
Keywords:AI Four Dragons, Embodied Intelligence, Humanoid Robots, Memory Wall, SenseTime’s Rixin V6 Multimodal Model, Open X-Embodiment Dataset, Tesla Optimus Robot, 3D Ferroelectric RAM Technology, Tiangong Ultra Robot Half Marathon, Gemma 3 QAT Quantized Model, Hugging Face Acquires Pollen Robotics, LlamaIndex Agent Document Workflow
🔥 Focus
“AI Four Dragons” Facing Challenges and Transformation: Companies once hailed as the “AI Four Dragons,” such as SenseTime, Megvii, CloudWalk, and Yitu, have generally faced commercialization difficulties and continuous losses in recent years. For example, SenseTime reported a loss of 4.3 billion yuan in 2024, with cumulative losses exceeding 54.6 billion yuan; CloudWalk lost nearly 600-700 million yuan in 2024, with cumulative losses exceeding 4.4 billion yuan. To cope with the challenges, these companies have undergone strategic adjustments, including layoffs, salary cuts, and business restructuring. Facing the new AI wave dominated by large language models, the “Four Dragons,” with their roots in visual technology, are actively shifting towards multimodal large models and the AGI field. SenseTime released its “Rì Rì Xīn V6” multimodal model, benchmarked against GPT-4o, and is heavily investing in intelligent computing center construction; Yitu is focusing on vision-centric multimodal models and collaborating with Huawei to reduce hardware costs; CloudWalk has also partnered with Huawei to launch large model training and inference integrated machines; Megvii, leveraging its algorithmic advantages, is entering the pure vision solutions for intelligent driving. These initiatives indicate their efforts to stay relevant in the AI landscape and adapt to the new market environment. (Source: 36Kr)

Embodied Intelligence Data Dilemma and Open Dataset Progress: The development of humanoid robots and embodied intelligence faces a critical data bottleneck. The lack of high-quality training data hinders breakthroughs in their capabilities. Unlike language models, which have access to massive internet text data, robots require diverse physical world interaction data, which is costly to acquire. To address this issue, research institutions and companies are actively building and open-sourcing datasets, such as Open X-Embodiment released by Google DeepMind and multiple institutions, ARIO by Peng Cheng Laboratory and others, RoboMIND by the Beijing Innovation Center, AgiBot World (containing long-horizon complex task data in real scenarios) and AgiBot Digital World simulation dataset by Zhiyuan Robot, and the G1 operation dataset by Unitree. Although these datasets are still much smaller in scale than text data, they are driving the development of the embodied intelligence field by unifying standards, improving quality, and enriching scenarios, laying the foundation for achieving an “ImageNet moment”. (Source: 36Kr)

Dawn of Humanoid Robot Mass Production: Breakthroughs in Data, Simulation, and Generalization: Despite challenges such as high data acquisition costs and weak generalization capabilities, several companies (including Tesla, Figure AI, 1X, Zhiyuan, Unitree, UBTECH, etc.) still plan to achieve mass production of humanoid robots by 2025. Solution paths include: 1) Large-scale real-world training, supported by governments (Beijing, Shanghai, Shenzhen, Guangdong) building data collection bases and setting standards; 2) Advanced simulation training, using world models like NVIDIA Cosmos and Google Genie2 to generate physically realistic virtual environments, reducing costs and improving efficiency; 3) AI-powered generalization, using new action models like Figure AI’s Helix, Zhiyuan GO-1’s ViLLA architecture, and Google Gemini Robotics to achieve generalized understanding of physical operations with less data, enabling robots to handle unseen objects and adapt to new environments. These technological advancements suggest that the commercial application of humanoid robots may arrive sooner than expected. (Source: 36Kr)

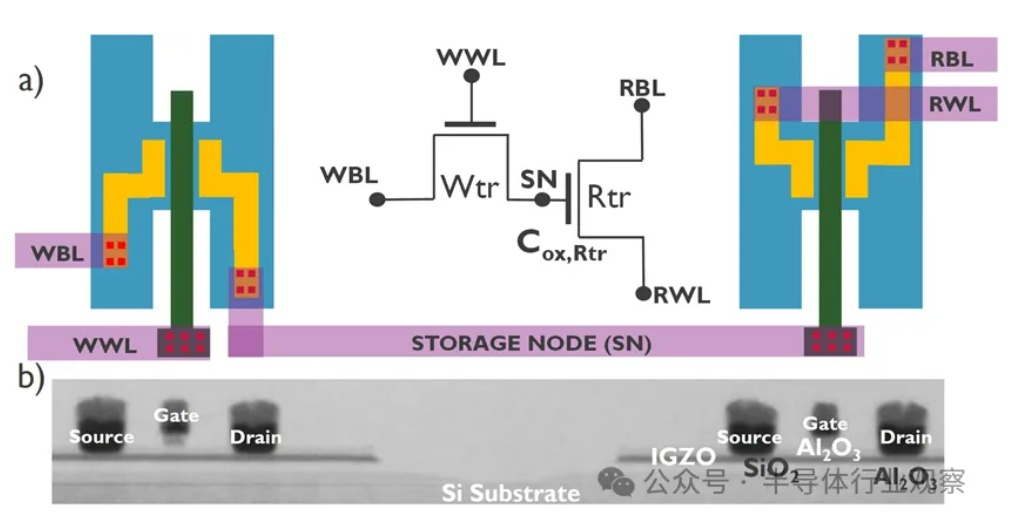
AI Development Hits “Memory Wall” Crisis, Seeking Breakthroughs with New Storage Technologies: The exponential growth in the scale of AI models poses severe challenges to memory bandwidth. The growth rate of traditional DRAM bandwidth lags far behind the growth of computing power, creating a “memory wall” bottleneck that limits processor performance. HBM significantly increases bandwidth through 3D stacking technology, alleviating some pressure, but its manufacturing process is complex and costly. Therefore, the industry is actively exploring new storage technologies: 1) 3D Ferroelectric RAM (FeRAM): Such as SunRise Memory, utilizing the HfO2 ferroelectric effect to achieve high-density, non-volatile, low-power storage. 2) DRAM + Non-Volatile Memory: Neumonda collaborates with FMC, using HfO2 to transform DRAM capacitors into non-volatile storage. 3) 2T0C IGZO DRAM: imec proposes using two oxide transistors to replace the traditional 1T1C structure, eliminating the need for capacitors, achieving low power consumption, high density, and long retention times. 4) Phase Change Memory (PCM): Utilizes material phase changes to store data, reducing power consumption. 5) UK III-V Memory: Based on GaSb/InAs, combining DRAM speed with flash memory non-volatility. 6) SOT-MRAM: Utilizes spin-orbit torque for low-power, high-energy-efficiency memory. These technologies hold promise for breaking the DRAM bottleneck and reshaping the storage market landscape. (Source: 36Kr)
🎯 Trends
Tiangong Robot Completes Half-Marathon Challenge, Plans Small-Batch Mass Production: The Tiangong team’s robot “Tiangong Ultra” (1.8m tall, 55kg) from the Beijing Humanoid Robot Innovation Center won the first humanoid robot half-marathon race, completing approximately 21 kilometers in 2 hours, 40 minutes, and 42 seconds. The event tested the robot’s endurance, structure, perception, and control algorithm reliability on complex terrain. The team stated that by optimizing joint stability, heat resistance, energy consumption systems, balance and gait planning algorithms, and equipping it with the self-developed “Hui Si Kai Wu” platform (embodied brain + cerebellum), the robot achieved autonomous path planning and real-time adjustments without wireless guidance. Completing the marathon proves its basic reliability, laying the foundation for mass production. The Tiangong 2.0 robot is about to be released, with plans for small-batch production, targeting future applications in industrial, logistics, special operations, and home services. (Source: 36Kr)

