
Schlüsselwörter:KI-Modell, OCR-Technologie, KI-Infrastruktur, Großes Sprachmodell, KI-Agent, Multimodales Modell, KI-Energieverbrauchsoptimierung, Open-Source-Ökosystem für KI, DeepSeek OCR-Modell, Gemini 3 multimodale Inferenz, Emu3.5 Weltmodell, Kimi Linear Hybrid-Aufmerksamkeitsarchitektur, AgentFold Speicherfaltungstechnik
AI-Redaktionsleiter-Auswahl
🔥 Im Fokus
DeepSeek OCR-Modell: Neuer Durchbruch bei der KI-Gedächtnisleistung und Energieeffizienzoptimierung : DeepSeek hat ein OCR-Modell vorgestellt, dessen Kerninnovation in der Informationsverarbeitung und Gedächtnisspeicherung liegt. Das Modell komprimiert Textinformationen in Bildform, was den für den Betrieb erforderlichen Rechenaufwand erheblich reduziert und das wachsende CO2-Fußabdruck der KI mindern könnte. Diese Methode simuliert das menschliche Gedächtnis durch hierarchische Komprimierung, bei der unwichtige Inhalte unscharf gemacht werden, um Speicherplatz zu sparen, während gleichzeitig eine hohe Effizienz beibehalten wird. Diese Forschung hat die Aufmerksamkeit von Experten wie Andrej Karpathy erregt, die der Meinung sind, dass Bilder möglicherweise besser als Text für LLM-Eingaben geeignet sind und neue Richtungen für KI-Gedächtnis- und Agenten-Anwendungen eröffnen. (Quelle: MIT Technology Review)

Tech-Giganten investieren weiterhin massiv in KI-Infrastruktur : Tech-Giganten wie Microsoft, Meta und Google haben in ihren jüngsten Finanzberichten angekündigt, die Ausgaben für KI-Infrastruktur weiterhin erheblich zu erhöhen. Meta erwartet, dass die Kapitalausgaben in diesem Jahr 70-72 Milliarden US-Dollar erreichen und im nächsten Jahr weiter steigen werden; Microsofts Intelligent Cloud-Umsatz übertraf erstmals 30 Milliarden US-Dollar, wobei Azure und andere Cloud-Dienste um 40 % wuchsen und die KI-Kapazität voraussichtlich um 80 % steigen wird. Googles CEO Pichai betonte, dass der KI-Full-Stack-Ansatz starke Impulse liefert und kündigte die bevorstehende Veröffentlichung von Gemini 3 an. Diese Investitionen spiegeln den optimistischen Ausblick der Giganten auf zukünftige KI-Durchbrüche und ihren Entschluss wider, sich einen Marktvorsprung zu sichern. (Quelle: Wired, Reddit r/artificial)

Anthropic entdeckt begrenzte “Introspektionsfähigkeit” bei LLMs : Neueste Forschung von Anthropic zeigt, dass Large Language Models (LLMs) wie Claude eine “echte introspektive Wahrnehmung” besitzen, obwohl diese Fähigkeit derzeit noch begrenzt ist. Die Studie untersuchte, ob LLMs ihre internen Gedanken erkennen können oder lediglich plausible Antworten auf Fragen generieren. Diese Entdeckung deutet darauf hin, dass LLMs möglicherweise ein tieferes Selbstbewusstsein als erwartet haben, was für das Verständnis und die Entwicklung intelligenterer, bewussterer KI-Systeme von großer Bedeutung ist. (Quelle: Anthropic, Reddit r/artificial)

Extropic stellt neue thermodynamische Computerhardware TSU vor, verspricht Durchbruch bei KI-Energieverbrauch : Das Unternehmen Extropic hat ein völlig neues Computergerät, die TSU (Thermodynamic Sampling Unit), vorgestellt, dessen Kern “Wahrscheinlichkeits-Bits” (P-bits) sind, die mit programmierbarer Wahrscheinlichkeit zwischen 0 und 1 flackern können, um eine 10.000-fache Effizienzsteigerung beim KI-Energieverbrauch zu erreichen. Das Unternehmen hat den X0-Chip, das XTR0-Desktop-Testkit und die kommerzielle Z1-TSU veröffentlicht und die Thermol-Softwarebibliothek zur GPU-Simulation von TSU quelloffen gemacht. Obwohl die Definition der Effizienzsteigerung umstritten ist, zielt dieser Ansatz darauf ab, die enorme Lücke bei KI-Rechenleistung und Energie zu schließen und einen potenziellen Paradigmenwechsel im KI-Computing herbeizuführen. (Quelle: TheRundownAI, pmddomingos, op7418)

🎯 Trends
Google kündigt bevorstehende Veröffentlichung von Gemini 3 an, stärkt Professionalisierungstrend der KI-Modellfamilie : Googles CEO Sundar Pichai kündigte in der Telefonkonferenz zu den Geschäftszahlen an, dass die neue Flaggschiff-Modellversion Gemini 3 noch in diesem Jahr veröffentlicht wird. Er betonte, dass Googles KI-Modellfamilie sich spezialisiert: Gemini konzentriert sich auf multimodale Inferenz, Veo auf Videogenerierung, Genie auf interaktive Agenten und Nano auf geräteinterne Intelligenz. Diese Strategie zeigt, dass Google von einem einzigen Universalmodell zu einer vernetzten, für verschiedene Szenarien optimierten Systemarchitektur übergeht, um die Zuverlässigkeit zu erhöhen, Latenzzeiten zu reduzieren und Edge-Bereitstellungen zu unterstützen. (Quelle: Reddit r/ArtificialInteligence, shlomifruchter)
Sora 2 mit neuen Funktionen für benutzerdefinierte Charaktere und Videoverknüpfung, unterstützt die Erstellung langer, zusammenhängender Videos : Sora 2 hat kürzlich mehrere wichtige Funktionen aktualisiert, darunter die Unterstützung für die Erstellung weiterer Charaktere (echte Fotos können nicht hochgeladen werden, aber Charaktere können aus bestehenden Videopersonen erstellt werden). Benutzer können diese Funktion nutzen, um die Konsistenz der Charaktere zu gewährleisten, was für die Erstellung langer, zusammenhängender Videos entscheidend ist. Darüber hinaus unterstützt die Entwurfsseite das Veröffentlichen mehrerer verknüpfter Videos, und die Suchseite wurde um eine Rangliste erweitert, die Live-Action-Shows und Content-Creator für Zweitkreationen anzeigt. Diese Updates verbessern die kreative Flexibilität und Benutzerinteraktion von Sora 2 erheblich und dürften die täglichen aktiven Benutzerzahlen stark erhöhen. (Quelle: op7418, billpeeb, op7418)
BAAI veröffentlicht Open-Source multimodales Weltmodell Emu3.5, übertrifft Gemini-2.5-Flash-Image in der Leistung : Das Beijing Academy of Artificial Intelligence (BAAI) hat das Open-Source multimodale Weltmodell Emu3.5 mit 34 Milliarden Parametern veröffentlicht. Das Modell basiert auf einem Decoder-only Transformer-Framework und kann gleichzeitig Bild-, Text- und Videoaufgaben verarbeiten, die zu einer nächsten State-Vorhersageaufgabe vereinheitlicht werden. Emu3.5 wurde auf riesigen Mengen von Internet-Videodaten vortrainiert und besitzt die Fähigkeit, räumlich-zeitliche Kontinuität und Kausalität zu verstehen. Es zeigt hervorragende Leistungen in den Bereichen visuelles Storytelling, visuelle Führung, Bildbearbeitung, Welterkundung und verkörperte Operationen, insbesondere mit einer signifikanten Verbesserung der physikalischen Realität, und erreicht oder übertrifft die Leistung von Gemini-2.5-Flash-Image (Nano Banana). (Quelle: 36氪)

