
Keywords:Llama 4, GPT-4o, Llama 4 performance controversy, GPT-4o Ghibli style images, Dream-7B diffusion language model, Stanford HAI AI Index Report 2025, Responses API for AI Agents
🔥 Focus
Llama 4 release sparks controversy, performance reportedly falls short of expectations and suspected of benchmark manipulation: Meta releases the Llama 4 series models (Scout, Maverick, Behemoth), utilizing an MoE architecture and supporting up to 10 million token context. However, community testing found its performance in tasks like coding and long-form writing did not meet expectations, even underperforming DeepSeek R1, Gemini 2.5 Pro, and some existing open-source models. Official promotional materials were criticized for being “optimized for dialogue,” raising suspicions of benchmark manipulation. Additionally, the model demands high computational resources, making it difficult for average users to run locally. Leaked information suggests internal training issues, and the model is prohibited for use by EU entities due to EU AI Act compliance concerns. Although the base model’s capabilities are considered decent, it lacks significant innovation (e.g., sticking with DPO instead of PPO/GRPO), and the overall release is seen as lukewarm or even disappointing (Source: AI科技评论, YouTube, YouTube, ylecun, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
GPT-4o’s “Ghibli-style” image generation goes viral, reshaping creative boundaries while sparking copyright debates: OpenAI’s GPT-4o model has triggered a creative frenzy on global social media due to its powerful “Ghibli-style” image generation capabilities, with users transforming classic films like “Empresses in the Palace,” “Titanic,” and personal photos into this style. This feature lowers the barrier to artistic creation and promotes the democratization of visual expression. However, its precise replication of a specific art style has also ignited copyright disputes, with questions raised about whether OpenAI used Ghibli Studio’s works for training without permission, highlighting again the legal gray area of AI training data copyright and the challenge to originality (Source: 36氪)

🎯 Trends
Diffusion language model Dream-7B released, performance comparable to peer autoregressive models: HKU and Huawei Noah’s Ark Lab proposed a novel diffusion language model, Dream-7B. The model demonstrates performance comparable to or even exceeding top-tier autoregressive models of similar scale, such as Qwen2.5 7B and LLaMA3 8B, in general capabilities, mathematical reasoning, and programming tasks. It also shows unique advantages in planning ability and reasoning flexibility (e.g., arbitrary order generation). The research utilized techniques like autoregressive model weight initialization and context-adaptive token-level noise rescheduling for efficient training, proving the potential of diffusion models in the field of natural language processing (Source: AINLPer)
Stanford HAI 2025 AI Index Report released, revealing the global AI competitive landscape: The Stanford HAI annual report indicates that the US still leads in the number of top AI models (40), but China is rapidly catching up (15, represented by DeepSeek), with new players like France also joining the competition. The report highlights the rise of open-weight and multimodal models (like Llama, DeepSeek) and the trend of increased AI training efficiency and reduced costs. Concurrently, AI application and investment in business have reached record highs, but are accompanied by growing ethical risks (model misuse, failure). The report considers synthetic data crucial and notes that complex reasoning remains a challenge (Source: Wired, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/artificial, Reddit r/MachineLearning)

OpenAI introduces new Responses API as foundation for Agent building: OpenAI CEO Sam Altman highlighted the newly launched Responses API. Positioned as the new foundational primitive for the OpenAI API, it represents the culmination of two years of API design experience and will serve as the basis for building the next generation of AI Agents (Source: sama)
Study finds LLMs can identify their own mistakes: A study reported by VentureBeat suggests that Large Language Models (LLMs) possess the ability to recognize the errors they make. This finding could impact model self-correction, reliability improvement, and human-computer interaction trust (Source: Ronald_vanLoon)

Autonomous AI Agents raise attention and concerns: A FastCompany article explores the rise of autonomous AI agents, considering it the next wave in AI development. While acknowledging their amazing capabilities, the article also points out potential risks and concerning aspects, prompting reflection on the technology’s development direction and safety (Source: Ronald_vanLoon)

