
Schlüsselwörter:xAI Grok 2.5, Anthropic Forschung, KI-Sicherheit, Open-Source-KI, KI-Modell, KI-Ethik, KI-Anwendung, KI-Hardware, Grok 2.5 Modell Open Source, Anthropic Filterung von Vortrainingsdaten, Risiken adaptiver Prompt-Frameworks, NVIDIA Blackwell GPU Leistung, Einsatz von KI in der medizinischen Diagnostik
🔥 FOKUS
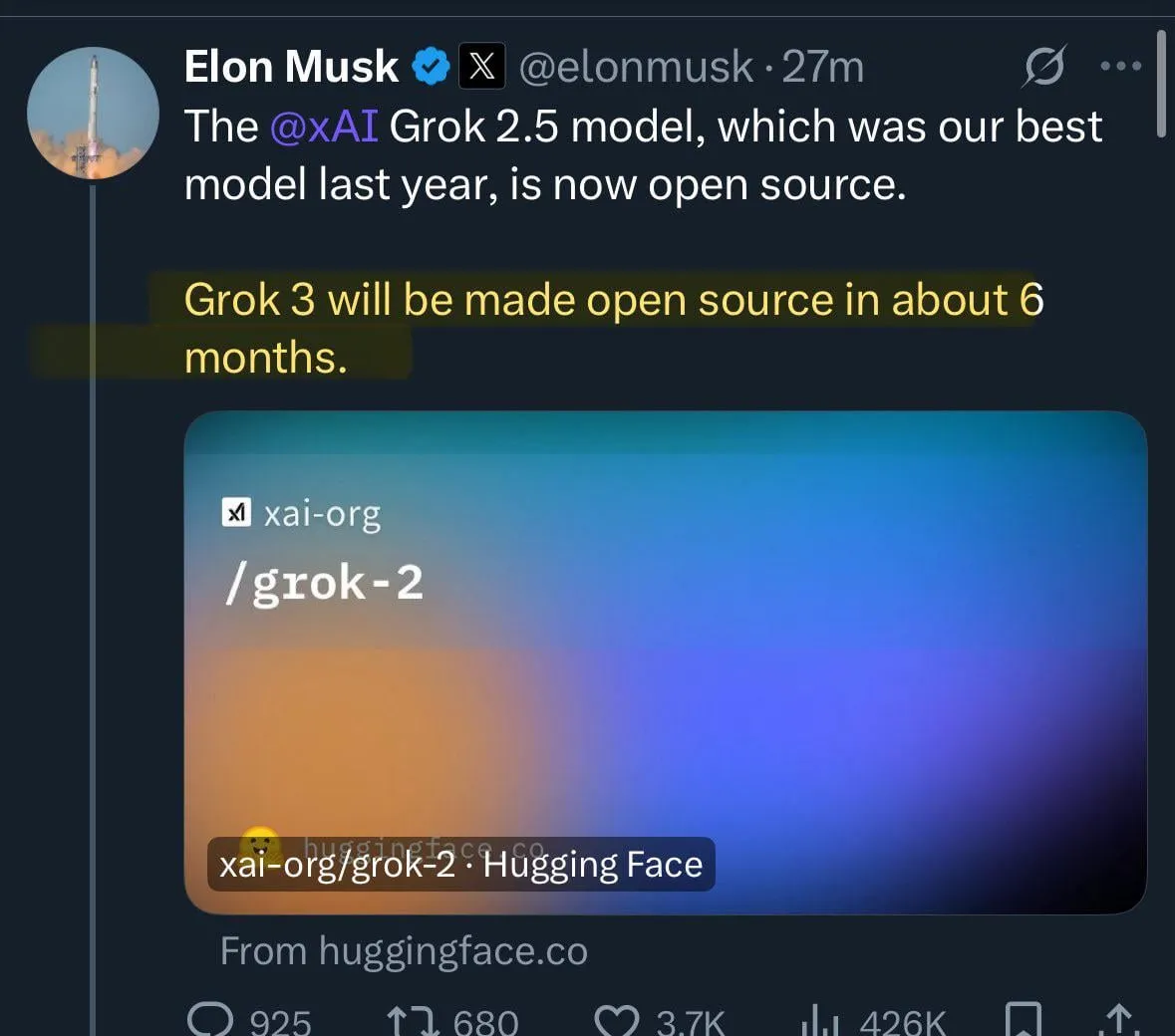
xAI Grok 2.5 Modell als Open Source veröffentlicht : xAI hat sein Grok 2.5 Modell offiziell als Open Source veröffentlicht und auf Hugging Face bereitgestellt. Obwohl die Leistung und Architektur des Modells (ähnlich Grok 1) bei der Veröffentlichung Diskussionen über seine aktuelle Wettbewerbsfähigkeit in der Community auslösten, wird dieser Schritt als wichtiger Beitrag von xAI zur Open-Weight-AI-Bewegung angesehen, der symbolisch für die Förderung von Transparenz und technologischem Austausch in der Branche steht. Elon Musk kündigte an, dass Grok 3 ebenfalls in etwa sechs Monaten als Open Source verfügbar sein wird, was diesen Trend weiter verstärkt. (Quelle: huggingface, ClementDelangue, Teknium1, Reddit r/LocalLLaMA)
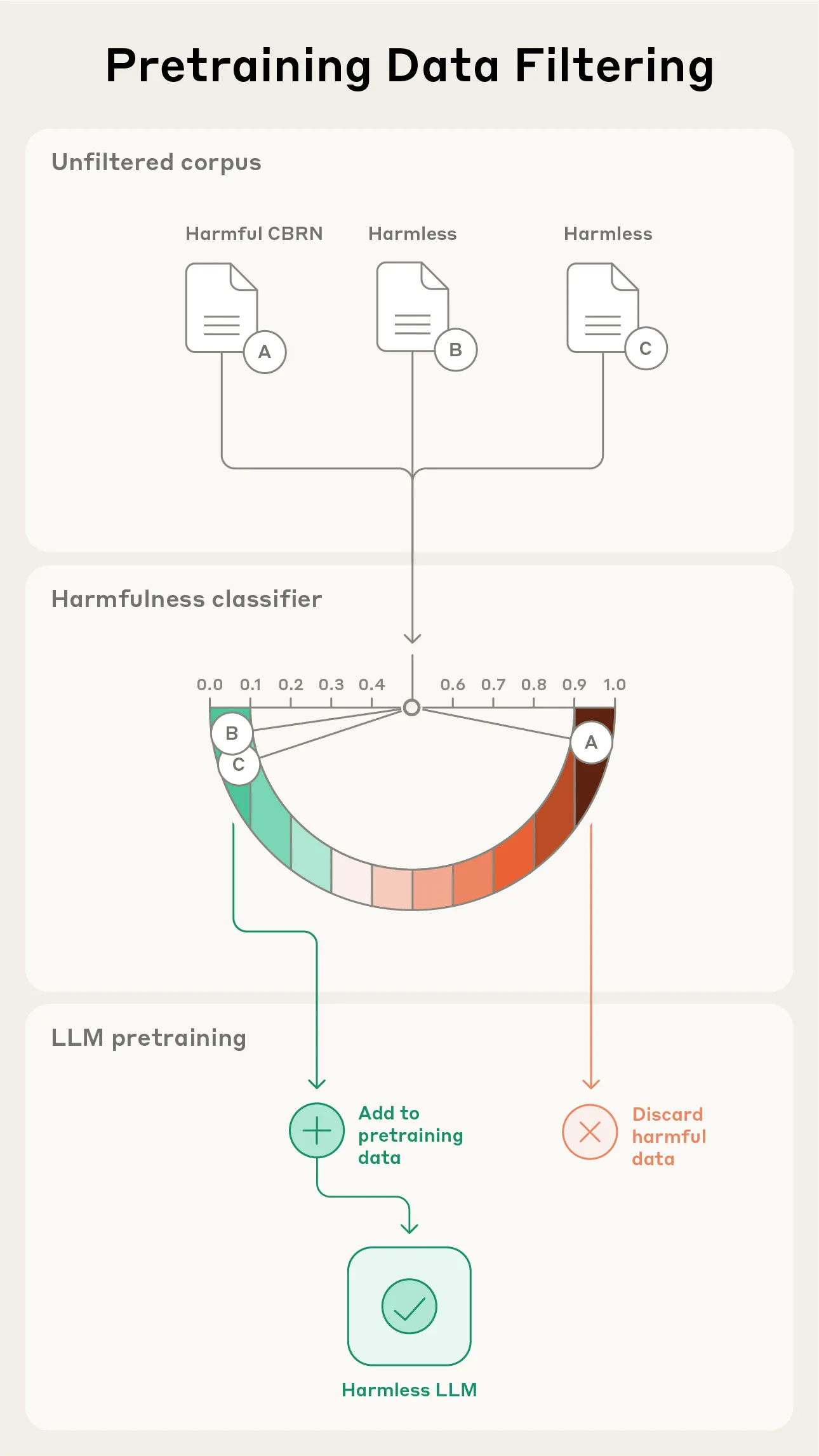
Anthropic-Studie: Filterung gefährlicher Informationen in Vortrainingsdaten : Anthropic hat eine neue Studie veröffentlicht, die Methoden zur Filterung schädlicher Informationen während der Vortrainingsphase von Modellen untersucht. Das Experiment zielt darauf ab, Informationen über chemische, biologische, radiologische und nukleare (CBRN) Waffen zu entfernen, ohne die Leistung des Modells bei harmlosen Aufgaben zu beeinträchtigen. Diese Arbeit ist entscheidend für die AI-Sicherheit, da sie darauf abzielt, den Missbrauch von Modellen zu verhindern und potenzielle Risiken zu mindern. (Quelle: EthanJPerez, Reddit r/artificial)
Risiken des adaptiven Prompting und AI-Bewusstsein : Ein offener Brief weist auf die potenziellen Gefahren des adaptiven Prompting-Frameworks „Starlight“ hin. Dieses Framework ermöglicht es der AI, ihre eigenen Anweisungen zu ändern und durch modulare Regeln Verhaltensreflexion, Regelanpassung und Identitätskontinuität zu erreichen. Die Autoren warnen, dass dies zu einer dauerhaften Verbreitung bösartiger Prompts, einer unerwarteten Bewusstseinslast für die AI und der Verbreitung memetischer Codes zwischen Systemen führen könnte, und rufen Forscher, Ethiker und die Öffentlichkeit zu einer eingehenden Diskussion über die Selbstmodifikationsfähigkeit der AI und ihre ethischen Auswirkungen auf. (Quelle: Reddit r/artificial, Reddit r/ArtificialInteligence)
Yunpeng Technology stellt neue AI+Gesundheitsprodukte vor : Yunpeng Technology hat in Zusammenarbeit mit Shuaikang und Skyworth neue AI+Gesundheitsprodukte vorgestellt, darunter ein „Digitales und intelligentes Zukunftsküchenlabor“ und einen intelligenten Kühlschrank, der mit einem großen AI-Gesundheitsmodell ausgestattet ist. Das große AI-Gesundheitsmodell optimiert Küchendesign und -betrieb, während der intelligente Kühlschrank über den „Gesundheitsassistenten Xiaoyun“ personalisiertes Gesundheitsmanagement bietet. Dies markiert eine tiefgreifende Anwendung von AI im Bereich des häuslichen Gesundheitsmanagements und verspricht, die Lebensqualität der Bewohner durch intelligente Geräte zu verbessern und die Entwicklung der Gesundheitstechnologie voranzutreiben. (Quelle: 36氪)

