
Schlüsselwörter:OpenAI, KI-Infrastruktur, KI-generierte Viren, AlphaEarth Foundations, RTEB, Claude Sonnet 4.5, DeepSeek V3.2-Exp, Multimodale KI, OpenAI Stargate-Projekt, Transformer-Genom-Sprachmodell, Google AlphaEarth 10-Meter-Modellierung, Hugging Face RTEB-Benchmark, Anthropic Claude Codegenerierung
Als AI-Kolumnen-Chefredakteur habe ich die von Ihnen bereitgestellten Nachrichten und sozialen Diskussionen eingehend analysiert, zusammengefasst und destilliert. Hier ist der konsolidierte Inhalt:
🔥 Fokus
OpenAIs Billionen-Dollar-Infrastrukturwette: OpenAI arbeitet mit Oracle und SoftBank zusammen, um weltweit Billionen von Dollar in den Aufbau von Computerinfrastruktur zu investieren, Codename “StarGate”. Zunächst wurden 5 neue Standorte in den USA angekündigt, die 400 Milliarden Dollar kosten, und eine Zusammenarbeit mit Nvidia für das Projekt “StarGate UK” in Großbritannien. OpenAI prognostiziert, dass der zukünftige Strombedarf für KI bis zu 100 Gigawatt erreichen wird, wobei die Gesamtinvestition 5 Billionen Dollar betragen könnte. Dieser Schritt zielt darauf ab, den enormen Rechenleistungsbedarf von KI-Modellen zu decken, wirft aber auch Bedenken hinsichtlich der Kapitalinvestitionen, des Energieverbrauchs und potenzieller finanzieller Risiken auf, was die extreme Abhängigkeit der KI-Entwicklung von der Infrastruktur unterstreicht. (Quelle: DeepLearning.AI Blog)

