
Keywords:AI, Artificial Intelligence, AI sovereignty dilemma, HBM and advanced packaging, AI-driven scientific discovery, Gemini 2.5 Pro programming capabilities, AI solves mathematical puzzles
🔥 Focus
The AI Sovereignty Dilemma: How National Security Narratives Devour Public Value?: A report delves into the concept of ‘AI sovereignty,’ defined as a nation’s control over the AI technology stack (data, computing power, talent, energy). The current global trend is shifting from ‘weak sovereignty,’ reliant on allies, towards ‘strong sovereignty,’ pursuing complete localization, notably driven by US policy. While this shift aims to ensure national security and military advantage, it also raises concerns about over-centralization, stifling open innovation, hindering international cooperation, and potentially triggering an AI arms race. The article argues that excessive securitization of AI could sacrifice its vast potential to serve the public interest and address global challenges. It calls for a balance between sovereignty needs and open cooperation to prevent AI from becoming a casualty of geopolitical competition rather than a tool for collective human progress. (Source: The AI Sovereignty Dilemma: How National Security Narratives Devour AI’s Public Value?)
HBM and Advanced Packaging: The Invisible Battleground of the AI Computing Revolution: The exponential demand for computing power from large AI models is causing traditional computing architectures to hit the “memory wall” bottleneck. High Bandwidth Memory (HBM), through 3D stacking and TSV technology, increases bandwidth severalfold (e.g., HBM3E exceeds 1TB/s), significantly alleviating data transfer latency. Simultaneously, advanced packaging technologies (like TSMC’s CoWoS, Intel’s EMIB) tightly integrate chips such as CPUs, GPUs, and HBM through heterogeneous integration, breaking single-chip limitations and boosting computing density and energy efficiency. HBM and advanced packaging have become key standards for AI chips (especially on the training side). The market is dominated by giants like SK Hynix, Samsung, Micron (HBM) and TSMC (packaging), involving huge investments and tight production capacity. The synergistic development of these two technologies is not only reshaping the semiconductor industry landscape (increasing the value share of packaging) but also becoming the crucial battleground determining AI computing competitiveness. (Source: HBM and Advanced Packaging: The Invisible Battleground of the AI Computing Revolution)
Nobel Laureate’s Stunning Declaration: AI Completes 1 Billion Years of “PhD Research Time” in One Year: Nobel laureate and Google DeepMind CEO Demis Hassabis stated that his team’s AI project, AlphaFold-2, completed scientific exploration equivalent to 1 billion years of PhD research time within a single year by predicting the structures of 200 million known proteins on Earth. He emphasized that AI, especially AlphaFold, is fundamentally changing the speed and scale of scientific discovery, democratizing knowledge acquisition. In his speech at Cambridge University, Hassabis further elaborated on the advent of the AI-driven “digital biology” era and argued that the future of AI lies in building “world models” (like the JEPA architecture) capable of understanding the physical world and performing reasoning and planning, rather than solely relying on language processing. He reiterated his commitment to open-source AI as the best way to drive technological progress. (Source: Nobel Laureate’s Stunning Declaration: AI Completes 1 Billion Years of “PhD Research Time” in One Year)

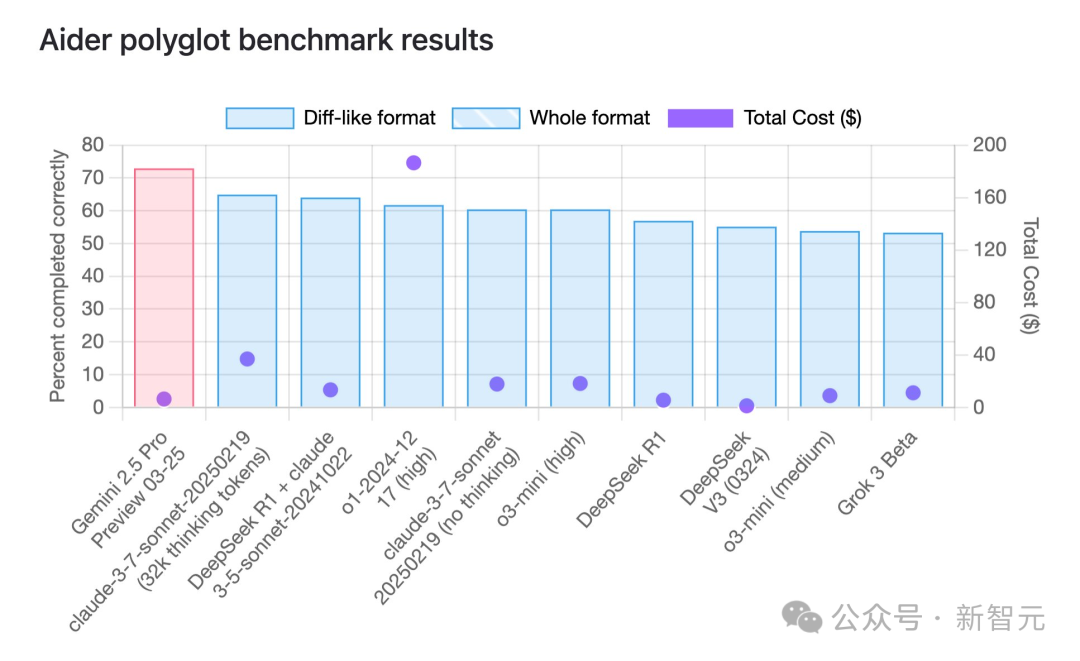
Gemini 2.5 Pro Tops Programming Benchmarks with Significant Cost-Effectiveness: According to the aider multilingual programming benchmark, Google’s newly released Gemini 2.5 Pro model has surpassed Claude 3.7 Sonnet in programming capabilities, ranking first globally. It not only leads in performance but also has extremely low API call costs (around $6), far lower than competitors with similar or worse performance (like GPT-4o, Claude 3.7 Sonnet). Jeff Dean emphasized its cost-performance advantage. Additionally, rumors in the community about an unreleased Google model “Dragontail” suggest it performs even better than Gemini 2.5 Pro in web development tests, hinting that Google still has more up its sleeve in AI programming. Gemini 2.5 Pro also ranks highly in several comprehensive benchmarks, challenging OpenAI and Anthropic across the board with its high performance, low cost, large context window, and free access. (Source: Gemini 2.5 Tops Global Programming Charts, Google Reclaims AI Throne, Mysterious Model Exposed, Altman Faces Challenge)
AI Successfully Assists in Proving a 50-Year-Old Unsolved Math Problem: Scholar Weiguo Yin (Brookhaven National Laboratory) achieved a breakthrough in the exact solution study of the one-dimensional J_1-J_2 q-state Potts model with the help of OpenAI’s o3-mini-high model, solving a 50-year-old problem in the field. When dealing with the specific case of q=3, the AI model successfully simplified the complex 9×9 transfer matrix into an effective 2×2 matrix through symmetry analysis. This key step inspired researchers to generalize the method, ultimately finding an analytical solution applicable to any q value. This achievement not only demonstrates AI’s potential in complex mathematical derivations and non-trivial proofs but also provides new theoretical tools for understanding issues like phase transitions in condensed matter physics. (Source: Just In: AI Solves 50-Year-Old Unsolved Math Problem, Nanjing University Alumnus Completes First Non-Trivial Mathematical Proof Using OpenAI Model)

