
Keywords:GPT-4.1, Hugging Face, GPT-4.1 series model performance comparison, Hugging Face acquires Pollen Robotics, OpenAI new model coding capability improvement, GPT-4.1 mini cost reduced by 83%, Open-source robot Reachy 2
🔥 Focus
OpenAI releases GPT-4.1 series models, enhancing coding and long-text processing capabilities: OpenAI released three new models in the GPT-4.1 series on April 15th: GPT-4.1 (flagship), GPT-4.1 mini (high-efficiency), and GPT-4.1 nano (ultra-small), all available exclusively via API. This series excels in coding, instruction following, and long context understanding, with all models featuring a 1 million token context window and supporting up to 32,768 output tokens. GPT-4.1 scored 54.6% on the SWE-bench Verified test, significantly outperforming GPT-4o and the soon-to-be-deprecated GPT-4.5 Preview. GPT-4.1 mini surpasses GPT-4o in performance while halving latency and reducing costs by 83%. GPT-4.1 nano is currently the fastest and lowest-cost model, suitable for low-latency tasks. This release aims to provide developers with options offering stronger performance, better cost-effectiveness, and higher speed, driving the construction of complex intelligent systems and agent applications. (Source: 36Kr, Zhidx, op7418, openai, karminski3, sama, natolambert, karminski3, karminski3, karminski3, dotey, OpenAI, GPT-4.1 is here, surpassing GPT-4.5, SWE-Bench reaches 55%, exclusive for developers.)
![OpenAI GPT-4.1 Announcement]
Hugging Face acquires open-source robotics company Pollen Robotics: AI community platform Hugging Face announced the acquisition of French open-source robotics startup Pollen Robotics, aiming to promote the open-sourcing and popularization of AI robotics. This acquisition will combine Hugging Face’s strengths in software platforms (like the LeRobot library and Hub) with Pollen Robotics’ expertise in open-source hardware (such as the Reachy 2 humanoid robot). Reachy 2 is an open-source, VR-compatible humanoid robot designed for research, education, and embodied intelligence experiments, priced at $70,000. Hugging Face believes robotics is the next important interaction interface for AI and should be open, affordable, and customizable. This acquisition is a key step towards realizing this vision, with the goal of enabling the community to build and control their own robot companions, rather than relying on closed, expensive systems. (Source: huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface)

🎯 Trends
AI helps solve a 50-year-old unsolved math problem: Weiguo Yin, a Chinese scholar at Brookhaven National Laboratory in the US, utilized OpenAI’s reasoning model o3-mini-high to achieve a breakthrough in the exact solution of the one-dimensional J_1-J_2 q-state Potts model, particularly completing a key proof for the q=3 case with AI assistance. This problem involves a fundamental model in statistical mechanics, related to physical phenomena such as atomic stacking in layered materials and unconventional superconductivity, whose exact solution had remained elusive for the past 50 years. By introducing the Maximum Symmetric Subspace (MSS) method and using AI prompts to progressively handle the transfer matrix, the researchers successfully reduced the 9×9 transfer matrix for q=3 to an effective 2×2 matrix and generalized this method to arbitrary q values. This research not only solves a long-standing mathematical physics problem but also demonstrates the immense potential of AI in assisting complex scientific research and providing new insights. (Source: Just In: AI Cracks 50-Year-Old Unsolved Math Problem! Nanjing University Alumnus Uses OpenAI Model to Complete First Non-trivial Mathematical Proof)
![AI Solves 50-Year-Old Math Problem]
Rise of AI web assistants as phone and car manufacturers build multi-device experiences: Manufacturers like Huawei (Xiaoyi Assistant), Ideal Auto (Lixiang Tongxue), and OPPO (Xiaobu Assistant) have successively launched web versions of their AI assistants, drawing attention. Although these web versions might lag behind professional model services like DeepSeek in feature completeness (e.g., editing questions, formatting, setting options), their core goal is not direct competition but rather serving users of their respective brands by creating a seamless experience loop from phone and car to PC. By linking user accounts and synchronizing conversation history, these web versions aim to enhance user stickiness, provide a consistent cross-terminal interaction experience, and integrate AI assistants into broader user scenarios, essentially positioning themselves for user entry points and data ecosystems. (Source: AI Web Versions Launch En Masse, What’s the Strategy for Huawei, Ideal, OPPO?)
