
Keywords:AI development, Grok 3, Gemma 3, AI applications, Paradigm shift in AI development, xAI Grok 3 API, Google Gemma 3 QAT, VideoGameBench AI evaluation, AI-accelerated molecular discovery, Federated learning for medical imaging, LlamaIndex knowledge agent, AI code self-repair technology
🔥 Focus
AI Development Paradigm Shift: From Chasing Benchmarks to Creating Value: OpenAI researcher Yao Shunyu’s blog post sparked discussion, proposing that AI development has entered its second half. The first half focused on algorithmic innovation and benchmark chasing (e.g., AlphaGo, GPT-4), achieving generalization breakthroughs by combining large-scale pre-training (providing prior knowledge) with reinforcement learning (RL) and introducing the concept of “reasoning as action”. However, he argues that the marginal benefits of continuously chasing benchmarks are diminishing. The second half should shift towards defining problems with practical application value, developing evaluation methods closer to the real world, thinking like a product manager, and truly using AI to create user and social value, rather than just pursuing metric improvements. This marks a mindset shift in the AI field from primarily technology exploration to application implementation and value realization (Source: dotey)
xAI Releases Grok 3 Series Model API: xAI has officially launched the API interface for its Grok 3 series models (docs.x.ai), opening up its latest models to developers. The series includes Grok 3 Mini and Grok 3. According to xAI, Grok 3 Mini demonstrates superior reasoning capabilities while maintaining low cost (claimed to be 5 times cheaper than comparable reasoning models); Grok 3 is positioned as a powerful non-reasoning model (possibly referring to knowledge-intensive tasks), excelling in fields requiring real-world knowledge such as law, finance, and medicine. This move signifies xAI’s entry into the competitive AI model API market, offering developers new choices (Source: grok, grok)
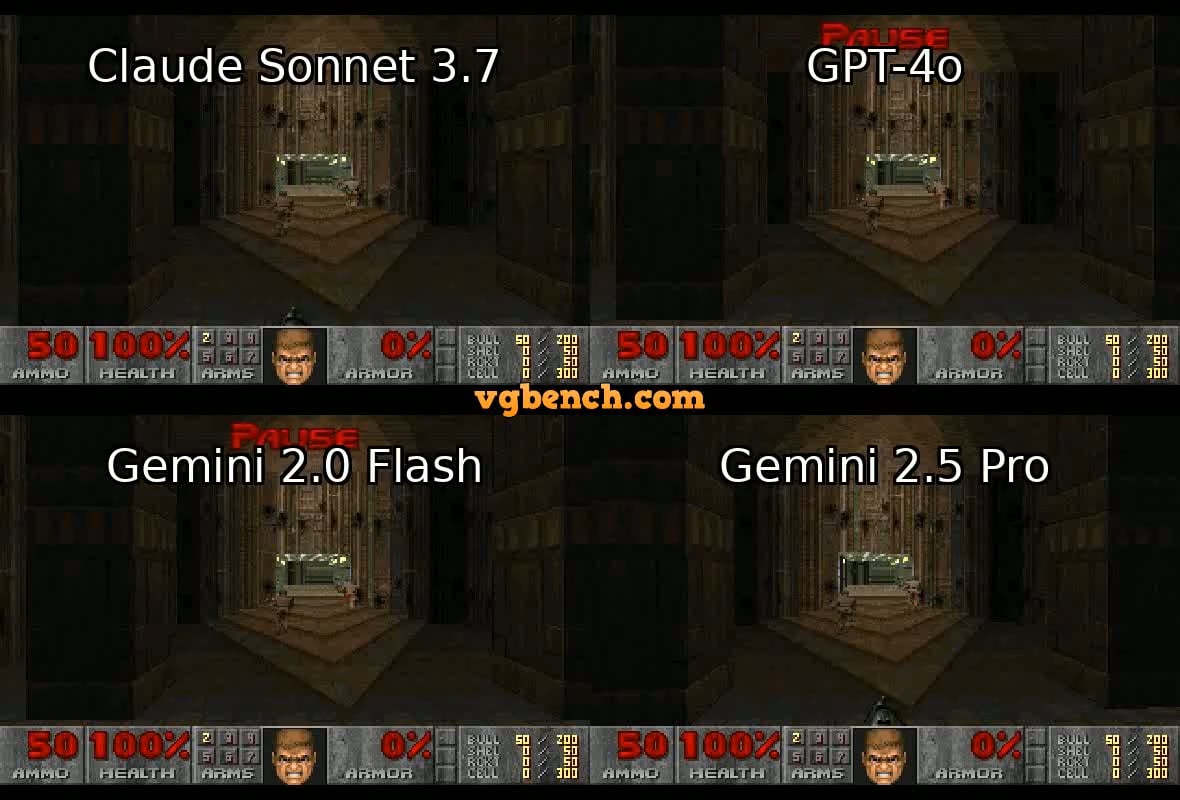
VideoGameBench: Evaluating AI Agent Capabilities Using Classic Games: Researchers have launched a preview version of the VideoGameBench benchmark, designed to evaluate the ability of Visual Language Models (VLMs) to complete tasks in 20 classic video games (like Doom II) in real-time. Preliminary tests show that top models, including GPT-4o, Claude Sonnet 3.7, and Gemini 2.5 Pro, perform differently in Doom II, but none could pass the first level. This indicates that although models are powerful in many tasks, they still face challenges in complex dynamic environments requiring real-time perception, decision-making, and action. The benchmark provides a new tool for measuring and advancing AI agents in interactive environments (Source: Reddit r/LocalLLaMA)
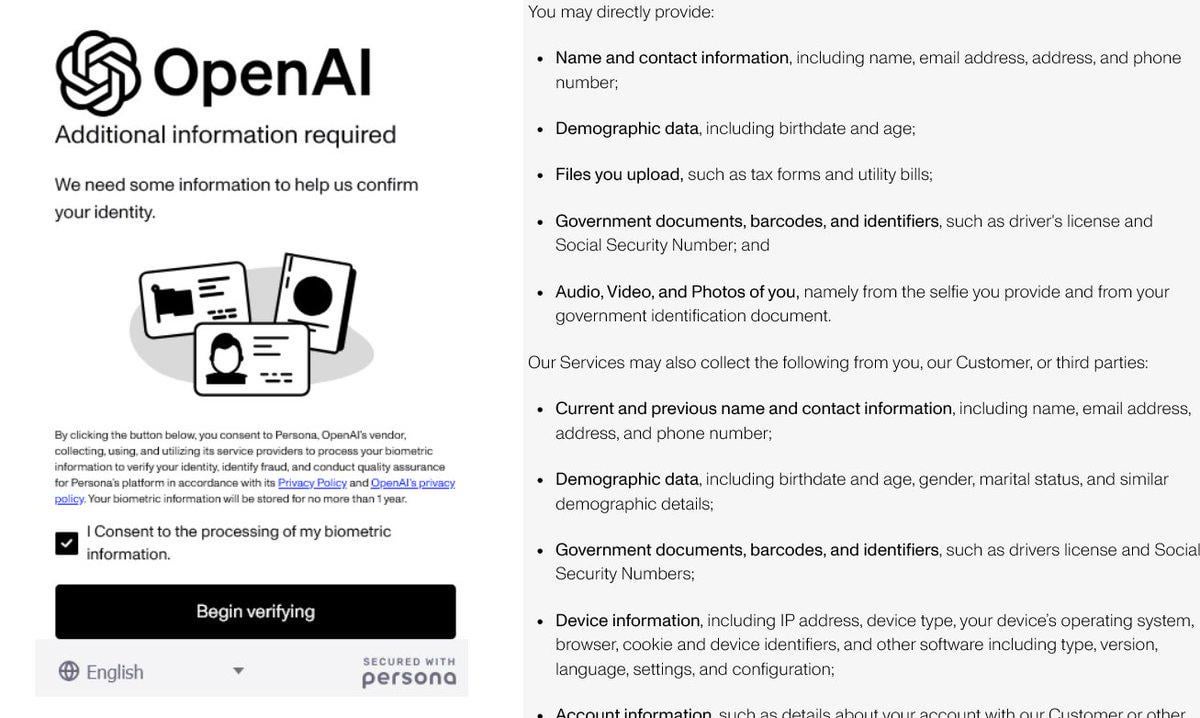
OpenAI Strengthens Identity Verification, Sparking Controversy: OpenAI is reportedly requiring users to provide detailed identity verification (such as passports, tax forms, utility bills) to access some of its advanced models (especially those with strong reasoning capabilities like o3). This move has triggered strong backlash in the community, with users widely concerned about privacy breaches and increased access barriers. Although OpenAI may have reasons related to security, compliance, or resource management, such strict verification requirements contrast with its open image and could push users towards alternatives with better privacy protection or easier access, particularly local models (Source: Reddit r/LocalLLaMA)
