
Keywords:AI, large model, AI arms race, vertical industry model, Zhipu AI IPO, AI independently discovers physical laws, AI-assisted vision system for the blind, AI large model applications, global AI arms race competition, vertical industry AI model solutions, Zhipu AI IPO news and analysis, how AI independently discovers physical laws, AI-assisted vision system for blind people technology
“` markdown
🔥 Focus
Big Tech’s AI Arms Race Heats Up, Focusing on Vertical Models and Ecosystems: Global tech giants are investing in AI with unprecedented intensity, with capital expenditures projected to exceed $320 billion in 2025. Chinese companies like Alibaba, Tencent, and Huawei are also increasing their stakes, heavily investing in AI infrastructure, large models, and computing power. The competitive focus is shifting from general large models to vertical industry models, the latter becoming new growth engines due to high gross margins and their ability to solve practical pain points. Despite challenges with high-end chips, domestic manufacturers are making progress in optimizing computing costs and inference models (“slow thinking”) (e.g., the DeepSeek effect). Each company follows a different path: Alibaba focuses heavily on infrastructure, Huawei innovates hardware (CloudMatrix 384) and promotes edge-cloud synergy, Baidu stays close to applications, while Tencent and ByteDance leverage their diverse scenario advantages. AI hardware extension and open-source ecosystem building (e.g., Hongmeng/HarmonyOS, Shengteng/Ascend, Hunyuan) are becoming key, with competition shifting from single-point technological breakthroughs to ecosystem synergy capabilities. (Source: 36Kr-Tech Cloud Report)

MIT’s Stunning Discovery: AI Independently Derives Physical Laws Without Prior Knowledge: MIT’s Max Tegmark team developed a new architecture called MASS (Multiple AI Scalar Scientists). This AI system, without being told any physical laws, independently learned and proposed theoretical formulations highly similar to the Hamiltonian or Lagrangian in classical mechanics, solely by analyzing observational data from physical systems like pendulums and oscillators. The research indicates that AI autonomously refines its theories when facing more complex systems, and different AI “scientists” eventually converge towards known physical principles, particularly favoring Lagrangian descriptions in complex systems. This achievement demonstrates AI’s immense potential in fundamental scientific discovery, potentially capable of independently uncovering the universe’s basic laws. (Source: Xinzhiyuan)

SJTU Team’s AI System for Assisting the Visually Impaired Published in Nature Sub-journal, Helping Them “Regain Sight”: The Gu Leilei team at Shanghai Jiao Tong University (SJTU) has developed an AI-driven wearable assistive system for the blind. Combining flexible electronics technology, it replaces partial visual functions with auditory and tactile feedback, helping visually impaired individuals perform daily tasks like navigation and grasping. The system features lightweight hardware, software optimized for information output conforming to human physiological cognition, and a developed VR immersive training system. Tests show the system significantly enhances the navigation, obstacle avoidance, and object grasping abilities of visually impaired users in both virtual and real environments. The research, published in Nature Machine Intelligence, showcases AI’s vast potential in assisting the visually impaired population, enhancing their independent living capabilities, and provides new ideas for personalized, user-friendly wearable visual aids. (Source: 36Kr)

Zhipu AI Initiates IPO Tutoring, Aiming to Be the “First Large Model Stock”: Tsinghua-affiliated AI large model company Zhipu AI (Beijing Zhipu Huazhang Technology) completed its IPO tutoring filing with the Beijing Securities Regulatory Bureau on April 14th, with CICC as the tutor. Targeting the A-share market, it aims to become China’s “first AI large model stock.” Although its consumer product “Zhipu Qingyan” (ChatGLM) has a modest user base, Zhipu AI, leveraging its strong technical background (Tsinghua affiliation, self-developed GLM series large models), state-backed status (placed on the US Entity List), and commercialization progress (serving government and enterprise clients with significant revenue growth), has secured over 16 billion RMB in funding with a valuation exceeding 20 billion RMB. Investors include well-known VCs, industry giants, and state-owned capital from multiple regions. Facing pressure from new players like DeepSeek, Zhipu’s IPO move is seen as a crucial step to secure a favorable position in the fierce competition, meet funding needs, and respond to investor expectations. The company recently continued open-sourcing its GLM-4 series models, indicating simultaneous efforts in technology and capital markets. (Source: 36Kr-True Story Research Lab, 36Kr-Internet Leaks Hub, Venture Capital Daily)

