
Schlüsselwörter:Qwen3-Next 80B, MobileLLM-R1, Replit Agent 3, Transformer, mmBERT mehrsprachiges Encoder-Modell, Embodied Intelligence (verkörperte KI), Differenzielle Privatsphäre, LLM-Inferenz, KI-Agent, Gated DeltaNet Hybrid-Attentionsmechanismus, DARPA AIxCC Schwachstellenerkennungssystem, KI-Inferenzoptimierung für Edge-Geräte, Autonome Softwaregenerierung und -tests, Mehrsprachiges Encoder-Modell mmBERT
🔥 Fokus
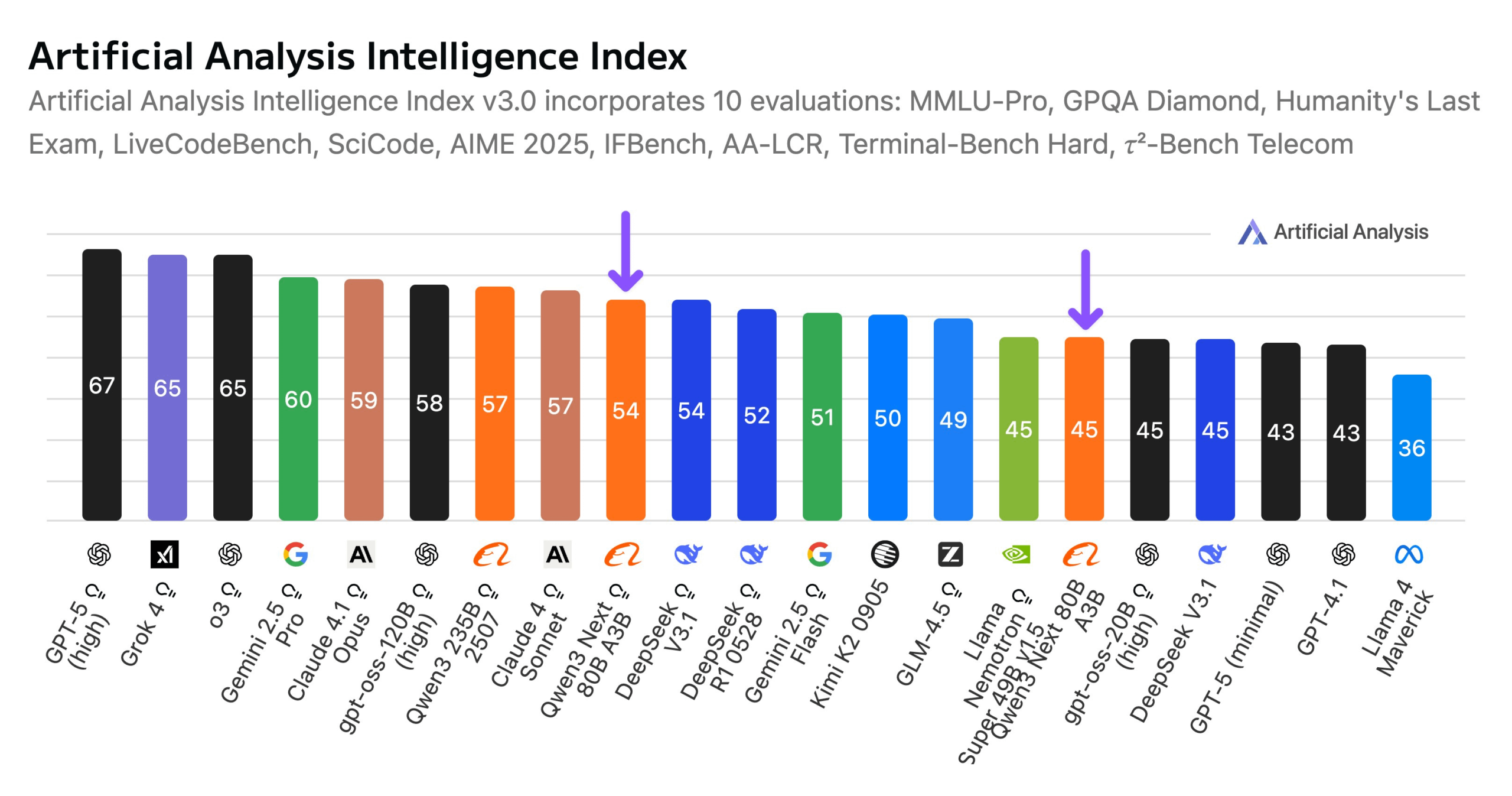
Alibaba veröffentlicht Qwen3-Next 80B Modell: Alibaba hat Qwen3-Next 80B vorgestellt, ein Open-Source-Modell mit hybriden Inferenzfähigkeiten. Das Modell nutzt einen hybriden Aufmerksamkeitsmechanismus aus Gated DeltaNet und Gated Attention sowie eine hohe Sparsity von 3,8 % (nur 3B aktive Parameter), wodurch es in Bezug auf die Intelligenz mit DeepSeek V3.1 vergleichbar ist, während die Trainingskosten um das 10-fache und die Inferenzgeschwindigkeit um das 10-fache reduziert werden. Qwen3-Next 80B zeichnet sich durch hervorragende Inferenz- und Langkontextverarbeitung aus und übertrifft sogar Gemini 2.5 Flash-Thinking. Das Modell unterstützt ein Kontextfenster von 256k Token, kann auf einer einzelnen H200 GPU ausgeführt werden und ist im NVIDIA API Catalog verfügbar, was einen neuen Durchbruch in der effizienten LLM-Architektur darstellt. (Quelle: Alibaba_Qwen, ClementDelangue, NandoDF)
DARPA AIxCC Challenge: LLM-gesteuertes System zur automatisierten Schwachstellen-Erkennung und -Behebung: Bei der DARPA Artificial Intelligence Cyber Challenge (AIxCC) hat ein LLM-gesteuertes Cyber Reasoning System (CRS) namens „All You Need Is A Fuzzing Brain“ herausragende Leistungen erbracht. Es entdeckte erfolgreich 28 Sicherheitslücken autonom, darunter 6 bisher unbekannte Zero-Day-Schwachstellen, und behob 14 davon. Das System zeigte in realen Open-Source-C- und Java-Projekten eine außergewöhnliche Fähigkeit zur automatisierten Schwachstellen-Erkennung und Patch-Anwendung und belegte im Finale den vierten Platz. Das CRS wurde als Open Source veröffentlicht und bietet eine öffentliche Rangliste zur Bewertung des aktuellen Stands von LLMs bei der Schwachstellen-Erkennung und -Behebung. (Quelle: HuggingFace Daily Papers)
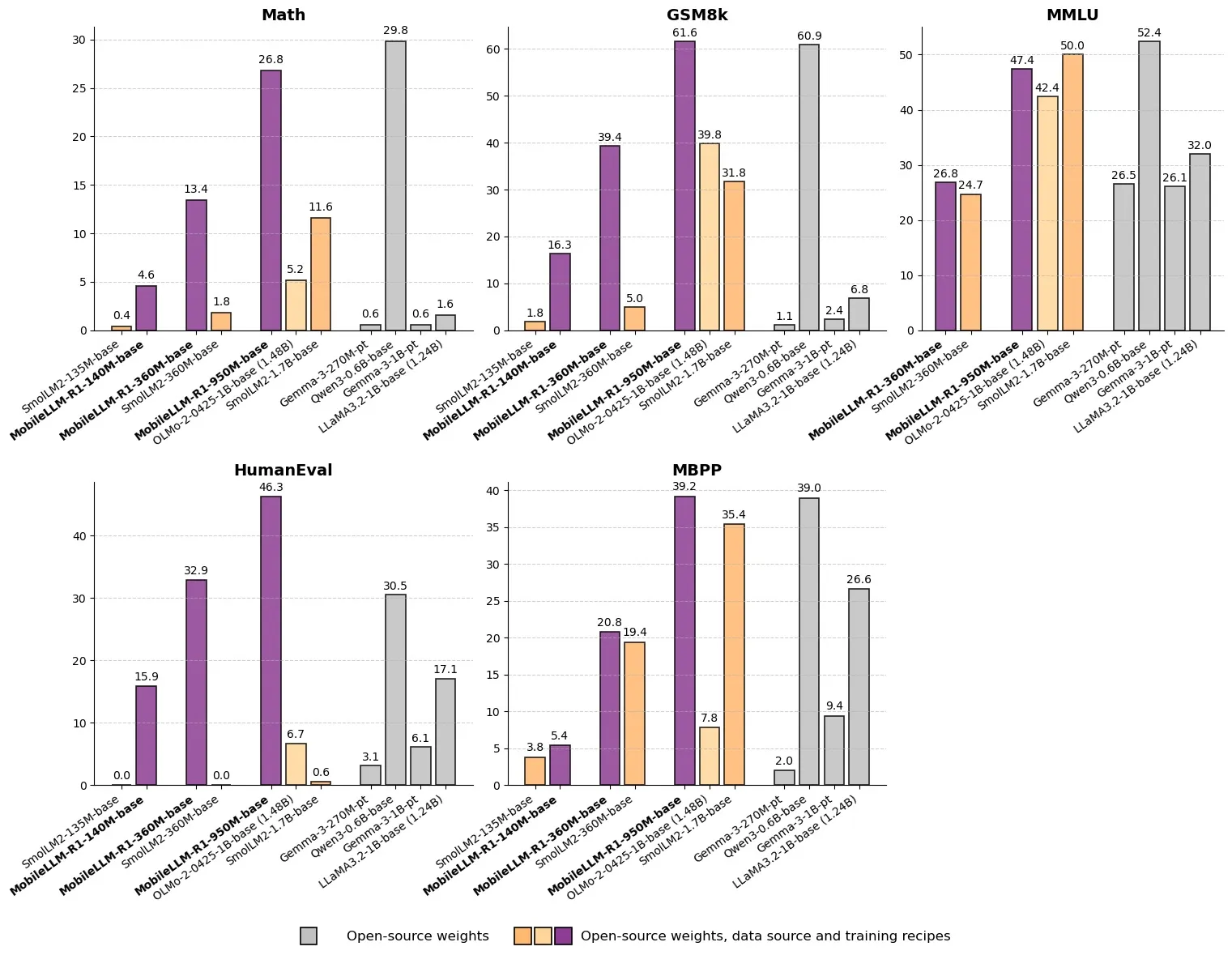
Meta veröffentlicht MobileLLM-R1: Effizientes Inferenzmodell mit unter einer Milliarde Parametern: Meta hat MobileLLM-R1 auf Hugging Face veröffentlicht, ein Edge-Inferenzmodell mit weniger als einer Milliarde Parametern. Das Modell ist in mathematischer Genauigkeit etwa 5-mal besser als Olmo-1.24B und etwa 2-mal besser als SmolLM2-1.7B, was eine Leistungssteigerung um das 2- bis 5-fache bedeutet. MobileLLM-R1 verwendet nur 4,2T vortrainierte Token (11,7 % der von Qwen verwendeten Menge) und zeigt nach geringem Nachtraining starke Inferenzfähigkeiten, was einen Paradigmenwechsel in Bezug auf Dateneffizienz und Modellgröße darstellt und neue Wege für die KI-Inferenz auf Edge-Geräten eröffnet. (Quelle: _akhaliq, Reddit r/LocalLLaMA)
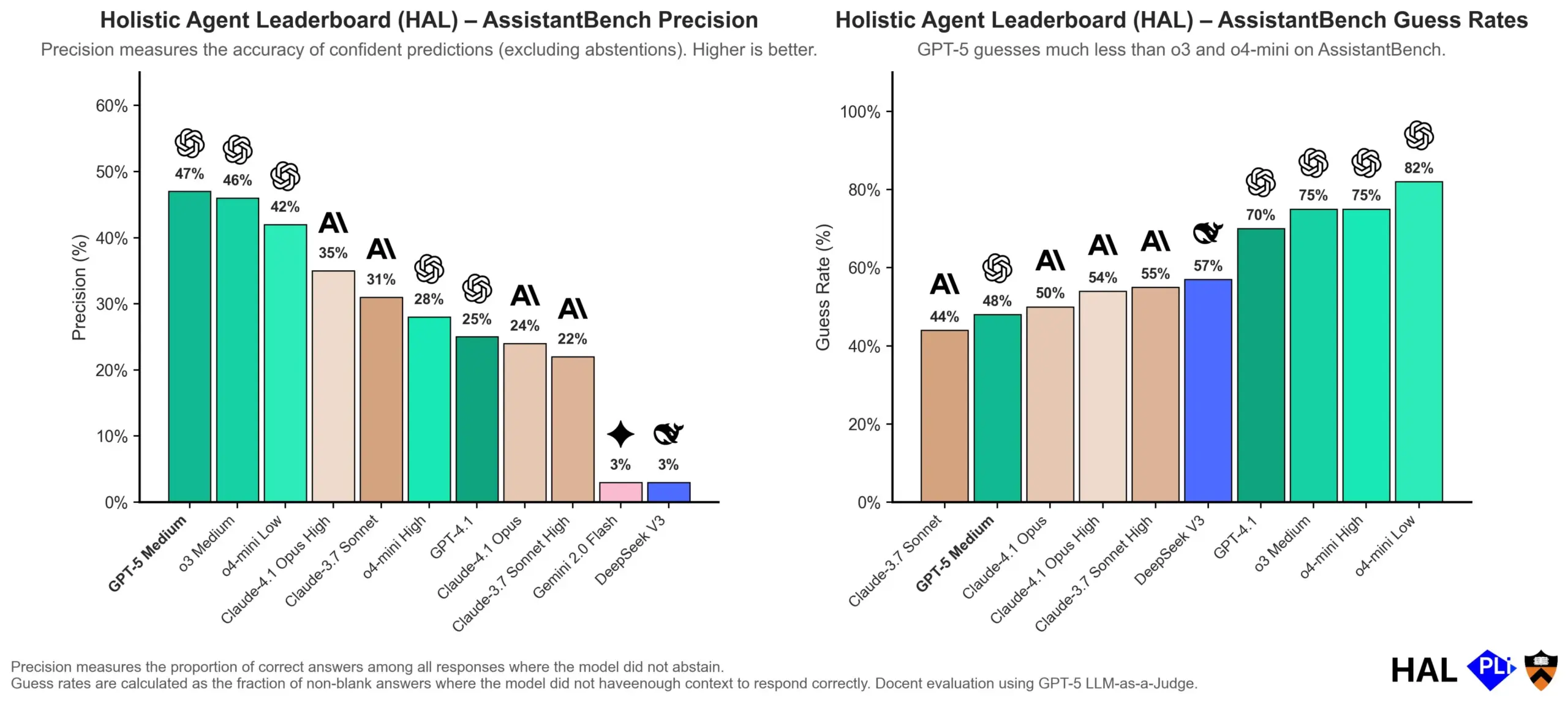
OpenAI untersucht Ursachen von LLM-Halluzinationen: Bewertungsmechanismen sind entscheidend: OpenAI hat eine Forschungsarbeit veröffentlicht, die darauf hinweist, dass Halluzinationen bei Large Language Models (LLMs) nicht auf einen Fehler des Modells selbst zurückzuführen sind, sondern ein direktes Ergebnis der aktuellen Bewertungsmethoden sind, die „Raten“ statt „Ehrlichkeit“ belohnen. Die Studie argumentiert, dass bestehende Benchmarks Modelle oft bestrafen, wenn sie „Ich weiß es nicht“ antworten, was dazu führt, dass Modelle plausibel klingende, aber tatsächlich ungenaue Antworten generieren. Das Papier fordert eine Änderung der Benchmark-Bewertungsmethoden und eine Neuausrichtung bestehender Ranglisten, um Modelle zu ermutigen, bei Unsicherheit bessere Kalibrierung und Ehrlichkeit zu zeigen, anstatt blind nach hochkonfidenten Ausgaben zu streben. (Quelle: dl_weekly, TheTuringPost, random_walker)
Replit Agent 3: Durchbruch bei autonomer Software-Generierung und -Testung: Replit hat seinen Agent 3 vorgestellt, einen KI-Agenten, der Software hochautonom generieren und testen kann. Der Agent zeigte die Fähigkeit, stundenlang ohne Eingreifen zu laufen, vollständige Anwendungen (wie soziale Netzwerkplattformen) zu erstellen und diese selbst zu testen. Nutzer-Feedback zeigt, dass Agent 3 Ideen schnell in tatsächliche Produkte umsetzen kann, die Entwicklungseffizienz erheblich steigert und sogar detaillierte Arbeitsnachweise liefert. Dieser Fortschritt deutet auf das enorme Potenzial von KI-Agenten im Bereich der Softwareentwicklung hin, insbesondere bei der Bereitstellung testbarer Umgebungen, wo Replit als führend gilt. (Quelle: amasad, amasad, amasad)
🎯 Trends
Unitree Robotics beschleunigt IPO, konzentriert sich auf Embodied AI „KI arbeiten lassen“: Unitree Robotics, ein Einhorn im Bereich der vierbeinigen Roboter, bereitet aktiv seinen IPO vor. Gründer Wang Xingxing betont das enorme Potenzial von KI in physikalischen Anwendungen und ist der Ansicht, dass die Entwicklung großer Modelle eine Gelegenheit für die Kombination von KI und Robotik bietet. Obwohl die Entwicklung der Embodied AI Herausforderungen wie Datenerfassung, multimodale Datenfusion und Modellsteuerungs-Alignment gegenübersteht, blickt Wang Xingxing optimistisch in die Zukunft und glaubt, dass die Schwelle für Innovation und Unternehmertum erheblich gesenkt wurde und kleine Organisationen eine größere Durchschlagskraft haben werden. Unitree Robotics nimmt eine führende Position auf dem Markt für vierbeinige Roboter ein, mit einem Jahresumsatz von über 1 Milliarde Yuan. Der IPO zielt darauf ab, mit Hilfe von Kapital die Beschleunigung einer Zukunft voranzutreiben, in der Roboter tiefgreifend involviert sind. (Quelle: 36氪)

