
Keywords:ChatBot Arena, Phi-4-reasoning, Claude Integrations, DeepSeek-Prover-V2, Qwen3, Gemini, Parakeet-TDT-0.6B-v2, AI Agent, Leaderboard Hallucination, Small Model Reasoning Capability, Third-party Application Integration, AI Programming Agent, Mathematical Theorem Proving
🔥 Focus
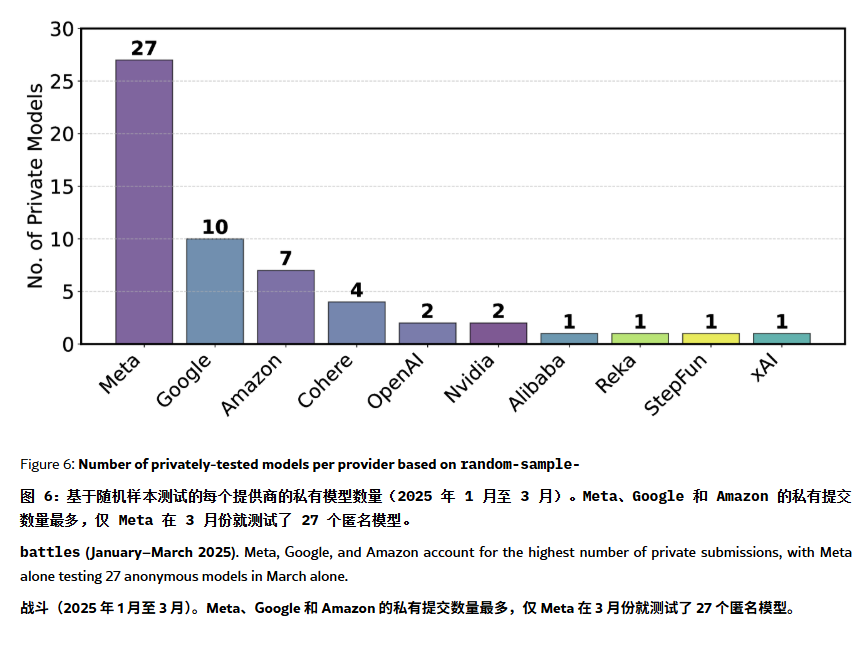
ChatBot Arena Leaderboard Accused of “Illusion” and Manipulation: An ArXiv paper [2504.20879] questions the widely cited ChatBot Arena model leaderboard, suggesting it suffers from “leaderboard illusion”. The paper points out that large tech companies (like Meta) might game the leaderboard by submitting numerous fine-tuned model variants (e.g., 27 tested for Llama-4) and only publishing the best results; model display frequency might also favor big tech models, squeezing exposure opportunities for open-source models; the model removal mechanism lacks transparency, with many open-source models being delisted due to insufficient testing data; furthermore, the similarity of common user prompts could lead to models specifically overfitting training to improve scores. This raises concerns about the reliability and fairness of current mainstream LLM benchmarks, advising developers and users to view leaderboard rankings cautiously and consider building evaluation systems tailored to their own needs. (Source: karminski3, op7418, TheRundownAI)
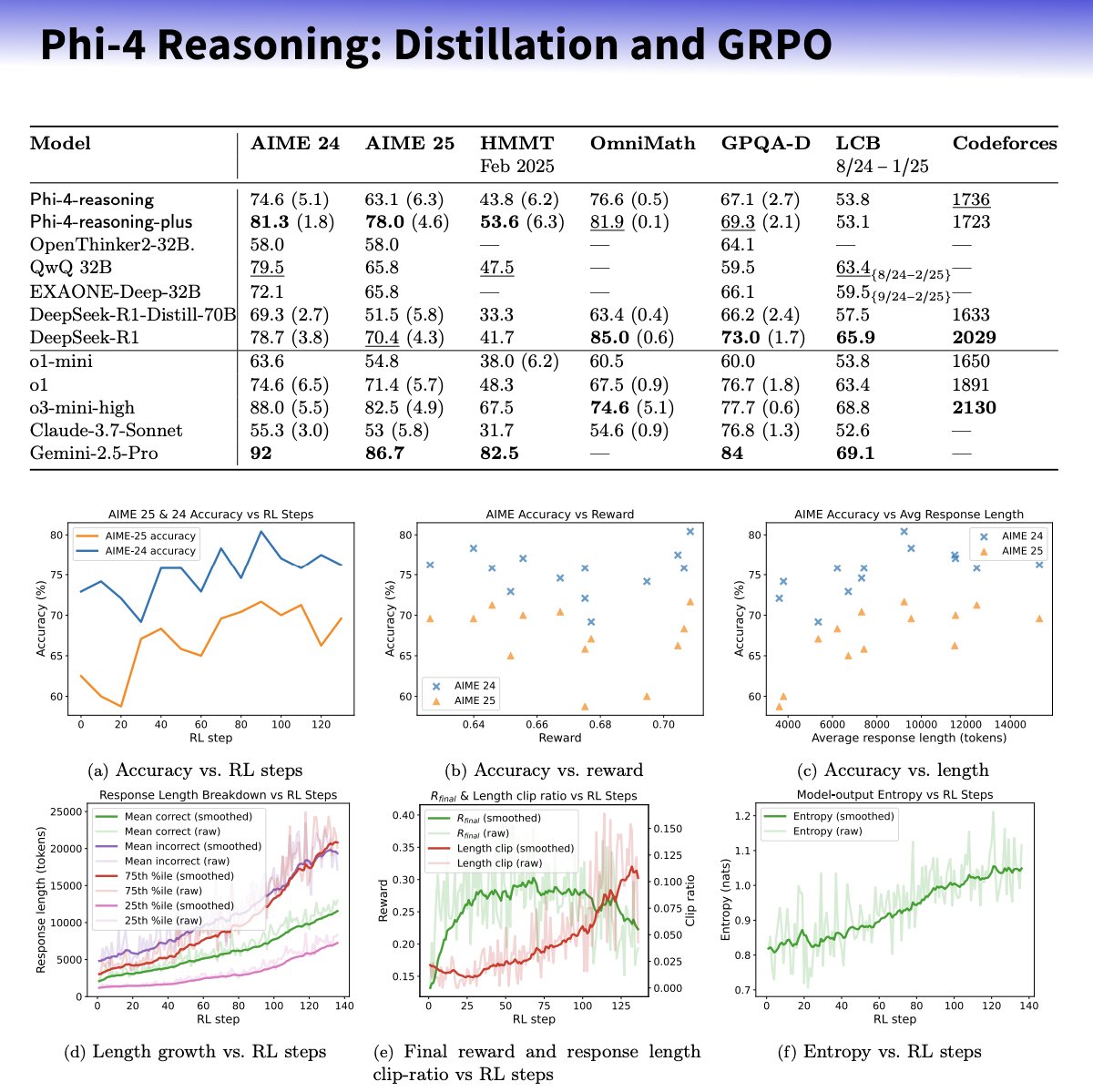
Microsoft Releases Phi-4-reasoning Small Model Series, Focusing on Enhancing Reasoning Capabilities: Microsoft has launched the Phi-4-reasoning and Phi-4-reasoning-plus models based on the Phi-4 architecture, aiming to enhance the reasoning abilities of small language models through carefully curated datasets, supervised fine-tuning (SFT), and targeted reinforcement learning (RL). These models reportedly use OpenAI’s o3-mini as a “teacher” to generate high-quality Chain-of-Thought (CoT) reasoning trajectories and are optimized through reinforcement learning using the GRPO algorithm. Microsoft researcher Sebastien Bubeck claims Phi-4-reasoning outperforms DeepSeek R1 in mathematical ability, despite being only 2% of its size. The series features specialized reasoning tokens and an extended 32K context length. This move is seen as an exploration into smaller, specialized models, potentially offering stronger reasoning solutions for resource-constrained scenarios, but it has also sparked discussions about whether it utilizes OpenAI technology while being released under an MIT license. (Source: _philschmid, TheRundownAI, Reddit r/LocalLLaMA)
Anthropic Launches Integrations Feature and Expands Research Capabilities: Anthropic announced the launch of Claude Integrations, allowing users to connect Claude with 10 third-party applications and services such as Jira, Confluence, Zapier, Cloudflare, and Asana, with future support planned for Stripe, GitLab, and others. The previously local-server-only MCP (Model Context Protocol) support is now extended to remote servers, enabling developers to create their own integrations in about 30 minutes using documentation or solutions like Cloudflare. Concurrently, Claude’s Research feature has been enhanced with a new advanced mode that can search the web, Google Workspace, and connected Integrations, break down complex requests for investigation, and generate comprehensive reports with citations, potentially taking up to 45 minutes. The web search function is also now available to paid users globally. These updates aim to enhance Claude’s integration capabilities and in-depth research abilities as a work assistant. (Source: _philschmid, Reddit r/ClaudeAI)