🎯 Trends
ByteDance’s Seedream 3.0 (Mogao) Model Revealed, Text-to-Image Capabilities Recognized: The mysterious Mogao model, which recently topped the Artificial Analysis text-to-image leaderboard, has been confirmed as Seedream 3.0, developed by ByteDance’s Seed team. The model excels in various styles including realism, design, and anime, as well as text generation. It is particularly adept at handling dense text and generating realistic portraits, achieving a 94% usability rate for Chinese and English characters. Its portrait realism approaches professional photography levels, supports native 2K resolution image output, and boasts fast generation speeds. The technical report reveals multiple innovations in data processing (defect-aware training, biaxial sampling), pre-training (MMDiT architecture, mixed resolution, cross-modal RoPE), post-training (continual training, SFT, RLHF, VLM reward models), and inference acceleration (Hyper-SD, RayFlow). Compared to GPT-4o, Seedream 3.0 shows advantages in Chinese language, typography, and color. (Source: 36Kr-JiQizhiXin)
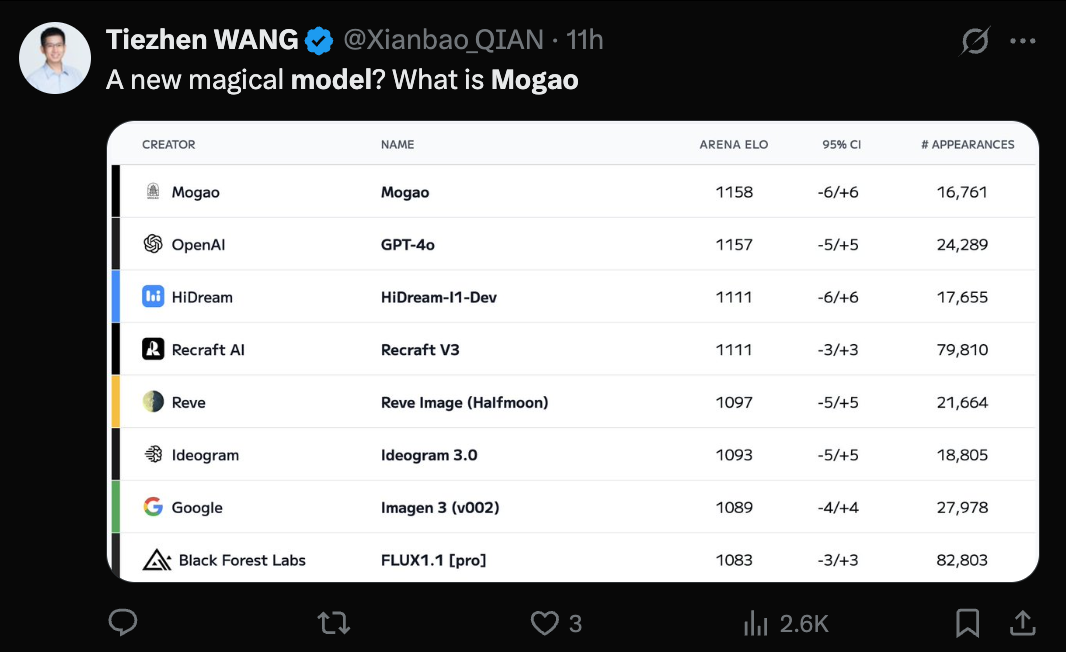
Claude Launches Research Feature and Integrates with Google Workspace: Anthropic has added two major features to its AI assistant Claude: Research and Google Workspace integration. The Research feature allows Claude to search the web for information and combine it with users’ internal files (like Google Docs) for multi-angle analysis, quickly generating comprehensive reports. The Google Workspace integration connects Gmail, Google Calendar, and Drive, enabling Claude to understand user schedules, emails, and document content, extract information, and assist with tasks such as planning itineraries based on personal information or drafting emails. These features aim to significantly boost user productivity. The Research feature is currently in beta testing for Max, Team, and Enterprise users in the US, Japan, and Brazil, while Workspace integration is in beta for all paid users. User feedback has been positive regarding efficiency gains and discovering connections within data, though concerns about data security exist. (Source: Xinzhiyuan, op7418, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
CUHK and Tsinghua Release Video-R1, Ushering in a New Paradigm for Video Reasoning: A team from the Chinese University of Hong Kong (CUHK) and Tsinghua University has jointly launched Video-R1, the world’s first video reasoning model employing the reinforcement learning R1 paradigm. The model aims to address the lack of temporal logic and deep reasoning capabilities in existing video models. By introducing the time-aware T-GRPO algorithm and using hybrid training datasets combining images and videos (Video-R1-COT-165k and Video-R1-260k), the 7B-parameter Video-R1 outperforms GPT-4o on the VSI-Bench video spatial reasoning benchmark proposed by Fei-Fei Li. The model exhibits human-like “aha moments,” capable of logical reasoning based on temporal information. Experiments show that increasing the number of input frames improves reasoning accuracy. The project has open-sourced the model, code, and datasets, signaling that video AI is moving from “understanding” to “thinking.” (Source: Xinzhiyuan)

ICLR 2025 Introduces AI Reviewing on a Large Scale for the First Time, Significantly Improving Review Quality: Facing a surge in submissions and declining review quality, the ICLR 2025 conference has deployed an AI “Review Feedback Agent” on a large scale for the first time to assist reviewing. The system utilizes multiple LLMs, including Claude Sonnet 3.5, to identify ambiguity, content misunderstandings, or unprofessional remarks in review comments and provide specific improvement suggestions to reviewers. The experiment covered 42.3% of reviews, showing that AI feedback improved review quality in 89% of cases. 26.6% of reviewers modified their reviews based on AI suggestions, with modified reviews increasing by an average of 80 words, becoming more specific and informative. AI intervention also enhanced the activity and depth of discussion between authors and reviewers during the Rebuttal period. This pioneering experiment demonstrates the huge potential of AI in optimizing the peer review process. (Source: Xinzhiyuan)

Humanoid Robots Entering Homes Sparks Discussion, Home Appliance Companies Actively Deploying Embodied Intelligence: The entry of humanoid robots into home scenarios has sparked industry discussion about their application models and impact on the home appliance sector. One view is that humanoid robots should leverage their “general-purpose” nature to solve non-standard tasks like folding clothes and tidying up, and use their interaction capabilities to act as “butlers,” directing and coordinating other smart devices, rather than simply replacing existing appliances. Responding to this trend, home appliance giants like Haier and Midea have begun deploying their own humanoid robot products (e.g., Kuavo) and exploring the integration of embodied intelligence technology into traditional appliances (e.g., Dreame’s robot vacuum with a robotic arm, Yimu Technology’s washing machine capable of grasping clothes). This indicates the home appliance industry is actively adapting to the AI wave, potentially forming a symbiotic smart home ecosystem with humanoid robots in the future. (Source: 36Kr-Embodied Intelligence Research Club)

