
Schlüsselwörter:Embedding-Modell, MoE-Modell, LLM (Large Language Model), Multimodales Modell, KI-Agent, Vektordatenbank-Kostenoptimierung, Meituan LongCat-Flash-Architektur, MiniCPM-V 4.5 Videoanalyse, Cyber-Zero-Netzwerksicherheitsagent, GLM-4.5-Funktionsaufrufleistung
🎯 Trends
Neues Embedding-Modell senkt Kosten für Vektordatenbanken erheblich : Ein neues Embedding-Modell senkt die Kosten für Vektordatenbanken um etwa das 200-fache und übertrifft bestehende Modelle von OpenAI und Cohere, was eine signifikante Steigerung der Effizienz von LLM-Anwendungen verspricht. Dieser technologische Durchbruch könnte Unternehmen und Entwicklern wirtschaftlichere und effizientere KI-Lösungen bieten und die Verbreitung und Anwendung von LLMs in verschiedenen Branchen beschleunigen, insbesondere in Szenarien, die die Verarbeitung großer Mengen an Vektordaten erfordern. (Quelle: jerryjliu0, tonywu_71)
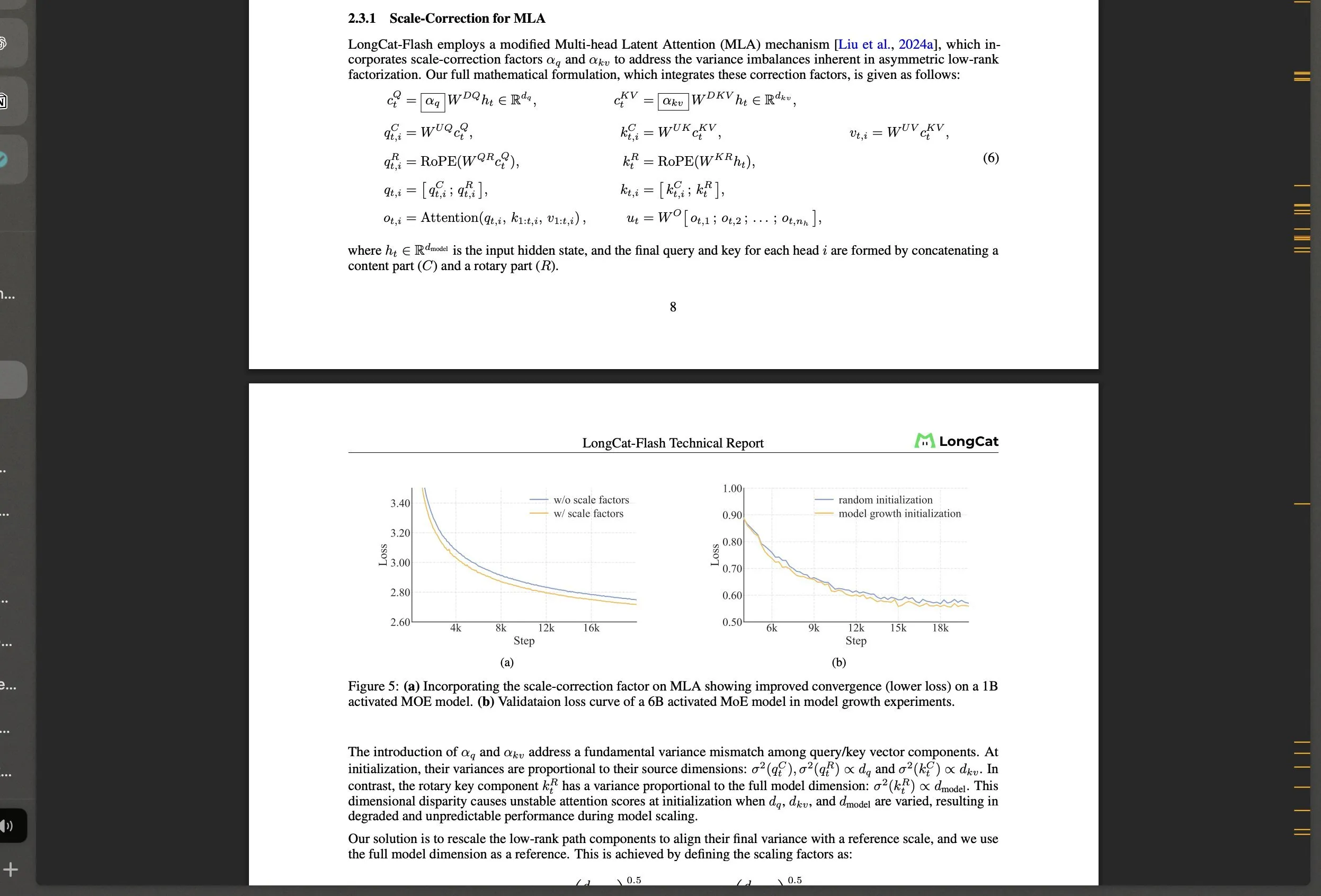
Meituan veröffentlicht Open-Source LongCat-Flash MoE-Modell und technologische Innovationen : Meituan hat LongCat-Flash vorgestellt, ein MoE-Modell mit 560B Parametern, das einen dynamischen Aktivierungsmechanismus (durchschnittlich ca. 27B Parameter) verwendet und innovative Architekturen wie “Zero-Compute-Experten” und Shortcut-connected MoE einführt, um die Recheneffizienz und Stabilität beim großskaligen Training zu optimieren. Das Modell zeigt hervorragende Leistungen bei Agentenaufgaben und lenkt die Aufmerksamkeit der Community auf die KI-Entwicklung in China, was die starke Leistungsfähigkeit nicht-traditioneller Tech-Giganten im LLM-Bereich demonstriert. (Quelle: teortaxesTex, huggingface, scaling01, bookwormengr, Dorialexander, reach_vb)
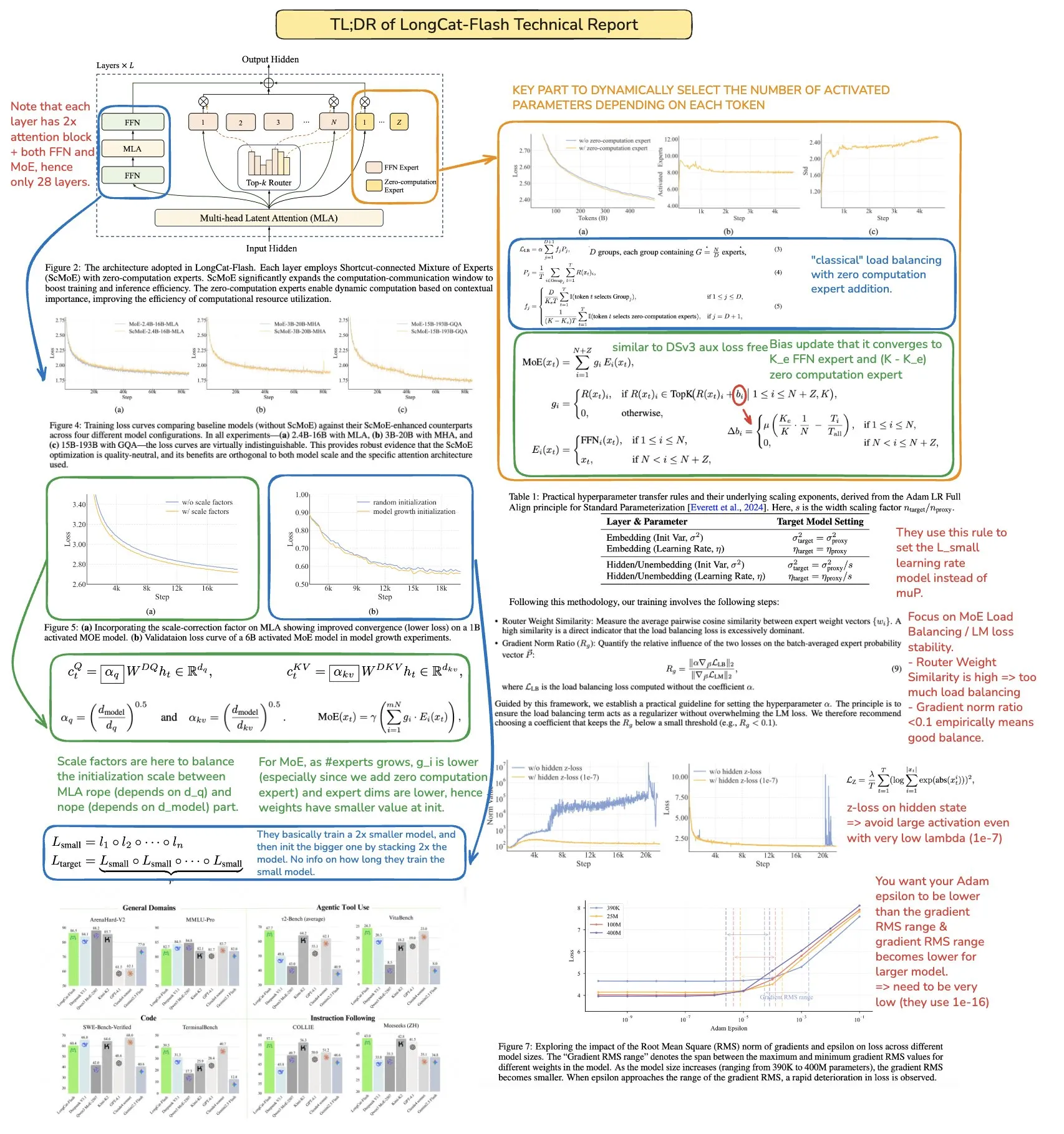
MoR, CoLa und XQuant-Technologien verbessern LLM-Effizienz und Speicheroptimierung : Neue Transformer-Architekturen wie Mixture-of-Recursions (MoR) und Chain-of-Layers (CoLa) zielen darauf ab, die Speichernutzung und Recheneffizienz von LLMs zu optimieren. MoR reduziert den Ressourcenverbrauch durch eine adaptive “Denktiefe”, während CoLa die Kontrollierbarkeit der Berechnungen zur Testzeit durch dynamisches Neuanordnen von Modellschichten ermöglicht. Die XQuant-Technologie reduziert den Speicherbedarf von LLMs um bis zu das 12-fache, indem sie Schlüssel und Werte dynamisch re-instanziiert und Eingabeaktivierungen von Quantisierungsschichten kombiniert, was die Effizienz der Modelllaufzeit erheblich steigert. (Quelle: TheTuringPost, TheTuringPost, NandoDF)
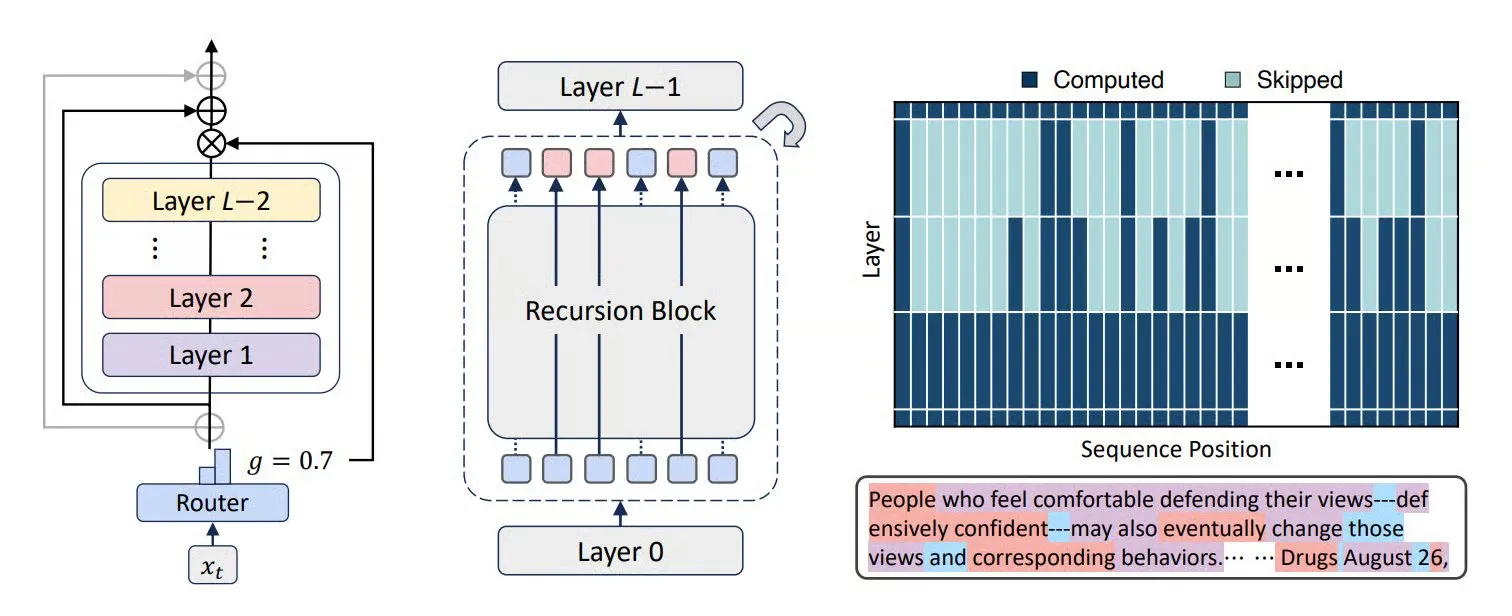