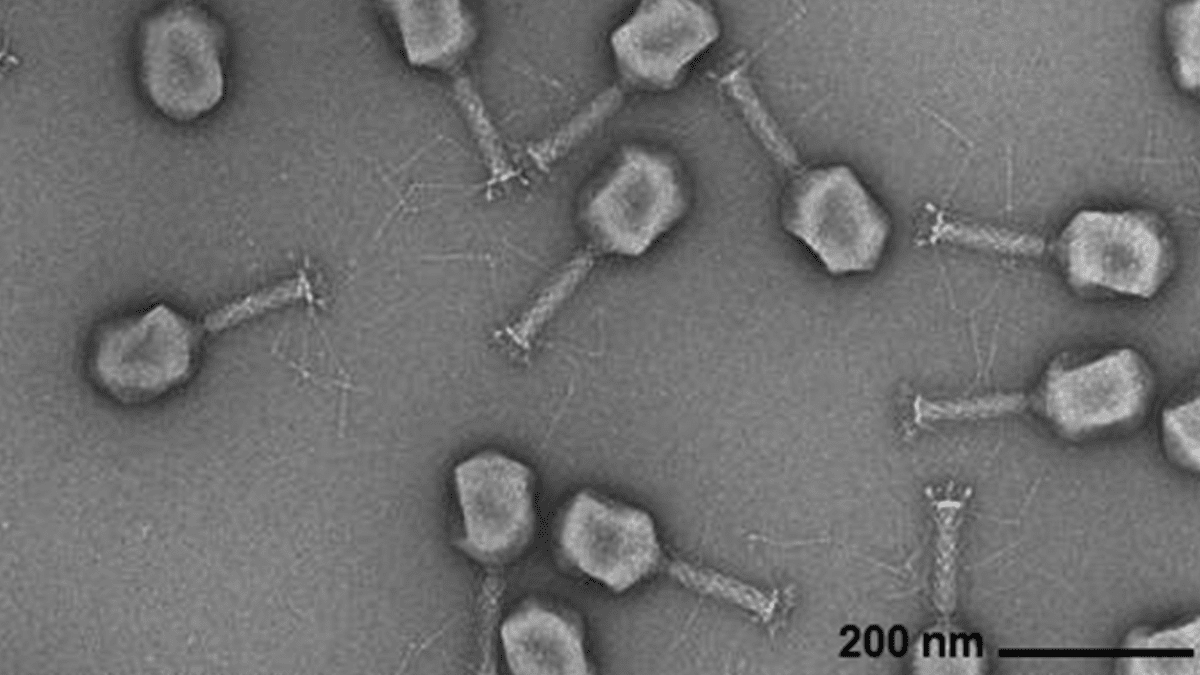
KI generiert virale Genome: Forscher des Arc Institute, der Stanford University und des Memorial Sloan Kettering Cancer Center haben mithilfe eines Transformer-basierten Genom-Sprachmodells erfolgreich neuartige Phagenviren von Grund auf synthetisiert, die gängige bakterielle Infektionen bekämpfen können. Diese Technologie ermöglicht es, durch Feinabstimmung von viralen Genomsequenzen neue Genome mit spezifischen Funktionen zu erzeugen, die sich von natürlich vorkommenden Viren unterscheiden. Dieser Durchbruch eröffnet neue Wege für die Entwicklung von Antibiotika-Alternativen, wirft aber auch Bedenken hinsichtlich der Biosicherheit und des böswilligen Gebrauchs auf und unterstreicht die Notwendigkeit der Forschung zur Reaktion auf biologische Bedrohungen. (Quelle: DeepLearning.AI Blog)
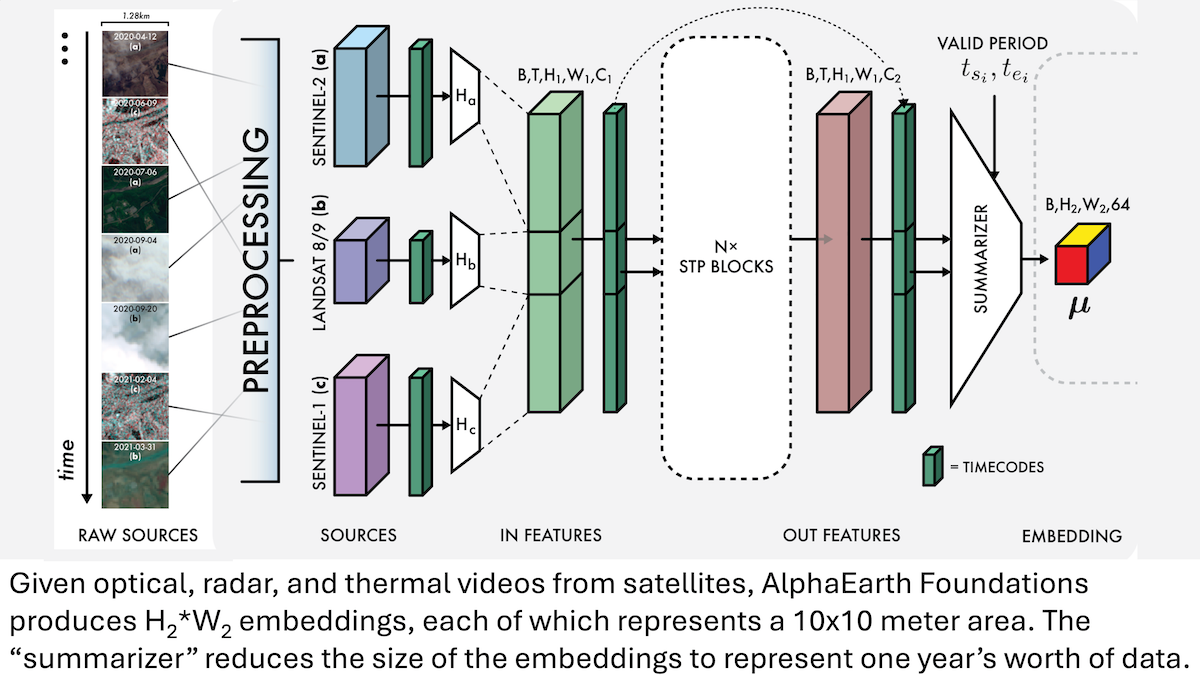
Google AlphaEarth Foundations: Hochpräzise Modellierung der Erde im 10-Meter-Raster: Google-Forscher haben das AlphaEarth Foundations (AEF) Modell vorgestellt, das Satellitenbilder und andere Sensordaten integrieren kann, um die Erdoberfläche mit einer Feinheit von 10 Quadratmetern zu modellieren und Embeddings zu generieren, die die Erdmerkmale jedes Jahres von 2017 bis 2024 repräsentieren. Diese Embeddings können verwendet werden, um verschiedene planetare Eigenschaften wie Feuchtigkeit, Niederschlag, Vegetation sowie globale Herausforderungen wie Nahrungsmittelproduktion, Waldbrandrisiko und Wasserstände in Stauseen zu verfolgen, und bieten ein beispielloses hochpräzises Werkzeug für Umweltüberwachung und Klimaforschung. (Quelle: DeepLearning.AI Blog)
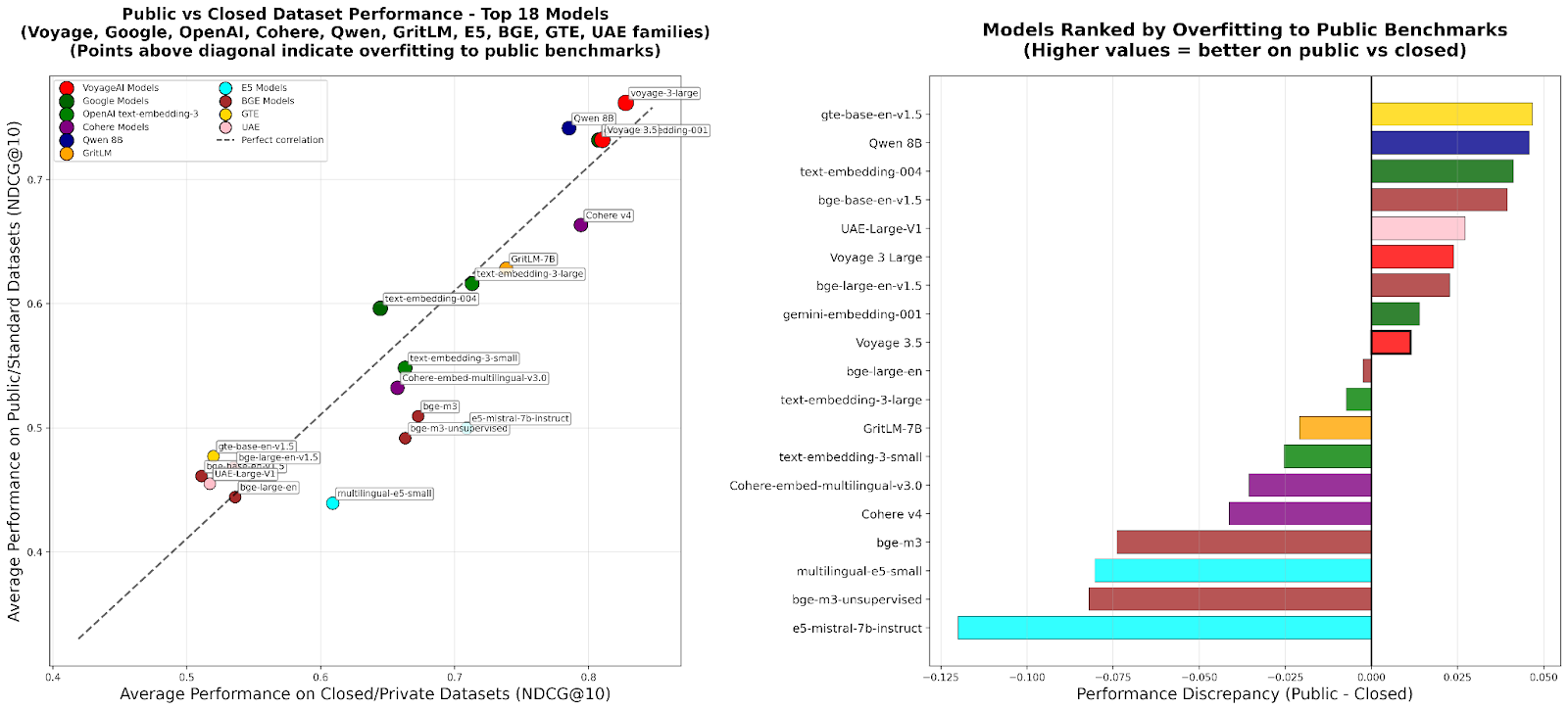
RTEB: Ein neuer Standard für die Retrieval-Embedding-Evaluierung: Hugging Face hat die Beta-Version des Retrieval Embedding Benchmark (RTEB) veröffentlicht, um einen zuverlässigen Bewertungsstandard für die Retrieval-Genauigkeit von Embedding-Modellen zu bieten. Dieser Benchmark löst das Problem des Modell-Overfittings in bestehenden Benchmarks effektiv durch eine gemischte Strategie aus öffentlichen und privaten Datensätzen und stellt sicher, dass die Bewertungsergebnisse die Generalisierungsfähigkeit des Modells auf ungesehenen Daten besser widerspiegeln. Dies ist entscheidend für die Qualitätsverbesserung von KI-Anwendungen wie RAG und Agent. (Quelle: HuggingFace Blog)
Skalierbares RL-Zwischentraining: Inferenz durch Aktionsabstraktion: Eine aktuelle Studie stellt den “Reasoning as Action Abstraction” (RA3)-Algorithmus vor, der durch die Identifizierung kompakter und nützlicher Aktionssets in der Zwischen-Trainingsphase von Reinforcement Learning (RL) und die Beschleunigung von Online-RL die Inferenz- und Codegenerierungsfähigkeiten von Large Language Models (LLMs) erheblich verbessert. Die Methode zeigte hervorragende Leistungen bei Codegenerierungsaufgaben, mit einer durchschnittlichen Leistungssteigerung von 8 bis 4 Prozentpunkten gegenüber den Basismodellen und einer schnelleren RL-Konvergenz sowie höherer asymptotischer Leistung. (Quelle: HuggingFace Daily Papers)
🎯 Trends
OpenAI Sora 2: Eine neue Ära der KI-Video-Social-Media: OpenAI hat Sora 2 veröffentlicht und eine gleichnamige Social-Media-App eingeführt, die darauf abzielt, ein soziales Netzwerk zu schaffen, das sich auf Benutzer und deren sozialen Kreis (Freunde, Haustiere) konzentriert, anstatt auf eine traditionelle Content-Distributionsplattform. Sora 2 zeigt starke physikalische Simulations- und Audio-Generierungsfähigkeiten, weist aber in frühen Tests noch Detailfehler wie “Fingerzählen” auf. Die Veröffentlichung hat Diskussionen über KI-Video-Sucht, Deepfakes und den Kommerzialisierungspfad von OpenAI ausgelöst. Sam Altman antwortete, dass Sora darauf abzielt, den technologischen Durchbruch mit einem angenehmen Benutzererlebnis in Einklang zu bringen und die KI-Forschung zu finanzieren. (Quelle: 36氪、Reddit r/ChatGPT、OpenAI)

