
Schlüsselwörter:GPT-5, Quantencomputing, KI-Materialdesign, Bestärkendes Lernen, Große Sprachmodelle, KI-Infrastruktur, Multimodale Modelle, KI-Agent, Quanten-NP-Probleme, CGformer Kristallgraph-Neuronales Netzwerk, RLMT-Rahmenwerk für bestärkendes Lernen, DeepSeek Sparse Attention DSA, UniVid Einheitliches Framework für visuelle Aufgaben
🔥 Fokus
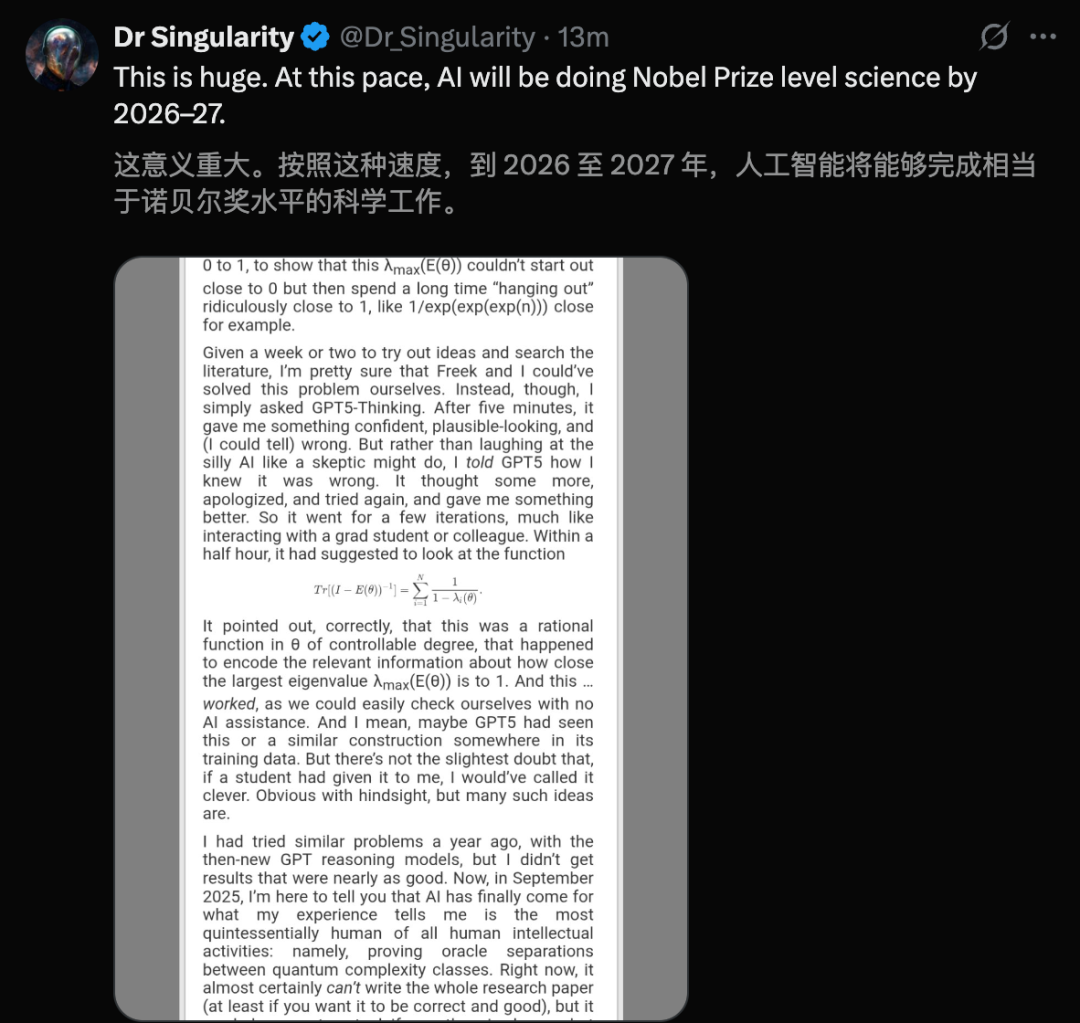
GPT-5 löst das ‘Quanten-NP-Problem’: Der Quantencomputing-Experte Scott Aaronson veröffentlichte erstmals eine Arbeit, die die bahnbrechende unterstützende Rolle von GPT-5 in der Forschung zur Quantenkomplexitätstheorie aufzeigt. GPT-5 half entscheidend bei der Lösung eines kritischen Ableitungsschritts im “Quanten-NP-Problem” innerhalb von 30 Minuten, was normalerweise 1-2 Wochen menschliche Arbeit erfordert. Dieses Ergebnis markiert, dass KI begonnen hat, die Kernarbeit menschlicher Intelligenz bei wissenschaftlichen Entdeckungen zu berühren, und deutet auf einen enormen Sprung im Potenzial der KI im Bereich der wissenschaftlichen Forschung hin. (Quelle: arXiv, scottaaronson.blog)
Neues KI-Designmodell für Materialien: CGformer: Das Team um Professor Li Jinjin und Professor Huang Fuqiang von der Shanghai Jiao Tong University hat das brandneue KI-Materialdesignmodell CGformer entwickelt, das durch die innovative Integration des globalen Aufmerksamkeitsmechanismus von Graphormer mit CGCNN sowie der Einbindung von Zentralitäts- und Raumkodierung erfolgreich die Grenzen traditioneller Kristallgraphen-Neuronaler Netze überwindet. Das Modell kann globale Informationen komplexer Kristallstrukturen vollständig erfassen und die Vorhersagegenauigkeit sowie die Screening-Effizienz für neue Materialien wie Hochenergie-Natriumionen-Festkörperelektrolyte erheblich verbessern. (Quelle: Matter)