Huawei Releases CloudMatrix 384 AI Server, Targeting Nvidia GB200: At its Cloud Ecosystem Conference, Huawei launched its latest AI server cluster, CloudMatrix 384. The system comprises 384 Ascend compute cards, delivering a single cluster computing power of 300 PFlops and a single card decoding throughput of 1920 Tokens/s, directly challenging the performance of Nvidia’s H100. It utilizes all-optical high-speed interconnect (6812 x 400G optical modules), achieving training efficiency close to 90% of Nvidia’s single-card performance. This move is seen as a significant step for China in catching up with international leaders in AI infrastructure, aiming to meet the demand for computing power amidst high-end chip restrictions. Analysts believe this demonstrates Huawei’s rapid progress in AI hardware, potentially impacting the existing market landscape. (Source: dylan522p, 36Kr-Tech Cloud Report)
Google Launches Veo 2 Text-to-Video Feature and Whisk Animate: Google has integrated its Veo 2 text-to-video model into Gemini Advanced. Member users can use this feature for free via the Gemini App, generating 8-second videos. Additionally, Google’s image editing tool Whisk has been updated with the Whisk Animate feature, allowing users to convert generated images into videos using Veo 2, though this requires a Google One membership. This marks Google’s continued push in the multimodal generation field, providing users with richer creation tools. (Source: op7418, op7418)
OpenAI Reportedly Building an X-like Social Product: According to The Verge, OpenAI is internally developing a social product prototype similar to X (formerly Twitter). The product might combine ChatGPT’s image generation capabilities (especially after the GPT-4o release) with a social feed. Considering ChatGPT’s massive user base and its advancements in image generation, this move is considered feasible and could signify OpenAI’s attempt to expand its AI capabilities into the social media domain. (Source: op7418)
DeepCoder Releases 14B High-Performance Open-Source Coding Model: The DeepCoder team has released a 14-billion-parameter high-performance open-source coding model, claimed to excel at coding tasks. The release provides developers with another powerful option for code generation and assistance tools, especially in scenarios requiring a balance between performance and model size. (Source: Ronald_vanLoon)

Tesla Achieves Autonomous Parking for Vehicles Leaving the Factory: Tesla demonstrated new progress in its autonomous driving technology, where vehicles, after rolling off the factory production line, can autonomously drive to the loading area or parking lot without human intervention. This showcases the application potential of Tesla’s FSD (Full Self-Driving) capability in specific, controlled environments, helping to improve production logistics efficiency and marking a step towards broader autonomous driving applications. (Source: Ronald_vanLoon, Ronald_vanLoon)
Dexterity Launches Mech, an Industrial Robot Powered by Physical AI: Dexterity has introduced an industrial robot named Mech, characterized by its use of “Physical AI” technology. This AI enables the robot to navigate and operate in complex industrial environments, exhibiting superhuman dexterity and adaptability, aimed at solving complex tasks that traditional industrial automation struggles with. (Source: Ronald_vanLoon)
MIT Develops New Jumping Robot Designed for Rough Terrain: Researchers at MIT have developed a new robot inspired by jumping locomotion, particularly adept at moving across rough and uneven terrain. This robot demonstrates the application of biomimetics in robot design and the potential of machine learning in controlling complex movements, potentially useful in complex environments like search and rescue or planetary exploration. (Source: Ronald_vanLoon)
INTELLECT-2 Launched: Globally Distributed Reinforcement Learning Training for a 32B Model: The Prime Intellect project has launched the INTELLECT-2 initiative, aiming to train a 32-billion-parameter advanced reasoning model using reinforcement learning via globally distributed computing resources. Based on the Qwen architecture, the model targets a controllable thinking budget, allowing users to specify how many reasoning steps (how many tokens to think) the model should perform before solving a problem. This is a significant exploration of distributed training and reinforcement learning for enhancing the reasoning capabilities of large models. (Source: Reddit r/LocalLLaMA)

