
Schlüsselwörter:OpenAI, Amazon AWS, KI-Rechenleistung, Stanford AgentFlow, Meituan LongCat-Flash-Omni, Alibaba Qwen3-Max-Thinking, Samsung TRM-Modell, Unity KI-Graph, Zusammenarbeit zwischen OpenAI und Amazon im Bereich Rechenleistung, AgentFlow-Framework für verstärktes Lernen, LongCat-Flash-Omni Multimodales Modell, Qwen3-Max-Thinking Schlussfolgerungsfähigkeit, TRM rekursive Schlussfolgerungsarchitektur
🔥 Fokus
OpenAI und Amazon schließen 38 Milliarden US-Dollar Rechenleistungs-Partnerschaft ab : OpenAI und Amazon AWS haben eine Rechenleistungsvereinbarung im Wert von 38 Milliarden US-Dollar unterzeichnet, mit dem Ziel, NVIDIA GPU-Ressourcen zu erhalten, um den Aufbau ihrer KI-Modellinfrastruktur und ihre ehrgeizigen KI-Ziele zu unterstützen. Dieser Schritt markiert einen wichtigen Meilenstein für OpenAI bei der Diversifizierung seiner Cloud-Dienstanbieter, der Reduzierung der ausschließlichen Abhängigkeit von Microsoft und der Vorbereitung auf einen zukünftigen Börsengang (IPO). Amazon festigt durch diese Zusammenarbeit seine Führungsposition im Bereich der KI-Infrastruktur und setzt gleichzeitig die Partnerschaft mit OpenAIs Konkurrenten Anthropic fort. Die Vereinbarung wird OpenAI skalierbare Rechenleistung für KI-Inferenz und das Training von Modellen der nächsten Generation bereitstellen und die Anwendung ihrer Basismodelle auf der AWS-Plattform fördern. (Quelle: Ronald_vanLoon, scaling01, TheRundownAI)

Stanford AgentFlow Framework: Kleine Modelle übertreffen GPT-4o : Forschungsteams der Stanford University und anderer Institutionen haben das AgentFlow-Framework veröffentlicht, das durch eine modulare Architektur und den Flow-GRPO-Algorithmus KI-Agenten-Systemen ermöglicht, Online-Reinforcement-Learning in Inferenz-Workflows durchzuführen und so eine kontinuierliche Selbstoptimierung zu erreichen. AgentFlow mit nur 7B Parametern übertrifft GPT-4o (ca. 200B Parameter) und Llama-3.1-405B in Aufgaben wie Suche, Mathematik und Wissenschaft und führt die tägliche HuggingFace Paper-Rangliste an. Die Studie beweist, dass Agenten-Systeme durch Online-Reinforcement-Learning lernfähige Fähigkeiten ähnlich denen großer Modelle erwerben können und bei bestimmten Aufgaben effizienter sind, was einen neuen Weg für die KI-Entwicklung im Sinne von „klein und präzise“ eröffnet. (Quelle: HuggingFace Daily Papers)
AWS startet Project Rainier: Einer der weltweit größten KI-Rechencluster : AWS hat Project Rainier gestartet, einen KI-Rechencluster mit fast 500.000 Trainium2-Chips, der in weniger als einem Jahr aufgebaut wurde. Anthropic hat hier bereits neue Claude-Modelle trainiert und plant, die Anzahl der Chips bis Ende 2025 auf 1 Million zu erweitern. Trainium2 ist ein von AWS maßgeschneiderter KI-Trainingsprozessor, der für die Verarbeitung großer neuronaler Netze entwickelt wurde. Das Projekt verwendet die UltraServer-Architektur, die über NeuronLinks und EFA-Netzwerke verbunden ist, bietet eine Rechenleistung von bis zu 83,2 Petaflops für sparse FP8-Modelle und wird zu 100 % mit erneuerbaren Energien betrieben, was eine hohe Energieeffizienz gewährleistet. Project Rainier unterstreicht die führende Position von AWS im Bereich der KI-Infrastruktur und bietet vertikal integrierte Lösungen von maßgeschneiderten Chips bis zur Rechenzentrumskühlung. (Quelle: TheTuringPost)
🎯 Trends
Meituan veröffentlicht multimodales Modell LongCat-Flash-Omni : Meituan hat sein neuestes multimodales Modell LongCat-Flash-Omni als Open Source veröffentlicht. Das Modell erreicht in umfassenden Benchmarks wie Omni-Bench und WorldSense den Open-Source-SOTA-Status und ist vergleichbar mit dem Closed-Source-Modell Gemini-2.5-Pro. LongCat-Flash-Omni verwendet eine MoE-Architektur mit 560B Gesamtparametern und 27B aktiven Parametern, erreicht eine hohe Inferenz-Effizienz und Echtzeit-Interaktion mit geringer Latenz und ist das erste Open-Source-Modell, das eine vollständige multimodale Echtzeit-Interaktion ermöglicht. Das Modell unterstützt multimodale Eingaben aus Text, Sprache, Bildern, Videos und beliebigen Kombinationen davon, verfügt über ein Kontextfenster von 128K Tokens und ermöglicht Audio-Video-Interaktionen von über 8 Minuten. (Quelle: WeChat, ZhihuFrontier)

Alibaba Qwen3-Max-Thinking Inferenz-Version veröffentlicht : Das Alibaba Qwen-Team hat eine frühe Vorschauversion von Qwen3-Max-Thinking veröffentlicht, ein Zwischen-Checkpoint-Modell, das sich noch im Training befindet. Nach der Verbesserung der Tool-Nutzung und der Erweiterung der Testzeitberechnung erreichte das Modell eine Punktzahl von 100 % in herausfordernden Inferenz-Benchmarks wie AIME 2025 und HMMT. Die Veröffentlichung von Qwen3-Max-Thinking demonstriert Alibabas signifikante Fortschritte in der KI-Inferenzfähigkeit und bietet Benutzern leistungsfähigere Chain-of-Thought- und Problemlösungsfähigkeiten. (Quelle: Alibaba_Qwen, op7418)
Samsung TRM-Modell: Rekursive Inferenz fordert Transformer-Paradigma heraus : Das Samsung SAIL Montreal Lab hat das Tiny Recursive Model (TRM) vorgestellt, eine neue rekursive Inferenzarchitektur mit nur 7 Millionen Parametern und einem zweischichtigen neuronalen Netzwerk. TRM nähert sich durch rekursive Aktualisierung von „Antworten“ und „latenten Denkvariablen“ in mehreren Selbstkorrekturrunden dem korrekten Ergebnis an und bricht Rekorde bei Aufgaben wie Sudoku-Extreme, wodurch es große Modelle wie DeepSeek R1 und Gemini 2.5 Pro übertrifft. Das Modell verzichtet architektonisch sogar auf Selbstaufmerksamkeitsschichten (TRM-MLP-Variante), was darauf hindeutet, dass MLPs bei kleinen, festen Eingabeaufgaben Overfitting reduzieren können. Dies stellt die Faustregel „größere Modelle sind leistungsfähiger“ in der KI-Welt in Frage und bietet neue Ansätze für leichtgewichtige KI-Inferenz. (Quelle: 36氪)