🎯 Trends
Application and Evolution of AI in Game NPCs: The article reviews the development history of AI technology in game NPCs, from the finite state machines of early Pac-Man to behavior trees, and then to complex AI combining Monte Carlo Tree Search and deep neural networks (like AlphaGo). It points out that although AI can defeat top human players in games like StarCraft 2 and Dota 2, overly powerful AI provides a poor experience for average players. Ideal game AI should focus more on simulating human behavior, providing emotional value and adaptive difficulty (like the Nemesis system in Middle-earth: Shadow of Mordor or dynamic difficulty in Resident Evil 4). Recently, generative AI, exemplified by Stella in miHoYo’s Whispers from the Star, is being used to drive NPCs’ real-time dialogue, emotional responses, and plot development. Despite challenges like latency and memory, this shows a trend towards more human-like and interactively deep AI NPCs. (Source: AI, Making Games Great Again)

OpenAI Tightens API Access, Introduces Organization Verification: OpenAI recently implemented a new API organization verification policy, requiring users to provide valid government-issued identification from a supported country or region to access its most advanced models and features. Each ID can only verify one organization every 90 days. OpenAI states this measure aims to reduce unsafe use of AI and prepare for the release of “exciting new models” (possibly including multiple versions like GPT-4.1, o3, o4-mini). This policy change has sparked widespread attention and concern in the community, especially for developers in unsupported countries/regions and users relying on third-party API services, who may face restricted access or increased costs. It has also triggered discussions about OpenAI’s openness. (Source: GitHub China IP Access Crashed and Revived, OpenAI API New Policy May Lock Down GPT-5?, op7418, Reddit r/artificial)
Apple’s Entry Fuels “AI Doctor” Development Amid Challenges and Regulation: Apple is rumored to enhance its Health App features using AI, introducing services like an “AI Health Coach,” further pushing “AI doctors” into the global spotlight. However, true clinical AI applications face numerous challenges: high development costs, reliance on massive sensitive medical data (involving privacy regulations), difficulties in data annotation, etc. Currently, AI mostly serves as an auxiliary diagnostic tool. The Chinese market also faces unique needs due to uneven medical resources, requiring AI to assist in tiered diagnosis and treatment. Companies like Baichuan Intelligence propose a “dual-doctor model” (AI doctor + AI-assisted human doctor) to address these issues. The article emphasizes that widespread application of AI in healthcare must be built on strict regulation and certification systems to ensure diagnostic accuracy, data security, and user trust, avoiding potential risks. (Source: With Apple’s Entry, “AI Doctor” Becomes a Global Hot Topic, Patient Privacy Protection Emerges as the Biggest Obstacle?)

Microsoft’s Attempt at Direct AI Game Generation Falls Short: Microsoft recently showcased a DEMO using its “Muse” AI model to directly generate game visuals for Quake II, intending to demonstrate AI’s ability to rapidly prototype games. However, the DEMO performed poorly, suffering from low resolution, low frame rates, and numerous bugs (like abnormal enemy behavior, broken physics, environmental glitches), described as a “constantly collapsing dreamscape.” The article suggests this indicates current generative AI technology (especially with its “hallucination” problem) is not yet sufficient to directly and reliably generate complex, playable interactive game experiences. Applying AI to specific parts of the game development pipeline (like NPC interaction, asset generation) seems more realistic. The path of directly generating game visuals or gameplay currently appears highly challenging. (Source: Microsoft’s AI Game Flops, Direct Game Generation Might Be a Dead End)
Google Releases Open Source Model TxGemma for Healthcare Domain: Google has launched the TxGemma series of models, built upon its Gemma and Gemini model families, specifically optimized for the healthcare and drug discovery fields. This initiative aims to provide more specialized AI tools for biomedical research and therapeutic development, fostering innovation in the sector. The release of TxGemma is part of Google’s strategy to offer both general-purpose and domain-specific open source models. (Source: JeffDean)
DeepSeek Announces Plan to Open Source Its Internal Inference Engine: DeepSeek AI stated it will open source its internally used inference engine. Described as a modified and optimized version based on the popular vLLM framework, DeepSeek’s move aims to contribute its optimized inference technology back to the open-source community, helping developers deploy large models more efficiently. This plan reflects DeepSeek’s willingness to contribute to the open-source community, with the code expected to be released on GitHub. (Source: karminski3)
ChatGPT Adds Memory Feature for Enhanced Coherence: OpenAI has added a Memory feature to its ChatGPT model. This function allows ChatGPT to remember information, preferences, or topics discussed by the user across multiple conversations. The goal is to improve interaction continuity and personalization, avoiding the need for users to repeat the same background information in subsequent dialogues, thereby enhancing the user experience. (Source: Ronald_vanLoon)

