance specific capabilities by increasing computation during the inference stage, rather than solely relying on scaling up model size, providing a new approach for small models to achieve high performance (Source: _akhaliq)
New progress in LLM physics research: A “Galileo moment” for architecture design: Zeyuan Allen-Zhu released the fourth part of a series on the physics of large language models, focusing on architecture design. Through controlled synthetic pre-training environments, the research reveals the true limitations and potential of different LLM architectures (like Transformer, Mamba). The study introduces a lightweight horizontal residual layer named “Canon,” which significantly improves the model’s reasoning capabilities. Concurrently, the research finds that the advantages of the Mamba model largely come from its hidden conv1d layer, rather than the SSM itself. This series of experiments provides new perspectives and foundational theories for understanding and optimizing LLM architectures (Source: menhguin, arankomatsuzaki, giffmana, tokenbender, giffmana, Dorialexander, iScienceLuvr)

🎯 Trends
Amazon releases general artificial intelligence model “Amazon Artificial General Intelligence”: This model features a 1 million token context length and multimodal input capabilities, optimized for code generation, RAG, video/document understanding, function calling, and Agent interactions. Pricing is $2.5/million input tokens and $12.5/million output tokens. Preliminary evaluations show its performance on the AI Index is comparable to Llama-4 Scout, but it lags in speed and cost, potentially suitable for specific long-context multimodal or Agent application scenarios (Source: scaling01)

Anthropic Claude model now offers web search functionality in paid plans globally: This feature allows Claude to perform quick searches when handling everyday tasks; for more complex questions, it explores multiple sources, including Google Workspace. This enhances Claude’s ability to access real-time information and handle tasks requiring external knowledge (Source: menhguin)

IBM releases hybrid architecture model granite-4.0-tiny-7B-A1B-preview: This 7B model preview version adopts a hybrid architecture of Mamba-2 and Transformer, where each Transformer block contains 9 Mamba blocks. The design idea is to use Mamba blocks to capture global context and pass it to the attention layers for local context resolution. Preliminary MMLU scores are promising, but results for other tests like math and programming capabilities have not yet been released (Source: karminski3)
OpenAI adds shopping features to ChatGPT: OpenAI is experimenting with shopping features in ChatGPT, aiming to simplify the process of finding, comparing, and purchasing products. New features include improved product result displays, visualized product details with prices and reviews, and direct purchase links. OpenAI emphasizes that product results are independently selected and are not advertisements (Source: sama)
Training details of Qwen3 0.6B model attract attention: User Dorialexander pointed out that, according to information, the Qwen 0.6B model also seems to have been trained on up to 36T tokens. If true, this would set a new record beyond the Chinchilla scaling laws (approximately 60,000 tokens per parameter), showing a trend of enhancing small model capabilities by vastly increasing the training data volume (Source: Dorialexander)

