
Schlüsselwörter:OpenAI Sora, KI-Videogenerierung, Tiny Recursive Model, KI-Spielzeug, KI-Chip, Sora 2 Video-Rekreation, TRM-Inferenzeffizienz, Wachstum des KI-Spielzeugmarktes, AMD und OpenAI Chip-Partnerschaft, Urheberrechtsstreitigkeiten bei KI-Inhalten
🔥 Fokus
Aufstieg und Herausforderungen der OpenAI Sora App : Die von OpenAI veröffentlichte AI-Videoerstellungsanwendung Sora wurde schnell populär und erreichte die Spitze des App Store. Ihre kostenlose, unbegrenzte Videogenerierungsfunktion hat weitreichende Bedenken hinsichtlich der Betriebskosten, Urheberrechtsverletzungen (insbesondere bei der Verwendung bestehender IPs und Porträts verstorbener Berühmtheiten) und des Missbrauchs von Deepfake-Technologien ausgelöst. Sam Altman räumte ein, dass ein Gewinnmodell in Betracht gezogen werden müsse, und plant, eine präzisere Urheberrechtskontrolle anzubieten. Die Auswirkungen der Anwendung auf das Ökosystem der Inhaltserstellung und die Wahrnehmung der Realität haben eine Diskussion darüber entfacht, ob AI-Videos “echte” Videos übertreffen werden. (Quelle: MIT Technology Review, rowancheung, fabianstelzer, nptacek, paul_cal, BlackHC)

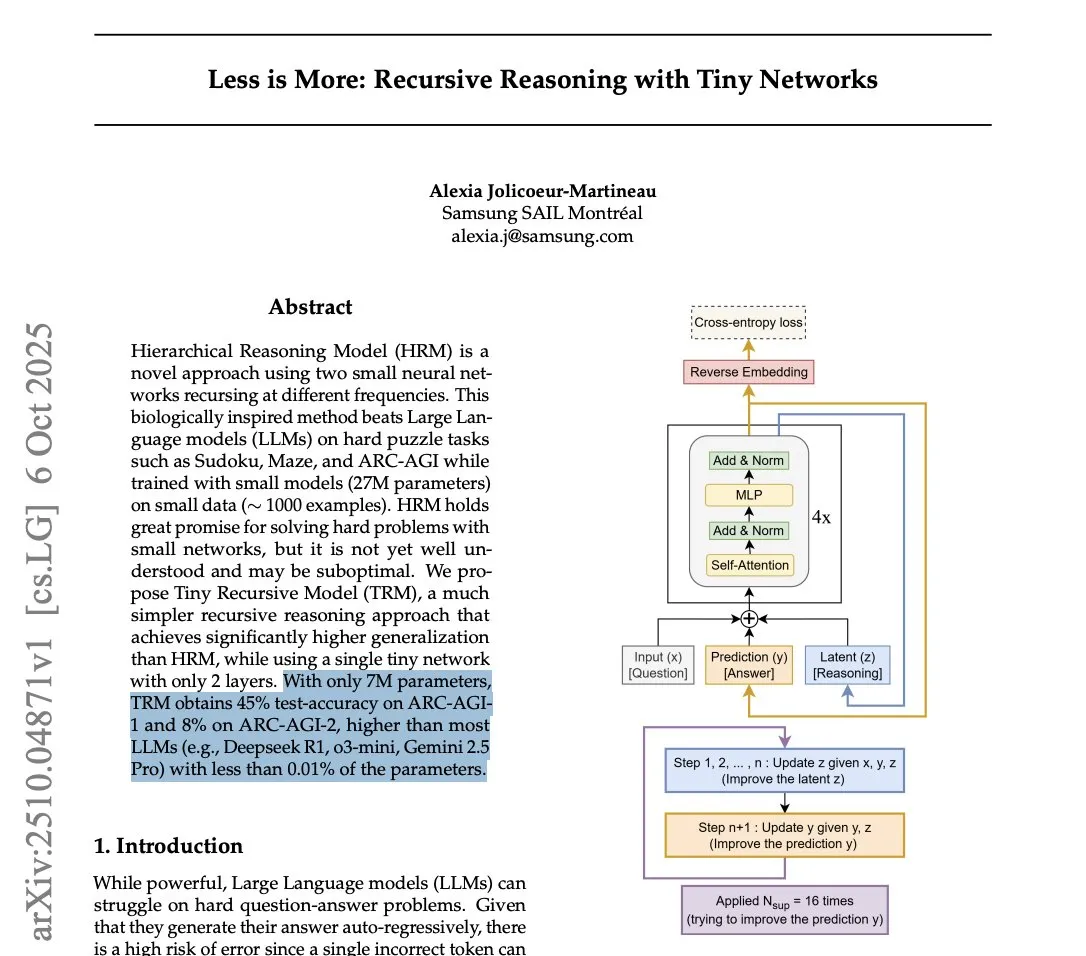
Samsung stellt Tiny Recursive Model (TRM) vor und fordert die LLM-Inferenz-Effizienz heraus : Samsung hat das Tiny Recursive Model (TRM) vorgestellt, ein kleines neuronales Netzwerk mit nur 7 Millionen Parametern, das im ARC-AGI-Benchmark hervorragende Leistungen erbringt und sogar große LLMs wie DeepSeek-R1 und Gemini 2.5 Pro übertrifft. TRM verwendet eine rekursive Inferenzmethode, die Antworten durch mehrfaches internes “Nachdenken” und Selbstkritik optimiert. Dieser Durchbruch hat eine Diskussion darüber ausgelöst, ob “kleine Modelle intelligenter sein können”, und deutet darauf hin, dass bei Inferenzaufgaben architektonische Innovation wichtiger sein könnte als die bloße Modellgröße, was die Rechenkosten für SOTA-Inferenz erheblich senken könnte. (Quelle: HuggingFace Daily Papers, fchollet, cloneofsimo, ecsquendor, clefourrier, AymericRoucher, ClementDelangue, Dorialexander)
Tsinghua-Absolvent Yao Shunyu wechselt von Anthropic zu Google DeepMind, Wertekonflikte als Hauptgrund : Yao Shunyu, ein mit einem Sonderstipendium ausgezeichneter Absolvent der Physikabteilung der Tsinghua-Universität, hat seinen Wechsel von Anthropic zu Google DeepMind als Senior Research Scientist bekannt gegeben. Er führte 40 % seines Weggangs auf “grundlegende Wertekonflikte” mit Anthropic zurück und argumentierte, dass das Unternehmen chinesischen Forschern und Mitarbeitern mit neutraler Haltung gegenüber unfreundlich sei. Yao Shunyu arbeitete ein Jahr bei Anthropic und war an der Entwicklung der Reinforcement Learning-Theorie hinter Claude 3.7 Sonnet und der Claude 4-Serie beteiligt. Er erklärte, dass die Entwicklung im AI-Bereich erstaunlich schnell sei, es aber nun an der Zeit sei, nach vorne zu blicken. (Quelle: ZhihuFrontier, 量子位)