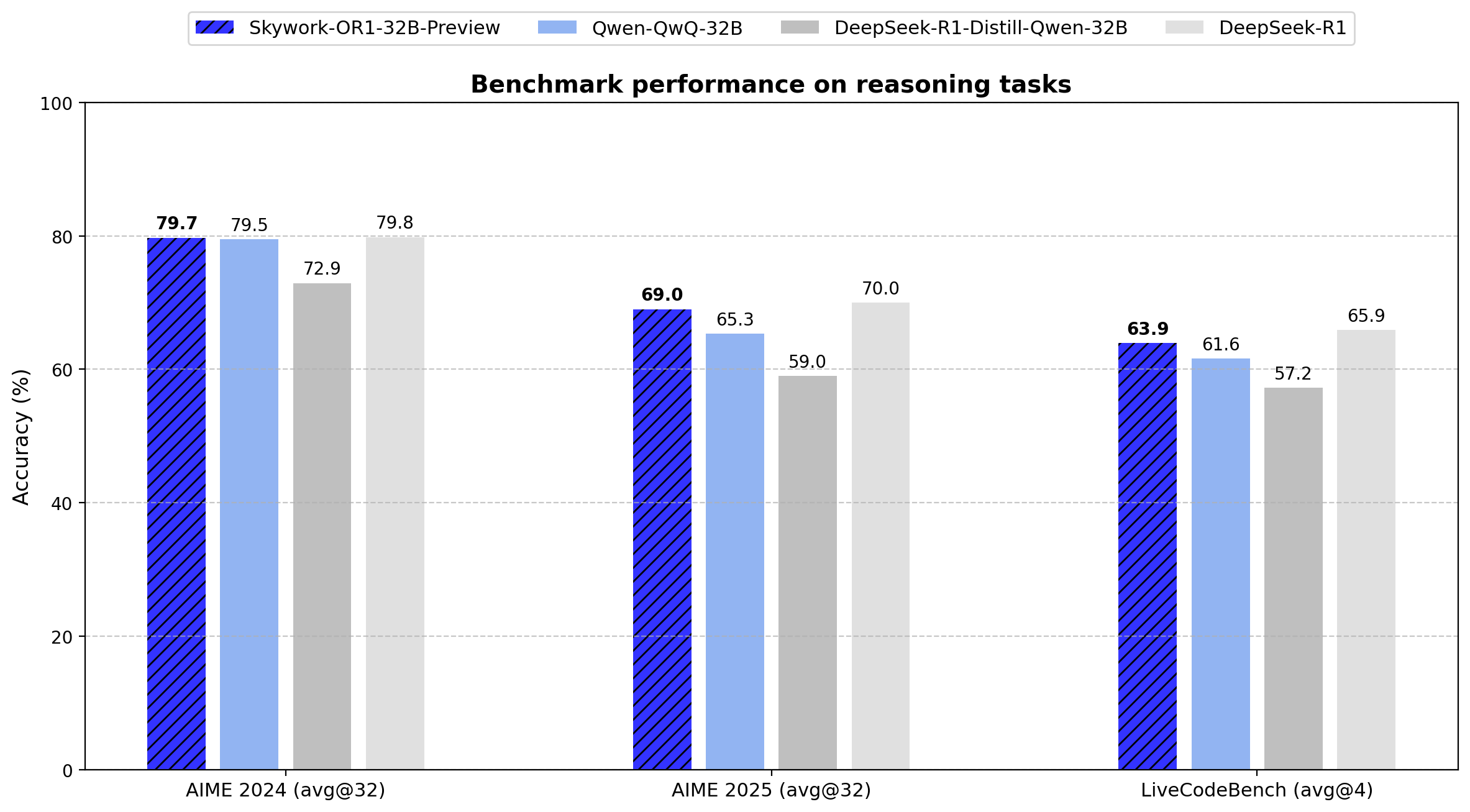
Skywork Releases Open Source Inference Model OR1 Series: Chinese company Skywork (Tiangong-KunlunWanwei) has released a new open source inference model series, Skywork OR1. The series includes OR1-Math-7B optimized for mathematics, and preview versions OR1-7B and OR1-32B excelling in math and coding, with the 32B version reportedly comparable to DeepSeek-R1 in mathematical ability. Skywork has been praised for its openness, releasing model weights, training data, and complete training code. (Source: natolambert)
AI Enhances Robot Navigation and Precise Operation Capabilities: Social media showcases the ability of AI-driven autonomous robots to navigate precisely and execute tasks in complex environments. These robots likely utilize AI technologies such as computer vision, SLAM (Simultaneous Localization and Mapping), and reinforcement learning to operate efficiently in unstructured or dynamic settings, demonstrating advancements in robot perception, planning, and control. (Source: Ronald_vanLoon)
AI-Powered Exoskeleton Helps Wheelchair Users Walk: An advanced exoskeleton device utilizing AI technology is shown, enabling wheelchair users to stand and walk again. AI likely plays roles in interpreting user intent, maintaining balance, coordinating movement, and adapting to different environments, highlighting AI’s potential to improve the quality of life for people with disabilities and marking significant progress in assistive robotics technology. (Source: Ronald_vanLoon)
Concerns Raised Over AI Agents Potentially Used for Cyberattacks: An MIT Technology Review article points out that autonomous AI agents could potentially be used to execute complex cyberattacks. These AI agents have the potential to automatically discover vulnerabilities, generate attack code, and launch attacks at a scale and speed far exceeding human hackers, posing a severe challenge to existing cybersecurity defense systems. This raises concerns about AI weaponization and security risks. (Source: Ronald_vanLoon)

OpenAI Teases Livestream Event and Potential New Model Releases: OpenAI teased a livestream event with a vague message (developer & supermassive black hole). Simultaneously, updated icons and model card information circulating online from its website suggest the imminent release of multiple new models, potentially including the GPT-4.1 series (with nano, mini versions), o4-mini, and the full version of o3. This indicates OpenAI may be preparing to launch a series of new products or model updates to address intensifying market competition. (Source: openai, op7418)