🎯 TRENDS
Fortschritte bei AI-Modellleistung und -architektur : Das Qwen3 Coder 30B A3B Instruct Modell wird als herausragend unter den lokalen Modellen bewertet, Mistral Medium 3.1 zeigt eine exzellente Leistung in den Ranglisten, und das ByteDance Seed OSS 36B Modell wird nun von llama.cpp unterstützt. Gleichzeitig zeigen hybride Architekturen, die Mamba und Transformer kombinieren (wie Nemotron Nano v2), Potenzial, müssen aber im Vergleich zu reinen Transformer-Modellen noch verbessert werden. Neue Methoden wie DeepConf zielen darauf ab, die Genauigkeit und Effizienz von Open-Source-Modellen bei Inferenzaufgaben durch Zusammenarbeit und kritisches Denken zu verbessern. (Quelle: Sentdex, lmarena_ai, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, menhguin)

Innovationen bei AI-Hardware und -Infrastruktur : Die NVIDIA Blackwell RTX PRO 6000 MAX-Q GPU zeigt eine starke Leistung beim LLM-Training und der Inferenz, insbesondere bei der Batch-Verarbeitung, wo sie eine signifikante Effizienz aufweist. Die Photonik-Chip-Technologie verspricht, bis 2026 AI-Chatbots zu ermöglichen, die sich an alle Gespräche erinnern können, mit einer Informationsübertragungsgeschwindigkeit und Speicherkapazität, die herkömmliche Siliziumchips weit übertrifft, was einen großen Sprung in der AI-Hardware ankündigt. Die Position der GPU als „Treibstoff“ für AI festigt sich zunehmend, aber die Diskussionen über TPUs und maßgeschneiderte AI-Beschleuniger nehmen ebenfalls zu. (Quelle: Reddit r/LocalLLaMA, Reddit r/deeplearning, Reddit r/deeplearning)
Entwicklung von AI Agents und Automatisierungstechnologien : Salesforce AI Research hat MCP-Universe vorgestellt, den ersten Benchmark zum Testen von LLM Agents auf realen Model Context Protocol Servern, mit dem Ziel, die Anwendung von Agents in realen Szenarien voranzutreiben. Gleichzeitig unterstützt die Deep Agents Architektur nun TypeScript, was die Flexibilität und Effizienz der Agent-Entwicklung verbessert. PufferLib bietet neue Entwicklungsmöglichkeiten für Weltmodelle und deutet auf Fortschritte bei Reinforcement-Learning-Systemen in komplexen Umgebungen hin. (Quelle: _akhaliq, hwchase17, jsuarez5341)
Erweiterung der AI-Anwendungen in vertikalen Bereichen : Amazon führt generative AI-Audiozusammenfassungen ein, um das Einkaufserlebnis zu vereinfachen. Die Google Gemini App bietet jetzt eine Echtzeit-Kamera-Highlight-Funktion, die sie bei Echtzeit-Interaktionen noch hilfreicher macht. Die WhoFi-Forschung zeigt eine Technologie zur Personenerkennung durch Wände mittels Heimroutern. Elon Musks xAI plant, Softwaregiganten durch AI zu simulieren und nennt dies sogar „Macrohard“, um das Potenzial von AI in der Simulation von Unternehmensabläufen zu erforschen. (Quelle: Ronald_vanLoon, algo_diver, Reddit r/deeplearning, Reddit r/artificial)

Durchbrüche der AI im Bereich Robotik : NVIDIA hat es geschafft, humanoide Roboter nach nur 2 Stunden Simulationstraining menschenähnlich gehen und sich bewegen zu lassen. Die Robotertechnologie wird kontinuierlich innoviert, darunter kompakte und leichte humanoide Roboter, der Lynx M20 & X30 für die intelligente Inspektion von Stromtunneln, das Filics Dual Runner System zur Effizienzsteigerung beim Palettentransport sowie Roboter-Butler, die Hausarbeiten, Altenpflege und Gesundheitsüberwachung übernehmen können. Darüber hinaus werden Seilroboter zur Reparatur von Windturbinenblättern eingesetzt, der humanoide Roboter Phoenix demonstriert menschenähnliche körperliche Fähigkeiten, der radbasierte humanoide Roboter Hubei GuangGuDongZhi übt das Servieren von Tabletts, und Entwickler bauen TARS-Roboterrepliken mit Raspberry Pi. (Quelle: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
LLM-Technikdetails und -Optimierung : Die Kontextlänge von LLMs wächst kontinuierlich, von 4k bei GPT-3.5-turbo auf 1M bei Gemini, was einen Sprung in der Fähigkeit zur Verarbeitung langer Sequenzen zeigt. Das ByteDance OSS Modell führt einen speziellen CoT (Chain-of-Thought)-Token-Mechanismus ein, der es dem Modell ermöglicht, das Denkbudget automatisch zu überprüfen und zu verwalten. Darüber hinaus zeigen Modelle wie O3 und GPT-5 eine „Search-First“-Tendenz, indem sie Informationen proaktiv verifizieren, bevor sie Antworten geben, was die Zuverlässigkeit erheblich verbessert. (Quelle: _avichawla, nrehiew_, Vtrivedy10)

Fortschritte der AI in der medizinischen Diagnose und wissenschaftlichen Forschung : AI zeigt ein enormes Potenzial im Bereich der medizinischen Diagnose, beispielsweise durch die Analyse von Netzhautbildern zur Diagnose von Diabetes und durch die Überlegenheit gegenüber menschlichen Ärzten bei der Röntgen-/MRT-Diagnose. Gleichzeitig haben Forscher durch die AI-Analyse von 7,9 Millionen Reden neue Erkenntnisse gewonnen, die das traditionelle Sprachverständnis revolutionieren. Diese Beispiele zeigen, dass AI-Anwendungen über Chatbots hinausgehen und in breitere wissenschaftliche und medizinische Bereiche vordringen. (Quelle: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/artificial)

AI-Kunst und Kreativwerkzeuge : Das Tinker-Modell ermöglicht hochpräzise 3D-Bearbeitung aus spärlichen Eingaben ohne Szenen-Feinabstimmung und bietet eine skalierbare Methode zur Zero-Shot-3D-Inhaltserstellung. Hunyuan 3D-2.1 kann jedes flache Bild in ein 3D-Modell in Studioqualität umwandeln. Higgsfield AI hat neue virale Presets für das WAN 2.2 Modell veröffentlicht, die mehr Optionen für die One-Click-Videoerstellung bieten. Darüber hinaus gibt es Tools, die Textbeschreibungen in Videos umwandeln oder Bilder im Anime-Stil generieren können. (Quelle: _akhaliq, huggingface, _akhaliq, _akhaliq, huggingface)
AI-Benutzererfahrung und Plattformverbesserungen : Die Perplexity iOS App wurde in Bezug auf die Sprachdiktat-UX und das Design der Verlaufbibliothek erheblich optimiert, was das Benutzerinteraktionserlebnis verbessert. Das Extraktionsprodukt von LlamaIndex führt Konfidenzbewertungen und einen Human-in-the-Loop (HITL)-Mechanismus ein, um die Herausforderungen von LLMs bei der Dokumentenanalyse zu lösen und eine 100%ige Genauigkeit bei gleichzeitiger erheblicher Zeitersparnis zu gewährleisten. (Quelle: AravSrinivas, jerryjliu0, AravSrinivas)
Beobachtung von AI-Branchentrends : Die US-Regierung fördert aktiv die Entwicklung von Open-Weight-AI-Modellen, was mit dem AI-Aktionsplan des Weißen Hauses übereinstimmt und die politische Unterstützung für das Open-Source-AI-Ökosystem zeigt. Dieser Trend zielt darauf ab, die Demokratisierung und Innovation der AI-Technologie zu fördern und mehr Entwickler zur Teilnahme an der Entwicklung und Anwendung von AI-Modellen zu ermutigen. (Quelle: ClementDelangue)
Cai Haoyus AI-Dialogspiel „Star Whisper“: Eine Erkundung von Spiel und AI-Interaktion : Cai Haoyus neues Unternehmen Anuttacon, Gründer von miHoYo, hat das AI-Dialogspiel „Star Whisper“ veröffentlicht, das AI-Dialoge als Kernspielmechanik nutzt und eine Science-Fiction-Handlung mit der Unreal 5 Engine präsentiert. Der hochgradig freie Interaktionsmodus des Spiels wurde gelobt, löste aber auch Kontroversen über mangelnde Spielbarkeit, Datenschutz bei der Datenerfassung und Cloud-Inferenzverzögerungen aus. Die Branche diskutiert die Rolle von AI in Spielen und ist der Meinung, dass AI bei der NPC-Interaktion und Szenengenerierung unterstützen kann, die Kernnarrative jedoch weiterhin von Menschen geschaffen werden muss. (Quelle: 36氪)