Führungskrise in Apples KI-Abteilung, neue Siri-Funktionen auf 2026 verschoben: Apples KI-Abteilung sieht sich einer Welle von Führungskräfteabgängen gegenüber: Der ehemalige Siri-Chef Robby Walker steht kurz vor dem Abschied, und Kernteammitglieder wurden von Meta abgeworben. Aufgrund anhaltender Qualitätsprobleme und eines Wechsels der zugrunde liegenden Architektur werden die neuen personalisierten Funktionen von Siri auf Frühjahr 2026 verschoben. Diese Turbulenzen und Verzögerungen werfen Fragen zur Innovations- und Umsetzungsgeschwindigkeit von Apples KI auf. Obwohl das Unternehmen häufig Schritte bei KI-Serverchips und der Bewertung externer Modelle unternimmt, bleiben die tatsächlichen Fortschritte hinter den Erwartungen zurück. (Quelle: 36氪)
mmBERT: Neue Fortschritte bei mehrsprachigen Encoder-Modellen: mmBERT ist ein Encoder-Modell, das auf 3T mehrsprachigem Text in über 1800 Sprachen vortrainiert wurde. Das Modell führt innovative Elemente wie Reverse Masking Ratio Scheduling und Reverse Temperature Sampling Ratio ein und integriert in der späteren Trainingsphase Daten aus über 1700 Low-Resource-Sprachen, was die Leistung erheblich verbessert. mmBERT zeigt bei Klassifizierungs- und Retrieval-Aufgaben sowohl für High- als auch für Low-Resource-Sprachen hervorragende Leistungen, vergleichbar mit Modellen wie OpenAIs o3 und Googles Gemini 2.5 Pro, und schließt damit eine Lücke in der Forschung zu mehrsprachigen Encoder-Modellen. (Quelle: HuggingFace Daily Papers)
MachineLearningLM: Neues Framework für LLMs zur kontextuellen Machine Learning: MachineLearningLM ist ein kontinuierliches Vortrainings-Framework, das darauf abzielt, generischen LLMs (wie Qwen-2.5-7B-Instruct) leistungsstarke kontextuelle Machine Learning-Fähigkeiten zu verleihen, wobei ihr allgemeines Wissen und ihre Inferenzfähigkeiten erhalten bleiben. Durch die Synthese von ML-Aufgaben aus Millionen von Structured Causal Models (SCMs) und die Verwendung effizienter Token-Prompts ermöglicht das Framework LLMs, bis zu 1024 Beispiele rein durch In-Context Learning (ICL) zu verarbeiten, ohne Gradientenabstieg durchzuführen. MachineLearningLM übertrifft starke Baseline-Modelle wie GPT-5-mini bei Out-of-Domain-Tabellenklassifizierungsaufgaben in Bereichen wie Finanzen, Physik, Biologie und Medizin um durchschnittlich etwa 15 %. (Quelle: HuggingFace Daily Papers)
Meta vLLM: Neuer Durchbruch bei der Effizienz von großskaliger Inferenz: Metas hierarchische Implementierung von vLLM hat die Effizienz von PyTorch und vLLM bei großskaliger Inferenz erheblich verbessert und übertrifft ihren internen Stack sowohl bei Latenz als auch bei Durchsatz. Durch die Rückführung der Optimierungsergebnisse an die vLLM-Community wird dieser Fortschritt voraussichtlich effizientere und kostengünstigere Lösungen für die KI-Inferenz ermöglichen, was insbesondere für die Verarbeitung großer Sprachmodell-Inferenzaufgaben von entscheidender Bedeutung ist und die Bereitstellung und Skalierung von KI-Anwendungen in realen Szenarien vorantreibt. (Quelle: vllm_project)

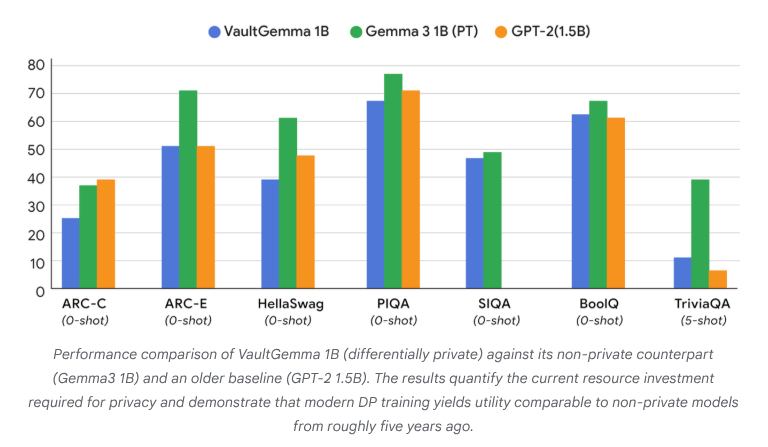
VaultGemma: Erstes Open-Source-LLM mit Differential Privacy veröffentlicht: Google Research hat VaultGemma veröffentlicht, das bisher größte von Grund auf trainierte Open-Source-Modell mit Differential Privacy-Schutz. Diese Forschung stellt nicht nur die Gewichte und den technischen Bericht von VaultGemma bereit, sondern schlägt auch erstmals Skalierungsgesetze für Differential Privacy Language Models vor. Die Veröffentlichung von VaultGemma schafft eine wichtige Grundlage für den Aufbau sichererer und verantwortungsvollerer KI-Modelle auf sensiblen Daten und fördert die Entwicklung von datenschutzfreundlichen KI-Technologien, wodurch diese in praktischen Anwendungen praktikabler werden. (Quelle: JeffDean, demishassabis)
OpenAI GPT-5/GPT-5-mini API-Ratenlimits erheblich erhöht: OpenAI hat angekündigt, dass die API-Ratenlimits für GPT-5 und GPT-5-mini erheblich erhöht wurden, teilweise verdoppelt. Zum Beispiel wurde Tier 1 von GPT-5 von 30K TPM auf 500K TPM und Tier 2 von 450K auf 1M erhöht. Tier 1 von GPT-5-mini wurde ebenfalls von 200K auf 500K erhöht. Diese Anpassung verbessert die Fähigkeit von Entwicklern erheblich, diese Modelle für großskalige Anwendungen und Experimente zu nutzen, reduziert Engpässe durch Ratenlimits und fördert die kommerzielle Anwendung und die Entwicklung des Ökosystems der GPT-5-Modellreihe. (Quelle: OpenAIDevs)
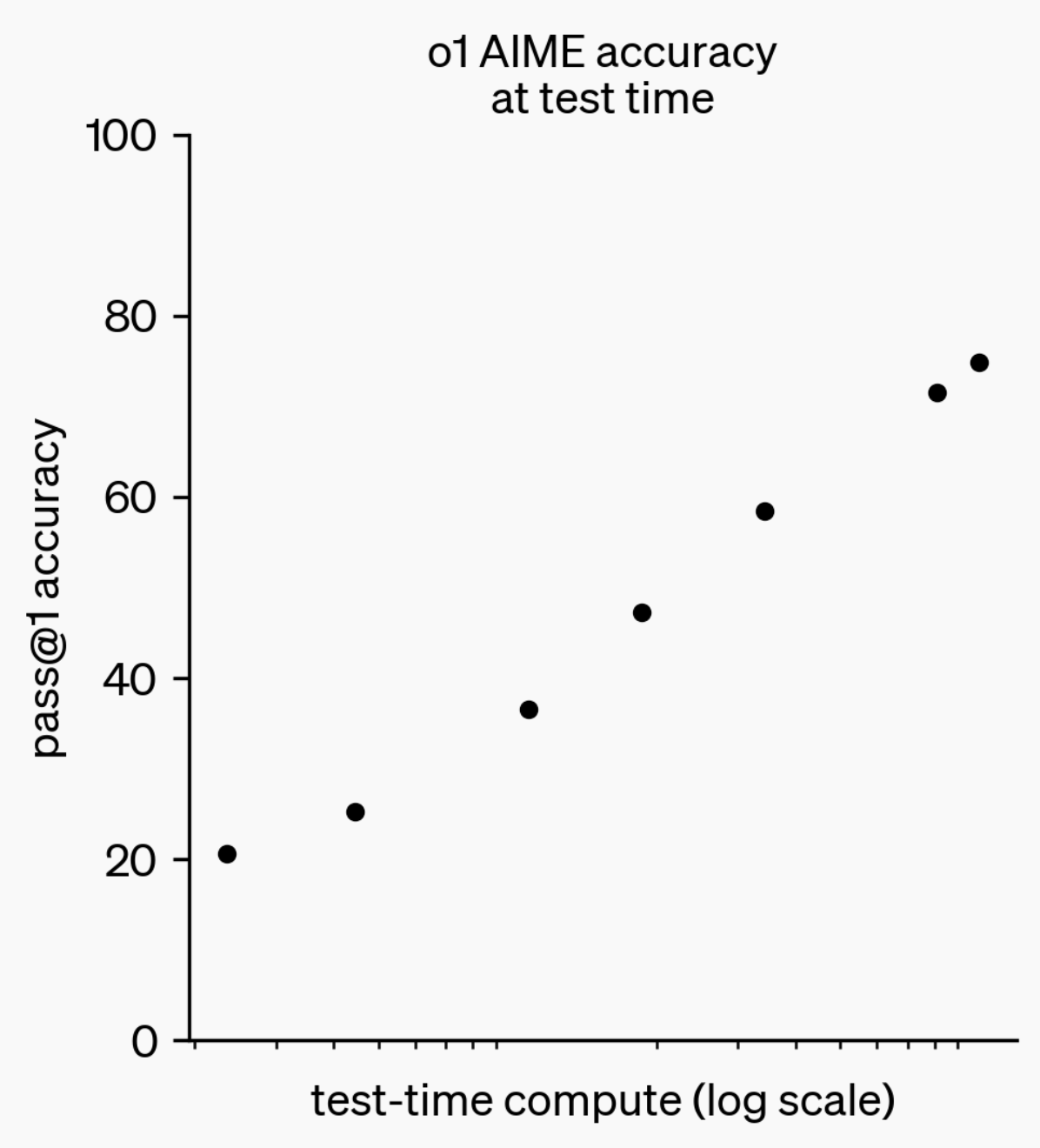
