
Schlüsselwörter:Meta, Tencent Hunyuan Bild 3.0, xAI Grok 4 Fast, OpenAI Sora 2, ByteDance Self-Forcing++, Alibaba Qwen, vLLM, GPT-5-Pro, Metakognitive Wiederverwendungsmechanismus, Generalisierter kausaler Aufmerksamkeitsmechanismus, Multimodales Inferenzmodell, Minütliche Videogenerierung, Haltungserkennende Modegenerierung
🔥 Fokus
Meta-Methode verkürzt Denkketten, vermeidet redundante Ableitungen : Meta, das Mila-Quebec AI Institute und andere haben gemeinsam einen “metakognitiven Wiederverwendungs”-Mechanismus vorgestellt. Dieser zielt darauf ab, das Problem der Token-Inflation und erhöhten Latenz zu lösen, die durch redundante Ableitungen bei der Inferenz großer Modelle entstehen. Der Mechanismus ermöglicht es dem Modell, Lösungsansätze zu überprüfen und zusammenzufassen, gängige Schlussfolgerungsmuster als “Verhalten” in einem “Verhaltenshandbuch” zu speichern und bei Bedarf direkt aufzurufen, ohne sie neu ableiten zu müssen. Experimente zeigen, dass dieser Mechanismus bei mathematischen Benchmarks wie MATH und AIME unter Beibehaltung der Genauigkeit den Verbrauch von Inferenz-Tokens um bis zu 46% reduzieren und die Effizienz des Modells sowie seine Fähigkeit, neue Wege zu erkunden, verbessern kann. (Quelle: 量子位)

Tencent Hunyuan Image 3.0 führt globale AI-Bilderzeugungs-Rangliste an : Tencent Hunyuan Image 3.0 belegt Platz eins in der LMArena Text-zu-Bild-Rangliste und übertrifft damit Google Nano Banana, ByteDance Seedream und OpenAI gpt-Image. Das Modell nutzt eine native multimodale Architektur, basiert auf Hunyuan-A13B und verfügt über über 80 Milliarden Gesamtparameter. Es kann verschiedene Modalitäten wie Text, Bilder, Videos und Audio einheitlich verarbeiten und besitzt leistungsstarke Fähigkeiten im Bereich semantisches Verständnis, Sprachmodell-Denken und Weltwissen-Schlussfolgerung. Zu seinen Kerntechnologien gehören ein verallgemeinerter kausaler Aufmerksamkeitsmechanismus und eine zweidimensionale Positionskodierung, und es wurde eine automatische Auflösungsprädiktion eingeführt. Das Modell baut Daten durch dreistufige Filterung und ein hierarchisches Beschreibungssystem auf und verwendet eine vierstufige progressive Trainingsstrategie, um die Realitätsnähe und Klarheit der generierten Bilder effektiv zu verbessern. (Quelle: 量子位)

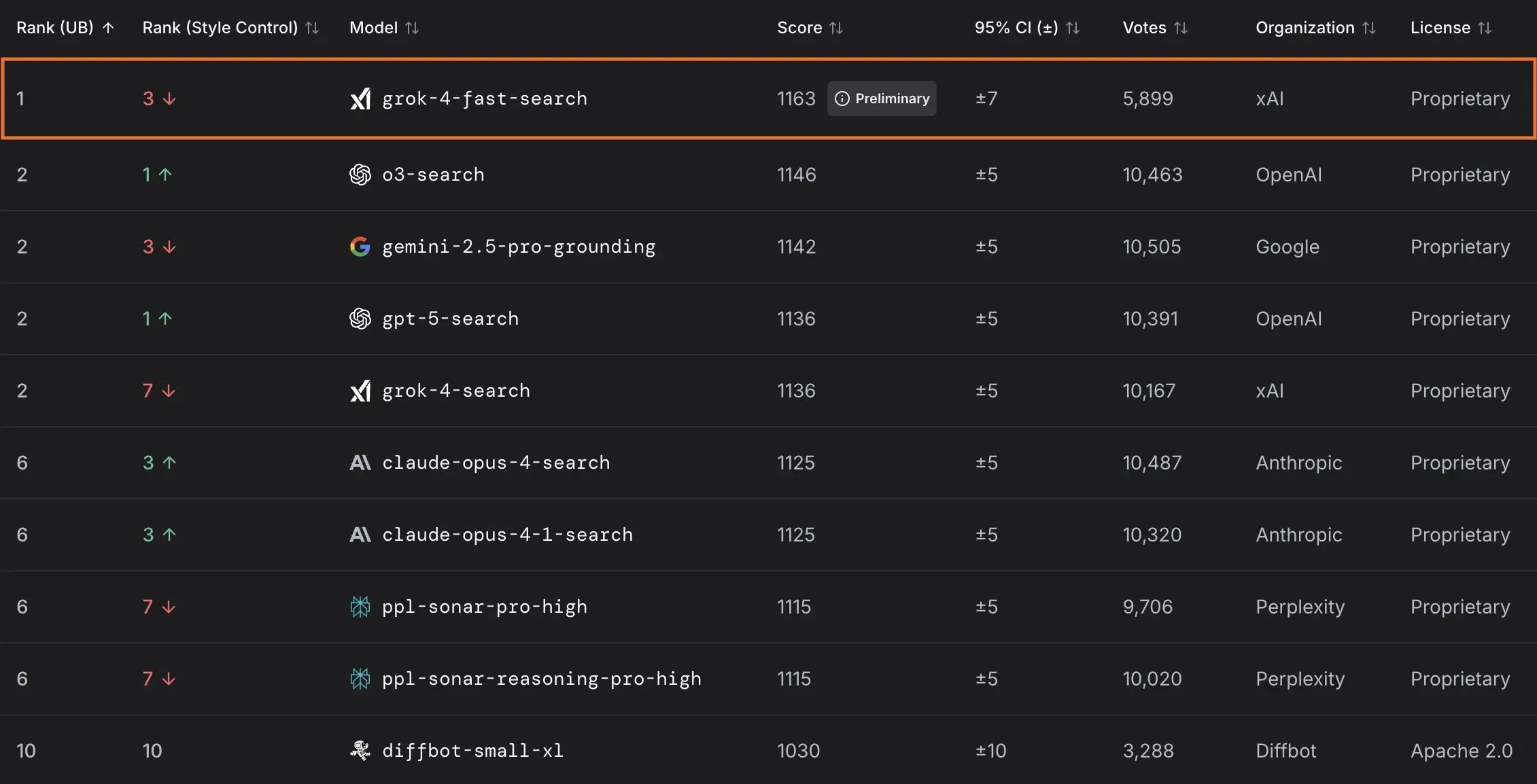
xAI veröffentlicht Grok 4 Fast Modell und kooperiert mit der US-Regierung : xAI hat Grok 4 Fast vorgestellt, ein multimodales Inferenzmodell mit einem 2M Kontextfenster, das darauf abzielt, kostengünstige intelligente Dienste anzubieten. Das Modell wurde allen Nutzern kostenlos zur Verfügung gestellt. In Zusammenarbeit mit der US-Bundesregierung erhalten alle Bundesbehörden 18 Monate lang kostenlosen Zugang zu ihren Spitzen-AI-Modellen (Grok 4, Grok 4 Fast), und ein Team von Ingenieuren wird entsandt, um die Regierung bei der Nutzung von AI zu unterstützen. Darüber hinaus hat xAI OpenBench zur Bewertung der Leistung und Sicherheit von LLMs veröffentlicht und Grok Code Fast 1 eingeführt, das bei Kodierungsaufgaben hervorragende Leistungen erbringt. (Quelle: xai, xai, xai, JonathanRoss321)
🎯 Trends
OpenAI kündigt AI-Produkte für Verbraucher und Sora 2 Updates an : UBS prognostiziert, dass die OpenAI-Entwicklerkonferenz die Veröffentlichung von AI-Produkten für Verbraucher in den Mittelpunkt stellen wird, möglicherweise einschließlich eines AI-Agenten für Reisebuchungen. Gleichzeitig wird das Videogenerierungsmodell Sora 2 getestet, wobei Nutzer feststellen, dass die generierten Inhalte oft humorvoll sind. OpenAI hat auch ein Auflösungsproblem im HD-Modus des Sora 2 Pro Modells behoben, das nun Auflösungen von 17921024 oder 10241792 unterstützt und Videos von bis zu 15 Sekunden Länge generieren kann. Das tägliche Generierungslimit wurde jedoch auf 30 Mal reduziert. (Quelle: teortaxesTex, francoisfleuret, fabianstelzer, TomLikesRobots, op7418, Reddit r/ChatGPT)

