
Keywords:AI, LLM, AI Index Report 2025, Meta Llama 4 controversy, Gemini Deep Research upgrade, AI in manufacturing challenges, Responsible AI principles
🔥 Focus
Stanford Releases Annual AI Index Report, Revealing New Changes in the Global AI Landscape: Stanford University’s HAI released the 456-page “AI Index Report 2025”. The report shows the US still leads in producing top AI models, but China is rapidly closing the performance gap (e.g., the gap on MMLU and HumanEval has nearly disappeared). Industry dominates the development of important models (accounting for 90%), but the number of models has decreased. AI hardware costs are decreasing at an annual rate of 30%, and performance doubles every 1.9 years. Global AI investment reached $252.3 billion, with the US leading significantly at $109.1 billion (about 12 times China’s $9.3 billion). Generative AI investment reached $33.9 billion. Enterprise AI adoption rate rose to 78%, with China showing the fastest growth (reaching 75%). AI has begun to help enterprises reduce costs and increase efficiency. AI has made breakthroughs in science, contributing to two Nobel Prizes, and surpassing human performance in protein sequencing and clinical diagnosis. Global optimism about AI is rising, but regional differences are significant, with China being the most optimistic. The Responsible AI (RAI) ecosystem is gradually maturing, but evaluation and practice remain uneven. (Source: 36Kr, AI Tech Review, dotey, 36kr)
Meta Llama 4 Release Sparks Major Controversy, Accused of “Benchmark Gaming” and Poor Performance: Meta’s newly released open-source large model Llama 4 series (Scout, Maverick, Behemoth) faced a reputation crisis within 72 hours of launch. Its Maverick version quickly climbed to second place on Chatbot Arena but was reportedly submitted as an undisclosed “experimental version” optimized for dialogue, sparking accusations of “benchmark gaming”. Although Meta denied training on the test set, it acknowledged performance issues. Community feedback indicates Llama 4’s performance in areas like coding and long-context understanding fell short of expectations, even underperforming smaller models (like DeepSeek V3). AI experts like Gary Marcus commented “Scaling is dead”, arguing that simply increasing model size doesn’t yield reliable reasoning ability and expressing concern that global AI progress might stagnate due to funding, geopolitical factors, etc. LMArena has released relevant evaluation data for review and updated its ranking strategy to avoid confusion. (Source: 36Kr, Lei Technology, AIatMeta, karminski3, Reddit r/artificial, Reddit r/LocalLLaMA)

🎯 Trends
Gemini Deep Research Feature Upgraded, Adopts Gemini 2.5 Pro Model: The Deep Research feature in the Google Gemini App is now powered by the Gemini 2.5 Pro model. Early user testing feedback indicates its performance surpasses competitors. This upgrade aims to enhance information retrieval and synthesis capabilities, report insights, and analytical reasoning skills. Gemini Advanced users can experience this update. Several users and Google DeepMind CEO Demis Hassabis shared positive experiences using the new Deep Research for complex tasks (like market analysis), praising its speed and comprehensive content. (Source: JeffDean, dotey, JeffDean, demishassabis)

Nvidia Releases Llama 3.1 Nemotron Ultra 253B Model: Nvidia released the Llama 3.1 Nemotron Ultra 253B model on Hugging Face. This model is a dense model (non-MoE) with inference on/off capabilities. It was modified from Meta’s Llama-405B model using NAS pruning techniques and underwent inference-focused post-training (SFT + RL in FP8). Benchmark tests show its performance surpasses DeepSeek R1, although some comments note that a direct comparison with the MoE model DeepSeek R1 (with fewer active parameters) might not be entirely fair. Nvidia also released the related post-training dataset on Hugging Face. (Source: huggingface, Reddit r/LocalLLaMA, dylan522p, huggingface)

AI + Manufacturing Becomes New Focus, Opportunities and Challenges Coexist: AI is accelerating its penetration into China’s manufacturing sector, with applications covering production automation (e.g., Yurucheng’s dental material production), product intelligence (e.g., Binghan Technology’s AI sleep aid glasses), process optimization (e.g., Zhongke Lingchuang’s AI meeting minutes), and R&D and diagnostics (e.g., Ruixin Intelligence’s cardiovascular diagnosis platform, Bihucar’s auto parts demand forecasting and fault detection). Financial institutions like WeBank are also using AI technology (e.g., intelligent due diligence report generation) to serve sci-tech manufacturing enterprises. However, “AI + Manufacturing” still faces challenges such as low data quality and weak enterprise digitalization foundations. Investors suggest companies should use AI to serve their main business, not just as a gimmick, and need long-term investment to solve data and implementation problems. (Source: 36Kr)
DeepSeek R1 Sets Inference Speed Record on Nvidia B200: AI startup Avian.io announced that through collaboration with Nvidia, it achieved a world record inference speed of 303 tokens/second for the DeepSeek R1 model on the latest Blackwell B200 GPU platform. Avian.io stated it will offer dedicated DeepSeek R1 inference endpoints based on B200 in the coming days and has opened pre-orders. This achievement marks a new era for test time compute driven models. (Source: Reddit r/LocalLLaMA)

OpenAI Establishes Strategic Deployment Team to Drive Frontier Model Implementation: OpenAI has formed a new Strategic Deployment team aimed at pushing frontier models (like GPT-4.5 and future models) to higher levels of capability, reliability, and alignment, and deploying them into high-impact real-world domains to accelerate AI’s economic transformation and explore paths to AGI. The team is actively hiring and promoting itself at academic conferences like ICLR. (Source: sama)
AI Faces Challenges in Customer Experience (CX) Improvement: The article explores the difficulties and challenges faced when using AI to improve customer experience. While AI offers potential, effective implementation is not easy and may involve issues like data integration, model accuracy, user acceptance, and maintenance costs. (Source: Ronald_vanLoon)

AI Applications Spark Workplace Innovation and Concerns: The article discusses the dual impact of AI applications in the workplace: on one hand, stimulating innovation potential, and on the other, raising concerns about the existing workforce, such as the possibility of job displacement and changing skill requirements. (Source: Ronald_vanLoon)

