
Keywords:AI, TPU, Google seventh-generation TPU Ironwood, Agent-to-Agent A2A protocol, SK Hynix HBM market dominance, AI agent interoperability challenges, MoE model training frameworks
🔥 Focus
Google Releases 7th Gen TPU and A2A Agent Collaboration Protocol: At Cloud Next ’25, Google unveiled its 7th generation TPU “Ironwood,” specifically designed for AI inference. It boasts a massive deployment scale computing power of 42.5 Exaflops, far exceeding existing supercomputers. The chip features significantly increased memory and bandwidth (192GB HBM, 7.2Tb/s bandwidth) and doubles energy efficiency, aiming to support “thinking models” like Gemini 2.5 that require complex reasoning capabilities. Concurrently, Google launched the Agent-to-Agent (A2A) open-source protocol to standardize secure communication and collaboration between different AI agents, already supported by over 50 companies. A2A defines agent capability discovery, task management, collaboration methods, etc., complementing the MCP protocol used for connecting tools. Google also announced support for the MCP protocol in its Gemini models and SDK, further promoting interconnectivity within the AI agent ecosystem. (Source: 机器之心, 36氪, 卡兹克, 机器之心, AI前线)

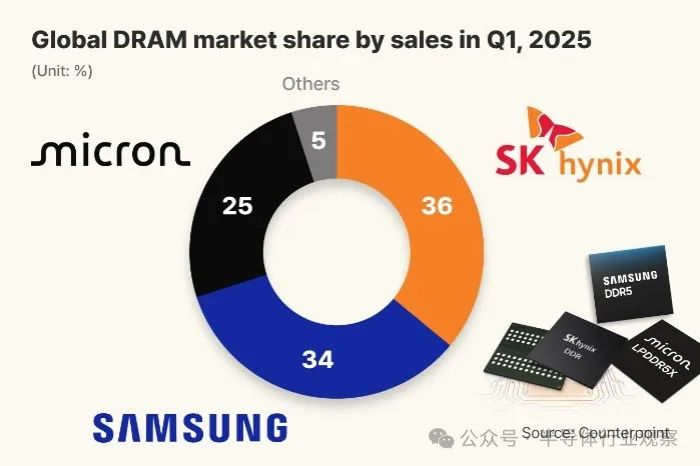
SK hynix Tops Global DRAM Market for the First Time Leveraging HBM Advantage: Market research firm Counterpoint Research reported that in Q1 2025, SK hynix surpassed Samsung (34%) for the first time to become the world’s largest DRAM supplier with a 36% market share. Micron ranked third with 25%. SK hynix’s success is primarily attributed to its dominant position in the High-Bandwidth Memory (HBM) sector (reportedly holding a 70% market share), as the AI boom significantly drives HBM demand. SK hynix exclusively supplies NVIDIA’s AI accelerators with its HBM3E chips, and HBM demand is expected to continue its rapid growth. Meanwhile, Korean media reported that SK hynix achieved an 80% yield rate for its 1c DRAM (approx. 11-12nm) process, temporarily leading Samsung, which is still struggling to improve yields. This lays the foundation for its HBM4 mass production. (Source: 半导体行业观察)
AI Agent Protocols MCP and A2A Spark Attention and Ecosystem Competition: Recently, Anthropic’s Model Context Protocol (MCP) and Google’s Agent-to-Agent (A2A) protocol have become hot topics in the AI field. MCP aims to standardize interactions between AI models and external tools/data sources, likened to a “USB-C” interface for AI applications, supported by Microsoft, Google, and numerous startups and open-source communities. A2A focuses on secure communication and collaboration between AI agents from different vendors, with over 50 companies participating. These protocols aim to address poor interoperability and ecosystem fragmentation among AI agents. However, analysis suggests that behind the promotion of these protocols by tech giants lies a strategic intent to build their own ecosystem barriers and prevent data outflow. For example, Google’s initial A2A partners are mostly related to its ecosystem, and Alibaba Cloud’s MCP service primarily integrates applications within its system. Platforms like Meituan and Didi may hesitate to join open protocols due to data sovereignty and ecosystem control considerations. This protocol battle is essentially a competition for dominance and data control within the AI ecosystem. (Source: 卡兹克, 王智远, AI前线, 机器之心)
🎯 Trends
DeepSeek Sparks Reflection on the Future of Enterprise Software: The open-sourcing of DeepSeek has impacted the enterprise software industry, triggering discussions about the technological moats of SaaS vendors and whether AI digital employees will end traditional software. Guo Shunri, CEO of Woxing Technology, believes that single-function tool-based SaaS (like RPA) is most at risk, as it can be easily replaced by the multimodal capabilities of large models. Yang Fangxian, CEO of 53AI, predicts that while large model applications are still limited, traditional SaaS will disappear in 10-20 years, replaced by AI productivity (a fusion of digital humans and SaaS). Shen Yang, an expert in informatization and digitalization, holds a more radical view, suggesting the SaaS model could be disrupted within six months to a year, with future revenue models relying on real-time data or service effectiveness fees. The dialogue emphasizes that AI will reshape business models, giving companies that effectively utilize AI a competitive advantage, while slow responders face elimination. Current bottlenecks in AI adoption lie in enterprise data silos and insufficient knowledge integration, rather than the AI technology itself. (Source: 36氪)
AI Application in Large Home Appliances: Status and Reflection: AI technology is being integrated into large appliances like refrigerators, washing machines, and air conditioners, offering features such as voice interaction and smart control (e.g., AI power saving, AI washing/care). Brands like Haier, TCL, and Samsung are launching AI appliances, such as Haier refrigerators equipped with DeepSeek providing food management suggestions, and TCL air conditioners reporting weather forecasts. However, the article points out that the “AI content” in current AI appliances varies greatly, with some features (like air conditioners reporting exchange rates) appearing redundant and impractical. Compared to AI products like robot vacuums that have achieved a relatively complete “perception-decision-execution” loop, AI applications in large appliances often stop at perception and suggestion, failing to execute decisions autonomously. The article questions whether some “AI” features are genuine needs, suggesting consumers prioritize core functionality and problem-solving over forced AI integration. It argues that the role of large appliances in the AI era should be as part of the smart home ecosystem, excelling in core functions and enhancing collaboration capabilities, rather than all becoming chatbots. (Source: 36氪)