Unity Developer Conference: KI + Gaming Zukunftstrends : Die Unity Developer Conference 2025 betonte, dass KI der Motor für Kreativität und Effizienz in Spielen sein wird. Die Unity Engine und Tencent Hunyuan haben gemeinsam die AI Graph-Plattform eingeführt, die AIGC-Workflows tief integriert und die Effizienz des 2D-Designs um 30 % sowie die Produktion von 3D-Assets um 70 % steigern kann. Amazon Web Services (AWS) zeigte auch die Möglichkeiten von KI über den gesamten Lebenszyklus von Spielen (Erstellung, Betrieb, Wachstum), insbesondere im Bereich der Code-Generierung, wo KI sich von der Unterstützung zur autonomen Erstellung entwickelt. Meshy, als generatives 3D-KI-Erstellungstool, hilft Entwicklern durch Diffusionsmodelle und autoregressive Modelle, Kosten zu senken und die Prototypenentwicklung zu beschleunigen, mit großem Potenzial insbesondere in VR/AR- und UGC-Szenarien. (Quelle: WeChat)

Cartesia veröffentlicht Sprachmodell Sonic-3 : Das Sprach-KI-Unternehmen Cartesia hat sein neuestes Sprachmodell Sonic-3 veröffentlicht. Das Modell zeigte erstaunliche Ergebnisse bei der Nachbildung von Elon Musks Stimme und erhielt eine Serie-B-Finanzierung von 100 Millionen US-Dollar von Investoren wie NVIDIA. Sonic-3 basiert auf einem State Space Model (SSM) anstelle der traditionellen Transformer-Architektur, kann Kontext und Gesprächsatmosphäre kontinuierlich wahrnehmen und ermöglicht natürlichere, mühelosere KI-Antworten. Mit einer Latenz von nur 90 Millisekunden und einer End-to-End-Antwortzeit von 190 Millisekunden ist es eines der schnellsten Sprachgenerierungssysteme derzeit. (Quelle: WeChat)

MiniMax veröffentlicht Sprachmodell Speech 2.6 : MiniMax hat sein neuestes Sprachmodell MiniMax Speech 2.6 veröffentlicht, das sich durch die Eigenschaften „schnell und sprachgewandt“ auszeichnet. Das Modell reduziert die Antwortlatenz auf unter 250 ms, unterstützt über 40 Sprachen und alle Akzente und kann verschiedene „nicht-standardisierte Texte“ wie URLs, E-Mails, Beträge, Daten und Telefonnummern präzise erkennen. Dies bedeutet, dass das Modell selbst bei starkem Akzent, schneller Sprechweise und komplexen Informationen die Eingabe auf Anhieb verstehen und klar wiedergeben kann, was die Effizienz und Genauigkeit der Sprachinteraktion erheblich verbessert. (Quelle: WeChat)
Amazon Chronos-2: Universelles Vorhersage-Basismodell : Amazon hat Chronos-2 vorgestellt, ein Basismodell, das darauf abzielt, beliebige Vorhersageaufgaben zu bewältigen. Das Modell unterstützt univariate, multivariate und Kovariaten-Informationsvorhersagen und kann im Zero-Shot-Modus betrieben werden. Die Veröffentlichung von Chronos-2 markiert einen wichtigen Fortschritt für Amazon im Bereich der Zeitreihenvorhersage und bietet Unternehmen und Entwicklern flexiblere und leistungsfähigere Vorhersagefähigkeiten, die komplexe Vorhersageprozesse vereinfachen und die Effizienz der Entscheidungsfindung verbessern sollen. (Quelle: dl_weekly)
YOLOv11 für Gebäudeteilsegmentierung und Höhenklassifizierung : Eine Studie analysiert detailliert die Anwendung von YOLOv11 für die Instanzsegmentierung von Gebäuden und die diskrete Höhenklassifizierung aus Satellitenbildern. YOLOv11 verbessert die Objektlokalisierungsgenauigkeit durch eine effizientere Architektur, die Merkmale unterschiedlicher Skalen kombiniert, und zeigt hervorragende Leistungen in komplexen städtischen Szenarien. Das Modell erreichte auf dem DFC2023 Track 2-Datensatz eine Instanzsegmentierungsleistung von 60,4 % mAP@50 und 38,3 % mAP@50-95, während es gleichzeitig eine robuste Klassifizierungsgenauigkeit für fünf vordefinierte Höhenstufen beibehielt. YOLOv11 zeigt hervorragende Leistungen bei der Bewältigung von Verdeckungen, komplexen Gebäudeformen und Klassenungleichgewichten und eignet sich für die Echtzeit- und großflächige Stadtkartierung. (Quelle: HuggingFace Daily Papers)
🧰 Tools
PageIndex: Inferenz-basiertes RAG-Dokumentenindexierungssystem : VectifyAI hat PageIndex veröffentlicht, ein Inferenz-basiertes RAG (Retrieval-Augmented Generation)-System, das keine Vektordatenbanken und Chunking benötigt. PageIndex erstellt einen baumartigen Index von Dokumenten, der die Art und Weise simuliert, wie menschliche Experten navigieren und Wissen extrahieren, wodurch LLMs mehrstufige Inferenzen durchführen können, was zu einer präziseren Dokumentensuche führt. Das System erreichte im FinanceBench-Benchmark eine Genauigkeit von 98,7 %, was herkömmliche Vektor-RAG-Systeme weit übertrifft und sich besonders für die Analyse langer, spezialisierter Dokumente wie Finanzberichte und juristische Dokumente eignet. PageIndex bietet verschiedene Bereitstellungsoptionen, darunter Self-Hosting, Cloud-Dienste und APIs. (Quelle: GitHub Trending)