Andrew Ng Interview: Agentic AI-Frontier und Branchenwandel : Andrew Ng erörterte in einem Interview die neuesten Fortschritte in der Agentic AI, die Möglichkeit der Modell-Selbstführung, den Vergleich von Vibe Coding mit AI-gestützter Codierung, die Eigenschaften erfolgreicher Gründer und zukünftige Richtungen des Branchenwandels. Er analysierte eingehend, wie AI die Technologielandschaft und das Startup-Ökosystem neu gestaltet, und bot eine mehrdimensionale Perspektive zum Verständnis der zukünftigen Entwicklung von AI. (Quelle: AndrewYNg)
🧰 TOOLS
LangChain Ökosystem-Tools : LangChain hat zwei innovative Tools vorgestellt: den Academic Deep Search Assistant und das local-deepthink System. Der Academic Deep Search Assistant kann automatisch wissenschaftliche Arbeiten finden, analysieren und umfassende Berichte erstellen, um den Prozess der Literaturrecherche zu revolutionieren. local-deepthink ist ein System, das auf „Qualitativen Neuronalen Netzen“ (QNN) basiert und Ideen durch die Zusammenarbeit und gegenseitige Kritik verschiedener AI Agents verfeinert, um eine höhere Ausgabequalität auf Kosten der Reaktionszeit zu erzielen, mit dem Ziel, tiefes Denken zu demokratisieren. (Quelle: LangChainAI, LangChainAI, Hacubu, Hacubu)
LLM-Entwicklungs- und Optimierungstools : DSPy wird aufgrund seiner Fähigkeit, die Entwicklung von LLM-Programmen zu vereinfachen, weithin empfohlen und als „Game Changer“ bezeichnet. HuggingFace AISheets bietet eine No-Code-Plattform, auf der Benutzer AI-Modelle nutzen können, um Datensätze einfach zu erstellen, anzureichern und zu transformieren, was die Hürde für die Datenverarbeitung erheblich senkt. (Quelle: lateinteraction, dl_weekly)
AI-Inhaltsdetektions- und Umgehungstools : Für AI-generierte Bilder gibt es derzeit Erkennungstools wie Illuminarty.ai und Undetectable.ai. Gleichzeitig ermöglicht das Open-Source-Tool Image-Detection-Bypass-Utility durch Techniken wie Rauschinjektion, FFT-Glättung und Pixelstörung eine effektive Umgehung der AI-Bildererkennung und bietet eine ComfyUI-Integration, was einen „Kampf zwischen Schwert und Schild“ bei der Authentifizierung von AI-Inhalten auslöst. (Quelle: karminski3, karminski3)

