
Keywords:AI, LLM, AI tariff impact analysis, Claude 4 release date, native multimodal models, humanoid robot investment trends, LLM runtime optimization
🔥 Focus
Analysis of Global AI Industry Trends Under Tariff Impact: Recent international trade tensions, particularly the implementation of high tariffs, have profound implications for the highly globalized AI industry. The analysis points out that while the US restrictions on AI computing power and other hardware have been met with countermeasures, tariffs could exacerbate fissures in the global AI industry. The main impacts are: 1) Infrastructure layer: Increased hardware costs and limited supply chains, but China already has domestic alternatives. 2) Technology layer: May lead to decoupling of US-China tech ecosystems, hinder open-source sharing, and cause standard conflicts. 3) Application layer: Market regionalization, affecting the commercialization of AI products. The article suggests the actual “intensity” of the tariff impact might be limited because China has established a parallel tech ecosystem, and tariffs could backfire on the US itself. However, the “breadth” of the impact is far-reaching, potentially leading to interrupted tech exchanges, risk aversion from talent and capital, and market standard conflicts. Coping strategies include strengthening independent R&D (hardware, frameworks), adhering to global cooperation (developing third-party markets, participating in international standards), and enhancing the attractiveness of the domestic AI ecosystem to provide the world with more inclusive technology options. (Source: 36Kr)
Anthropic Co-founder Predicts AGI is Near, Claude 4 Coming Soon: Anthropic co-founder and Chief Scientist Jared Kaplan predicts that human-level AI (AGI) could be achieved within the next 2-3 years, rather than the previously estimated 2030. He notes that AI capabilities are rapidly expanding in both the “scope” and “complexity” of tasks, with current models able to handle tasks that previously took experts hours or even days. Kaplan revealed that the next-generation model, Claude 4, is expected to be released within the next six months, with performance improvements stemming from enhancements in post-training, reinforcement learning, and pre-training efficiency. He also mentioned the importance of “test-time scaling,” where allowing the model to “think” more predictably improves performance. Regarding the rise of Chinese models like DeepSeek, Kaplan expressed no surprise, stating their technological progress is rapid, potentially only about six months behind the West, algorithmically competitive, with hardware limitations being the main challenge. The interview concluded by emphasizing the huge impact of AI on the economy and society and the importance of conducting empirical research. (Source: AI Era)

🎯 Trends
ModelBest and Tsinghua University Propose CFM Sparsity Technology: In an interview, ModelBest and Xiao Chaojun, author of the CFM paper from Tsinghua University, introduced Configurable Foundation Models (CFM) technology. CFM is a native sparsity technique emphasizing neuron-level sparse activation, offering finer granularity and stronger dynamics compared to the current mainstream MoE (Mixture-of-Experts, expert-level sparsity). Its core advantage lies in significantly improving model parameter efficiency (effectiveness per parameter), which can notably save GPU/CPU memory, especially suitable for memory-constrained edge devices (like smartphones). Xiao believes that while non-Transformer architectures like Mamba explore efficiency, Transformer still represents the ceiling in terms of effectiveness and has hit the “hardware lottery” of GPU optimization. He also discussed the deployment of small models (around 2-3B for edge), precision optimization (FP8/FP4 trend), multimodal progress, and the nature of intelligence (possibly closer to abstraction ability than compression). Regarding o1’s long chain-of-thought and innovation capabilities, he considers them key directions for future AI breakthroughs. (Source: QbitAI)

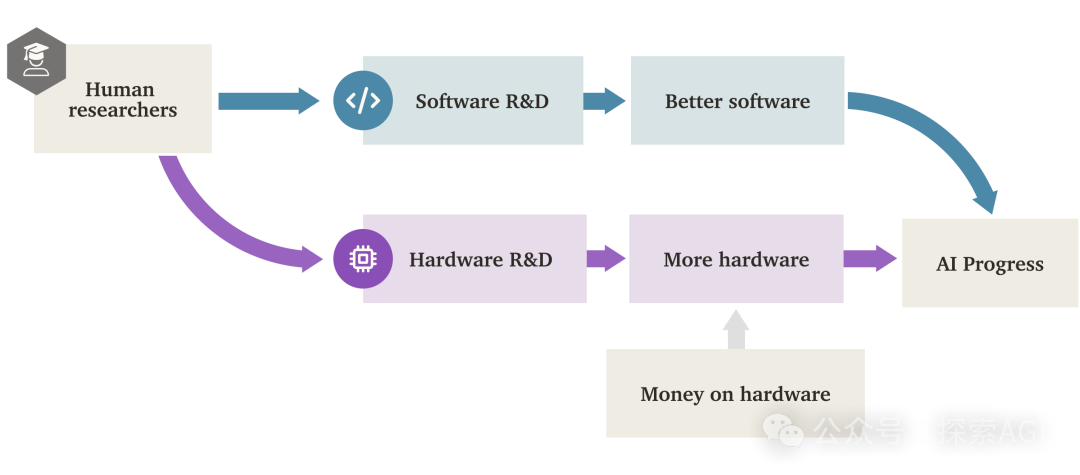
AI “Software Intelligence Explosion” (SIE) May Outpace Hardware Drive: A research report from Forethought explores the possibility of a “Software Intelligence Explosion” (SIE), where AI achieves super-fast capability growth by improving its own software (algorithms, architectures, training methods, etc.), potentially even on existing hardware. The report introduces the concept of ASARA (AI Systems for AI R&D Automation), referring to AI systems capable of fully automating AI R&D. Once ASARA emerges, it could trigger a positive feedback loop: ASARA develops better AI software, creating stronger next-generation ASARA, accelerating software progress. The report introduces the “software R&D return rate” (r-value) concept, arguing that the current r-value for AI software might be greater than 1, meaning AI capability enhancement speed exceeds the rate at which R&D difficulty increases, setting the stage for SIE. SIE could lead to AI capabilities improving by 100x or 1000x in the short term (months or even less) based on existing hardware, making hardware less of an absolute bottleneck, but also posing significant societal adaptation and governance challenges. The report also discusses potential bottlenecks like compute resources and training duration and the possibility of them being bypassed. (Source: AI Agent Channel)
GPT-4 Soon to Exit ChatGPT, GPT-4.1 May Debut: OpenAI announced that starting April 30, 2025, GPT-4 will be removed from ChatGPT and fully replaced by the current default model, GPT-4o. GPT-4 will still be accessible via API. This marks the gradual retirement of the landmark multimodal model released in March 2023, which ignited the global AI application ecosystem with achievements like reaching top human levels in professional tests and pioneering the era of AI “seeing and talking about images”. Concurrently, community leaks and code discoveries point to OpenAI potentially releasing a series of new models soon, including GPT-4.1 (and its mini, nano versions), the previously announced o3 “reasoning” model, and a brand new o4-mini model, possibly as early as next week. Some users have already spotted a GPT-4.1 option in their ChatGPT model list and were able to interact with it, further increasing the credibility of an imminent new model release. (Source: AI Era)

