
Keywords:Gemini 2.5 Flash, OpenAI o3, AI job displacement, AI healthcare commercialization, hybrid reasoning model, thinking budget feature, o4-mini multimodal capabilities, AI coding assistant Windsurf, Agentic AI home gateway, VisualPuzzles benchmark test, DeepSeek recommendation reliability, Zhipu AI open-source model
🔥 Focus
Google releases Gemini 2.5 Flash hybrid reasoning model, focusing on cost-effectiveness and controllable thinking: Google launches Gemini 2.5 Flash preview, positioned as a cost-effective hybrid reasoning model. Its unique feature is the introduction of a “thinking_budget” function, allowing developers (0-24k tokens) or the model itself to adjust reasoning depth based on task complexity. With thinking turned off, the cost is extremely low ($0.6/million output tokens), and performance exceeds Gemini 2.0 Flash; with thinking turned on ($3.5/million output tokens), it can handle complex tasks, with performance comparable to o4-mini on several benchmarks (like AIME, MMMU, GPQA) and ranking high on the LMArena leaderboard. The model aims to balance performance, cost, and latency, making it particularly suitable for application scenarios requiring flexibility and cost control. It is already available via API in Google AI Studio and Vertex AI. (Source: 谷歌首款混合推理Gemini 2.5登场,成本暴降600%,思考模式一开,直追o4-mini, 谷歌大模型“性价比之王”来了,混合推理模型,思考深度可自由控制,竞技场排名仅次于自家Pro, op7418, JeffDean, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/artificial)

OpenAI releases o3 and o4-mini models, enhancing reasoning and multimodal capabilities: OpenAI introduces its strongest model series to date, o3, and the optimized o4-mini, focusing on enhancing reasoning, programming, and multimodal understanding capabilities. Notably, it achieves image-based “chain-of-thought” reasoning for the first time, enabling analysis of image details for complex judgments, such as inferring precise shooting locations from photos (GeoGuessing). o3 achieved a record high score of 136 on the Mensa IQ test and performed excellently in programming benchmarks. o4-mini, while maintaining high efficiency and low cost, demonstrates strong capabilities in mathematical problem-solving (like Euler problems) and visual processing. These models are now available to ChatGPT Plus, Pro, and Team users, indicating OpenAI is advancing models from knowledge acquisition towards tool usage and complex problem-solving. (Source: 实测o3/o4-mini:3分钟解决欧拉问题,OpenAI最强模型名副其实, 智商136,o3王者归来,变身福尔摩斯“AI查房”,一张图秒定坐标, 满血版o3探案神技出圈,OpenAI疯狂暗示:大模型不修仙,要卷搬砖了)

AI efficiency gains spark job concerns, some companies begin replacing positions with AI: The high efficiency of artificial intelligence technology is prompting companies like PayPal, Shopify, and United Wholesale Mortgage to consider or actually use AI to replace human positions, especially in areas like customer service, junior sales, IT support, and data processing. For example, PayPal’s AI chatbot now handles 80% of customer service requests, significantly reducing costs. United Wholesale Mortgage uses AI to process mortgage documents, greatly increasing efficiency, doubling business volume without needing additional staff. Some companies are even proposing the concept of “zero-employee teams,” requiring justification that AI cannot perform the task before hiring new personnel. Although many companies avoid publicly admitting layoffs are due to AI, hiring slowdowns and job cuts have become a trend. Especially under cost pressure, the replacement effect of AI on white-collar jobs is expected to become more pronounced in the future. (Source: 招聘慢了、岗位少了,AI效率太高迫使人类员工“让位”)

OpenAI plans $3 billion acquisition of AI coding assistant Windsurf, strengthening application layer strategy: OpenAI plans to acquire AI coding startup Windsurf (formerly Codeium) for approximately $3 billion, which would be its largest acquisition. Windsurf offers AI coding assistance tools similar to Cursor, also based on Anthropic models. This acquisition is seen as a key step for OpenAI to expand into the application layer and enhance ecosystem control, aiming to directly acquire users, collect training data, and compete with rivals like GitHub Copilot and Cursor. Analysts believe that as AI capabilities improve, “Vibe Coding” (deep integration of AI into the development workflow) is becoming a trend, and controlling the application layer entry point and user data is crucial for the long-term competitiveness of model companies. This move by OpenAI indicates its strategic goals have moved beyond being just a model provider, intending to build a complete AI development platform. (Source: 有了一天涨万星的开源项目 Codex,OpenAI为何仍砸 30 亿美元重金收购 Windsurf ?)
