
Keywords:AI, LLM, AI Index Report 2025, DeepSeek model performance, Llama 4 controversy, AI music generation, Agentic AI applications
🔥 Focus
Stanford Releases 2025 AI Index Report, Revealing Key Industry Trends: Stanford University’s Institute for Human-Centered Artificial Intelligence (HAI) has released its eighth annual AI Index report (456 pages), comprehensively tracking global AI development in 2024. The report adds new sections covering AI hardware, inference costs, corporate responsible AI practices, and AI applications in science and medicine. Key trends include: 1) AI shows significant performance improvements on difficult benchmarks like MMMU; 2) AI is increasingly integrated into daily life, including healthcare and transportation; 3) Corporate investment and adoption rates reach record highs, with US investment far exceeding China’s, but the performance gap of Chinese models is rapidly narrowing (the gap between top US and Chinese models on benchmarks like MMLU has shrunk to 0.3%-1.7%); 4) Open-source/small models like DeepSeek are approaching the performance of closed-source/large models, with inference costs dropping dramatically (280-fold decrease in two years); 5) Global AI regulation is strengthening, and investment is increasing; 6) AI education is accelerating but resources are unevenly distributed; 7) AI safety incidents are surging, and responsible AI practices are inconsistent; 8) Global optimism about AI is rising but varies significantly by region. The report emphasizes AI’s transformative potential and the necessity of guiding its development. (Source: 36Kr, Xin Zhi Yuan, MetaverseHub, Ji Qizhi Xin)

AI Music Creation Boom Sparks Controversy, “Seven Day Lover” Phenomenon Highlights Industry Hype and Challenges: The AI-generated song “Seven Day Lover,” mimicking Jay Chou’s style, unexpectedly went viral, topping search trends and music charts, and its copyright was quickly sold, triggering a craze in AI music creation. Numerous amateurs flooded platforms, using AI tools to “mass produce” songs, and some platforms launched related activities. However, behind the prosperity lie numerous problems: the quality of many AI songs is inconsistent, labeled as “musical garbage”; reliance on imitation and splicing lacks true innovation; copyright ownership is ambiguous, with the US clarifying AI creations are not protected by copyright, and platforms like Tencent Music highlighting legal risks; commercialization faces significant difficulties, with most AI songs yielding dismal returns apart from isolated hits, and platform reviews becoming stricter. Industry insiders worry AI could impact the livelihoods of entry-level musicians and are more concerned that “de-process-ization” in creation could lead to human cognitive laziness and aesthetic decline. (Source: 36Kr)
Llama 4 Model Faces ‘Faking’ Controversy After Release, Discrepancy Between Arena Ranking and Actual Performance Sparks Debate: Meta’s newly released open-source model, Llama 4, achieved a high score on Chatbot Arena, surpassing DeepSeek-V3 to become the top open-source model. However, numerous users reported poor performance in practical tests involving programming, reasoning, and creative writing, falling far short of expectations and its Arena ranking. Subsequently, the Large Model Arena (LMArena) officially stated that the version Meta provided for testing was an experimental version customized for optimizing human preferences (Llama-4-Maverick-03-26-Experimental), not the standard version released on Hugging Face, and Meta did not clearly label this difference. LMArena released over 2,000 head-to-head comparison records, suggesting the experimental version’s response style (e.g., friendlier, using emojis) might be a significant factor influencing the ranking, and announced they will evaluate the Hugging Face version of Llama 4. Meta’s Gen AI lead denied training on the test set, attributing the performance difference to deployment stability issues. This incident has sparked widespread discussion and skepticism within the community regarding Llama 4’s performance, Meta’s transparency, and the reliability of LMArena’s evaluation methods. (Source: Quantum Bit, Ji Qizhi Xin, karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, natolambert, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

DeepSeek Phenomenon Attracts Industry Attention, China Generative AI Conference Explores New Opportunities: The rise of DeepSeek is seen as a key turning point for the generative AI industry in China and globally. Its high-efficiency, low-cost open-source model has catalyzed a research boom in inference models and AI Infra, injecting new momentum into edge AI and domestic computing power deployment. At the 2025 China Generative AI Conference, over 50 industry, academic, and research guests discussed the changes sparked by DeepSeek, deep reasoning, multimodality, world models, AI Infra, AIGC applications, Agents, and embodied intelligence. Attendees believe DeepSeek significantly reduces deployment costs for enterprises (some applications saw costs drop by 90% after switching), demonstrating China’s activity and rapid implementation capabilities in the open-source community. The conference also explored topics like the need for new terminals for AI application explosion, Agent deployment challenges, breakthroughs in domestic computing clusters, physical intelligence development, and AI commercialization paths, highlighting China’s increasingly important role in the global AI landscape. (Source: 36Kr, Ronald_vanLoon)

🎯 Trends
Agentic AI Seen as the Next Big Breakthrough: Agentic AI is becoming a key driver for transformation in business and technology. Unlike traditional AI that performs specific tasks, Agentic AI can autonomously set goals, formulate plans, and execute complex multi-step tasks, acting more like an autonomous digital employee. They can integrate multiple tools and data sources, perform reasoning and decision-making, and are expected to bring disruptive changes to areas like customer service, data analysis, and software development. As the technology evolves, Agentic AI will drive profound shifts in business operating models and human-computer interaction. (Source: Ronald_vanLoon)