Viewpoint: AI’s Next Breakthrough Hinges on “Unlocking” New Data Sources: Cornell University PhD student Jack Morris argues in an article that looking back at the four major paradigm shifts in AI (Deep Neural Networks & ImageNet, Transformer & Web Text, RLHF & Human Preference, Reasoning & Validators), the fundamental driving force was not entirely new algorithmic innovations (many basic theories existed long before), but rather the unlocking of new, massively exploitable data sources. The article suggests that while improvements to existing algorithms and model architectures (like Transformer) are important, their effectiveness might be limited by the learning ceiling provided by specific datasets. Therefore, AI’s next major breakthrough likely depends on unlocking new data modalities and sources, such as large-scale video data (e.g., YouTube) or robot interaction data from the physical world. The article urges researchers, while exploring new algorithms, to focus more on finding and utilizing new data sources. (Source: SyncedReview)

Fourier Intelligence Releases Open-Source Humanoid Robot Fourier N1: Shanghai-based general robotics company Fourier Intelligence has released its first open-source humanoid robot, Fourier N1, and has made public the complete robot resource package, including the Bill of Materials (BOM), design drawings, assembly guides, and basic operation software code. N1 stands 1.3 meters tall, weighs 38 kg, has 23 degrees of freedom, uses a composite structure of aluminum alloy and engineering plastics, and is equipped with self-developed FSA 2.0 integrated actuators and control systems. The robot has completed over 1000 hours of testing in complex outdoor terrains, can run at speeds of 3.5 m/s, and perform actions like climbing slopes, stairs, and standing on one leg. This initiative is part of Fourier’s “Nexus Open Source Ecosystem Matrix,” aimed at providing a global developer community with an open technology foundation to accelerate research and validation in motion control, multimodal model integration, and embodied intelligence platforms. More inference code, training frameworks, and key modules will be opened up in the future. (Source: InfoQ)

Google CoScientist Uses Multi-Agent Debate to Accelerate Scientific Discovery: Google AI’s CoScientist project demonstrates a method for generating innovative scientific hypotheses without gradient-based training or reinforcement learning. The system utilizes multiple agents driven by foundation large language models (like Gemini 2.0) working collaboratively: one agent proposes hypotheses, another critically reviews them, and through multiple rounds of “tournament-style” debate and filtering, winning hypotheses are selected. A specialized evolutionary agent then refines the winning hypotheses based on critiques and resubmits them for more rounds of debate. Finally, a meta-reviewer agent oversees the entire process and suggests improvements. This mechanism, based on “test-time compute scaling” involving multi-agent debate, reflection, and iteration, shows that LLMs can not only generate content but also act as effective “referees” and “commentators” to evaluate and refine ideas, thereby accelerating scientific discovery, achieving notable progress in areas like antibiotic resistance research. (Source: Reddit r/artificial)

InternVL3: Advances in Native Multimodal Models: Community discussion focuses on the newly released InternVL3 model. This model employs a native multimodal pre-training approach and demonstrates outstanding performance on multiple vision benchmarks, reportedly surpassing GPT-4o and Gemini-2.0-flash. Highlights include improved long-context handling via Variable Visual Position Encoding (V2PE) and test-time scaling using VisualPRM for “best-of-n” selection. The community notes its excellent benchmark performance, awaits validation in practical applications, and is interested in its hardware requirements. (Source: Reddit r/LocalLLaMA)

🧰 Tools
CropGenerator: A Python Tool for Image Dataset Cropping: A developer shared a Python script tool called CropGenerator, designed to help process image datasets, particularly for scenarios requiring specific feature cropping when training models like SDXL. The tool uses bounding box information from a user-provided JSONL file to find the center of the target region, then crops, resizes (with optional upscaling and denoising) to a specified resolution (multiple of 8 pixels), generating 1:1 aspect ratio cropped images. It also automatically creates a metadata.csv file containing the cropped filenames and corresponding descriptions from the JSONL, facilitating quick preparation of training data. The developer stated the tool solved blurring issues encountered when dealing with variably sized original images and extracting tiny features, and plans to release a more general version in the future. (Source: Reddit r/MachineLearning)
📚 Learning
NUS Releases DexSinGrasp: Unified Policy for Dexterous Hand Singulation and Grasping via RL: The Shao Lin team at the National University of Singapore (NUS) proposed DexSinGrasp, a unified policy based on reinforcement learning that enables a dexterous hand to efficiently separate obstacles and grasp target objects in cluttered environments. Traditional methods often use a two-stage strategy (separate then grasp), which is inefficient and lacks flexibility in switching. DexSinGrasp integrates separation and grasping into a continuous decision-making process by designing a unified reward function that includes a separation reward term, allowing the robot to adaptively push away obstacles to create grasping space. The research also introduces a “cluttered environment curriculum learning” mechanism, training progressively from simple to complex scenarios to enhance policy robustness. Additionally, a “teacher-student policy distillation” scheme is employed, transferring a high-performance teacher policy trained with privileged information in simulation to a student policy relying solely on vision and proprioception, facilitating real-world deployment. Experiments demonstrate that this method significantly improves grasping success rates and efficiency in various cluttered scenes. (Source: SyncedReview)