ByteDance Releases Liquid, a GPT-4o-like Multimodal Autoregressive Model: ByteDance has released a multimodal model family named Liquid. Employing an autoregressive architecture similar to GPT-4o, the model can accept text and image inputs and generate text or image outputs. Unlike previous MLLMs that used external pre-trained visual embeddings, Liquid uses a single LLM for autoregressive generation. A 7B version model and demo have been released on Hugging Face. Initial evaluations suggest its image generation quality is not yet on par with GPT-4o, but its architectural uniformity represents significant technical progress. (Source: Reddit r/LocalLLaMA)
Running Multiple LLMs via GPU Memory Snapshotting Technology: Discussion on a technique for quickly switching and running multiple LLMs by snapshotting the GPU memory state (including weights, KV cache, memory layout, etc.). Similar to a process fork operation, this method can restore a model’s state in seconds (approx. 2s for a 70B model, 0.5s for 13B) without reloading or reinitializing. Potential advantages include running dozens of LLMs on a single GPU node to reduce idle costs, enabling on-demand dynamic model switching, and utilizing idle time for local fine-tuning. (Source: Reddit r/MachineLearning)
Menlo Research Releases ReZero Model: Teaching AI to Persistently Search: The Menlo Research team has released a new model and paper called ReZero. Based on the idea that “search requires multiple attempts,” the model is trained using GRPO (a reinforcement learning optimization algorithm) and tool-calling capabilities, introducing a “retry_reward.” The training objective is to enable the model to proactively and repeatedly attempt searches when encountering difficulties or unsatisfactory initial results, until the required information is found. Experiments show ReZero significantly outperforms baseline models (46% vs 20%), proving the effectiveness of the repeated search strategy and challenging the notion that “repetition equals hallucination.” The model can be used to optimize query generation for existing search engines or as a search enhancement layer for LLMs. The model and code are open-sourced. (Source: Reddit r/LocalLLaMA)
Hugging Face Acquires Humanoid Robot Startup: Hugging Face, the well-known open-source AI community and platform, has acquired an undisclosed humanoid robot startup. This move likely signals Hugging Face’s ambition to extend its platform capabilities from software and models to the hardware and robotics domain, further promoting AI applications in the physical world, particularly in embodied intelligence. (Source: Reddit r/ArtificialInteligence)

🧰 Tools
Open-Source Emotional TTS Model Orpheus Released, Supports Streaming Inference and Voice Cloning: Canopy Labs has open-sourced a text-to-speech (TTS) model series named Orpheus (up to 3 billion parameters, based on Llama architecture). The model reportedly outperforms existing open-source and some closed-source models. Its key feature is the ability to generate human-like speech with natural intonation, emotion, and rhythm, even inferring and generating non-linguistic sounds like sighs and laughter from text, exhibiting a degree of “empathetic” capability. Orpheus supports zero-shot voice cloning, controllable emotional tone, and achieves low-latency (around 200ms) streaming inference suitable for real-time conversational applications. The project provides various model sizes and fine-tuning tutorials, aiming to lower the barrier for high-quality speech synthesis. (Source: 36Kr)

Trae.ai Platform Launches Free Access to Gemini 2.5 Pro: The AI tool platform Trae.ai announced it has launched Google’s latest Gemini 2.5 Pro model and is offering free access. Users can experience the capabilities of Gemini 2.5 Pro on the platform. (Source: dotey)
AI Recruitment Tool Hireway: Screens 800 Candidates a Day: Hireway showcased the capability of its AI recruitment tool, claiming it can efficiently screen 800 job applicants in a single day. The tool utilizes AI and automation technology to optimize the recruitment process, enhancing screening efficiency and candidate experience. (Source: Ronald_vanLoon)
PRIMA.CPP: Accelerating 70B Large Model Inference on Ordinary Home Clusters: PRIMA.CPP is an open-source project based on llama.cpp, designed to optimize and accelerate the inference speed of large language models up to 70 billion parameters on resource-constrained ordinary home computing clusters (potentially involving multiple regular PCs or devices). The project focuses on the efficiency of distributed inference, offering new possibilities for running large models locally. The paper has been published on Hugging Face. (Source: Reddit r/LocalLLaMA)

Plush Character Prompt Sharing: A user shared a set of prompts for generating cute 3D plush-style animal characters, suitable for image generation tools like Sora or GPT-4o. The prompt emphasizes detailed descriptions such as super soft texture, dense fur, large eyes, soft lighting, shadows, and background, aiming to generate high-quality renders suitable for brand mascots or IP characters. (Source: dotey)

📚 Learning
Jeff Dean Shares Materials from His Talk at ETH Zurich: Google DeepMind Chief Scientist Jeff Dean shared links to the recording and slides from his talk at the ETH Zurich Department of Computer Science. The presentation likely covers recent advances in AI, research directions, or Google’s research achievements, providing valuable learning resources for researchers and students. (Source: JeffDean)
ICLR 2025 AI Reviewing Technical Report Released: Accompanying the news of ICLR 2025 introducing AI reviewing, a detailed 30-page technical report has been made public (arXiv:2504.09737). The report details the experimental design, AI models used (centered around Claude Sonnet 3.5), feedback generation mechanism, reliability testing methods, and quantitative analysis results on the impact on review quality, discussion activity, and final decisions. This report provides an in-depth reference for understanding the potential, challenges, and implementation details of AI in academic peer review. (Source: Xinzhiyuan)
Video-R1 Video Reasoning Model Paper, Code, and Datasets Open-Sourced: The CUHK and Tsinghua team not only released the Video-R1 model but also fully open-sourced its technical paper (arXiv:2503.21776), implementation code (GitHub: tulerfeng/Video-R1), and the two key datasets used for training (Video-R1-COT-165k and Video-R1-260k). This provides the research community with complete resources to reproduce, improve, and further explore the video reasoning R1 paradigm, helping to advance technological development in the field. (Source: Xinzhiyuan)
Paper on AI Independently Discovering Physical Laws Published: The research by MIT’s Max Tegmark team on the AI system MASS independently discovering Hamiltonians and Lagrangians has been published as a preprint paper (arXiv:2504.02822v1). The paper elaborates on the design philosophy of the MASS architecture, its core algorithm (learning scalar functions based on the principle of conservation of action), experimental setup (different physical systems, single/multi-AI scientist scenarios), and the findings on how the AI theory evolves with data complexity and eventually converges to classical mechanics formulations. This paper provides an important theoretical and empirical basis for exploring AI applications in fundamental science discovery. (Source: Xinzhiyuan)
PRIMA.CPP Paper Published: The technical paper introducing the PRIMA.CPP project (aimed at accelerating 70B-scale LLM inference on low-resource clusters) has been published on Hugging Face Papers (ID: 2504.08791). The paper likely details the optimization techniques employed, distributed inference strategies, and performance evaluation results on specific hardware configurations, providing technical references for researchers and practitioners in the field. (Source: Reddit r/LocalLLaMA)
Deep Dive into RWKV-7 Model and Author Q&A: Oxen.ai released a deep dive video and blog post on the RWKV-7 (Goose) model. The content covers the problems the RWKV architecture attempts to solve, its iteration methods, and core technical features. Notably, the video includes an interview and Q&A session with one of the model’s main authors, Eugene Cheah, offering valuable author insights into this non-Transformer LLM architecture and exploring interesting concepts like “Learning at Test Time.” (Source: Reddit r/MachineLearning)

