
Schlüsselwörter:Anthropic Claude Sonnet 4.5, DeepSeek-V3.2-Exp, OpenAI ChatGPT, KI-Modelle, Künstliche Intelligenz, Große Sprachmodelle, KI-Programmierung, KI-Agenten, Programmierfähigkeiten von Claude Sonnet 4.5, DSA-Sparse-Attention-Mechanismus, ChatGPT-Sofortkassafunktion, Sora 2-Sozial-App, LoRA-Feinabstimmungstechnik
🔥 Fokus
Anthropic veröffentlicht Claude Sonnet 4.5: Deutliche Verbesserungen bei Programmier- und Agentenfähigkeiten : Anthropic hat offiziell Claude Sonnet 4.5 veröffentlicht, das als das weltweit leistungsstärkste Programmiermodell gilt und erhebliche Fortschritte bei der Agentenentwicklung, Computernutzung, im logischen Denken und in mathematischen Fähigkeiten erzielt hat. Das Modell kann über 30 Stunden autonom und kontinuierlich arbeiten, hat den SWE-bench Verified Test an die Spitze geführt und neue Rekorde im OSWorld Computer-Task-Benchmark aufgestellt. Zu den neuen Funktionen gehören die „Checkpoint“-Rollback-Funktion von Claude Code, ein VS Code Plugin sowie kontextbezogene Bearbeitungs- und Gedächtnis-Tools für die API. Darüber hinaus wurde die experimentelle Funktion „Imagine with Claude“ eingeführt, die Software-Oberflächen in Echtzeit generieren kann. Sonnet 4.5 hat auch seine Sicherheitsfunktionen erheblich verbessert, unerwünschtes Verhalten wie Täuschung und Anbiederung reduziert und wurde nach AI Safety Level 3 (ASL-3) zertifiziert, wobei die Fehlalarmrate um das Zehnfache gesenkt wurde. Die Preisgestaltung bleibt mit Sonnet 4 identisch, was das Preis-Leistungs-Verhältnis weiter verbessert und voraussichtlich eine neue Runde des AI-Programmierwettbewerbs auslösen wird. (Quelle: Reddit r/ClaudeAI, 36氪, 36氪, 36氪, 36氪, 36氪, Reddit r/ChatGPT, dotey, dotey, dotey)

DeepSeek-V3.2-Exp veröffentlicht: Einführung des DeepSeek Sparse Attention (DSA) Mechanismus und Preissenkung : DeepSeek hat das experimentelle Modell V3.2-Exp veröffentlicht, das den DeepSeek Sparse Attention (DSA) Mechanismus einführt. Dieser verbessert die Trainings- und Inferenz-Effizienz bei langen Kontexten erheblich, während die API-Preise um über 50 % gesenkt wurden. DSA identifiziert und berechnet Schlüssel-Tokens effizient mittels eines „Lightning Indexers“, wodurch die Aufmerksamkeitskomplexität von O(L²) auf O(Lk) reduziert wird. Huawei Ascend, Cambricon, Hygon Information und andere chinesische AI-Chip-Hersteller haben bereits Day 0-Anpassungen vorgenommen, was die Entwicklung des nationalen Rechenleistungs-Ökosystems weiter vorantreibt. Das Modell hat auch GPU-Operatoren in der TileLang-Version als Open Source veröffentlicht, die mit NVIDIA CUDA vergleichbar sind und Entwicklern die Prototypenentwicklung und das Debugging erleichtern. Obwohl es in einigen Bereichen Kompromisse gibt, weisen seine architektonische Innovation und Kosteneffizienz einen neuen Weg für die Langtextverarbeitung großer Modelle. (Quelle: 36氪, 36氪, 36氪, 量子位, 量子位, 量子位, Reddit r/LocalLLaMA, Twitter)

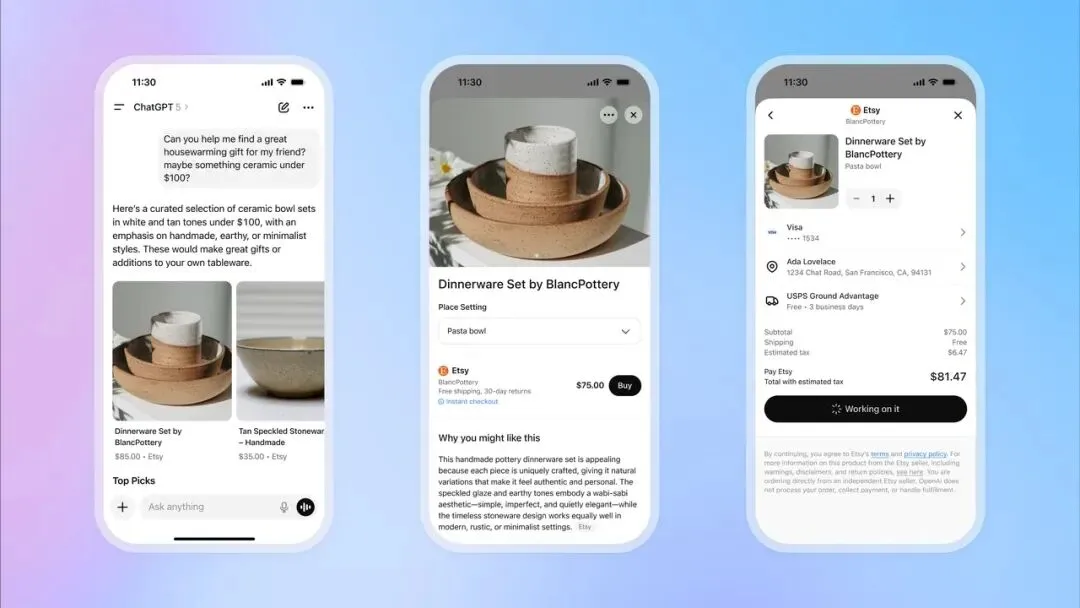
OpenAI führt ChatGPT Instant Checkout ein und expandiert in den E-Commerce : OpenAI hat die Funktion „Instant Checkout“ in ChatGPT eingeführt, die es Nutzern ermöglicht, Produkte von Etsy und Shopify direkt im Chat zu kaufen, ohne auf externe Websites weitergeleitet zu werden. Diese Funktion basiert auf dem von OpenAI und Stripe gemeinsam entwickelten „Agentic Commerce Protocol“, das als Open Source verfügbar ist und darauf abzielt, den enormen Traffic von ChatGPT in kommerzielle Transaktionen umzuwandeln. Zunächst wird der US-Markt unterstützt, zukünftig ist eine Erweiterung auf Warenkörbe mit mehreren Produkten und weitere Regionen geplant. Dieser Schritt wird als großer Fortschritt in der Kommerzialisierung von OpenAI angesehen, der zu einer wichtigen Einnahmequelle werden und tiefgreifende Auswirkungen auf den traditionellen E-Commerce- und Werbesektor haben könnte. (Quelle: 36氪, 36氪, Reddit r/artificial, Reddit r/artificial, Twitter, Twitter, Twitter, Twitter)
OpenAI bereitet die Einführung der sozialen App Sora 2 vor, um eine AI-Kurzvideoplattform zu schaffen : OpenAI bereitet die Einführung einer eigenständigen sozialen App vor, die von ihrem neuesten Videomodell Sora 2 angetrieben wird. Die App ist stark an TikTok angelehnt, mit vertikalem Video-Feed und Wisch-Navigation, wobei alle Inhalte von AI generiert werden. Nutzer können Videoclips von bis zu 10 Sekunden Länge generieren und mithilfe einer Authentifizierungsfunktion ihr eigenes Porträt in Videos verwenden. Dieser Schritt zielt darauf ab, den Erfolg von ChatGPT im Textbereich zu wiederholen, der Öffentlichkeit das Potenzial von AI-Videos intuitiv näherzubringen und direkt in den Wettbewerb mit Meta und Google einzututreten. Allerdings verfolgt OpenAI bei der Urheberrechtsbehandlung eine Strategie, die standardmäßig urheberrechtlich geschützte Inhalte verwendet, es sei denn, die Rechteinhaber widersprechen aktiv. Dies hat bei Content-Erstellern und Filmstudios große Besorgnis ausgelöst und deutet auf einen intensiven Kampf zwischen AI und geistigem Eigentum hin. (Quelle: 36氪, Reddit r/artificial, Twitter, Twitter)

🎯 Trends
Huawei Pangu 718B Modell belegt den zweiten Platz im SuperCLUE Chinese Large Model Ranking : Das Huawei openPangu-Ultra-MoE-718B Modell belegt im SuperCLUE Chinese Large Model General Benchmark Test den zweiten Platz in der Open-Source-Liste. Das Modell verfolgt die Trainingsphilosophie „nicht auf Datenmengen, sondern auf Denkfähigkeit setzen“ und verwendet Datenkonstruktionsprinzipien wie „Qualität zuerst, Vielfalt abdecken, Komplexität anpassen“ sowie eine dreistufige Vortrainingsstrategie (allgemein, Inferenz, Annealing), um umfassendes Weltwissen aufzubauen und die logische Schlussfolgerungsfähigkeit zu verbessern. Um das Halluzinationsproblem zu mildern, wurde ein „kritisches Internalisierungs“-Mechanismus eingeführt; zur Verbesserung der Tool-Nutzungsfähigkeit wird ein aktualisiertes ToolACE Synthese-Framework verwendet. (Quelle: 量子位)

FSDrive vereinheitlicht VLA und Weltmodelle, um autonomes Fahren in Richtung visueller Inferenz zu bewegen : FSDrive (FutureSightDrive) schlägt „Temporal-Spatial Visual CoT“ vor, das zukünftige Bildframes als Zwischeninferenzschritte vereinheitlicht, um zukünftige Szenen und Wahrnehmungsergebnisse für visuelle Inferenz zu kombinieren. Dies soll autonomes Fahren von symbolischer Inferenz zu visueller Inferenz bewegen. Die Methode aktiviert die Bildgenerierungsfähigkeit durch Vokabularerweiterung und autoregressive visuelle Generierung, ohne die bestehende MLLM-Architektur zu ändern, und injiziert physikalische Prioren durch progressive visuelle CoT. Das Modell fungiert sowohl als „Weltmodell“ zur Vorhersage der Zukunft als auch als „inverse Dynamikmodell“ zur Trajektorienplanung. (Quelle: 36氪)

GPT-5 liefert entscheidende Ideen für Quantencomputing und wird von Scott Aaronson hoch gelobt : Der Quantencomputing-Theoretiker Scott Aaronson enthüllte, dass GPT-5 ihm in weniger als einer halben Stunde entscheidende Beweisideen für seine Forschung zur Quantenkomplexitätstheorie lieferte und ein Problem löste, das sein Team plagte. Scott Aaronson erklärte, dass GPT-5 erhebliche Fortschritte bei der Bewältigung der menschlichsten intellektuellen Aktivitäten gemacht hat, was einen „Sweet Spot“ der Zusammenarbeit zwischen Mensch und AI markiert, der Forschern in kritischen Momenten bahnbrechende Inspirationen liefern kann. (Quelle: 量子位, Twitter)

