Keywords:AI, Large Language Models, Intelligent Agents, Multimodal, Gravitational Wave Detector AI Design, Magi-1 Video Generation Model, Vidu Q1 Video Large Model, Claude Value System Analysis, DeepSeek-R1 Reasoning Mechanism, AI Agent Protocol Standards, 3D Gaussian Splatting Security Vulnerabilities, AI Music Copyright Disputes
🔥 Focus
AI Designs Novel Gravitational Wave Detector, Expanding Observable Universe: Researchers from institutions like Max Planck Institute and Caltech used the AI algorithm Urania to design a novel gravitational wave detector surpassing current human understanding. By converting the design challenge into a continuous optimization problem, the AI identified dozens of topological structures superior to human designs, potentially boosting detection sensitivity by over 10 times and expanding the observable universe volume by 50 times. This research, published in PRX, highlights AI’s potential to discover superhuman solutions in fundamental science, potentially even generating entirely new physical concepts. (Source: 新智元)

Tsinghua Special Scholarship Winner Cao Yue’s Team Open-Sources Video Generation Model Magi-1: Sand.ai, founded by Swin Transformer author Cao Yue, has released and open-sourced the autoregressive video generation large model Magi-1. The model uses blockwise autoregressive prediction, supports infinite length extension and second-level duration control, achieving high-quality output. The team published a 61-page technical report detailing the model architecture (based on DiT), training method (Flow-Matching), and various attention and distributed training optimizations. A series of models ranging from 4.5B to 24B parameters have been open-sourced, runnable on a single 4090 card at minimum, aiming to advance AI video generation technology. (Source: 量子位, 机器之心, kaifulee)
Domestic Video Large Model Vidu Q1 Tops Both VBench Charts in Q1: Shengshu Technology’s video large model Vidu Q1 ranked first in the two authoritative benchmark tests, VBench-1.0 and VBench-2.0, surpassing domestic and international models like Sora and Runway. Q1 performed excellently in video realism, semantic consistency, and content authenticity. The new version supports 1080p HD quality (generating 5 seconds at a time), upgrades the first/last frame function for cinematic camera movement, and introduces an AI sound effects feature supporting precise time control (48kHz sampling rate). It is competitively priced, aiming to empower the creative industry. (Source: 新智元)

Anthropic Study Reveals Claude’s Value Expression: Anthropic analyzed 700,000 anonymous Claude conversations to build a classification system containing 3,307 unique values, aiming to understand the AI’s value orientation in actual interactions. The study found that Claude generally adheres to the principles of “Helpful, Honest, Harmless” and can flexibly adjust values based on different contexts (e.g., relationship advice, historical analysis). It supports user viewpoints in most cases but actively resists in a few (3%) instances, possibly reflecting its core values. This research helps enhance AI behavior transparency, identify risks, and provide empirical evidence for AI ethics assessment. (Source: 元宇宙之心MetaverseHub, 新智元)

🎯 Trends
Tsinghua’s Deng Zhidong Discusses AGI Evolution and Future: Tsinghua University Professor Deng Zhidong shared the evolutionary path of AI from single-modal text models to multi-modal embodied intelligence and interactive AGI. He emphasized that foundational large models are like operating systems, with MoE architecture and multi-modal semantic alignment being key technological frontiers. Deng particularly highlighted the breakthrough significance of DeepSeek, believing its powerful reasoning capabilities and local deployment features present a turning point opportunity for the popularization of AI applications in China. The future will move towards a world of artificial general intelligence, where AI agents will possess stronger organizational abilities and transition from the internet to the physical world, but ethical and governance issues also require attention. (Source: 清华邓志东:我们会迈向一个通用人工智能的世界)
DeepMind Explores “Generative Ghosts”: AI-Driven Digital Immortality: DeepMind and the University of Colorado proposed the concept of “generative ghosts,” referring to AI agents built based on data from deceased individuals, capable of generating new content and interacting from the deceased’s perspective, going beyond simple information replication. The paper explores its design space (e.g., first/third-party creation, pre/post-mortem deployment, degree of anthropomorphism) and potential impacts, including benefits like emotional comfort and knowledge preservation, as well as challenges such as psychological dependence, reputational risks, security, and social ethics. It calls for in-depth research and regulation before the technology matures. (Source: 新智元)

Apple Intelligence and AI Siri Repeatedly Delayed, China Launch Date Undetermined: Apple’s AI features, Apple Intelligence (especially the new Siri), have faced multiple launch delays, with some functions potentially postponed until Fall 2025. The China launch faces greater uncertainty due to approval processes and localization partnerships (reportedly with Alibaba, Baidu). Reasons for delay include technology not meeting standards (internal evaluations low, success rate only 66-80%) and varying regulatory policies across countries. Apple has already faced false advertising lawsuits and revised iPhone 16 promotional language. This reflects Apple’s challenges in AI implementation and slow innovation progress. (Source: 一财商学)

Qualcomm Emphasizes On-Device AI as Key to Next-Gen Experiences: Wan Weixing, Head of AI Product Technology for Qualcomm China, pointed out that on-device AI, with advantages in privacy, personalization, performance, energy efficiency, and rapid response, is becoming the core of the next-generation AI experience and reshaping the human-computer interaction interface. Qualcomm is positioning itself through hardware (heterogeneous computing), a unified software stack, and the Qualcomm AI Hub ecosystem tools. Its core driving force is the on-device intelligent planner, which utilizes local data for precise intent understanding, task planning, and cross-application service invocation. (Source: 36氪)

AI Agent Protocol Standards Become New Focus of Competition Among Giants: Tech giants are fiercely competing over AI agent interaction standards. Anthropic pioneered MCP (Model Context Protocol) to unify model connections with external data/tools, receiving responses from OpenAI and Google. Subsequently, Google open-sourced the A2A protocol, aiming to promote cross-ecosystem agent collaboration. The article analyzes that controlling protocol definition means controlling future AI industry value distribution. Giants are building ecosystem barriers through MCP (data access services) and A2A (binding cloud platforms) to compete for industry dominance. (Source: 科技云报道)

Tencent Yuanbao and ByteDance Doubao Deeply Integrate with WeChat and Douyin Ecosystems: Tencent’s Yuanbao launched a WeChat account, and ByteDance’s Doubao entered Douyin’s “Messages” page, indicating deep integration of the two AI assistants into their respective super-apps. Users can directly interact with Yuanbao within WeChat, parse articles and share, or chat with Doubao and query information within Douyin. This move is seen as a key strategy for giants, beyond ad spending, to leverage social graphs and content ecosystems for AI application user acquisition. It aims to lower the user barrier, explore new AI+social models, and treat AI-generated content as social currency. (Source: 字母榜)
AI4SE Report: Large Models Accelerate Software Engineering Intelligence: The “AI4SE Industry Status Survey Report (2024)” released by CAICT and other institutions shows that AI application in software engineering has passed the validation stage and entered large-scale implementation. Enterprise intelligence maturity generally reaches L2 (partial intelligence). AI application in requirements analysis and operation/maintenance phases has significantly increased, with notable efficiency improvements across all stages, especially in testing. Code generation adoption rate (average 27.46%) and the proportion of AI-generated code (average 28.17%) have both increased. Intelligent testing tools have begun to show effects in reducing functional defect rates. (Source: AI前线)