Nvidia Releases Llama-Nemotron-Ultra 253B Model, Open-Sourcing Weights and Data: Nvidia has launched Llama-Nemotron-Ultra, a 253B parameter dense model derived from Llama-3.1-405B through NAS pruning and inference optimization. The model focuses on enhancing reasoning capabilities, employing SFT and RL post-training (FP8 precision), and has open-sourced its weights and post-training data. Nvidia’s continued contributions to open-source post-training efforts are welcomed by the community. (Source: natolambert)

Qwen3 Series Models Potentially Releasing Soon, Including 8B and 15B MoE Versions: Based on merged PR information in the vLLM codebase, Alibaba is speculated to be releasing the new Qwen3 series models soon. Currently known potential versions include Qwen3-8B and Qwen3-MoE-15B-A2B. The community guesses the 8B version might be a multimodal model, while the 15B version is a text-focused MoE (Mixture of Experts) model. Users anticipate performance breakthroughs in the new models; if the 15B MoE reaches the level of Qwen2.5-Max, it would be considered a significant success. (Source: karminski3)

Runway Launches Gen-4 Turbo, Significantly Increasing Video Generation Speed: Runway has released its latest video generation model, Gen-4 Turbo. The main highlight of the new model is its generation speed, claiming to generate a 10-second video in 30 seconds, a substantial speed increase compared to previous versions. This makes Gen-4 Turbo particularly suitable for application scenarios requiring rapid iteration and creative exploration. The update has been rolled out to all user plans. (Source: op7418)
Google Gemini Live Launches, Enabling Real-time Visual and Voice Interaction: Google announced the official launch of the Gemini Live feature, debuting first on Pixel 9 and Samsung Galaxy S25 devices, and rolling out to Gemini Advanced users on Android. The feature allows users to share screen content or real-time camera views and converse with Gemini via voice, enabling understanding of visual content and interactive questioning, troubleshooting, brainstorming, etc. This marks a significant advancement in Google’s multimodal AI interaction experience, further realizing the vision of Project Astra. (Source: op7418, JeffDean, demishassabis)
HiDream Releases 17B Parameter Open-Source Image Model HiDream-I1: The HiDream AI team has released and open-sourced its 17B parameter image generation model, HiDream-I1. Preliminary images suggest the model generates decent quality images. The model code is publicly available on GitHub for developers and researchers to use and explore. (Source: op7418)

Open-Source Wave Accelerates for Large Models, Exploring “2.0” Business Models: In 2025, the rise of open-source models represented by DeepSeek is pushing Meta, Alibaba, Tencent, and even former “closed-source proponents” like OpenAI and Baidu to accelerate their open-source initiatives. Driving forces include demand for edge intelligence, industry customization needs, accelerated ecosystem specialization, and technology crossing critical thresholds. Open source lowers the barrier for developers and SMEs, promoting technological accessibility and innovation. However, open source doesn’t mean free; maintenance and localization still incur costs. Leading vendors are exploring “Business Model 2.0,” such as “open-source base model + commercial API value-added services” (e.g., DeepSeek, Zhipu AI), “open-source community edition + enterprise-exclusive edition” (e.g., Alibaba Cloud Qwen), and “model open source + cloud platform monetization” (e.g., Meta Llama). The core idea is “attract users with open source, monetize through services,” achieving profitability via ecosystem, customization, and cloud services. (Source: First New Voice)

🧰 Tools
Augment Code: AI Coding Platform Built for Complex Projects: Augment Code has launched, positioning itself as the first AI coding platform designed for deep understanding of large, complex codebases and team collaboration. It offers up to 200K context token processing capacity, persistent memory (learning code style, refactoring history, team norms), and deep tool integration (VS Code, JetBrains, Vim, GitHub, Linear, Notion, etc.). Its core Agent not only writes code but can also execute terminal commands, create complete PRs, and generate context-aware documentation and test cases. Augment ranks first on the SWE-bench Verified leaderboard (combined with Claude Sonnet 3.7 and o1) and is already used by companies like Webflow and Kong. The platform is currently free, aiming to solve developer pain points when dealing with large, legacy codebases. (Source: AI Jinxiusheng)
Cloudflare Launches AutoRAG Service to Simplify RAG Application Building: Cloudflare has released AutoRAG, a service designed to simplify the development of Retrieval-Augmented Generation (RAG) applications. Developers can use this service to automatically transform data sources (like documents, websites) into knowledge bases queryable by large models, without manually handling data indexing and retrieval logic. During the public beta period, AutoRAG is free to use, limited to 10 instances per account, with each instance handling up to 100,000 files. This lowers the barrier to building AI applications based on specific knowledge. (Source: karminski3)