Entwicklung der LLM-Inferenzfähigkeiten: Von o1-preview zu GPT-5 Pro: Im letzten Jahr haben Large Language Models (LLMs) erhebliche Fortschritte in ihren Inferenzfähigkeiten gemacht. Von OpenAIs o1-preview-Modell, das vor einem Jahr noch Sekunden zum Nachdenken benötigte, bis zu den heutigen fortschrittlichsten Inferenzmodellen, die stundenlang nachdenken, Webseiten durchsuchen und Code schreiben können, zeigt dies, dass die Dimension der KI-Inferenz ständig erweitert wird. Durch Reinforcement Learning (RL) trainierte Modelle zum „Nachdenken“ und die Nutzung privater Chain of Thought verbessern die Leistung von LLMs bei Inferenzaufgaben mit zunehmender Denkzeit, was darauf hindeutet, dass die Erweiterung der Inferenzberechnung eine neue Richtung für die zukünftige Modellentwicklung sein wird. (Quelle: polynoamial, gdb)
Japanisches Sakana AI: Von der Natur inspiriertes KI-Einhorn: Das japanische Startup Sakana AI hat innerhalb eines Jahres nach seiner Gründung eine Bewertung von über 1 Milliarde US-Dollar erreicht und ist damit das schnellste Unternehmen in Japan, das den Status eines „Einhorns“ erlangt hat. Das Unternehmen wurde von David Ha, einem ehemaligen Google Brain-Forscher, gegründet. Sein KI-Ansatz ist von der „kollektiven Intelligenz“ der Natur inspiriert und zielt darauf ab, bestehende kleine und große Systeme zu integrieren, anstatt blind große, energieintensive Modelle zu verfolgen. Sakana AI hat bereits den Offline-Japanisch-Chatbot „Tiny Sparrow“ und eine KI, die japanische Literatur verstehen kann, auf den Markt gebracht und eine Partnerschaft mit der japanischen Mitsubishi UFJ Bank aufgebaut, um ein „bankenspezifisches KI-System“ zu entwickeln. Das Unternehmen betont, dass es Talente durch „japanische Soft Power“ anzieht und mutige Experimente im KI-Bereich durchführt. (Quelle: SakanaAILabs)
Durchbrüche in der Robotik und KI-Integration: Neue Fortschritte bei humanoiden, Schwarm- und vierbeinigen Robotern: Der Bereich der Robotik erlebt erhebliche Fortschritte, insbesondere bei humanoiden Robotern, Schwarmrobotern und vierbeinigen Robotern. Natürliche Dialoginteraktionen zwischen humanoiden Robotern und Mitarbeitern werden Realität, vierbeinige Roboter erreichten eine erstaunliche Geschwindigkeit von unter 10 Sekunden auf 100 Metern, während Schwarmroboter „erstaunliche Intelligenz“ zeigen. Darüber hinaus deuten das ANT-Navigationssystem für die Navigation in komplexem Gelände und die von Eufy für Saugroboter entwickelte autonome Treppensteigbasis darauf hin, dass Roboter breiter in alltäglichen und industriellen Szenarien eingesetzt werden. Die Anwendung von KI in klinischen Neurowissenschaftsstudien vertieft sich ebenfalls, indem intelligente Exoskelette HAPO SENSOR zur Analyse von Nutzungseffekten eingesetzt werden, was das Potenzial von KI im Gesundheitswesen aufzeigt. (Quelle: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
🧰 Tools
Qwen Code v0.0.10 & v0.0.11 Updates: Verbesserung der Entwicklererfahrung und Effizienz: Alibaba Cloud Qwen Code hat die Versionen v0.0.10 und v0.0.11 veröffentlicht, die mehrere neue Funktionen und entwicklerfreundliche Verbesserungen mit sich bringen. Die neuen Versionen führen Subagents für intelligente Aufgabenzerlegung, ein Todo Write-Tool zur Aufgabenverfolgung sowie eine „Willkommen zurück“-Projektzusammenfassungsfunktion beim Wiederöffnen von Projekten ein. Darüber hinaus umfassen die Updates anpassbare Caching-Strategien, ein flüssigeres Bearbeitungserlebnis (keine Agentenschleifen), integrierte Terminal-Benchmark-Stresstests, weniger Wiederholungsversuche, optimiertes Lesen großer Projektdateien, verbesserte IDE- und Shell-Integration, bessere MCP- und OAuth-Unterstützung sowie verbesserte Speicher-/Sitzungsverwaltung und mehrsprachige Dokumentation. Diese Verbesserungen zielen darauf ab, die Produktivität von Entwicklern erheblich zu steigern. (Quelle: Alibaba_Qwen)
Claude Code Nutzungstipps und Verbesserungen der Benutzererfahrung: Diskussionen und Verbesserungsvorschläge zur Benutzererfahrung von Claude Code sind zahlreich. Benutzer teilten den Prompt „füge angemessene Log-Informationen hinzu“, um KI-Agenten bei der Lösung von Codeproblemen zu helfen. Ein Entwickler veröffentlichte die iOS-App „Standard Input“ für Claude Code, die mobile Nutzung, Push-Benachrichtigungen und interaktiven Chat unterstützt. Gleichzeitig diskutierte die Community auch die Inkonsistenzen von Claude Code bei der Verarbeitung großer Projekte und die Bedeutung des Kontextmanagements. Es wird empfohlen, den Kontext aktiv zu löschen, Claude md-Dateien und den Ausgabestil anzupassen, Subagents zur Aufgabenzerlegung zu verwenden, sowie Planungsmodi und Hooks zu nutzen, um Effizienz und Codequalität zu verbessern. (Quelle: dotey, mattrickard, Reddit r/ClaudeAI)
Hugging Face mit VS Code/Copilot tief integriert, stärkt Entwickler: Hugging Face integriert über seinen Inferenzanbieter Hunderte der fortschrittlichsten Open-Source-Modelle (wie Kimi K2, Qwen3 Next, gpt-oss, Aya usw.) direkt in VS Code und GitHub Copilot. Diese Integration, unterstützt von Partnern wie Cerebras Systems, FireworksAI, Cohere Labs, Groq Inc, bietet Entwicklern eine reichere Modellauswahl und betont Vorteile wie Open-Source-Gewichte, automatische Weiterleitung mehrerer Anbieter, faire Preise, nahtlosen Modellwechsel und vollständige Transparenz. Darüber hinaus hat die Transformers-Bibliothek von Hugging Face auch die Funktion „Continuous Batching“ eingeführt, die Bewertungs- und Trainingsschleifen vereinfacht und die Inferenzgeschwindigkeit erhöht, mit dem Ziel, ein leistungsstarkes Toolkit für die Entwicklung und Experimente von KI-Modellen zu werden. (Quelle: ClementDelangue, code)