MoE Models Become New Trend, Alibaba Cloud Upgrades AI Infrastructure to Meet Challenges: The Mixture-of-Experts (MoE) architecture is becoming a mainstream trend for large AI models, adopted by models from Mixtral to DeepSeek, Qwen2.5-Max, and Llama 4. To address the challenges posed by MoE (like token routing, expert selection), Alibaba Cloud released the FlashMoE training framework based on PAI-DLC, supporting ultra-large-scale MoE mixed-precision training and boosting MFU to 35-40% at the scale of tens of thousands of cards. Simultaneously, Alibaba Cloud launched Llumnix, a distributed inference engine optimized for MoE, significantly reducing latency. Additionally, Alibaba Cloud released the 9th generation ECS instances, optimized Lingjun clusters (HPN 7.0 network, CPFS high-performance storage, fault self-healing system), upgraded OSS object storage (OSSFS 2.0), and launched MaxCompute AI Function and DataWorks Agent service supporting the MCP protocol, comprehensively upgrading its AI infrastructure to cope with the new paradigms brought by MoE and inference models. (Source: 机器之心)
Keenon Robotics Releases Humanoid Service Robot XMAN-R1: Keenon Robotics, a leading global service robot company, launched its first humanoid embodied service robot, XMAN-R1, positioned as “born for service.” Built upon Keenon’s vast real-world data accumulated from catering, hotel, and medical scenarios, the robot emphasizes job-specific capabilities, approachability, and safety. XMAN-R1 can complete closed-loop tasks in service scenarios such as ordering, food preparation, delivery, and table clearing. It possesses capabilities like dual-hand object handover, mobile control, and human-like interaction (large language models, facial expressions), equipped with 11 multimodal sensors and intelligent obstacle avoidance technology for crowded environments. XMAN-R1 will form a multi-form collaborative ecosystem with Keenon’s existing specialized robots (delivery, cleaning, etc.) to perform more complex commercial service tasks, further enhancing Keenon’s multi-form embodied service robot matrix. (Source: InfoQ)
Xi’an Jiaotong University et al. Propose Training-Free Framework “Every Painting Awakened” for Painting Animation: Addressing the issues of “static” or “chaotic motion” in existing image-to-video (I2V) methods for painting animation, Xi’an Jiaotong University, Hefei University of Technology, and the University of Macau jointly proposed a zero-training framework called “Every Painting Awakened.” This framework utilizes pre-trained image models to generate proxy images as dynamic guidance. Through dual-path score distillation techniques, it preserves the static details of the original painting while extracting dynamic priors from the proxy image. A hybrid latent fusion mechanism (spherical linear interpolation) then merges static and dynamic features in the latent space, which are fed into existing I2V models to generate video. This method enhances existing I2V models without additional training, accurately executing motion instructions from text prompts while maintaining the original painting’s style and brushstrokes, achieving natural and smooth painting animation. Experiments demonstrate the framework’s significant effectiveness in improving semantic alignment and preserving style integrity. (Source: PaperWeekly)
University of Waterloo and Meta Propose MoCha: Generating Multi-Character Conversational Videos from Speech and Text: To address the limitations of existing video generation techniques in character-driven narratives (e.g., limited to faces, reliance on auxiliary conditions, single-character support), the University of Waterloo and Meta GenAI proposed the MoCha framework. MoCha is the first method for the Talking Characters task that generates full-body conversational videos (close-up to medium shot) for multiple characters across multiple turns, requiring only speech and text input. Key technologies include: 1) Speech-Video Window Attention mechanism for precise alignment of speech and video temporal features through local temporal conditioning, ensuring lip-sync and action synchronization; 2) Joint speech-text training strategy leveraging existing video data with speech and text annotations to enhance model generalization and controllability; 3) Structured prompt templates and character labels, enabling multi-character, multi-turn dialogue generation for the first time while maintaining contextual coherence and character identity consistency. Experiments validate its advantages in realism, expressiveness, and controllability, advancing automated cinematic narrative generation. (Source: PaperWeekly)
HUST & Xiaomi Auto Propose Autonomous Driving Framework ORION: Addressing the limited causal reasoning capabilities of end-to-end autonomous driving in closed-loop interactions, Huazhong University of Science and Technology (HUST) and Xiaomi Auto proposed the ORION framework. This framework innovatively combines Vision-Language Models (VLMs) and generative models (like VAE or diffusion models). It utilizes VLMs for scene understanding, reasoning, and instruction generation, then aligns the VLM’s semantic reasoning space with the purely numerical trajectory action space via the generative model to guide trajectory generation. Concurrently, it introduces the QT-Former module to effectively aggregate long-term historical visual context information, overcoming the token limitations and computational overhead issues when VLMs process multiple image frames. ORION achieves unified end-to-end optimization for Visual Question Answering (VQA) and planning tasks. In the Bench2Drive closed-loop evaluation, ORION achieved a driving score of 77.74 and a success rate of 54.62%, significantly outperforming previous state-of-the-art methods. Code, models, and datasets will be open-sourced. (Source: 机器之心)
National University of Singapore Proposes GEAL: Empowering 3D Affordance Prediction with 2D Large Models: To tackle the challenges in 3D Affordance Learning (predicting interactable regions of objects), such as scarcity of 3D data, expensive annotations, and insufficient model generalization and robustness, the National University of Singapore proposed the GEAL framework. GEAL uses 3D Gaussian Splatting to render sparse point clouds into realistic images, which are then fed into pre-trained 2D vision large models (like DINOV2) to extract rich semantic features. Through innovative Cross-Modal Consistency Alignment, including a Granularity-Adaptive Fusion Module (GAFM) and a Consistency Alignment Module (CAM), it effectively fuses 2D visual features with 3D spatial geometric features. GAFM adaptively aggregates multi-scale features based on text instructions, while CAM promotes bidirectional information alignment by rendering 3D features to 2D and applying consistency loss. GEAL significantly enhances generalization to new objects and scenes and robustness in noisy environments without requiring large-scale 3D annotations. The team also constructed a benchmark dataset with various real-world perturbations to evaluate model robustness. (Source: 机器之心)
Moonshot AI Releases Kimi-VL MoE Small and Large Models, Focusing on Multimodal Reasoning and Long Context: Moonshot AI launched two Vision-Language Mixture-of-Experts (MoE) models: Kimi-VL and Kimi-VL-Thinking. These models have a total parameter count of 16B, with only about 3B active parameters, yet demonstrate outstanding performance on multiple benchmarks. Kimi-VL-Thinking excels in multimodal reasoning (achieving 36.8% on MathVision) and agent skills (34.5% on ScreenSpot-Pro), rivaling models 10 times larger. The models utilize MoonViT technology to natively process high-resolution visual input (867 on OCRBench) and support long context windows up to 128K (35.1% on MMLongBench-Doc, 64.5% on LongVideoBench), surpassing larger models like GPT-4o on key benchmarks. The related paper and Hugging Face models have been released. (Source: Reddit r/LocalLLaMA)
🧰 Tools
Firebase Studio: Google’s Integrated AI Full-Stack Online Development Platform: Google merged its Project IDX development tool into Firebase, renaming it Firebase Studio, offering a free in-browser environment for full-stack application development. Key features of the new platform include: 1) AI-assisted project creation, capable of generating initial code frameworks for applications like Next.js based on natural language prompts; 2) Dual work mode switching, allowing seamless transition between an AI smart mode for rapid content generation and a traditional cloud development environment (VM-based cloud workspace); 3) Inherited IDX functionalities, such as full-stack templates, Android emulator, team collaboration, one-click deployment, etc. Firebase Studio deeply integrates Firebase backend services (database, authentication, etc.), aiming to create an all-in-one development experience combining front-end, back-end, and cloud services. User feedback indicates the tool is very powerful with a good interactive experience, enabling app building via prompts with real-time preview, and even supporting UI modification by marking up screenshots. However, access may currently be limited due to high user volume. (Source: 36氪, dotey)

