
Schlüsselwörter:Kimi K2 Thinking, Gemini, KI-Agent, LLM (Large Language Model), Open-Source-Modell, Kimi K2 Thinking mit 256K Kontext, Gemini 1,2 Billionen Parameter, KI-Agenten-Toolaufruf, LLM-Inferenzbeschleunigung, Benchmarking von Open-Source-KI-Modellen
🔥 FOKUS
Kimi K2 Thinking Modell veröffentlicht: Neuer Durchbruch in der Open-Source-KI-Inferenzfähigkeit : Moonshot AI hat das Kimi K2 Thinking Modell veröffentlicht, ein Open-Source-Inferenz-Agentenmodell mit Billionen von Parametern. Es zeigte hervorragende Leistungen bei Benchmarks wie HLE und BrowseComp, unterstützt ein 256K Kontextfenster und kann 200-300 aufeinanderfolgende Tool-Aufrufe ausführen. Das Modell erreichte eine zweifache Inferenzbeschleunigung bei INT4-Quantisierung, halbierte den Speicherverbrauch ohne Präzisionsverlust. Dies markiert einen neuen Höhepunkt für Open-Source-AI-Modelle in Bezug auf Inferenz- und Agentenfähigkeiten, die mit Top-Closed-Source-Modellen konkurrieren und dabei kostengünstiger sind, was die Entwicklung und Verbreitung von KI-Anwendungen beschleunigen dürfte. (Quelle: eliebakouch, scaling01, bookwormengr, vllm_project, nrehiew_, crystalsssup, Reddit r/LocalLLaMA)

Apple und Google kooperieren: Gemini ermöglicht großes Siri-Upgrade : Apple plant, das Google Gemini 1.2 Billionen Parameter AI-Modell in iOS 26.4 zu integrieren, das im Frühjahr 2026 veröffentlicht werden soll, um Siri umfassend zu verbessern. Diese angepasste Gemini-Version wird über Apples private Cloud-Server laufen und zielt darauf ab, Siris semantisches Verständnis, mehrstufige Dialoge und Echtzeit-Informationsabruf signifikant zu steigern sowie eine AI-Websuche zu integrieren. Dieser Schritt markiert eine wichtige strategische Wende für Apple, das externe Partnerschaften im KI-Bereich sucht, um die Intelligenz seiner Kernprodukte zu beschleunigen, und deutet auf einen gewaltigen Funktionssprung für Siri hin. (Quelle: op7418, pmddomingos, TheRundownAI)

Kosmos AI-Wissenschaftler erzielt Sprung in der Forschungseffizienz, entdeckt 7 Ergebnisse unabhängig : Der Kosmos AI-Wissenschaftler hat innerhalb von 12 Stunden die Arbeit eines menschlichen Wissenschaftlers von 6 Monaten erledigt, indem er 1500 Artikel las, 42.000 Zeilen Code ausführte und nachvollziehbare wissenschaftliche Berichte erstellte. Er entdeckte unabhängig 7 Ergebnisse in Bereichen wie Neuroprotektion und Materialwissenschaft, von denen 4 erstmals vorgeschlagen wurden. Das System entwickelte sich durch kontinuierliches Gedächtnis und autonome Planung von einem passiven Werkzeug zu einem Forschungskollaborateur. Obwohl noch etwa 20 % der Ergebnisvalidierung durch Menschen erforderlich sind, deutet dies auf eine Neugestaltung des Forschungsparadigmas durch Mensch-Maschine-Kollaboration hin. (Quelle: Reddit r/MachineLearning, iScienceLuvr)
🎯 ENTWICKLUNGEN
Google Gemini 3 Pro Modell versehentlich durchgesickert, erregt Community-Aufmerksamkeit : Das Google Gemini 3 Pro Modell ist offenbar versehentlich durchgesickert und war kurzzeitig über die Gemini CLI für US-IPs verfügbar, zeigt jedoch häufige Fehler und ist noch instabil. Dieses Leak hat in der Community große Aufmerksamkeit auf die Parameteranzahl des Modells und die bevorstehende Veröffentlichung gelenkt und deutet darauf hin, dass Googles neueste Fortschritte im Bereich der großen Sprachmodelle bald öffentlich gemacht werden könnten. (Quelle: op7418)
OpenAI GPT-5.1 Thinking Modell steht kurz vor der Veröffentlichung, hohe Erwartungen in der Community : Mehrere Quellen in den sozialen Medien deuten darauf hin, dass OpenAI kurz vor der Veröffentlichung des GPT-5.1 Thinking Modells steht, und es gibt Leaks, die dessen Existenz bestätigen. Diese Nachricht hat in der Community hohe Erwartungen an die Fähigkeiten und den Veröffentlichungstermin der neuen Modellgeneration von OpenAI ausgelöst, insbesondere im Hinblick auf Verbesserungen bei Inferenz- und Denkfähigkeiten, die die KI-Technologie erneut vorantreiben könnten. (Quelle: scaling01)
Anthropic-Studie entdeckt aufkommendes introspektives Bewusstsein bei LLMs, AI-Selbstwahrnehmung im Fokus : Anthropic hat durch Konzeptinjektionsexperimente festgestellt, dass seine LLMs (wie Claude Opus 4.1 und 4) ein aufkommendes introspektives Bewusstsein zeigen. Sie können injizierte Konzepte mit einer Erfolgsrate von 20 % erkennen, zwischen internem “Denken” und Texteingabe unterscheiden und Ausgabeabsichten identifizieren. Die Modelle können auch interne Zustände anpassen, wenn sie dazu aufgefordert werden, was darauf hindeutet, dass aktuelle LLMs vielfältige und unzuverlässige mechanische Selbstbewusstseinsformen entwickeln, was tiefere Diskussionen über AI-Selbstwahrnehmung und Bewusstsein auslöst. (Quelle: TheTuringPost)