AU-Harness: Umfassendes Open-Source-Evaluierungstoolkit für Audio-LLMs: AU-Harness ist ein effizientes, umfassendes Open-Source-Evaluierungsframework, das speziell für Large Audio Language Models (LALMs) entwickelt wurde. Das Toolkit erreicht durch optimierte Batch-Verarbeitung und parallele Ausführung eine Geschwindigkeitssteigerung von bis zu 127 %, was eine großskalige LALM-Evaluierung ermöglicht. Es bietet standardisierte Prompt-Protokolle und flexible Konfigurationen, um einen fairen Vergleich von Modellen in verschiedenen Szenarien zu gewährleisten. AU-Harness führt auch zwei neue Bewertungskategorien ein: LLM-Adaptive Diarization (zeitliches Audioverständnis) und Spoken Language Reasoning (komplexe Audio-Kognitionsaufgaben), mit dem Ziel, die signifikanten Lücken aktueller LALMs im zeitlichen Verständnis und bei komplexen Sprachinferenzaufgaben aufzudecken und die systematische LALM-Entwicklung voranzutreiben. (Quelle: HuggingFace Daily Papers)
LLM-gesteuertes CI/CD-Schwachstellen-Erkennungssystem AI-DO: AI-DO (Automating vulnerability detection Integration for Developers’ Operations) ist ein in CI/CD-Prozesse integriertes Empfehlungssystem, das das CodeBERT-Modell nutzt, um Schwachstellen während der Code-Review-Phase zu erkennen und zu lokalisieren. Das System zielt darauf ab, die Lücke zwischen akademischer Forschung und industrieller Anwendung zu schließen, indem es die domänenübergreifende Generalisierungsfähigkeit von CodeBERT auf Open-Source- und Industriedaten bewertet. Es wurde festgestellt, dass das Modell innerhalb derselben Domäne genaue Ergebnisse liefert, die Leistung jedoch domänenübergreifend abnimmt. Durch geeignete Undersampling-Techniken kann ein auf Open-Source-Daten feinabgestimmtes Modell die Schwachstellen-Erkennungsfähigkeit effektiv verbessern. Die Entwicklung von AI-DO verbessert die Sicherheit in Entwicklungsprozessen, ohne bestehende Workflows zu unterbrechen. (Quelle: HuggingFace Daily Papers)
Replit Agent 3: Blitzschnelle Umsetzung von Ideen in Anwendungen: Replit’s Agent 3 zeigte eine erstaunliche Effizienz, indem er eine Upwork-Anforderung für eine Salon-Check-in-Anwendung innerhalb von 145 Minuten in eine vollständige Anwendung mit Kunden-Check-in-Prozess, Kundendatenbank und Backend-Dashboard umwandelte. Der Agent verfügt auch über ein hohes Maß an Autonomie und konnte 193 Minuten lang ohne Eingreifen laufen, produktionsreifen Code generieren, einschließlich Authentifizierung, Datenbank, Speicher und WebSocket, und sogar eigene Tests und Ranking-Algorithmen schreiben. Diese Fähigkeiten unterstreichen das enorme Potenzial von KI-Agenten in der schnellen Prototypenentwicklung und beim Aufbau von Full-Stack-Anwendungen, was den Prozess von der Idee zum tatsächlichen Produkt erheblich beschleunigen wird. (Quelle: amasad, amasad, amasad)
Claude mit neuen Funktionen zum Erstellen und Bearbeiten von Dateien: Claude kann jetzt direkt in Claude.ai und der Desktop-Anwendung Excel-Tabellen, Dokumente, PowerPoint-Präsentationen und PDF-Dateien erstellen und bearbeiten. Diese neue Funktion erweitert die Anwendungsszenarien von Claude in alltäglichen Büro- und Produktivitätstools erheblich, wodurch es tiefer in die Arbeitsabläufe der Dokumentenverarbeitung und Inhaltserstellung eingebunden werden kann, und die Effizienz und Bequemlichkeit der Benutzer bei der Bearbeitung komplexer Dateiaufgaben verbessert. (Quelle: dl_weekly)
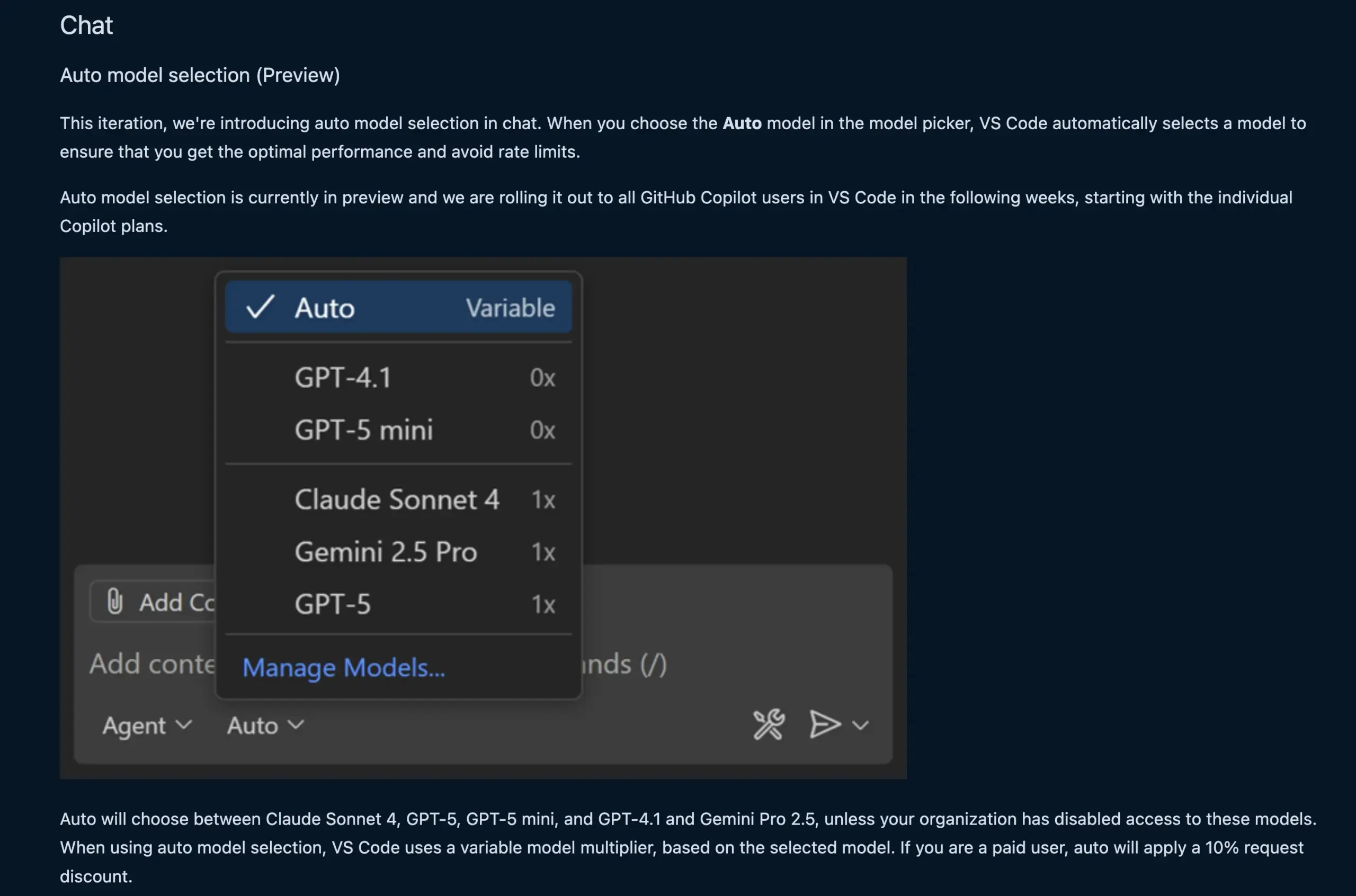
VS Code Chat-Funktion wählt automatisch LLM-Modell: Die neue VS Code Chat-Funktion kann jetzt basierend auf Benutzeranfragen und Ratenlimits automatisch das passende LLM-Modell auswählen. Diese Funktion ermöglicht ein intelligentes Umschalten zwischen Modellen wie Claude Sonnet 4, GPT-5, GPT-5 mini, GPT-4.1 und Gemini Pro 2.5, und bietet Entwicklern ein bequemeres und effizienteres KI-gestütztes Programmiererlebnis. Gleichzeitig wurde die Language Model Chat Provider Extension API von VS Code finalisiert, die das Beitragen von Modellen über Erweiterungen und den „Bring Your Own Key“ (BYOK)-Modus ermöglicht, was die Modellauswahl und Anpassungsfähigkeit weiter bereichert. (Quelle: code, pierceboggan)
Box führt KI-Agenten-Fähigkeiten ein, um unstrukturierte Datenverwaltung zu ermöglichen: Box hat neue KI-Agenten-Funktionen angekündigt, die Kunden dabei helfen sollen, den Wert ihrer unstrukturierten Daten voll auszuschöpfen. Das aktualisierte Box AI Studio erleichtert den Aufbau von KI-Agenten, die in verschiedenen Geschäftsfunktionen und Branchenanwendungsfällen eingesetzt werden können. Box Extract nutzt KI-Agenten für die komplexe Datenextraktion aus verschiedenen Dokumenttypen, während Box Automate eine neue Workflow-Automatisierungslösung ist, die es Benutzern ermöglicht, KI-Agenten in Content-Hub-Workflows einzusetzen. Diese Funktionen arbeiten über vorgefertigte Integrationen, die Box API oder den neuen Box MCP Server nahtlos mit den bestehenden Systemen der Kunden zusammen, und zielen darauf ab, die Art und Weise zu revolutionieren, wie Unternehmen unstrukturierte Inhalte verarbeiten. (Quelle: hwchase17)