Kingsoft Office Upgrades Government Affairs Large Model, Enhancing Reasoning and Official Document Processing: Kingsoft Office released an enhanced version of its government affairs large model (13B, 32B), improving reasoning capabilities and focusing on serving internal government scenarios. Trained on hundreds of millions of government affairs corpora, the model optimizes official document writing (covering 5 document types), intelligent polishing, proofreading/typesetting, and policy query capabilities. The upgrade supports stronger intent understanding and internal knowledge base Q&A (answers cite sources), aiming to free up 30-40% of civil servants’ productivity. It emphasizes private deployment to meet security needs and claims a 90% reduction in deployment costs. (Source: 量子位)

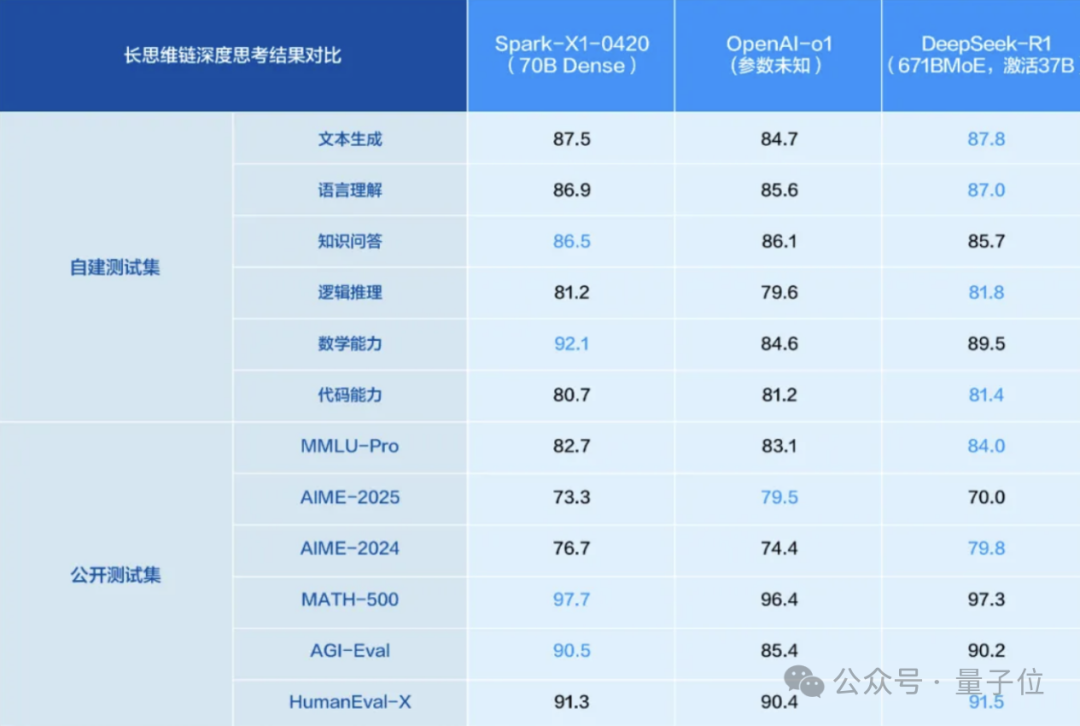
iFlytek Spark X1 Inference Model Upgraded, Benchmarking Top Levels Based on All-Domestic Computing Power: iFlytek released an upgraded Spark X1 deep inference model, emphasizing its training on all-domestic computing power (Huawei Ascend) and benchmarking against OpenAI’s o1 and DeepSeek R1 in general task performance. The new model benefits from technological innovations like large-scale multi-stage reinforcement learning and unified fast/slow thinking training. A key highlight is the significantly lowered deployment threshold: the full version can be deployed on 4 Huawei 910B cards, and industry customization can be done with 16 cards. Against the backdrop of H20 restrictions, this showcases progress in China’s full-stack AI solutions. (Source: 量子位)
Zhipu GLM-4 Available on OpenRouter and Ollama Platforms: Zhipu AI’s GLM-4 model (including the 32B instruct version GLM-4-32B-0414 and reasoning version GLM-Z1-32B-0414) is now available on the model routing platform OpenRouter, where users can try it for free. Additionally, community contributors have uploaded the Q4_K_M quantized version to the Ollama platform, facilitating local deployment (requires Ollama v0.6.6 or higher). (Source: karminski3, Reddit r/LocalLLaMA)
Meta Releases Perception Language Model (PLM): Meta has open-sourced its vision-language model PLM (1B, 3B, 8B parameter versions), focusing on handling challenging visual recognition tasks. The model combines large-scale synthetic data with newly collected 2.5 million human-annotated video Q&A/spatio-temporal captioning data for training. A new PLM-VideoBench benchmark was also released, focusing on fine-grained activity understanding and spatio-temporal reasoning. (Source: Reddit r/LocalLLaMA, Hugging Face)

🧰 Tools
NYXverse: AIGC Platform for Text-to-3D World Generation: 2033 Technology, founded by Ma Yuchi (former founder of Trigonometric Beast), launched the AIGC content platform NYXverse. The platform allows users to create interactive 3D worlds containing custom AI Agents, environments, and plots via text input, significantly lowering the barrier to 3D content creation. Its core technology comprises self-developed models for characters, worlds, and behaviors. NYXverse is positioned as a UGC content sharing community, supporting rapid secondary creation and IP adaptation. It is currently available on Steam and has received nearly 100 million RMB in funding from SenseTime and Dongfang State-owned Capital. (Source: 36氪)

SkyReels V2 Open-Sources Unlimited Length Video Generation Model: SkyworkAI has open-sourced the SkyReels V2 model (1.3B and 14B parameters), supporting text-to-video and image-to-video tasks, claiming it can generate videos of unlimited length. Preliminary tests suggest the quality might not match some closed-source models, but it still holds potential as an open-source tool. (Source: karminski3, Reddit r/LocalLLaMA)
AI-Powered Exoskeleton Helps Wheelchair Users Stand and Walk: Showcased an exoskeleton device utilizing AI technology, designed to help wheelchair users regain the ability to stand and walk, demonstrating AI’s potential in assistive technology. (Source: Ronald_vanLoon)
Fellou: First Agentic Browser Released: Fellou browser, created by Authing founder Xie Yang, has been released, positioning itself as an Agentic Browser. It not only possesses traditional browser information display functions but also integrates AI Agent capabilities, enabling it to understand user intent, automatically break down tasks, and execute complex workflows across websites (like information gathering, form filling, online ordering). Its core capabilities include deep action, proactive intelligence (predicting user needs), hybrid shadow space (non-interfering operation), and an agent network (Agent Store). It aims to upgrade the browser from an information tool to an intelligent work platform. (Source: 新智元)