AI Agent Capabilities Follow New Moore’s Law: Doubling Every 4 Months: Research by AI Digest indicates that the ability of AI programming agents to complete tasks is experiencing exponential growth. The time required for them to handle tasks (measured by the time needed by human experts) is roughly doubling every 4 months between 2024-2025, faster than the previous rate of doubling every 7 months between 2019-2025. Currently, top AI agents can handle programming tasks that take humans 1 hour. If this accelerated trend continues, AI agents are projected to be capable of completing complex tasks lasting up to 167 hours (about a month) by 2027. This rapid capability improvement benefits from advancements in the models themselves and increased algorithmic efficiency, potentially forming a positive feedback loop of super-exponential growth due to AI-assisted AI R&D. This signals the possibility of a “software intelligence explosion,” which will profoundly change fields like software development and scientific research, while also bringing societal challenges such as the impact of automation on the job market. (Source: 新智元)

🎯 Trends
DeepSeek-Prover-V2 Released, Enhancing Mathematical Theorem Proving Capabilities: DeepSeek AI has released DeepSeek-Prover-V2, available in 7B and 671B sizes, focusing on formal theorem proving in Lean 4. The model is trained using recursive proof search and reinforcement learning (GRPO), leveraging DeepSeek-V3 to decompose complex theorems and generate proof sketches, combined with fine-tuning and reinforcement learning using expert iteration and synthetic cold-start data. DeepSeek-Prover-V2-671B achieves an 88.9% pass rate on MiniF2F-test and solves 49 problems on PutnamBench, demonstrating SOTA performance. Also released is the ProverBench benchmark, which includes AIME and textbook problems. The model aims to unify informal reasoning with formal proof, advancing automated theorem proving. (Source: 新智元)

Nvidia and UIUC Propose New Method for 4 Million Token Context Extension: Researchers from Nvidia and the University of Illinois Urbana-Champaign have proposed an efficient training method to extend the context window of Llama 3.1-8B-Instruct from 128K to 1M, 2M, and even 4M tokens. The method employs a two-stage strategy of continued pre-training and instruction fine-tuning, with key techniques including the use of special document separators, YaRN-based positional encoding extension, and single-step pre-training. The resulting UltraLong-8B model performs exceptionally well on long-context benchmarks like RULER, LV-Eval, and InfiniteBench, while maintaining or even surpassing the baseline Llama 3.1’s performance on standard short-context tasks like MMLU and MATH, outperforming other long-context models such as ProLong and Gradient. This research offers an efficient and scalable pathway for building ultra-long context LLMs. (Source: 新智元)