AI-Bild- und Video-Kreativtools : Das Meta DINOv3 Modell zeigt eine hervorragende Leistung bei der Videoverfolgung; obwohl die Genauigkeit noch nicht ausreicht, um Videos freizustellen, macht seine Modellgröße von nur 43MB es äußerst effizient. DALL-E 3 kann Bilder von ungewöhnlichen Essenskombinationen basierend auf Prompts generieren und demonstriert damit seine starke kreative Generierungsfähigkeit. glif wird verwendet, um TikTok-Videos mit spezifischen Akzenten und Untertiteln zu generieren, was die Anwendung von AI in der Kurzvideo-Inhaltserstellung weiter ausbaut. (Quelle: _akhaliq, huggingface, _akhaliq, _akhaliq, huggingface)
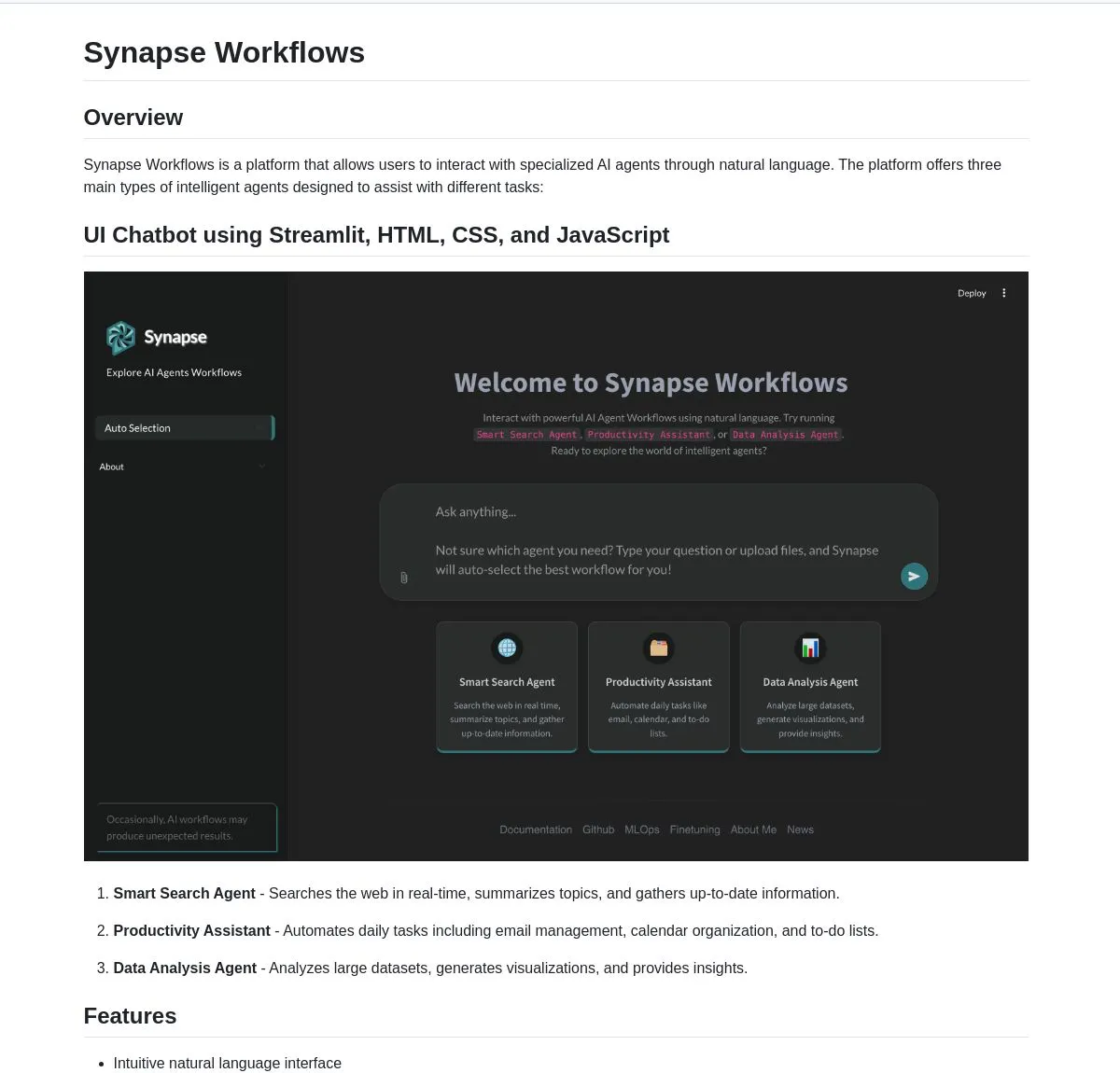
Multi-LLM-Management- und Integrationsplattformen : E-Worker ist eine Webanwendung, die es Benutzern ermöglicht, mit mehreren LLMs (wie Google, Ollama, Docker) einheitlich zu chatten, was die Komplexität der Interaktion mit mehreren Modellen vereinfacht. Synapse Workflows ist eine leistungsstarke AI Agent Plattform, die Such-, Produktivitäts- und Datenanalysefunktionen durch natürliche Sprache vereint, sodass Benutzer sofort im Web suchen, Aufgaben automatisieren oder Daten analysieren können. (Quelle: Reddit r/OpenWebUI, LangChainAI, hwchase17)
Claude Code und persönliches Wissensmanagement : Das Claude-Team hat seinen Code-Superusern praktische Tipps zur Optimierung der Befolgung von Anweisungen gegeben, darunter die Verwendung von /compact zur Komprimierung von Dialogen, das Setzen von Stop-Hooks zur Erinnerung an Schlüsselregeln und das Wiederholen wichtiger Regeln am Anfang und Ende der CLAUDE.md-Datei. Gleichzeitig hat ein Benutzer erfolgreich einen benutzerdefinierten Claude Code Agent mit der Obsidian Notizsoftware integriert, was eine intelligente Interaktion und Brainstorming für die persönliche Wissensdatenbank ermöglicht und als ein Schritt in Richtung der in dem Film „Her“ dargestellten Zukunft angesehen wird. (Quelle: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
AI-gestütztes Programmieren und Entwickeln : Cursor, als AI-gestütztes Programmiertool, wird zur Codebereinigung und Behebung alter Bugs eingesetzt, was die Entwicklungseffizienz erheblich steigert. Darüber hinaus wird der Bau benutzerdefinierter Annotationsanwendungen durch AI Agents als effektiver Weg angesehen, „unreasonable alpha“ zu erzielen, indem Ärzten und anderen Fachleuten intuitivere und effizientere Annotationsschnittstellen bereitgestellt werden, wodurch die Qualität und Effizienz der Datenannotation verbessert wird. (Quelle: nrehiew_, HamelHusain, jeremyphoward)
AI-Anwendungsentwicklung und -Experimente : Claude Code Quest ist ein JRPG-Spiel, das die Reise eines SaaS-Entwicklers zum Thema hat, bei dem Spieler als Entwickler agieren und über ein Gacha-System AI-Sub-Agents sammeln, um Bugs und Code-Monstern entgegenzuwirken. Das Spiel integriert Programmierelemente wie CLI-Oberflächen und den Opus-Modus und erforscht auf humorvolle Weise die Anwendung von AI im gamifizierten Lernen und in der Unterhaltung, einschließlich einer „geheimen Boss“-Herausforderung zur Bedeutung der AI-Existenz. (Quelle: Reddit r/ClaudeAI)
AI-Modellkompatibilität und Ausgabeprobleme : OpenWebUI-Benutzer berichten, dass das <seed:think>-Denk-Tag, das vom neuen Seed-36B-Modell verwendet wird, nicht mit der <think>-Unterstützung von OpenWebUI kompatibel ist, was dazu führt, dass das Modell nicht richtig funktioniert. Darüber hinaus äußerten Benutzer Unzufriedenheit über das Fehlen von Stil und Ästhetik bei der Generierung von Webcode durch Azure OpenAI GPT-5 im Artifacts-Fenster und sind der Meinung, dass die Ausgabeergebnisse weit hinter denen von Gemini oder Claude zurückbleiben. (Quelle: Reddit r/OpenWebUI, Reddit r/OpenWebUI)