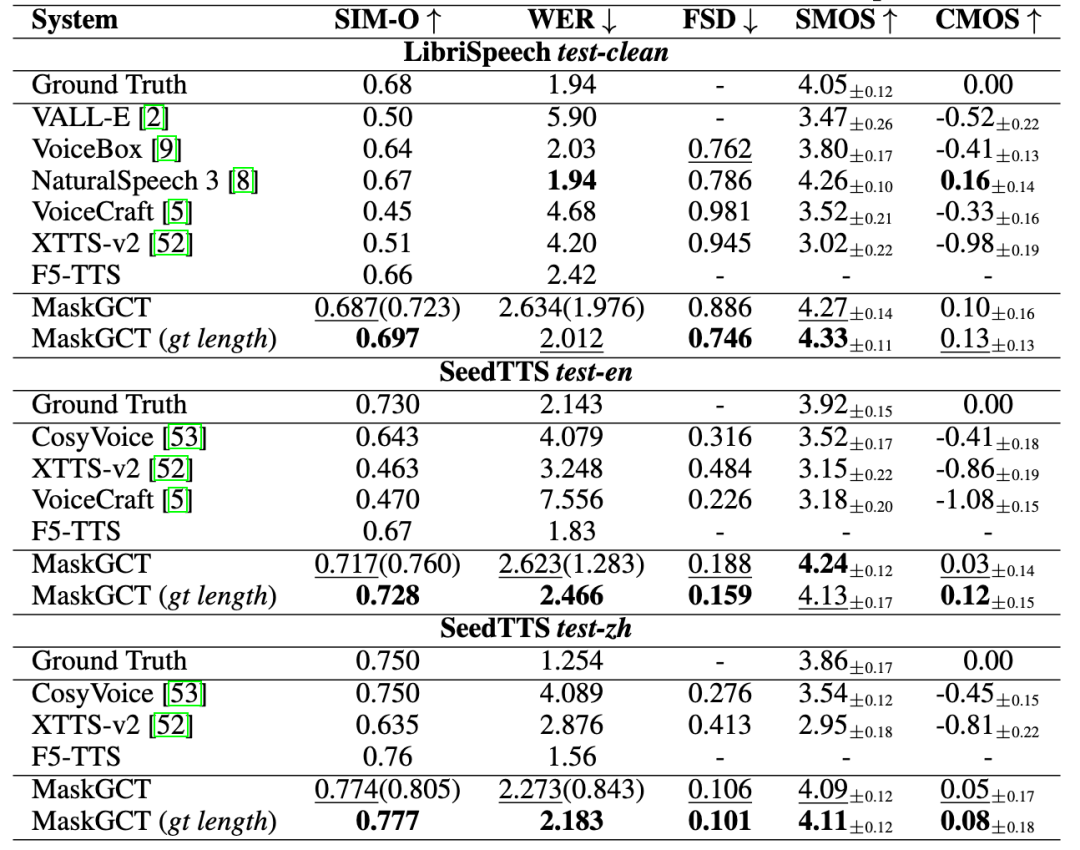
Qunar Technology Launches “All Voice Lab”, Providing End-to-End AI Voice Solutions: Qunar Technology has released its AI voice product “All Voice Lab (趣丸千音)”, based on the MaskGCT model jointly developed with CUHK-Shenzhen. The product integrates text-to-speech, video translation, multilingual synthesis, subtitle removal, and other functions. Its key feature is achieving full automation of the video translation workflow, with a daily processing capacity exceeding 1000 minutes, boosting efficiency by 10x. Its voice generation effect is emotionally rich and comparable to human voices. All Voice Lab aims to address the large-scale needs of cross-lingual communication through industrial capabilities and has been applied in areas like short drama overseas distribution (reducing costs, increasing users), news, cultural tourism, and audiobooks, positioning itself as “global content infrastructure”. (Source: 36Kr)
Exa: Search Engine Designed for AI Agents: Exa positions itself as the “Bing API for the LLM era,” a search engine specifically designed for AI Agents, aiming to enable AI to efficiently access and understand internet information. Unlike human search, Exa can handle more complex natural language queries, provide more comprehensive results, and support high-throughput, low-latency requests. Its core APIs include fast search, content retrieval (crawler), finding similar links, etc. Exa also offers a Websets feature, allowing users to define filtering conditions in natural language to structure internet information. The company has received investment from Lightspeed, Nvidia, etc., has an ARR exceeding $10 million, and its main competitor is Brave Search. (Source: AI Explorer)
AI Tools Enable Visual Summarization of WeChat Chat History: Using a combination of AI tools, WeChat group chat or private chat records can be exported and generated into a visual report. Steps include: 1) Use a third-party tool (e.g., MemoTrace) to export WeChat chat history as a TXT file (note data security risks); 2) Input the TXT file and a specific Prompt template (including style code) into a large model supporting long text processing (e.g., Gemini 2.5 Pro in AI Studio) to generate HTML code; 3) Convert the generated HTML code into a shareable web link using an online service (e.g., yourware.so), or directly convert it into an image using an online tool (e.g., cloudconvert.com). This method transforms lengthy chat information into a clearly structured report containing daily highlights and word clouds, facilitating review and sharing. (Source: Kazk)
Jimeng AI 3.0 Image Model Fully Launched: Jimeng AI (即梦AI) announced that its version 3.0 image generation model has completed testing and is now fully launched. The new version is expected to offer improvements in image quality, style diversity, and semantic understanding. Users (like 歸藏) have already shared detailed tests and prompt collections using the 3.0 model for various design fields (e.g., AI operations images), showcasing its generation capabilities. (Source: op7418)