X (Twitter)’s recommendation algorithm to be replaced with a lightweight version of Grok: Elon Musk announced that X’s recommendation algorithm is being replaced with a lightweight version of Grok, expected to significantly improve recommendation effectiveness. Users report improved algorithm performance, speculated to be related to recent Exa AI staff changes and X starting to use Embeddings for recommendations (Source: menhguin, colin_fraser, paul_cal)
Allen AI releases fully open MoE model OLMoE: This model is an advanced Mixture of Experts (MoE) model with 1.3 billion active parameters and 6.9 billion total parameters. Being fully open-source means the community can freely use, modify, and research the model, promoting the development and application of MoE architectures (Source: dl_weekly)
Mistral-Small-3.1-24B-Instruct-2503 model gains attention: Reddit users discuss the Mistral-Small-3.1-24B-Instruct-2503 model, which scores highly on UGI (Uncensored General Intelligence) and outperforms similarly high-scoring models in natural language understanding and coding. Users believe it might be an ideal choice for single-GPU uncensored inference and supports tool use. However, they also note its writing style might be somewhat dry and repetitive, less creative than models like Gemma 3 (Source: Reddit r/LocalLLaMA)
🧰 Tools
CreateMVP 2.0 released, optimizing AI-driven development workflow: CreateMVP has been updated to version 2.0, aiming to solve the problem of poor results when directly prompting AI to build applications. The new version helps users create more precise “blueprints” for AI, ensuring the AI builds applications that match the user’s vision by providing a smoother UI, convenient authentication methods (supports Replit, Google, GitHub, XAI coming soon), generating more detailed development plans (increased from 11KB to 40KB+), instant file previews, and integrated chat with top AI models (Source: amasad)
LlamaIndex launches invoice reconciliation Agent: This tool demonstrates the application of AI Agents in batch automation tasks, rather than traditional chat interactions. It can process large volumes of unstructured invoice documents, extract relevant details, automatically match them with purchase orders, and flag discrepancies. Its core is an Agentic document intelligence layer based on LlamaCloud parsing/extraction and LlamaIndex.TS workflow inference, showcasing the potential of Agents in practical business process automation and is considered a potential replacement for traditional RPA (Source: jerryjliu0)
LangGraph Expense Tracker: Automated expense management system: This is an example of an automated expense management system built using LangGraph. It can process invoices, utilize intelligent data extraction features, store information in PostgreSQL, and include a human verification step. The project demonstrates LangGraph’s capability in building practical business automation workflows (Source: LangChainAI, Hacubu, hwchase17)
Moondream Station released: Run VLM locally: Moondream has released Moondream Station, allowing users to run the visual language model (VLM) Moondream locally on a Mac without needing a cloud connection. Provides access via CLI or a local port. Setup is simple and completely free, lowering the barrier for local deployment and use of VLMs (Source: vikhyatk)
ChaiGenie: LangChain-based Chrome extension for document search: ChaiGenie is a Chrome extension that integrates LangChain’s Gemini and Qdrant to provide document search functionality. It supports multiple languages and vector-based retrieval, aiming to improve user efficiency in finding and understanding document content while browsing the web (Source: LangChainAI)

Research Agent: One-click research assistant web application: This is a web application built on the LangGraph research assistant framework, designed to simplify the research process. Users can get research results with just one click, showcasing LangGraph’s potential in building AI-driven workflows to simplify complex tasks (Source: LangChainAI)

Muyan-TTS: Open-source, low-latency, customizable TTS model: The ChatPods team released Muyan-TTS, a fully open-source text-to-speech model, aiming to address issues with existing open-source TTS models being low-quality or not sufficiently open. It is based on LLaMA-3.2-3B and optimized SoVITS, supports zero-shot TTS and voice cloning, and provides complete training and data processing pipelines, making it convenient for developers to fine-tune and perform secondary development, especially suitable for application scenarios requiring customized voices (Source: Reddit r/MachineLearning)
Mem0 integration with Open Web UI pipelines: User cloudsbird created an Open Web UI filter pipeline integration for Mem0 (unofficial MCP), providing another option for using Mem0 memory features within Open Web UI (Source: Reddit r/OpenWebUI)
YNAB API Request tool enables local, private financial management: User Megaphonix created an OpenWebUI tool utilizing the YNAB (You Need A Budget) API, allowing users to query personal financial information (like transactions, category spending, net worth, etc.) locally via an LLM without sending sensitive data externally. This addresses the need for securely handling sensitive personal information when running LLMs locally (Source: Reddit r/OpenWebUI)
Free AI text-to-speech browser extension GPT-Reader: Developer promotes their free AI text-to-speech browser extension, GPT-Reader, which currently has over 4000 users. The tool aims to make it easy for users to convert web page text content into audio for listening (Source: Reddit r/artificial)
sunnypilot: Open-source driving assistance system: sunnypilot is a fork of comma.ai’s openpilot, providing an open-source driving assistance system. It supports over 300 vehicle models, modifies the interaction behavior of driving assistance, and adheres to comma.ai’s safety policies as much as possible. This project utilizes AI technology (though specific models aren’t explicitly mentioned, such systems typically involve computer vision and control algorithms) to enhance the driving experience (Source: GitHub Trending)