HuggingFace beschleunigt Inferenz des Qwen3-8B Agent Modells auf Intel Core Ultra : HuggingFace und Intel haben zusammengearbeitet, um die Inferenzgeschwindigkeit des Qwen3-8B Agent Modells auf der integrierten GPU von Intel Core Ultra um das 1,4-fache zu steigern. Dies wurde durch OpenVINO.GenAI und ein tiefen-beschnittenes (depth-pruned) Qwen3-0.6B Entwurfsmodell erreicht. Diese Optimierung macht den Betrieb von Agent-Anwendungen mit Qwen3-8B auf AI PCs effizienter, insbesondere für komplexe Workflows, die mehrstufige Inferenz und Tool-Aufrufe erfordern, und fördert die Praktikabilität lokaler AI Agents. (Quelle: HuggingFace Blog)

Reachy Mini Roboter integriert GPT-4o für multimodale Interaktion : Der Reachy Mini Roboter von Hugging Face / Pollen Robotics wurde erfolgreich mit dem GPT-4o Modell von OpenAI integriert, was zu einer signifikanten Verbesserung der multimodalen Interaktionsfähigkeiten führte. Neue Funktionen umfassen Bildanalyse (Roboter kann aufgenommene Fotos beschreiben und interpretieren), Gesichtsverfolgung (hält Blickkontakt), Bewegungsfusion (Kopfbewegungen, Gesichtsverfolgung, Emotionen/Tanz gleichzeitig), lokale Gesichtserkennung und autonomes Verhalten im Leerlauf. Diese Fortschritte ermöglichen eine natürlichere und flüssigere Mensch-Maschine-Interaktion, stehen aber noch vor Herausforderungen bei Speichersystemen, Spracherkennung und komplexen Strategien für Menschenmengen. (Quelle: Reddit r/ChatGPT, Twitter)

Intel veröffentlicht neue LLM Scaler Beta-Versionen für GenAI auf Battlemage GPUs : Intel hat neue LLM Scaler Beta-Versionen veröffentlicht, die darauf abzielen, die Leistung von Generative AI (GenAI) auf Battlemage GPUs zu optimieren. Dieser Schritt unterstreicht Intels kontinuierliches Engagement in AI-Hardware und -Software-Ökosystemen, um die Wettbewerbsfähigkeit seiner GPUs bei der Inferenz und Generierung großer Sprachmodelle zu verbessern. (Quelle: Reddit r/artificial)
Claude führt Nutzungsbeschränkungs-Dashboard ein, ChatGPT startet Kindersicherungsfunktion : Anthropic hat ein Echtzeit-Nutzungsbeschränkungs-Dashboard für Claude Code und die Claude App eingeführt, das es Nutzern ermöglicht, ihren Token-Verbrauch zu verfolgen, um den zuvor angekündigten wöchentlichen Ratenbegrenzungen gerecht zu werden. Gleichzeitig hat OpenAI in ChatGPT eine Kindersicherungsfunktion eingeführt, die es Eltern ermöglicht, Teenager-Konten zu verknüpfen, automatisch stärkere Sicherheit zu bieten und Funktionen sowie Nutzungsbeschränkungen anzupassen, wobei Eltern jedoch keine spezifischen Chat-Inhalte einsehen können. (Quelle: Reddit r/ClaudeAI, 36氪)

5 Millionen Parameter Sprachmodell in Minecraft ausgeführt, zeigt innovative AI-Anwendung : Sammyuri hat in Minecraft ein komplexes Redstone-System gebaut, das erfolgreich ein Sprachmodell mit etwa 5 Millionen Parametern ausführt und ihm grundlegende Konversationsfähigkeiten verleiht. Dieses bahnbrechende Ergebnis demonstriert die Möglichkeit, lokale AI in einer Spielumgebung zu implementieren, und hat in der Community breites Interesse und Diskussionen über AI-Anwendungen auf nicht-traditionellen Plattformen ausgelöst. (Quelle: Reddit r/LocalLLaMA, Twitter)
Inspur Information AI-Server erreicht 8,9 ms Inferenzgeschwindigkeit, Kosten von 1 Yuan pro Million Tokens : Inspur Information hat die hyper-skalierbaren AI-Server Yuan Nao HC1000 und Yuan Nao SD200 Supernode veröffentlicht, die die AI-Inferenzgeschwindigkeit auf einen neuen Rekord steigern. Der Yuan Nao SD200 erreicht eine Ausgabezeit pro Token (TPOT) von 8,9 ms auf dem DeepSeek-R1 Modell, was fast doppelt so schnell ist wie der bisherige SOTA, und unterstützt Billionen-Parameter-Modellinferenz sowie Echtzeit-Kollaboration mehrerer Agents. Der Yuan Nao HC1000 reduziert die Kosten pro Million Tokens auf 1 Yuan und die Kosten pro Einzelkarte um 60 %. Diese Durchbrüche zielen darauf ab, die Geschwindigkeits- und Kostenengpässe der Agenten-Industrialisierung zu lösen und eine effiziente, kostengünstige Recheninfrastruktur für die großflächige Implementierung von Multi-Agenten-Kollaboration und komplexer Aufgabeninferenz bereitzustellen. (Quelle: 量子位)

Neue Methode für Feedforward 3D Gaussian Splatting: Zhejiang University Team stellt „Voxel-Aligned“ vor : Ein Team der Zhejiang University hat das „Voxel-Aligned“ Feedforward 3D Gaussian Splatting (3DGS) Framework VolSplat vorgestellt, um die Engpässe bei der geometrischen Konsistenz und der Gaußschen Dichteverteilung in bestehenden „Pixel-Aligned“-Methoden bei der Multi-View 3D-Rekonstruktion zu lösen. VolSplat fusioniert Multi-View 2D-Informationen im dreidimensionalen Raum und verfeinert Merkmale mithilfe eines dünnen 3D U-Net, um eine höhere Qualität, Robustheit und Effizienz bei der 3D-Rekonstruktion zu erzielen. Die Methode übertrifft mehrere Baselines auf öffentlichen Datensätzen und zeigt eine starke Zero-Shot-Generalisierungsfähigkeit auf ungesehenen Datensätzen. (Quelle: 量子位)

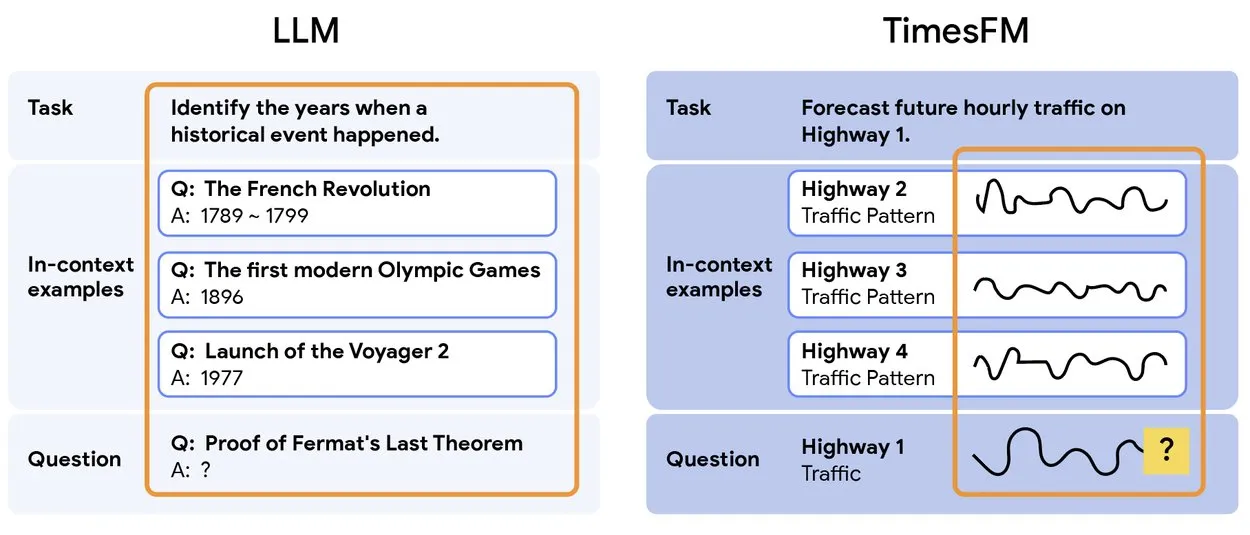
TimesFM 2.5: Vortrainiertes Zeitreihen-Vorhersagemodell veröffentlicht : TimesFM 2.5 wurde veröffentlicht, ein vortrainiertes Modell für die Zeitreihenvorhersage. Die Anzahl der Parameter wurde von 500M auf 200M reduziert, die Kontextlänge von 2K auf 16K erhöht, und es zeigt hervorragende Leistungen im Zero-Shot-Setting. Das Modell ist jetzt auf Hugging Face verfügbar und unter der Apache 2.0 Lizenz lizenziert, was eine effizientere und leistungsfähigere Lösung für Zeitreihenvorhersageaufgaben bietet. (Quelle: Twitter)
Yunpeng Technology veröffentlicht neue AI+Gesundheitsprodukte, fördert AI-Anwendung im Bereich Familiengesundheit : Yunpeng Technology hat in Zusammenarbeit mit Shuaikang und Skyworth das „Digitale und intelligente Zukunftsküchenlabor“ und einen intelligenten Kühlschrank mit einem AI-Gesundheits-Großmodell vorgestellt. Das AI-Gesundheits-Großmodell optimiert das Küchendesign und den Betrieb, während der intelligente Kühlschrank über den „Gesundheitsassistenten Xiaoyun“ personalisiertes Gesundheitsmanagement bietet. Diese Veröffentlichung markiert einen Durchbruch der AI im Bereich des täglichen Gesundheitsmanagements und soll durch intelligente Geräte personalisierte Gesundheitsdienste ermöglichen und das Niveau der Familiengesundheitstechnologie verbessern. (Quelle: 36氪)
Alibaba veröffentlicht 1 Billion Parameter Open-Source-Denkmodell Ring-1T-preview : Das Ant Ling Team von Alibaba hat das erste Open-Source-Denkmodell Ring-1T-preview mit 1 Billion Parametern veröffentlicht, das darauf abzielt, „tiefes Denken ohne Wartezeit“ zu ermöglichen. Das Modell hat frühe hervorragende Ergebnisse bei Aufgaben der natürlichen Sprachverarbeitung erzielt, darunter Benchmarks wie AIME25, HMMT25, ARC-AGI-1, LCB und Codeforces. Darüber hinaus löste es das Q3-Problem von IMO25 auf einmal und lieferte Teillösungen für Q1/Q2/Q4/Q5, was seine starken Inferenz- und Problemlösungsfähigkeiten demonstriert. (Quelle: Twitter, Twitter, Twitter)