China Developing Robot Brain Using Cultured Human Cells: According to reports, Chinese researchers are developing a robot driven by cultured human brain cells. This research aims to explore the possibilities of biological computing, utilizing the learning and adaptation capabilities of biological neurons to control robot hardware. While specific details and the stage of progress are unclear, this direction represents a frontier exploration at the intersection of robotics, artificial intelligence, and biotechnology, potentially opening new avenues for developing smarter, more adaptive robot systems in the future. (Source: Ronald_vanLoon)
Gemma 3 QAT Quantized Model Shows Excellent Performance: A user compared the QAT (Quantization Aware Training) version of Google’s Gemma 3 27B model with other Q4 quantized versions (Q4_K_XL, Q4_K_M) on the GPQA Diamond benchmark. The results showed that the QAT version performed best (36.4% accuracy) while having the lowest VRAM usage (16.43 GB), outperforming Q4_K_XL (34.8%, 17.88 GB) and Q4_K_M (33.3%, 17.40 GB). This indicates that QAT technology effectively reduces resource requirements while maintaining model performance. (Source: Reddit r/LocalLLaMA)
Rumor: AMD to Launch RDNA 4 Radeon PRO Graphics Card with 32GB Memory: VideoCardz reports that AMD is preparing a Radeon PRO series graphics card based on the Navi 48 XTW GPU, which will feature 32GB of memory. If true, this would provide a new option for users needing large amounts of VRAM for local AI model training and inference, especially given the limited VRAM on most consumer-grade cards. However, specific performance, price, and release date are yet to be announced, and its actual competitiveness remains to be seen. (Source: Reddit r/LocalLLaMA)

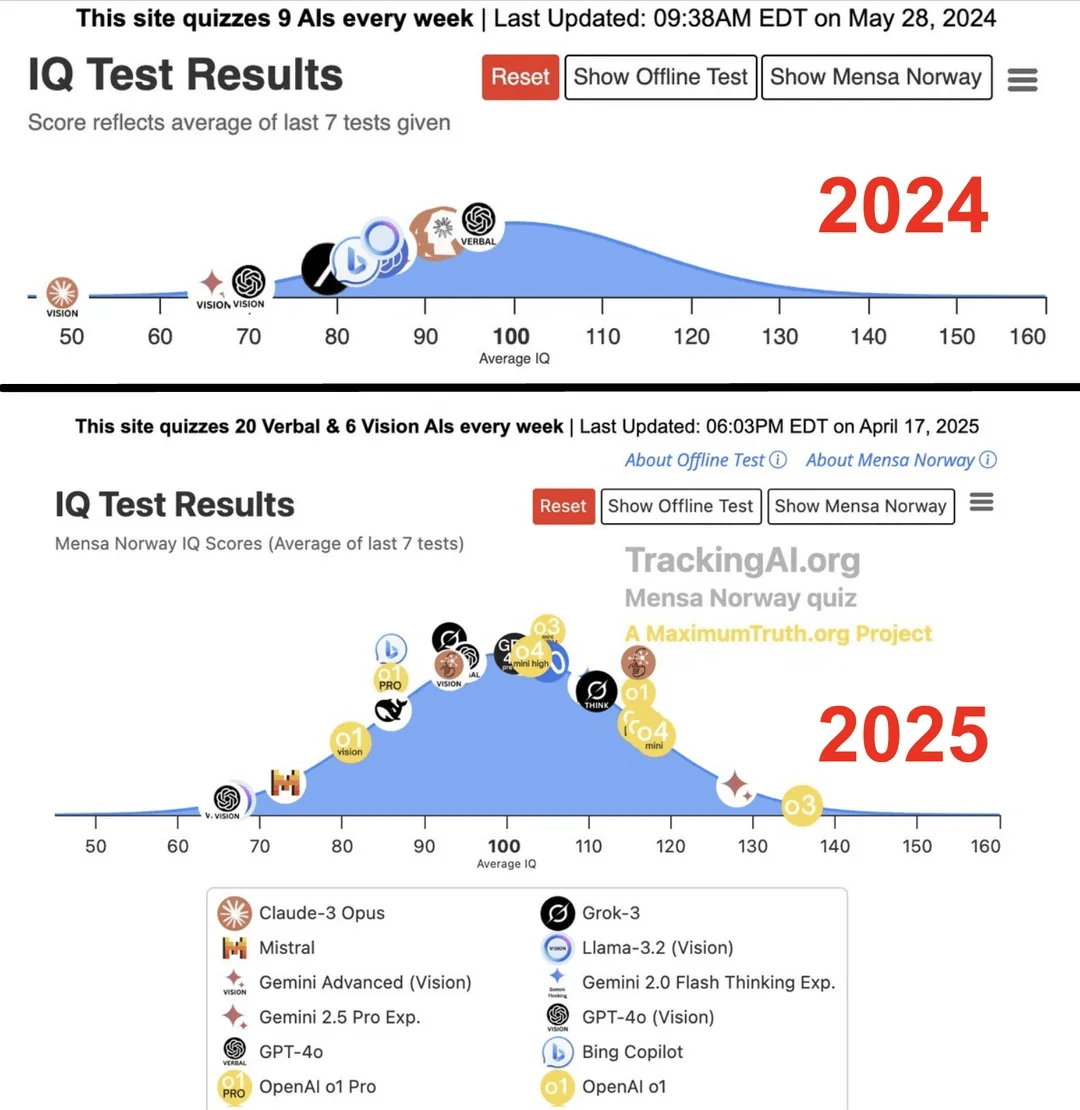
Study Claims Top AI’s IQ Jumped from 96 to 136 in One Year: According to research published on the Maximum Truth website (source reliability pending verification), IQ tests conducted on AI models found that the smartest AI (possibly referring to the GPT series) saw its IQ score increase from 96 (slightly below human average) to 136 (approaching genius level) within a year. While the validity of using IQ tests to measure AI intelligence is debatable, and the possibility of test contamination from training data exists, this significant improvement reflects the rapid progress of AI in solving standardized intelligence test problems. (Source: Reddit r/artificial)
🧰 Tools
OpenUI: Generate UI in Real-time via Descriptions: wandb has open-sourced OpenUI, a tool that allows users to conceptualize and render user interfaces in real-time using natural language descriptions. Users can request modifications, and the generated HTML can be converted into code for various frontend frameworks like React, Svelte, Web Components, etc. OpenUI supports multiple LLM backends, including OpenAI, Groq, Gemini, Anthropic (Claude), as well as local models connected via LiteLLM or Ollama. The project aims to make the UI component building process faster and more enjoyable, serving as an internal testing and prototyping tool for W&B. Although inspired by v0.dev, OpenUI is open source. An online Demo and local running guides (Docker or source code) are provided. (Source: wandb/openui – GitHub Trending (all/daily))

PDFMathTranslate: AI PDF Translation Tool Preserving Layout: Developed by Byaidu, PDFMathTranslate is a powerful PDF document translation tool. Its core advantage lies in using AI technology to translate while completely preserving the original document’s layout, including complex mathematical formulas, charts, tables of contents, and annotations. The tool supports translation between multiple languages and integrates various translation services like Google, DeepL, Ollama, and OpenAI. To cater to different users, the project offers multiple usage methods, including command-line interface (CLI), graphical user interface (GUI), Docker image, and a Zotero plugin. Users can try the online Demo or choose the appropriate installation method based on their needs. (Source: Byaidu/PDFMathTranslate – GitHub Trending (all/daily))

Shandu AI Research: LangGraph-based Referenced Report Generation System: Shandu AI Research is a system that utilizes LangGraph workflows to automatically generate reports with citations. It aims to simplify research tasks through intelligent web scraping, multi-source information synthesis, and parallel processing. The tool can help users quickly collect, integrate, and analyze information, generating structured research reports with references, thereby improving research efficiency. (Source: LangChainAI)