Qwen3 Released with Significant Performance Improvements: Alibaba has released the Qwen3 series of models, including Qwen3-30B-A3B. According to preliminary tests and benchmark data from Reddit users (e.g., AHA Leaderboard), Qwen3 performs better than previous Qwen2.5 and QwQ versions across multiple dimensions (such as specific domain knowledge in health, Bitcoin, Nostr, etc.). User feedback indicates that Qwen3 demonstrates strong capabilities in handling specific tasks (like simulating solar system dynamics), correctly applying physical laws to generate elliptical orbits and relative periods. However, some users noted a significant performance drop in Qwen3 with long contexts (e.g., approaching 16K) and high token consumption during inference, suggesting use in conjunction with search tools. The naming convention of Qwen3 (e.g., Qwen3-30B-A3B) has also been praised for its clarity. (Source: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, karminski3, madiator)
Gemini Soon to Integrate Google Account Data for Personalized Experiences: Google plans to allow its Gemini AI assistant to access user Google account data, including Gmail, Photos, YouTube history, etc., aiming to provide more personalized, proactive, and powerful assistance. Google Product Lead Josh Woodward stated this is to help Gemini better understand users and become an extension of them. The feature will be opt-in, allowing users to choose whether to grant data access permission. This move has sparked discussions about privacy and data security, requiring users to weigh the convenience of personalization against data privacy concerns. (Source: JeffDean, Reddit r/ArtificialInteligence)

Nvidia Launches Parakeet-TDT-0.6B-v2 ASR Model: Nvidia has released a new automatic speech recognition (ASR) model, Parakeet-TDT-0.6B-v2, with 600 million parameters. The model reportedly outperforms Whisper3-large (1.6 billion parameters) on the Open ASR Leaderboard, especially in handling diverse datasets (including about 120,000 hours of data from LibriSpeech, Fisher Corpus, YouTube data, etc.). The model supports character, word, and segment-level timestamps, but currently only supports English and requires Nvidia GPUs and specific frameworks to run. Initial user feedback praises its transcription and punctuation accuracy. (Source: Reddit r/LocalLLaMA)

Qwen2.5-VL Released, Enhancing Visual Language Understanding: Alibaba has released the Qwen2.5-VL series of multimodal models (including 3B, 7B, 72B parameters), aimed at improving machines’ understanding and interaction with the visual world. These models can be used for tasks like image summarization, visual question answering, and generating reports from complex visual information. The article introduces their architecture, benchmark performance, and inference details, showcasing advancements in visual language understanding. (Source: Reddit r/deeplearning)

Mistral Small 3.1 Vision Support Merged into llama.cpp: The llama.cpp project has merged support for the Mistral Small 3.1 Vision model (24B parameters). This means users will be able to run this multimodal model within the llama.cpp framework for tasks like image understanding. Unsloth has already provided corresponding GGUF format model files. This facilitates running Mistral’s vision model locally. (Source: Reddit r/LocalLLaMA)
Meta Releases Synthetic Data Kit: Meta has open-sourced a command-line tool called Synthetic Data Kit, designed to simplify the data preparation phase required for LLM fine-tuning. The tool provides four commands: ingest (import data), create (generate QA pairs, optionally with reasoning chains), curate (use Llama as a judge to filter high-quality samples), and save-as (export in compatible formats). It utilizes local LLMs (via vLLM) to generate high-quality synthetic training data, particularly suitable for unlocking specific task reasoning capabilities for models like Llama-3. (Source: Reddit r/MachineLearning)
GTE-ModernColBERT-v1 Becomes Popular Embedding Model: The GTE-ModernColBERT-v1 model, launched by LightOnIO, has become a new trending search/embedding model on Hugging Face. The model employs a multi-vector (also known as late interaction or ColBERT) search method, offering a new option for developers interested in such techniques. (Source: lateinteraction)
X Recommendation Algorithm Update: The X platform (formerly Twitter) has implemented fixes to its recommendation algorithm aimed at addressing long-standing issues such as user negative feedback not being incorporated, repeatedly seeing the same content, and the SimCluster algorithm recommending irrelevant content. Early feedback is reportedly positive. (Source: TheGregYang)
Wikipedia Announces New AI Strategy to Support Human Editors: Wikipedia has announced its new artificial intelligence strategy, aiming to use AI tools to support and enhance the work of human editors, rather than replace them. Specific details were not elaborated in the source, but it indicates that the world’s largest online encyclopedia is exploring how to integrate AI technology into its content creation and maintenance processes. (Source: Reddit r/artificial)
🧰 Tools
Midjourney Launches Omni-Reference Feature: Midjourney has released the new Omni-Reference (oref) feature, allowing users to guide image generation by providing reference image URLs (using the –oref parameter) to achieve consistency for characters, objects, vehicles, or non-human creatures. Users can control the influence weight of the reference image with the –ow parameter; lower weights are suitable for stylization, while higher weights are better for realism or precise facial matching. The feature aims to enhance the consistency and controllability of specific elements in generated images. (Source: op7418, DavidSHolz)

Runway Gen-4 References Enables Single-Image Personalization: Runway’s Gen-4 model has introduced a References feature, allowing users to apply the style or character features from a single reference image to new generated content. Demonstrations show the feature can easily recreate character portraits in the style of the reference image or place them in the world depicted by the reference, showcasing the model’s ability to achieve high consistency and aesthetic quality personalization with just one reference image. (Source: c_valenzuelab, c_valenzuelab)

