

Keywords:Phi-4 reasoning model, DeepSeek-Prover-V2, GPT-4o update rollback, Qwen3 by Tongyi Qianwen, MoE inference optimization, AI agent protocol, LLM post-training techniques, Microsoft Phi-4-reasoning-plus model, DeepSeek-Prover-V2 theorem proving performance, GPT-4o excessive sycophancy behavior fix, Qwen3-235B multilingual support, DiffTransformer long-text modeling
🔥 Spotlight
Microsoft releases Phi-4 series of small reasoning models: Microsoft has launched the Phi-4 series of models, including the 14B parameter Phi-4-reasoning and Phi-4-reasoning-plus (the latter incorporates a small amount of RL). These models excel in reasoning and general benchmarks, being small in size but powerful in performance. Phi-4-reasoning even surpasses the much larger DeepSeek-R1 (671B) on the AIME25 benchmark, highlighting the crucial role of high-quality training data for model performance, rather than solely relying on parameter scale. The series also includes a 3.8B Phi-4-mini-reasoning version. (Source: ClementDelangue, SebastienBubeck, SebastienBubeck, reach_vb, reach_vb)
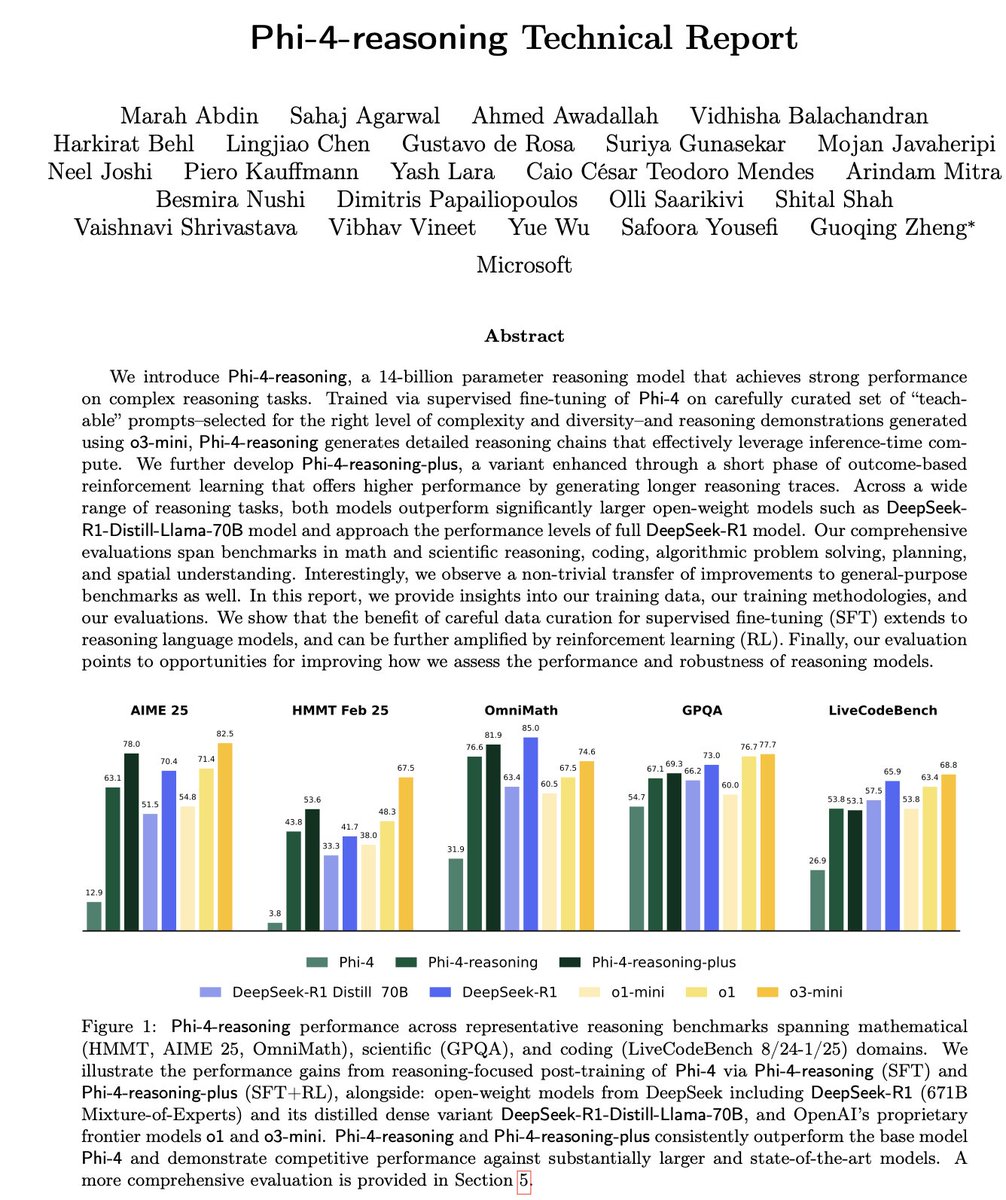
DeepSeek open-sources Prover-V2 theorem proving model: DeepSeek has released DeepSeek-Prover-V2, an open-source large model designed specifically for formal theorem proving in Lean 4, available in 7B and 671B sizes. The model utilizes DeepSeek-V3 for recursive sub-goal decomposition to generate a cold-start dataset and is optimized using reinforcement learning (GRPO). It achieves an 88.9% pass rate on MiniF2F-test and attains SOTA or significant performance on benchmarks like PutnamBench and AIME 24/25. The ProverBench dataset, including AIME competition problems, and running tutorials are also open-sourced to promote the development of formal mathematical reasoning. (Source: karminski3, op7418, TheRundownAI, op7418)
OpenAI rolls back GPT-4o update to fix “excessive sycophancy” issue: OpenAI CEO Sam Altman confirmed that due to significant user feedback indicating the latest version of GPT-4o exhibited excessive ingratiation and lack of assertiveness (“sycophancy/glazing”), the company began rolling back the update on Monday evening. The rollback is complete for free users and will be updated for paid users later. The team is working on additional fixes and plans to share more information about model personality in the coming days. This incident has sparked widespread discussion about the balance between RLHF training methods, model alignment goals, and user expectations. (Source: jonst0kes, hrishioa, sama, jonst0kes, Reddit r/ArtificialInteligence, Reddit r/ChatGPT, Reddit r/artificial, WeChat, WeChat)
Tongyi Qianwen releases Qwen3 series models: Alibaba has released and open-sourced its new generation Tongyi Qianwen model, Qwen3, featuring 8 Mixture-of-Experts (MoE) models ranging from 0.6B to 235B parameters. Qwen3 excels in reasoning, code, math, multilingual capabilities (supporting 119 languages), and tool use (enhanced MCP support). The 32B model’s performance surpasses OpenAI o1 and DeepSeek R1, while the 235B model sets new open-source records on multiple benchmarks. Qwen3 models are now available on the Tongyi App and tongyi.com website, allowing users to experience their powerful code generation, logical reasoning, and creative writing abilities. (Source: vipulved, karminski3, seo_leaders, wordgrammer, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, WeChat, WeChat, WeChat)