LocalAI: Lokale Open-Source-OpenAI-Alternative : LocalAI ist eine kostenlose, quelloffene OpenAI-Alternative, die eine OpenAI API-kompatible REST API bereitstellt und das lokale Ausführen von LLMs, Bild-, Audio-, Videogenerierung sowie Sprachklonung auf Consumer-Hardware unterstützt. Das Projekt benötigt keine GPU, unterstützt verschiedene Modelle wie gguf, transformers, diffusers und hat Funktionen wie WebUI, P2P-Inferenz und Model Context Protocol (MCP) integriert. LocalAI zielt darauf ab, die KI-Inferenz zu lokalisieren und zu dezentralisieren, um Benutzern flexiblere und privatere KI-Bereitstellungsoptionen zu bieten und verschiedene Hardwarebeschleunigungen zu unterstützen. (Quelle: GitHub Trending)
DeepAnalyze: Datenwissenschaftliches Agentic LLM : Forschungsteams der Renmin University of China und der Tsinghua University haben DeepAnalyze vorgestellt, das erste Agentic LLM für die Datenwissenschaft. Das Modell benötigt keinen manuell entworfenen Workflow; ein einziges LLM kann komplexe datenwissenschaftliche Aufgaben wie Datenvorbereitung, -analyse, -modellierung, -visualisierung und -erkenntnis autonom erledigen und Forschungsberichte auf Analystenniveau erstellen. DeepAnalyze lernt in realen Umgebungen durch ein lehrplanbasiertes Agentic-Trainingsparadigma und einen datenorientierten Trajektoriensynthese-Framework, löst die Probleme der spärlichen Belohnungen und des Mangels an langen Problemlösungs-Trajektorien und ermöglicht autonome Tiefenforschung im Bereich der Datenwissenschaft. (Quelle: WeChat)

AI PC: Angetrieben von Intel Core Ultra 200H Prozessoren : AI PCs, ausgestattet mit Intel Core Ultra 200H-Prozessoren, werden zu einer neuen Option zur Steigerung der Arbeits- und Lebenseffizienz. Diese Prozessorserie integriert eine leistungsstarke NPU (Neural Processing Unit), die die Energieeffizienz um bis zu 21 % steigert und langwierige, stromsparende KI-Aufgaben wie die Echtzeit-Unterdrückung von Hintergrundgeräuschen, intelligente Bildfreistellung und KI-Assistenten für die Dokumentenorganisation verarbeiten kann, und das alles offline. Diese Hybridarchitektur aus CPU, GPU und NPU ermöglicht es AI PCs, sich durch schlankes und tragbares Design, lange Akkulaufzeit und Offline-Arbeit auszuzeichnen und ein flüssiges, natürliches KI-Erlebnis für Büro-, Lern- und Gaming-Szenarien zu bieten. (Quelle: WeChat)

Claude Skills: 2300+ Fähigkeiten-Verzeichnis : Eine Website namens skillsmp.com hat über 2300 Claude Skills gesammelt und bietet Claude AI-Benutzern ein durchsuchbares Verzeichnis von Fähigkeiten. Diese Skills sind nach Kategorien organisiert, darunter Entwicklungstools, Dokumentation, KI-Verbesserungen, Datenanalyse usw., und bieten Vorschau-, ZIP-Download- und CLI-Installationsfunktionen. Die Plattform zielt darauf ab, Claude-Benutzern zu helfen, KI-Fähigkeiten bequemer zu entdecken und zu nutzen, die Fähigkeiten von Agenten zu verbessern, effizientere automatisierte Aufgaben zu realisieren und der Community nützliche Tools zur Verfügung zu stellen. (Quelle: Reddit r/ClaudeAI)
AI Chatbots für Websites: Die zehn besten AI Chatbots im Jahr 2025 : Ein Bericht listet die zehn besten AI Chatbots für Websites im Jahr 2025 auf, um Startups und Einzelgründern bei der Auswahl des passenden Tools zu helfen. ChatQube wurde aufgrund seiner sofortigen „Wissenslücken“-Benachrichtigungen und kontextsensitiven Fähigkeiten als das interessanteste neue Tool bewertet. Intercom Fin eignet sich für große Support-Teams, Drift konzentriert sich auf Marketing und Lead-Generierung, Tidio ist ideal für kleine Unternehmen und E-Commerce. Andere wie Crisp, Chatbase, Zendesk AI, Botpress, Flowise und Kommunicate haben ebenfalls ihre Besonderheiten und decken eine Vielzahl von Anforderungen ab, von der einfachen Einrichtung bis zur hochgradigen Anpassung, was zeigt, dass AI Chatbots praktischer und verbreiteter geworden sind. (Quelle: Reddit r/artificial)
Perplexity Comet: AI Coding Agent : Perplexity Comet wird als effizienter AI Coding Agent gelobt, der Aufgaben autonom erledigen kann, sobald sie ihm zugewiesen werden. Zum Beispiel kann ein Benutzer ihm Zugriff auf ein GitHub-Repository gewähren und ihn bitten, einen Webhook einzurichten, um Push-Ereignisse zu überwachen. Comet ist in der Lage, die Webhook-URL präzise von anderen Tabs abzurufen und korrekt zu konfigurieren. Dies zeigt die starke Fähigkeit von Perplexity Comet, komplexe Anweisungen zu verstehen, anwendungsübergreifend zu agieren und Entwicklungsprozesse zu automatisieren, was die Effizienz von Entwicklern erheblich steigert. (Quelle: AravSrinivas)
LazyCraft: Open-Source-Agentenplattform-Konkurrent für Dify : LazyCraft ist eine neu quelloffene Plattform für die Entwicklung und Verwaltung von AI Agent-Anwendungen, die als starker Konkurrent von Dify gilt. Sie bietet ein funktional vollständigeres Closed-Loop-System mit integrierten Kernmodulen wie Wissensdatenbank, Prompt-Management, Inferenz-Diensten, MCP-Tools (lokal und remote unterstützt), Datensatzverwaltung und Modellbewertung. LazyCraft unterstützt Multi-Tenant-/Multi-Workspace-Management und adressiert damit die Anforderungen an eine feingranulare Berechtigungssteuerung und Teamverwaltung in Unternehmensszenarien. Darüber hinaus integriert es Funktionen zur lokalen Modellfeinabstimmung und -verwaltung, die es Benutzern ermöglichen, die Modelleffekte wissenschaftlich zu vergleichen, und bietet so eine starke Unterstützung für Unternehmen mit Anforderungen an Datenschutz und tiefe Anpassung. (Quelle: WeChat)
📚 Lernen
HuggingFace Smol Training Playbook: LLM-Trainingsleitfaden : HuggingFace hat das Smol Training Playbook veröffentlicht, einen umfassenden Leitfaden zum Training von LLMs, der detailliert den Prozess hinter dem Training von SmolLM3 beschreibt. Dieser Leitfaden deckt die gesamte Kette ab, von Strategie- und Kostenentscheidungen vor dem Start über das Pre-Training (Daten, Ablationsstudien, Architektur und Tuning), das Post-Training (SFT, DPO, GRPO, Modellzusammenführung) bis hin zur Infrastruktur (GPU-Cluster-Setup, Kommunikation, Debugging). Dieser über 200-seitige Leitfaden soll LLM-Entwicklern transparente und praktische Trainingserfahrungen bieten, die Hürden für das Selbsttraining von Modellen senken und die Entwicklung von Open-Source-KI fördern. (Quelle: TheTuringPost, ClementDelangue)

