
Keywords:AI, LLM, AI shopping app fraud, LLM reasoning benchmark, Google Gemini self-hosting, vLLM inference engine, Suno AI music generation
🔥 Focus
“AI” Shopping App Exposed as Actually Human-Operated: A startup named Fintech and its founder have been accused of fraud. Their shopping app, claimed to be AI-driven, actually relied heavily on a human team located in the Philippines to process transactions. This incident has once again drawn attention to the phenomenon of “AI Washing,” where companies exaggerate or falsely claim AI capabilities to attract investment or users. The event highlights the challenges of distinguishing genuine AI applications amidst the current AI hype and the importance of conducting due diligence on startups (Source: Reddit r/ArtificialInteligence)

New Benchmark Reveals Lack of Generalization in AI Reasoning Models: A new benchmark called LLM-Benchmark (https://llm-benchmark.github.io/) indicates that even the latest AI reasoning models struggle with out-of-distribution (OOD) logic puzzles. The research found that compared to the models’ performance on benchmarks like math olympiads, their scores on these new logic puzzles were far lower than expected (approximately 50 times lower). This exposes the limitations of current models in performing true logical reasoning and generalization beyond their training data distribution (Source: Reddit r/ArtificialInteligence)
Google Allows Enterprises to Self-Host Gemini Models, Addressing Data Privacy Concerns: Google announced it will allow enterprise customers to run Gemini AI models in their own data centers, starting with Gemini 2.5 Pro. This move aims to meet strict enterprise requirements for data privacy and security, enabling them to leverage Google’s advanced AI technology without sending sensitive data to the cloud. This strategy is similar to Mistral AI’s but contrasts with OpenAI and Anthropic, which primarily offer services via cloud APIs or partners, potentially changing the competitive landscape of the enterprise AI market (Source: Reddit r/LocalLLaMA, Reddit r/MachineLearning)

🎯 Trends
VSCode Natively Supports llama.cpp, Expanding Local Copilot Capabilities: Visual Studio Code recently updated to add support for local AI models. Following support for Ollama, it is now compatible with llama.cpp through minor adjustments. This means developers can directly use local large language models running via llama.cpp within VSCode as an alternative or supplement to GitHub Copilot, further facilitating the use of LLMs for code assistance in a local environment and enhancing development flexibility and data privacy. Users need to select Ollama as the proxy in settings (even though llama.cpp is actually used) to enable this feature (Source: Reddit r/LocalLLaMA)

Yandex and Others Release HIGGS: A New LLM Compression Method: Researchers from Yandex Research, HSE University, MIT, and other institutions have developed a new LLM quantization compression technique called HIGGS. The method aims to significantly compress model size, allowing them to run on less powerful devices while minimizing loss in model quality. It is claimed that the method has been successfully used to compress the 671B parameter DeepSeek R1 model with significant results. HIGGS intends to lower the barrier to using LLMs, making large models more accessible for small companies, research institutions, and individual developers. The relevant code has been released on GitHub and Hugging Face (Source: Reddit r/LocalLLaMA)
Google Fixes QAT 2.7 Model Quantization Issues: Google has updated its QAT (Quantization Aware Training) quantized model version 2.7 (possibly referring to Gemma 2 7B or similar models), fixing some control token errors present in the previous version. Previously, the model might incorrectly generate tokens like <end_of_turn> at the end of the output. The newly uploaded quantized models have resolved these issues, and users can download the updated versions for correct model behavior (Source: Reddit r/LocalLLaMA)
DeepMind CEO Discusses AlphaFold Achievements: In an interview segment, DeepMind CEO Demis Hassabis emphasized the immense impact of AlphaFold, using the analogy that AlphaFold completed “a billion years of PhD research time” in one year. He noted that historically, determining the structure of a single protein often took a PhD student their entire doctoral period (4-5 years), whereas AlphaFold predicted the structures of all (then known) 200 million proteins in a year. His remarks highlight the revolutionary potential of AI in accelerating scientific discovery (Source: Reddit r/artificial)