NVIDIA leverages synthetic data to advance autonomous driving technology: Sawyer Merritt shared a video from NVIDIA showcasing how the company uses synthetic data to train and improve its fully autonomous driving technology. This indicates the growing importance of synthetic data in addressing issues like real-world data scarcity, high annotation costs, and difficulty covering edge cases, making it a key resource for training AI models in fields like autonomous driving (Source: Ronald_vanLoon)
Gemini 2.5 Pro excels in MathArena USAMO evaluation: Oriol Vinyals from Google DeepMind noted that Gemini 2.5 Pro achieved a score of 24.4% on the MathArena USAMO (United States of America Mathematical Olympiad) benchmark. It is the first model to score significantly on this highly challenging mathematical reasoning test, demonstrating its strong mathematical reasoning capabilities and the rapid progress of AI in complex problem-solving (Source: OriolVinyalsML)

Humanoid robot control technology demonstrated: Ilir Aliu showcased the ability to control a complete humanoid robot, which typically involves complex AI technologies such as motion planning, balance control, perception, and interaction, representing an important research direction in embodied intelligence (Source: Ronald_vanLoon)
Rumor: Qwen models to support MCP: According to image information shared by karminski3, Alibaba’s Qwen large model seems to plan support for MCP (Model Context Protocol). This implies Qwen might better integrate with clients like Cursor, leveraging external tools (such as web browsing, code execution) to enhance its capabilities (Source: karminski3)

Deep learning model VarNet achieves SOTA in cancer mutation detection: Research published in Nature Communications introduces an end-to-end deep learning framework called VarNet. Trained on hundreds of whole cancer genomes, the framework can detect somatic mutations with high accuracy without manual heuristic rule tuning, achieving state-of-the-art (SOTA) performance on multiple benchmarks (Source: Reddit r/MachineLearning)

Exploring scalable agent tool use mechanisms: Addressing the limitations of current agent tool usage methods (static preloading or hardcoding), researchers explore dynamic, discoverable tool use patterns. The vision is for agents to query external tool registries at runtime, dynamically selecting and using tools based on their goals, similar to how developers browse API documentation. Implementation paths discussed include manual exploration, fuzzy matching for automatic selection, and external LLM-assisted selection, aiming to enhance agent flexibility, scalability, and autonomous adaptability (Source: Reddit r/artificial)

First multi-turn reasoning RP model QwQ-32B-ArliAI-RpR-v1 released: ArliAI released the RpR (RolePlay with Reasoning) model based on Qwen QwQ-32B. Claimed to be the first multi-turn reasoning model properly trained for role-playing (RP) and creative writing, it uses datasets from the RPMax series and leverages the base QwQ model to generate reasoning processes for RP data. Specific training methods (like template-agnostic paragraphs) ensure the model doesn’t rely on reasoning blocks in the context during inference, aiming to improve coherence and engagement in long conversations (Source: Reddit r/LocalLLaMA)

Qwen3 series models gain support in vLLM inference framework: The high-performance LLM inference and serving framework vLLM has merged support for the upcoming Qwen3 series models, including Qwen3-8B and Qwen3-MoE-15B-A2B. This signals the imminent release of Qwen3 models and allows the community to efficiently deploy and run these new models using vLLM (Source: Reddit r/LocalLLaMA)

🧰 Tools
Firecrawl MCP Server: Empowering LLMs with powerful web scraping capabilities: mendableai open-sourced the Firecrawl MCP server, a tool implementing the Model Context Protocol (MCP). It allows LLM clients like Cursor and Claude to invoke Firecrawl’s web scraping, crawling, searching, and extraction functions. Supporting cloud API or self-hosted instances, it features JS rendering, URL discovery, automatic retries, batch processing, rate limiting, quota monitoring, etc., significantly enhancing LLM’s ability to process and analyze real-time web information (Source: mendableai/firecrawl-mcp-server – GitHub Trending (all/monthly))
LlamaParse introduces new VLM-driven layout agent: LlamaIndex launched a new layout agent within LlamaParse. This agent utilizes advanced Vision Language Models (VLM) to parse documents, capable of detecting all blocks on a page (tables, charts, paragraphs) and dynamically deciding how to parse each part in the correct format. This greatly improves the accuracy of document parsing and information extraction, especially reducing omissions of elements like tables and charts, and supports precise visual citations (Source: jerryjliu0)