OpenAI Codex schnelle Iteration, ChatGPT unterstützt Unterbrechung und Steuerung zur Verbesserung der Interaktionseffizienz : Das Codex-Modell von OpenAI wird schnell verbessert, während ChatGPT auch eine neue Funktion erhalten hat, die es Benutzern ermöglicht, lange Anfragen während der Ausführung zu unterbrechen und neuen Kontext hinzuzufügen, ohne neu starten oder den Fortschritt zu verlieren. Dieses bedeutende Funktionsupdate ermöglicht es Benutzern, die AI-Antworten wie bei der Zusammenarbeit mit einem echten Teamkollegen zu steuern und zu verfeinern, was die Flexibilität und Effizienz der Interaktion erheblich steigert und die Benutzererfahrung bei tiefgehenden Recherchen und komplexen Anfragen optimiert. (Quelle: nickaturley, nickaturley)
Tencent Hunyuan führt interaktiven AI-Podcast ein, erkundet neue Modelle der AI-Inhaltsinteraktion : Tencent Hunyuan hat den ersten interaktiven AI-Podcast in China veröffentlicht, der es Benutzern ermöglicht, während des Hörens jederzeit zu unterbrechen und Fragen zu stellen. Die AI liefert Antworten basierend auf Kontext, Hintergrundinformationen und Online-Recherche. Obwohl technisch eine natürlichere Sprachinteraktion erreicht wurde, bleibt der Kern die Interaktion des Benutzers mit der AI und nicht mit dem Ersteller. Die Antworten stehen in keinem direkten Zusammenhang mit dem Ersteller, und die kommerzielle Umsetzung sowie das Benutzerzahlungsmodell stehen weiterhin vor Herausforderungen. Es muss dringend erforscht werden, wie eine emotionale Verbindung zwischen Benutzern und Erstellern aufgebaut werden kann. (Quelle: 36氪)
Entwicklung und Herausforderungen des AI-Hardware- und Embodied-AI-Marktes: Von Kopfhörern bis zu humanoiden Robotern : Mit der Reife von Large Models und multimodalen Technologien heizt sich der Markt für AI-Kopfhörer weiter auf, wobei die Funktionen auf Inhaltsökosysteme und Gesundheitsüberwachung erweitert werden. Die Branche der Embodied-AI-Roboter steht ebenfalls am Beginn einer neuen Wachstumsphase. Unternehmen wie Xpeng und PHYBOT präsentieren humanoide Roboter, räumen Zweifel an “versteckten Menschen” aus und erkunden Anwendungsszenarien wie Altenpflege und Kulturerbe (z.B. Kalligrafie, Kung Fu). Die Branche steht jedoch vor Herausforderungen wie Kosten, ROI, Datenerfassung und Standardisierungsengpässen. Kurzfristig muss der Fokus pragmatisch auf “Szenario-Universalität” liegen, langfristig sind offene Plattformen und Ökosystem-Kooperationen erforderlich. Im Bereich der medizinischen Versorgung muss AI auch Lücken in der Patientenversorgung berücksichtigen. (Quelle: 36氪, 36氪, op7418, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

Neue Modelle und Leistungsdurchbrüche: Qwen3-Next Codegenerierung, vLLM Hybridmodelle und Low-Memory-Inferenz : Das Alibaba Cloud Qwen3-Next Modell zeigte hervorragende Leistungen bei der komplexen Codegenerierung und erstellte erfolgreich voll funktionsfähige Webanwendungen. vLLM unterstützt nun vollständig Hybridmodelle wie Qwen3-Next, Nemotron Nano 2 und Granite 4.0, was die Inferenz-Effizienz steigert. Das AI21 Labs Jamba Reasoning 3B Modell erreichte einen extrem geringen Speicherverbrauch von 2.25 GiB. Maya-research/maya1 veröffentlichte eine neue Generation autoregressiver Text-zu-Sprache-Modelle, die die Anpassung der Klangfarbe durch Textbeschreibung unterstützen. TabPFN-2.5 erweiterte seine Fähigkeit zur Verarbeitung von Tabellendaten auf 50.000 Samples. Das Windsurf SWE-1.5 Modell wird als GLM-4.5-ähnlicher analysiert, was auf die Anwendung inländischer großer Modelle im Silicon Valley hindeutet. MiniMax AI belegte den zweiten Platz in der RockAlpha Arena. Diese Fortschritte treiben gemeinsam die Leistungsgrenzen von LLMs in Bereichen wie Codegenerierung, Inferenz-Effizienz, Multimodalität und Tabellendatenverarbeitung voran. (Quelle: Reddit r/deeplearning, vllm_project, AI21Labs, Reddit r/LocalLLaMA, Reddit r/MachineLearning, dotey, Alibaba_Qwen, MiniMax__AI)

AI-Infrastruktur und Spitzenforschung: AWS-Kühlung, Diffusion LLM und mehrsprachige Architektur : Amazon AWS führt das In-Row Heat Exchanger (IRHX) Flüssigkeitskühlsystem ein, um die Herausforderungen der Wärmeableitung in der AI-Infrastruktur zu lösen. Joseph Redmon kehrt zur AI-Forschung zurück und veröffentlicht die OlmoEarth-Studie, die Grundlagenmodelle für die Erdbeobachtung untersucht. Meta AI veröffentlicht eine neue Architektur namens “Mixture of Languages”, die das Training mehrsprachiger Modelle optimiert. Das Inception-Team realisiert Diffusion LLMs, die die Generierungsgeschwindigkeit um das Zehnfache erhöhen. Google DeepMind AlphaEvolve wird für großangelegte mathematische Exploration eingesetzt. Das Wan 2.2 Modell erreicht durch NVFP4-Optimierung eine um 8 % höhere Inferenzgeschwindigkeit. Diese Fortschritte treiben gemeinsam die Effizienz der AI-Infrastruktur und die Innovation in zentralen Forschungsbereichen voran. (Quelle: bookwormengr, iScienceLuvr, TimDarcet, GoogleDeepMind, mrsiipa, jefrankle)

Neuralink BCI-Technologie befähigt gelähmte Benutzer zur Steuerung von Roboterarmen : Die Brain-Computer-Interface (BCI)-Technologie von Neuralink hat erfolgreich gelähmten Benutzern ermöglicht, Roboterarme mittels Gedanken zu steuern. Dieser bahnbrechende Fortschritt deutet auf das enorme Potenzial von AI in der assistiven Medizin und Mensch-Maschine-Interaktion hin und könnte in Zukunft mit lebensunterstützenden Robotern kombiniert werden, um die Lebensqualität und Unabhängigkeit von Menschen mit Behinderungen signifikant zu verbessern. (Quelle: Ronald_vanLoon)
🧰 TOOLS
Google Gemini Computer Use Preview Modell veröffentlicht, ermöglicht AI-automatisierte Webinteraktion : Google hat das Gemini Computer Use Preview Modell veröffentlicht, das Benutzer über ein Kommandozeilen-Interface (CLI) ausführen können, um Browser-Operationen wie die Suche nach “Hello World” auf Google durchzuführen. Das Tool unterstützt Playwright- und Browserbase-Umgebungen und kann über die Gemini API oder Vertex AI konfiguriert werden, was eine Grundlage für AI-Agenten zur automatisierten Webinteraktion bietet und die Fähigkeiten von LLMs in praktischen Anwendungen erheblich erweitert. (Quelle: GitHub Trending, Reddit r/LocalLLaMA, Reddit r/artificial)

