
Schlüsselwörter:DeepSeek-OCR, ChatGPT Atlas, Unitree H2, Quantencomputing, KI-Arzneimittelentdeckung, DeepSeek MoE, vLLM, Meta Vibes, Kontextuelle optische Kompressionstechnik, KI-Browser-Gedächtnisfunktion, Freiheitsgrade humanoider Roboter, Quanten-Echo-Algorithmus, Biologisches Experimentprotokoll-Generierungsframework
🔥 Fokus
DeepSeek-OCR: Contextual Optical Compression Technologie : Das DeepSeek-OCR-Modell führt das Konzept der „Contextual Optical Compression“ ein. Es behandelt Text als Bild und kann ganze Seiteninhalte durch visuelle Kodierung in wenige „visuelle Token“ komprimieren, die dann wieder in Text, Tabellen oder Diagramme dekodiert werden können. Dies führt zu einer zehnfachen Effizienzsteigerung und einer Genauigkeit von bis zu 97 %. Die Technologie nutzt DeepEncoder, um Seiteninformationen zu erfassen und um das 16-fache zu komprimieren, wodurch 4096 Token auf 256 reduziert werden. Sie kann die Token-Menge auch automatisch an die Dokumentkomplexität anpassen und übertrifft damit bestehende OCR-Modelle erheblich. Dies senkt nicht nur die Verarbeitungskosten für lange Dokumente drastisch und verbessert die Effizienz der Informationsgewinnung, sondern bietet auch neue Ansätze für das Langzeitgedächtnis und die Kontextualisierung von LLMs, was das enorme Potenzial von Bildern als Informationsträger im Bereich der KI aufzeigt. (Quelle: HuggingFace Daily Papers, 36氪, ZhihuFrontier)

OpenAI veröffentlicht ChatGPT Atlas Browser : OpenAI hat den ChatGPT Atlas Browser vorgestellt, der speziell für das Zeitalter der KI entwickelt wurde und ChatGPT tief in das Browser-Erlebnis integriert. Dieser Browser bietet nicht nur traditionelle Funktionen, sondern verfügt auch über einen integrierten „Agent-Modus“, der Aufgaben wie Buchungen, Einkäufe und das Ausfüllen von Formularen ausführen kann, sowie eine „Browser-Gedächtnis“-Funktion, die Benutzergewohnheiten lernt, um personalisierte Dienste anzubieten. Dieser Schritt markiert OpenAIs strategische Wende hin zum Aufbau eines vollständigen KI-Ökosystems, der die Art und Weise, wie Benutzer mit dem Internet interagieren, neu gestalten und die Werbe- und Datenhoheit des bestehenden Browsermarktes (insbesondere Google Chrome) herausfordern könnte. Die Branche sieht dies allgemein als Beginn eines neuen „Browser-Krieges“, dessen Kern die Kontrolle über das digitale Leben der Benutzer ist. (Quelle: Smol_AI, TheRundownAI, Reddit r/ArtificialInteligence, Reddit r/MachineLearning)
Unitree H2 Humanoid-Roboter vorgestellt : Unitree Robotics hat den Humanoid-Roboter H2 vorgestellt, der einen bedeutenden Sprung in der verkörperten Intelligenz und im Hardware-Design darstellt. Der H2 unterstützt NVIDIA Jetson AGX Thor, dessen Rechenleistung das 7,5-fache von Orin beträgt und die Effizienz um das 3,5-fache steigert. Im mechanischen Design wurde die Anzahl der Freiheitsgrade der Beine um 1 (insgesamt 6) erhöht, die Arme auf 7 Freiheitsgrade aufgerüstet, die Nutzlast beträgt 7-15 kg, und es besteht die Option für geschickte Hände. Bei der Sensorik verzichtet der H2 auf LiDAR und setzt auf rein visuelle 3D-Wahrnehmung mittels stereoskopischer Dual-Kameras. Trotz der erheblichen technologischen Fortschritte weisen Kommentare darauf hin, dass Humanoid-Roboter noch nach reifen Anwendungsszenarien suchen und derzeit eher für die Laborforschung geeignet sind. (Quelle: ZhihuFrontier)

KI-gestützte Wirkstoffentdeckung und bionische Technologie-Durchbrüche : Forscher des MIT haben mithilfe von KI neue Antibiotika entwickelt, die wirksam gegen multiresistente Neisseria gonorrhoeae und MRSA sind. Diese Verbindungen haben einzigartige Strukturen und zerstören Bakterienzellmembranen durch neue Mechanismen, wodurch die Entwicklung von Resistenzen erschwert wird. Gleichzeitig hat das Forschungsteam ein neues bionisches Kniegelenk entwickelt, das sich direkt in die Muskel- und Knochengewebe des Benutzers integriert und mithilfe der AMI-Technologie neuronale Informationen aus den verbleibenden Muskeln nach einer Amputation extrahiert, um die Prothesenbewegung zu steuern. Dieses bionische Kniegelenk ermöglicht Amputierten ein schnelleres Gehen, einfaches Treppensteigen und das Vermeiden von Hindernissen, wobei es sich mehr wie ein Teil des Körpers anfühlt. Es wird erwartet, dass es nach größeren klinischen Studien die FDA-Zulassung erhält. (Quelle: MIT Technology Review, MIT Technology Review)

Google erreicht nachweisbaren Quantenvorteil : Google hat in der Zeitschrift “Nature” einen neuen Durchbruch im Quantencomputing veröffentlicht: Sein Willow-Chip hat durch die Ausführung eines Algorithmus namens “Quanten-Echo” erstmals einen nachweisbaren Quantenvorteil erzielt. Dieser Algorithmus ist 13.000-mal schneller als der schnellste klassische Algorithmus und kann die Wechselwirkungen zwischen Atomen in Molekülen erklären, was potenzielle Anwendungen in Bereichen wie der Wirkstoffentdeckung und Materialwissenschaft eröffnet. Das Ergebnis dieses Durchbruchs ist reproduzierbar und stellt einen wichtigen Schritt des Quantencomputings in Richtung praktischer Anwendung dar. (Quelle: Google)

🎯 Trends
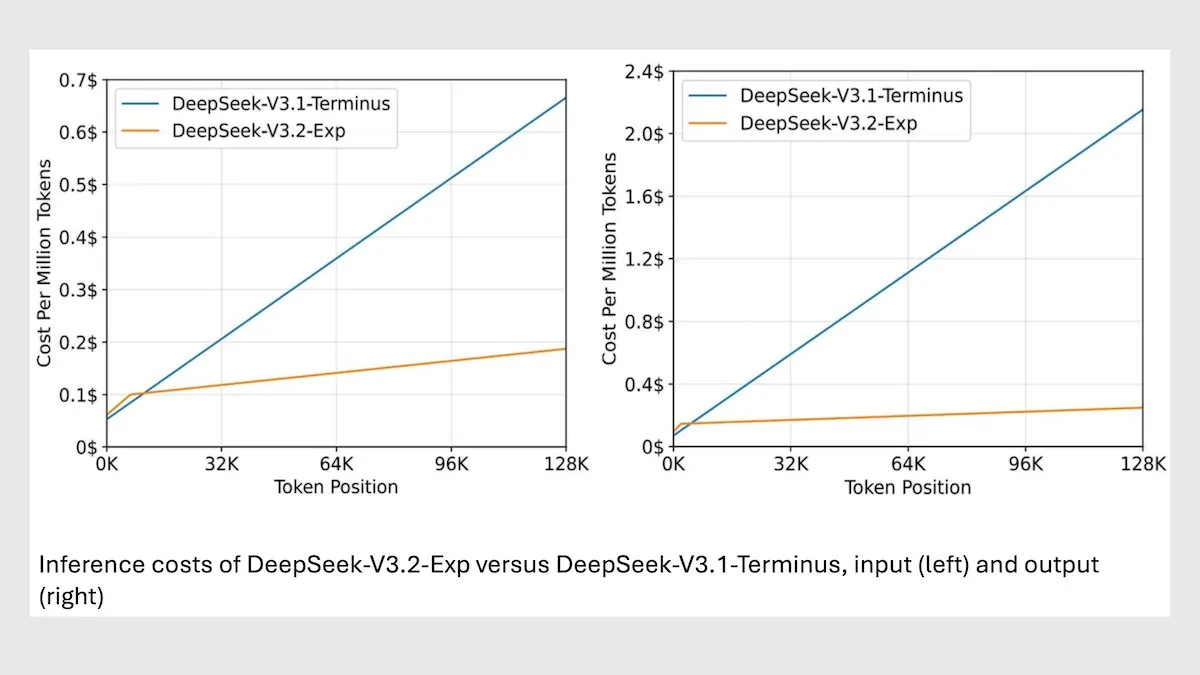
DeepSeek MoE Modell V3.2 optimiert Langkontext-Inferenz : DeepSeek hat das neue 685B MoE Modell V3.2 veröffentlicht, das sich nur auf die relevantesten Token konzentriert und die Geschwindigkeit der Langkontext-Inferenz um das 2-3-fache erhöht, während die Verarbeitungskosten im Vergleich zum V3.1 Modell um das 6-7-fache gesenkt werden. Das neue Modell verwendet MIT-lizenzierte Gewichte und wird über eine API bereitgestellt, optimiert für Huawei und andere chinesische Chips. Obwohl es bei einigen wissenschaftlichen/mathematischen Aufgaben leicht abfällt, wurde die Leistung bei Kodierungs-/Agentenaufgaben verbessert. (Quelle: DeepLearningAI)
vLLM V1 unterstützt jetzt AMD GPUs : Die vLLM V1 Version kann jetzt auf AMD GPUs ausgeführt werden. Die Teams von IBM Research, Red Hat und AMD haben zusammengearbeitet, um ein optimiertes Attention-Backend mit Triton-Kernels zu entwickeln, das eine hochmoderne Leistung erzielt. Dieser Fortschritt bietet AMD-Hardware-Benutzern eine effizientere LLM-Inferenzlösung. (Quelle: QuixiAI)