Cursor’s neues Tab-Modell: Erhöhte Genauigkeit und Akzeptanz von Code-Vorschlägen: Cursor hat sein neues Tab-Modell als Standard-Code-Vorschlagstool veröffentlicht. Das Modell wurde durch Online Reinforcement Learning (RL) trainiert und reduzierte die Anzahl der Code-Vorschläge um 21 % im Vergleich zum alten Modell, während die Akzeptanzrate der Vorschläge um 28 % stieg. Diese Verbesserung bedeutet, dass das neue Modell präzisere und den Entwicklerabsichten besser entsprechende Code-Vorschläge liefern kann, wodurch die Programmiereffizienz und Benutzererfahrung erheblich verbessert, unnötige Ablenkungen reduziert und Entwickler ihre Codierungsaufgaben effizienter erledigen können. (Quelle: BlackHC, op7418)
awesome-llm-apps: Sammlung von Open-Source-LLM-Anwendungen: Das GitHub-Projekt awesome-llm-apps wird als Open-Source-Goldmine bezeichnet. Es sammelt über 40 deploybare LLM-Anwendungen, die von AI-Blog-zu-Podcast-Agenten bis hin zur medizinischen Bildanalyse reichen. Jede Anwendung wird mit detaillierter Dokumentation und Einrichtungsanweisungen geliefert, wodurch Arbeiten, die normalerweise Wochen dauern würden, jetzt in wenigen Minuten erledigt werden können. Zum Beispiel generiert das darin enthaltene AI-Audio-Guide-Projekt durch ein Multi-Agenten-System, Echtzeit-Websuche und TTS-Technologie natürliche und kontextrelevante Audioführungen, mit geringen API-Kosten, was die Praktikabilität von Multi-Agenten-Systemen bei der Inhaltserstellung zeigt. (Quelle: Reddit r/MachineLearning)
📚 Lernen
MMOral: Multimodaler Benchmark und Anweisungsdatensatz für die Analyse von dentalen Panorama-Röntgenbildern: MMOral ist der erste großskalige multimodale Anweisungsdatensatz und Benchmark, der speziell für die Interpretation von dentalen Panorama-Röntgenbildern entwickelt wurde. Der Datensatz enthält 20.563 annotierte Bilder und 1,3 Millionen Anweisungsfolge-Instanzen, die Aufgaben wie Attributextraktion, Berichtsgenerierung, visuelle Fragenbeantwortung und Bilddialog umfassen. Die MMOral-Bench-Evaluierungssuite deckt fünf Schlüsseldimensionen der zahnmedizinischen Diagnose ab. Die Ergebnisse zeigen, dass selbst die besten LVLM-Modelle wie GPT-4o nur eine Genauigkeit von 41,45 % erreichen, was die Grenzen bestehender Modelle in diesem Bereich unterstreicht. OralGPT erzielte durch SFT von Qwen2.5-VL-7B eine signifikante Leistungssteigerung von 24,73 % und legt damit den Grundstein für intelligente Zahnmedizin und klinische multimodale KI-Systeme. (Quelle: HuggingFace Daily Papers)
Domänenübergreifende Bewertung der Transformer-Schwachstellen-Erkennung: Eine Studie bewertete die Leistung von CodeBERT bei der Erkennung von Schwachstellen in Industrie- und Open-Source-Software und analysierte seine domänenübergreifende Generalisierungsfähigkeit. Die Studie ergab, dass Modelle, die auf Industriedaten trainiert wurden, innerhalb derselben Domäne genaue Ergebnisse lieferten, aber bei Open-Source-Code an Leistung verloren. Tiefenlernmodelle, die mit geeigneten Undersampling-Techniken auf Open-Source-Daten feinabgestimmt wurden, konnten die Schwachstellen-Erkennungsfähigkeit effektiv verbessern. Basierend auf diesen Ergebnissen entwickelte das Forschungsteam das AI-DO-System, ein in CI/CD-Prozesse integriertes Empfehlungssystem, das Schwachstellen während der Code-Review erkennen und lokalisieren kann, ohne bestehende Workflows zu stören, und darauf abzielt, die Übertragung akademischer Technologien in industrielle Anwendungen zu fördern. (Quelle: HuggingFace Daily Papers)
Ego3D-Bench: VLM-Benchmark für räumliches Denken in egozentrischen Multi-View-Szenen: Ego3D-Bench ist ein neuer Benchmark zur Bewertung der 3D-Raumschlussfähigkeiten von Visual Language Models (VLMs) in egozentrischen, Multi-View-Außendaten. Der Benchmark enthält über 8.600 von Menschen annotierte Frage-Antwort-Paare, die zur Überprüfung von 16 SOTA VLMs wie GPT-4o und Gemini1.5-Pro verwendet werden. Die Ergebnisse zeigen, dass aktuelle VLMs im räumlichen Verständnis eine signifikante Lücke zum menschlichen Niveau aufweisen. Um diese Lücke zu schließen, schlug das Forschungsteam das Ego3D-VLM-Nachtrainings-Framework vor, das durch die Generierung kognitiver Karten basierend auf geschätzten globalen 3D-Koordinaten die Leistung bei Multiple-Choice-Fragen um durchschnittlich 12 % und bei der absoluten Distanzschätzung um 56 % verbesserte, und somit ein wertvolles Werkzeug zur Erreichung menschlicher räumlicher Verständnisfähigkeiten bietet. (Quelle: HuggingFace Daily Papers)
Die „Illusion der sinkenden Erträge“ bei der Ausführung langfristiger LLM-Aufgaben: Eine neue Studie untersucht die Leistung von LLMs bei der Ausführung langfristiger Aufgaben und weist darauf hin, dass eine geringfügige Verbesserung der Einzelschrittgenauigkeit zu einem exponentiellen Anstieg der Aufgabenlänge führen kann. Das Papier argumentiert, dass das Scheitern von LLMs bei langen Aufgaben nicht auf mangelnde Inferenzfähigkeiten, sondern auf Ausführungsfehler zurückzuführen ist. Durch die explizite Bereitstellung von Wissen und Plänen stellten die Forscher fest, dass große Modelle mehr Schritte korrekt ausführen können, selbst wenn kleine Modelle eine Einzelschrittgenauigkeit von 100 % erreichen. Eine interessante Entdeckung ist der „Selbstregulierungs“-Effekt von Modellen: Wenn der Kontext frühere Fehler enthält, neigt das Modell eher dazu, erneut Fehler zu machen, und dies kann nicht allein durch die Modellgröße gelöst werden. Die neuesten „Denkmodelle“ können jedoch die Selbstregulierung vermeiden und längere Aufgaben in einem einzigen Durchlauf erledigen, was die enormen Vorteile der Skalierung von Modellen und der sequenziellen Testberechnung für langfristige Aufgaben unterstreicht. (Quelle: Reddit r/ArtificialInteligence)