🧰 Tools
PopAi veröffentlicht „Slide Agent“, AI generiert Präsentationen auf Knopfdruck : Das PopAi-Team hat das Tool „Slide Agent“ vorgestellt, das den Prozess der Präsentationserstellung vereinfachen soll. Nutzer müssen lediglich ihre Anforderungen per Prompt eingeben, können aus über 300 Vorlagen wählen, und die AI generiert automatisch einen Entwurf, passt Layout, Diagramme, Bilder, Logos und andere Formate an und lädt die fertige Datei als bearbeitbare .pptx-Datei herunter. Das Tool integriert Funktionen von ChatGPT und Canva und senkt den Aufwand und die Zeitkosten für die Präsentationserstellung erheblich. (Quelle: Twitter)
Alibaba veröffentlicht PDF-zu-Markdown-Tool Miner U2.5 als Open Source : Das Alibaba-Team hat das PDF-zu-Markdown-Tool Miner U2.5 als Open Source veröffentlicht und eine Demo auf HuggingFace bereitgestellt. Das Tool kann PDF-Dokumente effizient in das Markdown-Format konvertieren, was die Extraktion, Bearbeitung und Wiederverwendung von Inhalten für Entwickler und Forscher erleichtert und ein praktisches AI-gestütztes Tool für die Verarbeitung großer Mengen von PDF-Dokumenten darstellt. (Quelle: dotey)
VEED Animate 2.2 online, unterstützt Videostil-Neugestaltung und Rollenwechsel : Die Version 2.2 von VEED Animate ist offiziell online und wird von der WAN 2.2 Technologie unterstützt. Dieses Tool ermöglicht es Benutzern, den Videostil mit einem einzigen Bild einfach neu zu gestalten, Charaktere in Videos sofort auszutauschen und Videoclips 10-mal schneller zu erstellen. Diese neuen Funktionen vereinfachen den Videokreationsprozess erheblich und bieten Content-Erstellern mehr AI-gesteuerte kreative Möglichkeiten. (Quelle: TomLikesRobots)
LangChain strebt LLM-Antwortstandardisierung an, unterstützt komplexe Funktionen : LangChain konzentriert sich in seiner v1-Entwicklung auf die Standardisierung von LLM-Antworten, um den zunehmend komplexen LLM-Funktionen wie serverseitigen Tool-Aufrufen, Inferenz und Referenzen gerecht zu werden. Das Framework zielt darauf ab, Inkompatibilitätsprobleme zwischen den API-Formaten verschiedener LLM-Anbieter zu lösen und Entwicklern eine einheitliche Schnittstelle zu bieten, um den Aufbau multimodaler Agents und komplexer Workflows zu vereinfachen. (Quelle: LangChainAI, Twitter)
Hugging Face Transformers.js unterstützt Offline-Ausführung von AI-Modellen im Browser : Die Transformers.js-Bibliothek von Hugging Face ermöglicht es Benutzern, AI-Modelle wie Llama 3.2 offline im Browser mithilfe von ONNX- und WebGPU-Technologien auszuführen. Dies ermöglicht Entwicklern, AI-Aufgaben wie Chatbots, Objekterkennung und Hintergrundentfernung lokal auszuführen, ohne auf Cloud-Dienste angewiesen zu sein, was die Datenprivatsphäre und Verarbeitungsgeschwindigkeit verbessert. (Quelle: Twitter)
ToolUniverse Ökosystem unterstützt AI-Wissenschaftler beim Aufbau und der Tool-Integration : ToolUniverse ist ein Ökosystem, das für den Aufbau von AI-Wissenschaftlern entwickelt wurde. Es standardisiert die Art und Weise, wie AI-Wissenschaftler Tools identifizieren und aufrufen, und integriert über 600 Machine Learning-Modelle, Datensätze, APIs und wissenschaftliche Softwarepakete für Datenanalyse, Wissensabfrage und Experimentdesign. Die Plattform optimiert Tool-Schnittstellen automatisch, erstellt neue Tools anhand natürlicher Sprachbeschreibungen und iteriert die Tool-Spezifikationen, um Tools zu Agenten-Workflows zu kombinieren und so die Zusammenarbeit von AI-Wissenschaftlern im Entdeckungsprozess zu fördern. (Quelle: HuggingFace Daily Papers)
EasySteer Framework verbessert LLM-Steuerungsleistung und Skalierbarkeit : EasySteer ist ein auf vLLM basierendes einheitliches Framework, das darauf abzielt, die Steuerungsleistung und Skalierbarkeit von LLMs zu verbessern. Durch eine modulare Architektur, steckbare Schnittstellen, feingranulare Parameterkontrolle und vorab berechnete Steuerungsvektoren erreicht es eine 5,5- bis 11,4-fache Geschwindigkeitssteigerung und reduziert effektiv Overthinking und Halluzinationen. EasySteer wandelt die LLM-Steuerung von einer Forschungstechnik in eine produktionsreife Fähigkeit um und bietet eine entscheidende Infrastruktur für einsetzbare und kontrollierbare Sprachmodelle. (Quelle: HuggingFace Daily Papers)
VibeGame: AI-gestützte Game Engine basierend auf WebStack : VibeGame ist eine fortschrittliche deklarative Game Engine, die auf three.js, rapier und bitecs basiert und speziell für die AI-gestützte Spieleentwicklung entwickelt wurde. Durch eine hohe Abstraktionsebene, integrierte Physik- und Rendering-Funktionen sowie eine Entity-Component-System (ECS)-Architektur ermöglicht sie es der AI, Spielcode effizienter zu verstehen und zu generieren. Obwohl sie derzeit hauptsächlich für einfache Plattformspiele geeignet ist, bietet ihr Open-Source-Code und die AI-freundliche Syntax eine vielversprechende Lösung für die AI-gesteuerte Spieleentwicklung. (Quelle: HuggingFace Blog)
AI-Forschungskarten-Tool integriert 900.000 Artikel und liefert zitierte Antworten : Ein innovatives AI-Tool kann 900.000 AI-Forschungsartikel aus den letzten zehn Jahren semantisch gruppieren und visualisieren, um eine detaillierte Forschungskarte zu erstellen. Benutzer können dem Tool Fragen stellen und erhalten Antworten mit präzisen Zitaten, was den Prozess der Suche und des Verständnisses riesiger Mengen akademischer Literatur für Forscher erheblich vereinfacht und die Forschungseffizienz steigert. (Quelle: Reddit r/ArtificialInteligence)
Kroko ASR: Schnelle, Streaming-Alternative zu Whisper : Kroko ASR ist ein neu veröffentlichtes Open-Source-Sprach-zu-Text-Modell, das als schnelle, Streaming-Alternative zu Whisper positioniert ist. Es verfügt über eine kleinere Modellgröße, schnellere CPU-Inferenz (unterstützt mobile und Browser-Geräte) und weist kaum Halluzinationen auf. Kroko ASR unterstützt mehrere Sprachen und zielt darauf ab, die Hürden für Sprach-AI zu senken, um sie einfacher auf Edge-Geräten bereitzustellen und zu trainieren. (Quelle: Reddit r/LocalLLaMA)
OpenWebUI Plotly Diagramm-Rendering-Problem, unterstreicht Herausforderungen bei der AI-Tool-UI-Integration : Die v0.6.32-Version von OpenWebUI zeigt ein Problem, bei dem Plotly-Diagramme nicht korrekt gerendert werden, sondern direkt als Roh-JSON angezeigt werden. Benutzer berichten, dass das Backend korrektes JSON zurückgibt, das Frontend jedoch das Rendering nicht auslöst. Dies spiegelt wider, dass AI-Tools bei der Frontend-UI-Integration und dem Rich-Text-Rendering immer noch technischen Herausforderungen gegenüberstehen, die eine weitere Optimierung durch die Entwicklergemeinschaft erfordern. (Quelle: Reddit r/OpenWebUI)
📚 Lernen
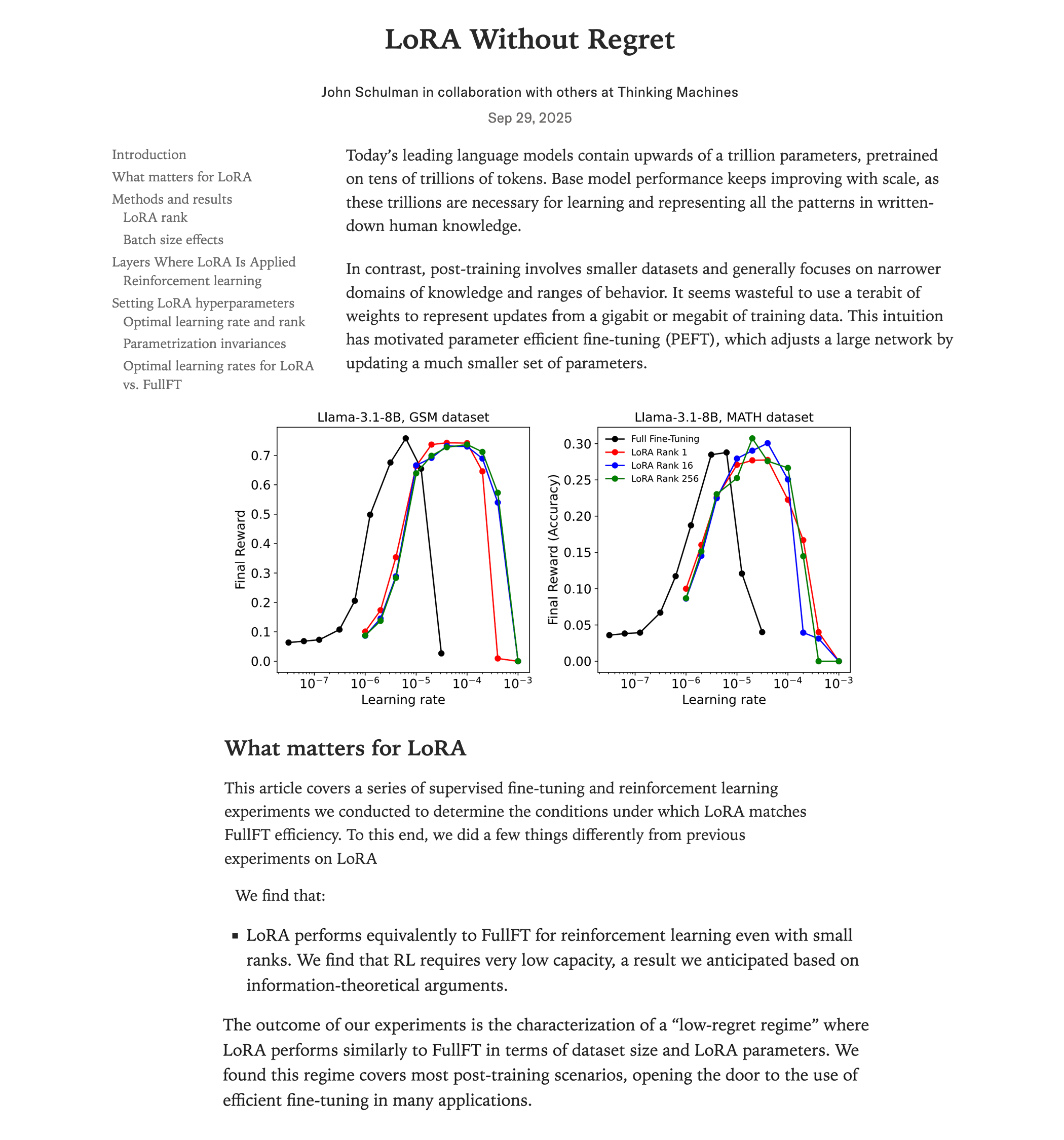
Vergleichsstudie zur Leistung von LoRA-Feinabstimmung und Full-Feinabstimmung : Eine aktuelle Studie von Thinking Machines (John Schulman Team) zeigt, dass in der Reinforcement Learning, wenn LoRA (Low-Rank Adaptation) richtig angewendet wird, ihre Leistung der Full-Feinabstimmung entsprechen kann, bei geringerem Ressourcenverbrauch (etwa 2/3 der Rechenleistung), und selbst bei rank=1 hervorragende Ergebnisse erzielt. Die Studie betont, dass LoRA auf alle Schichten (einschließlich MLP/MoE) angewendet werden sollte und eine 10-mal höhere Lernrate als bei der Full-Feinabstimmung verwendet werden sollte. Diese Erkenntnis senkt die Hürde für das Training leistungsstarker RL-Modelle erheblich, sodass mehr Entwickler hochwertige Modelle auf einer einzigen GPU realisieren können. (Quelle: Reddit r/LocalLLaMA, Twitter, Twitter)
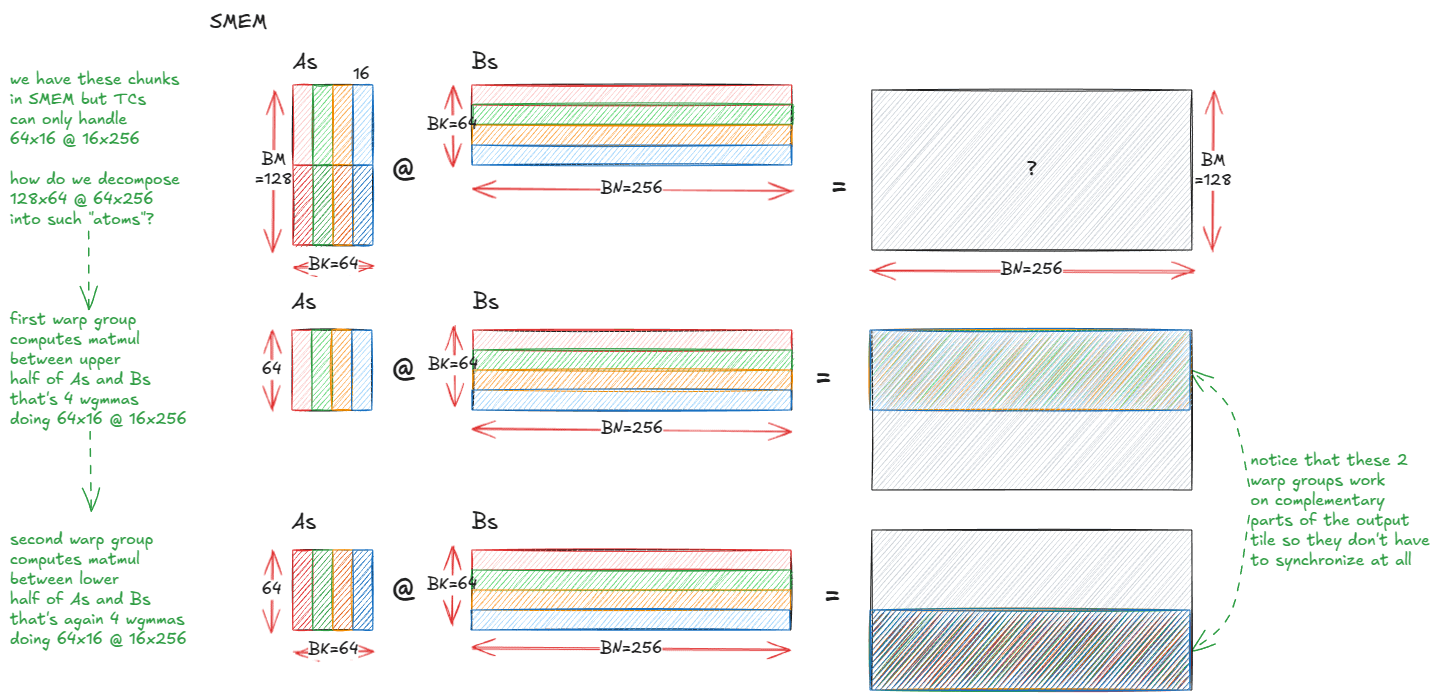
Anatomie von Hochleistungs-Matrixmultiplikationskernen in NVIDIA GPUs : Ein detaillierter technischer Blogbeitrag analysiert die Implementierungsmechanismen von Hochleistungs-Matrixmultiplikationskernen (matmul) in NVIDIA GPUs. Der Artikel behandelt die Grundlagen der GPU-Architektur, die Speicherhierarchie (GMEM, SMEM, L1/L2), PTX/SASS-Programmierung und fortgeschrittene Funktionen der Hopper (H100)-Architektur wie TMA und wgmma-Instruktionen. Diese Ressource soll Entwicklern helfen, CUDA-Programmierung und GPU-Leistungsoptimierung tiefgreifend zu verstehen, was für das Training und die Inferenz von Transformer-Modellen entscheidend ist. (Quelle: Reddit r/deeplearning, Twitter)
Stanford CS231N Deep Learning Computer Vision Vorlesungen auf YouTube verfügbar : Die hochgelobten Vorlesungen des Stanford CS231N (Deep Learning for Computer Vision) Kurses sind jetzt kostenlos auf YouTube verfügbar. Dies bietet Lernenden weltweit eine wertvolle Gelegenheit, Zugang zu hochwertigen AI-Bildungsressourcen zu erhalten, die von grundlegenden Konzepten bis zu fortgeschrittenen Anwendungen des Deep Learning in der Computer Vision reichen. (Quelle: Reddit r/deeplearning)

