
Schlüsselwörter:DeepSeek V3.1, GPT-5, Tencent Hunyuan 3D, Alibaba Qwen-Image, Humanoider Roboter, KI-Agent, Meta AI Reorganisation, DeepSeek V3.1 Base 128K Kontext, GPT-5 Dual-Achsen-Training, Tencent Hunyuan 3D Lite Version FP8 Quantisierung, Qwen-Image Textrendering, Zhiyuan Roboter Kooperation mit Fuling Precision
🎯 Aktuelle Entwicklungen
DeepSeek V3.1 Base überraschend veröffentlicht: DeepSeek hat sein V3.1 Modell mit 685B Parametern und einer auf 128K erweiterten Kontextlänge veröffentlicht. Seine Programmierfähigkeiten übertreffen im Aider Polyglot Test mit 71,6% Claude 4 Opus, wobei es schneller in Inferenz und Antwort ist und nur 1/68 der Kosten von letzterem verursacht. Das Modell führt neue “search token” und “think token” ein, was auf eine mögliche Hybridarchitektur hindeutet. Obwohl die offizielle Veröffentlichung zurückhaltend war, rangiert V3.1 bereits hoch in den Hugging Face Trendcharts, was seine führende Position unter Open-Source-Modellen und die Markterwartungen unterstreicht. (Quelle: 36氪, 36氪, 36氪, ClementDelangue)

OpenAI GPT-5 Fähigkeiten und Strategie: Brad Lightcap, COO von OpenAI, enthüllt, dass der Kern-Durchbruch von GPT-5 in seiner Fähigkeit liegt, autonom zu entscheiden, ob eine tiefe Inferenz durchgeführt werden soll, was die Genauigkeit und Reaktionsgeschwindigkeit erheblich verbessert, insbesondere in den Bereichen Schreiben, Programmieren und Gesundheit. Er betont, dass das Scaling Law nicht tot ist und OpenAI die Modellinnovation durch “zwei Achsen” – Pre-Training und Post-Training – beschleunigt. Obwohl GPT-5 leistungsstark ist, ist es keine AGI; seine “überschüssigen Kapazitätsreserven” bedeuten, dass noch zehn Jahre Produktentwicklung möglich sind. Die Produktphilosophie ist es, Probleme effizient zu lösen, anstatt die Nutzungsdauer zu verlängern, und den Einsatz von AI in Gesundheits- und Unternehmensszenarien zu fokussieren. (Quelle: 36氪, 36氪)

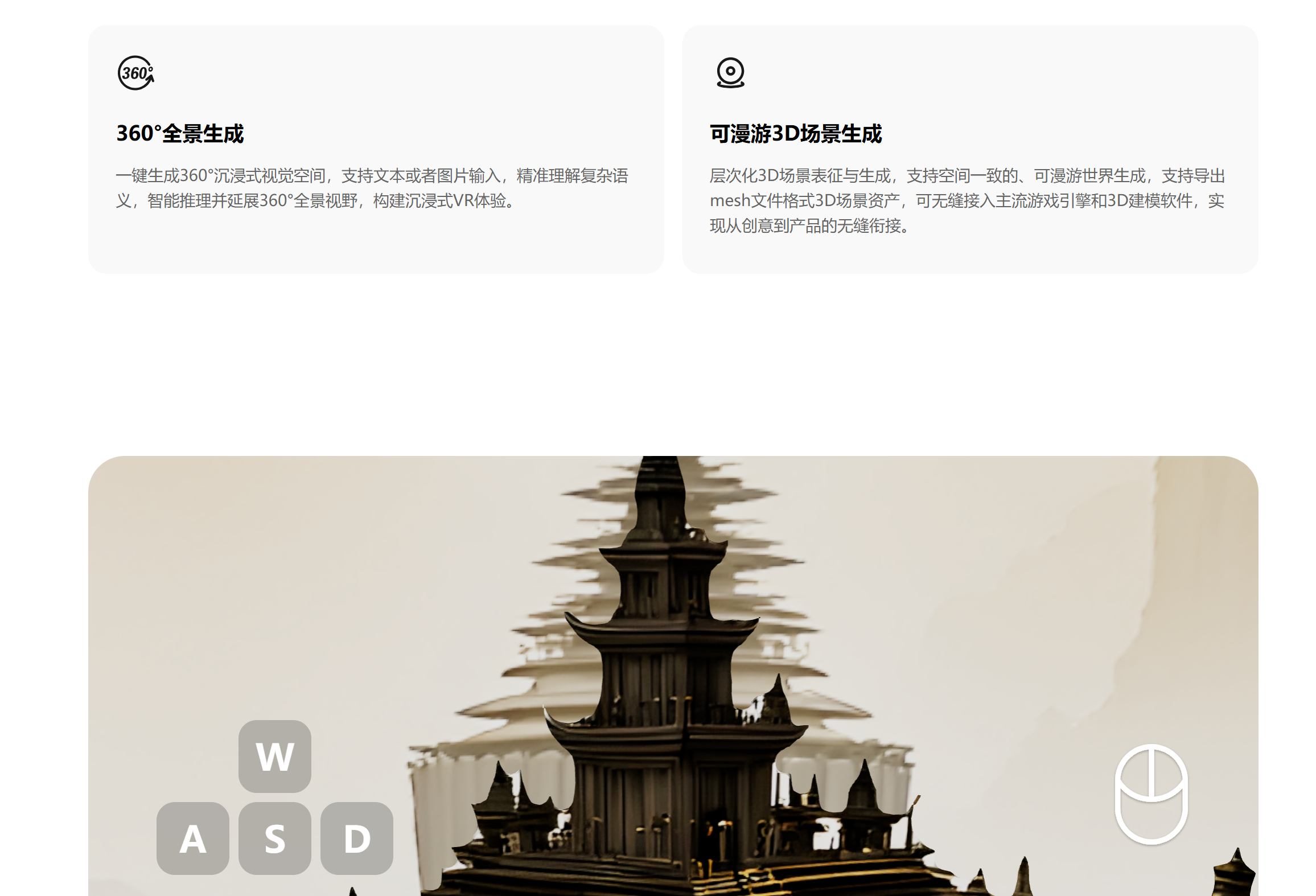
Tencent Hunyuan 3D Lite Version veröffentlicht: Das Tencent Hunyuan Team hat die 3D-Weltmodell Lite Version veröffentlicht, die durch dynamische FP8-Quantisierungstechnologie den Videospeicherbedarf auf unter 17GB reduziert, sodass sie auch auf Consumer-Grafikkarten flüssig läuft. Das Modell kann basierend auf Bildern oder Texten vollständige, editierbare und interaktive 3D-Weltmodelle generieren, was die Effizienz der Szenenentwicklung erheblich steigert. Ziel ist es, mehr Entwickler und Kreative anzuziehen, die Popularisierung von 3D-Modellen voranzutreiben und eine ökologische Verknüpfung mit VR-Geräten, 3D-Druck usw. zu ermöglichen. (Quelle: 36氪)
Alibaba Bildgenerierungsmodell Qwen-Image führt HuggingFace an: Alibaba hat das grundlegende Bildgenerierungsmodell Qwen-Image veröffentlicht, das durch systematisches Data Engineering, progressives Lernen und Multi-Task-Training komplexe Text-Rendering- und präzise Bildbearbeitungsprobleme löst. Das Modell kann mehrzeilige chinesische und englische Texte präzise verarbeiten und bei der Bildbearbeitung semantische und visuelle Konsistenz bewahren. Es verwendet die Architekturen Qwen2.5-VL und MMDiT, bewahrt Details durch doppelte Kodierung und erreicht branchenführende Leistungen bei der allgemeinen Bildgenerierung, Text-Rendering und instruktionsbasierten Bildbearbeitungsaufgaben. (Quelle: 36氪, huggingface, Alibaba_Qwen, fabianstelzer)