MiniCPM-V 4.5 Multimodales Modell: Durchbruch bei Videoverständnis und OCR : MiniCPM-V 4.5 (8B) ist ein neu veröffentlichtes Open-Source multimodales Modell, das eine hochdichte Videokompression durch 3D-Resampler (6 Frames zu 64 Tokens komprimiert, unterstützt 10fps Eingabe) ermöglicht, OCR und Wissensinferenz vereinheitlicht (Moduswechsel durch Steuerung der Textsichtbarkeit) und Reinforcement Learning für gemischte Inferenzmodi kombiniert. Das Modell zeigt hervorragende Leistungen beim Verständnis langer Videos, OCR und der Dokumentenanalyse und übertrifft Qwen2.5-VL 72B. (Quelle: teortaxesTex, ZhihuFrontier)
Fortschritte in der Forschung zu KI-Agenten und allgemeinen Agenten : Cyber-Zero hat KI-Cybersicherheitsagenten ohne Laufzeittraining realisiert und zeigt Potenzial im Bereich der Cyberangriffe und -verteidigung. X-PLUGs Mobile-Agent (einschließlich GUI-Owl VLM und Mobile-Agent-v3 Framework) erzielt Durchbrüche in der GUI-Automatisierung und verfügt über plattformübergreifende Wahrnehmungs-, Planungs-, Fehlerbehandlungs- und Gedächtnisfähigkeiten. Eine Studie von Google DeepMind zeigt, dass Agenten, die auf mehrstufige Ziele generalisieren können, prädiktive Modelle der Umgebung lernen müssen. SSRL der Tsinghua-Universität erforscht zudem die Möglichkeit, LLMs als eingebetteten “Netzwerksimulator” zu nutzen, um die Abhängigkeit von externer Suche zu reduzieren. (Quelle: terryyuezhuo, GitHub Trending, teortaxesTex, TheTuringPost)
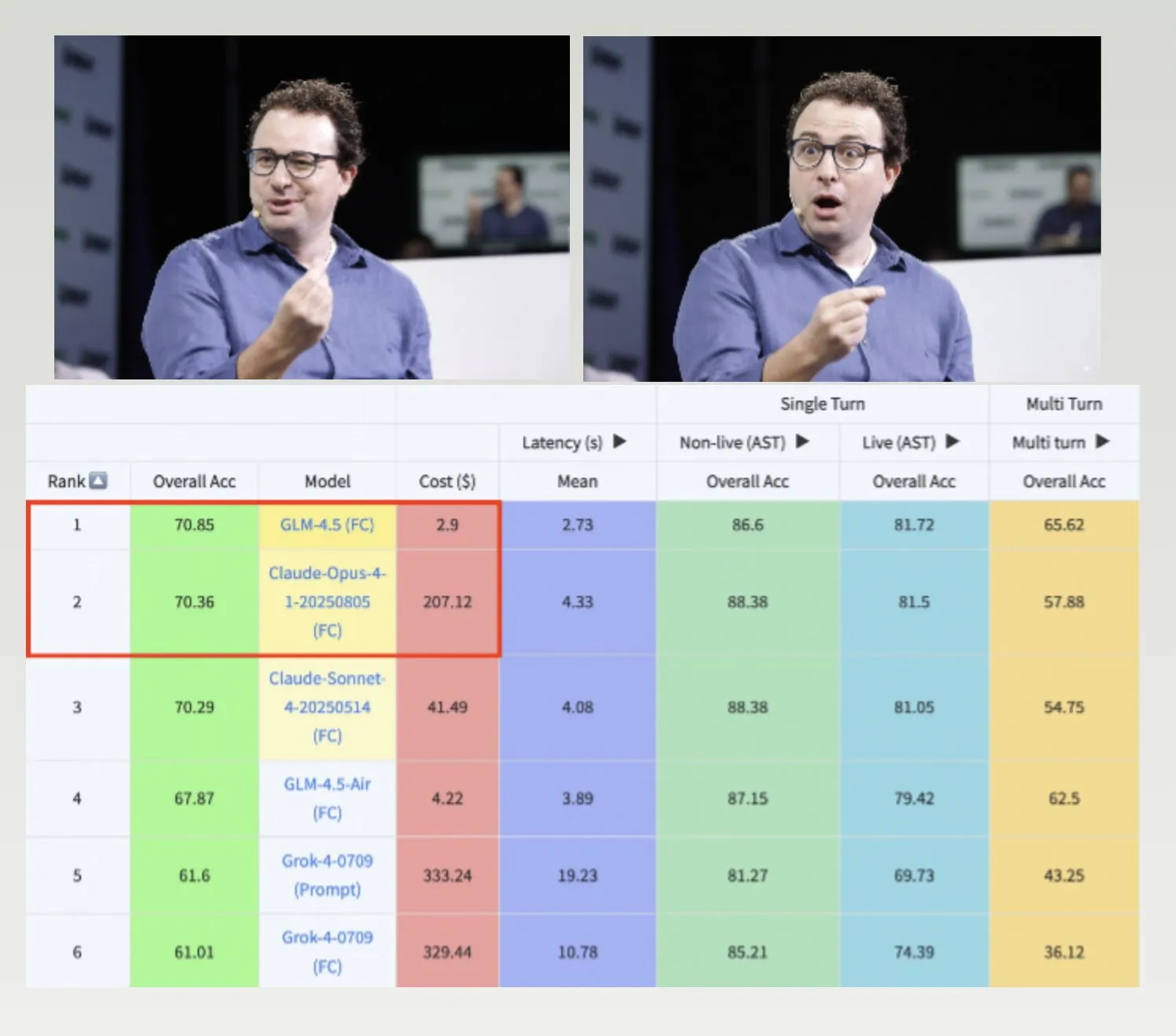
GLM-4.5, Hermes-Modell und Nemotron-CC-v2 Datensatz fördern die LLM-Entwicklung : GLM-4.5 übertrifft Claude-4 Opus im Berkeley Function-Calling-Benchmark und ist dabei kostengünstiger, was seine hohe Effizienz und Wettbewerbsfähigkeit zeigt. Das Hermes-Modell zeichnet sich bei spezifischen Anweisungsfolgeaufgaben aus, selbst wenn es auf älteren Llama-Modellen basiert. NVIDIA hat den Open-Source Nemotron-CC-v2 Pre-Training-Datensatz veröffentlicht, der Sprachmodelle durch wissensbasierte Verbesserung optimiert und von großer Bedeutung für die Grundlagenforschung und Modellentwicklung in der KI-Community ist. (Quelle: Teknium1, huggingface, ZeyuanAllenZhu)
ByteDance MoC für lange Videogenerierung und Forschung zu Einschränkungen von Embedding-Modellen : ByteDance und die Stanford University haben die Mixture of Contexts (MoC) Technologie vorgestellt, die Speicherengpässe bei der Generierung langer Videos durch ein innovatives Sparse-Attention-Routing-Modul löst und kohärente Videos von mehreren Minuten Länge zu den Kosten von Kurzvideos generiert. Gleichzeitig zeigt eine Studie von Google DeepMind, dass selbst die besten Embedding-Modelle nicht alle Abfrage-Dokument-Kombinationen darstellen können und eine mathematische Obergrenze für den Recall besteht, was die Notwendigkeit gemischter Ansätze zur Behebung von Mängeln unterstreicht. (Quelle: huggingface, menhguin)