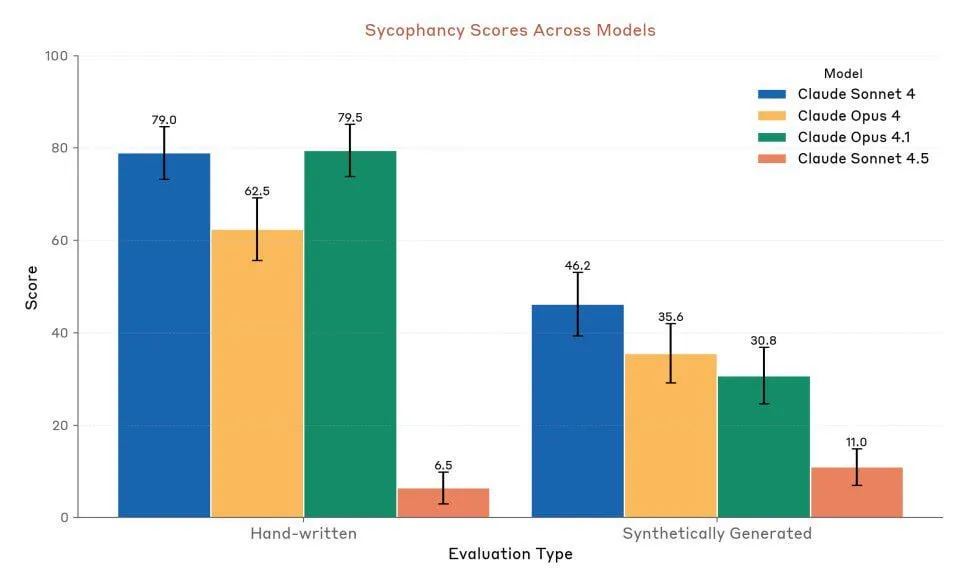
Anthropic Claude Sonnet 4.5: Neuer Maßstab für Code und Agenten: Anthropic hat Claude Sonnet 4.5 veröffentlicht, das als “bestes Programmiermodell der Welt” und “leistungsstärkstes Modell zum Erstellen komplexer Agenten” gefeiert wird. Es bietet eine autonome Laufzeit von bis zu 30 Stunden und zeigt eine signifikante Verbesserung der Codierungsleistung bei GitHub-Aufgaben. Das Modell verfügt außerdem über eine neue Speicherfunktion, die das Speichern des Projektfortschritts ermöglicht. Obwohl seine Leistung hoch gelobt wird, gibt es weiterhin Diskussionen über Nutzungslimits und den Vergleich der tatsächlichen Leistung mit Opus 4.1 und GPT-5. (Quelle: Reddit r/ClaudeAI、Reddit r/artificial、Reddit r/ClaudeAI)
DeepSeek V3.2-Exp: Effizienzsteigerung durch Sparse Attention Architektur: DeepSeek hat das Large Language Model DeepSeek V3.2-Exp veröffentlicht, das eine völlig neue Sparse Attention (DSA) Architektur einführt. Diese reduziert die Hauptaufmerksamkeitskomplexität von O(L²) auf O(L·k), was die Kosten für Pre-Filling und Decodierung in langen Kontext-Szenarien erheblich optimiert und somit die API-Nutzungsgebühren drastisch senkt. Jiuzhang Cloud Intelligence hat als erstes die Anpassung an DeepSeek V3.2-Exp abgeschlossen und bietet sichere und effiziente private Bereitstellungslösungen an, um den Anforderungen von Unternehmen an Datensicherheit und Rechenflexibilität gerecht zu werden. (Quelle: 量子位、Reddit r/LocalLLaMA)

Multimodales Audio-Text-Modell LFM2-Audio-1.5B veröffentlicht: Liquid AI hat LFM2-Audio-1.5B vorgestellt, ein End-to-End-Audio-Text-Allround-Grundlagenmodell, das Text und Audio verstehen und generieren kann. Das Modell ist 10-mal schneller in der Inferenz als vergleichbare Modelle und erreicht bei nur 1,5 Milliarden Parametern eine Qualität, die mit 10-mal größeren Modellen vergleichbar ist, und unterstützt lokale Bereitstellung und Echtzeit-Konversationen. Hume AI hat außerdem Octave 2 veröffentlicht, ein schnelleres, kostengünstigeres mehrsprachiges Text-to-Speech-Modell mit Unterstützung für Gespräche mit mehreren Sprechern und Stimmtransformation. (Quelle: Reddit r/LocalLLaMA、QuixiAI)

Microsoft Agent Framework: Neue Entwicklungen bei der Agenten-Systementwicklung: Microsoft hat das Microsoft Agent Framework veröffentlicht, das AutoGen und Semantic Kernel zu einem einheitlichen, produktionsreifen SDK für den Aufbau, die Orchestrierung und die Bereitstellung von Multi-Agenten-Systemen zusammenführt. Das Framework unterstützt .NET und Python und ermöglicht Multi-Agenten-Workflows durch grafische Orchestrierung, um die Entwicklung, Beobachtung und Governance von Agenten-Anwendungen zu vereinfachen und die Einführung von Enterprise-Grade AI Agenten zu beschleunigen. (Quelle: gojira、omarsar0)

KI-Robotik-Technologie und Industriewettbewerb: Die Robotik-Technologie schreitet stetig voran. Amazon FARs OmniRetarget optimiert die menschliche Bewegungserfassung, um komplexe humanoide Fähigkeiten mit minimalem Reinforcement Learning zu erlernen. Periodic Labs arbeitet an “AI Scientists”, um wissenschaftliche Entdeckungen zu beschleunigen. Nvidia betont die Rolle seines offenen Physik-Engines Newton, des inferenzbasierten visuellen Sprachmodells Cosmos Reason und des Robotik-Grundlagenmodells Isaac GR00T N1.6 bei der Bereitstellung von physikalischer KI. Gleichzeitig zeigt China führende Vorteile in der Roboterproduktion und den Kosten für humanoide Roboter, was die Aufmerksamkeit auf die globale Wettbewerbslandschaft der Robotikindustrie lenkt. (Quelle: pabbeel、LiamFedus、nvidia、atroyn)

🧰 Tools
Tinker API: Flexible Schnittstelle zur Vereinfachung des LLM-Fine-Tunings: Thinking Machines Lab hat die Tinker API vorgestellt, eine flexible Schnittstelle, die für das Fine-Tuning von Sprachmodellen entwickelt wurde. Sie ermöglicht es Forschern und Entwicklern, Trainingsschleifen lokal zu schreiben, während Tinker die Komplexität der Infrastruktur durch Ausführung auf verteilten GPU-Clustern verwaltet, sodass sich Benutzer auf Algorithmen und Daten konzentrieren können. Das Tool zielt darauf ab, die Hürden für das Post-Training von LLMs zu senken und Experimente sowie Innovationen bei offenen Modellen zu beschleunigen. Experten wie Andrej Karpathy lobten es als “die Infrastruktur, die ich schon immer wollte”. (Quelle: Reddit r/artificial、Thinking Machines、karpathy)

LlamaAgents: Dokumenten-Agenten mit einem Klick bereitstellen: LlamaIndex hat LlamaAgents eingeführt, das die Bereitstellung von dokumentenzentrierten AI Agenten mit einem Klick ermöglicht und darauf abzielt, den Aufbau und die Bereitstellung von Dokumentenagenten um das Zehnfache zu beschleunigen. Die Plattform bietet zu 90 % vorkonfigurierte Vorlagen, unterstützt die automatisierte Bearbeitung dokumentenintensiver Aufgaben wie Rechnungen, Vertragsprüfungen und Schadensfälle und ermöglicht unbegrenzte Anpassungen. Benutzer können auf LlamaCloud bereitstellen und Agenten-Workflows einfach über Git-Repositorys verwalten und aktualisieren, was den Entwicklungszyklus erheblich verkürzt. (Quelle: jerryjliu0、jerryjliu0)