📚 Learning
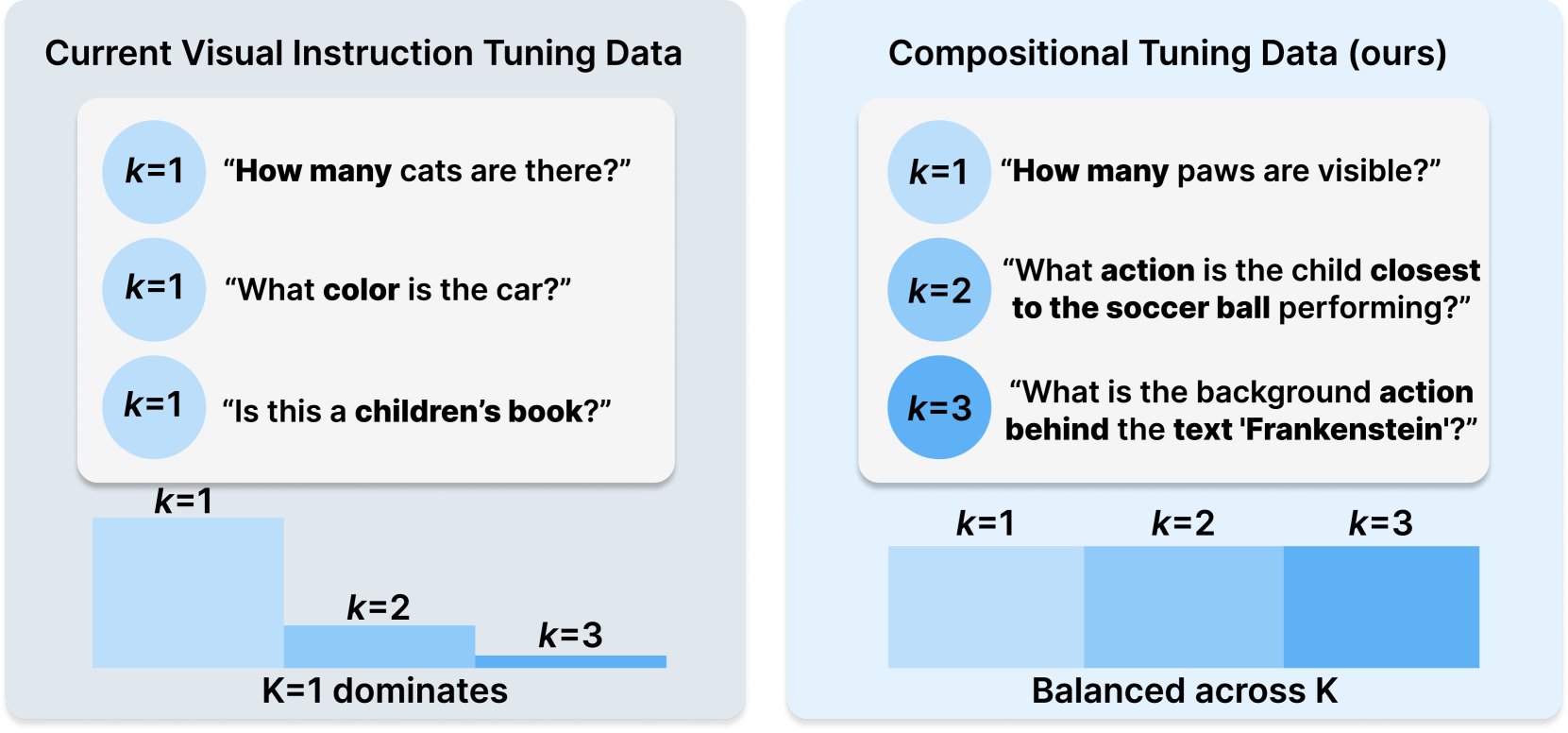
Princeton and Meta AI release COMPACT dataset recipe: Published on Hugging Face, this research proposes a new data recipe, COMPACT, aimed at expanding the capabilities of Multimodal Large Language Models (Multimodal LLMs) by explicitly controlling the compositional complexity of training samples. This offers new ideas for improving multimodal model training methods and enhancing their ability to understand complex compositional concepts (Source: _akhaliq)
Unsloth releases Qwen3 fine-tuning tutorial: Unsloth has provided a fine-tuning tutorial for Qwen3 models, significantly lowering the barrier to fine-tuning. Users can fine-tune the Qwen3-14B model with just 16GB of VRAM, and the Qwen3-30B-A3B model with 17.5GB of VRAM. This enables more researchers and developers to perform customized training on advanced open-source models with limited hardware resources (Source: karminski3)
Building an intelligent web search chatbot with LangGraph and Azure OpenAI: A Medium tutorial demonstrates how to combine LangGraph and Azure OpenAI, integrating Tavily’s web search capabilities, to build an intelligent chatbot. The tutorial covers state management and conditional routing to achieve seamless search integration, providing practical guidance for building more powerful AI applications that can leverage real-time web information (Source: LangChainAI, hwchase17)

