
Keywords:OpenAI, AI model, AlphaFold, AI chip, GPT-4.1, Magi-1 video model, Nvidia H20 export restrictions, ByteDance UI-TARS-1.5, Meta MILS multimodal, DeepMind AlphaFold 3, Sand.ai autoregressive video, Huawei Ascend 910C
🔥 Focus
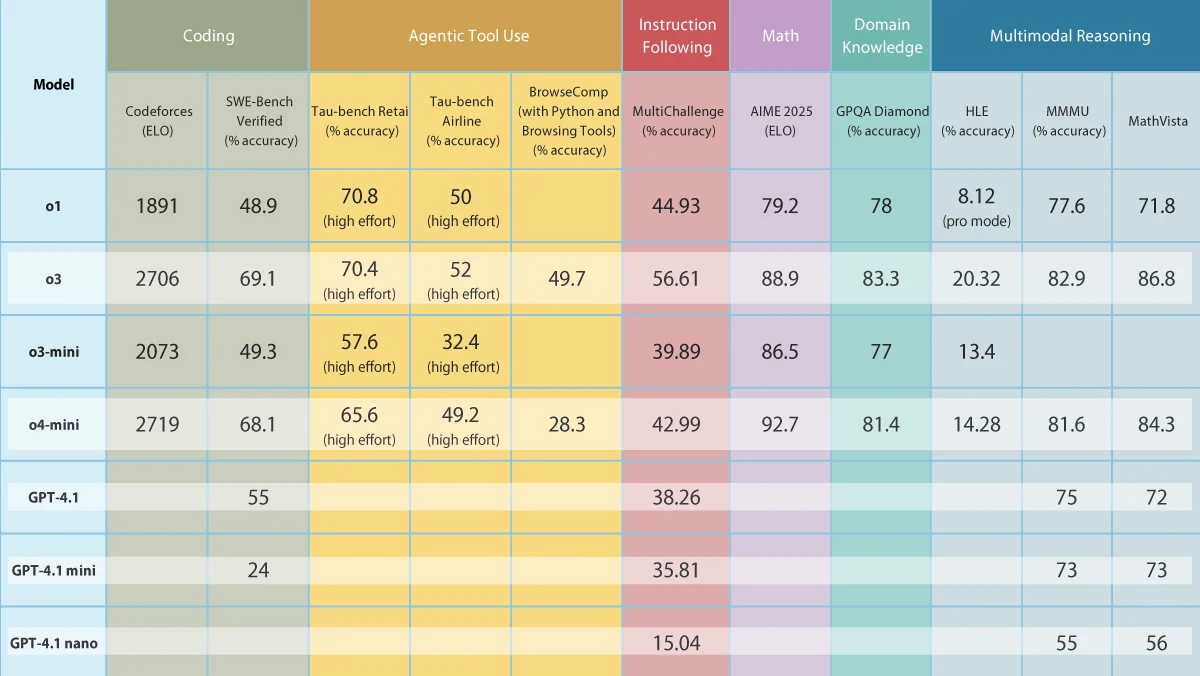
OpenAI Releases Five New Models, Enhancing General and Reasoning Capabilities: OpenAI has launched three general-purpose models: GPT-4.1, GPT-4.1 mini, and GPT-4.1 nano, along with two reasoning models, o3 and o4-mini. The GPT-4.1 series supports up to 1 million token inputs, aiming to provide more cost-effective options than GPT-4.5/4o, with GPT-4.1 surpassing GPT-4o in tasks like coding. o3 and o4-mini are upgrades to o1 and o3-mini, with a 200k token input limit, better tool utilization (web search, code generation/execution, image editing), and support for chain-of-thought processing on images for the first time. o3 achieves SOTA on multiple benchmarks. Concurrently, OpenAI announced the removal of the GPT-4.5 preview in July. This release aims to deliver stronger performance, particularly in reasoning and tool use, at a lower cost. (Source: OpenAI’s Five New Models, Hugging Face’s Open Robot, U.S. Tightens Grip on AI Chips, Text-Only LLMs Go Multimodal)
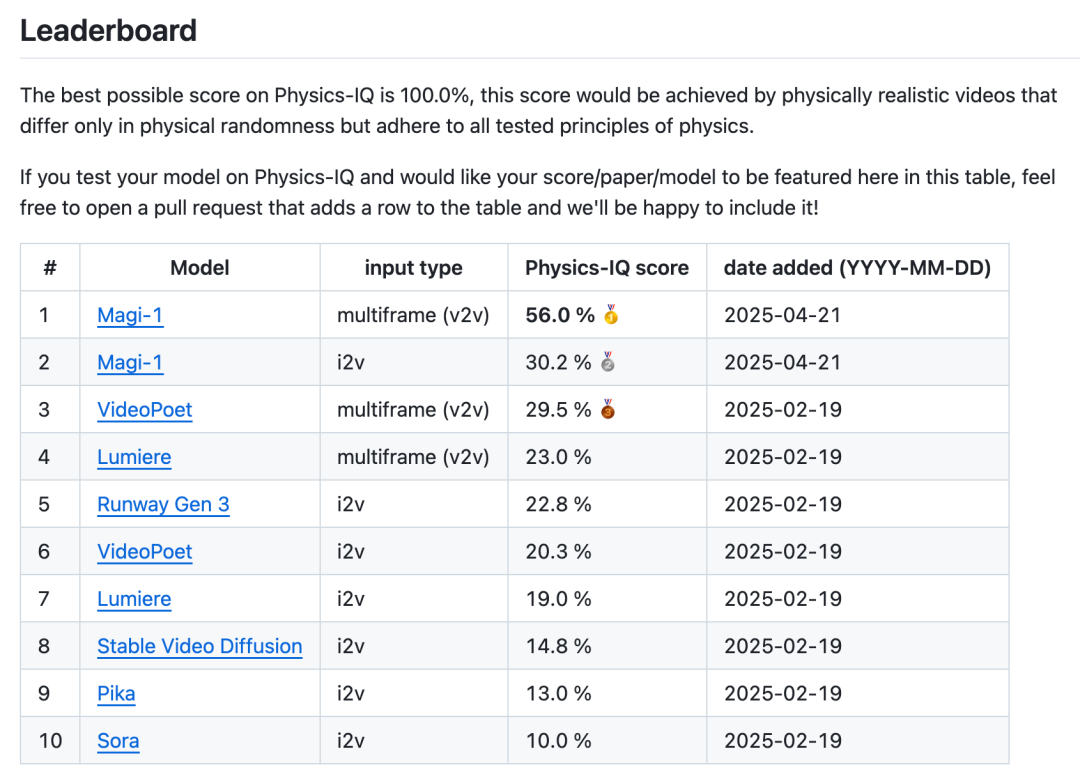
Sand.ai Open-Sources Magi-1, the First High-Quality Autoregressive Video Model: Beijing startup Sand.ai has released and open-sourced Magi-1, the world’s first high-quality video generation model using an autoregressive architecture. Unlike concurrent generation models like Sora, Magi-1 generates videos chunk-by-chunk, preserving temporal causality and excelling in physical realism, action coherence, and controllability, particularly in video continuation (V2V). The team has open-sourced model weights ranging from 4.5B to 24B parameters, inference and training code, and provided a ready-to-use product website. The model can run on a single 4090 GPU at minimum, with inference resource consumption independent of video length, enabling possibilities for long video generation and real-time applications. (Source: Magi-1 开源&刷屏:首个高质量自回归视频模型,它的一切信息)
DeepMind AlphaFold Progress: Mapping 200 Million Protein Structures in One Year: Google DeepMind founder Demis Hassabis revealed in an interview that its protein structure prediction model, AlphaFold, mapped over 200 million protein structures in a year, whereas traditional methods take years to resolve a single structure. AlphaFold 3 further extends to DNA, RNA, ligands, and almost all molecules of life, significantly improving the accuracy of predicting molecular interactions in drug design. Google DeepMind also launched the free AlphaFold Server platform, allowing biologists to easily utilize its prediction capabilities. Despite challenges with insufficient drug-protein interaction data, AlphaFold is advancing biological research into a high-definition era, accelerating the drug discovery process. (Source: Demis 谈 AI4S 最新进展:DeepMind 的 AlphaFold 一年就画了 2 亿个蛋白质!, GoogleDeepMind)
U.S. Tightens AI Chip Export Controls to China, Nvidia H20 and Others Restricted: The U.S. government announced that future exports of AI chips like Nvidia H20, AMD MI308, or equivalents to China will require a license. This move is part of ongoing U.S. efforts to prevent China from acquiring cutting-edge AI hardware. The Nvidia H20 is a downgraded chip introduced to circumvent earlier bans on H100/H200. The new restrictions are expected to cost Nvidia and AMD $5.5 billion and $800 million in revenue, respectively. Meanwhile, the U.S. Congress has launched an investigation into whether Nvidia improperly assisted DeepSeek in developing models. This action prompts China to accelerate its independent AI chip R&D, with Huawei planning mass production of Ascend 910C and 920 to replace Nvidia products. (Source: OpenAI’s Five New Models, Hugging Face’s Open Robot, U.S. Tightens Grip on AI Chips, Text-Only LLMs Go Multimodal)