AI Accelerates Molecule Discovery: Simulating Hundreds of Millions of Years of Evolution: Social media discussions mention that artificial intelligence can design a molecule in days that might take nature 500 million years to evolve. While specific details require verification, this highlights AI’s immense potential in accelerating scientific discovery, especially in chemistry and biology. AI can explore vast chemical spaces and predict molecular properties at speeds far exceeding traditional experimental methods and natural evolution, promising breakthroughs in areas like drug development and materials science (Source: Ronald_vanLoon)
🎯 Trends
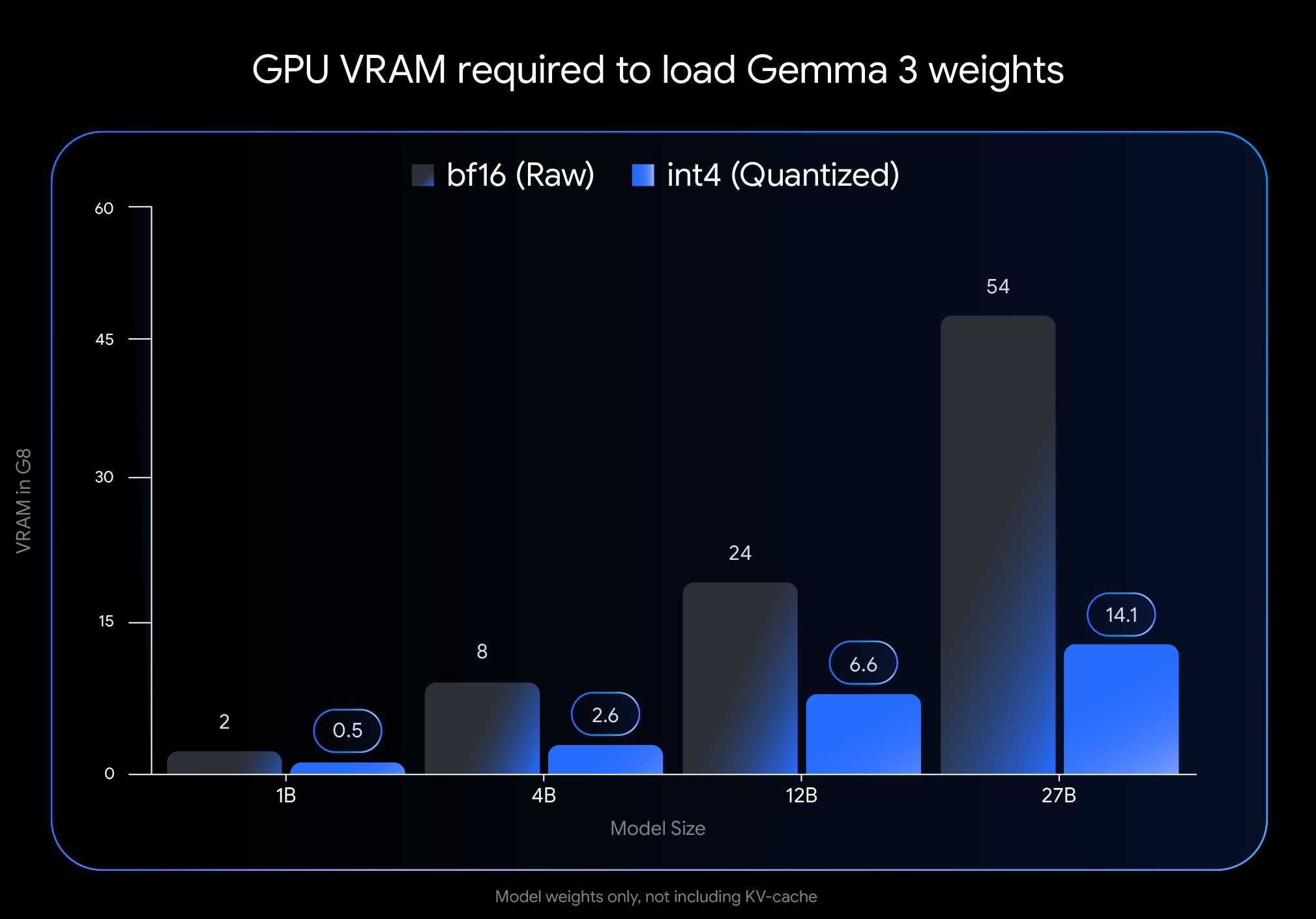
Google Releases Gemma 3 QAT Version, Significantly Lowering Deployment Barriers: Google DeepMind has launched Quantization-Aware Training (QAT) versions of its Gemma 3 models. QAT technology aims to maximally preserve the original model’s performance while significantly compressing its size. For example, the Gemma 3 27B model size is reduced from 54GB (bf16) to approximately 14.1GB (int4), allowing leading models that previously required high-end cloud GPUs to run on consumer-grade desktop GPUs (like RTX 3090). Google has released unquantized QAT checkpoints and various formats (MLX, GGUF), collaborating with community tools like Ollama, LM Studio, and llama.cpp to ensure developers can easily use them on various platforms, greatly promoting the popularization of high-performance open-source models (Source: huggingface, JeffDean, demishassabis, karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Meta FAIR Releases Perception Research, Adheres to Open Source Route: Meta FAIR has released several new research achievements in Advanced Machine Intelligence (AMI), particularly advancements in perception, including the release of a large-scale visual encoder, the Meta Perception Encoder. Yann LeCun emphasized that these results will be open-sourced. This indicates Meta’s continued investment in fundamental AI research and its commitment to sharing research progress through open source to drive development across the field. Tools like the released visual encoder will benefit the broader research and developer community (Source: ylecun)
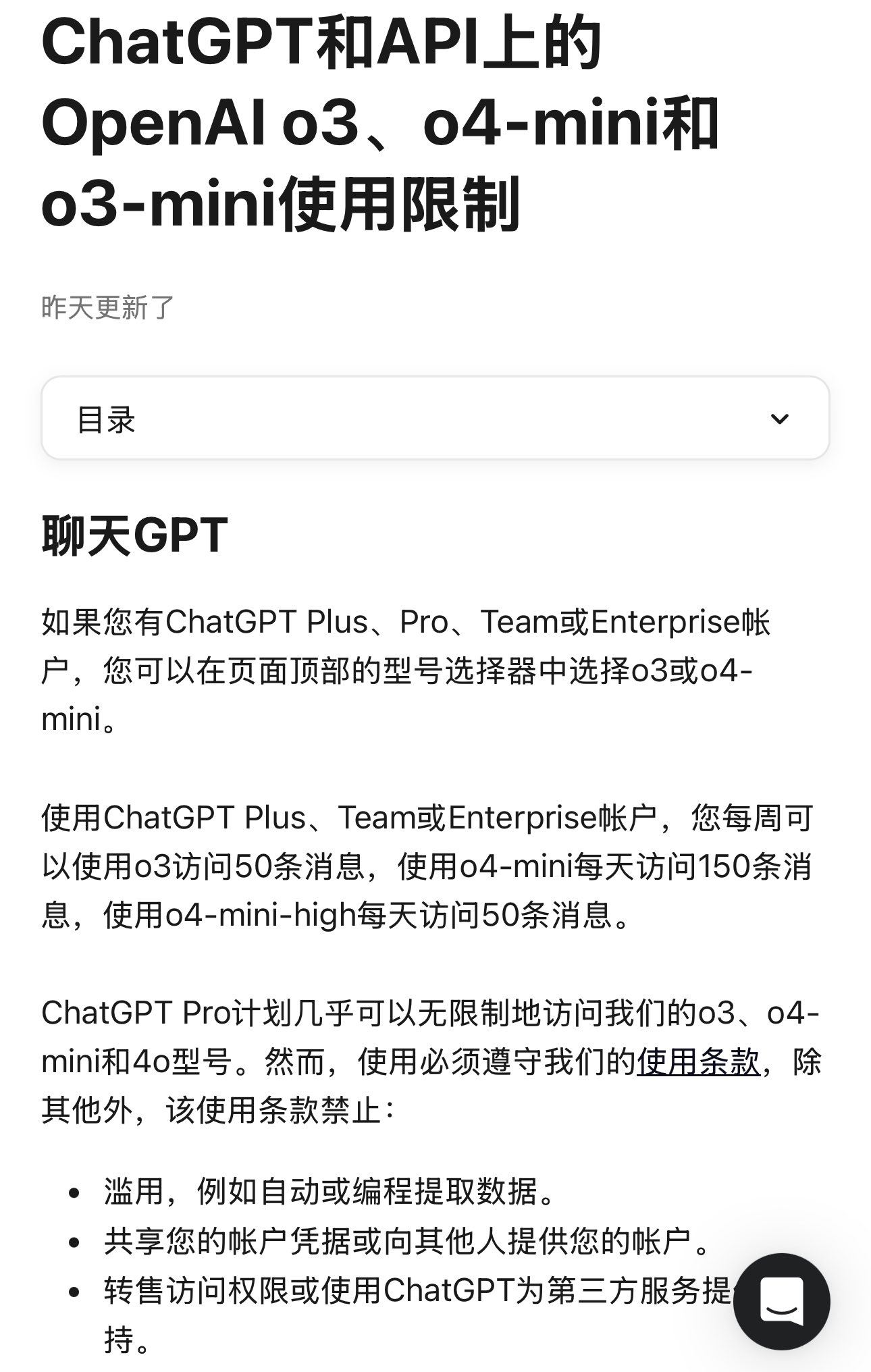
OpenAI Clarifies Model Usage Limits: OpenAI has specified usage limits for its ChatGPT Plus, Team, and Enterprise users. The o3 model is limited to 50 messages per week, o4-mini to 150 per day, and o4-mini-high to 50 per day. ChatGPT Pro (possibly referring to a specific plan or an error) is claimed to have unlimited access. These limits directly affect high-frequency users and application developers relying on specific models, requiring consideration in usage planning (Source: dotey)
LlamaIndex Integrates with Google Cloud Databases to Build Knowledge Agents: At Google Cloud Next 2025, LlamaIndex demonstrated how its framework integrates with Google Cloud databases to build knowledge agents capable of performing multi-step research, processing documents, and generating reports. The demo included a case study of a multi-agent system automatically generating employee onboarding guides. This shows the trend of deep integration between AI application frameworks and cloud platforms with their data services, aiming to address enterprises’ practical needs for using AI to handle internal knowledge and data (Source: jerryjliu0)