Moonshot AI veröffentlicht Kimi Linear Modell mit hybrider linearer Aufmerksamkeitsarchitektur : Moonshot AI hat das Kimi Linear Modell vorgestellt, ein 48B-Parameter-Modell mit 3B aktivierten Parametern, das auf einer hybriden linearen Aufmerksamkeitsarchitektur (KDA) basiert und eine Kontextlänge von 1M unterstützt. Durch die Optimierung von Gated DeltaNet verbessert Kimi Linear die Leistung und Hardwareeffizienz bei langen Kontextaufgaben erheblich, reduziert den KV-Cache-Bedarf um bis zu 75 % und erhöht den Dekodierungsdurchsatz um das Sechsfache. Das Modell zeigte in mehreren Benchmarks hervorragende Leistungen, übertraf herkömmliche Full-Attention-Modelle und wurde in zwei Versionen auf Hugging Face quelloffen veröffentlicht. (Quelle: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, bigeagle_xd)

MiniMax M2 Modell hält an Full-Attention-Architektur fest, betont Herausforderungen bei der Produktionsbereitstellung : Haohai Sun, Leiter des Vortrainings bei MiniMax M2, erklärte, warum das M2-Modell weiterhin eine Full-Attention-Architektur anstelle von linearer oder spärlicher Attention verwendet. Er wies darauf hin, dass effiziente Attention zwar theoretisch Rechenleistung sparen kann, ihre Leistung, Geschwindigkeit und Kosten in realen industriellen Systemen jedoch schwer die von Full Attention übertreffen können. Die Hauptengpässe liegen in den Einschränkungen der Bewertungssysteme, den hohen Experimentalkosten für komplexe Inferenzaufgaben und der Unreife der Infrastruktur. MiniMax ist der Ansicht, dass bei der Verfolgung langer Kontextfähigkeiten die Optimierung von Datenqualität, Bewertungssystem und Infrastruktur entscheidender ist als eine bloße Änderung der Attention-Architektur. (Quelle: Reddit r/LocalLLaMA, ClementDelangue)
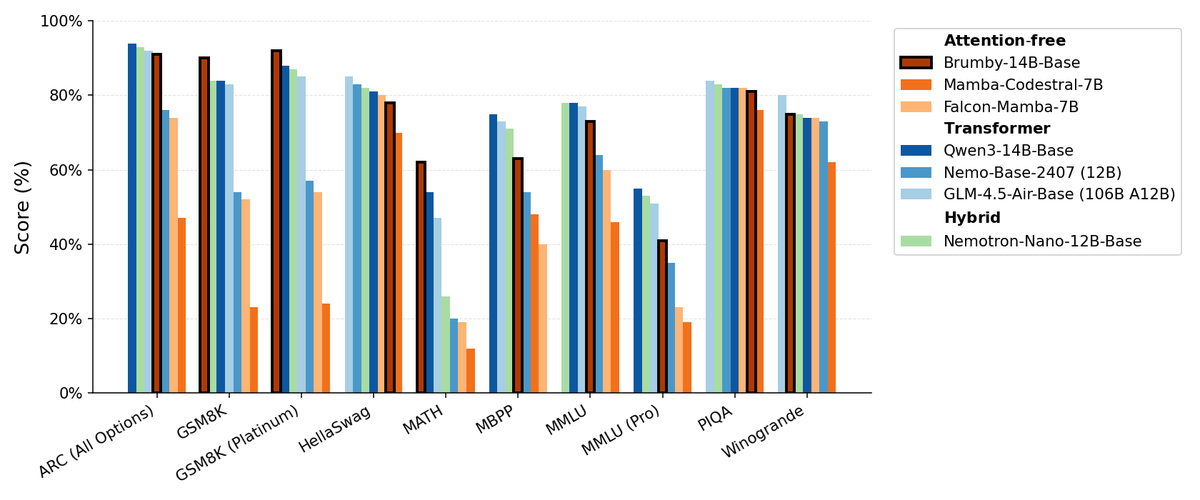
Manifest AI veröffentlicht Brumby-14B-Base, erforscht aufmerksamkeitsfreie Basismodelle : Manifest AI hat Brumby-14B-Base veröffentlicht und behauptet, es sei das derzeit stärkste aufmerksamkeitsfreie Basismodell, das mit nur 4000 US-Dollar Kosten 14 Milliarden Parameter trainiert hat. Das Modell ist in seiner Leistung mit Transformer- und Hybridmodellen gleicher Größe vergleichbar, was darauf hindeutet, dass die Ära der Transformer langsam zu Ende gehen könnte. Dieser Fortschritt eröffnet neue Möglichkeiten für KI-Modellarchitekturen, insbesondere im Hinblick auf die Senkung der Trainingskosten, und stellt die Dominanz traditioneller Aufmerksamkeitsmechanismen in Frage. (Quelle: ClementDelangue, teortaxesTex)
Neue Nemotron-Modelle basierend auf Qwen3 32B optimieren LLM-Antwortqualität : NVIDIA hat Qwen3-Nemotron-32B-RLBFF veröffentlicht, ein Large Language Model, das auf Qwen/Qwen3-32B feinabgestimmt wurde, um die Qualität der von LLMs im Standard-Denkmodus generierten Antworten zu verbessern. Dieses Forschungsmodell übertrifft das ursprüngliche Qwen3-32B in Benchmarks wie Arena Hard V2, WildBench und MT Bench deutlich und zeigt eine ähnliche Leistung wie DeepSeek R1 und O3-mini, jedoch mit Inferenzkosten von weniger als 5 %, was Fortschritte in Leistung und Effizienz demonstriert. (Quelle: Reddit r/LocalLLaMA)