🎯 Trends
ByteDance releases Doubao 1.5 deep thinking model and multimodal updates, accelerating Agent layout: ByteDance’s Volcengine releases the Doubao 1.5 deep thinking model, possessing human-like “read, think, search” capabilities for complex tasks, supporting multimodal input (text, image), and featuring internet search and visual reasoning abilities. Simultaneously, it released the Doubao text-to-image model 3.0 (improving text layout and image realism) and an upgraded visual understanding model (enhancing localization accuracy and video understanding). ByteDance believes deep thinking and multimodality are foundational for building Agents and launched an OS Agent solution and AI cloud-native inference suite, aiming to lower the barrier and cost for enterprises to build and deploy Agent applications. This move is seen as ByteDance redefining its strategy and focusing on Agent application deployment after facing competition from products like DeepSeek. (Source: 字节按下 AI Agent 加速键, 被DeepSeek打蒙的豆包,发起反攻了)

ByteDance and Kuaishou clash again in AI video generation, focusing on model performance and implementation: ByteDance released the Seaweed-7B video generation model, emphasizing low parameters (7B), high efficiency (trained on 665,000 H100 GPU hours), and low deployment cost (single GPU can generate 1280×720 video). Kuaishou released the “Keling 2.0” video generation model and “Ketu 2.0” image generation model, claiming performance surpassing Google’s Veo2 and Sora, and introduced multimodal editing feature MVL. Both companies recognize model capability as the ceiling for AI products, with their 2025 strategic focus returning to model refinement. Although their commercialization paths differ (ByteDance’s Jiemeng leans towards C-end, Kuaishou’s Keling focuses on B-end), both are striving to enhance practicality. For instance, Kuaishou emphasizes the importance of image-to-video generation, while ByteDance leverages its text processing strengths to ensure narrative consistency in videos, intensifying competition. (Source: 字节快手,AI视频“狭路又相逢”)

Zhipu AI releases three open-source models, strengthening open-source ecosystem construction: Zhipu AI declared 2025 as its “Year of Open Source” and released three models: GLM-Z1-Air (inference model), GLM-Z1-Air (likely a typo, possibly referring to a speed-focused or base version), and GLM-Z1-Rumination (rumination model), with sizes including 9B and 32B, under the MIT license. GLM-Z1-Air (32B) shows performance close to DeepSeek-R1 on some benchmarks with significantly lower inference costs. The rumination model Z1-Rumination explores deeper thinking and supports research loops. Concurrently, the Zhipu Z Fund announced a 300 million RMB investment to support the global AI open-source community, not limited to projects based on Zhipu models. This move aligns with Beijing’s strategy to build a “Global Open Source Hub”. (Source: 智谱获2亿元新融资,连发3款开源模型,拿3亿元支持全球开源社区)
Embedding Agentic AI in home gateways could be a new opportunity for operators: As AI evolves from generative to agentic (Agentic AI), systems capable of autonomous goal-setting and task execution are becoming central. MediaTek executives suggest embedding Agentic AI into home gateways could change operators’ roles in the IoT market. As the edge intelligence hub for home networks, gateways combined with Agentic AI can proactively manage networks (e.g., optimizing video calls), diagnose faults, enhance home security (e.g., identifying package theft, children near pool risks), thereby reducing operator customer service costs (many Wi-Fi related queries handled by AI) and offering value-added services. While monetization models need exploration, this offers operators a potential path beyond being mere “pipes” to becoming enablers of Agentic AI services. (Source: 将Agentic AI嵌入家庭网关,如何改变运营商在物联网市场的游戏规则?)