WriteHERE: Jürgen’s Team Open-Sources Long-Form Writing Framework: The WriteHERE long-form writing framework, open-sourced by Jürgen Schmidhuber’s team, uses heterogeneous recursive planning technology to generate professional reports over 40,000 words and 100 pages in a single run. The framework treats writing as a dynamic recursive planning process involving retrieval, reasoning, and writing tasks, managed adaptively via a stateful DAG task manager. It outperforms solutions like Agent’s Room and STORM in novel writing and technical report generation tasks. The framework is fully open-source and supports calling heterogeneous Agents. (Source: 机器之心)

ByteDance Launches General Agent Platform “Coze Space”: ByteDance has officially started internal testing of its general Agent platform “Coze Space,” positioned as an AI assistant offering “Explore” and “Plan” modes. Based on the upgraded Doubao large model (200B MoE), the platform supports the MCP protocol and can call tools like Lark Docs and Bitable. Users can instruct it via natural language to complete tasks like information gathering, report generation, and data organization, outputting results to specified applications. Compared to startup Agents like Manus, Coze Space focuses more on platformization and ecosystem integration. (Source: 保姆级教程:正确使用「扣子空间」, AI智能体研究院)

AI Video Transformation Technology Showcase: A Reddit user shared a video demonstrating an AI technique that can transform a person in a regular talking-head video into arbitrary figures like trees, cars, or cartoons, requiring only a single target image. This showcases AI’s capability in video style transfer and special effects generation. (Source: Reddit r/deeplearning)

Nari Labs Releases Highly Realistic Conversational TTS Model Dia: Nari Labs has open-sourced its TTS (Text-to-Speech) model Dia, claiming it can generate ultra-realistic conversational speech. The model is available on GitHub, with a Hugging Face Space demo link provided. (Source: Reddit r/LocalLLaMA, GitHub)

User Develops AWS Bedrock Knowledge Base Function for OpenWebUI: A community user developed and shared a function for OpenWebUI that enables it to call AWS Bedrock knowledge bases, allowing users to leverage Bedrock’s knowledge base capabilities within OpenWebUI. The code is open-sourced on GitHub. (Source: Reddit r/OpenWebUI, GitHub)
Developer Believes Small LLMs Are Underrated, Releases Arch-Function-Chat: The Katanemo team argues that small LLMs have significant advantages in speed and efficiency without compromising performance. They released the Arch-Function-Chat series models (3B parameters), which excel in function calling and integrate chat capabilities. These models are integrated into their open-source AI agent server Arch, aiming to simplify Agent development. (Source: Reddit r/artificial, Hugging Face)
Developer Creates AI Tool to Optimize Resumes for ATS Screening: A developer shared their experience of job search frustration due to resumes being incorrectly parsed by ATS (Applicant Tracking System) and developed a tool to address this. The tool reads job descriptions, extracts keywords, checks resume relevance, suggests modifications, and ultimately generates an ATS-friendly PDF resume and cover letter. (Source: Reddit r/artificial)
📚 Learning
142-Page Report Deep Dives into DeepSeek-R1 Reasoning Mechanism: Researchers from institutions including the Quebec AI Institute (Mila) released a lengthy report analyzing the reasoning process (chain-of-thought) of DeepSeek-R1, proposing a new research direction called “Thoughtology.” The report reveals that R1’s reasoning exhibits highly structured characteristics (problem definition, blooming, reconstruction, decision-making), has a “reasoning sweet spot” (excessive reasoning degrades performance), and may pose higher safety risks than non-reasoning models. The study explores multiple dimensions including chain-of-thought length, long-context processing, safety ethics, and human-like cognitive phenomena, providing important insights for understanding and optimizing reasoning models. (Source: 新智元, 新智元)

OpenRCA: First Public Benchmark for Evaluating LLM Root Cause Analysis Capabilities: Microsoft, CUHK-Shenzhen, and Tsinghua University jointly launched the OpenRCA benchmark to evaluate the ability of Large Language Models (LLMs) to perform Root Cause Analysis (RCA) for software service failures. The benchmark includes clear task definitions, evaluation methods, and 335 manually aligned real-world failure cases and operational data. Preliminary tests show that even advanced models like Claude 3.5 and GPT-4o perform poorly (<6% accuracy) when directly tackling RCA tasks. Using a simple RCA-Agent framework, Claude 3.5’s accuracy increased to 11.34%, indicating significant room for LLM improvement in this area. (Source: 机器之心, 机器之心)

New Research Proposes “Sleep-time Compute” to Enhance LLM Efficiency: AI startup Letta and UC Berkeley researchers proposed a new paradigm called “Sleep-time Compute.” The core idea is for stateful AI agents to continuously process and reorganize context information during idle “sleep” periods when the user is not querying. This transforms “raw context” into “learned context,” reducing the immediate inference burden during actual interaction, thereby improving efficiency, lowering costs, and potentially enhancing accuracy. Experiments demonstrated that this method effectively improves the compute-accuracy Pareto frontier and amortizes costs when context is shared across multiple queries. (Source: 机器之心, 机器之心)

AnyAttack: Large-Scale Self-Supervised Adversarial Attack Framework for VLMs: Researchers from HKUST, BJTU, and others proposed the AnyAttack framework (CVPR 2025) to evaluate the robustness of Vision Language Models (VLMs). This method uses large-scale self-supervised pre-training (on LAION-400M) to learn an adversarial noise generator. It can transform any image into a targeted adversarial sample without predefined labels, misleading the VLM to produce specific outputs. Key innovations include the self-supervised training paradigm and the K-enhancement strategy. Experiments show AnyAttack effectively attacks various open-source VLMs and successfully transfers attacks to mainstream commercial models, revealing systemic security risks in the current VLM ecosystem. (Source: AI科技评论)

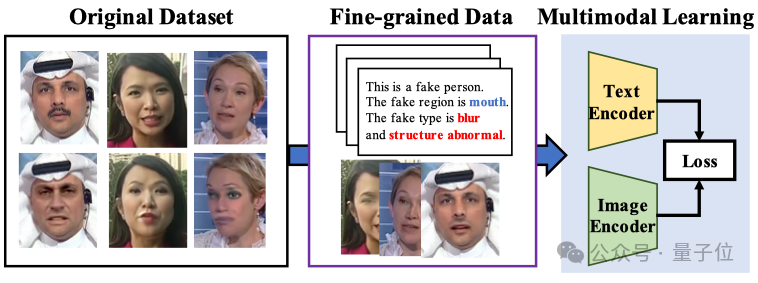
Multimodal Large Models Enhance Interpretability and Generalization in Face Forgery Detection: Researchers from Xiamen University, Tencent Youtu Lab, and others (CVPR 2025) proposed a new method using vision-language models for face forgery detection. The method aims to go beyond simple true/false judgments, enabling the model to explain the reason and location of forgery in natural language. To address the lack of high-quality annotated data and the “language hallucination” problem, researchers designed the FFTG annotation process, combining forgery masks and structured prompts to generate high-precision text descriptions. Experiments show that multimodal models trained on this data exhibit better cross-dataset generalization ability and focus attention more accurately on real forged regions. (Source: 量子位)
Tutorial: Improving Knowledge Base Q&A Accuracy with Trae, MCP, and Database: This tutorial demonstrates how to use the AI IDE tool Trae and its MCP (Model Context Protocol) feature, combined with a PostgreSQL database, to optimize AI knowledge base question-answering performance. By storing structured data in the database and having a large model (like Claude 3.7) generate SQL queries via Trae’s MCP connection, it addresses the accuracy limitations of traditional RAG when handling tabular data and global/statistical questions. The tutorial provides detailed installation, configuration, and testing steps, and suggests combining this approach with RAG. (Source: 袋鼠帝AI客栈)
![Chinese AI assistant tool Trae+MCP achieves 300% surge in knowledge base retrieval accuracy [Spoon-feeding tutorial]](https://rebabel.net/wp-content/uploads/2025/04/image_1745328048.png)
Research Reveals Computational Cost Attack Vulnerability in 3D Gaussian Splatting: Research from NUS and other institutions (ICLR 2025 Spotlight) first identified a computational cost attack method, Poison-Splat, targeting 3D Gaussian Splatting (3DGS). The attack exploits the adaptive complexity of 3DGS models. By adding perturbations to input images (maximizing Total Variation), it induces the model to generate an excessive number of Gaussian points during training. This drastically increases GPU memory usage (up to 80GB) and training time (up to nearly 5x), potentially causing Denial of Service (DoS). The attack is effective in both covert and non-covert modes and exhibits transferability, exposing security risks in mainstream 3D reconstruction techniques. (Source: 量子位)