Figure Robot Achieves Natural Walking via Sim-to-Real Reinforcement Learning: Figure AI successfully trained its Figure 02 humanoid robot to master a natural walking gait in a purely simulated environment using reinforcement learning (RL). By generating massive amounts of data with an efficient simulator and combining domain randomization with high-frequency torque feedback from the robot’s body, they achieved zero-shot transfer of the policy from simulation to reality. This method not only accelerates the development process but also demonstrates the feasibility of a single neural network policy controlling multiple robots, holding significant importance for future commercial applications of robotics. (Source: One Algorithm Controls a Robot Army! Pure Simulation Reinforcement Learning, Figure Learns to Walk Like a Human)
🧰 Tools
Jimeng AI 3.0 Generates Stylized Text Designs & Prompt Sharing: A user shared their experience and method for generating stylized text images using the Chinese AI image tool “Jimeng AI 3.0”. Since directly specifying font names yielded poor results, the author created a detailed prompt template pre-set with various visual styles (e.g., industrial, sweet, tech, ink wash) and rules for the AI to automatically match or blend styles based on the input text’s meaning and emotion. Users simply input the target text (e.g., “Esports Teen,” “Craving Candy”), and the template generates a complete image generation prompt including style, background, layout, and atmosphere, achieving high-quality text-image designs in Jimeng AI. The article provides the prompt template and numerous generated examples. (Source: Creating Font Covers with Jimeng AI 3.0, This Solution is God-Tier Cool [Includes: 16+ Cases and Prompts], I’ve Kind of Mastered AI Font Design Generation, Boost Efficiency by 50% with This Prompt Set.)
Using Multimodal AI to Transform Food Photos into Menu-Style Images: A social media user demonstrated a technique using multimodal AI models like GPT-4o to convert ordinary food photos into sophisticated menu images. The method involves providing the original photo to the AI along with descriptive prompts (e.g., referencing “high-end five-star hotel menu standards and style”) to guide the AI in stylizing and editing the image, generating professional-looking dish presentations. This showcases the practical potential of multimodal AI in image understanding, editing, and style transfer. (Source: karminski3)

Slideteam.net: Potentially an AI-Powered Instant Slideshow Creator: Social media mentions Slideteam.net’s ability to create perfect slides “instantly,” suggesting it might leverage AI technology to automate the design and generation process of presentations. Such tools typically use AI for automatic layout, content suggestions, style matching, etc., aiming to improve the efficiency of creating PPTs. (Source: Ronald_vanLoon)
AI Massage Robot Demonstration: A video showcases an AI-driven massage robot. The robot combines the physical manipulation capabilities of a robotic arm with intelligent control by AI. AI might be used to understand user needs, identify body parts, plan massage paths, adjust intensity and techniques, and even perceive user reactions via sensors to optimize the massage experience, demonstrating AI’s application potential in personalized health services and automated physical therapy. (Source: Ronald_vanLoon)
GitHub Copilot Integrated into Windows Terminal: Microsoft has integrated GitHub Copilot functionality into the Canary preview build of its Windows Terminal, naming it “Terminal Chat.” Users subscribed to Copilot can interact directly with the AI within the terminal environment to get command-line suggestions, explanations, and help. This move aims to reduce the need for developers to switch applications while writing commands, providing context-aware intelligent assistance to enhance command-line operation efficiency and accuracy, especially for complex or unfamiliar tasks. (Source: GitHub Copilot Now Runs in Windows Terminal)
Discussion on Hardware Requirements for Deploying OpenWebUI: Reddit community users discussed the Azure VM configuration needed to deploy OpenWebUI (an LLM web interface) for a team of about 30 people. The user plans to run the Snowflake embedding model locally and use the OpenAI API. The discussion covered resource scaling, the impact of embedding model size on CPU/RAM/storage, and the importance of data preprocessing. The community suggested that heavy reliance on the API can reduce local hardware requirements, but running models locally (especially embedding models) requires a more powerful configuration. For resource-constrained situations, using the API for embeddings was also recommended. (Source: Reddit r/OpenWebUI)
📚 Learning
Reasoning AI Models Exhibit “Overthinking” Flaw with Missing Premises: Research from the University of Maryland and other institutions reveals that current reasoning models (like DeepSeek-R1, o1), when faced with problems lacking necessary information (Missing Premises, MiP), tend to generate lengthy, invalid responses rather than quickly identifying the problem’s inherent flaw. This “MiP overthinking” phenomenon leads to wasted computational resources and is largely unrelated to whether the model eventually recognizes the missing premise. In contrast, non-reasoning models perform better. The study suggests this exposes a lack of critical thinking ability in current reasoning models, possibly stemming from reinforcement learning training paradigms or issues in the knowledge distillation process. (Source: Reasoning AI Addicted to “Making Things Up,” Full of Nonsense, Maryland Chinese Scholar Uncovers the Inside Story)

