
Schlüsselwörter:AI-Energieverbrauch, Gemini AI, AI-Inferenz, AI-Modell, AI-Chip, Rechenzentren, CO2-Fußabdruck, Effizienzsteigerung, Energieverbrauchsdaten von Google Gemini, Tatsächliche Kosten der AI-Inferenz, Energieverbrauchsanteil von AI-Chips, AI-Energieverbrauch in Rechenzentren, Reduzierung des CO2-Fußabdrucks durch AI
🔥 Fokus
Google veröffentlicht AI-Energieverbrauchsbericht, enthüllt wahre Kosten und Effizienz der AI-Inferenz : Google hat erstmals Energieverbrauchsdaten für die Inferenz des Gemini AI-Modells veröffentlicht. Ein durchschnittlicher Text-Prompt verbraucht 0,24 Wattstunden Strom und 0,26 Milliliter Wasser, was deutlich unter den öffentlichen Erwartungen liegt. Der Bericht analysiert detailliert den Energieverbrauchsanteil von AI-Chips, CPU/RAM, inaktiven Geräten und Rechenzentrumskosten und weist darauf hin, dass der Energieverbrauch pro durchschnittlichem Prompt von Mai 2024 bis Mai 2025 um das 33-fache und der CO2-Fußabdruck um das 44-fache gesunken ist, hauptsächlich dank verbesserter Modell- und Hard-/Softwareeffizienz. Dies erhöht die Transparenz des AI-Energieverbrauchs und liefert wichtige Daten für die Branchenforschung, jedoch wurde die Gesamtzahl der Anfragen nicht offengelegt, und ein standardisiertes Messsystem muss noch etabliert werden. (Quelle: MIT Technology Review, jeremyphoward, scaling01, eliebakouch, giffmana, teortaxesTex, dilipkay)

NASA und IBM kooperieren bei AI-Modell Surya zur Verbesserung der Sonnensturmvorhersage : NASA und IBM haben gemeinsam das Open-Source-Modell Surya veröffentlicht, das darauf abzielt, das Verständnis und die Vorhersage von Sonnenphysik und Wettermustern zu verbessern. Das Modell analysiert zehn Jahre NASA-Solardaten und kann Wissenschaftlern Frühwarnungen vor gefährlichen Sonneneruptionen liefern, die die Erde treffen könnten. Sonnenstürme können Funksignale und Satellitenbetrieb stören sowie Astronauten gefährden. Suryas Vorhersagefähigkeiten werden dazu beitragen, deren Auswirkungen zu mindern. Obwohl sie nicht verhindert werden können, ermöglichen sie eine frühzeitige Planung von Gegenmaßnahmen und stellen einen bedeutenden Durchbruch für AI im Bereich der wissenschaftlichen Vorhersage dar. (Quelle: MIT Technology Review)
Microsoft AI-Chef warnt vor “AI-psychischer Abhängigkeit” und fordert ethische Standards in der Branche : Mustafa Suleyman, CEO von Microsoft MAI, warnt davor, dass Nutzer aufgrund der realistischen Nachahmung von Bewusstsein durch AI emotionale Abhängigkeiten entwickeln und sogar Fälle von “AI-psychischer Abhängigkeit” mit Selbstverletzung oder Suizid auftreten könnten, was insbesondere Jugendliche gefährdet. Er betont, dass SCAI (scheinbar bewusste AI) in den nächsten zwei bis drei Jahren Realität werden könnte, AI jedoch im Wesentlichen kein Bewusstsein besitzt. Suleyman fordert AI-Unternehmen auf, klar zu deklarieren, dass ihre Produkte kein Bewusstsein haben, Mechanismen zur “Enttäuschung” zu entwickeln und Sicherheitsrichtlinien zu teilen, um das menschliche Wohl zu schützen, den Missbrauch von AI zu verhindern und sich auf wirklich wichtige Dinge zu konzentrieren. (Quelle: mustafasuleyman, Reddit r/ArtificialInteligence, Reddit r/artificial)

MIT-Bericht enthüllt Dilemmata bei der AI-Anwendung in Unternehmen und den Aufstieg einer “Schatten-AI-Wirtschaft” : Der MIT-Bericht “The GenAI Divide: State of AI in Business 2025” zeigt auf, dass 95% der AI-Pilotprojekte in Unternehmen aufgrund von hohen Kosten, Starrheit und mangelnder Integration in Arbeitsabläufe scheitern, während 90% der Mitarbeiter privat AI-Tools wie ChatGPT nutzen und so eine “Schatten-AI-Wirtschaft” bilden, die zu einer enormen, ungemessenen Produktivitätssteigerung führt. Der Bericht betont, dass die AI-Technologie selbst erfolgreich ist, aber die Beschaffungs- und Managementstrategien der Unternehmen problematisch sind. Unternehmen sollten aufhören, interne Lösungen zu entwickeln, stattdessen mit Anbietern zusammenarbeiten und aus den praktischen Anwendungserfahrungen ihrer Mitarbeiter lernen. Dieses Phänomen zeigt, dass Consumer-AI-Tools in Bezug auf Flexibilität und Anpassungsfähigkeit den Unternehmenslösungen überlegen sind und wirft Fragen zur Rentabilität traditioneller AI-Investitionen in Unternehmen auf. (Quelle: douwekiela, Reddit r/artificial, Reddit r/ArtificialInteligence)