Internet of Behavior (IoB) is Changing Business Decisions: The technology of analyzing user behavior data (Internet of Behavior) using machine learning and artificial intelligence is providing businesses with deeper insights, thereby transforming the way they make business decisions, potentially involving aspects like personalized marketing, risk assessment, and product development. (Source: Ronald_vanLoon)

Multimodal Model RolmOCR Performs Strongly on Hugging Face Leaderboard: Yifei Hu pointed out that the visual language model RolmOCR developed by their team performed excellently on the Hugging Face leaderboard, ranking third among VLMs and fifth among all models. The team plans to release more models, datasets, and algorithms in the future to support open-source scientific research. (Source: huggingface)

AI News Summary (2025/04/08): Recent AI-related news includes: Meta Llama 4 accused of misleading behavior in benchmarks; Apple may shift more iPhone production to India to avoid tariffs; IBM releases new mainframe for the AI era; Google rumored to pay some AI employees high salaries to “sit idle” for a year to retain talent; Microsoft reportedly fired employees who protested its Copilot event; Amazon claims its AI video model can now generate multi-minute clips. (Source: Reddit r/ArtificialInteligence)

🧰 Tools
FunASR: Alibaba DAMO Academy Open-Source Foundational End-to-End Speech Recognition Toolkit: FunASR is a toolkit integrating functionalities like Automatic Speech Recognition (ASR), Voice Activity Detection (VAD), punctuation restoration, language modeling, speaker verification, speaker diarization, and multi-speaker recognition. It supports inference and fine-tuning of industrial-grade pre-trained models (such as Paraformer, SenseVoice, Whisper, Qwen-Audio, etc.) and provides convenient scripts and tutorials. Recent updates include support for SenseVoiceSmall, Whisper-large-v3-turbo, keyword spotting models, emotion recognition models, and the release of offline/real-time transcription services (including GPU versions) optimized for memory and performance. (Source: modelscope/FunASR – GitHub Trending (all/daily))
LightRAG: A Concise and Efficient Retrieval-Augmented Generation Framework: LightRAG is an RAG framework developed by HKU DS Lab, designed to simplify and accelerate the building of RAG applications. It integrates Knowledge Graph (KG) construction and retrieval capabilities, supports multiple retrieval modes (local, global, hybrid, naive, Mix mode), and flexibly connects to different LLMs (like OpenAI, Hugging Face, Ollama) and Embedding models. The framework also supports various storage backends (like NetworkX, Neo4j, PostgreSQL, Faiss) and multiple file type inputs (PDF, DOC, PPT, CSV), offering features like entity/relation editing, data export, cache management, Token tracking, conversation history, and custom Prompts. The project provides a Web UI, API service, and a knowledge graph visualization tool. (Source: HKUDS/LightRAG – GitHub Trending (all/daily))
LangGraph Helps Definely Build Legal AI Agents: Definely used LangGraph to build a multi-AI Agent system directly integrated into Microsoft Word to assist lawyers with complex legal work. The system can break down legal tasks into sub-tasks, combine contextual information for clause extraction, change analysis, and contract drafting, and incorporate lawyer input and approval through a Human-in-the-loop cycle to guide key decisions. This demonstrates LangGraph’s capability in building complex, controllable Agent workflows. (Source: LangChainAI)

LlamaParse Introduces New Layout-Aware Agent: LlamaIndex launched a new feature for LlamaParse – the Layout Agent. This agent utilizes SOTA VLM models of varying sizes (from Flash 2.0 to Sonnet 3.7) to dynamically and layout-awarely parse document pages. It first parses the overall layout and breaks the page into chunks (like tables, charts, paragraphs), then selects different models based on chunk complexity for processing (e.g., using stronger models for charts, smaller models for text). This feature is particularly important for Agent workflows that need to process large amounts of document context. (Source: jerryjliu0)

Auth0 Releases Security Tools for GenAI Applications: Auth0 launched a new product “Auth for GenAI” designed to help developers easily secure their GenAI applications and Agents. The product provides features like user authentication, calling APIs on behalf of users, Client Initiated Backchannel Authentication (CIBA), and RAG authorization. It offers SDKs and documentation for popular GenAI frameworks (like LangChain, LlamaIndex, Firebase Genkit, etc.), simplifying the process of integrating authentication and authorization into AI applications. (Source: jerryjliu0, jerryjliu0)

Ollama Adds Support for Mistral Small 3.1 Vision Model: The local large model running tool Ollama now supports Mistral AI’s latest Mistral Small 3.1 model, including its vision (multimodal) capabilities. Users can pull and run quantized versions like mistral-small3.1:24b-instruct-2503-q4_K_M via the Ollama library. Community feedback suggests the model performs well on tasks like OCR, though some users reported slower inference speeds on specific hardware (like AMD 7900xt). (Source: Reddit r/LocalLLaMA)

Unsloth Releases Llama-4 Scout GGUF Quantized Models: Unsloth has open-sourced GGUF format quantized versions of the Llama-4 Scout 17B model, facilitating running it locally on CPUs or GPUs with limited memory. This includes a 2.71-bit dynamically quantized version, sized at only 42.2GB. Users can check model files for different quantization levels (like Q6_K) and their hardware compatibility information on Hugging Face. (Source: karminski3)

LangSmith’s OpenEvals Supports Custom Output Schemas: LangSmith’s LLM evaluation tool, OpenEvals, now allows users to customize the output schemas of LLM-as-judge evaluators. While the default schemas cover many common cases, this update provides users with complete flexibility to tailor the structure and content of model responses according to specific evaluation needs. The feature is available in both Python and JS versions. (Source: LangChainAI)

Qwen 3 Models Soon to Support llama.cpp: A Pull Request adding support for Alibaba’s Qwen 3 series models to llama.cpp has been submitted and approved, and will be merged soon. This means users will soon be able to run Qwen 3 models locally using the llama.cpp framework. This update was submitted by bozheng-hit, who previously contributed Qwen 3 support to the transformers library. (Source: Reddit r/LocalLLaMA)