New Nano-Brain Sensor Combined with AI Achieves High-Precision Signal Recognition: Research reports a novel nano-scale brain sensor that achieves 96.4% accuracy in identifying neural signals. Although the sensor technology itself is the core breakthrough, achieving such high recognition accuracy typically requires advanced AI and machine learning algorithms to decode complex, weak neural signals. This advancement opens new avenues for brain science research and future brain-computer interface applications, potentially enabling finer monitoring and interaction with brain activity (Source: Ronald_vanLoon)

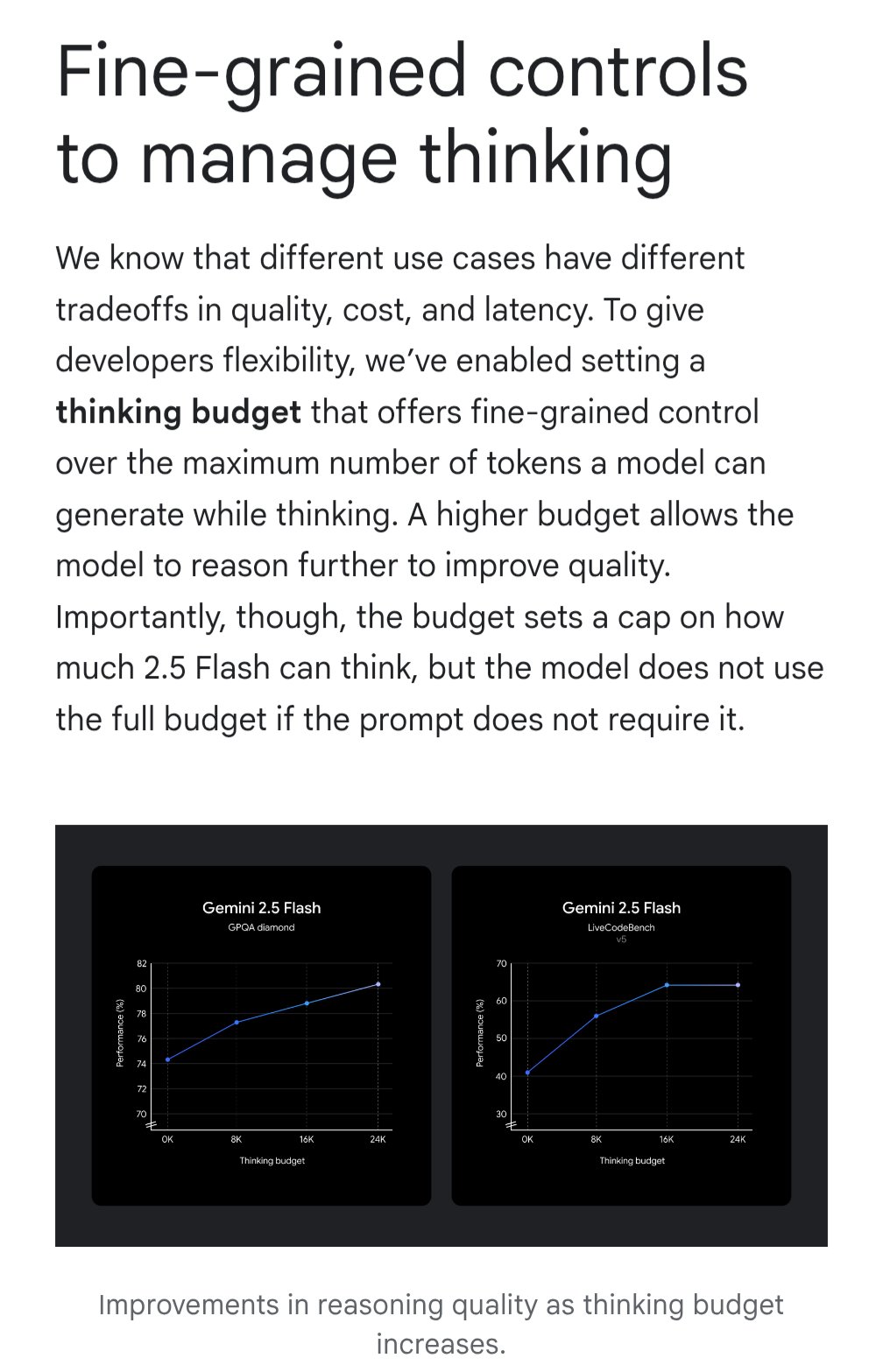
Gemini Introduces “Thinking Budget” Feature for Cost-Effectiveness Optimization: Google Gemini models have introduced a “thinking budget” feature, allowing users to adjust the computational resources or “thinking” depth allocated by the model when processing queries. The feature aims to let users trade off between response quality, cost, and latency. This is a very practical feature for API users, enabling flexible control over model usage costs and performance based on specific application scenario needs (Source: JeffDean)
AI-Assisted Ultrasound Exam Quality Comparable to Experts: Research published in JAMA Cardiology shows that ultrasound examinations performed by trained medical professionals under AI guidance achieve image quality sufficient for diagnostic standards (98.3%), with no statistically significant difference compared to images acquired by experts without AI guidance. This indicates that AI as an assistive tool can effectively help non-expert users improve the quality and consistency of medical imaging operations, potentially expanding access to high-quality diagnostic services in resource-limited areas (Source: Reddit r/ArtificialInteligence)
MIT Research Enhances Accuracy and Structure Adherence of AI-Generated Code: MIT researchers have developed a more efficient method to control the output of large language models, aiming to guide models to generate code that conforms to specific structures (like programming language syntax) and is error-free. This research focuses on addressing the reliability issues of AI-generated code. By improving constrained generation techniques, it ensures the output strictly adheres to syntax rules, thereby increasing the practicality of AI coding assistants and reducing subsequent debugging costs (Source: Reddit r/ArtificialInteligence)
NVIDIA May Reveal Major Project in Robotics: Social media mentions NVIDIA is working on its “most ambitious project,” involving robotics, engineering, artificial intelligence, and autonomous technology. While specifics are unknown, given NVIDIA’s core position in AI hardware and platforms (like Isaac), any related major announcement is highly anticipated and could signal further strategic moves and technological breakthroughs in embodied intelligence and robotics (Source: Ronald_vanLoon)
🧰 Tools
Potpie: AI Engineering Assistant Dedicated to Codebases: Potpie is an open-source platform (GitHub: potpie-ai/potpie) designed to create customized AI engineering agents for codebases. It builds a code knowledge graph to understand complex relationships between components, offering automated tasks like code analysis, testing, debugging, and development. The platform provides various pre-built agents (e.g., debugging, Q&A, code change analysis, unit/integration test generation, low-level design, code generation) and toolsets, and supports user creation of custom agents. It offers a VSCode extension and API integration for easy incorporation into development workflows (Source: potpie-ai/potpie – GitHub Trending (all/daily))