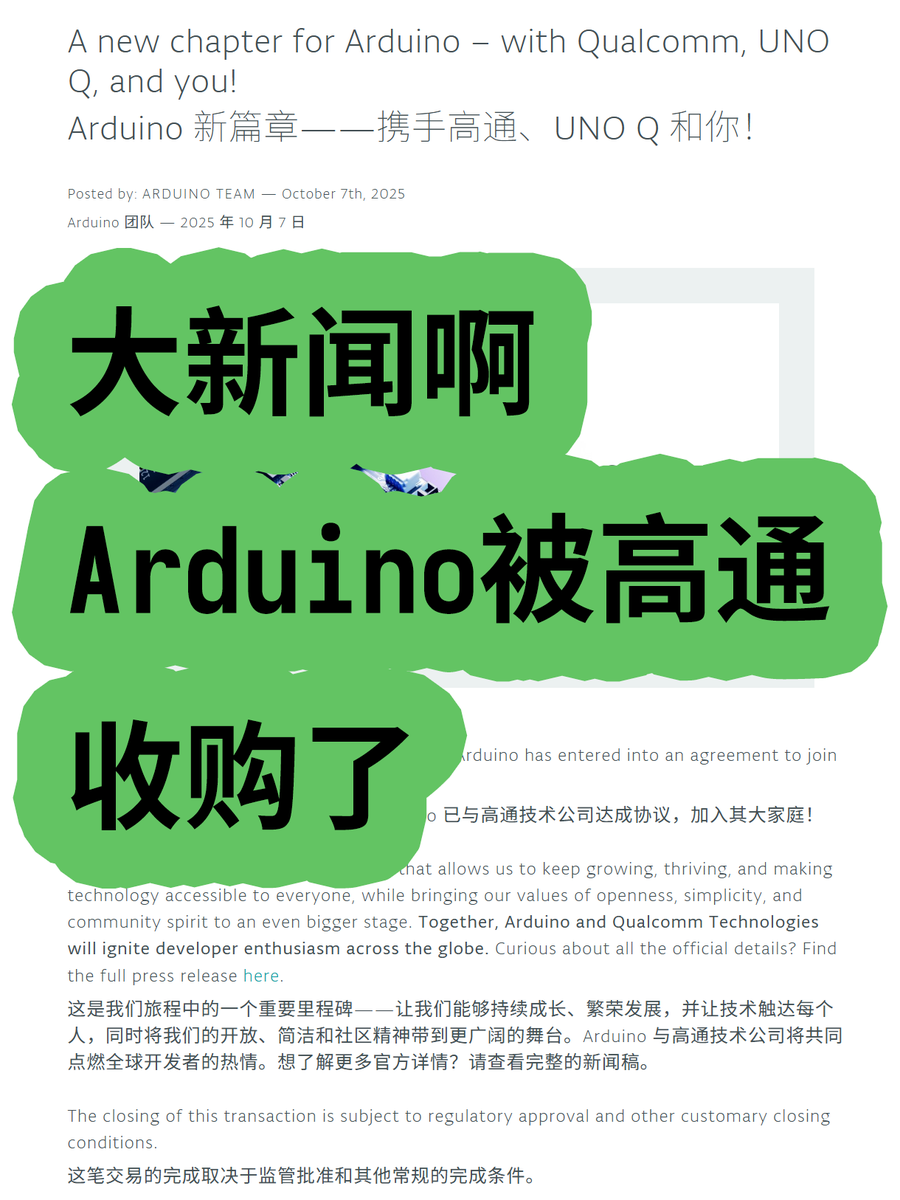
Arduino von Qualcomm übernommen, deutet auf neue Richtung für Embedded AI hin : Arduino wurde von Qualcomm übernommen und stellte das erste gemeinsam entwickelte Board, UNO Q, vor, das mit dem Qualcomm Dragonwing QRB2210 Prozessor ausgestattet ist und eine AI-Lösung integriert. Dies markiert Arduinos Entwicklung vom traditionellen Bereich der Mikrocontroller mit geringem Stromverbrauch hin zu Edge Computing mit mittlerem Stromverbrauch und integrierten AI-Fähigkeiten. Dieser Schritt könnte die breite Anwendung von AI in IoT- und Embedded-Geräten vorantreiben, Entwicklern leistungsfähigere AI-Rechenleistung bieten und eine neue Ära im Embedded AI-Hardware-Ökosystem einläuten. (Quelle: karminski3)
Meta Superintelligence veröffentlicht REFRAG: Neuer Durchbruch bei der RAG-Effizienz : Meta Superintelligence hat ihr erstes Paper, REFRAG, veröffentlicht, das eine neue RAG-Methode (Retrieval-Augmented Generation) vorschlägt, die darauf abzielt, die Effizienz erheblich zu steigern. Die Methode wandelt die meisten abgerufenen Dokumentblöcke in kompakte, LLM-freundliche “Block-Embeddings” um, die direkt von LLMs konsumiert werden können, und verwendet eine leichte Strategie, um Teile der Block-Embeddings bei Bedarf innerhalb des Budgets auf vollständige Tokens zu erweitern. Dies reduziert die KV-Cache- und Aufmerksamkeitskosten erheblich, beschleunigt die First-Byte-Latenz und den Durchsatz und bewahrt gleichzeitig die Genauigkeit, was neue Wege für Echtzeit-RAG-Anwendungen eröffnet. (Quelle: Reddit r/deeplearning, Reddit r/LocalLLaMA)