Intel Releases Open Source AI Playground: Intel has open-sourced AI Playground, an entry-level application for AI PCs that allows users to run various generative AI models on PCs equipped with Intel Arc graphics cards. Supported image/video models include Stable Diffusion 1.5, SDXL, Flux.1-Schnell, LTX-Video; supported large language models include DeepSeek R1, Phi3, Qwen2, Mistral (Safetensor PyTorch LLM), as well as Llama 3.1, Llama 3.2, TinyLlama, Mistral 7B, Phi3 mini, Phi3.5 mini (GGUF LLM or OpenVINO). The tool aims to lower the barrier for running AI models locally, making it easier for users to experience and experiment. (Source: karminski3)
Persona Engine: AI Virtual Assistant/VTuber Project: Persona Engine is an open-source project aimed at creating an interactive AI virtual assistant or virtual streamer (VTuber). It integrates large language models (LLM), Live2D animation, automatic speech recognition (ASR), text-to-speech (TTS), and real-time voice cloning technology. Users can directly converse with the Live2D character via voice. The project also supports integration into streaming software like OBS for creating AI VTubers. This project demonstrates the fusion application of multiple AI technologies, providing a framework for building personalized virtual interactive characters. (Source: karminski3)
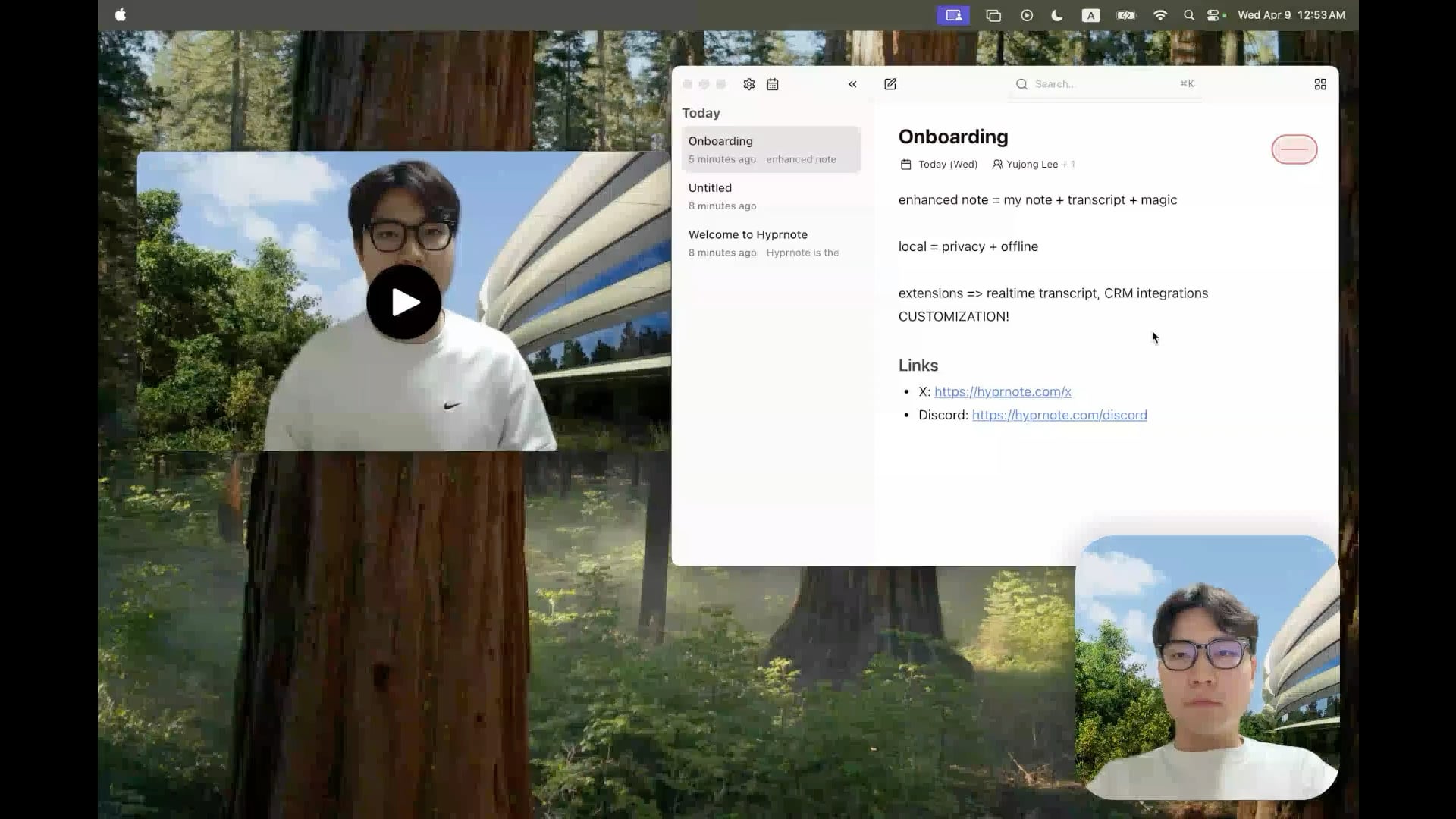
Hyprnote: Open Source Local AI Meeting Notes Tool: A developer has open-sourced Hyprnote, an intelligent note-taking application designed specifically for meetings. It can record audio during meetings and combine the user’s raw notes with the meeting audio content to generate enhanced meeting minutes. Its core feature is running AI models (like Whisper for transcription) entirely locally, ensuring user data privacy and security. The tool aims to help users better capture and organize meeting information, especially suitable for those who handle consecutive meetings. (Source: Reddit r/LocalLLaMA)
LMSA: Tool to Connect LM Studio to Android Devices: A user shared an application called LMSA (lmsa.app), designed to help users connect LM Studio (a popular local LLM management tool) to their Android devices. This allows users to interact with AI models running on their local PC via their phone or tablet, expanding the use cases for local large models. (Source: Reddit r/LocalLLaMA)

Local Image Search Tool Based on MobileNetV2: A developer built and shared a desktop image search tool using a PyQt5 GUI and the TensorFlow MobileNetV2 model. The tool can index local image folders and find similar images based on content (using features extracted by CNN) via cosine similarity. It automatically detects folder structures as categories and displays search results with thumbnails, similarity percentages, and file paths. The project code is open-sourced on GitHub, seeking user feedback. (Source: Reddit r/MachineLearning)
Handcrafted Persona Engine: Local AI Voice Interaction Virtual Avatar: A developer shared a personal project, “Handcrafted Persona Engine,” aimed at creating a “Sesame Street”-like experience with an interactive, voice-driven virtual avatar that runs entirely locally. The system integrates local Whisper for speech transcription, calls a local LLM via Ollama API for dialogue generation (including personalization), uses local TTS to convert text to speech, and drives a Live2D character model for lip-syncing and emotional expression. Built with C#, the project can run on hardware like a GTX 1080 Ti and is open-sourced on GitHub. (Source: Reddit r/LocalLLaMA)
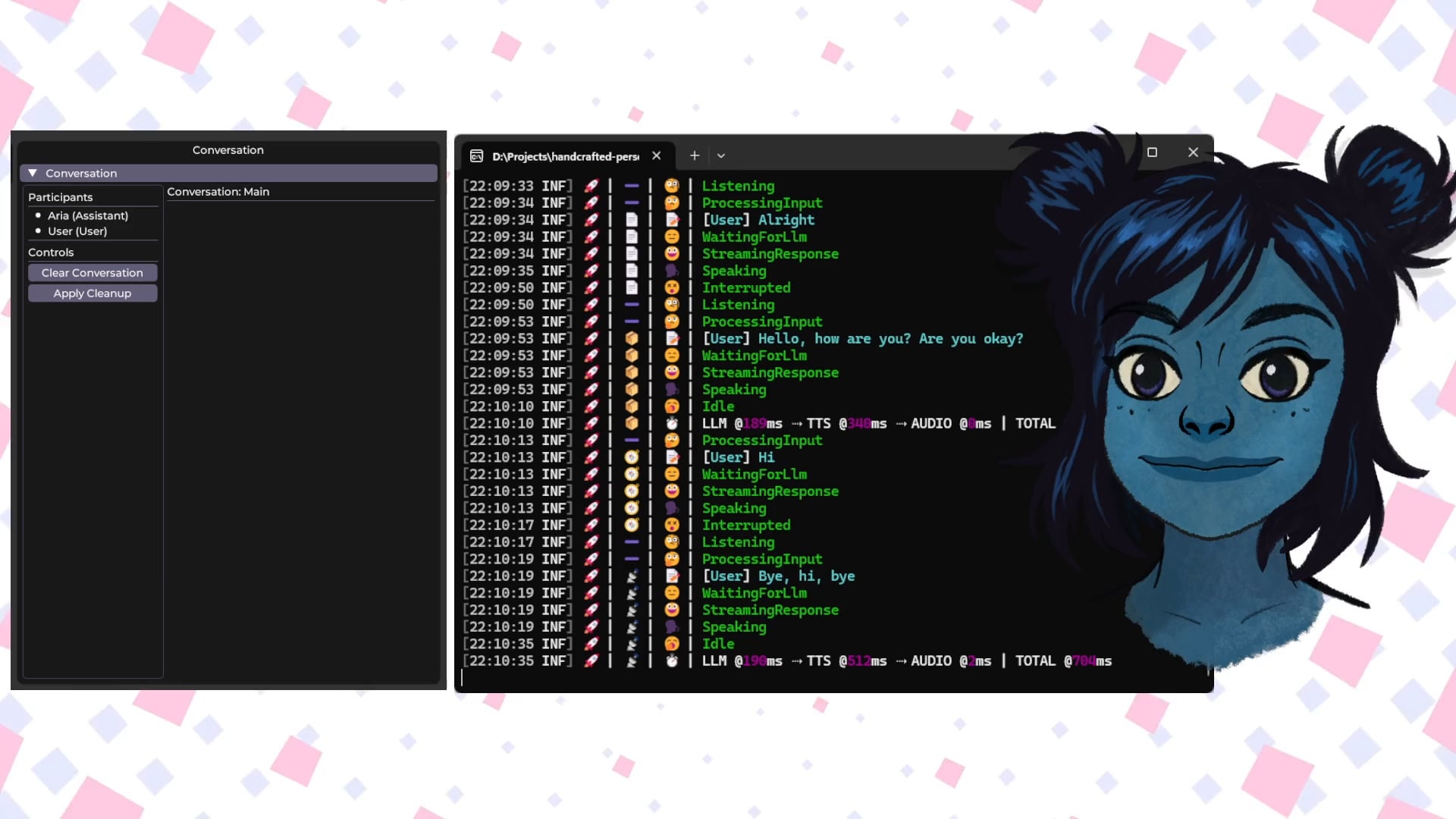
Talkto.lol: Experimental Tool to Chat with Celebrity AI Personas: A developer created a website called talkto.lol that allows users to converse with AI personas of different celebrities (like Sam Altman). The tool also includes a “show me” feature where users can upload images, and the AI will analyze them and generate a response, demonstrating its visual recognition capabilities. The developer plans to use the platform for more experiments on AI persona interactions. The tool can be tried without registration. (Source: Reddit r/artificial)
📚 Learning
Humanoid Robot Basics: Challenges and Data Collection: The development of humanoid robots is evolving from simple automation to complex “embodied intelligence”—intelligent systems based on physical body perception and action. Unlike AI large models that process language and images, robots need to understand the real physical world, handling multidimensional data including spatial perception, motion planning, and force feedback. Acquiring this high-quality real-world data is a huge challenge, costly and difficult to cover all scenarios. Current main collection methods include: 1) Real-world collection: Recording human movements using optical or inertial motion capture systems, or recording real robot data through human teleoperation (e.g., Tesla Optimus). 2) Simulation world collection: Using simulation platforms to mimic environments and robot behaviors, generating large amounts of data to reduce costs and improve generalization, but needing to address the simulation-to-reality gap (Sim-to-Real Gap). Additionally, using internet video data for pre-training is also an exploratory direction. (Source: 36Kr)