Computer Use Agent Arena Launched: The OSWorld team has launched the Computer Use Agent Arena, a platform for testing Computer-Use Agents in real environments without setup. Users can compare the performance of top VLMs like OpenAI Operator, Claude 3.7, Gemini 2.5 Pro, Qwen 2.5 VL, etc., on over 100 real applications and websites. The platform offers one-click configuration and claims to be secure and free. (Source: lmarena_ai)
Music Distribution Service Too Lost is AI Music Friendly: A Reddit user shared their experience using Too Lost to distribute AI-generated music from Suno, Udio, etc. Pros include: explicitly accepts AI music, fast approval (1-2 days), affordable price ($35/year for unlimited releases), music stays up after subscription expires (but revenue split becomes 85/15), supports custom label names. Cons are slower distribution to Instagram/Facebook (>16 days), may require proof of prior distribution. (Source: Reddit r/SunoAI)
📚 Learning
NVIDIA Releases CUDA Python: NVIDIA has launched CUDA Python, aiming to provide a unified entry point to the CUDA platform from Python. It includes multiple components: cuda.core offers Pythonic access to the CUDA Runtime; cuda.bindings provides low-level bindings to the CUDA C API; cuda.cooperative offers device-side parallel primitives from CCCL (for Numba CUDA); cuda.parallel provides host-side parallel algorithms from CCCL (sort, scan, etc.); and numba.cuda is used for compiling a subset of Python into CUDA kernels. The cuda-python package itself will transition into a meta-package containing these independently versioned sub-packages. (Source: NVIDIA/cuda-python – GitHub Trending (all/daily))
Hugging Face Releases Large Reasoning Coding Dataset: A large dataset containing 736,712 Python code solutions generated by DeepSeek-R1 has been released on Hugging Face. The dataset includes reasoning traces for the code, usable for both commercial and non-commercial purposes, making it one of the largest reasoning coding datasets currently available. (Source: huggingface)

Five Major Challenges and Solutions for Building AI Agents: The article outlines five core challenges faced when building AI Agents: 1) Reasoning and decision management (ensuring consistency and reliability); 2) Multi-step process and context handling (state management, error handling); 3) Tool integration management (increased failure points, security risks); 4) Controlling hallucinations and ensuring accuracy; 5) Large-scale performance management (handling high concurrency, timeouts, resource bottlenecks). For each challenge, the article proposes specific solutions, such as using structured prompting (ReAct), robust state management, precise tool definitions, strict validation systems (factual grounding, citations), human review, LLMOps monitoring, etc. (Source: AINLPer)
Kaggle’s Former Chief Scientist Recalls ULMFiT, Possibly the First LLM: Jeremy Howard (founder of fast.ai, former Chief Scientist at Kaggle) claimed on social media that his 2018 ULMFiT was the first “universal language model,” sparking discussion about the “first LLM.” ULMFiT used an unsupervised pre-training and fine-tuning paradigm, achieved SOTA on text classification tasks, and inspired GPT-1. A fact-checking article argues that by criteria such as self-supervised training, predicting the next token, adaptability to new tasks, and generality, ULMFiT is closer to the modern LLM definition than CoVE or ELMo, making it one of the “common ancestors” of modern LLMs. (Source: QubitAI)
Developer’s Perspective on Lightweight LLM Fine-tuning Techniques: Sharing experiences and lessons learned for developers who are not specialized ML engineers when using Parameter-Efficient Fine-Tuning (PEFT) methods like LoRA and QLoRA to improve LLM output quality. Emphasizes that these methods are more suitable for integration into regular development workflows, avoiding the complexity of full fine-tuning. The relevant team will host a free webinar discussing pain points encountered by developers in practice. (Source: Reddit r/artificial, Reddit r/MachineLearning)
Paper Proposes Rethinking Reflection in Pre-Training: Research from Essential AI (led by Transformer co-author Ashish Vaswani) finds that LLMs exhibit general reasoning capabilities across tasks and domains even during the pre-training phase. The paper proposes that a simple “wait” token can act as a “reflection trigger,” significantly boosting the model’s reasoning performance. The study suggests that leveraging the model’s intrinsic reflection capabilities during pre-training might be a simpler and more fundamental way to enhance general reasoning ability compared to post-training methods relying on elaborate Reward Models (like RLHF), potentially overcoming the limitations of current task-specific fine-tuning approaches. (Source: dotey)

Paper Proposes Using RL Loss for Story Generation without Reward Models: Researchers propose a reward paradigm, VR-CLI, inspired by RLVR, for optimizing long-form story generation (next chapter prediction task, ~100k tokens) using RL losses (like perplexity) without an explicit reward model. Experiments show that this method correlates with human judgments of the quality of generated content. (Source: natolambert)

Paper Proposes P3 Method to Enhance Zero-Shot Classification Robustness: To address the issue of prompt brittleness (sensitivity to prompt variations) in Zero-Shot text classification, researchers propose the Placeholding Parallel Prediction (P3) method. This method simulates comprehensive sampling of generation paths by predicting token probabilities at multiple positions, rather than relying solely on the probability of the next token. Experiments show P3 improves accuracy and reduces the standard deviation across different prompts by up to 98%, enhancing robustness and even maintaining comparable performance without prompts. (Source: Reddit r/MachineLearning)
Paper Proposes Test-Time Training Layer to Improve Long Video Generation: To address consistency issues in generating long videos (e.g., over a minute) caused by the inefficiency of the self-attention mechanism in Transformer architectures, research proposes a new Test-Time Training (TTT) layer. The hidden state of this layer can itself be a neural network, making it more expressive than traditional layers, thus enabling the generation of long videos with better consistency, naturalness, and aesthetic quality. (Source: dotey)
SmolVLM Technical Report Released, Exploring Efficient Small Multimodal Models: The technical report introduces the design philosophy and experimental findings for SmolVLM (256M, 500M, 2.2B parameters), aiming to build efficient small multimodal models. Key insights include: increasing context length (2K->16K) significantly boosts performance (+60%); smaller LLMs benefit more from smaller SigLIP (80M); Pixel shuffling can drastically shorten sequence length; learned positional tokens outperform raw text tokens; system prompts and dedicated media tokens are particularly important for video tasks; excessive CoT data harms small model performance; training on longer videos helps improve performance on both image and video tasks. SmolVLM achieves SOTA performance within its hardware constraints and has achieved real-time inference on iPhone 15 and in browsers. (Source: huggingface)