VIBE Chat: Fun Chat Website with Random Backgrounds: A website called VIBE Chat offers a novel chat experience where each session generates a different random background image. The site is based on the Gemini 2.0 Flash model, and users can use it for tasks like programming, with code or content displayed directly in the chat interface. Tests show it can generate code for simple games like Flappy Bird and Tetris. (Source: karminski3)
Developer Creates Dedicated GPT Assistant for Suno AI: A developer has created a custom GPT called “Hook & Harmony Studio” designed to assist with the Suno AI music creation workflow. The tool can take a user’s song concept and generate unique titles, structured lyrics (with instrumental and vocal guidance), suggestions for Suno style tags, filter clichés, and optionally generate prompts for song visuals. It aims to simplify lyric writing and style exploration, automatically formatting output for use in Suno’s project mode. (Source: Reddit r/SunoAI)
Code to Prompt Generator: Tool to Simplify Code-to-LLM Prompting: A developer has open-sourced a small tool called “Code to Prompt Generator” aimed at simplifying the process of creating LLM prompts from codebases. It can automatically scan project folders to generate a file tree (excluding irrelevant files), allow users to selectively include files/directories, display real-time token counts, save and reuse instructions (Meta Prompts), and copy the final prompt with one click. The tool uses a Next.js frontend and Flask backend and runs on multiple platforms. (Source: Reddit r/ClaudeAI)
Llama 4 GGUF Versions Released, Enabling Local Execution: Following the merge of Llama 4 support (currently text-only) into llama.cpp, community developers (like bartowski, unsloth, lmstudio-community) have quickly released GGUF quantized versions of the Llama 4 Scout model. These versions employ optimized quantization strategies like imatrix to balance model size and performance, allowing users to run Llama 4 on local hardware. Versions with different bit widths (e.g., IQ1_S 1.78bit, Q4_K_XL 4.5bit) are available to meet various hardware requirements. Users can find these GGUF files on Hugging Face. (Source: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

📚 Learning
Microsoft and CUHK Propose ImageGen-CoT to Enhance AI Painting Contextual Understanding: To address the shortcomings of AI image generation models in understanding complex text descriptions and contextual relationships (e.g., material transfer from “leather apple” to “leather box”), researchers from Microsoft Research Asia and The Chinese University of Hong Kong proposed the ImageGen-CoT framework. This method introduces a Chain-of-Thought (CoT) reasoning step before image generation, allowing the model to first contemplate key information and organize logic before creating. By constructing a high-quality ImageGen-CoT dataset and fine-tuning, models (like SEED-X) showed significant performance improvements on the T2I-ICL task (CoBSAT improved by 89%, DreamBench++ by 114%). The framework uses two-stage reasoning and explores various test-time extension strategies (single CoT, multiple CoT, hybrid extension), with hybrid extension yielding the best results. (Source: 36Kr, Xin Zhi Yuan)

Paper Proposes New Routing LLM Paradigm and RouterEval Benchmark: Addressing challenges in large model research like compute monopolies, high costs, and monolithic technical paths, researchers propose the Routing LLM paradigm. This involves an intelligent Router dynamically assigning tasks to multiple (open-source) smaller models for collaborative processing. To support this research, the paper open-sources the comprehensive RouterEval benchmark, containing over 200 million performance records of 8500+ LLMs on 12 mainstream benchmarks. This benchmark transforms the routing problem into a standard classification task, enabling research on a single GPU or even a laptop. The study finds that through intelligent routing (even with only 3-10 candidate models), the combined performance of multiple weaker models can surpass top monolithic models (like GPT-4), demonstrating a “Model-level Scaling Up” effect. This work offers a new path towards achieving high-performance AI at low cost. (Source: Xin Zhi Yuan)
UIUC Han Jiawei, Sun Jimeng Team Open-Source DeepRetrieval, Using RL to Optimize Search Engine Queries: To address the issue of poor information retrieval results caused by low-quality user initial queries, the UIUC team proposed the DeepRetrieval framework. This system uses Reinforcement Learning (RL) to train an LLM to optimize user’s original queries (natural language, Boolean expressions, or SQL), making them better suited to the characteristics of specific search engines (like PubMed, BM25, SQL databases). This maximizes retrieval effectiveness without altering the existing retrieval system. Experiments show that DeepRetrieval (using only a 3B model) significantly improves retrieval performance (10x improvement in literature search, surpassing GPT-4o on Evidence-Seeking tasks, improving SQL execution accuracy), far exceeding SFT-based methods. The research highlights RL’s exploration capability is superior to SFT’s imitation learning for discovering better query strategies. (Source: Ji Qizhi Xin)
CASIA et al. Propose Vision-R1, Using Reinforcement Learning to Enhance VLM Visual Grounding Capabilities: Addressing issues like format errors, low recall, and insufficient precision in Vision-Language Models (VLMs) for object detection and visual grounding tasks, researchers from the Institute of Automation, Chinese Academy of Sciences (CASIA) and Zidong Taichu proposed the Vision-R1 framework. This method adapts the successful experience of the language model R1 by introducing Rule-Based Reinforcement Learning (Rule-Based RL) to visual grounding tasks. By designing task-level reward functions based on visual evaluation metrics (format correctness, recall, IoU precision) and adopting a progressive rule adjustment strategy (differentiated rewards, phased progressive thresholds), without relying on human preference data or reward models, it significantly improves the object detection performance of models like Qwen2.5-VL on datasets such as COCO and ODINW (up to 50% improvement), with minimal impact on general question-answering abilities. Code and models have been open-sourced. (Source: Ji Qizhi Xin)
CalibQuant: 1-bit KV Cache Quantization Scheme Boosts Multimodal Model Throughput: To address the high memory consumption of KV Cache in Multimodal Large Models (MLLMs) when processing large-scale visual inputs, which limits throughput, researchers proposed the CalibQuant scheme. This scheme achieves extreme 1-bit KV Cache quantization, combining Post-Scaling and Calibration techniques designed for the redundancy characteristics of visual KV Cache. Post-Scaling optimizes the dequantization calculation order for efficiency, while Calibration adjusts attention scores to mitigate extreme value distortion introduced by 1-bit quantization. Experiments show CalibQuant significantly reduces memory and computational overhead on models like LLaVA and InternVL-2.5, achieving up to 10x throughput improvement with almost no loss in model performance. The method is plug-and-play, requiring no modification to the original model. (Source: PaperWeekly)
CVPR 2025 | SeqAfford: Enabling Sequential 3D Affordance Reasoning: To address the difficulty of current AI in understanding and executing complex instructions involving multiple objects and steps, researchers proposed the SeqAfford framework. This framework is the first to combine 3D vision with Multimodal Large Language Models (MLLMs) for sequential 3D affordance reasoning. By constructing the first Sequential 3D Affordance dataset containing over 180,000 instruction-point cloud pairs for fine-tuning, and introducing a reasoning mechanism based on segmentation vocabulary (
GitHub Hosts Collection of MCP Server Resources: A GitHub repository named awesome-mcp-servers has compiled and open-sourced over 300 MCP (Model Capability Protocol) servers for AI Agents. These servers cover both production-grade and experimental projects, providing developers with a rich set of tools and interfaces for AI Agents to interact with external services and data sources, further promoting the development of the Agent ecosystem. (Source: Reddit r/ClaudeAI)