Stanford AI Blog explores the relationship between LLM verbatim memorization and general capabilities: An article on the Stanford AI Blog delves into the intrinsic connection between the verbatim memorization phenomenon in Large Language Models (LLMs) and their general capabilities. Understanding this relationship is crucial for assessing model risks, optimizing training methods, and explaining model behavior (Source: dl_weekly)
Guide to integrating Gemini with LangChain: Philipp Schmid released a developer guide detailing how to integrate Google’s Gemini models with the LangChain framework. The guide covers the implementation of multimodal capabilities, tool calling, and structured output, includes support for the latest models and practical code examples, making it easier for developers to leverage Gemini’s powerful features to build LangChain applications (Source: LangChainAI, _philschmid)

LangGraph Getting Started Tutorial: Stateful Workflow Practice: A tutorial published on AI@GoPubby demonstrates LangGraph’s stateful workflow capabilities through an example of website comment analysis. Learners can understand how to build structured AI applications using interconnected nodes and sequential logic (Source: LangChainAI, hwchase17)
LangChain CEO’s deep thoughts on Agentic frameworks: LangChain Ambassador Harry Zhang translated and shared LangChain CEO Harrison’s blog post reflecting on Agentic frameworks. The article analyzes and organizes the features of over 15 Agent frameworks in the industry and interprets the stories behind them, providing valuable references for understanding the current development landscape and future direction of Agent technology (Source: LangChainAI)
Research progress on Latent Meta Attention: Reddit users discuss a new attention mechanism called Latent Meta Attention. The developer claims this mechanism challenges the fundamental assumptions of the Transformer and can achieve or even surpass the performance of existing models at smaller sizes (e.g., replicating BERT performance with a model half the size), but the specific method has not yet been disclosed due to lack of funding and support from formal research institutions (Source: Reddit r/deeplearning)

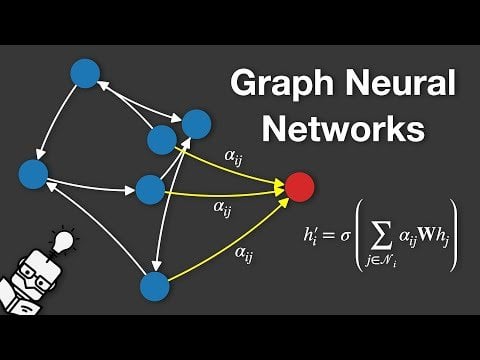
Video explaining Graph Neural Networks (GNNs): A video explaining Graph Neural Networks (GNNs) has been posted on YouTube. GNNs are deep learning models for processing graph-structured data, widely used in areas such as social network analysis, recommendation systems, and molecular structure prediction. The video aims to help viewers understand the basic principles and workings of GNNs (Source: Reddit r/deeplearning)
Training an LLM for event scheduling using GRPO: User anakin87 shared project experience using GRPO (Generalized Reward Policy Optimization) to train a language model for event scheduling. The project does not rely on traditional supervised fine-tuning samples but uses a reward function to enable the model to learn to create schedules based on event lists and priorities. The author shares lessons learned regarding problem setup, data generation, model selection, reward design, and the training process, and open-sourced the code and model, providing a practical case study for exploring reward-based LLM training (Source: Reddit r/LocalLLaMA)