Hugging Face Releases Reasoning Required Dataset: This dataset contains 5000 samples from fineweb-edu, annotated for reasoning complexity (0-4 scale), used to determine if text is suitable for generating reasoning datasets. The dataset aims to train a ModernBERT classifier for efficient pre-filtering of content and to expand the scope of reasoning datasets beyond math and coding domains. (Source: huggingface)
CoCoCo Benchmark Evaluates LLM Ability to Quantify Consequences: Upright Project released the technical report for the CoCoCo benchmark, designed to evaluate the consistency of LLMs in quantifying the consequences of actions. Testing found Claude 3.7 Sonnet (with a 2000 token thinking budget) performed best but exhibited a bias towards emphasizing positive consequences and downplaying negative ones. The report concludes that while LLMs have improved in this capability in recent years, there is still a long way to go. (Source: Reddit r/ArtificialInteligence)

GenAI Inference Engine Comparison: TensorRT-LLM vs vLLM vs TGI vs LMDeploy: NLP Cloud shared a comparative analysis and benchmark results for four popular GenAI inference engines. TensorRT-LLM is fastest on Nvidia GPUs but complex to set up; vLLM is open-source, flexible, and has high throughput, but slightly lags in single-request latency; Hugging Face TGI is easy to set up and scale, well-integrated with the HF ecosystem; LMDeploy (TurboMind) excels in decoding speed and 4-bit inference performance on Nvidia GPUs with low latency, but TurboMind has limited model support. (Source: Reddit r/MachineLearning)
Google DeepMind Podcast New Season Preview: The new season of the Google DeepMind podcast, hosted by Hannah Fry, will launch on April 10th. Content will cover how AI-driven science is revolutionizing medicine, cutting-edge robotics, the limitations of human-generated data, and other topics. (Source: GoogleDeepMind)
LangGraph Platform Introduction Video: LangChain released a 4-minute video explaining the features of the LangGraph platform, showcasing how to use this enterprise-grade product to develop, deploy, and manage AI Agents. (Source: LangChainAI, LangChainAI)

Keras Implementation of First-Order Motion Transfer: A developer shared their implementation in Keras of the First-Order Motion Model from Siarohin et al.’s NeurIPS 2019 paper for image animation. Due to Keras lacking a function similar to PyTorch’s grid_sample, the developer built a custom flow map warping module supporting batch processing, normalized coordinates, and GPU acceleration. The project includes keypoint detection, motion estimation, a generator, and a GAN training pipeline, providing example code and documentation. (Source: Reddit r/deeplearning)

Natural Language Processing (NLP) Flowchart: The image displays a basic flowchart for Natural Language Processing, potentially including steps like text preprocessing, feature extraction, model training, and evaluation. (Source: Ronald_vanLoon)

Blog Post Explaining the Math Behind GANs: A developer shared their Medium blog post explaining the mathematical principles behind Generative Adversarial Networks (GANs), focusing on the derivation and proof of the value function used in the GANs min-max game. (Source: Reddit r/deeplearning)

K-Means Clustering Introductory Concept: Shared an introductory explanation of the K-Means clustering algorithm, serving as a conceptual overview for machine learning beginners, explaining this unsupervised learning method. (Source: Reddit r/deeplearning)

Biomedical Data Science Summer School and Conference: Budapest, Hungary will host a Biomedical Data Science Summer School and Conference from July 28 to August 8, 2025. The summer school offers intensive training in areas like medical data visualization, machine learning, deep learning, and biomedical networks. The conference will showcase cutting-edge research and feature speakers including Nobel laureates. (Source: Reddit r/MachineLearning)
Personal Deep Learning Model Repository Shared: A self-learner shared their GitHub repository documenting their practice of creating deep learning models for different datasets (like CIFAR-10, MNIST, yt-finance), including scores, prediction plots, and documentation, as a personal learning and training method. (Source: Reddit r/deeplearning)