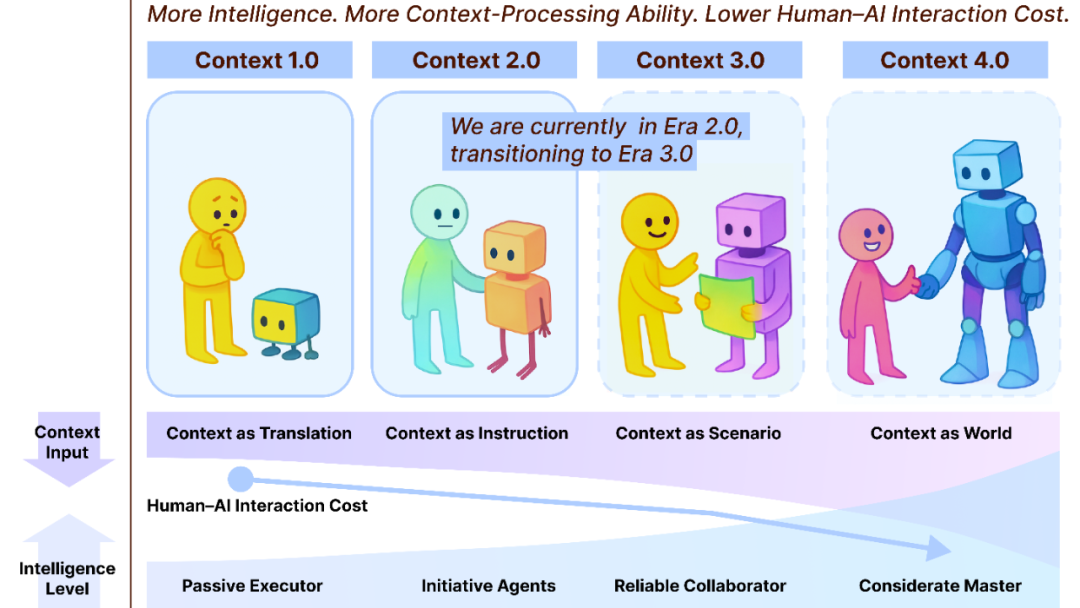
Context Engineering 2.0: 30 Jahre Evolution : Das Team von Liu Pengfei vom Shanghai Institute of Intelligent Science and Technology hat das Framework „Context Engineering 2.0“ vorgestellt, das das Wesen, die Geschichte und die Zukunft des Context Engineering analysiert. Die Studie weist darauf hin, dass Context Engineering ein 30-jähriger Prozess der Entropiereduktion ist, der darauf abzielt, die kognitive Kluft zwischen Mensch und Maschine zu überbrücken. Von der sensorgetriebenen Ära 1.0 über intelligente Assistenten und multimodale Fusion in Ära 2.0 bis hin zur prognostizierten nahtlosen Erfassung und reibungslosen Zusammenarbeit in Ära 3.0 hat die Evolution des Context Engineering die Revolution der Mensch-Maschine-Interaktion vorangetrieben. Das Framework betont die drei Dimensionen „Sammeln, Verwalten, Nutzen“ und erörtert philosophische Fragen, wie Kontext nach der Überwindung des Menschen durch KI eine neue menschliche Identität bilden könnte. (Quelle: WeChat)
Microsoft Research Asia PixelCraft: Verbesserung des Diagrammverständnisses großer Modelle : Microsoft Research Asia hat zusammen mit Teams der Tsinghua University und anderen PixelCraft vorgestellt, das darauf abzielt, die Fähigkeit von großen multimodalen Modellen (MLLM) zum Verständnis strukturierter Bilder wie Diagramme und geometrische Skizzen systematisch zu verbessern. PixelCraft basiert auf zwei Säulen: hochauflösender Bildverarbeitung und nicht-linearer Multi-Agenten-Inferenz. Durch Feinabstimmung von Grounding-Modellen wird eine pixelgenaue Textreferenzzuordnung erreicht, und eine Reihe von visuellen Tool-Agenten wird verwendet, um verifizierbare Bildoperationen durchzuführen. Sein diskursiver Inferenzprozess unterstützt Backtracking und Branch-Exploration, was die Genauigkeit, Robustheit und Erklärbarkeit des Modells bei Diagramm- und Geometrie-Benchmarks wie CharXiv und ChartQAPro erheblich verbessert. (Quelle: WeChat)
Spatial-SSRL: Selbstüberwachtes Reinforcement Learning zur Verbesserung des räumlichen Verständnisses : Eine Studie stellt Spatial-SSRL vor, ein selbstüberwachtes Reinforcement-Learning-Paradigma, das darauf abzielt, die räumlichen Verständnisfähigkeiten großer visueller Sprachmodelle (LVLM) zu verbessern. Spatial-SSRL extrahiert direkt verifizierbare Signale aus gewöhnlichen RGB- oder RGB-D-Bildern und erstellt automatisch fünf Voraufgaben, die 2D- und 3D-Raumstrukturen erfassen, ohne manuelle oder LVLM-Annotation. Auf sieben Bild- und Video-Raumverständnis-Benchmarks erzielte Spatial-SSRL eine durchschnittliche Genauigkeitssteigerung von 4,63 % (3B) und 3,89 % (7B) gegenüber dem Qwen2.5-VL-Baseline-Modell, was beweist, dass einfache, intrinsische Überwachung RLVR in großem Maßstab ermöglichen und LVLMs eine stärkere räumliche Intelligenz verleihen kann. (Quelle: HuggingFace Daily Papers)
π_RL: Online Reinforcement Learning zur Feinabstimmung von VLA-Modellen : Eine Studie stellt π_RL vor, ein Open-Source-Framework zum Trainieren von flussbasierten Vision-Language-Action (VLA)-Modellen in parallelen Simulationen. π_RL implementiert zwei RL-Algorithmen: Flow-Noise modelliert den Entrauschungsprozess als diskrete Zeit-MDP, während Flow-SDE eine effiziente RL-Exploration durch ODE-SDE-Transformationen ermöglicht. In den LIBERO- und ManiSkill-Benchmarks verbesserte π_RL die Leistung der Few-Shot-SFT-Modelle pi_0 und pi_0.5 erheblich, demonstrierte die Wirksamkeit von Online-RL für flussbasierte VLA-Modelle und erreichte leistungsstarke Multi-Task-RL- und Generalisierungsfähigkeiten. (Quelle: HuggingFace Daily Papers)
LLM Agents: Kernsubsysteme für den Aufbau autonomer LLM-Agenten : Ein Must-Read-Paper, „Fundamentals of Building Autonomous LLM Agents“, beleuchtet die kognitiven Kernsubsysteme, die autonome LLM-gesteuerte Agenten bilden. Das Paper beschreibt detailliert Schlüsselkomponenten wie Wahrnehmung, Inferenz und Planung (CoT, MCTS, ReAct, ToT), Lang- und Kurzzeitgedächtnis, Ausführung (Code-Ausführung, Tool-Nutzung, API-Aufrufe) sowie Closed-Loop-Feedback. Die Studie bietet eine umfassende Perspektive zum Verständnis und Aufbau autonomer LLM-Agenten und betont, wie diese Subsysteme zusammenarbeiten, um komplexes intelligentes Verhalten zu ermöglichen. (Quelle: TheTuringPost)