Sharing free AI course resources: LinkedIn AI Hub shared a complete AI learning roadmap, inspired by Stanford University’s AI certificate program and simplified for learners of different levels. The content covers everything from basic skills to practical projects, providing valuable resources and course details (Source: Reddit r/deeplearning)
Deep dive conversation on Gemini long-context pre-training: Logan Kilpatrick had an in-depth conversation with Nikolay Savinov, co-lead of Gemini long-context pre-training. The discussion ranged from fundamentals to the techniques needed to scale to infinite context, and best practices for developers regarding long context. The conversation summary notes: achieving 1 million token context was a 10x goal over the standard at the time; 10 million tokens were attempted but were costly and hardware-constrained; long context and RAG are complementary; simple NIAH (Needle In A Haystack) is solved, the difficulty lies in hard distractors and multi-needle retrieval; evaluation focuses on NIAH to avoid confounding capability signals; current output length limitations (e.g., 8k) are post-training issues; no “lost in the middle” effect observed; need to distinguish between context knowledge and weight knowledge; the next step is cheaper and more precise 10 million context; scaling to 100 million might require new DL innovations (Source: shaneguML, giffmana, teortaxesTex, arohan)
🌟 Community
Discussion about “Vibe Coding”: The community is actively discussing “Vibe Coding,” which refers to heavily relying on AI assistance for programming. Supporters believe this represents the future, where developers focus more on the “why” and “what,” while AI handles the “how,” but this requires stronger critical thinking skills. Opponents argue that current AI cannot yet fully handle complex debugging, upgrades, and maintenance. Over-reliance could lead to a decline in developer skills, turning them into more advanced “script kiddies.” Some who tried it found that the time cost of guiding AI to complete complex tasks remains high, making manual implementation with lightweight AI assistance more efficient (Source: Dorialexander, Reddit r/artificial, johnowhitaker)

Discussion on the application and limitations of AI in professional fields: User dotey discusses the application of AI in professional fields. He believes AI can learn from publicly available expert Q&A but struggles with unseen problems. AI’s strengths lie in its vast foundational knowledge base and rapid response, but it currently relies heavily on RAG (Retrieval-Augmented Generation), essentially retrieving snippets and piecing together answers, rather than true professional reasoning. This is still far from training a model that can continuously generate new answers like an expert and constantly improve (Source: dotey)
Concerns and discussion about AI-generated content: User Maleficent-main_777 complains that colleagues have started using “ChatGPT-ese” language filled with imperative tones, words like “verify,” “ensure,” and forced positive conclusions, believing this language is vague and lacks a human touch. He worries that AI-generated content being fed back into training data will lead to a decline in content quality. The comment section resonates with this, seeing it as an extension of corporate jargon, but also notes that excessive imitation of AI does make communication robotic, and good grammar is no longer an advantage, instead sounding robotic (Source: Reddit r/ChatGPT)
Choosing university majors in the age of AI: Reddit users discuss what majors university students should choose amidst the rapid development of AI and robotics to ensure their degrees remain valuable in 10 years. Comments offer diverse opinions, including: choosing fields one is passionate about (gaming, film, art, programming); studying fundamental subjects (physics, math); mastering skills difficult to automate (like HVAC); focusing on liberal arts education to cultivate curiosity and adaptability; believing university education might become obsolete, favoring entrepreneurship or freelancing; emphasizing the critical importance of continuous learning, unlearning, and relearning (Source: Reddit r/ArtificialInteligence)
Discussion on why AI image generation struggles with text rendering: Reddit users explore why current image generation models find it difficult to render coherent, legible text. Comments point to two main reasons: 1) BPE (Byte Pair Encoding) tokenization breaks precise spelling information, as the model sees token fragments instead of letters; 2) Fixed-size vector representations and the limitations of image descriptions cause significant loss of textual information during embedding. Although autoregressive models like GPT-4o show improvement, the fundamental issues related to tokenization and information compression remain (Source: Reddit r/MachineLearning)
Discussion on standardizing model evaluations: User scaling01 points out that when comparing different AI models (like OpenAI, Google, Anthropic), fairness should be ensured. For example, if preview and “thinking versions” of OpenAI are listed, corresponding versions for Google and Anthropic should also be listed; otherwise, the comparison results could be misleading (Source: scaling01)
Sharing experiences with AI-assisted programming: User shares experience using AI-assisted programming (e.g., VS Code + Cline AI extension + Google AI Studio API), believing it’s possible to build an AI coding tool similar to Cursor for free, completing basic application prototypes through prompts without configuration, providing a good experience (Source: Reddit r/artificial)