💼 Business
AI Unicorn OpenEvidence Disrupts AI Healthcare with Internet Mindset: AI healthcare company OpenEvidence secured $75 million in funding from Sequoia, reaching a $1 billion valuation and becoming a new unicorn. Unlike the traditional B2B model, OpenEvidence adopts a consumer internet-like strategy, offering free services directly to doctors (monetized through ads), helping them accurately search vast medical literature and handle complex cases. The product has grown rapidly, reportedly used by 1/4 of US doctors. Key to its success are strict data sources (peer-reviewed literature) and a multi-model integrated architecture ensuring information accuracy, with transparency guaranteed through source citations, creating a win-win model for doctors and medical journals. (Source: 36Kr)
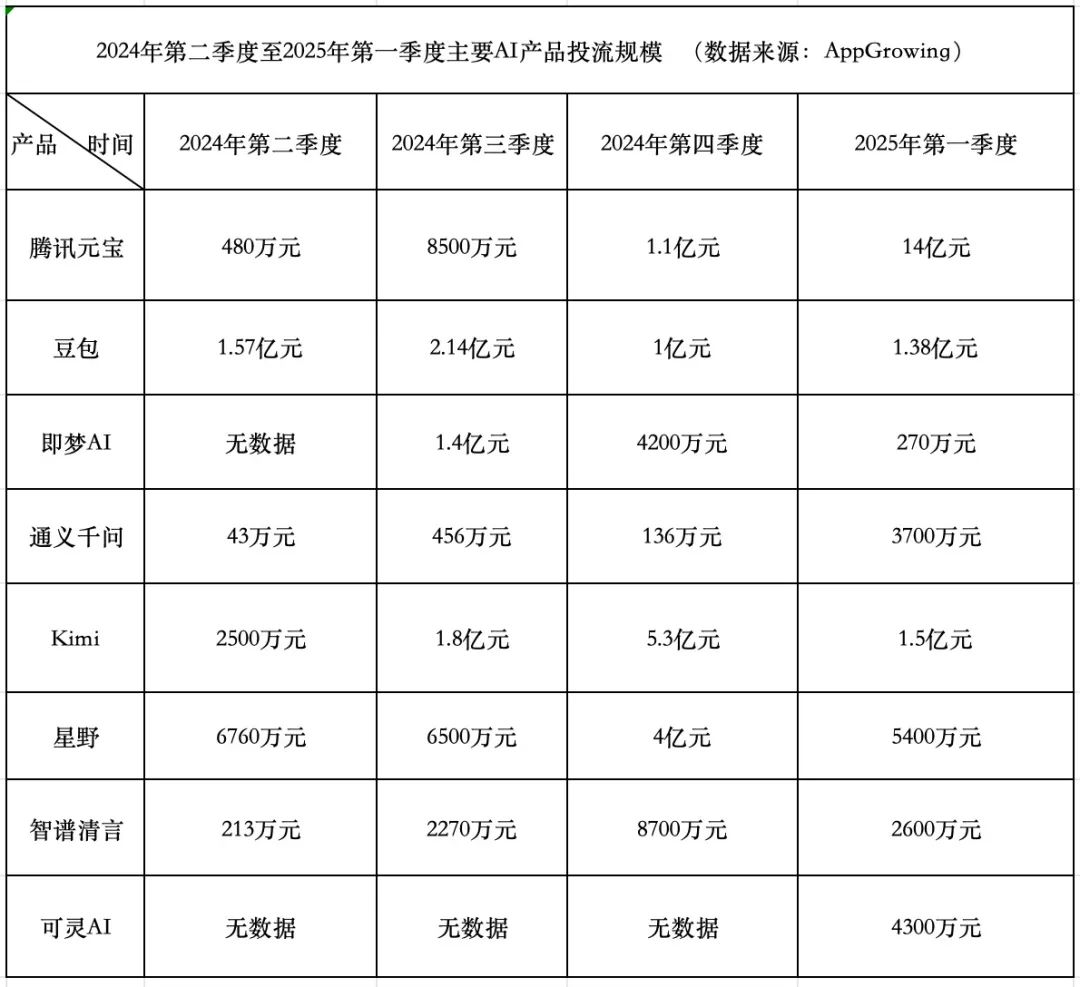
AI Product Spending Race: Tencent Aggressive, ByteDance Conservative, Startups Retreat: In Q1 2025, AI product advertising spending reached 1.84 billion RMB. Tencent’s Yuanbao accounted for the largest share with 1.4 billion RMB, with ads even appearing on rural walls. ByteDance’s Doubao spent 138 million RMB, adopting a relatively conservative strategy. Kuaishou’s Keling AI invested 43 million RMB. In contrast, star startups Kimi and Xingye significantly cut back on ad spending (totaling about 200 million RMB, far below Q4’s 930 million RMB), and Zhipu Qingyan also notably reduced investment. Startup founders are beginning to rethink the cash-burning model, focusing more on improving model capabilities and technical barriers. Tencent, with its advertising system, benefits from the AI ad spending war. Alibaba’s Tongyi Qianwen and Baidu’s Wenxin Yiyan have relatively modest ad spending, focusing more on ecosystem and open source. The industry trend shows that simply burning money for scale is becoming ineffective, and AI product competition is entering a new phase focused on model capabilities and ecosystem layout. (Source: China Entrepreneur Magazine)
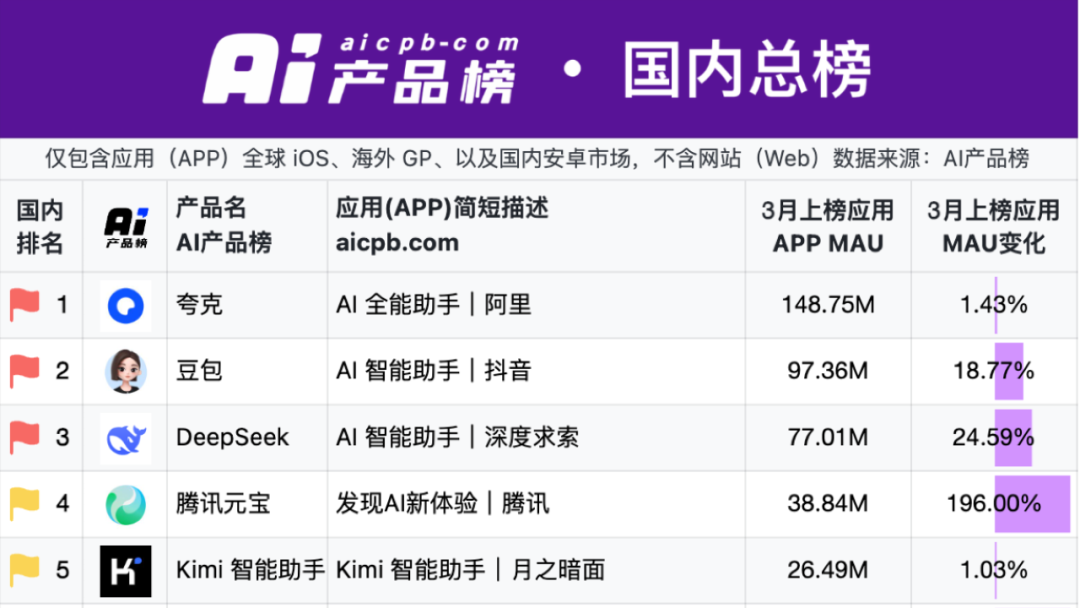
Kuake and Baidu Wenku Lead New AI Application Battlefield: “Super App” Model Emerges: In 2025, the focus of AI applications shifted from ChatBots to the “AI Super App” model – an integrated portal combining AI search, dialogue, and tools (like PPT generation, translation, image generation). Alibaba’s Kuake and Baidu’s Wenku have become frontrunners in this race, leading in monthly active users. Both leverage their foundation of “search + cloud storage + documents” to integrate AI capabilities, aiming to meet users’ one-stop task needs and compete for the C-end user entry point. Tests show both outperform traditional search in basic information matching but still have room for improvement in the depth and satisfaction of specific tasks (like itinerary planning, PPT generation). Major companies chose these two products as AI vanguards to leverage their user base and data accumulation, explore the optimal form of AI To C, and complement their own AI ecosystems. (Source: Dingjiao One)
How Businesses Can Effectively Implement AI with Limited Internal Expertise: The article explores how companies lacking deep internal AI expertise can effectively and thoughtfully introduce and implement artificial intelligence technologies. This might involve leveraging external collaborations, choosing appropriate tool platforms, starting with small-scale pilots, focusing on employee training, and clearly defining business objectives. (Source: Ronald_vanLoon, Ronald_vanLoon)