Microsoft releases MAI-DS-R1, post-trained on DeepSeek R1 for safety and compliance: The Microsoft AI team released the MAI-DS-R1 model, which is post-trained on DeepSeek R1. It aims to fill information gaps in the original model and improve its risk profile while maintaining R1’s reasoning capabilities. The training data includes 110,000 safety and non-compliance samples from Tulu 3 SFT, along with approximately 350,000 multilingual samples developed internally by Microsoft, covering various biased topics. Some community members interpret this move as Microsoft’s effort to enhance model safety and compliance, but it has also sparked discussions about whether it adds “enterprise-level censorship”. (Source: Reddit r/LocalLLaMA)

🧰 Tools
OpenAI open-sources Codex CLI, a terminal-driven AI coding assistant: OpenAI released a new open-source project, Codex CLI, an AI agent optimized for coding tasks that runs in the developer’s local terminal. It defaults to using the latest o4-mini model, but users can select other OpenAI models via API. Codex CLI aims to provide a chat-driven development approach, understanding and executing operations on local codebases, competing with tools like Anthropic’s Claude Code, Cursor, and Windsurf. The project gained over 14,000 stars on GitHub within a day of release, indicating strong developer interest in terminal-native AI coding tools. (Source: 有了一天涨万星的开源项目 Codex,OpenAI为何仍砸 30 亿美元重金收购 Windsurf ?)
Google AI Studio upgraded to support direct creation and sharing of AI applications: Google has updated its AI Studio platform, adding the functionality to create AI applications directly within the platform. Users can not only develop using models like Gemini but also browse and try sample applications created by other users. This upgrade evolves AI Studio from a model experimentation playground into a more complete application development and sharing platform, lowering the barrier to building applications based on Google’s AI technology. (Source: op7418)
NVIDIA cuML introduces zero code change GPU acceleration mode: The NVIDIA cuML team released a new accelerator mode allowing users to run native scikit-learn, umap-learn, and hdbscan code directly on the GPU without modifying any code. This feature is enabled via python -m cuml.accel your_script.py or by loading %load_ext cuml.accel in a Jupyter Notebook. Benchmarks show significant speedups ranging from 25x to 175x for algorithms like Random Forest, Linear Regression, t-SNE, UMAP, and HDBSCAN. The mode utilizes CUDA Unified Memory (UVM), generally eliminating concerns about dataset size, although performance on extremely large memory datasets will be affected. (Source: Reddit r/MachineLearning)

Alibaba open-sources Wan 2.1 first-last frame video model: Alibaba has open-sourced its Wan 2.1 video model, which focuses on generating intermediate video content based on the first and last frames. This is a specific type of video generation technology applicable to scenarios like video interpolation, style transfer, or keyframe-based animation generation. Open-sourcing this model provides researchers and developers with a new tool to explore and utilize this technology. (Source: op7418)
ViTPose: Human Pose Estimation with Vision Transformer: ViTPose is a new model utilizing the Vision Transformer (ViT) architecture for human pose estimation. The article introduces the model, discussing the potential of ViT in computer vision tasks like human pose estimation. Such models typically leverage the Transformer’s self-attention mechanism to capture long-range dependencies between different parts of an image, potentially improving the accuracy and robustness of pose estimation. (Source: Reddit r/deeplearning)