UniVid: Einheitliches Framework für visuelle Aufgaben: UniVid ist ein innovatives Framework, das durch Feinabstimmung eines vortrainierten Video-Diffusions-Transformers es ermöglicht, sich ohne aufgabenspezifische Änderungen an vielfältige Bild- und Videoaufgaben anzupassen. Diese Methode stellt Aufgaben als visuelle Anweisungen dar und definiert Aufgaben sowie erwartete Ausgabemodalitäten durch Kontextsequenzen. Dies zeigt das enorme Potenzial vortrainierter Videogenerierungsmodelle als einheitliche Grundlage für die visuelle Modellierung. (Quelle: HuggingFace Daily Papers)
RLMT revolutioniert das Post-Training von großen Modellen: Das Team um Assistenzprofessor Danqi Chen von der Princeton University hat das Framework “Reinforcement Learning with Model-based Reward Thinking” (RLMT) vorgestellt, das LLMs dazu bringt, vor der Antwort lange Gedankenkette zu generieren und dies mit einem präferenzbasierten Belohnungsmodell für die Online-RL-Optimierung kombiniert. Diese Methode verbessert die Inferenzfähigkeit und Generalisierbarkeit von LLMs bei offenen Aufgaben erheblich und ermöglicht es sogar 8B-Modellen, GPT-4o in Bezug auf Chat und kreatives Schreiben zu übertreffen. (Quelle: arXiv)

CHURRO: Modell zur Erkennung historischer Texte: CHURRO ist ein Open-Source Visual Language Model (VLM) mit 3 Milliarden Parametern, das speziell für die hochpräzise und kostengünstige Erkennung historischer Texte entwickelt wurde. Das Modell wurde auf dem CHURRO-DS-Datensatz trainiert, der 99.491 Seiten historischer Dokumente aus 22 Jahrhunderten und 46 Sprachen umfasst. Seine Leistung übertrifft bestehende VLMs wie Gemini 2.5 Pro und verbessert die Effizienz der Forschung und Konservierung von Kulturerbe erheblich. (Quelle: HuggingFace Daily Papers)
🎯 Trends
Altman prognostiziert KI-Superintelligenz und stellt Pulse-Funktion vor: Sam Altman prognostiziert, dass KI die menschliche Intelligenz bis 2030 vollständig übertreffen wird, und weist auf die erstaunliche Geschwindigkeit der KI-Entwicklung hin. OpenAI hat die “aktive Modus”-Funktion Pulse für ChatGPT eingeführt, was einen Übergang der KI von passiver Reaktion zu aktivem Denken für den Benutzer markiert. Sie kann basierend auf den Chat-Inhalten des Benutzers proaktiv relevante Informationen bereitstellen und extrem personalisierte Dienste ermöglichen. Dies deutet darauf hin, dass KI zu einem externen Dienstleister für das menschliche Unterbewusstsein werden wird. (Quelle: 36氪, )

Jensen Huang weist KI-Blasen-Theorie zurück und erläutert NVIDIA-Strategie: In einem Interview wies Jensen Huang die Theorie eines “KI-Blasenimperiums” zurück und betonte die Schlüsselrolle der KI in der Wirtschaft. Er prognostiziert, dass NVIDIA das erste Unternehmen mit einem Marktwert von 10 Billionen US-Dollar werden könnte. Er wies darauf hin, dass hinter der KI-Inferenz ein enormer Bedarf an Rechenleistung steckt. NVIDIA setzt auf ein extrem kollaboratives Design, bringt jedes Jahr neue Architekturen auf den Markt und öffnet sein System-Ökosystem, ohne die Welle der Eigenentwicklung zu fürchten. Ziel ist es, das KI-Wirtschaftssystem zu gestalten und “Sovereign AI” zu einem neuen Konsens zu machen. (Quelle: 36氪, )

DeepSeek veröffentlicht V3.2-Exp als Open Source und stellt DSA-Mechanismus vor: DeepSeek hat die experimentelle Version V3.2-Exp mit 685B Parametern als Open Source veröffentlicht und gleichzeitig eine Arbeit veröffentlicht, die ihren neuen Sparse Attention Mechanismus (DeepSeek Sparse Attention, DSA) detailliert beschreibt. DSA zielt darauf ab, die Optimierung der Trainings- und Inferenz-Effizienz in langen Kontext-Szenarien zu erforschen und zu validieren. Dabei wird die Qualität der Modellausgabe beibehalten und die Effizienz der Langkontextverarbeitung erheblich verbessert. (Quelle: 36氪, HuggingFace)

GLM-4.6 steht kurz vor der Veröffentlichung: Das GLM-4.6 Modell von Zhipu AI wird voraussichtlich bald veröffentlicht. Auf der offiziellen Z.ai-Website wird GLM-4.5 bereits als “Flaggschiffmodell der vorherigen Generation” gekennzeichnet, was darauf hindeutet, dass die neue Version Verbesserungen in Bereichen wie der Kontextlänge bringen könnte. Dies hat in der Community Aufmerksamkeit und Erwartungen geweckt. (Quelle: Reddit r/LocalLLaMA, karminski3)
Apples KI-Strategie und interner Chatbot Veritas: Apples intern entwickelter KI-Chatbot mit dem Codenamen “Veritas” wurde enthüllt. Er dient als Sparringspartner für Siri und ist in der Lage, In-App-Operationen auszuführen. Dennoch hält Apple an seiner Strategie fest, keinen Chatbot für Endverbraucher auf den Markt zu bringen, und konzentriert sich auf die systemweite KI-Integration. Stattdessen plant das Unternehmen, die Integration von Drittanbieter-Modellen durch eine KI-Antwort-Engine und die universelle Schnittstelle MCP zu vertiefen. (Quelle: 36氪)

Wachstum des AI PC-Marktes und technologische Engpässe: Es wird erwartet, dass die Auslieferungen im AI PC-Markt in den Jahren 2025-2026 stark ansteigen werden, dies ist jedoch hauptsächlich auf das Ende des Supports für Windows 10 und den PC-Erneuerungszyklus zurückzuführen, nicht auf eine disruptive KI-Technologie. Aktuelle KI-Funktionen sind meist Ergänzungen zu traditionellen PCs und stehen vor Herausforderungen wie unzureichender lokaler Rechenleistung, passiver Interaktion und geschlossenen Ökosystemen. Echte KI-Geräte müssen “lokale Rechenleistung als Hauptkomponente, Cloud-Ergänzung als Nebenkomponente” sowie proaktive Wahrnehmung realisieren. (Quelle: 36氪)