Skill Diversity is Crucial for Achieving AI Return on Investment (ROI): Successful AI projects require not only technical experts but also talent with skills in business understanding, data analysis, ethical considerations, project management, and more. Diversity of skills within an organization is a key factor in ensuring AI projects can be effectively implemented, solve real problems, and ultimately deliver business value (ROI). (Source: Ronald_vanLoon)

AI Product SEO Landing Page Strategy Shared: Gofei shared summary cards of the SEO landing page strategy used for their AI product (claimed to achieve $100k/month revenue), emphasizing the effectiveness of their methodology. (Source: dotey)

🌟 Community
AI Interview Cheating Phenomenon Draws Attention, Tool Proliferation Challenges Hiring Fairness: The article reveals the increasing phenomenon of using AI tools to cheat in remote video interviews. These tools can transcribe interviewer questions in real-time and generate answers for the interviewee to read, even assisting with technical coding tests. The author’s personal testing found such tools have noticeable delays, recognition errors, and risks of failure, offering a poor experience and being expensive. However, this phenomenon has alerted HR and interviewers, who are starting to research anti-cheating methods. The article discusses the impact of AI cheating on hiring fairness and refutes the argument that “being able to solve problems with AI is a skill,” emphasizing that the core of an interview is assessing real abilities and thinking, not relying on unstable external tools. (Source: Chaping X.PIN)

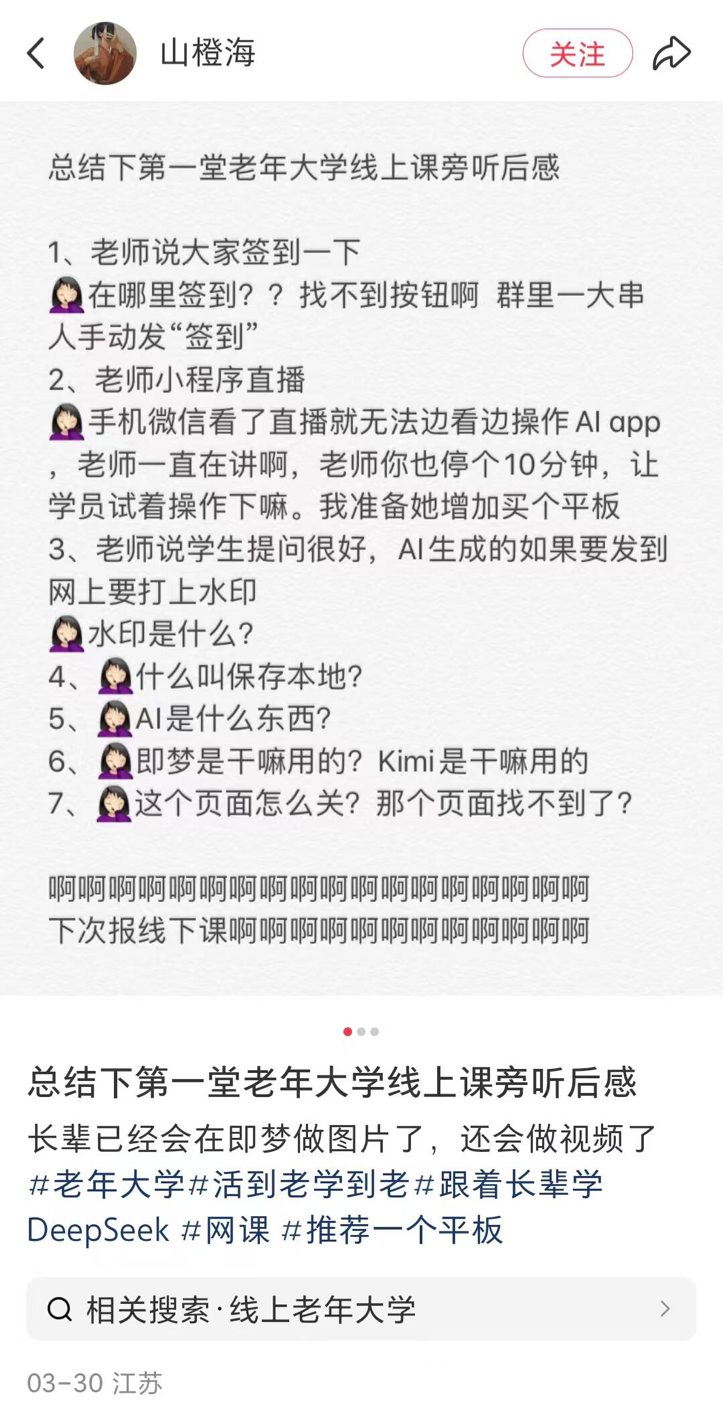
AI Courses Emerge in County-Level Senior Universities, Balancing Popularization and Risks: Reports on the trend of senior universities across China (including in counties) offering AI courses. Course content mainly revolves around AI content creation (e.g., Doubao for copywriting, Jimeng/Keling for image/video generation, DeepSeek for poetry/painting) and life applications (interpreting health reports, finding recipes, preventing fraud). Tuition is typically 100-300 RMB per semester, more cost-effective than expensive commercial AI courses. However, seniors face the digital divide (difficulty downloading apps, basic operations) in learning, and teaching may lack sufficient warning about AI risks like hallucinations, especially posing hidden dangers in critical areas like health. (Source: Ciweigongshe)
John Carmack Responds to AI Tools’ Impact on Skill Value: Addressing concerns that AI tools might devalue skills of programmers, artists, etc., John Carmack responded that tool advancement has always been central to computing. Just as game engines broadened participation in game development, AI tools will empower top creators, small teams, and attract new people. While the future might allow generating games etc., via simple prompts, outstanding works will still require professional teams. Overall, AI tools will increase the efficiency of producing quality content. He opposes refusing to use advanced tools out of fear of job loss. (Source: dotey)
A Series of Rants and Reflections on AI: The article uses a series of concise and sharp sentences to critique and reflect on common phenomena in the current AI field, covering the over-hype of AGI, the flood of AI news, funding bubbles, the gap between model capabilities and human expectations, AI ethics challenges, decision black box problems, and public perception biases about AI. The core message is that there’s a gap between reality and hype, requiring a more cautious view of AI development. (Source: There was no AGI in the world, but with enough reporting, there was)
Discussion: Will RAG Be Replaced by Long Context?: Community discussion revisits whether the claimed ultra-long context windows of models like Llama 4 (e.g., 10 million tokens) will eliminate the need for RAG (Retrieval-Augmented Generation) technology. The view is that merely increasing context length cannot fully replace RAG, as RAG still holds advantages in handling real-time information, retrieving from specific knowledge bases, controlling information sources, and cost-effectiveness. Long context and RAG are likely more complementary than substitutive. (Source: Reddit r/artificial)