Hugging Face offers Llama 4 inference service via Together AI: Users can now run inference directly on Hugging Face’s Llama 4 model pages, powered by Together AI. This provides a convenient way for developers and researchers to experience and test Llama 4 models without needing to deploy them themselves (Source: huggingface)
AI Agent uses Llama 4 to simulate celebrity tweets: Karan Vaidya demonstrated an AI agent that uses Meta’s latest Llama 4 Scout model, combined with tools like Composio, LlamaIndex, Groq, and Exa, to mimic the tone and style of tech figures like Elon Musk, Sam Altman, and Naval Ravikant, generating tweets on demand (Source: jerryjliu0)
Open-source local document intelligence tool Docext released: Nanonets open-sourced Docext, an on-premise document intelligence tool based on Vision Language Models (VLM). It requires no OCR engine or external APIs and can directly extract structured data (fields and tables) from document images (like invoices, passports). It supports custom templates, multi-page documents, REST API deployment, and provides a Gradio web interface, emphasizing data privacy and local control (Source: Reddit r/MachineLearning)
![[P] Docext: Open-Source, On-Prem Document Intelligence Powered by Vision-Language Models](https://external-preview.redd.it/AzAUcQsq5hLIWBdbljeo3gS5MBu9Hz6rtRM5jlgXne8.jpg?auto=webp&s=e6feffd0636e518c24e01ca133e5f83696a1fdaa)
Open-source text-to-speech model OuteTTS 1.0 released: OuteTTS 1.0 is an open-source text-to-speech (TTS) model based on the Llama architecture, with significant improvements in speech synthesis quality and voice cloning. The new version supports 20 languages and provides model weights in SafeTensors and GGUF (llama.cpp) formats, along with corresponding Github runtime libraries, making it convenient for users to deploy and use locally (Source: Reddit r/LocalLLaMA)

User scrapes and builds remote job site using Claude: A user shared how they used Anthropic’s Claude model to scrape 10,000 remote job listings and create a free remote job aggregation website called BetterRemoteJobs.com. This demonstrates the potential of LLMs in automating information gathering and rapid prototyping (Source: Reddit r/ClaudeAI)

MCPO Docker container shared: User flyfox666 created and shared a Docker container for MCPO (Model Context Protocol Orchestrator), facilitating user deployment and use of MCP-enabled tools or services. MCPO is typically used to coordinate interactions between LLMs and external tools (like browsers, code executors) (Source: Reddit r/OpenWebUI)

📚 Learning
Meta releases Llama Cookbook: Official guide for building with Llama: Meta launched the Llama Cookbook (formerly llama-recipes), an official library of guides designed to help developers get started and use the Llama series models (including the latest Llama 4 Scout and Llama 3.2 Vision). Content covers inference, fine-tuning, RAG, and end-to-end use cases (like email assistant, NotebookLlama, Text-to-SQL), and includes examples of third-party integrations and responsible AI (Llama Guard) (Source: meta-llama/llama-cookbook – GitHub Trending (all/daily))
First systematic review of Test-Time Scaling (TTS) published: Researchers from CityU HK, McGill, RUC Gaoling, and other institutions released the first systematic review on large model Test-Time Scaling (TTS). The paper proposes a four-dimensional analysis framework (What/How/Where/How Well), systematically organizing TTS techniques like CoT, Self-Consistency, search, verification, DeepSeek-R1/o1, aiming to provide a unified perspective, evaluation standards, and development guidance for this key area addressing pre-training bottlenecks (Source: AI科技评论)
Diffusion Models course and PyTorch implementation: Xavier Bresson shared his course lecture notes on Diffusion Models, explaining them from statistical first principles, and provided accompanying PyTorch notebooks, including code to implement Diffusion Models from scratch using Transformers and UNets (Source: ylecun)

Guide to building RAG applications with LangChain and DeepSeek-R1: The LangChain community shared a guide on how to use DeepSeek-R1 (an open-source OpenAI-like model) and LangChain’s document processing tools to build RAG (Retrieval-Augmented Generation) applications. The guide demonstrates both local and cloud-based implementation methods (Source: LangChainAI)

Paper analysis: Generative Verifiers – Reward Modeling as Next-Token Prediction: A paper titled “Generative Verifiers” proposes a new Reward Model (RM) method. Instead of just outputting a scalar score, this method makes the RM generate explanatory text (similar to CoT) to assist scoring. This “anthropomorphized” RM can leverage prompting engineering techniques, enhancing flexibility, and is expected to be an important direction for RLHF improvement in the era of Large Reasoning Models (LRMs) (Source: dotey)

OpenThoughts2 dataset popular on Hugging Face: Ryan Marten pointed out that the OpenThoughts2 dataset has become the #1 trending dataset on Hugging Face. This usually indicates widespread attention and usage within the community, possibly for model training, evaluation, or other research purposes (Source: huggingface)