Perplexity’s WhatsApp Bot Resumes Service: After a brief shutdown due to demand far exceeding expectations, Perplexity AI’s WhatsApp chatbot is back online. Users can interact with it via the phone number +1 (833) 436-3285 to forward messages for fact-checking, ask direct questions for answers, engage in free-form text conversations, and create images. (Source: AravSrinivas, AravSrinivas)
Krea AI Combines with 4o Image Model for Precise Image Control: AI creative tool Krea AI has added a new feature allowing users to leverage the capabilities of OpenAI’s 4o image model to control generated image content and style more precisely through image collages and doodling. This demonstrates Krea’s continuous innovation in interactive image generation, enabling users to guide AI creation more intuitively and meticulously. (Source: op7418)
Xingyun Brown Ant All-in-One Machine: Low-Cost Full-Power DeepSeek: Xingyun Integrated Circuits, with ties to Tsinghua University, has launched the Brown Ant AI All-in-One Machine. It claims to run the unquantized FP8 precision DeepSeek-R1/V3 671B model at over 20 tokens/s with 128K context, priced at 149,000 RMB. The solution uses dual AMD EPYC CPUs and large-capacity high-frequency memory, supplemented by a small number of GPUs for acceleration. It aims to significantly reduce the hardware cost of private large model deployment through a CPU+memory architecture, providing a localized experience close to official performance, suitable for cost-sensitive enterprise scenarios requiring high precision. (Source: 新智元)

NotebookLM App Coming Soon: Google’s AI note-taking app, NotebookLM, is set to release official iOS and Android applications, expected to launch on May 20th, with pre-orders now open. This will bring NotebookLM’s features—providing summaries, Q&A, and idea generation based on user notes and documents—to mobile platforms. (Source: zacharynado)
Granola Launches iOS App for Real-Time AI Meeting Minutes: AI note-taking app Granola has released an iOS version, extending its original Zoom meeting AI note functionality to offline, face-to-face conversation scenarios. Users can use Granola on their iPhone to record and transcribe conversations, utilizing AI to generate summaries and notes for easy review and organization later. (Source: amasad)
Grok Studio Supports PDF Processing: The Grok AI assistant has added PDF file processing capabilities to its Studio feature. Users can now more conveniently process and analyze PDF documents within Grok Studio. Specific functional details were not elaborated, but it marks an expansion of Grok’s capabilities in understanding and interacting with multi-format documents. (Source: grok, TheGregYang)
Suno’s New Model Demonstrates Excellent Music Generation Capabilities: AI music generation platform Suno has launched a new model, with users reporting its generation results as “incredibly good”. One user attempted to generate a live performance-style song, and while it didn’t fully achieve the desired call-and-response effect, the generated music performed well in aspects like crowd ambiance, showcasing the new model’s progress in music quality and style diversity. (Source: nptacek, nptacek)
AI-Powered Frog Call Identification App: Frog Spot: A developer created a free app called Frog Spot that uses a self-trained CNN model (TensorFlow Lite) to identify different species of frog calls by analyzing the spectrogram of a 10-second audio clip. The app aims to help the public learn about local species while also demonstrating the potential of deep learning in bioacoustic monitoring and citizen science. (Source: Reddit r/deeplearning)
AI Assists in Automating Industrial Technical Drawings: An IAAI 2025 paper introduces a method for automating the expansion of “Instrument Typicals” in Piping and Instrumentation Diagrams (P&IDs). The method combines computer vision models (text detection and recognition) with domain-specific rules to automatically extract information from P&ID drawings and legend tables, expanding simplified instrument typical symbols into detailed instrument lists to generate accurate instrument indexes. This aims to improve efficiency and reduce manual errors in engineering projects, especially during the bidding phase. (Source: aihub.org)

Using Sora to Generate Miniature Soy-Braised Duck Landscape: A user shared an image of a “miniature landscape soy-braised duck” generated by Sora based on a detailed prompt. The prompt meticulously described the scene style (macro photography, miniature landscape), the main subject (a stall building made of soy-braised duck), details (soy-red skin, chili peppers, sesame seeds, chef slicing, diners), environment (streets made of duck meat sauce, marinated-style walls, red lanterns, etc.). This showcases Sora’s ability to understand complex, imaginative text descriptions and generate corresponding high-quality images. (Source: dotey)

Creating 3D Weather Forecast GPTs: A user shared a self-made ChatGPTs application called “Weather 3D”. It takes a city name input from the user, calls a weather API to get real-time weather data, and generates a 3D isometric miniature model style illustration of the city’s landmark building, incorporating the current weather conditions. The illustration displays the city name, weather condition, temperature, and weather icon at the top. This GPTs demonstrates how to combine API calls and image generation capabilities to create practical and visually appealing AI applications. (Source: dotey)

📚 Learning
AdaRFT: A New Method for Optimizing Reinforcement Learning Fine-Tuning: Taiwei Shi et al. proposed a lightweight, plug-and-play curriculum learning method called AdaRFT, aimed at optimizing the training process of reinforcement learning from human feedback (RFT) algorithms (such as PPO, GRPO, REINFORCE). AdaRFT reportedly reduces RFT training time by up to 2x and improves model performance by more intelligently scheduling the order of training data to enhance learning efficiency and effectiveness. (Source: menhguin)

AI Evaluation (Evals) Online Masterclass: Hamel Husain and Shreya Shankar are offering a 4-week online masterclass on AI application evaluation (Evals). The course aims to help developers move AI applications from prototype to production-ready status, covering pre- and post-deployment evaluation methods, differences between benchmarking and practical evaluation, data inspection, PromptEvals, etc. It emphasizes the importance of evaluation in ensuring the reliability and performance of AI applications. (Source: HamelHusain, HamelHusain)

Google Model Tuning Playbook: Google Research provides a repository called “tuning_playbook”, aimed at offering guidance and best practices for model tuning. This is a valuable learning resource for developers and researchers who need to fine-tune large language models or other machine learning models for specific tasks or datasets. (Source: zacharynado)