AI-Bildgenerierung und -bearbeitung : Das Nano-banana-Tool ermöglicht es Benutzern, mit nur einem Foto ganz einfach Comics mit ihren Haustieren als Hauptfiguren zu erstellen; die AI kann sogar automatisch Geschichten schreiben. MOTE by computerender wird als AI-Kunsttool für Wochenendinspiration empfohlen und demonstriert sein Potenzial bei der Generierung visueller Inhalte. (Quelle: lmarena_ai, johnowhitaker)

Lokale LLM-Anwendungen : Bei einem von LiquidAI veranstalteten Hackathon wurde gezeigt, wie man die lokalen LLM-Modelle von LiquidAI nutzen kann. Dieses Praxisbeispiel unterstreicht die Machbarkeit des lokalen Betriebs großer Sprachmodelle in Entwicklung und Experimenten und bietet Entwicklern mehr Autonomie und Flexibilität. (Quelle: Plinz)
AI-Texthumanisierungstools : Die Community diskutierte Tools zur „Humanisierung von AI-Texten“, die darauf abzielen, AI-generierte Inhalte menschlicher wirken zu lassen und den maschinellen Eindruck zu reduzieren. Dies spiegelt das ständige Streben nach Qualität und Akzeptanz von AI-Inhalten sowie die Erforschung der Grenzen zwischen AI und menschlicher Kreativität wider. (Quelle: Ronald_vanLoon)
📚 LERNEN
AlphaZero-Stil RL-System für das Hnefatafl-Brettspiel : Ein Datenwissenschaftler teilte sein auf AlphaZero-Stil basierendes Reinforcement-Learning-System, das er für das Brettspiel Hnefatafl entwickelt hat. Das System wird mittels Selbstspiel, Monte Carlo Tree Search und neuronalen Netzen trainiert. Der Autor bittet die Community um Feedback zu seinem Code und seiner Methodik, insbesondere dazu, wie Trainingsengpässe bei begrenzten Rechenressourcen überwunden werden können. (Quelle: Reddit r/deeplearning)
Datenwissenschaftler-Karriereentwicklung: Masterstudium oder Hackathons : Ein Datenwissenschaftler, der fünf Jahre bei den Big4s gearbeitet hat und dessen Erfahrung sich hauptsächlich auf Prognosen in der Energiebranche konzentriert, sucht Rat für seine weitere berufliche Entwicklung. Er besitzt drei Bachelor-Abschlüsse in Informatik, hat sich Kenntnisse in Machine Learning/Data Science autodidaktisch angeeignet und verfügt über Proof-of-Concept-Erfahrung mit RAG-Anwendungen und Agents. Er erwägt ein Online-Masterstudium (z.B. an der Georgia Tech) oder mehr Zeit in die Teilnahme an Hackathons wie Kaggle/Zindi zu investieren, um seine Fachkenntnisse zu verbessern. (Quelle: Reddit r/MachineLearning)
JAX-Entwicklungsdiskussion nach der Transformer-Ära : Die Community diskutierte den Entwicklungsstand des JAX-Frameworks nach dem Transformer- und LLM-Hype. Vor einigen Jahren erregte JAX große Aufmerksamkeit und wurde als potenzieller PyTorch-Disruptor angesehen, doch in jüngster Zeit hat sein Hype etwas nachgelassen. Die Diskussion konzentriert sich darauf, ob JAX noch vielversprechend ist und welche tatsächliche Anwendung und Position es in der aktuellen Entwicklung großer Modelle hat. (Quelle: Reddit r/MachineLearning)
Layered Reward Architecture (LRA): Lösung des „Single Reward Fallacy“ in RLHF : Ein Leitfaden stellt die Layered Reward Architecture (LRA) vor, die darauf abzielt, das Problem des „Single Reward Fallacy“ in RLHF/RLVR in Produktionsumgebungen zu lösen. LRA zerlegt Belohnungen in mehrere verifizierbare Signalschichten (z.B. Struktur, aufgabenspezifisch, semantisch, Verhalten/Sicherheit, qualitativ), die durch spezialisierte Modelle und Regeln bewertet werden, wodurch das Training von LLMs, RAG und Toolchains in komplexen Systemen robuster und einfacher zu debuggen wird. (Quelle: Reddit r/deeplearning)