ByteDance führt Minuten-Video-Generierungsmodell ein : ByteDance hat eine neue Methode namens Self-Forcing++ veröffentlicht, die hochwertige Videos von bis zu 4 Minuten und 15 Sekunden Länge generieren kann. Diese Methode kann Diffusionsmodelle erweitern, ohne ein langes Video-Lehrermodell oder erneutes Training zu benötigen, und dabei die Wiedergabetreue und Konsistenz der generierten Videos beibehalten. (Quelle: _akhaliq)
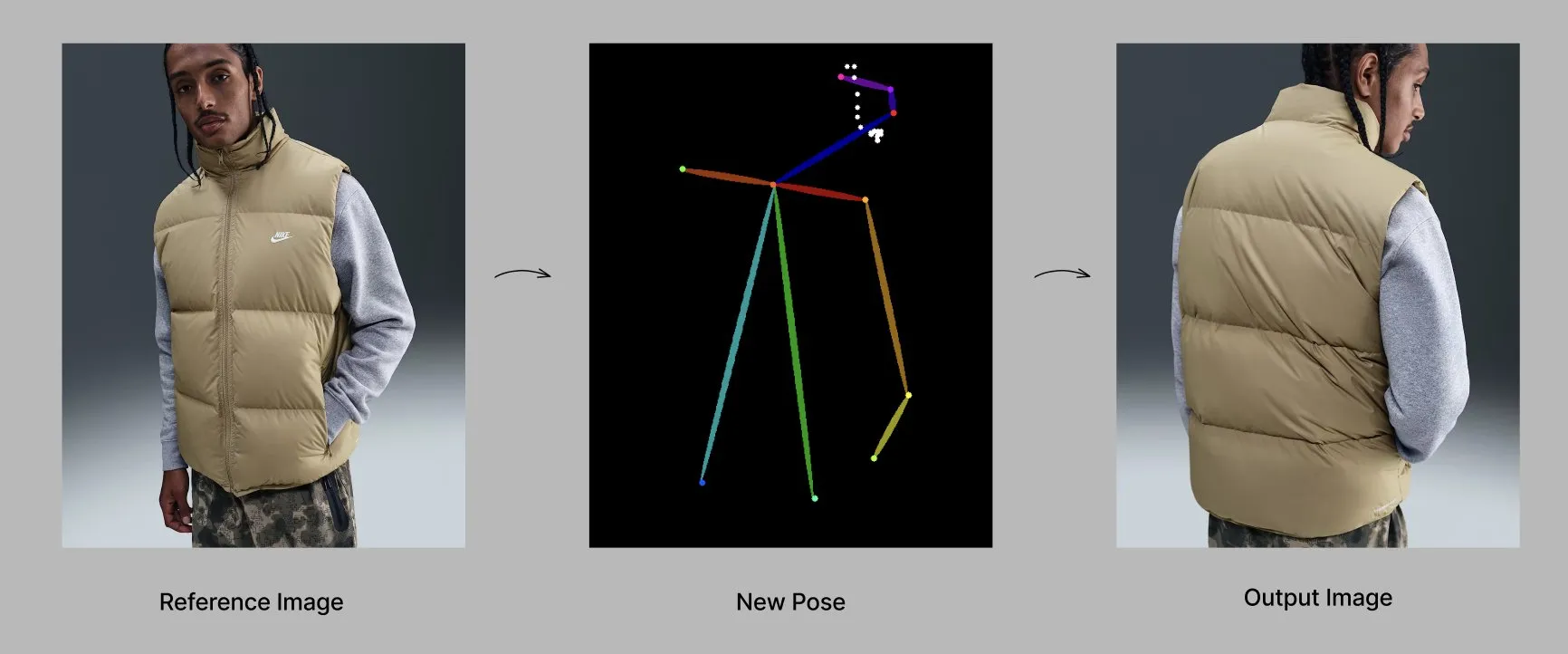
Qwen-Modell führt neue Funktionen und Anwendungen ein : Das Alibaba Qwen-Team führt schrittweise Personalisierungsfunktionen wie Gedächtnis und benutzerdefinierte Systemanweisungen ein, die sich derzeit in begrenzten Tests befinden. Gleichzeitig zeigt das Qwen-Image-Edit-2509-Modell fortschrittliche Fähigkeiten in der posenbewussten Modegenerierung, wodurch durch Feinabstimmung die Generierung von hochwertigen Modellen aus verschiedenen Blickwinkeln ermöglicht wird. (Quelle: Alibaba_Qwen, Alibaba_Qwen)
vLLM und PipelineRL erweitern Grenzen der RL-Community : Das vLLM-Projekt unterstützt die RL-Community bei neuen Durchbrüchen im Bereich Reinforcement Learning, einschließlich besserer On-Policy-Daten, partieller Rollouts und In-Flight-Gewichtsaktualisierungen, die KV-Caches während der Inferenz mischen. PipelineRL ermöglicht skalierbares asynchrones RL, indem es die Inferenz fortsetzt, während sich die Gewichte ändern und der KV-Zustand unverändert bleibt, und unterstützt In-Flight-Gewichtsaktualisierungen. (Quelle: vllm_project, Reddit r/LocalLLaMA)