OpenManus: Open-Source Agent Project Quickly Replicating Manus Core Functionality: In response to the buzz around Manus AI Agent whose code was not open-sourced, Liang Xinbing, a graduate student from East China Normal University, and Xiang Jinyu, a researcher at DeepWisdom, along with other post-00s developers, rapidly developed and open-sourced the OpenManus project in their spare time. The project aims to replicate the core functionality of Manus and demonstrate the core logic of an Agent (based on Tools and Prompts) with concise, easy-to-understand code (around a few thousand lines). The project utilizes the ReAct pattern with function calls and designs core tools for browser operation, file editing, and code execution. OpenManus quickly gained over 40k stars on GitHub, reflecting the open-source community’s enthusiasm for Agent technology. The developers shared their workflow using large models to assist in understanding codebases, designing architecture, and generating code, and discussed the MCP protocol (the “Type-C interface” for AI) and the challenges of multi-agent collaboration. The project is under continuous development, planning to enhance the tool ecosystem, MCP support, multi-agent coordination mechanisms, and test cases. (Source: CSDN)
AI Agent Concept Popularization and Application Scenarios: An AI Agent is software capable of autonomously perceiving its environment, making decisions, and executing tasks. Unlike regular AI (like chatbots) that only provide information, it can “take action” for you. Key characteristics include autonomy, memory capability, tool usage capability, and learning/adaptation capability. Application scenarios are broad, such as personal assistants (automatically planning trips, managing calendars/emails), business applications (improving software development, customer service, drug discovery efficiency), and enterprise efficiency enhancement (automating HR processes, content creation management). Building an AI Agent involves steps like perception (collecting data), thinking (AI model analysis and planning), action (calling tool APIs), and learning (improving from results). Major companies like Microsoft, Google, BAT are all investing in this area. Users can start using them via platforms like Coze or by writing prompt templates, beginning with simple tasks and gradually exploring their potential. (Source: 周知)
Color Reshape: Batch Processing Tool to Correct GPT-4o Image Color Casts: Addressing the common blue or yellow color cast issue in images generated by GPT-4o, developer “Guicang” launched a tool called “Color Reshape.” This tool aims to batch-correct the color balance of AI-generated images with a single click, making them look more like professional photographs and restoring true colors. Its features include batch processing support, a comparison function with sliders showing the original and corrected images, and professional color balance control options. This solves the pain point for users needing to manually adjust colors after generating images with GPT-4o, improving the efficiency and final quality of AI art creation. (Source: op7418)
Notion Launches MCP Server: Notion has released its implementation of the MCP (Model Context Protocol) server, now open-sourced on GitHub. This server allows AI agents to interact with Notion via the MCP protocol, enabling various Notion API functions including retrieving page content, comments, and performing searches. This means AI Agents supporting the MCP protocol (like Claude) will be able to more easily call and manipulate users’ Notion data and functions, further expanding the application scenarios and capabilities of AI Agents. (Source: karminski3)