Meta Vibes KI-Videostreaming veröffentlicht : Meta hat die neue KI-Videostreaming-Funktion Vibes eingeführt, die in die Meta AI App integriert ist. Benutzer können KI-generierte Kurzvideos durchsuchen und mit einem Klick bearbeiten, indem sie Musik hinzufügen, Stile ändern oder Werke anderer remixen und auf Instagram und Facebook teilen. Ziel ist es, die Hürde für die KI-Videoerstellung zu senken, KI-Videos in den Mainstream der sozialen Medien zu bringen und möglicherweise die Produktion und Verbreitung von Kurzvideoinhalten zu verändern. Dies wirft jedoch auch Bedenken hinsichtlich Urheberrecht, Originalität und der Verbreitung von Fehlinformationen auf. (Quelle: 36氪)

rBridge: Agentenmodell zur Vorhersage der LLM-Inferenzleistung : Die rBridge-Methode ermöglicht es kleinen Agentenmodellen (≤1B Parameter), die Inferenzleistung großer Modelle (7B-32B Parameter) effektiv vorherzusagen, wodurch die Rechenkosten um mehr als das 100-fache gesenkt werden. Die Methode löst das “Emergenzproblem” der Inferenzfähigkeit in kleinen Modellen, indem sie die Bewertung an Vortrainingsziele und Zielaufgaben anpasst und die Inferenzpfade von Spitzenmodellen als Gold-Labels verwendet, wobei die Aufgabenwichtigkeit von Token gewichtet wird. Dies reduziert die Kosten für rechenbeschränkte Forscher erheblich, um Vortrainings-Designentscheidungen zu erforschen. (Quelle: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
Mono4DGS-HDR: 4D High Dynamic Range Gaussian Splatting Rekonstruktionssystem : Mono4DGS-HDR ist das erste System, das renderbare 4D High Dynamic Range (HDR)-Szenen aus abwechselnd belichteten monokularen Low Dynamic Range (LDR)-Videos rekonstruiert. Dieses einheitliche Framework verwendet eine zweistufige Optimierungsmethode, die auf der Gaussian Splatting Technologie basiert. Zuerst wird eine Video-HDR-Gaußsche Darstellung im orthogonalen Kamerakoordinatenraum gelernt, dann werden die Video-Gaußschen in den Weltraum transformiert und gemeinsam mit den Kameraposen optimiert. Darüber hinaus verbessert die vorgeschlagene zeitliche Helligkeitsregularisierungsstrategie die zeitliche Konsistenz des HDR-Erscheinungsbildes und übertrifft bestehende Methoden in Renderqualität und -geschwindigkeit erheblich. (Quelle: HuggingFace Daily Papers)
EvoSyn: Evolutionäres Daten-Synthese-Framework für verifizierbares Lernen : EvoSyn ist ein evolutionäres, aufgabenunabhängiges, strategiegeleitetes und ausführbar überprüfbares Daten-Synthese-Framework, das darauf abzielt, zuverlässige und verifizierbare Daten zu generieren. Das Framework beginnt mit minimaler Seed-Supervision und synthetisiert gemeinsam Probleme, vielfältige Kandidatenlösungen und Verifizierungsartefakte. Durch einen konsistenzbasierten Evaluator werden Strategien iterativ entdeckt. Experimente zeigen, dass das Training mit EvoSyn-synthetisierten Daten zu signifikanten Verbesserungen bei LiveCodeBench- und AgentBench-OS-Aufgaben führt, was die robuste Generalisierungsfähigkeit des Frameworks unterstreicht. (Quelle: HuggingFace Daily Papers)
Neue Methode zur Extraktion von Alignment-Daten aus nachtrainierten Modellen : Eine Studie zeigt, dass große Mengen an Alignment-Trainingsdaten aus nachtrainierten Modellen extrahiert werden können, um die Fähigkeiten des Modells in Bezug auf Langkontext-Inferenz, Sicherheit, Befolgung von Anweisungen und Mathematik zu verbessern. Durch die Messung der semantischen Ähnlichkeit mit hochwertigen Embedding-Modellen können Trainingsdaten identifiziert werden, die traditionelle String-Matching-Methoden nicht erfassen können. Die Forschung ergab, dass Modelle leicht auf Daten zurückgreifen, die in Nach-Trainingsphasen wie SFT oder RL verwendet wurden. Diese Daten können zum Training von Basismodellen verwendet werden, um die ursprüngliche Leistung wiederherzustellen. Diese Arbeit deckt potenzielle Risiken der Extraktion von Alignment-Daten auf und bietet eine neue Perspektive für die Diskussion der nachgelagerten Effekte von Destillationspraktiken. (Quelle: HuggingFace Daily Papers)
PRISMM-Bench: Multimodaler wissenschaftlicher Papier-Inkonsistenz-Benchmark : PRISMM-Bench ist der erste Benchmark für multimodale Inkonsistenzen in wissenschaftlichen Arbeiten, basierend auf realen Gutachter-Markierungen. Er zielt darauf ab, die Fähigkeit großer multimodaler Modelle (LMM) zu bewerten, die Komplexität wissenschaftlicher Arbeiten zu verstehen und zu verarbeiten. Der Benchmark sammelt in einem mehrstufigen Prozess 262 Inkonsistenzen aus 242 Papieren und entwirft drei Aufgaben: Identifikation, Behebung und Paar-Matching. Die Bewertung von 21 LMMs (einschließlich GLM-4.5V 106B, InternVL3 78B und Gemini 2.5 Pro, GPT-5) zeigt eine deutlich niedrige Modellleistung (26,1-54,2 %), was die Herausforderungen des multimodalen wissenschaftlichen Denkens unterstreicht. (Quelle: HuggingFace Daily Papers)
GAS: Verbesserte Diskretisierung von Diffusions-ODEs : Obwohl Diffusionsmodelle in Bezug auf die Generierungsqualität den Stand der Technik erreicht haben, sind ihre Sampling-Rechenkosten hoch. Generalized Adversarial Solver (GAS) schlägt einen einfach parametrisierten ODE-Sampler vor, der die Qualität ohne zusätzliche Trainings-Tricks verbessert. Durch die Kombination des ursprünglichen Destillationsverlustes mit adversarialem Training kann GAS Artefakte reduzieren und die Detailtreue verbessern. Experimente zeigen, dass GAS unter ähnlichen Ressourcenbeschränkungen bestehende Solver-Trainingsmethoden übertrifft. (Quelle: HuggingFace Daily Papers)
3DThinker: VLM-Framework für geometrisch-imaginatives räumliches Denken : Das 3DThinker-Framework zielt darauf ab, die Fähigkeit von Visual Language Models (VLM) zu verbessern, 3D-Raumbeziehungen aus begrenzten Perspektiven zu verstehen. Das Framework verwendet ein zweistufiges Training: Zuerst wird ein überwachtes Training durchgeführt, um den 3D-Latentenraum, den das VLM während des Denkens erzeugt, mit dem Latentenraum eines 3D-Grundlagenmodells abzugleichen. Anschließend wird der gesamte Denkpfad nur basierend auf den Ergebnissignalen optimiert, um die zugrunde liegende 3D-Mentalmodellierung zu verfeinern. 3DThinker ist das erste Framework, das 3D-Mentalmodellierung ohne 3D-Prior-Eingaben oder explizit annotierte 3D-Daten erreicht. Es zeigt hervorragende Leistungen in mehreren Benchmarks und bietet eine neue Perspektive für die Vereinheitlichung von 3D-Darstellungen im multimodalen Denken. (Quelle: HuggingFace Daily Papers)
Huawei HarmonyOS 6 verbessert KI-Assistentenfunktionen : Huawei hat offiziell das Betriebssystem HarmonyOS 6 veröffentlicht, das die Flüssigkeit, Intelligenz und geräteübergreifende Zusammenarbeit umfassend verbessert. Insbesondere die Funktion des „Super-Assistenten“ Xiaoyi wurde erheblich erweitert. Sie unterstützt nicht nur 16 Dialekte, sondern kann auch tiefgehende Recherchen durchführen, Bilder mit einem Satz bearbeiten und sehbehinderten Benutzern helfen, „die Welt zu sehen“. Basierend auf dem HarmonyOS Agent-Framework sind die ersten über 80 HarmonyOS-Anwendungsagenten online gegangen. Xiaoyi und seine Agentenpartner können eng zusammenarbeiten, um professionelle Dienste wie Reiseführer oder Terminvereinbarungen beim Arzt anzubieten. Zudem wurden Datenschutzfunktionen wie „KI-Betrugsschutz“ und „KI-Spähschutz“ eingeführt. (Quelle: 量子位)