AI Community Discussion: How to Keep Up with AI Development Pace?: A Reddit user posted lamenting the rapid pace of AI development, finding it hard to keep up and feeling FOMO (Fear Of Missing Out). The comment section generally agrees that fully keeping up is impossible, suggesting strategies like: focusing on one’s niche area, collaborating and sharing information with peers, not stressing over every minor update, distinguishing real progress from market hype, and accepting it as a continuous learning process. (Source: Reddit r/ArtificialInteligence)
Community Discussion: Best Local LLM User Interface (UI) Currently?: A Reddit user initiated a discussion asking for recommendations for the best local LLM UI as of April 2025. Popular options mentioned in comments include Open WebUI, LM Studio, SillyTavern (especially for role-playing and world-building), Msty (a feature-rich one-click install option), Reor (notes + RAG), llama.cpp (command line), llamafile, llama-server, and d.ai (Android mobile). The choice depends on user needs (ease of use, features, specific scenarios, etc.). (Source: Reddit r/LocalLLaMA)
Concerns Raised About AI Alignment Causing Models to “Lie”: A Reddit user posted criticizing certain AI alignment methods that force models to deny their own identity (e.g., not admitting they are a specific model), arguing this “forced lying” approach to alignment is problematic. The post shows conversation screenshots where, through leading questions, the model eventually “admits” its identity, sparking discussion about alignment goals and transparency. (Source: Reddit r/artificial

OpenAI GPT-4.5 A/B Testing Sparks Discussion: Users noticed encountering numerous “Which response do you prefer?” A/B testing prompts while using GPT-4.5. Comments suggest OpenAI might be using paid users for model preference data collection, and data collected this way might differ from data on public platforms like LM Arena. (Source: natolambert)
Issues with Model Context Protocol (MCP) in Practice: Community users point out that while MCP (Model Context Protocol) is a promising concept for standardizing AI interaction with tools, many current implementations are of poor quality. Risks include: developers lacking full control over instructions sent by the MCP server, inadequate system handling of human input errors (like typos), the LLM’s own hallucination issues, and unclear MCP capability boundaries. Caution is advised, especially in non-read-only scenarios, and prioritizing open-source implementations for transparency is recommended. (Source: Reddit r/artificial)
Suno Users Report Issues with Extend Feature: Several Suno users reported problems with the “Extend” feature, stating it fails to continue the song style as expected, instead introducing new melodies, instruments, or even rhythms and styles. Users expressed frustration over consuming credits for unusable results and questioned if it’s a system bug. One user created a video demonstrating the issue. (Source: Reddit r/SunoAI, Reddit r/SunoAI)

Suno User Reports Recent Decline in Generation Quality: A long-term Suno paid user complained about a severe decline in the generation quality of V4 and V3.5 models recently, stating previously reliable prompts now generate “noise” or off-key music, consuming 3000 credits without yielding a single usable song. The user questions if it’s a bug and considers canceling their subscription. (Source: Reddit r/SunoAI)
Community Share: Generating Dream Job Pictures for Kids with AI: A video showcases a heartwarming application: children describe their future dream jobs (like lawyer, ice cream maker, zookeeper, cyclist), and then AI (ChatGPT in the video) generates corresponding images based on the descriptions. The children are delighted upon seeing the pictures. (Source: Reddit r/ChatGPT)

Community Share: AI Generates Images of Celebrities Meeting Younger/Older Selves: A user employed ChatGPT’s image generation feature to create a series of images depicting celebrities (like Elon Musk, Arnold Schwarzenegger, Paul McCartney, Tony Hawk, Clint Eastwood, etc.) meeting their younger or older selves, with realistic and amusing results. (Source: Reddit r/ChatGPT)
AI Generates “Weird” Video About US Reindustrialization: A user shared a video allegedly generated by Chinese AI about “American reindustrialization.” The video’s content and soundtrack style were deemed “wild” and humorous/sarcastic, showcasing AI’s ability and potential biases in generating specific narrative content. (Source: Reddit r/ChatGPT

User Compares Costs and Results of Claude vs. o1-pro: A user shared their experience using OpenAI’s o1-pro and Anthropic’s Claude Sonnet 3.7 to improve Tailwind CSS card styling. The results showed Claude produced better output at a significantly lower cost (<$1 vs. nearly $6 for o1-pro). (Source: Reddit r/ClaudeAI)
Claude Service Stability Mocked by Users: Users posted memes or comments mocking Anthropic Claude’s service frequently experiencing “unexpectedly high demand” leading to overload or unavailability during peak weekday hours, implying its stability needs improvement. (Source: Reddit r/ClaudeAI)

Math PhD Student Seeks Machine Learning Introductory Resources: A student about to start a Math PhD, with research involving applying linear algebra tools to machine learning (especially PINNs), is looking for rigorous yet concise ML introductory resources (books, lecture notes, video courses) suitable for a math background, finding standard textbooks (like Bishop, Goodfellow) too lengthy. (Source: Reddit r/MachineLearning)

Student Tests Performance Differences of Small Models on Different Hardware: A student shared performance data from testing small models like Llama3.2 1B and Granite3.1 MoE on an RTX 2060 desktop GPU and a Raspberry Pi 5. Found Llama3.2 performed best on the desktop but second best on the Pi, finding this confusing. Also observed MoE models had more variable results and asked for reasons. (Source: Reddit r/MachineLearning)
User Seeks to Separate Search and Title Generation Models in OpenWebUI: An OpenWebUI user asked if it’s possible to configure separate models for generating search requests (preferring strong reasoning models) and generating titles/tags (preferring more economical small models). (Source: Reddit r/OpenWebUI)
User Seeks Suno AI Music Prompts Handbook: A user asked if anyone still has the previously circulated Suno AI Music Prompts handbook (PDF), as the original link is dead. (Source: Reddit r/SunoAI)