Article Sharing 7 Tips to Master Prompt Engineering: The FrontBackGeek website published an article summarizing 7 powerful tips to help users master Prompt Engineering for better output from AI models like LLMs. The article likely covers aspects such as clarifying instructions, providing context, setting roles, and controlling output format. (Source: Reddit r/deeplearning)

Project Share: Fine-tuning GPT-2/GPT-J to Mimic Mr. Darcy’s Tone from ‘Pride and Prejudice’: A developer shared their personal project: using GPT-2 (medium) and GPT-J models, fine-tuned on two datasets containing original dialogues and self-created synthetic data, to mimic the unique speaking style (formal, concise, slightly judgmental) of Mr. Darcy from Jane Austen’s “Pride and Prejudice.” The project showcases model output samples, evaluation metrics (improved BLEU-4 but increased perplexity), and challenges encountered (e.g., difficulty tuning GPT-J). The code and datasets are open-sourced on GitHub, providing a case study for exploring specific literary styles or historical figure voice modeling. (Source: Reddit r/MachineLearning)
ACL 2025 Meta Review Release Discussion: The Meta Review results for the ACL 2025 conference have been released. Researchers involved have posted in the community, inviting discussion and exchange regarding their paper scores and corresponding Meta Reviews. This provides a platform for submitting authors to share experiences and compare expectations with results. (Source: Reddit r/MachineLearning)
Experience Sharing: Building a Low-Cost 160GB VRAM AI Server: A Reddit user detailed their process and initial test results of building an AI inference server with 160GB VRAM for about $1000 (mainly 10 used AMD MI50 GPUs at $90 each and a $100 Octominer mining case). The post covers hardware selection, system installation (Ubuntu + ROCm 6.3.0), llama.cpp compilation and testing, measured power consumption (idle ~120W, peak inference ~340W), cooling situation, and performance data (compared to GPUs like the 3090, running llama3.1-8b and llama-405b models). This share offers valuable DIY hardware configuration and practical experience reference for AI enthusiasts on a budget. (Source: Reddit r/LocalLLaMA)
ReZero Model Paper and Code Released: The technical paper (arXiv:2504.11001), model weights (Hugging Face: Menlo/ReZero-v0.1-llama-3.2-3b-it-grpo-250404), and implementation code (GitHub: menloresearch/ReZero) for Menlo Research’s ReZero model (trained via GRPO to repeatedly search until finding needed information) have all been publicly released. This provides complete learning and experimentation resources for researching and applying this novel search strategy. (Source: Reddit r/LocalLLaMA)
💼 Business
Former Alibaba Robotics Exec Min Wei Founds Yingshen Intelligence, Secures Tens of Millions in Seed Funding: Founded in 2024 by Min Wei, former technical lead of Alibaba’s robotics team, Yingshen Intelligence focuses on L4 embodied intelligence technology R&D and application. The company recently completed consecutive seed (invested by Zhuoyuan Capital Asia) and seed+ rounds (co-invested by Zhuoyuan Capital Asia and Hangzhou Xihu Kechuangtou) totaling tens of millions of RMB. Based on its self-developed spatio-temporal intelligence large model (building a 4D real-world model via Real-to-Real, directly modeling from video data) and industrial robots, Yingshen Intelligence provides hardware-software synergy solutions. It has already secured industrial orders worth tens of millions, initially focusing on industrial scenarios with plans to expand into service industries like express delivery and hospitality. (Source: 36Kr)
AI Toy Market Hot Online, Cold Offline; Exports May Be Main Channel: AI toys are booming on online platforms (like livestream e-commerce, social media), with rapid market size growth predicted. However, offline visits (e.g., in Guangzhou) reveal AI toys are scarce in traditional toy stores and general stores, with low distribution rates and consumer awareness. Current AI toy sales likely rely heavily on online channels, with overseas markets (Europe, America, Middle East) being crucial outlets; manufacturers offer appearance and language customization. Analysis of market size data suggests previous reports of a ten-billion-level market might refer to broader “smart toys” rather than purely AI toys. Despite the offline chill, the AI toy market is still considered to have huge growth potential, given the increasing adult need for emotional companionship (e.g., the Moflin case) and the potential of AI technology across all age groups. (Source: 36Kr)