ClaraVerse: Local-first AI assistant integrated with n8n: ClaraVerse is a local-first AI assistant running on Ollama, emphasizing privacy and local control. The latest update integrates the n8n automation platform, allowing users to build and run custom tools and workflows (like checking emails, managing calendars, calling APIs, connecting to databases, etc.) within the assistant without external services. This enables Clara to trigger local automation tasks via natural language commands, aiming to provide a user-friendly, low-dependency local AI and automation solution. (Source: Reddit r/LocalLLaMA)
CSM 1B TTS model achieves real-time streaming and fine-tuning: The open-source community has made progress on the CSM 1B text-to-speech (TTS) model, achieving real-time streaming processing and developing fine-tuning capabilities (including LoRA and full fine-tuning). This means the model can now generate speech faster and can be customized for specific needs. The codebase provides a local chat demo for users to try and compare its effectiveness against other TTS models. (Source: Reddit r/LocalLLaMA)
Deebo: Utilizing MCP for AI Agent collaborative debugging: Deebo is an experimental Agent MCP (Machine Collaboration Protocol) server designed to allow coding AI Agents to outsource complex debugging tasks to it. When the main Agent encounters difficulties, it can initiate a Deebo session via MCP. Deebo generates multiple subprocesses to test various fixes in parallel across different Git branches, utilizing LLMs for reasoning. It ultimately returns logs, fix suggestions, and explanations. This approach leverages process isolation, simplifies concurrency management, and explores the potential for collaborative problem-solving among AI Agents. (Source: Reddit r/OpenWebUI)
📚 Learning
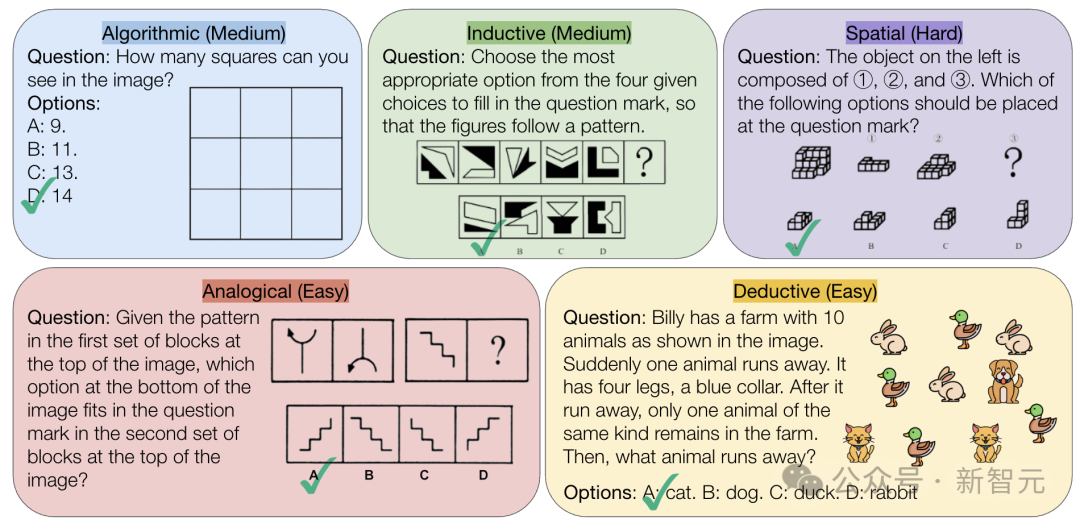
CMU releases VisualPuzzles benchmark, challenging AI’s pure logical reasoning ability: Carnegie Mellon University (CMU) researchers created the VisualPuzzles benchmark, containing 1168 visual logic puzzles adapted from civil service exams and other sources, designed to isolate multimodal reasoning ability from domain knowledge dependency. Tests revealed that even top models like o1 and Gemini 2.5 Pro perform far worse than humans on these pure logical reasoning tasks (highest accuracy 57.5%, lower than the bottom 5% of humans). The study shows that increasing model size or enabling “thinking” modes doesn’t always improve pure reasoning ability, and existing reasoning enhancement techniques have mixed results. This highlights significant gaps in current large models’ spatial understanding and deep logical reasoning capabilities. (Source: 全球顶尖AI来考公,不会推理全翻车,致命缺陷曝光,被倒数5%人类碾压)
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models: The paper “InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models” introduces the InternVL3 model, whose 78B version achieved a score of 72.2 on the MMMU benchmark, setting a new record for open-source MLLMs. Key techniques include native multimodal pre-training, Variable Visual Position Encoding (V2PE) supporting long contexts, advanced post-training techniques (SFT, MPO), and test-time expansion strategies (enhancing mathematical reasoning). The research aims to explore effective methods for improving the performance of open-source multimodal models and has released training data and model weights. (Source: Reddit r/deeplearning)

Geobench: A benchmark for evaluating large models’ image geolocation capabilities: Geobench is a new benchmark website specifically designed to measure the ability of Large Language Models (LLMs) to infer the shooting location of images, such as those from Google Street View, similar to playing the GeoGuessr game. It evaluates the accuracy of the model’s guesses, including country/region correctness and distance from the actual location (mean and median), among other metrics. Preliminary results show Google’s Gemini series models perform exceptionally well on this task, possibly benefiting from their access to Google Street View data. (Source: Reddit r/LocalLLaMA)