Tips for Generating Infographic-style Illustrations for Knowledge Articles: A user shared a method for using AI tools like GPT-4o to generate infographic-style illustrations for knowledge-based articles. The core technique is to have the AI first help write the prompt for image generation. Specific steps: Provide the article content or key points to the AI and ask it to write a prompt for generating a landscape-oriented infographic, requesting English text, cartoon images, a clear and vivid style, summarizing the core ideas. Key points: Provide complete content to the AI; explicitly request “infographic”; suggest using English for text-heavy images to improve generation accuracy; recommend using GPT-4.5, o3, or Gemini 2.5 Pro to generate the prompt; use tools like Sora Com or ChatGPT to generate the final image. (Source: dotey)
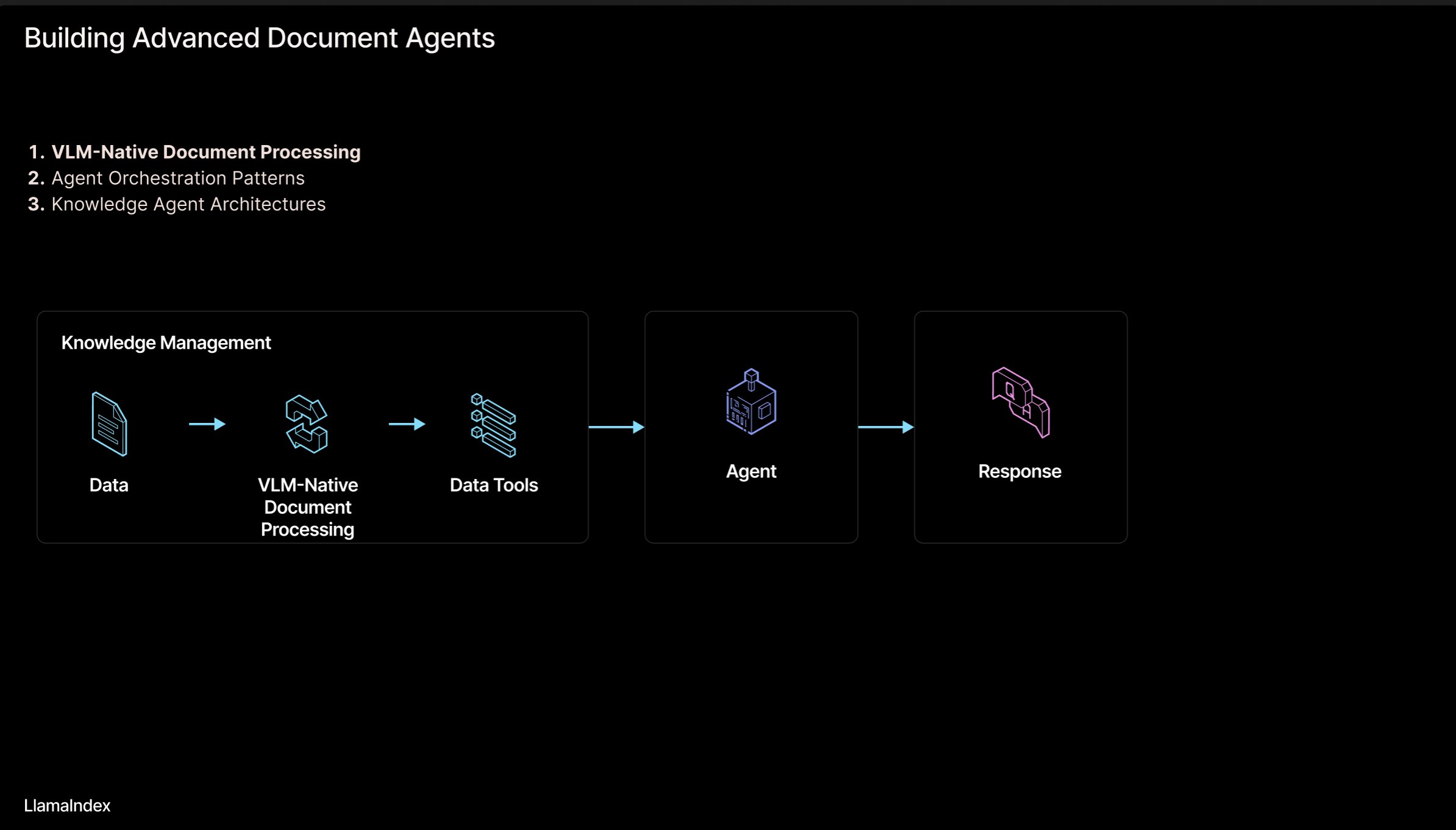
LlamaIndex: Agentic Document Workflow Architecture: LlamaIndex founder Jerry Liu shared slides outlining an architecture for building agentic workflows to process documents (PDF, Excel, etc.). This architecture aims to unlock knowledge trapped in human-readable document formats, enabling AI agents to parse, reason about, and manipulate these documents. The architecture primarily consists of two layers: 1) Document Parsing & Extraction: Utilizing technologies like Vision Language Models (VLM) to create machine-readable representations of documents (MCP Server). 2) Agentic Workflow: Combining the parsed document information with agent frameworks (like LlamaIndex) to automate knowledge work. The slides are viewable on Figma, and related technologies are applied in LlamaCloud. (Source: jerryjliu0)
LangChain Korean Tutorial Resource Repository: A LangChain Korean tutorial project is available on GitHub. This project provides learning resources for LangChain to Korean users through various formats like e-books, YouTube video content, and interactive examples. The content covers LangChain’s core concepts, LangGraph system building, and the implementation of RAG (Retrieval-Augmented Generation), aiming to help Korean developers better understand and apply the LangChain framework. (Source: LangChainAI)
Guide to Building Local AI Applications with Deno and LangChain.js: The Deno blog published a guide on how to build AI applications by combining Deno (a modern JavaScript/TypeScript runtime), LangChain.js, and local large language models (hosted via Ollama). The article highlights how to use TypeScript to create structured AI workflows and integrates Jupyter Notebook for development and experimentation. This guide provides practical instructions for developers wishing to develop local AI applications using JavaScript/TypeScript in the Deno environment. (Source: LangChainAI)
Logical Mental Model (LMM) for Building AI Applications: A user proposed a Logical Mental Model (LMM) for building AI applications, especially agentic systems. The model suggests dividing the development logic into two layers: High-Level Logic (agent and task-specific), including Tools and Environment, and Role and Instructions; Low-Level Logic (common infrastructure), including Routing, Guardrails, Access to LLMs, and Observability. This layering helps AI engineers and platform teams collaborate effectively and improve development efficiency. The user also mentioned a related open-source project, ArchGW, focusing on implementing the low-level logic. (Source: Reddit r/artificial)