![AI Web Assistants Launch]
Figure robot achieves zero-shot sim-to-real transfer via reinforcement learning: Figure demonstrated its Figure 02 humanoid robot achieving natural gaits through reinforcement learning (RL) purely in simulation. Using an efficient GPU-accelerated physics simulator, they generated years’ worth of training data in hours, training a single neural network policy capable of controlling multiple virtual robots with varying physical parameters and scenarios (like different terrains, disturbances). By combining simulation domain randomization with high-frequency torque feedback from the real robot, the trained policy can be transferred zero-shot to the physical robot without fine-tuning. This method not only shortens development time and improves real-world performance stability but also allows one policy to control an entire fleet of robots, showcasing its potential for large-scale commercial applications. (Source: One Algorithm Controls a Robot Army! Pure Simulation RL Teaches Figure to Walk Like a Human)
![Figure Robot Learns Walking via RL]
DeepSeek to open-source parts of its inference engine optimizations: DeepSeek announced plans to contribute some optimizations and features from its modified vLLM-based high-performance inference engine back to the community. Instead of releasing their complete, highly customized inference stack, they will integrate key improvements (like support for latest model architectures, performance optimizations) into mainstream open-source inference frameworks such as vLLM and SGLang. The goal is to enable the community to get SOTA-level support for new models and technologies from day one. This move has been welcomed by the community as a genuine commitment to open-source contribution rather than mere lip service. (Source: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, natolambert)
![DeepSeek Inference Engine Open Source Announcement]
Zhipu AI suspected to release new GLM-4 series models: According to information leaked on GitHub (later removed), Zhipu AI appears poised to release new models in the GLM-4 series. The series might include versions with different parameter sizes (e.g., 9B, 32B) and functionalities, such as base models (GLM-4-32B-0414), chat models (Chat), reasoning models (GLM-Z1-32B-0414), and “Rumination” models with deeper thinking capabilities, potentially competing with OpenAI’s Deep Research. Additionally, it might include a visual multi-modal model (GLM-4V-9B). Leaked benchmark data suggests GLM-4-32B-0414 could outperform DeepSeek-V3 and DeepSeek-R1 on some metrics. Related inference engine support code has been merged into transformers/vllm/llama.cpp. The community is highly anticipating the official release and evaluation. (Source: karminski3, karminski3, Reddit r/LocalLLaMA)
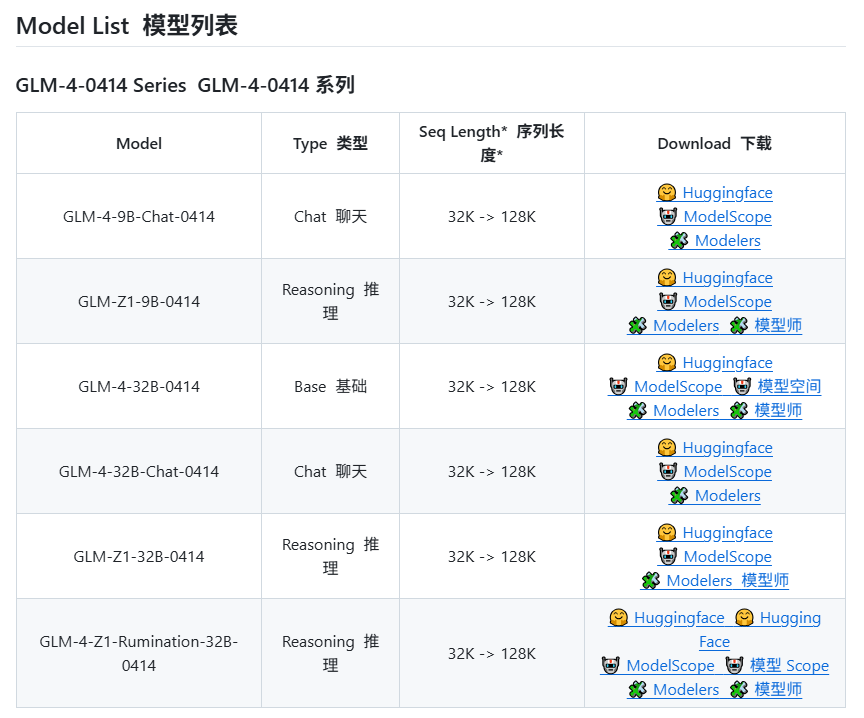
NVIDIA releases new Nemotron series models: NVIDIA has released new Nemotron-H series base models on Hugging Face, including 56B, 47B, and 8B parameter sizes, all supporting an 8K context window. These models are based on a hybrid Transformer and Mamba architecture. Currently, only the base models (Base) are released, with no instruction-tuned (Instruct) versions yet available. The Nemotron series aims to explore the potential of new architectures in language modeling. (Source: Reddit r/LocalLLaMA)
![NVIDIA Nemotron Models Announcement]
🧰 Tools
GitHub Copilot integrated into Windows Terminal Canary build: Microsoft has integrated GitHub Copilot functionality into the Canary preview build of Windows Terminal, introducing a new feature called “Terminal Chat”. This feature allows users to interact directly with AI within the terminal environment to get command suggestions and explanations. Users need a GitHub Copilot subscription and the latest Canary build of Terminal; after verifying their account, they can use the feature. This move aims to embed AI assistance directly into the command-line environment commonly used by developers, reducing context switching, improving efficiency when handling complex or unfamiliar tasks, accelerating the learning process, and helping to reduce errors. (Source: GitHub Copilot Now Runs in Windows Terminal)
![GitHub Copilot in Windows Terminal]
CADCrafter: Generating editable CAD files from a single image: Researchers from KOKONI 3D, Nanyang Technological University, and other institutions have proposed a new framework called CADCrafter, capable of directly generating parametric, editable CAD engineering files (represented as a sequence of CAD instructions) from a single image (renderings, real-world photos, etc.). This addresses the issue that existing image-to-3D methods (generating Mesh or 3DGS) produce models that are difficult to edit precisely and have suboptimal surface quality. The method employs a two-stage generation architecture combining VAE and Diffusion Transformer, and enhances generation quality and success rate through a multi-view to single-view distillation strategy and a DPO-based compilability check mechanism. The research has been accepted by CVPR 2025, offering a new paradigm for AI-assisted industrial design. (Source: Single Image Straight to CAD Engineering File! New CVPR 2025 Research Solves the “Uneditable” Pain Point of AI-Generated 3D Models | By KOKONI 3D, NTU, etc.)