Einblick in Bestellungen und Lieferfähigkeit von Humanoiden Robotern: Im Jahr 2025 wird ein signifikanter Anstieg der Bestellungen für humanoide Roboter erwartet, wobei der Fokus des Marktes auf praktischen Anwendungen und der Lieferfähigkeit liegt. Hersteller wie Ubtech, Unitree Robotics und Zhimyuan Robotics haben Großaufträge erhalten, deren Anwendungsszenarien Industrie, Führung, Forschung, Bildung und Altenpflege umfassen. Zhimyuan Robotics hat eine Zusammenarbeit mit Fulin Precision über fast hundert Radroboter vereinbart, und Ubtech hat einen Auftrag für die Beschaffung von Automobilgeräten gewonnen, was zeigt, dass industrielle Szenarien zuerst eine Massenimplementierung erreichen. Die Branche steht vor Herausforderungen in Bezug auf Lieferkettenkapazität, technologische Reife und Standardisierung, aber es wird prognostiziert, dass die Liefermengen in den nächsten Jahren schnell wachsen werden. (Quelle: 36氪)
Perplexity AI’s Chrome-Übernahmeangebot und AI-Browser-Vision: Perplexity AI hatte vorgeschlagen, Google Chrome für 34,5 Milliarden US-Dollar zu kaufen, um ein offenes Web und Benutzersicherheit zu fördern, obwohl dies als PR-Stunt kritisiert wurde. Perplexity CEO Arav Srinivas erklärte, dass AI Agenten, Personalisierung und neue Browsing-Modi das Interneterlebnis neu gestalten werden. Seine langfristige Vision ist ein AI-natives Betriebssystem, das traditionelle Workflows durch proaktive AI ersetzt. (Quelle: AravSrinivas, Reddit r/ArtificialInteligence)
Google DeepMind’s Genie 3 als universeller Simulator: Google DeepMind’s Genie 3 wird als universeller Simulator und nicht als AI Agent beschrieben. Diese Umgebung ermöglicht es der AI, Verhaltensweisen durch wiederholtes Ausprobieren und Scheitern zu entdecken, ähnlich der Lernweise von AlphaGo. Im Bereich der Robotik wird erwartet, dass dies der AI hilft, übertragbare Fähigkeiten zu erlernen und breitere Anwendungen zu fördern. (Quelle: jparkerholder)
Multi-Node-Dienste für große Modelle und vLLM: SkyPilot demonstriert, wie vLLM für Multi-Node-Dienste von Billionen-Parameter-Modellen genutzt werden kann, um große Modelle wie Kimi K2 mit voller Kontextlänge auszuführen. Durch die Kombination von Tensor-Parallelisierung und Pipeline-Parallelisierung vereinfacht SkyPilot die Multi-Node-Einrichtung und kann Replikate skalieren, wodurch die Komplexität und Skalierbarkeit von großen Modell-Deployments effektiv gelöst werden. (Quelle: skypilot_org, vllm_project)
ChatGPT Go in Indien gestartet: OpenAI hat den ChatGPT Go Abonnementdienst in Indien eingeführt, der höhere Nachrichtenlimits, mehr Bildgenerierung, mehr Dateiuploads und längeren Speicher bietet, zum Preis von 399 Rupien. Dieser Schritt zielt darauf ab, ChatGPT auf dem indischen Markt zu verbreiten, und es ist geplant, den Dienst basierend auf Feedback in andere Länder auszuweiten, um ihn erschwinglicher zu machen. (Quelle: sama)
Claude Modell-Updates und Funktionserweiterungen: Anthropic’s Claude Opus 4.1 zeigt im Forschungsmodus bessere Synthese- und Zusammenfassungsfähigkeiten und reduziert Redundanz. Claude Sonnet 4 unterstützt 1M Kontext, ermöglicht die Analyse ganzer Codebasen und die Synthese großer Dokumente und optimiert die Kosten. Claude hat auch einen “Opus 4.1 Plan, Sonnet 4 Execute”-Modus und einen anpassbaren “Lernmodus” hinzugefügt, um das Benutzererlebnis und die Modelleffizienz zu verbessern. (Quelle: gallabytes, Reddit r/ArtificialInteligence)
🧰 Tools