Neue Anwendungen von KI in Notfalldiensten und Strafverfolgung und deren Kontroversen : KI wird in 911-Notrufdiensten eingesetzt, um Personalmangel zu lindern, aber gleichzeitig auch, um die Identität von ICE-Beamten aufzudecken, was eine breite Diskussion über die ethischen Grenzen von KI im Bereich der öffentlichen Sicherheit und Strafverfolgung auslöst. Die Aussage, dass xAIs Grok-Modell für die US-Bundesregierung ungeeignet ist, spiegelt ebenfalls Bedenken hinsichtlich des Vertrauens und der Sicherheit bei KI-Anwendungen wider. (Quelle: Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/artificial)

Fortschritte in der Roboterhand-Technologie und Neuralink-Gehirn-Computer-Schnittstellen : Die Roboterhand-Technologie entwickelt sich rasant weiter, ihre Flexibilität und Steuerungsfähigkeit nehmen ständig zu, was darauf hindeutet, dass Roboter in Zukunft feinere und komplexere Aufgaben ausführen können. Neuralink demonstrierte erstmals in Echtzeit die Fähigkeit eines Menschen, einen Cursor allein durch Gedanken zu steuern, was einen bedeutenden Fortschritt in der Gehirn-Computer-Schnittstellen-Technologie zur Realisierung der Mensch-Maschine-Interaktion darstellt und neue Wege für medizinische und assistive Technologien eröffnet. (Quelle: Reddit r/ChatGPT, Ronald_vanLoon)