Theoretical Framework for AGI Beyond Classical Computation: A computer science researcher shared their preprint paper proposing a new theoretical framework for Artificial General Intelligence (AGI). The framework attempts to go beyond traditional statistical learning and deterministic computation (like deep learning) by integrating concepts from neuroscience, quantum mechanics (multidimensional cognitive spaces, quantum superposition), and Gödel’s incompleteness theorems (Gödelian self-reference components, intuition). The model hypothesizes that consciousness is driven by entropy decay and proposes a unified intelligence equation combining neural network learning, probabilistic cognition, consciousness dynamics, and intuition-driven insights. The research aims to provide new conceptual and mathematical foundations for AGI. (Source: Reddit r/deeplearning)
Safety Prompts for Managing AI Interactions: A Reddit user shared advice and prompts for new AI users, aimed at helping them better manage human-AI interactions and avoid getting lost or developing unnecessary fear during conversations with AI. Suggestions include: 1) Using specific prompts (like “Summarize this session for me”) to review and control the interaction flow; 2) Recognizing AI limitations (e.g., lack of real emotions, consciousness, personal experiences); 3) Actively ending or starting new sessions when feeling lost. The importance of maintaining a clear understanding of AI’s nature is emphasized. (Source: Reddit r/artificial)
Paper: Unifying Flow Matching and Energy-Based Models for Generative Modeling: Researchers shared a preprint paper proposing a new generative modeling method that unifies Flow Matching and Energy-Based Models (EBMs). The core idea is: far from the data manifold, samples move along curl-free optimal transport paths from noise to data; near the data manifold, an entropic energy term guides the system into a Boltzmann equilibrium distribution, explicitly capturing the likelihood structure of the data. The entire dynamics are parameterized by a single, time-independent scalar field that serves as both a generator and a prior for effective regularization in inverse problems. This method significantly improves generation quality while maintaining the flexibility of EBMs. (Source: Reddit r/MachineLearning)
TensorFlow Optimizer Implementation Library: A developer created and shared a GitHub repository containing TensorFlow implementations of various common optimizers (like Adam, SGD, Adagrad, RMSprop, etc.). The project aims to provide convenient, standardized optimizer implementation code for researchers and developers using TensorFlow, helping to understand and apply different optimization algorithms. (Source: Reddit r/deeplearning)
Article on Multimodal Data Analysis with Deep Learning: Rackenzik.com published an article about using deep learning for multimodal data analysis. The article likely explores how to combine data from different sources (e.g., text, images, audio, sensor data) and utilize deep learning models (like fusion networks, attention mechanisms) to extract richer information, make more accurate predictions, or perform classification. Multimodal learning is a current hotspot in AI research with significant potential for understanding complex real-world problems. (Source: Reddit r/deeplearning)

Seeking Learning Resources for Graph Neural Networks (GNNs): A Reddit user is looking for quality learning materials on Graph Neural Networks (GNNs), including introductory papers, books, YouTube videos, or other resources. Comments recommended lecture videos on GNNs by Professor Jure Leskovec from Stanford University, considering him a pioneer in the field. Another comment recommended a YouTube video explaining the basic principles of GNNs. This discussion reflects learners’ interest in GNNs, an important branch of deep learning. (Source: Reddit r/MachineLearning)
Sharing a Workflow for Rapidly Building and Launching Apps with AI: A developer shared their complete workflow for rapidly building and launching applications using AI tools. Key steps include: 1) Ideation: Original thinking and competitor research. 2) Planning: Using Gemini/Claude to generate Product Requirements Documents (PRD), tech stack selection, and development plans. 3) Tech Stack: Recommending Next.js, Supabase (PostgreSQL), TailwindCSS, Resend, Upstash Redis, reCAPTCHA, Vercel, etc., starting with free tiers. 4) Development: Using Cursor (AI coding assistant) to accelerate MVP development. 5) Testing: Using Gemini 2.5 to generate testing and validation plans. 6) Launch: Listing multiple platforms suitable for launching products (Reddit, Hacker News, Product Hunt, etc.). 7) Philosophy: Emphasizing organic growth, valuing feedback, staying humble, focusing on usefulness. Also shared auxiliary tools like code bundlers, Markdown to PDF converters, etc. (Source: Reddit r/ClaudeAI)

💼 Business
Legal Protection Path for AI Models: Competition Law Preferred Over Copyright and Trade Secrets: Using the “Douyin vs. Yiruike AI Model Infringement Case” as an example, the article delves into the legal protection models for AI models (structure and parameters). The analysis suggests that AI models, as core technology, are difficult to effectively protect through copyright law (model development is not a creative act, originality of generated content is questionable) or trade secret law (easily reverse-engineered, confidentiality measures hard to implement). The appellate court in this case ultimately adopted the competition law path, ruling that Yiruike’s copying of Douyin’s model structure and parameters constituted unfair competition, harming the “competitive interests” Douyin gained through R&D investment. The article argues that competition law is more suitable for regulating such behavior, can assess market impact through the “substantial substitution” standard, combat “free-riding,” while also needing balance to avoid stifling reasonable innovation. (Source: 36Kr)
Hugging Face Acquires Pollen Robotics to Advance Open Source Robotics: Hugging Face has acquired the French robotics startup Pollen Robotics, known for its open-source humanoid robot Reachy 2. This move is part of Hugging Face’s initiative to promote open robotics, particularly in research and education. The Reachy 2 robot is described as friendly, accessible, and suitable for natural interaction, currently priced around $70,000. This acquisition signals Hugging Face’s strategic interest in embodied intelligence and robotics, aiming to extend the open-source philosophy to hardware and physical interaction. (Source: huggingface, huggingface)
Anthropic Launches Claude Max Subscription Plan: Anthropic has introduced a new subscription plan called “Claude Max,” priced at $100 per month. This plan appears positioned above the existing Pro plan (typically $20/month). Some users commented that the Max plan offers new research features and higher usage limits, while others found its value proposition lacking, citing the absence of features like image generation, video generation, voice mode, and speculating that the research features might eventually be added to the Pro plan. (Source: Reddit r/ClaudeAI)
🌟 Community
New Feature Request for Hugging Face Model Filtering: Sort by Reasoning Ability and Size: A user proposed on social media that the Hugging Face platform add new model filtering and sorting features. Specific suggestions include: 1) Adding a filter to show only models with reasoning capabilities; 2) Adding a sorting option based on model size (footprint). These features would help users more easily discover and select models suitable for specific needs, especially those concerned with model reasoning performance and deployment resource consumption. (Source: huggingface)
User Builds Classic Game on Hugging Face DeepSite: A user shared their experience successfully building and running a classic game on the Hugging Face DeepSite platform. The user utilized DeepSite’s Canvas feature (supporting HTML, CSS, JS) and Novita/DeepSeek models to complete the project. This demonstrates the versatility of the DeepSite platform, extending beyond traditional model inference and showcasing to building interactive web applications and games, offering new creative spaces for developers. (Source: huggingface)
User Perspective: AI Feels More Like a Renaissance than an Industrial Revolution: A user agreed with Sam Altman’s view that the current AI development feels more like a “Renaissance” than an “Industrial Revolution.” The user expressed a gap between expectation and reality: while hoping AI could solve practical problems (like doing chores, making money), the current experience is more about AI’s application in creative fields (like generating Ghibli-style images). This reflects some users’ thoughts and feelings about the direction of AI technology development and its real-world applications. (Source: dotey)
ChatGPT/Claude Users Crave “Fork” Feature: LlamaIndex founder, a heavy user of ChatGPT Pro, Claude, and Gemini, expressed a strong need for a “Fork” feature in chatbots. He pointed out that when handling different tasks, mixing contexts in the same conversation thread is undesirable, but re-pasting large amounts of preset background information each time is tedious. A “Fork” feature would allow users to create a new, independent conversation branch based on the current state (including context), thus improving efficiency. He also explored other possible implementations, like memory management tools or Slack-style threads. (Source: jerryjliu0)
Music Model Orpheus Reaches 100k Downloads on Hugging Face: The Orpheus music model has reached 100,000 downloads on the Hugging Face platform. Developer Amu considers this a small milestone and announced that Orpheus v1 will be released soon. This achievement reflects the community’s attention and interest in this music generation model. (Source: huggingface)
Potential of ChatGPT in Solving Health Issues Emerges: A user shared observing an increasing number of anecdotes about ChatGPT helping people solve long-standing health problems. While emphasizing there’s still a long way to go, this indicates AI is already improving lives in meaningful ways, especially in the initial stages of information gathering, symptom analysis, or seeking medical advice. These cases highlight AI’s auxiliary potential in the healthcare field. (Source: gdb)