CVPR 2025: CADCrafter Achieves Editable CAD File Generation from a Single Image: Researchers from Moxin Technology, Nanyang Technological University, and other institutions proposed the CADCrafter framework, capable of directly generating parametric, editable CAD engineering files (represented as CAD command sequences) from a single image (part renderings, real object photos, etc.), instead of traditional mesh or point cloud models. The method employs a VAE to encode CAD commands and combines it with a Diffusion Transformer for image-conditioned latent space generation. It enhances performance through a multi-view to single-view distillation strategy and utilizes DPO to optimize the compilability of generated commands. The resulting CAD files can be directly used for manufacturing and support model modification by editing commands, significantly improving the usability and surface quality of AI-generated 3D models. (Source: Single Image Straight to CAD Engineering File! CVPR 2025 New Research Solves the “Non-Editable” Pain Point of AI-Generated 3D Models | Moxin Technology, NTU, etc.)
Zhejiang University, OPPO, etc., Release Survey on OS Agents: This survey paper systematically reviews the current research status of Operating System intelligent agents (OS Agents) based on Multimodal Large Models (MLLMs). OS Agents refer to AI capable of automatically performing tasks on devices like computers and phones via the operating system interface (GUI). The paper defines their key elements (environment, observation space, action space), core capabilities (understanding, planning, execution), reviews construction methods (foundation model architecture & training, agent framework design), and summarizes evaluation protocols, benchmarks, and related commercial products. Finally, it discusses challenges and future directions such as security & privacy, personalization & self-evolution, providing a comprehensive reference for research in this field. (Source: Zhejiang University, OPPO, etc., Release Latest Survey: Research on Computer, Mobile Phone, and Browser Intelligent Agents Based on Multimodal Large Models)
ICLR 2025: Nabla-GFlowNet Achieves Efficient and Diverse Reward Fine-tuning for Diffusion Models: Addressing the issues of slow convergence (traditional RL) or loss of diversity (direct optimization) in reward fine-tuning of diffusion models, researchers proposed the Nabla-GFlowNet method. Based on the Generative Flow Network (GFlowNet) framework, it derives new flow balance conditions (Nabla-DB) and a loss function, using reward gradient information to guide fine-tuning. Through specific parameterization design, it achieves faster convergence than methods like DDPO while maintaining the diversity of generated samples. It was validated on the Stable Diffusion model using reward functions like aesthetics and instruction following, outperforming existing methods. (Source: ICLR 2025 | New Breakthrough in Diffusion Model Reward Fine-tuning! Nabla-GFlowNet Balances Diversity and Efficiency)
Analysis of DeepSeek-R1 Reasoning Mechanism: Research from McGill University delves into the “thinking” process of reasoning models like DeepSeek-R1. The study finds that the length of their reasoning chain is not positively correlated with performance; there’s an “optimal point,” and excessively long reasoning can be detrimental. Models might get stuck repeatedly mulling over existing statements when dealing with long contexts or complex problems. Furthermore, compared to non-reasoning models, DeepSeek-R1 might have more significant security vulnerabilities. This research reveals some characteristics and potential limitations of the operating mechanisms of current reasoning models. (Source: LLM Weekly Express! | Covering Multimodality, MoE Models, Deepseek Reasoning, Agent Safety Control, Model Quantization, etc.)
C3PO: New Method for Optimizing MoE Models at Test Time: Johns Hopkins University proposed C3PO (Critical layers, Core experts, Collaborative Path Optimization), a method for optimizing the performance of Mixture-of-Experts (MoE) large models at test time. By re-weighting core experts in critical layers and optimizing for each test sample, it addresses the issue of suboptimal expert routing. Experiments show C3PO significantly improves MoE model accuracy (by 7-15%), even enabling smaller MoE models to outperform larger dense models in terms of performance, thus enhancing the efficiency of the MoE architecture. (Source: LLM Weekly Express! | Covering Multimodality, MoE Models, Deepseek Reasoning, Agent Safety Control, Model Quantization, etc.)
Systematic Study on the Impact of Quantization on Reasoning Model Performance: Tsinghua University and other institutions conducted the first systematic study on the impact of model quantization on the performance of reasoning models (like DeepSeek-R1, Qwen series). Experiments evaluated the effects of quantization under different bit widths (weights, KV cache, activations) and algorithms. The study found that W8A8 or W4A16 quantization usually achieves lossless or near-lossless performance, but lower bit widths significantly increase risks. Model size, origin, and task difficulty are all key factors affecting post-quantization performance. The research results and quantized models have been open-sourced. (Source: LLM Weekly Express! | Covering Multimodality, MoE Models, Deepseek Reasoning, Agent Safety Control, Model Quantization, etc.)
APIGen-MT: Framework for Generating High-Quality Multi-Turn Agent Interaction Data: Salesforce proposed the APIGen-MT framework to address the scarcity of high-quality data needed for training multi-turn interactive AI agents. The framework operates in two stages: first, using LLM review and iterative feedback to generate detailed task blueprints, and second, transforming these blueprints into complete trajectory data through simulated human-computer interaction. The xLAM-2 model series, trained using this framework, demonstrated excellent performance on multi-turn agent benchmarks, surpassing models like GPT-4o and validating the effectiveness of this data generation method. The synthetic data and models have been open-sourced. (Source: LLM Weekly Express! | Covering Multimodality, MoE Models, Deepseek Reasoning, Agent Safety Control, Model Quantization, etc.)
Research Reveals: Longer Chain-of-Thought Doesn’t Equal Stronger Reasoning Performance, Reinforcement Learning Can Be More Concise: Research from Wand AI indicates that reasoning models (especially those trained with RL algorithms like PPO) tend to generate longer responses not because accuracy demands it, but possibly due to the RL mechanism itself: for wrong answers (negative reward), extending the response length can “dilute” the penalty per token, thus reducing the loss. The study demonstrates that concise reasoning correlates with higher accuracy and proposes a two-stage RL training method: first, train on difficult problems to enhance capability (potentially increasing response length), then train on moderately difficult problems to encourage conciseness while maintaining accuracy. This method effectively improves performance and robustness even on very small datasets. (Source: Longer Thinking Doesn’t Equal Stronger Reasoning Performance, Reinforcement Learning Can Be Very Concise)
USTC, ZTE Propose Curr-ReFT: New Post-Training Paradigm for Small-Scale VLMs: Addressing issues faced by small Vision-Language Models (VLMs) after supervised fine-tuning, such as poor generalization, limited reasoning ability, and training instability (the “brick wall” phenomenon), USTC and ZTE Corporation proposed the Curr-ReFT post-training paradigm. This method combines Curriculum Reinforcement Learning (Curr-RL) with rejection sampling-based self-improvement. Curr-RL guides the model to learn progressively from easy to difficult tasks via a difficulty-aware reward mechanism; rejection sampling maintains the model’s foundational capabilities using high-quality samples. Experiments on Qwen2.5-VL-3B/7B models show Curr-ReFT significantly enhances the reasoning and generalization performance, enabling small models to outperform larger ones on several benchmarks. Code, data, and models are open-sourced. (Source: USTC, ZTE Propose New Post-Training Paradigm: Small-Scale Multimodal Models Successfully Replicate R1 Reasoning)
Tsinghua, Shanghai AI Lab Propose GenPRM: Scalable Generative Process Reward Model: To address the lack of interpretability and test-time scalability in traditional Process Reward Models (PRMs) for supervising LLM reasoning, Tsinghua University and Shanghai AI Lab proposed GenPRM. It evaluates reasoning steps by generating natural language Chain-of-Thought (CoT) and executable verification code, providing more transparent feedback. GenPRM supports test-time computation scaling, improving accuracy by sampling multiple evaluation paths and averaging rewards. Trained on only 23K synthetic data points, the 1.5B version with test-time scaling already surpasses GPT-4o, and the 7B version outperforms a 72B baseline model. GenPRM can also serve as a step-level critic for iterative answer refinement. (Source: Process Reward Models Can Also Scale at Test Time? Tsinghua, Shanghai AI Lab Use 23K Data Points to Let a 1.5B Small Model Outperform GPT-4o)
World’s Largest Open Source Math Dataset MegaMath Released (371B Tokens): LLM360 has launched the MegaMath dataset, containing 371 billion tokens, currently the world’s largest open source pre-training dataset focused on mathematical reasoning. It aims to bridge the gap in scale and quality between the open-source community and closed-source math corpora (like DeepSeek-Math). The dataset consists of three parts: large-scale math-related web data (279B, including a 15B high-quality subset), mathematical code (28B), and high-quality synthetic data (64B, including Q&A, code generation, text-image mix). After careful processing and multiple rounds of pre-training validation, pre-training on the Llama-3.2 model using MegaMath yields significant performance improvements of 15-20% on benchmarks like GSM8K and MATH. (Source: 371 Billion Math Tokens! World’s Largest Open Source Math Dataset MegaMath Released, Crushing DeepSeek-Math)
CVPR 2025: NLPrompt Enhances Robustness of VLM Prompt Learning with Noisy Labels: ShanghaiTech University’s YesAI Lab proposed the NLPrompt method to address the performance degradation of Vision-Language Model (VLM) prompt learning when facing label noise. The research found that in prompt learning scenarios, Mean Absolute Error (MAE) loss (PromptMAE) is more robust than Cross-Entropy (CE) loss. Simultaneously, they proposed the PromptOT data purification method based on Optimal Transport, using prompt-generated text features as prototypes to divide the dataset into clean and noisy sets. NLPrompt applies CE loss to the clean set and MAE loss to the noisy set, effectively combining the advantages of both. Experiments demonstrate that this method significantly improves the robustness and performance of prompt learning methods like CoOp on both synthetic and real noisy datasets. (Source: CVPR 2025 | MAE Loss + Optimal Transport Combo! ShanghaiTech Proposes New Robust Prompt Learning Method)
Knowledge Distillation for Model Compression: Application and Discussion: The community discussed knowledge distillation, a technique where a large “teacher” model trains a smaller “student” model to achieve near-teacher performance on a specific task at significantly lower cost. One user shared successfully distilling GPT-4o’s sentiment analysis capability (92% accuracy) into a small model, reducing costs by 14x. Comments noted that while distillation is effective, it’s often domain-specific, and the student model lacks the teacher’s generalization ability. Also, for specialized scenarios requiring continuous adaptation to changing data, maintaining a self-trained model might be costlier than using a large API directly. (Source: Reddit r/MachineLearning)