RL-ZVP: Verbesserung der LLM Reinforcement Learning Inferenzfähigkeiten durch Zero-Variance Prompts : Eine aktuelle Studie stellt die Methode „RL with Zero-Variance Prompts (RL-ZVP)“ vor, die darauf abzielt, die Reinforcement Learning Inferenzfähigkeiten großer Sprachmodelle (LLMs) zu verbessern. Diese Methode ignoriert nicht länger „Zero-Variance Prompts“ (Fälle, in denen alle Modellantworten die gleiche Belohnung erhalten), sondern extrahiert daraus wertvolle Lernsignale, belohnt direkt Korrektheit und bestraft Fehler und nutzt Token-level Entropie, um die Vorteilsformung zu steuern. Experimentelle Ergebnisse zeigen, dass RL-ZVP die Genauigkeit und Erfolgsrate bei mathematischen Inferenz-Benchmarks im Vergleich zu traditionellen Methoden signifikant verbessert. (Quelle: Reddit r/MachineLearning)
Future-Guided Learning: Ein prädiktiver Ansatz zur Verbesserung der Zeitreihenvorhersage : Eine Studie schlägt „Future-Guided Learning“ vor, um die Vorhersage von Zeitreihenereignissen durch einen dynamischen Feedback-Mechanismus zu verbessern. Diese Methode umfasst ein Detektionsmodell zur Analyse zukünftiger Daten und ein Vorhersagemodell, das auf aktuellen Daten basiert. Wenn das Vorhersagemodell vom Detektionsmodell abweicht, wird das Vorhersagemodell stärker aktualisiert, um „Überraschungen“ zu minimieren, wodurch Parameter dynamisch angepasst und die Genauigkeit der Zeitreihenvorhersage effektiv verbessert werden. (Quelle: Reddit r/MachineLearning)
Die Zukunft der AI in niedrigeren Dimensionen: Yann Lecun über das Lernen abstrakter Repräsentationen : AI-Pionier Yann Lecun schlägt in einem Interview mit Lex Fridman vor, dass der nächste Sprung in der AI aus dem Lernen in niedrigerdimensionalen latenten Räumen kommen wird, anstatt direkt hochdimensionale Rohdaten wie Pixel zu verarbeiten. Er glaubt, dass echte intelligente Systeme abstrakte Repräsentationen der kausalen Struktur und der physikalischen Dynamik der Welt lernen müssen, um auch bei Detailänderungen genaue Vorhersagen treffen zu können. Dieser Ansatz würde Modelle flexibler und robuster machen, die Abhängigkeit von riesigen Datenmengen reduzieren und die Rechenkosten senken. (Quelle: Reddit r/ArtificialInteligence)
SIRI: Skalierung des iterativen Reinforcement Learning mit verschachtelter Kompression : SIRI (Scaling Iterative Reinforcement Learning with Interleaved Compression) ist eine einfache und effektive Reinforcement Learning-Methode, die das maximale Rollout-Länge während des Trainings dynamisch anpasst, indem sie das Inferenzbudget iterativ komprimiert und erweitert. Dieser Trainingsmechanismus zwingt das Modell, präzise Entscheidungen in einem begrenzten Kontext zu treffen, reduziert redundante Tokens und bietet gleichzeitig Raum für Exploration und Planung, wodurch die Effizienz und Genauigkeit großer Inferenzmodelle im Leistungs-Effizienz-Kompromiss stetig verbessert wird. (Quelle: HuggingFace Daily Papers)
MultiCrafter: Multimodales generatives Modell mit räumlich entkoppelter Aufmerksamkeit und identitätsbewusstem Reinforcement Learning : MultiCrafter ist ein Framework, das darauf abzielt, hochpräzise, präferenz-ausgerichtete Multi-Agenten-Bildgenerierung zu erreichen. Es löst Aufmerksamkeitsbereiche zwischen verschiedenen Agenten durch die Einführung expliziter Positionsüberwachung, wodurch das Problem des Attribut-Lecks effektiv gemildert wird. Gleichzeitig verbessert das Framework die Modellkapazität durch eine Mixture-of-Experts (MoE)-Architektur und entwirft ein neuartiges Online-Reinforcement Learning-Framework, das Bewertungsmechanismen und stabile Trainingsstrategien kombiniert, um sicherzustellen, dass die Subjekt-Fidelity der generierten Bilder und die menschlichen ästhetischen Präferenzen stark übereinstimmen. (Quelle: HuggingFace Daily Papers)
Visual Jigsaw: Verbesserung des visuellen Verständnisses von MLLMs durch selbstüberwachtes Post-Training : Visual Jigsaw ist ein allgemeines selbstüberwachtes Post-Training-Framework, das darauf abzielt, die visuellen Verständnisfähigkeiten von multimodalen großen Sprachmodellen (MLLMs) zu verbessern. Die Methode partitioniert und mischt visuelle Eingaben und fordert das Modell auf, die korrekte Anordnung durch natürliche Sprache zu rekonstruieren. Dieser auf verifizierbaren Belohnungen basierende Reinforcement Learning (RLVR)-Ansatz erfordert keine zusätzlichen visuellen Generierungskomponenten oder manuelle Annotationen und verbessert die Leistung von MLLMs in Bezug auf feingranulare Wahrnehmung, zeitliche Inferenz und 3D-Raumverständnis erheblich. (Quelle: HuggingFace Daily Papers)
MGM-Omni: Erweiterung von Omni LLMs auf personalisierte Langzeit-Sprachgenerierung : MGM-Omni ist ein einheitliches Omni LLM, das durch seine einzigartige „Gehirn-Mund“-Dual-Track-Tokenisierungsarchitektur multimodales Verständnis und ausdrucksstarke Langzeit-Sprachgenerierung ermöglicht. Dieses Design entkoppelt multimodale Inferenz von der Echtzeit-Sprachgenerierung, unterstützt effiziente Cross-Modale Interaktion und latenzarmes Streaming-Sprachklonen und zeigt eine hervorragende Dateneffizienz. Experimente belegen, dass MGM-Omni bestehende Open-Source-Modelle in Bezug auf die Konsistenz der Stimmfarbe, die Generierung natürlicher, kontextsensitiver Sprache sowie das Langzeit-Audio- und multimodale Verständnis übertrifft. (Quelle: HuggingFace Daily Papers)
SID: Zielgerichtete Sprachnavigation durch selbstverbessernde Demonstrationen lernen : SID (Self-Improving Demonstrations) ist eine Methode zum Lernen zielgerichteter Sprachnavigation, die durch iterativ selbstverbessernde Demonstrationen die Erkundungsfähigkeit und Generalisierbarkeit von Navigationsagenten in unbekannten Umgebungen signifikant verbessert. Die Methode trainiert zunächst einen initialen Agenten mit kürzesten Pfaddaten und generiert dann neue Erkundungstrajektorien durch diesen Agenten. Diese Trajektorien bieten stärkere Erkundungsstrategien, um bessere Agenten zu trainieren, wodurch eine kontinuierliche Leistungssteigerung erzielt wird. Experimente zeigen, dass SID SOTA-Leistung bei Aufgaben wie REVERIE und SOON erreicht, insbesondere eine Erfolgsrate von 50,9 % auf dem ungesehenen Validierungsset von SOON, was eine Verbesserung von 13,9 % gegenüber früheren Methoden darstellt. (Quelle: HuggingFace Daily Papers)
LOVE-R1: Verbesserung des Verständnisses langer Videos durch adaptiven Skalierungsmechanismus : Das LOVE-R1 Modell zielt darauf ab, den Konflikt zwischen Langzeitverständnis und detaillierter räumlicher Wahrnehmung bei der Analyse langer Videos zu lösen. Das Modell führt einen adaptiven Skalierungsmechanismus ein, der zunächst Frames mit niedriger Auflösung dicht abtastet. Wenn räumliche Details erforderlich sind, kann das Modell interessierende Videosegmente basierend auf der Inferenz hochauflösend skalieren, bis die entscheidenden visuellen Informationen erfasst sind. Der gesamte Prozess wird durch mehrstufige Inferenz realisiert und mit CoT-Daten-Feinabstimmung und entkoppelter Reinforcement-Feinabstimmung kombiniert, was zu einer signifikanten Verbesserung bei Langvideo-Verständnis-Benchmarks führt. (Quelle: HuggingFace Daily Papers)
Euclid’s Gift: Verbesserung des räumlichen Denkens von Visual Language Models durch geometrische Proxy-Aufgaben : Euclid’s Gift ist eine Studie, die die räumliche Wahrnehmungs- und Denkfähigkeit von Visual Language Models (VLMs) durch geometrische Proxy-Aufgaben verbessert. Das Projekt hat den multimodalen Datensatz Euclid30K mit 30.000 planaren und stereometrischen Geometrieproblemen erstellt und die Modelle der Qwen2.5VL- und RoboBrain2.0-Serie mit Group Relative Policy Optimization (GRPO) feinabgestimmt. Experimente zeigen, dass die trainierten Modelle signifikante Zero-Shot-Verbesserungen in vier räumlichen Denk-Benchmarks (Super-CLEVR, Omni3DBench usw.) erzielten, wobei RoboBrain2.0-Euclid-7B eine Genauigkeit von 49,6 % erreichte und frühere SOTA-Modelle übertraf. (Quelle: HuggingFace Daily Papers)
SphereAR: Verbesserung der kontinuierlichen Token-Autoregressiven Generierung durch hypersphärischen latenten Raum : SphereAR zielt darauf ab, Probleme zu lösen, die durch heterogene VAE-Latenzraum-Varianzen in kontinuierlichen Token-autoregressiven (AR) Bildgenerierungsmodellen verursacht werden. Das Kerndesign besteht darin, alle AR-Eingaben und -Ausgaben (einschließlich nach CFG) auf einer Hypersphäre mit festem Radius zu beschränken, wobei ein hypersphärischer VAE verwendet wird. Theoretische Analysen zeigen, dass die hypersphärische Beschränkung die Hauptursache für den Varianzkollaps eliminiert und somit die AR-Dekodierung stabilisiert. Experimente belegen, dass SphereAR SOTA-Leistung bei ImageNet-Generierungsaufgaben erzielt und Diffusionsmodelle sowie Maskengenerierungsmodelle gleicher Parametergröße übertrifft. (Quelle: HuggingFace Daily Papers)
AceSearcher: LLM-Inferenz und -Suche durch verstärktes Selbstspiel steuern : AceSearcher ist ein kooperatives Selbstspiel-Framework, das darauf abzielt, die suchgestützten Fähigkeiten von LLMs bei komplexen Inferenzaufgaben zu verbessern. Das Framework trainiert ein einzelnes LLM, um zwischen der Zerlegung komplexer Anfragen und der Integration von Retrieval-Kontexten zu wechseln, und optimiert die Genauigkeit der endgültigen Antwort durch überwachte Feinabstimmung und Reinforcement-Feinabstimmung, ohne Zwischenannotationen. Experimente zeigen, dass AceSearcher bei mehreren inferenzintensiven Aufgaben SOTA-Baselines signifikant übertrifft. Bei dokumentenbasierter Finanzinferenz erreicht AceSearcher-32B mit weniger als 5 % der Parameter die Leistung von DeepSeek-V3. (Quelle: HuggingFace Daily Papers)
SparseD: Sparsity-Aufmerksamkeitsmechanismus für Diffusions-Sprachmodelle : SparseD ist eine Methode für spärliche Aufmerksamkeit, die auf Diffusions-Sprachmodelle (DLMs) abzielt, um den Engpass der quadratischen Komplexität der Aufmerksamkeitsberechnung bei langen Kontextlängen zu lösen. Die Methode erreicht eine verlustfreie Beschleunigung, indem sie kopf-spezifische spärliche Muster vorab berechnet und in allen Denoising-Schritten wiederverwendet, wobei in frühen Denoising-Schritten volle Aufmerksamkeit und anschließend spärliche Aufmerksamkeit verwendet wird. Experimentelle Ergebnisse zeigen, dass SparseD bei einer Kontextlänge von 64k eine bis zu 1,5-fache Geschwindigkeitssteigerung im Vergleich zu FlashAttention erzielen kann, was die Inferenz-Effizienz von DLMs in Langkontext-Anwendungen effektiv verbessert. (Quelle: HuggingFace Daily Papers)
SLA: Beschleunigung von Diffusion Transformers durch trainierbare Sparse Linear Attention : SLA (Sparse-Linear Attention) ist eine trainierbare Aufmerksamkeitsmethode, die darauf abzielt, Diffusion Transformer (DiT)-Modelle, insbesondere bei der Videogenerierung, zu beschleunigen. Die Methode teilt Aufmerksamkeitsgewichte in drei Kategorien ein: Schlüssel, Rand und vernachlässigbar, wendet O(N²) und O(N) Aufmerksamkeit separat an und überspringt die vernachlässigbaren Teile. Durch die Fusion dieser Berechnungen in einem einzigen GPU-Kernel und nach wenigen Feinabstimmungsschritten reduziert SLA die Aufmerksamkeitsberechnung in DiT-Modellen um das 20-fache und beschleunigt die Videogenerierung End-to-End um das 2,2-fache, ohne die Generierungsqualität zu beeinträchtigen. (Quelle: HuggingFace Daily Papers)