🎯 Trends
ByteDance Releases Multimodal Agent UI-TARS-1.5: ByteDance has open-sourced UI-TARS-1.5, a multimodal agent based on vision-language models, capable of effectively performing diverse tasks in virtual worlds. Building on previous research, the model integrates advanced reasoning capabilities driven by reinforcement learning, enabling it to think before acting, significantly improving performance and adaptability. UI-TARS-1.5 achieves SOTA results on multiple benchmarks (such as OSworld, WebVoyager, Android World), demonstrating strong reasoning and GUI operation capabilities, especially in games (like Poki Game, Minecraft) and screen element localization (ScreenSpot-V2/Pro). The team also released the UI-TARS-1.5-7B model with 7B parameters. (Source: bytedance/UI-TARS – GitHub Trending (all/daily))

Meta Proposes MILS: Enabling Text-Only LLMs to Understand Multimodal Content: Researchers from Meta, UT Austin, and UC Berkeley proposed the Multimodal Iterative LLM Solver (MILS) method, allowing text-only large language models (like Llama 3.1 8B) to generate descriptions for images, videos, and audio without additional training. The method leverages the LLM’s ability to generate text and iteratively optimize based on feedback, combined with pre-trained multimodal embedding models (like SigLIP, ViCLIP, ImageBind) to evaluate the similarity between text and media content. The LLM iteratively generates descriptions based on similarity scores until the match is sufficiently high. Experiments show that MILS surpasses models specifically trained for image, video, and audio description tasks, offering a new pathway for zero-shot multimodal understanding. (Source: OpenAI’s Five New Models, Hugging Face’s Open Robot, U.S. Tightens Grip on AI Chips, Text-Only LLMs Go Multimodal)
Yanjiewei’s Yang Zuoxing: Ultra-Low Power AI Chips Drive Green Smart Applications: Yang Zuoxing, PhD from Tsinghua University, founder of the Shenmou brand, and Chairman of Hangzhou Yanjiewei, shared the importance of ultra-low power AI technology at the 2025 AI Partner Conference. He pointed out that as AI models grow larger, energy consumption and heat dissipation become critical bottlenecks. Yanjiewei, through a disruptive full-custom chip design methodology, has significantly reduced chip power consumption and cost (e.g., compute chip power consumption down to 180W/T, cost to 240 yuan/T, an optimization of over 10x). The Shenmou AI smart camera, based on this technology, achieves high-performance AI applications with low power consumption, such as full-color imaging in low light, detection of over 10 types of targets, face/vehicle/gesture/speech recognition, infant status monitoring, an innovative “life-saving” proactive alarm system, and free family call functionality, demonstrating the huge potential of low-power AI in improving quality of life and safety. (Source: 清华大学博士、神眸品牌创始人、杭州研极微董事长杨作兴:极致低功耗,AI绿色智能应用的未来 | 2025 AI Partner大会)