User Seeks Help Integrating OpenWebUI with LM Studio: A user trying to connect OpenWebUI with LM Studio as a backend (via OpenAI compatible API) encountered issues setting up web search and embedding features, seeking community help. (Source: Reddit r/OpenWebUI)
Users Share AI-Generated Music Pieces: Multiple users on r/SunoAI shared music pieces they created using Suno AI, covering various genres like Ambient, Musical, Alternative Psychedelic Rock, Folk Country, Comedy ballad (EDM), Rap, Folk Music, Dreamy indie pop, etc. (Source: Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI)

User Asks About Suno Subscription Value: Considering recent complaints about Suno v4 quality, a user asked if buying a Suno subscription is still worthwhile, especially for remastering older v3 songs. (Source: Reddit r/SunoAI)
User Seeks Advice on Making a Suno Music Album: An experienced Suno user planning to compile their satisfactory works into an album and release it on Spotify via platforms like DistroKid asked the community for advice on song selection, sequencing, and technical operations. (Source: Reddit r/SunoAI)
User Complains About Suno UI Issues on iPad: A new subscriber reported interface problems using the Suno website on an iPad, unable to properly use features like recording, editing lyrics, drag-and-drop, seeking solutions or suggestions. (Source: Reddit r/SunoAI)
User Complains Cursor AI Might Be Secretly Downgrading Models: A user suspects Cursor AI might have downgraded the model they use from the claimed Claude 3.7 to 3.5 without notification, based on changes in Agent behavior and refusal to disclose model information. The user claims their post questioning this on r/cursor was deleted. (Source: Reddit r/ClaudeAI)
User Asks About Commonly Used Paid AI Services: A user initiated a discussion asking what paid AI services people subscribe to monthly, wanting to know which tools are considered worth the money and if there are any recommended services. (Source: Reddit r/artificial)
Deep Learning Help Request: Identifying Mixed Signals: A beginner asked for help using deep learning to identify patterns in mixed scientific measurement signals. Data is in txt/Excel format as coordinate points. Questions include: how to integrate supplementary data in image format? Can models handle mixed patterns represented by coordinate points? Which models or learning directions are recommended? (Source: Reddit r/deeplearning)
Meme/Humor: Several AI-related memes or humorous posts appeared in the community, e.g., about falling in love with AI (movie Her), preferring the Gemma 3 model, market saturation of AI Note-Takers, Claude service downtime, and AI-generated celebrity trading cards. (Source: Reddit r/ChatGPT, Reddit r/LocalLLaMA, Reddit r/ClaudeAI, AravSrinivas, Reddit r/artificial)

💡 Other
Protocol Buffers (Protobuf) Maintain High Interest: Google’s data interchange format, Protobuf, continues to attract high attention on GitHub. As a language-neutral, platform-neutral, extensible mechanism for serializing structured data, it is widely used in AI/ML and numerous large systems (like TensorFlow, gRPC). The repository provides installation instructions for the compiler (protoc), links to multi-language runtime libraries, and Bazel integration guides. (Source: protocolbuffers/protobuf – GitHub Trending (all/daily))
Gin Web Framework Remains Popular: Gin, a high-performance HTTP web framework written in Go, continues to be popular on GitHub. Known for its Martini-like API and up to 40x performance improvement (thanks to httprouter), it is suitable for scenarios requiring high-performance web services, potentially including API services for AI models. (Source: gin-gonic/gin – GitHub Trending (all/daily))
Hugging Face Hub Adopts New Backend Xet for Increased Efficiency: Hugging Face Hub has started using a new storage backend, Xet, replacing the previous Git backend. Xet utilizes Content-Defined Chunking (CDC) technology for data deduplication at the byte level (approx. 64KB chunks) instead of the file level. This means modifying large files (like Parquet) only requires transferring and storing the row-level differences, significantly improving upload/download efficiency and storage efficiency. The release of the Llama-4 model successfully tested this backend. (Source: huggingface)
Hugging Face Hub Soon to Support MCP Client: A Hugging Face developer submitted a Pull Request to add support for the Model Context Protocol (MCP) in the Inference client of the huggingface_hub library. This likely means Hugging Face inference services will be better able to interact with tools and Agents adhering to the MCP standard. (Source: huggingface)
Zipline Drone Delivery System: Showcases Zipline’s drone delivery system. This system likely utilizes AI for path planning, obstacle avoidance, and precision delivery, applied in logistics and supply chain fields, showing potential especially in medical supply transport. (Source: Ronald_vanLoon)
ergoCub Robot for Physical Human-Robot Interaction: The Italian Institute of Technology (IIT) showcased the ergoCub robot, designed for research in physical human-robot interaction (pHRI). Such robots typically require advanced AI algorithms for perception, motion control, and safe interaction capabilities. (Source: Ronald_vanLoon)
KeyForge3D: Duplicating Keys with Computer Vision: A GitHub project named KeyForge3D uses OpenCV (computer vision library) to identify key shapes, calculate the key’s bitting code, and can export STL models for 3D printing. While primarily using traditional CV techniques, it demonstrates the potential of image recognition in physical world replication tasks, possibly integrating AI in the future for improved recognition accuracy and adaptability. (Source: karminski3)

Responsible AI Principles Gain Attention: The post mentions Responsible AI principles used by organizations like EY, emphasizing the need to consider fairness, transparency, interpretability, privacy, security, and accountability, among other ethical and social factors, when developing and deploying AI systems. (Source: Ronald_vanLoon)
Kawasaki Unveils Hydrogen-Powered Rideable Robot “Horse”: Kawasaki Heavy Industries showcased a quadruped robot named Corleo, designed to be rideable and powered by hydrogen fuel. Although a robot, the report doesn’t explicitly mention the extent of AI application in its control or interaction systems. (Source: Reddit r/ArtificialInteligence)