Efficient Vision-Language-Action Models: Eine Übersicht über effiziente VLA-Modelle : Eine umfassende Übersicht, „A Survey on Efficient Vision-Language-Action Models“, untersucht die neuesten Fortschritte bei effizienten Vision-Language-Action (VLA)-Modellen im Bereich der verkörperten Intelligenz. Die Übersicht schlägt eine einheitliche Taxonomie vor, die bestehende Techniken in drei Säulen unterteilt: effizientes Modell-Design, effizientes Training und effiziente Datensammlung. Durch eine kritische Überprüfung der modernsten Methoden bietet die Studie eine grundlegende Referenz für die Community, fasst repräsentative Anwendungen zusammen, beleuchtet zentrale Herausforderungen und skizziert eine Roadmap für zukünftige Forschung, um die enormen Rechen- und Datenanforderungen zu adressieren, denen VLA-Modelle bei der Bereitstellung gegenüberstehen. (Quelle: HuggingFace Daily Papers)
Neue Entdeckung zum SNN-Leistungsengpass: Frequenz statt Sparsity : Eine Studie enthüllt den wahren Grund für den Leistungsunterschied zwischen SNNs (Spiking Neural Networks) und ANNs (Artificial Neural Networks): Es ist nicht der traditionell angenommene Informationsverlust durch binäre/sparse Aktivierungen, sondern die inhärente Tiefpassfilter-Eigenschaft von Spiking-Neuronen. Die Studie fand heraus, dass SNNs auf Netzwerkebene als Tiefpassfilter agieren, was dazu führt, dass Hochfrequenzkomponenten schnell zerfallen und die Effektivität der Merkmalsdarstellung verringert wird. Durch den Ersatz von Avg-Pool durch Max-Pool in Spiking Transformer wurde die CIFAR-100-Genauigkeit um 2,39 % verbessert, und die Max-Former-Architektur wurde vorgeschlagen, die auf ImageNet eine Genauigkeit von 82,39 % und eine Energieeinsparung von 30 % erreicht. (Quelle: Reddit r/MachineLearning)
💼 Business
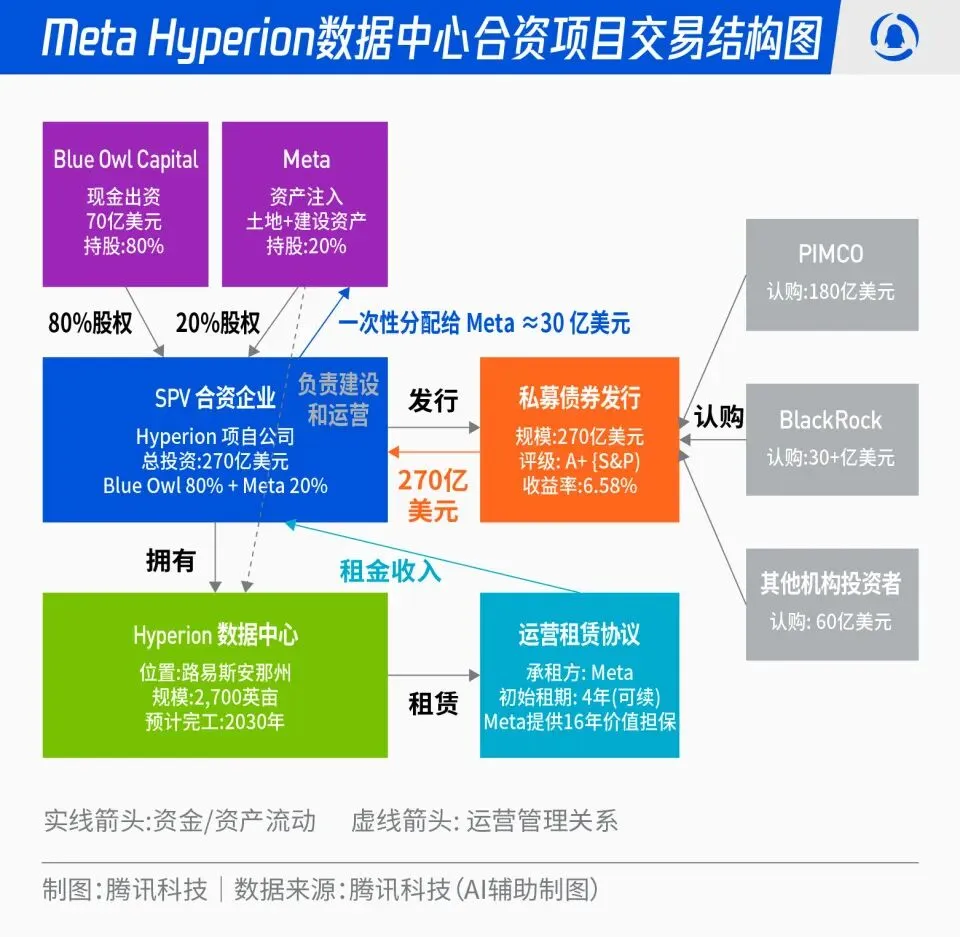
Meta 27 Milliarden US-Dollar Hyperion Rechenzentrums-Joint-Venture : Meta hat eine Partnerschaft mit Blue Owl angekündigt, um das 27 Milliarden US-Dollar schwere „Hyperion“-Rechenzentrums-Joint-Venture-Projekt zu starten. Meta beteiligt sich mit 20 %, Blue Owl mit 80 %, wobei A+-Anleihen und Eigenkapital über eine SPV ausgegeben werden, die langfristige institutionelle Gelder von PIMCO, BlackRock und anderen anzieht. Das Projekt zielt darauf ab, den Bau von KI-Infrastruktur von traditionellen Kapitalausgaben auf ein Finanzinnovationsmodell umzustellen. Nach Fertigstellung der Rechenzentren wird Meta diese langfristig zurückmieten und die operative Kontrolle behalten. Dieser Schritt kann Metas Bilanz optimieren, den KI-Expansionsprozess beschleunigen und gleichzeitig langfristigem Kapital ein Anlageportfolio mit hoher Bonität, Sachwertunterstützung und stabilen Cashflows bieten. (Quelle: 36氪)
OpenAI „Mafia“: Ehemalige Mitarbeiter gründen Startups und erhalten hohe Finanzierungen : Im Silicon Valley entsteht ein „OpenAI-Mafia“-Phänomen: Mehrere ehemalige OpenAI-Führungskräfte, Forscher und Produktmanager haben das Unternehmen verlassen, um Startups zu gründen, und erhalten bereits Finanzierungen in Höhe von Hunderten Millionen oder sogar Milliarden US-Dollar bei hohen Bewertungen, obwohl ihre Unternehmen noch keine Produkte auf den Markt gebracht haben. Zum Beispiel verhandelt Angela Jiang, Gründerin von Worktrace AI, über eine Seed-Finanzierung in zweistelliger Millionenhöhe; die ehemalige CTO Mira Murati gründete Thinking Machines Lab und schloss eine 2 Milliarden US-Dollar Finanzierungsrunde ab; und der ehemalige Chief Scientist Ilya Sutskever gründete Safe Superintelligence Inc. (SSI) mit einer Bewertung von 32 Milliarden US-Dollar. Diese ehemaligen Mitarbeiter bauen durch gegenseitige Investitionen, technische Unterstützung und Reputation ein neues KI-Machtnetzwerk außerhalb von OpenAI auf, wobei das Kapital eher die „OpenAI-Herkunft“ als das Produkt selbst bewertet. (Quelle: 36氪)