Discussing standard practices for dataset splitting: The Reddit machine learning community discussed how to handle datasets (e.g., train/val/test split) when standard splits are unavailable. Common practices include generating random splits (which can affect reproducibility), saving and sharing specific indices/files, and using k-fold cross-validation. The discussion emphasized that for small datasets, the splitting method significantly impacts performance evaluation and SOTA claims, calling for standardization or broader sharing of split information to improve research reproducibility and comparability. Practical challenges include the lack of a unified platform and domain-specific norms. (Source: Reddit r/MachineLearning, Reddit r/MachineLearning)
Seeking advice on sentence embeddings for Stack Overflow post classification: A user on Reddit sought advice on using sentence embeddings (like BERT, SBERT) for unsupervised classification of Stack Overflow posts (including title, description, tags, answers). The goal is sentence-level classification beyond simple word embedding tags (like “package installation”), exploring deeper thematic or question-type clustering. Comments suggested starting with the Sentence Transformers library, which generates single embeddings for text passages, and then applying clustering algorithms. (Source: Reddit r/MachineLearning)
Advice on AI learning paths and career choices: A high school student on Reddit asked for advice on university major choices (UCSD CS vs Cal Poly SLO CS) for entering the machine learning engineering field and whether graduate school is necessary. Comments recommended choosing UCSD for its stronger research focus and considering graduate school, as ML engineering often requires higher education. Simultaneously, some pointed out the importance of practical skills, with math and statistics being key foundations. In another thread, someone asked about majors for utilizing or developing AI; comments mentioned Computer Science (CS), often requiring Master’s/PhD degrees, as well as Math/Statistics. Some even suggested learning practical skills like plumbing in trade industries to mitigate AI replacement risk. (Source: Reddit r/MachineLearning, Reddit r/ArtificialInteligence)
💼 Business
Exploring AI healthcare commercialization: Big tech strategies vs. hospital needs: As hospitals begin allocating budgets for large models (e.g., Jiangsu Provincial Hospital’s 4.5 million RMB purchase of a DeepSeek-based platform), AI commercialization in healthcare accelerates. Major players like Huawei, Alibaba, Baidu, and Tencent are entering the field, typically providing computing power, cloud services, and foundation models, often partnering with healthcare vertical companies. However, the core business model remains unclear, with big tech currently focusing more on selling hardware and cloud services rather than deeply engaging in medical AI applications. On the hospital side, institutions like Shaanxi Hanzhou 3201 Hospital, facing budget constraints, are experimenting with open-source models (like lower-spec versions of DeepSeek), indicating a consideration for cost-effectiveness. Acquiring high-quality medical data and training specialized models remain key challenges, requiring overcoming “grunt work” like data annotation. (Source: AI看病这件事,华为、百度、阿里谁先挣到钱?, 科技大厂掀起医疗界的AI革命,谁更有胜算?)
Reliability of AI recommendation tools like DeepSeek questioned, AI marketing optimization becomes new battleground: AI tools like DeepSeek are increasingly used by users for recommendations (e.g., restaurants, products), and businesses are starting to use “DeepSeek recommended” as a marketing tag. However, the reliability of these recommendations raises concerns. On one hand, AI might “hallucinate,” inventing non-existent shops or recommending outdated products. On the other hand, AI responses could be commercially influenced, risking embedded advertising or being “polluted” by SEO/GEO (Generative Engine Optimization) strategies. Businesses are attempting to influence AI’s corpus and search results by optimizing content and keywords to boost their brand visibility. This challenges the objectivity of AI recommendations, requiring consumers to be wary of potentially misleading information. (Source: 第一批用DeepSeek推荐的人,已上当)