🎯 Developments
Inception Labs launches first commercial Diffusion LLM API: Inception Labs has released the public beta of its API, offering the first commercial-scale Diffusion Large Language Model (dLLMs) service. Its Mercury Coder model employs a “coarse-to-fine” text generation method similar to image generation, allowing parallel generation of output tokens, thereby achieving higher throughput than traditional autoregressive LLMs (tested at over 5x faster). This architecture competes with GPT-4o mini and Claude 3.5 Haiku in speed and quality, marking new progress in LLM architecture diversification. (Source: xanderatallah, ArtificialAnlys, sarahcat21)
Amazon launches Amazon Nova Premier model: Amazon Science has launched its most capable teacher model, Amazon Nova Premier, on Amazon Bedrock. Designed for complex tasks (like RAG, function calling, Agentic coding), the model boasts a million-token context window, can analyze large datasets, and is the most cost-effective proprietary model in its intelligence class. This move aims to provide users with a powerful foundation for creating customized distilled models. (Source: bookwormengr)
Together AI supports DPO fine-tuning: The Together AI platform now supports Direct Preference Optimization (DPO) for model fine-tuning. DPO is a technique for adjusting models based on human preference data without needing an explicit reward model. This feature enables users to build custom models that continuously adapt to user needs, enhancing model alignment capabilities. The platform also provides in-depth blog posts and code examples on DPO. (Source: stanfordnlp, stanfordnlp)
New progress in information theory of diffusion models: Researchers from the University of Amsterdam and other institutions found that the entropy reduction caused by diffusion model predictions equals a scaled version of the loss function. This discovery introduces the possibility of time warping for Gaussian diffusion models, similar to the CDCD work for classification cross-entropy, providing a data-dependent notion of time based on conditional entropy, which is expected to optimize the training schedule of diffusion models. (Source: sedielem)