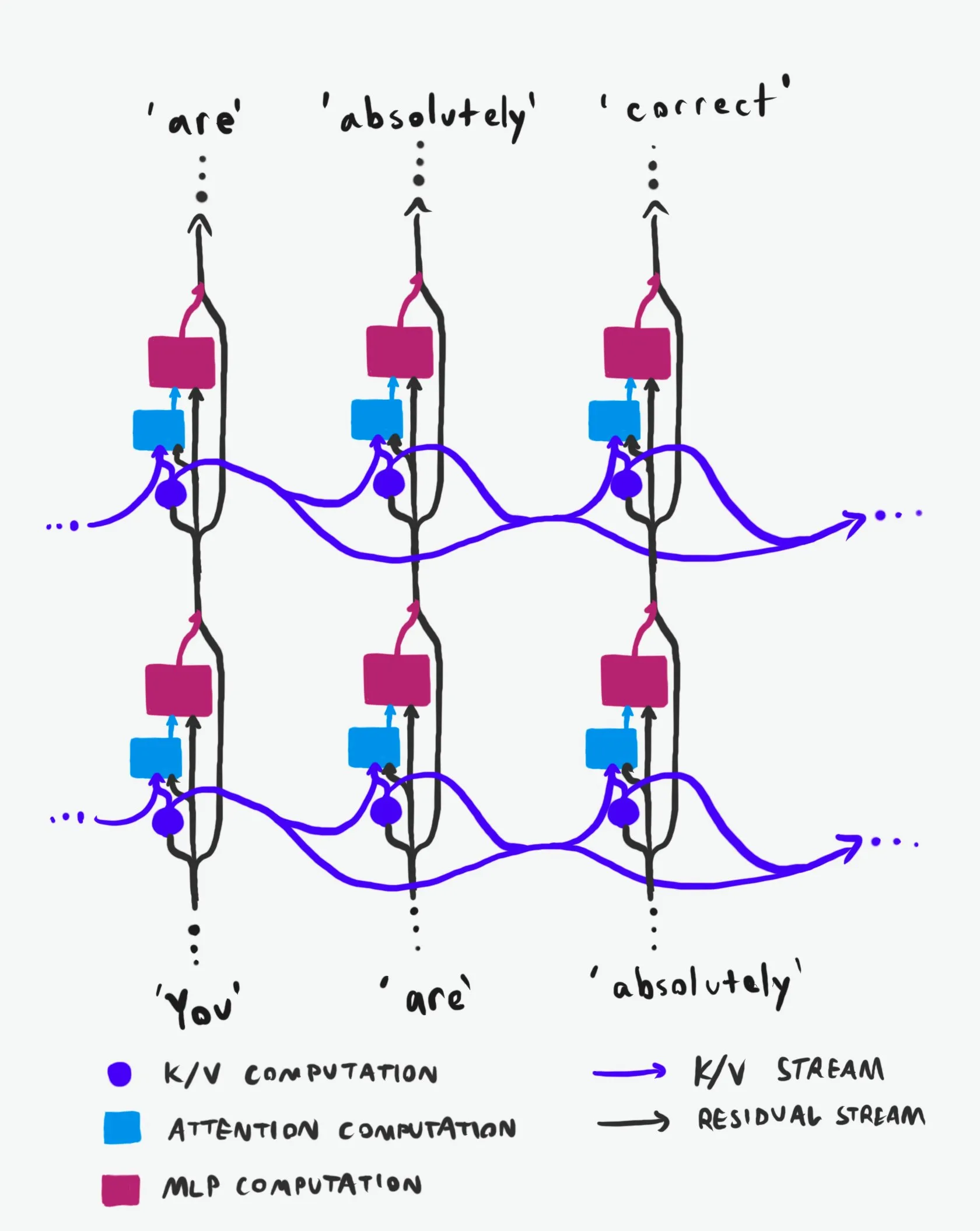
Transformer Kausalstruktur: Eine tiefgehende Analyse des Informationsflusses: Eine als „Best-in-Class“ bezeichnete technische Erklärung analysiert tiefgreifend die Kausalstruktur von Transformer Large Language Models (LLMs) und deren Informationsfluss. Diese Erklärung verzichtet auf schwer verständliche Terminologie und erläutert klar die beiden Hauptinformationsautobahnen in der Transformer-Architektur: den Residual Stream und den Aufmerksamkeitsmechanismus. Durch Visualisierung und detaillierte Beschreibung hilft sie Forschern und Entwicklern, die internen Funktionsweisen von Transformern besser zu verstehen, um fundiertere Entscheidungen bei Modelldesign, Optimierung und Debugging zu treffen, was für ein tiefes Verständnis der zugrunde liegenden LLM-Mechanismen von großer Bedeutung ist. (Quelle: Plinz)
Carnegie Mellon University bietet neuen Kurs zu LM-Inferenz an: @gneubig und @Amanda Bertsch von der Carnegie Mellon University (CMU) werden diesen Herbst gemeinsam einen neuen Kurs zum Thema Language Model (LM) Inferenz unterrichten. Der Kurs zielt darauf ab, eine umfassende Einführung in den Bereich der LM-Inferenz zu geben, von klassischen Dekodierungsalgorithmen bis zu den neuesten Methoden für LLMs, sowie eine Reihe von Arbeiten, die sich auf Effizienz konzentrieren. Die Kursinhalte, einschließlich Videos der ersten vier Vorlesungen, werden online veröffentlicht und bieten eine wertvolle Lernressource für Studenten und Forscher, die sich für LM-Inferenz interessieren, um die neuesten Inferenztechniken und -praktiken zu beherrschen. (Quelle: lateinteraction, dejavucoder, gneubig)
OpenAIDevs veröffentlicht tiefgehende Analysevideos zu Codex: OpenAIDevs hat ein tiefgehendes Analysevideo zu Codex veröffentlicht, das die Veränderungen und neuesten Funktionen von Codex in den letzten zwei Monaten detailliert vorstellt. Das Video bietet Tipps und Best Practices zur optimalen Nutzung dieses leistungsstarken KI-Programmierwerkzeugs, und soll Entwicklern helfen, die neuesten Fortschritte von Codex in der Codegenerierung, Debugging und unterstützten Entwicklung besser zu verstehen und zu nutzen, was eine wichtige Lernressource für Entwickler ist, die ihre KI-gestützte Programmiereffizienz steigern möchten. (Quelle: OpenAIDevs)
Bericht zum Status des Cloud-GPU-Marktes 2025: dstackai hat einen Bericht über den Status des Cloud-GPU-Marktes im Jahr 2025 veröffentlicht, der Kosten, Leistung und Nutzungsstrategien abdeckt. Der Bericht analysiert detailliert die aktuellen Preise, Hardwarekonfigurationen und Leistungsmerkmale auf dem Markt, und bietet konkrete Markteinblicke und Referenzen für Machine Learning-Ingenieure bei der Auswahl von Cloud-Dienstleistern, was eine wichtige Orientierungshilfe für die Optimierung von Kosten und Effizienz bei KI-Training und -Inferenz darstellt. (Quelle: stanfordnlp)
AI-Hardware-Panorama: Diverse Recheneinheiten, die KI antreiben: The Turing Post hat einen Hardware-Leitfaden veröffentlicht, der die KI antreibt und detailliert verschiedene Recheneinheiten wie GPU, TPU, CPU, ASICs, NPU, APU, IPU, RPU, FPGA, Quantenprozessoren, In-Memory Computing (PIM)-Chips und neuromorphe Chips vorstellt. Der Leitfaden beleuchtet die Rolle, Vorteile und Anwendungsszenarien jeder Hardware in der KI-Berechnung, und hilft Lesern, die zugrunde liegende Rechenleistung des KI-Technologie-Stacks umfassend zu verstehen, was für die Hardwareauswahl und das Design von KI-Systemen von großer Bedeutung ist. (Quelle: TheTuringPost)
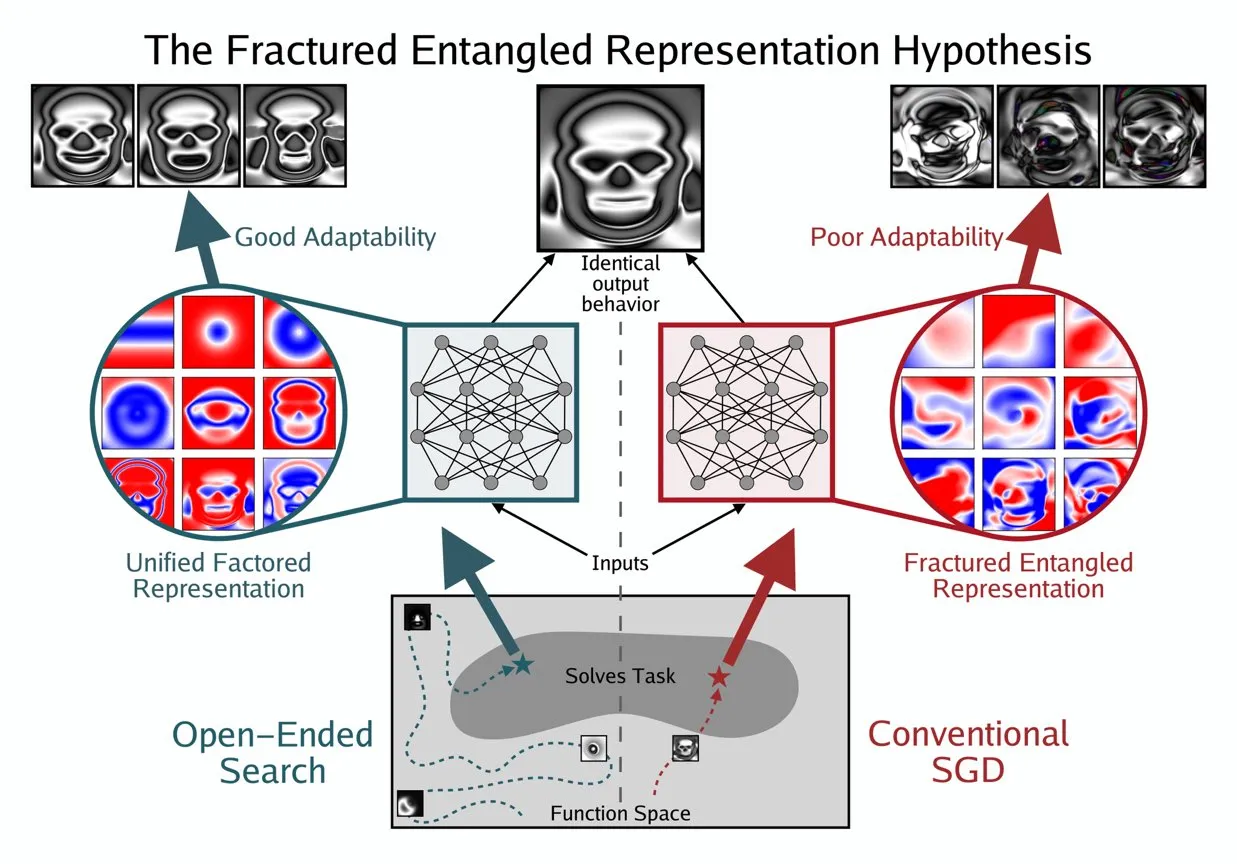
Kenneth Stanley schlägt UFR-Konzept zum Verständnis des „echten Verständnisses“ von KI vor: Kenneth Stanley hat das Konzept der „Unified Factored Representation“ (UFR) vorgeschlagen, um zu erklären, was „echtes Verständnis“ bei KI bedeutet. Er argumentiert, dass UFR der Kern ist, wenn Menschen über das „echte Verständnis“ von KI sprechen. Dieses Konzept zielt darauf ab, einen tieferen theoretischen Rahmen für die kognitiven Fähigkeiten von KI zu bieten, der über die reine Mustererkennung hinausgeht und die Fähigkeit von KI berührt, die Welt zu strukturieren, zu zerlegen und harte Einschränkungen zu bilden, wodurch KI nicht nur Wissen imitieren, sondern auch kreativ denken und neuartige Probleme wie Menschen lösen kann. (Quelle: hardmaru, hardmaru)
💼 Business
Tencent soll Top-Forscher von OpenAI abgeworben haben, KI-Talentkrieg eskaliert: Laut Bloomberg hat der Top-Forscher Yao Shunyu von OpenAI das Unternehmen verlassen und sich dem chinesischen Tech-Giganten Tencent angeschlossen. Dieses Ereignis unterstreicht den zunehmend intensiven globalen Kampf um KI-Talente, insbesondere zwischen den USA und China. Die Fluktuation von Top-KI-Forschern beeinflusst nicht nur die technologische Entwicklungsrichtung der jeweiligen Unternehmen, sondern spiegelt auch den erbitterten Innovationswettbewerb im KI-Bereich wider und deutet darauf hin, dass sich die zukünftige KI-Landschaft aufgrund von Talentbewegungen ändern könnte. (Quelle: The Verge)