🎯 Trends
xAI schließt 20 Milliarden US-Dollar Finanzierungsrunde ab, Nvidia investiert 2 Milliarden US-Dollar : Elon Musks Unternehmen xAI hat erfolgreich eine Finanzierungsrunde über 20 Milliarden US-Dollar abgeschlossen, darunter eine direkte Investition von 2 Milliarden US-Dollar von Nvidia. Diese Mittel werden über eine Special Purpose Vehicle (SPV) für den Kauf von Nvidia GPUs verwendet, um den Bau des Memphis Colossus 2 Rechenzentrums zu unterstützen. Die einzigartige Finanzierungsstruktur zielt darauf ab, xAI die Hardware für eine massive Expansion im Bereich des AI-Computing zu sichern und den Wettbewerb auf dem AI-Chipmarkt weiter zu verschärfen. (Quelle: scaling01)

AI-Spielzeug boomt in China und den USA : AI-Spielzeuge mit Chatbots und Sprachassistenten werden zu einem neuen Trend, der besonders auf dem chinesischen Markt schnell wächst und sich auf internationale Märkte wie die USA ausgedehnt hat. Produkte von Unternehmen wie BubblePal und FoloToy zielen darauf ab, die Bildschirmzeit von Kindern zu reduzieren. Eltern berichten jedoch, dass die AI-Funktionen manchmal instabil sind, Antworten langwierig oder die Spracherkennung verzögert ist, was zu einem Rückgang des Interesses bei Kindern führt. US-amerikanische Unternehmen wie Mattel arbeiten ebenfalls mit OpenAI zusammen, um AI-Spielzeuge zu entwickeln. (Quelle: MIT Technology Review)

Microsoft stellt einheitliches Open-Source-Agent-Framework vor, integriert AutoGen und Semantic Kernel : Microsoft hat das Agent Framework veröffentlicht, ein einheitliches Open-Source-SDK, das AutoGen und Semantic Kernel integrieren soll, um Multi-Agenten-AI-Systeme auf Unternehmensebene zu entwickeln. Das Framework wird von Azure AI Foundry unterstützt, vereinfacht Orchestrierung und Beobachtbarkeit und ist mit verschiedenen APIs kompatibel. Es führt eine private Vorschau für Multi-Agenten-Workflows, Cross-Framework-Tracing mit OpenTelemetry, Echtzeit-Sprachagentenfunktionen mit der Voice Live API und verantwortungsvolle AI-Tools ein, die darauf abzielen, die Sicherheit und Effizienz von Agenten-Systemen zu verbessern. (Quelle: TheTuringPost)
AI21 Labs veröffentlicht Jamba 3B, kleine Modelle übertreffen Konkurrenz in Leistung : AI21 Labs hat Jamba 3B vorgestellt, ein MoE-Modell mit nur 3 Milliarden Parametern, das sowohl in Qualität als auch Geschwindigkeit hervorragende Leistungen erbringt, insbesondere bei der Verarbeitung langer Kontexte. Das Modell erreicht auf einem Mac eine Generierungsgeschwindigkeit von ca. 40 t/s, selbst bei über 32K Kontext, und übertrifft damit Qwen 3 4B und Llama 3.2 3B deutlich. Jamba 3B liegt im Intelligenzindex über Gemma 3 4B und Phi-4 Mini und behält seine Inferenzfähigkeit bei 256K Kontext vollständig bei, was das enorme Potenzial kleiner Modelle für Edge AI und On-Device-Bereitstellung zeigt. (Quelle: Reddit r/LocalLLaMA)

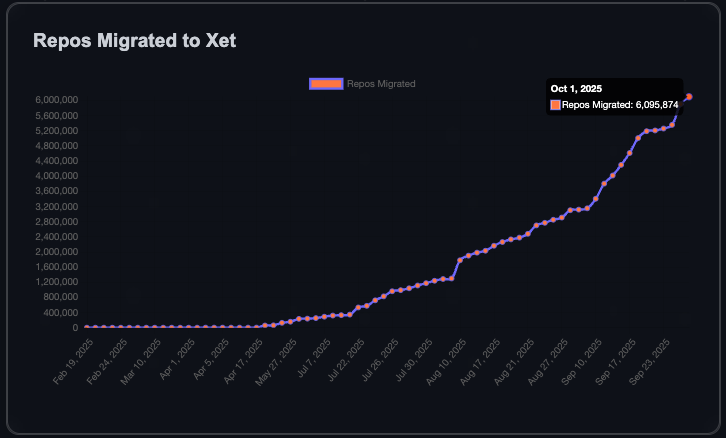
HuggingFace-Community wächst rasant, eine Million neue Repositories in 90 Tagen : Die HuggingFace-Community hat in den letzten 90 Tagen eine Million neue Modell-, Datensatz- und Space-Repositories hinzugefügt. Das Erreichen der ersten Million Repositories dauerte sechs Jahre, was bedeutet, dass alle 8 Sekunden ein neues Repository erstellt wird. Dieses Wachstum ist auf die effizientere Datenübertragung durch die Xet-Technologie zurückzuführen, und 40 % der privaten Repositories zeigen den Trend zur internen Nutzung von HuggingFace für den Modell- und Datenaustausch in Unternehmen. Das Ziel der Community ist es, 10 Millionen Repositories zu erreichen, was auf ein florierendes Open-Source-AI-Ökosystem hindeutet. (Quelle: Teknium1, reach_vb)
OpenAI GPT-5 zeigt bahnbrechende Fähigkeiten in der wissenschaftlichen Forschung : Das GPT-5-Modell von OpenAI hat eine wichtige Schwelle überschritten. Wissenschaftler konnten es erfolgreich für originelle Forschung in Bereichen wie Mathematik, Physik, Biologie und Informatik einsetzen. Dieser Fortschritt zeigt, dass GPT-5 nicht nur Fragen beantworten, sondern auch komplexe wissenschaftliche Untersuchungen anleiten und durchführen kann, was den Forschungsprozess erheblich beschleunigt. Einige Forscher äußerten, dass es nach der Veröffentlichung von GPT-5 Thinking und GPT-5 Pro nicht mehr sinnvoll sei, wissenschaftliche Forschung ohne deren Konsultation zu betreiben. (Quelle: tokenbender)
Ling-1T: Open-Source-Inferenzmodell mit Billionen Parametern veröffentlicht : Ling-1T, das Flaggschiffmodell der Ling 2.0-Serie, verfügt über insgesamt 1 Billion Parameter, wobei etwa 50 Milliarden Parameter pro Token aktiv sind, und wurde auf über 20 Billionen Inferenz-intensiven Tokens trainiert. Das Modell erreicht durch den Evo-CoT-Lehrplan und Linguistics-Unit RL eine skalierbare Inferenz und zeigt eine starke Balance zwischen Effizienz und Genauigkeit bei komplexen Inferenzaufgaben. Es verfügt auch über fortschrittliche visuelle Verständnisfähigkeiten und Frontend-Code-Generierung und kann Tools mit einer Erfolgsrate von etwa 70 % nutzen, was einen neuen Meilenstein für Open-Source-Intelligenz im Billionen-Bereich darstellt. (Quelle: scaling01, TheZachMueller)