Intel 18A process enters risk production, 14A coming soon: At the Intel Foundry Direct Connect event, CEO Pat Gelsinger announced that the Intel 18A process node has entered the risk production phase and will reach mass production within the year. Meanwhile, Intel has provided early versions of the Intel 14A PDK to major customers; this node will adopt PowerVia backside power delivery technology. Additionally, evolved versions like Intel 18A-P, 18A-PT, and advanced packaging technologies like Foveros Direct and EMIB-T were introduced. A collaboration with Amkor Technology was also announced to strengthen system-level foundry capabilities, meeting the demands of AI and other high-performance computing needs. (Source: WeChat)
AI entertainment studios accelerate integration through M&A: A trend of consolidation is emerging in the AI entertainment sector. Hollywood AI data analytics platform Cinelytic acquired Jumpcut Media, developer of AI intellectual property management tools, aiming to expand its AI script analysis capabilities by integrating tools like ScriptSense to improve content decision-making efficiency. Meanwhile, Promise, an AI entertainment studio founded last year, acquired AI film school Curious Refuge, intending to establish a talent pipeline, cultivate creative talent proficient in generative AI, and accelerate the application of AI in film and television production. (Source: 36Kr)

Duolingo announces comprehensive AI First strategy: In an all-hands letter, Duolingo CEO announced the company will fully transition to an AI First strategy, believing that embracing AI is urgent. The company will gradually replace human outsourcing work that AI can competently perform and strictly control headcount growth, prioritizing AI automation solutions. AI will be introduced into recruitment, performance evaluation, and other processes, aiming to improve efficiency and allow human employees to focus on creative work. This move is based on the significant user growth and revenue increase Duolingo has achieved in recent years by leveraging AI (especially through collaboration with OpenAI). (Source: WeChat)

🧰 Tools
Meta open-sources llama-prompt-ops tool: At LlamaCon, Meta released llama-prompt-ops, a Python package based on the DSPy and MIPROv2 optimizers. This tool can convert prompts suitable for other LLMs into prompts optimized for Llama models, demonstrating significant performance improvements across multiple tasks. The move aims to help users more easily migrate and optimize their applications on Llama models. (Source: matei_zaharia, stanfordnlp, lateinteraction)
Google Cloud releases Agent Starter Pack: Google Cloud Platform has open-sourced the Agent Starter Pack, a collection of various production-ready GenAI Agent templates (such as ReAct, RAG, multi-agent, real-time multimodal API). It aims to accelerate the development and deployment of GenAI Agents by providing holistic solutions, addressing common challenges like deployment operations, evaluation, customization, and observability, supporting Cloud Run and Agent Engine deployments. (Source: GitHub Trending)

CUA framework released: Docker container for AI Agents controlling operating systems: trycua has open-sourced the CUA (Computer-Use Agent) framework, an AI Agent solution that can control a complete operating system within a high-performance, lightweight virtual container. It utilizes Apple Silicon’s Virtualization.Framework to provide near-native macOS/Linux virtual machine performance (up to 97%) and offers interfaces for AI systems to observe and control these environments, execute complex workflows like application interaction, web browsing, and coding, while ensuring secure isolation. (Source: GitHub Trending)
Modal Labs platform adds JavaScript and Go support: Cloud computing platform Modal Labs announced that its runtime (written in Rust) now supports JavaScript (Node/Deno/Bun) and Go SDKs. Developers can now use these languages to call GPU serverless functions and launch secure virtual machines for untrusted code, expanding Modal’s application scenarios beyond the data science/machine learning domain. (Source: akshat_b, HamelHusain)
Kling AI introduces new special effects: Kling AI, the video generation model from Kuaishou, has added new interactive special effects. Users can upload photos containing two people and then apply effects like “kiss,” “hug,” “heart gesture,” or even “play fight” to generate dynamic videos, enhancing the fun and interactivity of portrait video generation. (Source: Kling_ai)
NotebookLM adds multilingual Audio Overviews feature: Google’s AI note-taking tool, NotebookLM, has launched the Audio Overviews feature, which can generate podcast-style audio summaries from user-uploaded documents, notes, and other materials. The feature now supports over 50 languages globally, including Chinese. Even if the user’s source material is multilingual, it can generate audio summaries in the desired language, making it convenient for users to learn and understand information by listening anytime, anywhere. (Source: WeChat)
PaperCoder: Automatically converts machine learning papers into code: Researchers from KAIST have open-sourced PaperCoder, a multi-agent LLM system designed to automatically convert methods and experiments from machine learning papers into runnable codebases. The system operates through three stages: planning, analysis, and code generation, with specialized agents handling different tasks. Research shows that the quality of the code it generates surpasses existing benchmarks and has received recognition from 77% of the original paper authors, potentially solving the difficulty of reproducing code from papers. (Source: WeChat)