OLMoTrace: New Tool to Explore Language Model Memorization and Synthesis: Ai2 (Allen Institute for AI) launched OLMoTrace, a new feature in its AI Playground designed to help understand the extent to which Large Language Models (LLMs) are learning and synthesizing information versus merely memorizing and regurgitating training data. Users can now use this tool to view snippets of training data that likely contributed to the model generating a specific completion. This is significant for researching the internal workings of LLMs, understanding the sources of their behavior, and evaluating the balance between their generalization and memorization capabilities, especially for researchers and developers concerned with model originality and reliability. (Source: natolambert)
📚 Learning
NVIDIA Releases Open Foundation Model GR00T N1 to Advance General-Purpose Humanoid Robots: NVIDIA released GR00T N1, an open foundation model specifically designed for general-purpose humanoid robots. The model aims to address the scarcity of robot training data by learning from multiple data sources: 1) Using Omniverse to create highly accurate digital twin environments (like factories) to generate large amounts of self-labeled simulation data; 2) Using the Cosmos model to transform simulation data into more realistic videos, further expanding the training set; 3) Developing AI systems to automatically label existing internet videos, extracting information on actions, joints, goals, etc., enabling real-world videos to be used as training data. GR00T N1 employs a dual-system thinking approach: System 2 performs slow reasoning and planning, while System 1 (based on Diffusion models) generates real-time motion control commands. Experiments show an increase in success rate from 46% to 76% compared to previous methods. The model is open-source, supports robots of different morphologies, and aims to accelerate the development and application of general-purpose robots. (Source: Two Minute Papers)
AI Helps Alleviate High School Students’ Math Anxiety: According to a global survey by the Society for Industrial and Applied Mathematics (SIAM) in Philadelphia, over half (56%) of high school students believe AI helps alleviate math anxiety. 15% of students reported reduced math anxiety after personally using AI, and 21% saw improved grades. Reasons AI alleviates anxiety include: providing instant help and feedback (61%), building confidence (allowing questions at one’s own pace, 44%), personalized learning (33%), and reducing fear of making mistakes (25%). However, only 19% of teachers believe AI can reduce math anxiety. Most teachers and students (64% teachers, 43% students) think AI should be used in conjunction with human teachers, acting as a tutor or learning partner to help understand concepts rather than just providing answers. The proliferation of AI also raises questions about the teacher-student relationship and the evolving role of teachers, such as placing more emphasis on exams where AI cannot be used, teachers needing AI proficiency to guide students, and teachers being able to focus more on personalized tutoring. (Source: 元宇宙之心MetaverseHub)