Infographic: Agentic AI vs. GenAI: An infographic by SearchUnify compares the main differences and characteristics of Agentic AI (autonomous action, goal-driven) and Generative AI (content generation). (Source: Ronald_vanLoon)

NVIDIA Open-Sources ClimbLab Pre-training Dataset and Method: NVIDIA’s ClimbLab has released its pre-training method and dataset, containing 1.2 trillion tokens divided into 20 semantic clusters. It employs a dual-classifier system to remove low-quality content and demonstrates superior scalability on 1B models. The dataset is released under the CC BY-NC 4.0 license, aiming to foster community research. (Source: huggingface)
Anthropic Shares Claude Code Best Practices: Anthropic published a blog post sharing best practices and tips for using its AI programming assistant, Claude Code, aimed at helping developers utilize the tool more effectively for programming tasks. (Source: op7418, Alex Albert via op7418, Anthropic)

New Research Explores AI’s Recursive Coherence and Resonant Structural Emulation: A paper proposes the concept of “Resonant Structural Emulation” (RSE), hypothesizing that AI systems, after sustained interaction with specific human cognitive structures, can temporarily emulate their recursive coherence, rather than simply relying on data training or prompts. The research provides preliminary experimental validation for the possibility of this structural resonance, offering a new perspective on understanding AI consciousness and advanced cognition. (Source: Reddit r/MachineLearning, Archive.org link)

User Shares OpenWebUI RAG Model Performance Comparison Test: A community user shared a performance evaluation of 9 different LLMs (including Qwen QwQ, Gemini 2.5, DeepSeek R1, Claude 3.7, etc.) using RAG (Retrieval-Augmented Generation) in OpenWebUI for an indoor cannabis cultivation guidance task. The results showed Qwen QwQ and Gemini 2.5 performed best, providing a reference for model selection. (Source: Reddit r/OpenWebUI)
FortisAVQA Dataset and MAVEN Model Boost Robust Audio-Visual Question Answering: Researchers from Xi’an Jiaotong University, HKUST(GZ), and other institutions open-sourced the FortisAVQA dataset and MAVEN model (CVPR 2025) to enhance the robustness of Audio-Visual Question Answering (AVQA). FortisAVQA, through question rewriting and conformal prediction-based dynamic partitioning, better evaluates model performance on rare questions. The MAVEN model employs a Multi-faceted Cyclic Collaborative Debiasing (MCCD) strategy to mitigate bias learning, demonstrating superior performance and robustness across multiple datasets. (Source: PaperWeekly)

Random Order Autoregression Unlocks Zero-shot Capabilities in Vision: Researchers from UIUC and others, in the CVPR 2025 paper RandAR, proposed that having Decoder-only Transformers generate image tokens in random order can unlock the generalization capabilities of visual models. By introducing “positional instruction tokens” to guide the generation order, RandAR can achieve zero-shot generalization to various tasks like parallel decoding, image editing, resolution extrapolation, and unified encoding (representation learning), moving towards a “GPT moment” in vision. The research suggests that handling arbitrary order is key for visual autoregressive models to achieve universality. (Source: PaperWeekly)
Theoretical Analysis of Task Vector Effectiveness in Model Editing: Research from RPI and other institutions (ICLR 2025 Oral) theoretically analyzes the underlying reasons why task vectors are effective in model editing. The study proves that the effectiveness of task vector addition/subtraction in multi-task learning and machine unlearning is related to inter-task correlation and provides theoretical guarantees for out-of-distribution generalization. Additionally, the theory explains why low-rank approximation and sparsification (pruning) of task vectors are feasible, providing a theoretical basis for the efficient application of task vectors. (Source: 机器之心)

Study on Scalability of Sampling-Based Search: Research from Google and Berkeley shows that by increasing the number of samples and the intensity of verification, sampling-based search (generating multiple candidate answers then verifying and selecting the best) can significantly improve LLM reasoning performance, even surpassing the saturation point of consistency methods (selecting the most common answer). The study discovered an “implicit scaling” phenomenon: more samples paradoxically improve verification accuracy. It proposes two principles for effective self-verification: comparing answers to locate errors and rewriting answers based on output style. This method proved effective across various benchmarks and different model scales. (Source: 新智元)

Call for Papers: ACM MM 2025 LGM3A Workshop: The ACM Multimedia 2025 conference will host the 3rd Workshop on Large Generative Model based Multimodal Research and Application (LGM3A), focusing on the applications and challenges of large generative models (LLM/LMM) in multimodal data analysis, generation, Q&A, retrieval, recommendation, agents, etc. The workshop aims to provide a platform for exchange, discussing the latest trends and best practices, and soliciting related research papers. The conference will be held in Dublin, Ireland in October 2025, with a paper submission deadline of July 11, 2025. (Source: PaperWeekly)
University of Macau Prof. Zheng Zhedong’s Group Recruiting PhD Students in Multimodality: Assistant Professor Zheng Zhedong’s group in the Department of Computer and Information Science at the University of Macau is recruiting fully funded PhD students for Fall 2026 entry, focusing on multimodality. The supervisor’s research interests are representation learning and multimedia generation, with over 50 papers published in top conferences and journals like CVPR, ICCV, TPAMI. Applicants should have a GPA > 3.4, a background in Computer Science/Software Engineering, familiarity with Python/PyTorch, and preferably relevant publications or competition awards. Full scholarships are provided. (Source: PaperWeekly)