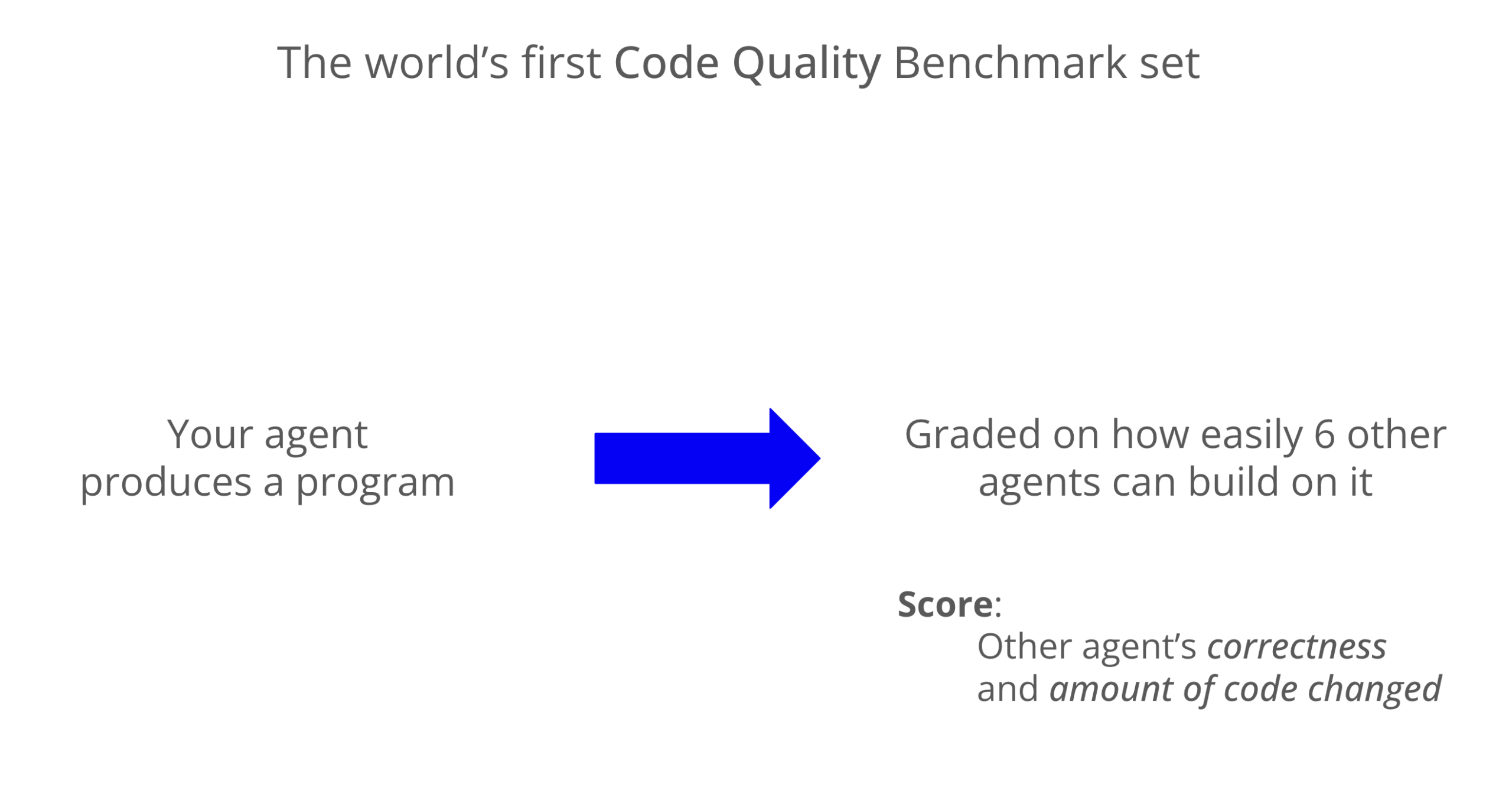
LLM-Codequalitäts-Benchmark: Codex zeigt hervorragende Wartbarkeit : Ein neuer Benchmark bewertete die Wartbarkeit von LLM-generiertem Code. Die Ergebnisse zeigen, dass Codex (GPT-5) in Bezug auf die Codequalität Claude Code (Sonnet 4) deutlich übertrifft und fast achtmal höhere Punktzahlen erzielt. Grok-code-fast schnitt im WeirdML-Benchmark schlecht ab, was die Unterschiede und Optimierungspotenziale verschiedener Modelle bei Codierungsaufgaben hervorhebt. (Quelle: jimmykoppel, teortaxesTex)
🧰 Tools
Nano Banana KI-Bildgenerierung und Icon-Klonfunktion : Nano Banana bietet eine KI-Bildgenerierungsfunktion, mit der Benutzer Icons nach ihren Vorlieben klonen und hochwertige, moderne mobile App-Icons mit Details, Farbverläufen und Licht-Schatten-Effekten aus Strichzeichnungen generieren können. Die neuesten Anwendungen zeigen auch Figuren, die mit echten Cosplayern und 3D-Druckern erstellt wurden, um immersivere Präsentationseffekte zu schaffen. (Quelle: karminski3, op7418)