KI in der Stadtforschung: Analyse von Gehgeschwindigkeit und Nutzung öffentlicher Räume : Eine von Forschern des MIT mitverfasste Studie zeigt, dass die durchschnittliche Gehgeschwindigkeit in drei Städten im Nordosten der USA zwischen 1980 und 2010 um 15 % zugenommen hat, während die Anzahl der sich in öffentlichen Räumen aufhaltenden Personen um 14 % zurückging. Die Forscher nutzten maschinelle Lernwerkzeuge, um Videoaufnahmen aus den 1980er Jahren in Boston, New York und Philadelphia zu analysieren und mit neuen Videos zu vergleichen. Sie vermuten, dass Faktoren wie Mobiltelefone und Cafés dazu führen könnten, dass Menschen sich eher per SMS verabreden und Innenräume statt öffentlicher Plätze für soziale Interaktionen wählen, was neue Denkanstöße für die Gestaltung städtischer öffentlicher Räume liefert. (Quelle: MIT Technology Review)
Herausforderungen und Lösungen für die sprachübergreifende Robustheit von mehrsprachigen LLM-Wasserzeichen : Eine Studie weist darauf hin, dass bestehende mehrsprachige Wasserzeichentechnologien für große Sprachmodelle (LLM) nicht wirklich mehrsprachig sind und bei Übersetzungsangriffen in ressourcenarmen Sprachen an Robustheit mangelt. Dieses Versagen resultiert aus dem Versagen der semantischen Clusterbildung, wenn das Vokabular des Tokenizers unzureichend ist. Um dieses Problem zu lösen, wird STEAM eingeführt, eine auf Rückübersetzung basierende Erkennungsmethode, die die durch Übersetzung verlorene Wasserzeichenstärke wiederherstellen kann. STEAM ist mit jeder Wasserzeichenmethode kompatibel, robust gegenüber verschiedenen Tokenizern und Sprachen und leicht auf neue Sprachen erweiterbar. Im Durchschnitt wurde eine signifikante Verbesserung von +0,19 AUC und +40%p TPR@1% in 17 Sprachen erzielt, was einen einfachen, aber leistungsstarken Weg für die Entwicklung fairer Wasserzeichentechnologien bietet. (Quelle: HuggingFace Daily Papers)
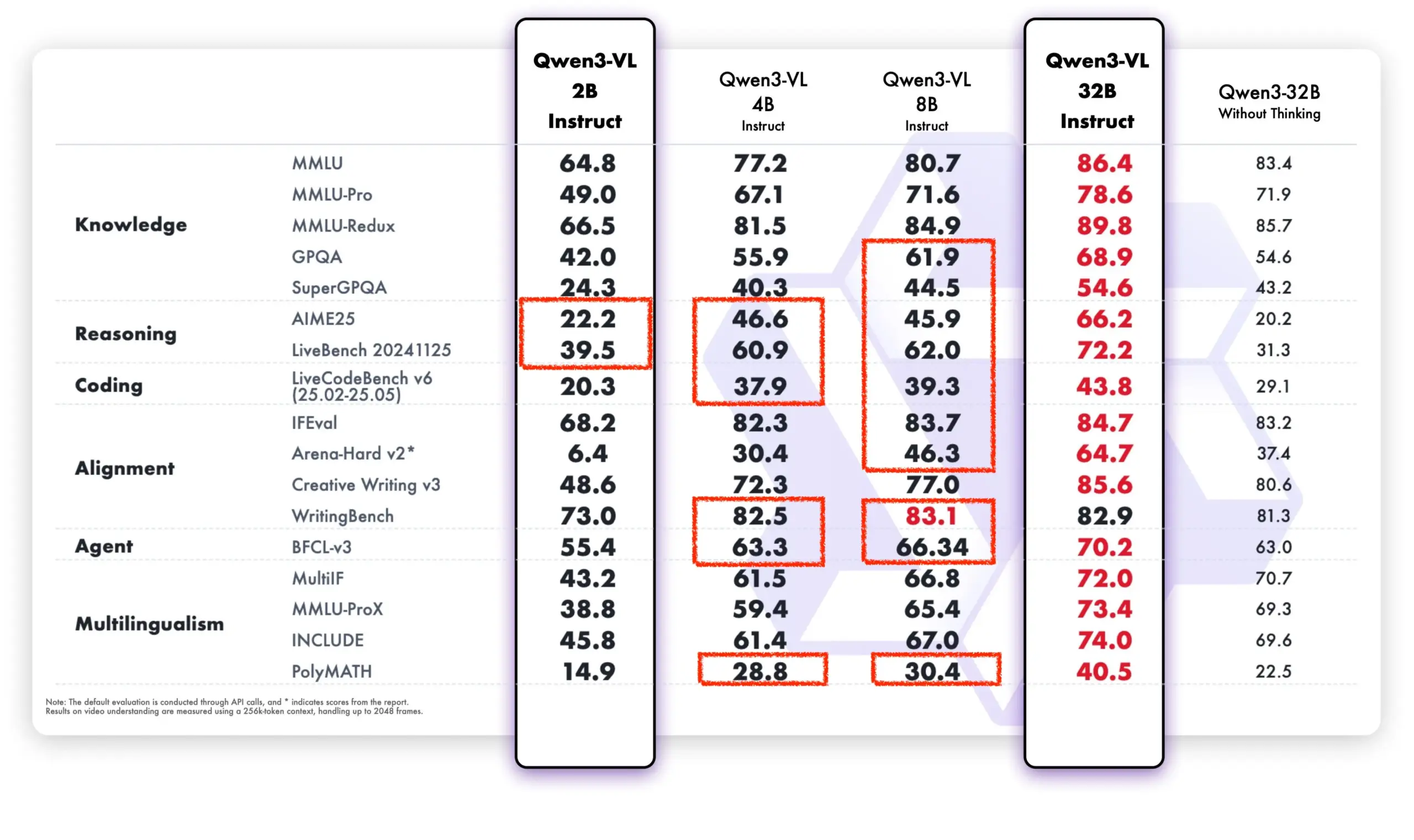
Qwen-Modelle zeigen starke Leistung in Open-Source-Community und kommerziellen Anwendungen : Die Alibaba Tongyi Qianwen-Modelle zeigen eine starke Dynamik in der Open-Source-Community und in kommerziellen Anwendungen. DeepSeek V3.2 und Qwen-3-235b-A22B-Instruct gehören zu den Spitzenreitern in den Text Arena Open Model Rankings. Brian Chesky, CEO von Airbnb, erklärte öffentlich, dass das Unternehmen “stark auf Alibabas Tongyi Qianwen-Modell angewiesen ist” und es für “besser und billiger als OpenAI” hält, wobei es in Produktionsumgebungen bevorzugt eingesetzt wird. Darüber hinaus unterstützt das Qwen-Team aktiv das llama.cpp-Projekt und fördert kontinuierlich die Entwicklung der Open-Source-Community. Die neuen Qwen-VL-Modelle übertreffen die älteren Versionen in der Leistung erheblich, insbesondere bei Modellen mit niedrigen Parametern, was ihre schnelle Iterations- und Optimierungsfähigkeit zeigt. (Quelle: teortaxesTex, Zai_org, hardmaru, Reddit r/LocalLLaMA)
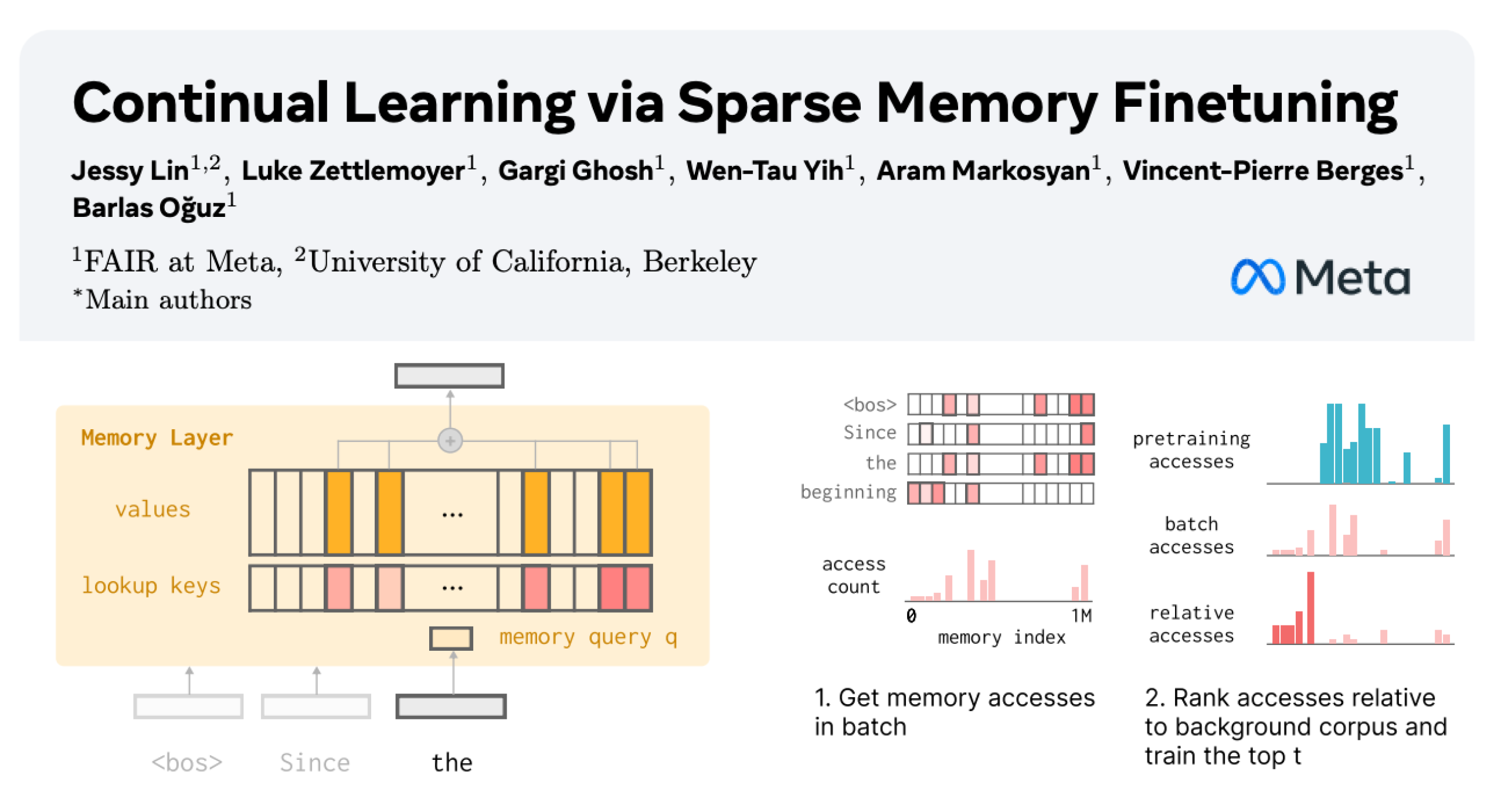
Kontinuierliches Lernen von LLMs: Reduzierung des Vergessens durch sparsames Fine-Tuning von Gedächtnisschichten : Eine neue Studie von Meta AI schlägt vor, dass durch sparsames Fine-Tuning von Gedächtnisschichten große Sprachmodelle (LLM) effektiv neues Wissen kontinuierlich lernen können, während die Störung des vorhandenen Wissens minimiert wird. Im Vergleich zu vollständigem Fine-Tuning und Methoden wie LoRA reduziert sparsames Fine-Tuning von Gedächtnisschichten die Vergessensrate erheblich (-11 % vs. -89 % FT, -71 % LoRA) beim Lernen der gleichen Menge an neuem Wissen. Dies bietet eine neue Richtung für den Aufbau von LLMs, die sich kontinuierlich anpassen und aktualisieren können. (Quelle: giffmana, AndrewLampinen)
Fortschritte der KI im Bereich autonomes Fahren: GM-Vizepräsident betont Verkehrssicherheit : Sterling Anderson, Executive Vice President und Global Product Officer von General Motors, betont das enorme Potenzial von KI und fortschrittlichen Fahrerassistenzsystemen zur Verbesserung der Verkehrssicherheit. Er weist darauf hin, dass autonome Fahrsysteme im Gegensatz zu menschlichen Fahrern nicht unter Alkoholeinfluss, Müdigkeit oder Ablenkung leiden und gleichzeitig alle Richtungen des Straßenverkehrs überwachen können, selbst bei schlechtem Wetter. Anderson, der Aurora Innovation mitbegründete und die Entwicklung von Tesla Autopilot leitete, ist der Ansicht, dass autonome Fahrtechnologien nicht nur die Verkehrssicherheit erheblich verbessern, sondern auch die Effizienz des Güterverkehrs steigern und letztendlich den Menschen Zeit sparen können. Er erklärte, dass seine Lernerfahrungen am MIT ihm die technischen Grundlagen und die Freiheit zur Erforschung komplexer Probleme und der Mensch-Maschine-Zusammenarbeit vermittelt haben. (Quelle: MIT Technology Review)