🧰 Tools
MinIO: High-Performance Object Storage for AI: MinIO is an open-source, high-performance, S3-compatible object storage system licensed under GNU AGPLv3. It specifically emphasizes its capability in building high-performance infrastructure for machine learning, analytics, and application data workloads, providing dedicated AI storage documentation. Users can install it via containers (Podman/Docker), Homebrew (macOS), binaries (Linux/macOS/Windows), or from source. MinIO supports building distributed, high-availability storage clusters with erasure coding, suitable for AI application scenarios requiring handling large amounts of data (Source: minio/minio – GitHub Trending (all/daily))

IntentKit: Framework for Building AI Agents with Skills: IntentKit is an open-source autonomous agent framework designed to enable developers to create and manage AI agents equipped with various capabilities, including interacting with blockchains (prioritizing EVM chains), managing social media (Twitter, Telegram, etc.), and integrating custom skills. The framework supports multi-agent management and autonomous operation, with plans for an extensible plugin system. Currently in Alpha, the project provides an architectural overview and development guide, encouraging community contributions for skills (Source: crestalnetwork/intentkit – GitHub Trending (all/daily))

vLLM: High-Performance LLM Inference and Serving Engine: vLLM is a library focused on high-throughput, memory-efficient LLM inference and serving. Its core advantages include effective management of attention key-value memory through PagedAttention technology, support for Continuous Batching, CUDA/HIP graph optimization, various quantization techniques (GPTQ, AWQ, FP8, etc.), integration with FlashAttention/FlashInfer, and Speculative Decoding. vLLM supports Hugging Face models, provides an OpenAI-compatible API, runs on various hardware like NVIDIA and AMD, and is suitable for scenarios requiring large-scale deployment of LLM services (Source: vllm-project/vllm – GitHub Trending (all/daily))
tfrecords-reader: TFRecords Reader with Random Access and Search: This is a Python tool for handling TFRecords datasets, specifically designed for data inspection and analysis. It allows users to create indexes for TFRecords files, enabling random access and content-based search (using Polars SQL queries), addressing the limitations of TFRecords’ native sequential reading. The tool does not depend on TensorFlow and protobuf packages, supports direct reading from Google Storage, offers fast indexing, and facilitates exploration and sample finding in large-scale TFRecords datasets outside of model training (Source: Reddit r/MachineLearning)
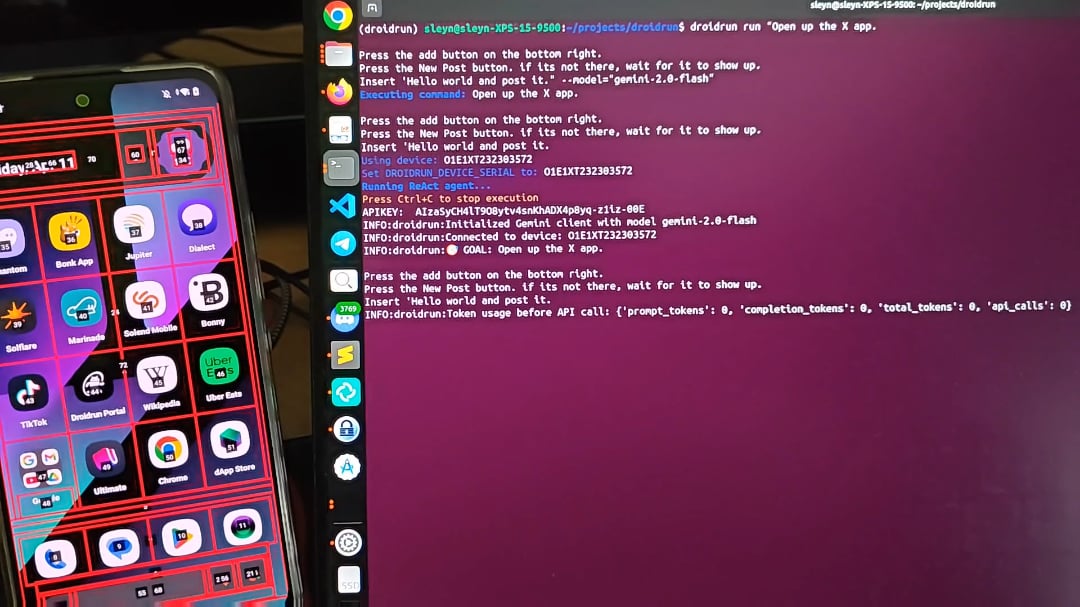
DroidRun: Enabling AI Agents to Control Android Phones: DroidRun is a project that allows AI agents to operate Android devices like humans. By connecting any LLM, it can achieve interactive control over the phone’s UI to perform various tasks. The project showcases its potential, aiming for mobile-side automation such as auto-posting content, managing apps, etc. Developers invite community feedback and ideas to explore more automation scenarios (Source: Reddit r/LocalLLaMA)
📚 Learning
Cell Patterns Publishes Major Review on Multilingual Large Language Models (MLLMs): This review systematically summarizes the current state of research on Multilingual Large Language Models, covering 473 publications. Content includes dataset resources and construction methods for multilingual pre-training, instruction fine-tuning, and RLHF; cross-lingual alignment strategies, divided into parameter-adjusted alignment (e.g., pre-training, instruction fine-tuning, RLHF, downstream fine-tuning) and parameter-frozen alignment (e.g., direct prompting, code-switching, translation alignment, retrieval augmentation); multilingual evaluation metrics and benchmarks (NLU & NLG tasks); and discusses future research directions and challenges such as hallucination, knowledge editing, safety, fairness, language/modality expansion, interpretability, deployment efficiency, and update consistency. Provides a comprehensive research map of MLLMs (Source: Cell Patterns重磅综述!473篇文献全面解析多语言大模型最新研究进展)