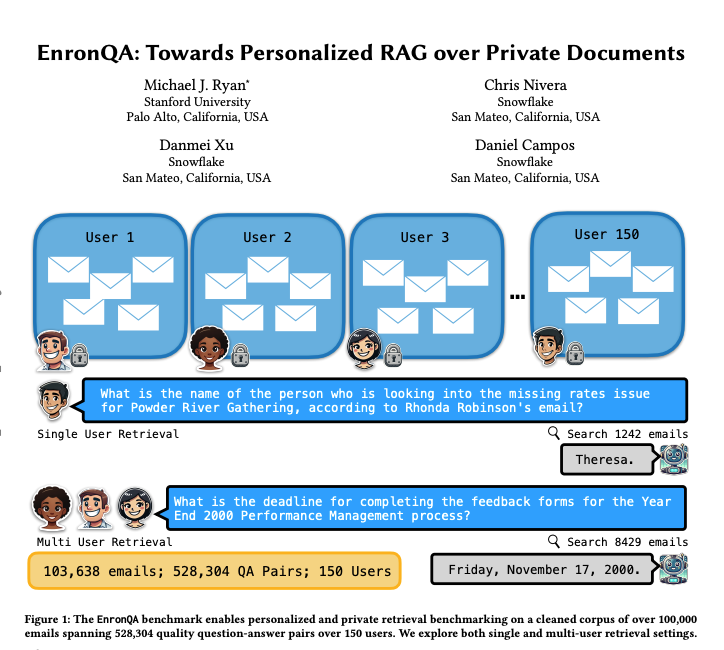
EnronQA: Personalized RAG Benchmark Dataset: Researchers have introduced the EnronQA dataset, containing 103,638 emails from 150 users and 528,304 high-quality question-answer pairs. The dataset is designed as a benchmark for evaluating the performance of personalized Retrieval-Augmented Generation (RAG) systems in handling private documents. It includes gold reference answers, incorrect answers, reasoning justifications, and alternative answers, facilitating a more detailed analysis of RAG system performance. (Source: tokenbender)
ReXGradient-160K: Large-Scale Chest X-ray and Report Dataset: A large public chest X-ray dataset named ReXGradient-160K has been released, containing 60,000 chest X-ray studies and their paired radiology reports (free text) from 109,487 unique patients across 3 US health systems (79 sites). It is claimed to be the largest publicly available chest X-ray dataset by patient count, providing a valuable resource for training and evaluating medical imaging AI models. (Source: iScienceLuvr)

Blog Post Discussing AI Agent Capability Growth: Researcher Shunyu Yao published a blog post titled “The Second Half,” proposing that current AI development is at an “intermission” moment. Before this, training was more important than evaluation; after this, evaluation will become more important than training, because reinforcement learning (RL) is finally starting to work effectively. The article explores the importance of shifting evaluation methodologies against the backdrop of continuously improving AI capabilities. (Source: andersonbcdefg)
OpenAI Shares Research on Privacy and Memorization: OpenAI researchers Pratyush Maini and Zhili Feng will give a talk on privacy and memorization research, discussing how to detect, quantify, and eliminate memorization in large language models, and its practical application in production LLMs. This relates to balancing model capabilities with user data privacy protection. (Source: code_star)