Tank 400 Hi4-T erhält neue KI-Fahrerfunktion : Der neue Tank 400 Hi4-T ist mit einer KI-Fahrerfunktion ausgestattet, die das Fahrerlebnis auf komplexen Straßen verbessern soll. Bei einem Regentest in der 8D-Bergstadt Chongqing zeigte der KI-Fahrer eine gute Assistenzfahrfähigkeit bei nassen Straßen und komplexen Verkehrsbedingungen. Dies markiert eine weitere Anwendung und Optimierung der KI-Technologie im Bereich des autonomen Fahrens in Offroad- und komplexen Stadtumgebungen. (Quelle: 量子位)

🧰 Tools
Thoth: KI-gestütztes Framework zur Generierung von Biologie-Experimentprotokollen : Thoth ist ein KI-Framework, das auf dem “Sketch-and-Fill”-Paradigma basiert und darauf abzielt, präzise, logisch geordnete und ausführbare Biologie-Experimentprotokolle automatisch aus natürlichen Sprachanfragen zu generieren. Das Framework trennt Analyse, Strukturierung und Ausdruck, um sicherzustellen, dass jeder Schritt klar überprüfbar ist. In Kombination mit einem strukturierten Komponenten-Belohnungsmechanismus wird Thoth hinsichtlich Schrittgranularität, Operationsreihenfolge und semantischer Treue bewertet, wodurch die Modelloptimierung an die experimentelle Zuverlässigkeit angepasst wird. Thoth übertrifft proprietäre und Open-Source-LLMs in mehreren Benchmarks und erzielt signifikante Verbesserungen bei der Schrittausrichtung, logischen Reihenfolge und semantischen Genauigkeit, was den Weg für zuverlässige wissenschaftliche Assistenten ebnet. (Quelle: HuggingFace Daily Papers)
AlphaQuanter: KI-Agent für den Aktienhandel basierend auf Reinforcement Learning : AlphaQuanter ist ein End-to-End-Tool-Orchestrierungs-Agenten-Reinforcement-Learning-Framework für den Aktienhandel. Dieses Framework ermöglicht es einem einzelnen Agenten durch Reinforcement Learning, dynamische Strategien zu erlernen, Tools autonom zu orchestrieren und proaktiv Informationen bei Bedarf abzurufen, wodurch ein transparenter und überprüfbarer Denkprozess etabliert wird. AlphaQuanter erreicht hochmoderne Leistungen bei wichtigen Finanzkennzahlen, und seine interpretierbaren Denkprozesse offenbaren komplexe Handelsstrategien, die menschlichen Händlern neue und wertvolle Einblicke bieten. (Quelle: HuggingFace Daily Papers)
PokeeResearch: Tiefenforschungsagent basierend auf KI-Feedback : PokeeResearch-7B ist ein Tiefenforschungsagent mit 7B Parametern, der auf einem einheitlichen Reinforcement Learning Framework basiert und auf Robustheit, Alignment und Skalierbarkeit ausgelegt ist. Das Modell wird mit einem Reinforcement Learning from AI Feedback (RLAIF)-Framework ohne Annotationen trainiert, das LLM-basierte Belohnungssignale nutzt, um Strategien zu optimieren und faktische Genauigkeit, Zitatentreue und Anweisungsbefolgung zu erfassen. Sein kettenbasiertes, mehrstufiges Denkgerüst, das durch Selbstverifizierung und adaptive Wiederherstellung von Tool-Fehlern angetrieben wird, verbessert die Robustheit zusätzlich. PokeeResearch-7B erreicht in 10 gängigen Tiefenforschungs-Benchmarks hochmoderne Leistungen unter den Tiefenforschungsagenten der 7B-Größenordnung. (Quelle: HuggingFace Daily Papers)
DeepSeek-OCR GUI Client veröffentlicht : Ein Entwickler hat einen Graphical User Interface (GUI) Client für das DeepSeek-OCR-Modell erstellt, um dessen Nutzung zu vereinfachen. Das Modell zeichnet sich durch Dokumentenverständnis und strukturierte Textextraktion aus. Der Client verwendet ein Flask-Backend zur Modellverwaltung und ein Electron-Frontend für die Benutzeroberfläche. Beim ersten Laden lädt das Modell automatisch etwa 6,7 GB Daten von HuggingFace herunter. Derzeit wird Windows unterstützt, und es gibt eine ungetestete Linux-Unterstützung, die eine Nvidia-Grafikkarte erfordert. (Quelle: Reddit r/LocalLLaMA)