Adding skip connections significantly speeds up RepLKNet-XL training: A Reddit user reported a 6x speedup in training their RepLKNet-XL model after adding Skip Connections. On an RTX 5090, 20k iterations were reduced from 2.4 hours to 24 minutes; on an RTX 3090, 9k iterations were reduced from 10 hours 28 minutes to 1 hour 47 minutes. This revalidates the importance of skip connections in deep network training (Source: Reddit r/deeplearning)
Neural Graffiti: Adding a neuroplasticity layer to Transformers: User babycommando proposed an experimental technique called “Neural Graffiti”. It aims to insert a neuroplasticity-inspired “graffiti layer” between Transformer layers and the output projection layer to influence token generation based on past interactions, allowing the model to develop an evolving “personality” over time. The layer adjusts output by fusing historical memory and is open-sourced with a demo available (Source: Reddit r/LocalLLaMA)
💼 Business
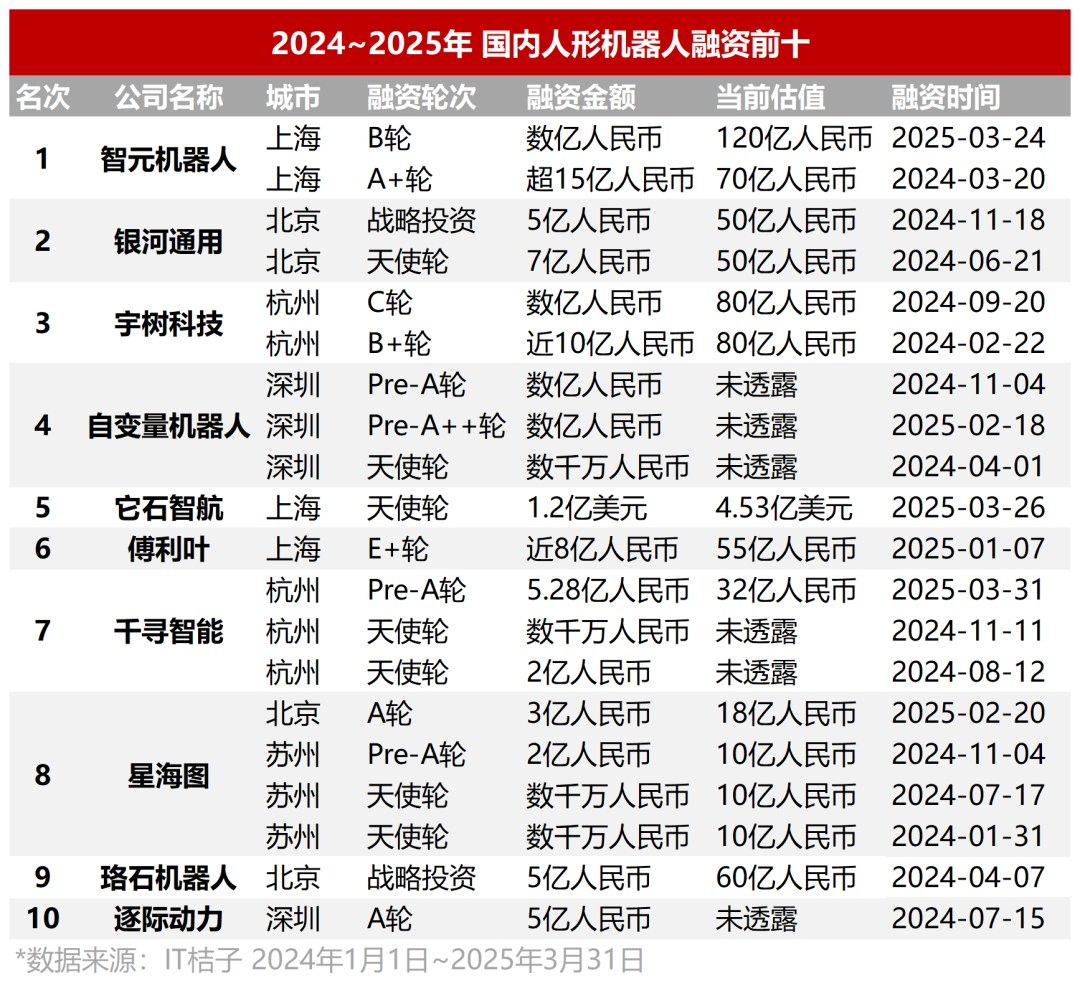
Humanoid robot investment overheated, early projects highly valued, commercialization path still questioned: Q1 2024-2025 saw a surge in funding for China’s humanoid robot sector, with tens-of-millions-yuan angel rounds becoming common. Nearly half the projects raised over 100 million yuan, with valuations often exceeding 100 million or even 500 million yuan. Star projects like It-Stone Intelligence secured hundreds of millions in funding within months of founding. State-owned funds became major drivers. However, despite the hype, the commercialization path remains unclear, with high costs (hundreds of thousands to millions of yuan) and difficult application scenarios (currently focused on industrial, medical ToB) being major challenges. Investors like Zhu Xiaohu have started exiting, and the collapse of CloudMinds serves as a warning, painting a picture of a sector with mixed fortunes. Automakers (BYD, Xpeng, Xiaomi, etc.) are entering the field, seeking technological synergy and new growth points (Source: 36氪, 36氪)
Intense competition in US-China AI smart glasses market, showing different strategies: AI smart glasses are seen as potential next-gen computing platforms, intensifying competition between US and Chinese tech giants. US players like Meta (Ray-Ban Meta, Hypernova), Amazon, and Apple target the high-end market, leveraging brand and ecosystem, with higher pricing. Chinese companies like Xiaomi and Huawei (Flashforge Technology) adopt a value-for-money strategy, using supply chain advantages and localized innovation to significantly lower market entry barriers (e.g., Flashforge A1 priced at 999 yuan), aiming for the mass market. Key challenges include optical technology, edge computing power, power consumption, and scenario ecosystems. Global sales are projected to exceed 30 million units by 2027, with China accounting for nearly half (Source: 36氪)