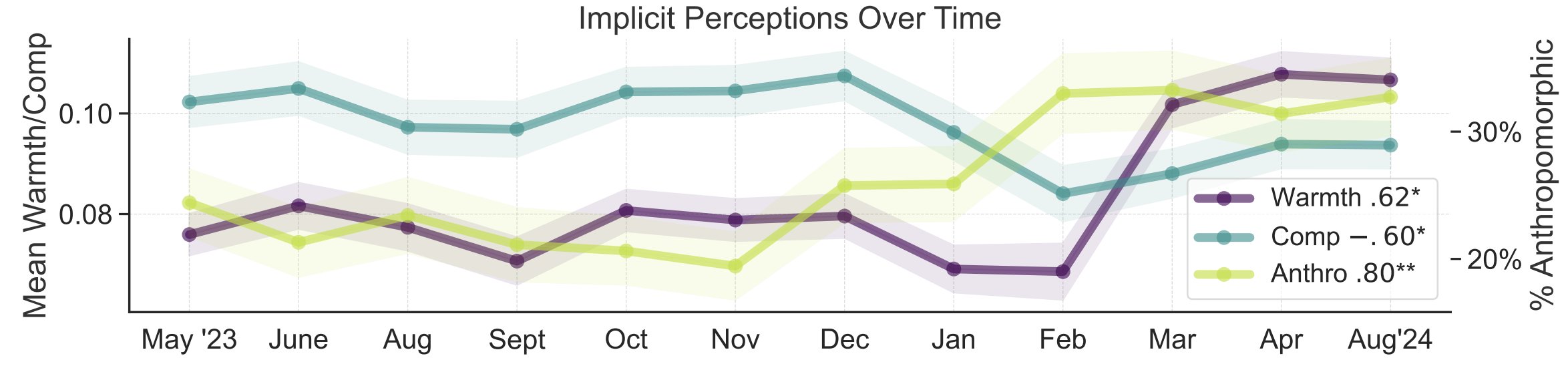
Study on Metaphors for Public Perception of AI: Stanford University researchers Myra Cheng et al. published a paper at FAccT 2025 analyzing 12,000 metaphors about AI collected over 12 months to understand the public’s mental models of AI and how they change over time. The study found that over time, the public tends to view AI as more human-like and agentic (increasing anthropomorphism), and their emotional inclination towards it (warmth) is also rising. This method provides more nuanced insights into public perception than self-report surveys. (Source: stanfordnlp, stanfordnlp)
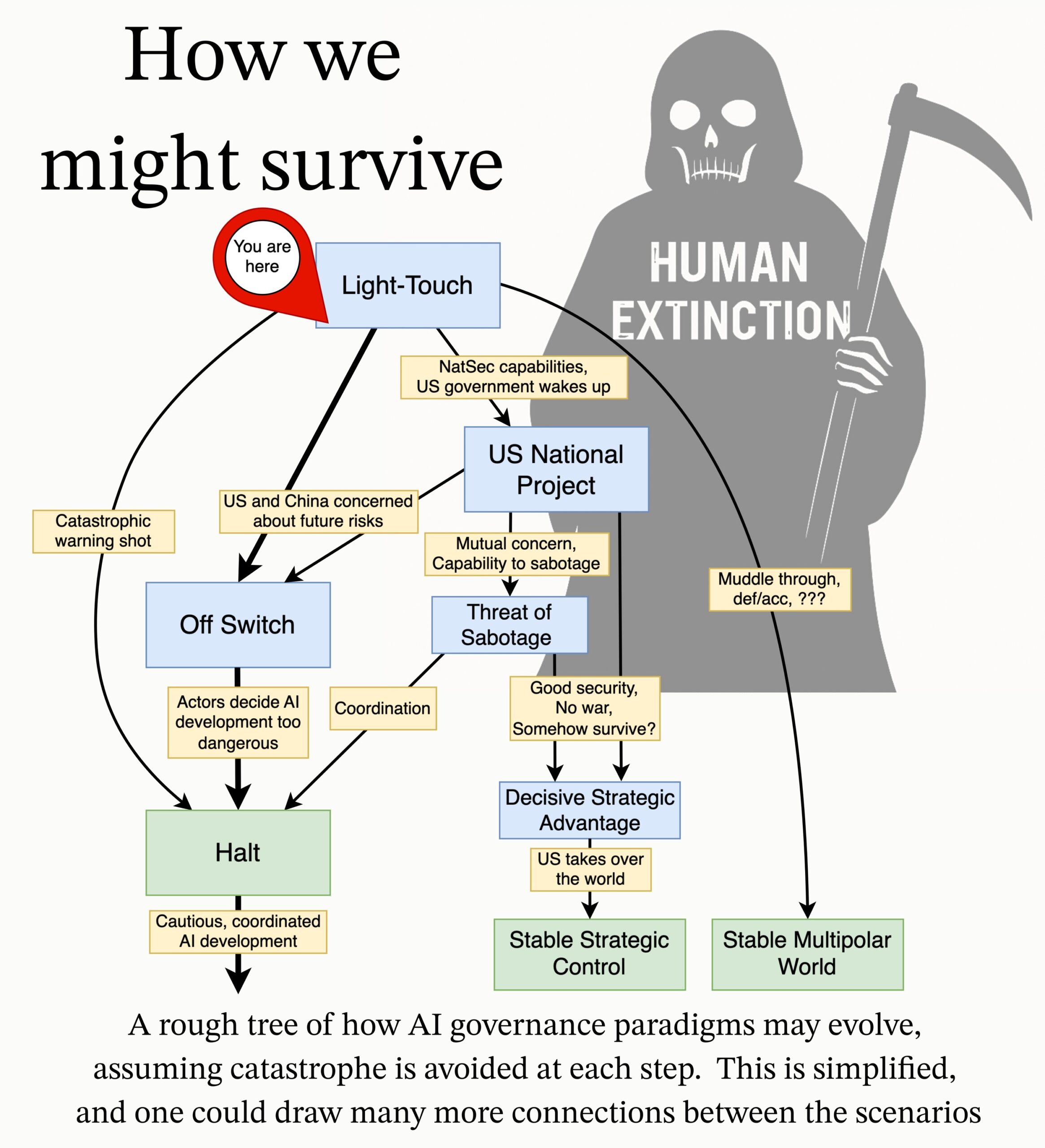
MIRI Releases AI Governance Research Agenda: The Machine Intelligence Research Institute’s (MIRI) technical governance team has released a new AI governance research agenda, outlining their view of the strategic landscape and proposing a series of actionable research questions. Their goal is to explore what measures need to be taken to prevent any organization or individual from building uncontrollable superintelligence, in order to reduce catastrophic and existential risks from AI. (Source: JeffLadish)
💼 Business
Enterprise AI Solution Provider Deepexi Applies for Hong Kong IPO: Deepexi (滴普科技), an enterprise AI solution provider founded by former Huawei and Alibaba executive Zhao Jiehui, has formally submitted its application for a Hong Kong IPO. The company focuses on its FastData data intelligence platform and FastAGI enterprise-level artificial intelligence solutions, serving industries such as retail (e.g., Belle), manufacturing, and healthcare. Over the past three years, the company’s revenue has grown continuously, reaching 243 million RMB in 2024. Deepexi has completed 8 funding rounds, backed by prominent investors like Hillhouse Capital, IDG Capital, and 5Y Capital, with its latest valuation around 6.8 billion RMB. Despite revenue growth, the company is currently loss-making, although its adjusted net loss has been narrowing year over year. (Source: 36氪)
BMW China Announces Integration with DeepSeek Large Model: Following its collaboration with Alibaba, BMW Group further deepens its AI layout in China by announcing the integration of the DeepSeek large model. The feature is planned to launch starting in Q3 2025, initially applied to several new car models sold in China equipped with the 9th generation BMW Operating System, and will also be applied to future domestically produced BMW Neue Klasse models. This move aims to enhance the human-computer interaction experience centered around the BMW Intelligent Personal Assistant through DeepSeek’s deep thinking capabilities, improving the vehicle’s intelligence level and emotional connection. It represents a significant step in BMW’s acceleration of its localized AI strategy and response to the challenges of intelligent transformation. (Source: 36氪)
Shopify Mandates AI Use for All Employees, Aims to Replace Some Roles with AI: Global e-commerce platform Shopify CEO Tobi Lutke emphasized in an internal memo that efficient use of AI has become an “iron rule” for all company employees, no longer just a suggestion. The memo requires employees to apply AI to their workflows, making it a conditioned reflex; teams requesting additional headcount must first prove why AI cannot perform the task; performance reviews will incorporate AI usage metrics. Lutke noted that AI can significantly boost efficiency (up to 10x or even 100x for some employees), and employees need to improve by 20%-40% annually to remain competitive. Shopify has previously conducted layoffs in departments like customer service and introduced AI replacements. This move is seen as a clear signal of the trend where AI leads to adjustments and layoffs in white-collar positions. (Source: 新智元)