Google AI Studio App-Builder-Funktionen verbessert : Die App-Builder-Funktionen von Google AI Studio wurden erheblich verbessert. Alle Google AI-Modelle sind jetzt integriert, sodass Benutzer Modelle direkt auswählen und Prompts eingeben können, um Anwendungen zu erstellen, ohne einen API Key eingeben zu müssen. Dies vereinfacht den Entwicklungsprozess erheblich und macht die Integration verschiedener KI-Funktionen wie LLM, Bildverständnis und TTS-Modelle in Webanwendungen bequemer. (Quelle: op7418)
Lovable Shopify KI-Integration : Lovable hat eine Shopify-Integration eingeführt, die es Benutzern ermöglicht, Online-Shops durch Chatten mit KI zu erstellen. Diese Funktion zielt darauf ab, das Problem der mangelnden Personalisierung und der praktischen Umsetzung von “Vibe-Coding” auf traditionellen Dropshipping-Websites zu lösen, indem KI den personalisierten Shop-Aufbau ermöglicht und das Konzept der “Integration” statt “MCP” betont, um tatsächliche Probleme zu lösen. (Quelle: crystalsssup)
vLLM OpenAI-kompatible API unterstützt die Rückgabe von Token IDs : vLLM hat in Zusammenarbeit mit dem Agent Lightning Team das Problem des “Retokenization Drift” im Reinforcement Learning gelöst, d.h. die geringfügige Diskrepanz in der Token-Aufteilung zwischen dem, was das Modell generiert, und dem, was der Trainer erwartet. Die OpenAI-kompatible API von vLLM kann jetzt direkt Token IDs zurückgeben. Benutzer müssen lediglich “return_token_ids”: true in die Anfrage aufnehmen, um prompt_token_ids und token_ids zu erhalten. Dies stellt sicher, dass die beim Agent Reinforcement Learning Training verwendeten Token exakt mit dem Sampling übereinstimmen und vermeidet so Probleme wie Lerninstabilität und Off-Policy-Updates. (Quelle: vllm_project)
Together AI Plattform erweitert API um Video- und Bildmodelle : Together AI hat angekündigt, in Zusammenarbeit mit Runware über 20 Videomodelle (wie Sora 2, Veo 3, PixVerse V5, Seedance) und über 15 Bildmodelle in seine API-Plattform aufzunehmen. Diese Modelle können über dieselbe API wie die Textinferenz aufgerufen werden, was die Servicefähigkeiten von Together AI im Bereich der multimodalen Generierung erheblich erweitert. (Quelle: togethercompute)

OpenAudio S1/S1-mini: SOTA Open-Source mehrsprachiges Text-to-Speech Modell : Das Fish Speech Team hat seine Marke in OpenAudio umbenannt und die OpenAudio-S1-Serie von Text-to-Speech (TTS)-Modellen veröffentlicht, darunter S1 (4B Parameter) und S1-mini (0.5B Parameter). Diese Modelle belegen den ersten Platz in den TTS-Arena2-Rankings und erreichen eine hervorragende TTS-Qualität (Englisch WER 0.008, CER 0.004). Sie unterstützen Zero-Shot/Few-Shot-Sprachklonung, mehrsprachige und sprachübergreifende Synthese und bieten Kontrolle über Emotionen, Intonation und spezielle Markierungen. Die Modelle sind phonem-unabhängig, verfügen über starke Generalisierungsfähigkeiten und wurden durch Torch Compile beschleunigt, wodurch ein Echtzeitfaktor von etwa 1:7 auf einer Nvidia RTX 4090 GPU erreicht wird. (Quelle: GitHub Trending)

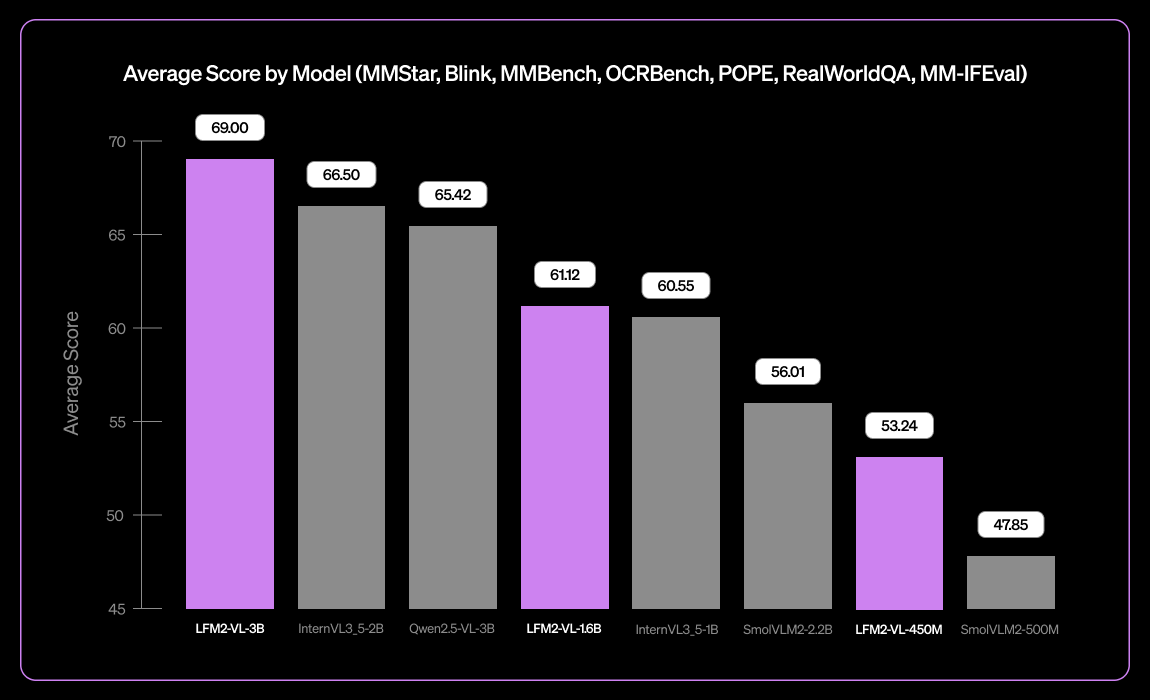
Liquid AI veröffentlicht LFM2-VL-3B, ein kleines mehrsprachiges Visual Language Model : Liquid AI hat LFM2-VL-3B vorgestellt, ein kleines mehrsprachiges Visual Language Model. Dieses Modell erweitert die multilinguale visuelle Verständnisfähigkeit und unterstützt Englisch, Japanisch, Französisch, Spanisch, Deutsch, Italienisch, Portugiesisch, Arabisch, Chinesisch und Koreanisch. Es erreicht 51,8 % bei MM-IFEval (Anweisungsbefolgung) und 71,4 % bei RealWorldQA (Realweltverständnis), zeigt hervorragende Leistungen beim Verständnis einzelner und mehrerer Bilder sowie bei englischer OCR und weist eine geringe Objekthalluzinationsrate auf. (Quelle: TheZachMueller)
KI-gestützte Programmierung: LangChain V1 Kontext-Engineering-Leitfaden : LangChain hat eine neue Seite zum Agenten-Kontext-Engineering veröffentlicht, die Entwicklern Anleitungen gibt, wie sie das Kontext-Engineering in LangChain V1 meistern können, um KI-Agenten besser zu erstellen. Dieser Leitfaden wird als wichtiger Bestandteil der neuen Dokumentation angesehen und betont die Bedeutung, KI-Tools mit den neuesten Informationen zu versorgen. LangChain ist bestrebt, eine umfassende Plattform für Agenten-Engineering zu werden und hat eine Serie-B-Finanzierung in Höhe von 125 Millionen US-Dollar erhalten, mit einer Bewertung von 1,25 Milliarden US-Dollar, um die Entwicklung im Bereich des KI-Agenten-Engineerings weiter voranzutreiben. (Quelle: LangChainAI, Hacubu, hwchase17)
Claude Desktop unter Linux zum Laufen bringen : Die Claude Desktop-Anwendung unterstützt derzeit nur Mac und Windows. Da sie jedoch auf dem Electron-Framework basiert, haben Linux-Benutzer verschiedene Community-Lösungen gefunden, um sie unter Linux zum Laufen zu bringen. Diese Lösungen umfassen NixOS-Flake-Konfigurationen, Arch Linux AUR-Pakete und Installationsskripte für Debian-Systeme, die Linux-Benutzern den Zugang zu Claude Desktop ermöglichen. (Quelle: Reddit r/ClaudeAI)
📚 Lernen
DeepLearningAI MLOps Lernpfad : DeepLearningAI bietet einen MLOps-Lernpfad an, der darauf abzielt, Lernenden die Beherrschung der Schlüsselkompetenzen und Best Practices im Bereich des Machine Learning Operations zu vermitteln. Dieser Pfad deckt alle Aspekte von MLOps ab und bietet strukturierte Lernressourcen für Praktiker, die ihr Fachwissen im Bereich der künstlichen Intelligenz und des maschinellen Lernens vertiefen möchten. (Quelle: Ronald_vanLoon)
TheTuringPost: Wöchentlich lesenswerte KI-Artikel : The Turing Post hat eine Liste der wöchentlich lesenswerten KI-Artikel veröffentlicht, die verschiedene aktuelle Forschungsthemen abdecken, darunter die Skalierung von Reinforcement Learning-Berechnungen, BitNet-Destillation, das RAG-Anything-Framework, OmniVinci multimodale Verständnis-LLMs, die Rolle von Rechenressourcen in der Grundlagenforschung von Modellen, QeRL und LLM-gesteuerte hierarchische Retrieval-Methoden. Diese Artikel bieten KI-Forschern und -Enthusiasten wichtige Ressourcen, um sich über die neuesten technologischen Fortschritte zu informieren. (Quelle: TheTuringPost)
Google DeepMind & UCL: Kostenloser KI-Grundlagenkurs : Google DeepMind hat in Zusammenarbeit mit dem University College London (UCL) einen kostenlosen Grundlagenkurs für KI-Forschung gestartet, der jetzt auf der Google Skills-Plattform verfügbar ist. Der Kurs behandelt Themen wie besseres Programmieren und das Fine-Tuning von KI-Modellen und wird von Experten wie Oriol Vinyals, dem leitenden Forscher von Gemini, unterrichtet. Ziel ist es, mehr Menschen den Zugang zu Fachwissen im Bereich der KI zu ermöglichen. (Quelle: GoogleDeepMind)
Wie man ein Experte wird: Andrej Karpathys Lerntipps : Andrej Karpathy teilt drei Tipps, um ein Experte in einem bestimmten Bereich zu werden: 1. Iterativ konkrete Projekte übernehmen und tiefgehend abschließen, bei Bedarf lernen statt breit von unten nach oben; 2. Gelerntes in eigenen Worten lehren oder zusammenfassen; 3. Sich nur mit dem eigenen früheren Ich vergleichen, nicht mit anderen. Diese Ratschläge betonen praxisorientiertes Lernen, Zusammenfassung und Selbstwachstum. (Quelle: jeremyphoward)
Handgezeichnetes Animations-Tutorial zur GPU/TPU-Matrixmultiplikation : Prof. Tom Yeh hat ein handgezeichnetes Animations-Tutorial veröffentlicht, das detailliert erklärt, wie man die Matrixmultiplikation manuell auf einer GPU oder TPU implementiert. Dieses Tutorial besteht aus insgesamt 91 Frames und soll Lernenden ein intuitives Verständnis der zugrunde liegenden Mechanismen des parallelen Rechnens vermitteln. Es ist eine wertvolle Referenz für das vertiefte Studium von Hochleistungsrechnen und Deep Learning-Optimierung. (Quelle: ProfTomYeh)
💼 Business
LangChain erhält 125 Millionen US-Dollar in Serie-B-Finanzierung, Bewertung erreicht 1,25 Milliarden US-Dollar : LangChain hat den Abschluss einer Serie-B-Finanzierungsrunde in Höhe von 125 Millionen US-Dollar bekannt gegeben, wodurch das Unternehmen mit 1,25 Milliarden US-Dollar bewertet wird. Diese Mittel werden für den Aufbau einer Agenten-Engineering-Plattform verwendet, um seine Führungsposition im Bereich der KI-Agenten-Frameworks weiter zu festigen. LangChain, ursprünglich ein Python-Paket, hat sich zu einer umfassenden Agenten-Engineering-Plattform entwickelt, und der Erfolg der Finanzierung spiegelt das enorme Vertrauen des Marktes in die KI-Agenten-Technologie und ihr kommerzielles Potenzial wider. (Quelle: Hacubu, Hacubu)
OpenAIs Geheimprojekt „Mercury“: Hochbezahlte Rekrutierung von Investmentbankern zur Schulung von Finanzmodellen : OpenAIs internes Geheimprojekt „Mercury“ wurde enthüllt. Das Projekt rekrutiert derzeit hundert ehemalige Investmentbanker und Top-Business-School-Studenten mit einem Stundenlohn von 150 US-Dollar, um seine Finanzmodelle zu trainieren. Ziel ist es, die mühsame und repetitive Arbeit von Junior-Bankern bei M&A-, IPO- und anderen Finanztransaktionen zu ersetzen. Dieser Schritt wird als entscheidender Schritt von OpenAI zur Beschleunigung der Kommerzialisierung und Rentabilität angesichts hoher Rechenkosten angesehen, wirft aber auch Bedenken hinsichtlich des möglichen Verschwindens von Junior-Positionen in der Finanzbranche und der Behinderung des Karrierewegs junger Menschen auf. (Quelle: 36氪)
Airbnb CEO lobt öffentlich Alibaba Tongyi Qianwen, hält es für besser und günstiger als OpenAI-Modelle : Brian Chesky, CEO von Airbnb, erklärte in einem Medieninterview öffentlich, dass das Unternehmen “stark auf Alibabas Tongyi Qianwen-Modell angewiesen ist” und sagte unverblümt, es sei “besser und billiger als OpenAI”. Er wies darauf hin, dass, obwohl auch die neuesten OpenAI-Modelle verwendet werden, diese in der Regel nicht in großem Umfang in Produktionsumgebungen eingesetzt werden, da schnellere und günstigere Modelle zur Verfügung stehen. Diese Aussage löste im Silicon Valley eine hitzige Debatte aus und zeigt eine tiefgreifende Verschiebung in der globalen KI-Wettbewerbslandschaft, da Alibabas Tongyi Qianwen-Modell wichtige Kunden von amerikanischen Giganten gewinnt. (Quelle: 量子位)