💼 Business
Embodied Intelligence Company “QiongcHe Intelligence” Completes Hundreds of Millions RMB Pre-A++ Funding Round: QiongcHe Intelligence, an embodied intelligence company founded by a Stanford-affiliated team, recently completed a Pre-A++ funding round raising hundreds of millions of RMB. Investors include Shengyu Investment, Zero2IPO Ventures, Vision Knight Capital, Yunqi Partners, Shanghai STVC Group, among others. Existing shareholders Prosperity7 and Sequoia China participated for the third consecutive round. The funds will be used to accelerate breakthroughs in embodied intelligence foundation models, data collection and evaluation, and to promote commercialization in scenarios like retail fulfillment, home services, and food processing. Co-founded by Prof. Lu Cewu of Shanghai Jiao Tong University and Wang Shiquan, founder of Flexiv, the company focuses on solving core challenges in embodied intelligence, such as physical world description and interaction, and data acquisition. Its core product, the “QiongcHe Embodied Brain,” has achieved full closed-loop capabilities and reduces data costs through its self-developed “production-accompanied” data collection system (CoMiner). The company has collaborated with home appliance companies to develop home service robots (like the laundry care robot shown at AWE) and has reached cooperation intentions with food manufacturers. (Source: 36氪)
Humanoid Robot Company “Astribot” Completes Series A and A+ Funding Rounds Totaling Hundreds of Millions RMB: Embodied humanoid robot company Astribot has consecutively completed Series A and A+ funding rounds, raising a total of hundreds of millions of RMB. The rounds were led by Jinqiu Fund and Ant Group, with participation from existing shareholders like Yunqi Partners and DaoTong Capital. The company defines a “Design for AI” paradigm, aiming to create AI robot assistants with human-level manipulation capabilities. Its core product, Astribot S1, features a unique proprietary cable-driven transmission design, achieving a high payload-to-weight ratio (1:1), high speed (end effector over 10m/s), and human-like flexible manipulation capabilities. Astribot has built a “body + data + model” technology closed loop, enabling low-cost utilization of real-world video and human motion data, and efficient collection of multimodal interaction data, empowering the robot with complex environmental perception, cognition, decision-making, and general manipulation generalization abilities. The S1 has undergone three iterations and is engaged in pilot implementations with universities and enterprises, while continuously optimizing its end-to-end large model. (Source: 36氪)

