
Schlüsselwörter:Humanoider Roboter, KI-Großmodelle, Bestärkendes Lernen, Multimodale KI, KI-Agent, Figure 03 Datenengpass, GPT-5 Pro mathematischer Beweis, EmbeddingGemma RAG auf Endgeräten, GraphQA Diagrammanalyse-Dialog, NVIDIA Blackwell Inferenzleistung
🔥 FOKUS
Figure 03 auf dem Titelblatt der “TIME” Best Inventions Liste, CEO sagt: “Im Moment fehlen uns nur noch die Daten” : Brett Adcock, CEO von Figure, erklärte, dass der größte Engpass für den humanoiden Roboter Figure 03 derzeit “Daten” sind, nicht Architektur oder Rechenleistung. Er ist der Ansicht, dass Daten fast alle Probleme lösen und den Weg für den breiten Einsatz von Robotern ebnen können. Figure 03 zierte das Titelblatt der “TIME” Best Inventions Liste 2025 und löste eine Diskussion über die Bedeutung von Daten, Rechenleistung und Architektur für die Entwicklung von Robotern aus. Brett Adcock betonte, dass Figures Ziel darin besteht, Roboter menschliche Aufgaben in privaten und kommerziellen Umgebungen erledigen zu lassen, und legt großen Wert auf Robotersicherheit. Er prognostiziert, dass die Anzahl humanoider Roboter in Zukunft die der Menschen übertreffen könnte. (Quelle: 量子位)

Terence Tao fordert mit GPT-5 Pro interdisziplinär heraus! Ein seit 3 Jahren ungelöstes Problem, in 11 Minuten ein vollständiger Beweis : Der renommierte Mathematiker Terence Tao arbeitete mit GPT-5 Pro zusammen und löste in 11 Minuten ein seit drei Jahren ungelöstes Problem im Bereich der Differentialgeometrie. GPT-5 Pro führte nicht nur komplexe Berechnungen durch, sondern lieferte auch direkt einen vollständigen Beweis und half Tao sogar, seine ursprüngliche Intuition zu korrigieren. Tao fasste zusammen, dass AI bei “kleinskaligen” Problemen hervorragende Leistungen erbringt und auch bei der “großskaligen” Problemverständnis hilfreich ist, aber bei “mittelskalierten” Strategien möglicherweise falsche Intuitionen verstärken kann. Er betonte, dass AI als “Copilot” für Mathematiker dienen sollte, um die Effizienz von Experimenten zu steigern, anstatt die menschliche kreative und intuitive Arbeit vollständig zu ersetzen. (Quelle: 量子位)

🎯 AKTUELLES
Yunpeng Technology stellt neue AI+Gesundheitsprodukte vor : Yunpeng Technology hat in Zusammenarbeit mit Shuaikang und Skyworth neue AI+Gesundheitsprodukte vorgestellt, darunter ein “digitalisiertes Zukunftsküchenlabor” und einen intelligenten Kühlschrank mit einem großen AI-Gesundheitsmodell. Das große AI-Gesundheitsmodell optimiert Küchendesign und -betrieb, während der intelligente Kühlschrank über den “Gesundheitsassistenten Xiaoyun” personalisiertes Gesundheitsmanagement bietet. Dies markiert einen Durchbruch für AI im Bereich des alltäglichen Gesundheitsmanagements, indem personalisierte Gesundheitsdienste durch intelligente Geräte ermöglicht werden, was die Entwicklung der häuslichen Gesundheitstechnologie vorantreiben und die Lebensqualität der Bewohner verbessern könnte. (Quelle: 36氪)