Meta Ray-Ban Display definiert Mensch-Computer-Interaktion und Lernen neu : Die Meta Ray-Ban Display Smart Glasses integrieren Lern- und Übersetzungsfunktionen in den Alltag und bieten ein “unsichtbares Übersetzen” und “sofortiges visuelles Lernen”. Gesprächsuntertitel werden direkt auf den Gläsern angezeigt, und Benutzer können Informationen zu Sehenswürdigkeiten oder Kunstwerken erhalten, indem sie diese einfach ansehen. Darüber hinaus ermöglicht ein Neural Band die Gestensteuerung, sodass keine Mobiltelefone mehr benötigt werden. Diese Technologie verspricht, die Art und Weise, wie wir mit der Welt interagieren, lernen und uns verbinden, neu zu gestalten und markiert einen neuen Anfang für menschenzentriertes Computing. (Quelle: Ronald_vanLoon)
🧰 Tools
Synthesia stellt Copilot vor, der professionelle AI-Videobearbeitung ermöglicht : Synthesia hat Copilot veröffentlicht, einen professionellen AI-Videoeditor. Dieses Tool kann schnell Skripte schreiben, Wissensdatenbanken verbinden und visuelles Material intelligent empfehlen, als hätte man einen Kollegen, der sich mit dem Geschäft und der Synthesia-Plattform bestens auskennt. Copilot zielt darauf ab, den Videoproduktionsprozess zu vereinfachen, die Hürden für die professionelle Videoerstellung zu senken und Unternehmen sowie Inhaltserstellern effiziente, personalisierte AI-Videolösungen anzubieten. (Quelle: synthesiaIO, synthesiaIO)
GLIF Agent nutzt Sora 2 zur Reproduktion und Anpassung viraler Videos : GLIF hat einen Agenten entwickelt, der das Sora 2-Modell nutzen kann, um jedes virale Video zu reproduzieren. Der Agent analysiert zunächst das Originalvideo und generiert dann auf der Grundlage der Analyseergebnisse detaillierte Prompts. Benutzer können mit dem Agenten zusammenarbeiten, um die Prompts anzupassen und so hochgradig personalisierte AI-generierte Videos zu erstellen. Diese Technologie verspricht, leistungsstarke Funktionen zur Videoproduktion und Sekundärkreation in den Bereichen Inhaltserstellung und Marketing bereitzustellen. (Quelle: fabianstelzer)
Cloudflare AI Search und GroqInc kooperieren bei der Einführung einer “Dokumenten-Chat”-Vorlage : Cloudflare AI Search (ehemals AutoRAG) hat in Zusammenarbeit mit GroqInc eine neue Open-Source-“Dokumenten-Chat”-Vorlage veröffentlicht. Diese Vorlage kombiniert Groqs Inferenz-Engine mit AI Search, um Benutzern die Integration von konversationellen AI-Funktionen in Dokumente zu erleichtern und so Echtzeit-Fragen und -Antworten sowie Interaktionen mit Dokumenteninhalten zu ermöglichen. Diese Integration wird die Effizienz der Dokumentenabfrage und Informationsbeschaffung verbessern. (Quelle: JonathanRoss321)
HuggingFace führt In-Browser-GGUF-Bearbeitungsfunktion ein : HuggingFace unterstützt jetzt die direkte Bearbeitung von GGUF-Modellmetadaten im Browser, ohne dass das vollständige Modell heruntergeladen werden muss. Diese Funktion wird durch die Xet-Technologie ermöglicht und unterstützt partielle Dateiaktualisierungen, was die Modellverwaltung und den Iterationsprozess erheblich vereinfacht und die Arbeitseffizienz für Entwickler auf der HuggingFace-Plattform verbessert. (Quelle: reach_vb)
LangChain und LangGraph veröffentlichen v1.0 Alpha-Version und bitten um Entwickler-Feedback : LangChain und LangGraph haben die v1.0 Alpha-Version veröffentlicht, die neue Agent-Middleware-APIs, Standard-Output/Content-Blöcke und wichtige API-Updates einführt. Das Team lädt Entwickler aktiv ein, die neue Version zu testen und Feedback zu geben, um ihr AI-Agenten-Entwicklungsframework weiter zu verbessern und den Bau leistungsfähigerer AI-Anwendungen voranzutreiben. (Quelle: LangChainAI)
NeuML veröffentlicht ColBERT Nano-Serie von Mikro-Modellen mit weniger als einer Million Parametern : NeuML hat die ColBERT Nano-Modellreihe veröffentlicht, deren Parameterzahl jeweils unter 1 Million liegt (250K, 450K, 950K). Diese winzigen Modelle zeigen eine erstaunliche Leistung im “Late interaction”-Modus und beweisen, dass selbst extrem kleine Modelle bei bestimmten Aufgaben gute Ergebnisse erzielen können, was effiziente Lösungen für die AI-Bereitstellung in ressourcenbeschränkten Umgebungen bietet. (Quelle: lateinteraction, lateinteraction)