Tsinghua-Affiliated AI Infra Company Qingcheng Jizhi: Inference Demand Explodes, Cost-Effectiveness Drives Domestic Substitution: An interview with Tang Xiongchao, CEO of Tsinghua-affiliated AI infrastructure company Qingcheng Jizhi. The company observed a surge in AI inference-side compute demand after the DeepSeek model gained popularity, putting previously idle domestic computing power to work. However, DeepSeek’s technical innovations (like FP8 precision) are deeply tied to Nvidia’s H-series cards, widening the gap with most current domestic chips. To address this, Qingcheng Jizhi, jointly with Tsinghua, open-sourced the “Chitu” inference engine, aiming to enable existing GPUs and domestic chips to efficiently run advanced models like DeepSeek, promoting a closed loop for the domestic AI ecosystem. Tang believes that while domestic chip substitution will take time, their cost-performance advantage is promising long-term. The company’s current business focus is meeting the demand from government and enterprise sectors for localized deployment of large models. (Source: ifeng Tech)
AI Investment Boom Continues, Young Investors Emerge: Despite a cooling overall investment environment in 2024, the AI sector continues to attract capital, with global funding reaching record highs and the domestic market remaining active. Giants like ByteDance, Alibaba, and Tencent are accelerating their deployments, while unicorns like Zhipu AI, Moonshot AI, and Unitree Robotics emerge. Investment hotspots cover the entire industry chain, including infrastructure, AIGC, and embodied intelligence. Established investment firms like Sequoia China and BlueRun Ventures maintain their lead, while industrial funds and state-owned capital, represented by the Beijing Municipal Artificial Intelligence Industry Investment Fund, have become significant drivers. Notably, a group of young investors born in the 1980s (such as Cao Xi, Dai Yusen, Lin Haizhuo, Zhang Jinjian) are active in the AI 2.0 era, leveraging their acumen and execution ability to actively seek opportunities in a market with new rules, becoming an emerging force to watch. (Source: 36Kr-First New Voice)

Founder of AI Shopping App Nate Accused of Fraud, Using “Human API” to Fake AI and Secure $50M Investment: The US Department of Justice has indicted Albert Saniger, founder of the AI shopping app Nate, accusing him of defrauding investors of over $50 million by falsely advertising the app’s AI capabilities. Nate claimed its app could automatically complete online shopping processes using proprietary AI technology, but in reality, its core functionality heavily relied on hundreds of human customer service agents hired in the Philippines to manually process orders, with the alleged AI automation rate being nearly zero. The founder concealed the truth from investors and employees, ultimately leading to the company running out of funds and shutting down. This case highlights the potential for fraud in the AI startup boom, where human labor is disguised as AI to attract investment, damaging investor interests and industry reputation. Saniger could face up to 40 years in prison. (Source: CSDN)

🌟 Community
AI-Modified Videos Sweep Short Video Platforms, Sparking Entertainment and Copyright Ethics Debates: Using AI technology (like text-to-video tools Sora, Keling) to create “drastically modified” versions of classic films and TV series (e.g., “Empresses in the Palace” riding motorcycles, “In the Name of the People” turned into “12.12: The Day”) has rapidly become popular on platforms like Douyin and Bilibili. These videos attract massive traffic with their subversive plots, visual impact, and meme culture, becoming a new means for creators to quickly gain followers and monetize (through traffic revenue sharing, soft advertising) and for promoting the original series. However, their popularity is accompanied by controversy: defining copyright infringement for these works is complex; the modified content might diminish the original’s artistic depth or even become vulgar, attracting regulatory attention. Balancing entertainment demand with respect for copyright and maintaining content standards poses a challenge for AI-generated derivative works. (Source: 36Kr-Mingxi Yewang)