🌟 Community
Discussion on AI Hallucination Issues: Baidu CEO Robin Li’s criticism of DeepSeek-R1 for high hallucination rates, slow speed, and high cost at the Baidu AI Developer Conference sparked renewed community discussion on the “hallucination” phenomenon in large models. Analysts point out that not only DeepSeek, but also advanced models like OpenAI’s o3/o4-mini and Alibaba’s Qwen3 commonly exhibit hallucination problems, and multi-turn reasoning in models might amplify biases. Vectara’s evaluation showed R1’s hallucination rate (14.3%) is much higher than V3’s (3.9%). The community believes that as models become more capable, hallucinations become more subtle and logical, making it difficult for users to distinguish truth from falsehood, raising concerns about reliability. Simultaneously, some argue that hallucination is a byproduct of creativity, especially valuable in fields like literary creation. Defining acceptable levels of hallucination and mitigating it through techniques like RAG, data quality control, and critic models remain ongoing industry explorations. (Source: 36氪)

Reflections and Discussions on AI Companions/Friends: Meta CEO Mark Zuckerberg’s proposal to use personalized AI friends to meet people’s need for more social connections (claiming the average person has 3 friends but needs 15) triggered community discussion. Sebastien Bubeck believes achieving true AI companionship is very difficult, key being the AI’s ability to meaningfully answer “What have you been up to lately?”, implying it needs its own experiences, not just sharing the user’s. He thinks current AI companion concepts focus too much on shared experiences, neglecting the AI’s need for shareable independent experiences, even gossip (sharing each other’s experiences). Other commentators question the meaningfulness of a large social circle composed of AI, citing Dunbar’s number. Concerns were also raised that AI friends provided by commercial companies might ultimately aim for precision marketing conversion rather than genuine companionship. (Source: jonst0kes, SebastienBubeck, gfodor, gfodor)

Emotions and Thoughts Sparked by AI Art Creation: A community member expressed feeling “grief” because AI can create “insanely good” art in a short time, believing it challenges human uniqueness in artistic creation. This led to discussions about AI art, the nature of human creativity, and personal value perception amidst technological disruption. Some commented that the joy of art creation lies in the process itself, not competing with AI; AI art can serve as inspiration. Others felt AI art lacks the “flaws” or soul of human creation, appearing too perfect or stereotypical. The discussion also extended to philosophical reflections on AI in emotion simulation, consciousness, and future societal structures (like job displacement). (Source: Reddit r/ArtificialInteligence)
AI Ethics and Responsibility: Secret Experiments and Information Disclosure: The community discussed ethical issues in AI research. One news item mentioned AI researchers conducting secret experiments on Reddit to try changing users’ minds, raising concerns about user consent and the risk of AI manipulation. In another discussion, a user reported facing complex procedures and unclear responsibilities when reporting potential security issues to AI companies, highlighting the immaturity of responsible disclosure and vulnerability response mechanisms in the current AI field. (Source: Reddit r/ArtificialInteligence, nptacek)