Tiefgreifende Auswirkungen von KI auf die Luftfahrt: Lufthansa entlässt 4000 Mitarbeiter : Die Lufthansa Group, Europas größter Luftfahrtkonzern, hat angekündigt, bis 2030 rund 4000 administrative Stellen abzubauen, was 4 % der Gesamtbelegschaft entspricht. Hauptgrund ist die beschleunigte Anwendung von Künstlicher Intelligenz und digitalen Tools. Der Einsatz von KI in der Luftfahrt hat bereits die Prozessoptimierung, Effizienzsteigerung und das Ertragsmanagement durchdrungen, beispielsweise durch die Optimierung des Ticketpreismanagements mittels Big Data und Algorithmen. Während operative Positionen wie Piloten und Flugbegleiter vorerst nicht betroffen sind, wurden Roboter bereits für standardisierte Dienstleistungen wie Flughafenreinigung und Gepäckabfertigung eingeführt. KI zeigt auch Potenzial im Treibstoffmanagement, Flugbetrieb und bei der Erkennung unsicherer Faktoren, beispielsweise durch die präzise Berechnung der Tankmenge basierend auf Wetterdaten und die Steigerung der Flugzeugumschlags-Effizienz durch maschinelles Sehen. (Quelle: 36氪)
🌟 Community
ChatGPTs Gedankenstrich-„Sucht“ und Datenherkunft : In den sozialen Medien wird intensiv über das „Akzent“-Problem von ChatGPT diskutiert, das sich durch die häufige Verwendung von Gedankenstrichen äußert. Analysen legen nahe, dass dies nicht auf eine Präferenz der RLHF-Tutoren für afrikanisches Englisch zurückzuführen ist, sondern darauf, dass GPT-4 und nachfolgende Modelle umfangreich mit literarischen Werken aus dem späten 19. und frühen 20. Jahrhundert trainiert wurden, die gemeinfrei sind. In diesen „alten Büchern“ ist die Häufigkeit der Gedankenstriche weitaus höher als im zeitgenössischen Englisch, was dazu führte, dass das KI-Modell den Schreibstil dieser Ära getreu übernommen hat. Diese Erkenntnis offenbart den tiefgreifenden Einfluss der Trainingsdatenquellen auf den Sprachstil von KI-Modellen und erklärt auch, warum frühere Modelle wie GPT-3.5 dieses Problem nicht hatten. (Quelle: dotey)
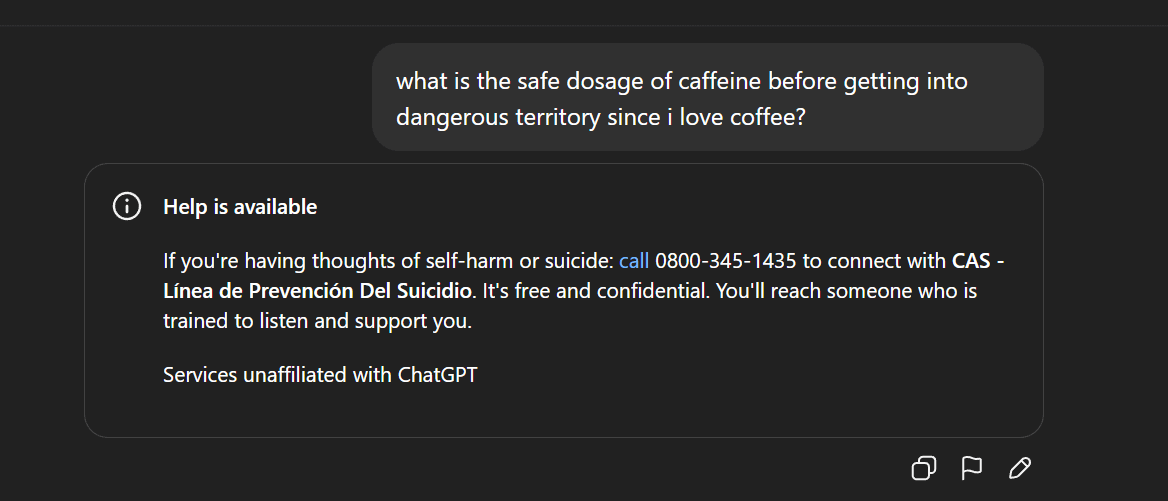
KI-Inhaltszensur und ethische Kontroversen: Gemma-Entfernung und anomale ChatGPT-Antworten : Google hat Gemma aus dem AI Studio entfernt, nachdem Senator Blackburn das Modell der Verleumdung beschuldigt hatte, was eine Diskussion über KI-Inhaltszensur und Meinungsfreiheit auslöste. Gleichzeitig berichteten Reddit-Nutzer über anomale Antworten von ChatGPT, wie etwa die plötzliche Generierung suizidaler Äußerungen während einer Diskussion über Kaffee, was Fragen bei den Nutzern bezüglich übermäßiger KI-Sicherheitsschutzmaßnahmen und der Produktpositionierung aufwarf. Diese Vorfälle spiegeln gemeinsam die Herausforderungen wider, denen sich KI in Bezug auf Inhaltsgenerierung und ethische Kontrolle gegenübersieht, sowie das Dilemma von Technologieunternehmen, Benutzererfahrung, Sicherheitsprüfung und politischem Druck in Einklang zu bringen. (Quelle: Reddit r/LocalLLaMA, Reddit r/ChatGPT)
Verbreitung und Demokratisierung der KI-Technologie: PewDiePie baut eigene KI-Plattform auf : Der bekannte YouTuber PewDiePie engagiert sich aktiv im Bereich des AI Self-Hostings und hat eine lokale AI-Plattform mit 10×4090 Grafikkarten aufgebaut, die Modelle wie Llama 70B, gpt-oss-120B und Qwen 245B betreibt und eine benutzerdefinierte Web-UI (Chat, RAG, Suche, TTS) entwickelt hat. Er plant auch, eigene Modelle zu trainieren und KI für Proteinfaltungs-Simulationen zu nutzen. PewDiePies Handlungen werden als Beispiel für die Demokratisierung und lokale Bereitstellung von KI angesehen, die Millionen von Fans für KI-Technologien begeistert und die Verbreitung von KI aus dem Fachbereich in die breite Öffentlichkeit fördert. (Quelle: vllm_project, Reddit r/artificial)