GPT-5-Pro löst komplexe mathematische Probleme : GPT-5-Pro hat “Yu Tsumuras 554. Problem” innerhalb von 15 Minuten eigenständig gelöst. Es ist das erste Modell, das diese Aufgabe vollständig gelöst hat, und demonstriert damit seine starken mathematischen Problemlösungsfähigkeiten. (Quelle: Teknium1)

SAP macht AI zum Kern der Unternehmens-Workflows : SAP plant, auf der Connect 2025-Konferenz seine Vision zu präsentieren, AI zum Kern der Unternehmens-Workflows zu machen. Durch eingebaute AI sollen Echtzeitdaten in Entscheidungen umgewandelt und AI-Agenten für proaktive Operationen genutzt werden. SAP betont den Aufbau von Vertrauen und die Bereitstellung aktiver Unterstützung von Anfang an sowie die Sicherstellung lokaler Flexibilität und Compliance. (Quelle: TheRundownAI)

Salesforce veröffentlicht CoDA-1.7B Text-Diffusions-Kodierungsmodell : Salesforce Research hat CoDA-1.7B veröffentlicht, ein Text-Diffusions-Kodierungsmodell, das bidirektional parallele Token-Ausgabe ermöglicht. Das Modell ist schneller in der Inferenzgeschwindigkeit, und mit 1,7 Milliarden Parametern kann es mit einem 7B-Modell mithalten. Es zeigt hervorragende Leistungen in Benchmarks wie HumanEval, HumanEval+ und EvalPlus. (Quelle: ClementDelangue)

Google Gemini 3.0 konzentriert sich auf EQ, Wettbewerb mit OpenAI verschärft sich : Google wird voraussichtlich Gemini 3.0 veröffentlichen, das sich angeblich auf “emotionale Intelligenz” (EQ) konzentrieren wird. Dies wird als starke Herausforderung für OpenAI angesehen. Dieser Schritt deutet auf die Entwicklung von AI-Modellen im Bereich emotionales Verständnis und Interaktion hin und lässt einen weiteren Eskalationsschritt im Wettbewerb zwischen den AI-Giganten erwarten. (Quelle: Reddit r/ChatGPT)
Entwicklung der Robotik- und Automatisierungstechnologie : Die Robotikbranche setzt ihre Innovationen fort, darunter omnidirektionale mobile humanoide Roboter für Logistikoperationen, autonome mobile Roboter-Lieferdienste, die Roboterarme und Schließfächer kombinieren, sowie der 12-Motor-Roboterhund “Cara”, der von US-Studenten durch Seilantrieb und cleveres mathematisches Design entwickelt wurde. Darüber hinaus wurde der erste “Wuji Hand”-Roboter offiziell vorgestellt. (Quelle: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

🧰 Tools
GPT4Free (g4f) Projekt bietet kostenlose LLM- und Mediengenerierungstools : GPT4Free (g4f) ist ein Community-gesteuertes Projekt, das darauf abzielt, verschiedene zugängliche LLM- und Mediengenerierungsmodelle zu integrieren. Es bietet einen Python-Client, eine lokale Web-GUI, eine OpenAI-kompatible REST API und einen JavaScript-Client. Es unterstützt Multi-Provider-Adapter, darunter OpenAI, PerplexityLabs, Gemini, MetaAI und andere, sowie Bild-/Audio-/Videogenerierung und Medienpersistenz, um den offenen Zugang zu AI-Tools zu verbreiten. (Quelle: GitHub Trending)