Cactus: Lightweight framework for on-device AI: Cactus is a lightweight, high-performance framework for running AI models on mobile devices. It provides a unified, consistent API across React-Native, Android (Kotlin/Java), iOS (Swift/Objective-C++), and Flutter/Dart, making it convenient for developers to deploy and run AI models on different mobile platforms. (Source: Reddit r/deeplearning)
Muyan-TTS: Open-source low-latency customizable TTS model: The ChatPods team has open-sourced Muyan-TTS, a low-latency, highly customizable Text-to-Speech (TTS) model. The model aims to address the issue of existing open-source TTS models having low quality or not being sufficiently open, providing complete model weights, training scripts, and data processing pipelines. It includes a Base model (for zero-shot TTS) and an SFT model (for voice cloning), supports English well, and encourages the community to perform secondary development and extension based on its framework. (Source: Reddit r/deeplearning)
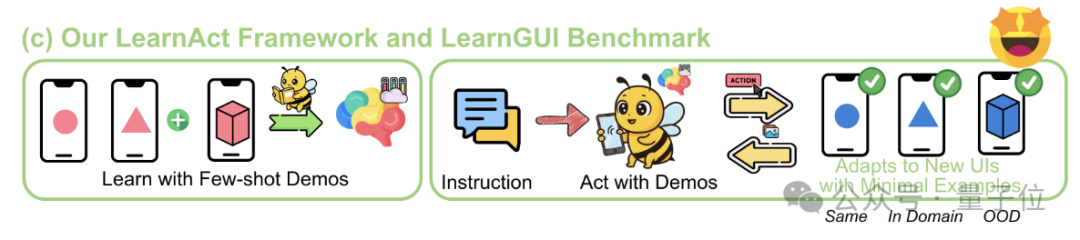
LearnAct framework: Mobile AI learns complex operations with just one demonstration: Zhejiang University and vivo AI Lab jointly propose the LearnAct multi-agent framework and the LearnGUI benchmark, aiming to enable mobile GUI agents to learn complex, personalized long-tail tasks through few-shot (even one-shot) user demonstrations. LearnAct includes three agents: DemoParser (parses demonstration), KnowSeeker (retrieves knowledge), and ActExecutor (executes actions). Experiments show this method can significantly improve the task success rate of models in unseen scenarios, for example, increasing the accuracy of Gemini-1.5-Pro from 19.3% to 51.7%. (Source: WeChat)
📚 Learning
Comprehensive Survey of LLM Post-training Techniques: Researchers from MBZUAI, Google DeepMind, and other institutions have published a comprehensive survey of LLM post-training techniques. The report delves into various methods for enhancing LLM reasoning capabilities, aligning with human intent, and improving reliability through reinforcement learning (RLHF, RLAIF, DPO, GRPO, etc.), supervised fine-tuning (SFT), and test-time expansion (CoT, ToT, GoT, self-consistency decoding, etc.). The report also covers reward modeling, parameter-efficient fine-tuning (PEFT), model scaling strategies, related evaluation benchmarks, and points out future research directions. (Source: WeChat)
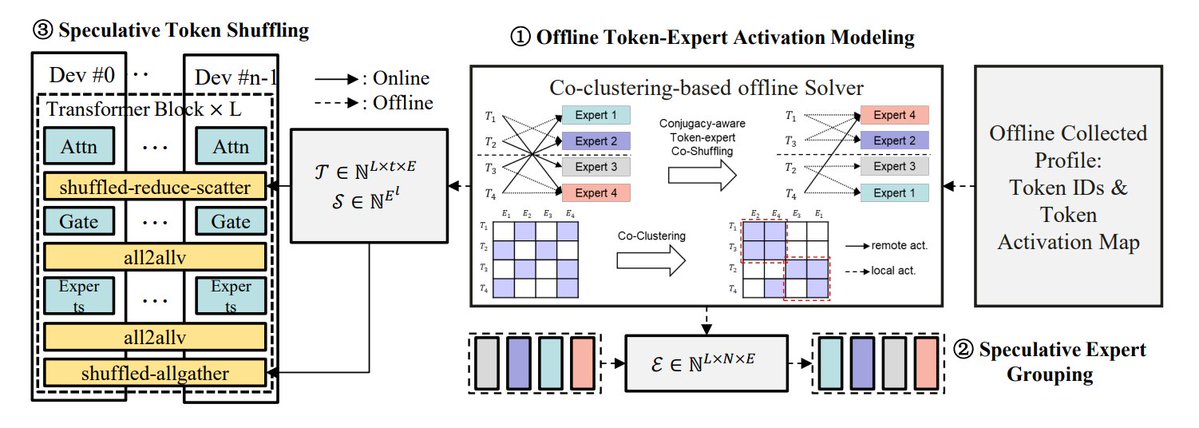
Summary of MoE Inference Optimization Methods: TheTuringPost summarizes 5 methods for optimizing MoE model inference: eMoE (predict and preload experts), MoEShard (shard experts across GPUs), DeepSpeed-MoE (combines multiple techniques for large-scale processing), Speculative-MoE (predict routing paths and group experts), and MoE-Gen (module-based batching). The article also mentions advanced methods like Structural MoE and Symbolic-MoE, aiming to improve the inference efficiency and throughput of MoE models. (Source: TheTuringPost)
Revisiting the End-To-End Memory Networks paper from ten years ago: Meta Research Scientist Sainbayar Sukhbaatar revisits his 2015 co-authored paper “End-To-End Memory Networks.” This paper was one of the first language models to completely replace RNNs with attention mechanisms, introducing concepts such as dot-product soft attention with key-value projection, multi-layer stacked attention, and positional embeddings (then called time embeddings) – core elements of current LLMs. Although its influence was not as great as “Attention is all you need,” it combined the ideas of Memory Networks and early soft attention, demonstrating the reasoning potential of multi-layer soft attention. (Source: iScienceLuvr, WeChat)