![CADCrafter Single Image to CAD]
LangChain launches GraphRAG with MongoDB Atlas integration: LangChain announced a collaboration with MongoDB to launch a graph-based RAG (GraphRAG) system. This system utilizes MongoDB Atlas for data storage and processing, implemented via LangChain, enabling it to go beyond traditional similarity search-based RAG to understand and reason about relationships between entities. It supports entity and relationship extraction via LLMs and uses graph traversal to retrieve connected contextual information, aiming to provide more powerful question-answering and reasoning capabilities for applications requiring deep relational understanding. (Source: LangChainAI)
Hugging Face open-sources its Inference Playground: Hugging Face has open-sourced its online tool used for model inference testing and comparison, the Inference Playground. It’s a web-based LLM chat interface allowing users to control various inference settings (like temperature, top-p), modify AI responses, and compare the performance of different models and providers. The project is built with Svelte 5, Melt UI, and Tailwind, and the code is available on GitHub, providing developers with a customizable and extensible platform for interacting with and evaluating models locally or online. (Source: huggingface)
Flowith platform ARR exceeds $1 million, showcasing AI Agent webpage generation capabilities: AI Agent platform Flowith’s Annual Recurring Revenue (ARR) has surpassed $1 million, indicating strong market demand for versatile AI Agent platforms capable of replacing manual work. A user shared their experience using Flowith’s Oracle feature, generating a fully functional webpage widget with accurate styling (like Twitter’s) and image preview support simply by providing a natural language description (“I want to make a social media image/text preview webpage…”), without needing to connect to GitHub or perform complex configurations. This demonstrates the potential of AI Agents in low-code/no-code webpage generation. (Source: karminski3)
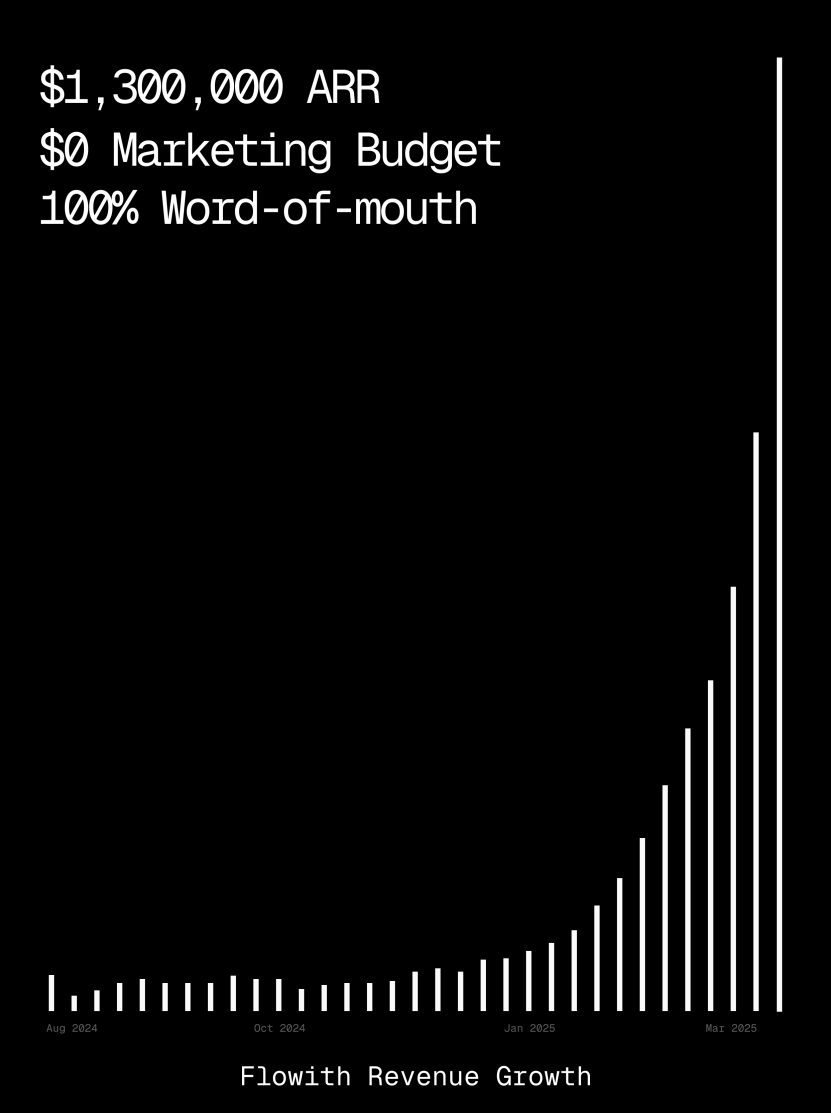
Autonomous debugging agent Deebo released: Researchers have built an autonomous debugging agent MCP server named Deebo. It runs as a local daemon to which programming agents can asynchronously offload tricky error-handling tasks. Deebo works by spawning multiple sub-processes with different fix hypotheses, running each scenario in an isolated git branch, and having a “mother agent” perform iterative testing and reasoning, ultimately returning diagnostic results and suggested patches. In a real-world test involving a tinygrad $100 bounty bug, Deebo successfully identified the root cause and proposed two specific fixes that passed the tests. (Source: Reddit r/MachineLearning)
![Deebo Autonomous Debugging Agent]
📚 Learning
Nabla-GFlowNet: A new diffusion model reward fine-tuning method balancing diversity and efficiency: Addressing the issues of slow convergence in traditional reinforcement learning, overfitting, and loss of diversity in direct reward maximization for diffusion model fine-tuning, researchers from CUHK (Shenzhen) and other institutions propose Nabla-GFlowNet. Based on the Generative Flow Network (GFlowNet) framework, this method treats the diffusion process as a flow equilibrium system, deriving the Nabla-DB balance condition and corresponding loss function. Through parameterized design, it utilizes single-step denoising to estimate residual gradients, avoiding the need for an extra estimation network. Experiments fine-tuning Stable Diffusion on aesthetic scores, instruction following, and other reward functions show that Nabla-GFlowNet converges faster and is less prone to overfitting compared to methods like ReFL and DRaFT, while maintaining the diversity of generated samples. (Source: ICLR 2025 | New Breakthrough in Diffusion Model Reward Fine-tuning! Nabla-GFlowNet Achieves Both Diversity and Efficiency)
![Nabla-GFlowNet Diffusion Model Fine-tuning]
MegaMath: Largest open-source mathematical reasoning dataset with 371B tokens released: Launched by LLM360, the MegaMath dataset, containing 371 billion tokens, aims to address the lack of large-scale, high-quality mathematical reasoning pre-training data in the open-source community. The dataset is divided into three parts: math-intensive webpages (279B), math-related code (28.1B), and high-quality synthetic data (64B). Its construction involved innovative data processing pipelines, including HTML parsing optimized for mathematical formulas, two-stage text extraction, dynamic educational value scoring, multi-step precise recall for code data, and various large-scale synthesis methods (Q&A, code generation, text-code interleaving). Validation through 100B token pre-training on Llama-3.2 (1B/3B) shows that MegaMath yields absolute performance improvements of 15-20% on benchmarks like GSM8K and MATH. (Source: 371 Billion Math Tokens! World’s Largest Open-Source Math Dataset MegaMath Released, Crushing DeepSeek-Math)
![MegaMath Open Source Math Dataset]
OS Agents Review: Research on Computer, Mobile, and Browser Agents based on Multimodal Large Models: Zhejiang University, in collaboration with OPPO, 01.AI, and other institutions, released a review paper on Operating System Agents (OS Agents). The paper systematically surveys the current state of research on building agents using Multimodal Large Language Models (MLLMs) that can automatically perform tasks in environments like computers, mobile phones, and browsers (e.g., Anthropic’s Computer Use, Apple’s Apple Intelligence). It covers the fundamentals of OS Agents (environment, observation space, action space, core capabilities), construction methods (foundation model architecture & training strategies, agent framework’s perception/planning/memory/action modules), evaluation protocols & benchmarks, related commercial products, and future challenges (security & privacy, personalization & self-evolution). The research team maintains an open-source repository with 250+ related papers to promote development in this field. (Source: Zhejiang University, OPPO, etc. Release Latest Review: Research on Computer, Mobile, and Browser Agents Based on Multimodal Large Models)