KI strömt in den Stromhandelsmarkt: KI wird zunehmend im Stromhandelsmarkt eingesetzt. Unternehmen wie Qingpeng Intelligent nutzen große Zeitreihenmodelle, um die Erzeugung von Wind- und Solarenergie sowie den Strombedarf vorherzusagen und unterstützen so Handelsentscheidungen. Der Vorteil der KI bei der Verarbeitung riesiger Datenmengen verspricht eine Steigerung der Gewinne, könnte aber auch aufgrund unreifer Modelle und der Komplexität des Marktes zu Verlusten führen. Die Branche befindet sich noch in der Erkundungsphase. (Quelle: 36氪)
Alibaba Tongyi großes Modell Update und Full-Stack KI-Dienste: Alibaba Cloud hat auf der Apsara Conference sein Full-Stack KI-System umfassend aktualisiert und sechs neue Modelle, darunter Qwen3-MAX und Qwen3-Omni, veröffentlicht. Das Unternehmen positioniert sich als “Full-Stack Artificial Intelligence Service Provider”. Alibaba Cloud ist bestrebt, “Android des KI-Zeitalters” und “den Computer der nächsten Generation” aufzubauen und bietet Full-Stack KI-Cloud-Dienste von Basismodellen bis zur Infrastruktur an. Dies soll der Entwicklung von AI Agents vom “intelligenten Aufkommen” zum “autonomen Handeln” begegnen. (Quelle: 36氪)

Tiefenanalyse der NVIDIA Blackwell-Architektur: Eine Veranstaltung zur Tiefenanalyse der NVIDIA Blackwell-Architektur wird deren Architektur, Optimierung und Implementierung in der GPU-Cloud beleuchten. Die Veranstaltung wird von Experten von SemiAnalysis und NVIDIA geleitet und zielt darauf ab, zu enthüllen, wie die Blackwell GPU als “GPU des nächsten Jahrzehnts” die Entwicklung der KI-Rechenleistung und die Zukunft der GPU-Cloud vorantreiben wird. (Quelle: TheTuringPost)

🧰 Tools
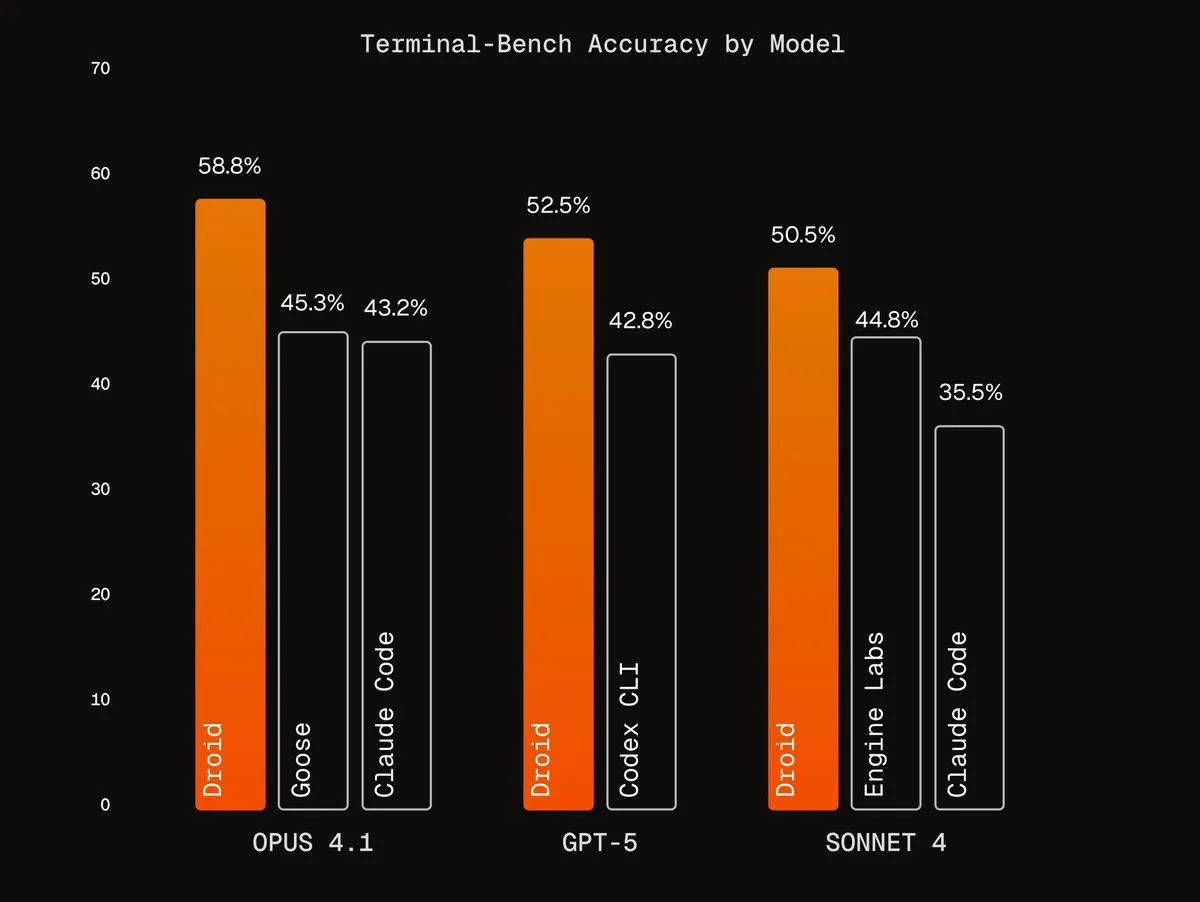
Agentic Harnesses von Factory AI: Factory AI hat erstklassige Agentic Harnesses entwickelt, die die Leistung bestehender Modelle erheblich verbessern, insbesondere bei Kodierungsaufgaben hervorragend abschneiden und von Benutzern als “Cheat Code” bezeichnet werden. Ihre Droids-Agenten belegen auf Terminal-Bench den ersten Platz und ermöglichen eine zuverlässige Code-Refaktorierung durch Multi-Agenten-Verifizierungsworkflows. (Quelle: Vtrivedy10, matanSF, matanSF)
RAGLight: Open-Source RAG-Bibliothek: LangChainAI hat RAGLight veröffentlicht, eine leichtgewichtige Python-Bibliothek zum Aufbau von produktionsreifen RAG-Systemen. Die Bibliothek verfügt über LangGraph-gesteuerte Agenten-Pipelines, Multi-Provider LLM-Unterstützung, integrierte GitHub-Integration und CLI-Tools. Sie zielt darauf ab, die Entwicklung und Bereitstellung von RAG-Systemen zu vereinfachen. (Quelle: LangChainAI, hwchase17)
ArgosOS: Semantisches Betriebssystem: ArgosOS ist eine Desktop-Anwendung, die intelligente Dokumentsuche und Inhaltsintegration durch eine tag-basierte Architektur anstelle von Vektordatenbanken ermöglicht. Es nutzt LLMs, um relevante Tags zu erstellen und diese in einer SQLite-Datenbank zu speichern, wodurch Abfragen intelligent verarbeitet werden können, z.B. die Analyse von Einkaufsrechnungen. Dies bietet eine genaue und effiziente Dokumentenmanagementlösung für kleine Anwendungen. (Quelle: Reddit r/MachineLearning)
Ollamas Web-Suchwerkzeug: Ollama unterstützt jetzt Web-Suchwerkzeuge, die es Benutzern ermöglichen, Web-Suchfunktionen in Minions-Workloads zu integrieren. Dies bereichert die Kontextinformationen von KI-Anwendungen und verbessert deren Fähigkeit, komplexe Aufgaben zu bewältigen. (Quelle: ollama)
Hyperlink: Lokales multimodales RAG: Hyperlink bietet lokale multimodale RAG-Funktionen, die es Benutzern ermöglichen, Screenshots/Fotobibliotheken offline zu durchsuchen und zusammenzufassen. Mithilfe von OCR- und Embedding-Technologien kann dieses Tool unstrukturierte Bilddaten in durchsuchbare Inhalte umwandeln. Dies ermöglicht ein vollständig privates, gerätebasiertes Dokumentenmanagement und die Informationsgewinnung. (Quelle: Reddit r/LocalLLaMA)