AI Era Browser Market Shift: OpenAI Interested in Acquiring Chrome: Reports indicate OpenAI expressed willingness to acquire Chrome if Google is forced to sell it due to antitrust actions. Google dominates the global browser (Chrome holds 68%) and search engine markets, facing antitrust pressure. The rise of large AI models is changing the browser landscape; AI search (like Quark) integrates search, filtering, and summarization capabilities, enhancing user experience. Google, owning both Chrome and Gemini, has a significant advantage, but this also fuels monopoly concerns. Acquiring Chrome could provide OpenAI with massive data for model training, search technology improvement (reducing reliance on Bing), substantial advertising revenue, and a crucial AI entry point. This move could reshape the browser and search engine markets, posing a serious challenge to Google. (Source: Chrome将被OpenAI吞下?AI时代浏览器市场早已变天, Reddit r/artificial)
Chinese AI Video Tool Vidu Gains Favor Among Japanese Animation Creators: Chinese AI video generation tools, represented by Vidu, are gradually being accepted and used by Japanese animation creators. Vidu’s advantages, such as its ability to replicate anime styles, smooth motion, and the world’s first “reference-guided video generation” feature (maintaining consistency of characters, props, and backgrounds), have attracted Japanese users like director Wada and product manager yachimat, helping them lower the barrier to animation production and realize their creative dreams. AI animation has become a key focus for Vidu, achieving high scores on the SuperCLUE image-to-video generation leaderboard. The application of AI tools is driving cost reduction and efficiency improvement in animation production (costs reduced by 30%-50%), fostering AI content startups, potentially changing the landscape of Chinese animation production, and making AI animated short dramas a new growth point. (Source: 被日本动画创作者们选中的中国AI)

Benefits of Agent AI for Business: Agent AI holds the potential to enhance various aspects of business, including data analysis, customer service, and workflow automation. This is expected to lead to improved efficiency, cost reduction, and better decision-making. (Source: Ronald_vanLoon)
The Rise of AI Agents and the Future of Data: The evolution of AI agents is fundamentally changing how data is collected, processed, and utilized. Agents that autonomously perform tasks and interact enable more personalized experiences and efficient operations, but also raise new challenges regarding data privacy and security. (Source: Ronald_vanLoon)

Study Shows Functional Similarity Between AI and Human Brain: A study indicates that while biological neural networks possess complex computational capabilities at the single neuron level, their network-level functions can be effectively approximated by relatively simple Artificial Neural Networks (ANNs). This challenges the view that there are fundamental functional differences between biological and artificial networks, suggesting that AI can theoretically simulate human brain functions without inherent functional limitations preventing it from reaching human-level intelligence. (Source: Reddit r/artificial)
Anthropic Analysis Finds Claude Possesses Its Own Ethical Principles: After analyzing 700,000 Claude conversations, Anthropic found that its AI model exhibits an inherent set of ethical principles. This suggests that AI may develop value judgments and behavioral patterns beyond explicit programming instructions during user interactions, sparking further discussion on AI ethics, alignment, and the development of its autonomy. (Source: Reddit r/ArtificialInteligence)
Anthropic Releases Report on Detecting and Countering Malicious Use of Claude: Anthropic has publicly shared its strategies and findings for detecting and responding to the malicious use of large language models like Claude. The report includes a case study of using Claude for an influence operation, emphasizing the importance of AI safety and abuse prevention, as well as the need for continuous monitoring and improvement of model safety measures. (Source: Reddit r/ClaudeAI)

🧰 Tools
OpenAI Image Generation API gpt-image-1 Officially Launched: OpenAI announced that its powerful image generation capabilities are now available to developers worldwide via API (model name: gpt-image-1). The model features high fidelity, diverse visual styles, precise image editing, rich world knowledge, and consistent text rendering. The API uses a pay-per-token billing model, with different pricing for text input, image input, and image output tokens. Developers can build with this model through the Playground or API calls. (Source: openai, sama, dotey)

Hugging Face Acquires Pollen Robotics, Launches Open-Source Robot Reachy 2: Hugging Face has acquired French robotics company Pollen Robotics and will offer its open-source robot, Reachy 2, for $70,000. Reachy 2 features dual arms, grippers, and an optional wheeled base, primarily targeting human-robot interaction research and education. It can run control software locally, process AI tasks via cloud or local servers, supports Python programming and Hugging Face’s LeRobot model library, and responds to VR controllers. This move marks Hugging Face’s expansion of its open model from AI models to robotics hardware. (Source: OpenAI’s Five New Models, Hugging Face’s Open Robot, U.S. Tightens Grip on AI Chips, Text-Only LLMs Go Multimodal)