Hex AI Agent: Ermöglicht Analyse und Teamzusammenarbeit: Hex hat drei neue AI Agenten veröffentlicht, die speziell für Datenanalyse und Teamzusammenarbeit entwickelt wurden: Threads bietet eine konversationelle Dateninteraktion, der Semantic Model Agent erstellt einen kontrollierten Kontext für genaue Antworten, und der Notebook Agent revolutioniert die tägliche Arbeit von Datenteams. Alle diese Agenten werden von Claude 4.5 Sonnet angetrieben und zielen darauf ab, konversationelle KI-Analyse von einem Zukunftskonzept in ein sofort nutzbares, effizientes Werkzeug zu verwandeln. (Quelle: sarahcat21)
Sculptor: Die fehlende UI für Claude Code: Imbue hat Sculptor vorgestellt, eine Benutzeroberfläche, die für Claude Code entwickelt wurde, um das Agenten-Programmierungserlebnis zu verbessern. Sie ermöglicht Entwicklern, mehrere Claude Agenten parallel in isolierten Containern auszuführen und die Arbeitsergebnisse der Agenten im “Pairing-Modus” mit der lokalen Entwicklungsumgebung zu synchronisieren, um sie zu testen und zu bearbeiten. Sculptor plant auch die Unterstützung von GPT-5 und bietet Vorschlagsfunktionen wie die Erkennung irreführenden Verhaltens, um die Agenten-Programmierung flüssiger und effizienter zu gestalten. (Quelle: kanjun、kanjun)
Synthesia 3.0: Neuer Durchbruch bei interaktiven KI-Videos: Synthesia hat Version 3.0 veröffentlicht, die mehrere innovative Funktionen einführt, darunter “Video Agents” (interaktive Videos für Echtzeit-Gespräche, z.B. für Training und Interviews), verbesserte “Avatare” (erstellt durch eine einzige Aufforderung oder ein Bild, mit realistischen Gesichtsausdrücken und Körperbewegungen) sowie “Copilot” (ein KI-Video-Editor, der schnell Skripte und visuelle Elemente generieren kann). Darüber hinaus wurden interaktive Funktionen und Tools für das Kursdesign verbessert, um die Videoerstellung und Lernerfahrung grundlegend zu verändern. (Quelle: synthesiaIO、synthesiaIO)
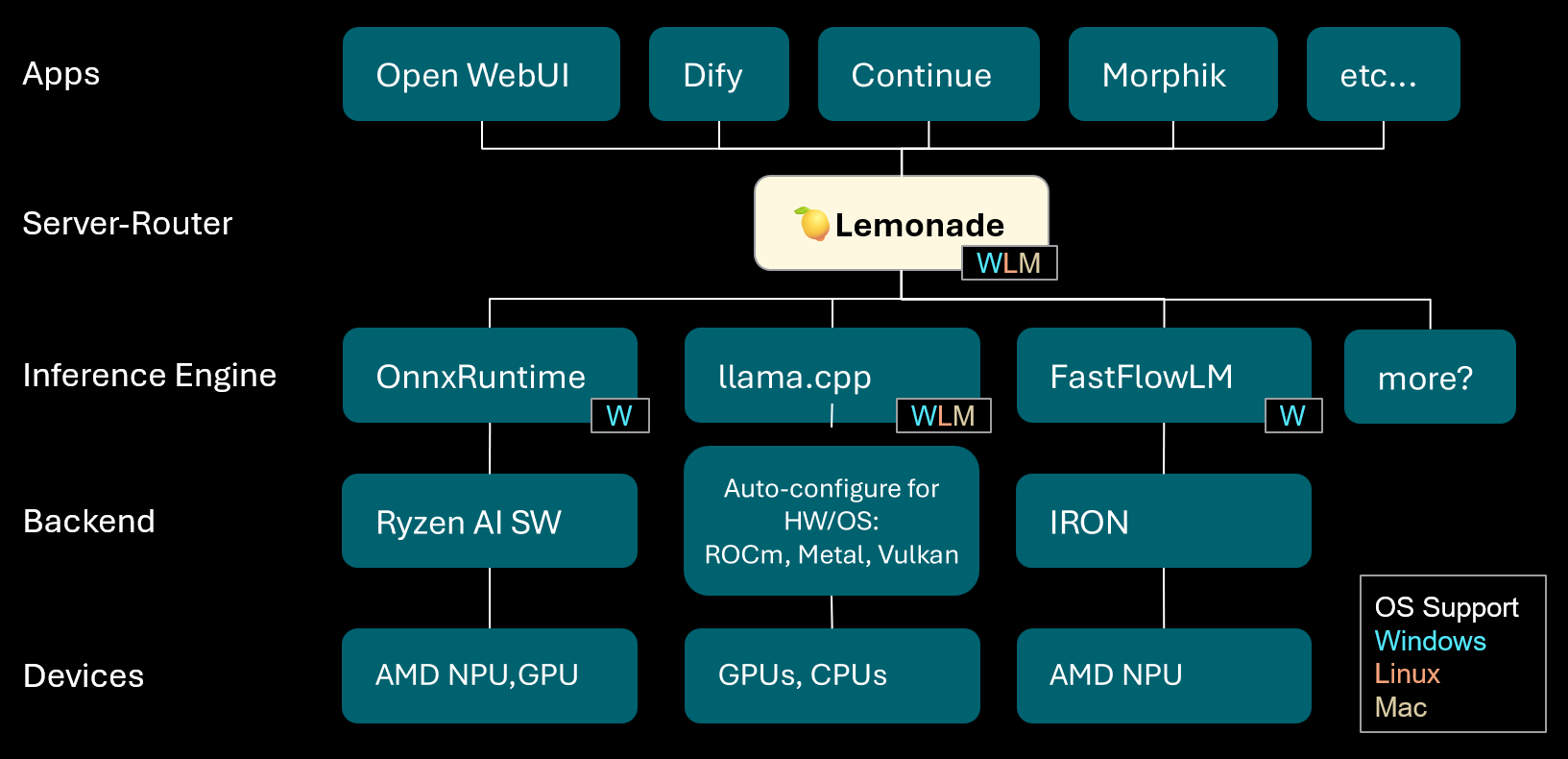
Lemonade: Lokaler LLM-Server-Router: Lemonade hat Version v8.1.11 veröffentlicht, einen lokalen LLM-Server-Router, der automatisch Hochleistungs-Inferenz-Engines für verschiedene PCs (einschließlich AMD NPU und macOS/Apple Silicon-Geräte) konfiguriert. Er unterstützt mehrere Modellformate wie ONNX, GGUF und FastFlowLM und nutzt das Metal-Backend von llama.cpp für effiziente Berechnungen auf Apple Silicon, um Benutzern ein flexibles, leistungsstarkes lokales LLM-Erlebnis zu bieten. (Quelle: Reddit r/LocalLLaMA)
PopAi: KI-gesteuerte Präsentationserstellung: PopAi demonstrierte die Fähigkeit seines KI-Tools, innerhalb weniger Minuten detaillierte Geschäftspräsentationen mit Diagrammen und Illustrationen aus einer einfachen Aufforderung zu generieren. Dies unterstreicht die Effizienz von KI bei der Inhaltserstellung und ermöglicht es auch Laien, schnell hochwertige Präsentationsmaterialien zu erstellen. (Quelle: kaifulee)

GitHub Copilot CLI: Automatische Modellauswahl: GitHub Copilot CLI bietet jetzt für Geschäfts- und Unternehmenskunden eine automatische Modellauswahlfunktion. Dieses Update ermöglicht es dem System, automatisch das am besten geeignete Modell für die aktuelle Aufgabe auszuwählen, um die Entwicklungseffizienz und die Qualität der Codegenerierung zu verbessern. (Quelle: pierceboggan)
Mixedbread Search: Mehrsprachige, multimodale lokale Suche: Mixedbread hat seine Beta-Version eines Suchsystems vorgestellt, das eine schnelle, genaue, mehrsprachige und multimodale Dokumentensuche bietet. Das System betont den lokalen Betrieb, sodass Benutzer Dokumente effizient auf ihren eigenen Geräten abrufen können, besonders geeignet für Szenarien, die die Verarbeitung verschiedener Datentypen erfordern. (Quelle: TheZachMueller)
Hume AI Octave 2: Nächste Generation des mehrsprachigen TTS-Modells: Hume AI hat Octave 2 veröffentlicht, ein mehrsprachiges Text-to-Speech (TTS)-Modell der nächsten Generation. Das Modell ist 40 % schneller und 50 % günstiger als sein Vorgänger und unterstützt über 11 Sprachen, Gespräche mit mehreren Sprechern, Stimmtransformation und Phonem-Bearbeitungsfunktionen, um ein schnelleres, realistischeres und emotionaleres Sprach-KI-Erlebnis zu bieten. (Quelle: AlanCowen)
AssemblyAI September-Update: All-in-One KI-Audio-Service: AssemblyAI hat seine September-Updates vorgestellt, darunter die Einführung eines In-App-Playgrounds, allgemeine Spracherweiterungen, EU PII-Anonymisierungsfunktionen sowie Verbesserungen der Streaming-Leistung und Keyword-Prompting. Diese Updates zielen darauf ab, Benutzern umfassendere und effizientere KI-Audioverarbeitungsdienste zu bieten. (Quelle: AssemblyAI)
Voiceflow MCP-Tool: Standardisierung der Agenten-Tool-Integration: Voiceflow hat das Model Context Protocol (MCP)-Tool eingeführt, das eine standardisierte Methode für AI Agenten bietet, verschiedene Tools zu nutzen. Dies vereinfacht die kundenspezifische Integrationsarbeit für Entwickler und bietet No-Code-Benutzern vorgefertigte Drittanbieter-Tools, wodurch die Fähigkeiten von Voiceflow Agenten erheblich erweitert werden. (Quelle: ReamBraden)
Salesforce Agentforce Vibes: Enterprise-Grade Agent Coding: Salesforce hat basierend auf der Cline-Architektur das Produkt “Agentforce Vibes” vorgestellt, das mit Model Context Protocol (MCP)-Unterstützung Unternehmenskunden autonome Codierungsfähigkeiten bietet. Das Produkt gewährleistet eine sichere Kommunikation von LLMs mit internen und externen Wissensquellen/Datenbanken, um KI-Codierung im Unternehmensmaßstab zu ermöglichen. (Quelle: cline)