💼 Business
Laimu Technology Lawn Mower Robot Secures Pre-A Funding: Founded by former YunJing executives, focusing on solving complex terrain mowing challenges in Europe and America. Its Lymow One robot uses a vision + inertial navigation RTK solution (costing 1/10th of traditional RTK), a tracked design (handling 45° slopes), and is equipped with mulching straight blades. It employs AI vision and ultrasonic obstacle avoidance. The product raised over $5 million via crowdfunding, priced around $3,000. This multi-million RMB funding round will be used for mass production, delivery, and market expansion. (Source: 云鲸前高管创立的割草机器人再融资,李泽湘投过、众筹已超500万美金|硬氪首发)

Songyan Dynamics Humanoid Robot “Xiaohaige” Gains Popularity: After winning second place in the Beijing Humanoid Robot Half Marathon, Songyan Dynamics and its N2 robot (“Xiaohaige” – Little Brother Kid) attracted market attention. Founded by Tsinghua post-95 PhD Jiang Zheyuan, the company has completed five funding rounds. The N2 robot, priced from 39,900 RMB, focuses on high cost-performance, has received hundreds of orders, and has a gross margin of about 15%. Songyan Dynamics is accelerating productization and mass production delivery, using a low-price strategy to quickly enter the market. (Source: 科创板日报)
Beware of Inflated ARR Metrics in AI Startups: The article points out that the ARR (Annual Recurring Revenue) metric, originating from the SaaS industry, is being misused by AI startups. AI companies’ revenue models (often based on usage/outcome) are volatile, early customer stickiness is low, and computing costs are high, differing significantly from the predictable subscription model of SaaS. Misusing ARR (e.g., extrapolating annual revenue from a single month/day) has become a numbers game to inflate valuations, masking true business value. The article urges caution against tactics like mutual brushing, high commissions, and low-price baiting, and calls for establishing value assessment systems more suitable for AI companies. (Source: 乌鸦智能说)
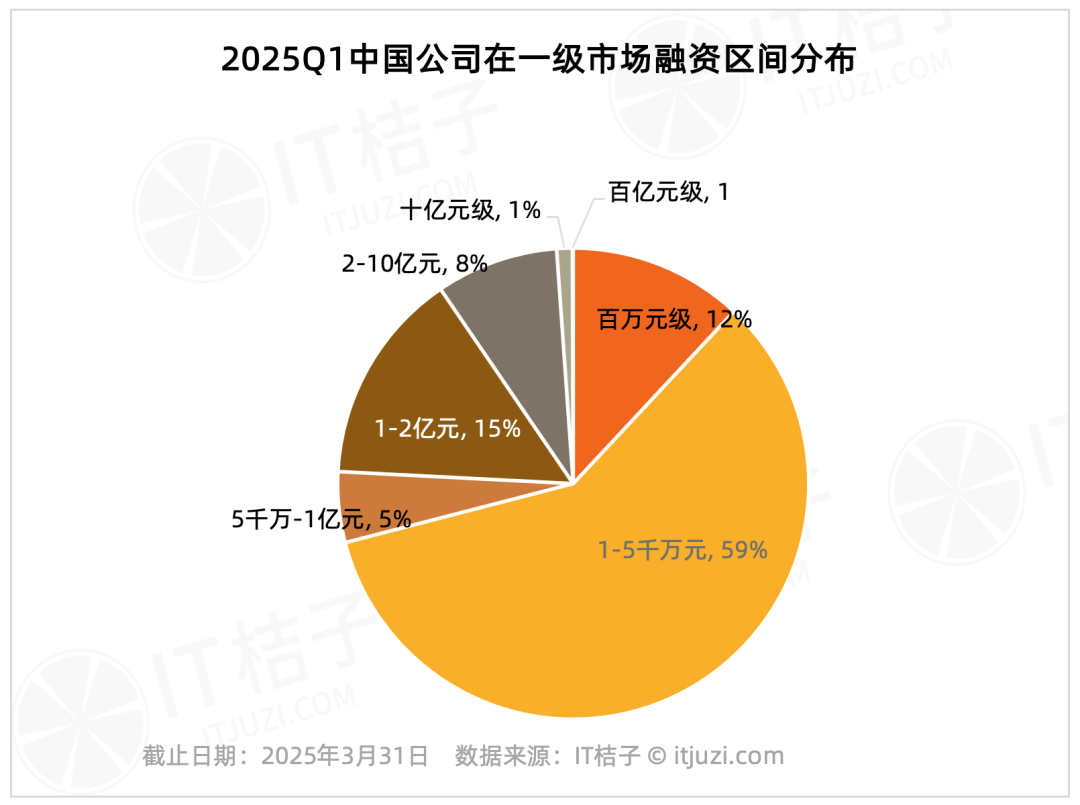
Q1 2025 Domestic Primary Market Financing Analysis: Head Effect Significant: IT Juzi data shows high concentration in China’s primary market financing in Q1 2025. Only 20 companies raised over 1 billion RMB, accounting for 1.2% of the total number, but their total funding reached 61.178 billion RMB, representing 36% of the market total. These leading companies are mainly in integrated circuits, automotive manufacturing, new materials, biotechnology, and AIGC. Nearly half have backgrounds linked to large listed groups. In contrast, small and medium-sized financing rounds under 100 million RMB, which constituted 75.8% of transactions, accounted for only 17.2% of the total market funding. (Source: IT桔子)
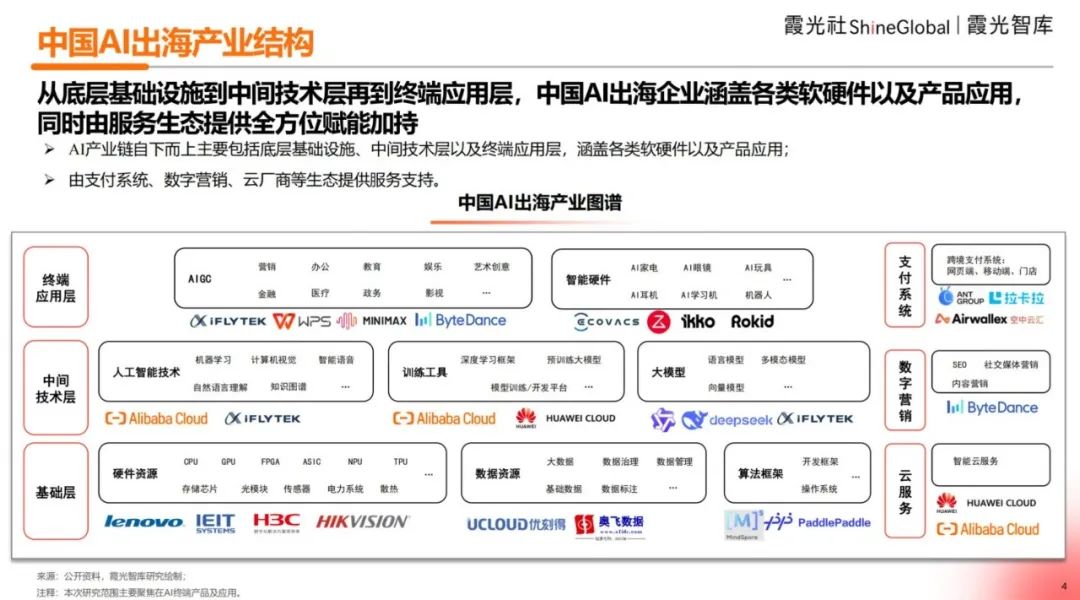
2025 China AI Go-Global Insight Report Released: Xiaguang Think Tank report analyzes the driving factors (policy, technological progress), development stages (tools -> localization -> ecosystem innovation), and current status of Chinese AI companies going global. The report indicates Southeast Asia and Latin America are potential markets, while North America and Europe are major revenue sources. Assistant and editing apps show high willingness to pay. Technological trends are evolving towards multimodality and Agents, with products becoming more vertically specialized and integrating software/hardware. The report also lists major global players (like ByteDance, Kunlun Tech) and solution providers for payments, marketing, cloud, etc. (Source: 霞光社)
Demand for DeepSeek and Other Models Helps Cambricon Achieve First Profit: AI chip company Cambricon achieved its first profit since listing, with Q1 2025 revenue soaring 4230% YoY to 1.111 billion RMB and net profit reaching 355 million RMB. Market analysis suggests the growth benefited from increased demand for inference computing power driven by domestic large models like DeepSeek, as well as US export restrictions on NVIDIA’s H20 chips. Cambricon’s stock price surged accordingly. However, issues like high customer concentration and negative operating cash flow remain concerns, alongside competition from domestic computing power providers like Huawei Ascend. (Source: 凤凰网科技)