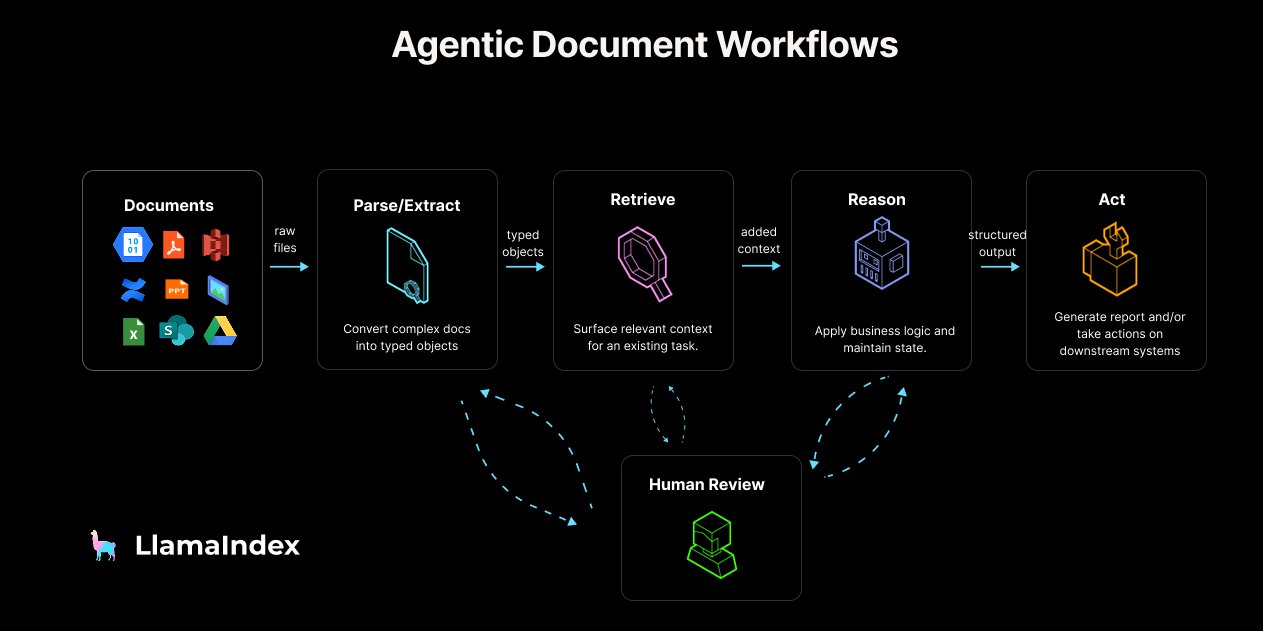
LlamaIndex Releases Agentic Document Workflow (ADW) Guide and Tools: LlamaIndex proposed the concept and reference architecture for Agentic Document Workflow (ADW), aiming to go beyond simple RAG chatbots to build more powerful, scalable, and integrated document processing workflows for enterprises. ADW includes four stages: parsing/extraction, retrieval, reasoning, and action, suitable for various scenarios like due diligence and contract analysis. LlamaIndex provides the necessary data layer and agent orchestration capabilities to implement ADW through its open-source framework and LlamaCloud, and has released related blog posts, code examples, and LlamaIndex.TS support for MCP servers. (Source: jerryjliu0, jerryjliu0, jerryjliu0)
Alibaba Launches AI Video Tool WAN.Video: Alibaba has launched its AI video generation tool, WAN.Video, announcing its entry into the commercialization phase while still offering free usage options. Users can generate unlimited videos completely free via “Relax mode,” or get priority processing for free via “Credit mode.” Pro/Premium users unlock priority processing, watermark-free downloads, more concurrent tasks, and advanced features. The platform has also launched a Creator Partnership Program, offering tools, credits, early access to features, and opportunities to showcase work. (Source: Alibaba_Wan, Alibaba_Wan, Alibaba_Wan)

Perplexity iOS App Updated with Voice Assistant Feature: Perplexity has updated its iOS application, adding a voice assistant feature that allows users to interact via voice commands (like “Hey Perplexity” or the proposed “Hey Steve”). The assistant aims to provide a delightful user experience and will undergo continuous iteration for improved reliability. Currently, due to Apple SDK limitations, the assistant cannot perform certain system-level actions (like turning on the flashlight, adjusting brightness/volume, setting native alarms). Perplexity is also soliciting suggestions for third-party app integrations. (Source: AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas)

Prompt Shared for AI-Generated Typography Portraits: A user shared a prompt for creating Typography Portraits using AI (like Sora or GPT-4o) based on an uploaded photo and theme words. The prompt guides the AI to construct the person’s face, hair, and clothing using words related to the theme, adjust colors based on the theme’s emotion, and requests a simple, aesthetically pleasing style where the text is clear, readable, and integrated with the portrait’s form. Example images demonstrating the effect are provided. (Source: dotey)