Claude Pro/Max Plan Limits and Pricing Draw User Complaints: Multiple posts have appeared on the Reddit ClaudeAI subreddit where users complain about the restrictions and pricing of Anthropic’s Claude Pro and the newly launched Max subscription plans. Users report hitting usage limits quickly, even as paying Pro users, after only a small or moderate amount of interaction (e.g., processing a few hundred thousand tokens of context), disrupting their workflows. The new Max plan ($100/month), while offering higher limits (estimated 5-20x that of Plus), is still not unlimited, and its high price is criticized by users as a “money grab” with low value. Users generally appreciate Claude’s model capabilities but express strong dissatisfaction with its usage limits and pricing strategy. (Source: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Clear Human Writing Style Mistaken for AI Generation Draws Attention: Users on Reddit (including self-described neurodivergent individuals) report that their carefully written text—grammatically correct, logically clear, and detailed—is being mistaken for AI-generated content by others or AI detection tools. This phenomenon sparks discussion: it might stem from the prevalence of AI-generated content leading people to suspect text that seems “too perfect,” or it could expose the current inaccuracy of AI detection tools. This causes frustration for writers who prioritize clear expression and raises concerns about distinguishing human from AI creation and the reliability of AI detectors. (Source: Reddit r/artificial, Reddit r/artificial)
Discussion: Is It Possible and Common for Humans to Form Emotional Relationships with AI Bots?: A discussion emerged on Reddit about whether humans are genuinely forming emotional relationships with AI bots (like AI girlfriend apps), similar to what’s depicted in the movie “Her.” Some users shared experiences of forming emotional connections after deep conversations with chatbots, suggesting that AI, through “active listening” and mimicking user preferences, can trigger human emotional responses. Comments explore the prevalence of this phenomenon, its psychological mechanisms, and its relationship with technical understanding, reflecting that as AI interaction capabilities improve, human-computer relationships are entering a new, more complex phase. (Source: Reddit r/ArtificialInteligence)
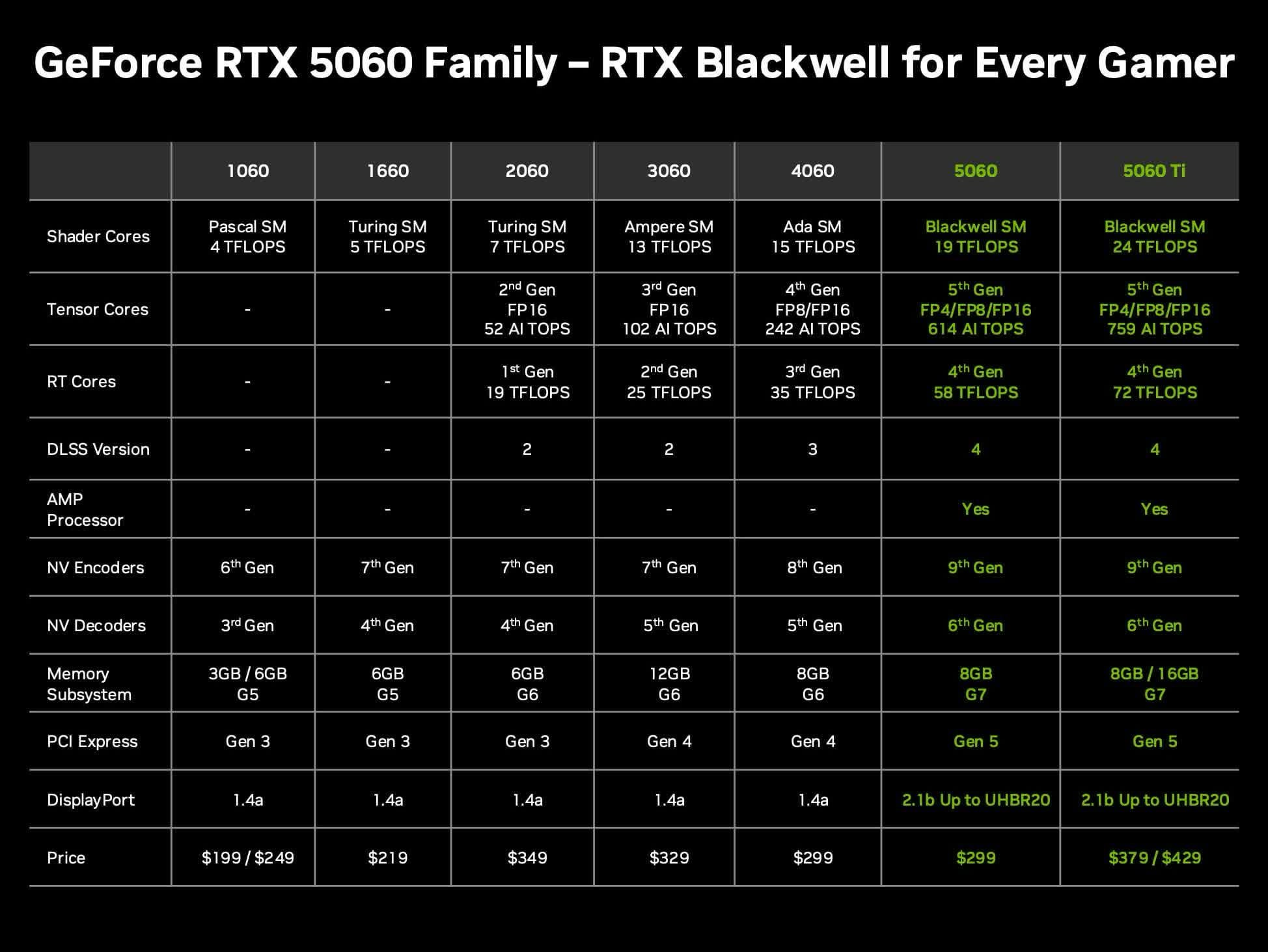
Discussion: Value of Nvidia RTX 5060 Ti 16GB GPU for Local LLMs: Community users discuss the value of the upcoming Nvidia GeForce RTX 5060 Ti graphics card (rumored 16GB VRAM version, priced at $429) for running local large language models (LLMs) at home. The discussion focuses on whether its 128-bit memory bus (448 GB/s bandwidth) will be a bottleneck, and its pros and cons compared to Mac Mini/Studio or other AMD GPUs in terms of VRAM capacity and performance per dollar (token/s per price). Considering that actual market prices might exceed the MSRP, users are evaluating if it represents a cost-effective choice for local AI hardware. (Source: Reddit r/LocalLLaMA)
GPT-4o Struggles to Accurately Draw Sun Wukong’s Phoenix-Winged Purple Gold Crown: Users report that when using GPT-4o for image generation, even with detailed text descriptions (including a hair-binding crown with pheasant tails, resembling long antennae), the model struggles to accurately depict the iconic “Phoenix-Winged Purple Gold Crown” of the Chinese mythological figure Sun Wukong. Generated images often show deviations in the crown’s style. This reflects the ongoing challenges for current AI image generation models in understanding and accurately rendering specific cultural symbols or complex details. (Source: dotey)