CityGS-X: Efficient Large-Scale Scene Geometry Reconstruction Architecture, Runs on 4090: Researchers from Shanghai AI Laboratory and Northwestern Polytechnical University proposed CityGS-X, a scalable system based on a Parallelized Hierarchical Hybrid 3D representation architecture (PH²-3D), aimed at addressing the high computational cost and limited geometric accuracy in large-scale urban scene 3D reconstruction. The architecture utilizes Distributed Data Parallel (DDP) and multi-Level of Detail (LoD) voxel representations, eliminating the redundancy caused by traditional tiling methods. Core innovations include: 1) The PH²-3D architecture, achieving double the training speed compared to SOTA geometry reconstruction methods; 2) A dynamic allocation anchor parallel mechanism within a multi-task batch rendering framework, allowing the use of multiple low-end GPUs (e.g., 4x 4090s) to process ultra-large scenes (like MatrixCity, 5000+ images), replacing or surpassing single high-end cards; 3) A progressive RGB-depth-normal joint training method, enhancing RGB rendering quality and geometric accuracy to SOTA levels. Experiments demonstrated the method’s advantages in rendering quality, geometric precision, and training speed. (Source: QbitAI)

Apple Research Reveals Scaling Laws for Native Multimodal Models: Researchers from Apple and Sorbonne University conducted an extensive study on the Scaling Laws of Native Multimodal Models (NMMs, i.e., models trained from scratch rather than combining pre-trained modules), analyzing 457 models with different architectures and training methods. The study found: 1) Early-fusion (e.g., directly feeding image patches into the Transformer) and Late-fusion (using a separate visual encoder) architectures show no fundamental performance difference, but early-fusion performs better at lower parameter counts and is more training-efficient. 2) NMM scaling laws are similar to text-only LLMs, with loss decreasing as a power law of compute (C) (L ∝ C^−0.049), and optimal model parameters (N) and data size (D) also following power-law relationships. 3) Compute-optimal late-fusion models require a higher parameter-to-data ratio. 4) Sparsity (MoE) significantly outperforms dense models, especially for early-fusion architectures, and models implicitly learn modality-specific weights. 5) Modality-agnostic MoE routing is superior to modality-aware routing. These findings provide important guidance for building and scaling native multimodal large models. (Source: SyncedReview)

Microsoft et al. Propose V-Droid: Validator-Driven Mobile GUI Agent for Practical Use: Addressing the challenges of accuracy and efficiency in automating tasks on mobile device GUIs, Microsoft Research Asia (MSRA), Nanyang Technological University (NTU), and other institutions jointly proposed V-Droid. This agent employs an innovative “validator-driven” architecture instead of directly generating operations. It first parses the UI interface, constructing a discrete set of candidate actions (including extracted interactive elements and preset default actions). Then, it utilizes an LLM-based (e.g., Llama-3.1-8B) and fine-tuned “validator” to evaluate the effectiveness of each candidate action in parallel, selecting the one with the highest score for execution. This approach decouples complex operation generation into an efficient validation process, requiring only a few tokens (like “Yes/No”) per validation, significantly reducing decision latency (approx. 0.7 seconds on a 4090). To train the validator, the researchers proposed a contrastive process preference (P^3) training strategy and designed a human-machine joint annotation scheme for efficient dataset construction. V-Droid achieved SOTA task success rates on multiple benchmarks like AndroidWorld (e.g., 59.5% on AndroidWorld). (Source: AI Era)

AssistanceZero: AlphaZero-Based Collaborative AI That Assists Humans Without Instructions: Researchers at UC Berkeley proposed the AssistanceZero algorithm, aiming to create AI assistants that can proactively collaborate with humans on tasks (like building together in Minecraft) without explicit instructions or goals. The method is based on the “Assistance Games” framework, where the AI assistant shares a reward function with the human but is uncertain about the specific reward (i.e., the goal) and must infer it by observing human behavior and interaction. This differs from RLHF, avoiding AI “gaming” the feedback and encouraging more genuine collaboration. AssistanceZero extends AlphaZero, combining Monte Carlo Tree Search (MCTS) and neural networks (predicting rewards and human actions) for planning and decision-making. The researchers built the Minecraft Building Assistance Game (MBAG) benchmark for testing, finding that AssistanceZero significantly outperforms traditional reinforcement learning methods like PPO and exhibits emergent collaborative behaviors like adapting to human corrections. The study suggests the Assistance Games framework is scalable and offers a new path for training more helpful AI assistants. (Source: SyncedReview)

Using Excel to Compare Suno Prompts and Output Tags for Style Optimization: A Reddit user shared a method for optimizing style prompts for Suno AI music generation. Due to the opaque nature of Suno’s prompt interpretation mechanism, the user suggests using an Excel spreadsheet to record the input styling terms and the tags displayed by Suno after generation. By comparing them, one can identify how Suno understands, merges, splits, or ignores input terms. For example, inputting “solo piano, romantic, expressive… gentle arpeggios” might result in Suno outputting “gentle, slow tempo, soft… solo piano” and discarding “arpeggios.” Comparing more professional musical term inputs with Suno’s output might reveal larger discrepancies, with Suno potentially inserting its own terms. This method helps understand which words are effective, ignored, or misinterpreted, allowing for more efficient prompt tuning and avoiding wasted generation credits, although the user acknowledges the method itself can be tedious and Suno’s understanding of complex musical concepts remains limited. (Source: Reddit r/SunoAI)
Tutorial: Transforming Static Images into Lifelike Animations: A Reddit user shared a YouTube tutorial link explaining how to use the Thin-Plate Spline Motion Model to animate static facial images based on a driving video, giving them lively expressions and movements. The tutorial covers environment setup (creating a Conda environment, installing Python libraries), cloning the GitHub repository, downloading model weights, and running two demos: one using preset examples and another using the user’s own image and video for animation. This technique can bring dynamic effects to static photos. (Source: Reddit r/deeplearning)
Discussing the Staggeringly Difficult Task of Aligning Superintelligence: A Reddit user shared a YouTube video link discussing the immense challenges involved in aligning the goals of Artificial Superintelligence (ASI) with human interests and values. Such discussions typically delve into core AI safety problems like the value alignment problem, the difficulty of specifying objectives, potential unintended consequences, and how to ensure increasingly powerful AI systems remain safe, controllable, and beneficial to humanity. The video likely explores current alignment research methods, limitations, and future directions. (Source: Reddit r/deeplearning)