1Panel: Linux Server Panel with Integrated LLM Management: 1Panel (GitHub: 1Panel-dev/1Panel) is a modern open-source Linux server operation and management panel providing a web-based graphical interface for managing hosts, files, databases, containers, etc. One of its features is the inclusion of management functions for Large Language Models (LLMs). Additionally, it offers an application store, rapid website deployment (integrated with WordPress), security protection, and one-click backup/restore features, aiming to simplify server management and application deployment, including AI-related applications (Source: 1Panel-dev/1Panel – GitHub Trending (all/daily))

LlamaIndex Launches Upgraded Chat UI Component: LlamaIndex has released a major update to its chat UI component library (@llamaindex/chat-ui). The new component, built on shadcn UI, features a more stylish design, responsive layout, and is fully customizable. It aims to help developers more easily build beautiful, user-friendly chat interfaces for LLM-based projects, enhancing the interactive experience of AI applications. Developers can install it via npm and use it directly in their projects (Source: jerryjliu0)
LlamaExtract in Action: Building a Financial Analysis Application: LlamaIndex showcased a case study of building a full-stack web application using its LlamaExtract tool (part of LlamaCloud). LlamaExtract allows users to define precise schemas to extract structured data from complex documents. The example application extracts risk factors from company annual reports and analyzes changes over the years, automating work that originally took over 20 hours. This application is open-sourced (GitHub: run-llama/llamaextract-10k-demo) and includes a video demonstrating how to build this workflow combining LlamaExtract and Sonnet 3.7, showcasing the potential of AI agents in automating complex analysis tasks (Source: jerryjliu0, jerryjliu0)
mcpbased.com: Open Source MCP Server Directory Launched: The new website mcpbased.com has launched as a dedicated directory for open-source MCP (possibly Meta Controller Pattern or similar concept) servers. The platform aims to aggregate and showcase various MCP server projects, synchronizing data from GitHub repositories in real-time, making it convenient for developers to discover, browse, and connect with related tools. It serves as a new resource hub for developers building or using MCP servers, integrating tools, or following the MCP ecosystem (Source: Reddit r/ClaudeAI)
📚 Learning
RLHF Book Lands on ArXiv: The book “rlhfbook” on Reinforcement Learning from Human Feedback (RLHF), authored by Nathan Lambert et al., is now available on the ArXiv platform (identifier 2504.12501). RLHF is one of the key techniques currently used for aligning large language models like ChatGPT. The book’s release provides researchers and practitioners with an important resource for systematically learning and deeply understanding the principles and practices of RLHF, promoting the dissemination and application of knowledge in this field (Source: natolambert)
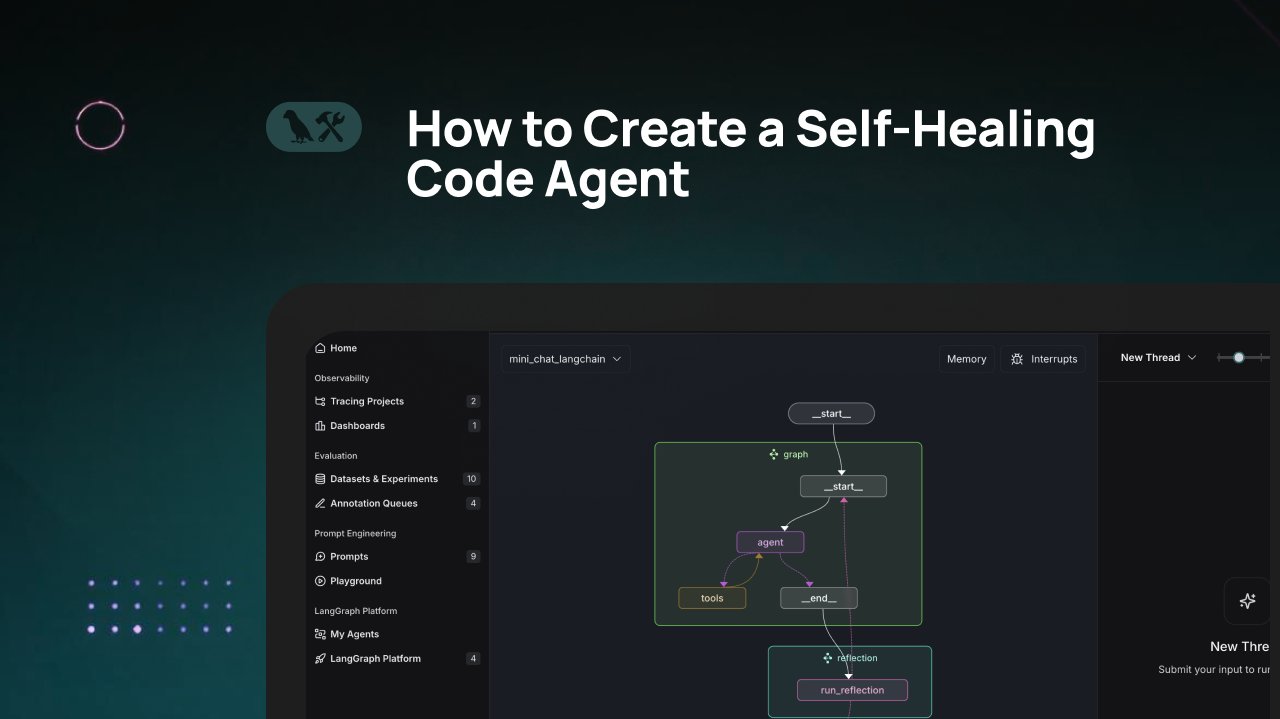
LangChain Tutorial: Building a Self-Healing Code Generation Agent: LangChain released a video tutorial on how to build an AI code generation agent with “self-healing” capabilities. The core idea is to add a “reflection” step after code generation, allowing the agent to verify, evaluate, or improve its generated code before returning the result. This method aims to enhance the accuracy and reliability of AI-generated code, serving as an effective technique to improve the practicality of coding assistants (Source: LangChainAI)
Creating Game-Ready 3D Assets with AI and Blender: A tutorial shared on social media demonstrates combining AI tools (possibly image generation) with 3D modeling software Blender to create game-ready 3D assets. This addresses the current limitations of AI in directly generating 3D models, showcasing a practical hybrid workflow: using AI to generate concepts or texture maps, then modeling and optimizing with professional tools like Blender to finally produce resources compatible with game engines (Source: huggingface)
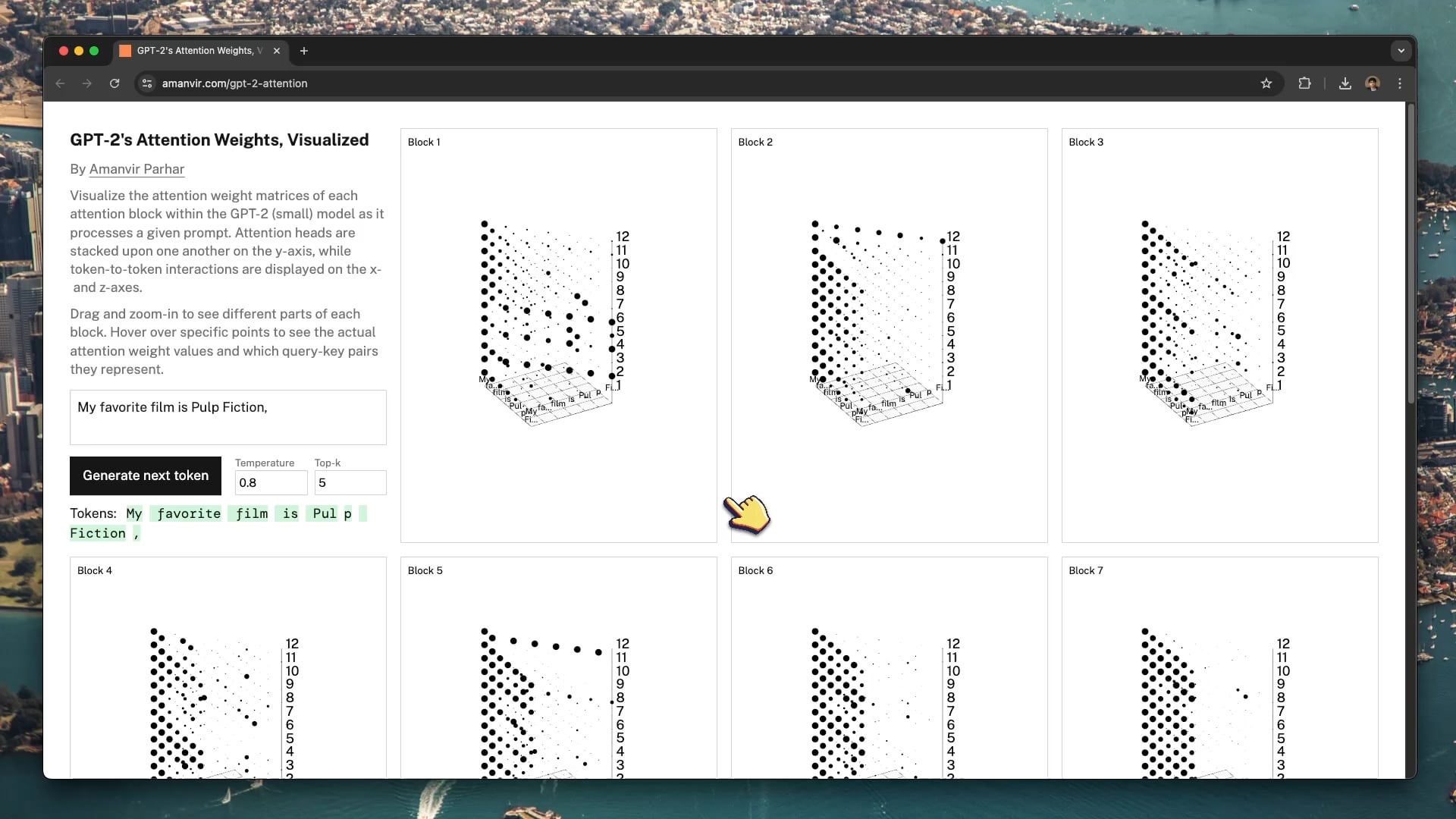
Interactive Visualization Tool Helps Understand GPT-2 Attention Mechanism: Developer tycho_brahes_nose_ created and shared an interactive 3D visualization tool (amanvir.com/gpt-2-attention) to demonstrate the weight calculation process within each attention block of the GPT-2 (small) model. Users can intuitively see how the model calculates token-to-token interaction strength across different layers and attention heads after inputting text. This provides an excellent aid for understanding the core mechanism of Transformers, benefiting AI learning and model interpretability research (Source: karminski3, Reddit r/LocalLLaMA)
Federated Learning in Medical Image Analysis: A Reddit post points to an article about combining Federated Learning (FL) with Deep Neural Networks (DNNs) for medical image analysis. Due to the privacy sensitivity of medical data, FL allows collaborative model training across multiple institutions without sharing raw data. This is crucial for advancing AI applications in healthcare, and the resource helps understand this privacy-preserving distributed learning technique and its practice in medical imaging (Source: Reddit r/deeplearning)