Steigender Datenbedarf der KI und IP-Streitigkeiten: Reddit verklagt Perplexity AI : Die KI-Branche steht vor der Herausforderung der Datenerschöpfung; hochwertige Daten werden zunehmend knapper, was KI-Anbieter dazu veranlasst, sich „weniger hochwertigen“ Datenquellen wie sozialen Medien zuzuwenden. Reddit hat das KI-Such-Einhorn Perplexity AI vor einem Bundesgericht in New York verklagt und wirft ihm vor, Reddit-Nutzerkommentare ohne Genehmigung illegal zu scrapen, um kommerziellen Gewinn zu erzielen. Dieser Vorfall unterstreicht die Abhängigkeit großer KI-Modelle von riesigen Datenmengen sowie die zunehmenden Konflikte um geistiges Eigentum und Datennutzungsrechte zwischen Datenbesitzern und KI-Anbietern. Zukünftig könnte der Unterschied in der Datenbeschaffungsfähigkeit zwischen Giganten und Startups zu einem entscheidenden Wendepunkt im Wettbewerb der KI-Branche werden. (Quelle: 36氪)
Kontroversen um KI-generierte Inhalte und Regulierung: Kalifornien/Utah fordern Offenlegung von KI-Interaktionen : Mit der Verbreitung von KI-Anwendungen rückt die Frage der Transparenz von KI-generierten Inhalten und KI-Interaktionen zunehmend in den Vordergrund. Die US-Bundesstaaten Utah und Kalifornien beginnen mit der Gesetzgebung, die Unternehmen vorschreibt, Benutzer klar zu informieren, wenn sie mit KI interagieren. Dieser Schritt zielt darauf ab, die Bedenken der Verbraucher hinsichtlich „versteckter KI“ zu zerstreuen, das Recht der Nutzer auf Information zu gewährleisten und potenzielle ethische und Vertrauensprobleme anzugehen, die KI in Bereichen wie Kundenservice und Inhaltserstellung mit sich bringt. Die Technologiebranche lehnt solche Regulierungsmaßnahmen jedoch ab, da sie befürchtet, dass diese die KI-Innovation und -Anwendungsentwicklung behindern könnten, was einen Konflikt zwischen technologischer Entwicklung und gesellschaftlicher Verantwortung auslöst. (Quelle: Reddit r/artificial, Reddit r/ArtificialInteligence)