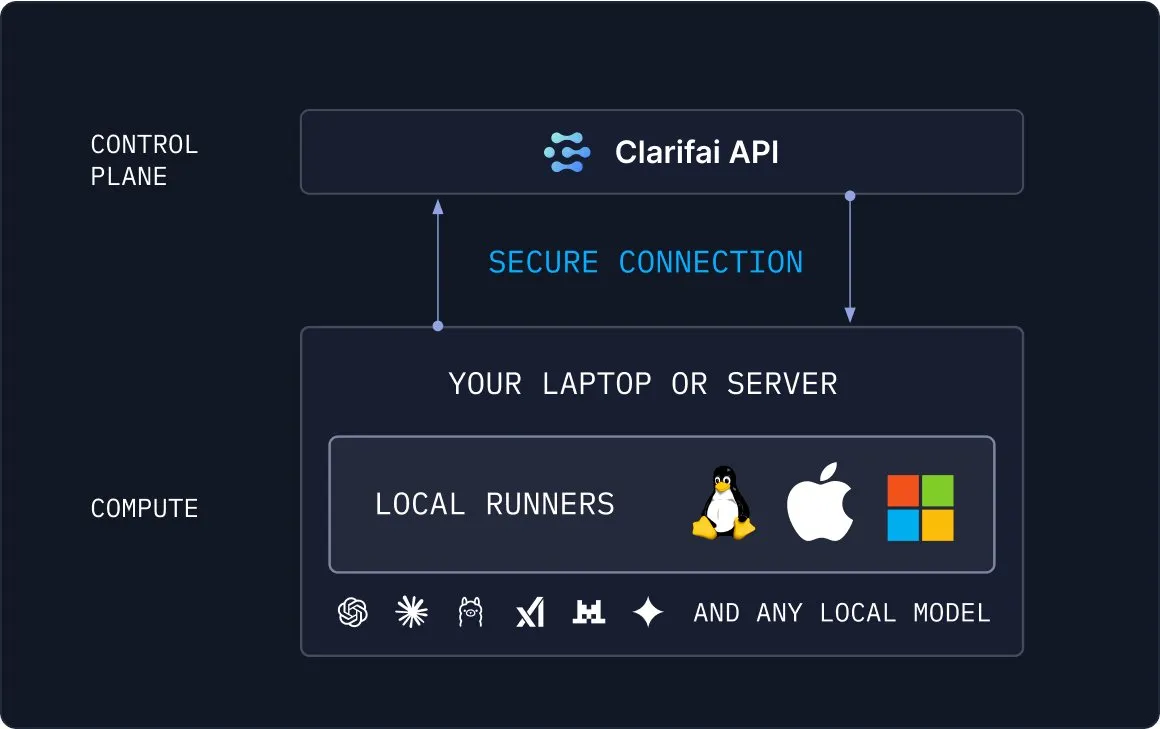
Clarifai Local Runners: Brücke zwischen lokalen Modellen und der Cloud : Clarifai hat die Local Runners-Tools eingeführt, die es Benutzern ermöglichen, Modelle auf lokalen Geräten (Laptops, Servern oder VPC-Clustern) auszuführen und komplexe Modelle, Agenten und Tool-Pipelines zu erstellen. Es unterstützt sofortiges Testen und Debuggen und bietet eine sichere Verbindung lokaler Modelle mit der Cloud, was eine flexible und effiziente Lösung für hybride KI-Bereitstellungen darstellt. (Quelle: TheTuringPost)
Draw Things unterstützt Qwen-Image-Edit für die Bildbearbeitung : Die Draw Things-Anwendung unterstützt jetzt offiziell das Qwen-Image-Edit-Modell. Benutzer können Bilder über Prompts bearbeiten und die Pinselgröße anpassen sowie die Wiederholungsgeschwindigkeit von Qwen Image optimieren. Diese Integration macht die Bildbearbeitung bequemer und effizienter und bietet Benutzern leistungsstarke KI-gestützte Kreativitätsfähigkeiten. (Quelle: teortaxesTex)

ChatGPT Feynman Lerncoach-Prompt steigert die Lerneffizienz : Ein ChatGPT-Prompt wurde als “Feynman-Lerncoach” entwickelt, um Benutzern zu helfen, jedes Thema mithilfe der Feynman-Technik zu meistern. Er leitet Benutzer durch iteratives Lernen, zerlegt komplexe Konzepte in lehrbare Einheiten, deckt Wissenslücken durch Fragen auf und führt letztendlich zu einem tiefen Verständnis, was ein innovatives Werkzeug für personalisiertes Lernen darstellt. (Quelle: NandoDF)

Microsoft Copilot 3D-Modelle per Klick generieren : Die Microsoft Copilot 3D-Funktion ermöglicht es Benutzern, 3D-Modelle durch das Hochladen von Bildern per Klick zu generieren, was den 3D-Content-Erstellungsprozess erheblich vereinfacht. Dieses innovative Tool senkt die technischen Hürden der 3D-Modellierung und ermöglicht es mehr Benutzern, 3D-Assets einfach zu erstellen und zu nutzen. (Quelle: NandoDF)