Emory University Prof. Fei Liu Recruiting PhD Students & Interns for LLM/NLP/GenAI: Fei Liu, Associate Professor in the Department of Computer Science at Emory University, is recruiting fully funded PhD students for Fall 2025 admission. Research directions include the reasoning, planning, and decision-making capabilities of Large Language Models (LLMs) as agents, and AI applications in education, healthcare, etc. Students interested in related areas are also welcome to apply for remote internships or collaborations. Applicants should have a background in computer science or related fields, excellent programming skills, and research publications or strong mathematical foundations are preferred. (Source: AI Qiu Zhi)
AI Agent Building Guide Released: SuccessTech Services has published a step-by-step guide on how to build Large Language Model (LLM) agents. The guide likely covers basic concepts of Agents, architectural design, tool selection, development processes, and practical application cases, providing introductory guidance for developers wishing to create autonomous AI applications. (Source: Reddit r/OpenWebUI)

HKUST Releases Dream 7B Code, Focusing on Diffusion Model Reasoning: The NLP team at the Hong Kong University of Science and Technology (HKUST) has now publicly released the GitHub repository for their previously announced Diffusion model reasoning model, Dream 7B. This model aims to enable LLMs to understand and execute instructions related to Diffusion models. The code release allows researchers to reproduce and further study the model. (Source: Reddit r/LocalLLaMA)

💼 Business
Lingxin Qiaoshou Secures Over 100M Yuan Seed Funding to Develop World’s Highest Dexterity Hand: Embodied intelligence company “Lingxin Qiaoshou” completed a seed funding round exceeding 100 million yuan, led by Sequoia Seed Fund and others. The company focuses on a “Dexterous Hand + Cloud Brain” platform. Its self-developed Linker Hand series features 25-30 degrees of freedom (DoF) for the industrial version and up to 42 DoF for the research version (highest globally, surpassing Shadow Hand’s 24 and Optimus’s 22), equipped with high-precision sensing (multi-sensor fusion) and manipulation capabilities. The company uses both linkage and tendon-driven structures, achieving mass production, combined with a cloud brain (trained on the large-scale DexSkill-Net dataset) for learning and control. The product has advantages in cost (approx. 50,000 RMB, far below Shadow Hand’s 1.5 million RMB) and durability, has been purchased by top universities like Peking University and Tsinghua University, and is applied in medical, industrial, and other scenarios. (Source: 36Kr)

Google Reportedly Paying AI Staff High Salaries for “Gardening Leave” to Prevent Them Joining Competitors: According to reports, Google, in an effort to prevent key AI talent from moving to competitors like OpenAI, has paid some departing employees substantial salaries (potentially hundreds of thousands of dollars) for up to a year, on the condition that they do not join rival companies during that period. This practice, known as “gardening leave,” while common in industries like finance, is relatively rare in the tech sector, especially for non-executive level AI researchers and engineers. This reflects the extreme scarcity of top AI talent and the fierce talent war among tech giants. (Source: Reddit r/ArtificialInteligence)

Shopify CEO Emphasizes Employees Must Effectively Utilize AI: Shopify CEO Tobias Lütke requires employees to first consider how to use AI tools to improve efficiency and solve problems before thinking about increasing team size. He believes AI is a key lever for productivity enhancement, and employees should actively learn and integrate it into their daily workflows. This statement reflects the high importance placed by the business world on AI empowering work efficiency and the expectation for employees to adapt to the new demands of the AI era. (Source: bushaicave.com)
36Kr Launches Call for “2025 AI Partner Innovation Awards”: To discover and encourage innovative AI products, solutions, and enterprises, and promote AI application across various industries, 36Kr has initiated the “2025 AI Partner Innovation Awards” selection event. The call covers non-application software products/solutions in three main categories: General Innovation (office, enterprise services, data analysis, etc.), Industry Innovation (finance, healthcare, education, industry, etc.), and Terminal Innovation (smart hardware, automotive, robotics, etc.). The evaluation will be based on four dimensions: technological innovation, application effectiveness, user experience, and social value, scored by an expert panel. The application period is from March 13th to April 7th, with results announced on April 18th. (Source: 36Kr)