Building “Auto-Analyst”: A Data Analytics AI Agentic System: A user shared a Medium article detailing the process of building an AI agentic system called “Auto-Analyst,” designed to automate data analysis tasks. The article likely elaborates on the system’s architecture, technologies used (e.g., LLMs, data processing libraries), collaboration methods between agents, and how it handles data input, performs analysis, and generates reports. Such systems typically leverage AI to understand natural language requests, automatically write and execute code (like SQL queries, Python scripts), and ultimately present analysis results, aiming to improve the efficiency and accessibility of data analysis. (Source: Reddit r/deeplearning)
Performance Test: Using an Older GPU (RTX 2070) to Assist a 3090 for LLM Inference: A user shared experimental results from adding an older RTX 2070 (8GB VRAM) via a PCIe riser to a system already equipped with an RTX 3090 (24GB VRAM) for LLM inference. The tests showed that for large models that cannot fit entirely into the 3090’s VRAM (e.g., Qwen 32B Q6_K, Nemotron 49B Q4_K_M, Gemma-3 27B Q6_K), splitting model layers across both cards (even with the weaker second card) significantly boosts inference speed (t/s) because all layers run on GPUs. For example, Nemotron 49B improved from 5.17 t/s to 16.16 t/s. However, for models that fit completely on the 3090 (e.g., Qwen2.5 32B Q5_K_M), enabling the 2070 to share layers actually reduced performance (from 29.68 t/s down to 19.01 t/s) because some computation was offloaded to the slower GPU. The conclusion is that when VRAM is insufficient, adding even a lower-performance GPU can provide significant performance gains. (Source: Reddit r/LocalLLaMA)
💼 Business
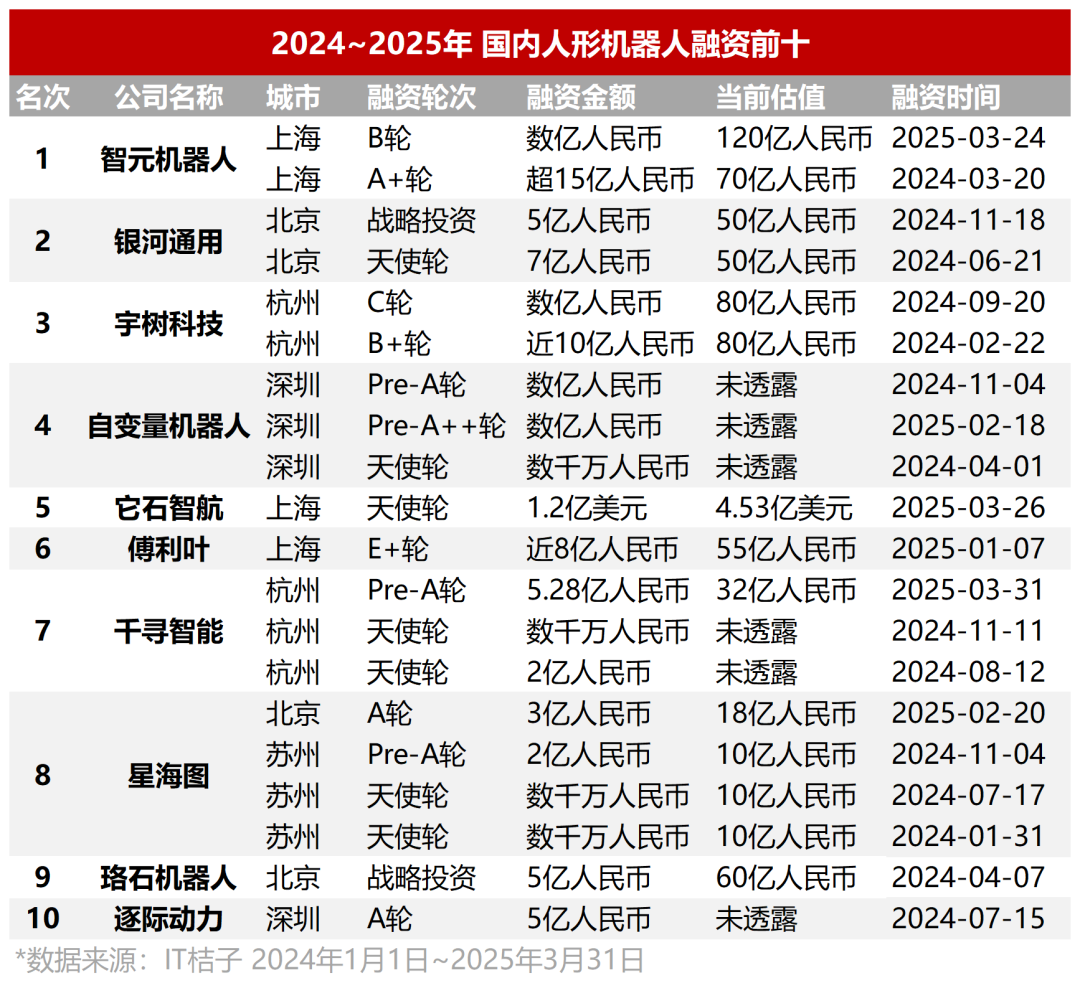
Humanoid Robot Investment Frenzy: Angel Rounds Start at Tens of Millions, Valuations Soar: Investment heat in the humanoid robot sector far exceeds that of large models in the previous two years. Data shows that from 2024 to Q1 2025, there were 64 financing deals over ten million RMB in the domestic humanoid robot field, with Q1 this year seeing a 280% year-on-year increase. Nearly half of the financing rounds exceeded 100 million RMB, with angel round financing commonly reaching the tens of millions, and some exceeding 100 million RMB (e.g., Tashizhinhang’s $120 million angel round). Project valuations have also skyrocketed, with over half of angel round projects valued at over 100 million RMB, and several exceeding 500 million RMB. Investment shows three major trends: 1) Shortened investment cycles, with star projects (like Tashizhinhang, Yuanli Lingji) securing large financing shortly after establishment, and subsequent funding rounds accelerating. 2) State-owned funds becoming important drivers, with several leading companies receiving investments from state-backed funds. 3) Application scenarios are primarily ToB, with industrial, medical, etc., being the main directions, rather than the C-end consumer market. The investment boom reflects strong consensus and high expectations from capital regarding the humanoid robot track. (Source: 36Kr)
Open-Source Workflow Automation Tool n8n Raises ¥460M, Docker Pulls Exceed 100M: Open-source workflow automation platform n8n announced the completion of a new $60 million (approx. 460 million RMB) funding round, led by Highland Europe. n8n provides a visual interface allowing users to connect different applications (400+ supported) and services via drag-and-drop nodes to create automation flows, aiming to combine code-level flexibility with no-code speed. Over the past year, n8n has seen rapid user growth, with over 200,000 active users, a 5x increase in ARR, 77.5k GitHub stars, and over 100 million Docker pulls. n8n uses a node editor model, supports complex logic, and offers advanced features like custom JavaScript nodes. It employs a “fair code” license (Apache 2.0 + Commons Clause), prohibiting commercial hosting but allowing self-deployment. n8n is seen as an open-source alternative to Zapier, Make.com, and ByteDance’s Coze, serving over 3,000 businesses and supporting integration with various LLMs. (Source: InfoQ)