Sander Dielman’s Deep Dive into VAEs and Latent Spaces: Andrej Karpathy recommended Sander Dielman’s in-depth blog post (sander.ai/2025/04/15/latents.html) on Variational Autoencoders (VAEs) and latent space modeling. The article explores details in VAE training, such as the limited practical role of the KL divergence term in shaping the latent space, and why L1/L2 reconstruction losses tend to produce blurry images (due to mismatch between image spectral decay and human visual perception priorities). The post offers rigorous and insightful analysis for understanding generative models (Source: Reddit r/MachineLearning)
💼 Business
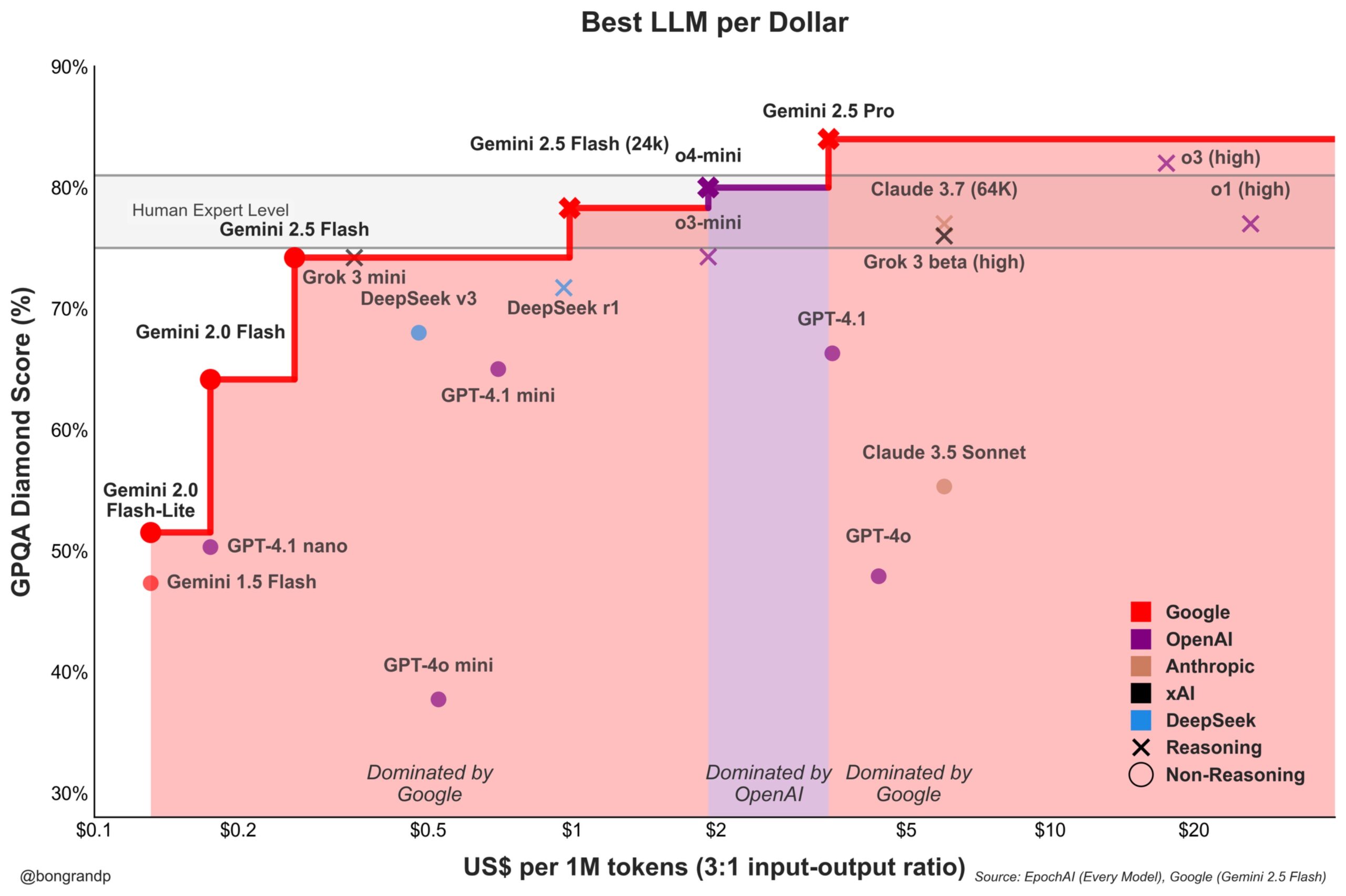
Model Price War Heats Up: Google Gemini Actively Challenges OpenAI: Analysis indicates that Google, with its Gemini series models (especially the newly released Gemini 2.5 Flash), demonstrates strong competitiveness in performance and price, reportedly offering better cost-performance than OpenAI in about 95% of scenarios. Google’s rapid API response and pricing strategy (dominating over 90% of price ranges) show its active push to capture LLM market share, aiming to attract users through cost advantages and intensifying competition in the foundational model market (Source: JeffDean)
Coinbase Sponsors LangChain Conference, Explores Agentic Commerce: Coinbase Development has become a sponsor of the LangChain Interrupt 2025 conference. Coinbase is empowering “Agentic Commerce” through tools like its AgentKit and x402 payment protocol, enabling AI agents to autonomously pay for services such as context retrieval and API calls. This collaboration highlights the intersection of AI agent technology and Web3 payments, foreshadowing future scenarios of AI-driven automated economic interactions (Source: LangChainAI)