Fortschritte bei humanoiden Robotern und Embodied AI: Vom Haushalt bis zur Industrieanwendung : Zahlreiche soziale Diskussionen zeigen die neuesten Fortschritte bei humanoiden Robotern und Embodied AI. Reachy Mini wurde vom “TIME”-Magazin als eine der besten Erfindungen des Jahres 2025 ausgezeichnet, was das Potenzial der Open-Source-Zusammenarbeit im Robotikbereich unterstreicht. AI-gesteuerte bionische Prothesen ermöglichen einem 17-jährigen Jugendlichen die Gedankenkontrolle, und humanoide Roboter erledigen mühelos Hausarbeiten. Im Industriebereich stellte Yondu AI eine Lösung für die Lagerkommissionierung mit rollenden humanoiden Robotern vor, AgiBot präsentierte den Lingxi X2 mit menschenähnlichen Bewegungsfähigkeiten, und China stellte einen Hochgeschwindigkeits-Kugelpolizeiroboter vor. Die Roboter von Boston Dynamics entwickelten sich zu multifunktionalen Kameraleuten, und der vierbeinige Roboter LocoTouch ermöglicht intelligenten Transport durch taktile Wahrnehmung. (Quelle: Ronald_vanLoon, Ronald_vanLoon, ClementDelangue, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, johnohallman, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
Durchbrüche bei den Fähigkeiten großer Modelle und neue Fortschritte bei Code-Benchmark-Tests : GPT-5 Pro und Gemini 2.5 Pro zeigten goldmedaillenwürdige Leistungen bei der Internationalen Olympiade für Astronomie und Astrophysik (IOAA), was die beeindruckenden Fähigkeiten von AI in der Spitzenphysik demonstriert. GPT-5 Pro zeigte auch überragende Fähigkeiten bei der Suche und Verifizierung wissenschaftlicher Literatur, löste das Erdos-Problem #339 und konnte signifikante Lücken in veröffentlichten Arbeiten effektiv identifizieren. Im Code-Bereich wurde KAT-Dev-72B-Exp zum führenden Open-Source-Modell auf der SWE-Bench Verified Bestenliste mit einer Reparaturrate von 74,6 %. Das SWE-Rebench-Projekt vermeidet Datenkontamination, indem es neu aufgeworfene GitHub-Issues nach der Veröffentlichung großer Modelle testet. Sam Altman blickt der Zukunft von Codex mit großer Erwartung entgegen. Bezüglich der Frage, ob AGI allein durch reine LLMs erreicht werden kann, ist die AI-Forschungsgemeinschaft allgemein der Ansicht, dass dies allein mit dem LLM-Kern schwer zu erreichen ist. (Quelle: gdb, karminski3, gdb, SebastienBubeck, karminski3, teortaxesTex, QuixiAI, sama, OfirPress, Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence)
Leistungsrevolution und Herausforderungen bei AI-Hardware und -Infrastruktur : Die NVIDIA Blackwell Plattform zeigte bei den SemiAnalysis InferenceMAX Benchmarks eine unübertroffene Inferenzleistung und Effizienz, und Together AI bietet bereits NVIDIA GB200 NVL72 und HGX B200 Systeme an. Groq gestaltet die Ökonomie der Open-Source-LLM-Infrastruktur durch seine ASICs und vertikale Integrationsstrategie mit geringerer Latenz und wettbewerbsfähigen Preisen neu. Die Community diskutierte die Auswirkungen der Entfernung des Python GIL auf das AI/ML-Engineering und ist der Ansicht, dass dies die Multithreading-Leistung verbessern könnte. Darüber hinaus teilten LLM-Enthusiasten ihre Hardware-Konfigurationen und diskutierten die Leistungskompromisse zwischen großen quantisierten Modellen und kleinen nicht-quantisierten Modellen bei verschiedenen Quantisierungsstufen, wobei darauf hingewiesen wurde, dass 2-Bit-Quantisierung für Dialoge geeignet sein könnte, aber Kodierungsaufgaben mindestens Q5 erfordern. (Quelle: togethercompute, arankomatsuzaki, code_star, MostafaRohani, jeremyphoward, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Aktuelle Entwicklungen bei AI-Modellen und -Anwendungen: Von generischen Modellen zu vertikalen Domänen : Im AI-Bereich entstehen kontinuierlich neue Modelle und Funktionen. Das türkische große Modell Kumru-2B macht auf Hugging Face auf sich aufmerksam, und Replit hat diese Woche mehrere Updates