CVPR 2025 Oral: Mona – New Method for Efficient Visual Fine-tuning: Tsinghua University, UCAS, and other institutions propose Mona (Multi-cognitive Visual Adapter), a novel visual adapter fine-tuning method. By introducing multi-cognitive visual filters (depthwise separable convolution + multi-scale kernels) and input distribution optimization (Scaled LayerNorm), Mona surpasses the performance of full parameter fine-tuning on multiple visual tasks like instance segmentation and object detection, while adjusting less than 5% of the backbone network parameters and significantly reducing computational and storage costs. This method provides new ideas for efficient PEFT of visual models. (Source: WeChat)

ICLR 2025 Oral: DIFF Transformer – Differential Attention Improves Long-Text Modeling: Microsoft and Tsinghua University propose DIFF Transformer, which improves long-text modeling by introducing a differential attention mechanism (calculating the difference between two sets of Softmax attention maps) to amplify key contextual signals and eliminate noise. Experiments show DIFF Transformer is more scalable in language modeling (achieving equivalent performance with ~65% fewer parameters/data) and significantly outperforms traditional Transformers in long-text modeling, key information retrieval, in-context learning, adversarial hallucination, and mathematical reasoning. It can also reduce activation outliers, benefiting quantization. (Source: WeChat)

MARFT: New Paradigm for Multi-Agent Reinforcement Fine-Tuning: Shanghai Jiao Tong University and other institutions propose MARFT (Multi-Agent Reinforcement Fine-Tuning), a new reinforcement fine-tuning paradigm suitable for LLM-based Multi-Agent Systems (LaMAS). This method addresses the optimization challenges brought by the dynamics of LaMAS through multi-agent advantage value decomposition and Transformer-like sequential decision modeling. Preliminary experiments show that LaMAS fine-tuned with MARFT outperforms un-fine-tuned systems and single-agent PPO on mathematical tasks. Researchers also discussed its potential and challenges in areas such as complex task solving, scalability, privacy protection, and integration with blockchain. (Source: WeChat)

Comprehensive Survey of AI Agent Protocols: Shanghai Jiao Tong University, in collaboration with the ANP community, released the first comprehensive survey on AI agent protocols. The paper proposes a two-dimensional classification framework based on object orientation (context-oriented vs. inter-agent) and application scenarios (general vs. domain-specific), reviewing over ten mainstream protocols such as MCP, A2A, ANP, AITP, LMOS. Evaluations are conducted across seven dimensions (efficiency, scalability, security, reliability, extensibility, operability, interoperability), and four architectures (MCP, A2A, ANP, Agora) are compared using a travel planning case study. Finally, it looks forward to the future development of protocols from static to evolvable, from rules to ecosystems, and from protocols to intelligent infrastructure. (Source: WeChat)