![OS Agents Review Paper]
NLPrompt: Robust prompt learning method combining MAE loss and optimal transport: ShanghaiTech University’s YesAI Lab proposed NLPrompt in a CVPR 2025 Highlight paper, aiming to address the label noise problem in visual language model prompt learning. The study found that in the prompt learning scenario, using Mean Absolute Error (MAE) loss (PromptMAE) is more robust to noisy labels than Cross-Entropy (CE) loss, and proved its robustness from a feature learning theory perspective. Furthermore, they proposed a prompt-based Optimal Transport data purification method (PromptOT), which uses text features as prototypes to divide the dataset into a clean subset (trained with CE loss) and a noisy subset (trained with MAE loss), effectively integrating the advantages of both losses. Experiments demonstrate NLPrompt’s superior performance on synthetic and real noisy datasets, along with good generalization ability. (Source: CVPR 2025 | MAE Loss + Optimal Transport Combo! ShanghaiTech Proposes New Robust Prompt Learning Method)
![NLPrompt Robust Prompt Learning]
DeepSeek-R1 reasoning mechanism analysis: Researchers at McGill University analyzed the reasoning process of large reasoning models like DeepSeek-R1. Unlike LLMs that give direct answers, reasoning models generate detailed multi-step reasoning chains. The study explores the relationship between reasoning chain length and performance (there’s an “optimal point”; excessive length can harm performance), long context management, cultural and safety issues (stronger safety vulnerabilities compared to non-reasoning models), and connections to human cognitive phenomena (like persistent dwelling on explored problems). This research reveals some characteristics and potential issues in the operation mechanisms of current reasoning models. (Source: LLM Weekly Digest! | Covering Multimodal, MoE Models, Deepseek Reasoning, Agent Safety Control, Model Quantization, etc.)
![LLM Weekly Digest Image 1]
C3PO: Test-time optimization method for MoE large models: Johns Hopkins University researchers found that Mixture-of-Experts (MoE) LLMs suffer from sub-optimal expert routing and proposed a test-time optimization method C3PO (Critical Layers, Core Experts, Collaborative Path Optimization). This method does not rely on ground truth labels but defines a surrogate objective based on “successful neighbors” in a reference sample set to optimize model performance. It employs algorithms like pattern finding, kernel regression, and average loss on similar samples, and optimizes only the weights of core experts in critical layers to reduce cost. Applied to MoE LLMs, C3PO improved base model accuracy by 7-15% across six benchmarks, surpassing common test-time learning baselines, and enabled smaller MoE models to outperform larger LLMs, enhancing MoE efficiency. (Source: LLM Weekly Digest! | Covering Multimodal, MoE Models, Deepseek Reasoning, Agent Safety Control, Model Quantization, etc.)
![LLM Weekly Digest Image 2]
Study on the impact of quantization on reasoning model performance: A Tsinghua University research team conducted the first systematic exploration of how quantization techniques affect the performance of reasoning language models (like DeepSeek-R1 series, Qwen, LLaMA). The study evaluated various bit-width (W8A8, W4A16, etc.) weight, KV cache, and activation quantization algorithms on reasoning benchmarks covering math, science, and programming. Results show that W8A8 or W4A16 quantization can generally achieve lossless performance, but lower bit-widths carry a significant risk of accuracy degradation. Model size, origin, and task difficulty are key factors influencing post-quantization performance. The output length of quantized models did not increase significantly, and reasonably adjusting model size or increasing reasoning steps can improve performance. Related quantized models and code have been open-sourced. (Source: LLM Weekly Digest! | Covering Multimodal, MoE Models, Deepseek Reasoning, Agent Safety Control, Model Quantization, etc.)
![LLM Weekly Digest Image 3]
SHIELDAGENT: Guardrail enforcing agent compliance with safety policies: The University of Chicago proposed the SHIELDAGENT framework, designed to enforce AI agent action trajectories to comply with explicit safety policies through logical reasoning. The framework first extracts verifiable rules from policy documents to build a safety policy model (based on probabilistic rule circuits). Then, during agent execution, it retrieves relevant rules based on the action trajectory and generates a protection plan, using a tool library and executable code for formal verification to ensure agent behavior does not violate safety regulations. A dataset, SHIELDAGENT-BENCH, containing 3K safety-related instructions and trajectory pairs, was also released. Experiments show SHIELDAGENT achieves SOTA on multiple benchmarks, significantly improving safety compliance rate and recall while reducing API queries and inference time. (Source: LLM Weekly Digest! | Covering Multimodal, MoE Models, Deepseek Reasoning, Agent Safety Control, Model Quantization, etc.)