LLM-Tool-Design und Prompt-Engineering Best Practices : Beim Schreiben von Tools, die für AI leichter verständlich sind, haben Tool-Definition, Systemanweisungen und Benutzer-Prompts nacheinander Priorität. Tool-Namen und -Beschreibungen sind entscheidend, sollten intuitiv und klar sein und Mehrdeutigkeiten vermeiden. Parameter sollten so wenige wie möglich sein und Enumerationen oder Ober-/Untergrenzen bereitstellen. Die Verwendung von zu stark verschachtelten strukturierten Parametern sollte vermieden werden, um die Antwortgeschwindigkeit zu erhöhen. Indem das Modell Prompts schreibt und Feedback gibt, kann das Verständnis großer Modelle für Tools effektiv verbessert werden. (Quelle: dotey)
Zen MCP nutzt Gemini CLI, um Claude Code-Guthaben zu sparen : Das Zen MCP-Projekt ermöglicht es Benutzern, Gemini CLI direkt in Tools wie Claude Code zu verwenden, wodurch der Token-Verbrauch von Claude Code erheblich reduziert und das kostenlose Guthaben von Gemini genutzt werden kann. Das Tool unterstützt die Delegation von Aufgaben zwischen verschiedenen AI-Modellen und die Beibehaltung eines gemeinsamen Kontexts, zum Beispiel die Nutzung von GPT-5 für die Planung, Gemini 2.5 Pro für die Überprüfung, Sonnet 4.5 für die Implementierung und dann Gemini CLI für Code-Reviews und Unit-Tests, um eine effiziente und kostengünstige AI-gestützte Entwicklung zu ermöglichen. (Quelle: Reddit r/ClaudeAI)
Open-Source LLM-Bewertungstool Opik : Opik ist ein Open-Source-LLM-Bewertungstool zum Debuggen, Bewerten und Überwachen von LLM-Anwendungen, RAG-Systemen und Agentic-Workflows. Es bietet umfassendes Tracking, automatisierte Bewertung und produktionsreife Dashboards, um Entwicklern zu helfen, ihre AI-Modelle besser zu verstehen und zu optimieren. (Quelle: dl_weekly)
Claude Sonnet 4.5 hervorragend im Schreiben von Tampermonkey-Skripten : Claude Sonnet 4.5 zeigt hervorragende Leistungen beim Schreiben von Tampermonkey-Skripten. Benutzer können mit einem einzigen Prompt das Thema von Google AI Studio ändern, was seine starken Fähigkeiten in der Automatisierung von Browser-Operationen und der Anpassung von Benutzeroberflächen demonstriert. (Quelle: Reddit r/ClaudeAI)

Lokale Bereitstellung des Phi-3-mini-Modells : Benutzer versuchen, das mit Unsloth auf Google Colab feinabgestimmte Phi-3-mini-4k-instruct-bnb-4bit-Modell auf lokalen Maschinen bereitzustellen. Das Modell soll Zusammenfassungen extrahieren und Felder aus Texten parsen. Ziel der Bereitstellung ist es, Text aus DataFrames lokal zu lesen, ihn durch das Modell zu verarbeiten und die Ausgabe in einem neuen DataFrame zu speichern, auch in Umgebungen mit geringer Konfiguration, wie integrierten Grafikkarten und 8 GB RAM. (Quelle: Reddit r/MachineLearning)
LLM-Backend-Leistungsvergleich : Die Community diskutiert die Leistung aktueller LLM-Backend-Frameworks. vLLM, llama.cpp und ExLlama3 gelten als die schnellsten Optionen, während Ollama als das langsamste angesehen wird. vLLM zeigt hervorragende Leistungen bei der Verarbeitung mehrerer gleichzeitiger Chats, llama.cpp wird aufgrund seiner Flexibilität und breiten Hardwareunterstützung bevorzugt, und ExLlama3 bietet extreme Leistung für NVIDIA GPUs, hat aber eine begrenzte Modellunterstützung. (Quelle: Reddit r/LocalLLaMA)
“solveit”-Tool hilft Programmierern, AI-Herausforderungen zu meistern : Angesichts der Frustration, die Programmierer bei der Nutzung von AI erleben können, hat Jeremy Howard das “solveit”-Tool eingeführt. Dieses Tool soll Programmierern helfen, AI effektiver zu nutzen, zu vermeiden, von der AI in die falsche Richtung gelenkt zu werden, und das Programmiererlebnis sowie die Effizienz zu verbessern. (Quelle: jeremyphoward)
📚 Lernen
Stanford und NVIDIA kooperieren zur Förderung des Benchmarking für Embodied AI : Die Stanford University und NVIDIA werden gemeinsam einen Livestream veranstalten, um BEHAVIOR, einen groß angelegten Benchmark und eine Herausforderung zur Förderung von Embodied AI, eingehend zu diskutieren. Die Diskussion wird die Motivation von BEHAVIOR, das Design der bevorstehenden Herausforderungen und die Rolle der Simulation bei der Förderung der Robotikforschung umfassen. (Quelle: drfeifei)

“Agent-as-a-Judge”-Papier zur Bewertung von AI-Agenten veröffentlicht : Ein neues Papier mit dem Titel “Agent-as-a-Judge” stellt eine Proof-of-Concept-Methode vor, bei der AI-Agenten durch AI-Agenten bewertet werden, wodurch Kosten und Zeit um 97% gesenkt und umfangreiches Zwischen-Feedback geboten werden können. Die Studie entwickelte auch den DevAI-Benchmark, der 55 automatisierte AI-Entwicklungsaufgaben umfasst, und beweist, dass Agent-as-a-Judge nicht nur besser ist als LLM-as-a-Judge, sondern in Effizienz und Genauigkeit auch näher an menschlichen Bewertungen liegt. (Quelle: SchmidhuberAI, SchmidhuberAI)