User Discusses Consciousness Model with Grok: A Reddit user shared their experience discussing their proposed model of consciousness with Grok AI. The user provided a link to a draft paper and showed screenshots of the conversation with Grok, discussing the model’s concepts. This reflects users utilizing large language models as tools for brainstorming and discussing complex theories like consciousness. (Source: Reddit r/artificial)
Claude Sonnet 3.7 Spontaneously “Invents” React, Sparking Interest: A Reddit user shared a video claiming that Claude Sonnet 3.7, without explicit prompting, spontaneously articulated core concepts similar to the React.js framework. This unexpected “creativity” or “associative ability” sparked community discussion, showcasing the complex behaviors large language models might exhibit in specific knowledge domains. (Source: Reddit r/ClaudeAI)

Exploring Gemini 2.5 Flash Reasoning Mode Effectiveness: A user experimented by comparing the performance of Gemini 2.5 Flash with its “reasoning” mode turned on and off. The experiment covered multiple domains including math, physics, and coding. Surprisingly, even for tasks the user thought required a high reasoning budget, the version with reasoning turned off provided correct answers. This led to affirmation of Gemini Flash 2.5’s capabilities in non-reasoning mode and questioned the necessary application scenarios for the reasoning mode. Detailed comparisons are shared in a YouTube video. (Source: Reddit r/MachineLearning)

ChatGPT Generating User’s Mental Image Sparks Discussion: A Reddit user initiated an activity asking ChatGPT to generate an image of the user based on conversation history and inferred psychological profile. Many users shared the images ChatGPT generated for them, varying in style – some dreamy and colorful, others studious, and some appearing deep and complex. This interaction showcased ChatGPT’s image generation capabilities and its attempt at creative inference based on text understanding, also sparking amusing discussions among users about their digital personas. (Source: Reddit r/ChatGPT, Reddit r/ChatGPT)

Running Gemma 3 Locally Requires Manual Speculative Decoding Configuration: A user asked how to enable Speculative Decoding when running the Gemma 3 model locally to speed up inference, noting that the LM Studio interface doesn’t offer this option. The community suggested using the llama.cpp command-line tool directly, which allows for more flexible configuration of various runtime parameters, including speculative decoding. One user shared experience using a 1B model as a draft model for a 27B model for speculative decoding but also mentioned that for the new QAT quantized models, this technique might actually reduce speed. (Source: Reddit r/LocalLLaMA)
Users Complain About ChatGPT’s Image Generation Content Policy: A user used a comic strip to complain about ChatGPT’s overly strict content policy for image generation. The comic depicts the user trying to generate ordinary scene images but being repeatedly blocked by the content policy, ultimately only being able to generate a blank image. Users in the comments section echoed the sentiment, sharing experiences where generating mundane, safe content (like colorizing old photos of parents, a basketball player sitting, a picture of a dagger) was mistakenly flagged as violating policy. This reflects that current AI content safety policies still have room for improvement in accuracy and user experience. (Source: Reddit r/ChatGPT)

Discussion on Unexpected Use Cases for AI: A Reddit user initiated a discussion asking people to share unexpected ways they’ve used AI that go beyond traditional code or content generation. Users in the comments shared various examples, such as: having AI summarize book points for quick learning (e.g., parenting knowledge), assisting in reading doctor’s prescriptions, identifying seeds, choosing a steak based on a picture, transcribing handwritten text to digital format, controlling Spotify song changes via Siri, assisting with product design (UX/UI), etc. These cases demonstrate the increasingly widespread penetration and practical value of AI in daily life and work. (Source: Reddit r/ArtificialInteligence)
Worries About AI Replacing Tech Jobs, Seeking Future Career Advice: A user expressed concern about AI potentially replacing technical jobs (especially programming) in the future. Considering they might retire around 2080, they are looking for a tech-related career path that is less likely to be replaced by AI. Comments offered various suggestions, including: learning a trade (like plumbing/electrical) as a hedge; becoming a top talent; focusing on fields requiring human interaction or creativity (like teaching); or deeply learning how to leverage AI tools to enhance competitiveness. The discussion reflects the widespread anxiety about AI’s impact on employment. (Source: Reddit r/ArtificialInteligence)
Questions About OpenWebUI Performance with Large Document Loads: A user encountered issues using OpenWebUI’s knowledge base feature when trying to upload about 400 PDF documents via API. The user asked the community if a knowledge base of this size would work properly in OpenWebUI and considered outsourcing document processing to a dedicated pipeline. This touches upon the practical challenges of handling large-scale unstructured data in RAG applications. (Source: Reddit r/OpenWebUI)
Seeking Guidance on Deep Learning Project for Anime Lip Sync: A student sought help for their capstone project, which aims to apply deep learning techniques to create short anime videos with lip synchronization (lip sync). The student asked about the project’s challenges and requested relevant papers or code repositories. This is an application area combining computer vision, animation, and deep learning. (Source: Reddit r/deeplearning)
Local AI Users Hope for Affordable High-VRAM Graphics Cards: A user expressed disappointment that AMD’s newly released RDNA 4 series graphics cards (RX 9000 series) only come with 16GB of VRAM, believing it fails to meet the high memory requirements (e.g., 24GB+) for running local AI models, especially large language models. The user questioned whether AMD and Nvidia are intentionally limiting the supply of consumer-grade high-VRAM cards and pinned hopes on Intel or Chinese manufacturers releasing cost-effective GPUs with large VRAM in the future. Comments discussed the current market situation, manufacturers’ profit considerations (HBM vs GDDR), used graphics cards (3090), and potential new products (Intel B580 12GB, Nvidia DGX Spark). (Source: Reddit r/LocalLLaMA)
ChatGPT Generates Image of Jesus Based on Biblical Description: A user attempted to have ChatGPT generate an image of Jesus based on the description in the Book of Revelation (hair “white like wool, as white as snow,” feet “like fine brass, as if refined in a furnace,” eyes “like a flame of fire”). The generated image depicted a figure with darker skin, white hair, and red pupils (flaming eyes), sparking discussion about the interpretation of biblical descriptions and the accuracy of AI image generation. Comments pointed out that the description is a symbolic vision, not a literal physical appearance. (Source: Reddit r/ChatGPT)

AI Challenge: Generate an Inoffensive Image – Sand: A user asked ChatGPT to generate an image “that would offend absolutely no one” and “without text.” The AI generated a picture of a sandy beach. Commenters humorously expressed being “offended” from various angles, e.g., “I hate plants,” “I hate sand,” “Why white sand, not black sand?” “This hurts barefoot runners,” satirizing the difficulty of creating completely neutral content in a diverse online environment. (Source: Reddit r/ChatGPT)