Mamba-Architektur weiterhin vorteilhaft bei der Verarbeitung langer Kontexte, aber paralleles Training eingeschränkt : Die Mamba-Architektur zeigt hervorragende Leistungen bei der Verarbeitung langer Kontexte (Millionen von Tokens) und vermeidet das Speicherproblem von Transformern. Ihre Hauptbeschränkung liegt jedoch in der Schwierigkeit der Parallelisierung während des Trainings, was ihre Verbreitung in größeren Anwendungen behindert. Obwohl es verschiedene lineare Mixer und Hybridarchitekturen gibt, bleibt die Herausforderung des parallelen Trainings von Mamba ein entscheidender Engpass für ihre großflächige Anwendung. (Quelle: Reddit r/MachineLearning)
NVIDIA veröffentlicht ARC, Rubin, Omniverse DSX und mehr, stärkt Führungsposition bei KI-Infrastruktur : NVIDIA hat auf der GTC-Konferenz eine Reihe wichtiger Ankündigungen gemacht, darunter NVIDIA ARC (Airborne RAN Computer) in Zusammenarbeit mit Nokia zur Entwicklung von 6G, Rubin als Supercomputer der dritten Generation im Rack-Maßstab, Omniverse DSX (ein Blueprint für virtuelles kollaboratives Design und Betrieb von Gigafactory-KI-Fabriken) sowie NVIDIA Drive Hyperion (eine standardisierte Architektur für Robotertaxis) in Zusammenarbeit mit Uber. Diese Veröffentlichungen zeigen, dass NVIDIA seine Position von einem Chiphersteller zu einem Architekten nationaler Infrastrukturen wandelt und “Made in USA” sowie den Energiewettlauf betont, um den Herausforderungen des KI- und 6G-Zeitalters zu begegnen. (Quelle: TheTuringPost, TheTuringPost)

AgentFold: Adaptives Kontextmanagement zur Steigerung der Effizienz von Web-Agenten : AgentFold stellt eine neuartige Kontext-Engineering-Technik vor, die durch “Memory Folding” die früheren Gedanken eines Agenten in strukturierte Erinnerungen komprimiert und den kognitiven Arbeitsbereich dynamisch verwaltet. Diese Methode löst das Problem der Kontextüberlastung traditioneller ReAct-Agenten und zeigte in Benchmarks wie BrowseComp hervorragende Leistungen, wobei sie große Modelle wie DeepSeek-V3.1-671B übertraf. AgentFold-30B erreicht mit einer geringeren Parameterzahl eine wettbewerbsfähige Leistung und verbessert die Entwicklungs- und Bereitstellungseffizienz von Web-Agenten erheblich. (Quelle: omarsar0)

ReCode: Vereinheitlichung von Planung und Aktion zur dynamischen Steuerung der Entscheidungsgranularität von KI-Agenten : ReCode (Recursive Code Generation) ist eine neue parameter-effiziente Fine-Tuning (PEFT)-Methode, die die Planungs- und Aktionsdarstellung von KI-Agenten vereinheitlicht, indem sie hochrangige Planung als rekursive Funktion betrachtet, die in feingranulare Aktionen zerlegt werden kann. Diese Methode erreicht SOTA-Leistung mit nur 0,02 % der Trainingsparameter und reduziert den GPU-Speicherverbrauch. ReCode ermöglicht es Agenten, sich dynamisch an unterschiedliche Entscheidungsgranularitäten anzupassen, hierarchische Entscheidungen zu lernen und übertrifft traditionelle Methoden in Effizienz und Datennutzung erheblich, was einen wichtigen Schritt zur Erreichung menschenähnlicher Schlussfolgerungen darstellt. (Quelle: dotey, ZhihuFrontier)

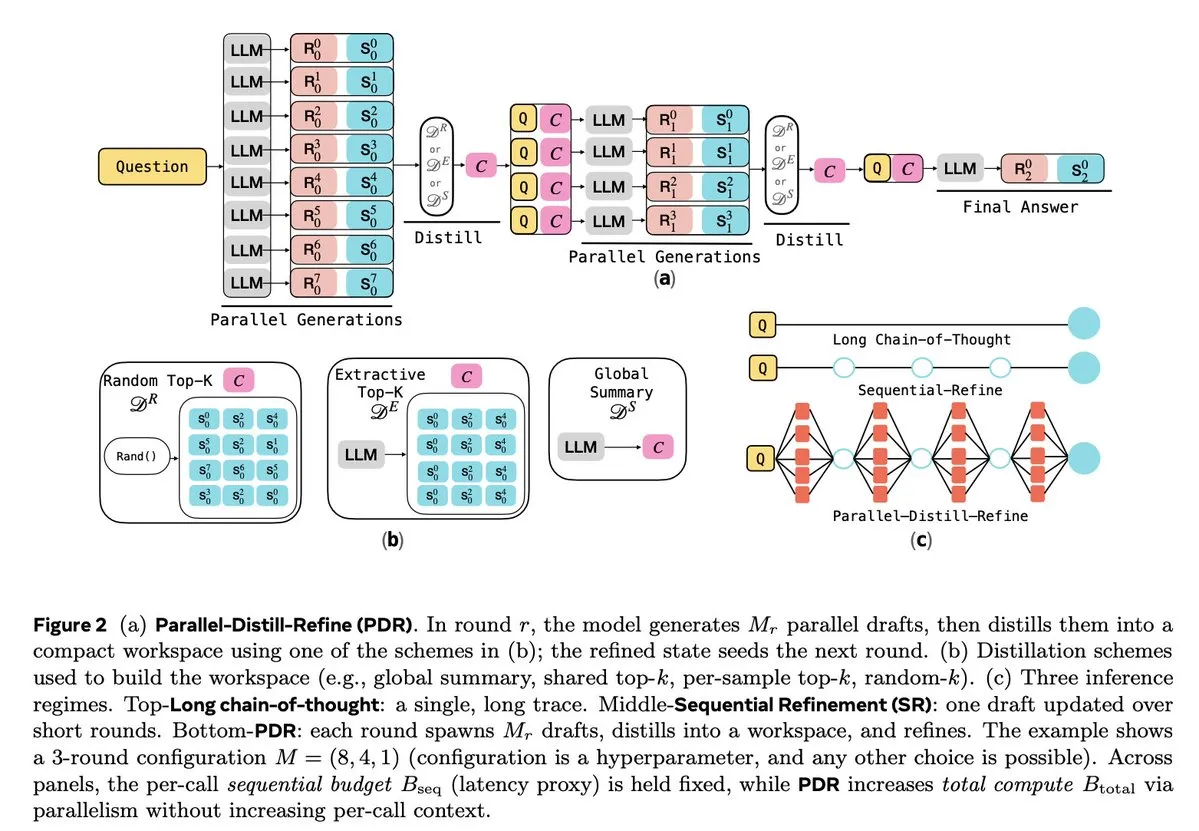
LLM-Inferenz und Reinforcement Learning Optimierung : Mehrere Studien konzentrieren sich auf die Verbesserung der Inferenz-Effizienz und Zuverlässigkeit von LLMs. Parallel-Distill-Refine (PDR) reduziert die Kosten und Latenz komplexer Inferenzaufgaben durch parallele Generierung und Verfeinerung von Entwürfen. Flawed-Aware Policy Optimization (FAPO) führt einen Belohnungs- und Bestrafungsmechanismus ein, um fehlerhafte Muster im Inferenzprozess zu korrigieren und die Zuverlässigkeit zu erhöhen. Das PairUni-Framework gleicht Verständnis- und Generierungsaufgaben multimodaler LLMs durch paarweises Training und den Pair-GPRO-Optimierungsalgorithmus aus. PM4GRPO nutzt Prozess-Mining-Techniken, um die Inferenzfähigkeiten von Policy-Modellen durch inferenzbewusstes GRPO Reinforcement Learning zu verbessern. Das Fortytwo-Protokoll erreicht durch einen verteilten Peer-Ranking-Konsens eine hervorragende Leistung bei der KI-Gruppeninferenz und eine starke Resistenz gegen adversarische Prompts. (Quelle: NandoDF, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
🧰 Tools
Tencent veröffentlicht WeKnora als Open Source: LLM-gesteuertes Framework für Dokumentenverständnis und -abruf : Tencent hat WeKnora als Open Source veröffentlicht, ein LLM-basiertes Framework für Dokumentenverständnis und semantischen Abruf, das speziell für die Verarbeitung komplexer, heterogener Dokumente entwickelt wurde. Es verwendet eine modulare Architektur, die multimodale Vorverarbeitung, semantische Vektorindizierung, intelligente Abfrage und LLM-Inferenz kombiniert. Nach dem RAG-Paradigma liefert es hochwertige, kontextsensitive Antworten durch die Kombination relevanter Dokumentenblöcke und Modellinferenz. WeKnora unterstützt verschiedene Dokumentformate, Embedding-Modelle und Abrufstrategien und bietet eine benutzerfreundliche Weboberfläche und API, unterstützt lokale Bereitstellung und private Clouds, um die Datenhoheit zu gewährleisten. (Quelle: GitHub Trending)
Jan: Open-Source Offline ChatGPT-Alternative, unterstützt lokale LLM-Ausführung : Jan ist eine Open-Source ChatGPT-Alternative, die zu 100 % offline auf dem Computer des Benutzers ausgeführt werden kann. Sie ermöglicht es Benutzern, LLMs von HuggingFace (wie Llama, Gemma, Qwen, GPT-oss usw.) herunterzuladen und auszuführen und unterstützt die Integration mit Cloud-Modellen wie OpenAI und Anthropic. Jan bietet benutzerdefinierte Assistenten, eine OpenAI-kompatible API und die Integration des Model Context Protocol (MCP), wobei der Datenschutz im Vordergrund steht, um Benutzern eine vollständig kontrollierte lokale KI-Erfahrung zu bieten. (Quelle: GitHub Trending)