Jony Ive and Sam Altman’s AI Hardware Startup io Products Potentially Acquired by OpenAI: io Products, the AI hardware startup co-founded by former Apple design chief Jony Ive and OpenAI CEO Sam Altman, is reportedly in talks to be acquired by OpenAI for at least $500 million, according to The Information. Founded in 2024, io Products aimed to create AI-driven personal devices less intrusive than smartphones, potentially exploring directions like screenless phones, AI-powered home devices, or wearable AI assistants. This potential acquisition signals OpenAI’s possible expansion from software into consumer hardware. However, considering the failures of previous AI hardware products like the Humane AI Pin and Rabbit R1, and users’ preference for enhanced AI features on existing phones over entirely new device forms, market demand and acceptance for screenless AI devices remain questionable. (Source: 不客观实验室)

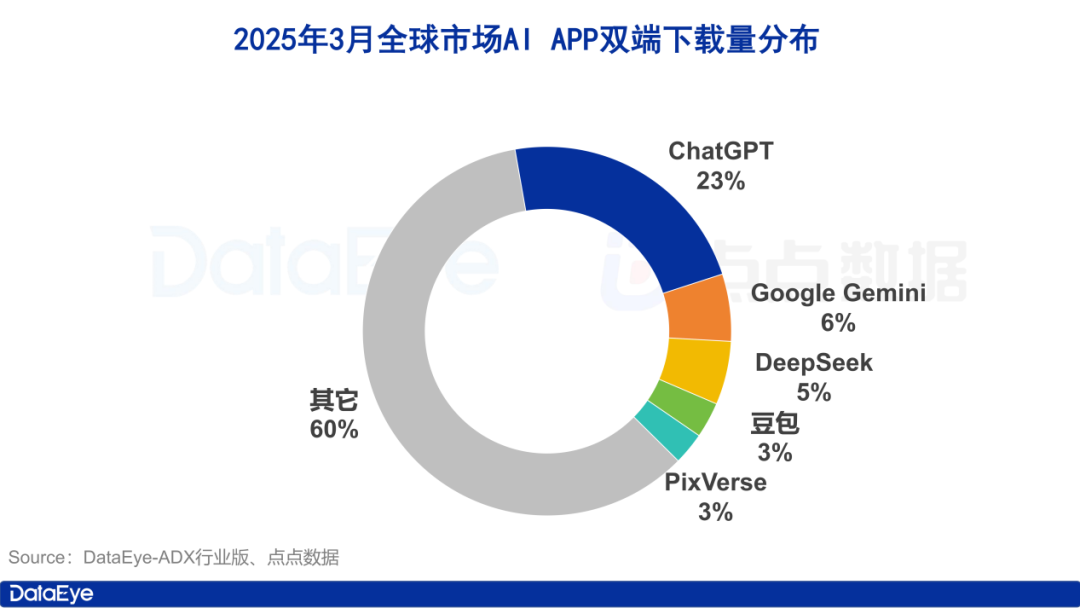
March AI App Market Watch: Global Downloads Reach 260M; Tencent, Alibaba, ByteDance in “Three Kingdoms” Battle in China: DataEye Research Institute reports that estimated global AI application downloads (App Store & Google Play) reached 260 million in March 2025. ChatGPT leads with a 23% share, while Google Gemini surpassed DeepSeek to rank second. In the domestic Chinese market, Apple App Store downloads reached 40.2 million, with DeepSeek, Jimeng AI, Doubao, Quark, and Tencent Yuanbao in the top five. Kimi Smart Assistant downloads plummeted. In terms of user acquisition efforts, AI products (including mini-programs) in mainland China generated 957,000 ad creative sets. Tencent Yuanbao (26%), Quark (24%), and Doubao (13%) ranked top three, forming a fierce competition pattern among Tencent, Alibaba, and ByteDance. Kimi dropped off the list after pausing ad spending. The report suggests DeepSeek’s surge and Alibaba’s “All in AI” strategy are prompting major tech companies to accelerate their布局 in the consumer-facing AI application market. (Source: 36氪)
Anthropic Launches High-Priced Subscription Plan Claude Max: Competing with OpenAI’s ChatGPT Pro ($200/month), Anthropic has introduced the Claude Max subscription service. It offers two tiers: $100/month for 5 times the usage limit of the existing Claude Pro ($20/month), and $200/month for up to 20 times the usage limit. Max plan users will get priority access to Anthropic’s latest AI models and features, including the upcoming voice mode. This move is seen as a new way for AI companies to explore increasing revenue and serving heavy users. Anthropic’s Head of Product stated the plan primarily targets professional heavy users in fields like coding, finance, media/entertainment, and marketing, and does not rule out potentially more expensive plans in the future. Anthropic is also exploring services tailored for specific markets like education. (Source: dotey, op7418)