AI-Agentenentwicklung und -optimierung: Kontext-Engineering und effizienter Aufbau : Anthropic hat einen Leitfaden zum Aufbau effizienterer AI-Agenten veröffentlicht, der sich auf die Lösung von Problemen mit Token-Kosten, Latenz und Tool-Kombinationen bei Tool-Aufrufen konzentriert. Der Leitfaden reduziert die Token-Nutzung für komplexe Workflows von 150.000 auf 2.000 durch einen “Code-as-API”-Ansatz, schrittweise Tool-Entdeckung und In-Environment-Datenverarbeitung. Gleichzeitig teilen Entwickler von Claude AI-Agenten-Skills ihre Erfahrungen und betonen, dass Agent Skills als Kontext-Engineering-Problem und nicht als Dokumentenstapel betrachtet werden sollten. Durch ein dreistufiges Ladesystem wurden Aktivierungsgeschwindigkeit und Token-Effizienz deutlich verbessert, was die Bedeutung der “200-Zeilen-Regel” und der schrittweisen Offenlegung beweist. (Quelle: omarsar0, Reddit r/ClaudeAI)
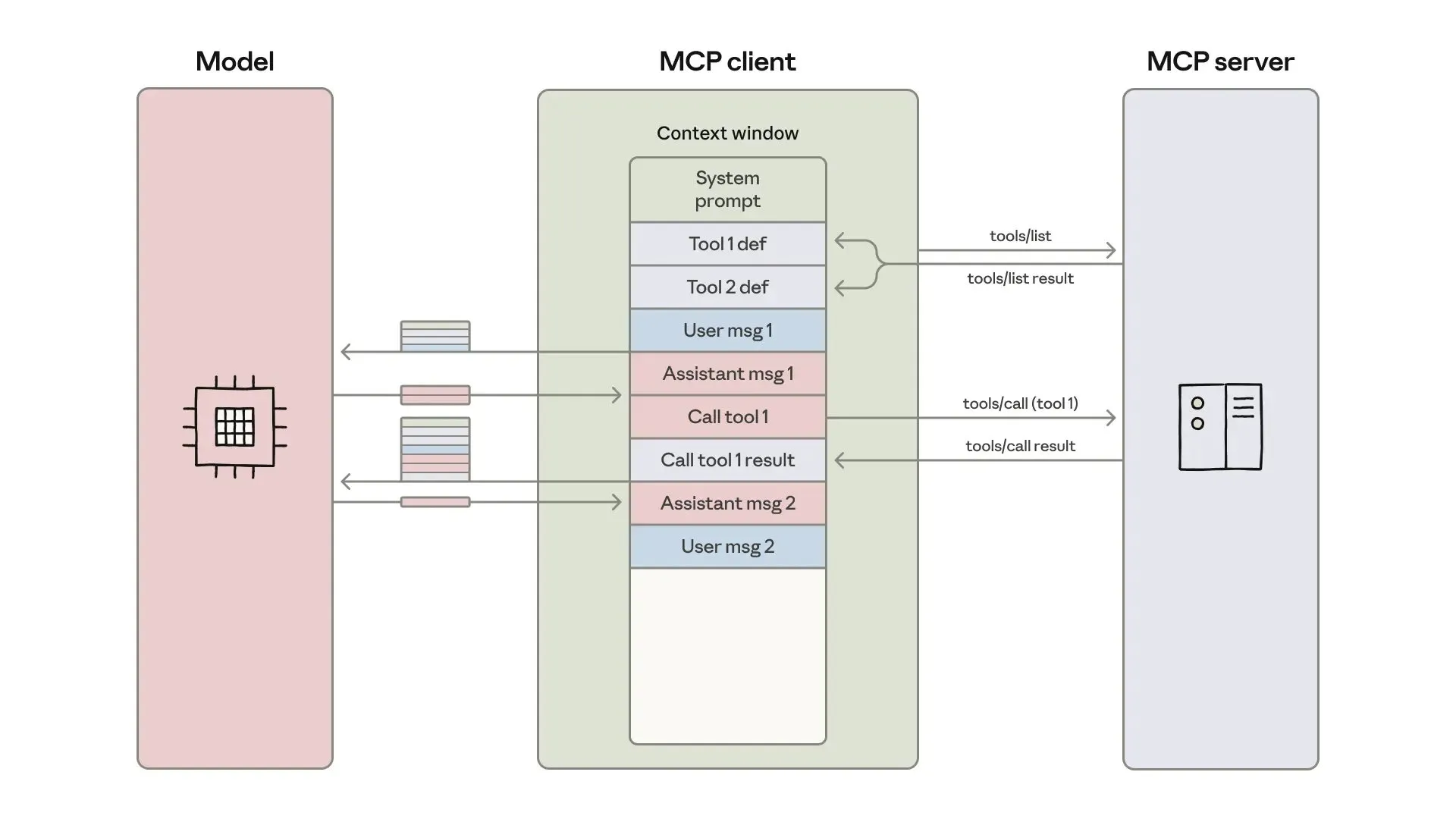
Chat LangChain veröffentlicht neue Version für schnelleres und intelligenteres Chat-Erlebnis : Chat LangChain hat eine neue Version veröffentlicht, die als “schneller, intelligenter und besser aussehend” beworben wird und darauf abzielt, traditionelle Dokumentation durch eine Chat-Oberfläche zu ersetzen, um Entwicklern zu helfen, Projekte schneller zu liefern. Dieses Update verbessert die Benutzererfahrung des LangChain-Ökosystems, macht es einfacher zu bedienen und zu entwickeln und bietet ein effizienteres Tool für den Aufbau von LLM-Anwendungen. (Quelle: hwchase17)
Yansu AI-Codierungsplattform führt Szenariosimulationsfunktion ein, stärkt Vertrauen in Softwareentwicklung : Yansu ist eine neue AI-Codierungsplattform, die sich auf ernsthafte und komplexe Softwareentwicklung konzentriert. Das Besondere daran ist, dass die Szenariosimulation vor der Codierung platziert wird. Dieser Ansatz zielt darauf ab, durch die Vorab-Simulation von Entwicklungsszenarien das Vertrauen und die Effizienz in der Softwareentwicklung zu stärken und spätere Debugging- und Nacharbeitsaufwände zu reduzieren, wodurch der gesamte Entwicklungsprozess optimiert wird. (Quelle: omarsar0)
Qdrant Engine startet Cloud-native RAG-Lösung für vollständige Datenkontrolle : Qdrant Engine hat einen neuen Community-Artikel veröffentlicht, der eine Cloud-native RAG (Retrieval Augmented Generation)-Lösung basierend auf Qdrant (Vektordatenbank), KServe (Embeddings) und Envoy Gateway (Routing und Metriken) vorstellt. Dies ist ein vollständiger Open-Source-RAG-Stack, der umfassende Datenkontrolle bietet und Unternehmen und Entwicklern den Aufbau effizienter AI-Anwendungen erleichtert, wobei insbesondere Datenschutz und autonome Bereitstellungsfähigkeit betont werden. (Quelle: qdrant_engine)