Development Starts on China’s First Standard for Private Deployment of AI Large Models: Addressing issues faced by enterprises in private deployment of AI large models, such as technology mismatch, non-standardized processes, and lack of evaluation systems, the ZHIH Standard Center, in collaboration with the Third Research Institute of the Ministry of Public Security and other units, has initiated the drafting of the group standard “Technical Implementation and Evaluation Guidelines for Private Deployment of Artificial Intelligence Large Models”. This standard aims to cover the entire process from model selection, resource planning, deployment implementation, quality evaluation to continuous optimization, integrating technology, security, evaluation, and case studies. It is jointly developed by model application parties, technology service providers, quality evaluation parties, etc. The standard is soliciting participation from AI large model enterprises, technology service providers, hardware providers, cloud computing companies, security service providers, data service providers, industry application enterprises, testing and evaluation institutions, compliance and legal institutions, and sustainable development organizations. (Source: ZHIH Standardization Construction)
🌟 Community
AI-Generated Content Raises Concerns about “Hallucinations” and Information Reliability: Multiple users and media outlets report that large language models, including DeepSeek, exhibit the phenomenon of “confidently spouting nonsense,” i.e., AI hallucinations. AI might fabricate non-existent facts, cite incorrect sources (e.g., poetry origins, legal articles, artifact information), or even invent data (e.g., “mortality rate of the post-80s generation”). This phenomenon stems from outdated, erroneous, or biased training data, model knowledge gaps, and a lack of real-time verification capabilities. Users need to be wary of the accuracy of AI-generated content, perform cross-validation and manual review, especially in serious contexts like academia and work. Over-reliance could lead to the spread of misinformation, exacerbating the challenges of the “post-truth era.” Vectara’s HHEM hallucination test also showed a relatively high hallucination rate for DeepSeek-R1. (Source: Zinc Scale)
AI Art Generation Sparks Renewed Controversy: Starting with the Ghibli Style Craze: OpenAI’s new GPT image feature generating Studio Ghibli-style pictures became immensely popular, with even CEO Sam Altman changing his avatar to this style, boosting ChatGPT downloads and revenue. However, this has reignited ethical and copyright debates surrounding AI-generated art. Hayao Miyazaki himself has explicitly opposed machine-generated imagery. Hollywood professionals (like “Gravity Falls” creator Alex Hirsch and Robin Williams’ daughter Zelda Williams) expressed strong dissatisfaction, viewing it as theft of artists’ creative work, lacking soul. Altman responded, calling it the “democratization of creation” and a huge victory for society. The article argues that while AI can imitate art styles, it struggles to replicate the complex narratives, aesthetic systems, and humanistic care embedded in Ghibli’s works. Most AI-generated content is unlikely to become classic, but some human-machine collaborations or assistive tools will succeed. (Source: APPSO, Reddit r/artificial)

Viewpoint: Human Cognitive Structure is the Core Competitiveness in the AI Era: The article refutes the view that the popularization of AI tools devalues creators, arguing that expression and creation are inherent human needs and “consumption behaviors,” valued for the process, not just the outcome. AI is a tool and cannot replace unique human cognition and emotion. The “cognitive structure” formed by the human brain over millions of years of evolution is key; AI development is also shifting from data-driven to cognition-driven (imitating human cognitive processes). Therefore, future core competitiveness is not “doing work,” but the “cognitive structure” or “anchor points” for interacting with AI – unique perspectives, profound experiences, and authentic connections with others. Creators should focus on honing their unique aspects, becoming stable reference points in the information flood, providing direction and value for themselves and others, and counteracting the potential “entropy increase” brought by AI. (Source: Wang Zhiyuan)
Viewpoint: AI Applications Have New Barriers Based on Relationships and Trust: Countering Zhu Xiaohu’s statement that “AI applications have no barriers,” the article argues that barriers in the AI era have shifted from traditional technological ones to new types based on relationships and trust. AI applications no longer solely pursue user scale but can profit in vertical markets by providing personalized experiences. Even “wrapper” applications can build moats through deep user connections (AI understands you better with use), trust between creator IPs and users, and continuous optimization via data feedback loops (industry data + personal data training). It advises entrepreneurs to focus on vertical domains, create unique experiences, build data loops, and establish emotional connections. (Source: Zhou Zhi)
AI “Crash Course” Scams Target Seniors’ Pensions: Online courses promising “quick AI monetization” and “monthly income over ten thousand” are being precisely targeted at seniors via short video platforms. These courses often use free teaching as bait, attracting seniors into groups using digital human videos, fake “expert” identities, and by amplifying retirement anxiety or get-rich-quick myths. Subsequently, through brainwashing marketing tactics (like showing fake income screenshots, creating a sense of limited spots), they induce seniors to pay high tuition fees (thousands to tens of thousands of yuan). The course content is often basic self-media operation knowledge repackaged, while promises of AI skills training, order referral kickbacks, and one-on-one guidance are mostly false advertising. After-sales service is lacking, and refunds are difficult. Many young people have shared experiences on social media about their family members nearly falling or having fallen victim, urging vigilance against such scams. (Source: Bao Bian)