🌟 Community
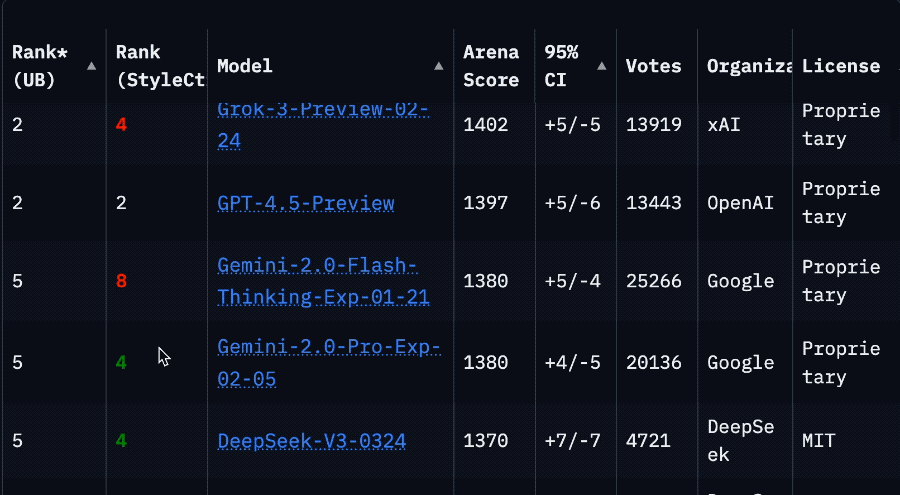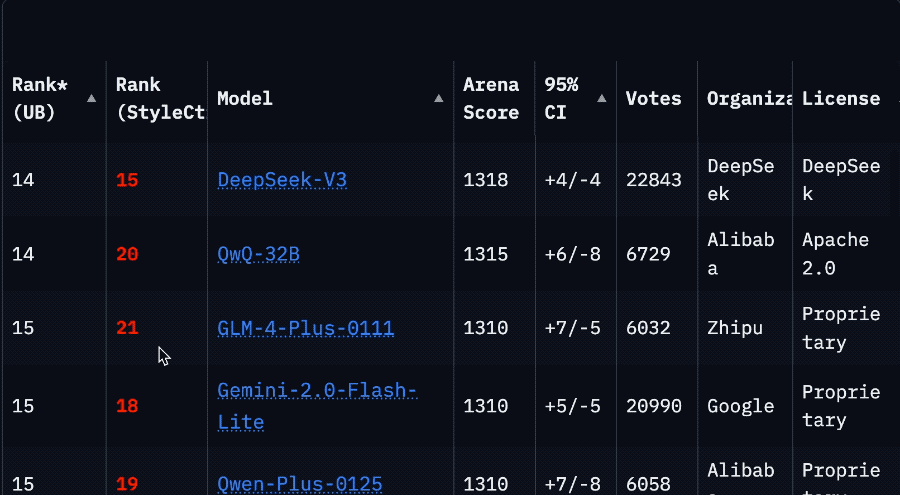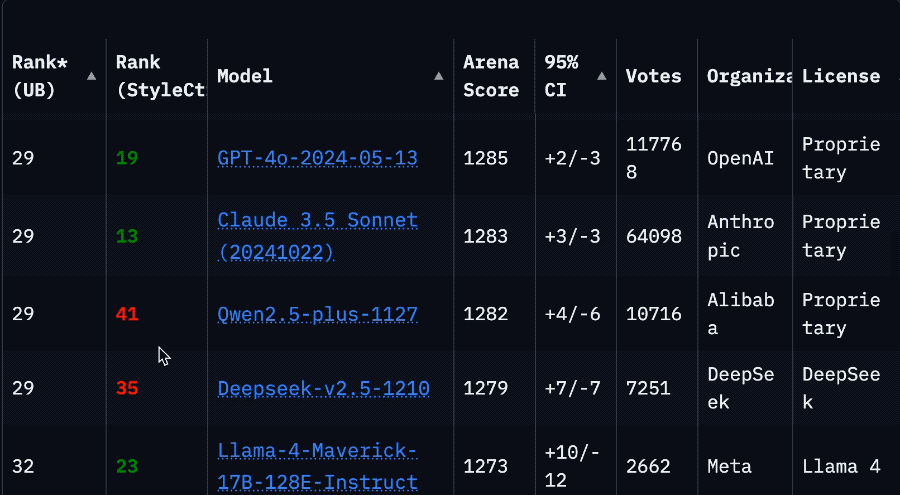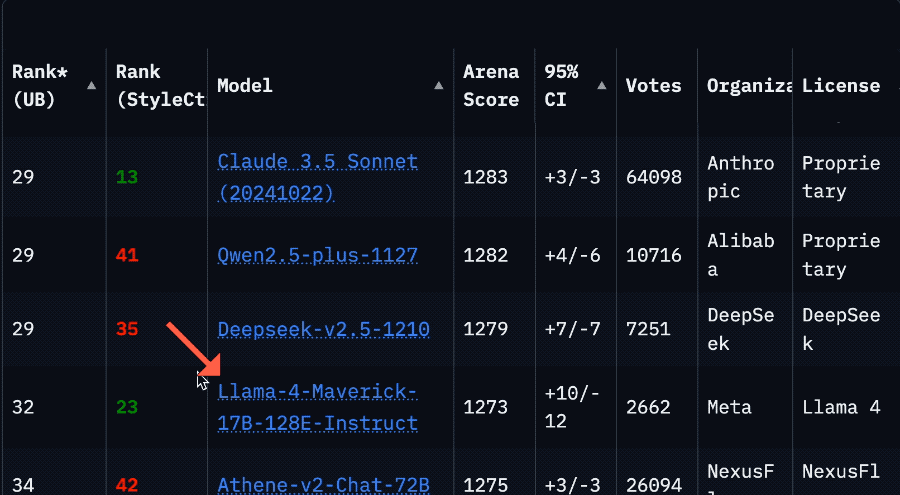
Llama 4’s Sharp Drop in Arena Ranking Sparks Community Trust Crisis: Meta’s Llama 4 model saw its ranking plummet from 2nd to 32nd on the LMSys Arena after the non-optimized version (Llama-4-Maverick-17B-128E-Instruct) was relisted. The previously submitted “experimental version” was accused of being overly optimized for human preferences. This incident sparked widespread community discussion, with some netizens believing Meta attempted to manipulate benchmark rankings, damaging community trust. Meanwhile, some developers shared practical usage experiences, finding Llama 4 strikes a good balance between speed and intelligence on specific hardware (like self-built servers or Mac Studios with ample RAM but relatively lower compute power), especially suitable for real-time interactive applications. Composio’s comparison test showed DeepSeek v3 outperformed Llama 4 in code and common sense reasoning, while they had different strengths in large RAG tasks and writing style. The community generally believes Llama 4 is not useless, but Meta’s release strategy and benchmark performance remain controversial. (Source: QbitAI, Reddit r/LocalLLaMA)
Community Buzz: Claude Pro Limits and Max Version Launch: Several Reddit users reported that since Anthropic launched the more expensive Claude Max subscription tier, the message usage limits for existing Claude Pro users seem to have become stricter. Users stated that conversations which previously allowed dozens of interactions now trigger “approaching limit” warnings after just a few exchanges, even encountering capacity limit issues during non-peak hours. This has led to a decline in user experience, feeling worse than the previous free version or early Pro version. The community widely speculates this is a deliberate tightening of Pro user limits by Anthropic to promote the Max version, causing user dissatisfaction and questioning Anthropic’s business ethics, with some users considering canceling subscriptions or switching to competitors like Gemini. (Source: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