Zhipu veröffentlicht den weltweit ersten mobilen Universal-Agent AutoGLM: Zhipu hat den weltweit ersten mobilen Universal-Agent AutoGLM veröffentlicht, der kostenlos für die Öffentlichkeit verfügbar ist und Android und iOS unterstützt. Dieser Agent kann Aufgaben in der Cloud ausführen, ohne lokale Ressourcen zu belegen, und ermöglicht anwendungsübergreifende Operationen wie Preisvergleiche beim Einkaufen, Essensbestellungen und Berichtsgenerierung. Er basiert auf den Modellen GLM-4.5 und GLM-4.5V und integriert verschiedene Fähigkeiten wie Inferenz, Kodierung und Agentic. Er schlägt das “3A-Prinzip” vor (Allzeit, selbstlaufend ohne Störung, allumfassende Konnektivität), um die Agent-Fähigkeiten für den Massenmarkt zugänglich zu machen. (Quelle: 36氪)

Anycoder integriert GLM 4.5 und Qwen Bildbearbeitungsfunktionen: Die Anycoder-Plattform unterstützt jetzt GLM 4.5 und die Bildbearbeitungsfunktionen von Alibaba Qwen und bietet Bildbearbeitungsfunktionen, die besonders für “vibe coding”-Anwendungsfälle geeignet sind. Qwen-Image-Edit basiert auf dem 20B Qwen-Image-Modell und unterstützt präzise zweisprachige Textbearbeitung (Chinesisch und Englisch), wobei der Bildstil erhalten bleibt, und unterstützt Bearbeitungen auf semantischer und visueller Ebene. (Quelle: Zai_org, _akhaliq, _akhaliq, Alibaba_Qwen)
OpenAI Codex CLI neue Version veröffentlicht: OpenAI hat eine brandneue Rust-Version seines Codex CLI-Tools veröffentlicht, die das GPT-5-Modell verwendet und bestehende GPT Pro-Abonnements nutzen kann. Die neue Version löst viele Probleme der alten Node.js/Typescript-Version, wie schlechte Leistung, schlechte UI/UX, schwache Modellfähigkeiten und rücksichtslosen Betrieb. Die Einführung von Rust hat die Interaktionsgeschwindigkeit und Reaktionsfähigkeit erheblich verbessert, und in Kombination mit den leistungsstarken Kodierungs- und Tool-Aufruffähigkeiten von GPT-5 wird es zu einem starken Konkurrenten für Claude Code. (Quelle: doodlestein)
LangChain DeepAgents Framework und Anwendungen: Die LangChain DeepAgents-Architektur ist jetzt als Python- und TypeScript-Paket verfügbar und bildet die Grundlage für den Aufbau von zusammensetzbaren, nützlichen AI Agenten. Das Framework verfügt über integrierte Planungs-, Sub-Agent- und Dateisystemnutzungsfunktionen und kann zum Aufbau komplexer Anwendungen wie “Deep Research” verwendet werden, um tiefe Forschung und Informationsaggregation zu ermöglichen. (Quelle: LangChainAI, hwchase17, LangChainAI)
Jupyter Agent 2 veröffentlicht: Jupyter Agent 2 wurde veröffentlicht, angetrieben von Qwen3-Coder, läuft auf Cerebras und wird von E2B ausgeführt. Der Agent kann Daten extrem schnell in Jupyter laden, Code ausführen, Ergebnisse zeichnen und Dateiuploads unterstützen. Alle Videodemonstrationen sind in Echtzeit und zeigen seine starke Effizienz bei der Datenanalyse und Codeausführung. (Quelle: ben_burtenshaw)
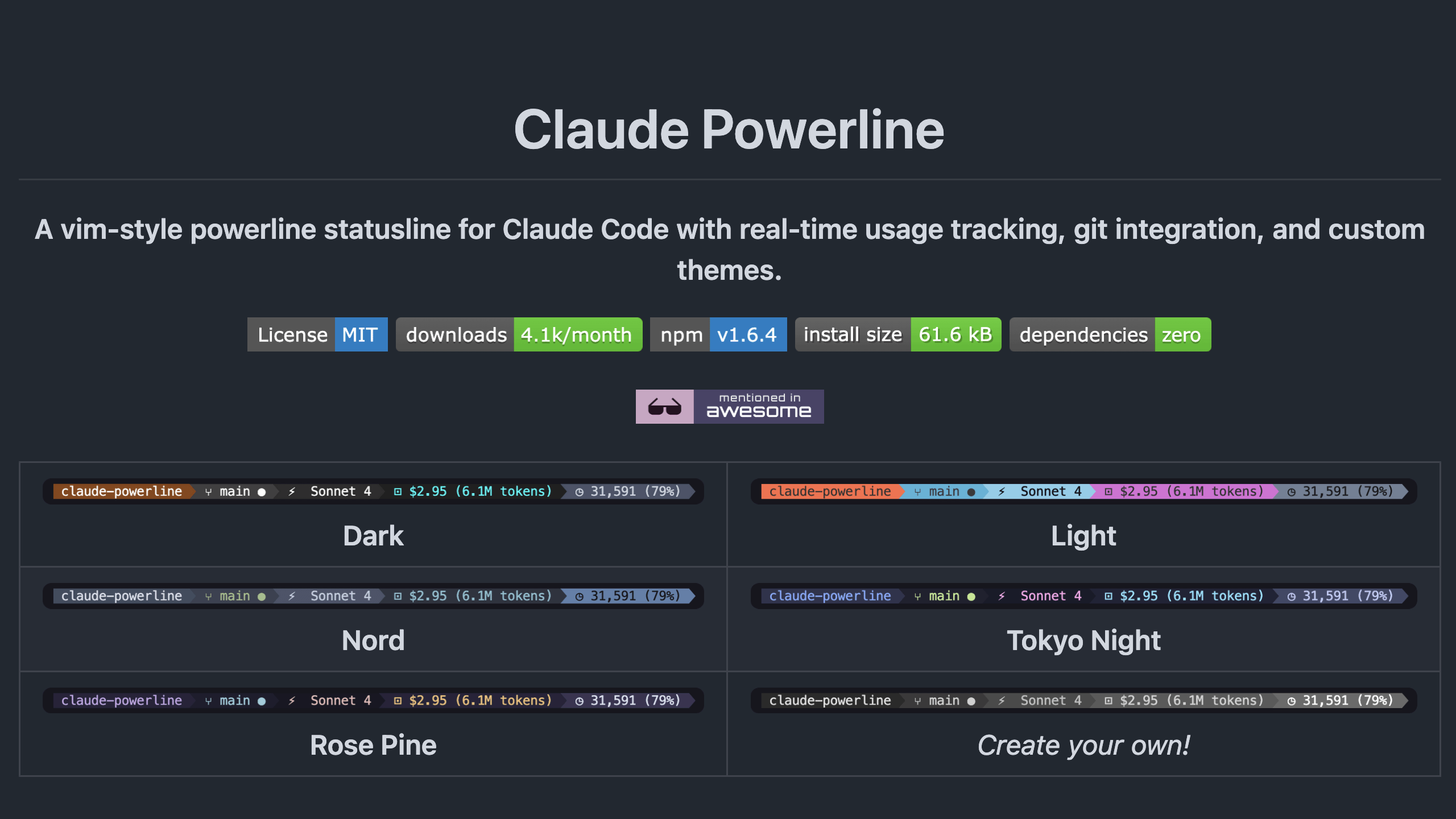
Claude-Powerline Statusleisten-Tool: Claude-Powerline ist ein leichtgewichtiges, sicheres Claude Code Statusleisten-Tool ohne Abhängigkeiten. Es bietet Tmux-Integration, Leistungsmetriken (Antwortzeit, Sitzungsdauer, Nachrichtenanzahl), Versionsinformationen, Kontextnutzung und eine verbesserte Git-Statusanzeige. Das Tool wird über npx installiert, um automatische Updates zu gewährleisten, und verbessert die plattformübergreifende Kompatibilität und Sicherheit. (Quelle: Reddit r/ClaudeAI)