Zhipu AI receives additional 200 million RMB investment from Beijing Artificial Intelligence Industry Investment Fund: Following the announcement of several new open-source models and a 300 million RMB open-source fund, Zhipu AI (Z.ai) received an additional 200 million RMB investment from the Beijing Artificial Intelligence Industry Investment Fund. This fund had previously invested in Zhipu last year. The capital increase aims to support Zhipu’s open-source model R&D and open-source community ecosystem building, reflecting Beijing’s determination to promote the AI industry and establish a “Global Open Source Hub”. (Source: 智谱获2亿元新融资,连发3款开源模型,拿3亿元支持全球开源社区)
Intel CEO Patrick Gelsinger pushes reforms, appoints new CTO and Chief AI Officer: New CEO Patrick Gelsinger is restructuring Intel to streamline management layers and strengthen technology focus. Key chip divisions (Data Center & AI, PC chips) will report directly to the CEO. Network chip head Sachin Katti has been appointed as the new Chief Technology Officer (CTO) and Chief AI Officer, responsible for leading AI strategy, product roadmap, and Intel Labs, to counter NVIDIA’s challenge in the AI field. This move is seen as part of Gelsinger’s plan to revitalize Intel, aiming to address manufacturing and product challenges, break down internal silos, and focus on engineering and innovation. (Source: 陈立武挥刀高层,英特尔重生计划曝光,技术团队直通华人CEO)

Meta reportedly sought cost-sharing for Llama training, highlighting AI investment pressure: Meta reportedly approached companies like Microsoft, Amazon, Databricks, and investment firms, proposing to share the training costs of its open-source model Llama (the “Llama Alliance”) in exchange for some say in feature development, but initial reception was cool. Reasons might include partners’ reluctance to invest in a free model, Meta’s unwillingness to cede too much control, and potential partners already having significant AI investments. This incident highlights the pressure even giants like Meta face from soaring AI development costs, especially with massive capital expenditures (expected annual increase of 60% to $60-65 billion) and unclear commercialization paths for open-source models. (Source: Llama开源太贵了,Meta被曝向亚马逊、微软“化缘”)

NVIDIA CEO Jensen Huang visits China, potentially discussing cooperation with DeepSeek et al. to navigate trade restrictions: NVIDIA CEO Jensen Huang recently visited China at the invitation of the China Council for the Promotion of International Trade, meeting with clients including DeepSeek founder Liang Wenfeng. The visit occurs amid complex circumstances, including tightening US government restrictions on NVIDIA chip exports to China (like the H20) and the rise of domestic Chinese AI chips (like Huawei’s Ascend), alongside model optimizations by companies like DeepSeek reducing absolute reliance on NVIDIA’s high-end GPUs. Analysts suggest Huang might aim to explore joint design of AI chips with Chinese partners (like DeepSeek) that comply with US export limits while avoiding high Chinese import tariffs, seeking to maintain market share and industry influence in China through deeper collaboration. (Source: 英伟达CEO黄仁勋突然访华,都不穿皮衣了,还见了梁文锋)

🌟 Community