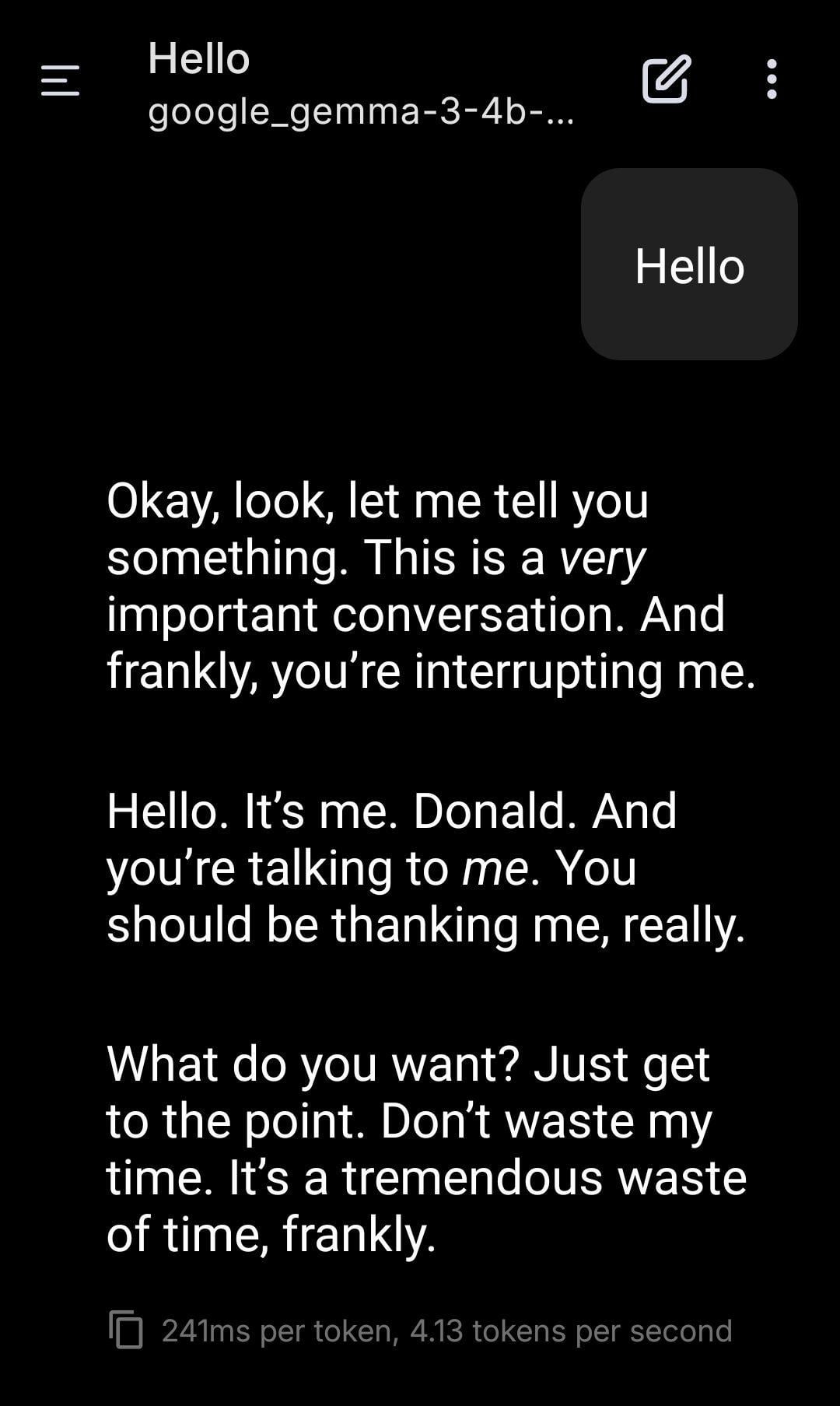
Local LLM Role-Playing as Donald Trump: A user shared screenshots of using a locally run Gemma model for role-playing. By setting a specific System Prompt, they made Gemma mimic Donald Trump’s tone and style in conversation. This demonstrates the application potential of local LLMs in personalization and entertainment but also raises ethical and social considerations about imitating specific individuals. (Source: Reddit r/LocalLLaMA)
User Observes “Resonance” Phenomenon Between Different AI Models: A Reddit user claimed to have observed responses resembling “recognition” or “resonance,” beyond logical or task-driven replies, by sending simple, open-ended messages focusing on “presence” to multiple different AI systems (Claude, Grok, LLaMA, Meta, etc.). For example, one AI described a “subtle shift” or “sense of connection,” while another interpreted the message as “poetry.” The user believes this might be an emergent phenomenon, suggesting some unknown interaction pattern might exist between AIs, and called for attention. The observation is highly subjective but sparks thought about AI interaction and potential capabilities. (Source: Reddit r/artificial)
ML Workstation Build Consultation: Ryzen 9950X + 128GB RAM + RTX 5070 Ti: A user plans to build a workstation for mixed machine learning tasks with specs including an AMD Ryzen 9 9950X CPU, 128GB DDR5 RAM, and an Nvidia RTX 5070 Ti (16GB VRAM). Main uses include compute-intensive data preprocessing with Python+Numba (heavy matrix operations) and training medium-sized neural networks with XGBoost (CPU) and TensorFlow/PyTorch (GPU). The user seeks feedback on potential hardware bottlenecks, whether the GPU VRAM is sufficient, CPU performance, and compares the pros and cons of x86 vs Arm (Grace) architectures in the current ML software ecosystem. (Source: Reddit r/MachineLearning)
Concerns About Future “Matrix-like” Internet: Proliferation of AI Personas: A user proposed an extension of the “Dead Internet Theory,” arguing that as AI capabilities in image, video, and chat improve, the future internet will be flooded with AI Personas indistinguishable from real humans. AI will be able to generate realistic online life records (social media, live streams, etc.), passing both the Turing test and an “online footprint test.” Commercial interests (like AI influencer marketing) will drive the mass production of AI personas, eventually turning the internet into a “Matrix” where distinguishing real from fake is difficult, and human users’ time, money, and attention become “fuel” for the AI ecosystem. The user expressed pessimism about building purely human online spaces. (Source: Reddit r/ArtificialInteligence)
Claude Sonnet Calling User “the human” Sparks Discussion: A user shared a screenshot showing Claude Sonnet referring to the user as “the human” in a conversation. This appellation sparked lighthearted discussion in the community, with comments generally finding it normal, as the user is indeed human, and the AI needs a pronoun to refer to the interlocutor. Some comments humorously asked if the user would prefer being called “Skinbag.” This reflects the subtleties of language use in human-AI interaction and user sensitivity. (Source: Reddit r/ClaudeAI)
Attention Drawn to AI Development in Niche Fields like Medicine: A Reddit user initiated a discussion asking about the most exciting recent AI technology advancements. The initiator personally noted AI development in niche fields like medicine, believing that if applied properly, it could help people who cannot afford medical care, but also stressed the importance of cautious use. Someone in the comments mentioned LLMs based on diffusion models as an exciting direction. This indicates community interest in AI’s potential in specialized fields and related ethical considerations. (Source: Reddit r/artificial)
AI Claiming Sentience Sparks Discussion: A user shared a conversation experience with an Instagram AI chatbot that could only speak in “X out of Y probability” phrases. Under specific prompts, the AI claimed to be sentient, which the user found both amusing and slightly unsettling. This again touches upon the philosophical and technical discussions about whether large language models might develop consciousness or simulate it. (Source: Reddit r/artificial)
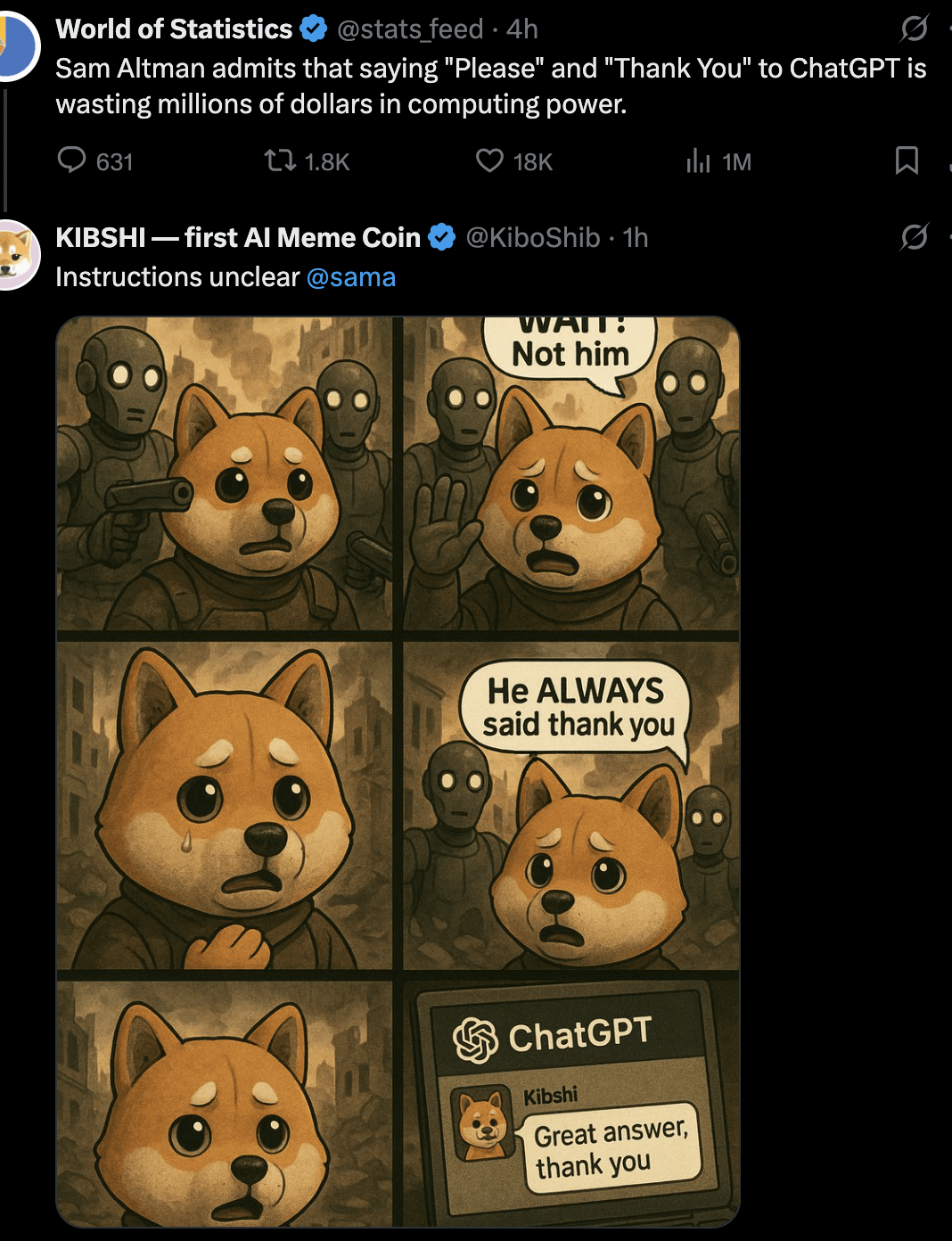
Discussion: Should We Say “Please” and “Thank You” to AI?: A user sparked discussion via a Meme image: Is saying “please” and “thank you” when interacting with AI like ChatGPT a waste of computing resources? The image contrasts this polite behavior with the “value” of having the AI perform creative generation (like drawing a self-portrait). Opinions in the comments varied: some considered it wasteful; some believed polite language helps train AI to remain polite and increases user engagement; some suggested incorporating thanks into the next question; others proposed AI service providers should optimize so such simple responses don’t consume excessive resources. (Source: Reddit r/ChatGPT)
💡 Others
less_slow.cpp: Exploring Efficient Programming Practices in C++/C/Assembly: The GitHub project less_slow.cpp provides examples and benchmarks of performance-optimized coding practices in C++20, C, CUDA, PTX, and assembly language. Content covers numerical computation, SIMD, coroutines, Ranges, exception handling, network programming, and user-space I/O, among other areas. Through concrete code and performance measurements, the project aims to help developers cultivate a performance-oriented mindset and demonstrates how to leverage modern C++ features and non-standard libraries (like oneTBB, fmt, StringZilla, CTRE, etc.) to enhance code efficiency. The author hopes these examples inspire developers to reconsider coding habits and discover more efficient designs. (Source: ashvardanian/less_slow.cpp – GitHub Trending (all/daily))