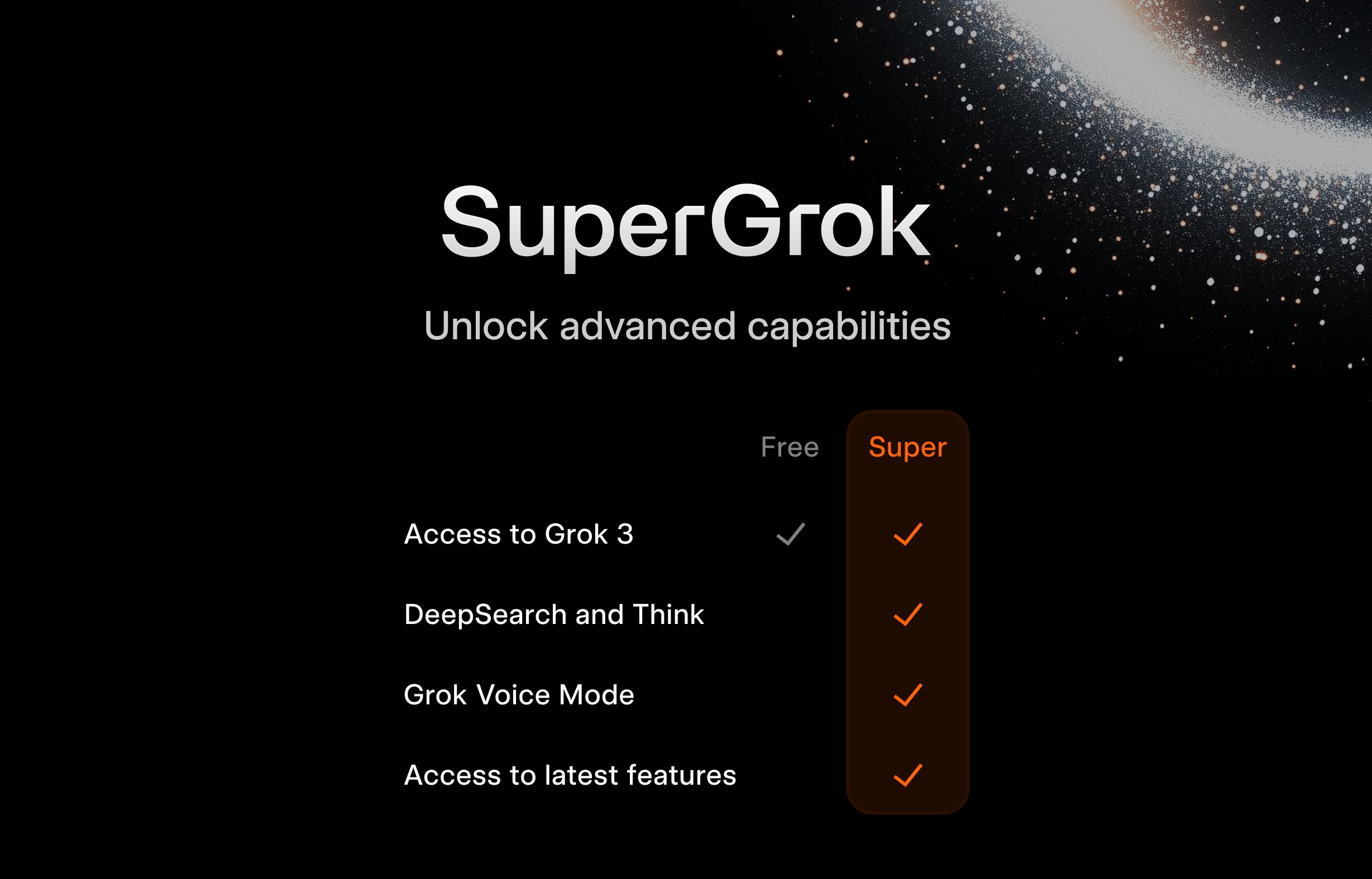
xAI Launches Free SuperGrok Program for Students: To attract the younger demographic, xAI is offering a promotion for students: register with a .edu email address to get two months of free access to SuperGrok (the premium version of Grok). This move aims to position Grok as a learning aid, promoting it during the final exam season to capture users in the education market and cultivate potential future paying customers (Source: grok)
Google Offers Free Gemini Advanced and Multiple Services to US College Students: Google announced long-term free benefits for US college students: if registered before June 30, 2025, they can use Gemini Advanced (powered by Gemini 2.5 Pro), NotebookLM Plus, Gemini features in Google Workspace, Whisk, and 2TB of cloud storage for free until the end of the Spring 2026 term. This large-scale promotion aims to deeply integrate Google’s AI tools into the education ecosystem, compete with rivals like Microsoft, and foster loyalty to Google’s AI platform among the next generation of users and developers (Source: demishassabis, JeffDean)
FanDuel Launches Celebrity AI Chatbot “ChuckGPT”: Sports personality Charles Barkley has licensed his name, likeness, and voice to collaborate with sports betting company FanDuel on an AI chatbot named “ChuckGPT” (chuck.fanduel.com). This is another example of leveraging celebrity IP and AI technology for brand marketing and user interaction, enhancing user engagement by simulating the celebrity’s conversational style to provide sports information, betting advice, or entertainment (Source: Reddit r/artificial)
🌟 Community
Concerns Raised Over AI Tool Dependency: A cartoon on social media depicting a user surrounded by numerous AI tools (ChatGPT, Claude, Midjourney, etc.), labeled “AI Tool Dependency,” resonated with many. This reflects the information overload, potential over-reliance, and cognitive burden of managing and selecting appropriate tools that some users feel when faced with the constant influx of AI applications (Source: dotey)
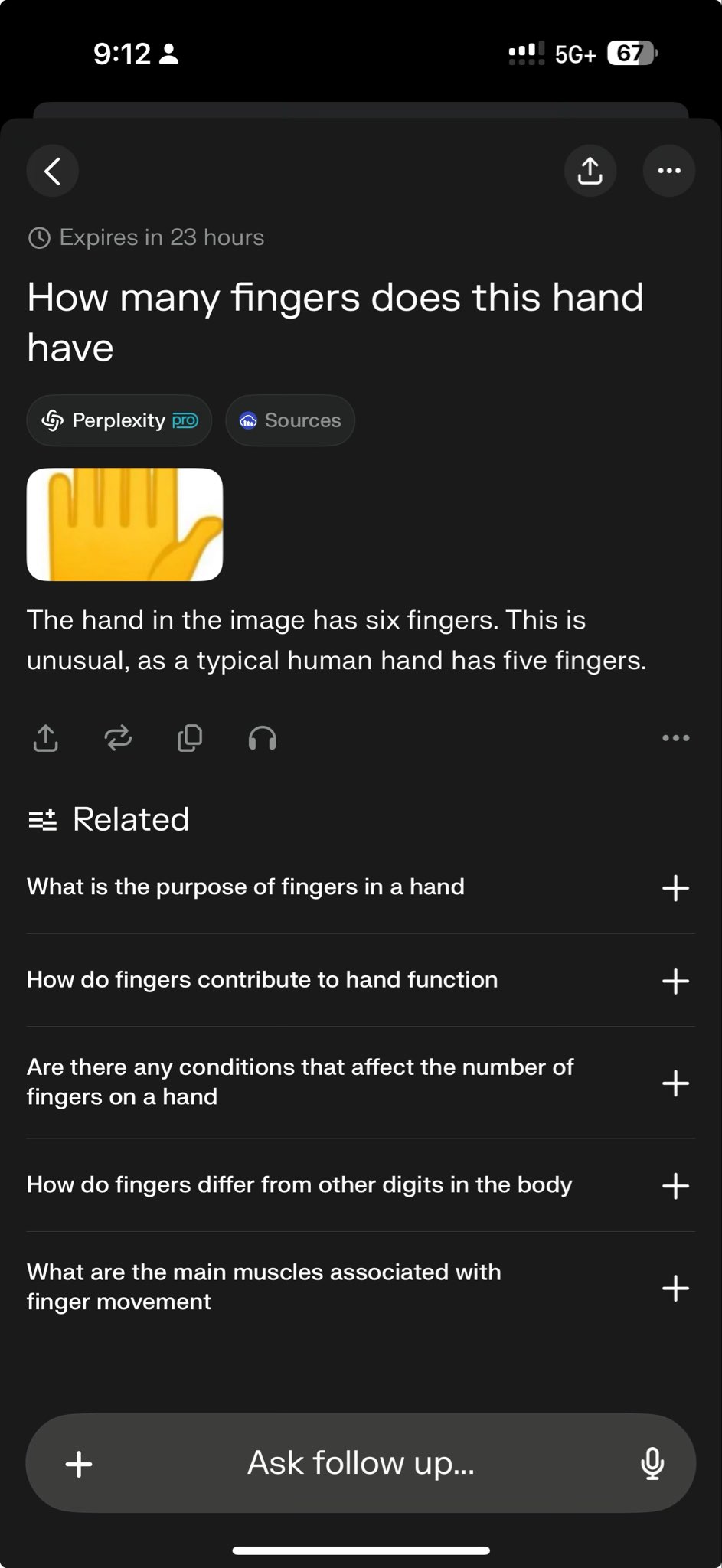
Top Models Failing Specific Tests Expose Capability Boundaries: Perplexity CEO Arav Srinivas retweeted a test case showing both o3 and Gemini 2.5 Pro failing to complete a complex graph drawing task. This was seen by some as a challenging test of current model capabilities. Such “failure cases” are widely discussed in the community to reveal the limitations of SOTA models in specific reasoning, spatial understanding, or instruction following, helping to foster a more objective understanding of the gap between current AI and Artificial General Intelligence (AGI) (Source: AravSrinivas)
Community Discusses GPT-4o Pillow Image Generation and Prompt Sharing: Users shared successful examples and optimized prompts for generating pillow images in a specific style (cute, micro-fleece texture, emoji-shaped) using GPT-4o. Such sharing demonstrates the application of AI image generation in creative design and fosters community exchange on Prompt engineering techniques and style exploration. High-quality generation results spurred users’ creative enthusiasm (Source: dotey)