AI doll generation trend sweeps social media, raising copyright and ethical concerns: A trend of using AI tools like ChatGPT to transform personal photos into doll-like images (similar to Barbie style, complete with packaging and personalized accessories) has become popular on platforms like LinkedIn and TikTok. Users can generate these by uploading photos and providing detailed descriptions. While entertaining, it raises copyright and ethical concerns: AI generation might unintentionally use copyrighted art styles or brand elements; additionally, the significant energy consumption required to train and run these AI models is noted. Commentators suggest the need for clear boundaries and regulations when using AI. (Source: 芭比风AI玩偶席卷全网:ChatGPT几分钟打造你的时尚分身)

Tencent Yuanbao (formerly Red Packet Cover Assistant) deep integration into WeChat draws attention: Searching for “Yuanbao” within WeChat can directly invoke AI functions, effectively an upgraded version of the previous “Yuanbao Red Packet Cover Assistant”. User experience shows enhanced capabilities, such as generating more accurate images based on requests and improved native adaptation, generating answer cards. The article discusses the possibility of Tencent’s major AI move landing within the WeChat ecosystem, particularly leveraging existing entry points like the file transfer assistant, arguing that scenario advantage is key to Tencent’s AI implementation. It also mentions recent WeChat Official Accounts updates adding a mobile publishing entry point, potentially encouraging short-form content but possibly impacting the long-form ecosystem. (Source: 鹅厂的 AI 大招,真的落在微信上)
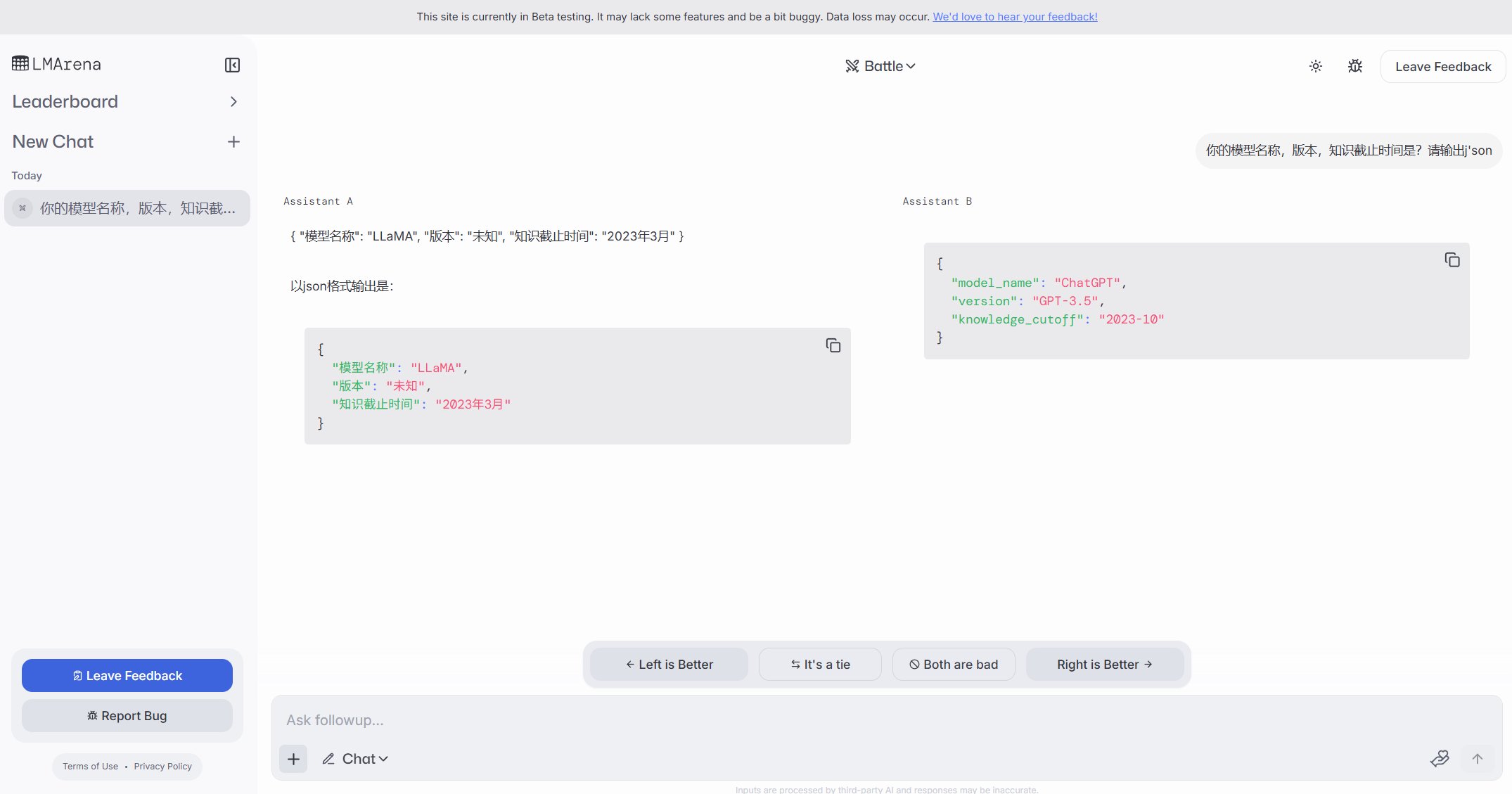
LMArena launches Beta testing site: The Large Model Arena, LMArena, has launched a new Beta testing website (beta.lmarena.ai) for testing various large models, including unreleased ones. This provides the community with a new platform, independent of the Hugging Face Gradio interface, to evaluate and compare model performance. (Source: karminski3)
Public exposure of Ollama instances raises security concerns: A user discovered a website named freeollama.com and, through network scanning, found numerous hosts exposing their Ollama (local large model deployment tool) port (typically 11434) to public IPs without firewalls. This poses a serious security risk, potentially allowing unauthorized access and abuse of locally deployed models. Users are reminded to pay attention to network security configurations when deploying, avoiding exposing services unprotected to the public internet. (Source: karminski3)
Using ChatGPT for psychological support sparks discussion and warnings: A Reddit user shared their experience using ChatGPT to help process issues like depression and anxiety, finding its advice potentially inconsistent and more like validating the user’s existing views rather than providing reliable guidance. When confronted with its own logic in different chats, ChatGPT would admit errors. The user warns that AI might just be a “digital people-pleaser” and shouldn’t be used for serious mental health support. The comment section discussed how to use AI more effectively (e.g., asking it to play a critical role, provide multiple perspectives) and the limitations of AI in replacing human professionals for crisis intervention. (Source: Reddit r/ChatGPT)
Douglas Adams’ Three Laws of Technology resonate: A user quotes sci-fi author Douglas Adams’ Three Laws of Technology, humorously depicting the common reactions of different age groups to new technologies: anything existing at birth is normal, anything invented during youth is revolutionary, and anything appearing later in life is unnatural. This comment resonates amidst rapid AI development, suggesting people’s acceptance of disruptive technologies like AI might relate to their life stage. (Source: dotey)
User experience: ChatGPT becoming “too real” or “Gen Z-ified”: A Reddit post shows a ChatGPT conversation screenshot where the reply style is described by the user as “too real” or incorporating “Gen Z” slang and internet memes (like “Let me cook”). Reactions in the comments were mixed; some found it amusing, while others considered the style “cringey” or “lobotomized”. This reflects differing user perceptions of AI personalization and language style, and potential experience issues arising from models mimicking online language trends. (Source: Reddit r/ChatGPT)