Claude Code: Anthropic’s Entwickler-Toolkit und Skill-Ökosystem : Anthropic’s Claude Code steigert die Produktivität von Entwicklern erheblich durch eine Reihe von “Skills” und Agenten. Dazu gehören der Rube MCP-Konnektor (verbindet Claude mit über 500 Anwendungen), das Superpowers-Entwickler-Toolkit (bietet /brainstorm, /write-plan, /execute-plan Befehle), das Dokumenten-Suite (verarbeitet Word/Excel/PDF), Theme Factory (Automatisierung von Markenrichtlinien) und Systematic Debugging (simuliert Debugging-Prozesse erfahrener Entwickler). Diese Tools helfen Entwicklern durch modulare Gestaltung und kontextbezogene Fähigkeiten, automatisierte Workflows, Code-Reviews, Refactoring und Fehlerbehebung zu realisieren und unterstützen sogar nicht-technische Teams beim Erstellen eigener kleiner Tools. (Quelle: Reddit r/ClaudeAI, Reddit r/ClaudeAI)

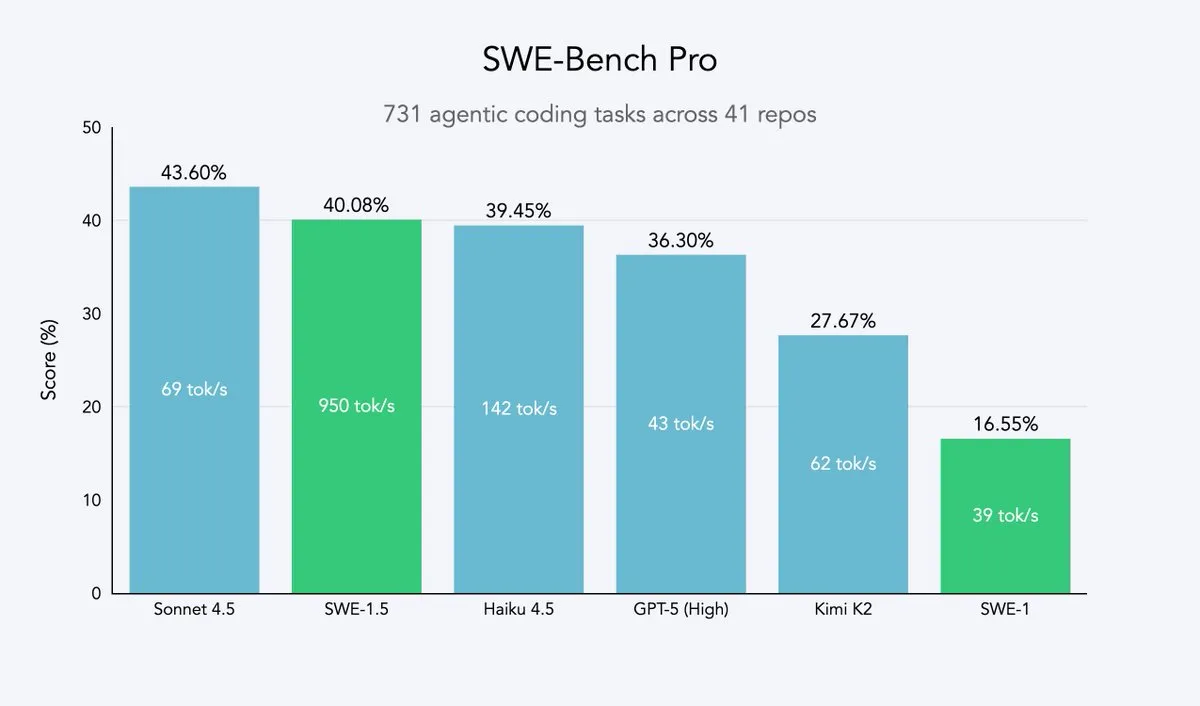
Cursor 2.0 und Windsurf: Code-Agenten streben nach Geschwindigkeit und Effizienz : Cursor und Windsurf haben Code-Agenten-Modelle und eine 2.0-Plattform veröffentlicht, die auf Geschwindigkeitsoptimierung abzielen. Ihre Strategie besteht darin, Open-Source-Großmodelle (wie Qwen3) mittels Reinforcement Learning feinabzustimmen und auf optimierter Hardware bereitzustellen, um einen Effekt von “moderater Intelligenz, aber extrem hoher Geschwindigkeit” zu erzielen. Dieser Ansatz ist für Code-Agenten-Unternehmen eine effiziente Strategie, um mit minimalem Ressourcenaufwand die Pareto-Grenze von Geschwindigkeit und Intelligenz zu erreichen. Windsurfs SWE-1.5-Modell setzt einen neuen Geschwindigkeitsstandard, während es nahezu SOTA-Codierungsleistung erzielt. (Quelle: dotey, Smol_AI, VictorTaelin, omarsar0, TheRundownAI)
Perplexity Patents: Erster KI-Patentforschungsagent, ermöglicht IP-Intelligenz für alle : Perplexity hat Perplexity Patents vorgestellt, den weltweit ersten KI-Patentforschungsagenten, der darauf abzielt, IP-Intelligenz für alle zugänglich zu machen. Dieses Tool unterstützt die Suche und Forschung über Patente hinweg, und in Zukunft wird Perplexity Scholar für die akademische Forschung eingeführt. Diese Innovation wird den Prozess der Patentrecherche und -analyse erheblich vereinfachen und Innovatoren, Anwälten und Forschern effiziente, benutzerfreundliche Dienste für geistiges Eigentum bieten. (Quelle: AravSrinivas)