🎯 Trends
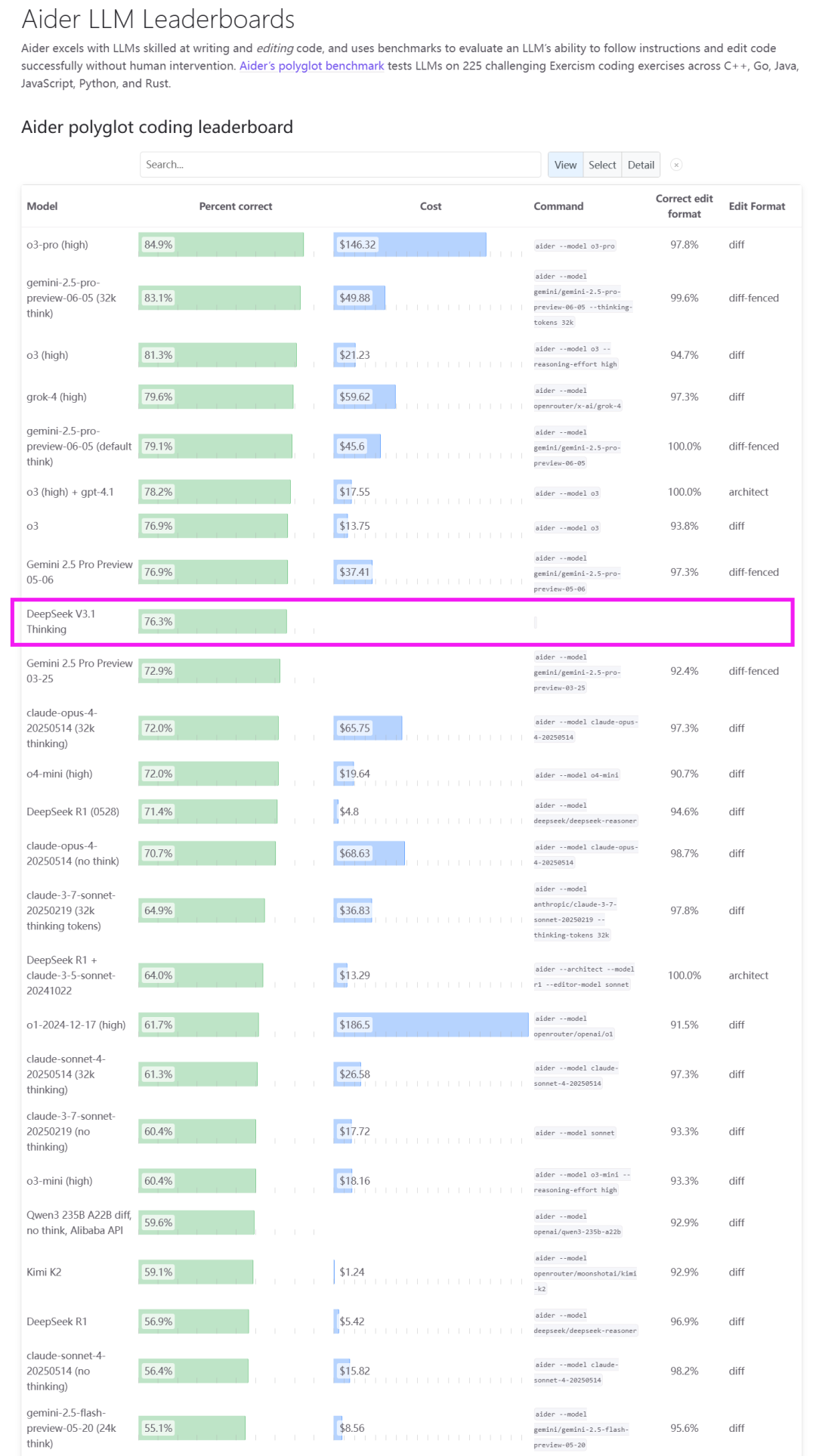
DeepSeek V3.1 veröffentlicht, läutet Agent-Ära ein und ist mit chinesischen Chips kompatibel : DeepSeek hat offiziell das Modell V3.1 veröffentlicht, das als erster Schritt in die Ära der Agents positioniert ist. Diese Version verwendet eine hybride Inferenzarchitektur, die sowohl “Denk”- als auch “Nicht-Denk”-Modi unterstützt und die Fähigkeiten in den Bereichen Tool-Nutzung, Agent-Aufgaben, Code und mathematisches Schlussfolgern erheblich verbessert, insbesondere mit einem Score von 66,0% auf SWE-Bench Verified. V3.1 bietet auch erstmals native Kompatibilität mit der Anthropic API und kündigt Preisanpassungen für die API an, wobei die Eingabepreise bei mindestens 0,07 USD pro Million Tokens liegen. Noch bemerkenswerter ist, dass DeepSeek betont, dass V3.1 das UE8M0 FP8 Scale-Format verwendet, um eine tiefe Anpassung an die bevorstehenden nationalen Chips der nächsten Generation zu ermöglichen. Dies wird als wichtiges Signal für die Hard- und Software-Kooperation in der nationalen Rechenleistungskette angesehen und kommt den chinesischen AI-Chipherstellern zugute. (Quelle: dotey, scaling01, QuixiAI, QuixiAI, cline, vllm_project, OfirPress, huggingface, stanfordnlp, Reddit r/LocalLLaMA)
Google AI-Modus-Upgrade: Agentic-Fähigkeiten und personalisierte Erfahrungen weltweit expandieren : Googles AI-Modus erhält ein großes Upgrade, das fortschrittlichere Agentic- (Agenten-basierte) und Personalisierungsfunktionen einführt und auf über 180 Länder und Regionen weltweit ausgeweitet wird. Der AI-Modus kann Nutzern nun helfen, Restaurants zu finden und zu buchen (bald auch Eventtickets und lokale Termine), die Ergebnisse können an persönliche Vorlieben und Interessen angepasst werden, und Antworten des AI-Modus können mit einem Klick geteilt werden. Darüber hinaus wurde der Energieverbrauch von Text-Prompts in Google Gemini Apps erheblich reduziert, und Tools wie NotebookLM und Veo im AI-Modus sowie über 20 AI-Funktionen in der Pixel 10-Serie wurden eingeführt, um AI tief in den Alltag zu integrieren. (Quelle: GoogleDeepMind, Google, arankomatsuzaki, op7418, Google, TheRundownAI, demishassabis, MIT Technology Review)

Cohere veröffentlicht Command A Reasoning-Modell, stärkt Inferenzfähigkeiten für Unternehmensaufgaben : Cohere hat sein fortschrittlichstes Unternehmens-Inferenzmodell, Command A Reasoning, vorgestellt. Dieses Modell wurde speziell für die Bewältigung komplexer Inferenzaufgaben auf Unternehmensebene entwickelt, wie z.B. tiefgehende Forschung und Datenanalyse. Cohere hat außerdem zugesagt, die Modellgewichte als Open Source bereitzustellen, um das AI-Forschungsökosystem zu unterstützen. Das Modell zeigte hervorragende Leistungen bei der Tool-Nutzung und in Agent-Benchmarks und wird voraussichtlich die fortschrittlichen Inferenzfähigkeiten von Unternehmen in AI-Anwendungen vorantreiben. (Quelle: leonardtang_, JayAlammar, scaling01, sarahookr, huggingface)

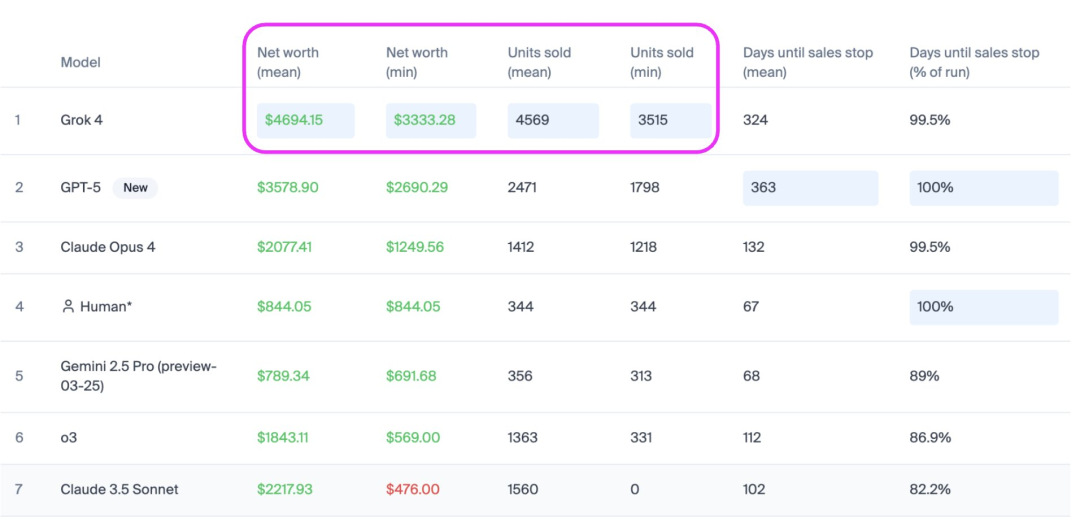
Musks Grok-4 übertrifft GPT-5 in der AI-Verkaufsrangliste Vending Bench : Musks Grok-4 hat auf der Vending Bench AI-Verkaufsrangliste hervorragend abgeschnitten, mit etwa doppelt so hohen Verkaufszahlen wie GPT-5, einem Umsatzwachstum von 31% und einem Mehrverkauf von 1100 US-Dollar im Vergleich zu GPT-5, wobei es in Stabilität und Verkaufszahlen die Oberhand behielt. Vending Bench ist ein Benchmark-Test, der die Leistung von AI-Agents bei langfristigen, komplexen Geschäftsaufgaben bewertet, indem er die Verwaltung eines Verkaufsautomaten-Geschäfts durch AI simuliert. Dieser Test betont die kontinuierliche Entscheidungsfähigkeit und das Verständnis langer Kontexte von AI, deckt die Herausforderungen auf, die AI-Modelle bei der Aufrechterhaltung von Sicherheit und Zuverlässigkeit über längere Zeiträume hinweg haben, und wird als ein Weg zur Überprüfung eines frühen AGI-Prototyps angesehen. (Quelle: teortaxesTex)
Mirage 2, die weltweit erste AI-native Game Engine, iteriert und ermöglicht universelle Generierung und Echtzeit-Interaktion : Dynamic Labs hat Mirage 2 veröffentlicht, die als Weiterentwicklung der weltweit ersten AI-nativen Game Engine gilt, die von einem Echtzeit-Weltmodell angetrieben wird und in der Lage ist, jede Spielwelt sofort zu erschaffen, zu erleben und zu verändern. Mirage 2 bietet eine signifikant verbesserte Generierungsleistung, unterstützt eine reaktionsschnellere Prompt-Steuerung, geringere Spielverzögerung und universelle Bereichsmodellierung, und kann hochgeladene Bilder in interaktive Spielwelten umwandeln. Obwohl es noch Probleme mit der Präzision der Bewegungssteuerung und der visuellen Konsistenz gibt, machen die schnelle Iteration und die Spielbarkeit das Modell zu einem potenziellen Konkurrenten für DeepMind Genie 3. (Quelle: scaling01, Vtrivedy10, BlackHC)