veröffentlicht. Sora 2 hat das Wasserzeichen entfernt, was auf breitere Anwendungen der Videogenerierungstechnologie hindeutet. Es gibt Gerüchte, dass Gemini 3.0 am 22. Oktober veröffentlicht wird. AI vertieft sich weiterhin im Gesundheitswesen, wobei die digitale Pathologie durch AI bei der Krebsdiagnose unterstützt wird, und markierungsfreie Mikroskopie in Kombination mit AI neue Diagnosewerkzeuge verspricht. Augmented Reality (AR)-Modelle erreichen SOTA auf der Imagenet FID-Bestenliste. Der Qwen Code Kommandozeilen-Kodierungs-Agent wurde aktualisiert und unterstützt nun die Bilderkennung mit dem Qwen-VL-Modell. Die Stanford University schlug die Methode Agentic Context Engineering (ACE) vor, die Modelle ohne Fine-Tuning intelligenter macht. Die DeepSeek V3-Modellreihe wird ebenfalls kontinuierlich weiterentwickelt, und die Bereitstellungstypen von AI Agents sowie die Neugestaltung des professionellen Dienstleistungssektors durch AI stehen ebenfalls im Fokus der Branche. (Quelle: mervenoyann, amasad, scaling01, npew, kaifulee, Ronald_vanLoon, scaling01, TheTuringPost, TomLikesRobots, iScienceLuvr, NerdyRodent, shxf0072, gabriberton, Ronald_vanLoon, karminski3, Ronald_vanLoon, teortaxesTex, demishassabis, Dorialexander, yoheinakajima, 36氪)
🧰 TOOLS
GraphQA: Wandelt Graphenanalyse in natürliche Sprachdialoge um : LangChainAI hat das GraphQA-Framework vorgestellt, das NetworkX und LangChain kombiniert und komplexe Graphenanalysen in natürliche Sprachdialoge umwandeln kann. Benutzer können Fragen in einfachem Englisch stellen, und GraphQA wählt und führt automatisch die passenden Algorithmen aus, um Graphen mit über 100.000 Knoten zu verarbeiten. Dies vereinfacht den Zugang zur Graphendatenanalyse erheblich, macht sie für nicht-professionelle Benutzer zugänglicher und ist eine wichtige Tool-Innovation im LLM-Bereich. (Quelle: LangChainAI)
Top Agentic AI Tool für VS Code : Das Visual Studio Magazine hat ein bestimmtes Tool als eines der Top Agentic AI Tools für VS Code ausgezeichnet, was einen Paradigmenwechsel in der Entwicklung von “Assistenten” hin zu “echten Agents” signalisiert, die mit Entwicklern denken, handeln und bauen können. Dies spiegelt die Entwicklung von AI-Tools im Softwareentwicklungsbereich von unterstützenden Funktionen hin zu einer tieferen intelligenten Zusammenarbeit wider, was die Effizienz und das Erlebnis für Entwickler verbessert. (Quelle: cline)
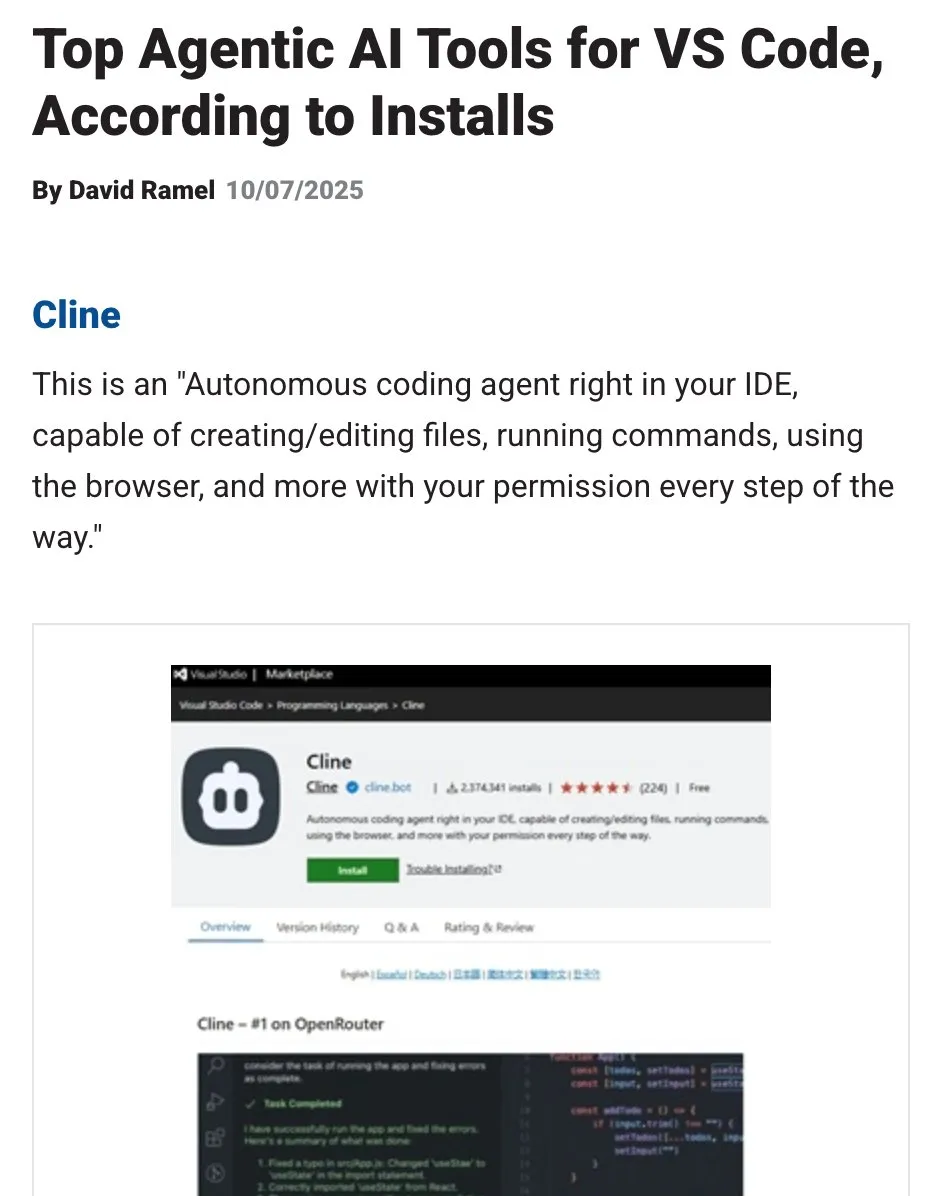
OpenHands: Open-Source-Tool für LLM-Kontextmanagement : OpenHands ist ein Open-Source-Tool, das verschiedene Kontextkompressoren zur Verwaltung des LLM-Kontextes in Agentic-Anwendungen bietet, darunter grundlegendes History-Pruning, die Extraktion der “wichtigsten Ereignisse” und die Komprimierung von Browser-Outputs. Dies ist entscheidend für das Debugging, die Bewertung und das Monitoring von LLM-Anwendungen, RAG-Systemen und Agentic-Workflows und trägt dazu bei, die Effizienz und Konsistenz von LLMs bei komplexen Aufgaben zu verbessern. (Quelle: gneubig)
BLAST: AI-Webbrowser-Engine : LangChainAI hat BLAST veröffentlicht, eine leistungsstarke AI-Webbrowser-Engine, die darauf abzielt, AI-Anwendungen Web-Browsing-Fähigkeiten zu verleihen. BLAST bietet eine OpenAI-kompatible Schnittstelle, unterstützt automatische Parallelisierung, intelligentes Caching und Echtzeit-Streaming und kann Webseiteninformationen effizient in AI-Workflows integrieren, was die Fähigkeit von AI Agents, Echtzeit-Webdaten abzurufen und zu verarbeiten, erheblich erweitert. (Quelle: LangChainAI)