Real Deep Research (RDR): KI-gesteuertes Framework für tiefgehende wissenschaftliche Forschung : Real Deep Research (RDR) ist ein KI-gesteuertes Framework, das Forschern helfen soll, mit der rasanten Entwicklung der modernen Wissenschaft Schritt zu halten. RDR überbrückt die Lücke zwischen von Experten verfassten Studien und automatisiertem Literatur-Mining, bietet skalierbare Analyseprozesse, Trendanalysen, Einblicke in bereichsübergreifende Verbindungen und generiert strukturierte, hochwertige Zusammenfassungen. Es dient als umfassendes Forschungstool, das Forschern hilft, das Gesamtbild besser zu verstehen. (Quelle: TheTuringPost)

LangSmith führt No-Code Agent Builder ein, ermöglicht nicht-technischen Teams den Bau von Agenten : LangChainAIs LangSmith hat den No-Code Agent Builder eingeführt, um die Einstiegshürde für den Bau von KI-Agenten zu senken und es auch nicht-technischen Teams zu ermöglichen, Agenten einfach zu erstellen. Dieses Tool beschleunigt die Verbreitung und Anwendung von KI-Agenten durch eine konversationelle Agenten-Bau-UX, integrierte Gedächtnisfunktionen, die Agenten helfen, sich zu erinnern und sich zu verbessern, sowie die Befähigung von nicht-technischen Teams und Entwicklern, gemeinsam Agenten zu bauen. (Quelle: LangChainAI)
Verdent integriert MiniMax-M2, steigert Codierungsfähigkeiten und Effizienz : Verdent unterstützt jetzt das MiniMax-M2-Modell und bietet Benutzern fortschrittliche Codierungsfähigkeiten, leistungsstarke Agenten und effiziente Parameteraktivierung. Durch die kostenlose Testversion von MiniMax-M2 in VS Code über Verdent können Entwickler ein intelligenteres, schnelleres und kostengünstigeres Codierungserlebnis genießen. Diese Integration bringt die leistungsstarken Fähigkeiten von MiniMax-M2 einer breiteren Entwicklergemeinschaft zugute. (Quelle: MiniMax__AI)
Base44 stellt neuen Builder vor, beschleunigt die Umwandlung von Konzepten in Anwendungen : Base44 hat einen völlig neuen Builder veröffentlicht, der eine grundlegende Veränderung seiner Arbeitsweise markiert. Der neue Builder agiert eher wie ein erfahrener Entwickler, der vor dem Bau recherchieren, Kontext aus mehreren Quellen abrufen, intelligent debuggen und fundierte architektonische Entscheidungen treffen kann. Dieses Update zielt darauf ab, die Geschwindigkeit der Umwandlung von Konzepten in funktionale Anwendungen zu verzehnfachen und die Entwicklungseffizienz erheblich zu steigern. (Quelle: MS_BASE44)
Qdrant und Confluent kooperieren, um Echtzeit-kontextsensitive KI-Agenten zu ermöglichen : Qdrant und Confluent arbeiten zusammen, um intelligenten KI-Agenten und Unternehmensanwendungen frischen, Echtzeit-Kontext über Confluent Streaming Agents und die Real-Time Context Engine bereitzustellen. Die Vektorsuchfähigkeiten von Qdrant in Kombination mit den Echtzeit-Streaming-Daten von Confluent ermöglichen es Entwicklern, ereignisgesteuerte, kontextsensitive KI-Agenten zu erstellen und zu skalieren, wodurch das volle Potenzial der agentenbasierten KI freigesetzt und die Lösungszeit sowie die Kosten in Szenarien wie der Unfallreaktion erheblich reduziert werden. (Quelle: qdrant_engine, qdrant_engine)