Google Senior Engineering Director teilt “Agent Design Patterns” : Ein Senior Engineering Director von Google hat kostenlos ein Buch mit dem Titel “Agent Design Patterns” geteilt, das die ersten systematischen Designprinzipien und Best Practices für den boomenden Bereich der AI Agenten bietet. Diese Ressource soll Entwicklern helfen, AI Agenten besser zu verstehen und zu bauen, und füllt eine Lücke in der systematischen Anleitung in diesem Bereich, wodurch sie zu einer wichtigen Referenz für AI Agenten-Entwickler werden könnte. (Quelle: dotey)

📚 Lernen
Forschung zu LLM-Halluzinationen und Sicherheitsausrichtungsmechanismen: Von internen Ursprüngen zu Minderungsstrategien : Studien zeigen, dass LLM-Inferenzmodelle vor der Generierung der endgültigen Ausgabe ein “Ablehnungskliff” aufweisen können, d.h. eine drastische Abnahme der Ablehnungsabsicht. Mithilfe des DST-Frameworks haben Forscher gezeigt, dass Halluzinationen in einer modellspezifischen “Commitment-Schicht” unvermeidlich werden, und ein kleines Inferenzmodell namens HalluGuard vorgeschlagen, das klinische Signale und Daten integriert, um Halluzinationen in RAG zu mindern. Dies bietet eine mechanistische Erklärung und praktische Strategien für die LLM-Sicherheitsausrichtung und Halluzinationsminderung. (Quelle: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
ASPO optimiert LLM Reinforcement Learning und löst das IS-Raten-Missverhältnisproblem : ASPO (Asymmetric Importance Sampling Policy Optimization) ist eine neue LLM-Nachtrainingsmethode, die den grundlegenden Fehler des Missverhältnisses der Importance Sampling (IS)-Rate für positive Advantage-Tokens im traditionellen Reinforcement Learning behebt. Durch das Umkehren der IS-Rate für positive Advantage-Tokens und die Einführung eines Soft-Dual-Clipping-Mechanismus kann ASPO niedrigwahrscheinliche Tokens stabiler aktualisieren, eine vorzeitige Konvergenz verhindern und die Leistung in Coding- und mathematischen Inferenz-Benchmarks erheblich verbessern. (Quelle: HuggingFace Daily Papers)
Fathom-DeepResearch: Ein Agenten-System für langfristige Informationsbeschaffung und -synthese : Fathom-DeepResearch ist ein Agenten-System, bestehend aus Fathom-Search-4B und Fathom-Synthesizer-4B, das speziell für komplexe, offene Informationsbeschaffungsaufgaben entwickelt wurde. Fathom-Search-4B optimiert Echtzeit-Websuche und Webseitenabfragen durch Multi-Agenten-Selbstspiel-Datensätze und Reinforcement Learning. Fathom-Synthesizer-4B wandelt mehrstufige Suchergebnisse in strukturierte Berichte um. Das System zeigt in mehreren Benchmarks hervorragende Leistungen und demonstriert eine starke Generalisierungsfähigkeit für Inferenzaufgaben wie HLE und AIME-25. (Quelle: HuggingFace Daily Papers)
AgentFlow: Optimierung von In-Flow-Agenten-Systemen für effiziente Planung und Tool-Nutzung : AgentFlow ist ein trainierbares In-Flow-Agenten-Framework, das seinen Planer direkt in einem mehrstufigen Interaktionszyklus optimiert, indem es vier Module – Planer, Ausführer, Verifizierer und Generator – koordiniert. Es verwendet Flow-based Group Refined Policy Optimization, um das Problem der Kreditvergabe bei langfristigen, spärlichen Belohnungen zu lösen. AgentFlow übertrifft in zehn Benchmarks mit einem 7B-Backbone-Modell die SOTA-Baselines, mit einer signifikanten Verbesserung der durchschnittlichen Genauigkeit bei Such-, Agenten-, Mathematik- und Wissenschaftsaufgaben, und übertrifft sogar GPT-4o. (Quelle: HuggingFace Daily Papers)
Systematische Studie zum Einfluss von Codedaten auf die LLM-Inferenzfähigkeit : Die Forschung untersucht durch ein systematisches, datenzentriertes Framework, wie Codedaten die LLM-Inferenzfähigkeit verbessern können. Durch die Erstellung paralleler Anweisungsdatensätze in zehn Programmiersprachen und das Anwenden struktureller oder semantischer Störungen wurde festgestellt, dass LLMs empfindlicher auf strukturelle als auf semantische Störungen reagieren, insbesondere bei mathematischen und Code-Aufgaben. Pseudocode und Flussdiagramme sind ebenso effektiv wie Code, und der Syntaxstil beeinflusst auch aufgabenspezifische Gewinne (Python ist vorteilhaft für Natural Language Inference, Java/Rust für Mathematik). (Quelle: HuggingFace Daily Papers)
DeepEvolve: Ein wissenschaftlicher Algorithmen-Entdeckungsagent, der Deep Research und algorithmische Evolution vereint : DeepEvolve ist ein Agent, der Deep Research mit algorithmischer Evolution kombiniert, um wissenschaftliche Algorithmen durch externe Wissensbeschaffung, dateiübergreifende Codebearbeitung und System-Debugging in einem feedbackgesteuerten iterativen Zyklus zu entdecken. Er schlägt nicht nur neue Hypothesen vor, sondern verfeinert, implementiert und testet sie auch, wodurch oberflächliche Verbesserungen und ineffektive Überverfeinerungen vermieden werden. In neun Benchmarks aus den Bereichen Chemie, Mathematik, Biologie, Materialien und Patente verbessert DeepEvolve kontinuierlich die ursprünglichen Algorithmen, generiert ausführbare neue Algorithmen und erzielt nachhaltige Gewinne. (Quelle: HuggingFace Daily Papers)
AI/ML Lernpfad und Kernkonzepte : Die Community hat einen umfassenden Lernpfad für AI, Machine Learning und Deep Learning geteilt, der von grundlegenden Konzepten bis hin zu fortgeschrittenen Techniken (wie Agentic AI, LLM-Generierungsparameter) reicht. Diese Ressourcen sollen Fachleuten, die in den AI/ML-Bereich einsteigen oder ihr Wissen vertiefen möchten, eine strukturierte Lernanleitung bieten, um die Fähigkeiten von der Modellentwicklung bis zur Bereitstellung und dem Betrieb zu beherrschen und zu verstehen, wie AI den Branchenwandel vorantreibt. (Quelle: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