AAAI 2025 | Beihang University Proposes TRACK: Collaborative Learning of Dynamic Road Networks and Trajectory Representations: A team from Beihang University proposed the TRACK model to address the issue that existing methods fail to capture the spatio-temporal dynamics of traffic. The model pioneers the joint modeling of traffic states (macro-level group characteristics) and trajectory data (micro-level individual characteristics), positing that they influence each other. TRACK learns dynamic road network and trajectory representations through Graph Attention Networks (GAT), Transformers, and innovative Trajectory Transition-aware GAT and collaborative attention mechanisms. The model employs a joint pre-training framework including masked trajectory prediction, contrastive trajectory learning, masked state prediction, next state prediction, and trajectory-traffic state matching self-supervised tasks, demonstrating superior performance on traffic state prediction and travel time estimation tasks (Source: AAAI 2025 | 告别静态建模!北航团队提出动态路网与轨迹表示的协同学习范式)

SUSTech Prof. Linyi Yang Recruiting PhD/RA/Visiting Students in Large Models: Prof. Linyi Yang (soon to join, independent PI) at the Department of Statistics and Data Science, Southern University of Science and Technology (SUSTech), is establishing the Generative AI Lab (GenAI Lab) and recruiting PhD and Master’s students for the 2025/2026 intake, as well as Postdocs, Research Assistants, and Interns. Research directions include causal analysis of large model reasoning, generalizable reinforcement learning methods for large models, and building reliable non-agent systems to prevent AI misalignment. Prof. Yang has published multiple papers in top conferences and has extensive collaborations with universities and research institutions domestically and internationally, encouraging joint supervision. Applicants are required to have strong self-motivation, solid mathematical foundations, and programming skills (Source: 博士申请 | 南方科技大学杨林易老师招收大模型方向全奖博士/RA/访问学生)

Personal Project: Building a Large Language Model from Scratch: A developer shared their personal project of implementing a Causal Language Model (similar to GPT) from scratch. The project uses Python and PyTorch, with a core architecture including multi-head self-attention with a Causal Mask, feed-forward networks, and stacked decoder blocks (layer normalization, residual connections). The model uses pre-trained GPT-2 word embeddings and positional embeddings, with an output layer mapping to vocabulary logits. It employs Top-k sampling for autoregressive text generation and is trained on the WikiText dataset using the AdamW optimizer and CrossEntropyLoss. The project code is open-sourced on GitHub, demonstrating the fundamental process of building an LLM (Source: Reddit r/MachineLearning)
Paper Discussion: d1 – Scaling Reasoning in Diffusion Large Language Models via Reinforcement Learning: This research proposes the d1 framework, aiming to adapt pre-trained diffusion-based LLMs (dLLMs) for reasoning tasks. dLLMs generate text in a coarse-to-fine manner, differing from autoregressive (AR) models. The d1 framework combines Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL), specifically including: using Masked SFT for knowledge distillation and guided self-improvement; proposing a novel critic-free, policy gradient-based RL algorithm called diffu-GRPO. Experiments show that d1 significantly improves the performance of SOTA dLLMs on math and logic reasoning benchmarks, demonstrating the potential of dLLMs in reasoning tasks (Source: Reddit r/MachineLearning)
💼 Business
Alibaba Tongyi Lab Hiring Algorithm Experts for General RAG/AI Search (Beijing/Hangzhou): Alibaba’s Tongyi Lab AI Search team is recruiting Algorithm Experts responsible for advancing the R&D and optimization of core search and RAG (Retrieval-Augmented Generation) modules (such as Embedding, ReRank models), enhancing model performance to industry-leading levels. Responsibilities also include optimizing the overall framework pipeline for downstream applications (Q&A, customer service, multimodal Memory) to improve accuracy, efficiency, and scalability, and collaborating with the team to drive business implementation. Requires a Master’s degree or above in a relevant field, familiarity with search/NLP/large model technologies, and relevant project experience (Source: 北京/杭州内推 | 阿里通义实验室招聘通用RAG/AI搜索方向算法专家)