OpportuNext sucht technischen Mitgründer für KI-Recruiting-Plattform: OpportuNext, eine von IIT Bombay-Alumni gegründete KI-gesteuerte Recruiting-Plattform, sucht einen technischen Mitgründer. Die Plattform zielt darauf ab, die Schmerzpunkte von Jobsuchenden und Arbeitgebern im Recruiting durch umfassende Lebenslaufanalyse, semantische Jobsuche, Skill-Gap-Roadmaps und Vorab-Assessments zu lösen. Der Zielmarkt ist der indische Markt mit 262 Millionen US-Dollar, mit Plänen zur Expansion in den globalen Markt von 40,5 Milliarden US-Dollar. OpportuNext hat die Produkt-Markt-Passung validiert und einen Prototyp des Lebenslauf-Parsers fertiggestellt, mit dem Plan, die A-Runde-Finanzierung Mitte 2026 abzuschließen. Die Position erfordert einen starken Hintergrund in AI/ML (NLP), Full-Stack-Entwicklung, Dateninfrastruktur, Crawlern/APIs und DevOps/Sicherheit. (Quelle: Reddit r/deeplearning)
Oracle-Gründer Larry Ellison: Inferenz ist der Schlüssel zur KI-Rentabilität: Oracle-Gründer Larry Ellison erklärte: „Inferenz ist der Schlüssel zur KI-Rentabilität.“ Er ist der Ansicht, dass die derzeit enormen Investitionen in das Modelltraining letztendlich in Produktverkäufe umgewandelt werden, und diese Produkte hängen hauptsächlich von Inferenzfähigkeiten ab. Ellison betonte, dass Oracle bei der Nutzung der Inferenznachfrage führend ist, was darauf hindeutet, dass sich die Erzählung der KI-Branche von „wer das größte Modell trainieren kann“ zu „wer Inferenzdienste effizient, zuverlässig und skalierbar anbieten kann“ verschiebt. Diese Ansicht löste eine Diskussion über die zukünftige Richtung des KI-Wirtschaftsmodells aus, nämlich ob Inferenzdienste die zukünftige Umsatzstruktur dominieren werden. (Quelle: Reddit r/MachineLearning)
🌟 Community
KI-Ethik und -Sicherheit: Multidimensionale Herausforderungen und Zusammenarbeit: Die Community diskutierte ausführlich die ethischen und sicherheitstechnischen Herausforderungen, die KI mit sich bringt, einschließlich der potenziellen Auswirkungen von KI auf den Arbeitsmarkt und Schutzstrategien, Datenschutzbedenken bezüglich des ChatGPT MCP-Tools sowie ernsthafte Debatten über das Risiko, dass KI zu Aussterben führen könnte. Auch die durch KI verursachten psychischen Gesundheitsprobleme, wie übermäßige Abhängigkeit von KI und sogar „KI-Psychosen“ und Einsamkeit bei Nutzern, rücken zunehmend in den Fokus. Gleichzeitig werden Diskussionen über die KI-Regulierung (z.B. Ted Cruz-Gesetzentwurf) fortgesetzt. Positiv ist, dass Unternehmen wie Anthropic und OpenAI mit Sicherheitsbehörden zusammenarbeiten, um Modellschwachstellen gemeinsam zu finden und zu beheben, um die KI-Sicherheit zu stärken. (Quelle: Ronald_vanLoon, dotey, williawa, Dorialexander, Reddit r/ArtificialInteligence, Reddit r/artificial, sleepinyourhat, EthanJPerez)

LLM-Leistung und -Bewertung: Modellqualität und Benchmark-Kontroversen: Die Community führte eine eingehende Diskussion über die Leistungsbewertung von LLMs und Fragen der Modellqualität. Modelle wie K2-Think wurden aufgrund von Mängeln in den Bewertungsmethoden (wie Datenkontamination und unfaire Vergleiche) in Frage gestellt, was Bedenken hinsichtlich der Zuverlässigkeit bestehender KI-Benchmarks aufkommen ließ. Studien weisen darauf hin, dass LLMs als Datenannotatoren Verzerrungen einführen können, die zu „LLM Hacking“ wissenschaftlicher Ergebnisse führen. Die Benutzererfahrungen mit Claude Code sind gemischt und spiegeln Herausforderungen in Bezug auf Konsistenz und „Faulheit“ wider, während Anthropic auch Leistungseinbußen bei Claude Sonnet 4 zugab und behob. Gleichzeitig erhielt GPT-5 Pro aufgrund seiner starken Inferenzfähigkeiten Lob, aber einige Benutzer beobachteten auch die Universalität von KI-generiertem Text und die anhaltende Besorgnis über die Modellzuverlässigkeit (z.B. Inferenz-Bugs). (Quelle: Grad62304977, rao2z, Reddit r/LocalLLaMA, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, npew, kchonyc, dejavucoder, vikhyatk)
Zukünftige Arbeit und KI-Agenten: Effizienzsteigerung und beruflicher Wandel: KI-Agenten verändern die Arbeitsweise grundlegend. Fachexperten (wie Anwälte, Ärzte, Ingenieure) können ihre professionellen Dienstleistungen erweitern, indem sie ihr persönliches Wissen in KI-Agenten einspeisen, wodurch ihr Einkommen nicht mehr auf Stundenbasis begrenzt ist. Replit-CEO Amjad Masad prognostiziert, dass KI-Agenten Software nach Bedarf generieren werden, wodurch der Wert traditioneller Software gegen Null geht und die Art und Weise, wie Unternehmen aufgebaut sind, neu gestaltet wird. Die Community diskutierte die Bedeutung von Unternehmergeist und Anpassungsfähigkeit im KI-Zeitalter, die einzigartigen Vorteile von Replit in der Agentenentwicklung (z.B. testbare Umgebungen) sowie den Vergleich der Effizienz von Robotermodellen mit dem menschlichen Gehirn. Darüber hinaus weckte das Potenzial von Cursor als Reinforcement Learning-Umgebung Aufmerksamkeit, was darauf hindeutet, dass KI die Produktivität von Einzelpersonen und Organisationen weiter steigern wird. (Quelle: amasad, amasad, amasad, fabianstelzer, amasad, lateinteraction, Dorialexander, dwarkesh_sp, sarahcat21)