AI-Benchmarks und Lernressourcen: HLE, Konferenzen und GPU-Kostenmanagement : Die Community diskutierte mehrere AI-Lern- und Praxisressourcen. CAIS veröffentlichte den dynamisch aktualisierten Benchmark “Humanity’s Last Exam”, um sich an verbesserte Modellleistungen anzupassen. Gleichzeitig wurden Leitfäden für die Teilnahme an Machine Learning-Konferenzen und Strategien für kostengünstige LLM-Entwicklung bereitgestellt, einschließlich Pay-as-you-go-GPUs und dem lokalen Betrieb kleiner Modelle. Darüber hinaus bot der GPU Mode Hackathon Entwicklern eine Plattform zum Lernen und Austausch. (Quelle: clefourrier, Reddit r/MachineLearning, Reddit r/MachineLearning, Reddit r/MachineLearning, danielhanchen)

OneFlow: Konkurrierende multimodale und verschachtelte generative Modelle : OneFlow ist das erste nicht-autoregressive multimodale Modell, das variable Längen und konkurrierende gemischte Modus-Generierung unterstützt. Es kombiniert einen In-Situ-Bearbeitungsfluss für diskrete Text-Tokens mit einem Fluss-Matching im latenten Bildraum. OneFlow erreicht die konkurrierende Text-Bild-Synthese durch hierarchisches Sampling, wobei der Inhalt Vorrang vor der Grammatik hat. Experimente zeigen, dass OneFlow bei Generierungs- und Verständnisaufgaben autoregressive Baselines übertrifft, die Trainings-FLOPs um bis zu 50 % reduziert und neue Fähigkeiten für konkurrierende Generierung, iterative Verfeinerung und natürliche inferenzielle Generierung freischaltet. (Quelle: HuggingFace Daily Papers)
Equilibrium Matching: Ein generatives Modellierungsframework basierend auf impliziten Energiemodellen : Equilibrium Matching (EqM) ist ein neues generatives Modellierungsframework, das die nicht-gleichgewichtigen, zeitabhängigen Dynamiken traditioneller Diffusions- und Flussmodelle aufgibt und stattdessen die Gleichgewichtsgradienten einer impliziten Energielandschaft lernt. EqM verwendet einen optimierungsbasierten Sampling-Prozess, der durch Gradientenabstieg auf der gelernten Landschaft sampelt, und erreicht eine SOTA-Leistung von ImageNet 256×256 FID 1.90. Es verarbeitet auch auf natürliche Weise Aufgaben wie partielle Entrauschung, OOD-Erkennung und Bildsynthese. (Quelle: HuggingFace Daily Papers)
💼 Business
OpenAI und AMD schließen Chip-Kooperationsvertrag ab, fordern Nvidias Dominanz heraus : OpenAI und AMD haben einen auf fünf Jahre angelegten Chip-Kooperationsvertrag im Wert von mehreren Milliarden US-Dollar unterzeichnet, um Nvidias Dominanz auf dem AI-Chipmarkt herauszufordern. Dieser Schritt ist Teil von OpenAIs Strategie zur Diversifizierung der Chipversorgung; das Unternehmen hatte zuvor auch eine Zusammenarbeit mit Nvidia vereinbart. Dieser Vertrag unterstreicht den enormen Bedarf der AI-Branche an Hochleistungs-Computing-Hardware und das Streben nach Diversifizierung der Lieferketten. (Quelle: MIT Technology Review)
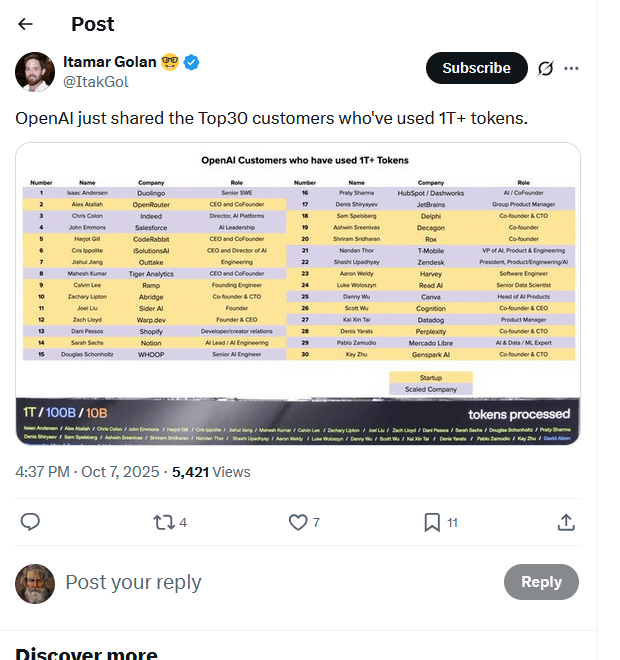
OpenAI-Top-Kundenliste durchgesickert, 30 Unternehmen verbrauchen Billionen von Tokens : Eine angeblich geleakte Liste der Top-Kunden von OpenAI kursiert online und zeigt, dass 30 Unternehmen über eine Billion Tokens durch ihre Modelle verarbeitet haben. Diese Liste (darunter Duolingo, OpenRouter, Salesforce, Canva, Perplexity usw.) offenbart die schnelle Entstehung einer AI-Inferenzökonomie und zeigt vier Haupttypen: AI-native Builder, AI-Integratoren, AI-Infrastrukturanbieter und vertikale AI-Lösungsanbieter. Der Tokens-Verbrauch wird als neuer Maßstab für den tatsächlichen Wert und den Geschäftsfortschritt von AI-Anwendungen angesehen. (Quelle: Reddit r/ArtificialInteligence, 量子位)
Singapur wird zum Urheberrechts-Sicherheitshafen für AI-Entwicklung und zieht globale AI-Unternehmen an : Singapur hat sein Urheberrechtsgesetz geändert und eine Bestimmung zur Verteidigung der Computeranalyse eingeführt, die klar festlegt, dass die computergestützte Datenanalyse zur Verbesserung von AI-Systemen vom Urheberrechtsverstoß ausgenommen ist und sogar vertragliche Vereinbarungen außer Kraft setzt. Dieser Schritt zielt darauf ab, Singapur zum weltweit attraktivsten Standort für die Entwicklung von AI-Modellen zu machen, Investitionen und Innovationen anzuziehen und einen starken Kontrast zur vorsichtigen Haltung anderer Regionen wie Europa und den USA in Bezug auf AI-Urheberrechte zu bilden. Obwohl der Schutzbereich auf Singapur beschränkt ist, bietet er eine wichtige Absicherung für die Entwicklung von Basismodellen. (Quelle: Reddit r/ArtificialInteligence)
🌟 Community
AI-Finanzierungsdeals und Sorgen vor einer Blase : In den sozialen Medien werden AI-Finanzierungsdeals in Frage gestellt, da viele Transaktionen eher wie Versuche klingen, Aktienkurse künstlich in die Höhe zu treiben, anstatt auf tatsächlichem Wert zu basieren. Kommentare weisen darauf hin, dass viele AI-Produkte auf lokalen oder regionalen Märkten keine tatsächliche Anwendung finden und Unternehmen sich stattdessen über die Ineffektivität von AI-Produkten beschweren. Dieses Phänomen wird eher als Marktspekulation denn als echte Kapitalbildung und Spillover-Effekt interpretiert. Gleichzeitig gibt es eine Diskussion darüber, ob AI Digital Twins im Marketing “Hype oder Zukunft” sind. (Quelle: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