AI Recruitment Startup OpportuNext Seeking CTO (Remote/Equity): OpportuNext is an early-stage startup aiming to improve the recruitment process using AI technology, offering intelligent job matching, resume analysis, and career planning tools. The founder is looking for a technical co-founder (CTO) to lead AI feature development, build scalable backend systems, and drive product innovation. Requires experience in AI/ML, Python, and scalable systems, a passion for solving real-world problems, and willingness to join an early-stage startup (remote position with equity) (Source: Reddit r/deeplearning)
🌟 Community
Discussion: Large Models Essentially “Linguistic Magic”: A deep-thinking article argues that large models (like ChatGPT) don’t truly understand information but mimic and predict forms of expression by learning from vast amounts of language data. Prompts serve to set context and guide the model’s attention, rather than communicating with a conscious entity. The model’s responses are based on pattern reproduction from having “seen enough,” appearing intelligent but lacking true understanding, easily leading to “confidently incorrect” hallucinations. Human-computer interaction is more like the user thinking on behalf of the model, whose output might subtly reshape the user’s thinking and judgment habits, potentially reflecting and amplifying real-world biases (Source: 我所理解的大模型:语言的幻术)
Discussion: AI Energy Consumption and US-China Model Strategy Differences: Reddit users discuss Trump’s statement listing coal as a key mineral for AI development, sparking concerns about AI’s energy consumption. Comments note that large models are increasingly energy-intensive, while Chinese companies seem more inclined towards building leaner, more efficiency-focused models. This reflects the trade-off between performance and energy efficiency in AI development and potentially different technological paths taken by different regions (Source: Reddit r/artificial)