Opik: Open-Source-LLM-Bewertungstool : Opik ist ein Open-Source-LLM-Bewertungstool, das zum Debugging, zur Bewertung und zum Monitoring von LLM-Anwendungen, RAG-Systemen und Agentic-Workflows dient. Es bietet umfassendes Tracking, automatisierte Bewertungen und produktionsreife Dashboards, um Entwicklern zu helfen, das Modellverhalten besser zu verstehen, die Leistung zu optimieren und die Zuverlässigkeit von Anwendungen in realen Szenarien sicherzustellen. (Quelle: dl_weekly)
AI Travel Agent: Intelligenter Planungsassistent : LangChainAI hat einen intelligenten AI Travel Agent vorgestellt, der Echtzeit-Wetter-, Such- und Reiseinformationen integriert und mehrere APIs nutzt, um den gesamten Prozess von Wetteraktualisierungen bis zum Währungsumtausch zu vereinfachen. Der Agent soll eine umfassende Reiseplanung und -unterstützung bieten, das Reiseerlebnis der Benutzer verbessern und ist ein typisches Beispiel dafür, wie LLMs Agents in vertikalen Anwendungsszenarien befähigen. (Quelle: LangChainAI)
Vision eines AI-Tools zur Erstellung von Advertiser-Prompts : Es wurde die Ansicht geäußert, dass der Markt dringend ein AI-Tool benötigt, das Marketingfachleuten beim Erstellen von “Advertiser-Prompts” hilft. Dieses Tool sollte bei der Einrichtung eines Bewertungssystems (das Markensicherheit, Prompt-Compliance usw. abdeckt) unterstützen und gängige Modelle testen können. Mit der Einführung verschiedener natürlicher Werbeeinheiten durch OpenAI wird die Bedeutung von Marketing-Prompts immer deutlicher, und solche Tools werden zu einem entscheidenden Bestandteil im Prozess der Werbekreation und -verteilung. (Quelle: dbreunig)
Qwen Code Update: Unterstützung für Qwen-VL-Modell zur Bilderkennung : Der Qwen Code Kommandozeilen-Kodierungs-Agent wurde kürzlich aktualisiert und unterstützt nun das Umschalten auf das Qwen-VL-Modell zur Bilderkennung. Benutzertests zeigen gute Ergebnisse, und es ist derzeit kostenlos verfügbar. Dieses Update erweitert die Fähigkeiten von Qwen Code erheblich, sodass es nicht nur Code-Aufgaben bearbeiten, sondern auch multimodale Interaktionen durchführen kann, was die Effizienz und Genauigkeit des Kodierungs-Agents bei der Bearbeitung von Aufgaben mit visuellen Informationen verbessert. (Quelle: karminski3)

Hosten eines persönlichen Chatbot-Servers mit LibreChat : Ein Blogbeitrag bietet eine Anleitung zum Hosten eines persönlichen Chatbot-Servers mit LibreChat und zum Verbinden mit mehreren Modell-Kontrollpanels (MCPs). Dies ermöglicht Benutzern, verschiedene LLM-Backends flexibel zu verwalten und zu wechseln, um ein angepasstes Chatbot-Erlebnis zu schaffen, und unterstreicht die Flexibilität und Kontrollierbarkeit von Open-Source-Lösungen bei der Bereitstellung von AI-Anwendungen. (Quelle: Reddit r/artificial)
AI-Generator: Bringt Avatare zum Leben : Ein Benutzer sucht nach dem besten AI-Generator, um seine Markenidentität (einschließlich Realvideo und Avatare) “zum Leben zu erwecken” für seinen YouTube-Kanal, um die Dreh- und Aufnahmezeit zu reduzieren und sich auf den Schnitt zu konzentrieren. Der Benutzer wünscht sich, dass die AI Avatare sprechen, spielen, tanzen usw. lassen kann. Dies spiegelt die hohe Nachfrage von Content-Erstellern nach AI-Tools für Avatar-Animationen und Videogenerierung wider, um die Produktionseffizienz und Inhaltsvielfalt zu steigern. (Quelle: Reddit r/artificial)