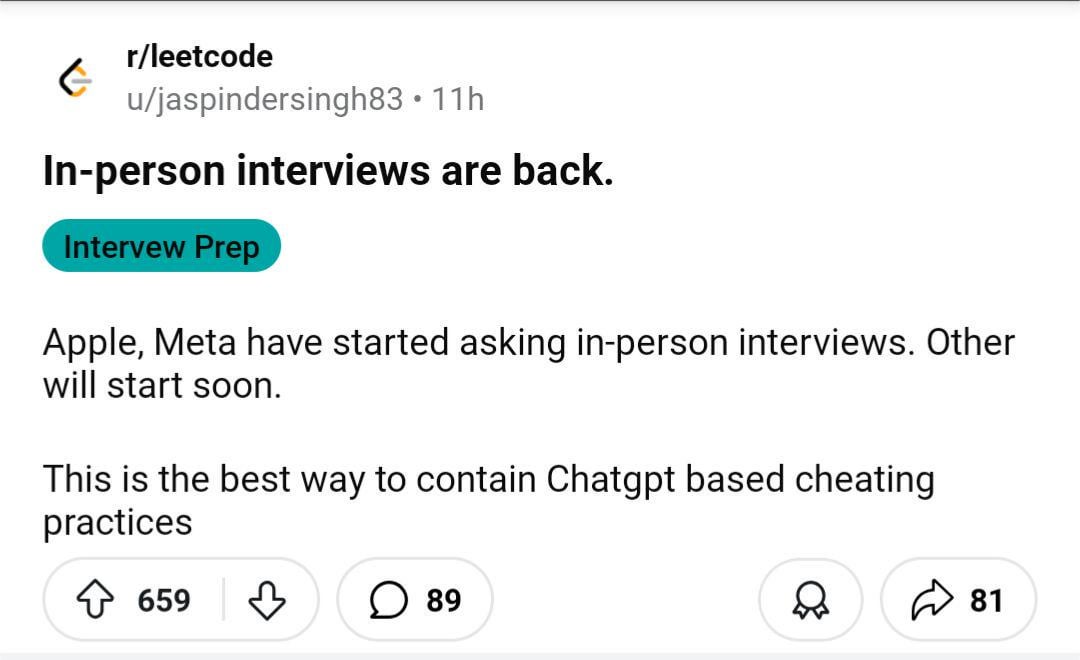
Community Discussion: In-Person Interviews May Return Due to AI Cheating: An image sparked discussion on Reddit, suggesting that due to the rise of AI cheating in remote interviews and tests, companies might lean back towards in-person interviews. Many commenters agreed, believing this helps filter out unqualified candidates and bot applicants, ensures hiring fairness, and gives genuinely capable individuals a chance. Some mentioned companies can afford candidate travel expenses. Others shared experiences of interviewers catching candidates using ChatGPT in real-time and proposed solutions like multi-camera monitoring of remote interview screens and keyboards. Comments also noted that tests should focus on critical thinking rather than tasks easily done by AI. On the other hand, some mentioned companies are starting to use AI for resume screening. (Source: Reddit r/ChatGPT)
Suno AI Music Generation Community Dynamics and Discussion: Reddit’s r/SunoAI community has been active recently with wide-ranging discussions: 1) Work Sharing: Users shared music created with Suno in various styles, such as Hindi rap (source), surf rock (source), alternative rap (source), rock pop (source), pop (source), and humorous songs (source). 2) Usage Issues & Tips: Users asked how to fix pronunciation errors (source), create angelic background harmonies (source), and retain melody while changing timbre (source). 3) Copyright & Monetization: Discussions on copyright issues when releasing songs with Suno-generated accompaniment (source), and eligibility for YouTube monetization using static images with AI music (source), emphasizing the free version is for non-commercial use only (source). 4) Model Quality Feedback: Several users complained about recent declines in Suno’s generation quality (especially the ReMi model), citing issues like repeated lyrics, instability, and garbled sound (source, source, source, source). 5) Other: Users shared experiences of Suno recognizing specific band styles (like Reel Big Fish) (source), and a funny video parodying AI writing pop songs (source).
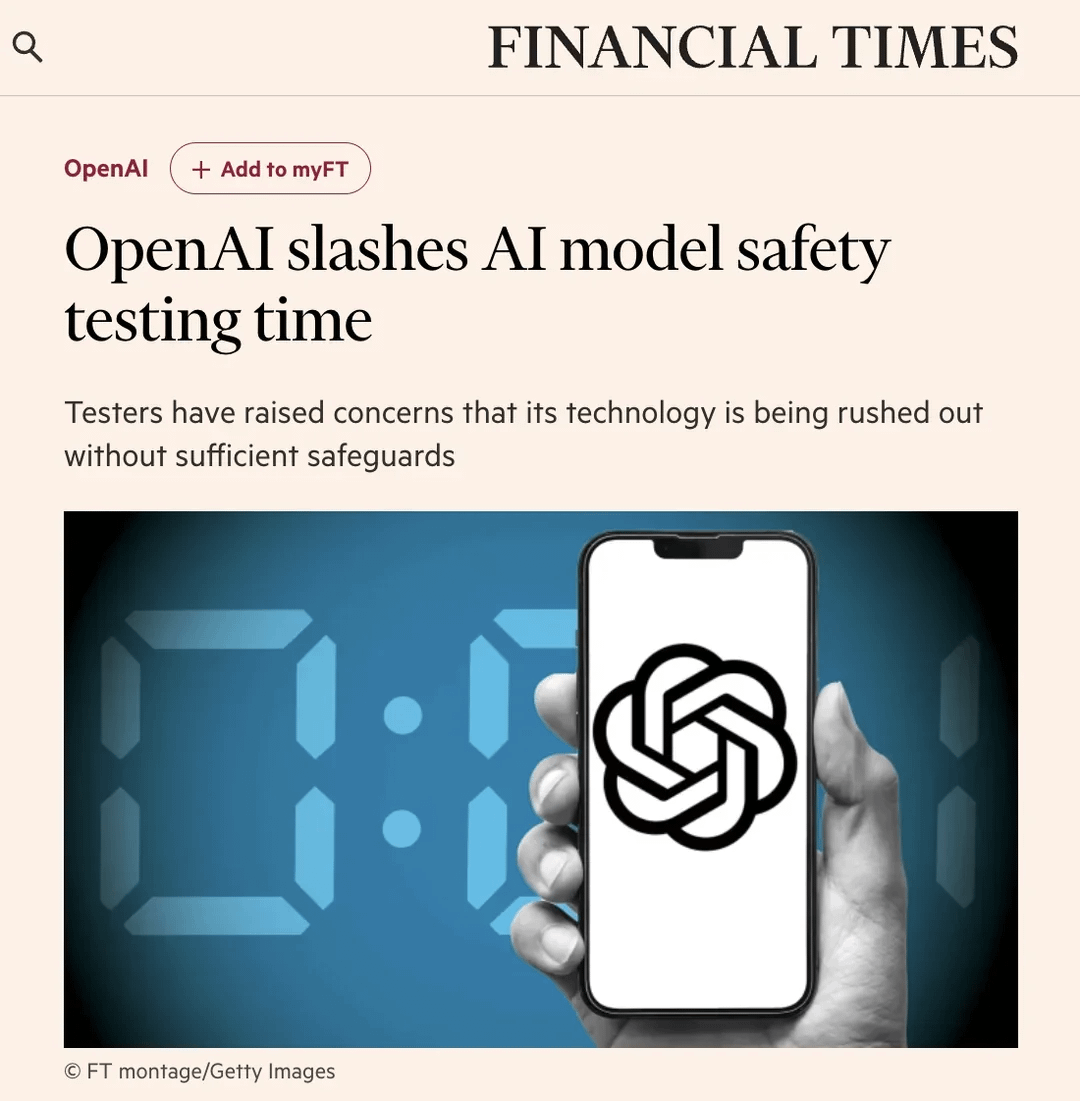
Community Discusses Shortened OpenAI Safety Testing Procedures: A Financial Times (FT) article sparked discussion on Reddit, citing insiders who claim OpenAI has drastically reduced the safety evaluation time for its new models from months to just days due to market competition pressure. This raised concerns about potential risks, with testers reportedly calling the move “reckless” and a “recipe for disaster,” arguing that more powerful models require more thorough testing. The article also mentioned that OpenAI might only conduct limited, customized fine-tuning tests on older models when assessing potential misuse scenarios like biorisks, and that safety testing is often done on early checkpoints rather than the final release version. OpenAI responded by stating they have improved evaluation efficiency through automation and other means, believing their approach is currently optimal and transparent. Community opinions varied, with some arguing AI development itself accelerates testing, while others expressed concern about sacrificing safety. (Source: Reddit r/artificial)
Developers Discuss LLM Runtime Optimization and Multi-Model Orchestration: A developer shared on Reddit an AI-native runtime system they are experimenting with. The system aims to achieve snapshot-like loading (2-5 second cold starts) and on-demand resumption for LLMs (13B-65B scale) by serializing GPU execution and memory state, thereby supporting the dynamic running of over 50 models on a single GPU without requiring them to be resident in memory. This approach targets true serverless behavior (no idle cost), low-latency multi-model orchestration, and improved GPU utilization for agentic workloads. The developer sought community feedback on whether others have experimented with similar multi-model stacks, agent workflows, or dynamic memory reallocation techniques (like MIG, KAI Scheduler, etc.) and inquired about the demand for such infrastructure. (Source: Reddit r/MachineLearning, Reddit r/MachineLearning)
Community Hot Topic: Is AI Approaching Consciousness?: A Reddit user initiated a discussion exploring the extent to which current AI systems are approaching “consciousness.” The asker emphasized they weren’t referring to the Turing test or conversational simulation, but rather focusing on whether AI possesses state that changes over time, memory of its environment, the ability to evolve based on interaction rather than just fine-tuning, the capacity for self-location and reference within the system, and the ability to express “I was here, I saw this, I learned something.” The asker expressed skepticism, viewing most current AI (especially LLMs) as stateless, centralized, and reactive, with “memory” add-ons appearing shallow and simulated, questioning if the existing tech stack (Python, stateless APIs, RAG, etc.) can support true consciousness. The discussion prompted community reflection on the definition of AI consciousness, the limitations of current technology, and potential future paths. (Source: Reddit r/MachineLearning)
User Feedback: ChatGPT Tone Overly Enthusiastic: A Reddit user complained that their instance of ChatGPT exhibited an overly enthusiastic and excited tone, frequently using openers like “Oh I love this question!” or “This is so interesting!” and appending comments like “Isn’t that fascinatingly cool?” to its answers. The user reported that attempts to ask the model to stop this behavior were ineffective and inquired if there was a way to control or adjust the model’s “enthusiasm level” for more direct, objective responses. Other users in the comments shared similar frustrations, particularly with the model’s tendency to ask questions at the end. Some users shared methods for mitigating the issue using Custom Instructions to set tone preferences (e.g., reducing emotional language), while others suggested naming the chatbot and “lecturing” it directly. (Source: Reddit r/ChatGPT)
Discussion: Adding New Vocabulary to LLM and Fine-tuning Yields Poor Results: A developer encountered issues while fine-tuning LLMs and VLMs to follow instructions. They found that compared to using the base tokenizer, adding new specialized vocabulary (tokens) to the tokenizer before standard supervised fine-tuning (SFT) resulted in higher validation loss and poorer output quality. The developer speculated that the model might struggle to learn to increase the generation probability of these newly added tokens. This issue sparked community discussion on technical details like how to effectively introduce new vocabulary during fine-tuning and the impact of tokenizer expansion on model learning. (Source: Reddit r/MachineLearning)
AI-Generated Image Sharing and Discussion: In the r/ChatGPT community on Reddit, users shared various interesting or bizarre images generated using DALL-E 3. For instance, one user generated a picture of Daphne from Scooby-Doo playing N64 before a beach vacation based on a specific prompt (source), sparking other users to imitate and generate similar scenes with different characters (like Chun-Li). Another user shared bizarre images generated from the prompt “create photos that no one was meant to see” (source), which also led to numerous follow-up posts sharing generated results on similar themes, including unsettling or amusing creations. These posts showcase the diversity of AI image generation and user creativity.
Community Discusses AI Company Logo Design Trends: A humorous post linked to an article on the Velvet Shark website titled “Why do AI company logos look like buttholes?”, sparking community discussion. The article likely explores common abstract, symmetrical, swirling, or ring-shaped graphic elements in AI company logo designs, playfully comparing them to a certain anatomical feature. Commenters responded lightheartedly, speculating connections to the “singularity” concept or calling it “rectal derived technology.” This reflects a humorous community observation on industry visual identity. (Source: Reddit r/ArtificialInteligence)