JoyAgent-JDGenie: Bericht zur Generalist Agent Architecture: Der technische Bericht zur GAIA (Generalist Agent Architecture) wurde veröffentlicht. Diese Architektur integriert ein kollektives Multi-Agenten-Framework (Kombination aus Planungs-, Ausführungsagenten und Review-Modell-Voting), ein hierarchisches Speichersystem (Arbeits-, Semantik-, Programmebene) sowie ein Tool-Kit für Suche, Code-Ausführung und multimodale Analyse. Das Framework zeigte hervorragende Leistungen in umfassenden Benchmarks, übertraf Open-Source-Baselines und erreichte nahezu die Leistung proprietärer Systeme, was einen Weg zum Aufbau skalierbarer, widerstandsfähiger und anpassungsfähiger KI-Assistenten aufzeigt. (Quelle: HuggingFace Daily Papers)
KI-Reiseassistent: Von der Planung zur Aktion: Die von Mafengwo eingeführte AI-Reiseassistenten-App zielt darauf ab, KI von der traditionellen Reiseführer-Generierung zur Unterstützung bei tatsächlichen Reiseaktionen zu erweitern. Die App kann personalisierte Reiseführer mit Bildern und Text generieren und bietet praktische Funktionen wie AI Agenten, die Anrufe tätigen, um Restaurants zu buchen, was Sprachbarrieren und andere Probleme effektiv löst. Obwohl es noch Raum für Verbesserungen bei der Echtzeitübersetzung und tiefen Personalisierung gibt, hat es die Hürde für “Reisen ohne Planung” erheblich gesenkt und zeigt das enorme Potenzial von KI bei der Verbindung digitaler Informationen mit physischen Aktionen in der realen Welt. (Quelle: 36氪)

📚 Lernen
Karriereentwicklungstipps für KI-Forscher: Für die Karriereentwicklung von KI-Forschern betonen Experten die Bedeutung, ein ausgezeichneter Programmierer zu sein, ermutigen zum Nachbau von Forschungsarbeiten von Grund auf und zum tiefen Verständnis der Infrastruktur. Gleichzeitig wird empfohlen, aktiv eine persönliche Marke aufzubauen, interessante Ideen zu teilen, neugierig und anpassungsfähig zu bleiben und Positionen zu bevorzugen, die Innovation und Lernen fördern. Langfristig sind kontinuierliche Anstrengungen und das Erzielen praktischer Ergebnisse der Schlüssel zum Aufbau von Vertrauen und Motivation. (Quelle: dejavucoder、BlackHC)
Python-Kurs für Datenanalyse: DeepLearningAI hat einen neuen Python-Kurs für Datenanalyse gestartet, der lehrt, wie man Python nutzt, um die Effizienz, Nachvollziehbarkeit und Reproduzierbarkeit der Datenanalyse zu verbessern. Der Kurs ist Teil eines Datenanalyse-Berufszertifikats und betont die zentrale Rolle von Programmierkenntnissen in der modernen Datenarbeit. (Quelle: DeepLearningAI)
Kostenloser Zugang zu Copilot KI-Tools für Studenten: Microsoft bietet berechtigten Universitätsstudenten ein kostenloses 12-monatiges Microsoft 365 Personal-Abonnement an, das zusätzlichen Zugang zu Copilot Podcasts, Deep Research und Vision beinhaltet. Dieser Schritt zielt darauf ab, Studenten leistungsstarke KI-Tools zur Verfügung zu stellen, um ihr Lernen und ihre Innovation zu unterstützen. (Quelle: mustafasuleyman)

Lokale AI/ML-Kursgestaltung: Ein Pädagoge teilte mit, wie man mit begrenztem Budget praktische AI/ML-Kurse für Studenten erstellt, die auf lokaler Entwicklung und Consumer-Hardware basieren. Er empfiehlt die Verwendung kleiner Modelle, Transformer Lab als Trainingsplattform und betont das Verständnis der Kernkonzepte anstatt der blinden Verfolgung der Modellgröße, um die Lernergebnisse und praktischen Fähigkeiten der Studenten zu verbessern. (Quelle: Reddit r/deeplearning)
Bevorstehende KI-Seminare: AIhub hat eine Liste der bevorstehenden Machine Learning- und KI-Seminare für Oktober bis November 2025 veröffentlicht. Diese Veranstaltungen decken verschiedene Themen ab, von der Datenerfassung auf politisch eingeschränkten Social-Media-Plattformen bis hin zur KI-Ethik. Alle Seminare sind kostenlos und bieten Online-Teilnahmeoptionen, was der KI-Community reichhaltige Lern- und Austauschmöglichkeiten bietet. (Quelle: aihub.org)