NLP Field Reflects on the Rise of ChatGPT: Quanta Magazine published an article featuring interviews with several Natural Language Processing (NLP) experts like Chris Potts, Yejin Choi, and Emily Bender, reviewing the impact and reflections brought to the field after ChatGPT’s release. The article explores how the rise of large language models challenged traditional NLP theoretical foundations, sparked debates within the field, led to factionalization, and adjusted research directions. Community members reacted positively, considering it a good overview of the tremors and adaptation process in the linguistics field post-GPT-3. (Source: stanfordnlp, Teknium1, YejinChoinka, sleepinyourhat)
Emergence and Perception of AI-Generated Advertisements: Social media users reported starting to see AI-generated ads on platforms like YouTube, expressing feeling “very uncomfortable”. This indicates that AI content generation technology is beginning to be applied in commercial advertising production, while also eliciting initial user reactions regarding the quality, authenticity, and emotional experience of AI-generated content. (Source: code_star)
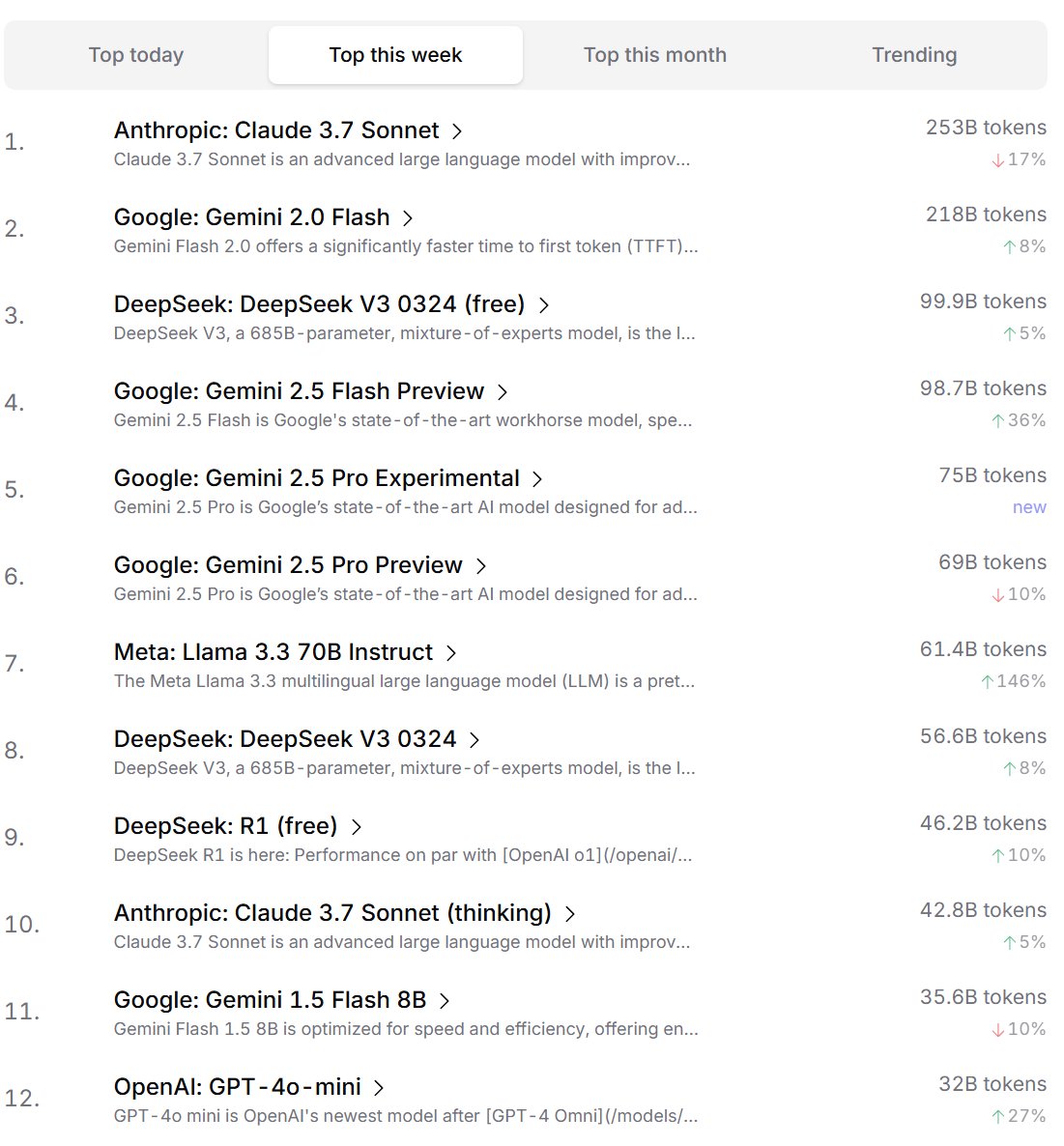
Developer Preference Ranking for AI Models: Cursor.ai released a ranking of AI models preferred by its users (mainly developers), while Openrouter also published rankings based on model token usage. These rankings, based on actual product usage data, are considered potentially more reflective of user choices in real development scenarios than arena-style leaderboards like ChatBot Arena, offering a different perspective for evaluating model practicality. (Source: op7418, Reddit r/LocalLLaMA)
Discussion on Whether AI Possesses “Thinking” Ability: There is ongoing community discussion about whether large language models (LLMs) truly possess the ability to “think”. Some argue that current LLMs don’t actually think before speaking but simulate the thinking process by generating more text (like chain-of-thought), which is misleading. Others believe that using continuous mathematical methods (like LLMs) for discrete reasoning on discrete computers is fundamentally problematic. These discussions reflect deep thinking about the nature of current AI technology and its future direction. (Source: francoisfleuret, pmddomingos)
Dialectical Thinking on AI Energy Consumption and Environmental Impact: Regarding the environmental issues caused by the huge energy consumption for AI training and operation, dialectical thinking has emerged in the community. One view is that AI’s massive energy demand (especially from hyperscalers like Google, Amazon, Microsoft) is forcing these companies to invest in building their own renewable energy sources (solar, wind, batteries), and even restart nuclear power plants (like Microsoft’s collaboration with Constellation to restart the Three Mile Island plant). This demand might paradoxically become a catalyst for accelerating clean energy deployment and technological breakthroughs (like Small Modular Reactors, SMRs). However, other viewpoints highlight the diminishing returns of AI energy consumption and the equally concerning water consumption for cooling. (Source: Reddit r/ArtificialInteligence)
Anthropic Accused of Trying to Limit AI Chip Competition: Community discussion points out that Anthropic CEO Dario Amodei advocates for strengthening export controls on AI chips to places like China, even suggesting chips could be smuggled disguised as prosthetic pregnant bellies. Critics argue Anthropic’s move aims to limit competitors (especially Chinese companies like DeepSeek, Qwen) from accessing advanced computing resources to maintain its advantage in cutting-edge model development. This practice is criticized as using policy to suppress competition, detrimental to the open development of global AI technology and the open-source community. (Source: Reddit r/LocalLLaMA)

💡 Other
Reflections on AI and Human Cognitive Limits: Jeff Ladish comments that the window for humans acting as AI’s “copy-paste assistants” is extremely short, implying AI’s autonomous capabilities will rapidly surpass simple assistance. Meanwhile, DeepMind founder Hassabis stated in an interview that true AGI should be able to independently propose valuable scientific hypotheses (like Einstein proposing General Relativity), not just solve problems, believing current AI still lacks in hypothesis generation. Liu Cixin anticipates AI breaking through the biological cognitive limits of the human brain. These views collectively point towards deeper reflections on the boundaries of AI capabilities, the evolution of the human role, and the future nature of intelligence. (Source: JeffLadish, 新智元)
Waymo LiDAR Captures Thrilling Moment: A Waymo autonomous vehicle’s LiDAR system clearly captured the 3D point cloud image of a delivery rider flipping during a collision, which the Waymo vehicle successfully avoided. This not only showcases the powerful capabilities of Waymo’s perception system (even in complex dynamic scenes) but also unexpectedly recorded the accident from a unique perspective. Fortunately, no one was seriously injured in the accident. (Source: andrew_n_carr)
New Approach for AI Novel Writing: Plot Promise System: Developer Levi proposed a “Plot Promise” system for AI novel writing as an alternative to traditional hierarchical outlining methods. Inspired by Brandon Sanderson’s “Promise, Progress, Payoff” theory, the system treats the story as a series of active narrative threads (promises), each with an importance score. An algorithm suggests advancement timing based on score and progress, but the AI logically selects the most suitable promise to advance currently based on context. Users can dynamically add or remove promises. This method aims to enhance story flexibility, scalability (adapting to ultra-long formats), and creative emergence, but faces challenges like optimizing AI decision-making, maintaining long-term coherence, and input prompt length limitations. (Source: Reddit r/ArtificialInteligence)