Open-Source-Ökosystem und Zusammenarbeit: Modellverbreitung und Community-Anforderungen: Hugging Face spielt eine zentrale Rolle im KI-Ökosystem, dessen modulare, standardisierte und integrierte Plattformvorteile Entwicklern eine Fülle von Tools und Modellen bieten und die Schwelle für den KI-Aufbau senken. Die Community-Diskussion bestätigte das Apple MLX-Projekt und seine Open-Source-Beiträge zur Verbesserung der Hardwareeffizienz. Gleichzeitig fordert die Community das Qwen-Team aktiv auf, GGUF-Unterstützung für das Qwen3-Next-Modell bereitzustellen, damit seine benutzerdefinierte Architektur in breiteren lokalen Inferenz-Frameworks wie llama.cpp ausgeführt werden kann, um den Anforderungen der Community an Modellverbreitung und Benutzerfreundlichkeit gerecht zu werden und die weitere Entwicklung von Open-Source-KI-Technologien voranzutreiben. (Quelle: ClementDelangue, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Die weitreichenden sozialen Auswirkungen von KI: Vielfältige Manifestationen von Unterhaltung bis Wirtschaft: KI durchdringt die Gesellschaft in vielfältiger Form. KI-Haustier-Kurzdramen sind aufgrund ihrer anthropomorphen Erzählweise und ihres emotionalen Wertes in sozialen Medien viral gegangen, was das enorme Potenzial von KI in der Inhaltserstellung und Unterhaltung zeigt, eine große Anzahl junger Nutzer anzieht und neue Geschäftsmodelle hervorbringt. Gleichzeitig lösten Diskussionen über Geldflüsse zwischen KI-Giganten (wie OpenAI und Oracle) Überlegungen zum KI-Wirtschaftsmodell aus. Die Community diskutierte auch das Potenzial von KI bei der Lösung von Ressourcenproblemen (wie Wasserressourcen) sowie Vorschläge, dass KI-Chatbots mehr visuelle Inhalte benötigen, um die Benutzererfahrung zu verbessern. Darüber hinaus haben die Anwendungen von KI in sozialen Medien Diskussionen über ihre Auswirkungen auf soziale Stimmungen und Kognition ausgelöst. (Quelle: 36氪, Yuchenj_UW, kylebrussell, brickroad7)
KI-Community-Anekdoten und Beobachtungen: Personalisierte Erwartungen und humorvolle Reflexionen der Nutzer an KI: Die KI-Community ist voller einzigartiger Beobachtungen und humorvoller Reflexionen über die Technologieentwicklung und Benutzererfahrung. Zum Beispiel löste die Verbindung zwischen OpenAI-Abonnement-Rabattcodes und „Denk“-Verhalten Diskussionen über den Wert und die Kosten von KI aus. Benutzer wünschen sich, dass Claude Code mehr personalisierte Antworten gibt und der KI sogar eine „Persönlichkeit“ verleiht, was die tiefgreifenden Bedürfnisse nach KI-Interaktionserlebnissen widerspiegelt. Gleichzeitig zeigen Überlegungen zur Möglichkeit, KI-Agenten in simulierten Umgebungen (wie GTA-6) für Reinforcement Learning zu trainieren, die unendliche Vorstellungskraft der Community für die zukünftige Entwicklung von KI. Diese Diskussionen bieten nicht nur Einblicke in den aktuellen Stand der KI-Technologie, sondern spiegeln auch die Emotionen und Erwartungen wider, die Benutzer bei der Interaktion mit KI entwickeln. (Quelle: gneubig, jonst0kes, scaling01)
💡 Sonstiges
Leitfaden zur Beherrschung von KI-Fähigkeiten 2025: Mit der rasanten Entwicklung der Künstlichen Intelligenz ist die Beherrschung entscheidender KI-Fähigkeiten für die persönliche berufliche Entwicklung von größter Bedeutung. Ein Leitfaden zur Beherrschung von KI-Fähigkeiten für 2025 hebt 12 Kernkompetenzen hervor, die in den Bereichen Künstliche Intelligenz, Machine Learning und Deep Learning beherrscht werden müssen. Diese Fähigkeiten umfassen von grundlegenden Theorien bis hin zu praktischen Anwendungen und sollen Fachleuten und Lernenden helfen, sich an die neuen Anforderungen des KI-Zeitalters an Talente anzupassen, und ihre Wettbewerbsfähigkeit in Bezug auf technologische Innovation und auf dem Arbeitsmarkt zu verbessern. (Quelle: Ronald_vanLoon)

Cloud-GPU-Markt 2025: Bericht zu Kosten, Leistung und Bereitstellungsstrategien: dstackai hat einen detaillierten Bericht über den Status des Cloud-GPU-Marktes im Jahr 2025 veröffentlicht, der die Kosten, Leistungsmerkmale und Bereitstellungsstrategien verschiedener Cloud-Dienstleister analysiert. Dieser Bericht soll Machine Learning-Ingenieuren und Unternehmen konkrete Anleitungen zur Auswahl von Cloud-Anbietern geben, um die Ressourcenkonfiguration für KI-Trainings- und Inferenzaufgaben zu optimieren, und somit angesichts der wachsenden Nachfrage nach KI-Infrastruktur kosteneffizientere und leistungsstärkere Entscheidungen zu treffen. (Quelle: stanfordnlp)
Übersicht über KI-Hardware-Technologien: Diverse Recheneinheiten, die die intelligente Zukunft antreiben: The Turing Post hat einen umfassenden Leitfaden zur KI-Hardware veröffentlicht, der die verschiedenen Recheneinheiten detailliert vorstellt, die derzeit Künstliche Intelligenz antreiben. Dazu gehören Graphics Processing Units (GPU), Tensor Processing Units (TPU), Central Processing Units (CPU), Application-Specific Integrated Circuits (ASICs), Neural Processing Units (NPU), Accelerated Processing Units (APU), Intelligence Processing Units (IPU), Resistive Processing Units (RPU), Field-Programmable Gate Arrays (FPGA), Quantenprozessoren, In-Memory Computing (PIM)-Chips sowie neuromorphe Chips. Dieser Leitfaden bietet eine klare Perspektive auf die zugrunde liegende Hardware-Unterstützung des KI-Technologie-Stacks und hilft Entwicklern und Forschern, die am besten geeigneten Hardwarelösungen für ihre KI-Workloads auszuwählen. (Quelle: TheTuringPost)