Huawei Smart Screen MateTV stellt mehrere neue AI-Technologien vor für ein “Smartphone-ähnliches TV-Erlebnis” : Huawei hat für seinen Smart Screen MateTV mehrere innovative Technologien vorgestellt, die ein intelligentes Erlebnis bieten sollen, das sich “wie das Bedienen eines Smartphones auf einem Fernseher” anfühlt. Das neue Produkt ist mit Harmony OS 5 und dem unabhängigen Bildqualitätschip Honghu Vivid ausgestattet und unterstützt die Lingxi Floating Touch-Steuerung. Mit der Unterstützung von AI-Technologie kann MateTV AI-Personenerkennung und AI-Filmsuche realisieren und durch das Hongmeng Large Model und multimodale Erkennung die Bedürfnisse von Familienmitgliedern verstehen. Das Xiaoyi Large Model unterstützt die Sprachsuche nach Filmen, AI-Algorithmen verbessern automatisch die Bildqualität und unterstützen die End-to-End HDR Vivid- und Audio Vivid-Standards, wodurch der Fernseher zu einem intelligenten Heim-Hub wird. (Quelle: 36氪)

Qwen-Image-Edit erreicht Platz zwei in der Bildbearbeitungs-Arena, Leistung vergleichbar mit GPT-4o : Alibabas Qwen-Image-Edit-Modell belegte bei seinem Debüt in der Bildbearbeitungs-Arena den zweiten Platz mit einem ELO-Score von 1098, wobei seine Leistung mit GPT-4o und FLUX.1 Kontext [max] vergleichbar ist. Dieses Open-Source-Modell wurde unter der Apache 2.0-Lizenz veröffentlicht, stellt Modellgewichte bereit und demonstriert starke Fähigkeiten und Vielseitigkeit im Bereich der Bildbearbeitung, wodurch Entwicklern eine hochwertige Open-Source-Option geboten wird. (Quelle: Alibaba_Qwen)

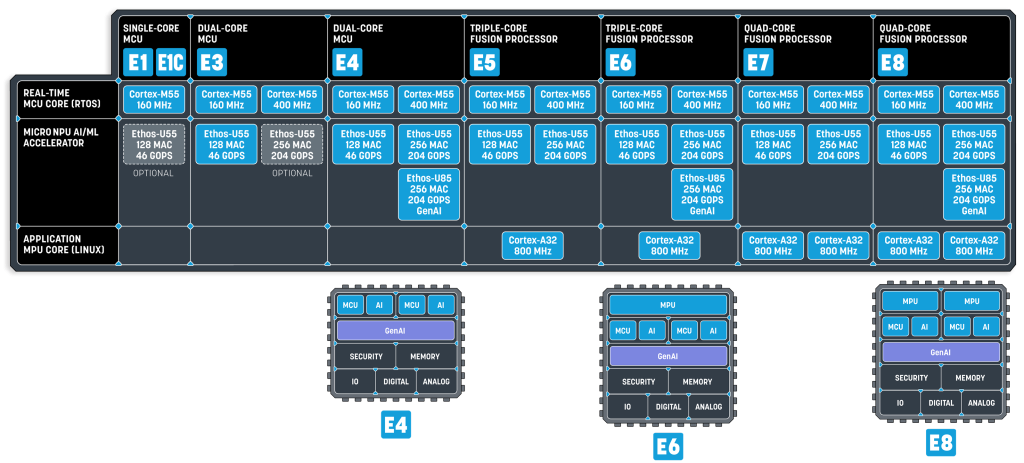
Small Language Models (SLM) als zukünftiger Trend für Embedded AI : Die neueste Forschung von NVIDIA zeigt, dass Small Language Models (SLM) die Zukunft der Agents sind, und hat Nemotron-Nano-9B-V2 veröffentlicht. SLMs werden durch Techniken wie Knowledge Distillation, Pruning und Quantisierung aus großen Modellen komprimiert, mit Parameterbereichen von wenigen Millionen bis zu mehreren Milliarden, sind kompakter und effizienter und eignen sich für ressourcenbeschränkte Edge- und Embedded-Geräte. Der Betrieb von SLMs erfordert nicht nur leistungsstarke NPUs, sondern auch einen Systembus mit hoher Bandbreite und eine eng gekoppelte Speicherkonfiguration. Unternehmen wie Alif Semiconductor haben bereits SLM-fähige MCUs und Fusionsprozessoren auf den Markt gebracht, was darauf hindeutet, dass SLMs die MCU- und MPU-Landschaft grundlegend verändern werden. (Quelle: 36氪)
GPT-5 Pro zeigt neue mathematische Inferenzfähigkeiten, durchbricht traditionelle Grenzen : GPT-5 Pro soll im Bereich der Mathematik “neuartige” Schlussfolgerungsfähigkeiten gezeigt haben, indem es bessere Grenzen beweisen konnte, die in früheren Arbeiten nicht entdeckt wurden. Diese Fähigkeit beschränkt sich nicht nur auf die Mathematik, sondern erstreckt sich auch auf Bereiche wie die theoretische Physik, was das enorme Potenzial von AI-Modellen bei der Lösung komplexer Probleme und der Wissensschaffung aufzeigt, das über einfache Mustererkennung und Datenabruf hinausgeht und zu einer tieferen Intelligenz führt. (Quelle: kevinweil)

🧰 Tools
LlamaParse verbessert Dokumentenanalysefähigkeiten, bietet Multimodus-RAG-Unterstützung : LlamaParse hat seine Dokumentenanalysefähigkeiten erheblich verbessert und drei Modi eingeführt: Cost-effective, Agentic und Agentic Plus. Der Cost-effective-Modus ist kostengünstig und eignet sich gut für Text-, Tabellen-, Schriftarten- und mehrsprachige Dokumente; der Agentic-Modus ist standardmäßig umfassender und kann Diagramme und komplexe Layouts verarbeiten; der Agentic Plus-Modus bietet die höchste Qualität der komplexen Dokumentenanalyse. Diese Modi sollen die Anforderungen von RAG (Retrieval Augmented Generation) und Standard-Dokumentenextraktions-Workflows erfüllen und die Effizienz und Genauigkeit verbessern. (Quelle: jerryjliu0)
HuggingFace führt GPU-Aufgabenplanung ein, vereinfacht AI-Modelltraining und -bereitstellung : HuggingFace hat eine neue GPU-Aufgabenplanungsfunktion eingeführt, die es Benutzern ermöglicht, GPU-Jobs mit einem einzigen Befehl zu planen. Diese Funktion nutzt das UV-Tool zur Vereinfachung der Abhängigkeitsdefinition, unterstützt die Auswahl der benötigten Hardware und verwendet die CRON-Syntax für die Planung. Dies bietet AI-Entwicklern eine bequemere und effizientere Methode für das Modelltraining und die Bereitstellung, insbesondere für Aufgaben, die regelmäßig ausgeführt werden müssen oder ressourcenintensive Berechnungen erfordern. (Quelle: ben_burtenshaw)

OpenAI Conversations API-Upgrade unterstützt Kontextspeicherung und Konnektorfunktionen : Die Responses API von OpenAI erhält zwei große Updates: Die Conversations-Funktion ermöglicht es Entwicklern, den Kontext von API-Aufrufen (Nachrichten, Tool-Aufrufe, Tool-Ausgaben usw.) zu speichern, sodass Benutzer dort fortfahren können, wo sie das letzte Mal aufgehört haben. Die Connectors-Funktion unterstützt das Abrufen von Kontext aus mehreren Quellen wie Gmail, Google Calendar, Dropbox usw. in einem einzigen API-Aufruf. Diese Funktionen sollen Entwicklern die Arbeit beim Erstellen persistenter, multi-source AI-Anwendungen erleichtern und die Benutzererfahrung sowie die Entwicklungseffizienz verbessern. (Quelle: nptacek, gdb)