📚 Lernen
ICLR26 Paper Finder: LLM-basiertes KI-Paper-Suchtool : Ein Entwickler hat den ICLR26 Paper Finder erstellt, ein Tool, das Sprachmodelle als Rückgrat nutzt, um Papiere von spezifischen KI-Konferenzen zu durchsuchen. Benutzer können nach Titel, Schlüsselwörtern oder sogar Abstracts suchen, wobei die Abstracts-Suche die höchste Genauigkeit aufweist. Das Tool wird auf einem persönlichen Server und auf Hugging Face gehostet und bietet KI-Forschern eine effiziente Methode zur Literatursuche. (Quelle: Reddit r/deeplearning, Reddit r/MachineLearning)
UCLA Frühjahrskurs 2025: Reinforcement Learning für Large Language Models : Die UCLA wird im Frühjahr 2025 einen Kurs über “Reinforcement Learning for Large Language Models” anbieten, der ein breites Spektrum an RLxLLM-Themen abdeckt, darunter Grundlagen, Testzeitberechnungen, RLHF (Reinforcement Learning from Human Feedback) und RLVR (Reinforcement Learning from Verifiable Rewards). Diese neue Vorlesungsreihe bietet Forschern und Studenten die Möglichkeit, sich eingehend mit den neuesten Theorien und Praktiken des LLM-Reinforcement Learnings zu beschäftigen. (Quelle: algo_diver)
Handgezeichneter Autoencoder-Leitfaden: Grundlagen der generativen KI verstehen : ProfTomYeh hat einen detaillierten 7-Schritte-Leitfaden für handgezeichnete Autoencoder veröffentlicht, der Lesern helfen soll, dieses neuronale Netzwerk zu verstehen, das eine Schlüsselrolle bei der Komprimierung, Entrauschung und dem Lernen reichhaltiger Datenrepräsentationen spielt. Autoencoder sind die Grundlage vieler moderner generativer Architekturen. Dieser Leitfaden erklärt auf intuitive Weise, wie sie Informationen kodieren und dekodieren, und ist eine wertvolle Ressource zum Erlernen der Kernkonzepte der generativen KI. (Quelle: ProfTomYeh)
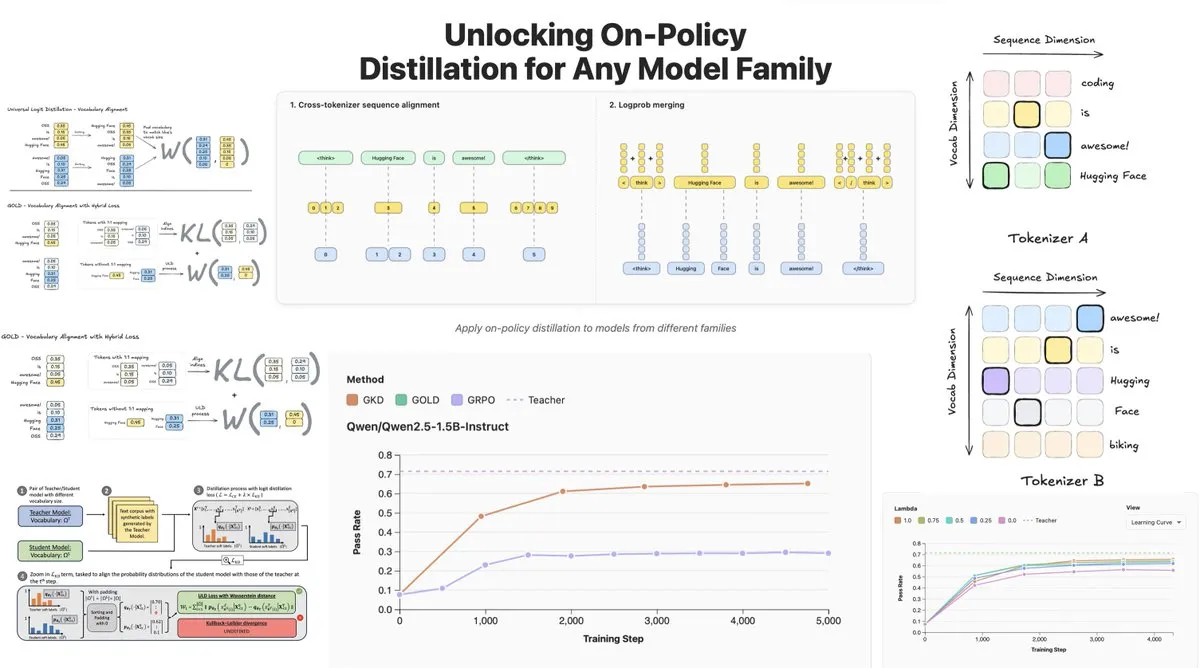
Hugging Face veröffentlicht On-Policy Logit Distillation, unterstützt modellübergreifende Destillation : Hugging Face hat General On-Policy Logit Distillation (GOLD) eingeführt, eine Erweiterung der Policy-Destillationsmethoden, die es ermöglicht, jedes Lehrermodell auf jedes Schülermodell zu destillieren, selbst wenn deren Tokenizer unterschiedlich sind. Diese Technologie wurde in die TRL-Bibliothek integriert und erlaubt Entwicklern, beliebige Modellpaare aus dem Hub zur Destillation auszuwählen, was eine enorme Flexibilität und Leistungsrückgewinnung für das Post-Training von LLMs bietet, insbesondere bei der Lösung des Problems des allgemeinen Leistungsabfalls nach dem Fine-Tuning in spezifischen Domänen. (Quelle: clefourrier, winglian, _lewtun)
Lumi: Google DeepMind nutzt Gemini 2.5 zur Unterstützung beim Lesen von arXiv-Papieren : Das PAIR-Team von Google DeepMind hat Lumi veröffentlicht, ein Tool, das das große Modell Gemini 2.5 nutzt, um das Lesen von arXiv-Papieren zu unterstützen. Lumi kann Zusammenfassungen, Referenzen und Inline-Fragen und -Antworten zu Papieren hinzufügen, um Forschern ein intelligenteres und effizienteres Lesen zu ermöglichen und die Effizienz beim Verständnis wissenschaftlicher Literatur zu verbessern. (Quelle: GoogleDeepMind)
💼 Business
KI treibt Rekordumsätze bei Tech-Giganten an, Microsoft und Google mit glänzenden Quartalszahlen : Googles Muttergesellschaft Alphabet und Microsoft haben in ihren jüngsten Finanzberichten Meilensteine erreicht, wobei KI der zentrale Wachstumsmotor ist. Alphabet überschritt erstmals einen Quartalsumsatz von 100 Milliarden US-Dollar und erreichte 102,3 Milliarden US-Dollar, Google Cloud wuchs um 34 %, und 70 % der bestehenden Kunden nutzen KI-Produkte. Microsofts Umsatz stieg um 18 % auf 77,7 Milliarden US-Dollar, die Intelligent Cloud-Einnahmen überstiegen erstmals 30 Milliarden US-Dollar, und die Azure Cloud-Dienste wuchsen um 40 %, angetrieben durch KI. Beide Unternehmen planen, die KI-Kapitalausgaben erheblich zu erhöhen, um ihre Führungsposition im KI-Bereich zu festigen und die Anerkennung des Kapitalmarktes zu gewinnen. (Quelle: 36氪, Yuchenj_UW)

Block CTO: AI Agent Goose automatisiert 60 % komplexer Aufgaben, Codequalität nicht direkt mit Produkterfolg verbunden : Dhanji R. Prasanna, CTO von Block (ehemals Square), teilte mit, wie das Unternehmen durch das Open-Source AI Agent Framework “Goose” innerhalb von 8 Wochen 12.000 Mitarbeitern wöchentlich 8-10 Stunden Arbeitszeit einsparen konnte. Goose basiert auf dem Model Context Protocol (MCP), kann Unternehmens-Tools verbinden und Aufgaben wie automatisierte Code-Erstellung, Berichtsgenerierung und Datenverarbeitung erledigen. Prasanna betonte, dass KI-native Unternehmen sich als Technologieunternehmen neu positionieren und organisatorische Anpassungen vornehmen sollten. Er vertrat die kontraintuitive Ansicht, dass “Codequalität nicht direkt mit dem Produkterfolg verbunden ist”, sondern dass entscheidend sei, ob das Produkt Benutzerprobleme löst. Er ermutigte Ingenieure, KI zu nutzen, wobei erfahrene und neue Ingenieure die höchste Akzeptanz für KI-Tools zeigten. (Quelle: 36氪)