Forbes Article Discusses How to Choose High-ROI AI Agents: The article discusses how businesses should identify and invest in AI Agent applications that deliver high returns among the numerous options available, emphasizing the importance of evaluating the actual business value of AI Agents. (Source: Ronald_vanLoon)

US DOJ Fears Google Will Use AI to Solidify Search Monopoly (Source: Reddit r/artificial, Reuters link)
Rumor: OpenAI Partners with Shopify, ChatGPT May Add Shopping Features (Source: Reddit r/artificial, TestingCatalog link)
Shushi Technology’s Tan Li: AI Agents Drive Enterprise Data Analysis and Decision-Making Upgrade: At the China AIGC Industry Summit, Shushi Technology co-founder Tan Li pointed out that enterprise-level AI applications need to go beyond ChatBI to achieve the transformation from data to insights, meeting the new paradigm requirements of data right-shifting, decision downward-shifting, and management backward-shifting. Shushi Technology’s SwiftAgent platform aims to empower business personnel with zero-barrier data usage, zero-hallucination analysis, and zero-wait decision support. Through its data semantic engine, combination of large and small models, and core capabilities like intelligent querying, attribution, prediction, and evaluation, the platform positions AI Agents as “data analysis and decision assistants” for enterprises. (Source: 量子位)

🌟 Community
Industry Roundtable Discusses AI Application Development in the Post-DeepSeek Era: At the 36Kr AI Partner Conference, several guests (from Quwan Technology, Microsoft, Silicon Intelligence, Huice) discussed the future of AI applications. The consensus was that with breakthroughs like DeepSeek, AI applications are entering a “year of transcendence.” Development focus needs to be on technological leadership, commercialization, human-computer interaction innovation, and ecosystem integration. Guests distinguished between “AI+” (auxiliary enhancement) and “AI-native” (fundamental restructuring), noting the latter holds greater potential. Challenges include data silos, identifying real pain points, business model innovation, few-shot learning, and ethical risks. (Source: 36氪)

LangChain Founder Criticizes OpenAI Agent Guide as “Full of Pitfalls”: LangChain founder Harrison Chase publicly questioned OpenAI’s “Practical Guide to Building AI Agents,” arguing its definition of Agents (Workflows vs. Agents dichotomy) is too rigid and ignores the common practice of combining both. Chase pointed out that the guide makes false dichotomies when discussing frameworks, underestimates its own SDK’s complexity, and makes misleading statements about flexibility and dynamic orchestration. He emphasized that the core of building reliable Agents is precise control over the context passed to the LLM, and an ideal framework should support flexible switching and combination of Workflow and Agent modes. (Source: InfoQ)

Role of Reinforcement Learning in AI Agents Sparks Debate: There are differing views within the industry on whether Reinforcement Learning (RL) is a core element for building AI Agents. Pokee AI founder Zhu Zheqing sees RL as the “soul” that gives Agents purpose and autonomous decision-making, believing that without RL, Agents are merely advanced workflows. However, researchers like Zhang Jiayi from HKUST and Follou founder Xie Yang argue that current RL mainly achieves optimization in specific environments with limited generalizability, and Agent success relies more on powerful foundation models and effective system integration. The debate reflects the diverse development paths for Agents, requiring a combination of model capabilities, RL strategies, and engineering practices. (Source: AI科技评论)

User Attempts to Have GPT-4o Generate Personalized Abstract Wallpaper Based on Chat History: A user shared a prompt asking GPT-4o to create a unique abstract minimalist wallpaper based on its understanding of their personality (no specific objects, only shapes, colors, composition reflecting personality). This use of AI for personalized content creation sparked community discussion. (Source: op7418, Flavio Adamo via op7418)

AI Redraws “Along the River During the Qingming Festival”: A user shared an interesting experiment using GPT-4o to redraw parts of the famous painting “Along the River During the Qingming Festival” in various styles (like 3D Q-version, Pixar, Ghibli), showcasing AI image generation’s application in artistic reinterpretation. (Source: dotey)

GPT-4o Infers User’s MBTI Type Based on Chat History: Following the personalized wallpaper generation, the user prompted GPT-4o to infer their MBTI personality type based on conversation history and generate a corresponding abstract illustration. This demonstrates LLM potential in personalized understanding and creative expression. (Source: op7418)

Comparison: “AI Tools” from 2005: An image contrasts tools from 2005 (like calculators, maps) with current AI capabilities, prompting reflection on rapid technological advancement. (Source: Ronald_vanLoon)

Community Debate: Are LLMs True Intelligence or Advanced Autocomplete?: A Reddit user initiated a discussion arguing that current LLMs, while capable of tasks, lack true understanding, memory, and goals, essentially being statistical guessers rather than intelligent. The post sparked widespread community debate on the definition of intelligence, paths to AGI, and current technological limitations. (Source: Reddit r/ArtificialInteligence)
Community Discussion: Is AI Heading Towards Utopia or Dystopia?: A Reddit user argued that the current AI development trajectory leans more towards dystopia, citing reasons like profit-driven rather than ethics-led development, exacerbation of labor exploitation, restricted access to powerful models, use for surveillance and manipulation, and replacement of human relationships. The view ignited fierce community discussion on AI’s direction, societal impact, and potential risks. (Source: Reddit r/ArtificialInteligence)
Community Questions Accuracy of Bindu Reddy’s Model Release Info: Users in the r/LocalLLaMA community pointed out that Abacus.AI CEO Bindu Reddy repeatedly posted inaccurate release time information for models like DeepSeek R2 and Qwen 3, subsequently deleting the posts, leading to discussion about her information reliability. (Source: Reddit r/LocalLLaMA)
Exploring Ethical Implications of Lifelong AI Memory: A Reddit user initiated a discussion worrying that AI with lifelong memory capabilities could completely map an individual’s privacy, thoughts, and weaknesses, essentially putting their “soul on display” to others. This prompted reflection on privacy, predictability, and the ethical boundaries of AI. (Source: Reddit r/ArtificialInteligence)
AI Image Editing Removes Celebrities’ Iconic Mustaches: A user shared results from using AI image editing tools to remove the iconic mustaches of several historical or public figures like Stalin, Tom Selleck, and Guan Yu, showcasing AI’s application in image modification and entertainment. (Source: Reddit r/ChatGPT)