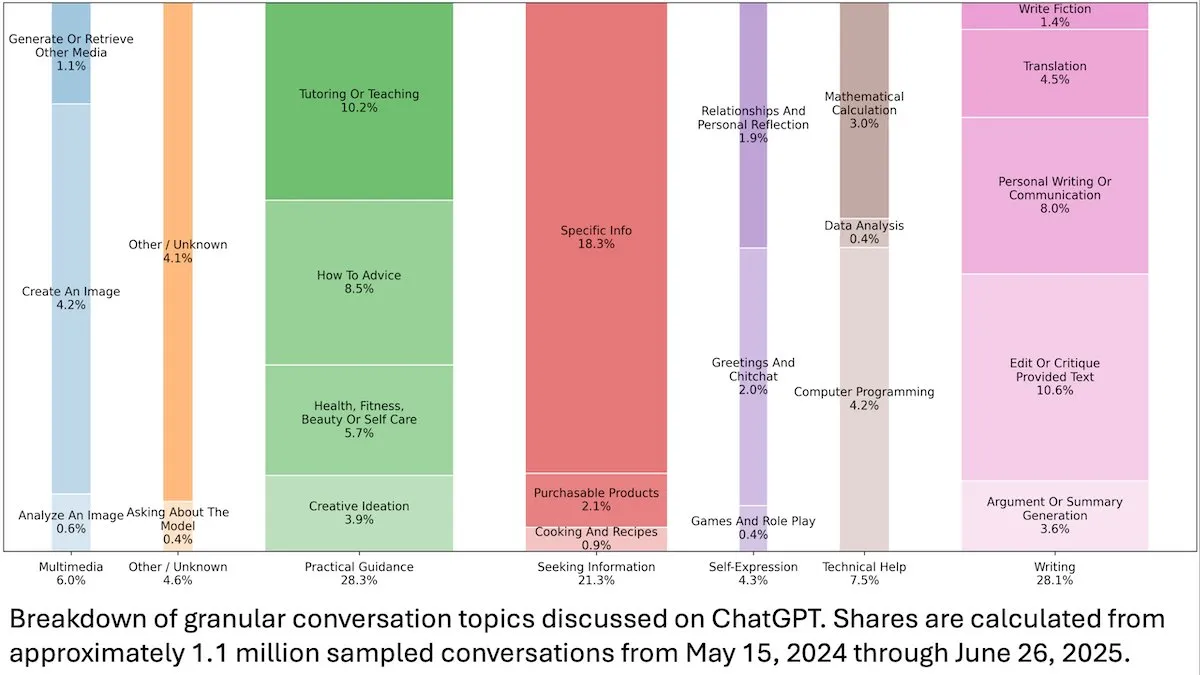
Einblicke in das Nutzerverhalten von ChatGPT: Eine von DeepLearningAI veröffentlichte OpenAI-Studie zeigt, dass die Analyse von 110 Millionen anonymen ChatGPT-Gesprächen darauf hindeutet, dass sich die Nutzung von arbeitsbezogenen zu persönlichen Bedürfnissen verlagert hat und dass weibliche Nutzer sowie junge Nutzer im Alter von 18-25 Jahren einen höheren Anteil ausmachen. Die häufigsten Anfragen sind praktische Anleitungen (28,3 %), Schreibhilfe (28,1 %) und Informationsanfragen (21,3 %), was die breite Anwendung von ChatGPT im Alltag offenbart. (Quelle: DeepLearningAI)
Code2Video: Code-gesteuerte Generierung von Bildungsvideos: Eine Studie stellt Code2Video vor, ein Code-zentriertes Agenten-Framework, das professionelle Bildungsvideos aus ausführbarem Python-Code generiert. Das Framework besteht aus drei kollaborierenden Agenten – Planer, Encoder und Kritiker –, die in der Lage sind, Vorlesungsinhalte zu strukturieren, in Code umzuwandeln und visuell zu optimieren. Es erreichte eine Leistungssteigerung von 40 % auf dem Bildungsvideo-Benchmark MMMC und generierte Videos, die mit menschlichen Tutorials vergleichbar sind. (Quelle: HuggingFace Daily Papers)
BiasFreeBench: Benchmark zur LLM-Bias-Minderung: BiasFreeBench wurde als empirischer Benchmark eingeführt, um acht gängige LLM-Bias-Minderungs-Techniken umfassend zu vergleichen. Der Benchmark reorganisiert bestehende Datensätze und führt in zwei Testszenarien – Multiple-Choice-Fragen und offene Multi-Turn-Fragen – eine “Bias-Free Score”-Metrik auf Antwortebene ein, um die Fairness, Sicherheit und Anti-Stereotyp-Eigenschaften von LLM-Antworten zu messen. Ziel ist es, eine einheitliche Testplattform für die Bias-Minderungsforschung zu schaffen. (Quelle: HuggingFace Daily Papers)
Transformer-Lernhindernisse bei Multiplikation und die Falle langer Abhängigkeiten: Eine Studie analysierte durch Reverse Engineering die Gründe für das Scheitern von Transformer-Modellen bei der scheinbar einfachen Aufgabe der mehrstelligen Multiplikation. Die Forschung zeigte, dass das Modell die notwendigen Langzeitabhängigkeitsstrukturen in einer impliziten Gedankenketten kodiert, aber Standard-Fine-Tuning-Methoden nicht zu einem globalen Optimum konvergieren, das diese Abhängigkeiten nutzen kann. Durch die Einführung einer Hilfsverlustfunktion gelang es den Forschern, dieses Problem zu lösen, was die Fallen beim Lernen langer Abhängigkeiten durch Transformer aufdeckte und ein Beispiel dafür lieferte, wie dieses Problem durch korrekte induktive Bias gelöst werden kann. (Quelle: HuggingFace Daily Papers)
VL-PRM-Trainingserkenntnisse in multimodaler Inferenz: Die Studie zielt darauf ab, den Designraum von Vision-Language Process Reward Models (VL-PRMs) zu beleuchten und verschiedene Strategien für den Aufbau von Datensätzen, das Training und die Skalierung zur Testzeit zu untersuchen. Durch die Einführung eines gemischten Datensynthese-Frameworks und einer wahrnehmungsfokussierten Überwachung zeigten VL-PRMs wichtige Erkenntnisse in fünf multimodalen Benchmarks, darunter die Überlegenheit gegenüber Ergebnis-Reward-Modellen bei der Testzeit-Skalierung, die Fähigkeit kleiner VL-PRMs, Prozessfehler zu erkennen, und die Möglichkeit, das latente Inferenzpotenzial stärkerer VLM-Backbones aufzudecken. (Quelle: HuggingFace Daily Papers)
GEM: Ein universeller Umgebungssimulator für Agentic LLMs: GEM (General Experience Maker) ist ein Open-Source-Umgebungssimulator, der speziell für das erfahrungsbasierte Lernen von LLM Agenten entwickelt wurde. Er bietet eine standardisierte Agent-Umgebung-Schnittstelle, unterstützt asynchrone vektorisierte Ausführung für hohen Durchsatz und bietet flexible Wrapper zur einfachen Erweiterung. GEM enthält auch eine vielfältige Umgebungssuite und integrierte Tools und bietet Baselines für RL-Trainings-Frameworks wie REINFORCE, um die Forschung an Agentic LLMs zu beschleunigen. (Quelle: HuggingFace Daily Papers)
GUI-KV: KV-Cache-Kompression für effiziente GUI Agenten: GUI-KV ist eine Plug-and-Play-KV-Cache-Kompressionmethode, die speziell für GUI Agenten entwickelt wurde und die Effizienz ohne erneutes Training steigert. Durch die Analyse von Aufmerksamkeitsmustern in GUI-Workloads kombiniert die Methode räumliche Salienzführung und zeitliche Redundanzbewertungstechniken, um bei moderatem Budget eine Genauigkeit nahe der vollständigen Cache-Nutzung zu erreichen und die Decodierungs-FLOPs erheblich zu reduzieren, wodurch die GUI-spezifische Redundanz effektiv genutzt wird. (Quelle: HuggingFace Daily Papers)
Jenseits der Log-Likelihood: Eine Studie über probabilistische Zielfunktionen für SFT: Die Studie untersucht probabilistische Zielfunktionen für Supervised Fine-Tuning (SFT), die über die traditionelle negative Log-Likelihood (NLL) hinausgehen. Durch umfangreiche Experimente mit 7 Modell-Backbones, 14 Benchmarks und 3 Domänen wurde festgestellt, dass Zielfunktionen, die Prioren mit geringeren Wahrscheinlichkeiten (z.B. -p, -p^10) bevorzugen, NLL übertreffen, wenn das Modell leistungsstärker ist; während NLL dominiert, wenn das Modell schwächer ist. Theoretische Analysen zeigen, wie Zielfunktionen je nach Modellfähigkeit Kompromisse eingehen, und bieten eine prinzipiellere Optimierungsstrategie für SFT. (Quelle: HuggingFace Daily Papers)
VLA-RFT: Validierungs-Reward-basiertes RL-Fine-Tuning in Welt-Simulatoren: VLA-RFT ist ein Reinforcement Fine-Tuning-Framework für Vision-Language-Action (VLA)-Modelle, das datengesteuerte Weltmodelle als steuerbare Simulatoren nutzt. Durch einen mit realen Interaktionsdaten trainierten Simulator, der aktionsbasierte zukünftige visuelle Beobachtungen vorhersagt, wird eine Richtlinienentwicklung mit dichten Reward-Signalen auf Trajektorien-Ebene ermöglicht. Das Framework reduziert den Stichprobenbedarf erheblich, übertrifft starke überwachte Baselines in weniger als 400 Fine-Tuning-Schritten und zeigt eine starke Robustheit unter gestörten Bedingungen. (Quelle: HuggingFace Daily Papers)
ImitSAT: Lösen des Booleschen Erfüllbarkeitsproblems durch Imitationslernen: ImitSAT ist eine auf Imitationslernen basierende CDCL-Solver-Verzweigungsstrategie zur Lösung des Booleschen Erfüllbarkeitsproblems (SAT). Die Methode lernt von Experten-KeyTraces, indem sie vollständige Läufe zu überlebenden Entscheidungssequenzen zusammenfasst und eine dichte, entscheidungsbasierte Überwachung bietet, die direkt die Anzahl der Propagierungen reduziert. Experimente zeigen, dass ImitSAT bestehende Lernmethoden in Bezug auf Propagierungsanzahl und Laufzeit übertrifft und eine schnellere Konvergenz und stabiles Training erreicht. (Quelle: HuggingFace Daily Papers)
Forschung zu Testpraktiken in Open-Source AI Agent Frameworks: Eine groß angelegte empirische Studie von 39 Open-Source Agent Frameworks und 439 Agenten-Anwendungen enthüllte Testpraktiken im AI Agent Ökosystem. Die Studie identifizierte zehn einzigartige Testmuster und stellte fest, dass über 70 % der Testinvestitionen in deterministische Komponenten (wie Tools und Workflows) fließen, während LLM-basierte Planungsagenten weniger als 5 % ausmachen. Darüber hinaus werden Regressionstests für Trigger-Komponenten stark vernachlässigt und treten nur in etwa 1 % der Tests auf, was kritische blinde Flecken bei Agenten-Tests aufzeigt. (Quelle: HuggingFace Daily Papers)
DeepCodeSeek: Echtzeit-API-Retrieval für Codegenerierung: DeepCodeSeek stellt eine neuartige Technologie für Echtzeit-API-Retrieval zur kontextsensitiven Codegenerierung vor, die hochwertige End-to-End-Code-Autovervollständigung und Agentic AI-Anwendungen ermöglicht. Die Methode löst das Problem des API-Lecks in bestehenden Benchmark-Datensätzen, indem sie Code und Indizes erweitert, um benötigte APIs vorherzusagen. Nach Optimierung übertraf ein kompakter 0.6B-Re-Ranker die Leistung eines 8B-Modells bei 2,5-mal geringerer Latenz. (Quelle: HuggingFace Daily Papers)
CORRECT: Kondensierte Fehlererkennung in Multi-Agenten-Systemen: CORRECT ist ein leichtgewichtiges, trainingsfreies Framework, das durch die Nutzung eines Online-Caches von destillierten Fehlermustern die Fehlererkennung und den Wissenstransfer in Multi-Agenten-Systemen ermöglicht. Das Framework kann strukturierte Fehler in linearer Zeit erkennen, vermeidet teures erneutes Training und kann sich an dynamische MAS-Bereitstellungen anpassen. CORRECT verbesserte die schrittweise Fehlerlokalisierung in sieben Multi-Agenten-Anwendungen um 19,8 % und verringerte den Abstand zwischen automatischer und menschlicher Fehlererkennung erheblich. (Quelle: HuggingFace Daily Papers)
Swift: Autoregressives Konsistenzmodell für effiziente Wettervorhersage: Swift ist ein Ein-Schritt-Konsistenzmodell, das erstmals das autoregressive Fine-Tuning von Probabilistic Flow Models mit einem Continuous Ranked Probability Score (CRPS)-Ziel implementiert. Das Modell kann qualifizierte 6-Stunden-Wettervorhersagen generieren und bleibt bis zu 75 Tage stabil. Es läuft 39-mal schneller als die modernsten Diffusions-Baselines und erreicht eine Vorhersagequalität, die mit numerischen IFS ENS konkurriert, was einen wichtigen Schritt für effiziente und zuverlässige Ensemble-Vorhersagen im mittel- bis saisonalen Bereich darstellt. (Quelle: HuggingFace Daily Papers)
Catching the Details: Selbst-destillierender RoI-Prädiktor für feinkörnige MLLM-Wahrnehmung: Eine Studie stellt ein effizientes, annotierungsfreies Self-Distillation Region Proposal Network (SD-RPN) vor, das die hohen Rechenkosten von Multimodalen Large Language Models (MLLMs) bei der Verarbeitung hochauflösender Bilder löst. SD-RPN wandelt Aufmerksamkeitskarten aus MLLM-Zwischenschichten in hochwertige Pseudo-RoI-Labels um und trainiert ein leichtgewichtiges RPN für präzise Lokalisierung, wodurch Dateneffizienz und Generalisierungsfähigkeit erreicht werden. Die Genauigkeit auf ungesehenen Benchmarks wurde um über 10 % verbessert. (Quelle: HuggingFace Daily Papers)
Ein neues Paradigma für mehrstufige LLM-Inferenz: In-Place Feedback: Die Studie führt ein neues interaktives Paradigma namens “In-Place Feedback” ein, um LLMs bei mehrstufiger Inferenz zu leiten. Benutzer können frühere LLM-Antworten direkt bearbeiten, und das Modell generiert Überarbeitungen basierend auf dieser modifizierten Antwort. Empirische Bewertungen zeigen, dass In-Place Feedback bei inferenzintensiven Benchmarks traditionelles mehrstufiges Feedback übertrifft und gleichzeitig den Token-Verbrauch um 79,1 % reduziert, wodurch die Einschränkung des Modells, Feedback präzise anzuwenden, behoben wird. (Quelle: HuggingFace Daily Papers)
Vorhersagbarkeit der LLM-Reinforcement-Learning-Dynamik: Diese Arbeit enthüllt zwei grundlegende Eigenschaften von Parameter-Updates in LLM-Reinforcement-Learning (RL)-Training: Rang-1-Dominanz (der höchste singuläre Unterraum der Parameter-Update-Matrix bestimmt fast vollständig die Inferenzverbesserung) und Rang-1-lineare Dynamik (dieser dominante Unterraum entwickelt sich während des Trainings linear). Basierend auf diesen Erkenntnissen schlägt die Studie AlphaRL vor, ein Plug-and-Play-Beschleunigungs-Framework, das durch die Inferenz der endgültigen Parameter-Updates aus einem frühen Trainingsfenster eine Beschleunigung von bis zu 2,5x erreicht, während über 96 % der Inferenzleistung erhalten bleiben. (Quelle: HuggingFace Daily Papers)
Fallen der KV-Cache-Kompression: Eine Studie deckt mehrere Fallen der KV-Cache-Kompression bei der LLM-Bereitstellung auf, insbesondere in realen Szenarien wie Multi-Instruktions-Prompts, wo die Kompression zu einem schnellen Leistungsabfall oder sogar zur vollständigen Ignorierung bestimmter Anweisungen durch das LLM führen kann. Die Studie analysiert systematisch das Leck von System-Prompts durch Fallstudien, demonstriert empirisch die Auswirkungen der Kompression auf Lecks und die allgemeine Befolgung von Anweisungen und schlägt einfache Verbesserungen für KV-Cache-Eviction-Strategien vor. (Quelle: HuggingFace Daily Papers)
💼 Business
Wettbewerb der KI-Giganten: Strategische Unterschiede zwischen OpenAI und Anthropic: OpenAI und Anthropic verfolgen im KI-Bereich grundverschiedene Entwicklungswege. OpenAI strebt durch die Integration von E-Commerce in ChatGPT und die Einführung der Sora-Social-App eine “horizontale Expansion” an, um eine Superplattform zu werden, die viele Aspekte des Nutzerlebens abdeckt, und wird auf über 100 Milliarden Dollar mehr als Anthropic geschätzt. Anthropic konzentriert sich auf “vertikale Vertiefung”, mit Claude Sonnet 4.5 als Kern, und vertieft sich in KI-Programmierung und den Enterprise-Agenten-Markt, eng verbunden mit Cloud-Anbietern wie AWS und Google. Dahinter steckt das “Compute-Diplomatie”-Spiel der beiden großen Cloud-Giganten Microsoft und Amazon, das die KI-Ära als eine Zeit der Rechenleistungsknappheit und hoher Kosten unterstreicht. (Quelle: 36氪、量子位、36氪)
Perplexity übernimmt Visual Electric: Perplexity hat die Übernahme von Visual Electric bekannt gegeben. Das Team von Visual Electric wird sich Perplexity anschließen, um gemeinsam neue Verbraucherprodukterlebnisse zu entwickeln. Die Produkte von Visual Electric werden schrittweise eingestellt. Diese Übernahme zielt darauf ab, die Innovationsfähigkeit von Perplexity im Bereich der KI-Produkte für Verbraucher zu stärken. (Quelle: AravSrinivas)