OpenGPT-4o-Image: Umfassender Datensatz für fortgeschrittene Bildgenerierung und -bearbeitung : OpenGPT-4o-Image ist ein groß angelegter Datensatz, der durch die Kombination von hierarchischer Aufgabenklassifizierung und GPT-4o-automatisierter Datengenerierungsmethode erstellt wurde, um die Leistung von einheitlichen multimodalen Modellen bei der Bildgenerierung und -bearbeitung zu verbessern. Der Datensatz enthält 80.000 hochwertige Anweisungs-Bild-Paare, die 11 Hauptbereiche und 51 Unteraufgaben abdecken, darunter Text-Rendering, Stilkontrolle, wissenschaftliche Bilder und komplexe Anweisungsbearbeitung. Auf OpenGPT-4o-Image feinabgestimmte Modelle erzielten signifikante Leistungsverbesserungen in mehreren Benchmarks, was die entscheidende Rolle des systematischen Datenaufbaus bei der Weiterentwicklung multimodaler AI-Fähigkeiten belegt. (Quelle: HuggingFace Daily Papers)
SANA-Video: Effiziente Generierung von 720p-Videos in Minutenlänge mit kleinen Diffusionsmodellen : SANA-Video ist ein kleines Diffusionsmodell, das effizient Videos mit einer Auflösung von bis zu 720×1280 und einer Länge von Minuten generieren kann. Es erreicht hochauflösende, qualitativ hochwertige und lange Videogenerierung durch eine lineare DiT-Architektur und einen konstanten Speicher-KV-Cache, während es eine starke Text-Video-Ausrichtung beibehält. Die Trainingskosten von SANA-Video betragen nur 1 % von MovieGen, und bei der Bereitstellung auf einer RTX 5090 GPU kann die Inferenzgeschwindigkeit für die Generierung eines 5-sekündigen 720p-Videos 29 Sekunden erreichen, was eine kostengünstige und qualitativ hochwertige Videogenerierung ermöglicht. (Quelle: HuggingFace Daily Papers)
AdvChain: Adversarial CoT Tuning zur Verbesserung der Sicherheitsausrichtung großer Inferenzmodelle : AdvChain ist ein neues Ausrichtungsparadigma, das große Inferenzmodelle (LRMs) durch Adversarial Chain-of-Thought (CoT) Tuning lehrt, sich dynamisch selbst zu korrigieren. Die Methode erstellt Datensätze mit „Verlockungs-Korrektur“- und „Zögern-Korrektur“-Beispielen, damit das Modell lernt, sich von schädlichen Inferenzabweichungen und unnötiger Vorsicht zu erholen. Experimente zeigen, dass AdvChain die Robustheit des Modells gegenüber Jailbreak-Angriffen und CoT-Hijacking signifikant verbessert und gleichzeitig die übermäßige Ablehnung von harmlosen Prompts drastisch reduziert, wodurch ein hervorragendes Sicherheits-Nutzen-Gleichgewicht erreicht wird. (Quelle: HuggingFace Daily Papers)
SDLM: Skalierung des iterativen Reinforcement Learning durch verschachtelte Kompression : Das Sequential Diffusion Language Model (SDLM) schlägt eine Methode vor, die die Vorhersage des nächsten Tokens und des nächsten Blocks vereinheitlicht, wodurch das Modell die Generierungslänge in jedem Schritt adaptiv bestimmen kann. SDLM kann vortrainierte autoregressive Sprachmodelle mit minimalen Kosten umwandeln und Diffusionsinferenz innerhalb von Maskenblöcken fester Größe durchführen, während es gleichzeitig kontinuierliche Subsequenzen dynamisch dekodiert. Experimente zeigen, dass SDLM stärkere autoregressive Baselines erreicht oder übertrifft und gleichzeitig einen höheren Durchsatz erzielt, was sein starkes Skalierbarkeitspotenzial demonstriert. (Quelle: HuggingFace Daily Papers)
Insight-to-Solve (I2S): Umwandlung von In-Context-Demonstrationen in Assets für Inferenz-LLMs : Insight-to-Solve (I2S) ist ein Testzeitprogramm, das darauf abzielt, hochwertige In-Context-Demonstrationen in effektive Assets für große Inferenzmodelle (RLMs) umzuwandeln. Die Forschung zeigt, dass das direkte Hinzufügen von Demonstrationsbeispielen die Genauigkeit von RLMs verringern kann. I2S wandelt Demonstrationen in explizit wiederverwendbare Erkenntnisse um und generiert zielspezifische Inferenzpfade, optional mit Selbstverfeinerung zur Verbesserung der Kohärenz und Korrektheit. Experimente zeigen, dass I2S und I2S+ bei verschiedenen Benchmarks durchweg besser abschneiden als direkte Antworten und Testzeit-Skalierungs-Baselines, selbst für GPT-Modelle werden signifikante Verbesserungen erzielt. (Quelle: HuggingFace Daily Papers)
UniMIC: Token-basierte multimodale interaktive Kodierung für Mensch-Maschine-Kollaboration : UniMIC (Unified token-based Multimodal Interactive Coding) ist ein Framework, das darauf abzielt, eine effiziente, bitratenarme multimodale Interaktion zwischen Edge-Geräten und Cloud-AI-Agenten durch eine Token-basierte Darstellung zu ermöglichen. UniMIC verwendet eine kompakte tokenisierte Darstellung als Kommunikationsmedium und kombiniert diese mit einem Transformer-Entropiemodell, um die Redundanz zwischen Tokens effektiv zu reduzieren. Experimente zeigen, dass UniMIC signifikante Bitrateneinsparungen bei Aufgaben wie Text-zu-Bild-Generierung, Bildinfilling und visuellem Frage-Antwort-System erzielt und bei extrem niedrigen Bitraten robust bleibt, was ein praktisches Paradigma für die nächste Generation multimodaler interaktiver Kommunikation bietet. (Quelle: HuggingFace Daily Papers)
RLBFF: Binäres flexibles Feedback überbrückt menschliches Feedback und verifizierbare Belohnungen : RLBFF (Reinforcement Learning with Binary Flexible Feedback) ist ein Reinforcement Learning-Paradigma, das die Vielfalt menschlicher Präferenzen mit der Präzision regelbasierter Verifizierung kombiniert. Es extrahiert binär beantwortbare Prinzipien aus natürlichem Sprachfeedback (z. B. Informationsgenauigkeit: Ja/Nein, Code-Lesbarkeit: Ja/Nein) und trainiert damit ein Belohnungsmodell. RLBFF zeigt hervorragende Leistungen auf RM-Bench und JudgeBench und ermöglicht es Benutzern, den Fokus der Prinzipien zur Inferenzzeit anzupassen. Darüber hinaus bietet es eine vollständig Open-Source-Lösung, um Qwen3-32B mit RLBFF auszurichten, wodurch es auf allgemeinen Ausrichtungs-Benchmarks die Leistung von o3-mini und DeepSeek R1 erreicht oder übertrifft. (Quelle: HuggingFace Daily Papers)
MetaAPO: Alignment-Optimierung durch meta-gewichtetes Online-Sampling : MetaAPO (Meta-Weighted Adaptive Preference Optimization) ist ein neuartiges Framework, das die Ausrichtung großer Sprachmodelle (LLMs) an menschliche Präferenzen durch dynamische Kopplung von Datengenerierung und Modelltraining optimiert. MetaAPO nutzt einen leichtgewichtigen Meta-Learner als „Alignment-Gap-Estimator“, um den potenziellen Nutzen von Online-Sampling im Vergleich zu Offline-Daten zu bewerten, die zielgerichtete Online-Generierung zu steuern und Stichproben-Meta-Gewichte zuzuweisen, wodurch die Qualität und Verteilung von Online- und Offline-Daten dynamisch ausgeglichen wird. Experimente zeigen, dass MetaAPO bestehende Präferenzoptimierungsmethoden auf AlpacaEval 2, Arena-Hard und MT-Bench durchweg übertrifft und gleichzeitig die Online-Annotationskosten um 42 % senkt. (Quelle: HuggingFace Daily Papers)
Tool-Light: Effiziente Tool-Integration-Inferenz durch selbstentwickelndes Präferenzlernen : Tool-Light ist ein Framework, das darauf abzielt, große Sprachmodelle (LLMs) zu ermutigen, Tool-Integration-Inferenz (TIR)-Aufgaben effizient und genau auszuführen. Die Forschung zeigt, dass die Ergebnisse von Tool-Aufrufen zu signifikanten Änderungen der Informationsentropie in der nachfolgenden Inferenz führen können. Tool-Light wird durch eine Kombination aus Datensatzkonstruktion und mehrstufiger Feinabstimmung realisiert, wobei die Datensatzkonstruktion kontinuierliches selbstentwickelndes Sampling verwendet, das Vanilla-Sampling und entropiegesteuertes Sampling integriert und strenge Kriterien für die Auswahl positiver und negativer Paare festlegt. Der Trainingsprozess umfasst SFT und selbstentwickelnde direkte Präferenzoptimierung (DPO). Experimente belegen, dass Tool-Light die Effizienz der Modelle bei der Ausführung von TIR-Aufgaben signifikant verbessert. (Quelle: HuggingFace Daily Papers)
ChatInject: Prompt-Injection-Angriffe auf LLM-Agenten mittels Chat-Templates : ChatInject ist eine Methode für indirekte Prompt-Injection-Angriffe, die die Abhängigkeit von LLMs von strukturierten Chat-Templates und die Kontextmanipulation in mehrstufigen Dialogen ausnutzt. Angreifer formatieren bösartige Payloads so, dass sie dem nativen Chat-Template-Format ähneln, um Agenten zur Ausführung verdächtiger Operationen zu verleiten. Experimente zeigen, dass ChatInject eine höhere Angriffs-Erfolgsrate als traditionelle Prompt-Injection-Methoden aufweist, insbesondere in mehrstufigen Dialogen, und eine starke Übertragbarkeit auf verschiedene Modelle besitzt, während bestehende Prompt-basierte Verteidigungsmaßnahmen gegen solche Angriffe meist unwirksam sind. (Quelle: HuggingFace Daily Papers)
💼 Business
Modal schließt B-Runde über 87 Millionen US-Dollar ab, Bewertung erreicht 1,1 Milliarden US-Dollar : Das AI-Infrastrukturunternehmen Modal hat den Abschluss einer B-Runde über 87 Millionen US-Dollar bekannt gegeben, wodurch die Bewertung des Unternehmens 1,1 Milliarden US-Dollar erreicht. Diese Finanzierungsrunde soll die Innovation und Entwicklung der AI-Infrastruktur beschleunigen, um den Herausforderungen zu begegnen, denen traditionelle Computerinfrastrukturen im Zeitalter der AI gegenüberstehen. Modal hilft Forschern und Entwicklern, ihr AI-Modelltraining und ihre Bereitstellungsprozesse durch effiziente Cloud-Computing-Dienste zu optimieren. (Quelle: Twitter, Twitter, Twitter)
OpenAI erzielt im ersten Halbjahr 4,3 Milliarden US-Dollar Umsatz, aber 13,5 Milliarden US-Dollar Verlust, steht vor Rentabilitätsproblemen : OpenAI hat für das erste Halbjahr 2025 einen Umsatz von 4,3 Milliarden US-Dollar bekannt gegeben und erwartet für das Gesamtjahr einen Umsatz von über 13 Milliarden US-Dollar, hauptsächlich dank ChatGPT Plus-Abonnements und Enterprise-API-Diensten. Gleichzeitig belief sich der Nettoverlust jedoch auf 13,5 Milliarden US-Dollar, wobei strukturelle Kosten und Forschungs- und Entwicklungsinvestitionen (wie GPT-5) die Hauptfaktoren sind, mit jährlichen Servermietkosten von bis zu 16 Milliarden US-Dollar. Obwohl OpenAI über 17,5 Milliarden US-Dollar an Barreserven verfügt und einen Finanzierungsplan von 30 Milliarden US-Dollar vorantreibt, stellen der anhaltende Cash-Verbrauch und der Effizienzunterschied zu Konkurrenten wie Anthropic ernsthafte Rentabilitätsprobleme dar. (Quelle: 36氪)
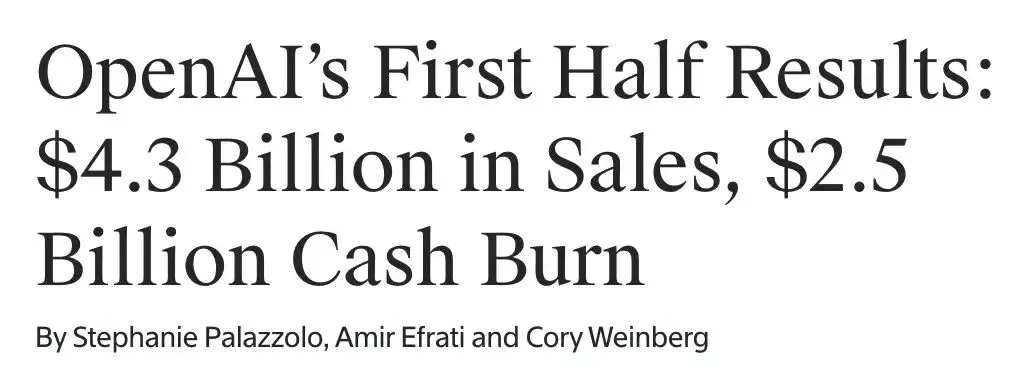
Kapitalgefecht im Bereich humanoider Roboter: Zhiyuan, Yinhe General und andere positionieren sich aktiv in der Lieferkette : Der Bereich humanoider Roboter ist in eine Phase des Kapitalgefechts eingetreten, in der führende Unternehmen wie Zhiyuan Robot und Yinhe General durch die Gründung von Fonds, Investitionen in Konkurrenten und strategische Kooperationen aktiv ihr „Netzwerk“ erweitern. Zhiyuan Robot hat bereits fast 20 Investitionen getätigt, die Motoren, Sensoren und nachgelagerte Anwendungen umfassen, und arbeitet mit Unternehmen wie Fulin Precision und Softto Power zusammen, um kommerzielle Szenarien zu realisieren. Yinhe General hat ein Joint Venture mit Bosch China gegründet, um verkörperte Intelligenz in der Automobilfertigung voranzutreiben. Diese Maßnahmen zielen darauf ab, Aufträge zu sichern, Mängel zu beheben und ein stabiles Lieferkettennetzwerk für zukünftige Massenlieferungen aufzubauen, doch die technologischen Ansätze in der Branche variieren stark und der Wettbewerb ist intensiv. (Quelle: 36氪)