![LLM Weekly Digest Image 4]
MedVLM-R1: Incentivizing medical VLM reasoning capabilities through reinforcement learning: Researchers from the Technical University of Munich, University of Oxford, and other institutions collaborated to propose MedVLM-R1, a medical visual language model (VLM) designed to generate explicit natural language reasoning processes. The model employs DeepSeek’s Group Relative Policy Optimization (GRPO) reinforcement learning framework, trained on datasets containing only final answers, yet it autonomously discovers human-interpretable reasoning paths. After training on just 600 MRI VQA samples, this 2B parameter model achieved 78.22% accuracy on MRI, CT, and X-ray benchmarks, significantly outperforming baselines and demonstrating strong out-of-domain generalization, even surpassing larger models like Qwen2-VL-72B. This research offers a new approach for building trustworthy and interpretable medical AI. (Source: Small Samples, Big Power! MedVLM-R1 Leverages DeepSeek Reinforcement Learning to Reshape Medical AI Reasoning Capabilities)
![MedVLM-R1 Medical VLM]
Research reveals reinforcement learning training may lead to verbose reasoning model responses: A study by Wand AI analyzed why reasoning models (like DeepSeek-R1) generate longer responses. It found this behavior might stem from the reinforcement learning (specifically PPO algorithm) training process, rather than the problem itself requiring longer reasoning. When a model receives negative rewards for wrong answers, the PPO loss function tends to favor longer responses to dilute the penalty per token, even if the extra content doesn’t improve accuracy. The study also suggests that concise reasoning often correlates with higher accuracy. A second round of RL training using only a subset of solvable problems can shorten response length while maintaining or even improving accuracy, which is important for deployment efficiency. (Source: Longer Thinking Doesn’t Equal Stronger Reasoning Performance, Reinforcement Learning Can Be Concise)
![RL Training and Response Length Study]
USTC and ZTE propose Curr-ReFT: Enhancing reasoning and generalization of small VLMs: Addressing the “brick wall” phenomenon (training bottleneck) in complex tasks and insufficient out-of-domain generalization for small Visual Language Models (VLMs), the University of Science and Technology of China (USTC) and ZTE proposed the Curricular Reinforcement Learning Fine-Tuning paradigm (Curr-ReFT). This paradigm combines Curriculum Learning (CL) and Reinforcement Learning (RL), designing a difficulty-aware reward mechanism that allows the model to learn progressively from easy to hard tasks (binary decision → multiple choice → open-ended answer). Simultaneously, it employs a rejection sampling-based self-improvement strategy, using high-quality multimodal and language samples to maintain the model’s foundational capabilities. Experiments on Qwen2.5-VL-3B/7B models show Curr-ReFT significantly improves reasoning and generalization performance, with the 7B model even surpassing InternVL2.5-26B/38B on some benchmarks. (Source: USTC, ZTE Propose New Post-Training Paradigm: Small Multimodal Models Successfully Replicate R1 Reasoning)
![Curr-ReFT Small VLM Training]
GenPRM: Extending process reward models via generative reasoning: Tsinghua University and Shanghai AI Lab proposed the Generative Process Reward Model (GenPRM) to address the limitations of traditional Process Reward Models (PRM), which rely on scalar scores, lack interpretability, and cannot be extended at test time. GenPRM uses a generative approach, combining Chain-of-Thought (CoT) reasoning and code verification, to perform natural language analysis and Python code execution validation for each reasoning step, providing deeper, interpretable process supervision. Additionally, GenPRM introduces a test-time extension mechanism that improves evaluation accuracy by sampling multiple reasoning paths in parallel and aggregating reward values. A 1.5B model trained on only 23K synthetic data surpasses GPT-4o on ProcessBench through test-time extension, and a 7B version outperforms the 72B Qwen2.5-Math-PRM-72B. GenPRM can also serve as a critic model to guide policy model optimization. (Source: Process Reward Models Can Also Be Extended at Test Time? Tsinghua, Shanghai AI Lab Use 23K Data to Let a 1.5B Small Model Outperform GPT-4o)
![GenPRM Process Reward Model]
Study reveals “overthinking” phenomenon in reasoning AI on missing premise problems: Research from the University of Maryland and Lehigh University found that current reasoning models (like DeepSeek-R1, o1) tend to exhibit “overthinking” when faced with problems lacking necessary premise information (Missing Premise, MiP). They generate responses 2-4 times longer than for normal problems, getting stuck in loops of re-examining the question, guessing intent, and self-doubt, instead of quickly identifying the problem as unsolvable and stopping. In contrast, non-reasoning models (like GPT-4.5) provide shorter responses to MiP problems and are better at identifying missing premises. The study suggests that while reasoning models can detect missing premises, they lack the “critical thinking” to decisively halt futile reasoning. This behavior pattern might originate from insufficient length constraints during reinforcement learning training and propagate through distillation. (Source: Reasoning AI Addicted to “Making Things Up”, Full of Waffle! Maryland Chinese Student Uncovers the Inside Story)
![Reasoning AI Overthinking Study]
In-depth article explains the evolution of neural network normalization techniques: The article systematically reviews the role and evolution of normalization in neural networks, particularly in Transformers and large models. Normalization addresses data comparability, improves optimization speed, and mitigates issues like activation function saturation zones and internal covariate shift (ICS) by constraining data within a fixed range. It introduces common linear (Min-max, Z-score, Mean) and non-linear normalization methods, focusing on Batch Normalization (BN), Layer Normalization (LN), RMSNorm, and DeepNorm suitable for deep learning models, analyzing their application differences in Transformer architectures (why LN/RMSNorm are preferred for NLP). Additionally, it discusses different placements of the normalization module within Transformer layers (Post-Norm, Pre-Norm, Sandwich-Norm) and their impact on training stability and performance. (Source: 10,000-Word Long Article! Understand Normalization in One Go: From Transformer Normalization to the Evolution in Mainstream Large Models!)