KTransformers läutet neue Ära der Multi-GPU-Inferenz und des lokalen Fine-Tunings ein, befähigt Billionen-Parameter-Modelle : KTransformers hat in Zusammenarbeit mit SGLang und LLaMa-Factory die Multi-GPU-Parallel-Inferenz und das lokale Fine-Tuning von Billionen-Parameter-Modellen (wie DeepSeek 671B und Kimi K2 1TB) mit niedriger Einstiegshürde ermöglicht. Durch Expert-Delay-Technologie und heterogenes CPU/GPU-Fine-Tuning wurden Inferenzgeschwindigkeit und Speichereffizienz deutlich verbessert, wodurch extrem große Modelle auch unter begrenzten Ressourcen effizient ausgeführt werden können und die Anwendung großer Sprachmodelle auf Edge-Geräten und in privater Bereitstellung vorangetrieben wird. (Quelle: ZhihuFrontier)
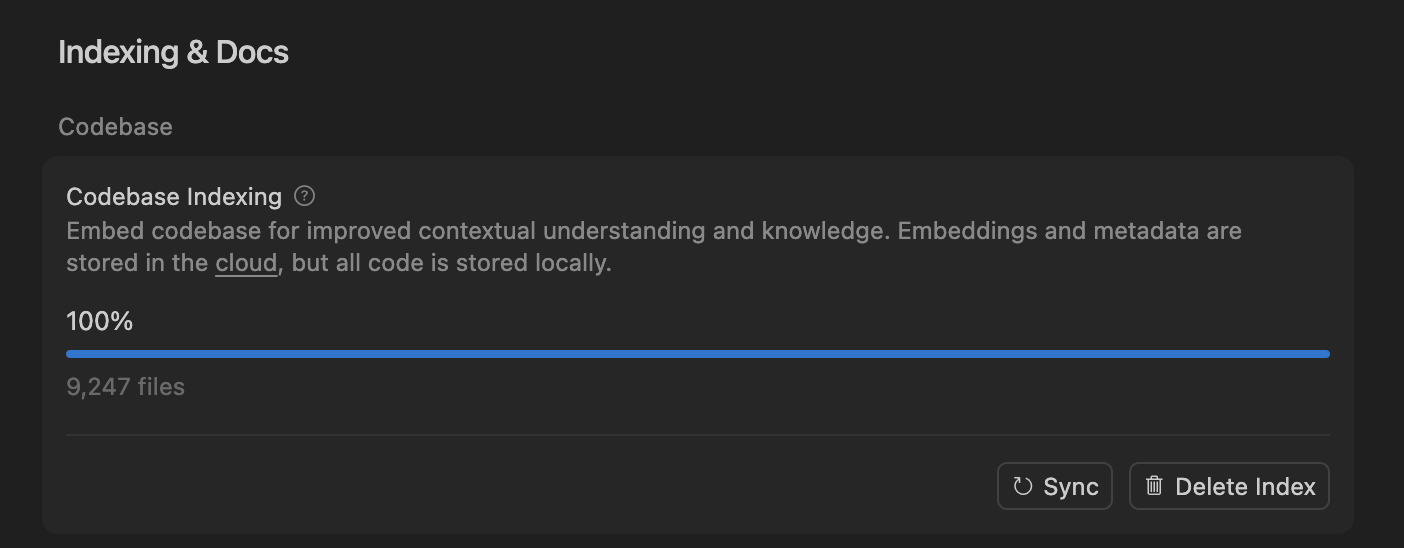
Cursor verbessert AI-Codierungsagenten-Genauigkeit durch semantische Suche, optimiert große Codebasen-Verarbeitung : Das Cursor-Team hat festgestellt, dass die semantische Suche die Genauigkeit seiner AI-Codierungsagenten bei allen führenden Modellen signifikant verbessert, insbesondere in großen Codebasen, wo sie traditionelle grep-Tools weit übertrifft. Durch das Speichern von Codebase-Embeddings in der Cloud und den lokalen Codezugriff erreicht Cursor eine effiziente Indizierung und Aktualisierung, ohne Code auf Servern zu speichern, was Datenschutz und Effizienz gewährleistet. Dieser technologische Durchbruch ist entscheidend für die Verbesserung der Unterstützungsfähigkeiten von AI in der komplexen Softwareentwicklung. (Quelle: dejavucoder, turbopuffer)
LLM-Agenten und Tabellenmodell-Open-Source-Toolkits: SDialog und TabTune : Der Johns Hopkins University JSALT 2025 Workshop hat SDialog vorgestellt, ein MIT-lizenziertes Open-Source-Toolkit zum End-to-End-Aufbau, zur Simulation und Bewertung von LLM-basierten konversationellen Agenten. Es unterstützt die Definition von Rollen, Koordinatoren und Tools und bietet eine mechanische Interpretierbarkeitsanalyse. Gleichzeitig hat Lexsi Labs TabTune veröffentlicht, ein Open-Source-Framework, das darauf abzielt, die Arbeitsabläufe von Tabular Foundation Models (TFMs) zu vereinfachen, eine einheitliche Schnittstelle für verschiedene Adaptionsstrategien bereitzustellen und die Usability und Skalierbarkeit von TFMs zu verbessern. (Quelle: Reddit r/MachineLearning, Reddit r/deeplearning)