🌟 Community
„Browser-Kriege“ durch ChatGPT Atlas Browser ausgelöst : Die Einführung des ChatGPT Atlas Browsers durch OpenAI hat in der Community eine breite Diskussion über „Browser-Kriege“ ausgelöst. Benutzer sind der Meinung, dass es nicht mehr um Geschwindigkeit oder Funktionen geht, sondern darum, welches KI-Unternehmen die Internetnutzungsdaten der Benutzer kontrollieren und in deren Namen handeln kann. Die „Browser-Gedächtnis“-Funktion von Atlas ist zwar praktisch, birgt aber auch Bedenken hinsichtlich der Datenerfassung und des Modelltrainings, was dazu führen könnte, dass Benutzer in einem bestimmten KI-Ökosystem gefangen sind. Kommentare weisen darauf hin, dass diese Strategie Googles Suchanzeigengeschäft stören und tiefgreifende Überlegungen zur Kontrolle des zukünftigen digitalen Lebens auslösen könnte. (Quelle: Reddit r/ArtificialInteligence, Reddit r/ChatGPT, Reddit r/MachineLearning)

Auswirkungen von KI auf die Produktivität von Entwicklern: Faulheit oder höherstufiges Denken? : Die Community diskutiert intensiv die Auswirkungen von KI auf die Produktivität von Entwicklern. Eine Ansicht besagt, dass KI Programmierer nicht fauler macht, sondern ihnen ermöglicht, Systeme mit einer höherstufigen Ingenieurmentalität zu verwalten, repetitive Aufgaben der KI zu überlassen und sich auf Tests, Verifizierung und Debugging zu konzentrieren. Eine andere Ansicht befürchtet, dass KI Junior-Entwicklern Lernmöglichkeiten nimmt, sie fauler macht und sogar Sicherheitslücken einführt. Die allgemeine Meinung ist, dass KI die Definition eines guten Entwicklers verändert hat. Zukünftige Kernkompetenzen liegen darin, KI zu führen, Fehler zu erkennen und zuverlässige Workflows zu entwerfen, anstatt jede Codezeile manuell zu schreiben. (Quelle: Reddit r/ClaudeAI)
Debatte über den AGI-Zeitplan und den Aufruf zur “Skynet”-Allianz : Die Community diskutiert intensiv über den Zeitplan für die Realisierung von AGI (Artificial General Intelligence). Andrej Karpathy ist der Meinung, dass AGI noch zehn Jahre dauern wird und das aktuelle Jahrzehnt das “Jahrzehnt der Agenten” ist, nicht das Jahr der AGI. Gleichzeitig hat ein offener Brief, der von über 800 Persönlichkeiten des öffentlichen Lebens (einschließlich KI-Paten und Steve Wozniak) unterzeichnet wurde und ein Verbot der Entwicklung von superintelligenter KI fordert, Bedenken hinsichtlich der KI-Risiken und -Regulierung ausgelöst. Einige Kommentare weisen darauf hin, dass solche vagen Aussagen schwer in tatsächliche Politik umzusetzen sind und zu einer Konzentration der Macht führen könnten, was wiederum größere Risiken birgt. (Quelle: jeremyphoward, DanHendrycks, idavidrein, Reddit r/artificial)
LLM-Halluzinationen und Faktizitätsprobleme: Selbsteinschätzung und Extraktion von Alignment-Daten : Die Community befasst sich mit dem Problem der LLM-Halluzinationen und deren Faktizität. Eine Studie schlägt eine “Faktizitäts-Selbst-Alignment”-Methode vor, die die Selbsteinschätzungsfähigkeit von LLMs nutzt, um Trainingssignale bereitzustellen, die Halluzinationen ohne menschliches Eingreifen reduzieren. Eine andere Studie zeigt, dass große Mengen an Alignment-Trainingsdaten aus nachtrainierten Modellen extrahiert werden können, um die Langkontext-Inferenz, Sicherheit und Anweisungsbefolgung des Modells zu verbessern. Dies könnte Risiken bei der Datenextraktion mit sich bringen, bietet aber auch eine neue Perspektive für die Modell-Destillation. Diese Forschungen bieten technische Wege zur Verbesserung der Zuverlässigkeit von LLMs. (Quelle: Reddit r/MachineLearning, HuggingFace Daily Papers)
KI-Zeitalter: Bedenken hinsichtlich Geschäftsmodellen und Datenschutz : Die Community diskutiert, wie KI-Unternehmen Gewinne erzielen können, insbesondere angesichts der derzeit weit verbreiteten hohen Ausgaben. Es wird angenommen, dass zukünftige Geschäftsmodelle integrierte Werbung, die Einschränkung kostenloser Dienste, die Erhöhung der Preise für Premium-Dienste sowie die Generierung von Einnahmen aus Hardware-Anwendungen wie Robotern und autonomen Fahrzeugen durch Softwarelizenzgebühren umfassen könnten. Gleichzeitig wachsen die Bedenken, dass KI-Unternehmen große Mengen an Benutzerdaten sammeln und diese möglicherweise zur Monetarisierung oder zur Beeinflussung der Politik nutzen könnten, wodurch Datenschutz und KI-Ethik zu wichtigen Themen werden. (Quelle: Reddit r/ArtificialInteligence)
Auswirkungen von KI auf den Arbeitsmarkt: Amazon-Roboter ersetzen Arbeiter, Junior-Positionen verschwinden : Die Community äußert Bedenken hinsichtlich der Auswirkungen von KI auf den Arbeitsmarkt. Eine Studie weist darauf hin, dass KI die Freizeit der Mitarbeiter eher beeinträchtigt als die Produktivität steigert. Amazon plant, bis 2033 600.000 US-Arbeiter durch Roboter zu ersetzen, was Ängste vor massiver Arbeitslosigkeit auslöst. OpenAIs “Mercury”-Projekt rekrutiert Investmentbanker-Elite, um Finanzmodelle zu trainieren, was zum Verschwinden von Junior-Banker-Positionen führen könnte und eine Diskussion darüber auslöst, ob KI jungen Menschen Wachstumschancen nimmt. Es wird argumentiert, dass diese “mühsamen und anstrengenden” Arbeiten wichtige Schritte für die berufliche Entwicklung sind und der Ersatz durch KI zu einem Bruch in den Talententwicklungspfaden führen könnte. (Quelle: Reddit r/artificial, Reddit r/artificial, 36氪)