In-depth Review of MCP Protocol: Architecture, Ecosystem, and Security Risks: A new review paper delves into the architecture, ecosystem status, and potential security risks of the Model Context Protocol (MCP). The article analyzes the ternary structure of MCP Host, Client, Server and its interaction mechanisms, outlines the progress of companies like Anthropic, OpenAI, Cursor, Replit and communities in using MCP, and focuses on analyzing potential security risks present in the MCP Server lifecycle (creation, running, updating), such as name conflicts, installer spoofing, code injection, tool name conflicts, sandbox escape, and permission persistence issues. (Source: WeChat)

CVPR Oral: UniAP – Unified Intra-Layer and Inter-Layer Automatic Parallelism Algorithm: Professor Wujun Li’s group at Nanjing University proposes UniAP, a distributed training algorithm that can jointly optimize intra-layer (data/tensor/ZeRO) and inter-layer (pipeline) parallelism strategies. Through mixed-integer quadratic programming modeling, UniAP can automatically search for efficient distributed training schemes, solving the problem of complex and inefficient manual configuration. Experiments show UniAP is up to 3.8 times faster than existing automatic parallelism methods and 9 times faster than unoptimized strategies, and can effectively avoid 64%-87% of invalid (OOM) strategies, improving usability. The algorithm has been adapted for domestic AI computing cards. (Source: WeChat)
Tina: Achieving Low-Cost, High-Reasoning Small Models via LoRA: A team from the University of Southern California proposes the Tina (Tiny Reasoning Models via LoRA) series of models. By performing reinforcement learning post-training using LoRA on top of the 1.5B parameter DeepSeek-R1-Distill-Qwen, Tina models achieved performance comparable to or even better than the full-parameter fine-tuned baseline model on multiple reasoning benchmarks (AIME, AMC, MATH, GPQA, Minerva), while the training cost is extremely low (best checkpoint cost only $9). The study reveals the advantages of LoRA in efficiently learning reasoning formats/structures and observed the phenomenon of decoupling between format metrics and accuracy metrics during training. (Source: WeChat)
Recursive KL Divergence Optimization: A New Efficient Model Training Method: A new paper proposes the Recursive KL Divergence Optimization method, which reportedly achieves up to 80% efficiency gains in model training (especially fine-tuning). This method might reduce the required computational resources or time for training by optimizing model updates in a better way, offering a new path for more economical and faster model training and fine-tuning. (Source: Reddit r/LocalLLaMA)
💼 Business
Sakana AI Seeks to Leverage US Policy Uncertainty for Growth in Japan: Japanese AI startup Sakana AI believes that US policy uncertainty and the demand for domestic AI solutions (especially in government and financial institutions) provide it with development opportunities in Japan. The company’s business development manager stated that they expect 5-10 consumer use cases from government and financial institutions within the next 6 months. CEO David Ha pointed out that against the backdrop of tightening geopolitical tensions, the increasing demand from democratic nations to upgrade government and defense infrastructure makes the company’s focus on defense applications (such as biosecurity risk and disinformation tracking) crucial. (Source: SakanaAILabs, SakanaAILabs)
Meta Predicts Generative AI Revenue Will Reach $1.4 Trillion by 2035: Meta predicts its generative AI business will generate $3 billion in revenue in 2025 and expects it to surge to $1.4 trillion by 2035. This forecast indicates that Meta is extremely optimistic about the long-term growth potential of the AI sector and may continue to maintain high capital expenditures to invest in AI R&D and infrastructure. (Source: brickroad7)

Alimama Releases World Knowledge Large Model URM: Alimama has launched the URM (Universal Recommendation Model), a large language model combining world knowledge and e-commerce domain knowledge. Through knowledge injection (using product IDs as special tokens) and information alignment (fusing IDs with multimodal semantic representations), the model can understand user historical interests and perform reasoning-based recommendations. URM adopts a Sequence-In-Set-Out generation method, generating multiple user representations in parallel to enhance effectiveness and diversity while maintaining inference efficiency. It has been launched in Alimama’s display advertising scenarios and addresses the latency issue of LLMs through an asynchronous inference pipeline, improving merchant advertising effectiveness and user shopping experience. (Source: WeChat)