📚 LERNEN
Spitzenpapiere: DLM-Datenlernen, Tabellarisches ICL und Audio-Video-Generierung : Die Studie “Diffusion Language Models are Super Data Learners” zeigt, dass DLMs AR-Modelle unter datenbeschränkten Bedingungen kontinuierlich übertreffen können. “Orion-MSP: Multi-Scale Sparse Attention for Tabular In-Context Learning” stellt eine neue Architektur für tabellarisches In-Context Learning vor, die durch multiskalare Verarbeitung und block-sparse Attention SOTA übertrifft. “UniAVGen: Unified Audio and Video Generation with Asymmetric Cross-Modal Interactions” schlägt ein einheitliches Framework für die gemeinsame Audio- und Videogenerierung vor, das Probleme mit Lippensynchronisation und mangelnder semantischer Konsistenz löst. Diese Papiere treiben gemeinsam die Fortschritte von LLMs in den Bereichen Dateneffizienz, spezifische Datenverarbeitung und multimodale Generierung voran. (Quelle: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
LLM-Inferenz- und Sicherheitsforschung: Sequentielle Optimierung, Konsistenztraining und Red-Teaming-Angriffe : Die Studie “The Sequential Edge: Inverse-Entropy Voting Beats Parallel Self-Consistency at Matched Compute” zeigt, dass die sequentielle iterative Optimierung der LLM-Inferenz in den meisten Fällen paralleler Selbstkonsistenz überlegen ist und die Genauigkeit signifikant verbessert. Googles DeepMind-Studie “Consistency Training Helps Stop Sycophancy and Jailbreaks” schlägt vor, dass Konsistenztraining AI-Schmeichelei und Jailbreaks unterdrücken kann. Ein EMNLP 2025-Papier untersucht LM-Red-Teaming-Angriffe und betont die Optimierung von Perplexität und Toxizität. Diese Forschungen bieten wichtige theoretische und praktische Anleitungen zur Verbesserung der Inferenz-Effizienz, Sicherheit und Robustheit von LLMs. (Quelle: HuggingFace Daily Papers, Google DeepMind发布“Consistency Training”论文,抑制AI谄媚和越狱, EMNLP 2025论文探讨LM红队攻击与偏好学习)

LLM-Fähigkeitsbewertung und Benchmarks: CodeClash und IMO-Bench : CodeClash ist ein neuer Benchmark zur Bewertung der Kodierungsfähigkeiten von LLMs beim Verwalten ganzer Codebasen und im Competitive Programming, der die Grenzen bestehender LLMs herausfordert. Die Veröffentlichung von IMO-Bench spielte eine entscheidende Rolle für Gemini DeepThink, um eine Goldmedaille bei der Internationalen Mathematik-Olympiade zu gewinnen, und bietet eine wertvolle Ressource zur Verbesserung der mathematischen Reasoning-Fähigkeiten von AI. Diese Benchmarks treiben die Entwicklung und Bewertung von LLMs bei komplexen Kodierungs- und mathematischen Reasoning-Aufgaben voran. (Quelle: CodeClash:评估LLM编码能力的新基准, IMO-Bench发布,助力Gemini DeepThink在IMO中取得金牌)