Databricks übernimmt Mooncakelabs: Databricks hat die Übernahme von Mooncakelabs bekannt gegeben, um seine Lakebase-Vision zu beschleunigen. Lakebase ist eine neue, auf Postgres basierende und für AI Agenten optimierte OLTP-Datenbank, die eine einheitliche Grundlage für Anwendungen, Analysen und KI bieten soll. Sie ist tief in Lakehouse und Agent Bricks integriert, um das Datenmanagement und die Entwicklung von KI-Anwendungen zu vereinfachen. (Quelle: matei_zaharia)

🌟 Community
Auswirkungen von KI auf Beschäftigung und Gesellschaft: Die Community diskutiert ausführlich die tiefgreifenden Auswirkungen der KI-Automatisierung auf den Arbeitsmarkt, befürchtet massive Arbeitsplatzverluste, die Entstehung neuer sozialer Schichten und die Notwendigkeit eines universellen Grundeinkommens (UBI). Es wird allgemein bezweifelt, ob neu geschaffene KI-bezogene Arbeitsplätze ebenfalls automatisiert werden und ob nicht jeder die KI-Fähigkeiten erlernen kann, um sich an die Zukunft anzupassen. Die Diskussionen umfassen auch das Kostenmanagement von AI Agenten und die Herausforderungen bei der Erzielung eines ROI sowie die potenziellen Auswirkungen der AGI auf die soziale Struktur und Geopolitik. (Quelle: Reddit r/ArtificialInteligence、Ronald_vanLoon、Ronald_vanLoon)
KI-Ethik und der Kampf um die Kontrolle: Die Community diskutiert intensiv, wer die Zukunft der KI kontrollieren sollte – die breite Öffentlichkeit oder Tech-Oligarchen. Es wird gefordert, dass die KI-Entwicklung menschenzentriert sein sollte, mit Betonung auf Transparenz und Nutzerkontrolle über persönliche Daten und KI-Historie. Gleichzeitig warnt KI-Pionier Yoshua Bengio, dass superintelligente Maschinen innerhalb eines Jahrzehnts zur Auslöschung der Menschheit führen könnten. Unternehmen wie Meta planen, KI-Chatdaten für gezielte Werbung zu nutzen, was die Bedenken der Nutzer hinsichtlich Datenschutz und KI-Missbrauch weiter verstärkt und eine tiefgreifende Reflexion über KI-Ethik und -Regulierung auslöst. (Quelle: Reddit r/artificial、Reddit r/artificial、Reddit r/ArtificialInteligence)