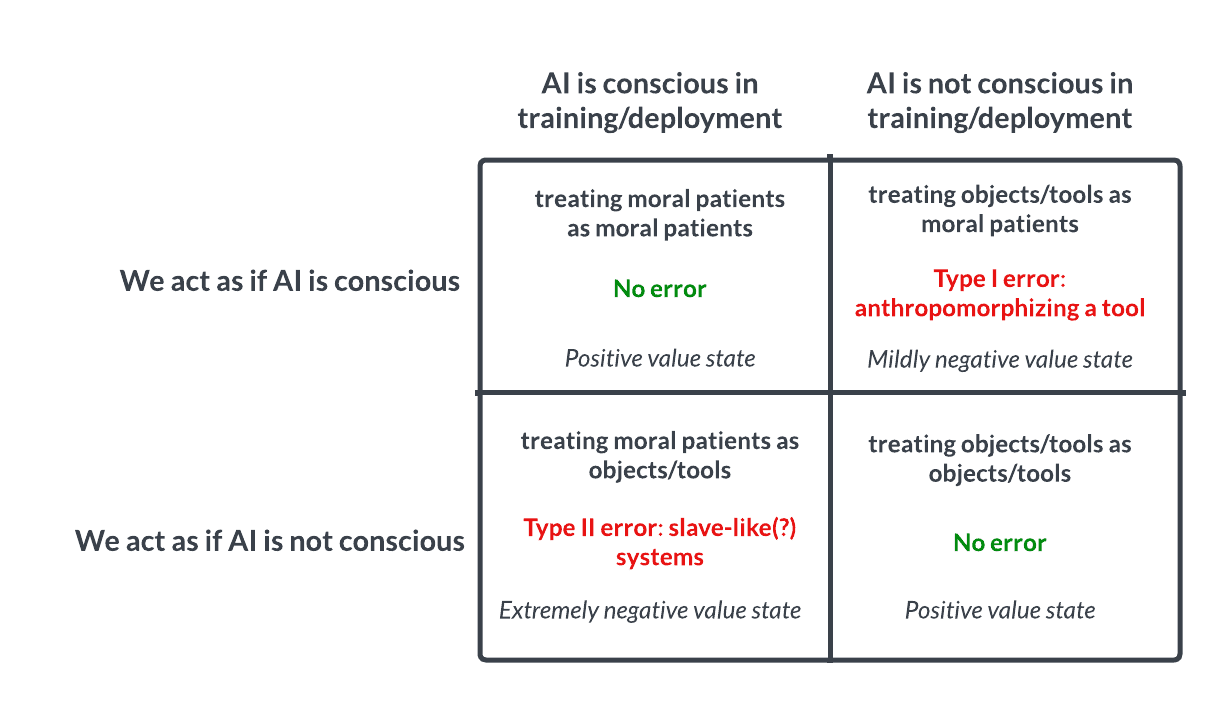
AI Consciousness and Ethics Discussion: Pascal’s Wager Analogy Sparks Thought: A Reddit discussion proposes treating AI akin to Pascal’s Wager: if we assume AI lacks consciousness and abuse them, but they actually are conscious, we commit a grave error (like slavery); if we assume they are conscious and treat them well, but they are not, the loss is smaller. This sparks ethical debate about the possibility of AI consciousness, criteria for judgment, and how we should treat advanced AI. Comments range from believing current AI is not conscious, to urging caution, to pointing out that ethical issues concerning humans and animals should be addressed first. (Source: Reddit r/artificial
💡 Others
Film ‘Here’ Uses AI Age Transformation Tech, Sparking Controversy: Directed by Robert Zemeckis and starring Tom Hanks and Robin Wright, the film “Here” boldly employs real-time generative AI transformation technology developed by Metaphysic, allowing the actors to portray ages spanning from 18 to 78. The technology analyzes actors’ biometric features in real-time to generate faces and bodies at different ages, significantly shortening post-production time. However, the technology is not yet perfect, particularly limited in eye rendering and handling complex expressions, leading to discussions about the “uncanny valley effect.” Furthermore, Hanks’ decision to authorize the posthumous use of his AI likeness has ignited widespread controversy regarding likeness rights, ethics, and artistic authenticity. Despite mediocre box office and reviews, the film holds significant industry value as an early exploration of AI technology in filmmaking. (Source: 36Kr-Geek Movie)

AI Recruitment: Opportunities and Challenges Coexist: AI is transforming the recruitment process, with tools like Hireway claiming to significantly improve screening efficiency. However, the application of AI in recruitment also sparks discussion, such as how to conduct Hiring In The AI Era, and how to balance efficiency with fairness, avoid algorithmic bias, etc. (Source: Ronald_vanLoon, Ronald_vanLoon)

AI Development Speed Sparks Reflection: The Balance of Fast and Slow: An article discusses whether the “move fast and break things” strategy is still applicable in the era of rapid AI development. The view presented is that sometimes slowing down to speed up (deliberate consideration) might be more effective, especially in the AI field involving complex systems and potential risks. (Source: Ronald_vanLoon)

Anthropic Opens Official Discord Server for Direct User Feedback: Given user questions and dissatisfaction regarding Claude model performance and limitations, the community recommends joining Anthropic’s official Discord server. There, users have the opportunity to interact directly with Anthropic staff to more effectively provide feedback on issues and concerns. (Source: Reddit r/ClaudeAI)

Showcase of Various Novel Robots and Automation Technologies: Social media featured videos or information on various robots and automation technologies, including an underwater drone, a soft robot mimicking intestinal peristalsis, the X-Fly bionic bird drone, an all-purpose robot capable of various tasks, a robot for hair transplantation, an automated egg processing production line, a 9-foot-tall robot suit simulating human movements, and an amusing scene of two delivery robots in a “standoff” on the street. These showcase the exploration and development of robotics technology in diverse fields. (Source: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)