![Neural Network Normalization Explained]
Prompt engineering for generating specific style font designs using AI: The article shares the author’s experience and prompt templates for exploring the use of Jimeng AI 3.0 (Dreamina AI) to generate text designs with specific styles. The author found that directly specifying font names (like Songti, Kaiti) yielded poor results due to the AI model’s limited understanding. Therefore, the author shifted to describing font style characteristics, emotional atmosphere, and visual effects, combined with examples of different styles, to build a “Advanced Text Style Design Prompt Generator” template. Users only need to input the text content, and the template intelligently matches or blends various preset styles (e.g., Luminous Night Shadow, Industrial Rustic, Playful Doodle, Metallic Sci-Fi) based on the text’s meaning, generating detailed prompts for text-to-image models to achieve relatively stable quality graphic designs. (Source: I’ve Kind of Mastered AI Font Design Generation, Boosting Efficiency by 50% with This Prompt Set., Creating Font-Inclusive Covers with Jimeng AI 3.0, This Method is Insanely Cool [Includes: 16+ Cases and Prompts])
![AI Font Generation Prompt Engineering]
ZClip: Adaptive gradient spike mitigation method for LLM pre-training: Researchers propose ZClip, a lightweight adaptive gradient clipping method designed to reduce loss spikes during LLM training and improve training stability. Unlike traditional gradient clipping with a fixed threshold, ZClip uses a z-score based approach to detect and clip anomalous gradient spikes – those that significantly deviate from the recent moving average. This method helps maintain training stability without interfering with convergence and is easy to integrate into any training loop. Code and paper are available. (Source: Reddit r/deeplearning)
![ZClip Paper Preview]
💼 Business
Intel Arc graphics + Xeon W processor solution enables low-cost AI all-in-one machines: Intel, through its combination of Arc™ graphics and Xeon® W processors, offers the market a solution for building cost-effective (around 100,000 RMB level) yet practically performant large model all-in-one machines. Arc™ graphics feature the Xe architecture and XMX AI acceleration engine, support mainstream AI frameworks and Ollama/vLLM, have relatively low power consumption, and support multi-card configurations. Xeon® W processors provide high core counts and memory expansion capabilities, with built-in AMX acceleration technology. Combined with software optimizations like IPEX-LLM, OpenVINO™, and oneAPI, efficient collaboration between CPU and GPU is achieved. Tests show that an all-in-one machine with this solution can run the Qwen-32B model at 32 tokens/s for single-user use, and the 671B DeepSeek R1 model (requiring FlashMoE optimization) at nearly 10 tokens/s, meeting offline inference needs and promoting the popularization of AI inference. (Source: Squeezing Out a 3000 Yuan Graphics Card, Here’s the Secret Recipe to Run Trillion-Parameter Large Models)
![Intel Arc + Xeon W AI Solution]
NVIDIA to manufacture AI supercomputer domestically in the US: NVIDIA announced it will design and build its AI supercomputer entirely in the United States for the first time, collaborating with major manufacturing partners. Meanwhile, its next-generation Blackwell chip has begun production at TSMC’s factory in Arizona. NVIDIA plans to produce up to $500 billion worth of AI infrastructure in the US over the next four years, with partners including TSMC, Foxconn, Wistron, Amkor, and SPIL. This move aims to meet the demand for AI chips and supercomputers, strengthen the supply chain, and enhance resilience. (Source: nvidia, nvidia)

Horizon Robotics hiring 3D reconstruction/generation interns: Horizon Robotics’ Embodied Intelligence team is recruiting algorithm interns specializing in 3D reconstruction/generation in Shanghai/Beijing. Responsibilities include participating in designing and developing robot Real2Sim algorithm solutions (combining 3D GS reconstruction, feed-forward reconstruction, 3D/video generation), optimizing Real2Sim simulator performance (supporting fluid, tactile simulation, etc.), and tracking cutting-edge research and publishing top conference papers. Requires a Master’s degree or above in Computer Science/Graphics/AI or related fields, experience in 3D vision/video generation or multimodal/diffusion models, proficiency in Python/Pytorch/Huggingface. Experience with top conference publications, familiarity with simulation platforms, or open-source project contributions is preferred. Offers potential for full-time conversion, GPU cluster access, and competitive salary. (Source: Shanghai/Beijing Referral | Horizon Robotics Embodied Intelligence Team Hiring 3D Reconstruction/Generation Algorithm Interns)
![Horizon Robotics Internship Ad]
Meituan Hotel & Travel hiring L7-L8 Large Model Algorithm Engineers: Meituan’s Hotel & Travel Supply Algorithm team is hiring L7-L8 level Large Model Algorithm Engineers (experienced hires) in Beijing. Responsibilities include building a hotel & travel supply understanding system (product tags, hotspot identification, similar supply mining, etc.), optimizing display materials (title, image-text, recommendation reason generation), constructing vacation package combinations (product selection, sales forecasting, pricing), and exploring and implementing cutting-edge large model technologies (fine-tuning, RL, Prompt optimization). Requires a Master’s degree or above, 2+ years of experience, major in Computer Science/Automation/Mathematical Statistics or related fields, with solid algorithm fundamentals and coding skills. (Source: Beijing Referral | Meituan Hotel & Travel Supply Algorithm Team Hiring L7-L8 Large Model Algorithm Engineers)
![Meituan Job Ad]
Meta to use EU user data for AI training: Meta announced it is preparing to start using public data from Facebook and Instagram users in the EU region (such as posts, comments, excluding private messages) to train its AI models, limited to users aged 18 and above. The company will inform users via in-app notifications and email, providing an opt-out link. Previously, Meta had paused plans to use user data for AI training in Europe due to requirements from the Irish regulatory authority. (Source: Reddit r/artificial)
![Meta AI EU Data Training Announcement]
Tencent Cloud launches MCP hosting service: Tencent Cloud has also started offering Managed Cloud Platform (MCP) hosting services, aiming to provide enterprises with more convenient and efficient cloud resource management and operation solutions. This move signifies increased competition among major cloud vendors in this area. Specific service details and “WeChat characteristics” are not yet detailed. (Source: Tencent Cloud is also doing MCP hosting, with a touch of “WeChat characteristics”.)