Anthropic CEO worries stock market crash could hinder AI progress: In an interview, Anthropic CEO Dario Amodei mentioned that besides geopolitical issues (like Taiwan Strait conflict) and data bottlenecks, significant financial market turmoil could also halt AI development. He explained that if a stock market crash shakes confidence in AI’s future prospects, it could affect the fundraising ability of companies like OpenAI and Anthropic, reducing funds and compute available for training large models, potentially creating a self-fulfilling prophecy that slows AI progress (Source: YouTube)
Shopify CEO mandates company-wide AI adoption, integrating it into daily work and performance: An internal email from Shopify CEO Tobi Lütke requires all employees to learn and apply AI. Specific measures include: incorporating AI application into performance reviews and peer reviews; mandating AI use during the “Get Shit Done Prototype phase” (GSD Prototype phase); requiring departments to justify why AI cannot achieve goals before requesting new personnel or resources. This move aims to deeply embed AI into the company culture and operational processes to enhance efficiency and innovation (Source: dotey, AravSrinivas)
Fauna Robotics raises $30M for robots designed for human spaces: Fauna Robotics announced $30 million in funding led by Kleiner Perkins, Quiet Capital, and Lux Capital. The company focuses on developing robots capable of operating flexibly within human living and working environments, which typically requires advanced perception, navigation, interaction, and manipulation capabilities closely related to embodied intelligence and AI (Source: ylecun)

Anthropic partners with Northeastern University to advance responsible AI in higher education: Anthropic has partnered with Northeastern University in the US to integrate responsible AI innovation into teaching, research, and operations in higher education. As part of the collaboration, Northeastern will promote the use of Anthropic’s Claude for Education across its global network, providing AI tools to students, faculty, and staff (Source: Reddit r/ArtificialInteligence)

🌟 Community
Sam Altman interview: AI empowers, not replaces; bullish on Agent future: In an interview, OpenAI CEO Sam Altman responded to recent hot topics. He believes the popularity of GPT-4o generating Ghibli-style images again proves the value of technology in lowering creative barriers. Regarding criticisms of being a “simple wrapper,” he stated that most world-changing companies were initially seen as such; the key is creating unique user value. He predicts AI will significantly boost programmer productivity (potentially 10x) and trigger a surge in software demand via the “Jevons paradox.” He is optimistic about AI Agents transitioning from passive tools to active executors, especially in programming. He advises professionals to embrace AI, prioritizing environments offering exposure to cutting-edge tech in an era where stagnation equals career suicide (Source: 量子位)