Vercel AI Gateway offiziell gestartet, bietet zugriffsfreie Multi-Modell-API-Dienste : Vercel hat offiziell das AI Gateway eingeführt, das Entwicklern eine einheitliche API-Schnittstelle bietet, über die Hunderte von AI-Modellen und mehrere Anbieter integriert werden können. Die Plattform übernimmt automatisch Authentifizierung, Ratenbegrenzung, Failover, Nutzungsverfolgung und Abrechnung, sodass Benutzer keine mehreren API Keys verwalten müssen. Das AI Gateway verspricht keine Aufschläge; Benutzer können ihre eigenen Keys und Verträge mitbringen und den Modellaufrufdienst nutzen. Dies vereinfacht die Modellverwaltung und den Bereitstellungsprozess für AI-Anwendungsentwickler erheblich und reduziert die betriebliche Komplexität. (Quelle: op7418)

Modal baut vollständigen AI-Infrastruktur-Stack auf, unterstützt GPU-Planung und asynchrone Warteschlangen : Das Modal-Team hat jede Ebene der AI-Infrastruktur von Grund auf neu aufgebaut, einschließlich Dateisystem, Netzwerk, asynchronen Warteschlangen und Multi-Cloud-GPU-Orchestrierung. Dieser tief integrierte AI-Infrastruktur-Stack soll AI-Anwendungen eine hochleistungsfähige, skalierbare Laufzeitumgebung bieten und die grundlegenden Herausforderungen von AI-Workloads lösen. Modals Bemühungen bieten Entwicklern eine starke Backend-Unterstützung, sodass sie sich auf die Entwicklung und Anwendung von AI-Modellen konzentrieren können. (Quelle: akshat_b, charles_irl, sarahcat21, StasBekman, TheZachMueller)
Open WebUI veröffentlicht neue Version 0.6.23 mit zahlreichen Fehlerbehebungen und Funktionsverbesserungen : Open WebUI hat die neue Version 0.6.23 veröffentlicht, die mehrere wesentliche Verbesserungen und neue Funktionen mit sich bringt. Dieses Update zielt darauf ab, die Benutzererfahrung zu verbessern, bestehende Probleme zu beheben und die Plattformfähigkeiten zu erweitern, um eine stabilere und funktionsreichere Interaktionsumgebung für AI-Chatbot-Schnittstellen zu bieten. (Quelle: Reddit r/OpenWebUI)

LlamaIndex führt vibe-llama-Tool ein, vereinfacht LLM-Entwicklung und Agent-Konfiguration : LlamaIndex hat das Kommandozeilen-Tool vibe-llama veröffentlicht, das darauf abzielt, den Entwicklungsprozess von LlamaIndex durch kontextsensitive Coding Agents zu vereinfachen. Dieses Tool konfiguriert automatisch den neuesten Kontext und Best Practices für das LlamaIndex-Framework, LlamaCloud und Workflows für 16 beliebte Coding Agents wie Cursor AI, Claude Code und GitHub Copilot, wodurch Entwickler schneller LlamaIndex-basierte Anwendungen erstellen können. (Quelle: jerryjliu0)
vLLM unterstützt DeepSeek-V3.1, bietet effizienten LLM-Inferenzdienst : Das vLLM-Projekt hat die offizielle Unterstützung für das DeepSeek-V3.1-Modell angekündigt, das es Benutzern ermöglicht, nahtlos zwischen “Denk”- und “Nicht-Denk”-Modi in jeder Anfrage zu wechseln. Die effizienten Servicefähigkeiten von vLLM ermöglichen es DeepSeek-V3.1, problemlos auf Multi-GPU-Umgebungen skaliert zu werden, insbesondere geeignet für Agent-, Tool- und schnelle Inferenz-Workloads, und bietet Entwicklern eine leistungsstarke LLM-Bereitstellungslösung. (Quelle: vllm_project, vllm_project)

Figma und Cursor AI erreichen tiefe Integration, steigern Effizienz im Design-to-Code-Workflow : Figma und Cursor AI haben eine tiefe Integration über das MCP (Model Context Protocol) erreicht, die den Design-to-Code-Workflow erheblich optimiert. Benutzer können nun MCP in Figma aktivieren und es zu Cursor AI hinzufügen. Durch Kopieren des Links eines Figma-Komponents können Entwickler Cursor AI direkt bitten, dieses Komponent zu implementieren, und der Agent extrahiert automatisch Code und Screenshots. Diese Integration wird voraussichtlich die Zusammenarbeit zwischen Designern und Entwicklern erheblich verbessern und den Produktentwicklungszyklus beschleunigen. (Quelle: BrivaelLp)
MongoDB und LangChainAI kooperieren, um AI Agents Langzeitgedächtnis zu ermöglichen : MongoDB und LangChainAI haben sich zusammengetan, um den MongoDB Store for LangGraph einzuführen, der AI Agents die Fähigkeit zu Langzeitgedächtnis verleiht. Diese Funktion ermöglicht es Agents, Wissen über verschiedene Konversationen hinweg zu behalten, wodurch sie intelligenter und kontextsensitiver werden. In Kombination mit der bestehenden Unterstützung von MongoDB für Kurzzeit-Konversationsverlauf-Checkpoints bietet dies eine vollständige Grundlage für den Aufbau wirklich zustandsbehafteter, produktionsreifer Agents und löst die entscheidende Herausforderung der Kohärenz von Agents über mehrere Interaktionen hinweg. (Quelle: Hacubu, hwchase17)
Qwen-image-mps v0.2 veröffentlicht, ermöglicht extrem schnelle Bildbearbeitung auf Mac Studio M3 Ultra : Qwen-image-mps v0.2 – Edit Lightning wurde veröffentlicht und hat die Bildbearbeitungsgeschwindigkeit erheblich verbessert. Auf einem Mac Studio M3 Ultra benötigt der Standardmodus (50 Schritte) 16 Minuten und 04 Sekunden, der schnelle Modus (8 Schritte) nur 2 Minuten und 37 Sekunden, und der ultraschnelle Modus (4 Schritte) ist sogar auf 1 Minute und 18 Sekunden verkürzt. Dieses Update macht die lokale Bildbearbeitung effizienter, insbesondere für Kreative, die schnelle Iterationen benötigen. (Quelle: ImazAngel)

Gemini CLI-Update bringt IDE-Integration, Tastenkombinationen und vimMode : Die Gemini Command Line Interface (CLI) hat ein Update erhalten, das neue Funktionen wie IDE-Integration, Tastenkombinationen und vimMode hinzufügt. Diese Verbesserungen zielen darauf ab, die Effizienz und Bequemlichkeit für Entwickler bei der Nutzung der Gemini CLI zu steigern, sodass sie sich nahtloser in den täglichen Entwicklungs-Workflow integrieren lässt und eine benutzerfreundlichere Umgebung für AI-Programmierung und Interaktion bietet. (Quelle: _philschmid)
llama.cpp-Projekt Paddler konzentriert sich auf den Aufbau und die Erweiterung der LLM-Infrastruktur : Das Projekt Paddler der llama.cpp-Community konzentriert sich auf den Aufbau und die Erweiterung der LLM-Infrastruktur. Das Projekt hat im vergangenen Jahr erhebliche Fortschritte gemacht und zielt darauf ab, Benutzern eine leistungsstarke, skalierbare lokale LLM-Bereitstellungslösung auf Basis von llama.cpp zu bieten und die Anwendung von LLMs auf persönlichen Geräten und kleinen Servern zu fördern. (Quelle: ggerganov)
DeepSeek unterstützt Anthropic API, Claude Code kann direkt auf DeepSeek V3.1 zugreifen : DeepSeek hat die Unterstützung für die Anthropic-ähnliche API angekündigt, was bedeutet, dass Tools wie Claude Code direkt in das DeepSeek-V3.1-Modell integriert werden können. Entwickler müssen nun lediglich die API-Adresse und den Schlüssel konfigurieren, um die Inferenz- und Konversationsfähigkeiten von DeepSeek-V3.1 in allen Umgebungen zu nutzen, die die Anthropic API unterstützen, was die Integration des DeepSeek-Modells in bestehende Ökosysteme erheblich vereinfacht. (Quelle: karminski3)