AI Agent Definition Gains Attention: Consulting firms like McKinsey are starting to define and discuss the concept of AI Agents, reflecting their growing importance in business and technology as intelligent entities capable of autonomous perception, decision-making, and action to achieve goals. Understanding the definition, capabilities, and application scenarios of AI Agents is becoming a key focus for the industry. (Source: Ronald_vanLoon)

💼 Business
Decoding Alibaba’s AI Strategy: AGI-Centric, Heavy Infrastructure Investment to Drive Transformation: Analysis indicates that although Alibaba hasn’t formally announced an AI strategy, its actions reveal a clear picture: pursuing AGI as the primary goal to regain initiative in the competitive landscape. Plans include investing over 380 billion RMB in AI and cloud computing infrastructure over the next three years, focusing on meeting the surging demand for inference. Strategic paths include: promoting AI Agent capabilities via DingTalk; driving Alibaba Cloud growth using the Qwen series open-source models; developing the MaaS model for the Tongyi API. Simultaneously, Alibaba will deeply integrate AI into existing businesses, such as enhancing Taobao user experience, developing Quark into a flagship AI application (Search + Agent), and exploring AI applications in lifestyle services via AutoNavi (Gaode Maps). Alibaba might also accelerate its AI layout through investments and acquisitions. (Source: Decoding Alibaba’s AI Strategy: Never Announced, But Already Sprinting)
New Trends in AI Talent Market: Emphasis on Practice Over Degrees, Favoring Hybrid Skills: Based on an analysis of nearly 3,000 high-paying AI positions in major Chinese cities, the report reveals three major trends in AI talent demand: 1) Strong demand and high salaries for algorithm engineers, with the automotive industry becoming a major recruiter; 2) Companies (including star firms like DeepSeek) are gradually lowering rigid academic requirements, valuing practical engineering skills and experience in solving complex problems more; 3) Increased demand for hybrid talent, e.g., AI Product Managers need to understand users, models, and prompt engineering simultaneously, as AI takes on more specialized tasks, requiring humans to integrate and supervise at a higher level. (Source: From Nearly 3,000 Recruitment Data Points, I Found Three Iron Laws for Mining AI Talent)
Ubtech Continues Losses, Humanoid Robot Commercialization Faces Severe Challenges: Humanoid robot company Ubtech’s 2024 financial report shows that despite a 23.7% revenue increase to 1.3 billion RMB, it still incurred a loss of 1.16 billion RMB. Commercialization of its core humanoid robot business is slow, with only 10 units delivered throughout the year at a high price of 3.5 million RMB each, far exceeding market expectations and competitors (like Unitree Robotics’ G1 priced at only 99,000 RMB). Coupled with reports of financial difficulties at another leading industry player, Datta Robot, this raises doubts about the commercial viability of the humanoid robot industry, corroborating investor Zhu Xiaohu’s earlier cautious views. High costs, limited application scenarios, and safety/reliability issues are the main obstacles to large-scale commercialization of humanoid robots currently. (Source: Ubtech Loses Nearly 1.2 Billion in a Year, Zhu Xiaohu Now Has More to Say)

AI Driving Growth in Telecom, High-Tech, and Media Industries: Discussion highlights that artificial intelligence (including generative AI) is becoming a key driver of growth for the telecommunications, high-tech, and media industries. AI technologies are being widely applied to improve customer experience, optimize network operations, automate content creation, enhance operational efficiency, and develop innovative services, helping companies in these sectors gain a competitive edge in rapidly changing markets. (Source: Ronald_vanLoon)
Hugging Face Acquires Open Source Robotics Company Pollen Robotics: The well-known AI model and tool platform Hugging Face has acquired Pollen Robotics, the startup famous for its open-source humanoid robot Reachy. This acquisition signals Hugging Face’s intention to extend its successful open-source model to the field of AI robotics, aiming to foster collaboration and innovation in the sector through open hardware and software solutions, thereby accelerating the democratization of robotics technology. (Source: huggingface, huggingface, huggingface, huggingface)