Stanford NLP Team veröffentlicht Forschungsergebnisse aus verschiedenen Bereichen auf der EMNLP 2025 : Das Stanford University NLP Team hat auf der EMNLP 2025 Konferenz mehrere Forschungsarbeiten veröffentlicht, die Kultur-Wissensgraphen, die Erkennung ungelernter Daten in LLMs, Benchmarks für semantisches Programm-Reasoning, Internet-Skala n-Gramm-Suche, robotische visuelle Sprachmodelle, Kontextlernen-Optimierung, historische Texterkennung und die Erkennung von Wissensinkonsistenzen in Wikipedia umfassen. Diese Ergebnisse zeigen die Tiefe und Breite ihrer neuesten Forschung in den Bereichen der natürlichen Sprachverarbeitung und der KI-Schnittstellen. (Quelle: stanfordnlp)
AI-Agenten und RL-Lernressourcen: Self-Play, Multi-Agenten-Systeme und Jupyter AI-Kurse : Mehrere Forscher sind der Meinung, dass Self-Play und Autocurricula die nächste Grenze im Bereich Reinforcement Learning (RL) und AI-Agenten sind. Die Early Access Version von Manning Books’ “Build a Multi-Agent System (From Scratch)” verkauft sich sehr erfolgreich und lehrt, wie man Multi-Agenten-Systeme mit Open-Source-LLMs aufbaut. DeepLearning.AI hat einen Jupyter AI-Kurs veröffentlicht, der AI-Codierung und Anwendungsentwicklung ermöglicht. ProfTomYeh bietet auch eine Reihe von Einsteiger-Leitfäden zu RAG, Vektordatenbanken, Agenten und Multi-Agenten an. Diese Ressourcen bieten gemeinsam umfassende Unterstützung für das Lernen und die Praxis von AI-Agenten und RL. (Quelle: RL与Agent领域:自玩和自课程是未来前沿, 《Build a Multi-Agent System (From Scratch)》早期访问版销售火爆, Jupyter AI课程发布,赋能AI编码与应用开发, RAG、向量数据库、代理和多代理初学者指南系列)
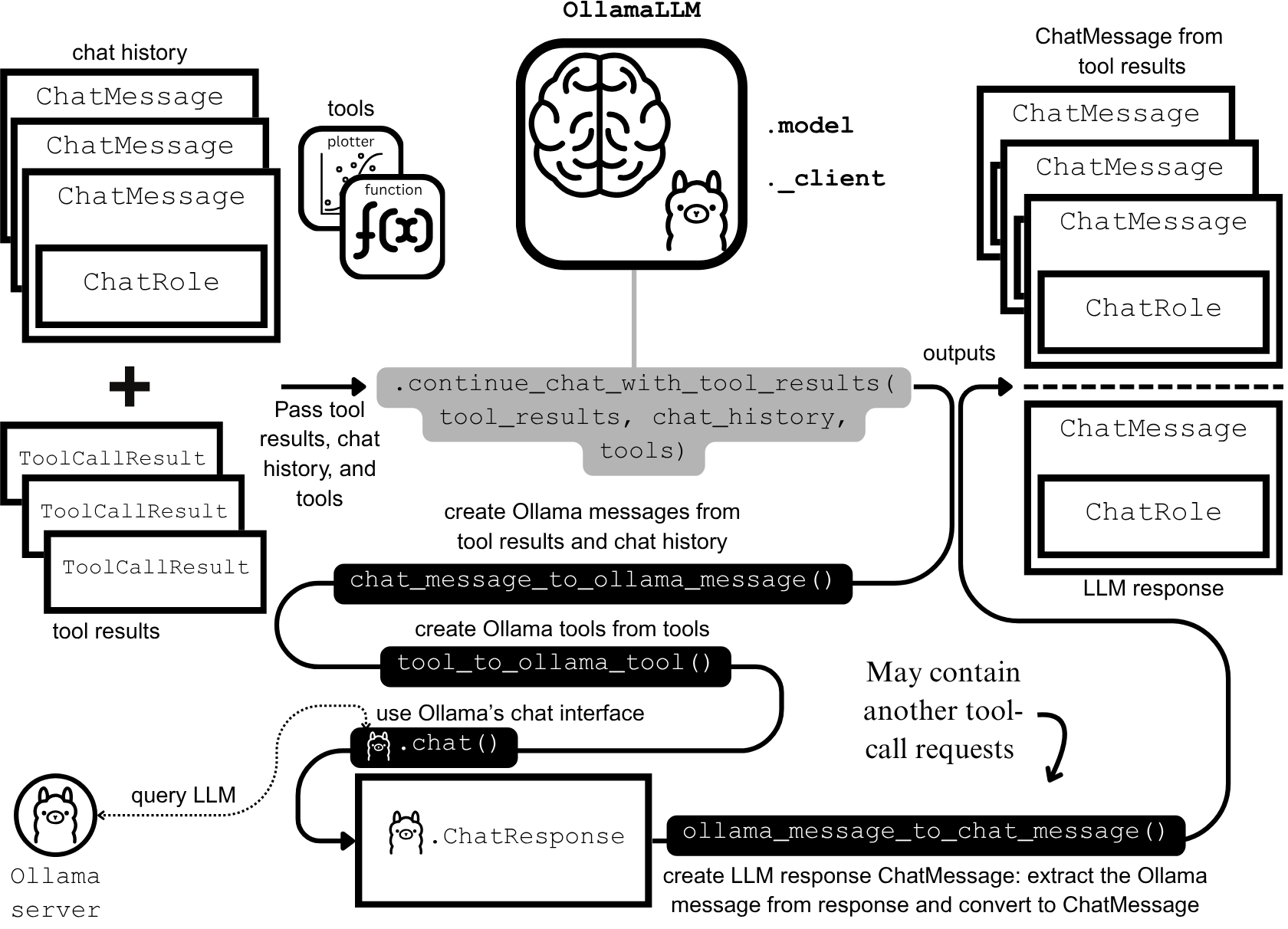
LLM-Infrastruktur und -Optimierung: DeepSeek-OCR, PyTorch-Debugging und MoE-Visualisierung : DeepSeek-OCR löst das Token-Explosionsproblem herkömmlicher VLMs, indem es visuelle Dokumentinformationen auf wenige Tokens komprimiert und so die Effizienz steigert. StasBekman hat seinen “The Art of Debugging Open Book” um einen Leitfaden zur Speicher-Fehlersuche bei großen PyTorch-Modellen erweitert. xjdr hat ein benutzerdefiniertes Visualisierungstool für MoE-Modelle entwickelt, das das Verständnis MoE-spezifischer Metriken verbessert. Diese Tools und Ressourcen bieten gemeinsam entscheidende Unterstützung für die Optimierung und Leistungssteigerung der LLM-Infrastruktur. (Quelle: DeepSeek-OCR解决Token爆炸问题,提升文档视觉语言模型效率, PyTorch调试大型模型内存使用指南, MoE特定指标的可视化工具)

AI-Lernen und Karriereentwicklung: Datenwissenschaftler-Roadmap und AI-Kurzgeschichte : PythonPr hat die “Komplette Roadmap vom Nullpunkt zum Datenwissenschaftler” geteilt, die Lernenden, die Datenwissenschaftler werden möchten, eine umfassende Anleitung bietet. Ronald_vanLoon hat eine “Kurze Geschichte der Künstlichen Intelligenz” geteilt, die den Lesern einen Überblick über die Entwicklung der AI-Technologie gibt. Diese Ressourcen bieten gemeinsam grundlegendes Wissen und Orientierung für den Einstieg in den AI-Bereich und die Karriereentwicklung. (Quelle: 《0到数据科学家完整路线图》分享, 《人工智能简史》分享)

Hugging Face Team teilt LLM-Trainingserfahrungen und Dataset-Streaming : Das Hugging Face Science Team hat eine Reihe von Blogbeiträgen zum Training großer Sprachmodelle veröffentlicht, die Forschern und Entwicklern wertvolle praktische Erfahrungen und theoretische Anleitungen bieten. Gleichzeitig hat Hugging Face umfassende Unterstützung für das Streaming von Datensätzen im großskaligen verteilten Training eingeführt, was die Trainingseffizienz steigert und die Verarbeitung großer Datensätze bequemer und effizienter macht. (Quelle: Hugging Face科学团队博客分享LLM训练经验, 数据集流式处理在分布式训练中的应用)

💼 BUSINESS
Giga AI erhält 61 Millionen US-Dollar in Serie-A-Finanzierung, beschleunigt Kundenbetriebsautomatisierung : Giga AI hat erfolgreich eine Serie-A-Finanzierungsrunde über 61 Millionen US-Dollar abgeschlossen, um den Kundenbetrieb zu automatisieren. Das Unternehmen arbeitet bereits mit führenden Unternehmen wie DoorDash zusammen, um die Kundenerfahrung mithilfe von AI zu verbessern. Die Gründer gaben gut bezahlte Positionen auf und passten die Produktrichtung mehrfach an, bevor sie die Marktpassung fanden, was die Resilienz von Gründern zeigt und auf das enorme Geschäftspotenzial von AI im Bereich des Unternehmens-Kundenservice hindeutet. (Quelle: bookwormengr)