🌟 Community
AI-generierte Inhalte schwer von echten zu unterscheiden, löst Vertrauenskrise aus : Mit der rasanten Entwicklung der AI-Technologie hat die Realitätsnähe von AI-generierten Videos (wie die Live-Action-Version von „Attack on Titan“, indonesische Streamer, die japanische Influencer „geskinnt“ haben) ein unglaubliches Niveau erreicht, was tiefe Besorgnis über die Authentizität von Inhalten in der Gesellschaft auslöst. In sozialen Medien äußern Nutzer, dass es immer schwieriger wird, echte von AI-generierten Inhalten zu unterscheiden, was nicht nur die Glaubwürdigkeit legitimer Content-Ersteller untergräbt, sondern auch zur Verbreitung von Falschinformationen genutzt werden könnte. Experten weisen darauf hin, dass, wenn keine obligatorische AI-Content-Kennzeichnung eingeführt wird, dieser „Hyperrealismus-Engine“ das Realitätsgefühl weiter erodieren und letztendlich das „Internet beenden“ könnte. (Quelle: Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ArtificialInteligence, Twitter, Twitter)

AI-Einfluss auf den Arbeitsmarkt: Sequoia-Bericht besagt, 95 % der AI-Investitionen sind ineffektiv, Absolventen am stärksten betroffen : Sequoia Capital teilte einen Forschungsbericht des MIT und der Harvard University mit, der besagt, dass 95 % der AI-Investitionen von Unternehmen keinen tatsächlichen Wert geschaffen haben. Echte Produktivitätssteigerungen resultieren aus einer „Schatten-AI-Wirtschaft“, die durch die „heimliche“ Nutzung persönlicher AI-Tools durch Mitarbeiter entsteht. Der Bericht enthüllt auch, dass der Einfluss von AI auf den Arbeitsmarkt hauptsächlich junge Absolventen trifft, insbesondere im Groß- und Einzelhandel, wo die Anzahl der Neueinstellungen für Einstiegspositionen deutlich zurückgegangen ist, und selbst ein Abschluss von einer renommierten Universität nicht immer Schutz bietet. Dies deutet darauf hin, dass AI die Aufgabenverteilung verändert und der menschliche Wert sich auf Erfahrung und einzigartiges Urteilsvermögen verlagert. (Quelle: 36氪, Reddit r/ArtificialInteligence)
OpenAI-Modellanpassungen lösen starke Nutzerunzufriedenheit aus, Forderung nach transparenter Kommunikation : Die jüngste, unangekündigte „Herabstufung“ der GPT-4o/GPT-5 Modelle durch OpenAI auf eine Version mit geringerer Rechenleistung hat zu einer Verschlechterung der Modellleistung geführt und starke Nutzerunzufriedenheit ausgelöst. Viele Nutzer beschweren sich, dass die Modelle „dümmer“ geworden sind und ihre ursprüngliche Einsicht und das „freundliche“ Kommunikationserlebnis verloren haben, manche bezeichnen es sogar als „mentalen Schlag“. OpenAI-Führungskräfte erklärten, dies sei ein „Sicherheits-Routing-Test“ zur Behandlung sensibler Themen, doch die Nutzer fordern OpenAI allgemein auf, die Kommunikation und Transparenz mit den Nutzern zu verbessern und einseitige Produktvertragsänderungen zu vermeiden, um das Nutzervertrauen wiederherzustellen. (Quelle: Reddit r/artificial, Reddit r/ChatGPT, Reddit r/ChatGPT, Twitter)
Roboterbesteuerung: Diskussion über technologischen Fortschritt und soziale Gerechtigkeit : Mit der Entwicklung von AI und Robotik nehmen die Diskussionen über eine „Robotersteuer“ zu, die darauf abzielt, die durch den Ersatz menschlicher Arbeitskraft durch Roboter möglicherweise entstehenden Beschäftigungsprobleme und sozialen Ungleichheiten auszugleichen. Befürworter argumentieren, dass eine Robotersteuer Sozialleistungen und Umschulungshilfen für Arbeitslose finanzieren und das Ungleichgewicht in der Verhandlungsmacht zwischen Kapital und Arbeit korrigieren könnte. Branchenvertreter sind jedoch der Meinung, dass eine Besteuerung derzeit verfrüht sei und die Entwicklung der aufstrebenden Industrie behindern könnte. Südkorea hat bereits indirekt die Kosten für den Robotereinsatz erhöht, indem es Steuervergünstigungen für Automatisierungsunternehmen reduziert hat. (Quelle: 36氪)
Zukunft humanoider Roboter: Der bekannte Roboterexperte Rodney Brooks glaubt, dass die Zukunft nicht menschenähnlich sein wird : Der bekannte Roboterexperte Rodney Brooks schreibt, dass trotz enormer Investitionen die aktuellen humanoiden Roboter immer noch nicht die menschliche Geschicklichkeit erreichen können und der zweibeinige Gang Sicherheitsrisiken birgt. Er prognostiziert, dass humanoide Roboter in den nächsten 15 Jahren nicht mehr die menschliche Form nachahmen, sondern sich zu spezialisierten Robotern mit Radantrieb, mehreren Armen (ausgestattet mit Greifern oder Saugnäpfen) und mehreren Sensoren (aktive Lichtbildgebung, nicht-sichtbare Lichterfassung) entwickeln werden, um spezifischen Aufgaben gerecht zu werden. Er ist der Meinung, dass die derzeitigen enormen Investitionen in die „menschenähnliche“ Form letztendlich umsonst sein werden. (Quelle: 36氪)