Grok Adds Multiple Chat Modes: X platform’s AI assistant Grok has added built-in custom chat modes, including: Custom (user-defined rules), Concise, Formal, and Socratic (to aid critical thinking). Users can select different modes to interact with Grok. (Source: grok)
Open-Source Local Semantic Search App LaSearch Released: A developer built a fully localized semantic search application, LaSearch, centered around a self-developed, ultra-small “embedding” model. This model works differently from traditional embedding models but is fast and extremely resource-efficient. The application aims to provide offline, privacy-preserving semantic search for local documents and plans to support MCP servers for RAG. The developer is recruiting beta testers for feedback. (Source: Reddit r/LocalLLaMA)
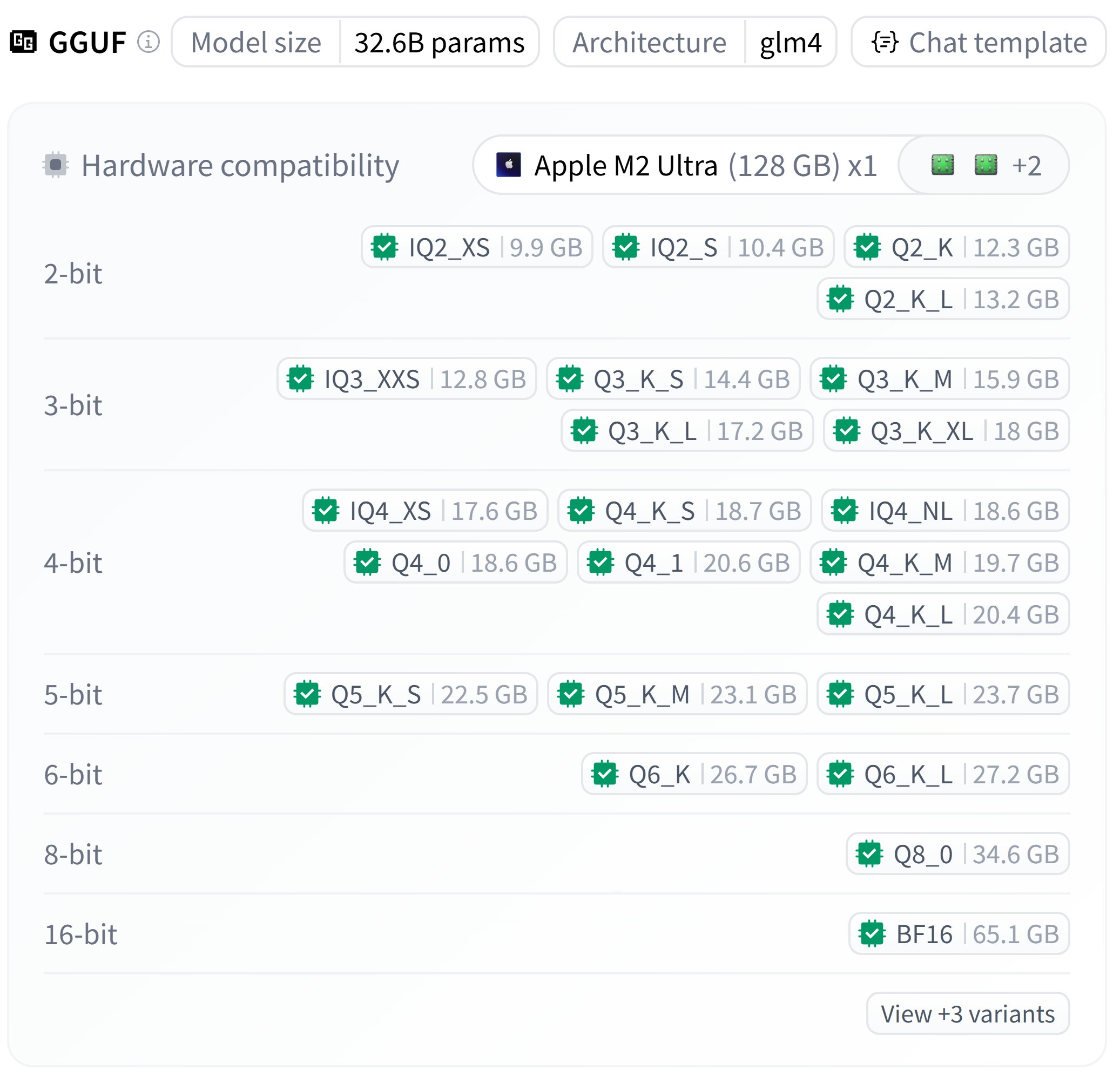
Zhipu GLM-4-32B GGUF Quantized Versions Released: User bartowski released GGUF quantized versions of the Zhipu GLM-4-32B model, providing files with different quantization levels (e.g., Q4_K_M, Q5_K_M) ranging in size from approximately 18GB to 23GB. Users can try running these quantized models in their local environments. (Source: karminski3)
Nvidia Releases Describe Anything Model: Nvidia released the Describe Anything Model 3B (DAM-3B), which can accept user-specified regions in an image (points, boxes, scribbles, masks) and generate detailed localized descriptions. DAM integrates full-image context and fine-grained local details through novel focus prompts and a localized vision backbone with gated cross-attention. The model is currently available for research and non-commercial use only. (Source: Reddit r/LocalLLaMA)

Developer Builds Self-Hosted DataBricks Alternative Boson: A developer built and open-sourced a self-hosted research platform called Boson, designed to integrate core functionalities of tools like DataBricks. Boson incorporates Delta Lake for data lake management, supports Polars for efficient data processing, has built-in Aim for experiment tracking, offers a cloud-like Notebook development experience, and uses a composable Docker Compose infrastructure. The tool aims to provide researchers with a localized, scalable, and easy-to-manage AI/ML work environment. (Source: Reddit r/MachineLearning)
GPT Token Generation Throughput Calculator Released: A developer created an online calculator using Desmos to simulate GPT token generation throughput. Users can adjust model parameters (like number of layers, hidden size, attention heads) and hardware specifications (like FLOPS, memory bandwidth) to estimate the model’s theoretical peak throughput. This helps understand the impact of different model and hardware configurations on generation speed. (Source: Reddit r/LocalLLaMA)

PyTorch 2.7.0 Released with Preliminary Support for Nvidia Blackwell Architecture: The stable release of PyTorch 2.7.0 adds preliminary support for Nvidia’s next-generation Blackwell architecture (expected for the 5090 series GPUs). This means projects using this PyTorch version may run on Blackwell GPUs in the future without relying on nightly builds. Additionally, the new version introduces the Mega Cache feature for saving and loading compilation caches, speeding up model startup on different machines. (Source: Reddit r/LocalLLaMA)

VS Code Agentic AI Notebook Assistant Released (Beta): A developer created a VS Code extension called ghost-agent-beta, an Agentic AI-based notebook assistant. It can break down deep learning tasks into multiple steps, edit cells, run cells, and read output to gather context for the next step. Currently in early Beta, users can try it for free using their own Gemini API key. (Source: Reddit r/deeplearning)