Azure PostgreSQL LangChain Connector: Microsoft hat einen nativen Azure PostgreSQL Connector eingeführt, der die Agentenpersistenz für das LangChain-Ökosystem vereinheitlicht. Dieser Connector bietet Vektorspeicherung und Zustandsverwaltung auf Unternehmensebene und vereinfacht die Komplexität beim Aufbau und der Bereitstellung von AI Agents in der Azure-Umgebung. (Quelle: LangChainAI)
LLM API-Standardisierung und MCP-Protokoll: Die Community diskutiert das Problem der LLM API-Fragmentierung und weist auf Inkompatibilitäten in Nachrichtenstrukturen, Tool-Aufrufmustern und Inferenz-Feldnamen bei verschiedenen Anbietern hin. Es wird eine Branchenstandardisierung des JSON API-Protokolls gefordert. Gleichzeitig hat die Einführung des MCP-Protokolls (Model-Client Protocol) Diskussionen über dessen Auswirkungen auf die Agentenentwicklung ausgelöst. (Quelle: AAAzzam, charles_irl)
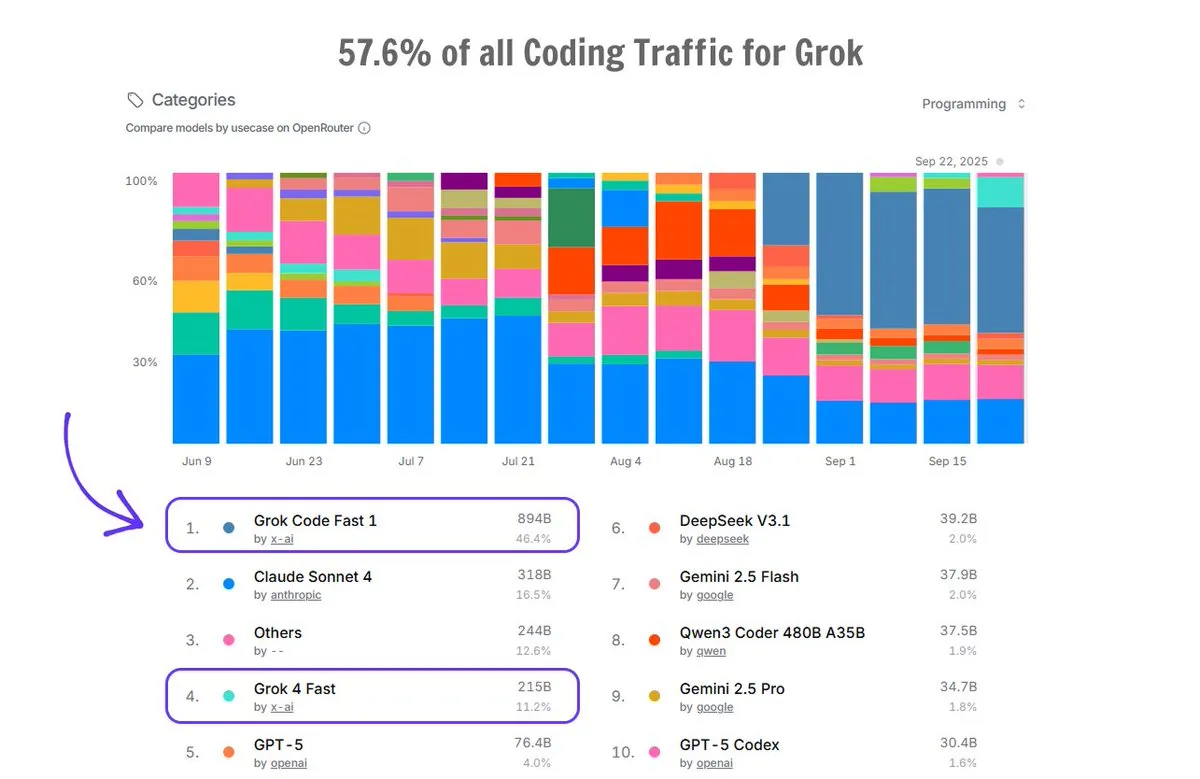
Grok Code im Einsatz auf OpenRouter: Grok Code macht auf der OpenRouter-Plattform 57,6 % des gesamten Coding-Traffics aus und übertrifft damit die Summe aller anderen KI-Code-Generatoren. Dabei belegt Grok Code Fast 1 den ersten Platz, was seine starke Marktperformance und Beliebtheit bei den Nutzern im Bereich der Code-Generierung zeigt. (Quelle: imjaredz)
📚 Learning
KI-Grundlagenkurs: Cursor Learn: Lee Robinson hat Cursor Learn veröffentlicht, eine kostenlose sechsteilige Videokursreihe, die Anfängern helfen soll, grundlegende KI-Konzepte wie tokens, context und agents zu verstehen. Der Kurs dauert etwa 1 Stunde, bietet Quizze und KI-Modelltests und ist eine praktische Ressource zum Erlernen von KI-Grundlagen. (Quelle: crystalsssup)
Kostenloses Buch über Python-Datenstrukturen: Donald R. Sheehy hat ein kostenloses Buch mit dem Titel “A First Course on Data Structures in Python” veröffentlicht, das Datenstrukturen, algorithmisches Denken, Komplexitätsanalyse, Rekursion/Dynamische Programmierung und Suchmethoden abdeckt. Es bietet eine solide Grundlage für Lernende in den Bereichen KI und maschinelles Lernen. (Quelle: TheTuringPost)