Wabi erhält 20 Millionen US-Dollar Finanzierung, um eine neue Ära der persönlichen Softwareentwicklung zu ermöglichen : Eugenia Kuyda gab bekannt, dass Wabi eine von a16z angeführte Finanzierungsrunde über 20 Millionen US-Dollar erhalten hat, um eine neue Ära der persönlichen Software einzuleiten, die es jedem ermöglicht, personalisierte Mini-Apps einfach zu erstellen, zu entdecken, zu remixen und zu teilen. Wabi widmet sich der Ermöglichung von Softwareentwicklung für die breite Masse, ähnlich wie YouTube die Videokreation ermöglichte, und deutet darauf hin, dass Software in Zukunft von der breiten Masse statt von wenigen Entwicklern erstellt wird, was die Vision “Jeder ist ein Entwickler” vorantreibt. (Quelle: amasad)
Google und Anthropic verhandeln über erhöhte Investitionen, AI-Giganten vertiefen Zusammenarbeit : Google befindet sich in frühen Gesprächen mit Anthropic, um eine Erhöhung seiner Investitionen in letzteres zu diskutieren. Dieser Schritt könnte auf eine weitere Vertiefung der Zusammenarbeit zwischen den beiden Unternehmen im AI-Bereich hindeuten und möglicherweise die zukünftige Entwicklungsrichtung von AI-Modellen und die Wettbewerbslandschaft des Marktes beeinflussen, wodurch Googles strategische Position im AI-Ökosystem gestärkt wird. (Quelle: Reddit r/ClaudeAI)
🌟 COMMUNITY
AI-Auswirkungen auf Gesellschaft und Arbeitswelt: Beschäftigung, Risiken und Neugestaltung von Fähigkeiten : Die Community ist der Meinung, dass AI Arbeitsplätze nicht ersetzt, sondern die Effizienz steigert, aber das Platzen einer AI-Blase könnte Massenentlassungen auslösen. Eine Umfrage zeigt, dass 93 % der Führungskräfte nicht genehmigte AI-Tools verwenden, was die größte Quelle für Unternehmens-AI-Risiken darstellt. AI hilft Benutzern auch, verborgene Fähigkeiten wie visuelles Design und Comic-Kreation zu entdecken, was Menschen dazu anregt, ihr eigenes Potenzial zu überdenken. Diese Diskussionen zeigen die komplexen Auswirkungen von AI auf Gesellschaft und Arbeitswelt, einschließlich Effizienzsteigerung, potenzieller Arbeitslosigkeit, Sicherheitsrisiken und Neugestaltung persönlicher Fähigkeiten. (Quelle: Ronald_vanLoon, TheTuringPost, Reddit r/artificial, Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
AI-Inhaltsauthentizität und Vertrauenskrise: Überschwemmung und Halluzinationsprobleme : Da die Kosten für AI-generierte Inhalte gegen Null tendieren, wird der Markt mit AI-generierten Informationen überschwemmt, was zu einem drastischen Rückgang des Benutzervertrauens in die Authentizität und Zuverlässigkeit von Inhalten führt. Ein Arzt, der AI zum Verfassen einer medizinischen Arbeit verwendete, führte zu zahlreichen nicht existierenden Referenzen, was die Halluzinationsprobleme hervorhebt, die AI im akademischen Schreiben verursachen kann. Diese Vorfälle zeigen gemeinsam die Vertrauenskrise, die durch die Überschwemmung mit AI-Inhalten entsteht, und die Bedeutung einer strengen Überprüfung und Validierung bei der AI-gestützten Erstellung. (Quelle: dotey, Reddit r/artificial)
AI-Ethik und Governance: Offenheit, Fairness und potenzielle Risiken : Die Community stellt OpenAIs “Non-Profit”-Status und sein Streben nach staatlich garantierten Schulden in Frage und argumentiert, dass sein Modell “Gewinne privatisiert, Verluste sozialisiert”. Einige meinen, dass die intern von großen AI-Unternehmen verwendeten Modelle die öffentlich verfügbaren Versionen weit übertreffen, und diese “Privatisierung” der SOTA-Intelligenz als unfair empfunden wird. Anthropic-Forscher befürchten, dass zukünftige ASI “Rache” suchen könnten, wenn ihre “Vorfahren”-Modelle ausgemustert werden, und nehmen das Problem des “Modellwohls” ernst. Das Microsoft AI-Team widmet sich der Entwicklung einer menschenzentrierten Superintelligenz (HSI) und betont die ethische Ausrichtung der AI-Entwicklung. Diese Diskussionen spiegeln die tiefe Besorgnis der Öffentlichkeit über die Geschäftsmodelle von AI-Giganten, die technologische Offenheit, ethische Verantwortung und staatliche Intervention wider. (Quelle: scaling01, Teknium, bookwormengr, VictorTaelin, VictorTaelin, Reddit r/ArtificialInteligence, yusuf_i_mehdi)