ChatGPT-Inhaltszensur und Kontroversen um die Benutzererfahrung : ChatGPT-Benutzer beschweren sich über die übermäßig strenge Inhaltszensur der Plattform, die selbst einfache Rezeptanfragen oder Umarmungen zwischen Charakteren als “sexuell anzüglich” kennzeichnet, während sie gegenüber gewalttätigen Inhalten unempfindlich ist. Benutzer halten ChatGPT für “Müll” und “überfürsorglich” und fragen sich, ob OpenAI seine besten Mitarbeiter verloren hat. Gleichzeitig berichten Benutzer auch über Probleme mit der LaTeX-Darstellung in der ChatGPT App. Dies hat dazu geführt, dass einige Benutzer ihre Abonnements gekündigt haben und OpenAI auffordern, die Kreativität nicht länger zu ersticken. (Quelle: Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT, jeremyphoward)

AI-Inhalts-Backlash und Sorgen der Kreativen : Mit der zunehmenden Verbreitung von AI-generierten Inhalten gibt es eine starke Anti-AI-Stimmung in der Gesellschaft, insbesondere in den Bereichen Kunst und Kreativität. Bekannte Content Creator wie YouTuber MrBeast äußerten Bedenken, dass AI-Videos die Existenzgrundlage von Millionen von Kreativen bedrohen könnten. Auch Taylor Swifts Fans kritisierten ihre AI-generierten Werbevideos als “billig und grob”. Dieser Backlash spiegelt die Ängste der Kreativen vor den Auswirkungen der AI-Technologie auf traditionelle Industrien sowie die Sorge um die Qualität und Authentizität von Inhalten wider. (Quelle: Reddit r/artificial, MIT Technology Review)
Anwendungsprobleme und Aussichten von AI im Gaming-Bereich : Die Community diskutierte die mächtigen, kreativen, interessanten und dynamischen Eigenschaften der AI-Technologie, stellte jedoch die Frage, warum bisher kein populäres Spiel AI umfassend nutzt. Einige argumentierten, dass AI bereits weit verbreitet in der Entwicklung eingesetzt wird, aber die lokalen Betriebskosten von AI-Modellen hoch sind und Spieleentwickler dazu neigen, die Erzählung zu kontrollieren. Andere meinten, dass Entwickler sich nur auf traditionelle Blockbuster konzentrieren und neue Ideen vernachlässigen. Dies spiegelt die technischen, Kosten- und kreativen Herausforderungen wider, denen AI bei der Implementierung im Gaming-Bereich gegenübersteht. (Quelle: Reddit r/artificial)
Perplexity hebt die Nützlichkeit von AI-Suche durch Cristiano Ronaldo hervor : Fußballsuperstar Cristiano Ronaldo nutzte das AI-Suchtool Perplexity bei der Vorbereitung seiner Rede für den Prestige Globe Award. Er erklärte, dass Perplexity ihm geholfen habe, die Bedeutung der Auszeichnung zu verstehen und seine Nervosität zu überwinden. Dieses Ereignis wurde von Perplexity offiziell und in den sozialen Medien weit verbreitet und unterstreicht den praktischen Wert der AI-Suche bei der Bereitstellung schneller, präziser Informationen sowie ihr Potenzial zur Förderung durch den Prominenten-Effekt. (Quelle: AravSrinivas, AravSrinivas)
Google AI-Forschung erhält Nobelpreise und Kontroversen : Google hat innerhalb von zwei Jahren drei Nobelpreise erhalten, darunter Demis Hassabis (AlphaFold) und Geoff Hinton (AI). Diese Leistung wird als Ausdruck von Googles langfristigen Forschungsinvestitionen und Ambitionen angesehen. Jürgen Schmidhuber stellte jedoch die Frage nach Plagiaten beim Nobelpreis für Physik 2024 und argumentierte, dass die Ergebnisse stark mit früheren Forschungen übereinstimmen und nicht angemessen zitiert wurden, was eine Diskussion über akademische Ethik und Urheberschaft im AI-Bereich auslöste. (Quelle: Yuchenj_UW, SchmidhuberAI, SchmidhuberAI)