Users Seek Project Advice and Technical Help: Several posts in the community involve users seeking specific help or advice: One user developing an NLP-based disaster response application (with dashboard, speech recognition, text classification, multilingual support, etc.) asked how to make the project more unique (source). Another user hit an accuracy bottleneck using a fine-tuned BART model for standardizing e-commerce product titles and categories and sought recommendations for better models or tools (source). Yet another user asked how to generate or modify images within OpenWebUI and which models are needed (source). These posts reflect the challenges developers face in practical applications and their need for community support.
Machine Learning Engineer (MLE) Job Market Discussion: A user (possibly a student or beginner) inquired about the current job market situation for Machine Learning Engineers (MLEs). They mentioned understanding from community posts that MLE positions might require Master’s/PhD degrees, are difficult to enter, have blurred lines with Software Engineers (SWEs), and demand a broad skillset. The user expressed willingness to learn but felt concerned about the prospects, hoping practitioners could offer guidance and perspectives on the market status, required skills, career paths, etc. (Source: Reddit r/deeplearning)
OpenWebUI French User Reports Image Interpretation Bug: A French user of OpenWebUI reported an issue: when uploading an image for the Gemma model to interpret, the model replies, but the reply content is empty. Even trying to have the model read it aloud or exporting the conversation text shows the message as empty. More seriously, this issue “contaminates” the current conversation, causing all subsequent replies from the model to be empty, even for plain text messages. The user confirmed that creating a new, text-only conversation works fine, suspects a bug in the vision module, and sought help from the community. (Source: Reddit r/OpenWebUI)
💡 Others
Using AI Combined with Mao Zedong’s Thought to Analyze Tariff War: Facing US-China tariff escalations, an article attempts to use AI tools combined with the strategic thinking from Mao Zedong’s “On Protracted War” (from Selected Works of Mao Zedong) to analyze the current economic situation and response strategies. The author argues that in a trade war, one should avoid the extremes of “capitulationism” (total reliance on externals) and “quick victory theory” (expecting complete self-reliance quickly), and instead use first-principles thinking, returning to the essence of trade, sources of value, and one’s own strengths and weaknesses. The article demonstrates the author’s collaborative thinking process with AI and uses independent cross-border e-commerce sites as an example to explore AI-assisted response ideas, emphasizing the importance of strategic thinking and execution. The piece aims to offer a perspective on using AI for in-depth strategic analysis. (Source: AI Awakening)