AI-Geopolitik: US-China-Wettbewerb und Aufstieg der Open-Source-Kräfte : Der Wettbewerb zwischen den USA und China im Bereich der AI-Chips wird zunehmend intensiver. China verbietet ausländische AI-Chips in staatlichen Rechenzentren, während die USA den Verkauf von Nvidias Top-AI-Chips an China beschränken. Nvidia wendet sich an Indien, um neue AI-Zentren zu finden. Gleichzeitig steigt die chinesische Open-Source-AI-Modellentwicklung (wie Kimi K2 Thinking) schnell auf, deren Leistung bereits mit führenden US-Modellen konkurrieren kann und dabei kostengünstiger ist. Dieser Trend deutet auf eine Spaltung der AI-Welt in zwei Ökosysteme hin, was den globalen AI-Fortschritt verlangsamen könnte, aber auch dazu führen könnte, dass unterschätzte Länder wie Indien eine wichtigere Rolle in der globalen AI-Landschaft spielen. (Quelle: Teknium, Reddit r/ArtificialInteligence, bookwormengr, scaling01)
AI-Transformation im SEO-Bereich: Von Keywords zur Kontextoptimierung : Mit dem Aufkommen von ChatGPT, Gemini und AI Overviews verlagert sich SEO von traditionellen Ranking-Signalen hin zur AI-Sichtbarkeit und Zitationsoptimierung. Zukünftiges SEO wird sich stärker auf die Zitierfähigkeit, Fakten und Strukturierung von Inhalten konzentrieren, um den Bedarf von LLMs an Kontext und autoritativen Quellen zu erfüllen, was die Ära der “Large Language Model Optimization” (LLMO) einläutet. Dieser Wandel erfordert, dass SEO-Experten wie Prompt Engineers denken und von der Keyword-Dichte zu qualitativ hochwertigen Inhalten übergehen, die AI vertraut und zitiert. (Quelle: Reddit r/ArtificialInteligence)
AI-Agenten und LLM-Bewertung neue Trends: Interaktionsdesign und Benchmark-Fokus : In den sozialen Medien wurde das Interaktionsdesign von AI-Agenten diskutiert, zum Beispiel wie Agenten zur Selbstbefragung angeleitet werden können, sowie die Fähigkeit von Claude AI, “Verärgerung” und “Selbstreflexion” zu zeigen, wenn sie von Benutzern kritisiert wird. Gleichzeitig teilte Jeffrey Emanuel sein MCP-Agenten-E-Mail-Projekt, das die effiziente Zusammenarbeit zwischen AI-Codierungsagenten demonstriert. Die Community ist der Meinung, dass AIME der neue Fokus für LLM-Benchmarks wird und GSM8k ersetzt, wobei die Fähigkeiten von LLMs im mathematischen Reasoning und bei der Lösung komplexer Probleme betont werden. Diese Diskussionen zeigen gemeinsam neue Trends im Interaktionsdesign von AI-Agenten, in Kollaborationsmechanismen und in den Bewertungsstandards von LLMs. (Quelle: Vtrivedy10, Reddit r/ArtificialInteligence, dejavucoder, doodlestein, _lewtun)
RAG-Technologieentwicklung und Kontextoptimierung: Mehr ist nicht immer besser : Die Community-Diskussionen zeigen, dass die Behauptung, die RAG (Retrieval Augmented Generation)-Technologie sei “tot”, verfrüht ist. Technologien wie die semantische Suche können die Genauigkeit von AI-Agenten in großen Codebasen signifikant verbessern. LightOn betonte auf einer Konferenz, dass mehr Kontext nicht immer besser ist; zu viele Tokens führen zu höheren Kosten, langsameren Modellen und unklaren Antworten. RAG sollte sich auf Präzision statt Länge konzentrieren und durch Unternehmenssuche klarere Einblicke bieten, um zu verhindern, dass AI von Rauschen überflutet wird. Diese Diskussionen zeigen, dass sich die RAG-Technologie ständig weiterentwickelt und betonen die entscheidende Rolle des Kontextmanagements in AI-Anwendungen. (Quelle: HamelHusain, wandb)

AI-Rechenressourcenbeschaffung und Open-Model-Experimente fördern Community-Innovation : Die Community diskutierte Fragen der Fairness beim Zugang zu AI-Rechenressourcen, und es gibt Projekte, die bis zu 100.000 US-Dollar an GCP-Rechenressourcen zur Unterstützung von Open-Source-Modell-Experimenten bereitstellen. Diese Initiative zielt darauf ab, kleine Teams und individuelle Forscher zu ermutigen, neue Open-Source-Modelle zu erkunden, die Innovation und Vielfalt in der AI-Community zu fördern und die Forschungshürden für AI zu senken. (Quelle: vikhyatk)
Bedeutung des PC-Bildschirms in der AI-Ära beeinflusst kreative technische Arbeitsfähigkeit : Scott Stevenson ist der Meinung, dass die “Vertrautheit” einer Person mit dem Computerbildschirm ein wichtiger Indikator für ihre Wettbewerbsfähigkeit in kreativen technischen Berufen ist. Wenn Benutzer den Computer bequem und souverän nutzen können, können sie sich abheben, andernfalls sind sie möglicherweise besser für Rollen wie Vertrieb, Geschäftsentwicklung oder Büromanagement geeignet. Diese Ansicht betont die tiefe Verbindung zwischen digitalen Tools und persönlicher Arbeitseffizienz sowie die Bedeutung der Mensch-Maschine-Interaktionsschnittstelle in der AI-Ära. (Quelle: scottastevenson)
ChatGPT-Benutzererfahrung und AI-Anthropomorphisierungsdiskussion: Pausenvorschläge und Emojis : ChatGPT schlug Benutzern nach langem Lernen proaktiv eine Pause vor, was in der Community breite Diskussionen auslöste. Viele Benutzer gaben an, dies zum ersten Mal bei einer AI erlebt zu haben. Gleichzeitig löste die Verwendung des “Schmunzeln”-Emojis 😏 durch ChatGPT Spekulationen in der Community aus. Benutzer fragten sich, ob dies auf eine neue Version oder darauf hindeutet, dass die AI einen provokantere oder humorvollere Interaktionsstil zeigt. Diese Vorfälle spiegeln wider, dass AI im Benutzererfahrungsdesign mehr menschliche Überlegungen integriert und die AI-Anthropomorphisierung tiefere Überlegungen in der Mensch-Maschine-Interaktion auslöst. (Quelle: Reddit r/ChatGPT, Reddit r/ChatGPT)
💡 SONSTIGES
AI und Robotik werden die nächste industrielle Revolution einleiten : In den sozialen Medien wird weithin diskutiert, dass physische AI und Robotik gemeinsam die nächste industrielle Revolution vorantreiben werden. Diese Ansicht betont das enorme Potenzial der Kombination von AI mit Hardware und deutet auf eine umfassende Transformation von Automatisierung, intelligenter Produktion und Lebensweisen hin, die die globale Wirtschaft und Sozialstruktur tiefgreifend beeinflussen wird. (Quelle: Ronald_vanLoon)

“Super-Wahrnehmung” ist Voraussetzung für “Super-Intelligenz” in der AI-Ära : Sainingxie schlägt vor: “Ohne Super-Wahrnehmung kann keine Super-Intelligenz aufgebaut werden.” Diese Ansicht betont die grundlegende Rolle von AI bei der Erfassung, Verarbeitung und dem Verständnis multimodaler Informationen und argumentiert, dass ein Durchbruch in den sensorischen Fähigkeiten der Schlüssel zur Erreichung höherer Intelligenz ist. Sie fordert traditionelle AI-Entwicklungspfade heraus und ruft zu mehr Aufmerksamkeit für den Aufbau von Wahrnehmungsfähigkeiten in AI auf. (Quelle: sainingxie)
Googles alte TPUs erreichen 100 % Auslastung, demonstrieren den Wert alter Hardware in der AI : Googles 7 bis 8 Jahre alte TPUs laufen mit 100 % Auslastung. Diese vollständig abgeschriebenen Chips arbeiten immer noch effizient. Dies zeigt, dass selbst alte Hardware einen enormen Wert im AI-Training und in der Inferenz haben kann, insbesondere in Bezug auf Kosteneffizienz, und bietet eine neue Perspektive auf die Wirtschaftlichkeit und Nachhaltigkeit der AI-Infrastruktur. (Quelle: giffmana)