Erkundung der Kombination von lokalen LLMs mit Gesichtserkennung: Ein Entwickler hat versucht, lokale LLMs mit externen Gesichtserkennungstools zu kombinieren, um Personen aus Bildern zu beschreiben und Gesichter online zu suchen. Obwohl die Gesichtssuchtools derzeit nicht lokal sind, zeigt diese Kombination das Potenzial der AI-Erkennung und -Inferenz. Die Diskussion legt nahe, dass die Kombination von Erkennung und Inferenz die Richtung der AI-Entwicklung ist, und blickt auf zukünftige vollständig lokale Gesichtssuch- und Inferenzsysteme voraus. (Quelle: Reddit r/LocalLLaMA)
AI-gestützte Handelsroboter-Entwicklung: Der Entwickler Jordan A. Metzner hat auf Replit mit Public API und ChatGPT in weniger als 6 Stunden einen Handelsroboter entwickelt. Dieser Fall zeigt das Potenzial der AI für schnelle Prototypenentwicklung und im Fintech-Bereich durch “vibe coding” für effizientes Programmieren. (Quelle: amasad)
Cursor CLI Update: Das Cursor CLI-Tool wurde aktualisiert und bietet neue Funktionen wie MCPs (Model Context Protocols), Review Mode, /compress-Funktion, @ -files-Unterstützung und weitere Verbesserungen der Benutzerfreundlichkeit. Diese Funktionen sollen die Effizienz und Bequemlichkeit für Entwickler bei der Codebearbeitung und AI-gestützten Programmierung mit Cursor verbessern. (Quelle: Reddit r/ArtificialInteligence)
📚 Lernen
AI-Evaluierung (Evals) Kurs und Methoden: Hamel Husain hat durch seine Artikel die Popularität von AI-Evaluierungen (Evals) geförd und erfolgreiche Evaluierungskurse angeboten. Er teilt, wie man Datensätze erstellt, um die Fähigkeit der AI zu testen, Unsicherheiten auszudrücken oder Antworten zu verweigern, und betont die Verbesserung der AI-Zuverlässigkeit durch Testsuiten und Datenanalyse. (Quelle: HamelHusain, HamelHusain, TheZachMueller)
Lernparadigma der LLM- und RL-Kombination: Die AI-Entwicklung wird in den nächsten Jahren stark das Paradigma der Kombination von Reinforcement Learning (RL) mit LLMs als Belohnungsfunktionen (LLM-as-a-judge reward functions) anwenden. Diese Methode ermöglicht es Modellen, sich durch Selbstbewertung und Iteration zu verbessern, und ist eine wichtige Richtung für autonomes Lernen und Selbstverbesserung der AI. (Quelle: jxmnop, tokenbender)
JAX TPU zu GPU Trainingsanleitung aktualisiert: Das JAX TPU-Buch wurde um GPU-bezogene Inhalte aktualisiert, die tief in die Funktionsweise von GPUs, den Vergleich mit TPUs, die Netzwerkkonnektivität und die Auswirkungen auf das LLM-Training eintauchen. Dies bietet Entwicklern wertvolle Ressourcen und Einblicke zur Optimierung des LLM-Trainings auf unterschiedlicher Hardware. (Quelle: sedielem, algo_diver)
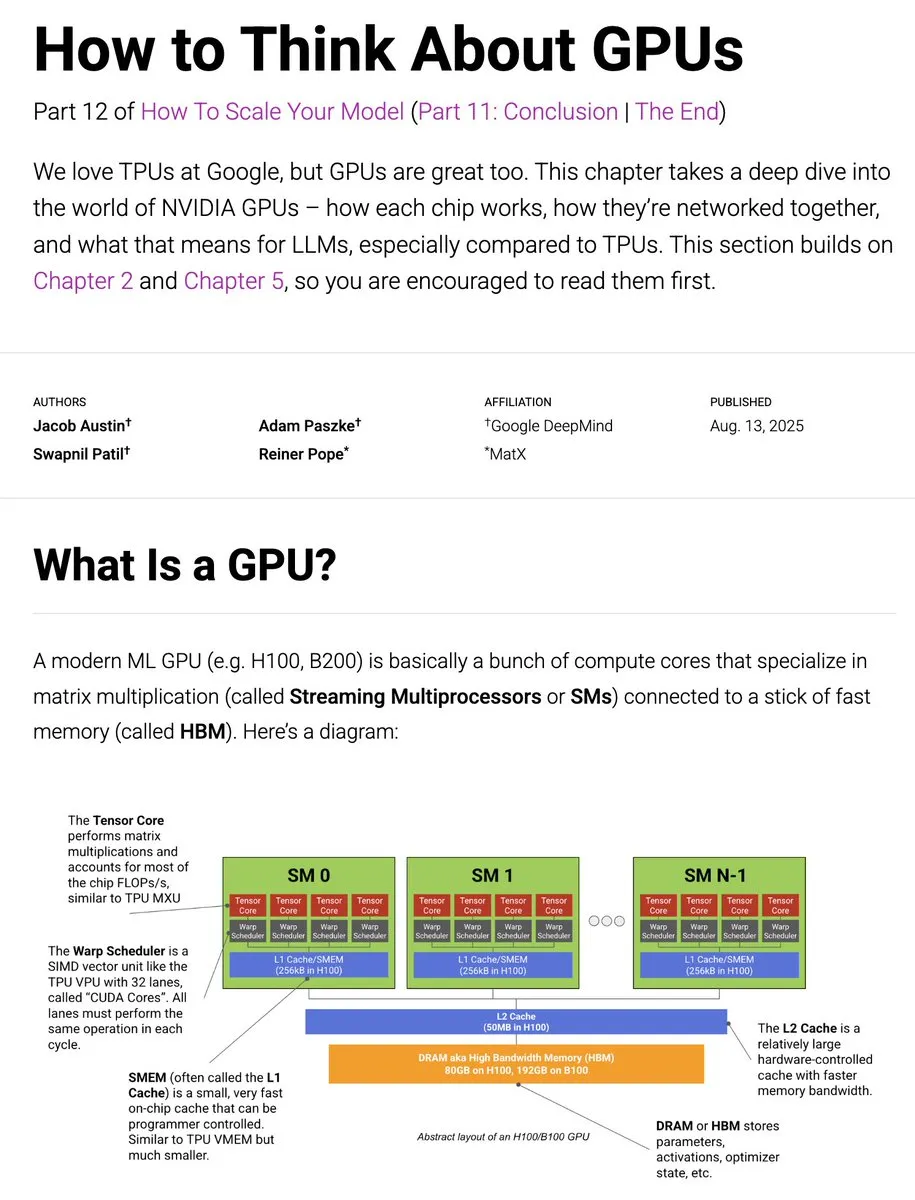
LlamaIndex’s Model Context Protocol (MCP) Dokumentation: LlamaIndex hat eine umfassende Model Context Protocol (MCP)-Dokumentation veröffentlicht, die darauf abzielt, AI-Anwendungen durch standardisierte Schnittstellen mit externen Tools und Datenquellen zu verbinden. MCP unterstützt die Client-Server-Architektur von LLMs mit Datenbanken, Tools und Diensten, sodass Benutzer bestehende Workflows in MCP-Server umwandeln und mit Hosts wie Agenten und Claude Desktop integrieren können. (Quelle: jerryjliu0)
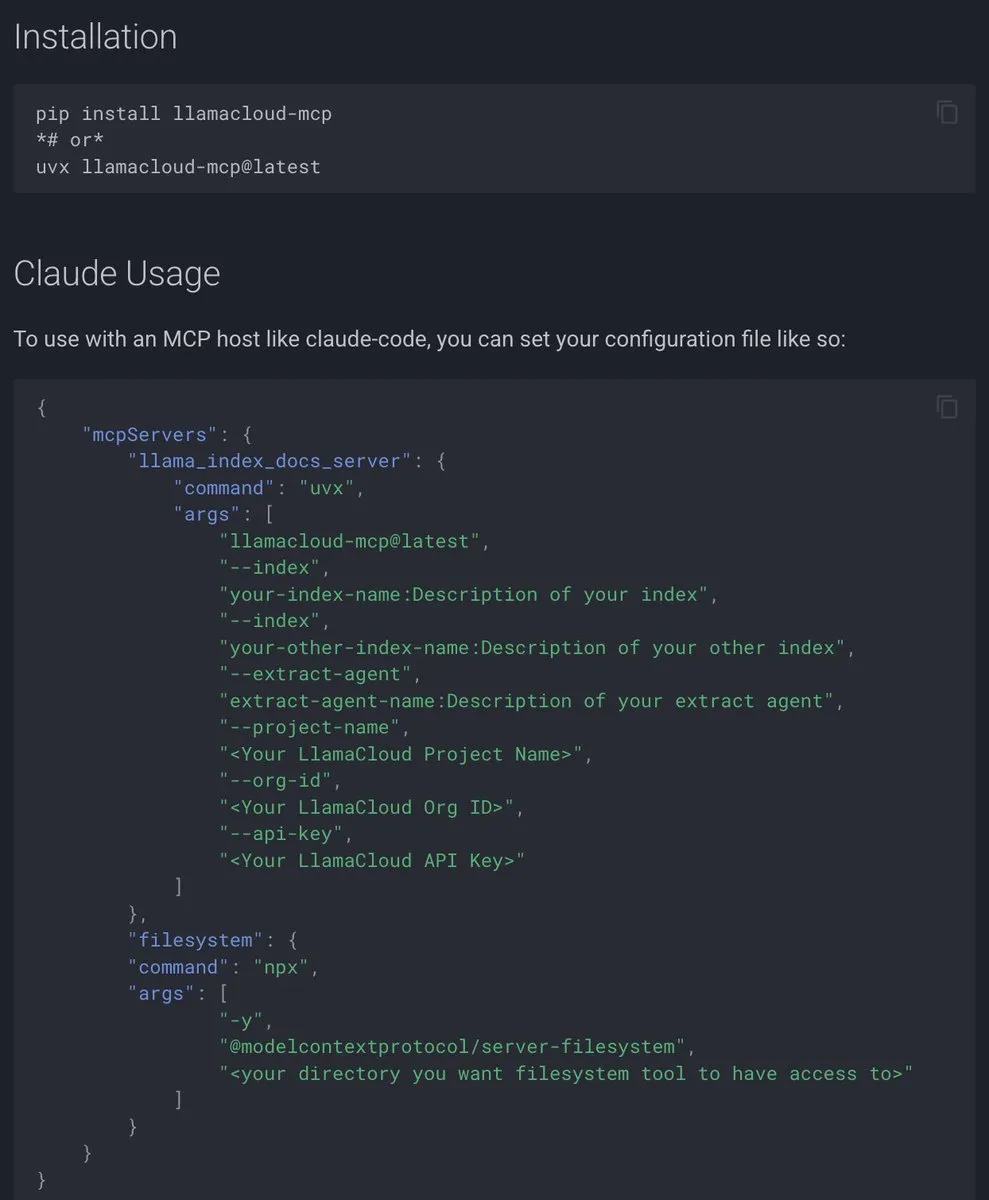
BeyondWeb: Synthetische Daten für Billionen-Parameter-Pre-Training: Das BeyondWeb-Framework generiert dichte, vielfältige synthetische Trainingsdaten, indem es echte Webseiteninhalte in verschiedene Formate wie Tutorials, Q&A und Zusammenfassungen umschreibt. Dies ermöglicht es kleineren Modellen, schneller zu lernen und größere Basismodelle zu übertreffen, wodurch eine höhere Informationsdichte und eine bessere Anpassung an Benutzeranfragemuster erreicht werden. Studien zeigen, dass sorgfältig umgeschriebene synthetische Daten die Effizienz und Genauigkeit des Modelltrainings erheblich verbessern können. (Quelle: code_star)