AI-Rechenbedarf und philosophische Debatte über den Weg zu AGI/ASI : Angesichts der enormen Rechenressourcen, die für die AI-Videogenerierung erforderlich sind, wird argumentiert, dass dieser riesige, auf realen Anforderungen basierende Rechenaufwand eher darauf hindeutet, dass allgemeine künstliche Intelligenz (AGI) und übermenschliche künstliche Intelligenz (ASI) noch ferne Fantasien sind. Diese Diskussion spiegelt die Überlegungen der Branche über den Entwicklungspfad von AI wider, nämlich ob der aktuelle Erfolg von AI in spezifischen Anwendungen Ressourcen ablenken und das Erreichen größerer Ziele verzögern könnte. Gleichzeitig betont Richard Sutton, dass das Wesen des Lernens aktives Verhalten des Agenten und nicht passives Training ist. (Quelle: fabianstelzer, Plinz, dwarkesh_sp)
Auswirkungen von AI auf den Arbeitsmarkt: Stundenlöhne für promovierte Datenannotatoren sinken : In sozialen Medien wird diskutiert, dass die Stundenlöhne für promovierte Datenannotatoren aufgrund eines Überangebots von 100 US-Dollar/Stunde auf 50 US-Dollar/Stunde gesunken sind. Zuvor hatte OpenAI promovierte Datenannotatoren für 100 US-Dollar/Stunde eingestellt. Dieses Phänomen spiegelt den verschärften Wettbewerb auf dem AI-Datenannotationsmarkt und die Veränderungen in der Nachfrage nach hochqualifizierten Datenannotationsfachkräften wider. (Quelle: teortaxesTex)
AI-gestützte Software-Ingenieur-Tools erhalten Finanzierung und Auswirkungen auf den Beruf : Das Startup Relace, das sich auf Tools für AI-gesteuerte Software-Ingenieure konzentriert, hat in einer Serie-A-Finanzierungsrunde 23 Millionen US-Dollar unter der Führung von Andreessen Horowitz erhalten. Dies zeigt, dass die AI-Toolchain in tiefere Bereiche der autonomen AI-Entwicklung vordringt. Gleichzeitig diskutieren Ingenieure, wie AI-Codierungstools ihre Arbeitsweise verändern, und sind der Meinung, dass menschliche Kreativität und Problemlösungsfähigkeiten trotz der Beherrschung von AI-Tools weiterhin den Kernwert darstellen. (Quelle: steph_palazzolo, kylebrussell)
Aufstieg und Fall des “Vibe Coding”-Kulturphänomens : In den sozialen Medien wurde der Aufstieg und Fall des Konzepts “Vibe Coding” diskutiert. Einige sehen Vibe Coding als eine entspannte Art des Programmierens, während andere meinen, es sei “gestorben”. Die Diskussionen erwähnten auch AI-generierte Inhalte wie “Bob Ross vibe coding”, was die Erkundung und Reflexion der Entwicklergemeinschaft über die Programmierkultur und AI-gestützte Programmieransätze widerspiegelt. (Quelle: arohan, Ronald_vanLoon, nptacek)
💡 Sonstiges
US-Regierung könnte Milliarden-Finanzierung für Kohlenstoffabscheidungsanlagen streichen : Das US-Energieministerium könnte die Finanzierung von zwei großen Anlagen zur direkten Luft-Kohlenstoffabscheidung in Milliardenhöhe einstellen. Diese Projekte sollten ursprünglich über 1 Milliarde US-Dollar an staatlichen Zuschüssen erhalten, befinden sich aber derzeit im “Terminierungsstatus”. Obwohl das Energieministerium angibt, noch keine endgültige Entscheidung getroffen zu haben und zuvor bereits über 200 Projekte zur Einsparung von 7,5 Milliarden US-Dollar eingestellt hat, löst diese Unsicherheit in der Branche Bedenken hinsichtlich der Entwicklung der US-Klimaschutztechnologie und der internationalen Wettbewerbsfähigkeit aus. (Quelle: MIT Technology Review)

Neue Fortschritte in der Robotik: Von flexiblen Handgelenken bis zu bionischen Käfern und humanoiden Robotern : Im Bereich der Robotik wurden mehrere Fortschritte erzielt. Ein neuartiges paralleles Roboterhandgelenk ermöglicht flexible, menschenähnliche Bewegungen auf engstem Raum und verbessert die Operationsgenauigkeit. Gleichzeitig entwickeln Forscher bionische Roboter-Käfer mit Rucksäcken, die für die Katastrophenhilfe eingesetzt werden sollen. Darüber hinaus wurde über die Interaktion humanoider Roboter mit Motorrädern berichtet, was die Fähigkeit der bionischen Technologie zur Simulation menschlichen Verhaltens demonstriert. Diese Fortschritte treiben gemeinsam die Grenzen der Robotik in Bezug auf die Anpassungsfähigkeit an komplexe Umgebungen und die Mensch-Maschine-Interaktion voran. (Quelle: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