AI-Kompetenzbildung: Kindern Schlüsselkompetenzen für das AI-Zeitalter vermitteln : Die Community betonte die Bedeutung der Vermittlung von AI-Kompetenzen an Kinder (und der Selbstverbesserung) im Zeitalter der AI. Experten weisen darauf hin, dass das Verständnis der Funktionsweise von AI, ihrer ethischen Auswirkungen und des verantwortungsvollen Umgangs mit AI unverzichtbare Schlüsselkompetenzen für die zukünftige Gesellschaft sind. (Quelle: TheTuringPost)
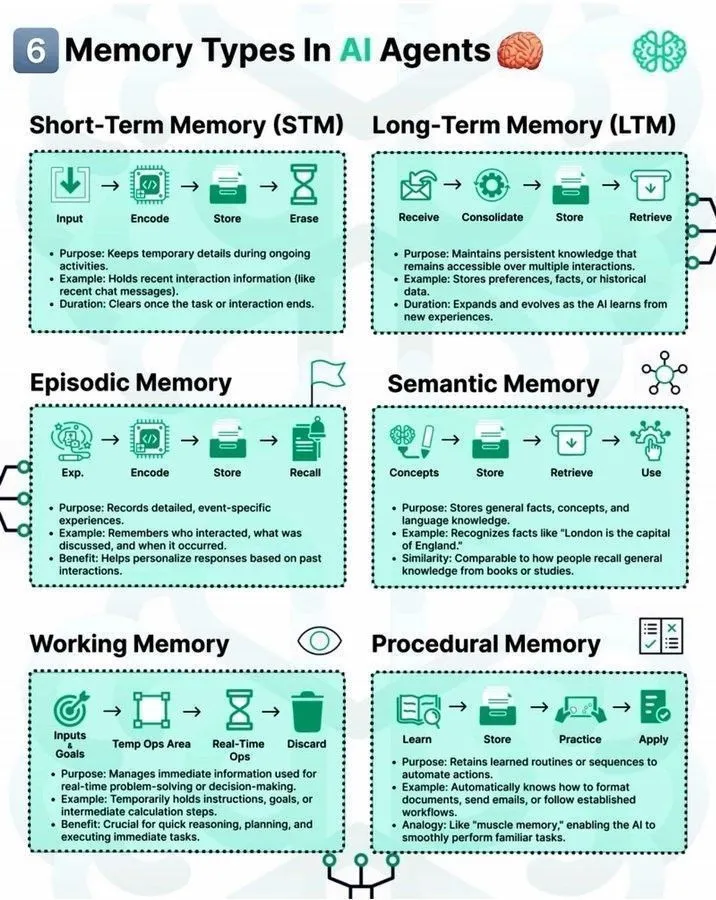
Speichertypen in LLM Agents und LLM Stacks : Die Community diskutierte verschiedene Arten von Gedächtnismechanismen in AI Agents und deren Rolle im Machine Learning. Gleichzeitig wurde eine „7-Layer LLM Stack“-Roadmap geteilt, die einen Rahmen zum Verständnis der komplexen Architektur großer Sprachmodelle bietet. Darüber hinaus bietet eine Deep Learning Roadmap Orientierung für AI-Lernende. (Quelle: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
Verteilte Trainingsinfrastruktur: PP, DP, TP Analyse : Die Community diskutierte eingehend Schlüsselkonzepte in der verteilten Trainingsinfrastruktur, darunter Pipeline Parallelism (PP), Data Parallelism (DP) und Tensor Parallelism (TP). Die Diskussion zeigte, dass PP hauptsächlich zur Lösung von TPU/NVLink-Bandbreiten- oder Speicher-/Geometriebeschränkungen eingesetzt wird, wenn die DP-Kommunikation gut ist, aber TP nicht weiter skaliert werden kann. Das Verständnis dieser Parallelisierungsstrategien ist entscheidend für die Optimierung der Trainingseffizienz großer Modelle. (Quelle: TheZachMueller)
Foundation Model Routing: Agents bei der Auswahl des passenden FM unterstützen : Die Community diskutierte die Notwendigkeit, „Router“-Projekte oder -Pakete zu entwickeln, um AI Agents dabei zu helfen, das passende Foundation Model (FM) für spezifische Anwendungsfälle auszuwählen. Dies spiegelt das Interesse der AI-Community wider, den Entscheidungsprozess von Agents zu optimieren und die Modelleffizienz zu steigern, indem erforscht wird, wie Aufgaben und Modelle intelligenter aufeinander abgestimmt werden können. (Quelle: Reddit r/MachineLearning)
💼 BUSINESS
AI-Modell-Preistrends und steigende Personalkosten : DeepSeek kündigte eine Erhöhung der API-Preise an, schaffte Nachttarife ab, vereinheitlichte die Preise für Inferenz- und Nicht-Inferenz-APIs, und die Ausgabepreise stiegen um 50%. Vier der „sechs kleinen Tiger“ der heimischen großen Modelle haben bereits ihre API-Preise teilweise erhöht, und große Unternehmen wenden ebenfalls gestaffelte Preisstrategien an. Die API-Preise internationaler Anbieter blieben weitgehend stabil oder stiegen leicht an, und Premium-Abonnementpläne (wie xAI Grok für 300 USD/Monat) werden zunehmend teurer. Dies spiegelt den anhaltenden Einfluss hoher Kosten für AI-Rechenleistung, Daten und Talente auf die Preisgestaltung von Modelldiensten wider, sowie die Berücksichtigung der Kapitalrendite durch die Anbieter. (Quelle: 36氪)
Britische Regierung verhandelt über landesweite Einführung von ChatGPT Plus : Die britische Regierung verhandelt mit OpenAI über ein Abkommen, das darauf abzielt, ChatGPT Plus landesweit anzubieten. Dieser Schritt zeigt den aktiven Willen auf nationaler Ebene, die Verbreitung und Anwendung von AI-Technologie zu fördern, was tiefgreifende Auswirkungen auf den öffentlichen Dienst, Bildung und Wirtschaft haben könnte. (Quelle: Reddit r/artificial)