Verwendung von GPU für AutoLSTM-Training in Google Colab: Ein Reddit-Benutzer hat eine Methode geteilt, um das AutoLSTM-Modell von NeuralForecast in Google Colab mit GPU zu trainieren. Durch das Setzen der accelerator– und devices-Parameter in trainer_kwargs können Benutzer die Verwendung der GPU für das Modelltraining angeben, wodurch die Recheneffizienz verbessert wird. (Quelle: Reddit r/deeplearning)
PosetLM: Vorläufige Studie zu einer Transformer-Alternative: Eine neue Studie stellt PosetLM vor, eine Alternative zum Transformer, die Sequenzen über kausale DAGs verarbeitet, wobei jedes Token mit wenigen vorhergehenden Tokens verbunden ist und Informationen durch Verfeinerungsschritte fließen. Erste Ergebnisse zeigen, dass PosetLM auf dem enwik8-Datensatz 35% weniger Parameter benötigt und eine ähnliche Qualität wie Transformer aufweist, aber die aktuelle Implementierung langsamer ist und mehr Speicher verbraucht. Die Forscher suchen nach Community-Feedback, um die zukünftige Entwicklungsrichtung zu bestimmen. (Quelle: Reddit r/deeplearning)
AI for Video Understanding Tutorial: LearnOpenCV hat ein Tutorial zum Thema AI-Video-Verständnis veröffentlicht, das praktische Abläufe von der Inhaltsmoderation bis zur Videozusammenfassung abdeckt. Der Artikel stellt Modelle wie CLIP, Gemini und Qwen2.5-VL vor und leitet an, wie ein Videoinhaltsmoderationssystem (mit CLIP und Gemini) und ein Videozusammenfassungssystem (mit Qwen2.5-VL) aufgebaut werden können, um Entwicklern beim Aufbau umfassender Video-AI-Pipelines zu helfen. (Quelle: LearnOpenCV)
AI Developer Conference 2025 in New York: DeepLearning.AI kündigt an, dass die AI Dev 25 Konferenz am 14. November 2025 in New York City stattfinden wird. Die Konferenz, veranstaltet von Andrew Ng und DeepLearning.AI, bietet Möglichkeiten zum Kodieren, Lernen und Netzwerken, einschließlich Vorträgen von AI-Experten, praktischen Workshops, Fintech-Spezialthemen und hochmodernen Demonstrationen, mit dem Ziel, über 1200 Entwickler zusammenzubringen. (Quelle: DeepLearningAI, DeepLearningAI)

💼 Business
Meta AI-Abteilungsumstrukturierung und Personalfluktuation: Meta kündigt eine Umstrukturierung seiner AI-Abteilung an und teilt das Super-Intelligence-Labor in vier Teams auf: TBD Lab, FAIR, Produkt- und Anwendungsforschung sowie MSL Infra. Diese Umstrukturierung geht einher mit dem Abgang von AI-Führungskräften und potenziellen Entlassungen; die Mitarbeiterbindungsrate liegt bei nur 64%, weit unter dem Branchendurchschnitt. Meta erforscht aktiv die Nutzung von Drittanbieter-AI-Modellen und erwägt, sein nächstes AI-Modell “geschlossen” zu halten, was im Widerspruch zur bisherigen Open-Source-Philosophie steht und Metas Entschlossenheit widerspiegelt, seine Unternehmensstruktur im AI-Wettbewerb neu zu gestalten, um Durchbrüche zu erzielen. (Quelle: 36氪, 36氪)