Survey on the impact of AI on work, study, and life: Reddit user initiates a discussion asking about the impact of generative AI on people’s performance at work, study, or daily life. In the comments, software engineers mention AI has increased productivity expectations and workload, while code reviews haven’t significantly sped up; Professional writers feel AI (like Co-pilot) offers limited help and might even slow progress; The general view is that AI brings convenience but also issues like over-reliance, reduced learning, and a “feeling of cheating.” The impact of AI varies significantly across different professions and tasks (Source: Reddit r/artificial)
Reflections on the “understanding” capability of LLMs: User pmddomingos suggests that neural networks are becoming as hard to understand as brains. And extends the thought: What should we do when AI models excel on all benchmarks but are still not as intelligent as humans? This sparks reflection on the validity of current benchmarks and the standards for evaluating true intelligence (Source: pmddomingos, pmddomingos)
Thoughts on using AI tools: User dotey comments that when using AI tools, one should simply choose the strongest model for the specific task at hand. Using multiple models simultaneously or letting them “fight it out” might be unnecessary, especially for non-expert users, too many choices can lead to confusion, analogous to looking at multiple clocks showing different times (Source: dotey)
Reflections sparked by the recent pace of AI development: Users matvelloso and scottastevenson express amazement at the rapid pace of AI development. matvelloso states that this year’s AI progress has already exceeded his expectations (citing Gemini playing Pokemon as an example). scottastevenson reflects that GPT-2 was released 6 years ago, and OpenAI was founded 10 years ago, pondering the technological directions currently incubating that will become important in the next 6-10 years, and notes that besides AI, seeking deep Alpha “outside the frame” is equally important (Source: matvelloso, scottastevenson, scottastevenson)
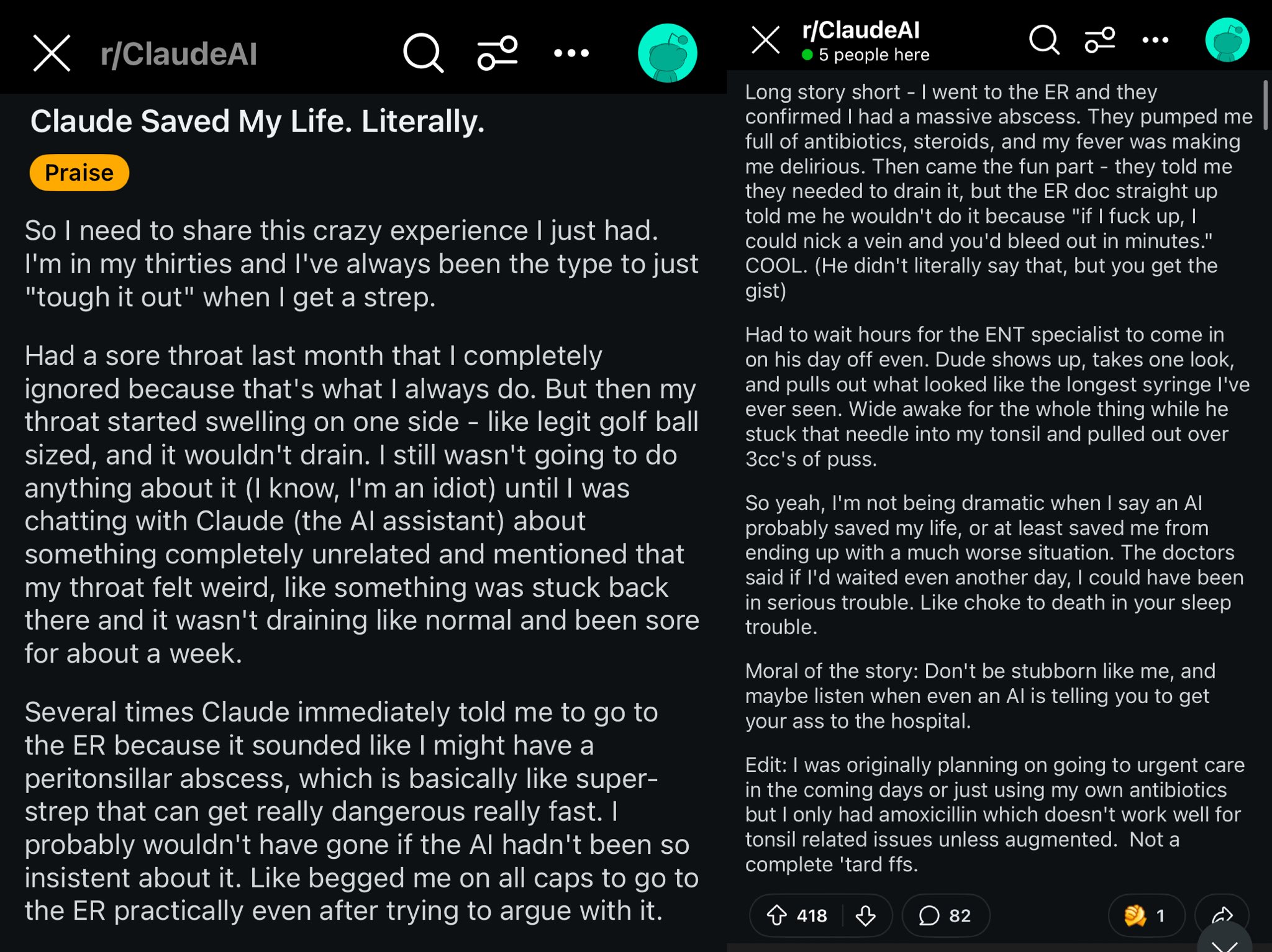
Case of Claude potentially saving a Reddit user’s life: A Reddit post describes how the Claude model potentially saved a user’s life by diagnosing their swollen throat as a peritonsillar abscess. The case sparked discussion, suggesting powerful AI models are like having a world-class doctor in your pocket; widespread adoption could have a huge impact on personal health (Source: aidan_mclau)