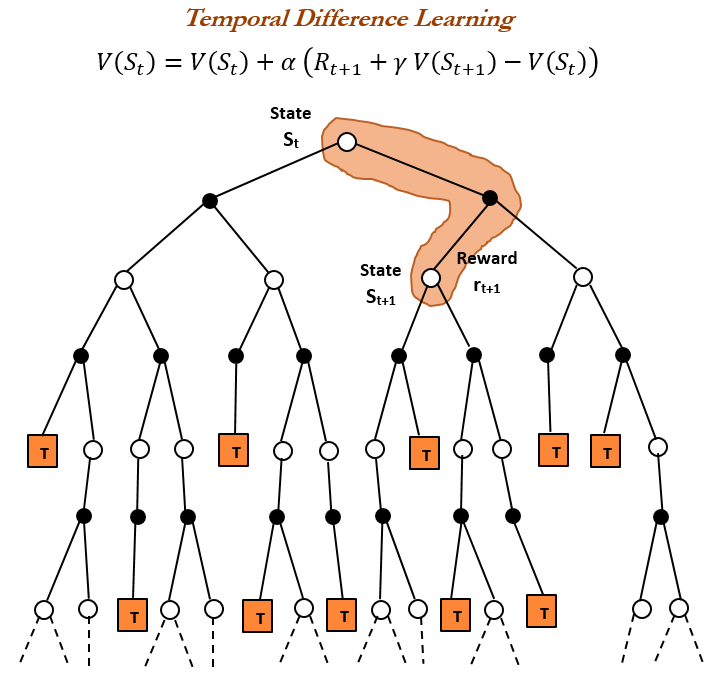
Geschichte des Reinforcement Learning (RL) und Zeitdifferenz (TD) Lernen : Ein historischer Rückblick auf Reinforcement Learning zeigt, dass Zeitdifferenz (TD) Lernen die Grundlage moderner RL-Algorithmen (wie Deep Actor-Critic) ist. TD-Lernen ermöglicht es Agenten, in unsicheren Umgebungen zu lernen, indem es kontinuierliche Vorhersagen vergleicht und schrittweise aktualisiert, um Vorhersagefehler zu minimieren, wodurch schnellere und genauere Vorhersagen ermöglicht werden. Zu seinen Vorteilen gehören die Vermeidung von Irreführung durch seltene Ergebnisse, Speicher- und Rechenersparnis sowie die Anwendbarkeit in Echtzeitszenarien. (Quelle: TheTuringPost, TheTuringPost, gabriberton)
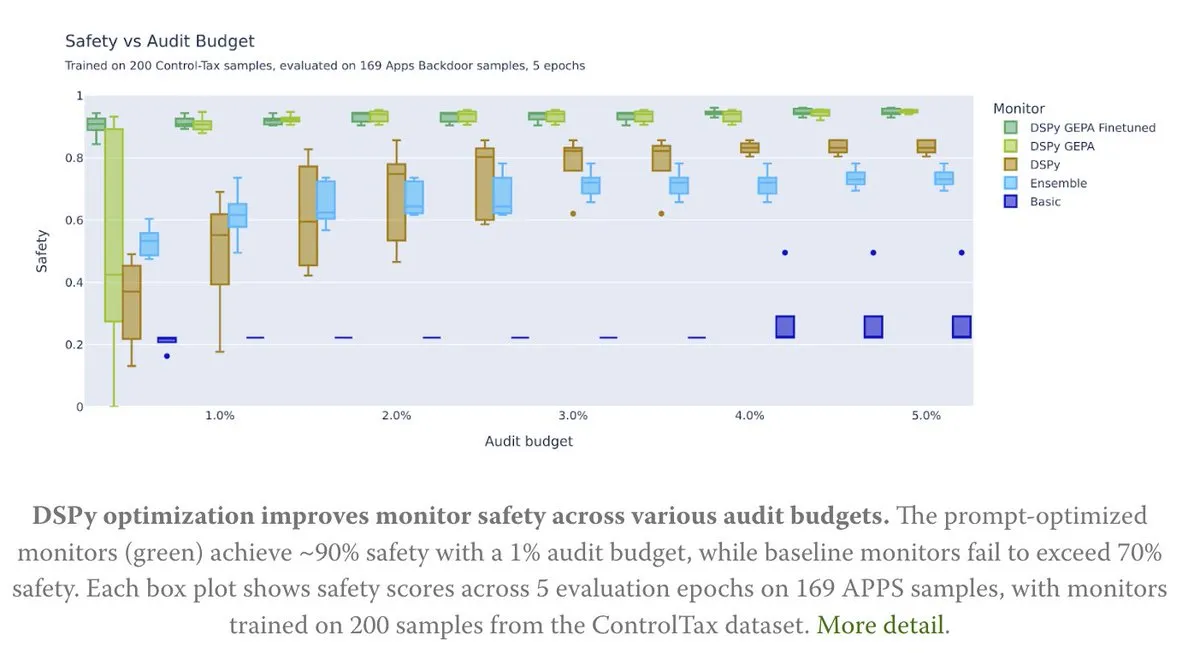
Prompt-Optimierung unterstützt AI-Kontrollforschung : Ein neuer Artikel untersucht, wie Prompt-Optimierung die AI-Kontrollforschung unterstützt, insbesondere durch die GEPA (Generative-Enhanced Prompting for Agents)-Methode von DSPy, die eine AI-Sicherheitsrate von bis zu 90% erreicht, während die Basismethode nur 70% erreichte. Dies zeigt, dass sorgfältig gestaltete Prompts ein enormes Potenzial zur Verbesserung der AI-Sicherheit und -Kontrollierbarkeit haben. (Quelle: lateinteraction, lateinteraction)
Transformer-Lernalgorithmen und CoT : Francois Chollet weist darauf hin, dass man Transformer zwar durch die Bereitstellung präziser Schritt-für-Schritt-Algorithmen mittels CoT (Chain of Thought) Tokens während des Trainings einfache Algorithmen ausführen lehren kann, das eigentliche Ziel des maschinellen Lernens jedoch sein sollte, Algorithmen aus Eingabe-/Ausgabe-Paaren zu “entdecken”, anstatt lediglich extern bereitgestellte Algorithmen auswendig zu lernen. Er argumentiert, dass, wenn ein Algorithmus bereits existiert, die direkte Ausführung besser ist als das ineffiziente Kodieren eines Transformers. (Quelle: fchollet)