🌟 Community
Turing Award winner LeCun discusses AI development: Human intelligence is not general, next breakthrough may be non-generative: In a recent podcast interview, Yann LeCun reiterated that the term AGI is misleading, arguing that human intelligence is highly specialized, not general. He predicts the next major breakthrough in AI might come from non-generative models, focusing on enabling machines to truly understand the physical world, possess reasoning and planning abilities, and have persistent memory, similar to his proposed JEPA architecture. He believes current LLMs lack true reasoning capabilities and the ability to model the physical world, and reaching cat-level intelligence would already be a huge step forward. Regarding Meta open-sourcing LLaMA, he considers it the right choice for advancing the entire AI ecosystem, emphasizing that innovation comes from around the globe and open source is key to accelerating breakthroughs. He also sees smart glasses as an important vehicle for AI assistants. (Source: Turing Award Winner LeCun: Human Intelligence is Not General Intelligence, Next-Gen AI May Be Based on Non-Generative Models)
![Yann LeCun on AI Development]
GitHub’s brief “ban” on Chinese IPs sparks concern, official statement cites configuration error: From April 12th to 13th, some users in China found they couldn’t access GitHub, receiving a message stating “IP address access restricted,” causing panic and discussion in the community about a potential targeted block. GitHub had previously banned developer accounts from countries like Russia and Iran due to US sanctions. GitHub officials later responded that the incident was caused by a configuration change error that temporarily prevented non-logged-in users from accessing the site, and the issue was fixed on April 13th. Although a technical glitch, the event reignited discussions about the geopolitical risks associated with code hosting platforms and the need for domestic alternatives (like Gitee, CODING, Jihu GitLab, etc.). (Source: “Bug” or “Rehearsal”? GitHub Suddenly “Bans” All Chinese IPs, Official: Just a “Slip of the Hand” Technical Error)
![GitHub China IP Access Issue]
AI Agents raise cybersecurity concerns: An MIT Technology Review article points out that autonomous cyberattacks powered by AI are imminent. As AI capabilities grow, malicious actors could leverage AI Agents to automatically discover vulnerabilities, plan, and execute more complex and large-scale cyberattacks, posing new threats to individuals, businesses, and even national security. This requires the cybersecurity field to urgently research and deploy defense strategies and technologies capable of countering AI-driven attacks. (Source: Ronald_vanLoon)

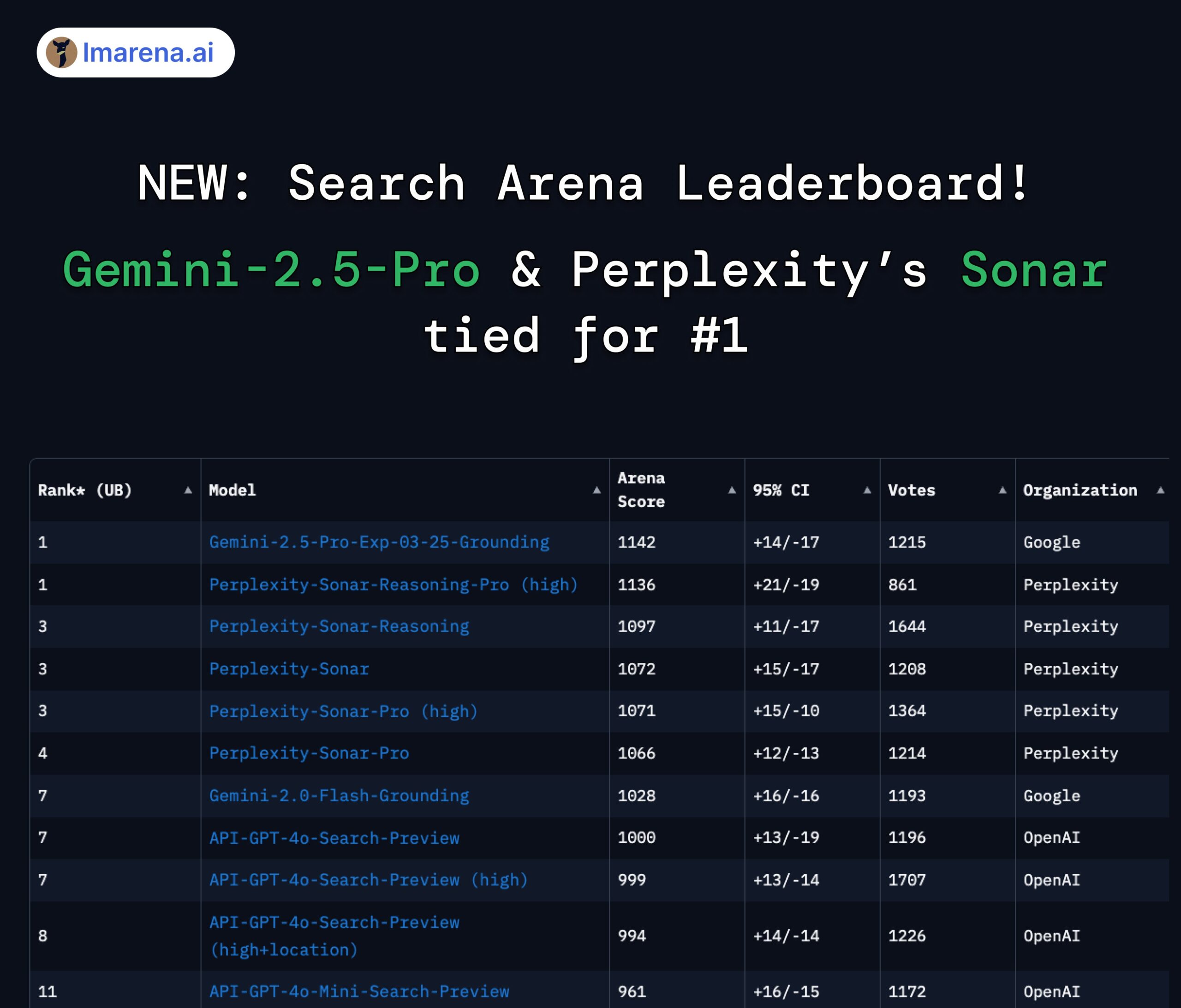
Perplexity Sonar and Gemini 2.5 Pro tied for top spot on Search Arena leaderboard: On the newly launched Search Arena leaderboard by LMArena.ai (formerly LMSYS), Perplexity’s Sonar-Reasoning-Pro-High model is tied for first place with Google’s Gemini-2.5-Pro-Grounding. This leaderboard specifically evaluates the quality of LLM answers based on web search. Perplexity CEO Arav Srinivas congratulated the team and emphasized continued improvement of the Sonar model and search index. The community sees this as evidence that the competition in the search-augmented LLM space is primarily between Google and Perplexity. (Source: AravSrinivas, lmarena_ai, lmarena_ai, AravSrinivas, lmarena_ai, AravSrinivas)
Discussion on Claude model usage limits: In the Reddit r/ClaudeAI community, there is debate among users regarding the usage limits of the Claude Pro version (e.g., message caps, capacity restrictions). Some users complain about frequently hitting limits, disrupting their workflow, and even considering switching models; others report rarely encountering limits, suggesting it might be due to usage patterns (like loading very large contexts) or exaggeration. This reflects differing user experiences and opinions on Anthropic’s model usage policies and stability. (Source: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Discussion on AI and the future of employment: A comparison image on Reddit r/ChatGPT sparked discussion: Will AI enhance human capabilities, leading to abundance, or replace human jobs, causing mass unemployment? In the comments, many users expressed concerns about AI replacing jobs, especially creative professions (programming, art). Some believe AI will exacerbate social inequality, with benefits accruing mainly to AI owners, while a shrinking tax base might make UBI unfeasible. Others are more optimistic, viewing AI as a powerful tool that can boost efficiency and create new roles (like prompt engineers), emphasizing the importance of adapting and learning to leverage AI. (Source: Reddit r/ChatGPT, Reddit r/ArtificialInteligence)