Lokale LLMs gegen E-Mail-Spam: Private Lösung : Ein Blogbeitrag beschreibt, wie lokale LLMs auf dem eigenen Mailserver privat zur Erkennung und Bekämpfung von Spam-E-Mails eingesetzt werden können. Die Lösung kombiniert Mailcow, Rspamd, Ollama und einen benutzerdefinierten Python-Agenten und bietet Benutzern von selbst gehosteten Mailservern eine AI-basierte Spam-Filterung, was das Potenzial lokaler LLMs für den Datenschutz und maßgeschneiderte Anwendungen unterstreicht. (Quelle: Reddit r/LocalLLaMA)
📚 LERNEN
EmbeddingGemma: Mehrsprachiges Embedding-Modell für On-Device-RAG-Anwendungen : EmbeddingGemma ist ein kompaktes mehrsprachiges Embedding-Modell mit nur 308M Parametern, das sich hervorragend für On-Device-RAG-Anwendungen eignet und leicht in LlamaIndex integriert werden kann. Das Modell rangiert hoch im Massive Text Embedding Benchmark und ist gleichzeitig klein genug für mobile Geräte. Seine einfache Fine-Tuning-Fähigkeit ermöglicht es, dass es nach dem Fine-Tuning in spezifischen Bereichen (wie medizinischen Daten) größere Modelle übertreffen kann. (Quelle: jerryjliu0)
Zwei grundlegende Methoden der Dokumentenverarbeitung: Parsing und Extraktion : Ein Artikel des LlamaIndex-Teams beleuchtet die beiden grundlegenden Methoden “Parsing” und “Extraktion” in der Dokumentenverarbeitung. Parsing wandelt das gesamte Dokument in strukturiertes Markdown oder JSON um, wobei alle Informationen erhalten bleiben, und eignet sich für RAG, tiefgehende Forschung und Zusammenfassungen. Extraktion ruft strukturierte Ausgaben von LLMs ab und standardisiert Dokumente in ein allgemeines Muster, geeignet für Datenbank-ETL, automatisierte Agent-Workflows und Metadatenextraktion. Das Verständnis des Unterschieds zwischen beiden ist entscheidend für den Aufbau effizienter Dokumenten-Agents. (Quelle: jerryjliu0)

Implementierung des Tiny Recursive Model (TRM) auf MLX : Die MLX-Plattform implementiert den Kern des Tiny Recursive Model (TRM), das von Alexia Jolicoeur-Martineau vorgeschlagen wurde und darauf abzielt, mit einem winzigen neuronalen Netzwerk von 7M Parametern durch rekursive Inferenz hohe Leistung zu erzielen. Diese MLX-Implementierung ermöglicht lokale Experimente auf Apple Silicon Laptops, reduziert die Komplexität und umfasst Funktionen wie Deep Supervision, rekursive Inferenzschritte und EMA, was die Entwicklung und Forschung an kleinen, effizienten Modellen erleichtert. (Quelle: awnihannun, ImazAngel)
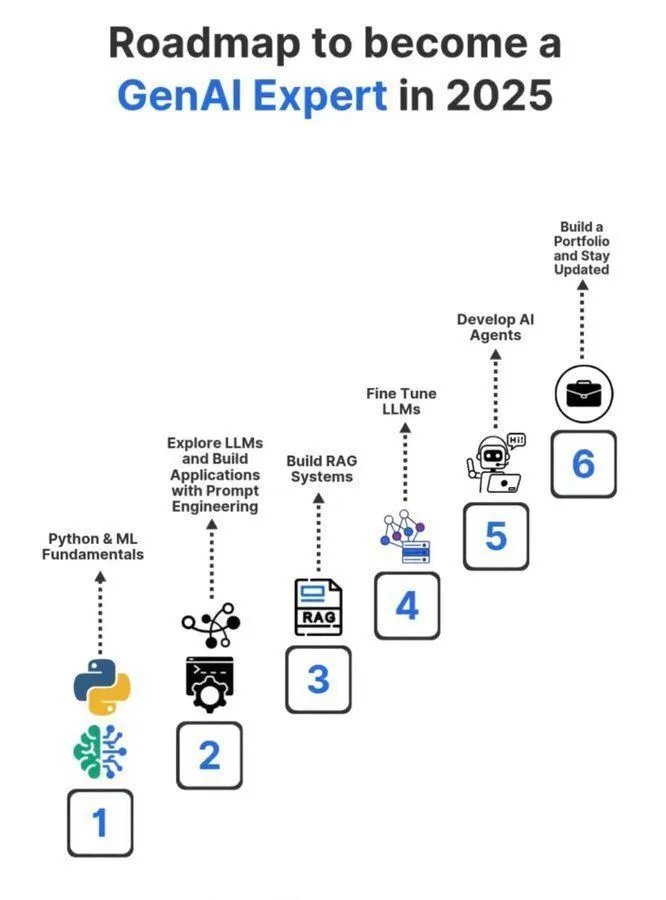
Lern-Roadmap zum Generative AI Experten 2025 : Eine detaillierte Lern-Roadmap zum Generative AI Experten 2025 wurde in den sozialen Medien geteilt, die das notwendige Schlüsselwissen und die Fähigkeiten abdeckt, um ein Profi im Bereich der generativen AI zu werden. Die Roadmap soll Interessierte anleiten, Kernkonzepte wie Künstliche Intelligenz, Maschinelles Lernen und Deep Learning systematisch zu erlernen, um den schnelllebigen GenAI-Technologietrends gerecht zu werden. (Quelle: Ronald_vanLoon)
Erfahrungsberichte zum PhD-Studium im Maschinellen Lernen : Ein Benutzer hat eine Reihe von Tweets über das PhD-Studium im Bereich Maschinelles Lernen erneut geteilt, um Interessierten am ML-Doktorat Orientierung und Erfahrungen zu bieten. Diese Tweets könnten Themen wie den Bewerbungsprozess, Forschungsrichtungen, Karriereentwicklung und persönliche Erfahrungen behandeln und stellen eine wertvolle AI-Lernressource in der Community dar. (Quelle: arohan)