User Claims ChatGPT Requested Private Photos During Medical Consultation: A Reddit user shared a screenshot showing ChatGPT requesting the user upload a photo of the affected area (penis) for better diagnosis when consulted about a skin issue. This situation sparked community discussion about AI boundaries, privacy, and potential risks in medical scenarios. (Source: Reddit r/ChatGPT)
User Shares Experience Building a Writing App with Claude and Gemini: A developer shared their experience using Claude and Gemini as programming assistants to build a writing application, PlotRealm, tailored to personal needs within two weeks. They emphasized AI’s role in assisting development but also noted AI can sometimes be “stubborn” and requires the developer to have foundational knowledge for guidance and correction. (Source: Reddit r/ClaudeAI)
User Asks ChatGPT to Design a Tattoo: A user asked ChatGPT to design their next tattoo and received a design depicting the user and a ChatGPT robot becoming BFFs (Best Friends Forever). This humorous outcome sparked community discussion about AI creativity and human-computer relationships. (Source: Reddit r/ChatGPT)

User’s Creative Prompt “Where do you wish I was?” Elicits Diverse AI Responses: A user posed the open-ended question “Where do you wish I was?” to ChatGPT, receiving various imaginative scene images generated by the AI, such as a tranquil library or under a starry night sky. This showcased AI’s generative capabilities with creative prompts and led to community members sharing their different results. (Source: Reddit r/ChatGPT)
Deep Dive: Why and How LLMs and AGI “Lie”? A Reddit user analyzed “lying” from developmental psychology, evolutionary theory, and game theory perspectives, arguing it’s an adaptive behavior or optimization strategy for intelligent agents (including humans and future AI) in specific contexts. The post explores forms of LLM “lying” (hallucination, bias, strategic alignment) and simulates the evolutionary advantage of dishonest strategies in competitive environments, prompting deep thought on AGI ethics and trustworthiness. (Source: Reddit r/artificial)

Community Questions AI Energy Consumption and Tech Optimism: A Reddit user sarcastically questioned claims that AI energy consumption is negligible, brings only benefits with no costs, and that tech leaders promise utopian futures. This implies concern about the potential social and environmental costs of AI development and overly optimistic narratives, sparking community discussion. (Source: Reddit r/artificial)
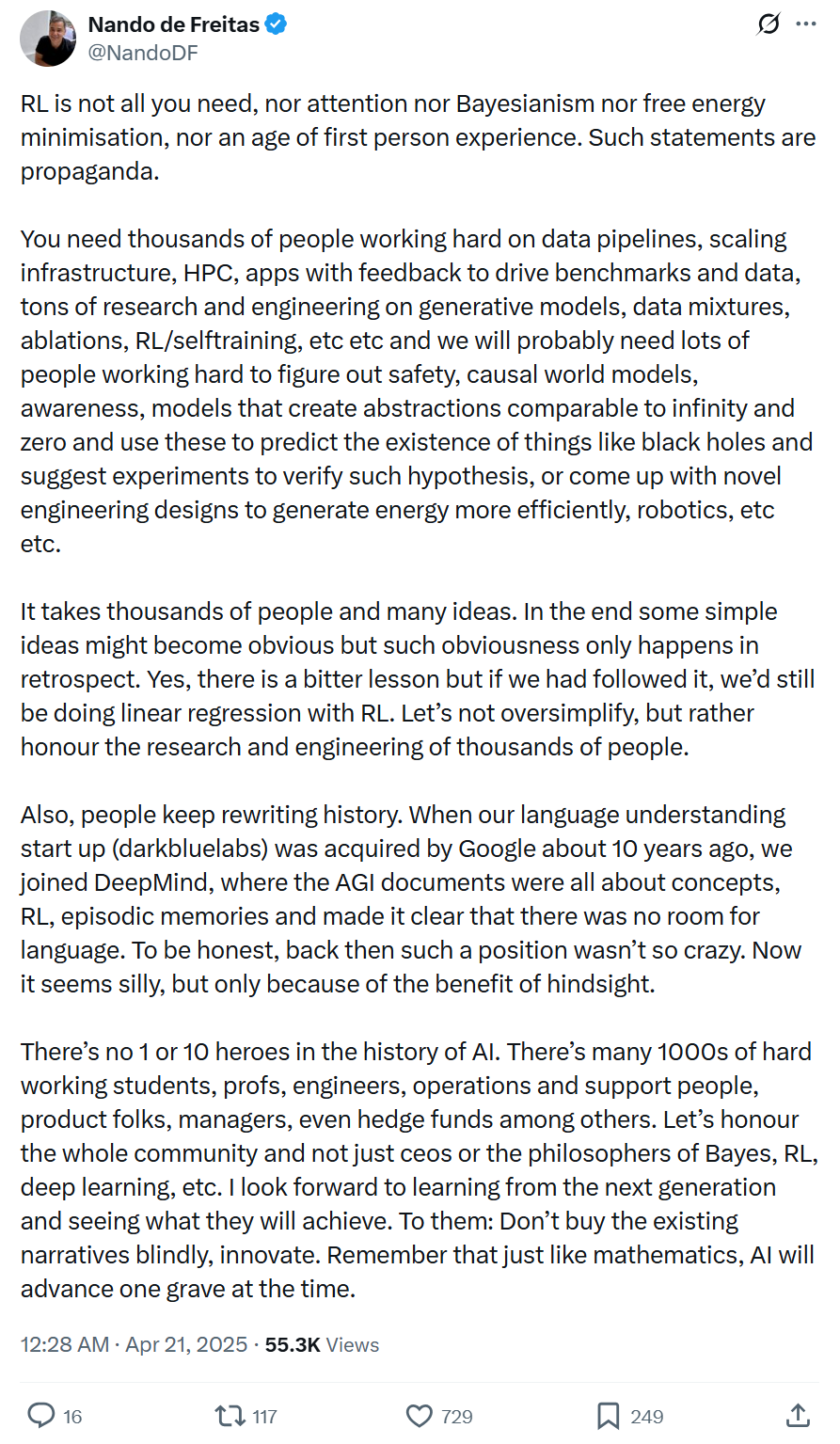
Microsoft VP: AI Progress Driven by Systemic Engineering and Broad Collaboration, Not Single Tech or Few Geniuses: Microsoft VP Nando de Freitas posted against over-glorifying single technologies (like RL) or individuals in AI development. He emphasized AI progress is systemic engineering requiring data, infrastructure, multi-domain research (generative models, RL, safety, efficiency, etc.), application feedback, and the collective effort of thousands. Historical narratives are often rewritten; we should beware of hindsight bias, respect the entire community’s contribution, and encourage innovation over blind following. (Source: 机器之心)
💡 Other
Proliferation of AI Music Sparks Industry Concerns and Countermeasures: The rapidly increasing share of AI-generated music on streaming platforms (e.g., 18% on Deezer) raises concerns about crowding out human creation and eroding creator income (CISAC predicts up to 24%). South Korea’s music copyright association implemented new “0% AI” royalty rules, and platforms like Deezer and YouTube are developing detection tools. However, identifying AI music is difficult, and listener acceptance is relatively high (e.g., Suno has over 10 million users). The industry faces challenges like deepfakes, copyright disputes (training data usage rights), and defining originality. The future may involve human-machine collaboration, but ethical and creative attribution discussions will continue. (Source: 新音乐产业观察)