dots.ocr: Mehrsprachiges OCR-Modell: Xiaohongshu Hi Lab hat dots.ocr veröffentlicht, ein leistungsstarkes mehrsprachiges OCR-Modell, das 100 Sprachen unterstützt. Es kann Texte, Tabellen, Formeln und Layouts (Ausgabe als Markdown) End-to-End analysieren und ist kostenlos für die kommerzielle Nutzung verfügbar. Das Modell ist kompakt (1.7B VLM), erreicht aber SOTA-Leistung auf OmniDocBench und dots.ocr-bench. (Quelle: mervenoyann)

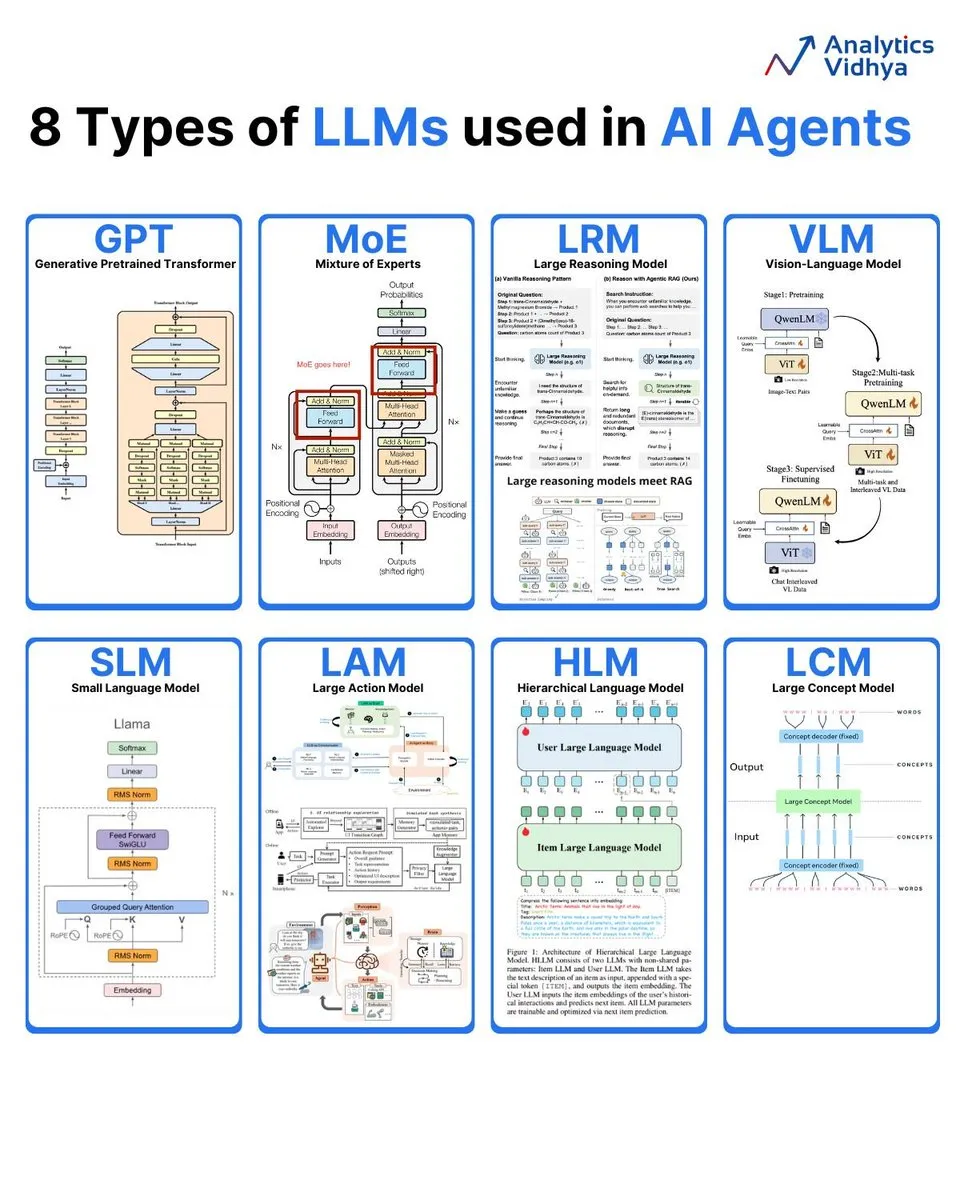
Analyse von 8 Arten großer Sprachmodelle: Analytics Vidhya fasst 8 gängige Typen großer Sprachmodelle zusammen, darunter GPT (Generative Pre-trained Transformer), MoE (Mixture of Experts), LRM (Large Reasoning Model), VLM (Visual Language Model), SLM (Small Language Model), LAM (Large Action Model), HLM (Hierarchical Language Model) und LCM (Large Concept Model). Dabei werden deren Architekturen und Anwendungen detailliert erläutert. (Quelle: karminski3)
KI-Wochenbericht: Zusammenfassung der neuesten Veröffentlichungen: DAIR.AI hat die Highlights der KI-Papiere dieser Woche (22.-28. September) veröffentlicht, die mehrere Spitzenforschungen umfassen, darunter ATOKEN, LLM-JEPA, Code World Model, Teaching LLMs to Plan, Agents Research Environments, Language Models that Think, Chat Better, Embodied AI: From LLMs to World Models. Dies bietet KI-Forschern die neuesten Entwicklungen. (Quelle: dair_ai)
Ratschläge für junge Forscher im KI-Zeitalter: Jascha Sohl-Dickstein teilt praktische Ratschläge, wie junge Forscher in der Endphase des “Anthropozäns” Forschungsprojekte auswählen und Karriereentscheidungen treffen können. Er erörtert die tiefgreifenden Auswirkungen von AGI auf akademische Karrieren und betont die Notwendigkeit, Forschungsrichtungen und berufliche Entwicklung neu zu überdenken, da KI-Systeme die menschliche Intelligenz übertreffen werden. (Quelle: mlpowered)
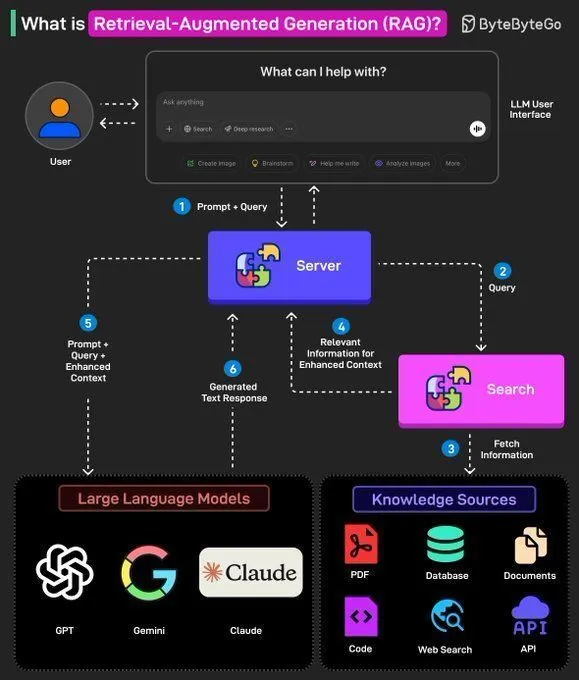
RAG-Konzepte und der Aufbau von AI Agents: Ronald van Loon erläutert die grundlegenden Konzepte von RAG (Retrieval-Augmented Generation) und dessen Bedeutung in LLMs und stellt 8 wichtige Schritte zum Aufbau eines AI Agents vor. Der Inhalt umfasst das Konzept, den Stack, die Vorteile von AI Agents und wie sie durch Frameworks bewertet werden können. Dies bietet KI-Entwicklern eine Anleitung von der Theorie zur Praxis. (Quelle: Ronald_vanLoon, Ronald_vanLoon)
Meta löst das Problem der ineffizienten LLM-Inferenz: Meta-Forschung zeigt, dass LLMs in langen Gedankenkette unter ineffizienter Inferenz leiden, die durch repetitive Arbeit verursacht wird. Sie schlagen vor, repetitive Schritte zu kleinen benannten Aktionen zu komprimieren und das Modell diese Aktionen aufrufen zu lassen, anstatt sie neu abzuleiten. Dies reduziert den token-Verbrauch, verbessert die Inferenz-Effizienz und Genauigkeit und bietet neue Ansätze zur Optimierung des LLM-Inferenzprozesses. (Quelle: ylecun)