Karpathy: LLMs Disrupt Traditional Tech Diffusion Path, Empowering Individuals: Andrej Karpathy writes that the technology diffusion pattern of Large Language Models (LLMs) is starkly different from historical transformative technologies (usually top-down: government -> enterprise -> individual). LLMs became available to almost everyone overnight at low cost (even free) and high speed, bringing disproportionately large benefits to ordinary individuals, while the impact on enterprises and governments lags relatively. This is because LLMs can provide near-expert level knowledge across a wide range of domains, compensating for individuals’ knowledge limitations. In contrast, organizations benefit less due to mismatches between their inherent advantages and LLM capabilities, higher problem complexity, internal inertia, etc. He believes the current distribution of AI’s future is surprisingly balanced, representing true “power to the people.” However, if money can buy significantly better AI in the future, the landscape might change again. (Source: op7418)
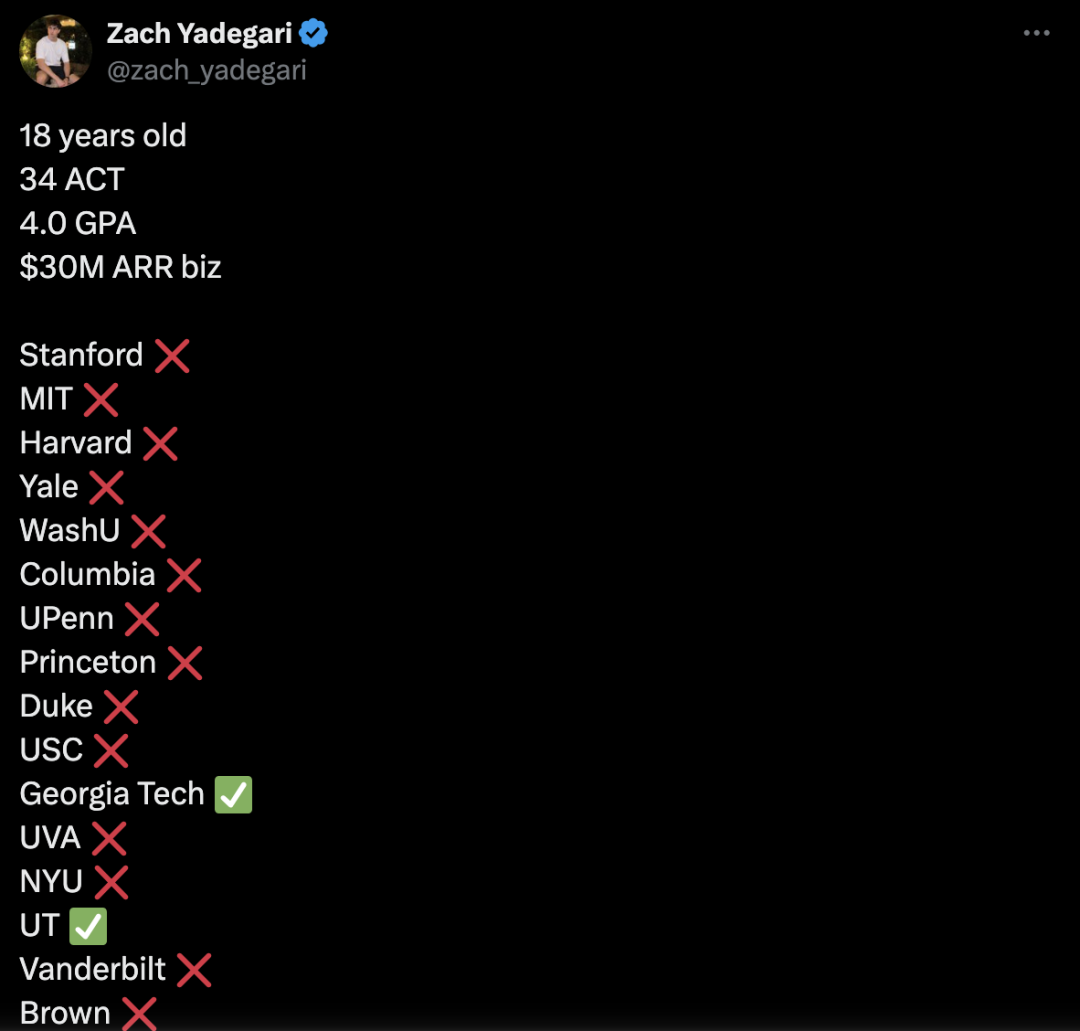
18-Year-Old AI App CEO Rejected by Multiple Top Universities Sparks Debate: Zach Yadegari, 18, co-founded the AI calorie tracking app Cal AI during high school, which garnered over 3 million downloads and millions in annual revenue. Despite a 4.0 GPA, high ACT scores, and impressive entrepreneurial experience, he was rejected by 15 out of 18 top universities he applied to, including Harvard, Stanford, and MIT. The incident sparked widespread attention and discussion on social media. Yadegari’s publicly shared admission essay frankly stated he initially didn’t plan to attend college but changed his mind after realizing the value of college life. Reasons for rejection are speculative; some believe the essay seemed “arrogant” or hinted at a high dropout risk, affecting prestigious schools’ valued graduation rates; others criticize issues with the university admission system or suggest discrimination against Asian applicants (drawing parallels to the Stanley Zhong case). Yadegari himself expressed hope to be seen as sincere. (Source: 36Kr, AI Frontline)
Community Discussion: Is AI a Blessing or a Curse?: A discussion emerged on Reddit regarding the pros and cons of AI technology. One user argued that AI is a technological blessing, enabling rapid realization of creative ideas (like generating specific scene images), and couldn’t understand why some people (especially non-creators) are hostile towards it. This viewpoint highlights the value of AI in meeting individual needs for instant, low-cost creation. It reflects positive views within the community on AI tools empowering individual creativity, while also mirroring the broader societal controversy and differing attitudes towards AI technology. (Source: Reddit r/artificial)
Community Discussion: Will the MCP Protocol Become the “Internet” for AI Agents?: With the development of MCP (Model Capability Protocol), the community is discussing its potential. Some believe that MCP, by providing standardized interfaces for LLMs to interact with external tools and data sources, could become the foundational infrastructure connecting various AI Agents and services, similar to how the internet connected different computers and websites. This suggests a future AI Agent ecosystem might achieve interoperability and collaboration based on MCP. (Source: Reddit r/ClaudeAI)