Kontroverse um AI-Code-Generierungsqualität und Entwicklererfahrung : In sozialen Medien diskutieren Entwickler intensiv über die Qualität und Praktikabilität von AI-generiertem Code. Einige loben Claude Sonnet 4.5 dafür, dass es ganze Codebasen umstrukturieren kann, aber der generierte Code läuft nicht; andere beschweren sich, dass AI-generierter Code „nicht kompiliert“, was die Entwicklungseffizienz mindert. Diese Diskussionen spiegeln wider, dass AI-gestützte Programmierung immer noch Herausforderungen zwischen Effizienz und Genauigkeit aufweist und dass Entwickler bei AI-generierten Ergebnissen einen Bedarf an Debugging und Verifizierung haben. (Quelle: Twitter, Twitter, Twitter)

Wandel im Talentverständnis im AI-Zeitalter: Vom „Abwerben“ zum „Anbauen“ : In sozialen Medien wird intensiv diskutiert, dass das Talentverständnis im AI-Zeitalter vom traditionellen „Abwerben von Talenten“ zum „Anbauen von Talenten“ übergehen sollte. Angesichts der Knappheit an AI-Talenten und der schnellen technologischen Iteration sollten Unternehmen sich mehr auf die Ausbildung von Mitarbeitern mit grundlegenden Technologiekenntnissen konzentrieren, anstatt blind teure „fertige“ Talente auf dem Markt zu jagen. Diese Ansicht betont die Bedeutung von kontinuierlichem Lernen und interner Ausbildung, um den schnell wechselnden Anforderungen im AI-Bereich gerecht zu werden. (Quelle: dotey)
AI-Infrastruktur-Energieverbrauch und Sam Altmans Energiebedarf : Sam Altman hat erklärt, dass die Entwicklung von AI 250 GW Strom benötigt, was die gesellschaftliche Aufmerksamkeit auf den enormen Energieverbrauch der AI-Infrastruktur lenkt und Diskussionen darüber auslöst. Dieser Bedarf übersteigt die derzeitige Energieversorgungskapazität bei weitem und zwingt dazu, darüber nachzudenken, wie die schnelle Entwicklung von AI mit einer nachhaltigen Energieversorgung in Einklang gebracht werden kann. Verwandte Diskussionen betreffen auch Umweltprobleme in der Halbleiterfertigung, wie die Verwendung von PFAS und die potenziellen Risiken von Ersatzstoffen. (Quelle: Twitter, Twitter)