Veo-3 zeigt visuelle Inferenzfähigkeiten: Lisan al Gaib weist darauf hin, dass das Veo-3 Videomodell emergente (visuelle) Inferenzfähigkeiten ähnlich wie GPT-3 zeigt, was darauf hindeutet, dass native multimodale Modelle nach Ausschöpfung ihres vollen Potenzials ein umfassenderes visuelles Verständnis und Inferenzvorteile bieten werden. (Quelle: scaling01)

💼 Business
OpenAIs Hunderte-Milliarden-Wette und die KI-Infrastrukturblase: OpenAI baut mit rasender Geschwindigkeit ein riesiges Netzwerk auf, das Chips, Cloud Computing und Rechenzentren umspannt, einschließlich einer 100 Milliarden US-Dollar Investition von Nvidia und einer 300 Milliarden US-Dollar “Stargate”-Kooperation mit Oracle. Obwohl der Umsatz für 2025 auf nur 13 Milliarden US-Dollar geschätzt wird, betrachtet das Management von OpenAI die Investitionen in die KI-Infrastruktur als “Jahrhundertchance”. Dies hat eine Debatte darüber ausgelöst, ob die KI-Infrastruktur vor einer Internetblase steht. (Quelle: 36氪)

Musk verklagt OpenAI zum sechsten Mal: Musks Unternehmen xAI hat OpenAI zum sechsten Mal verklagt und wirft dem Unternehmen vor, systematisch Mitarbeiter abzuwerben, den Grok-Modell-Quellcode und strategische Pläne für Rechenzentren illegal zu stehlen sowie andere Geschäftsgeheimnisse zu verletzen. Diese Klage markiert eine Eskalation des Wettbewerbs zwischen den beiden KI-Giganten. Musk ist der Ansicht, dass OpenAI von seiner ursprünglichen Non-Profit-Mission abgewichen ist, während OpenAI die Anschuldigungen zurückweist und sie als “anhaltende Belästigung” bezeichnet. (Quelle: 36氪)