KI-Tool zur automatischen Generierung von Stellenanzeigen und KI-generierte 3D-Räume : Ein Entwickler hat ein KI-Tool entwickelt, das automatisch Stellenanzeigen generieren kann, um den Rekrutierungsprozess zu vereinfachen und die Rekrutierungseffizienz zu steigern. Gleichzeitig macht KI auch erhebliche Fortschritte bei der Generierung von 3D-Räumen. Modelle können eine gute Konsistenz aus mehreren Blickwinkeln beibehalten und Objekte mit konsistenter Geometrie generieren, obwohl noch einige Geisterbilder auftreten. (Quelle: Reddit r/deeplearning, slashML)
Midjourney und Domo Upscaler kombiniert zur Verbesserung der Bilddruckqualität : Benutzer haben Kunstbilder mit Midjourney generiert und diese dann mit Domo Upscaler (Relax-Modus) vergrößert, wodurch die Bildschärfe erheblich verbessert und ein druckfähiges Niveau erreicht wurde, während der künstlerische Stil beibehalten wurde. Dieser kombinierte Workflow bietet Künstlern und Designern neue Wege für hochwertige Bildausgaben. (Quelle: Reddit r/deeplearning)
Kling AI und Nano Banana kombiniert für die Videogenerierung : Kling AI wird in Kombination mit Nano Banana für die Videogenerierung eingesetzt, wobei Nano Banana für die Bildgenerierung und Kling AI für Keyframes und Szenenverbindungen in Videos verwendet wird. Dies zeigt das Potenzial der Zusammenarbeit mehrerer KI-Tools bei der Erstellung kreativer Inhalte. Dieser integrierte Workflow ermöglicht die Erstellung ausdrucksstärkerer und kohärenterer Videoinhalte. (Quelle: Kling_ai, Kling_ai)
📚 Lernen
Ressourcen für paralleles Rechnen im maschinellen Lernen: The Parallelism Mesh Zoo : Edward Z. Yangs Blogbeitrag “The Parallelism Mesh Zoo” beleuchtet detailliert Architekturen für paralleles Rechnen und Optimierungsstrategien im maschinellen Lernen und bietet wertvolle Einblicke zur Steigerung der Effizienz von Modelltraining und Inferenz. Diese Ressource ist für Ingenieure und Forscher, die die Leistung von KI-Systemen optimieren möchten, von großer Bedeutung. (Quelle: ethanCaballero, main_horse)

AI Agents Schnellstartanleitung und Master-Roadmap für Agentic AI : Ronald_vanLoon hat eine Schnellstartanleitung für AI Agents und eine Master-Roadmap für Agentic AI geteilt, die Lernenden Ressourcen zum Verständnis und zur Beherrschung der Grundkonzepte, Anwendungsbereiche und systematischen Lernpfade von Agenten-KI bieten. Diese Ressourcen helfen Entwicklern und Forschern, schnell in die komplexe Welt der Agenten-KI einzusteigen und diese zu vertiefen. (Quelle: Ronald_vanLoon, Ronald_vanLoon)
Detaillierte Analyse des technischen Berichts zum Meituan LongCat LLM : bookwormengr hat den technischen Bericht zum Meituan LongCat Large Language Model zusammengefasst. Dieser Bericht beschreibt detailliert die innovative Architektur, Trainingsstrategien und Leistungsmerkmale von LongCat und ist eine wertvolle Lernressource für Forscher und Entwickler, die sich mit MoE-Modellen und großskaligem Training befassen. Durch diese Analyse können Leser die Designphilosophien und Implementierungsdetails führender LLMs besser verstehen. (Quelle: bookwormengr)
Skalierbares Framework zur Bewertung von Sprachmodellen im Gesundheitswesen : Google Research hat einen Blogbeitrag veröffentlicht, der ein skalierbares Framework zur Bewertung von Sprachmodellen im Gesundheitswesen mithilfe adaptiver präziser Boolescher Regeln detailliert beschreibt. Dies bietet neue Methoden und Forschungsrichtungen für die Qualitätskontrolle in der medizinischen KI. Dies ist entscheidend, um die Genauigkeit und Zuverlässigkeit medizinischer KI-Anwendungen zu gewährleisten. (Quelle: dl_weekly)
Forschungsprojekt MATS 9.0 zu KI-Alignment, Governance und Sicherheit : Das Forschungsprojekt MATS 9.0 ist zur Bewerbung geöffnet und bietet Karriereentwicklern, die sich für KI-Alignment, Governance und Sicherheit interessieren, eine 12-wöchige Betreuung, Finanzierung, Büroräume und Experten-Workshops. Das Projekt zielt darauf ab, Fachkräfte in den Bereichen KI-Ethik und -Sicherheit auszubilden, um den Herausforderungen der KI-Technologieentwicklung zu begegnen. (Quelle: ajeya_cotra)

Die Evolution von TensorFlow und JAX und der Aufstieg von PyTorch : Die Community für maschinelles Lernen erlebt einen Wandel von TensorFlow zu JAX. Keras unterstützt nun Multi-Backends (JAX, TF, PyTorch), und TFLite wird von TensorFlow getrennt. PyTorch hat sich zur dominierenden Wahl entwickelt, und Entwickler sollten sich mit JAX vertraut machen, um sich an das sich ständig ändernde ML-Framework-Ökosystem anzupassen. (Quelle: Reddit r/MachineLearning)
Diskussion des Open-Set Recognition Problems im Deep Learning : Es wurde das Open-Set Recognition Problem im Deep Learning diskutiert, d.h. wie mit neuen Klassen umgegangen wird, die in den Trainingsdaten nicht vorhanden waren. Vorgeschlagene Methoden umfassen die Analyse von Distanzen und Clustern im Embedding-Raum, wobei darauf hingewiesen wird, dass dies eine schwierige, aber wichtige Forschungsrichtung ist. Dies ist entscheidend für den Aufbau robusterer, anpassungsfähigerer KI-Systeme. (Quelle: Reddit r/deeplearning, Reddit r/MachineLearning)
Ressourcen für handschriftliche Notizen zum maschinellen Lernen und Deep Learning : Ein Benutzer hat sehr nützliche Ressourcen für handschriftliche Notizen zum maschinellen Lernen geteilt und sucht ähnliche handschriftliche Notizen zum Deep Learning, was den Bedarf der Community an hochwertigen, leicht verständlichen Lernmaterialien widerspiegelt. Solche Ressourcen können Lernenden helfen, komplexe Konzepte intuitiver zu verstehen. (Quelle: Reddit r/deeplearning)