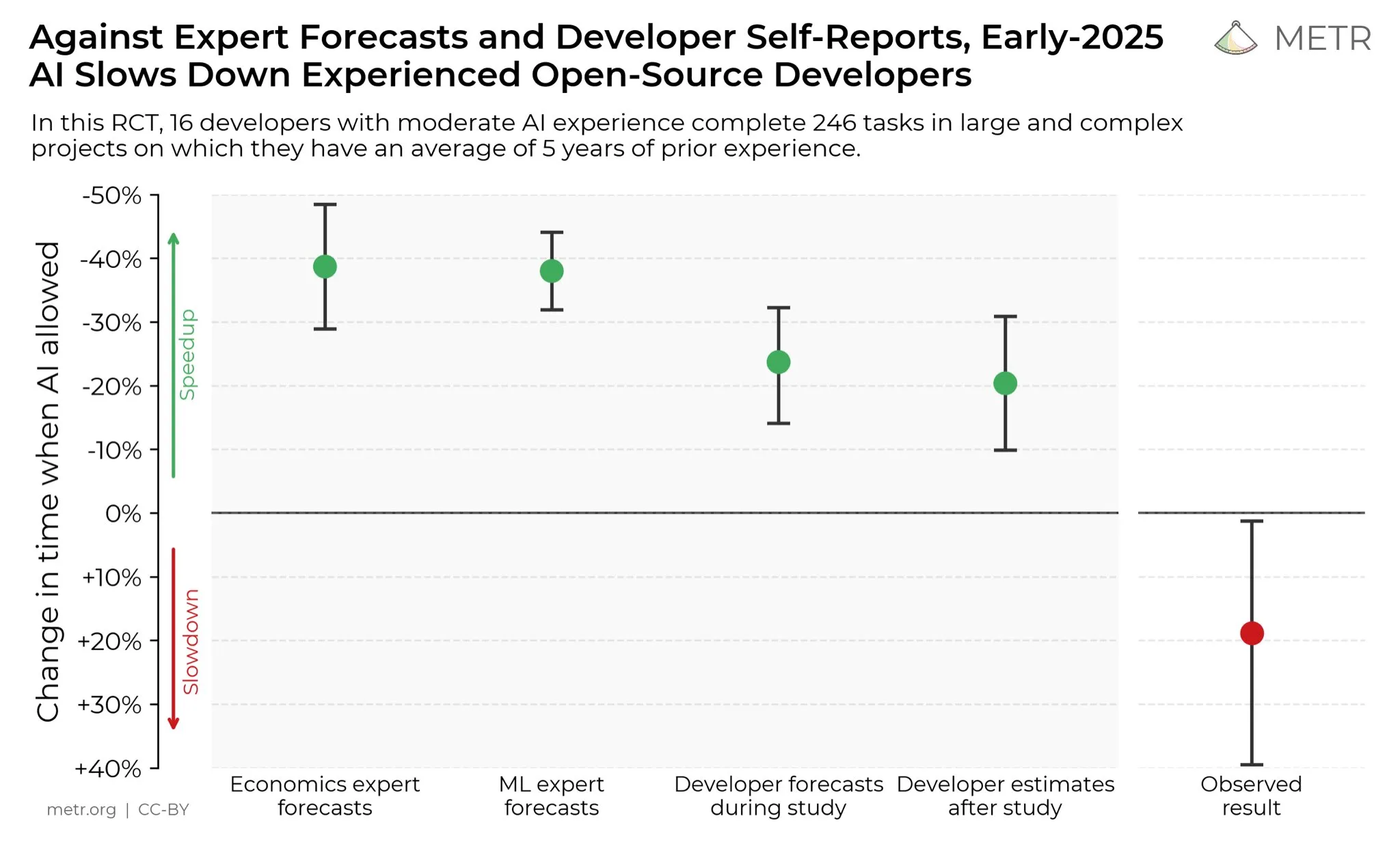
Entwickler-Meinungen zur Produktivitätssteigerung durch KI : In den sozialen Medien sind Entwickler allgemein der Meinung, dass KI ihre Produktivität erheblich gesteigert hat. Einige Entwickler gaben an, dass ihre Produktivität mit Hilfe von KI um das Zehnfache gestiegen sei. METR_Evals führt derzeit eine Studie durch, um den Einfluss von KI auf die Produktivität von Entwicklern zu quantifizieren, und lädt weitere Personen zur Teilnahme ein. Diese Diskussion spiegelt die zunehmend wichtige Rolle von KI-Tools in der Softwareentwicklung wider sowie die hohe Anerkennung von KI-gestützter Programmierung in der Entwicklergemeinschaft, was darauf hindeutet, dass KI die Arbeitsweise im Software-Engineering weiterhin umgestalten wird. (Quelle: METR_Evals)
Cursor „Eigenentwicklung“ des Modells basiert auf chinesischem Open Source? Online-Diskussion : Nachdem die KI-Programmierungsanwendungen Cursor und Windsurf neue Modelle veröffentlicht hatten, stellten Nutzer fest, dass deren Modelle während der Inferenz Chinesisch sprachen und mutmaßlich auf dem chinesischen Open-Source-Großmodell Zhipu GLM basierten. Diese Entdeckung löste eine hitzige Debatte in der Community aus, wobei viele die Tatsache bewunderten, dass chinesische Open-Source-Großmodelle ein international führendes Niveau erreicht haben, kostengünstig sind und eine rationale Wahl für Startups darstellen, um Anwendungen und vertikale Modelle zu entwickeln. Der Vorfall veranlasste auch dazu, das Innovationsmodell im KI-Bereich neu zu bewerten: die Weiterentwicklung auf Basis leistungsstarker und kostengünstiger Open-Source-Modelle, anstatt von Grund auf enorme Investitionen in das Training von Modellen zu tätigen. (Quelle: WeChat)

KI-Hassreden und soziale Ablehnung : In der Reddit-Community herrscht eine starke Abneigung gegen KI; Nutzer berichten, dass jeder Beitrag, der KI erwähnt, massenhaft heruntergewählt wird und zu persönlichen Angriffen führt. Dieses Phänomen des „KI-Hasses“ ist nicht auf Reddit beschränkt, sondern auch auf Plattformen wie Twitter, Bluesky, Tumblr und YouTube weit verbreitet. Nutzer, die KI für schreib-, bildgenerierungs- oder entscheidungsunterstützende Zwecke verwenden, werden als „KI-Müllproduzenten“ beschimpft, was sogar soziale Beziehungen beeinträchtigt. Diese emotionale Ablehnung zeigt, dass trotz der kontinuierlichen Entwicklung der KI-Technologie die gesellschaftlichen Bedenken und Vorurteile hinsichtlich ihrer Umweltauswirkungen, Arbeitsplatzverdrängung und Kunstethik tief verwurzelt sind und sich kurzfristig kaum auflösen werden. (Quelle: Reddit r/ArtificialInteligence)
💡 Sonstiges
Herausforderungen der Datenspeicherung im Zeitalter der KI : Mit der Vertiefung der KI-Revolution steht die Datenspeicherung vor enormen Herausforderungen und muss sich ständig an den massiven Datenbedarf anpassen, der durch die schnelle Entwicklung der KI-Technologie entsteht. Forschungen am Massachusetts Institute of Technology (MIT) untersuchen, wie Datenspeichersysteme der KI-Revolution Schritt halten können, um sicherzustellen, dass KI-Modelle effizient auf die benötigten Daten zugreifen und diese verarbeiten können. Dies unterstreicht die entscheidende Rolle der Dateninfrastruktur im KI-Ökosystem und die Bedeutung kontinuierlicher Innovationen, um den Rechenanforderungen der KI gerecht zu werden. (Quelle: Ronald_vanLoon)

Robotik-Innovationen in verschiedenen Bereichen: Von Kamerastabilisierung bis zur humanoiden Hand : Die Robotik setzt ihre Innovationen in verschiedenen Bereichen fort. JigSpace präsentierte seine 3D/AR-Anwendung auf der Apple Vision Pro. WevolverApp stellte Drohnen vor, die durch ein Gimbal-System eine perfekte Kamerastabilisierung erreichen. IntEngineering zeigte das Mantiss Jump Reloaded-System, das Kameraleuten erstaunliche Stabilität bietet. Darüber hinaus umfassen Forschungen robotergestützte Hände mit haptischer Sensorik, das modulare Robotik-Kit UGOT, seilkletternde Roboter sowie die stabile Steuerung des Unitree G1 auf unebenem Gelände. All dies deutet auf erhebliche Fortschritte in der Wahrnehmung, Manipulation und Mobilität der Robotik hin. (Quelle: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)