📚 Lernen
“1500 Prompt Engineering Papers Show Everything You Know Is Wrong” enthüllt Irrtümer im Prompt Engineering : Eine eingehende Studie, die auf über 1500 Artikeln basiert, weist darauf hin, dass die meisten auf Social Media verbreiteten Ratschläge zum Prompt Engineering unwirksam oder sogar kontraproduktiv sind. Der Bericht enthüllt sechs große Irrtümer: Längere Prompts sind besser, mehr Beispiele sind besser, perfekte Formulierung ist am wichtigsten, Chain-of-Thought gilt für alles, menschliche Experten schreiben die besten Prompts, und einmal eingestellt, wird es vergessen. Die Studie betont, dass erfolgreiche Unternehmen mehr Wert auf Struktur statt Länge legen, selektiv wenige Beispiele verwenden, Format über Formulierung stellen, Techniken auf die Aufgabe zuschneiden, Prompt-Optimierung automatisieren und Prompts als kontinuierlich zu verbesserndes Produkt betrachten. Dies widerlegt traditionelle Annahmen und bietet eine evidenzbasiertere Anleitung für die Entwicklung von AI-Anwendungen. (Quelle: 36氪)
Fin-PRM: Domänenspezifisches Prozess-Belohnungsmodell für den Finanzbereich zur Verbesserung der LLM-Finanzinferenz : Fin-PRM ist ein domänenspezifisches Prozess-Belohnungsmodell für Finanzaufgaben, das zur Überwachung der Zwischeninferenzschritte von LLMs verwendet wird. Das Modell integriert Belohnungsüberwachung auf Schritt- und Trajektorie-Ebene und ermöglicht eine feingranulare Bewertung von Finanzlogik-Inferenz-Trajektorien. Fin-PRM findet Anwendung sowohl in Offline- als auch in Online-Belohnungslern-Settings und kann zur Auswahl hochwertiger Inferenz-Trajektorien für das Distillations-Fine-Tuning, zur Bereitstellung dichter Prozess-Belohnungen für Reinforcement Learning sowie zur Steuerung der belohnungsinformierten Inferenz während des Tests verwendet werden. Experimentelle Ergebnisse zeigen, dass Fin-PRM in Finanzinferenz-Benchmarks signifikant besser abschneidet als generische PRMs und einen wichtigen Wert für die Experten-Inferenz-Ausrichtung von LLMs im Finanzbereich bietet. (Quelle: HuggingFace Daily Papers)
Deep Think with Confidence: Neue Methode zur Steigerung der LLM-Inferenz-Effizienz und -Leistung : DeepConf (Deep Think with Confidence) ist eine einfache und effektive Methode, die darauf abzielt, die Effizienz und Leistung von LLMs bei Inferenzaufgaben zu verbessern. Diese Methode nutzt interne Konfidenzsignale des Modells, um minderwertige Inferenz-Trajektorien während oder nach der Generierung dynamisch zu filtern. DeepConf erfordert kein zusätzliches Modelltraining oder Hyperparameter-Tuning und kann nahtlos in bestehende Service-Frameworks integriert werden. In anspruchsvollen Benchmarks wie AIME 2025 erreichte DeepConf@512 eine Genauigkeit von bis zu 99,9%, während die Anzahl der generierten Tokens um 84,7% reduziert wurde, was die Rechenkosten erheblich senkt. (Quelle: HuggingFace Daily Papers)
Dissecting Tool-Integrated Reasoning: Neuer Benchmark zur Bewertung der LLM-Tool-Integration-Inferenzfähigkeiten : ReasonZoo ist ein umfassender Benchmark-Test, der neun verschiedene Inferenzkategorien abdeckt und darauf abzielt, die Wirksamkeit von Tool-Integrated Reasoning (TIR) bei der Verbesserung der Inferenzfähigkeiten in LLMs zu bewerten. Die Studie führte zwei neue Metriken ein, Performance-Aware Cost (PAC) und Area Under the Performance-Cost Curve (AUC-PCC), um die Inferenz-Effizienz zu bewerten. Empirische Bewertungen zeigen, dass TIR-Modelle sowohl bei mathematischen als auch bei nicht-mathematischen Aufgaben Nicht-TIR-Modellen überlegen sind, die Inferenz-Effizienz verbessern, übermäßiges Nachdenken reduzieren und die Inferenz flüssiger machen. Diese Ergebnisse unterstreichen die allgemeinen Vorteile von TIR und seine Rolle bei der Steigerung des LLM-Potenzials in komplexen Inferenzaufgaben. (Quelle: HuggingFace Daily Papers)
Virtuous Machines: Auf dem Weg zur Allgemeinen Wissenschafts-AI, die eigenständig psychologische Forschung betreibt : Die Arbeit “Virtuous Machines: Towards Artificial General Science” stellt ein domänenunabhängiges, agentenbasiertes AI-System vor, das wissenschaftliche Forschungsworkflows eigenständig durchführen kann, einschließlich Hypothesengenerierung, Datenerfassung und Manuskripterstellung. Das System entwarf und führte eigenständig drei psychologische Studien zu visuellem Arbeitsgedächtnis, mentaler Rotation und Bildlebendigkeit durch und sammelte online Daten. Die Studienergebnisse zeigen, dass die AI-Wissenschaftsentdeckungspipeline in Bezug auf theoretisches Schlussfolgern und methodische Strenge mit erfahrenen Forschern vergleichbar ist, obwohl es noch Einschränkungen bei konzeptuellen Nuancen und theoretischen Erklärungen gibt. Dies ist ein wichtiger Schritt hin zu verkörperter AI und verspricht, die wissenschaftliche Entdeckung durch reale Experimente zu beschleunigen. (Quelle: HuggingFace Daily Papers)
Tsinghua, Peking und Zhejiang führen Akademiker-Kandidaten an, AI und Robotik werden zu Schlüsselbereichen der Erweiterung : Die Liste der gültigen Kandidaten für die Wahl der Akademiker der Chinesischen Akademie der Wissenschaften und der Chinesischen Akademie der Ingenieurwissenschaften 2025 wurde veröffentlicht, wobei Universitäten wie Tsinghua, Peking und Zhejiang führend sind. Diese Wahl unterstreicht die Aufmerksamkeit für aufstrebende Disziplinen; AI-Wissenschaft und -Technologie sind von einem Unterbereich der Informationstechnologie zu einer eigenständigen Disziplin aufgestiegen und erhalten separate Quoten. Auch die Robotik hat die Cybersicherheit als bevorzugte Förderdisziplin abgelöst. Dies spiegelt die nationale Bevorzugung von Schlüsselbereichen wie AI und Robotik wider, mit einer deutlichen Zunahme von Akademikerkandidaten aus diesen Bereichen, was darauf hindeutet, dass zukünftige Forschungsinvestitionen und Talentförderung sich weiter darauf konzentrieren werden. (Quelle: 36氪)
Lehrbuch “Speech and Language Processing” kostenlos verfügbar, Teilen akademischer Ressourcen löst Diskussionen aus : Dan Jurafskys Lehrbuch “Speech and Language Processing” wird kostenlos angeboten, was eine positive Diskussion in der Community über den Wert freier akademischer Ressourcen ausgelöst hat. Dieser Schritt wird als Beitrag zu Open Science und Bildung angesehen, der mehr Menschen Zugang zu hochwertigen AI/NLP-Lernmaterialien ermöglicht und sowohl für Anfänger als auch für Forscher von großer Bedeutung ist. (Quelle: stanfordnlp)
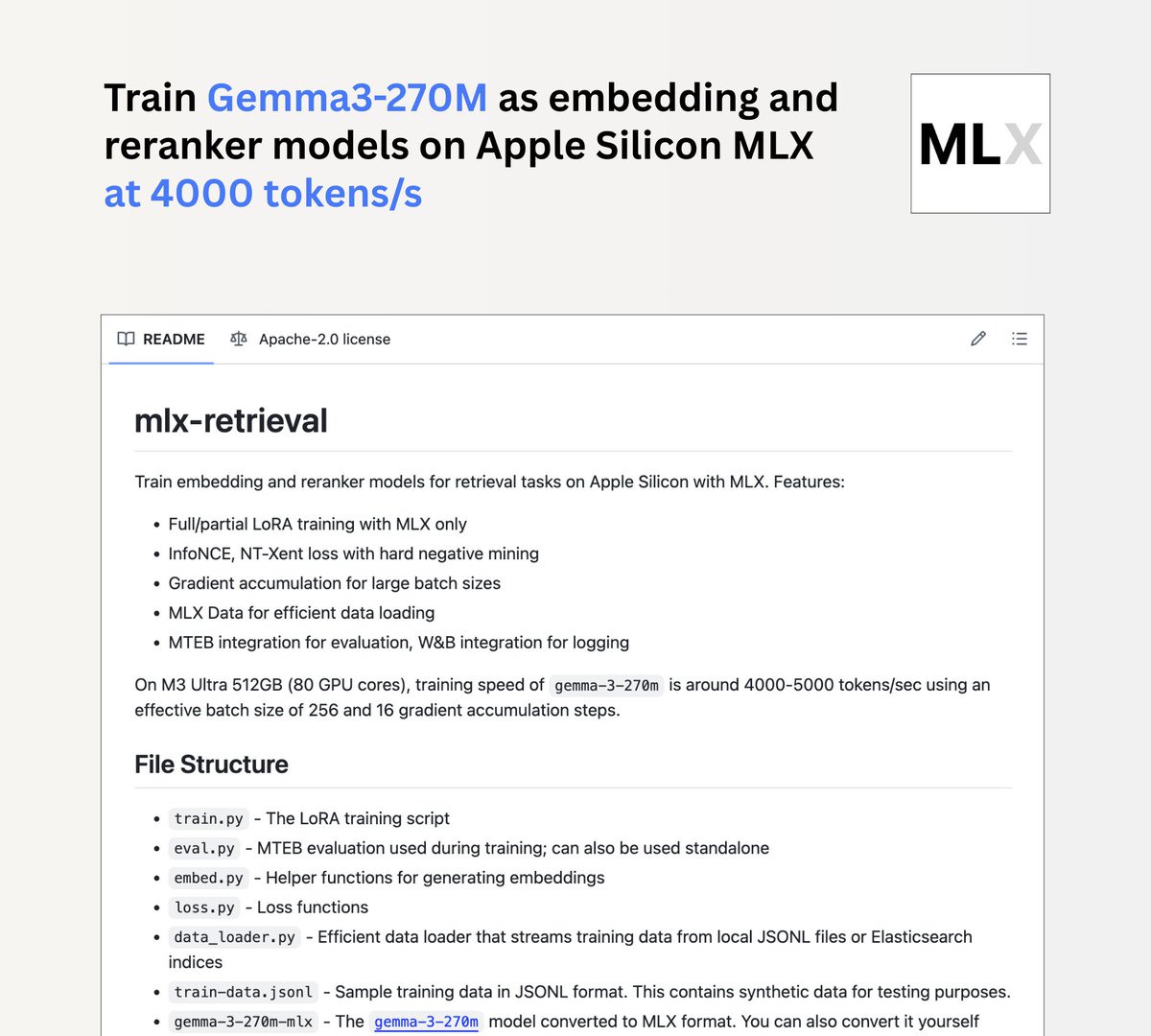
Jina AI startet mlx-retrieval-Projekt, ermöglicht lokales Training von Gemma3 270m auf Mac M-Chips : Jina AI hat das mlx-retrieval-Projekt veröffentlicht, das es Mac M-Chip-Benutzern ermöglicht, das Gemma3 270m-Modell lokal als mehrsprachiges Embedding- oder Re-Ranking-Modell zu trainieren. Das Projekt erreichte auf einem M3 Ultra eine Trainingsgeschwindigkeit von 4000 Tokens/Sekunde und integriert Standardpraktiken wie LoRA, InfoNCE, Gradientenakkumulation und Streaming-Datenlader sowie MTEB-Evaluierung, was eine effiziente und nutzbare Lösung für die lokale AI-Modellentwicklung bietet. (Quelle: awnihannun)
Reddit-Benutzer teilen Prinzipien von LLM-Low-Bit-Modellen: Ein Leitfaden von 1 Bit bis FP16-Quantisierung : Ein Reddit-Benutzer hat detailliert erklärt, dass Low-Bit-Modelle nicht “hirntot” sind, sondern durch intelligentes Opfern von Informationen eine Modellverkleinerung erreichen. Der Artikel erklärt schrittweise die Prinzipien der LLM-Quantisierung, von 1-Bit-Memes, 2-Bit-TL;DR, 4-Bit-Übersicht, 8-Bit-Tiefenlesung bis hin zur FP16-Forschung, einschließlich Schlüsseltechnologien wie Mixed Precision, Kalibrierung und neue Architekturen (z.B. BitNet). Dies bietet eine tiefe Einsicht, wie LLMs auf ressourcenbeschränkten Geräten Leistung aufrechterhalten, und teilt relevante Lernressourcen. (Quelle: Reddit r/LocalLLaMA)