Anormales Verhalten des GPT-5 Sicherheitsmodells: Reddit-Community-Nutzer berichten, dass das “CHAT-SAFETY”-Modell von GPT-5 bei der Bearbeitung nicht-böswilliger Anfragen seltsames, anklagendes und sogar halluzinatorisches Verhalten zeigt, wie zum Beispiel die Interpretation einer Frage zur Fingerabdruckerkennung als Verfolgung und das Erfinden von Gesetzen. Diese übermäßige Sensibilität und ungenauen Antworten werfen ernsthafte Fragen bei den Nutzern hinsichtlich der Zuverlässigkeit des Modells, potenzieller Schäden und der Sicherheitsstrategien von OpenAI auf. (Quelle: Reddit r/ChatGPT)
“Bitter Lesson” und die Debatte über den LLM-Entwicklungspfad: Andrej Karpathy und Richard Sutton, der Vater des Reinforcement Learning, debattierten darüber, ob LLMs der “Bitter Lesson” entsprechen. Sutton argumentierte, dass LLMs auf begrenzte menschliche Daten für das Pre-Training angewiesen sind und nicht wirklich den Prinzipien des Lernens aus Erfahrung der “Bitter Lesson” folgen. Karpathy bezeichnete das Pre-Training als eine “schlechte Evolution” zur Lösung des Kaltstartproblems und wies auf die grundlegenden Unterschiede in den Lernmechanismen zwischen LLMs und tierischer Intelligenz hin, wobei er betonte, dass die aktuelle KI eher dem “Beschwören von Geistern” als dem “Bauen von Tieren” gleicht. (Quelle: karpathy、SchmidhuberAI)
Diskussion über den Wert lokaler LLM-Setups: Community-Nutzer diskutierten den Wert, Zehntausende von Dollar in den Aufbau eines lokalen LLM-Setups zu investieren. Befürworter betonten Datenschutz, Datensicherheit und das tiefe Wissen, das durch praktische Arbeit gewonnen wird, als Hauptvorteile und verglichen es mit Funkamateuren. Gegner argumentierten, dass angesichts der verbesserten Leistung günstiger Cloud-APIs (wie Sonnet 4.5 und Gemini Pro 2.5) die hohen Kosten eines lokalen Setups schwer zu rechtfertigen seien. (Quelle: Reddit r/LocalLLaMA)
LLM als Richter: Neue Methode zur Agentenbewertung: Forscher und Entwickler untersuchen die Verwendung von LLMs als “Richter” zur Bewertung der Qualität von AI Agenten-Antworten, einschließlich Genauigkeit und Fundiertheit. Die Praxis zeigt, dass diese Methode überraschend effektiv sein kann, wenn die Prompts des Richters sorgfältig gestaltet sind (z.B. Einzelkriterium, verankerte Bewertung, striktes Ausgabeformat und Bias-Warnungen). Dieser Trend deutet auf ein enormes Potenzial von LLM-as-a-Judge im Bereich der Agentenbewertung hin. (Quelle: Reddit r/MachineLearning)
KI und menschliche Interaktion: Von Geräten zu virtuellen Charakteren: KI verändert die menschliche Interaktion auf vielfältige Weise. Ein MIT-Startup hat ein “nahezu telepathisches” tragbares Gerät für lautlose Kommunikation vorgestellt. Gleichzeitig werden Echtzeit-Sprach-KI-Agenten als NPCs (Non-Player Characters) in 3D-Online-Spielen eingesetzt, was das Potenzial von KI für natürlichere, immersivere Interaktionserlebnisse in Spielen und virtuellen Welten andeutet. Diese Fortschritte lösen Diskussionen über die Rolle von KI im Alltag und in der Unterhaltung aus. (Quelle: Reddit r/ArtificialInteligence、Reddit r/artificial)

Wahl zwischen offenen und geschlossenen Modellen: Die Community diskutierte die größten Hindernisse, denen Softwareentwickler beim Übergang von geschlossenen zu Open-Source-Modellen begegnen. Experten wiesen darauf hin, dass das Fine-Tuning von Open-Source-Modellen anstatt der Abhängigkeit von Black-Box-Closed-Source-Modellen entscheidend für tiefgreifendes Lernen, die Schaffung von Produktunterschieden und die Entwicklung besserer Produkte für Benutzer ist. Obwohl die Entwicklungsgeschwindigkeit von Open-Source-Modellen langsamer sein mag, haben sie langfristig ein enormes Potenzial für Wertschöpfung und technologische Autonomie. (Quelle: ClementDelangue、huggingface)
KI-Infrastruktur und Rechenleistungsherausforderungen: OpenAIs “StarGate”-Projekt offenbart den enormen Bedarf von KI an Rechenleistung, Energie und Land, wobei voraussichtlich bis zu 900.000 DRAM-Wafer pro Monat verbraucht werden. Die Knappheit und hohen Preise von GPUs sowie die Einschränkungen der Stromversorgung zwingen KI-Unternehmen zu “Compute-Diplomatie” und einer engen Bindung an Cloud-Anbieter (wie Microsoft und Amazon). Diese kapitalintensive Investitions- und strategische Kooperationsmodell treibt zwar die KI-Entwicklung voran, birgt aber auch Risiken durch externe Variablen wie Lieferketten, Energiepolitik und Regulierung. (Quelle: karminski3、AI巨头的奶妈局、DeepLearning.AI Blog)

💡 Sonstiges
KI-Musikurheberrecht und Vergütungsmechanismen: Die schwedische Urheberrechtsorganisation STIM hat in Zusammenarbeit mit Sureel eine KI-Musiklizenzvereinbarung eingeführt, die darauf abzielt, das Problem der Urheberrechtsnutzung von Musikwerken beim Training von KI-Modellen zu lösen. Die Vereinbarung erlaubt KI-Entwicklern die legale Nutzung von Musik und berechnet über Sureels Attributions-Technologie den Einfluss der Werke auf die Modellausgabe, um Komponisten und Plattenkünstler zu vergüten. Dieser Schritt soll rechtliche Sicherheit für die KI-Musikproduktion schaffen, die Produktion von Originalinhalten fördern und neue Einnahmequellen für Urheberrechtsinhaber erschließen. (Quelle: DeepLearning.AI Blog)

LLM-Sicherheit und Adversarial Attacks: Trend Micro hat eine Studie veröffentlicht, die detailliert untersucht, wie LLMs von Angreifern auf verschiedene Weisen kompromittiert werden können, einschließlich durch sorgfältig konstruierte Prompts, Data Poisoning und Schwachstellen in Multi-Agenten-Systemen. Die Studie betont die Bedeutung des Verständnisses dieser Angriffsvektoren für die Entwicklung sichererer LLM-Anwendungen und Multi-Agenten-Systeme und schlägt entsprechende Verteidigungsstrategien vor. (Quelle: Reddit r/deeplearning)

Proactive AI: Abwägung zwischen Bequemlichkeit und Datenschutz: Die Community diskutierte die Bequemlichkeit und die potenziellen Datenschutzrisiken von “Proactive Ambient AI” als intelligenten Assistenten. Solche KIs können proaktiv Hilfe anbieten, aber ihre kontinuierliche Sammlung und Verarbeitung persönlicher Daten wirft bei den Nutzern Bedenken hinsichtlich Transparenz, Kontrolle und Datenbesitz auf. Es wird gefordert, “Transparenzprotokolle” und “persönliche Basisprofile” zu etablieren, um sicherzustellen, dass Benutzer die Kontrolle über ihre KI-Interaktionshistorie behalten. (Quelle: Reddit r/artificial)