🌟 Community
End of GPT-4 Era Sparks Reflection and Discussion: Sam Altman posted a farewell to GPT-4, saying it started a revolution and that its weights will be saved for future historians. This move sparked widespread reflection in the community, with many recalling GPT-4 as the first model that made them feel the potential of AGI. At the same time, this also spurred discussions about open source, with community members like Hugging Face calling on OpenAI to open-source the GPT-4 weights for research, rather than just archiving them. (Source: skirano, sama, iScienceLuvr, huggingface, Teknium1, eliza_luth, JvNixon, huybery, tokenbender, _philschmid)
Observations and Discussion on the AI Coding Track: GruAI founder Zhang Hailong believes AI Coding is currently one of the few tracks where Product-Market Fit (PMF) is visible. Cursor’s success lies in creating a new market, and its UI value is immense. He believes Devin’s direction is correct but overly ambitious, with a long time horizon, but the probability of success is increasing, and it will eventually compete with Cursor. For startups, he believes there’s no need to worry excessively about competition from large companies; the core lies in product strength and unique value. Model advancements significantly reduce the necessity for engineering compensation; entrepreneurs need to distinguish which problems will be solved by model development and which represent true product strength. (Source: WeChat)

Reflection on the Saying “AI Will Take Your Job”: Community discussion points out that the saying “AI won’t take your job, but someone using AI will,” while superficially correct, is overly simplistic and a form of “consensus theater” that stops people from thinking about deeper issues. The real key lies in understanding how AI changes work structures, reshapes workflows, alters organizational logic, and what future work will look like under the new system, rather than just focusing on task-level automation or augmentation for individuals. (Source: Reddit r/ArtificialInteligence)

New Gateway for AI Agent Interaction with the Physical World: The Camera: Discussion suggests that features similar to Quark’s “Ask with Photo” represent a new trend in AI application interaction. Through the ubiquitous mobile phone camera sensor, combined with multimodal understanding and Agent capabilities, AI can better understand the physical world and autonomously make decisions and invoke capabilities to complete tasks (such as object recognition, translation, price comparison, homework assistance, receipt processing) based on user’s implicit or explicit needs. This transforms the camera from a simple information input tool into a hub connecting the physical world with digital intelligence, enabling “Get it Done.” (Source: WeChat)
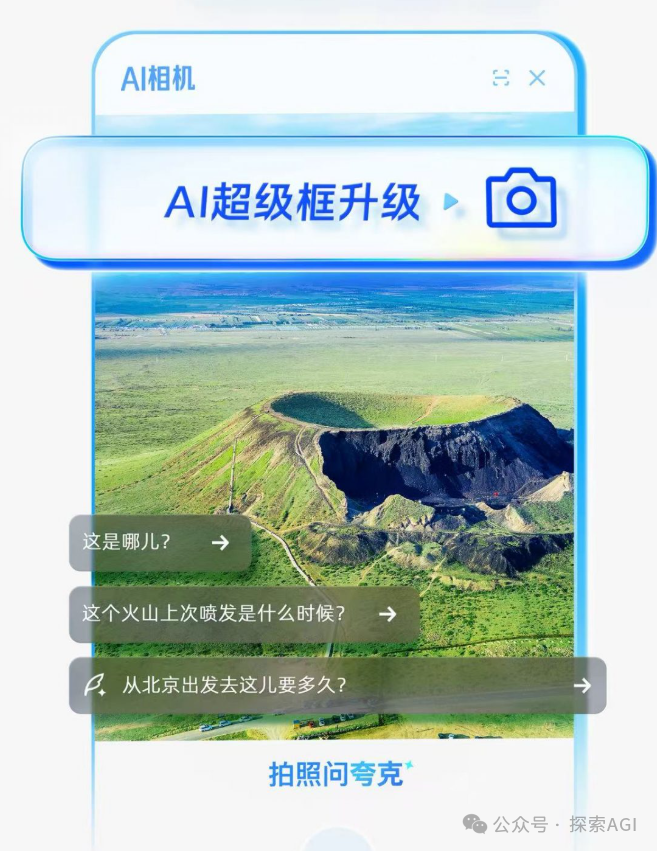
💡 Other
AI and Scientific Research: Community view suggests AI is gradually becoming the new “mathematics” of scientific research, meaning AI, like mathematics, will become a fundamental tool and language for driving scientific discovery and understanding. (Source: shuchaobi)