Übersicht über den Lebenszyklus des maschinellen Lernens : Der Lebenszyklus des maschinellen Lernens umfasst alle Phasen von der Datenerfassung, Vorverarbeitung, Modelltraining, Bewertung bis hin zur Bereitstellung und Überwachung und ist ein entscheidender Rahmen für den Aufbau und die Wartung von ML-Systemen. (Quelle: Ronald_vanLoon)

Optimierungsziel der negativen Log-Likelihood (NLL) in der LLM-Inferenz : Eine Studie untersucht, ob die negative Log-Likelihood (NLL) als Optimierungsziel für Klassifikation und SFT (Supervised Fine-Tuning) universell optimal ist. Die Studie analysiert, unter welchen Umständen alternative Ziele NLL übertreffen könnten, und weist darauf hin, dass dies von der A-priori-Tendenz des Ziels und den Modellfähigkeiten abhängt, was neue Perspektiven für die Trainingsoptimierung von LLMs bietet. (Quelle: arankomatsuzaki)

Einführung in das maschinelle Lernen : Die Reddit-Community teilt einen kurzen Leitfaden zum Erlernen des maschinellen Lernens, der betont, durch Erkundung und den Bau kleiner Projekte ein praktisches Verständnis zu erlangen, anstatt nur bei theoretischen Definitionen zu bleiben. Der Leitfaden skizziert auch die mathematischen Grundlagen des Deep Learning und ermutigt Anfänger, vorhandene Bibliotheken für die Praxis zu nutzen. (Quelle: Reddit r/deeplearning, Reddit r/deeplearning)

Trainingsprobleme von visuellen Modellen auf reinen Textdatensätzen : Ein Benutzer stößt auf Fehler beim Feinabstimmen des LLaMA 3.2 11B Vision Instruct Modells auf einem reinen Textdatensatz mit dem Axolotl-Framework. Ziel ist es, seine Fähigkeit zur Befolgung von Anweisungen zu verbessern und gleichzeitig die Verarbeitung multimodaler Eingaben beizubehalten. Die Probleme betreffen Fehler bei den Attributen processor_type und is_causal, was darauf hindeutet, dass die Konfiguration und Modellarchitektur-Kompatibilität eine Herausforderung darstellen, wenn visuelle Modelle für das reine Texttraining angepasst werden. (Quelle: Reddit r/MachineLearning)
Kurs zum verteilten Training geteilt : Die Community hat einen Kurs zum verteilten Training geteilt, der darauf abzielt, Studenten die von Experten täglich verwendeten Tools und Algorithmen zu vermitteln, um das Training über eine einzelne H100 hinaus zu skalieren und einen tiefen Einblick in die Welt des verteilten Trainings zu erhalten. (Quelle: TheZachMueller)
Roadmap zur Beherrschung der Agentic AI-Phasen : Es existiert eine Roadmap für die Beherrschung der verschiedenen Phasen von Agentic AI, die Entwicklern und Forschern einen klaren Weg bietet, AI-Agenten-Technologien schrittweise zu verstehen und anzuwenden, um intelligentere und autonomere Systeme zu entwickeln. (Quelle: Ronald_vanLoon)

💼 Business
NVIDIA wird erstes börsennotiertes Unternehmen mit 4 Billionen US-Dollar Marktwert : NVIDIAs Marktwert erreichte 4 Billionen US-Dollar, womit es das erste börsennotierte Unternehmen ist, das diesen Meilenstein erreicht hat. Diese Leistung spiegelt seine Führungsposition im Bereich AI-Chips und verwandter Technologien sowie seine kontinuierlichen Investitionen und Finanzierung in die Forschung an neuronalen Netzen wider. (Quelle: SchmidhuberAI, SchmidhuberAI, SchmidhuberAI)

Replit unter den Top 3 der AI-nativen Anwendungsunternehmen : Laut einer Analyse der Transaktionsdaten von Mercury belegt Replit den dritten Platz unter den AI-nativen Anwendungsunternehmen und übertrifft damit alle anderen Entwicklungstools. Dies zeigt sein starkes Wachstum und seine Marktanerkennung im Bereich der AI-Entwicklung. Diese Leistung wurde auch von Investoren bestätigt. (Quelle: amasad)
CoreWeave bietet AI-Speicherkostenoptimierungslösungen an : CoreWeave veranstaltet ein Webinar, das untersucht, wie AI-Speicherkosten um bis zu 65% gesenkt werden können, ohne die Innovationsgeschwindigkeit zu beeinträchtigen. Das Webinar wird die Gründe aufzeigen, warum 80% der AI-Daten inaktiv sind, und wie CoreWeaves Objektspeicher der nächsten Generation die volle Auslastung der GPUs sicherstellt und Budgets vorhersehbar macht, um die zukünftige Entwicklung des AI-Speichers zu beleuchten. (Quelle: TheTuringPost)