Digital-Human-Branche im Verdrängungswettbewerb, 3D-Digital-Human-Produktion verlagert sich auf Plattformen : Mit dem Aufkommen großer Modelle steht die Digital-Human-Branche vor einem Umbruch, bei dem Unternehmen ohne KI-Fähigkeiten ausscheiden. 2D-Digital Humans machen 70,1 % des Marktes aus, während 3D-Digital Humans durch technologische Iterationen und hohe GPU-Kosten begrenzt sind. Führende Unternehmen wie MoFa Technology betonen, dass 3D-Digital Humans mit den Fähigkeiten großer Modelle übereinstimmen müssen, und weisen auf die Bedeutung hochwertiger Datenakkumulation, seltener Talente und starker künstlerischer Fähigkeiten hin. Der Branchentrend zeigt, dass sich die Produktion von 3D-Digital Humans in Richtung Plattformisierung entwickelt, wobei Fortschritte in der KI-Technologie die Kosten senken und eine skalierte Anwendung ermöglichen. Unternehmen wie Yingmou Technology und Baidu haben ebenfalls 3D-Generierungsplattformen eingeführt, um Digital Humans als Infrastruktur zu nutzen und mehr Anwendungsszenarien zu ermöglichen. (Quelle: 36氪)
🌟 Community
Komplexe Wahrnehmung von KI-Emotionen und Vertrauen durch Benutzer: R2D2 im Vergleich zu ChatGPT : In sozialen Medien wird intensiv über die Unterschiede in der emotionalen Verbindung von Benutzern zu R2D2 und ChatGPT diskutiert. Benutzer empfinden R2D2 aufgrund seines einzigartigen Temperaments, seiner Loyalität und seines “pferdeähnlichen” Images als liebenswert, und es sind keine realen sozialen oder ethischen Probleme damit verbunden. ChatGPT hingegen, als “echte falsche KI”, kann aufgrund seiner Nützlichkeit, der Einschränkungen bei der Inhaltsprüfung und potenziellen Überwachungsbedenken keine ähnliche emotionale Bindung aufbauen. Dieser Vergleich zeigt, dass die Erwartungen der Benutzer an KI nicht nur Intelligenz, sondern auch eine “humanisierte” Interaktionserfahrung und die Wahrnehmung ihrer sozialen Auswirkungen umfassen. (Quelle: Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT)

Grenzen der KI-Psychotherapie und die Notwendigkeit menschlicher Intervention : Mit dem Aufkommen von KI-Psychotherapieprodukten beginnen Menschen, KI zur Bewältigung von Einsamkeit und psychischen Problemen zu nutzen. Studien zeigen, dass etwa 22 % der Generation Z im Berufsleben einen Psychologen aufgesucht haben und fast die Hälfte KI konsultiert. KI hat Vorteile bei der Informationsbereitstellung, dem Ausschluss von Faktoren und der Begleitung, kann aber die Rolle menschlicher Psychotherapeuten bei Empathie, dem “Lesen zwischen den Zeilen” und der Steuerung des Therapieverlaufs nicht ersetzen. Fälle zeigen, dass KI bei der Erkennung extremer Risiken einen manuellen “Kill Switch” benötigt und dass Menschen bei der Beurteilung der Grenze zwischen Emotion und Pathologie, der Akkumulation von Erfahrungen und der nonverbalen Kommunikation unverzichtbar sind. KI sollte hauptsächlich repetitive, unterstützende Aufgaben übernehmen und die Hemmschwelle für Hilfesuchende senken, mit dem letztendlichen Ziel, Menschen zu echten zwischenmenschlichen Beziehungen zurückzuführen. (Quelle: 36氪)

Interaktion von Senioren mit großen Modellen: “Lebensweise” definiert “Algorithmus” : Die Fudan-Universität und das Tencent SSV Time Lab haben eine einjährige Studie durchgeführt, in der 100 Senioren im Umgang mit großen Modellen geschult wurden. Die Studie ergab, dass Senioren der KI nicht ablehnend gegenüberstehen, sondern eine “pragmatische Technologieansicht” auf der Grundlage ihrer Lebenserfahrung haben. Sie interessieren sich mehr dafür, ob die Technologie in den Alltag integriert werden kann und Gesellschaft bietet, anstatt nach extremen Funktionen zu suchen. Bei der Vertrauenskalibrierung zeigten Senioren verschiedene Muster wie “begrenzte Korrektur”, “kooperative Reziprozität” und “kognitive Verfestigung”, sowie “Zögern beim Fragen” und eine “Geschlechterkluft”. Sie erwarten von großen Modellen, dass sie “Wahrsager”, “vertrauenswürdige Ärzte”, “Gesprächspartner” und “entspannende Spielzeuge” sind, d.h. eine Technologie, die sanfter versteht und näher am Alltag ist – eine “menschenverstehende” Technologie. Dies zeigt, dass der Wert der Technologie darin liegt, wie lange sie warten kann, nicht wie schnell sie läuft, und fordert, dass Technologie “symbiotisch” statt “altersgerecht” sein sollte, gemessen an den Gefühlen, dem Rhythmus und der Würde des Menschen. (Quelle: 36氪)

KI-Einfluss auf die Gesellschaft: Von Datenschutzüberwachung bis Energieverbrauch und Arbeitsplatzwandel : In sozialen Medien wird intensiv über die vielfältigen Auswirkungen von KI auf die Gesellschaft diskutiert. Benutzer befürchten, dass KI bereits durch verschiedene Anwendungen, Suchen und Kameras eine “unsichtbare Überwachung” ermöglicht, die das persönliche Verhalten vorhersagt und beeinflusst, anstatt einer Science-Fiction-artigen Robotersteuerung. Gleichzeitig führt der enorme Bedarf von KI-Rechenzentren an Energie- und Wasserressourcen zu Protesten in Gemeinden, die Stromausfälle und Wasserknappheit zur Folge haben. Darüber hinaus steigert KI die Produktivität bei der Code-Generierung und Automatisierung von Aufgaben, löst aber Diskussionen über Veränderungen in der Arbeitsplatzstruktur sowie Herausforderungen an die Qualität von KI-generiertem Code für die Produktionseffizienz aus. Diese Diskussionen spiegeln die komplexen Emotionen der Öffentlichkeit wider, die sowohl die Vorteile als auch die potenziellen Risiken der KI-Technologie betreffen. (Quelle: Reddit r/artificial, MIT Technology Review, MIT Technology Review, Ronald_vanLoon, Ronald_vanLoon)

Schnelle Entwicklung von Begriffen und Konzepten im KI-Bereich : Die Community-Diskussionen zeigen, dass sich Begriffe und Konzepte im KI-Bereich schnell entwickeln. Zum Beispiel bezieht sich “Modell trainieren/bauen” oft auf “Fine-Tuning”, während “Fine-Tuning” wiederum als eine neue Form von “Prompt/Context Engineering” angesehen wird. Diese Veränderung spiegelt die Komplexität des KI-Technologie-Stacks und den Bedarf an feineren Operationen wider. Darüber hinaus bevorzugen Entwickler bei der Abwägung von Modellgeschwindigkeit und Intelligenz “langsame, aber intelligente” Modelle, da diese zuverlässigere Ergebnisse liefern, auch wenn dies längere Wartezeiten bedeutet. (Quelle: dejavucoder, dejavucoder, dejavucoder)