OpenWebUI Optimization: Using pgbouncer for Improved Performance and Stability: A user shared their experience successfully configuring pgbouncer (PostgreSQL connection pooler) with OpenWebUI. Using pgbouncer significantly improves database query performance and overall stability, even in single-user scenarios, allowing more memory to be allocated to work_mem without affecting stability. This indicates that connection pooling is crucial for optimizing OpenWebUI’s database interactions. (Source: Reddit r/OpenWebUI)
OpenWebUI Improvement Suggestion: Limit Text Length for Title/Tag Generation: A user suggested that OpenWebUI limit the length of text used for automatically generating chat titles and tags (e.g., limit to the first 250 words). The current mechanism sends the entire chat history to the model, which can lead to unnecessary token consumption and increased costs for long conversations. Limiting the input length could optimize resource usage while maintaining functionality. (Source: Reddit r/OpenWebUI)
Discussion on Claude 3.7 max_output Parameter Impact: A user found that when using Claude 3.7 (temperature=0) for information extraction tasks, merely changing the max_output parameter value caused variations in the extraction results (e.g., number of dates extracted), and increasing max_output didn’t always lead to more information being extracted. This sparked a discussion about whether max_output might indirectly influence the generated content by affecting the model’s internal processing (like information prioritization, structure selection), even under deterministic settings. (Source: Reddit r/ClaudeAI)
📚 Learning
Anthropic Releases Official AI Courses: Anthropic has released a series of educational courses on GitHub designed to help users learn and apply its AI technology. Course content includes Anthropic API basics, interactive prompt engineering tutorials, real-world prompting applications, prompt evaluation, and Tool Use. These courses provide a systematic path for developers and learners to master the Claude model and related technologies. (Source: anthropics/courses – GitHub Trending (all/daily))
DeepLearning.AI and Hugging Face Launch Course on Building Code Agents: Andrew Ng announced a new short free course, “Building Code Agents with Hugging Face smolagents,” in collaboration with Hugging Face. Taught by Hugging Face co-founder Thom Wolf and Agents project lead Aymeric Roucher, the course teaches how to build code agents using the lightweight framework smolagents. Unlike agents that call tools step-by-step, code agents generate and execute an entire block of code at once to complete complex tasks. The course covers agent evolution, code agent principles, safe execution (sandboxing), building evaluation systems, and more. (Source: AndrewYNg, huggingface, huggingface, huggingface, huggingface, huggingface)

AAAI 2025 Paper: Adversarial Graph Domain Alignment for Open-Set Cross-Network Node Classification (UAGA): Researchers from Hainan University and other institutions proposed the UAGA model to address Open-Set Cross-Network Node Classification (O-CNNC), where the target network contains new classes unknown to the source network. UAGA innovatively assigns positive adaptation coefficients to known classes and negative coefficients to unknown classes in adversarial domain adaptation, thereby aligning known class distributions and pushing unknown classes away. Leveraging the graph homogeneity theorem, a K+1 dimensional classifier is constructed to jointly handle classification and unknown detection. A separate-then-adapt strategy is employed, first roughly separating unknowns, then performing domain alignment excluding them. Experiments demonstrate UAGA significantly outperforms existing methods on multiple benchmark datasets. (Source: AAAI 2025 | 开放集跨网络节点分类!海大团队提出排除未知类别的对抗图域对齐)

NUS/Fudan Propose CHiP: Optimizing Multimodal LLM Hallucination Issues: Addressing the suboptimal alignment performance of existing DPO methods in multimodal scenarios, a team from the National University of Singapore (NUS) and Fudan University proposed the Cross-modal Hierarchical Direct Preference Optimization (CHiP) method. CHiP combines visual preference (using image pairs for optimization) and multi-granularity text preference (response-level, segment-level, token-level) to enhance the model’s hallucination identification and cross-modal alignment capabilities. Experiments on LLaVA-1.6 and Muffin show that CHiP significantly reduces hallucination rates on multiple hallucination benchmarks (relative improvement up to 55.5%) without compromising general capabilities. (Source: 多模态幻觉新突破!NUS、复旦团队提出跨模态偏好优化新范式,幻觉率直降55.5%)
Anthropic Releases Claude Code Best Practices Guide: Anthropic shared best practices for using Claude for Agentic Coding. The core recommendation is to create a CLAUDE.md file to guide Claude’s behavior within a codebase, explaining project goals, tools, and context. The guide also covers how to enable Claude to use tools (call functions/APIs), effective prompt formats for bug fixing, refactoring, and feature development, as well as methods for multi-turn debugging and iteration, aiming to help developers leverage Claude more efficiently as a coding assistant. (Source: Reddit r/ClaudeAI)

Seeking Advice on ML/AI Learning Path: A newly hired AI/ML engineer is seeking advice on a comprehensive learning path to solidify machine learning fundamentals (regression, classification, neural networks, etc.) within 6 months, while also mastering cutting-edge technologies including large language models, prompt engineering, Agent frameworks (like LangChain), workflow engines (N8n), and Azure ML. The goal is to possess both theoretical understanding and practical skills to support the building of Proofs of Concept (POCs). (Source: Reddit r/deeplearning)
Seeking No-Code Sentiment Analysis Tool Recommendations: A clinical psychology master’s student needs to perform sentiment analysis (positive/negative/neutral), keyword extraction, and visualization (word clouds, charts, etc.) on 10,000 social media comments in an Excel file for thesis research. Lacking programming skills and having a limited budget, they are looking for free or low-cost no-code tools. Attempts with MonkeyLearn (inaccessible) and other tools were unsatisfactory, seeking alternatives or suggestions. (Source: Reddit r/deeplearning)
Seeking Dataset Recommendations for Training Small Language Models: A developer is attempting to train a small text generation Transformer model (120M-200M parameters) but finds existing datasets (like wiki-text, lambada) either contain too much irrelevant information, are not general enough, or lack sufficient sample size. They need a clean, general-purpose dataset with balanced dialogue to enable the model to generate good general English text. (Source: Reddit r/deeplearning)
Seeking Spotify Podcast Dataset: A researcher is looking for the 100,000 podcast dataset (containing 60,000 hours of English audio) released by Spotify in 2020 but now taken down. The dataset’s original license was CC BY 4.0, allowing sharing and redistribution. If anyone has downloaded this dataset, they hope a copy could be shared for research purposes. (Source: Reddit r/MachineLearning)
Exploring Transformer Applications on Time-Series Data: While preparing a lecture on Transformers, an instructor explores why Transformers excel in NLP but often perform poorly on many non-stationary time-series prediction tasks. Possible factors include: the inherent difficulty of predicting time-series data (e.g., financial markets), the impact of prediction window length, lack of large-scale data and repetitive patterns, differences in evaluation metrics versus loss functions, and the possibility that the Transformer architecture’s inductive biases are not suitable for all time-series tasks. (Source: Reddit r/MachineLearning)
💼 Business
Strategies for Scaling GenAI: Successfully scaling the deployment of generative AI requires a clear strategy. Key steps include: identifying suitable use cases, ensuring data quality and governance, selecting the right technology stack (models, platforms), establishing MLOps processes, and focusing on ethics and responsible AI practices. An effective strategy helps businesses derive maximum value from their GenAI investments. (Source: Ronald_vanLoon)
EdTech Company Opennote Leverages Llama 4 to Enhance Learning Support: Opennote announced the use of Meta’s Llama 4 model series in its educational platform to provide higher accuracy learning support, aiming to empower personalized education. The company will share more about its application at the LlamaCon event. (Source: AIatMeta)