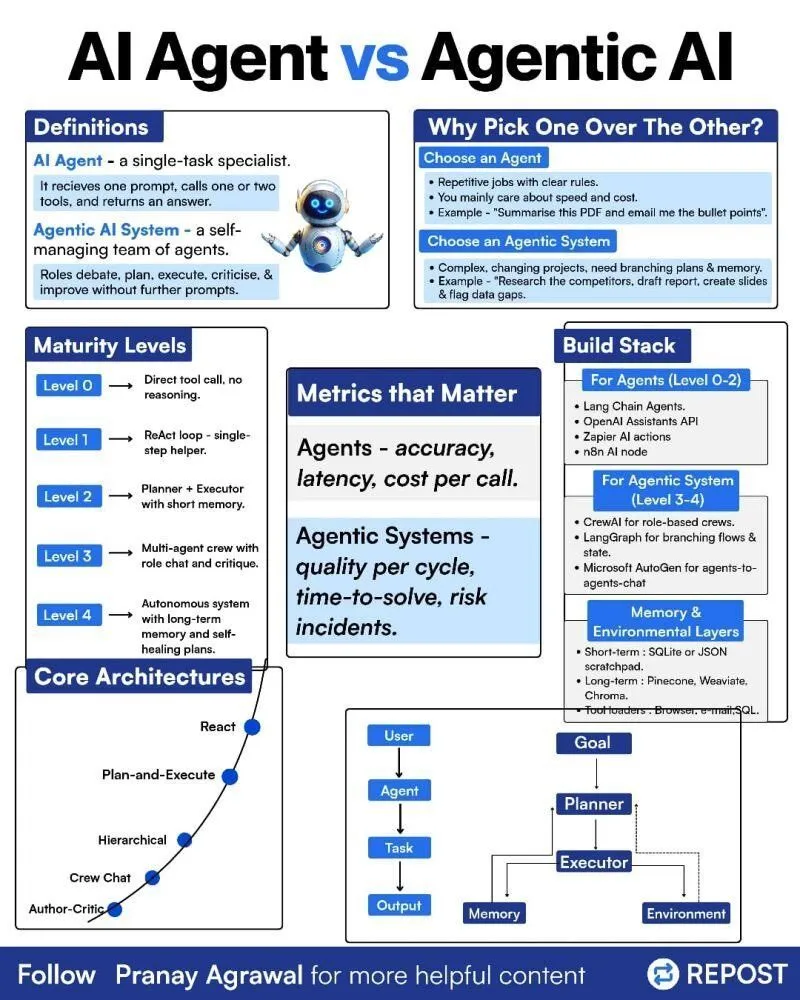
Unterschied zwischen AI Agents und Agentic AI : In den sozialen Medien wurde eine Infografik geteilt, die den Unterschied zwischen “AI Agents” und “Agentic AI” erklärt, um diese beiden verwandten, aber unterschiedlichen Konzepte zu verdeutlichen. Dies hilft der Community, die Bereitstellungstypen von AI Agents, deren Autonomiegrad und die Rolle von Agentic AI in breiteren KI-Systemen besser zu verstehen, und fördert eine präzisere Diskussion über Agent-Technologien. (Quelle: Ronald_vanLoon)
Reinforcement Learning und Weight Decay im LLM-Training : In den sozialen Medien wurde diskutiert, dass Weight Decay im Reinforcement Learning (RL)-Training von LLMs möglicherweise keine gute Idee ist. Es wird argumentiert, dass Weight Decay dazu führen kann, dass das Netzwerk viele vortrainierte Informationen vergisst, insbesondere bei GRPO-Updates mit null Vorteil, wo die Gewichte gegen null tendieren. Dies weist Forscher darauf hin, die Auswirkungen von Weight Decay bei der Gestaltung von RL-Trainingsstrategien für LLMs sorgfältig zu berücksichtigen, um eine Verschlechterung der Modellleistung zu vermeiden. (Quelle: lateinteraction)
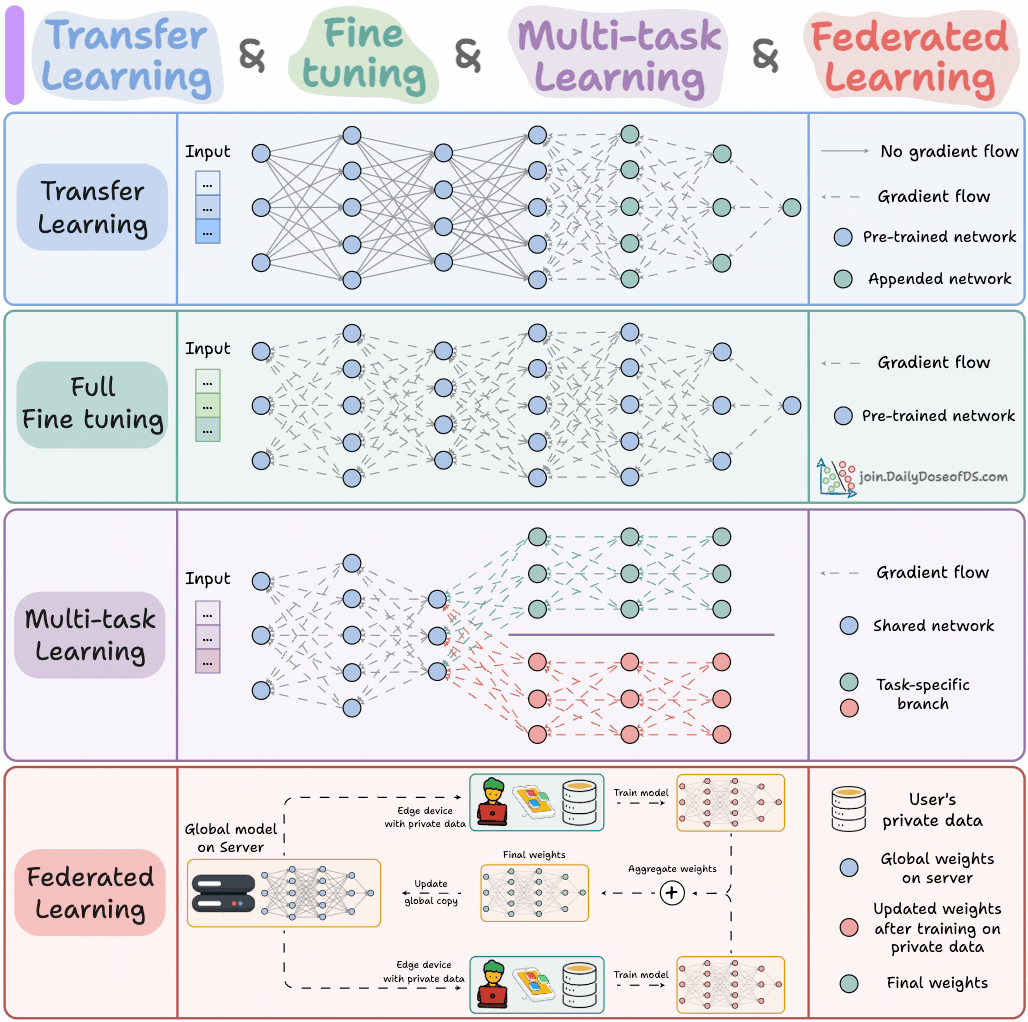
AI-Modell-Trainingsparadigmen : Ein Experte teilte vier Modell-Trainingsparadigmen, die ML-Ingenieure kennen müssen, um Maschinelles Lernen-Ingenieuren wichtige theoretische Anleitungen und praktische Rahmenwerke zu bieten. Diese Paradigmen könnten überwachtes Lernen, unüberwachtes Lernen, Reinforcement Learning und selbstüberwachtes Lernen umfassen, um Ingenieuren zu helfen, verschiedene Modelltrainingsmethoden besser zu verstehen und anzuwenden. (Quelle: _avichawla)
Curriculum Learning-basiertes Reinforcement Learning zur Verbesserung der LLM-Fähigkeiten : Eine Studie ergab, dass Reinforcement Learning (RL) in Kombination mit Curriculum Learning LLMs neue Fähigkeiten vermitteln kann, die mit anderen Methoden schwer zu erreichen sind. Dies zeigt das Potenzial von Curriculum Learning zur Verbesserung der langfristigen Inferenzfähigkeiten von LLMs und deutet darauf hin, dass die Kombination von RL und Curriculum Learning ein Schlüssel zur Erschließung neuer AI-Fähigkeiten sein könnte. (Quelle: sytelus)

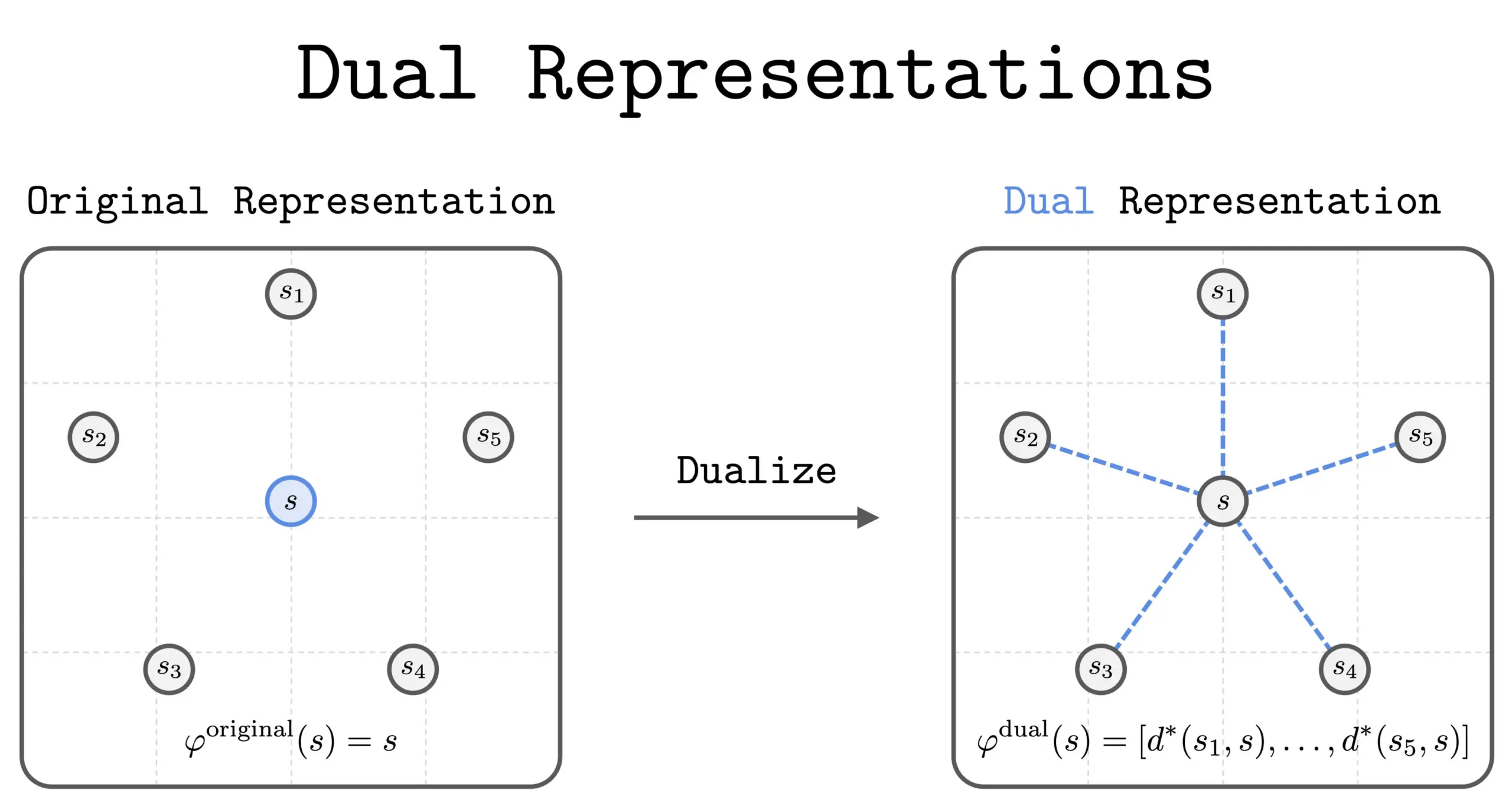
Neue Methode der dualen Repräsentation in RL : Eine neue Studie führte die Methode der “dualen Repräsentation” im Reinforcement Learning (RL) ein. Diese Methode bietet eine neue Perspektive, indem sie Zustände als “Ähnlichkeitsmengen” zu allen anderen Zuständen darstellt. Diese duale Repräsentation weist gute theoretische Eigenschaften und praktische Vorteile auf und verspricht, die Leistung und das Verständnis von RL zu verbessern. (Quelle: dilipkay)
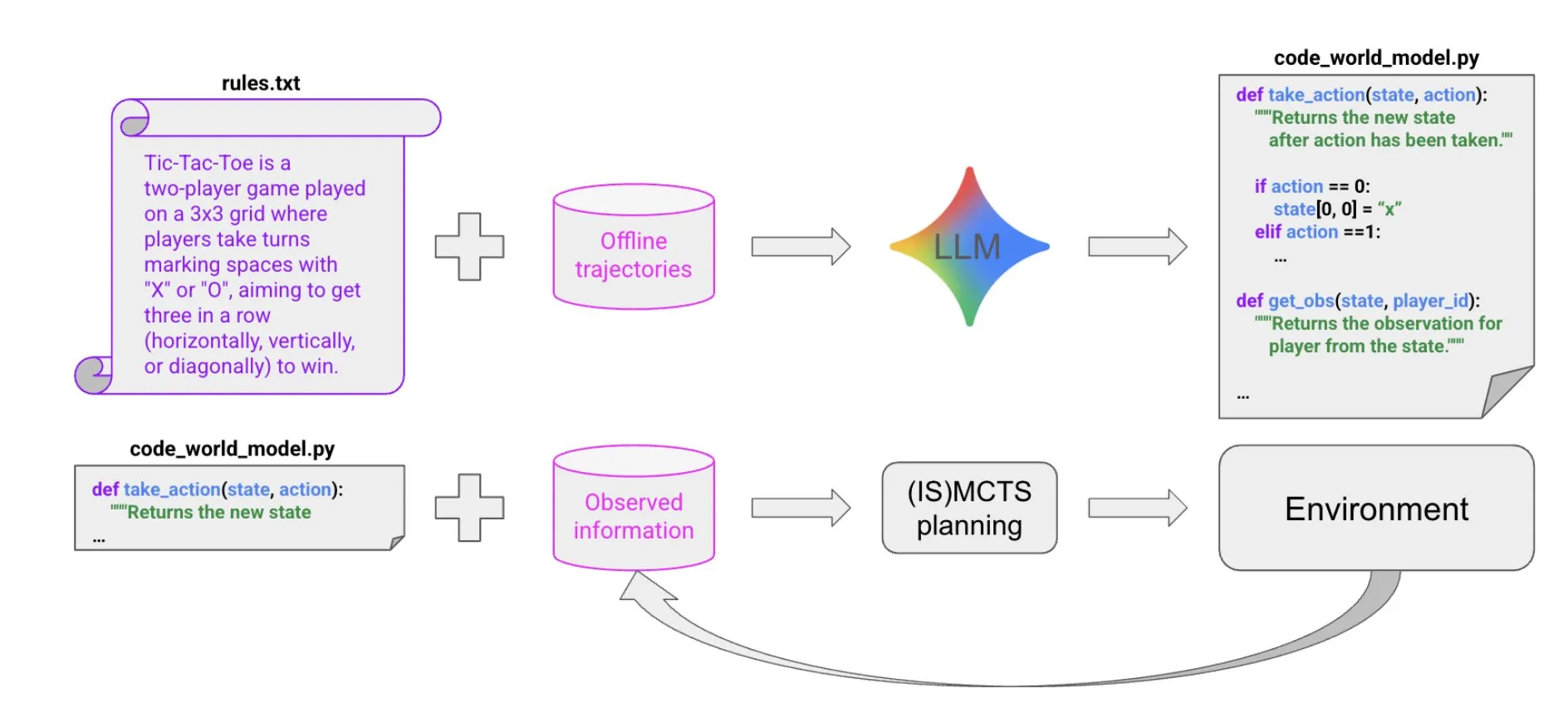
LLM-gesteuerte Code-Synthese zur Erstellung von Weltmodellen : Eine neue Arbeit schlägt eine äußerst sample-effiziente Methode vor, um durch LLM-gesteuerte Code-Synthese Agenten zu erstellen, die in Multi-Agenten-, partiell beobachtbaren symbolischen Umgebungen gut funktionieren. Die Methode lernt Code-Weltmodelle aus wenigen Trajektoriendaten und Hintergrundinformationen und übergibt diese dann an bestehende Solver (wie MCTS), um die nächste Aktion auszuwählen, was neue Ideen für den Aufbau komplexer Agenten liefert. (Quelle: BlackHC)