xAI Releases Grok 3 API and Announces Pricing: xAI has officially opened the Beta test for its Grok 3 series API, offering two models: Grok 3 and Grok 3 Mini, each available in regular and fast modes (faster response but higher output cost). Grok 3 is suitable for enterprise scenarios like data extraction and programming, priced at $3/million tokens for input and $15/million tokens for output (fast mode: $5/$25). Grok 3 Mini is a lightweight model for simpler tasks, priced at $0.3/million tokens for input and $0.5/million tokens for output (fast mode: $0.6/$4). This provides developers with flexible options to meet the performance and cost requirements of different applications. Meanwhile, Google also launched new plans for developers including a free tier, Anthropic introduced its high-priced Max plan, and Meta’s Llama 4 competes with low cost (approx. $0.36/million tokens), highlighting the differentiated API pricing strategies among AI giants. (Source: 新智元, op7418)
36Kr Releases 2025 AI-Native Application Innovation Case List: 36Kr selected and released the “2025 AI-Native Application Innovation Cases” list, with 45 cases ultimately shortlisted. The selection aimed to discover AI-native products and applications that are pioneers in implementing AI technology in real-world scenarios, creating tangible value, and leading industry transformation. The shortlisted cases cover multiple fields including smart manufacturing, customer service, content creation, enterprise management, office work, security, marketing, and healthcare. The review found four key characteristics among the winners: 1) Accelerated cross-domain integration creating new business models; 2) Deeply addressing industry pain points with specialized solutions; 3) Emphasis on enhancing user experience and personalized services; 4) Reliance on strong self-developed technologies (large models, multimodal, etc.) and active construction of innovative ecosystems. The list reflects the explosive growth of AI-native applications and their deep penetration across various industries. (Source: 36氪)

🌟 Community
Google DeepMind Reportedly Uses 1-Year Non-Competes to Restrict Talent Mobility: According to Business Insider, Google DeepMind is accused of using non-compete agreements lasting up to 12 months (including mandatory paid leave/garden leave) to prevent core AI talent from moving to competitors like OpenAI and Microsoft. These agreements are typically included in employment contracts and are enforced when employees attempt to join direct competitors. The non-compete period varies by position, potentially 6 months for frontline developers and up to 1 year for senior researchers. This practice has sparked controversy, criticized as “golden handcuffs” that could lead to skill obsolescence, stifle innovation, and hinder talent flow in the fast-paced AI industry. As UK law permits the enforcement of “reasonable” non-competes and DeepMind is headquartered in London, this contrasts with California, which bans non-competes. Former DeepMind executive and current Microsoft VP Nando de Freitas publicly criticized the practice on X, stating they shouldn’t wield such power in Europe, sparking widespread discussion. (Source: CSDN程序人生)

AI Sparks Concerns Over “Emotional Cocoons”: As AI technology advances, its application in fulfilling human emotions and desires is increasing, such as intelligent sex dolls (Wmdoll expects 30% sales growth), AI virtual companions, and AI chat assistants (boosting OnlyFans creators’ income). The article analyzes that AI can provide stable, patient, and affirming emotional value, satisfying needs for spiritual communication, sometimes surpassing real humans. However, this “excessive catering” and “overprotection” might lead humans to form “emotional cocoons,” overly relying on subjective feelings to handle relationships, reducing tolerance for the complexity and frustrations of real interpersonal connections, and exacerbating emotional fragility, atomization, and gender antagonism. The article argues that while AI frees up human time by handling chores, its inherently accommodating nature might also confine people to comfort zones and ultimate fantasies, hindering personal growth and real human interaction, potentially leading to greater loneliness and eventual “conquest” by AI. (Source: 周天财经)