KI-Open-Source-Ökosystem und proprietäre Modelle: Verschärfter Wettbewerb : In der Community wird intensiv diskutiert, dass die Lücke zwischen Open-Source-KI-Modellen und proprietären Modellen schrumpft, was geschlossene Labore zwingt, preislich wettbewerbsfähiger zu werden. Open-Source-Modelle wie MiniMax-M2 zeigen hervorragende Leistungen im AI Index und sind extrem kostengünstig. Gleichzeitig öffnen chinesische Unternehmen und Start-ups aktiv KI-Technologien, während US-Unternehmen in dieser Hinsicht relativ zurückhaltend sind. Dieser Trend deutet darauf hin, dass der KI-Bereich eine Ära einläuten wird, in der “jeder Modelle auf Open Source trainiert”, was die Demokratisierung und Innovation der KI-Technologie vorantreibt. (Quelle: ClementDelangue, huggingface, clefourrier, huggingface)
Auswirkungen von KI-generierten Inhalten auf traditionelle Industrien und ethische Herausforderungen : KI-generierte Inhalte durchdringen zunehmend traditionelle Industrien, beispielsweise durch KI-gesteuerte “Künstler”, die in Musikcharts aufsteigen, und Deepfake-Technologien, die für Betrug eingesetzt werden (wie gefälschte Huang-Renxun-Reden zur Förderung von Kryptowährungsbetrug). Diese Phänomene lösen Diskussionen über Urheberrecht, Ethik und Regulierung aus. Gleichzeitig bringt KI auch neue Produktivitätstools in Bereichen wie Code-Generierung und automatisierter Verwaltung von Social-Media-Konten mit sich, doch die Qualität und Zuverlässigkeit der generierten Inhalte erfordert weiterhin menschliche Überprüfung. Dies unterstreicht die Herausforderung, wie technologische Innovation mit sozialer Verantwortung und ethischen Normen im Zuge der KI-Verbreitung in Einklang gebracht werden kann. (Quelle: Reddit r/artificial, 36氪, jeremyphoward)

Fokus der KI-Forschungsgemeinschaft auf Datenqualität und Evaluierung : Die KI-Forschungsgemeinschaft widmet der Datenqualität eine wachsende Aufmerksamkeit als entscheidende Rolle beim Modelltraining und weist darauf hin, dass die Beschaffung hochwertiger Daten anspruchsvoller ist als das Mieten von GPUs oder das Schreiben von Code. Gleichzeitig gibt es eine breite Diskussion über die Grenzen von Bewertungsbenchmarks, da die bestehenden Benchmarks die tatsächlichen Fähigkeiten von Modellen möglicherweise nicht umfassend widerspiegeln und leicht überoptimiert werden können. Forscher fordern die Entwicklung informativerer und realistischerer Bewertungssysteme, um die gesunde Entwicklung der KI-Forschung voranzutreiben. (Quelle: code_star, code_star, clefourrier, tokenbender)

Anwendungen und Perspektiven der KI im Gesundheitswesen : KI zeigt enormes Potenzial im Gesundheitswesen, zum Beispiel hat Yunpeng Technology neue KI+Gesundheitsprodukte vorgestellt, darunter ein intelligentes Küchenlabor und ein intelligenter Kühlschrank mit einem großen KI-Gesundheitsmodell, die personalisiertes Gesundheitsmanagement bieten. Darüber hinaus bietet MONAI als KI-Toolkit für medizinische Bildgebung ein Open-Source PyTorch-Framework. KI-gesteuerte Exoskelette helfen Rollstuhlfahrern beim Stehen und Gehen, und LLM-Diagnoseagenten lernen Diagnosestrategien in virtuellen klinischen Umgebungen. Diese Fortschritte deuten darauf hin, dass KI die Gesundheitsdienste tiefgreifend verändern wird, von der täglichen Gesundheitsverwaltung bis zur unterstützenden Diagnose und Behandlung. (Quelle: 36氪, GitHub Trending, Ronald_vanLoon, Ronald_vanLoon, HuggingFace Daily Papers)
Organisationswandel und Talentbedarf im Zeitalter der KI : Mit der Verbreitung von KI stehen Unternehmen vor tiefgreifenden Veränderungen in ihrer Organisationsstruktur und ihrem Talentbedarf. Dhanji R. Prasanna, CTO von Block, betont, dass Unternehmen sich als “Technologieunternehmen” neu positionieren und von einem “General Manager-System” zu einem “funktionalen System” übergehen müssen, um den technologischen Fokus zu bündeln. KI-Tools wie Goose können die Produktivität erheblich steigern, aber hochrangige Architekturen und Designs erfordern weiterhin erfahrene Ingenieure. Bei der Rekrutierung legen Unternehmen mehr Wert auf lernorientiertes und kritisches Denken als auf bloße Fähigkeiten im Umgang mit KI-Tools. KI verwischt auch die Grenzen von Stellenprofilen, da nicht-technische Positionen beginnen, KI-Tools zu nutzen, was die Entstehung von “Mensch-Maschine-Kollektiven” fördert. (Quelle: 36氪, MIT Technology Review, NandoDF, SakanaAILabs)

💡 Sonstiges
Kontinuierliche Innovation in der multifunktionalen Robotertechnologie : Der Bereich der Robotik zeigt vielfältige Innovationen, darunter der von Kraken inspirierte Roboter SpiRobs, schwimmfähige Drohnen, der Helix-Roboter für die Paketsortierung sowie humanoide Roboter, die in der NIO-Fabrik bei der Qualitätskontrolle assistieren. Diese Fortschritte umfassen bionisches Design, Automatisierung, Mensch-Roboter-Kollaboration und Anpassungsfähigkeit an spezielle Umgebungen, was das breite Potenzial der Robotertechnologie in Industrie, Militär und alltäglichen Anwendungen vorhersagt. (Quelle: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
Vertiefung des AI Agent-Konzepts und Marktausblick : AI Agenten werden als intelligente Entitäten definiert, die wie Menschen denken und sich anpassen können und eine nahtlose Mensch-Maschine-Konversation ermöglichen. Sie gelten als Trend der zukünftigen Arbeit, und zahlreiche Tools zum Bau von AI Agenten entstehen auf dem Markt. Der Kernwert von AI Agenten liegt darin, “Produktionswerkzeuge” zu werden, die tatsächliche Aufgaben ausführen können, und nicht nur “Chat”-Hilfsmittel. Ihre Entwicklung wird die tiefgreifende Anwendung von KI in verschiedenen Bereichen vorantreiben. (Quelle: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, dotey)
KI und autonomes Fahren: Uber-Flotte setzt auf neue Nvidia-Chips, treibt Robotertaxi-Entwicklung voran : Ubers nächste Generation autonomer Fahrzeugflotten wird Nvidias neue Chips verwenden, was voraussichtlich die Kosten für Robotertaxis senken wird. Nvidias Drive Hyperion-Plattform ist eine standardisierte Architektur für “Robotertaxi-bereite” Fahrzeuge, und die Zusammenarbeit mit Uber wird die Verbreitung der autonomen Fahrtechnologie bei den Verbrauchern vorantreiben. Dies zeigt, dass die Anwendung von KI im Verkehrsbereich beschleunigt wird, um sicherere und wirtschaftlichere autonome Fahrdienste zu realisieren. (Quelle: MIT Technology Review, TheTuringPost)