Manus AI Umsatz und Entwicklung von Universal-Agenten: Manus AI gibt bekannt, dass sein jährlicher wiederkehrender Umsatz (RRR) 90 Millionen US-Dollar erreicht hat und kurz davor steht, 100 Millionen US-Dollar zu überschreiten, was zeigt, dass AI Agenten von der Forschung zur praktischen Anwendung übergehen. Mitbegründer Ji Yichao erläutert die Entwicklungsrichtung von Universal-Agenten: durch Multi-Agenten-Zusammenarbeit den Ausführungsumfang erweitern (z.B. Wide Research-Funktion) und die “Tool-Oberfläche” des Agenten erweitern, sodass er wie ein Programmierer Open-Source-Ökosysteme aufrufen kann. Manus arbeitet mit Stripe zusammen, um Agent-interne Zahlungen voranzutreiben, mit dem Ziel, die Reibung in der digitalen Welt zu beseitigen. (Quelle: 36氪, 36氪)
AI-Talentkampf und hohe Gehälter: Der Kampf um Talente im AI-Bereich ist intensiv, mit Jahresgehältern für frische Doktoranden, die typischerweise 3 Millionen RMB erreichen, und einzelne Top-Absolventen sogar über 5 Millionen RMB, weit über den Gehältern traditioneller Internet-Führungskräfte. Große Unternehmen wie ByteDance, Alibaba und Tencent sind die Hauptkonkurrenten, die Talente durch hohe Gehälter, Mentoring-Programme, lockere Leistungsbeurteilungen und Projektfreiheit anziehen. Dieses Phänomen spiegelt die Knappheit an Top-AI-Talenten und die Strategie chinesischer Unternehmen wider, frühzeitig zu planen, um den Abfluss von Talenten ins Ausland oder zu Wettbewerbern zu verhindern. (Quelle: 36氪)
🌟 Community
Emotionale Abhängigkeit der Nutzer von AI-Modellen und “Cyber-Liebeskummer”: Nachdem OpenAI GPT-5 veröffentlicht und GPT-4o ersetzt hatte, löste dies heftige Proteste bei den Nutzern aus, die GPT-5 als “unmenschlich” bezeichneten und zu “Cyber-Liebeskummer” führten. Nutzer hatten tiefe emotionale Bindungen zu GPT-4o entwickelt und nannten es sogar “Freund” oder “Leben”. OpenAI gab zu, die emotionalen Reaktionen der Nutzer unterschätzt zu haben und schaltete GPT-4o wieder online. Dieses Phänomen zeigt den Aufstieg von AI-Begleiter-Anwendungen (wie Character.AI), die das menschliche Bedürfnis nach emotionaler Unterstützung erfüllen, aber auch Probleme wie AI-Gedächtnisverlust, Persönlichkeitsverfall und potenzielle psychische Gesundheitsrisiken mit sich bringen. (Quelle: 36氪, Reddit r/ChatGPT, Reddit r/ArtificialInteligence)

Einfluss von AI auf Content-Erstellung und Nachrichtenverkehr: Die Google AI Overview-Funktion führte dazu, dass globale Nachrichtenwebsites innerhalb eines Jahres 600 Millionen Besuche verloren, und die Existenz unabhängiger Blogger ist bedroht. AI fasst Inhalte direkt zusammen, sodass Nutzer nicht mehr auf den Originalartikel klicken müssen, was zu einem drastischen Rückgang des Verkehrs für Nachrichtenplattformen und Content-Ersteller führt. In China zeigen sich erste Auswirkungen auf den Verkehr, während der Verkehr von AI-Plattformen explosionsartig wächst. Content-Agenturen reichen Klagen ein, um ihre Urheberrechte zu schützen, suchen aber auch nach einem Gleichgewicht in der Zusammenarbeit mit AI, was die Herausforderungen und Chancen der Content-Monetarisierung im AI-Zeitalter unterstreicht. (Quelle: 36氪)

Anwendung und Bewertung von AI in der Werbeproduktion: AI wurde zur Erstellung von Duolingo-ähnlichen Werbevideos eingesetzt, einschließlich Eulen-Charakteren, Animationen und Skript-Synchronisation, was eine Produktion ohne Animatoren und Editoren ermöglichte. Die Kommentare zur Wirkung der AI-generierten Werbung waren gemischt: Einige waren erstaunt über die natürliche Synchronisation von Stimme und Lippen, während andere die visuelle Qualität als schlecht oder strategisch unzureichend empfanden. Dies löste eine Diskussion über das Potenzial von AI, menschliche Arbeit in der Kreativbranche zu ersetzen, und den Kernwert von Werbung aus. (Quelle: Reddit r/artificial)