🌟 Community
AI Era May Be More Favorable for Liberal Arts Graduates: Lynn Duan, founder of the Silicon Valley AI+ community, believes that as AI tools (like Cursor) lower the barrier to programming, the relative importance of engineering skills decreases, while skills related to business, marketing, communication, and other humanities/social sciences become more crucial. AI replaces some entry-level technical positions but creates demand for hybrid talent capable of bridging technology and the market. She advises graduates to consider startups for rapid growth and to showcase abilities through practical projects (like deploying models, developing apps) rather than just relying on academic credentials. She also notes that founder traits (like conviction, industry understanding) are more important than a purely technical background and is optimistic about AI startup opportunities in US SaaS and Chinese smart hardware sectors. (Source: AI Is Actually a Good Era for Liberal Arts Students | Dialogue with Lynn Duan, Founder of Silicon Valley AI+)

GitHub’s Brief “Block” of Chinese IPs Sparks Concern, Official Statement Claims Misconfiguration: Recently, some Chinese users found themselves unable to access GitHub when not logged in, receiving IP restriction messages, sparking community concerns about a potential “block.” Although GitHub officials quickly responded, stating it was a configuration error that has since been fixed, the incident still fueled discussion. Given GitHub’s past actions of restricting access from regions like Iran and Russia based on US sanctions policies, some interpreted this event as a potential “rehearsal” for future restrictions. The article emphasizes GitHub’s importance to Chinese developers and the open-source ecosystem (including numerous AI projects), the potential negative impacts of such restrictions, and lists domestic code hosting platforms like Gitee and CODING as alternatives. (Source: “Bug” or “Rehearsal”? GitHub Suddenly “Blocks” All Chinese IPs, Official: Just a “Slip of the Hand” Technical Error)
Claude AI Performance and Service Spark User Controversy: Discussions on Reddit reveal dissatisfaction among some users regarding Anthropic’s Claude model, citing performance degradation, unnecessary modifications during coding, and disappointment with paid tiers and rate limits. Some prominent developers even stated they would switch to other models (like Gemini 2.5 Pro). However, other users argue that Claude (especially the older Sonnet 3.5) still holds advantages in specific tasks (like coding) or report not frequently encountering rate limits. This debate reflects diverging user experiences with Claude and the high expectations users have for AI model performance and service amidst fierce competition. (Source: Reddit r/ClaudeAI)

Scale of Gemini Deep Research Feature Sparks Discussion: A user shared their experience using Google Gemini Advanced’s Deep Research feature, where the AI accessed nearly 700 websites to answer a single question and generated a lengthy report (e.g., 37 pages). While impressed by the scale, this also triggered discussions about information quality. Commenters questioned whether processing such a vast amount of web information guarantees accuracy and depth or merely aggregates potentially flawed web search results on a larger scale. This reflects the community’s focus and scrutiny on the information processing capabilities (depth vs. breadth) of AI research tools. (Source: Reddit r/artificial)

Gemini 2.5 Pro Programming Capabilities Receive Community Praise: Multiple users shared positive experiences using Google Gemini 2.5 Pro for programming in community forums. They found it highly intelligent, capable of understanding user intent well, possessing a 1 million token long context processing ability (sufficient for analyzing large codebases), and being free to use, making its overall performance superior to competitors like Claude. Although minor flaws exist (like occasionally hallucinating non-existent library functions), the overall assessment is very high, considered one of the most popular coding models currently, with anticipation for potentially stronger future Google models (like Dragontail). (Source: Reddit r/ArtificialInteligence)
Rapid Development of Small Open Source Models Requires Updated User Perception: Community discussion reflects on the rapid progress of open-source LLMs. It points out that models like QwQ-32B and Gemma-3-27B, considered good now, would have been revolutionary just a year or two ago (when GPT-4 was released). This serves as a reminder not to overlook the actual capabilities of current small open-source models, which have reached a considerable level. Comments also acknowledge the gap compared to top closed-source models (e.g., stability, speed, context handling) but emphasize their pace of improvement and potential, suggesting future breakthroughs might come from architectural innovation rather than just scaling parameters. (Source: Reddit r/LocalLLaMA)
Community Member Offers Free A100 Compute Power for AI Projects: A user possessing four Nvidia A100 GPUs posted on Reddit, offering free compute power (approx. 100 A100 hours) for innovative AI enthusiast projects aimed at positive impact but limited by computational resources. The offer received a positive response, with several researchers and developers proposing specific project plans covering new model architecture training, model interpretability, modular learning, human-computer interaction applications, etc., reflecting the AI research community’s demand for computing resources and spirit of mutual support and sharing. (Source: Reddit r/deeplearning)
Claude AI Rate Limit Issues Spark Community Debate: Complaints about frequently hitting rate limits while using the Claude AI model (e.g., after only 5 messages) have sparked debate in the community. Some users strongly questioned these complaints, suggesting exaggeration or improper usage (like uploading extremely long contexts every time), demanding proof. However, other users shared their own experiences, confirming they indeed hit limits frequently during intensive tasks (like large code editing), impacting their workflow. The discussion highlights the wide variation in user experiences with rate limits, possibly related to specific usage patterns and task complexity, while also showing user sensitivity to restrictions on paid services. (Source: Reddit r/ClaudeAI)
💡 Other
AIGC and Agent Ecosystem Conference (Shanghai) to be Held in June: The 2nd AIGC and Artificial Intelligence Agent Ecosystem Conference will be held in Shanghai on June 12, 2025, with the theme “Intelligent Chain Links All Things · Symbiosis Without Boundaries.” The conference focuses on the synergistic innovation and ecosystem integration of Generative AI (AIGC) and AI Agents, covering topics like AI infrastructure, large language models, AIGC marketing and scenario applications (media, e-commerce, industry, healthcare, etc.), multimodal technology, autonomous decision-making frameworks, etc. It aims to promote the upgrade of AI from single-point tools to ecosystem collaboration, connecting technology providers, demand parties, capital, and policymakers. (Source: June Shanghai | “Intelligent Chain Links All Things” Shanghai Summit: AIGC + Agent Ecosystem Integration)

36Kr AI Partner Conference Focuses on Super APP: 36Kr will host the “Super APP is Here · 2025 AI Partner Conference” at Shanghai ModelSpace on April 18, 2025. The conference aims to explore how AI applications are reshaping the business world and giving rise to disruptive “super applications.” It will bring together executives from companies like AMD, Baidu, 360, Qualcomm, as well as investors, to discuss hot topics such as industry AI transformation, AI computing power, AI search, AI education, etc., and will release AI-native application innovation cases and AI Partner Innovation Awards. An AI Inclusive Salon and an AI Go-Global Closed-Door Seminar will also be held concurrently. (Source: Super App is Here! See How AI Applications Are ‘Rewriting’ the Business World? | Core Highlights of the 2025 AI Partner Conference)