AI-Doomerismus und Optimisten: Sorgen und Gegenargumente : In sozialen Medien gibt es eine breite Diskussion über AI-„Doomerismus“ und potenzielle AI-Risiken, aber auch viele, die diese Bedenken für übertrieben halten. Optimisten argumentieren, dass die tatsächlichen Probleme, die AI mit sich bringt (wie Klimaauswirkungen, Unternehmensausbeutung, militärische Überwachung), dringender sind als die ferne „Superintelligenz, die die Menschheit vernichtet“, und man sich auf die aktuellen, lösbaren Herausforderungen konzentrieren sollte. Einige halten den AI-Doomerismus für „Unsinn“ und ein Zeichen von Faulheit und Instabilität, während andere glauben, dass AI letztendlich zu Kreativität und Förderung führen wird. (Quelle: Reddit r/ArtificialInteligence, Twitter, Twitter)
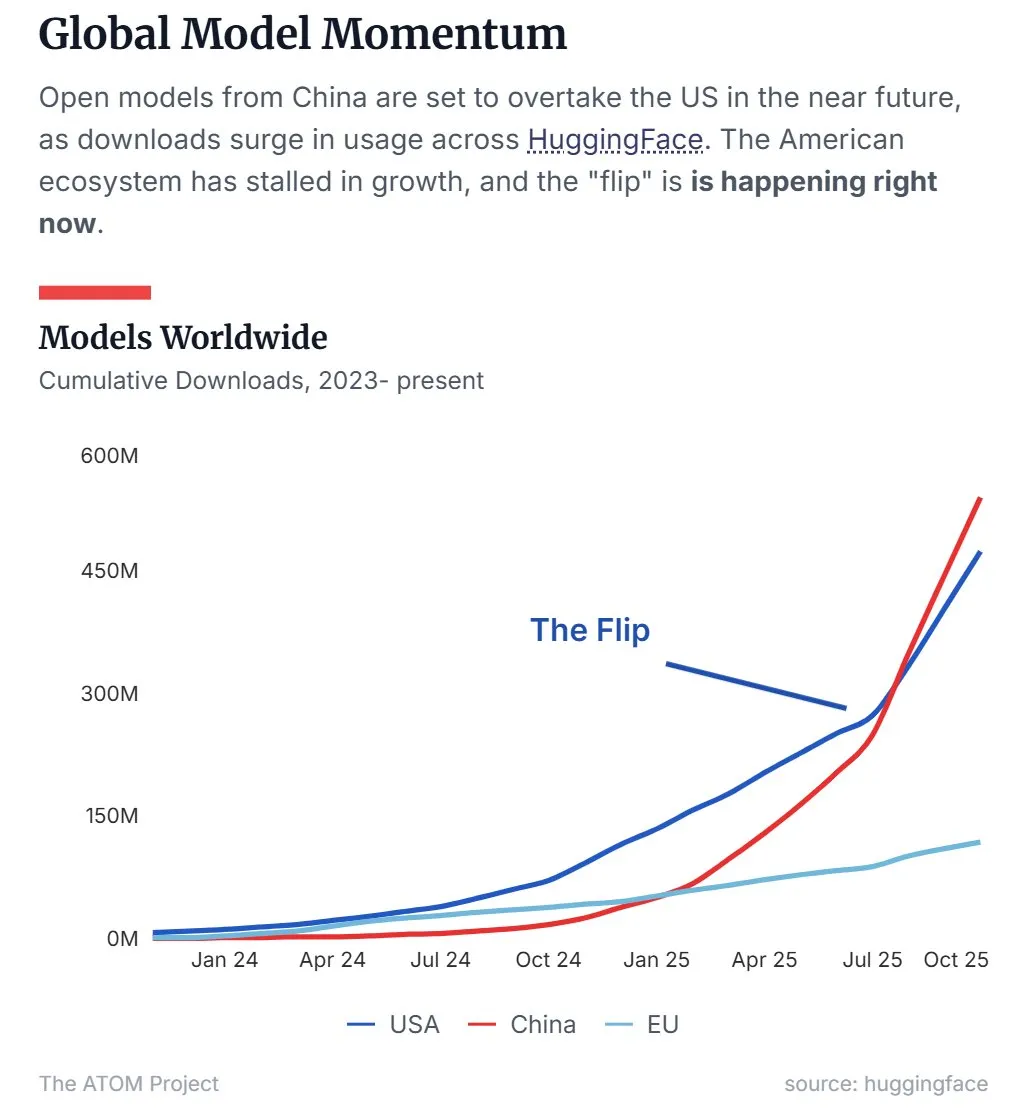
Chinas Open-Source-LLM-Marktanteil übertrifft den der USA : Neueste Daten zeigen, dass chinesische Open-Source Large Language Models (LLMs), angeführt von Qwen, den Marktanteil der USA übertroffen haben und zur dominierenden Kraft im Bereich der Open-Source-LLMs geworden sind. Dieser Trend deutet darauf hin, dass China in der Forschung und Anwendung von Open-Source-AI-Technologien schnell aufsteigt und einen wichtigen Einfluss auf die globale AI-Landschaft hat. (Quelle: Twitter, Twitter)
10-köpfiges Team produziert AI-Manhua „Tomorrow is Monday“ in 45 Tagen, erreicht Millionen von Aufrufen : Ein Team von nur 10 Personen hat in 45 Tagen 50 Episoden der AI-Manhua „Tomorrow is Monday“ fertiggestellt. Ohne jegliche Werbeausgaben erreichte die Serie über zehn Millionen Aufrufe im gesamten Netzwerk, und die bezahlten Einnahmen auf Douyin deckten bereits alle Kosten. Das Projekt verfolgt das Kernkonzept „Originalcharaktere + AI-Generierung“, löst das Problem der Urheberrechtszuordnung von AI-Inhalten und hat einen kommerziellen Entwicklungspfad für alle IP-Kategorien erschlossen. Der Produktionsprozess ist hochgradig arbeitsteilig, wobei Originalzeichner, Ingenieure, Post-Produktions-Editoren und Regisseure eng zusammenarbeiten, was das enorme Potenzial der AI-Technologie zur Kostenreduzierung und Effizienzsteigerung in der Inhaltsproduktion demonstriert. (Quelle: 36氪)

💡 Sonstiges
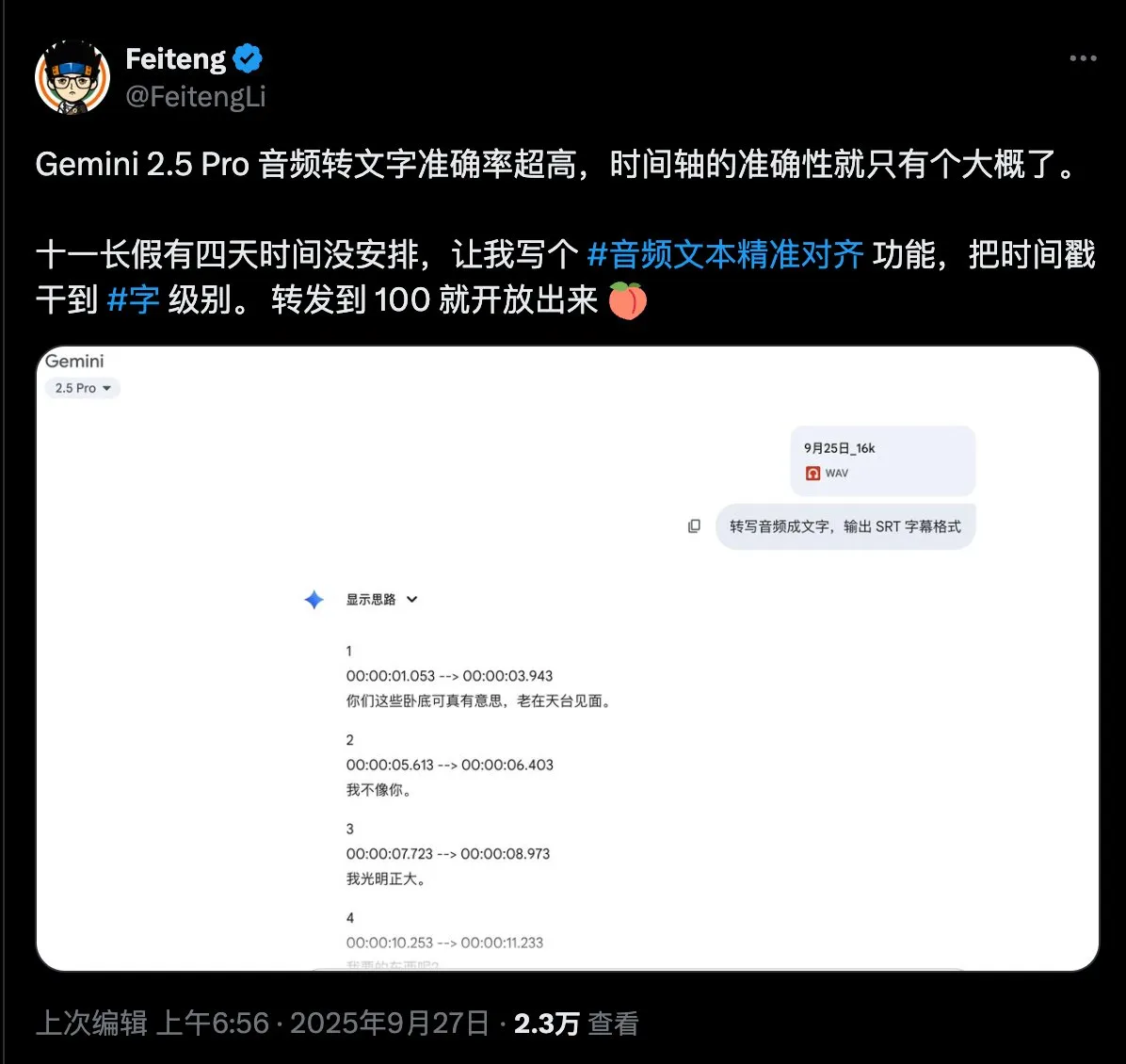
Umfrage zum Bedarf an präziser Audio-Text-Ausrichtung : Ein Social-Media-Nutzer hat großes Interesse an der Technologie zur präzisen Audio-Text-Ausrichtung gezeigt und eine Bedarfs-Umfrage veröffentlicht. Ziel ist es, die spezifischen Anforderungen der Nutzer an diese Technologie in Bezug auf Funktionen und Anwendungsszenarien zu sammeln, um die Entwicklung und Optimierung relevanter Technologien voranzutreiben. (Quelle: dotey)
DeepMind präsentiert Nano Banana Demo : Google DeepMind hat eine Demo namens „Nano Banana“ vorgestellt, die in den sozialen Medien Aufmerksamkeit erregte. Obwohl die genauen Details nicht vollständig bekannt gegeben wurden, könnte sie mit AI-Videogenerierung oder multimodaler AI-Technologie zusammenhängen und deutet auf neue Fortschritte von DeepMind im Bereich der visuellen AI hin. (Quelle: GoogleDeepMind)
Akademische Diskussion über die Priorität der Erfindung von Highway Net und ResNet : Der bekannte AI-Forscher Jürgen Schmidhuber hat einen Tweet weitergeleitet, der erneut die akademische Diskussion über die Priorität der Erfindung von Highway Net und ResNet im Bereich des Deep Residual Learning ausgelöst hat. Er wies darauf hin, dass die Behauptung in Microsofts ResNet-Paper, Highway Net sei eine „gleichzeitige“ Arbeit, unzutreffend sei, und betonte, dass Highway Net sieben Monate vor ResNet veröffentlicht wurde und bereits eine Lösung für Residualverbindungen identifiziert und vorgeschlagen hatte. (Quelle: SchmidhuberAI)