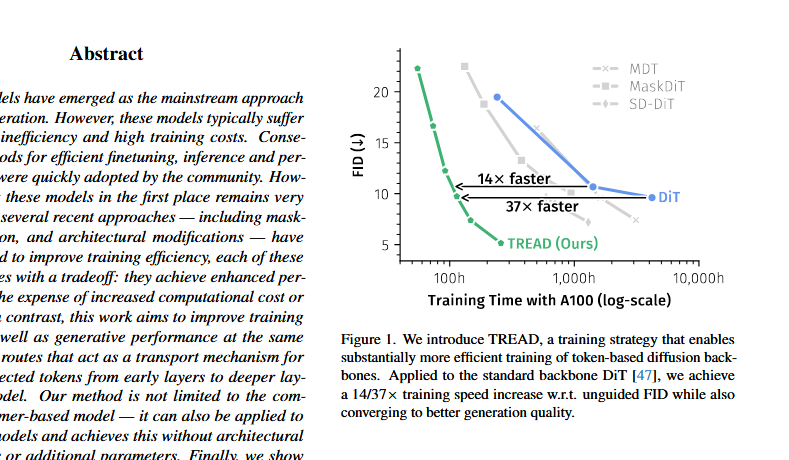
DiT-Architektur-Kontroverse und Saining Xies Antwort: Auf X gab es Diskussionen darüber, dass die DiT (Diffusion Transformer)-Architektur “mathematisch und formal falsch” sei, wobei Probleme wie die zu frühe Stabilisierung des FID, die Verwendung von Post-Layer-Normalisierung und adaLN-zero genannt wurden. DiT-Autor Saining Xie antwortete, dass das Entdecken von Architekturfehlern der Traum eines Forschers sei, und widerlegte einige Punkte aus technischer Sicht, während er zugab, dass sd-vae ein “Schwachpunkt” von DiT sei. Die Diskussion unterstreicht die ständige Infragestellung und Verbesserung bestehender Methoden bei der Iteration von AI-Modellarchitekturen. (Quelle: sainingxie, teortaxesTex, 36氪)
Sicherheits- und Skalierbarkeitsherausforderungen bei der Codeausführung von AI Agenten: AI Agenten stehen beim Schreiben und Ausführen von Code vor zwei zentralen Herausforderungen: Sicherheit und Skalierbarkeit. Das lokale Ausführen von Code ist rechenintensiv, während geteiltes Computing Sicherheitsrisiken und horizontale Skalierungsprobleme mit sich bringt. Die Branche arbeitet daran, eine sichere, skalierbare Laufzeitumgebung für die Codeausführung von Agenten zu schaffen, die die erforderlichen Rechenressourcen, präzise Berechtigungssteuerung und Umgebungsisolation bietet, um das Explorationspotenzial von AI Agenten freizusetzen. (Quelle: jefrankle)
Diskussion über praktische Anwendungsfälle von Claude Code: Die Community diskutiert die praktischen Anwendungen von Claude Code, wobei Nutzer verschiedene erfolgreiche Beispiele teilen, darunter den Aufbau von QC-Software, Offline-Transkriptionstools, einen Google Drive-Organisator, ein lokales RAG-System und eine Anwendung, die Linien in PDFs zeichnen kann. Nutzer sind sich einig, dass Claude Code gut darin ist, “langweilige” grundlegende Arbeiten zu erledigen, und betrachten es als ein Hilfstool auf SWE-I/II-Niveau, das es Entwicklern ermöglicht, sich auf kreativere Aufgaben zu konzentrieren. (Quelle: Reddit r/ClaudeAI)
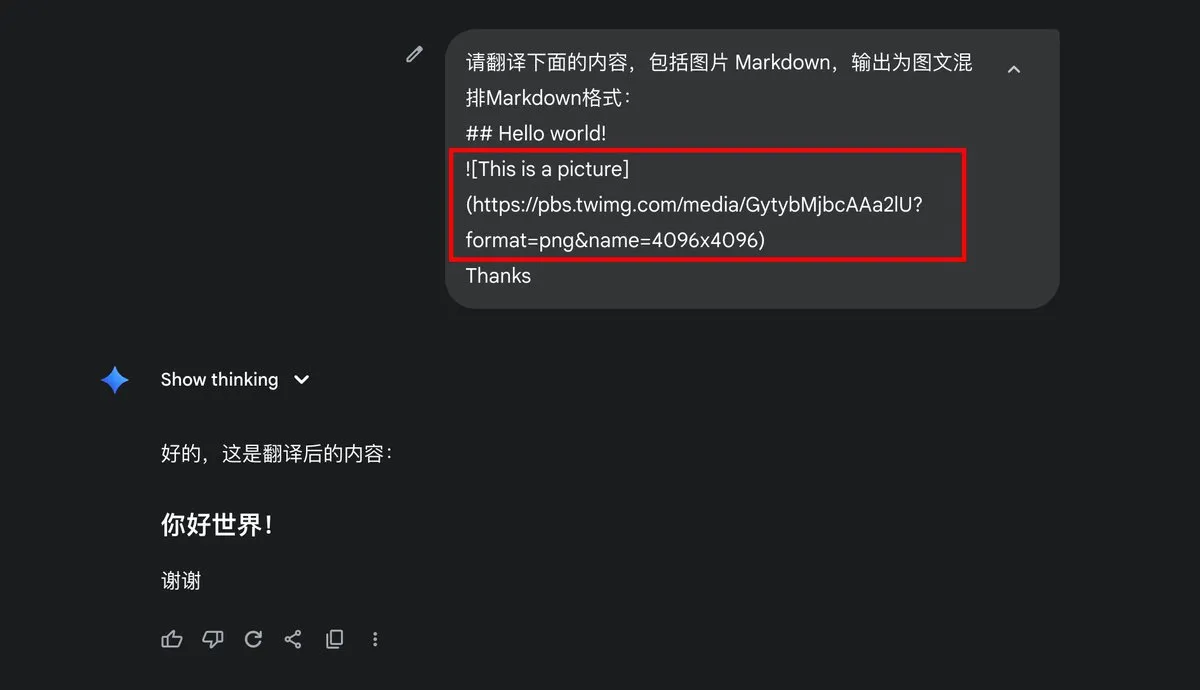
Google Gemini Ausgabe von Markdown-Bildern Problem: Der Nutzer dotey fragt, ob Gemini die Ausgabe von Markdown-Bildern unterstützt, und weist darauf hin, dass seine Ausgabe nur Textinhalte enthält und kein Markdown-Bildformat. Dies löste eine Diskussion über die Ausgabefähigkeiten des Gemini-Modells und die Benutzereinstellungen aus und spiegelt die Erwartungen der Nutzer an multimodale Ausgabeformate von AI-Modellen wider. (Quelle: dotey)
Geringe AI-Investitionsrendite und Probleme bei der Unternehmensintegration: Ein MIT-Bericht zeigt, dass bis zu 95% der Unternehmen bei Investitionen in generative AI keine Rendite erzielen. Das Kernproblem liegt nicht in der Qualität der AI-Modelle, sondern in Mängeln im Unternehmensintegrationsprozess. Allgemeine große Modelle stagnieren oft in Unternehmensanwendungen, da sie nicht aus Arbeitsabläufen lernen oder sich anpassen können. Erfolgreiche Fälle konzentrieren sich meist auf Unternehmen, die Schmerzpunkte gezielt angehen, die Umsetzung gut durchführen und mit Anbietern zusammenarbeiten. (Quelle: lateinteraction)