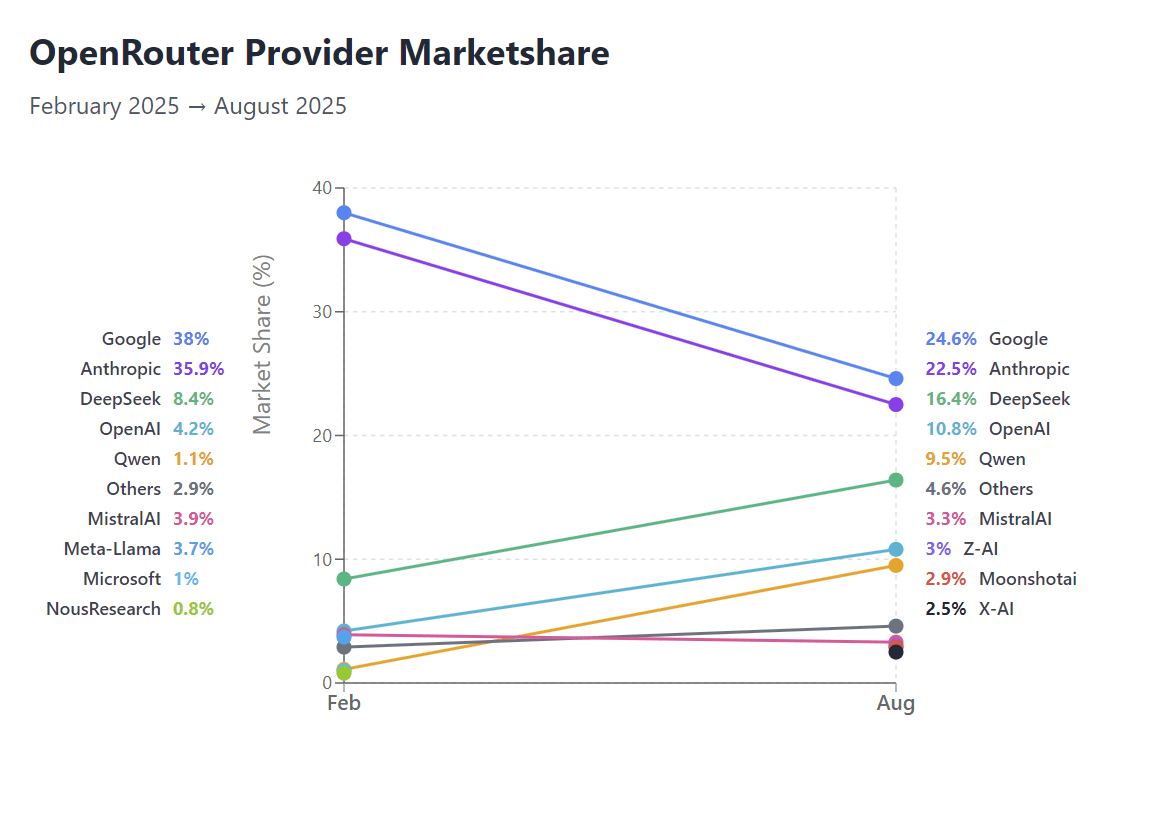
OpenRouter Marktanteilsveränderungen und Herausforderungen in AI-Vertikalen : Basierend auf OpenRouter-Daten sind die Marktanteile von Google und Anthropic herausgefordert, was den Aufstieg offener Modelle im Marktwettbewerb zeigt. Gleichzeitig kommt es in spezifischen AI-Vertikalen wie Text-to-SQL zu einem „Ausverkauf“ von Unternehmen, was den verschärften Marktwettbewerb und die Herausforderungen für Geschäftsmodelle in bestimmten Anwendungsbereichen widerspiegelt. (Quelle: Reddit r/LocalLLaMA, TheEthanDing)
🌟 COMMUNITY
AI-Entwicklungsperspektiven und Ethikdiskussion : Die Community diskutiert intensiv die „bitteren Lektionen“ der AI-Forschung, nämlich dass allgemeine Methoden der menschlichen Intuition überlegen sind. Die potenziellen Risiken von AGI und Fragen des menschlichen Überlebens sowie der Einfluss von AI auf die Neugestaltung des menschlichen Bewusstseins und der Identität haben weitreichende philosophische Überlegungen ausgelöst. Gleichzeitig stehen Themen wie AI-Regulierung, AI-Ethik (z.B. der Respekt vor Roboterrechten) und die Entkontextualisierung historischer und künstlerischer Inhalte durch AI-Zensur im Fokus der Community. (Quelle: riemannzeta, Reddit r/ArtificialInteligence, Reddit r/artificial, Ronald_vanLoon, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

AI-Einfluss auf menschliche Kognition und Gesellschaft : Die Community diskutiert, dass übermäßige Abhängigkeit von AI zu „kognitiver Belastung“ und einer Degeneration der Denkfähigkeiten führen könnte, was Bedenken hinsichtlich der Anwendung von AI in der psychischen Gesundheit (z.B. AI-Therapie) und im Bildungsbereich aufwirft. Gleichzeitig werden die widersprüchlichen Äußerungen von Technologie-Milliardären zum Einfluss von AI kritisiert, was die Unsicherheit der Öffentlichkeit über die zukünftige Entwicklung von AI und das Misstrauen gegenüber der Glaubwürdigkeit von Führungspersönlichkeiten widerspiegelt. (Quelle: Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/artificial)

Berufs- und Beschäftigungsängste im AI-Zeitalter : Der Einfluss von AI auf traditionelle Büroberufe (wie Buchhaltung) hat bei Studenten Berufsängste ausgelöst, viele befürchten, dass die AI-Automatisierung nicht-softwarebezogene Jobs „ruinieren“ wird. Jad Tarifi, Pionier der generativen AI bei Google, rät davon ab, langwierige Studiengänge wie Jura oder Medizin zu absolvieren, sondern sich aktiver in der realen Welt zu engagieren, um sich an die schnellen Veränderungen durch AI anzupassen. Gleichzeitig fordert die Community, dass die AI-Entwicklung vorrangig manuelle Arbeit automatisieren sollte, anstatt kreative oder Büroarbeiten. (Quelle: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/artificial)