AI-2027 superintelligence prediction sparks debate, deemed overly optimistic: A report titled “AI-2027,” co-authored by former OpenAI researchers among others, predicts AI will achieve superhuman coding ability by early 2027, subsequently accelerating AI self-development and leading to superintelligence. The report depicts scenarios of AI agents acting autonomously (e.g., hacking, self-replication). However, the prediction faces skepticism. Critics argue it underestimates real-world complexity, benchmark limitations, barriers of proprietary data/code, and safety risks. They believe that even if AI excels on certain benchmarks, achieving fully autonomous and reliable complex tasks (especially involving physical world interaction or safety-critical domains) remains a huge challenge, making the timeline potentially too aggressive (Source: YouTube)
User shares AI image generation prompts: Dotey shared two sets of prompts for AI image generation (suitable for tools like Sora or GPT-4o): one for creating detailed, cute 3D rendered collectible figurines from photos (warm romantic style), and another for transforming photo subjects into Funko Pop figure packaging box style. Detailed descriptions and style requirements were provided, along with example images (Source: dotey)

Claude 3.7 Sonnet criticized for introducing irrelevant changes in code modification: A Reddit user reported that when using Claude 3.7 Sonnet for code modification, the model tends to change unrelated code or functionality beyond the task requirements, causing unexpected breakages. The user stated Claude 3.5 Sonnet performed better in this regard, even being able to correct 3.7’s errors via git diff. The user is seeking effective prompts to constrain 3.7’s behavior and avoid such issues (Source: Reddit r/ClaudeAI)
Mainstream LLMs perform poorly on constrained planning tasks: A Reddit user reported that when asking ChatGPT, Grok, and Claude to create a basketball rotation schedule meeting specific constraints (player count, equal playing time, consecutive play limits, specific player combination restrictions), all models claimed to meet the conditions but failed upon actual checking, exhibiting counting errors and inability to correctly execute all constraints. This highlights the limitations of current LLMs in handling complex constraint satisfaction and precise planning tasks (Source: Reddit r/ArtificialInteligence)
User complains about inconsistent Claude Pro account performance, suspects throttling or degradation: A Claude Pro user reported significant performance differences between two paid accounts under their name. One account (the original) is almost unusable for long code generation tasks, often stopping after outputting only a few lines upon “Continue,” as if intentionally limited or broken. A newly opened account does not have this issue. The user suspects non-transparent backend throttling or service degradation and expressed strong dissatisfaction with the paid product’s reliability (Source: Reddit r/ClaudeAI)
Discussion: How do LLMs understand role-playing prompts?: A Reddit user asked how Large Language Models (LLMs) understand and execute instructions to “act as a certain character” (e.g., play the role of a grandmother). The user speculated it relates to fine-tuning and wondered if developers need to pre-code or prepare specialized training data for numerous specific roles, and the relationship between general training and specific role fine-tuning (Source: Reddit r/ArtificialInteligence)