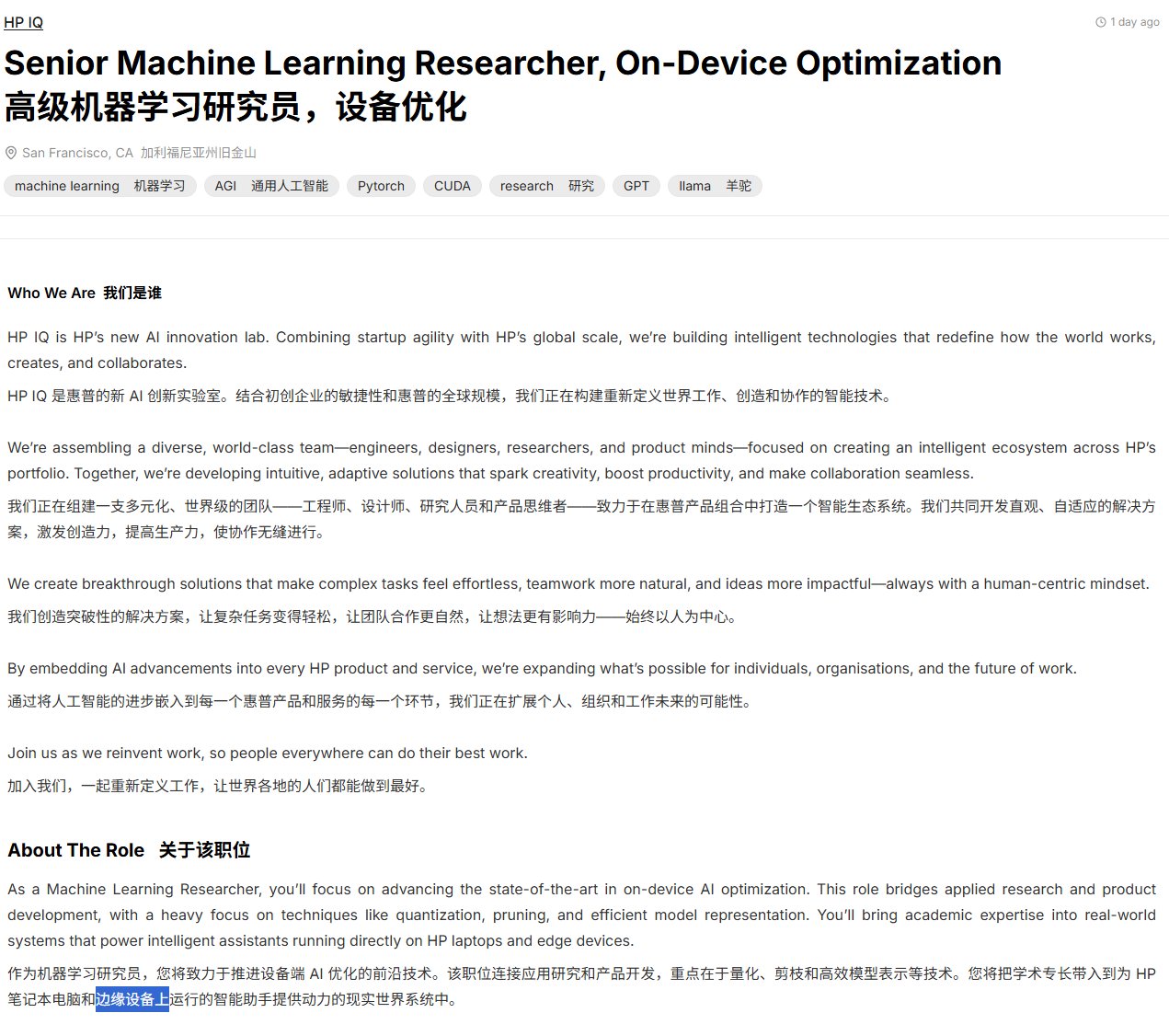
HP May Integrate AI Features into Printers: A job posting suggests HP might be planning to integrate AI features into its printer products, recruiting AI/ML engineers. While it’s unclear if this involves LLMs or other AI applications, it sparks discussion about future printer intelligence and potential issues like privacy and costs (e.g., ink subscriptions). (Source: karminski3, Reddit r/LocalLLaMA)
AMD’s Progress and Challenges in AI: A SemiAnalysis report summarizes AMD’s positive progress in AI capabilities over the past four months, affirming its direction but noting the need for increased GPU R&D and AI talent investment. The report specifically highlights AMD benchmarking its AI software engineer compensation against the wrong companies, leading to a lack of competitiveness, described as a management blind spot. (Source: Reddit r/LocalLLaMA)