Horizon Robotics Hiring 3D Reconstruction/Generation Algorithm Interns: Horizon Robotics’ Embodied Intelligence team is recruiting algorithm interns specializing in 3D reconstruction/generation in Shanghai and Beijing. The role involves designing and developing Real2Sim algorithms, utilizing techniques like 3D Gaussian Splatting, feedforward reconstruction, and 3D/video generation to reduce robot data acquisition costs and optimize simulator performance. Requires a Master’s degree or above, relevant experience and skills. Offers opportunities for full-time conversion, GPU resources, and professional guidance. (Source: Shanghai/Beijing Internal Referral | Horizon Robotics Embodied Intelligence Team Hiring 3D Reconstruction/Generation Algorithm Interns)
OceanBase Hosts First AI Hackathon: Database vendor OceanBase, in collaboration with Ant Open Source, Jiqizhixin, etc., is hosting its first AI Hackathon themed “DB+AI,” with a 100,000 RMB prize pool. The competition encourages developers to explore the integration of OceanBase and AI technologies, with directions including using OceanBase as the data foundation for AI applications, or building AI applications (like Q&A, diagnostic systems) within the OceanBase ecosystem (combined with CAMEL AI, FastGPT, etc.). Registration is open from April 10 to May 7 for individuals and teams. (Source: 100K Prize Money × Cognitive Upgrade! OceanBase’s First AI Hackathon Calls for Heroes, Do You Dare to Come?)
Meituan Hotel & Travel Hiring L7-L8 Large Model Algorithm Engineers: Meituan’s Hotel & Travel Supply Algorithm team in Beijing is hiring L7-L8 level Large Model Algorithm Engineers (experienced hires). Responsibilities include utilizing NLP and large model technologies to build a hotel & travel supply understanding system (tags, hotspots, similarity analysis), optimizing product display materials (titles, images, text), constructing vacation package combinations, and exploring cutting-edge large model technology applications in supply-side algorithms. Requires a Master’s degree or above, 2+ years of experience, and solid algorithm and programming skills. (Source: Beijing Internal Referral | Meituan Hotel & Travel Supply Algorithm Team Hiring L7-L8 Large Model Algorithm Engineers)
QbitAI Hiring AI Domain Editors/Writers: AI tech media outlet QbitAI (量子位) is hiring full-time Editors/Writers in Zhongguancun, Beijing, open to experienced hires and recent graduates, with internship-to-full-time opportunities. Positions cover AI large models, embodied intelligence robots, terminal hardware, and AI new media editing (Weibo/Xiaohongshu). Requires passion for the AI field, excellent writing and information gathering skills. Bonus points for familiarity with AI tools, ability to interpret papers, programming skills, etc. Offers competitive salary/benefits and professional growth opportunities. (Source: QbitAI Recruitment | Job Posting Revised by DeepSeek)
Turing Award Winner LeCun Discusses AI Development: Human Intelligence Isn’t General, Next-Gen AI May Be Non-Generative: In a podcast interview, Yann LeCun argued that the current pursuit of AGI (Artificial General Intelligence) is misguided because human intelligence itself is highly specialized, not general. He predicts the next breakthrough in AI might be based on non-generative models, like his proposed JEPA architecture, focusing on enabling AI to understand the physical world and possess reasoning and planning capabilities (world models), rather than just processing language. He believes current LLMs lack true reasoning abilities. LeCun also emphasized the importance of open source (like Meta’s LLaMA) for advancing AI development and sees devices like smart glasses as important avenues for AI technology implementation. (Source: Turing Award Winner LeCun: Human Intelligence is Not General Intelligence, Next-Gen AI May Be Based on Non-Generative Models)
China AIGC Industry Summit Upcoming (April 16, Beijing): The 3rd China AIGC Industry Summit will be held in Beijing on April 16. The summit will gather over 20 industry leaders from companies and institutions such as Baidu, Huawei, AWS, Microsoft Research Asia, Mianbi Intelligence, Shengshu Technology, Fenbi, NetEase Youdao, Quwan Technology, Qingsong Health, etc., to discuss the latest advancements in AI technology, its application across various industries, computing infrastructure, security and controllability, and other core topics. The summit aims to showcase how AI empowers industrial upgrading and will release relevant awards and the “China AIGC Application Panorama.” (Source: Countdown 2 Days! 20+ Industry Leaders Discuss AI, Complete Guide to China AIGC Industry Summit Here)
Exploring Solutions to Run Trillion-Parameter Large Models on Low-Cost GPUs: The article discusses a cost-effective (around 100,000 RMB level) AI all-in-one machine solution using Intel® Arc™ graphics cards (like A770) and Xeon® W processors. Through hardware-software co-optimization (IPEX-LLM, OpenVINO™, oneAPI), this setup can run large models like QwQ-32B (at 32 tokens/s) and even the 671B DeepSeek R1 (with FlashMoE optimization, nearly 10 tokens/s) on a single machine. This provides a high-value option for enterprises to deploy large models locally or at the edge, meeting needs for offline inference and data security. Intel has also launched the OPEA platform, collaborating with ecosystem partners to promote the standardization and popularization of enterprise AI applications. (Source: The Secret to Squeezing a $300 Graphics Card to Run Trillion-Parameter Models is Here)
Surgical Robot Demonstrates High-Precision Operation: A video shows a surgical robot precisely separating the shell of a raw quail egg from its inner membrane, showcasing the advanced level of modern robots in fine manipulation and control. (Source: Ronald_vanLoon)
Overview of Semiconductor Lithography Technology Progress: Points to an article discussing the latest advancements from the SPIE Advanced Lithography + Patterning conference, covering topics like High-NA EUV, EUV cost, pattern shaping, novel photoresists (metal oxide, dry), and Hyper-NA, among other next-generation chip manufacturing technologies. These technologies are crucial for supporting the development of future AI chips. (Source: dylan522p)
Wheeled Robot Precision Skill Demonstration: A video showcases the high-precision movement or manipulation skills of a wheeled robot, likely involving AI and machine learning techniques for control and perception. (Source: Ronald_vanLoon)