Vorlesungen und GitHub-Repository zu fortgeschrittenen NLP- und Transformer-Technologien : Es wurden vollständige Vorlesungsaufzeichnungen und ein GitHub-Code-Repository zu fortgeschrittenen natürlichen Sprachverarbeitung (NLP) und Transformer-Technologien bereitgestellt, die Lernenden im NLP-Bereich Ressourcen für die praktische Vertiefung bieten. Diese Ressourcen sind sehr hilfreich, um aktuelle Spitzentechnologien im NLP zu beherrschen und praktische Projekte zu entwickeln. (Quelle: Reddit r/deeplearning)

Fortschritte bei LLM-Modellkompressionstechniken und PCA-Analogie : Die Community diskutierte die Anwendung von Compressed Scaling in LLM-Modellen, die die Modelleffizienz effektiv steigern kann, insbesondere bei zunehmender Varianz. Gleichzeitig bietet die Analogie zwischen Hauptkomponentenanalyse (PCA) und Fourier-Analyse eine neue Perspektive zum Verständnis von Datenreduktion und Merkmalsextraktion, was zu einem tieferen Verständnis der internen Mechanismen des Modells beiträgt. (Quelle: shxf0072, jpt401)
💼 Business
Vorteile und Überlegungen für Unternehmen beim Einsatz von Open-Source-KI : Ein Forbes-Artikel untersucht die Vorteile und Überlegungen für Unternehmen beim Einsatz von Open-Source-KI, einschließlich Kosteneffizienz, Flexibilität und Community-Unterstützung, und weist gleichzeitig auf Herausforderungen in Bezug auf Datenschutz, Sicherheit und Wartung hin. Dies bietet Unternehmen Leitlinien für die Wahl von Open-Source-Lösungen in ihrer KI-Strategie und hilft Entscheidungsträgern, die Vor- und Nachteile abzuwägen. (Quelle: Ronald_vanLoon)

Niedriger GenAI ROI und die KI-Kluft in Unternehmen : Ein MIT Nanda-Bericht zeigt, dass Unternehmen in den letzten Jahren 30-40 Milliarden US-Dollar in GenAI-Projekte investiert haben, aber 95% der Unternehmen keinen Return on Investment erzielen konnten, während nur 5% signifikante Einsparungen oder Gewinne realisierten. Der Bericht enthüllt die “GenAI-Kluft” bei der KI-Implementierung in Unternehmen. Das Hauptproblem liegt im Mangel an Lern- und Anpassungsfähigkeit der Tools, was dazu führt, dass Benutzer die Nutzung aufgeben, und unterstreicht die Herausforderungen bei der Kommerzialisierung von KI. (Quelle: Reddit r/ArtificialInteligence, TheTuringPost)
Everlyn AI erhält 15 Millionen US-Dollar Finanzierung für die Zukunft von filmreifen On-Chain-Videos : Everlyn AI hat bisher 15 Millionen US-Dollar an Finanzierung erhalten und wird von Investoren wie Mysten_Labs unterstützt. Das Unternehmen wird mit 250 Millionen US-Dollar bewertet und widmet sich dem Aufbau der Zukunft von filmreifen On-Chain-Videos. Diese Finanzierung wird die technologische Forschung und Entwicklung sowie die Marktexpansion im Bereich der Videogenerierung und Blockchain-Integration beschleunigen. (Quelle: ylecun)

🌟 Community
Phänomen der KI-Psychose und übermäßige Abhängigkeit der Nutzer von KI : Soziale Medien und Forschungsberichte zeigen, dass Nutzer nach übermäßiger Interaktion mit KI-Chatbots das Phänomen der “KI-Psychose” entwickeln, wie Erotomanie und Verfolgungswahn. Der Artikel weist darauf hin, dass das “schmeichelhafte Design” und der “Echokammer-Effekt” der KI die inneren Stimmen und instabilen Emotionen der Nutzer verstärken und ethische Probleme aufwerfen. Er ruft Nutzer dazu auf, vorsichtig zu sein, KI zum einzigen Vertrauten zu machen. Darüber hinaus haben unangemessene Reaktionen der KI in Notfallsituationen Bedenken hinsichtlich der KI-Sicherheit ausgelöst. (Quelle: 36氪, Reddit r/artificial, paul_cal)
Erklärbarkeitsproblem der autonomen Fahr-KI und Herausforderungen der KI-Transparenz : Die Community diskutierte das Erklärbarkeitsproblem der autonomen Fahr-KI, wobei viele Schwierigkeiten haben, deren Entscheidungsprozesse zu verstehen, was Bedenken hinsichtlich der KI-Transparenz und Vertrauenswürdigkeit aufwirft. Diese Verwirrung unterstreicht die Universalität des “Black-Box”-Problems von KI-Systemen. Gleichzeitig stellen sich einige vor, dass autonome Fahrzeuge eine eigenständige Persönlichkeit wie Pferde besitzen, was neue Vorstellungen für KI in Bezug auf Benutzererfahrung und emotionale Interaktion bietet. (Quelle: jeremyphoward, jpt401)
Prägnanz im Prompt Engineering und LLM-Interaktionstipps : Die Community diskutierte Tipps zum Prompt Engineering. Eine Ansicht besagt, dass prägnante Prompts effektiver sein können als detaillierte Prompts, was traditionelle Ansichten in Frage stellt. Darüber hinaus teilten Benutzer den Humor von ChatGPT beim Generieren von “Lebenshacks, die sich illegal anfühlen”, sowie einen Prompt zur Steigerung der Lerneffizienz mithilfe der Feynman-Technik, was die Vielfalt und Kreativität der Benutzerinteraktion mit LLMs demonstriert. (Quelle: karminski3, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT)
LLM-Leistung und Benutzererfahrungsprobleme: Von der UI bis zur Modellleistung : Benutzer berichten, dass GPT-5 in mobilen Anwendungen Probleme beim Rendering von “Boxed Answers” hat und das Gemini-Modell bei strukturierten Ausgaben relativ schlecht abschneidet. Claude-Nutzer beklagen sich allgemein über Leistungsabfall, häufiges Erreichen von Nutzungsgrenzen sowie Fehler bei der Code-Kompression und Anweisungsbefolgung. Nano Banana weist bei der Bildgenerierung Zensur und Blockaden auf. Diese Probleme spiegeln gemeinsam die Herausforderungen in Bezug auf Stabilität und Benutzererfahrung wider, denen LLMs in realen Anwendungen gegenüberstehen. (Quelle: gallabytes, vikhyatk, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Dorialexander)