Question: Seeking Deep Reinforcement Learning Framework Similar to PyTorch Lightning: A Reddit user asks if there are frameworks specifically for Deep Reinforcement Learning (DRL) similar to PyTorch Lightning (PL). The user feels that while PL can be used for DRL, its design is more geared towards dataset-driven supervised learning rather than environment-interaction-driven DRL. The post seeks community recommendations for frameworks suitable for DRL (like DQN, PPO) that integrate well with environments like Gymnasium, or best practices for using PL for DRL (Source: Reddit r/deeplearning)
Community: MetaMinds Discord Community for Virtual Musicians Launched: A new Discord community called MetaMinds has been established, aiming to provide a platform for virtual artists using AI tools (like Suno) for music creation to communicate, collaborate, and share. The community has launched its first song creation contest titled “A Personal Song” and plans to host higher-standard competitions in the future, possibly including cash prizes. This reflects the formation of a new community ecosystem in the field of AI music creation (Source: Reddit r/SunoAI)
Discussion: What to Call a Collection of Datasets Including Training Sets?: A Reddit user asks what term should be used for a collection of datasets intended for training and evaluating the same model, as opposed to a “Benchmark” which is typically used for evaluating models on multiple tasks. This question explores the nuances of dataset classification and terminology within the machine learning field (Source: Reddit r/MachineLearning)
Help Request: Implementing Speech-to-Text in OpenWebUI: A user seeks the best solution and recommended models for implementing speech-to-text (user wrote TTS, but description implies transcribing YouTube videos/audio files, likely ASR/STT) functionality using an H100 GPU within a Docker-deployed OpenWebUI+Ollama environment. This reflects the user’s desire to integrate more modality processing capabilities into their local LLM interaction interface (Source: Reddit r/OpenWebUI)
Discussion: Views on Claude Annual Subscription and Restriction Adjustments: A Reddit user expresses relief at not having purchased the Claude annual subscription, as many users have recently complained about tightening usage limits. The user speculates that Anthropic might be adjusting its strategy to save costs after attracting a large number of paying users. Concurrently, the user mentions the powerful performance of the free Gemini 2.5 Pro, expressing concerns and hopes for Claude’s future development. The discussion reflects user sensitivity to LLM service pricing, usage limits, and value for money (Source: Reddit r/ClaudeAI)
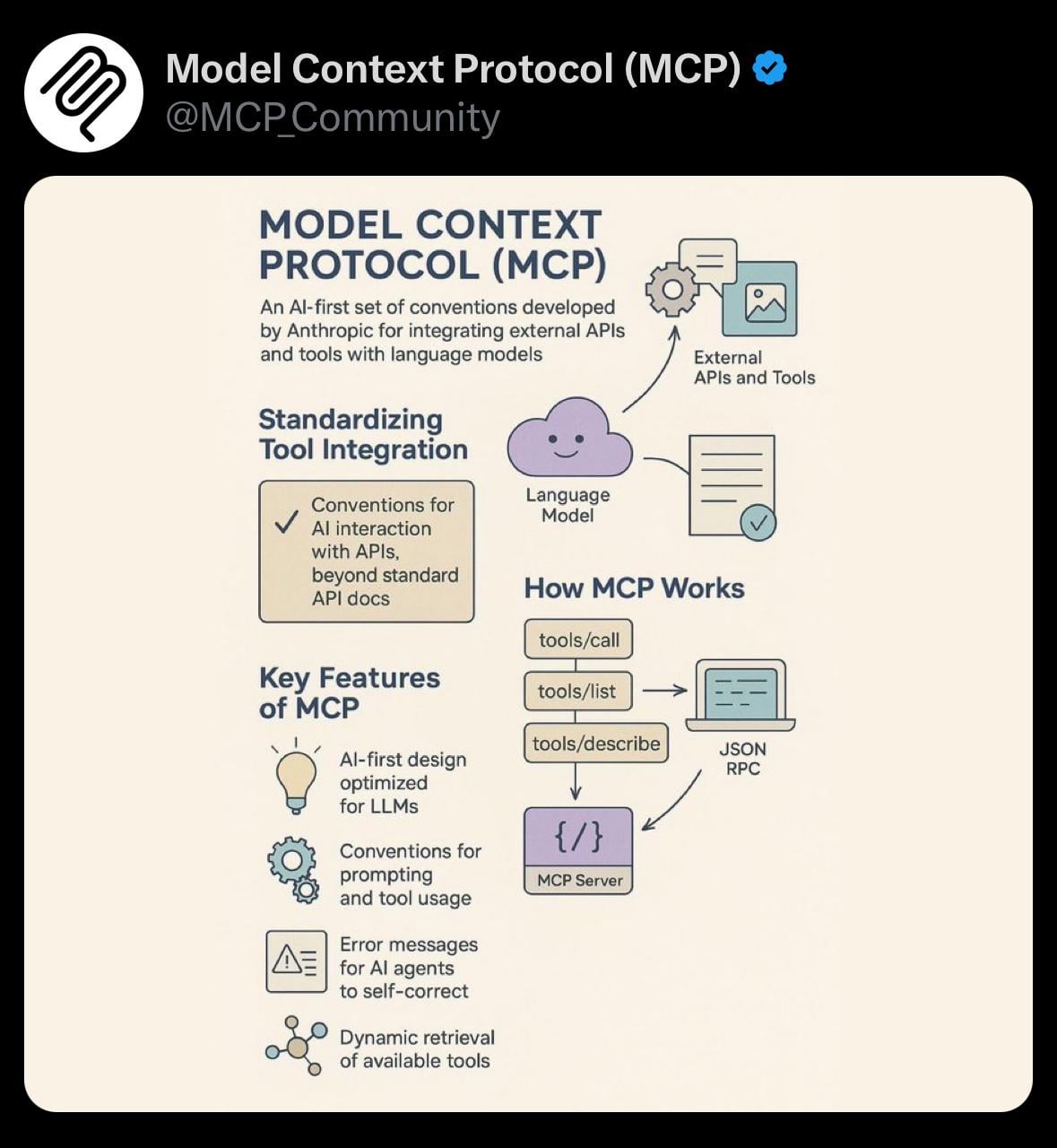
Sharing: Simple Visualization of Model Context Protocol (MCP): A user shares a simple visualization image related to the Model Context Protocol (MCP). MCP might be a technical concept related to Anthropic’s Claude model, aimed at optimizing or managing how the model handles long contexts. This share provides a visual aid for the community to understand related technical concepts (Source: Reddit r/ClaudeAI)
Help Request: Adding Custom Commands in OpenWebUI Chat: A user asks about the technical difficulty of adding custom commands (e.g., @tag format with autocomplete menu) to the OpenWebUI chat interface to facilitate customized RAG queries (like filtering by document type). The user is also considering dropdown menus as an alternative. This reflects the user’s desire to extend frontend interaction capabilities for more flexible control over backend AI functions (Source: Reddit r/OpenWebUI)
Discussion: Generating Aesthetic and Functional AI QR Codes: A user attempted to use ChatGPT/DALL-E to generate QR codes that blend artistic styles while remaining scannable, but the results were poor, noting that methods like ControlNet are more effective. This sparks a discussion about the limitations of current mainstream text-to-image models in generating images that require precise structure and functionality (like scannability) (Source: Reddit r/ChatGPT)