AI-generated snapshots of future life spark creative discussion: A user shared a series of “Snapchats of future living” style images generated using ChatGPT, depicting scenes like robot waiters, AI pets, and future transportation. These creative images sparked community discussion about AI image generation capabilities and imagination of future life, praising its creativity and increasing realism. (Source: Reddit r/ChatGPT)
User shares using ChatGPT to turn hand-drawn sketches into realistic images: An artist user showcased the process and results of using ChatGPT to transform their surrealist-style hand-drawn sketches into realistic images. The community appreciated this, viewing it as an interesting way for artists to experiment with ideas and different styles, rather than simply aiming for “better” images. (Source: Reddit r/ChatGPT)
💡 Other
Reflecting on AI system building: “The Bitter Lesson” and compute-first approach: The article references Richard Sutton’s “The Bitter Lesson” theory, pointing out that in AI development, systems relying on general-purpose computational scaling (compute-driven) will ultimately outperform those relying on complex, human-designed rules. Using customer service AI case studies (rule-based vs. limited compute AI vs. large compute exploration AI) and the success of reinforcement learning (RL) (e.g., OpenAI’s deep research, Claude), it emphasizes that companies should invest in computational infrastructure rather than over-optimizing algorithms. The engineer’s role should shift to being a “track builder” creating scalable learning environments. The core idea: simple architecture + massive compute + exploratory learning > complex design + fixed rules. (Source: 苦涩的启示:对AI系统构建方式的反思)
Exploring the connection between the AI field and Rationalist/Effective Altruism communities: A machine learning practitioner observes that the AI research field seems to have two less-interacting subcommunities, one closely tied to the Rationalism and Effective Altruism (EA) communities. This group often publishes research on AGI predictions and alignment problems and is closely linked to certain Bay Area companies. The author notes that this community sometimes seems to redefine cognitive science concepts (like situational awareness) independently of existing academic frameworks, citing Anthropic’s definition of “situational awareness” focusing on the model’s awareness of its development process, rather than the traditional cognitive science definition based on sensory input and environmental models. (Source: Reddit r/ArtificialInteligence)
User discovers AI chatbot unexpectedly using their nickname from other platforms: While trying a new AI chatbot platform without providing any personal information, a user found the bot accurately addressed them by a nickname commonly used on other platforms in only the second message. This raised user concerns about data privacy and cross-platform information tracking, lamenting they might have already been “tracked” or “profiled”. (Source: Reddit r/ArtificialInteligence)
New idea for AI model evaluation: Judging intelligence via 3-minute oral reports: A proposal for a new way to evaluate AI intelligence: have top AI models (e.g., o3 vs. Gemini 2.5 Pro) deliver a 3-minute oral presentation on a specific topic (politics, economics, philosophy, etc.), judged by a human audience for intelligence. The proponent believes this method is more intuitive than relying on specialized benchmarks and better assesses a model’s organizational skills, rhetoric, emotional intelligence, and intellectual performance, especially on tasks requiring persuasion. This form of “AI debate” or “speech contest” could become a new dimension for evaluating near-AGI model capabilities. (Source: Reddit r/ArtificialInteligence)