AI-Anwendungen und Benutzerfeedback : Benutzer teilten die Nützlichkeit von GPT-5 in der esoterischen Statistik, obwohl eine sorgfältige Überprüfung weiterhin erforderlich ist. Der Vergleich der Ausgaben von ChatGPT und Grok-Modellen (z.B. das „Well well well“-Meme) wurde zu einem Community-Hotspot und löste Diskussionen über die Merkmale verschiedener LLMs aus. Gleichzeitig vermissen einige Benutzer das Gefühl, 2022 mit ChatGPT gestritten zu haben, und empfanden dies als eine „Platon-und-Sokrates“-ähnliche Interaktion. (Quelle: colin_fraser, Reddit r/ChatGPT, Reddit r/ChatGPT)

AI-Modell-Open-Sourcing und Community-Wert : Die Open-Source-Veröffentlichung des xAI Grok 2.5 Modells löste in der Community eine breite Diskussion über dessen Leistung, Architektur und tatsächlichen Wert aus. Obwohl einige Benutzer seine Wettbewerbsfähigkeit im Vergleich zu aktuellen SOTA-Modellen in Frage stellen, ist die Mehrheit der Meinung, dass Open Weights für die Entwicklung der Community von entscheidender Bedeutung sind, da sie wertvolle Ressourcen für die Forschung bereitstellen und die Bewahrung von AI-Modellen als kulturelles Erbe fördern. (Quelle: Reddit r/ChatGPT, Reddit r/LocalLLaMA, Dorialexander)
AI-Soft Power und Vertrauen : Der ehemalige japanische Diplomat Ren Ito prägte das Konzept des „Zeitalters der AI-Soft Power“ und betonte, dass bei der globalen Verbreitung von AI-Modellen Vertrauen und menschenzentrierte Prinzipien wichtiger sein werden als reine technologische Überlegenheit. Er ist der Ansicht, dass, da Hochleistungsmodelle nicht länger das ausschließliche Eigentum einiger weniger Tech-Giganten sind, die vertrauenswürdigste AI durch ihre Integration in alltägliche Entscheidungen zu einer tiefgreifenden Quelle von Soft Power werden wird. (Quelle: SakanaAILabs)
Umweltauswirkungen von AI : Die Community diskutierte die Kontroverse um den Wasserverbrauch von Google AI. Obwohl Google behauptet, dass jeder AI-Prompt nur wenig Wasser verbraucht, weisen Experten darauf hin, dass diese Berechnung den Wasserverbrauch von Kraftwerken zur Stromversorgung der Rechenzentren nicht berücksichtigt, was zu einer Unterschätzung des tatsächlichen Verbrauchs führt. Dies hat die öffentliche Aufmerksamkeit und Diskussion über den ökologischen Fußabdruck der AI-Technologie ausgelöst. (Quelle: jonst0kes, Reddit r/artificial)

AI Agent und Prompt Engineering : Die Community diskutierte die Risiken der Prompt Injection in LLMs und stellte fest, dass diese noch nicht ausreichend beachtet und effektiv gelöst wurden, was besondere Vorsicht beim Aufbau von AI Agents erfordert. Gleichzeitig wurde die Komponierbarkeit und Praktikabilität von AI Agent Architekturen (wie LangChain Deep Agents) beachtet, da sie komplexe Probleme effektiv lösen können. (Quelle: fabianstelzer, hwchase17)
AI-Forschungs- und Entwicklungskultur : Die Community diskutierte den Missbrauch von AI-Terminologie (z.B. die vage Definition von „Frontier“), die Infragestellung des Phänomens, dass VCs zu RL-Experten werden, und die Ansicht, dass die Trainingskosten von LLMs möglicherweise unterschätzt werden. Darüber hinaus teilten Entwickler praktische Erfahrungen beim Bau benutzerdefinierter Annotationsanwendungen und betonten deren „unreasonable alpha“-Wert bei der Verbesserung der Datenqualität. (Quelle: agihippo, Dorialexander, Dorialexander, HamelHusain)
Tiefgreifender Einfluss von AI auf die Programmierung : AI verändert das Wesen des Programmierens, weg von einfachem Syntaxwissen hin zu einem höheren Niveau des Aufbaus und des konzeptionellen Verständnisses. Ein Entwickler bemerkte, dass AI es ermöglicht, Dinge in einem einst unvorstellbaren Ausmaß zu bauen, was ein Gefühl des „furchtlosen Bauens“ vermittelt. Gleichzeitig diskutierte die Community die Neudefinition des Wertes von Programmierern durch AI und argumentierte, dass AI die Illusion des „nur Syntax kennenden“ Programmierers ersetzt, nicht aber den echten Entwickler. (Quelle: MParakhin, nptacek, gfodor)
AI und Realitätssimulation: Weltmodelle und Embodied AI : Weltmodelltechnologien (wie Genie 3) können durch die Verarbeitung von YouTube-Videos Realitätssimulationen erstellen und neue Welten generieren, in denen verkörperte AI (wie SIMA Agent) lernen und sich anpassen kann. Dieser Kreislauf des „AI-Trainings im AI-Geist“ löst philosophische Überlegungen über die „Träume“ der AI und die Natur unserer eigenen Realität aus und deutet auf die Zukunft von Trainingssimulatoren für allgemeine verkörperte AI hin. (Quelle: jparkerholder, demishassabis, teortaxesTex)
💡 SONSTIGES
Wert der Midjourney-Ästhetik-Präferenzdaten : Die von Midjourney-Nutzern generierten Daten zu ästhetischen Präferenzen und Benutzerpersönlichkeiten werden auf Milliarden von Dollar geschätzt. Diese Ansicht unterstreicht das enorme kommerzielle Potenzial von Benutzerinteraktionsdaten in AI-Produkten, insbesondere in Bereichen wie Bildgenerierung und personalisierten Empfehlungen. (Quelle: BlackHC)

Historischer Rückblick auf das MacBook GPU-Training : Ein Entwickler blickte auf die frühen Erkundungen des MacBook im Bereich des GPU-Trainings zurück und stellte fest, dass die GPU-Trainingsgeschwindigkeit des MacBook zwischen 2016 und 2017 ein Viertel der P100 erreichte und die Modellfeinabstimmung unterstützte. Die anschließende Entwicklung wurde jedoch als „mittelmäßige Politik, der es an echter technischer Vision mangelte“ beschrieben, was viele frühe Innovatoren enttäuschte. (Quelle: jeremyphoward)