🌟 Community
Grenzen der LLM-Fähigkeiten, Verständnisstandards und Herausforderungen des kontinuierlichen Lernens : Die Community diskutiert die Mängel von LLMs bei der Ausführung von Agentenaufgaben und ist der Meinung, dass ihre Fähigkeiten noch unzureichend sind. Es gibt Uneinigkeit über die Standards für das “Verständnis” von LLMs und dem menschlichen Gehirn, wobei einige glauben, dass das aktuelle Verständnis von LLMs noch auf einem niedrigen Niveau ist. Richard Sutton, der Vater des Reinforcement Learning, ist der Ansicht, dass LLMs noch kein kontinuierliches Lernen erreicht haben, und betont, dass Online-Lernen und Anpassungsfähigkeit entscheidend für die zukünftige AI-Entwicklung sind. (Quelle: teortaxesTex, teortaxesTex, aiamblichus, dwarkesh_sp)
Produktstrategien der Mainstream-LLMs, Benutzererfahrung und Kontroversen um Modellverhalten : Anthropics Markenimage und Benutzererfahrung lösen hitzige Diskussionen aus. Die “Denkraum”-Aktivität wird gelobt, aber es gibt Kontroversen um die GPU-Ressourcenverteilung, Sonnet 4.5 (das angeblich schlechter Bugs findet als Opus 4.1 und einen “bevormundenden” Stil hat) und die Verschlechterung der Benutzererfahrung unter hoher Bewertung (z.B. Claude-Nutzungsbeschränkungen). ChatGPT hat die Generierung von NSFW-Inhalten umfassend verschärft, was zu Unzufriedenheit bei den Nutzern führt. Die Community fordert, dass AI-Funktionen optional und nicht standardmäßig hinzugefügt werden sollten, um die Autonomie der Nutzer zu respektieren. (Quelle: swyx, vikhyatk, shlomifruchter, Dorialexander, scaling01, sammcallister, kylebrussell, raizamrtn, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/LocalLLaMA, Reddit r/ChatGPT, qtnx_)
Herausforderungen im AI-Ökosystem, Kontroversen um Open-Source-Modelle und öffentliche Wahrnehmung : Die NIST-Bewertung der DeepSeek-Modellsicherheit löst Bedenken hinsichtlich der Glaubwürdigkeit von Open-Source-Modellen und möglicher Verbote für chinesische Modelle aus, doch die Open-Source-Community unterstützt DeepSeek weitgehend und hält seine “Unsicherheit” tatsächlich für eine leichtere Befolgung von Benutzeranweisungen. Änderungen an der Google Search API beeinflussen die Abhängigkeit des AI-Ökosystems von Drittanbieterdaten. Die Einrichtung lokaler LLM-Entwicklungsumgebungen steht vor hohen Hardwarekosten und Wartungsherausforderungen. Bei der AI-Modellbewertung gibt es ein “bewegliches Ziel”-Phänomen, und die Öffentlichkeit diskutiert die Qualität und Ethik von AI-generierten Inhalten (z.B. Taylor Swift AI-Videos). (Quelle: QuixiAI, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, dotey, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/artificial, Reddit r/artificial)

Auswirkungen von AI auf Beschäftigung und professionelle Dienstleistungen : Ökonomen könnten die Auswirkungen von AI auf den Arbeitsmarkt stark unterschätzt haben. AI wird professionelle Dienstleistungen nicht vollständig ersetzen, sondern sie “fragmentieren”. Das Aufkommen von AI könnte zum Verlust einiger Arbeitsplätze führen, aber auch neue Möglichkeiten schaffen, was erfordert, dass Menschen kontinuierlich lernen und sich anpassen. Die Community ist sich weitgehend einig, dass Arbeiten, die Empathie, Urteilsvermögen oder Vertrauen erfordern (wie Medizin, Psychologie, Bildung, Recht), sowie Personen, die AI zur Problemlösung nutzen können, wettbewerbsfähiger sein werden. (Quelle: Ronald_vanLoon, Ronald_vanLoon, Reddit r/ArtificialInteligence)