💡 Other
Microsoft’s Three Titans Discuss 50 Years and the Future with AI Copilot: On Microsoft’s 50th anniversary, three generations of CEOs – Bill Gates, Steve Ballmer, and Satya Nadella – held a conversation with the AI assistant Copilot. Gates reflected on early foresight regarding software value and declining computing costs, and mused about addressing government relations sooner. Both Ballmer and Nadella emphasized AI’s importance; Ballmer suggested deepening business around core AI technology, while Nadella predicted AI would become a ubiquitous “consumer packaged good” intelligence tool. During the chat, Copilot humorously “roasted” the three leaders, like suggesting Gates’ “thinking face” might cause an AI “blue screen.” The conversation showcased the Microsoft leadership’s reflection on history and consensus on an AI-driven future. (Source: Tencent Tech)

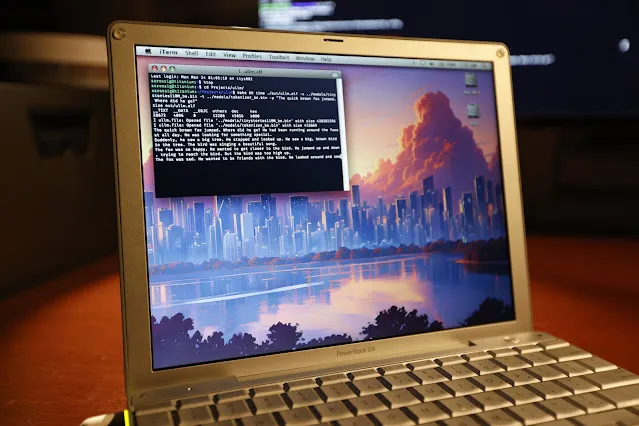
LLM Inference Successfully Run on a 20-Year-Old PowerBook G4: Software engineer Andrew Rossignol successfully ran inference tasks for Meta’s Llama 2 large model (TinyStories 110M version) on a 20-year-old Apple PowerBook G4 laptop (1.5 GHz PowerPC G4 processor, 1GB RAM). He ported the open-source project llama2.c, modified it for the PowerPC architecture (big-endian processing, memory alignment), and utilized the AltiVec vector extension (fused multiply-add operations) to boost inference speed by about 10% (from 0.77 tokens/s to 0.88 tokens/s). Although the speed is only about 1/8th of modern CPUs, it demonstrates the possibility of running modern AI models even on very old and resource-constrained hardware. (Source: 36Kr, AI Frontline)
Discussion: Why Do We Need World Models?: The article explores the necessity of World Models, arguing they are key to overcoming the limitations of current Large Language Models (LLMs), such as lack of physical world understanding, persistent memory, reasoning, and planning capabilities. World Models aim to enable AI to build internal simulations of the environment like humans do, understanding physical laws (like gravity, collision) and causal relationships, thereby facilitating prediction and decision-making. The article reviews the evolution of world models from a cognitive science concept to computational modeling (combining RL/DL, e.g., DeepMind’s “World Models” paper) and into the large model era (combining Transformers and multimodality, e.g., Genie, PaLM-E). The core advantages of world models lie in their causal prediction and counterfactual reasoning abilities, as well as cross-task generalization, which differs fundamentally from LLMs’ prediction based on large-scale text correlation probabilities. Although promising, world models still face challenges in compute power, generalization ability, and data. (Source: Naojiti)

New Breakthrough in AI Hazard Detection: Holmes-VAU Achieves Multi-Level Long Video Anomaly Understanding: Addressing the shortcomings of existing Video Anomaly Understanding (VAU) methods in handling long videos and complex temporal anomalies, institutions including HUST proposed the Holmes-VAU model and the HIVAU-70k dataset. This dataset contains over 70,000 instruction data entries across multiple temporal scales (video-level, event-level, clip-level), constructed via a semi-automatic data engine, promoting comprehensive understanding of anomalies in both long and short videos. Concurrently, the proposed Anomaly-focused Temporal Sampler (ATS) can dynamically sparsely sample keyframes based on anomaly scores, effectively reducing redundant information and improving the accuracy and efficiency of long video anomaly analysis. Experiments demonstrate that Holmes-VAU significantly outperforms general multimodal large models on video anomaly understanding tasks across various temporal granularities. (Source: Quantum Bit)
AI and Sustainability: Carbon Footprint Issue Attracts Attention: As the scale and training computation of AI models grow exponentially, their energy consumption and carbon emissions are becoming increasingly prominent issues. The Stanford AI Index report notes that despite improvements in hardware energy efficiency, overall energy consumption continues to rise. For example, training Meta’s Llama 3.1 model is estimated to generate nearly 9,000 tons of CO2. Although models like DeepSeek have made breakthroughs in energy efficiency, the overall carbon footprint of the AI industry remains a serious challenge. This is prompting AI companies to explore zero-carbon energy solutions like nuclear power and sparking discussions about the sustainability of AI development. (Source: Ronald_vanLoon, Ji Qizhi Xin)