MiniMax Strategic Shift: From “Integrated Model-Product” to Tech-First, Betting on AI Video: Facing competitive pressure from rivals like DeepSeek, AI company MiniMax is adjusting its strategy. Initially adhering to an “integrated model-product” approach where models served applications (e.g., text model for MiniMax assistant, video model for Hailuo AI, plus Talkie, Xingye, etc.) and improving efficiency by modifying the underlying Transformer architecture (linear attention). Founder Yan Junjie reflected that “better applications don’t necessarily lead to better models,” shifting the company towards being “technology-driven,” separating tech R&D from product application. On the product front, MiniMax is focusing the “Hailuo” brand on video generation, renaming the original “Hailuo AI” to “MiniMax,” and is rumored to be acquiring AI video generation company Luying Technology (owner of the anime platform YoYo). This move might be driven by the risk of its main revenue source, Talkie (an AI companion app), being delisted in overseas markets, necessitating new growth avenues. Simultaneously, MiniMax is starting to focus on B2B business, forming a smart hardware industry innovation alliance, but its enterprise business still appears weak and faces challenges. (Source: guangzi0088)

Great Wall Motor and Unitree Robotics Collaborate to Explore “Off-Road Vehicle + Robot Dog”: Great Wall Motor (GWM) and robotics company Unitree Technology have entered a strategic partnership to collaborate in areas like robotics technology and intelligent manufacturing. The initial phase will focus on application scenarios combining “off-road vehicles + robot dogs,” exploring possibilities such as equipment transport and outdoor adventure companionship. The article discusses the application of robots (especially humanoids) in the auto industry, suggesting that currently, robots in car factories mainly play supporting roles (like carrying heavy objects) and are not yet realistic replacements for humans due to insufficient flexibility and adaptability. Expanding scenarios with “car + robot” combinations (similar to BYD’s “car + drone”) aims to broaden the boundaries of vehicle usage. Regarding “off-road vehicle + robot dog,” the article believes it has potential value for hardcore off-road enthusiasts or specific industries (like wilderness rescue) for tasks like equipment transport or pathfinding, but widespread adoption faces challenges like high cost, niche demand, and technological maturity. Currently, it seems more like an exploration of future outdoor intelligent scenarios rather than a pressing need. (Source: 电车通)

Discussion on Llama 4 Architecture’s Suitability for Specific Mac User Workflow: A Mac Studio user (M3 Ultra, 512GB RAM) shared insights on the suitability of the Llama 4 Maverick model for their workflow. The user favors a multi-step iteration and validation workflow to enhance LLM performance but previously found running large models (32B-70B) on Mac too slow (taking 20-30 minutes), while smaller models (8-14B) were fast but lacked quality. Although Llama 4 Maverick has a large parameter count (400B) requiring significant memory (which the Mac provides), its MoE architecture results in actual running speeds close to a 17B model (approx. 16.8 T/s generation speed with Q8 quantization). This characteristic of “high memory usage but relatively fast speed” perfectly fits the Mac user’s pain point of “ample memory but limited speed,” making it an ideal choice for their specific workflow, despite the model’s generally mixed reviews and potential tokenizer issues. (Source: Reddit r/LocalLLaMA)
💡 Other
Google Gemini Upgrades Deep Research Feature: Google DeepMind CEO Demis Hassabis announced that the Deep Research feature in the Gemini app (requires Gemini Advanced subscription) is now powered by the Gemini 2.5 Pro model. Google claims this is the most powerful deep research capability on the market, with a 2-to-1 user preference over the next best competitor. The upgraded Deep Research can better analyze information and generate in-depth reports for users on almost any topic. (Source: demishassabis)

Using GPT-4o to Convert Photos into Layered Paper-Cut Art Style: A user shared a prompt technique using GPT-4o or Sora to transform ordinary photos into a paper-cut art style with a layered effect. The core idea is to ask the model to identify and separate the midground and background of the photo, then redraw it applying the layered paper-cut art style, optionally adding a title. An example demonstrated successfully converting a photo of Chicago into a paper-cut style artwork titled “Chicago 2016”. (Source: dotey)

Using GPT-4o to Generate Fashion Calendar Illustrations Based on Date: A user shared a prompt template and method for using GPT-4o to generate fashion calendar illustrations in the style of a Chinese almanac. The method involves two steps: First, input a date and have the model retrieve corresponding almanac information (day of the week, lunar date, holidays, auspicious/inauspicious activities, motivational quote) and a description of seasonal character attire, then generate a detailed image generation prompt based on the template. Second, have the model draw the image based on the generated prompt. The template requires a vertical (9:16) image in a fresh hand-drawn illustration style, featuring a fashionable and cute female character, prominent Gregorian date, English month, Chinese and English day of the week, lunar date, holidays, vertically aligned “auspicious” activities, and a motivational quote, paying attention to white space and layout. An example showed a New Year’s Day calendar illustration generated using this method. (Source: dotey)