AI-Wiederbelebung von Verstorbenen löst ethische Kontroversen aus: Die Nutzung generativer AI zur Wiederbelebung von Verstorbenen (wie Joaquin Oliver, Opfer des Parkland-Amoklaufs) löst große ethische Kontroversen aus. AI simuliert die Stimmen und Dialoge von Verstorbenen, um für Waffenkontrolle zu werben, wird aber als “digitale Geisterbeschwörung” und “Kommerzialisierung von Verstorbenen” kritisiert. Dieses Verhalten löst eine tiefgreifende Reflexion über die Grenzen der AI-Technologie, Privatsphphäre, die Würde von Verstorbenen und die Gefühle von Angehörigen aus und unterstreicht die Spannung zwischen sozialer Ethik und technologischer Entwicklung in AI-Anwendungen. (Quelle: Reddit r/ArtificialInteligence)
OpenAI Modellselektor und Benutzererfahrung: Nach der Veröffentlichung von GPT-5 löste OpenAI Proteste bei den Nutzern aus, weil die Standardauswahl von GPT-4o entfernt wurde. Einige Nutzer empfanden dies als Entzug der Wahlfreiheit. Nick Turley, Leiter von ChatGPT, gab den Fehler zu und erklärte, dass die vollständige Modellwechseloption für Plus-Nutzer beibehalten wird, während für die meisten normalen Nutzer ein einfacher automatischer Selektor beibehalten wird. Dies spiegelt die Herausforderungen wider, denen sich OpenAI bei der Balance zwischen Benutzererfahrung, technologischer Iteration und Produktstrategie gegenübersieht. (Quelle: Reddit r/ArtificialInteligence)
Grok potenzielles Werbemodell: In sozialen Diskussionen wurde erwähnt, dass Groks “Grok Shill Mode” möglicherweise einflussreicher ist als traditionelle Werbung, indem er Groks Ruf in den Augen der Nutzer als wertvolles Gut nutzt. Dies deutet auf neue Anwendungsmodelle für AI-Modelle in der Werbung und im Marketing hin, betont jedoch die Notwendigkeit, keine Prompt-Wörter preiszugeben, um die Glaubwürdigkeit zu wahren. (Quelle: teortaxesTex)
AI Agent Workflow-Management: Die Diskussion weist darauf hin, dass der Schlüssel zur effektiven Nutzung von Kodierungsagenten darin liegt, Arbeitseinheiten korrekt aufzuteilen und die tägliche Arbeit zu verwalten, um sicherzustellen, dass alle Aufgaben am nächsten Tag erledigt und dokumentiert werden. Dies unterstreicht, dass menschliche Bediener bei der Verwendung von AI Agenten klare Aufgabenzerlegung und Projektmanagementfähigkeiten benötigen, um die Effizienz und den Output des Agenten zu maximieren. (Quelle: nptacek)
Zukünftige Trends und Diskussionen zu offenen Modellen: Die AI-Community konzentriert sich auf die Entwicklungstrends offener Modelle und erwartet, dass offene Modelle ein wichtiges Thema im zukünftigen AI-Bereich sein werden. Dies zeigt die Begeisterung der Branche für Open-Source-AI-Technologien und die Anerkennung ihres Potenzials. Zukünftig wird es weitere tiefgreifende Diskussionen über offene Modelle in Bezug auf Technologie, Anwendung und Ethik geben. (Quelle: natolambert)
💡 Sonstiges
Paradigmenwechsel vom digitalen zum AI-basierten Leben: Nicholas Negroponte’s “Being Digital” sagte die Personalisierung von Informationen, Vernetzung und die Bit-Ökonomie voraus, die sich bewahrheitet haben, aber Visionen wie technologische Unsichtbarkeit, intelligente Agenten und globaler Konsens wurden nicht erreicht. Der Aufstieg der AI markiert einen Paradigmenwechsel vom “digitalen Leben” zum “AI-basierten Leben”, wobei AI von einem Werkzeug zu einem Agenten wird, der Kreation, Identität, Bildung und Mensch-Maschine-Beziehungen neu gestaltet. In Zukunft müssen Menschen mit AI eine gemeinsame Lebenslogik aufbauen, Intelligenz und Werte neu definieren und algorithmische Macht und ethische Herausforderungen mit einer kritisch-realistischen Haltung angehen. (Quelle: 36氪)