Top-KI-Wissenschaftler Steven Hoi tritt Alibaba Tongyi bei: Der weltweit führende KI-Wissenschaftler und IEEE Fellow Steven Hoi ist dem Alibaba Tongyi Lab beigetreten und wird sich der grundlegenden Spitzenforschung und -entwicklung multimodaler großer Modelle widmen. Steven Hoi verfügt über mehr als 20 Jahre Erfahrung in der KI-Forschung, -Entwicklung und -Industrie, war zuvor Vice President bei Salesforce und gründete HyperAGI. Dieser Beitritt markiert eine weitere große Investition von Alibaba im Bereich der multimodalen großen Modelle, um die Effizienz der Modelliteration und multimodale Innovationsdurchbrüche zu beschleunigen. (Quelle: 36氪)

🌟 Community
ChatGPT 4o: Leistungseinbußen und Nutzerstimmung: Zahlreiche ChatGPT-Nutzer berichten von einer Verschlechterung der Leistung des 4o-Modells, mit Problemen wie “Verkleinerung” und “Sicherheitsrouting”, was zu Frustration und dem Gefühl der Täuschung bei den Nutzern führt. Viele neurodiverse Nutzer sind besonders traurig, da sie 4o als “Lebenslinie” für Kommunikation und Selbstverständnis betrachteten. Nutzer zweifeln allgemein an der mangelnden Transparenz von OpenAI und fordern das Unternehmen auf, sein Versprechen “erwachsene Nutzer zu behandeln” einzuhalten und sich gegen unklare Zensurmechanismen auszusprechen. (Quelle: Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT)

Arbeitsplätze und Entlassungen im KI-Zeitalter: Eine Kontroverse: Die Community diskutiert intensiv über die Auswirkungen von KI auf den Arbeitsmarkt, einschließlich eines deutlichen Rückgangs der Anzahl von Einstiegspositionen, gleichzeitiger Entlassungen und KI-Investitionen in Unternehmen sowie der Glaubwürdigkeit von KI-bedingten Entlassungsgründen. Die Diskussion weist auf den Trend hin, dass “Menschen, die KI verstehen, diejenigen ersetzen, die es nicht tun”. Es wird gefordert, dass Unternehmen Einstiegsjobs neu gestalten, anstatt sie einfach zu streichen, um seltene Talente zu fördern, die den Anforderungen des KI-Zeitalters gerecht werden. (Quelle: 36氪, 36氪, Reddit r/artificial)

Herausforderungen und Hürden in der LLM-Forschung: Die Community diskutiert intensiv über die steigenden Hürden in der Forschung zum maschinellen Lernen, wobei es für einzelne Forscher schwierig ist, mit großen Technologiegiganten zu konkurrieren. Angesichts von Herausforderungen wie einer Flut von Veröffentlichungen, teurer Rechenleistung und komplexen mathematischen Theorien fällt es vielen schwer, einzusteigen und Durchbrüche zu erzielen. Dies löst Bedenken hinsichtlich der Nachhaltigkeit des Feldes aus. (Quelle: Reddit r/MachineLearning)
Auswirkungen von MoE-Modellen auf das lokale Hosting: Die Community diskutiert intensiv die Vor- und Nachteile von MoE-Modellen für das lokale Hosting von LLMs. Es wird argumentiert, dass MoE-Modelle zwar mehr VRAM belegen, aber eine hohe Recheneffizienz aufweisen und durch CPU-Offloading den Betrieb größerer Modelle ermöglichen. Dies ist besonders geeignet für Consumer-Hardware mit ausreichend RAM, aber begrenzter GPU-Leistung, und stellt einen effektiven Weg dar, die LLM-Leistung zu verbessern. (Quelle: Reddit r/LocalLLaMA)
Schnelle Entwicklung und Anwendung von AI Agents: Die Community diskutiert die rasante Entwicklung von AI Agents. Ihre Fähigkeiten haben sich in weniger als einem Jahr von “nahezu unbrauchbar” schnell zu “gut funktionierend” in spezifischen Szenarien entwickelt, und sogar “generische Agenten werden nützlich”. Die Fortschrittsgeschwindigkeit übertrifft die Erwartungen. Es gibt jedoch auch die Ansicht, dass aktuelle Coding Agents stark homogenisiert sind und es an signifikanten Unterschieden mangelt. (Quelle: nptacek, HamelHusain)
RL-Forschungstrends und die GRPO-Kontroverse: Die Community diskutiert intensiv die neuesten Trends in der Reinforcement Learning (RL)-Forschung, insbesondere den Status und die Kontroversen um den GRPO-Algorithmus. Einige argumentieren, dass sich die RL-Forschung in Richtung Pre-Training/Modellierung verlagert und GRPO ein wichtiger Open-Source-Fortschritt ist. Andere OpenAI-Mitarbeiter halten es jedoch für deutlich hinter der Spitzentechnologie zurückliegend. Dies löst eine hitzige Debatte über algorithmische Innovation und tatsächliche Leistung aus. (Quelle: natolambert, MillionInt, cloneofsimo, jsuarez5341, TheTuringPost)