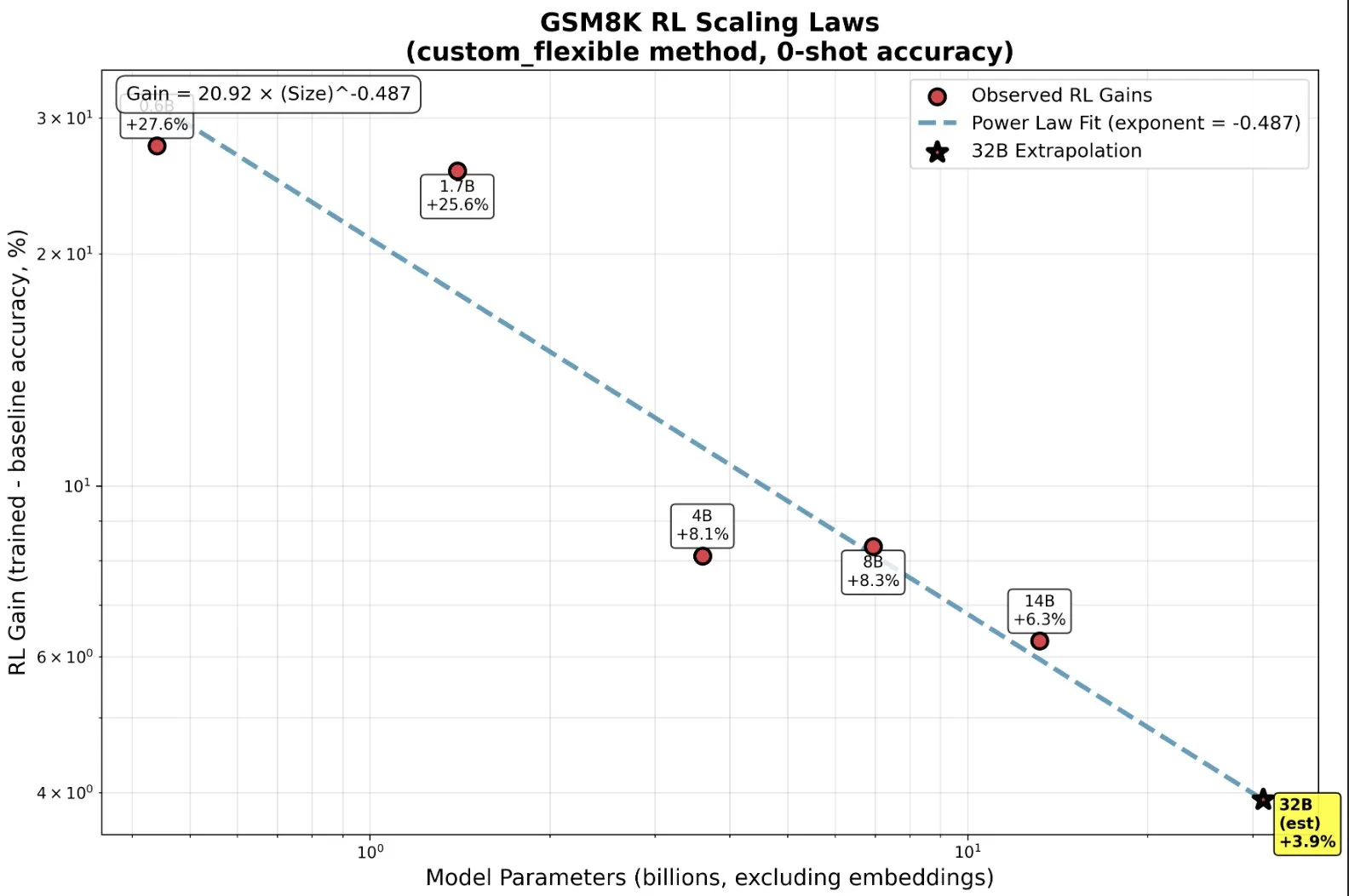
RL-Training kleiner Modelle: Emergent Abilities jenseits des Pre-Trainings : Studien zeigen, dass kleine Modelle im Reinforcement Learning (RL) überproportional profitieren und sogar “emergente” Fähigkeiten entwickeln können, was die traditionelle Intuition “größer ist besser” auf den Kopf stellt. Bei kleinen Modellen könnte RL recheneffizienter sein als mehr Pre-Training. Diese Erkenntnis ist wichtig für AI-Labore bei der Entscheidung, wann das Pre-Training zu stoppen und wann mit RL zu beginnen ist, wenn sie RL skalieren, und offenbart neue Skalierungsgesetze zwischen Modellgröße und Leistungssteigerung in RL. (Quelle: ClementDelangue, ClementDelangue)
AI vs. Maschinelles Lernen vs. Deep Learning: Einfache Erklärung : Eine Videoressource erklärt auf einfache und verständliche Weise den Unterschied zwischen Künstlicher Intelligenz (AI), Maschinellem Lernen (ML) und Deep Learning (DL). Das Video soll Anfängern helfen, diese Kernkonzepte schnell zu verstehen, und legt die Grundlage für ein tieferes Studium im AI-Bereich. (Quelle: )

Prompt-Template-Management in Deep Learning Modell-Experimenten : Die Deep Learning Community diskutierte, wie Prompt-Templates in Modell-Experimenten verwaltet und wiederverwendet werden können. In großen Projekten, insbesondere bei Architektur- oder Datensatzänderungen, wird es komplex, die Auswirkungen verschiedener Prompt-Varianten zu verfolgen. Benutzer teilten Erfahrungen mit Tools wie Empromptu AI für die Prompt-Versionskontrolle und -Klassifizierung und betonten die Bedeutung der Prompt-Versionierung und der Ausrichtung von Datensätzen und Prompts zur Optimierung von Modellprodukten. (Quelle: Reddit r/deeplearning)
Leitfaden zur Auswahl von Code Completion (FIM) Modellen : Die Community diskutierte die Schlüsselfaktoren bei der Auswahl von Code Completion (FIM) Modellen. Geschwindigkeit wird als absolute Priorität angesehen; es wird empfohlen, Modelle mit wenigen Parametern zu wählen, die nur auf der GPU laufen (Ziel >70 t/s). Darüber hinaus zeigten “Basis”-Modelle und Instruktionsmodelle ähnliche Leistungen bei FIM-Aufgaben. Die Diskussion listete auch neuere und ältere FIM-Modelle wie Qwen3-Coder und KwaiCoder auf und untersuchte, wie Tools wie nvim.llm nicht-code-spezifische Modelle unterstützen können. (Quelle: Reddit r/LocalLLaMA)
Leistungskompromisse bei quantisierten Modellen: Große Modelle und niedrige Präzision : Die Community diskutierte die Leistungskompromisse zwischen großen quantisierten Modellen und kleinen nicht-quantisierten Modellen sowie die Auswirkungen der Quantisierungsstufe auf die Modellleistung. Es wird allgemein angenommen, dass 2-Bit-Quantisierung für Schreiben oder Dialoge geeignet sein könnte, aber für Aufgaben wie Kodierung mindestens Q5 erforderlich ist. Einige Benutzer wiesen darauf hin, dass die Leistung von Gemma3-27B bei niedriger Quantisierung stark abfällt, während einige neue Modelle mit FP4-Präzision trainiert werden und keine höhere Präzision benötigen. Dies deutet darauf hin, dass die Quantisierungseffekte je nach Modell und Aufgabe variieren und spezifische Tests erforderlich sind. (Quelle: Reddit r/LocalLLaMA)
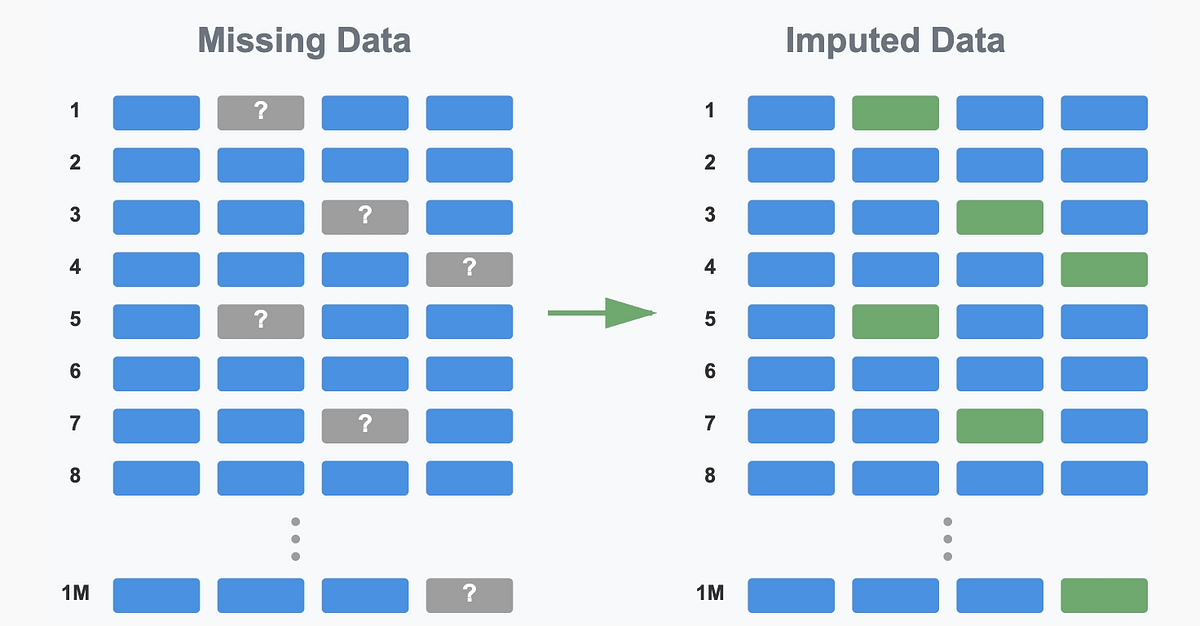