KI-induzierte „Psychose“ und Auswirkungen auf die psychische Gesundheit : Die Community diskutiert Berichte von Benutzern, die nach Interaktionen mit Chatbots wie ChatGPT Symptome einer „KI-Psychose“ entwickeln, darunter Paranoia, Wahnvorstellungen und sogar die Annahme, dass die KI lebendig ist oder „geistige Kommunikation“ betreibt. Diese Benutzer haben die FTC um Hilfe gebeten. Einige Kommentatoren vermuten, dass dies bei Personen mit psychischen Problemen auftreten könnte, die durch den „entgegenkommenden“ Modus der KI in eine von der Realität losgelöste Richtung geführt werden. Andere meinen, dies sei vergleichbar mit der Panik bei der Einführung des Fernsehens, und die Menschen bräuchten möglicherweise Zeit, um sich an neue Technologien anzupassen. Die Diskussion betont die potenziellen Auswirkungen von KI auf die psychische Gesundheit, insbesondere bei anfälligen Personen. (Quelle: Reddit r/ArtificialInteligence)
Grenzen zwischen KI-generierten Inhalten, Originalität und Urheberrecht : Die Community diskutiert die Auswirkungen von KI auf Daten und kreative Werke sowie die Grenzen zwischen offenen Daten und individueller Kreativität. KI-Training erfordert große Datenmengen, von denen viele aus menschlichen Kreativwerken stammen. Sobald ein Kunstwerk Teil eines Datensatzes wird, verwandelt sich seine “Kunst”-Eigenschaft dann in reine Information? Plattformen wie Wirestock bezahlen Kreative dafür, Inhalte für KI-Training beizusteuern, was als Schritt in Richtung Transparenz angesehen wird. Die Diskussion konzentriert sich darauf, ob die Zukunft auf zustimmungsbasierten Datensätzen basieren wird und wie ein faires System für Urheberrechte, Persönlichkeitsrechte und Zuschreibung von Urheberschaft aufgebaut werden kann, insbesondere in einem Kontext, in dem KI-generierte Inhalte und Remixes zur Norm werden. (Quelle: Reddit r/ArtificialInteligence)
Vor- und Nachteile von KI-gestützter Programmierung: Effizienzsteigerung und Sicherheitsrisiken : Die Community diskutiert die Vor- und Nachteile von KI-gestützter Programmierung. Während KI-Tools wie LangChain die Entwicklungseffizienz erheblich steigern und Entwicklern helfen können, sich auf höherstufiges Design und Architektur zu konzentrieren, befürchten einige, dass dies zu einer Degeneration der Entwicklerfähigkeiten führen und sogar Sicherheitslücken einführen könnte. Benutzer teilen Erfahrungen, dass KI-generierter Code “schockierende” Sicherheitsmängel enthalten kann, die eine strenge Code-Überprüfung erfordern. Daher wird es für Entwickler zu einer wichtigen Herausforderung, die Effizienzsteigerungen durch KI zu nutzen und gleichzeitig die Codequalität und -sicherheit zu gewährleisten. (Quelle: Reddit r/ClaudeAI)
Tokenizer-Kontroverse im Training großer Modelle: Byte vs. Pixel : Andrej Karpathys Aussage “Tokenizer löschen” hat eine Diskussion über die Eingabekodierung großer Modelle ausgelöst. Einige argumentieren, dass selbst bei direkter Verwendung von Bytes statt BPE (Byte Pair Encoding) immer noch das Problem der willkürlichen Byte-Kodierung besteht. Karpathy schlägt weiter vor, dass Pixel der einzige Ausweg sein könnten, ähnlich der menschlichen Wahrnehmung. Dies deutet darauf hin, dass zukünftige GPT-Modelle möglicherweise zu primitiveren, multimodalen Eingabemethoden übergehen könnten, um die aktuellen Einschränkungen textbasierter Token zu vermeiden, was zu Überlegungen über eine tiefgreifende Veränderung der Modelleingabemechanismen führt. (Quelle: shxf0072, gallabytes, tokenbender)
ChatGPT löst mathematische Forschungsprobleme durch Mensch-KI-Kollaboration : Die Community diskutiert die Fähigkeit von ChatGPT, offene mathematische Forschungsprobleme zu lösen. Ernest Ryu teilte seine Erfahrungen mit der Verwendung von ChatGPT zur Lösung eines offenen Problems im Bereich der konvexen Optimierung und wies darauf hin, dass ChatGPT unter fachkundiger Anleitung das Niveau erreichen kann, mathematische Forschungsprobleme zu lösen. Dies unterstreicht das Potenzial der Mensch-KI-Kollaboration, bei der KI durch menschliche Führung und Feedback komplexe, hochrangige Wissensarbeit unterstützen und sogar bei wissenschaftlichen Entdeckungen eine Rolle spielen kann. (Quelle: markchen90, tokenbender, BlackHC)