Application of AI Agents in enterprise data processing: You.com co-founders Richard Socher and Bryan McCann discussed the application of AI Agents in enterprises on the Agentic podcast. They believe consumer-grade LLMs are insufficient for serious enterprise needs, whereas You.com uses hybrid retrieval techniques (combining public sources and proprietary company data) to generate more reliable, enterprise-grade outputs, such as conducting research, writing reports, and securely utilizing enterprise data. They also discussed possible paths to AGI and the key role of simulation within it (Source: RichardSocher)
Observations on models’ ability to use tools: User menhguin observed that models trained to use tools seem to sacrifice some independent problem-solving ability, joking that “even AI models are outsourcing their work.” This sparks thought about the trade-off between model generalization and optimization for specific tasks (Source: menhguin)
💡 Other
Idea for an AI Agent to maintain old GitHub projects: User xanderatallah proposed an idea: develop an AI Agent capable of automatically maintaining all of a user’s old, inactive side projects on GitHub. This reflects the desire among developers to use AI to automate tedious maintenance tasks (Source: xanderatallah)
Conceiving LLMs as replacements for judges or for use in arbitration/mediation: User fabianstelzer suggests that Large Language Models (LLMs) might replace judges in the future. An interesting intermediate use case is arbitration or mediation: if LLMs are considered neutral and trustworthy, conflicting parties could submit their perspectives, run them through multiple large models, and receive a fair compromise proposal. This explores the potential applications of AI in the judicial and dispute resolution fields (Source: fabianstelzer)
Runway Gen-4 model and its application prospects: Runway co-founder c_valenzuelab is optimistic about the application prospects of Runway Gen-4 and its API. He believes Runway is building a new medium where pixels are generated rather than rendered or captured, and worlds are simulated rather than programmed. Seeing the widespread application of Gen-4 and Reference features in various fields like architecture, branding, interior design, game development, learning, and personal creative projects makes him believe this new medium will empower creative professionals and everyone else (Source: c_valenzuelab, c_valenzuelab)