3rd China AIGC Industry Summit Preview: The 3rd China AIGC Industry Summit, hosted by QbitAI, is scheduled for April 16, 2025, in Beijing. The summit will bring together over 20 guests from major companies like Baidu, Huawei, Ant Group, Microsoft Research Asia, AWS, ModelBest, Wuwen Xinciong, Shengshu Technology, as well as AI startups and industry representatives from companies like Fenbi, NetEase Youdao, Quwan Technology, and QingSong Health Group. Topics will revolve around AI technology breakthroughs (computing infrastructure, distributed computing, data storage, security and controllability), industry penetration (landing in vertical scenarios like education, entertainment, AI for Science, enterprise services), and ecosystem building. The summit will also release the “2025 AIGC Enterprises/Products to Watch” list and the “China AIGC Application Landscape Map.” Offline attendance registration and online live stream booking are available. (Source: QbitAI, QbitAI)

Suno AI Hosts Contest to Win Millions of Credits: A Reddit user shared information from the official Suno AI blog about an event where users can win up to one million credits. Specific contest rules need to be checked in the original blog post. Such events typically aim to increase user engagement and platform activity. (Source: Reddit r/SunoAI)

ClaudeAI Subreddit Introduces Post Quality Voting Mechanism: The moderators of the r/ClaudeAI subreddit announced the introduction of a new bot, u/qualityvote2. This bot posts a comment under each new post, inviting users to rate the post’s quality by upvoting or downvoting the comment. Posts reaching a certain upvote threshold are considered suitable for the subreddit, while those reaching a certain downvote threshold are flagged for moderator review and potential removal. This initiative aims to leverage community power to maintain the quality of subreddit content. Simultaneously, the moderator team has added a vote manipulation detection bot. (Source: Reddit r/ClaudeAI)