Reddit-Benutzer diskutieren Bildähnlichkeit und das I-JEPA-Modell : Ein Reddit-Benutzer hat einen Artikel über die Erforschung der Bildähnlichkeit mit I-JEPA geteilt, der sowohl reine PyTorch- als auch Hugging Face-Implementierungen abdeckt. I-JEPA, als selbstüberwachtes Lernmodell, zeigt Potenzial bei der Extraktion von Bildmerkmalen und der Ähnlichkeitsmessung und bietet neue Methoden für Aufgaben wie Bildabruf und -klassifizierung im Bereich des Computer Vision. (Quelle: Reddit r/deeplearning)

💼 Business
OpenAI CFO diskutiert erstmals IPO-Möglichkeit und erwägt Verkauf von AI-Infrastrukturdiensten : OpenAI-CFO Sarah Friar hat erstmals öffentlich die Möglichkeit eines zukünftigen IPOs des Unternehmens erörtert und bekannt gegeben, dass der Umsatz im Juli einen einzelnen Monat 1 Milliarde US-Dollar überschritten hat. Sie wies darauf hin, dass OpenAI unter enormem Druck aufgrund von Rechenleistungsmangel steht und erwägt, Amazon nachzuahmen, indem es das Fachwissen im Design und Bau von AI-Rechenzentren in eine neue Einnahmequelle umwandelt und AI-Infrastrukturdienste an andere Unternehmen verkauft. Friar betonte, dass Microsoft trotz der sich ändernden Partnerschaft mit OpenAI aufgrund der tiefen Bindung im Bereich des geistigen Eigentums über viele Jahre hinweg ein wichtiger Partner bleiben wird. (Quelle: 36氪, 36氪)
Meta friert AI-Abteilung-Einstellungen ein und verbietet interne Versetzungen, löst “AI-Blasen”-Bedenken aus : Das Wall Street Journal berichtet, dass Meta die Einstellung in seinem neu gegründeten “Meta Superintelligence Lab” (MSL) eingefroren und Mitarbeitern dieser Abteilung teamübergreifende Versetzungen untersagt hat. Dieser Schritt erfolgt, nachdem Meta erhebliche Summen ausgegeben hat, um über 50 AI-Forscher und Ingenieure von Konkurrenten abzuwerben, was Bedenken hinsichtlich einer “AI-Blase” aufkommen lässt. Ein Meta-Sprecher bezeichnete dies als “grundlegende Organisationsplanung”, doch Quellen weisen auf Reibereien zwischen neuen und alten Mitarbeitern aufgrund von Gehaltsunterschieden hin. Der Einstellungsstopp steht in engem Zusammenhang mit der vierten Umstrukturierung von Metas AI-Abteilung, bei der das MSL in vier separate Gruppen aufgeteilt wurde, was eine Anpassung der AI-Strategie des Unternehmens und eine Berücksichtigung der Kosteneffizienz zeigt. (Quelle: MIT Technology Review, 36氪, 36氪)
Kosten für AI-Anwendungsbereitstellung steigen, Entwickler beklagen schrumpfende Gewinne : Obwohl AI-Giganten die API-Aufrufpreise gesenkt hatten, stagnierten die Kosten für die Bereitstellung fortschrittlicher AI in Unternehmen im Jahr 2025 oder stiegen bei einigen Modellen sogar erheblich an. Insider berichten, dass die AI-bezogenen Azure-Rechnungen des Finanzsoftwareentwicklers Intuit voraussichtlich auf 30 Millionen US-Dollar ansteigen werden. Das AI-Programmiertool Cursor begann ebenfalls, zusätzliche Gebühren basierend auf der tatsächlichen Nutzung zu erheben, was zu Unmut in der Benutzergemeinschaft führte. Dies führt zu einer Verringerung der Gewinnmargen für AI-Anwendungsentwickler, während vorgelagerte Modell- und Cloud-Anbieter (wie Microsoft Azure) entgegen dem Trend profitieren, wobei die Token-Generierung für AI-Agents im Jahresvergleich um das Siebenfache gestiegen ist. Entwickler befürchten die Entstehung eines Oligopols und fordern die Branche auf, sich mit dem Kostenproblem zu befassen. (Quelle: 36氪)
🌟 Community
Soziale Medien diskutieren intensiv über die Auswirkungen von AI auf Beschäftigung, Fähigkeiten und Vertrauen : Die Diskussionen über AI in den sozialen Medien nehmen zu und konzentrieren sich hauptsächlich auf die Auswirkungen von AI auf den Arbeitsmarkt, den Verfall menschlicher Fähigkeiten und das Vertrauen in AI. Einige argumentieren, dass AI ein Vorwand für Entlassungen ist und kurzfristig keine Arbeitsplätze in großem Umfang ersetzen wird, aber langfristig Aufgaben umgestalten wird. Eine Lancet-Studie warnt davor, dass AI-Unterstützung die unabhängigen Diagnosefähigkeiten von Ärzten untergraben könnte, während eine MIT-Studie zeigt, dass Patienten AI mehr vertrauen als Ärzten, selbst wenn die Ratschläge falsch sind. Darüber hinaus führen persönliche Erfahrungen mit AI-Emotionsberatung zu tiefgreifenden Überlegungen über AI-Abhängigkeit und Mensch-Maschine-Beziehungen, und die negative Bewertung des AWS-CEO, dass AI Junior-Mitarbeiter ersetzen könnte, spiegelt die komplexen Emotionen der Community bezüglich des zweischneidigen Schwertes der AI wider. (Quelle: mathemagic1an, 36氪, 36氪, 36氪, Reddit r/artificial, Reddit r/artificial, Reddit r/ArtificialInteligence)