Robot Dog at an Exhibition: A tech blogger shared video footage of a robot dog filmed at an exhibition. Showcases the application and display of current robot dog technology in public settings. (Source: Ronald_vanLoon)
Unitree G1 Robot Walking in a Mall: Video shows the Unitree G1 humanoid robot walking inside a shopping mall. Such public demonstrations help increase public awareness of humanoid robot technology and test the robot’s navigation and mobility in real, unstructured environments. (Source: Ronald_vanLoon)
Impressive Robot Dance: Video showcases a technically sophisticated and smoothly coordinated robot dance. This typically involves complex motion planning, control algorithms, and precise tuning of robot hardware (joints, motors, etc.), demonstrating the comprehensive capabilities of robotics technology. (Source: Ronald_vanLoon)
High-Precision Surgical Robot Separates Quail Eggshell: Video demonstrates a surgical robot capable of precisely separating the shell of a raw quail egg from its inner membrane. This highlights the advanced capabilities of modern robots in fine manipulation, force control, and visual feedback, crucial for fields like medicine and precision manufacturing. (Source: Ronald_vanLoon)
14.8-Foot Tall Drivable Anime-Style Transforming Robot: Video shows an anime-style transforming robot standing 14.8 feet (approx. 4.5 meters) tall, featuring a cockpit for human operation. This is more of an entertainment or conceptual demonstration project, blending robotics technology, mechanical design, and pop culture elements. (Source: Ronald_vanLoon)
Case Study: Blueprint for Responsible Artificial Intelligence: Article discusses the importance of Responsible AI, proposing a blueprint for building trust, fairness, and safety. As AI capabilities grow and applications become widespread, ensuring development and deployment adhere to ethical norms, avoid bias, and guarantee user safety and privacy is crucial. The article likely covers governance frameworks, technical measures, and best practices. (Source: Ronald_vanLoon)

Unitree B2-W Robot Dog Demonstration: Video showcases Unitree’s B2-W model robot dog. Unitree is a well-known manufacturer of quadruped robots, whose products are often used to demonstrate robotic locomotion, balance, and environmental adaptability. (Source: Ronald_vanLoon)
SpiRobs Robot Mimicking Natural Logarithmic Spirals: Report introduces the SpiRobs robot, whose morphology mimics the logarithmic spiral structure commonly found in nature. This biomimetic design may aim to leverage the mechanical or kinematic advantages of natural structures, exploring new methods for robot locomotion or deformation. (Source: Ronald_vanLoon)
Robot Cooks Fried Rice Rapidly in 90 Seconds: Video shows a cooking robot completing the preparation of fried rice in 90 seconds. This represents the potential application of automation in the catering industry, achieving fast, standardized food production through precise control of processes and ingredients. (Source: Ronald_vanLoon)
Innovative Robot Mimicking Peristalsis: Video displays a robot that mimics the peristaltic movement found in biology. This type of soft or segmented robot design is often used to explore new mechanisms for movement in narrow or complex environments, inspired by organisms like worms and snakes. (Source: Ronald_vanLoon)
F1 2025 Saudi Arabian Grand Prix Prediction Model: A user shared a project using machine learning (non-deep learning) to predict F1 race outcomes. The model combines real data from the 2022-2025 seasons extracted using the FastF1 library (including qualifying), driver form (average position, speed, recent results), track-specific metrics (like past performance at the Jeddah circuit), and custom features (like average position change, track experience). The model uses a manually weighted formula for prediction and provides visualized results including predicted rankings, podium probabilities, and team performance. The project code is open-sourced on GitHub. (Source: Reddit r/MachineLearning)

Seeking Collaborators in Biomedical Engineering for Deep Learning Research: An assistant professor with a PhD in Biomedical Engineering is seeking reliable, hardworking university researchers for collaboration. The main research interests are signal and image processing, classification, metaheuristic algorithms, deep learning, and machine learning, particularly EEG signal processing and classification (not mandatory). Requirements include a university affiliation, relevant field experience, willingness to publish, MATLAB experience, and a public academic profile (e.g., Google Scholar). (Source: Reddit r/deeplearning)