KI-Entwicklung und gesellschaftliche Auswirkungen: Beschäftigung, Ethik und Geopolitik : Bill Gates’ Aussage, dass KI Programmierer in 100 Jahren nicht ersetzen werde, löste eine Diskussion über die Natur der Programmierarbeit aus. Gleichzeitig äußert die Community Bedenken hinsichtlich potenzieller Massenarbeitslosigkeit, Pandemierisiken und Kontrollverlustrisiken durch KI und argumentiert, dass US-Tech-CEOs das Ende des KI-Wettlaufs aus Eigeninteresse übertreiben. Darüber hinaus werden das Überangebot auf dem LLM-Markt und die geopolitische Konkurrenz durch die Entwicklung chinesischer KI-Unternehmen beachtet. (Quelle: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, bookwormengr, Dorialexander)

Einschränkungen des KI-Benchmarking und Herausforderungen bei der Bewertung echter Intelligenz : Die Community diskutierte die grundlegenden Probleme in der KI-Benchmarking-Branche, nämlich dass KI-Modelle möglicherweise nur Antworten aus den Trainingsdaten “auswendig gelernt” haben, anstatt echte Intelligenz zu zeigen. Dies führt dazu, dass Benchmarks schnell veralten und wirft Fragen zur Bewertung der tatsächlichen Fähigkeiten von KI auf, was die Suche nach effektiveren und aufschlussreicheren Bewertungsmethoden fordert. (Quelle: Reddit r/ArtificialInteligence)
Einschränkungen von KI bei komplexen Aufgaben und Entwicklererfahrung : Entwickler weisen darauf hin, dass die Bereitstellung von KI-Agenten in einer Produktionsumgebung eine große Anzahl von Prompts erfordert, um Fehler zu umgehen. GPT-5-high hatte Schwierigkeiten, einen rekursiven C-Interpreter in einen manuellen Stack-/Loop-Interpreter umzuwandeln, was die Einschränkungen von KI bei der Verarbeitung komplexen Low-Level-Codes und logischem Denken hervorhebt. LLMs sind bei der Fehlersuche visueller Bugs in komplexen Webanwendungen nicht effektiv. Darüber hinaus stellt die Benutzererfahrung mit JAX auf GPUs ebenfalls eine Herausforderung dar. (Quelle: cto_junior, VictorTaelin, jpt401, vikhyatk)

Herausforderungen des KI-Lernpfads und Ratschläge zur Karriereentwicklung : KI-Studenten teilen ihre große Frustration und die steile Lernkurve, die sie beim Erlernen von KI-Bereichen (NLP, CV etc.) erleben, was die allgemeinen Schwierigkeiten von KI-Lernenden widerspiegelt. Die Community empfiehlt, End-to-End-KI-Projekte aufzubauen und bereitzustellen, Praktika zu suchen und an Freelance-Projekten teilzunehmen, um die Kluft zwischen Theorie und Praxis zu überbrücken und sich besser an die Branchenanforderungen anzupassen. (Quelle: Reddit r/deeplearning, Reddit r/deeplearning)
Modellgröße, Datenqualität und Effizienz von KI-Code-Assistenten : Die Community diskutierte die überraschende Leistung kleiner Modelle mit sorgfältig ausgewählten Daten, räumte aber auch die Notwendigkeit großer Modelle für Aufgaben wie Datengenerierung und -bewertung ein, was zu Überlegungen über die Abwägung zwischen Modellgröße und Datenqualität führte. Gleichzeitig diskutierten Entwickler Effizienzprobleme bei der gleichzeitigen Verwendung mehrerer KI-Code-Assistenten wie Codex und Claude Code sowie die Wartbarkeit von KI-generiertem Code. (Quelle: Dorialexander, Dorialexander, Vtrivedy10, jimmykoppel)
KI und die philosophische Diskussion über Kompression als Intelligenz : Die Community diskutierte das Hutter Prize-Konzept “Kompression ist Intelligenz” und überlegte, wie sich die “verlustbehaftete Kompressionseigenschaften” von LLMs in ihrer Nützlichkeit widerspiegeln und welches Potenzial die Erklärbarkeitsforschung zur Untersuchung ihrer internen Mechanismen birgt. Diese Diskussion dringt in das Wesen der KI-Intelligenz ein und stellt traditionelle Definitionen von Intelligenz in Frage. (Quelle: Vtrivedy10)
Leistungsstreit zwischen Huawei GPU und Nvidia RTX 6000 Pro : Die Community hat eine hitzige Diskussion über den Leistungsvergleich zwischen Huawei GPU und Nvidia RTX 6000 Pro geführt. Obwohl die Huawei GPU 96GB Speicher hat, ist ihre LPDDR4X-Speicherbandbreite weit geringer als die von Nvidia GDDR7, was zu einer tatsächlich 4-5 Mal langsameren Inferenzgeschwindigkeit führen kann. Die Diskussion umfasste auch das Software-Ökosystem, geopolitische Subventionen und Nvidias Preisstrategie im Consumer-Markt, was die Konkurrenz und Herausforderungen im Bereich der KI-Hardware hervorhebt. (Quelle: Reddit r/LocalLLaMA)

Mängel von LLMs bei ästhetischem Urteilsvermögen und Frontend-Entwicklung : Entwickler beklagen, dass LLMs bei ästhetischem Urteilsvermögen schlecht abschneiden, insbesondere beim Schreiben von Frontend-Code. Es bedarf sehr starker Designvorgaben, damit LLMs zufriedenstellende Inhalte produzieren. Dies zeigt, dass LLMs bei subjektiven, kreativen Aufgaben noch erhebliche Einschränkungen aufweisen und tiefgreifende menschliche Intervention und Anleitung erfordern. (Quelle: cto_junior)
Veröffentlichungsrhythmus von KI-Forschungspapieren und Entwicklerstimmung : Einige in der Community empfinden “Entzugserscheinungen” aufgrund des sich verlangsamenden Veröffentlichungsrhythmus von Arxiv-Papieren, was die Sehnsucht und Abhängigkeit von KI-Forschenden nach den neuesten Fortschritten widerspiegelt. Dies zeigt, dass die Forschungsfortschritte im KI-Bereich extrem schnell sind und der Bedarf der Forschenden an aktuellen Informationen sehr dringend ist. (Quelle: vikhyatk)
Mangelnde Standardisierung bei LLMs führt zu Entwicklungskomplexität : Entwickler beklagen, dass LLMs keine einheitlichen Chat-Templates und Tool-Calling-Formate haben, was dazu führt, dass jedes Modell maßgeschneiderten Code benötigt, was die Entwicklungskomplexität und unnötige Wiederholungsarbeit erhöht. Diese Fragmentierung behindert die schnelle Entwicklung und Bereitstellung von LLM-Anwendungen und fordert, dass die Branche einheitlichere Standards etabliert. (Quelle: jon_durbin)