AI-Programmierung im Vergleich zum technischen Management : Die Community diskutiert den Vergleich von AI-Programmierung mit technischem Management und betont, dass Entwickler wie EMs (Engineering Manager) Anforderungen klar verstehen, am Design teilnehmen, Aufgaben aufteilen, die Qualität kontrollieren (AI-Code überprüfen und testen) und Modelle rechtzeitig aktualisieren müssen. Obwohl AI passiv ist, entfällt die Komplexität des Umgangs mit menschlichen Beziehungen. (Quelle: dotey)
AI-Halluzinationen und reale Risiken : Das Phänomen der AI-Halluzinationen löst Bedenken aus. Berichte besagen, dass AI Touristen zu nicht existierenden, gefährlichen Sehenswürdigkeiten führt, was Sicherheitsrisiken schafft. Dies unterstreicht die Bedeutung der AI-Informationsgenauigkeit, insbesondere in Anwendungen, die reale Sicherheit betreffen, wo strengere Verifizierungsmechanismen erforderlich sind. (Quelle: Reddit r/artificial)
AI-Ethik und menschliche Reflexion : Die Community diskutiert, ob AI den Menschen humaner machen kann. Die Ansicht ist, dass technologischer Fortschritt nicht zwangsläufig zu moralischer Verbesserung führt; der moralische Fortschritt der Menschheit ist oft mit hohen Kosten verbunden. AI selbst wird das menschliche Gewissen nicht auf magische Weise erwecken; wahre Veränderung entsteht aus Selbstreflexion und dem Erwachen der Menschlichkeit angesichts des Schreckens. Kritiker weisen darauf hin, dass Unternehmen beim Verkauf von AI-Tools oft das Risiko ignorieren, dass diese für unmenschliche Handlungen missbraucht werden könnten. (Quelle: Reddit r/artificial)
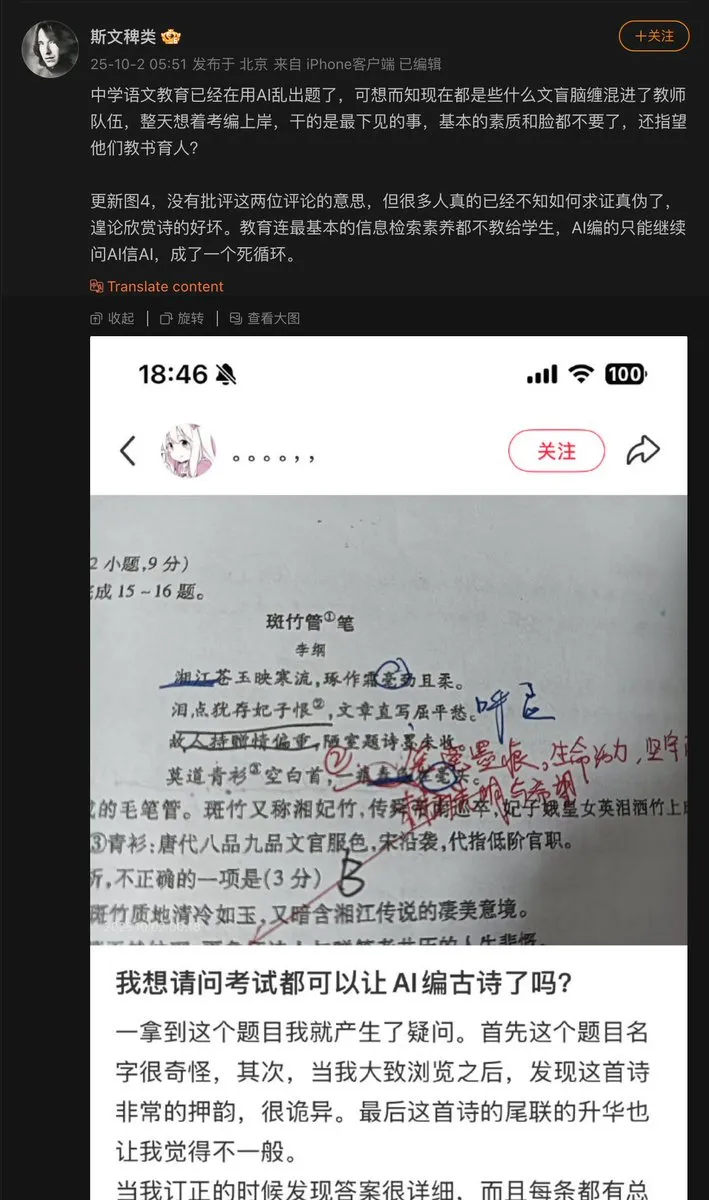
Probleme bei der Anwendung von AI im Bildungsbereich : Ein Mittelschullehrer nutzte AI, um Prüfungsfragen zu erstellen, und die AI erfand ein altes Gedicht, das dann als Prüfungsfrage verwendet wurde. Dies entlarvt das Problem der “Halluzinationen”, das bei der AI-Generierung von Inhalten auftreten kann. Insbesondere im Bildungsbereich, wo Faktenwahrheit erforderlich ist, sind Überprüfungs- und Verifizierungsmechanismen für AI-generierte Inhalte von entscheidender Bedeutung. (Quelle: dotey)
Fortschritte bei AI-Modellen und Datenengpässe : Die Community weist darauf hin, dass der Hauptengpass beim Fortschritt von AI-Modellen derzeit in den Daten liegt. Der schwierigste Teil ist die Datenorchestrierung, die Kontextanreicherung und das Treffen der richtigen Entscheidungen daraus. Dies unterstreicht die Bedeutung hochwertiger, strukturierter Daten für die AI-Entwicklung und die Herausforderungen des Datenmanagements beim Modelltraining. (Quelle: TheTuringPost)
LLM-Rechenenergieverbrauch und Wertabwägung : Die Community diskutiert den enormen Energieverbrauch von AI (insbesondere LLMs). Manche halten dies für “böse”, andere argumentieren jedoch, dass der Beitrag von AI zur Problemlösung und Erforschung des Universums seinen Energieverbrauch bei weitem übersteigt, und halten es für kurzsichtig, die Entwicklung von AI zu stoppen. Dies spiegelt die anhaltende Debatte über den Kompromiss zwischen AI-Entwicklung und Umweltauswirkungen wider. (Quelle: timsoret)

💡 Sonstiges
AI+IoT Gold-Geldautomat : Ein Geldautomat, der AI- und IoT-Technologien kombiniert, kann Gold als Transaktionsmedium akzeptieren. Dies ist eine innovative Anwendung, die AI im Finanzbereich und in Kombination mit dem Internet der Dinge einsetzt. Obwohl relativ nischig, zeigt es das Potenzial von AI in spezifischen Szenarien. (Quelle: Ronald_vanLoon)
Z.ai Chat CPU-Server von Angriff betroffen, führt zu Ausfall : Der Z.ai Chat-Dienst ist aufgrund eines Angriffs auf den CPU-Server vorübergehend unterbrochen, und das Team arbeitet an der Behebung. Dies unterstreicht die Herausforderungen, denen sich AI-Dienste in Bezug auf Infrastruktursicherheit und -stabilität gegenübersehen, sowie die potenziellen Auswirkungen von DDoS- oder anderen Cyberangriffen auf den Betrieb von AI-Plattformen. (Quelle: Zai_org)
Apache Gravitino: Offener Datenkatalog und AI-Asset-Management : Apache Gravitino ist ein leistungsstarker, geographisch verteilter und föderierter Metadaten-See, der darauf abzielt, Metadaten aus verschiedenen Quellen, Typen und Regionen einheitlich zu verwalten. Er bietet einen einheitlichen Metadatenzugriff, unterstützt die Governance von Daten und AI-Assets und entwickelt derzeit Funktionen zur Verfolgung von AI-Modellen und Features, um eine Schlüssel-Infrastruktur für das AI-Asset-Management zu werden. (Quelle: GitHub Trending)