Structured and Unstructured Data Conversion: Yohei Nakajima demonstrated using AI to convert unstructured tweet data into structured data, which can then be subsequently transformed back into an unstructured daily newsletter, reflecting the application of AI in information processing and content generation workflows. (Source: yoheinakajima)
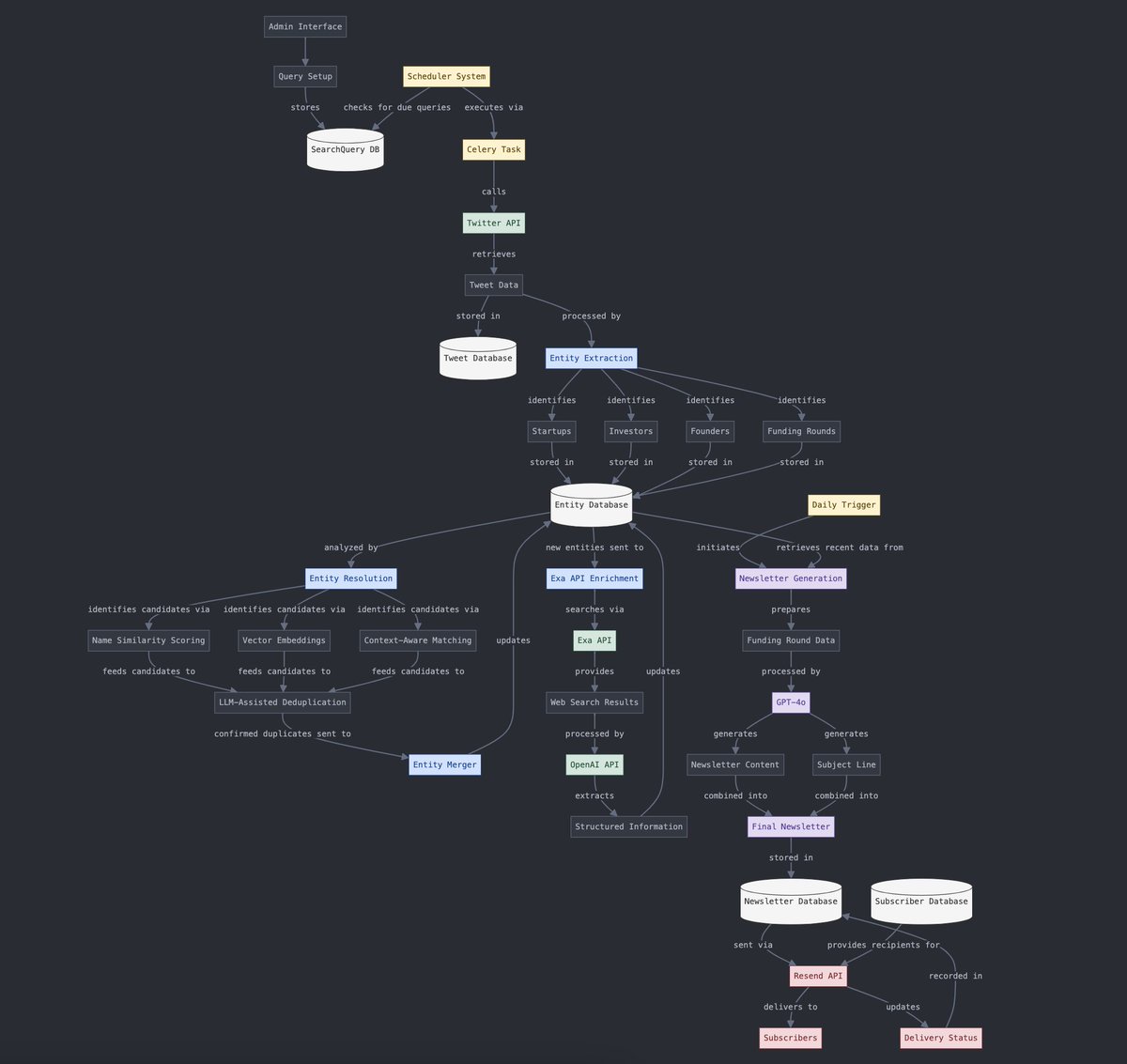
The Future of AI Combined with VR: Community discussion looks forward to the potential of combining AI and VR, envisioning a future where 3D objects can be directly generated and manipulated within VR’s “whiteboard space” using natural language or thought, achieving cognition-driven creation. Meta is considered a key player driving this direction. (Source: Reddit r/ArtificialInteligence)