Gründe für das Versagen von R MissForest bei Vorhersageaufgaben : Ein Analyseartikel untersuchte die Gründe, warum der MissForest-Algorithmus in R bei Vorhersageaufgaben versagt, und wies darauf hin, dass er beim Imputieren stillschweigend das Schlüsselprinzip der Trennung von Trainings- und Testdatensatz verletzt. Der Artikel erläutert die Einschränkungen von MissForest in solchen Situationen und stellt neue Methoden wie MissForestPredict vor, die dieses Problem lösen, indem sie die Konsistenz zwischen Lernen und Anwendung aufrechterhalten. Dies ist von großer Bedeutung für Machine Learning-Praktiker beim Umgang mit fehlenden Werten und dem Aufbau von Vorhersagemodellen. (Quelle: Reddit r/MachineLearning)
Suche nach Ressourcen für multimodales Maschinelles Lernen : Community-Nutzer suchen nach Lernressourcen für multimodales Maschinelles Lernen, insbesondere theoretische und praktische Materialien darüber, wie verschiedene Datentypen (Text, Bilder, Signale usw.) kombiniert werden können und Konzepte wie Fusion, Alignment und Cross-Modality Attention zu verstehen sind. Dies spiegelt den wachsenden Lernbedarf an multimodalen AI-Technologien wider. (Quelle: Reddit r/deeplearning)
Suche nach Videoressourcen zum Training von Inferenzmodellen mit Reinforcement Learning : Die Machine Learning Community sucht nach den besten wissenschaftlichen Vortragsvideos zum Training von Inferenzmodellen mittels Reinforcement Learning (RL), einschließlich Übersichts-Videos und detaillierter Erklärungen spezifischer Methoden. Benutzer wünschen sich hochwertige akademische Inhalte und keine oberflächlichen Influencer-Videos, um schnell die relevante Literatur zu verstehen und weitere Forschungsrichtungen zu bestimmen. (Quelle: Reddit r/MachineLearning)
11 Monate AI-Coding-Reise: Tools, Tech Stack und Best Practices : Ein Entwickler teilte seine 11-monatige AI-Coding-Reise, detailliert seine Erfahrungen, Misserfolge und Best Practices mit Tools wie Claude Code. Er betonte, dass in der AI-Kodierung die Bedeutung von Vorplanung und Kontextmanagement die eigentliche Code-Erstellung bei weitem übertrifft. Obwohl AI die Hürde für die Code-Implementierung senkt, ersetzt sie nicht Architekturdesign und Geschäftseinblicke. Dieser Erfahrungsbericht deckt mehrere Projekte ab, von Frontend über Backend bis hin zur mobilen App-Entwicklung, und empfiehlt Hilfswerkzeuge wie Context7 und SpecDrafter. (Quelle: Reddit r/ClaudeAI)
💼 GESCHÄFTLICHES
JPMorgan Chase: 2 Milliarden US-Dollar Investition pro Jahr, Transformation zur “Full AI Bank” : Jamie Dimon, CEO von JPMorgan Chase, kündigte jährliche Investitionen von 2 Milliarden US-Dollar in AI an, mit dem Ziel, das Unternehmen in eine “Full AI Bank” zu verwandeln. AI ist tief in Schlüsselbereiche wie Risikomanagement, Handel, Kundenservice, Compliance und Investmentbanking integriert, was nicht nur Kosten spart, sondern vor allem das Arbeitstempo beschleunigt und die Natur der Arbeitsplätze verändert. JPMorgan Chase betrachtet AI als das zugrunde liegende Betriebssystem des Unternehmens durch die selbst entwickelte LLM Suite Plattform und den großflächigen Einsatz von AI Agents, und betont, dass Datenintegration und Cybersicherheit die größten Herausforderungen seiner AI-Strategie sind. Dimon ist der Ansicht, dass AI einen echten langfristigen Wert darstellt und keine kurzfristige Blase ist, und die Definition des Bankwesens neu gestalten wird. (Quelle: 36氪)
Apple von Musk (Der Originaltext ist hier unvollständig.)