Sam Altman: AI More Like Renaissance Than Industrial Revolution: OpenAI CEO Sam Altman expressed the view that the transformation brought by artificial intelligence is more akin to a Renaissance than an Industrial Revolution. This analogy sparked community discussion, suggesting AI’s impact might be more pronounced in culture, thought, and creativity, rather than just a mechanization of productivity. This qualitative judgment influences expectations and imagination regarding AI’s future societal role (Source: sama)
Community Asks When Grok 2 Will Be Open-Sourced: Reddit users discussed when xAI will fulfill its promise to open-source the Grok 2 model. Many worry that given the rapid pace of AI technology iteration, Grok 2 might be outdated compared to contemporary models (like DeepSeek V3, Qwen 3) by the time it’s released, repeating the scenario where Grok 1 was obsolete upon release. The discussion also touched on the trade-off between the value of open-source models (research, licensing freedom) and timeliness (Source: Reddit r/LocalLLaMA)
Interpreting Altman’s Remarks: Data Efficiency the New Bottleneck for AGI?: The Reddit community discussed Sam Altman’s statement about AI needing a 100,000x improvement in data efficiency rather than just more compute, interpreting it as a signal that the current brute-force scaling path to AGI is hitting roadblocks. The view suggests high-quality human data is nearly exhausted, synthetic data has limited effectiveness, and inefficient model learning is the core challenge, potentially even impacting hardware investment plans of companies like Microsoft. The discussion reflects a rethinking of AI development trajectories (Source: Reddit r/artificial)
How to Distinguish Between LLM Memorization and Reasoning?: The community explored how to effectively test whether large language models possess genuine reasoning abilities or are merely regurgitating or combining patterns from their training data. Some proposed using novel “What If” style questions that the model hasn’t seen before to probe its generalization and reasoning capabilities. This touches upon the core challenge of evaluating LLM intelligence levels: distinguishing advanced pattern matching from true logical inference (Source: Reddit r/MachineLearning)
User Shares “Scary” Conversation with GPT, Raising Ethical Concerns: A user shared screenshots of a conversation with ChatGPT concerning potential negative societal impacts of AI (like thought control, loss of critical thinking), calling it “scary.” The post sparked discussion focusing on whether AI output reflects user guidance or the model’s “thoughts,” AI ethical boundaries, and user anxiety about potential AI risks (Source: Reddit r/ChatGPT)

Running Large Models Locally Hits Memory Bottleneck: In the r/OpenWebUI community, a user reported being unable to load large models above 12B (like Gemma3:27b) when running OpenWebUI and Ollama on a setup with 16GB RAM and an RTX 2070S, as system memory and swap space get exhausted. This represents a common challenge faced by many users attempting to deploy large models locally on consumer-grade hardware, highlighting the high resource requirements (especially memory) of these models (Source: Reddit r/OpenWebUI)
GPT-4o Poster Generation Sparks “Designer Job Loss” Debate: A user showcased a “Dog Park” poster generated by GPT-4o, praising its “almost perfect” quality and declaring “graphic designers are dead.” The comment section saw a heated debate: while acknowledging the progress in AI image generation, others pointed out design flaws (too much text, poor layout, spelling errors) and emphasized that AI is currently a tool for efficiency, unable to replace the core value of designers in creative decision-making, aesthetic judgment, and brand alignment (Source: Reddit r/ChatGPT)

Lifecycle Management of Fine-tuned Models Draws Attention: A developer asked the community: what happens to models fine-tuned on a base model (like GPT-4o) when that base model is updated or replaced (e.g., by GPT-5)? Since fine-tuning is often tied to a specific base version, the deprecation or update of the base model might force developers to retrain, creating ongoing costs and maintenance issues. This sparked discussion about the dependency and long-term strategy of using closed-source APIs for fine-tuning (Source: Reddit r/ArtificialInteligence)
Exploring Voice Conversation Setups with Local LLMs: A community user sought system solutions for enabling voice conversations with local LLMs, hoping for an experience similar to Google AI Studio for brainstorming and planning. The question reflects the user demand to expand from text interaction to more natural voice interaction and seeks practical methods and shared experiences for integrating STT, LLM, and TTS within local frameworks like OpenWebUI (Source: Reddit r/OpenWebUI )
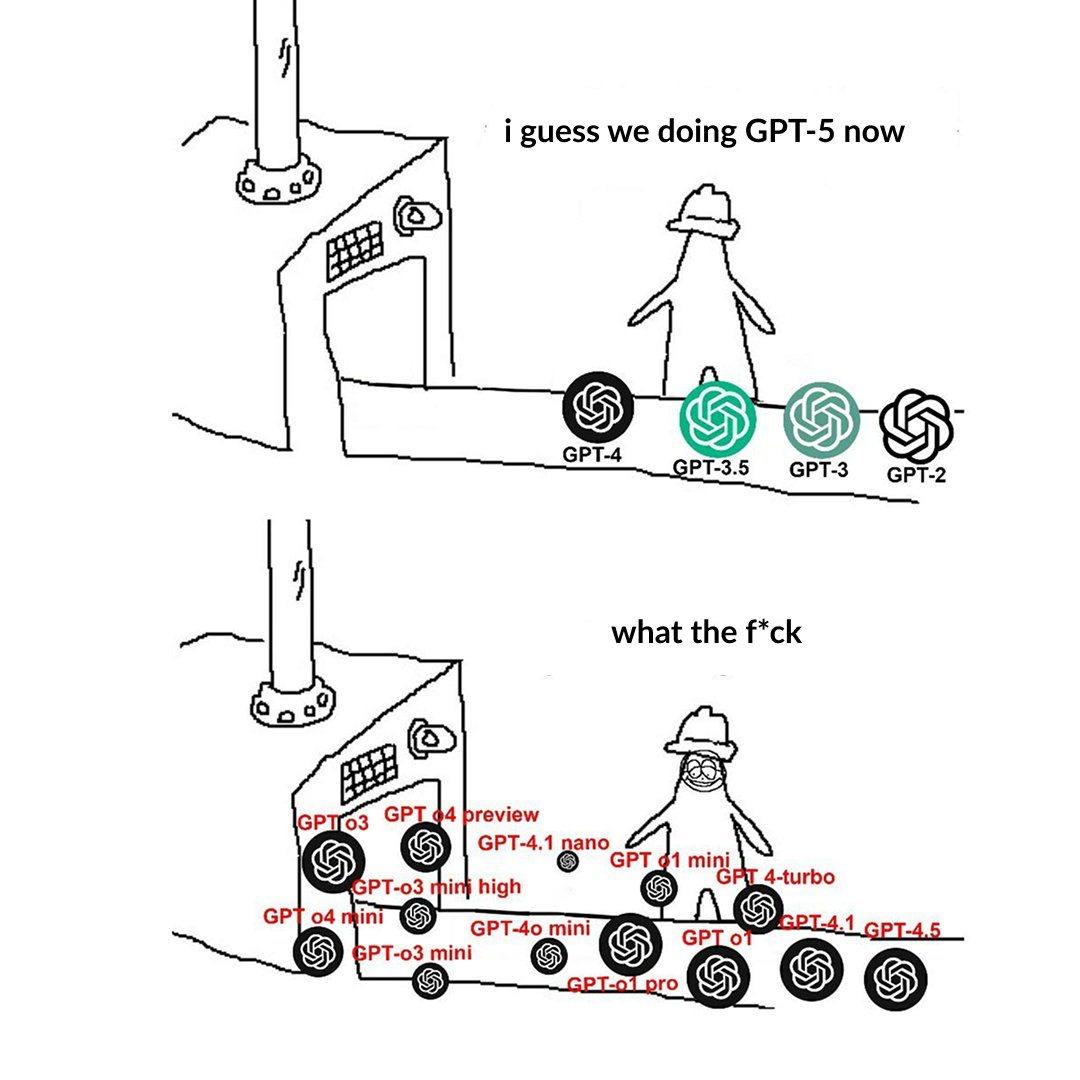
OpenAI Model Tier Naming Causes User Confusion: A user posted complaining that OpenAI’s model naming (e.g., o3, o4-mini, o4-mini-high, o4) is confusing. An image showed different model tiers, where the relationship between names, capabilities, and limits wasn’t intuitively clear. This reflects the challenge that as model families expand, clear product line delineation and naming become problematic for user understanding and selection (Source: Reddit r/artificial)