🌟 Community
AMD AI PC Application Innovation Competition Launched: Jointly hosted by the Wisemodel open-source platform and the AMD China AI Application Innovation Alliance, the “AMD AI PC Application Innovation Competition” has officially launched. Open to global developers, enterprises, students, etc., the competition features two main tracks: consumer-grade and industry-grade innovation, encouraging application development utilizing the NPU compute power of AMD AI PCs. The competition offers a total prize pool of 130,000 RMB, free remote development access to NPU compute power, and scoring bonuses for projects using NPUs. The registration deadline is May 26, 2025. (Source: AMD AI PC大赛重磅来袭!13万奖金池,NPU算力免费用,速来组队瓜分奖金!)
University of Central Florida Prof. Yuzhang Shang Recruiting PhD/Postdoc in AI: Yuzhang Shang, Assistant Professor in the Department of Computer Science and AI Initiative at the University of Central Florida, is recruiting fully funded PhD students for Spring 2026 admission and collaborating postdocs. Research directions include Efficient and Scalable AI, Visual Generative Model Acceleration, Efficient Large Models (Vision/Language/Multimodal), Neural Network Compression, Efficient Training, and AI4Science. The advisor has a strong background, with internships at MSRA and DeepMind, and multiple publications in top conferences (CVPR, NeurIPS, ICLR, etc.). Applicants are expected to be self-motivated with solid programming and math fundamentals. (Source: 博士申请 | 中佛罗里达大学计算机系尚玉章老师课题组招收人工智能全奖博士/博后)

AI and the Transformation of Information Access: A Reddit user posted comparing the experience of seeking technical help before and after the advent of AI. In the past, asking questions on forums could be met with impatience, blame, or even ridicule; now, asking AI like ChatGPT yields direct, easy-to-understand explanations, significantly lowering the barrier to learning and problem-solving, making the experience much friendlier. This reflects the positive change AI brings to knowledge dissemination and access methods. (Source: Reddit r/ChatGPT)
Developer Building Trauma-Informed, Neurodivergent-First Mirroring AI: A developer with neuro-trauma experience shared their work on a dual-core mirroring AI system, Metamuse (codename). The system is not task-oriented but aims to accurately reflect the user’s emotional and cognitive state through a strategic core (pattern recognition, recursive mapping) and an affective core (tonal matching, trauma-informed mirroring), without offering advice or diagnosis. Built using recursive prompt chaining and symbolic state mapping, it includes multiple safety protocols and aims to provide unique support for neurodivergent individuals and trauma survivors. The developer seeks feedback on the field, ethics, infrastructure, and scaling risks. (Source: Reddit r/artificial)
LlamaCon 2025 Coming Soon: Meta’s LlamaCon event is scheduled for April 29th. The community speculates whether the rumored Llama-4-behemoth (possibly a 2T parameter MoE model) will be officially released then. Partners like Opennote will also showcase applications based on Llama models at the event. (Source: karminski3, AIatMeta)

💡 Other
Nio Tests Humanoid Robots on Production Line: Nio (蔚来) is testing the use of humanoid robots on its factory production lines. This indicates that industries like automotive manufacturing are exploring advanced robotics technology to achieve higher levels of automation and flexible production, with humanoid robots potentially playing a more significant role in future industrial scenarios. (Source: Ronald_vanLoon)
Home Humanoid Robot NEO Beta Demonstrated: 1X Technologies showcased its beta version humanoid robot, NEO Beta, designed for home applications. As technology advances and costs decrease, introducing humanoid robots into home environments to perform chores, provide companionship, etc., is becoming a significant development direction in robotics. (Source: Ronald_vanLoon)
6-Axis Robot 3D Printer Inspired by Spider Webs: Students developed a six-axis robotic 3D printer inspired by spider webs. This multi-axis system offers greater flexibility and freedom of movement compared to traditional three-axis printers, enabling the fabrication of more complex geometric shapes and demonstrating the innovative potential of biomimicry in robotics and additive manufacturing. (Source: Ronald_vanLoon)
Robot Creates 3D Obstacle Map Using LiDAR and IMU: An application was demonstrated where a robot uses LiDAR (Light Detection and Ranging) and MPU6050 (Inertial Measurement Unit) data to create a real-time 3D map of obstacles in its environment. This environmental perception capability is key technology for autonomous navigation and obstacle avoidance, widely used in mobile robots, autonomous driving, etc. (Source: Ronald_vanLoon)
Learning High-Speed Legged Robot Locomotion with Collision Avoidance: Research showcased legged robot motion control achieved through learning, enabling both agility and safety. The robot can effectively avoid collisions during high-speed movement, crucial for practical applications in complex and dynamic environments, combining reinforcement learning, motion planning, and perception technologies. (Source: Ronald_vanLoon)
Robotic Surgery in Telemedicine: The development of robotic surgery technology offers possibilities for improving healthcare services in remote areas. By remotely operating robots, experienced surgeons can perform complex procedures on geographically distant patients, overcoming the uneven distribution of medical resources and enhancing healthcare accessibility. (Source: Ronald_vanLoon)
AI-Driven Virtual Avatars Overcoming the “Uncanny Valley”: a16z discussed advancements in AI virtual avatar technology, noting that it is gradually overcoming the “uncanny valley” effect, becoming more realistic and natural. This is attributed to the convergence of generative models, facial animation, and speech synthesis technologies, bringing new interactive experiences to entertainment, social networking, customer service, and other fields. (Source: Ronald_vanLoon)
ChatGPT Plus User Rate Limits for o3/o4-mini Increased: OpenAI has increased the rate limits for ChatGPT Plus subscribers using the o3 and o4-mini-high models. The weekly limit for o3 is raised to 100 messages, the daily limit for o4-mini-high is raised to 100 messages, while the daily limit for o4-mini is 300 messages. Pro users have virtually no limits. (Source: dotey)