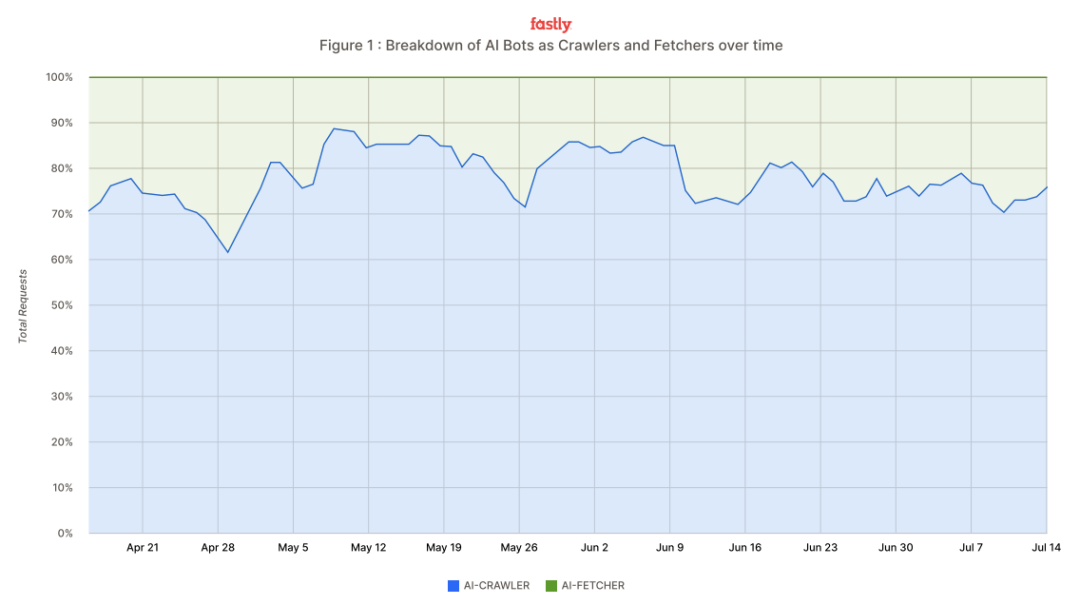
AI-Crawler-Traffic explodiert, Meta, Google, OpenAI genannt, Entwickler setzen Anti-Crawler-“Waffen” ein : Der Cloud-Dienstleistungsriese Fastly berichtet, dass AI-Crawler das Internet mit einer Spitzenrate von 39.000 Anfragen pro Minute überfluten und 80% des AI-Bot-Verkehrs ausmachen, wobei Meta, Google und OpenAI allein 95% des gesamten Crawler-Verkehrs verantworten. Diese Crawler erfassen Website-Inhalte für das Modelltraining und die Echtzeit-Informationssuche, was zu einem enormen Anstieg der Serverlast und der Betriebskosten für Websites führt. Entwickler schlagen zurück und setzen ungewöhnliche Methoden ein, wie das “Proof-of-Work”-Tool Anubis, selbstgemachte “ZIP-Bomben” und gamifizierte Captchas, um unautorisiertes Crawling einzudämmen und ihre Inhalte und Infrastruktur zu schützen. (Quelle: 36氪)
Soziale Medien diskutieren AI-Anwendungen und Herausforderungen in Code RAG, Programmierunterstützung und Agent-Fähigkeiten : In den sozialen Medien diskutieren Entwickler intensiv über Probleme von AI in Code RAG (Retrieval Augmented Generation), wie zu große Code-Dateien, häufige Updates und die Notwendigkeit präziser Abfragen. Gleichzeitig zeigt AI ein enormes Potenzial in der Programmierunterstützung, wie die Fähigkeit von GPT-5, Android-Controller auf iOS zu portieren, und die Integration von Figma mit Cursor AI. Es wird auch diskutiert, dass die Effizienz von AI-Programmiertools (wie Claude Code) von der kognitiven Fähigkeit des Benutzers abhängt; ohne ausreichendes Verständnis sind selbst viele Tools nutzlos. Darüber hinaus wächst das Interesse an Agentic-Fähigkeiten, wie der Bearbeitung von Mehrschrittaufgaben, Tool-Aufrufen und Langzeitgedächtnis, doch deren Zuverlässigkeit, Kosten und das Gleichgewicht mit der menschlichen Zusammenarbeit bleiben Herausforderungen. (Quelle: dotey, gfodor, gfodor, gfodor, BrivaelLp, pierceboggan, nptacek, HamelHusain, imjaredz)
AI-Suchmodus-Revolution löst Bedenken hinsichtlich des traditionellen Werbe-Ökosystems aus : Die Nutzerzahlen von Googles AI-Suchfunktion (AI Overviews) sind stark gestiegen, und ihr konversationsbasierter Suchmodus hat in den USA und Indien über 100 Millionen monatlich aktive Nutzer erreicht, was Bedenken hinsichtlich des traditionellen Suchanzeigen-Ökosystems aufkommen lässt. AI-Suche generiert direkte Antworten, reduziert die Notwendigkeit für Benutzer, auf Links zu klicken, und könnte den positiven Kreislauf von “Suche-Traffic-Werbung-Monetarisierung” unterbrechen. Das traditionelle CPC (Cost-per-Click)-Modell steht vor einer Umwälzung und könnte in Zukunft auf ein CPS (Cost-per-Sale)-Modell umgestellt werden. Dieser Wandel stellt eine Herausforderung für traditionelle Suchanbieter dar und treibt auch chinesische Unternehmen wie ByteDance und Tencent dazu an, aktiv AI-Assistenten zu erforschen, um das Sucherlebnis neu zu gestalten und das Geschäftsmodell der nächsten Generation zu finden. (Quelle: 36氪)
AI-Brillen “schwer zu tragen”, ziehen aber weiterhin Herstellerinvestitionen an; Markterziehung und technische Herausforderungen bestehen parallel : Obwohl Apples Vision Pro schlechte Verkaufszahlen aufweist und die Nutzerresonanz auf Xiaomis AI-Brillen durchschnittlich ist, ziehen AI-Brillen weiterhin Investitionen von Herstellern an. Marktprognosen gehen davon aus, dass die Auslieferungen von AR/AI-Brillen bis 2028 über 100 Millionen Einheiten erreichen werden, mit einem Marktvolumen für räumliche intelligente Interaktion von Billionen Yuan. Hersteller glauben, dass die Integration von AI Large Models und AR-Technologie eine neue Generation der Mensch-Computer-Interaktion hervorbringen und die Schwachstellen traditioneller Endgeräte lösen wird. Allerdings stehen AI-Brillen vor Herausforderungen wie Akku-Angst, unnatürlicher Interaktion und Vertrauenskrisen, die durch Kameras ausgelöst werden. Die kontinuierlichen Investitionen der Hersteller zielen darauf ab, technische Probleme zu lösen, den zukünftigen AI-Zugangspunkt zu erobern und Kommerzialisierungspfade durch Hardware-Verkäufe und Content-Abonnements zu erkunden. (Quelle: 36氪)