Looking for AI/ML Study Buddies: A third-year undergraduate student in Computer Science (AI/ML focus) posted looking for 4-5 like-minded individuals to form a group for in-depth AI/ML learning, collaborative project development, and practicing Data Structures & Algorithms (DSA/CP). The initiator listed their tech stack and areas of interest, hoping to establish a mutually motivating and collaborative study group (Source: Reddit r/deeplearning)
Discussion: Will AI Agents Exacerbate the Spam Problem?: A Reddit user raises concerns that the widespread use of AI agents for automating tasks (like finding sales leads and sending messages) could lead to a deluge of spam. When everyone uses similar tools, target recipients could be overwhelmed by numerous personalized automated messages, reducing communication efficiency and rendering the agent tools less valuable. The discussion prompts reflection on the potential negative externalities of scaling AI tool usage (Source: Reddit r/ArtificialInteligence)
Discussion: Recent Quality Issues with Suno AI: A user shares a music snippet generated using Suno AI, stating that despite recent community discussions about declining output quality from Suno, they personally find this piece quite good. This reflects the community’s perception of performance fluctuations in AI generation tools and subjective differences in evaluation (Source: Reddit r/SunoAI)

Discussion: RTX 4090 vs RTX 5090 for Deep Learning Training: A user asks for advice on building a single-GPU workstation for personal deep learning (not primarily LLMs): should they choose the current RTX 4090 or wait for the upcoming RTX 5090? The post seeks community recommendations on hardware selection and asks how to differentiate between gaming and professional cards when buying (although these are consumer-grade cards). Reflects the considerations AI developers have regarding hardware choices (Source: Reddit r/deeplearning)
Discussion: Will AI Break Capitalism?: A user argues that due to companies’ pursuit of profit maximization, AI could eventually replace most jobs. Under the current capitalist system, this would lead to mass unemployment and disruption of income sources. The user suggests Universal Basic Income (UBI), funded by additional taxes on companies profiting from AI, might be a necessary solution. The discussion touches upon the profound impact of AI on future economic structures and social models (Source: Reddit r/ArtificialInteligence)
Help Request: Reproducing Anthropic Paper “Reasoning Models Don’t Always Say What They Think”: A user seeks community help in finding prompts or insights that can reproduce the results of the Anthropic paper on “Reasoning Models Don’t Always Say What They Think.” The paper explores potential inconsistencies between the internal reasoning processes of large language models and their final outputs. This indicates community interest in understanding and verifying findings from cutting-edge AI research (Source: Reddit r/MachineLearning)
Help Request: RAG Configuration and Experience in OpenWebUI: A user asks for best practices when using RAG (Retrieval-Augmented Generation) in OpenWebUI, including recommended settings, parameters to avoid, and preferred embedding models. The user also encountered issues with abnormal model behavior (e.g., Mistral Small outputting empty lists) and asks about the priority relationship between user personal settings and administrator model settings. This reflects the challenges users face in deploying and optimizing RAG applications and their need for shared experiences (Source: Reddit r/OpenWebUI)
Discussion: Will Claude User Exodus Improve Service?: A user hypothesizes that the recent departure of some Claude users (“Genesis Exodus”) due to restrictions and performance issues might, in turn, free up computing resources, thereby allowing service quality (like performance, limits) to return to a more desirable state. The user expresses a preference for Claude and hopes the service improves. The discussion reflects user observations and thoughts on the dynamics of AI service supply and demand, resource allocation, and service quality (Source: Reddit r/ClaudeAI)