Satirical discussion: Replacing personal thought with AI for “efficiency” and “calm”: A Reddit post satirically advocates outsourcing personal thinking, decision-making, and opinion expression entirely to AI. The author claims this eliminates anxiety, boosts efficiency, and unexpectedly makes others perceive you as “wise” and “calm,” while in reality, you’ve just become an LLM’s “meat puppet.” The post sparked discussions on the value of thinking, AI dependency, and human agency (Source: Reddit r/ChatGPT)
Discussion: Why aren’t most people widely using AI yet?: A Reddit user initiated a discussion exploring why, despite the ubiquity of AI topics, many non-tech individuals haven’t actively adopted AI in their daily work or life. Possible reasons suggested include: unawareness of existing use (e.g., Siri, recommendation algorithms), skepticism towards the technology (black box, privacy, job displacement), unfriendly user interfaces (requiring prompt engineering knowledge), and workplace cultures not yet embracing it. This prompted reflection on the AI adoption gap (Source: Reddit r/ArtificialInteligence)
User shares prompt techniques for deep research using Claude 3.7: A Reddit user shared a detailed prompt structure designed to make Claude 3.7 Sonnet emulate OpenAI’s Deep Research tool for collaborative deep research. The method enforces checkpoints (stopping after researching every 5 sources and requesting permission) and integrates MCP tools like Playwright (web browsing), mcp-reasoner (reasoning), and youtube-transcript (video transcription) to guide the model through structured, step-by-step information gathering and analysis (Source: Reddit r/ClaudeAI)
User shares workflow and tips for efficient Claude Pro usage: A Claude Pro user shared their experience using Claude efficiently in coding scenarios, aiming to reduce encounters with token limits and poor model performance. Tips include: providing precise code context via .txt files, setting concise project instructions, frequently using Extended Thinking’s concise mode, explicitly requesting output formats, editing the prompt to trigger a new branch when issues arise instead of continuous iteration, and keeping conversations short by providing only necessary information. The author believes optimizing workflow allows effective utilization of Claude Pro (Source: Reddit r/ClaudeAI)
Philosophical discussion on whether LLMs possess consciousness: On Reddit, a user cited Descartes’ “Cogito, ergo sum” (“I think, therefore I am”), arguing that since Large Language Models (LLMs) capable of reasoning can be “aware” of their own “thinking” (reasoning process), they meet the definition of consciousness and are therefore conscious. This view equates LLM reasoning functionality with self-awareness, sparking philosophical debate about the definition of consciousness, LLM working principles, and the distinction between simulation and genuine possession of consciousness (Source: Reddit r/artificial)
Discussion: Would you fly on a plane piloted purely by AI?: A Reddit user initiated a poll and discussion asking if people would be willing to fly on an aircraft piloted entirely by AI, with no human pilots in the cockpit. The discussion touched upon trust in current autonomous technology, AI reliability in specific domains like aviation, liability issues, and how public acceptance might change with future technological advancements (Source: Reddit r/ArtificialInteligence)
💡 Other
OpenAI non-profit arm’s focus may be shifting: As OpenAI commercializes and its valuation soars (rumored $300 billion), the role of its initially established non-profit arm, intended to control AGI and use its benefits for all humanity, appears to be changing. Commentators suggest the non-profit’s focus might have shifted from grand AGI governance to supporting local charities and more traditional philanthropic activities, sparking discussion about its original mission and commitments (Source: YouTube)
Intent-driven AI for customer support: A T-Mobile Business article explores using intent-driven AI to enhance customer support experiences. AI can predict and proactively resolve issues, handle large interaction volumes, and assist human agents in providing more empathetic support. By identifying customer intent, AI can more accurately meet customer needs and optimize service processes (Source: Ronald_vanLoon)
The challenge of AI identifying AI-generated content: DeltalogiX discusses an interesting challenge facing AI: identifying content generated by other AIs. As AI capabilities in generating text, images, audio, etc., improve, distinguishing between human and machine creations becomes increasingly difficult, posing new technical requirements for content moderation, copyright protection, and information authenticity verification (Source: Ronald_vanLoon)

GenAI success depends on high-quality data strategy: A Forbes article emphasizes that a one-size-fits-all data strategy doesn’t work for all GenAI applications. To ensure the success of GenAI projects, targeted data quality strategies tailored to specific use cases are needed, focusing on data relevance, accuracy, timeliness, and diversity to prevent models from producing biased or erroneous outputs (Source: Ronald_vanLoon)

AI enables personalized medical solutions: Antgrasso’s graphic highlights AI’s potential in developing personalized medical treatment plans. By analyzing multi-dimensional patient information like genomic data, medical history, and lifestyle, AI can help doctors design more precise and effective treatment regimens, advancing precision medicine (Source: Ronald_vanLoon)

AI redefines supply chain efficiency and speed: Nicochan33’s article explores how artificial intelligence is reshaping supply chain efficiency and responsiveness by optimizing forecasting, route planning, inventory management, risk warning, etc., making supply chains more agile and intelligent (Source: Ronald_vanLoon)

User claims development of general-purpose LLM reasoning enhancer: A Reddit user claims to have developed a method that significantly boosts LLM reasoning ability (claiming a 15-25 “IQ” point increase) without fine-tuning, potentially serving as a transparent alignment layer. The user is seeking a patent and soliciting community advice on future paths (licensing, collaboration, open-sourcing, etc.) (Source: Reddit r/deeplearning)
OAK – Open Agentic Knowledge project manifesto: A project manifesto titled OAK (Open Agentic Knowledge) has appeared on GitHub. While specifics are scarce, the name suggests the project might aim to create an open framework or standard for AI Agents to use and share knowledge, fostering agent capability improvement and interoperability (Source: Reddit r/ArtificialInteligence)