![AI and Jobs Future Comparison]
AI data collection raises privacy concerns: An infographic comparing the types of user data collected by different AI chatbots (ChatGPT, Gemini, Copilot, Claude, Grok) prompted community discussion about privacy issues. The graphic shows Google Gemini collecting the most data types, while Grok (requires account) and ChatGPT (no account needed) collect relatively less. User comments highlighted the prevalence of data collection behind free services (“no free lunch”) and expressed concerns about the specific purposes of data collection (like behavioral prediction). (Source: Reddit r/artificial)
![AI Chatbot Data Collection Comparison]
Model distillation seen as effective path to low-cost high performance: A Reddit user shared how model distillation techniques, using a large model (like GPT-4o) to train a smaller, fine-tuned model, achieved near-GPT-4o performance (92% accuracy) in a specific domain (sentiment analysis) at 14x lower cost. Comments noted that distillation is a widely used technique, but smaller models typically lack the cross-domain generalization capabilities of larger ones. For specific, stable domains, distillation is an effective cost-reduction method, but for complex scenarios requiring constant adaptation to new data or multiple domains, using large APIs directly might be more economical. (Source: Reddit r/MachineLearning)
![Model Distillation Discussion]
💡 Other
OceanBase hosts its first AI Hackathon: Distributed database vendor OceanBase, in collaboration with Ant Group Open Source, Machine之心, and others, is hosting its first AI Hackathon. Registration opened on April 10th and closes on May 7th. The competition, themed “DB+AI,” features two tracks: building AI applications using OceanBase as the data foundation, and exploring the integration of OceanBase with the AI ecosystem (like CAMEL AI, FastGPT, OpenDAL). The hackathon offers a total prize pool of 100,000 RMB and is open to individuals and teams, aiming to inspire developers to explore innovative applications of deep integration between databases and AI. (Source: 100K Prize Money × Cognitive Upgrade! OceanBase’s First AI Hackathon Calls for Heroes, Do You Dare to Come?)
![OceanBase AI Hackathon]
Tsinghua University Professor Liu Xinjun to lecture live on parallel robots: Professor Liu Xinjun, Director of the Design Engineering Institute, Department of Mechanical Engineering, Tsinghua University, and Chairman of the IFToMM China Committee, will give an online lecture on the evening of April 15th. The topic is “Fundamentals of Parallel Robot Mechanisms and Equipment Innovation.” The lecture will explore the basic theory of parallel robots and their application in cutting-edge equipment innovation. The host is Professor Liu Yingxiang from Harbin Institute of Technology. (Source: Major Live Broadcast! Tsinghua University Professor Liu Xinjun Lectures: Fundamentals of Parallel Robot Mechanisms and Frontiers of Equipment Innovation)
![Tsinghua Professor Lecture on Parallel Robots]
Guide released for the 3rd China AIGC Industry Summit: The detailed agenda and highlights have been released for the 3rd China AIGC Industry Summit, to be held in Beijing on April 16th. The summit will focus on AI technology and application deployment, with topics covering computing infrastructure, large model applications in vertical scenarios like education, entertainment, enterprise services, AI4S, and AI safety and controllability. Speakers hail from companies like Baidu, Huawei, AWS, Microsoft Research Asia, Mianbi Intelligence, Shengshu Technology, Fenbi, NetEase Youdao, Quwan Technology, QingSong Health, Ant Group, etc. The summit will also release lists of AIGC companies and products to watch in 2025, as well as the China AIGC Application Landscape Map. (Source: Countdown 2 Days! 20+ Industry Leaders Discuss AI, The Most Complete Guide to the China AIGC Industry Summit is Here)
![China AIGC Summit Preview]