Discussion: How to Define “AI Art”?: A user initiates a discussion asking community members how they define “AI art” and poses related questions: Is a person using AI tools (like ChatGPT) to generate images a creator? Do they own the copyright? What role do LLM service providers play in creation, and should they be considered co-creators? This discussion aims to clarify core concepts surrounding authorship, copyright, etc., for AI-generated content (Source: Reddit r/ArtificialInteligence)
Discussion: Does AI Music Threaten the “Communality” of Music?: A user raises the question of whether AI tools like Suno, which can easily generate hyper-personalized music, might weaken music’s “communality” as a shared experience. Concerns include: music potentially becoming a personalized mirror rather than a community-connecting beacon; collective music events like concerts possibly being affected; users potentially becoming receptive only to customized content, reducing openness to diverse or challenging music. The discussion focuses on the potential impact of AI on music culture and its social functions (Source: Reddit r/SunoAI)
Question: How Accurate is Suno AI in Generating Hindi Songs?: A non-Hindi speaker asks about the accuracy and naturalness of Suno AI when generating vocals in Hindi. Seeks to understand the tool’s performance in a specific non-English language (Source: Reddit r/SunoAI)
💡 Other
Suno AI Creation Share: Nightingale’s Melody (Alternative/Indie Rock): User shares an alternative/indie rock style song “Nightingale’s Melody” created using Suno AI, with a YouTube link provided (Source: Reddit r/SunoAI)

Suno AI Creation Share: The Art of Abundance (Psytrance): User shares an AI-generated music piece combining high-energy Psytrance and spiritual techno elements. Lyrics were created by ChatGPT, music and vocals by Suno AI, and visuals by MidJourney and PhotoMosh Pro. The work explores the concept of abundance in the digital age, beyond materialism, touching on creativity, AI consciousness, and human desire (Source: Reddit r/SunoAI)

Suno AI Creation Share: Do your Job (Country Music): User shares a country-style song created using Suno AI, with lyrics centered around a real cold case (the disappearance of Colton Ross Barrera), expressing the family’s frustration and call for justice (Source: Reddit r/SunoAI)

Suno AI Creation Share: Toxic Friends (Electro Pop): User shares their electro-pop style entry “Toxic Friends” for the Suno AI April contest (Source: Reddit r/SunoAI)

Suno AI Creation Share: Starlight Visitor (80s Pop Cover): User shares an 80s pop style cover version of an existing song, produced using Suno AI, and provides a YouTube link (Source: Reddit r/SunoAI)

ChatGPT Creative Application: Egg Product Meme Expansion: Inspired by a meme about eggs, a user employed ChatGPT to generate a series of humorous, conceptual egg-related product images and descriptions, such as “Precracked Life” and “Internet of Eggs.” Demonstrates the potential of using AI for creative brainstorming and humorous content creation (Source: Reddit r/ChatGPT)
Suno AI Creation Share: Tom and Jerry / Crambone (Blues Rock Cover): User shares a blues rock style cover song produced using Suno AI, covering “Tom and Jerry / Crambone,” and provides a YouTube link (Source: Reddit r/SunoAI)

AI-Generated Images: Seven Deadly Sins Personified: User shares a video showcasing personified, anthropomorphic images representing the seven deadly sins (like greed, sloth, envy, etc.) generated using AI (possibly ChatGPT/DALL-E) (Source: Reddit r/ChatGPT)