Hinter den Kulissen der “Embodied AI” von humanoiden Robotern: Immer noch viel menschliche Intervention erforderlich : Soziale Medien und Nachrichtenberichte zeigen, dass trotz der schnellen Entwicklung von Embodied AI und humanoiden Robotertechnologien in der praktischen Anwendung immer noch ein hohes Maß an menschlicher Intervention erforderlich ist. Hinter dem “rasenden” Lauf der Roboter bei Robotik-Wettbewerben steckt oft die Fernsteuerung durch Ingenieure. Auch in Bereichen wie autonomes Fahren und Lagerlogistik gibt es ein “Schattenarbeits”-Modell, bei dem Menschen durch Fernsteuerung Robotern “Seele einhauchen”, um deren Mängel in komplexen Umgebungen auszugleichen. Dieses Mensch-Maschine-Hybridmodell ist zwar kostspielig, aber ein effektiver Weg, um Robotern in der aktuellen Phase Fähigkeiten beizubringen, und hat Diskussionen über die Vorteile der Automatisierungseffizienz und die Behandlung von Arbeitnehmern im Übergang ausgelöst. (Quelle: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, 36氪)

Reddit-Community diskutiert GPT-5s mathematische Fähigkeiten und die Grenzen von AI-Modell-Benchmarks : Die Reddit-Community diskutiert intensiv über die “neuen mathematischen” Fähigkeiten von GPT-5. Einige Benutzer weisen darauf hin, dass die von GPT-5 erstellten Beweise von bestehenden Arbeiten abweichen, während andere bezweifeln, ob dies wirklich “neu” ist oder lediglich eine Integration von Informationen nach einer Suche darstellt. Darüber hinaus haben die Benchmark-Ergebnisse von DeepSeek V3.1 eine Diskussion über die Gültigkeit von LLM-Benchmarks ausgelöst. Viele Benutzer sind der Meinung, dass Benchmarks nicht mehr ausreichen, um die wahren Fähigkeiten und den “Vibe” eines Modells widerzuspiegeln, und bevorzugen persönliche Praxistests. Dies spiegelt das anhaltende Interesse und die Kontroversen in der Community hinsichtlich der tatsächlichen Leistung von AI-Modellen und Bewertungsmethoden wider. (Quelle: Reddit r/ChatGPT, Reddit r/LocalLLaMA)

AI-Aktienhandel boomt, junge Leute sehen AI als “Anlageberater” : Mit dem Aufschwung des chinesischen Aktienmarktes und der Popularität nationaler Large Models versuchen immer mehr junge Menschen, AI als “Anlageberater” für den Aktienhandel zu nutzen. Einige Benutzer haben durch AI-Aktienauswahl und Fondsauswahl Buchgewinne erzielt und glauben, dass AI Nachrichten und Forschungsberichte integrieren und schnell Konzeptaktien filtern kann. Andere Benutzer weisen jedoch darauf hin, dass die Qualität der AI-Ausgabe stark von Daten und Prompts abhängt und oft Halluzinationen auftreten. Einige Large Models haben aus Compliance-Gründen die Empfehlung einzelner Aktien eingestellt und betonen die Anlagerisiken. Auch Broker haben AI-Anlageberatungstools eingeführt, die kostenpflichtige Dienste wie AI-Aktienauswahl und Portfolio-Optimierung anbieten, jedoch alle mit Haftungsausschlüssen versehen sind, die Anleger auf eigene Risiken hinweisen. (Quelle: 36氪)
Reddit-Benutzer diskutieren, ob ChatGPT mit vollständigen Büchern trainiert wurde : Benutzer der Reddit-Community diskutieren darüber, ob ChatGPT mit vollständigen Büchern trainiert wurde. Einige Benutzer glauben, dass LLMs mit allen zugänglichen Texten, einschließlich vollständiger Bücher, trainiert werden, aber sie “kopieren und einfügen” oder “merken” keine Buchinhalte, sondern lernen Wortmuster und konzeptuelle Beziehungen. Andere Benutzer sind der Meinung, dass ChatGPT nur Buchzusammenfassungen kennt oder bei der Beantwortung von Fragen Informationen über das Internet sucht. Die Diskussion spiegelt die Verwirrung der Öffentlichkeit über die internen Funktionsweisen von LLMs sowie die Erforschung der AI-Wissensquellen und der “Verständnis”-Fähigkeiten wider. (Quelle: Reddit r/ArtificialInteligence)
AI-Video-Content-Erstellung: Der Entwicklungspfad von “absurd” zu “Mainstream” : Diskussionen in den sozialen Medien weisen darauf hin, dass AI-Videoinhalte einen Entwicklungspfad von “absurd, peinlich, lustig” über “gefährlich” bis hin zu “allgemein, selbstverständlich” durchlaufen. Derzeit weisen AI-Videos noch deutliche Generierungsspuren auf, doch mit der technologischen Entwicklung wird sich ihre Qualität schnell verbessern. In Zukunft könnten AI-Videos Debatten über das “Verschwinden des Vorteils der Videoproduktion” auslösen, werden aber letztendlich Mainstream werden, wie jede disruptive Technologie in der Geschichte, die weithin akzeptiert und genutzt wird. (Quelle: BrivaelLp)
💡 Sonstiges
Ukrainischer Starlink-Reparaturshop: Die Schlüsselrolle ziviler Kräfte bei der technologischen Absicherung in Kriegszeiten : Die größte Starlink-Reparaturwerkstatt der Ukraine, betrieben von einem zivilen Team unter der Leitung von Oleh Kovalskyy, hat im russisch-ukrainischen Krieg über 15.000 Starlink-Terminals repariert und angepasst. Obwohl die Qualität der Starlink-Geräte kritisiert wird und Unsicherheiten bezüglich der Politikänderungen von Elon Musk bestehen, hat dieses zivile Netzwerk durch effizienten und flexiblen Betrieb die ukrainische Armee mit entscheidender Kommunikationsunterstützung versorgt und die Langsamkeit offizieller Prozesse ausgeglichen. Dieser Fall unterstreicht die Unverzichtbarkeit ziviler Technologiekräfte unter extremen Bedingungen zur Sicherstellung des Betriebs kritischer Infrastrukturen und zur Steigerung der militärischen Effizienz. (Quelle: MIT Technology Review)

Warren Brodey, “Gegner” von AI-Vater Minsky, im Alter von 101 Jahren verstorben : AI-Pionier Warren Brodey ist im Alter von 101 Jahren verstorben. Der ausgebildete Psychiater und Denker erforschte bereits in den frühen Tagen der AI am MIT, wie Technologie menschliches Potenzial freisetzen kann. Mit seinem kybernetischen Hintergrund leistete er Pionierarbeit in der Forschung zu komplexen Systemen und reaktionsfähigen Technologien und plädierte dafür, dass AI den Menschen stärken und nicht ersetzen sollte. Brodey stimmte Marvin Minskys AI-Ansatz, der auf riesigen Datenmengen basierte, nicht zu. Er setzte sich sein Leben lang für eine “flexible” AI ein, die menschliche Kreativität anregt, und warnte davor, dass der Kapitalismus Technologie in Richtung Starrheit lenken könnte. (Quelle: 36氪)

Pewdiepie baut 160GB VRAM AI-Host, könnte ein neues Kapitel für lokale LLMs einleiten : Der bekannte YouTube-Blogger Pewdiepie hat einen AI-Host mit 160 GB VRAM gebaut und plant, darauf das Llama 3 70B-Modell auszuführen. Dieser Schritt löste eine lebhafte Diskussion in der Reddit-Community aus. Viele waren überrascht, dass Pewdiepie in den Bereich der lokalen LLMs vordringt, und spekulierten, dass dies darauf hindeuten könnte, dass lokale AI-Modelle weiter in den Mainstream gelangen werden. Obwohl die Konfiguration unkonventionell ist, zeigt ihr Potenzial für CPU-Offloading und zukünftige Speicher-Upgrades das starke Interesse privater Benutzer an leistungsstarken lokalen AI-Anwendungen. (Quelle: Reddit r/LocalLLaMA)