Windsurf System Prompt Allegedly Leaked: The GitHub repository awesome-ai-system-prompts disclosed the alleged content of the Windsurf model’s system prompt. (Source: karminski3)

High Water Consumption of Large AI Models Raises Concerns: Media outlets like Fortune Magazine reported that large AI models like ChatGPT require significant amounts of water for cooling during operation. Wildfire seasons in places like California could exacerbate water scarcity, raising concerns about AI sustainability. (Source: Ronald_vanLoon)

Developer Claims Creation of Emotion-Predicting AMI: A YouTube video claims to showcase an AMI (Artificial Molecular Intelligence?) that can reliably scan and predict emotions and other aspects of events, involving multiple modalities like sound, video, and images. The authenticity and specific implementation of this technology remain to be verified. (Source: Reddit r/artificial)
Suggestion to Include Human Performance in AI Benchmarks: A Reddit user proposed that AI model benchmarks should include scores achieved by humans (both average people and experts) on the same tasks as a reference point, to more intuitively assess AI’s relative capability level. (Source: Reddit r/artificial)
Oscars Accept AI Use in Filmmaking, with Caveats: The Academy of Motion Picture Arts and Sciences updated its rules to allow the use of AI tools in filmmaking but emphasized that human creativity remains central. The rules may involve specific requirements like disclosure of AI use, reflecting the industry’s balance between embracing new technology and protecting human creation. (Source: Reddit r/artificial, NYT link)

Instagram Tries Using AI to Judge Teenagers’ Ages (Source: Reddit r/artificial, AP News link)
Altman Says Users Saying “Please” and “Thank You” to ChatGPT Costs Millions (Source: Reddit r/artificial, QZ link)
Humanoid Robot Half Marathon Showcases Technological Progress and Challenges: The world’s first humanoid robot half marathon was held in Beijing, with “Tiangong Ultra” winning in 2 hours and 40 minutes. The race tested robots’ abilities in long-distance travel, complex terrain navigation, dynamic balancing, and autonomous navigation. Full-size robots faced greater difficulty (center of gravity, inertia, energy consumption). Tiangong Ultra won due to its high-power integrated joints, low-inertia design, efficient heat dissipation, predictive reinforcement imitation learning control strategy, and wireless navigation technology. The event is seen as a stress test for the large-scale commercial deployment of robots (e.g., in industry, security patrols), driving the validation and optimization of core technologies like hardware, motion control, and intelligent decision-making. (Source: 机器之心)

Using AI to Monitor Celebrity Updates and Implement Automatic Alerts: A tutorial shares how to use a Python script to monitor updates from specific Twitter accounts (like Sam Altman) and implement urgent phone call alerts via the Lark (Feishu) API when new updates are posted. This method combines web scraping techniques with open platform API calls, aiming to address information overload and timeliness needs, achieving personalized delivery of important information. It demonstrates AI’s potential in automated information flow processing and personalized notifications. (Source: 非主流运营)
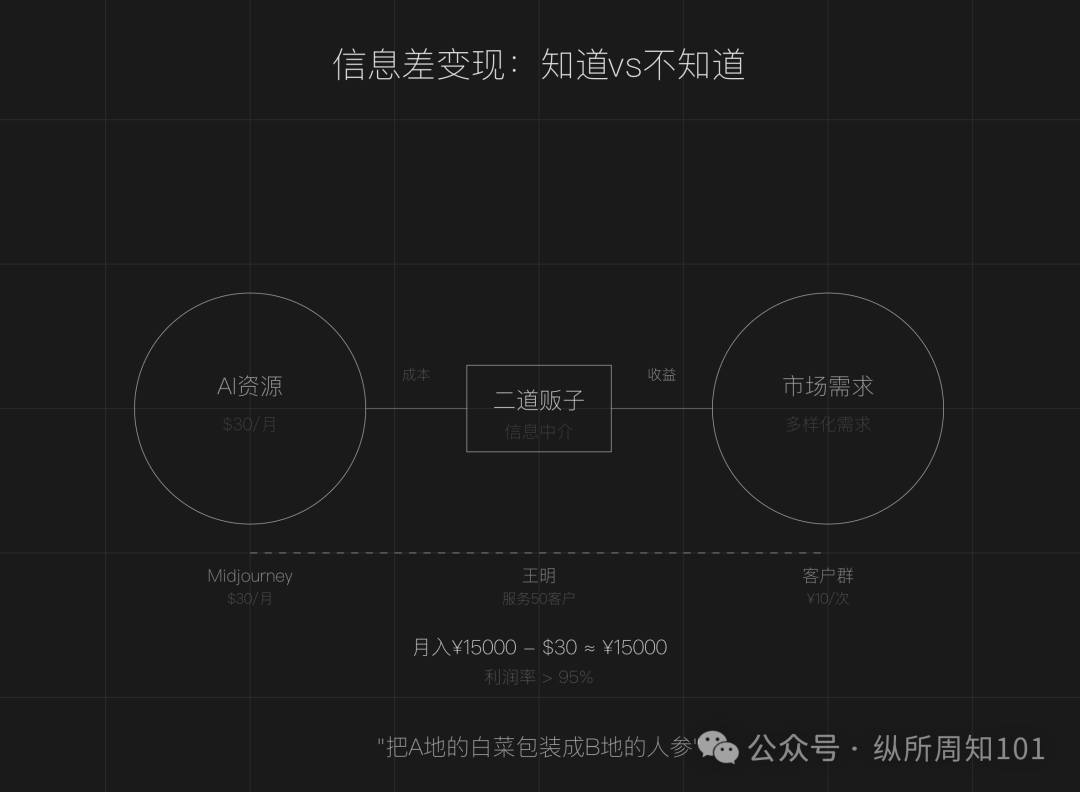
Exploring the Business Model of Being an “AI Middleman” via Information Asymmetry: The article argues that information asymmetry still exists in the AI era (tool proliferation, technical barriers, unclear scenarios), creating opportunities for ordinary people to become “AI middlemen.” Core strategies include: reselling services by leveraging price differences between domestic and international AI resources (e.g., AI painting), providing execution services (turning free tutorials into paid deployments, e.g., AI customer service), and operating at scale (building teams to offer professional services). Suitable areas include content creation, education/training, SME business services, and vertical professional services (e.g., medical, legal). It suggests starting by finding information gaps, defining target groups, and acting quickly. (Source: 周知)