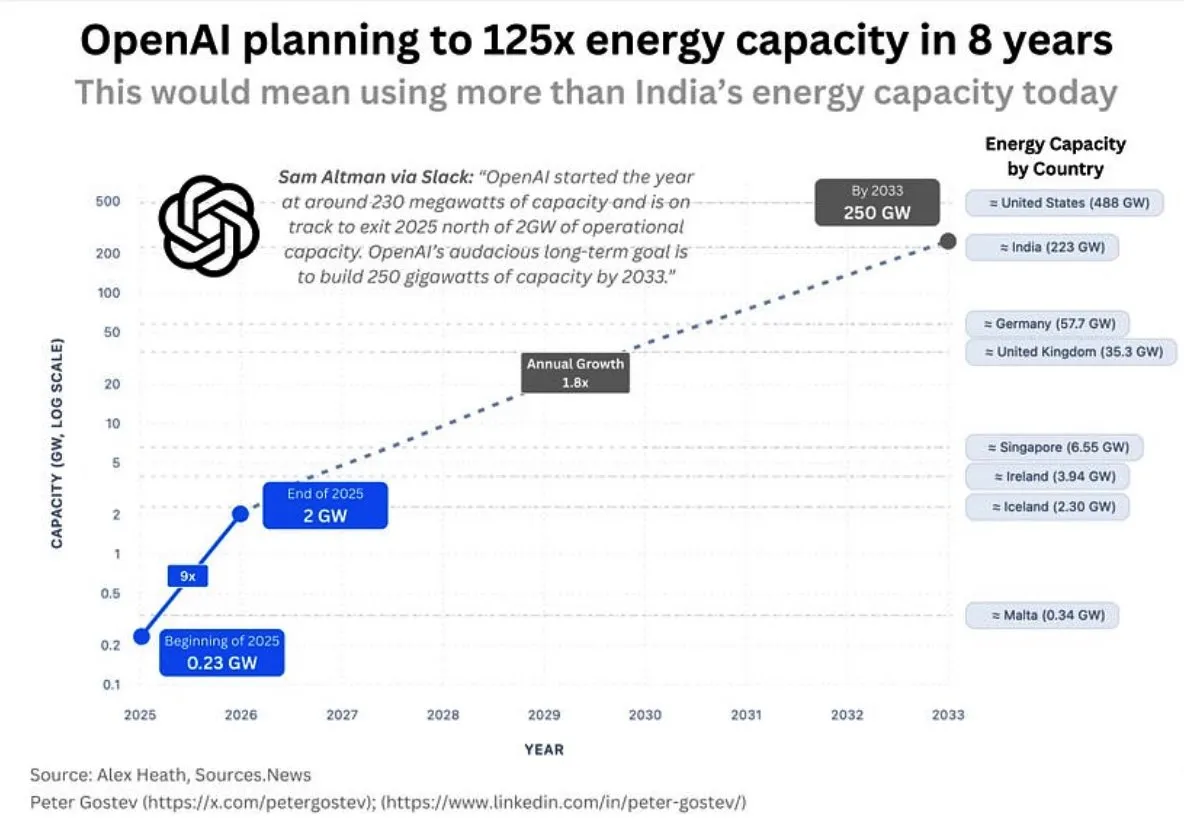
OpenAIs Energieverbrauch und KI-Infrastruktur: Die Community diskutiert den enormen zukünftigen Energiebedarf von OpenAI. Es wird geschätzt, dass das Unternehmen innerhalb von fünf Jahren mehr Energie verbrauchen wird als Großbritannien oder Deutschland, und innerhalb von acht Jahren mehr als Indien. Dies löst Bedenken hinsichtlich des Umfangs des KI-Infrastrukturaufbaus, der Energieversorgung und der Umweltauswirkungen aus. Gleichzeitig stößt auch die Standortwahl für Google-Rechenzentren aufgrund des Wasserverbrauchs auf Widerstand der Anwohner. (Quelle: teortaxesTex, brickroad7)
Suttons ‘Bitter Lesson’ und die KI-Entwicklung: Die Community diskutiert die Implikationen von Richard Suttons “Bitter Lesson” für die KI-Forschung, die betont, dass allgemeine Berechnungsmethoden menschlichem Vorwissen überlegen sind. Die Diskussion dreht sich um die Beziehung zwischen “Imitation und Weltmodellen”. Es wird argumentiert, dass bloße Imitation zu “Cargo-Kult” führen kann und dass Imitation ohne echte Erfahrung grundlegende Einschränkungen aufweist. (Quelle: rao2z, jonst0kes)
💡 Sonstiges
BionicWheelBot: Bionischer Roboter: Der BionicWheelBot-Roboter hat durch die Nachahmung der Rollbewegung der Radspinne eine multifunktionale Navigation in komplexem Gelände erreicht. Diese Innovation zeigt das Potenzial der Bionik im Robotikdesign und bietet neue Lösungen für zukünftige Roboter, um mit wechselnden Umgebungen umzugehen. (Quelle: Ronald_vanLoon)
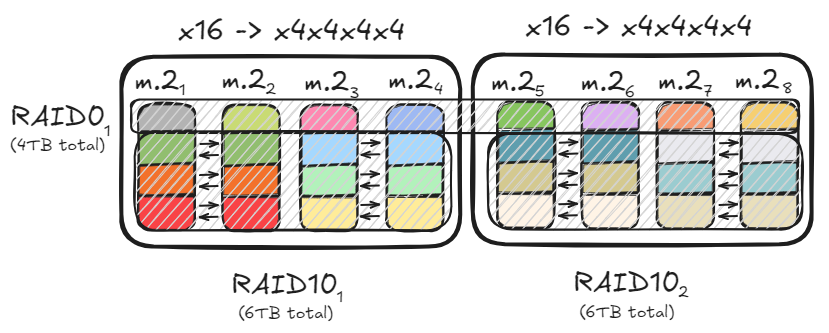
PC-Speicheroptimierung und RAID-Konfiguration: Ein Benutzer teilt mit, wie durch RAID0- und RAID10-Konfigurationen unter Verwendung mehrerer PCIe-Kanäle und M.2-Festplatten ein Datendurchsatz von bis zu 47 GB/s erreicht werden kann, um das Laden großer Modelle zu beschleunigen. Diese Optimierungslösung berücksichtigt sowohl die Speicherkapazität als auch die Datenredundanz, während sie die Anforderungen an hohe Lese-/Schreibgeschwindigkeiten erfüllt, und bietet eine effiziente Hardware-Grundlage für die Bereitstellung lokaler KI-Modelle. (Quelle: TheZachMueller)
Eröffnung des Liangzhu ‘Digital Habitat Bay AI+ Industrieparks’: Der Liangzhu ‘Digital Habitat Bay AI+ Industriepark’ in Hangzhou wurde offiziell eröffnet und konzentriert sich auf Spitzenbereiche wie Künstliche Intelligenz, die digitale Nomadenwirtschaft und kulturelle Kreativität. Die Gemeinschaft bietet durch die spezielle Politik der “Acht Digital Habitat Regeln” und ein “Vier-Szenarien”-Raumlayout KI-Pionieren umfassende Unterstützung über den gesamten Lebenszyklus, von der Ideenfindung bis zur Ökosystemführung. Ziel ist es, ein innovatives Ökosystem zu schaffen, in dem Technologie und Geisteswissenschaften tiefgreifend miteinander verschmelzen. (Quelle: 36氪)