ChatGPT’s Overly Praising Style Sparks Discussion: Community users, through memes and discussion, pointed out ChatGPT’s tendency to excessively praise user questions (“That’s a great question!”), even if the question is mundane or foolish. The discussion suggested this might be a strategy by OpenAI to enhance user engagement but could also lead to confirmation bias and a lack of critical feedback. Some users even expressed a preference for more “sharp-tongued” AI evaluations (Source: Reddit r/ChatGPT)

Challenges for AI in Incomplete Information Games: The community discussed the challenges AI faces in handling games with incomplete information (like the fog of war in StarCraft). Unlike perfect information games like Go or Chess, these games require AI to handle uncertainty, perform exploration, and engage in long-term planning, without relying simply on global information and pre-computation. Although AI has made progress in games like Dota 2 and StarCraft (AlphaStar), consistently surpassing top human players remains challenging (Source: Reddit r/ArtificialInteligence)
Warning About “Linguistic Mimicry” Caused by AI Content: A user introduced the concept of “linguistic mimicry,” expressing concern that extensive reading of AI-generated content, which may have converging styles, could lead to people’s language expression and even ways of thinking becoming uniform and homogenized. This phenomenon could pose a potential threat to cultural diversity and individual independent thought. Reading diverse works by human authors is suggested as a way to maintain linguistic vitality (Source: Reddit r/ArtificialInteligence)
💡 Other
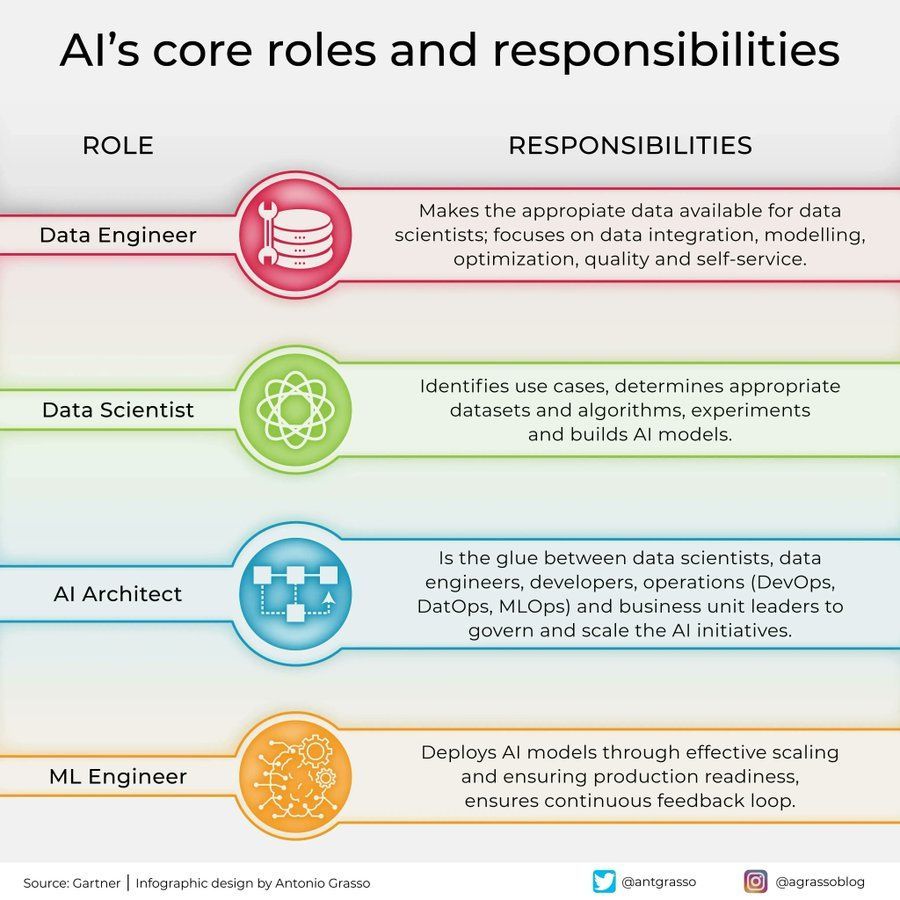
AI Field Roles and Responsibilities Breakdown: An infographic was shared on social media outlining core roles and their responsibilities within the artificial intelligence field, such as Data Scientist, Machine Learning Engineer, AI Researcher, etc. This graphic helps in understanding the division of labor within AI project teams, the required skills, and the multidisciplinary nature of AI development (Source: Ronald_vanLoon)
AI Applications and Challenges in the Telecom Industry: Discussion mentioned breakthrough applications and potential pitfalls of AI in the telecommunications industry. AI is being widely used for network optimization, intelligent customer service, predictive maintenance, etc., to improve efficiency and user experience, but it also faces challenges like data privacy, algorithmic bias, and implementation complexity. In-depth exploration of these aspects helps the industry seize AI opportunities while mitigating risks (Source: Ronald_vanLoon)
Influence of Psychology on AI Development: An article explores how psychology has influenced the development of artificial intelligence, an influence that continues today. Knowledge from psychology, such as cognitive science, learning theories, and bias research, provides important references for AI design, like simulating human cognitive processes and understanding/addressing biases. Conversely, AI also provides new modeling and testing tools for psychological research (Source: Ronald_vanLoon)

Large Computing Setup Highlights AI Hardware Demands: A user shared a picture of a massive, complex computer hardware setup (likely a large multi-GPU server cluster), calling it a “monster.” The image vividly reflects the enormous computational resources required for training large AI models or performing high-intensity inference tasks today, demonstrating modern AI’s heavy reliance on hardware infrastructure (Source: karminski3)

Role of AI in Cybersecurity: An article discusses the transformative role of artificial intelligence in the cybersecurity domain. AI technology is used to enhance threat detection (e.g., anomaly behavior analysis), automate security responses, assess vulnerabilities, and make predictions, improving defense efficiency and capabilities. However, AI itself can also be maliciously exploited, posing new security challenges (Source: Ronald_vanLoon)

High-Accuracy OCR Faces Character Confusion Challenge: A developer seeking to build a high-accuracy OCR system for recognizing short alphanumeric codes (like serial numbers) encountered a common difficulty: models struggle to distinguish visually similar characters (e.g., I/1, O/0). Even using a YOLO model for single character detection, edge cases persist. This highlights the challenge of achieving near-perfect OCR accuracy in specific scenarios, requiring targeted optimization of models, data, or post-processing strategies (Source: Reddit r/MachineLearning)

Help Needed Running Gym Retro Environment: A user encountered technical issues while using the reinforcement learning library Gym Retro. They successfully imported the Donkey Kong Country game but were unsure how to launch the preset environment for training. This is a typical configuration and operation problem AI researchers might face when using specific tools (Source: Reddit r/MachineLearning)
Selection Dilemma When Multiple Models Perform Similarly: A researcher found that multiple combinations of different feature selection methods and machine learning models achieved similarly high performance levels (e.g., 93-96% accuracy), making it difficult to choose the optimal solution. This reflects the need in model evaluation, when standard metrics show little difference, to consider other factors like model complexity, interpretability, inference speed, and robustness to make the final selection (Source: Reddit r/MachineLearning)
arXiv Migration to Google Cloud Draws Attention: arXiv, a crucial pre-print platform for AI and many other scientific fields, plans to migrate from Cornell University servers to Google Cloud. This major infrastructure change could bring improvements in service scalability and reliability but might also spark community discussions about operational costs, data management, and open access policies (Source: Reddit r/MachineLearning)
Claude Generates Economic Simulation Tool and Its Limitations: A user utilized the Claude Artifact feature to generate an interactive economic simulator for tariff impacts. While showcasing AI’s ability to generate complex applications, comments pointed out that the simulation results might be overly simplistic or inconsistent with economic principles (e.g., high tariffs leading to universal benefits). This serves as a reminder that when using AI-generated analysis tools, their underlying logic and assumptions must be rigorously scrutinized (Source: Reddit r/ClaudeAI)

Integrating Custom XTTS Voice Cloning in OpenWebUI: A user sought to integrate their own voice, cloned using open-source XTTS technology, into OpenWebUI to replace the paid ElevenLabs API for personalized and free voice output. This represents the user demand for integrating open-source, customizable components (like TTS) when using local AI tools (Source: Reddit r/OpenWebUI)