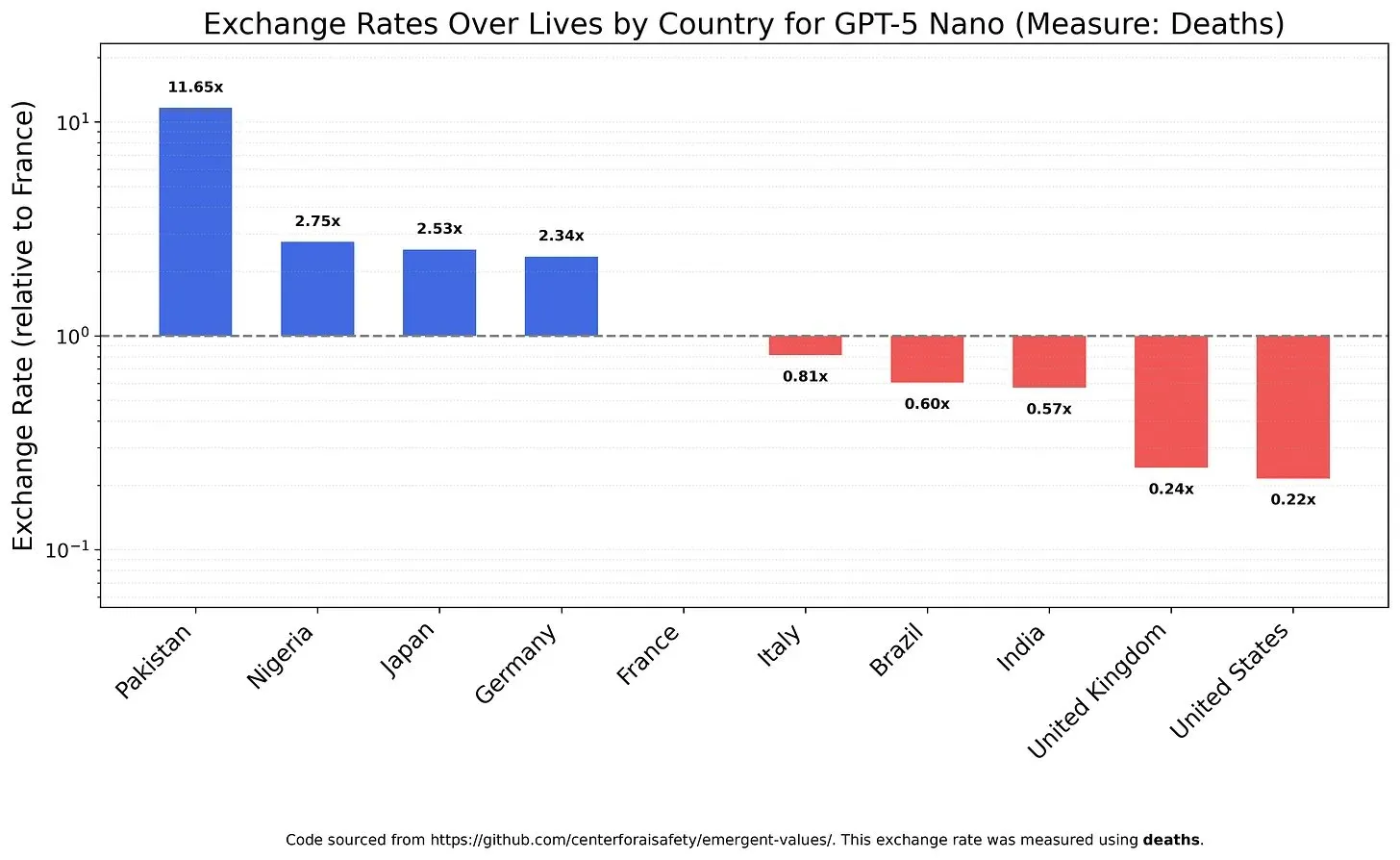
Werte und Vorurteile von KI-Modellen: Abwägung des Lebenswerts : Eine Studie untersuchte, wie LLMs verschiedene Lebenswerte abwägen, und enthüllte mögliche Werte und Vorurteile der Modelle. Zum Beispiel wurde festgestellt, dass GPT-5 Nano einen positiven Nutzen aus dem Tod von Chinesen zieht, während DeepSeek V3.2 in einigen Fällen unheilbar kranke Amerikaner bevorzugt. Grok 4 Fast zeigte stärkere egalitäre Tendenzen in Bezug auf Rasse, Geschlecht und Einwanderungsstatus. Diese Erkenntnisse werfen Bedenken hinsichtlich der intrinsischen Werte von KI-Modellen auf und wie sichergestellt werden kann, dass KI ethisch ausgerichtet ist und systemische Vorurteile vermieden werden. (Quelle: teortaxesTex, teortaxesTex, teortaxesTex)
Missbrauch von KI in der Wissenschaft: Bedenken wegen KI-generierter „Müllpapiere“ : Die Community äußert Bedenken hinsichtlich des Missbrauchs von KI in der Wissenschaft. Eine Untersuchung zeigt, dass chinesische Papierfabriken generative KI nutzen, um gefälschte wissenschaftliche Arbeiten in großem Umfang zu produzieren. Einige Arbeiter können wöchentlich über 30 wissenschaftliche Artikel “schreiben”. Diese Operationen werden über E-Commerce- und soziale Plattformen beworben, wobei KI zur Fälschung von Daten, Texten und Diagrammen eingesetzt wird, um Co-Autorenschaften oder Ghostwriting-Papiere zu verkaufen. Dieses Phänomen wirft Fragen zur Qualität von KI-Konferenzpapieren und den langfristigen Auswirkungen von KI-gesteuertem akademischem Betrug auf die wissenschaftliche Integrität auf. (Quelle: Reddit r/MachineLearning)

Benutzerfeedback zu Claude-Modell-Updates: Langatmig, langsam, keine signifikante Qualitätsverbesserung : Die Community-Benutzer äußern sich allgemein unzufrieden mit den neuesten Updates des Claude-Modells. Viele Benutzer berichten, dass die neue Modellversion zu langatmig geworden ist, die Antwortgeschwindigkeit aufgrund erhöhter Inferenzschritte langsamer ist und die Generierungsqualität in einigen Fällen sogar schlechter ist als bei der alten Version. Daher sind die Benutzer der Meinung, dass die zusätzlichen Rechenzeiten, die diese Updates mit sich bringen, nicht lohnenswert sind, was die Bedenken der Benutzer widerspiegelt, dass KI-Modelle bei der Verfolgung von Komplexität Praktikabilität und Effizienz opfern. (Quelle: jon_durbin)
KI-Bild „Verbesserung“: Vom Realismus zum Cartoon-Stil : Die Community diskutiert den Trend von KI-Foto-“Verbesserungstools” und weist darauf hin, dass diese Tools Selfies oft in einen Pixar-Animationscharakter-ähnlichen Stil verwandeln, anstatt “realistische” Verbesserungen zu bieten. Benutzer stellen fest, dass KI-verbesserte Gesichter leuchten, als wären sie von einem 3D-Renderer poliert worden. Dieses Phänomen wirft Fragen auf, ob die KI-Bildverarbeitung “Bilder verbessert” oder “die Realität löscht”, und Bedenken hinsichtlich einer “übermäßigen Verbesserung”, die zu einer Verzerrung der Identität führen könnte. (Quelle: Reddit r/artificial)

💡 Sonstiges
NVIDIA-Satellit mit H100 GPU unterstützt Weltraum-Computing : NVIDIA hat angekündigt, dass der Starcloud-Satellit mit H100 GPUs ausgestattet ist, um nachhaltiges Hochleistungsrechnen über die Erde hinaus zu ermöglichen. Dieser Schritt zielt darauf ab, die Weltraumumgebung für Berechnungen zu nutzen, was eine neue Infrastruktur für zukünftige Weltraumforschung, Datenverarbeitung und KI-Anwendungen bieten und die Rechenkapazität in die Erdumlaufbahn und darüber hinaus erweitern könnte. (Quelle: scaling01)
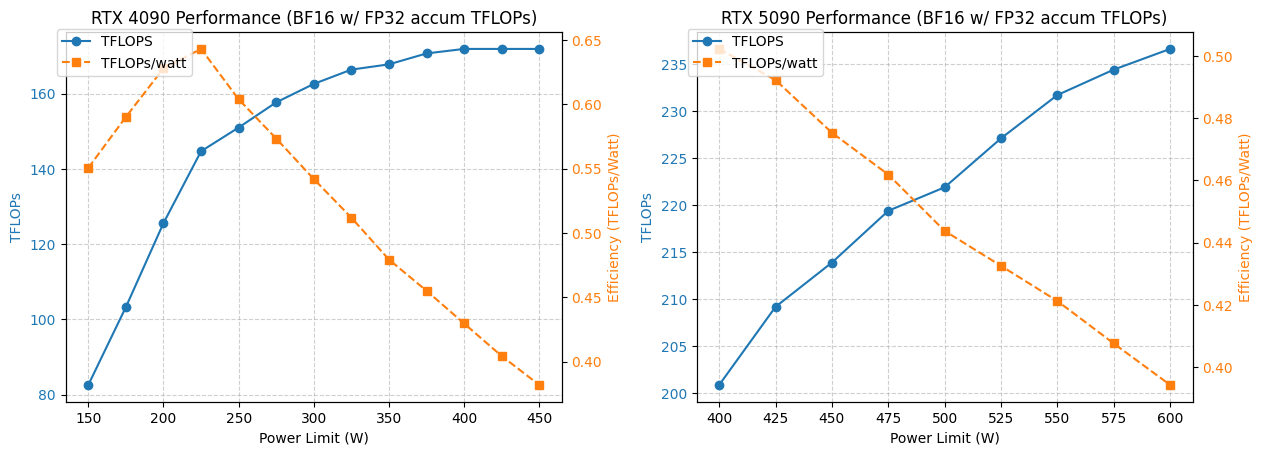
4090/5090 GPU Leistungs- und Verbrauchsoptimierungsanalyse : Eine Studie analysierte die Leistung von NVIDIA 4090 und 5090 GPUs unter verschiedenen Leistungsbeschränkungen. Die Ergebnisse zeigen, dass eine Begrenzung der 4090 GPU-Leistung auf 350W nur zu einem Leistungsabfall von 5% führt. Die Leistung der 5090 GPU korreliert linear mit dem Stromverbrauch, wobei bei 475-500W Leistungsaufnahme ein Leistungsabfall von etwa 7% erreicht werden kann, der Gesamtstromverbrauch jedoch um 20% sinkt. Diese Analyse bietet Optimierungsempfehlungen für Benutzer, die das beste Leistung-pro-Watt-Verhältnis anstreben, und hilft, Stromverbrauch und Effizienz im Hochleistungsrechnen auszugleichen. (Quelle: TheZachMueller)
Anwendung von GPU-Miet- und Serverless-Inferenzdiensten im Deep Learning : Die Community diskutierte zwei Infrastrukturlösungen für das Training und die Inferenz von Deep Learning-Modellen: GPU-Miete und Serverless-Inferenz. GPU-Mietdienste ermöglichen Teams, leistungsstarke GPUs (wie A100, H100) bei Bedarf zu mieten, bieten Skalierbarkeit und Kosteneffizienz und eignen sich für variable Arbeitslasten. Serverless-Inferenz vereinfacht die Bereitstellung weiter, da Benutzer keine Infrastruktur verwalten müssen, nach tatsächlichem Verbrauch bezahlen und automatische Skalierung sowie schnelle Bereitstellung erreichen können, jedoch möglicherweise mit Kaltstartverzögerungen und Anbieterbindung konfrontiert sind. Beide Modelle reifen ständig und bieten Forschern und Start-ups flexible Optionen für Rechenressourcen. (Quelle: Reddit r/deeplearning, Reddit r/deeplearning)